
🎓 Сделал серию заметок про бесплатные курсы на платформе stepik.org и как-то забыл про неё. Там много хороших и полезных курсов, так что продолжу. Если у вас тоже есть на примете хорошие бесплатные курсы, поделитесь информацией.
Регулярные выражения в Python
⇨ https://stepik.org/course/107335/
Здесь вы научитесь составлять и использовать регулярные выражения для решения повседневных задач. В курсе пройдёмся по всем функциям модуля re, разберём работу с группами, изучим флаги, и поймём для чего нужны регулярные выражения.
Рекомендацию на этот курс я получал неоднократно в заметках про регулярки. Перебирал свои записи и вспомнил про него.
Интерактивный тренажер по SQL
⇨ https://stepik.org/course/63054/
В курсе большинство шагов — это практические задания на создание SQL-запросов. Каждый шаг включает минимальные теоретические аспекты по базам данных или языку SQL, примеры похожих запросов и пояснение к реализации.
Админам и девопсам с SQL приходится взаимодействовать постоянно. Базовый синтаксис очень желательно знать. Я немного знаю, но всё равно по шпаргалкам всё делаю, когда надо таблицу создать или запрос выполнить.
Go (Golang) - первое знакомство
⇨ https://stepik.org/course/100208/
Это курс по языку программирования Go (Golang) для самых маленьких. Почему? Потому что показаны будут прежде всего азы (хотя и не только), при этом в достаточно краткой форме.
Go, как и Python, активно используется для создания вспомогательных утилит и сервисов в обслуживании и эксплуатации систем. Знать его хоть чуть-чуть в современном IT будет полезно всем. Я, к сожалению, совсем не знаю.
А может вам просто надоело обслуживание и вы хотите перейти в разработку? Вот пример человека, который из тех поддержки стал программистом на Go.
#обучение #бесплатно
Регулярные выражения в Python
⇨ https://stepik.org/course/107335/
Здесь вы научитесь составлять и использовать регулярные выражения для решения повседневных задач. В курсе пройдёмся по всем функциям модуля re, разберём работу с группами, изучим флаги, и поймём для чего нужны регулярные выражения.
Рекомендацию на этот курс я получал неоднократно в заметках про регулярки. Перебирал свои записи и вспомнил про него.
Интерактивный тренажер по SQL
⇨ https://stepik.org/course/63054/
В курсе большинство шагов — это практические задания на создание SQL-запросов. Каждый шаг включает минимальные теоретические аспекты по базам данных или языку SQL, примеры похожих запросов и пояснение к реализации.
Админам и девопсам с SQL приходится взаимодействовать постоянно. Базовый синтаксис очень желательно знать. Я немного знаю, но всё равно по шпаргалкам всё делаю, когда надо таблицу создать или запрос выполнить.
Go (Golang) - первое знакомство
⇨ https://stepik.org/course/100208/
Это курс по языку программирования Go (Golang) для самых маленьких. Почему? Потому что показаны будут прежде всего азы (хотя и не только), при этом в достаточно краткой форме.
Go, как и Python, активно используется для создания вспомогательных утилит и сервисов в обслуживании и эксплуатации систем. Знать его хоть чуть-чуть в современном IT будет полезно всем. Я, к сожалению, совсем не знаю.
А может вам просто надоело обслуживание и вы хотите перейти в разработку? Вот пример человека, который из тех поддержки стал программистом на Go.
#обучение #бесплатно
Stepik: online education
Регулярные выражения в Python
Здесь вы научитесь научитесь составлять и использовать регулярные выражения для решения повседневных задач. В курсе пройдёмся по всем функциям модуля re, разберём работу с группами, изучим флаги, и поймём для чего нужны регулярные выражения ❤️
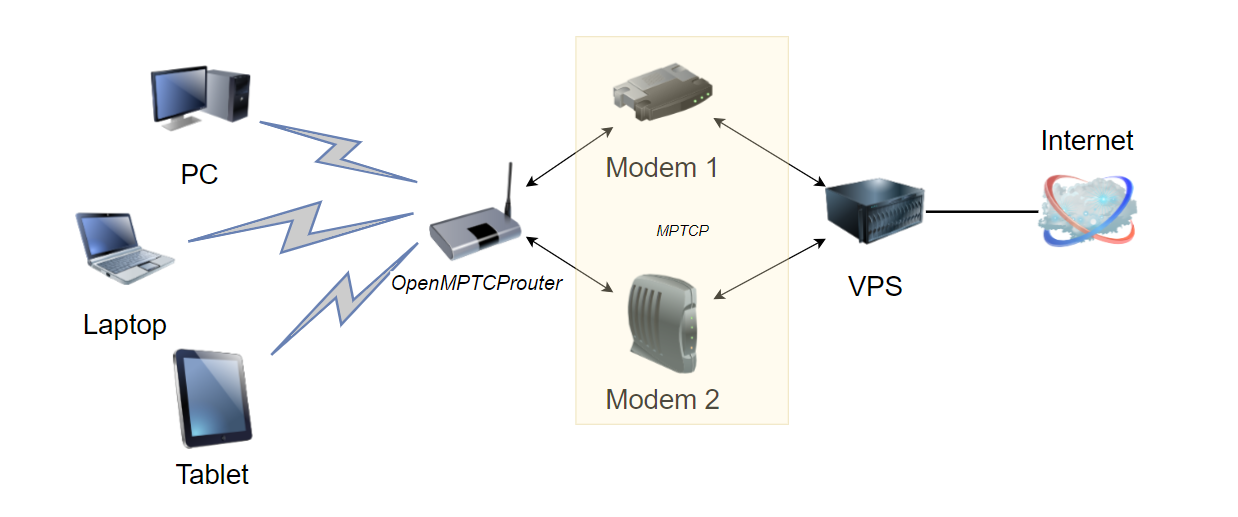
Меня часто спрашивают, каким образом можно объединить несколько интернет каналов в один общий. То есть настроить не резервирование, не переключение, не балансировку, а именно одновременное использование нескольких каналов для увеличения суммарной пропускной способности. При этом сами каналы чаще всего разного типа. То есть это не то же самое, что объединить порты на свитчах.
У меня никогда не было опыта подобной настройки. Я понимаю, что технически это сложная задача, как логически, так и архитектурно. Честное суммирование каналов будет приводить к явным проблемам. Например, у клиента канал 1000 мегабит, а у сервиса 3 канала по 100 мегабит. Клиент на полной скорости пытается забрать контент с сервера, который вынужден будет для максимальной скорости утилизировать все 3 канала одновременно. Получается один клиент будет забирать контент с трёх разных маршрутов с разными метриками, откликами, source ip шлюзов и т.д.
Ну и в обратную сторону те же самые проблемы, когда у клиента 3 канала, а у сервиса один. Всё это нужно как-то собирать в единую последовательность, чтобы данные не превращались в кашу. А есть ещё привязки аутентификаций и кук к IP. Что с ними будет?
К чему я всё это? Если у вас возникнет подобная задача (постарайтесь от неё отмахнуться), то дам вам подсказку в виде бесплатного OpenMPTCProuter. Это open source проект программного роутера, который умеет честно суммировать интернет каналы. Для этого он состоит из двух частей. Одна клиентская, которую вы ставите там, где суммируете каналы. А вторая часть располагается где-то в интернете для объединения подключений со всех интернет каналов. Только такая схема может обеспечить реальное объединение каналов и возможность приложениям нормально работать при такой схеме без потери пакетов и разрыва соединений.
Клиентская часть, где будут подключены интернет каналы, может быть установлена на обычный x86, x86_64 Linux, Raspberry PI 2B/3B/3B+/4B, Linksys WRT3200ACM/WRT32X, Teltonika RUTX12, Banana PI BPI-R2. Она построена на базе OpenWRT. Суммирующий сервер может быть развёрнут в интернете на обычном VPS на базе Debian или Ubuntu.
Настройка, на удивление для такого продукта, не сложная. Я сам не пробовал, но есть руководство на сайте и инструкции в интернете. Настраивается суммирующий сервер с помощью готового скрипта. Потом поднимаем из образа клиентскую часть. Через веб интерфейс настраиваем интернет каналы и указываем настройки подключения к суммирующему серверу. Этого минимума будет достаточно, чтобы всё заработало.
Это единственное бесплатное решение, которое мне знакомо по данной задаче. Все другие входят в состав дорогих коммерческих продуктов. Из не очень дорогого я когда-то видел коробочку с несколькими USB модемами, но не уверен, что там было честное объединение, а не резервирование и переключение. Да и то название забыл.
Если кто-то пользовался подобными или конкретно этой системой, то дайте обратную связь. Как на практике работает объединение каналов? Тут же куча сопутствующих проблем возникает от банальной настройки файрвола до проброса портов. Не понятно, как это должно работать в таких схемах.
#network
У меня никогда не было опыта подобной настройки. Я понимаю, что технически это сложная задача, как логически, так и архитектурно. Честное суммирование каналов будет приводить к явным проблемам. Например, у клиента канал 1000 мегабит, а у сервиса 3 канала по 100 мегабит. Клиент на полной скорости пытается забрать контент с сервера, который вынужден будет для максимальной скорости утилизировать все 3 канала одновременно. Получается один клиент будет забирать контент с трёх разных маршрутов с разными метриками, откликами, source ip шлюзов и т.д.
Ну и в обратную сторону те же самые проблемы, когда у клиента 3 канала, а у сервиса один. Всё это нужно как-то собирать в единую последовательность, чтобы данные не превращались в кашу. А есть ещё привязки аутентификаций и кук к IP. Что с ними будет?
К чему я всё это? Если у вас возникнет подобная задача (постарайтесь от неё отмахнуться), то дам вам подсказку в виде бесплатного OpenMPTCProuter. Это open source проект программного роутера, который умеет честно суммировать интернет каналы. Для этого он состоит из двух частей. Одна клиентская, которую вы ставите там, где суммируете каналы. А вторая часть располагается где-то в интернете для объединения подключений со всех интернет каналов. Только такая схема может обеспечить реальное объединение каналов и возможность приложениям нормально работать при такой схеме без потери пакетов и разрыва соединений.
Клиентская часть, где будут подключены интернет каналы, может быть установлена на обычный x86, x86_64 Linux, Raspberry PI 2B/3B/3B+/4B, Linksys WRT3200ACM/WRT32X, Teltonika RUTX12, Banana PI BPI-R2. Она построена на базе OpenWRT. Суммирующий сервер может быть развёрнут в интернете на обычном VPS на базе Debian или Ubuntu.
Настройка, на удивление для такого продукта, не сложная. Я сам не пробовал, но есть руководство на сайте и инструкции в интернете. Настраивается суммирующий сервер с помощью готового скрипта. Потом поднимаем из образа клиентскую часть. Через веб интерфейс настраиваем интернет каналы и указываем настройки подключения к суммирующему серверу. Этого минимума будет достаточно, чтобы всё заработало.
Это единственное бесплатное решение, которое мне знакомо по данной задаче. Все другие входят в состав дорогих коммерческих продуктов. Из не очень дорогого я когда-то видел коробочку с несколькими USB модемами, но не уверен, что там было честное объединение, а не резервирование и переключение. Да и то название забыл.
Если кто-то пользовался подобными или конкретно этой системой, то дайте обратную связь. Как на практике работает объединение каналов? Тут же куча сопутствующих проблем возникает от банальной настройки файрвола до проброса портов. Не понятно, как это должно работать в таких схемах.
#network
{kind=link}
Минцифры давно уже запустило маркетплейс российского ПО. Выглядит он удобно и содержательно:
⇨ https://russoft.ru
Только сразу прошу, не надо обсуждать политику, чиновников, импортозамещение и прочее. Это не имеет смысла. Я просто делюсь информацией о хорошо организованном каталоге. Даже и не знал, что существует столько отечественного ПО.
Например, идём в Системное ПО ⇨ Управление IT-инфраструктурой. Видим 17 продуктов, про большую часть которых я даже не слышал. Тут сразу указана примерная стоимость и есть ссылка на сайт продукта. Немного изучил список. Привлекло внимание название Управление IT-отделом 8. Посмотрел, а это help desk и инвентаризация на базе платформы 1С. Причём там и веб интерфейс есть, и интеграция с Telegram ботами. 1С, как ни крути, мощная платформа. На её базе всё, что угодно можно делать.
К каждому ПО указан список иностранных аналогов. Так что если вы ищите замену чему-либо, можно сразу по этому продукту искать. Для примера забил Zabbix и увидел список ПО для мониторинга. Вообще ни один продукт из этого списка не знаком.
Почитал новости о релизе этого каталога. Обещали в будущем сделать рейтинг и отзывы, но пока ничего этого нет. А последние новости на сайте от марта этого года. Такое ощущение, что портал сделали, бюджет кончился и его заморозили. Надеюсь, что разморозят и продолжат развивать. Идея хорошая.
#отечественное
⇨ https://russoft.ru
Только сразу прошу, не надо обсуждать политику, чиновников, импортозамещение и прочее. Это не имеет смысла. Я просто делюсь информацией о хорошо организованном каталоге. Даже и не знал, что существует столько отечественного ПО.
Например, идём в Системное ПО ⇨ Управление IT-инфраструктурой. Видим 17 продуктов, про большую часть которых я даже не слышал. Тут сразу указана примерная стоимость и есть ссылка на сайт продукта. Немного изучил список. Привлекло внимание название Управление IT-отделом 8. Посмотрел, а это help desk и инвентаризация на базе платформы 1С. Причём там и веб интерфейс есть, и интеграция с Telegram ботами. 1С, как ни крути, мощная платформа. На её базе всё, что угодно можно делать.
К каждому ПО указан список иностранных аналогов. Так что если вы ищите замену чему-либо, можно сразу по этому продукту искать. Для примера забил Zabbix и увидел список ПО для мониторинга. Вообще ни один продукт из этого списка не знаком.
Почитал новости о релизе этого каталога. Обещали в будущем сделать рейтинг и отзывы, но пока ничего этого нет. А последние новости на сайте от марта этого года. Такое ощущение, что портал сделали, бюджет кончился и его заморозили. Надеюсь, что разморозят и продолжат развивать. Идея хорошая.
#отечественное
{kind=link}
Я активно использую как в работе, так и в личных целях, Яндекс.Диск. У него очень низкая стоимость хранения данных. В Linux использую либо API для загрузки данных, либо rclone.
Для Windows использовал либо родной клиент, что не очень удобно, либо монтировал сетевой диск в Linux и там с ним работал. Не знал, что полнофункциональный rclone нормально работает в Windows, причём абсолютно так же, как в Linux. Настройка 1 в 1.
Установить можно как вручную, так и с помощью winget:
Через winget не сразу понял, куда он был установлен. Оказалось, что в директорию C:\Users\User\AppData\Local\Microsoft\WinGet\Packages\Rclone.Rclone_Microsoft.Winget.Source_8wekyb3d8bbwe\rclone-v1.63.1-windows-amd64.
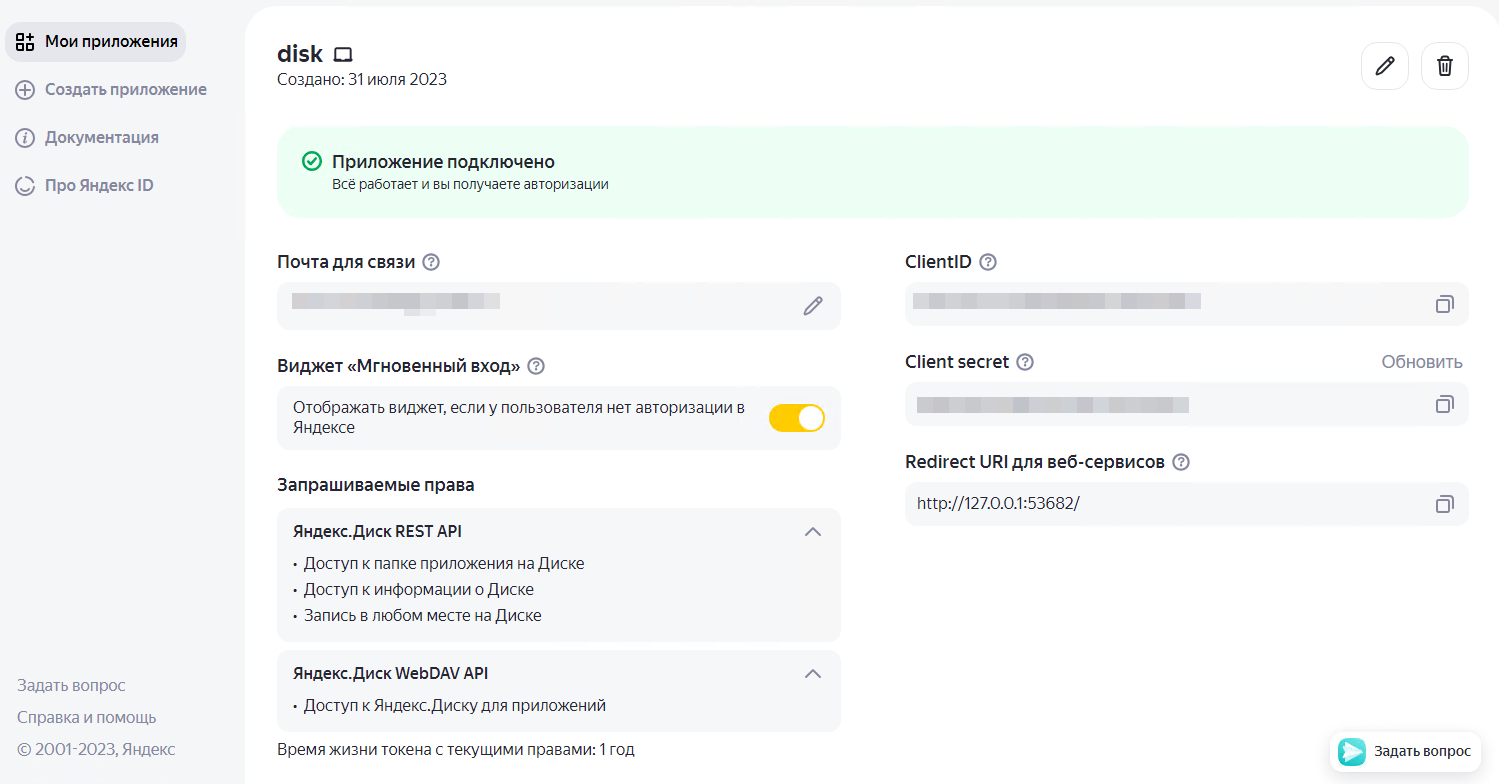
Для настройки работы rclone с Яндекс диском нужно получить токен. Как это сделать, я описывал в заметке по работе с API. Единственное отличие — нужно предоставить побольше прав:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
▪ Запись в любом месте на Диске
▪ Доступ к Яндекс.Диску для приложений
А в качестве Redirect URI использовать ссылку: http://127.0.0.1:53682/
После этого запускаете в консоли команду:
Выбираете New remote ⇨ указываете название, например yandex ⇨ номер 48, соответствующий хранилищу Яндекс диск ⇨ client_id и client_secret оставляете пустыми ⇨ выполняете запрос токена ⇨ сохраняете конфиг.
У вас появится файл в C:\Users\User\AppData\Roaming\rclone\rclone.conf примерно следующего содержания:
[yandex]
type = yandex
client_id =
client_secret =
token = {"access_token":"y0_AgAAAABvmXfPAALEtgAAAAKpIA8y2bb-M0IiRFu068gJJKvzSOGoBBs","token_type":"OAuth","refresh_token":"1:p0NRuhts1VI1N7Sq:NWEoGv963fVVGSpE_k8Mftn6Pd8AKsFcte2WGqv77mKgWaoer36TX4irbubWTfCgk9_Gxh5NLBzkWA:b_dCjrHMIEMkKeH-oOFrFQ","expiry":"2024-07-30T20:45:05.4991551+03:00"}
Теперь можно через консоль загружать туда файлы:
Положили в корень диска файл test.txt
Помимо загрузки файлов, rclone умеет монтировать внешние хранилища как локальные или сетевые диски. Для этого ему нужна программа winfsp. Поставить можно тоже через winget:
Монтируем яндекс диск в режиме чтения:
Или в режиме записи:
Яндекс диск смонтирован в виде локального диска X. Подробнее о монтировании в Windows, о правах доступа и прочих нюансах можно прочитать в документации.
Если для вас всё это слишком замороченно и хочется попроще, то вот набор программ, которые реализуют то же самое. Это платные программы, с ограниченными бесплатными версиями. Они удобны и популярны, так что при желании, вы найдёте репаки платных версий, но аккуратнее с ними. Я лично давно уже опасаюсь использовать ломаный софт.
🔹Air Explorer — двухпанельный файловый менеджер, который позволяет работать с облачными сервисами как с локальными директориями. Поддерживает и Яндекс.Диск, и диск от Mail ru.
🔹Air Live Drive — программа от того же производителя, которая позволят монтировать облачные диски как локальные.
🔹RaiDrive — писал об этой программе ранее. Позволяет подключать различные облачные сервисы как локальные диски.
#windows #rclone #backup
Для Windows использовал либо родной клиент, что не очень удобно, либо монтировал сетевой диск в Linux и там с ним работал. Не знал, что полнофункциональный rclone нормально работает в Windows, причём абсолютно так же, как в Linux. Настройка 1 в 1.
Установить можно как вручную, так и с помощью winget:
> winget install rcloneЧерез winget не сразу понял, куда он был установлен. Оказалось, что в директорию C:\Users\User\AppData\Local\Microsoft\WinGet\Packages\Rclone.Rclone_Microsoft.Winget.Source_8wekyb3d8bbwe\rclone-v1.63.1-windows-amd64.
Для настройки работы rclone с Яндекс диском нужно получить токен. Как это сделать, я описывал в заметке по работе с API. Единственное отличие — нужно предоставить побольше прав:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
▪ Запись в любом месте на Диске
▪ Доступ к Яндекс.Диску для приложений
А в качестве Redirect URI использовать ссылку: http://127.0.0.1:53682/
После этого запускаете в консоли команду:
> rclone configВыбираете New remote ⇨ указываете название, например yandex ⇨ номер 48, соответствующий хранилищу Яндекс диск ⇨ client_id и client_secret оставляете пустыми ⇨ выполняете запрос токена ⇨ сохраняете конфиг.
У вас появится файл в C:\Users\User\AppData\Roaming\rclone\rclone.conf примерно следующего содержания:
[yandex]
type = yandex
client_id =
client_secret =
token = {"access_token":"y0_AgAAAABvmXfPAALEtgAAAAKpIA8y2bb-M0IiRFu068gJJKvzSOGoBBs","token_type":"OAuth","refresh_token":"1:p0NRuhts1VI1N7Sq:NWEoGv963fVVGSpE_k8Mftn6Pd8AKsFcte2WGqv77mKgWaoer36TX4irbubWTfCgk9_Gxh5NLBzkWA:b_dCjrHMIEMkKeH-oOFrFQ","expiry":"2024-07-30T20:45:05.4991551+03:00"}
Теперь можно через консоль загружать туда файлы:
> rclone copy C:\Users\User\Downloads\test.txt yandex:/Положили в корень диска файл test.txt
Помимо загрузки файлов, rclone умеет монтировать внешние хранилища как локальные или сетевые диски. Для этого ему нужна программа winfsp. Поставить можно тоже через winget:
> winget install winfspМонтируем яндекс диск в режиме чтения:
> rclone mount yandex:/ X:Или в режиме записи:
> rclone mount yandex:/ X: --vfs-cache-mode writesЯндекс диск смонтирован в виде локального диска X. Подробнее о монтировании в Windows, о правах доступа и прочих нюансах можно прочитать в документации.
Если для вас всё это слишком замороченно и хочется попроще, то вот набор программ, которые реализуют то же самое. Это платные программы, с ограниченными бесплатными версиями. Они удобны и популярны, так что при желании, вы найдёте репаки платных версий, но аккуратнее с ними. Я лично давно уже опасаюсь использовать ломаный софт.
🔹Air Explorer — двухпанельный файловый менеджер, который позволяет работать с облачными сервисами как с локальными директориями. Поддерживает и Яндекс.Диск, и диск от Mail ru.
🔹Air Live Drive — программа от того же производителя, которая позволят монтировать облачные диски как локальные.
🔹RaiDrive — писал об этой программе ранее. Позволяет подключать различные облачные сервисы как локальные диски.
#windows #rclone #backup
{kind=link}
В Linux можно на ходу уменьшать или увеличивать количество используемой оперативной памяти. Единственное условие - если уменьшаете активную оперативную память, она должна быть свободна. Покажу на примерах.
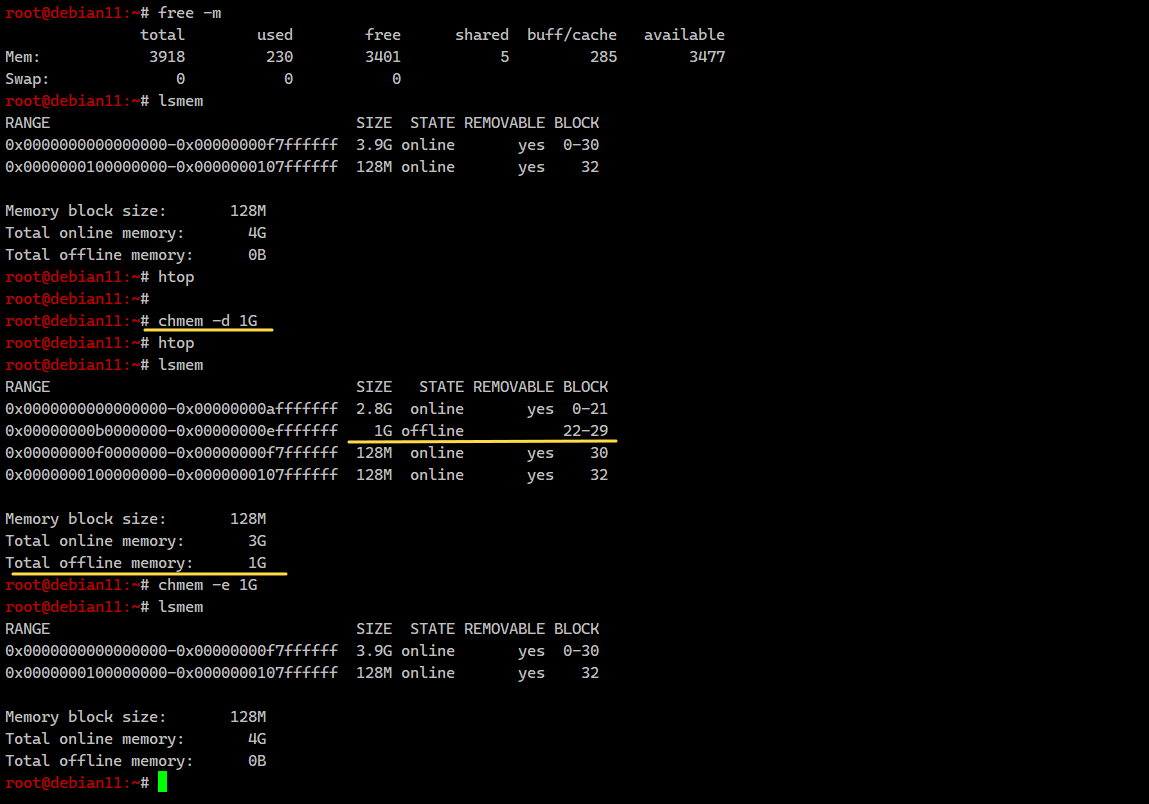
Для начала воспользуемся командой lsmem для просмотра информации об использовании оперативной памяти. Команда, кстати, полезная. Рекомендую запомнить и использовать. С её помощью можно быстро посмотреть полную информацию об оперативе сервера:
Команда показывает в том числе блоки оперативной памяти, на которые её разбивает ядро. Вот с этими блоками и можно работать. Видим, что у нас 32 блока по 128M, а всего 4G памяти и вся она активна. Отключим 1G c помощью chmem.
или отключим 8 произвольных блоков:
Утилита пройдётся по всем блокам памяти. Те, что могут быть освобождены, она отключит. Процесс может занимать много времени, так как утилита будет пытаться перемещать информацию по памяти, чтобы высвободить заданный объём.
Проверяем, что получилось:
Возвращаем всё как было:
Вряд ли вам часто может быть нужна эта возможность. Но иногда может пригодиться, так что стоит знать о ней. Например, в некоторых системах виртуализации, добавленная на ходу память добавляется как offline и её нужно вручную активировать.
Ещё вариант, если вы точно знаете диапазон битой памяти. Вы можете отключить содержащий её блок с помощью chmem и какое-то время сервер ещё поработает.
#linux #terminal
Для начала воспользуемся командой lsmem для просмотра информации об использовании оперативной памяти. Команда, кстати, полезная. Рекомендую запомнить и использовать. С её помощью можно быстро посмотреть полную информацию об оперативе сервера:
# lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x00000000f7ffffff 3.9G online yes 0-300x0000000100000000-0x0000000107ffffff 128M online yes 32Memory block size: 128MTotal online memory: 4GTotal offline memory: 0BКоманда показывает в том числе блоки оперативной памяти, на которые её разбивает ядро. Вот с этими блоками и можно работать. Видим, что у нас 32 блока по 128M, а всего 4G памяти и вся она активна. Отключим 1G c помощью chmem.
# chmem -d 1Gили отключим 8 произвольных блоков:
# chmem -d -b 22-29Утилита пройдётся по всем блокам памяти. Те, что могут быть освобождены, она отключит. Процесс может занимать много времени, так как утилита будет пытаться перемещать информацию по памяти, чтобы высвободить заданный объём.
Проверяем, что получилось:
# lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x00000000afffffff 2.8G online yes 0-210x00000000b0000000-0x00000000efffffff 1G offline 22-290x00000000f0000000-0x00000000f7ffffff 128M online yes 300x0000000100000000-0x0000000107ffffff 128M online yes 32Memory block size: 128MTotal online memory: 3GTotal offline memory: 1GВозвращаем всё как было:
# chmem -e 1GВряд ли вам часто может быть нужна эта возможность. Но иногда может пригодиться, так что стоит знать о ней. Например, в некоторых системах виртуализации, добавленная на ходу память добавляется как offline и её нужно вручную активировать.
Ещё вариант, если вы точно знаете диапазон битой памяти. Вы можете отключить содержащий её блок с помощью chmem и какое-то время сервер ещё поработает.
#linux #terminal
{kind=link}
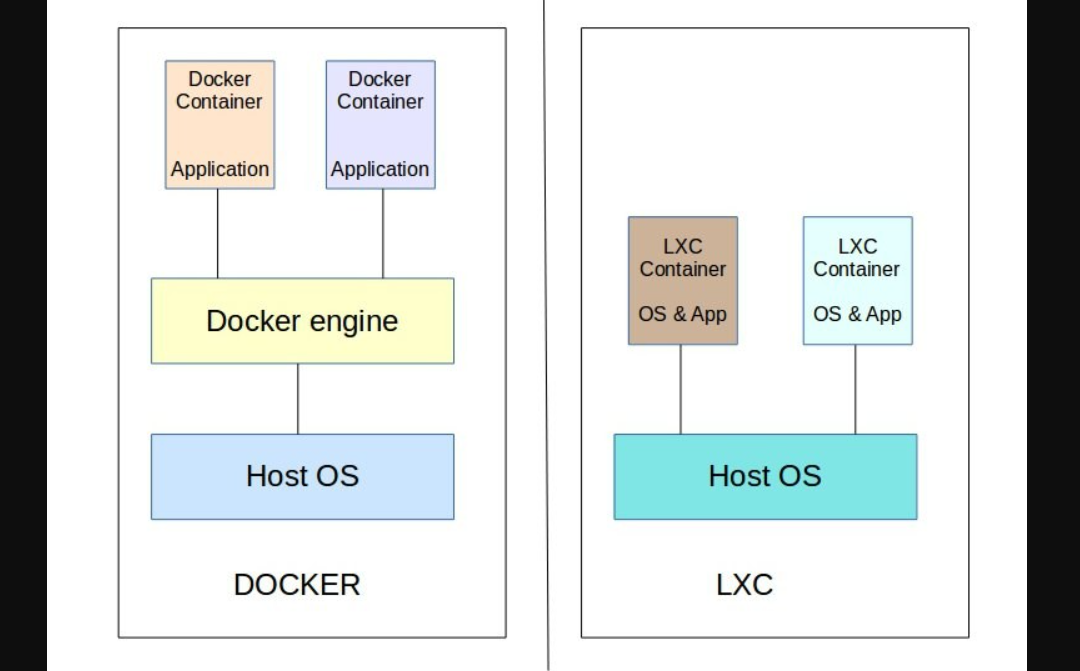
Объясню простыми словами отличия современных систем контейнеризации. Для тех, кто с ними постоянно не работает, не очевидно, что они могут различаться принципиально по областям применения. Акцент сделаю на наиболее популярных Docker и LXC, а в конце немного по остальным пройдусь.
Все контейнеры используют одно и то же ядро операционной системы Linux и работают в его рамках. Это принципиальное отличие от виртуальных машин. А принципиальное отличие Docker от LXC в том, что Docker ориентируется на запуск приложений, а LXC на запуск системы.
Поясню на конкретном примере. Допустим, вам надо запустить в работу веб сервер. Если вы будете делать это с помощью Docker, то на хостовой машине запустите контейнер с Nginx, контейнер с Php-fpm, создадите на хосте локальные директории с файлами сайта и конфигурациями сервисов и пробросите их внутрь контейнеров, чтобы у них был доступ к ним. В самих контейнерах кроме непосредственно сервисов Nginx и Php-fpm практически ничего не будет.
Если ту же задачу решать с помощью LXC, то вы просто запустите контейнер с нужной базовой системой внутри. Зайдёте внутрь контейнера и настроите там всё, как обычно это делаете на отдельной виртуальной машине. То есть LXC максимально повторяет работу полноценной системы, только работает на базе ядра хоста.
☝ Docker - это один контейнер, одна служба, LXC - набор служб для решения конкретной задачи. При этом в образ Docker тоже можно поместить практически полноценную систему, но так обычно никто не делает, хотя и есть исключения.
Исходя из этих пояснений, становятся понятны плюсы и минусы каждого подхода. Плюсы Docker:
◽минимальный объём образов, соответственно, максимальная скорость запуска нужных сервисов;
◽для бэкапа достаточно сохранить непосредственно данные, образы можно опустить, так как они типовые.
Минусы:
◽более сложная настройка по сравнению с обычной виртуальной машиной, особенно что касается сети и диагностики в целом.
Плюсы LXC:
◽настройка практически такая же, как на обычной VM, заходишь внутрь контейнера по SSH и настраиваешь.
Минусы LXC:
◽итоговые образы бОльшего объёма, так как содержат всё окружение стандартных систем.
◽сложнее автоматизировать и стандартизировать разворачивание масштабных сервисов.
LXC отлично подходит как замена полноценной VM. Его удобно настроить, забэкапить в единый образ и развернуть в том же виде в другом месте. Docker идеален для максимальной плотности сервисов на одном сервере. Думаю именно за это он стал так популярен. На больших масштабах это заметная экономия средств, поэтому крупные компании его активно используют и продвигают.
Аналогом Docker в плане подхода в виде запуска отдельных служб в контейнерах является Podman. Там есть незначительные отличия в реализации, но в целом они очень похожи. Это продукт компании RedHat, и они его всячески продвигают.
Ещё упомяну про LXD, который иногда сравнивают с LXC, хотя это разные вещи. По сути, LXD - надстройка над LXC, предоставляющая REST API для работы с контейнерами LXC. Она упрощает работу с ними, стандартизирует и даёт удобные инструменты управления. При этом LXD может работать не только с контейнерами LXC, но и с виртуальными машинами QEMU.
Надеюсь ничего нигде не напутал. Писал своими словами по памяти, так как с Docker и LXC практически постоянно работаю и примерно представляю, как они устроены.
#docker #lxc
Все контейнеры используют одно и то же ядро операционной системы Linux и работают в его рамках. Это принципиальное отличие от виртуальных машин. А принципиальное отличие Docker от LXC в том, что Docker ориентируется на запуск приложений, а LXC на запуск системы.
Поясню на конкретном примере. Допустим, вам надо запустить в работу веб сервер. Если вы будете делать это с помощью Docker, то на хостовой машине запустите контейнер с Nginx, контейнер с Php-fpm, создадите на хосте локальные директории с файлами сайта и конфигурациями сервисов и пробросите их внутрь контейнеров, чтобы у них был доступ к ним. В самих контейнерах кроме непосредственно сервисов Nginx и Php-fpm практически ничего не будет.
Если ту же задачу решать с помощью LXC, то вы просто запустите контейнер с нужной базовой системой внутри. Зайдёте внутрь контейнера и настроите там всё, как обычно это делаете на отдельной виртуальной машине. То есть LXC максимально повторяет работу полноценной системы, только работает на базе ядра хоста.
☝ Docker - это один контейнер, одна служба, LXC - набор служб для решения конкретной задачи. При этом в образ Docker тоже можно поместить практически полноценную систему, но так обычно никто не делает, хотя и есть исключения.
Исходя из этих пояснений, становятся понятны плюсы и минусы каждого подхода. Плюсы Docker:
◽минимальный объём образов, соответственно, максимальная скорость запуска нужных сервисов;
◽для бэкапа достаточно сохранить непосредственно данные, образы можно опустить, так как они типовые.
Минусы:
◽более сложная настройка по сравнению с обычной виртуальной машиной, особенно что касается сети и диагностики в целом.
Плюсы LXC:
◽настройка практически такая же, как на обычной VM, заходишь внутрь контейнера по SSH и настраиваешь.
Минусы LXC:
◽итоговые образы бОльшего объёма, так как содержат всё окружение стандартных систем.
◽сложнее автоматизировать и стандартизировать разворачивание масштабных сервисов.
LXC отлично подходит как замена полноценной VM. Его удобно настроить, забэкапить в единый образ и развернуть в том же виде в другом месте. Docker идеален для максимальной плотности сервисов на одном сервере. Думаю именно за это он стал так популярен. На больших масштабах это заметная экономия средств, поэтому крупные компании его активно используют и продвигают.
Аналогом Docker в плане подхода в виде запуска отдельных служб в контейнерах является Podman. Там есть незначительные отличия в реализации, но в целом они очень похожи. Это продукт компании RedHat, и они его всячески продвигают.
Ещё упомяну про LXD, который иногда сравнивают с LXC, хотя это разные вещи. По сути, LXD - надстройка над LXC, предоставляющая REST API для работы с контейнерами LXC. Она упрощает работу с ними, стандартизирует и даёт удобные инструменты управления. При этом LXD может работать не только с контейнерами LXC, но и с виртуальными машинами QEMU.
Надеюсь ничего нигде не напутал. Писал своими словами по памяти, так как с Docker и LXC практически постоянно работаю и примерно представляю, как они устроены.
#docker #lxc
{kind=link}
🔝Чуть не забыл про очередной топ постов за прошедший месяц. Надо будет попробовать собрать похожую информацию за прошедшее полугодие. И в целом сформировать какой-то список наиболее интересных и полезных заметок. Пока думаю, как это всё оформить. Написано уже море всего и какую-то часть я сам забываю. Приходится использовать поиск по каналу, чтобы не писать об одном и том же. Как же быстро летит время. Вроде недавно начал вести канал, а на самом деле прошло уже много лет и написаны тысячи заметок.
📌 Больше всего просмотров:
◽️Видео "Веселенький денек у сисадмина" (7381)
◽️Облачный сервис Grafana Cloud (7320)
◽️Списки IP адресов Google и Yandex (7301)
📌 Больше всего комментариев:
◽️Мифы про Astra Linux (154)
◽️Обновление Proxmox 7 до 8 (121)
◽️Заметка про бумажные копии электронных документов (69)
📌 Больше всего пересылок:
◽️Списки IP адресов по странам (489)
◽️Сервис уведомлений ntfy.sh (392)
◽️Создание ловушек с помощью canarytokens.org (372)
📌 Больше всего реакций:
◽️Мифы про Astra Linux (205)
◽️Заметка про бумажные копии электронных документов (180)
◽️Маркетплейс российского ПО от Минцифры (162)
◽️Расследование внезапной перезагрузки сервера (148)
#топ
📌 Больше всего просмотров:
◽️Видео "Веселенький денек у сисадмина" (7381)
◽️Облачный сервис Grafana Cloud (7320)
◽️Списки IP адресов Google и Yandex (7301)
📌 Больше всего комментариев:
◽️Мифы про Astra Linux (154)
◽️Обновление Proxmox 7 до 8 (121)
◽️Заметка про бумажные копии электронных документов (69)
📌 Больше всего пересылок:
◽️Списки IP адресов по странам (489)
◽️Сервис уведомлений ntfy.sh (392)
◽️Создание ловушек с помощью canarytokens.org (372)
📌 Больше всего реакций:
◽️Мифы про Astra Linux (205)
◽️Заметка про бумажные копии электронных документов (180)
◽️Маркетплейс российского ПО от Минцифры (162)
◽️Расследование внезапной перезагрузки сервера (148)
#топ
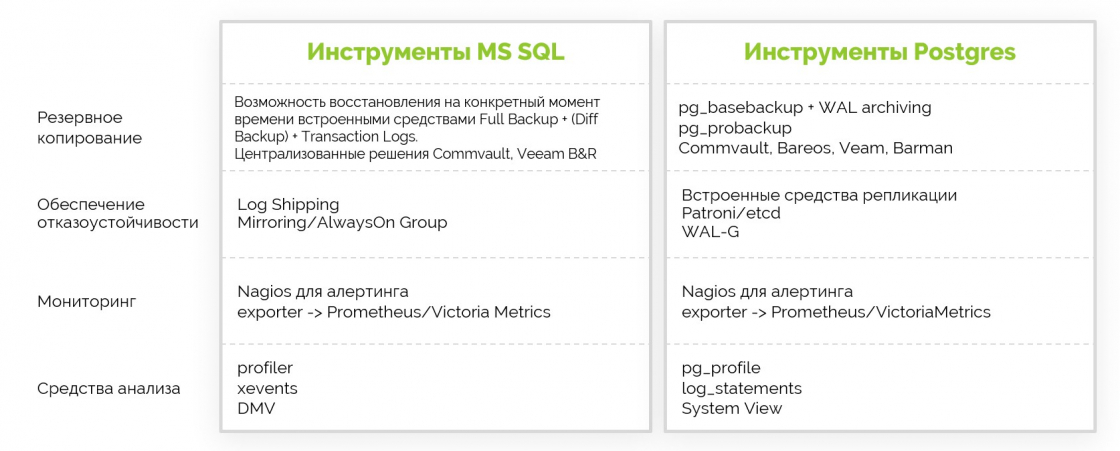
У меня на днях будет задача по переносу баз 1С с MSSQL на PostgreSQL. Переезжаем полностью с Windows Server на Debian. По этому поводу у меня есть относительно свежая ссылка (2022 год):
⇨ Частые вопросы по миграции базы данных 1С с MS SQL на PostgreSQL
Пришло время с ней поработать. Делаю для вас краткую выжимку, чтобы можно было использовать как шпаргалку. А когда сделаю перенос, напишу, как всё организовал. У меня есть свой подход к организации сервера для 1С.
1️⃣ Тюним PostgreSQL под ресурсы системы. Особое внимание на параметры shared_buffers, work_mem, temp_buffers, huge_pages. Если будете использовать сборку от PostgreSQL Pro, то там все важные параметры настраиваются автоматически после установки пакета.
Отдельно обратите внимание на autovacuum_max_workers. Параметр вычисляют так: кол-во vCPU / 2. И так же по этой теме настраиваем autovacuum_vacuum_scale_factor, autovacuum_analyze_scale_factor, autovacuum_vacuum_cost_limit.
2️⃣ Тюним систему под максимальную производительность СУБД:
3️⃣ Сам перенос проще всего выполнить через выгрузку в dt и последующую загрузку. Если база очень большая и недопустим простой, то перенос можно выполнять с помощью планов обмена.
4️⃣ Выгружать и загружать dt файлы быстрее и удобнее через автономный сервер ibcmd. В этот момент базу лучше отключить от сервера приложений, либо просто остановить его на время, если есть возможность.
Подробно всё это описано в статье по ссылке. Там же есть и сравнение производительности. В среднем по всем тестам MSSQL немного быстрее PostgreSQL, но не критично. Есть тесты, где одна база быстрее другой и наоборот. Среднее, как я уже сказал, выходит немного в пользу MSSQL.
#1С
⇨ Частые вопросы по миграции базы данных 1С с MS SQL на PostgreSQL
Пришло время с ней поработать. Делаю для вас краткую выжимку, чтобы можно было использовать как шпаргалку. А когда сделаю перенос, напишу, как всё организовал. У меня есть свой подход к организации сервера для 1С.
1️⃣ Тюним PostgreSQL под ресурсы системы. Особое внимание на параметры shared_buffers, work_mem, temp_buffers, huge_pages. Если будете использовать сборку от PostgreSQL Pro, то там все важные параметры настраиваются автоматически после установки пакета.
Отдельно обратите внимание на autovacuum_max_workers. Параметр вычисляют так: кол-во vCPU / 2. И так же по этой теме настраиваем autovacuum_vacuum_scale_factor, autovacuum_analyze_scale_factor, autovacuum_vacuum_cost_limit.
2️⃣ Тюним систему под максимальную производительность СУБД:
sysctl -w vm.swappines=2sysctl -w vm.overcommit_memory=23️⃣ Сам перенос проще всего выполнить через выгрузку в dt и последующую загрузку. Если база очень большая и недопустим простой, то перенос можно выполнять с помощью планов обмена.
4️⃣ Выгружать и загружать dt файлы быстрее и удобнее через автономный сервер ibcmd. В этот момент базу лучше отключить от сервера приложений, либо просто остановить его на время, если есть возможность.
Подробно всё это описано в статье по ссылке. Там же есть и сравнение производительности. В среднем по всем тестам MSSQL немного быстрее PostgreSQL, но не критично. Есть тесты, где одна база быстрее другой и наоборот. Среднее, как я уже сказал, выходит немного в пользу MSSQL.
#1С
{kind=link}
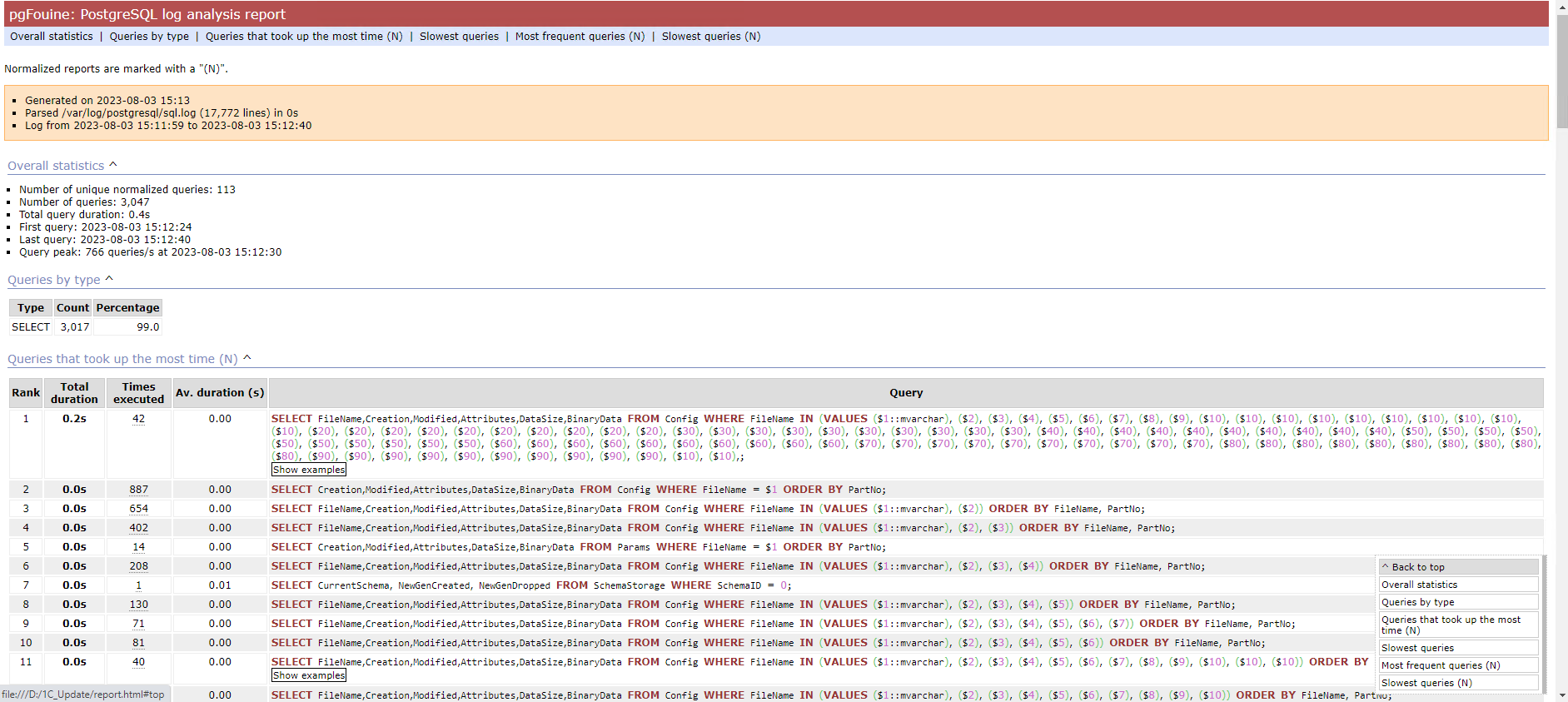
Пока занимался с PostgreSQL, вспомнил про простой и быстрый способ посмотреть статистику по запросам, который я использовал очень давно. Ещё во времена, когда не пользовался централизованными системами по сбору и анализу логов. Проверил методику, на удивление всё работает до сих пор, так что расскажу вам.
Речь пойдёт про анализатор запросов pgFouine. Продукт старый, последняя версия от 2010-го года. Обновление есть только для совместимости с версией php 7. Сам анализатор - это одиночный скрипт на php, который на входе берёт лог с запросами, а на выходе формирует одну html страницу со статистикой, которая включает в себя:
◽общую статистику по запросам, в том числе по их типам
◽запросы, которые занимают больше всего времени СУБД
◽топ медленных запросов
◽счётчик повторяющихся запросов
Для того, чтобы включить сбор логов, в конфигурационный файл PostgreSQL нужно добавить следующие параметры:
Это мы собираем только медленные запросы, дольше трех секунд. Если указать
Имеет смысл также отключить запись этих логов в общий лог, добавив
Перезапускаем сервисы:
Ждём, когда заполнится лог и отправляем его в pgFouine. Для этого достаточно скопировать себе файл pgfouine.php или весь репозиторий:
Теперь файл report.html можно открыть в браузере и посмотреть статистику. Предварительно нужно установить php, либо передать лог с запросами на машину, где php установлен. У меня нормально отработал на версии php 7.4.
Такой вот олдскул. Сейчас не знаю, кто так статистику смотрит. Есть парсеры логов для ELK или Graylog. Но для этого у вас должны быть эти системы. Надо туда отправить логи, распарсить, собрать дашборды. Это пуд соли съесть. А подобный разовый анализ можно сделать за 10 минут.
#postgresql
Речь пойдёт про анализатор запросов pgFouine. Продукт старый, последняя версия от 2010-го года. Обновление есть только для совместимости с версией php 7. Сам анализатор - это одиночный скрипт на php, который на входе берёт лог с запросами, а на выходе формирует одну html страницу со статистикой, которая включает в себя:
◽общую статистику по запросам, в том числе по их типам
◽запросы, которые занимают больше всего времени СУБД
◽топ медленных запросов
◽счётчик повторяющихся запросов
Для того, чтобы включить сбор логов, в конфигурационный файл PostgreSQL нужно добавить следующие параметры:
log_destination = 'syslog'syslog_facility = 'LOCAL0'syslog_ident = 'postgres'log_min_duration_statement = 3000 # 3000 мс = 3 секундыlog_duration = offlog_statement = 'none'Это мы собираем только медленные запросы, дольше трех секунд. Если указать
log_min_duration_statement = 0, будут логироваться все запросы. Логи будут писаться в syslog. Имеет смысл поместить их в отдельный файл. Для этого добавляем в конфигурационный файл rsyslog:LOCAL0.* -/var/log/postgresql/sql.logИмеет смысл также отключить запись этих логов в общий лог, добавив
LOCAL0.none:*.*;auth,authpriv.none;LOCAL0.none -/var/log/syslog*.=info;*.=notice;*.=warn;\ auth,authpriv.none;\ cron,daemon.none;\ mail,news.none;\ LOCAL0.none -/var/log/messagesПерезапускаем сервисы:
# systemctl restart postgresql# systemctl restart rsyslogЖдём, когда заполнится лог и отправляем его в pgFouine. Для этого достаточно скопировать себе файл pgfouine.php или весь репозиторий:
# git clone https://github.com/milo/pgFouine# cd pgFouine# php pgfouine.php -file /var/log/postgresql/sql.log > report.htmlТеперь файл report.html можно открыть в браузере и посмотреть статистику. Предварительно нужно установить php, либо передать лог с запросами на машину, где php установлен. У меня нормально отработал на версии php 7.4.
Такой вот олдскул. Сейчас не знаю, кто так статистику смотрит. Есть парсеры логов для ELK или Graylog. Но для этого у вас должны быть эти системы. Надо туда отправить логи, распарсить, собрать дашборды. Это пуд соли съесть. А подобный разовый анализ можно сделать за 10 минут.
#postgresql
{kind=link}
Дошли руки обработать ещё одно руководство от CIS на тему настройки Ubuntu Linux 22.04 LTS (нужна регистрация). Это огромный документ на 865 страниц. Я его весь просмотрел и постарался уместить в одну заметку то, что посчитал наиболее полезным и уместным для сервера общего назначения (рекомендации Level 1 - Server). Все детали упоминаемых настроек в подробностях описаны в исходном файле.
🔹Отключите поддержку неиспользуемых файловых систем (cramfs, squashfs, udf и т.д.). Достаточно отключить соответствующие модули ядра. Пример:
🔹/tmp и /var/tmp лучше вынести в отдельный раздел со своими параметрами. Например, noexec, nosuid, nodev и т.д. В идеале, отдельный раздел и настройки должны быть ещё и у /var/log, /home, /dev/shm. Пример параметров в fstab:
🔹Отслеживайте изменения в системных файлах, например с помощью AIDE (Advanced Intrusion Detection Environment):
🔹Убедитесь, что загрузка в single user mode требует аутентификации. Для этого обязательно установите пароль root:
🔹Отключите Apport Error Reporting Service, которая автоматически отправляет информацию о сбоях (по умолчанию включена):
🔹По возможности включайте, настраивайте AppArmor.
🔹Настройте синхронизацию времени какой-то одной службой (chrony, ntp или systemd-timesyncd).
🔹Проверьте все открытые порты и отключите всё ненужное:
🔹Отключите неиспользуемые сетевые протоколы. Например, ipv6. В документе представлена подробная инструкция, как это сделать. Но при этом сделана пометка, что в общем случае рекомендуется оставить ipv6, но корректно настроить всё, что с ним связано. Другие протоколы, которые в общем случае не нужны, но активны: dccp, sctp, rds, tipc. Только убедитесь, что они реально не используются. Какие-то из них могут быть нужны для работы некоторых кластеров.
🔹Настройте Firewall (UFW). Запретите все соединения, кроме разрешённых явно (нормально закрытый файрвол). Не забудьте про все используемые протоколы, в том числе ipv6.
🔹Настройте аудит доступа, изменения, удаления системных файлов с помощью auditctl.
Убедитесь, что доступ к логам сервиса ограничен.
🔹По возможности настройте отправку системных логов куда-то вовне. Используйте systemd-journal-remote или rsyslog.
🔹Настройте логирование действий через sudo. Добавьте через
Ограничьте использование
Документ огромный, но на самом деле там не так много информации. Очень много подробностей по аудиту, логам, файрволу. Если вам реально нужно разобраться, как всё это настраивается, то там есть все примеры вплоть до каждой команды и скрипта.
#cis #security #linux
🔹Отключите поддержку неиспользуемых файловых систем (cramfs, squashfs, udf и т.д.). Достаточно отключить соответствующие модули ядра. Пример:
# modprobe -f udf🔹/tmp и /var/tmp лучше вынести в отдельный раздел со своими параметрами. Например, noexec, nosuid, nodev и т.д. В идеале, отдельный раздел и настройки должны быть ещё и у /var/log, /home, /dev/shm. Пример параметров в fstab:
/tmp tmpfs tmpfs rw,nosuid,nodev,noexec,inode6🔹Отслеживайте изменения в системных файлах, например с помощью AIDE (Advanced Intrusion Detection Environment):
# apt install aide aide-common🔹Убедитесь, что загрузка в single user mode требует аутентификации. Для этого обязательно установите пароль root:
# passwd root🔹Отключите Apport Error Reporting Service, которая автоматически отправляет информацию о сбоях (по умолчанию включена):
# systemctl stop apport.service# systemctl --now disable apport.service# apt purge apport🔹По возможности включайте, настраивайте AppArmor.
# apt install apparmor🔹Настройте синхронизацию времени какой-то одной службой (chrony, ntp или systemd-timesyncd).
🔹Проверьте все открытые порты и отключите всё ненужное:
# ss -tulnp🔹Отключите неиспользуемые сетевые протоколы. Например, ipv6. В документе представлена подробная инструкция, как это сделать. Но при этом сделана пометка, что в общем случае рекомендуется оставить ipv6, но корректно настроить всё, что с ним связано. Другие протоколы, которые в общем случае не нужны, но активны: dccp, sctp, rds, tipc. Только убедитесь, что они реально не используются. Какие-то из них могут быть нужны для работы некоторых кластеров.
🔹Настройте Firewall (UFW). Запретите все соединения, кроме разрешённых явно (нормально закрытый файрвол). Не забудьте про все используемые протоколы, в том числе ipv6.
# apt install ufw🔹Настройте аудит доступа, изменения, удаления системных файлов с помощью auditctl.
# apt install auditctl audispd-pluginsУбедитесь, что доступ к логам сервиса ограничен.
🔹По возможности настройте отправку системных логов куда-то вовне. Используйте systemd-journal-remote или rsyslog.
🔹Настройте логирование действий через sudo. Добавьте через
visudo параметр:Defaults logfile="/var/log/sudo.log"Ограничьте использование
su.Документ огромный, но на самом деле там не так много информации. Очень много подробностей по аудиту, логам, файрволу. Если вам реально нужно разобраться, как всё это настраивается, то там есть все примеры вплоть до каждой команды и скрипта.
#cis #security #linux
{kind=link}
Недавно рассказывал, как я гипервизор случайно перезагрузил и не заметил. Тогда сразу в голове родился мем, но не было повода опубликовать.
У вас бывает небольшой мандраж, когда перезагружаете важный сервер? Особенно если это происходит редко. И особенно, если он железный, стоит где-то на удалённой площадке или в ЦОД, и при старте он очень долго поднимается, потому что там куча проверок железа.
Я обычно запускаю бесконечный пинг и жду 3-4 минуты. Если сервер не начинает отвечать за это время, открываю консоль сервера. Она есть не всегда.
Сейчас призадумался и вспомнил историю, когда сервер не поднялся. Из него вынули штатно одиночный диск, предварительно отмонтировав. Но забыли поправить fstab, он там остался. Проработал где-то пол года так, потом случился reboot. Сервер не поднялся, загрузился в single mode. Пришлось ехать, разбираться. Благо сразу понял в чём дело, как ошибку увидел. Отлегло, когда так быстро починил. Помню, что это был гипервизор XEN. Там под капотом Centos 5 стояла.
#мем
У вас бывает небольшой мандраж, когда перезагружаете важный сервер? Особенно если это происходит редко. И особенно, если он железный, стоит где-то на удалённой площадке или в ЦОД, и при старте он очень долго поднимается, потому что там куча проверок железа.
Я обычно запускаю бесконечный пинг и жду 3-4 минуты. Если сервер не начинает отвечать за это время, открываю консоль сервера. Она есть не всегда.
Сейчас призадумался и вспомнил историю, когда сервер не поднялся. Из него вынули штатно одиночный диск, предварительно отмонтировав. Но забыли поправить fstab, он там остался. Проработал где-то пол года так, потом случился reboot. Сервер не поднялся, загрузился в single mode. Пришлось ехать, разбираться. Благо сразу понял в чём дело, как ошибку увидел. Отлегло, когда так быстро починил. Помню, что это был гипервизор XEN. Там под капотом Centos 5 стояла.
#мем
Хочу продолжить вчерашнюю тему с удалёнными перезагрузками и отрубанием серверов. Немного повспоминал и решил сразу написать, пока не забыл, ещё несколько своих историй по этой теме.
1️⃣ Эту историю я тут описывал и даже статью написал. После обновления сделал штатную перезагрузку виртуалки, а она не поднялась. Немного подождал и пошёл смотреть консоль. Там принудительно началась проверка fsck диска на 3Тб. Длилась она несколько часов. Пришлось понервничать, так как не был уверен, что всё завершится благополучно. С тех пор на больших дисках слежу за этими проверками.
2️⃣ Этот случай был недавно. Достался в наследство сервер с MSSQL, где базы вынесены на отдельный дисковый массив, который представляет из себя внешнюю коробку, подключенную по SCSI разъёму (если не ошибаюсь, точно не помню уже). Проблема в том, что коробочка недорогая. Качество уровня desktop, больше для домашних пользователей. Решили сэкономить. После штатного отключения питания, коробочка не включилась. У неё было своё отдельное питание. Сервер загрузился, базы все лежат. Подключаюсь к серверу, массива нет, соответственно, ничего не работает. Попросил человека на месте проверить, в чём дело. Сказал, что коробка выключена и не включается.
Бэкапы все были, начал разворачивать. Проблема в том, что сервер железный. То есть пришлось поднимать новый сервер уже в VM. Пока это делал, инициативный человек на месте отключил коробку, разобрал, продул, собрал и она заработала. Пока работает, но на подхвате уже готов новый сервер, за бэкапами слежу. Переезд уже запланирован.
3️⃣ С подобной ситуацией сталкивался не раз и уже сильно учёный на этот счёт. Все серваки, подключенные к УПСу должны штатно завершать свою работу, когда заряд кончается. Обычно к этому приходят не сразу, а после того, как в один прекрасный день электричество вырубят не на 5 минут, а на пол дня.
И второй важный момент. Они не должны подниматься автоматически. К этому тоже приходят не сразу, а после того, как хапнут проблем. Я всё это проходил. Вырубается электричество, серваки штатно завершают работу, когда батареи пусты. Потом подаётся электричество, серваки включаются, а через 5 минут электричество опять отключают. И всё моментально аварийно падает в момент загрузки. На этом этапе я лично терял VM. С тех пор автоматически запускаются только гипервизоры. А виртуальные машины я или кто-то ещё включает вручную через некоторое время, когда точно понятно, что отключения прекратились и батареи немного зарядились.
❗️ Это просто совет. Когда меняете сетевые настройки, существенные параметры файрвола, либо что-то по железу (добавляете какое-то хранилище, сетевую карту с загрузкой драйвера), либо в системе то, что потенциально может приводить к проблемам загрузки или внешнего доступа. Не откладывайте перезагрузку, а сделайте её по возможности как можно раньше. Иначе может случиться так, что вы через пол года перезагрузите сервер и начнутся проблемы, которые вызваны этими изменениями, а вы про них забыли. Таких примеров у меня была масса.
Например, подключил хранилище, добавил запись в fstab или с ошибкой, или вообще забыл это сделать. А через несколько месяцев перезагрузил сервер. Включаешь его, а данных нет, служба не работает. Начинаешь в панике разбираться, в чём дело.
Либо настраиваешь firewall, применяешь правила, всё в порядке, доступ на месте. И забываешь включить автозапуск файрвола. Через несколько месяцев перезагружаешься и не замечаешь, что правил нет и у тебя всё в открытом доступе. Потом это долго можно не замечать, если не ставил на мониторинг.
Ещё пример. Меняешь сложный dialplan в asterisk. Перезагрузку откладываешь на потом, чтобы не прерывать текущую работу. И забываешь. А при очередной перезагрузке не можешь понять, почему что-то работает неправильно. Трудно быстро вникнуть и вспомнить, что ты менял несколько месяцев назад.
После существенных изменений лучше сразу же перезагрузиться и убедиться, что всё в порядке и работает так, как вы только что настроили.
#железо
1️⃣ Эту историю я тут описывал и даже статью написал. После обновления сделал штатную перезагрузку виртуалки, а она не поднялась. Немного подождал и пошёл смотреть консоль. Там принудительно началась проверка fsck диска на 3Тб. Длилась она несколько часов. Пришлось понервничать, так как не был уверен, что всё завершится благополучно. С тех пор на больших дисках слежу за этими проверками.
2️⃣ Этот случай был недавно. Достался в наследство сервер с MSSQL, где базы вынесены на отдельный дисковый массив, который представляет из себя внешнюю коробку, подключенную по SCSI разъёму (если не ошибаюсь, точно не помню уже). Проблема в том, что коробочка недорогая. Качество уровня desktop, больше для домашних пользователей. Решили сэкономить. После штатного отключения питания, коробочка не включилась. У неё было своё отдельное питание. Сервер загрузился, базы все лежат. Подключаюсь к серверу, массива нет, соответственно, ничего не работает. Попросил человека на месте проверить, в чём дело. Сказал, что коробка выключена и не включается.
Бэкапы все были, начал разворачивать. Проблема в том, что сервер железный. То есть пришлось поднимать новый сервер уже в VM. Пока это делал, инициативный человек на месте отключил коробку, разобрал, продул, собрал и она заработала. Пока работает, но на подхвате уже готов новый сервер, за бэкапами слежу. Переезд уже запланирован.
3️⃣ С подобной ситуацией сталкивался не раз и уже сильно учёный на этот счёт. Все серваки, подключенные к УПСу должны штатно завершать свою работу, когда заряд кончается. Обычно к этому приходят не сразу, а после того, как в один прекрасный день электричество вырубят не на 5 минут, а на пол дня.
И второй важный момент. Они не должны подниматься автоматически. К этому тоже приходят не сразу, а после того, как хапнут проблем. Я всё это проходил. Вырубается электричество, серваки штатно завершают работу, когда батареи пусты. Потом подаётся электричество, серваки включаются, а через 5 минут электричество опять отключают. И всё моментально аварийно падает в момент загрузки. На этом этапе я лично терял VM. С тех пор автоматически запускаются только гипервизоры. А виртуальные машины я или кто-то ещё включает вручную через некоторое время, когда точно понятно, что отключения прекратились и батареи немного зарядились.
❗️ Это просто совет. Когда меняете сетевые настройки, существенные параметры файрвола, либо что-то по железу (добавляете какое-то хранилище, сетевую карту с загрузкой драйвера), либо в системе то, что потенциально может приводить к проблемам загрузки или внешнего доступа. Не откладывайте перезагрузку, а сделайте её по возможности как можно раньше. Иначе может случиться так, что вы через пол года перезагрузите сервер и начнутся проблемы, которые вызваны этими изменениями, а вы про них забыли. Таких примеров у меня была масса.
Например, подключил хранилище, добавил запись в fstab или с ошибкой, или вообще забыл это сделать. А через несколько месяцев перезагрузил сервер. Включаешь его, а данных нет, служба не работает. Начинаешь в панике разбираться, в чём дело.
Либо настраиваешь firewall, применяешь правила, всё в порядке, доступ на месте. И забываешь включить автозапуск файрвола. Через несколько месяцев перезагружаешься и не замечаешь, что правил нет и у тебя всё в открытом доступе. Потом это долго можно не замечать, если не ставил на мониторинг.
Ещё пример. Меняешь сложный dialplan в asterisk. Перезагрузку откладываешь на потом, чтобы не прерывать текущую работу. И забываешь. А при очередной перезагрузке не можешь понять, почему что-то работает неправильно. Трудно быстро вникнуть и вспомнить, что ты менял несколько месяцев назад.
После существенных изменений лучше сразу же перезагрузиться и убедиться, что всё в порядке и работает так, как вы только что настроили.
#железо
▶️ В декабре 2022 года компания Google выпустила небольшой сериал из 6-ти серий на тему того, как она защищает себя и интернет от хакеров - HACKING GOOGLE Series. Получилось интересно и необычно. На русском языке нашёл только трейлер:
⇨ https://www.youtube.com/watch?v=ubLLES_iDtQ
Остальные серии на английском языке можно посмотреть на официальном канале Google в youtube:
⇨ https://www.youtube.com/playlist?list=PL590L5WQmH8dsxxz7ooJAgmijwOz0lh2H
Если на слух не понимаете английский, то нормально смотрится в Яндекс.Браузере с встроенным синхронным переводом. Любителям подобного рода информации крайне рекомендую. Чего то похожего я даже и не видел.
❗️Сразу предупреждаю, что смотреть это надо как развлекательное видео. Повесточки там везде, что можете заметить уже по трейлеру. Например, авторами вируса WannaCry назначили северокорейцев.
#видео #развлечение
⇨ https://www.youtube.com/watch?v=ubLLES_iDtQ
Остальные серии на английском языке можно посмотреть на официальном канале Google в youtube:
⇨ https://www.youtube.com/playlist?list=PL590L5WQmH8dsxxz7ooJAgmijwOz0lh2H
Если на слух не понимаете английский, то нормально смотрится в Яндекс.Браузере с встроенным синхронным переводом. Любителям подобного рода информации крайне рекомендую. Чего то похожего я даже и не видел.
❗️Сразу предупреждаю, что смотреть это надо как развлекательное видео. Повесточки там везде, что можете заметить уже по трейлеру. Например, авторами вируса WannaCry назначили северокорейцев.
#видео #развлечение
YouTube
ВЗЛОМАТЬ ГУГЛ | Сериал Тизер (RU)
Пять элитных команд безопасности. Шесть нерассказанных историй. Загляните за кулисы вместе с хакерскими командами Google, которые обеспечивают безопасность в Интернете большего числа людей, чем кто-либо другой в мире.
Если вы хотите продолжения - пишите…
Если вы хотите продолжения - пишите…
Свежая информация на тему настройки сервера 1С + PostgreSQL 15 на Debian. Я буквально на днях её выполнял. Моя статья по этой теме на текущий день полностью актуальна:
⇨ Установка и настройка 1С на Debian с PostgreSQL
Уточню только, что если будете настраивать выгрузку баз в dt, используйте сразу автономный сервер, если у вас нет желания и необходимости иметь полноценный клиент на сервере без установки графического окружения. Я этой теме много внимания уделил в статье, но необходимость в этом возникает редко и почти никому не нужно. А времени можно потратить много, так как настройка работы графических приложений через xvfb без установки полноценного рабочего стола нетривиальна и замороченна.
❗️ Важное дополнение, которое возможно сэкономит кому-то время. Сборка PostgreSQL 15 с патчами для 1С от Postgres Professional не поддерживает установку на Debian 12. Нету репозитория для этой системы. Мне хотелось всё развернуть на 12-й версии. Обманул установщик, подключил репы на Debian 12, но всё равно СУБД не установилась. Возникают проблемы с зависимостями.
Для получения этой версии PostgreSQL, необходимо сделать запрос на сайте https://1c.postgres.ru/ и вам придёт инструкция на почту. Кому не хочется этим заниматься, сразу даю ссылку на скрипт подключения репозиториев для всех поддерживаемых систем:
Или вот готовый репозиторий под Debian 11:
Соответственно, если у вас 1С сервера на Debian 11, не торопитесь обновлять систему. А я уже кое-где собирался обновляться. Надо подождать, пока не появятся репозитории Postgres Professional под 12-ю версию.
#1С
⇨ Установка и настройка 1С на Debian с PostgreSQL
Уточню только, что если будете настраивать выгрузку баз в dt, используйте сразу автономный сервер, если у вас нет желания и необходимости иметь полноценный клиент на сервере без установки графического окружения. Я этой теме много внимания уделил в статье, но необходимость в этом возникает редко и почти никому не нужно. А времени можно потратить много, так как настройка работы графических приложений через xvfb без установки полноценного рабочего стола нетривиальна и замороченна.
❗️ Важное дополнение, которое возможно сэкономит кому-то время. Сборка PostgreSQL 15 с патчами для 1С от Postgres Professional не поддерживает установку на Debian 12. Нету репозитория для этой системы. Мне хотелось всё развернуть на 12-й версии. Обманул установщик, подключил репы на Debian 12, но всё равно СУБД не установилась. Возникают проблемы с зависимостями.
Для получения этой версии PostgreSQL, необходимо сделать запрос на сайте https://1c.postgres.ru/ и вам придёт инструкция на почту. Кому не хочется этим заниматься, сразу даю ссылку на скрипт подключения репозиториев для всех поддерживаемых систем:
# wget https://repo.postgrespro.ru/1c-15/keys/pgpro-repo-add.sh# sh pgpro-repo-add.shИли вот готовый репозиторий под Debian 11:
deb http://repo.postgrespro.ru/1c-15/debian bullseye mainСоответственно, если у вас 1С сервера на Debian 11, не торопитесь обновлять систему. А я уже кое-где собирался обновляться. Надо подождать, пока не появятся репозитории Postgres Professional под 12-ю версию.
#1С
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
В логировании современных систем и программ в основном используют два подхода к распределению логов и событий по важности. Один из них поддерживает 8 уровней важности, или значимости. Не знаю, как правильно перевести severity levels, передав их смысл. Эти уровни пришли из формата логов syslog, появившемся в 80-х годах. Вот эти уровни:
▪ Emergency
▪ Alert
▪ Critical
▪ Error
▪ Warning
▪ Notice
▪ Informational
▪ Debug
Чем ниже идти по приведённому списку, тем больше информации будет в логах. Соответственно, если настраиваете систему логирования, то внимательно смотрите, какой уровень логов будете собирать.
Debug чаще всего не предназначен для долговременного хранения, а включается только во время отладки приложения. Если забудете отключить этот уровень, потом с удивлением обнаружите, что ваши логи разрослись до огромных размеров и работать с ними неудобно. Надо чистить. Постоянно информация уровня Debug обычно не нужна.
Например, такой формат логов поддерживает Nginx или Apache. В них явно можно указать, какого уровня события будут логироваться.
В современной разработке прижилась немного упрощённая и более конкретная схема важности логирования или ошибок:
▪ Fatal
▪ Error
▪ Warn
▪ Info
▪ Debug
▪ Trace
Уровни Trace и Debug нужны чаще всего для разработчиков, которые занимаются отладкой. Иногда они объединены в один уровень Debug. С остальными четырьмя уровнями приходится работать уже сопровождению или поддержке.
Уровень Info это обычно информация о работе сервиса: запуск, остановка, перезагрузка и т.д. Реакция на это не нужна. А вот на уровень Warn и выше уже может потребоваться реакция, хотя и не всегда. К примеру, если у вас почтовый сервер Postfix смотрит в интернет, то все неудачные попытки аутентификации будут уровня Warn. И реагировать на это не обязательно. А вот если у вас система в закрытом контуре и неудачных аутентификаций там быть не должно, то на подобное событие нужна реакция.
Уровни Error и Fatal самые критичные. Очевидно, что на них реакция требуется всегда. В соответствии с уровнями событий, настраиваются разные реакции. К примеру, я события типа Info в Zabbix собираю, но никаких реакций и оповещений на них не делаю. С дашбордов обычно тоже их убираю, либо делаю отдельные информационные панели. Например, со списком действий пользователей VPN, подключения и отключения. Реакция на это не нужна, но иногда бывает нужно быстро посмотреть, кто сейчас подключен. Отлично подойдёт виджет с такой информацией.
Так что рекомендую осмысленно подходить к классификации событий. Это помогает и упрощает настройку систем мониторинга и оповещений.
#linux #logs
▪ Emergency
▪ Alert
▪ Critical
▪ Error
▪ Warning
▪ Notice
▪ Informational
▪ Debug
Чем ниже идти по приведённому списку, тем больше информации будет в логах. Соответственно, если настраиваете систему логирования, то внимательно смотрите, какой уровень логов будете собирать.
Debug чаще всего не предназначен для долговременного хранения, а включается только во время отладки приложения. Если забудете отключить этот уровень, потом с удивлением обнаружите, что ваши логи разрослись до огромных размеров и работать с ними неудобно. Надо чистить. Постоянно информация уровня Debug обычно не нужна.
Например, такой формат логов поддерживает Nginx или Apache. В них явно можно указать, какого уровня события будут логироваться.
В современной разработке прижилась немного упрощённая и более конкретная схема важности логирования или ошибок:
▪ Fatal
▪ Error
▪ Warn
▪ Info
▪ Debug
▪ Trace
Уровни Trace и Debug нужны чаще всего для разработчиков, которые занимаются отладкой. Иногда они объединены в один уровень Debug. С остальными четырьмя уровнями приходится работать уже сопровождению или поддержке.
Уровень Info это обычно информация о работе сервиса: запуск, остановка, перезагрузка и т.д. Реакция на это не нужна. А вот на уровень Warn и выше уже может потребоваться реакция, хотя и не всегда. К примеру, если у вас почтовый сервер Postfix смотрит в интернет, то все неудачные попытки аутентификации будут уровня Warn. И реагировать на это не обязательно. А вот если у вас система в закрытом контуре и неудачных аутентификаций там быть не должно, то на подобное событие нужна реакция.
Уровни Error и Fatal самые критичные. Очевидно, что на них реакция требуется всегда. В соответствии с уровнями событий, настраиваются разные реакции. К примеру, я события типа Info в Zabbix собираю, но никаких реакций и оповещений на них не делаю. С дашбордов обычно тоже их убираю, либо делаю отдельные информационные панели. Например, со списком действий пользователей VPN, подключения и отключения. Реакция на это не нужна, но иногда бывает нужно быстро посмотреть, кто сейчас подключен. Отлично подойдёт виджет с такой информацией.
Так что рекомендую осмысленно подходить к классификации событий. Это помогает и упрощает настройку систем мониторинга и оповещений.
#linux #logs
Очень простой и быстрый способ настроить уведомления об успешном SSH подключении к серверу в Telegram. Для этого понадобится свой bot, простенький bash скрипт и изменение конфига PAM для SSH. Будем через него уведомления делать.
Рассказывать про создание бота не буду. Надо создать нового бота, получить его токен. Также понадобится ваш ID. Узнать можно разными способами, например через бота @my_id_bot.
Далее берём простой скрипт:
Тут мы проверяем переменную PAM_TYPE. Если это что-то отличное от закрытия сессии, то нам подходит. Проверить работу скрипта можно примерно так:
От бота вам должно прийти уведомление в указанном выше формате. Только имени пользователя не будет, потому что переменную PAM_USER не задали.
Копируем этот скрипт в директорию /etc/ssh/ и выставляем минимальные права:
Далее открываем конфиг
На этом всё. Теперь при успешном SSH подключении вы будете получать уведомление в Telegram.
По аналогии с этим скриптом, вы можете сделать уведомления и на другие события. Например, на закрытие сессии, или на неудачную аутентификацию.
Единственное, что мне хотелось бы сделать, но не получилось - вывести в уведомление IP адрес подключившегося пользователя. Я не нашёл в переменных PAM этой информации. А парсить лог ssh подключений не захотелось. Это делает решение неуниверсальным. В представленном виде сообщения будут такие:
2023-08-07, Monday 15:10
SSH Login: root@debian11
Подробная дата (date +"%Y-%m-%d, %A %R"), имя пользователя ($PAM_USER) и имя сервера (hostname). Можете добавить какую-то ещё информацию по своему усмотрению. Если кто-то знает переменную PAM с информацией об адресе подключившегося, подскажите. Я не нашёл такой информации.
#linux #bash #ssh #security
Рассказывать про создание бота не буду. Надо создать нового бота, получить его токен. Также понадобится ваш ID. Узнать можно разными способами, например через бота @my_id_bot.
Далее берём простой скрипт:
#!/bin/bashif [ "$PAM_TYPE" != "close_session" ]; then ID=1307682341 BOT_TOKEN=6327355747:AAEDcFIlhKSIOKS-t2I9ARTdT1usbq2a9W4 message="$(date +"%Y-%m-%d, %A %R")"$'\n'"SSH Login: $PAM_USER@$(hostname)" curl -s --data "text=$message" --data "chat_id=$ID" 'https://api.telegram.org/bot'$BOT_TOKEN'/sendMessage' > /dev/nullfiТут мы проверяем переменную PAM_TYPE. Если это что-то отличное от закрытия сессии, то нам подходит. Проверить работу скрипта можно примерно так:
# PAM_TYPE=open_session ./ssh-success.shОт бота вам должно прийти уведомление в указанном выше формате. Только имени пользователя не будет, потому что переменную PAM_USER не задали.
Копируем этот скрипт в директорию /etc/ssh/ и выставляем минимальные права:
# chown root /etc/ssh/ssh-success.sh# chmod 100 /etc/ssh/ssh-success.shДалее открываем конфиг
/etc/pam.d/sshd и добавляем туда:# Send a login notification to Telegram via ssh-success.shsession optional pam_exec.so seteuid /etc/ssh/ssh-success.shНа этом всё. Теперь при успешном SSH подключении вы будете получать уведомление в Telegram.
По аналогии с этим скриптом, вы можете сделать уведомления и на другие события. Например, на закрытие сессии, или на неудачную аутентификацию.
Единственное, что мне хотелось бы сделать, но не получилось - вывести в уведомление IP адрес подключившегося пользователя. Я не нашёл в переменных PAM этой информации. А парсить лог ssh подключений не захотелось. Это делает решение неуниверсальным. В представленном виде сообщения будут такие:
2023-08-07, Monday 15:10
SSH Login: root@debian11
Подробная дата (date +"%Y-%m-%d, %A %R"), имя пользователя ($PAM_USER) и имя сервера (hostname). Можете добавить какую-то ещё информацию по своему усмотрению. Если кто-то знает переменную PAM с информацией об адресе подключившегося, подскажите. Я не нашёл такой информации.
#linux #bash #ssh #security
{kind=link}
Некоторое время назад у Mikrotik вышли обновления long term прошивки 6-й версии RouterOS. Первое было в мае, второе в июле. До этого более 1,5 лет не было обновлений. И при этом там почти нет значительных изменений или латания каких-то дыр. Более того, описания этих двух обновлений почти совпадают, а в датах выхода, которые видно через интерфейс роутера, вообще ошибка. Одна и та же стоит для обоих версий.
Я даже как-то раз полгода назад специально проверял, не было ли long term обновлений. Было странно, что так долго нет обновлений. Раньше они регулярно выходили. Думал, что это у меня какие-то проблемы, или доступ к серверу обновлений ограничили. Но ничего этого не было. Версия CHR у меня тоже нормально работает, лицензия активна.
С одной стороны это говорит о том, что развитие 6-й версии фактически завершено. А с другой о том, что и дыр никаких за это время обнаружено не было, так что в обновлениях не было необходимости.
Как по мне, так это отлично для сетевых устройств. Чем меньше там дыр, обновлений и нововведений, тем лучше. Настроил один раз и забыл. При этом лично мне нововведения 7-й версии не нужны. Так что все устройства Mikrotik под моим управлением до сих пор на 6-й версии. Обновлять не планирую, пока не объявят прекращение поддержки этой версии.
#mikrotik
Я даже как-то раз полгода назад специально проверял, не было ли long term обновлений. Было странно, что так долго нет обновлений. Раньше они регулярно выходили. Думал, что это у меня какие-то проблемы, или доступ к серверу обновлений ограничили. Но ничего этого не было. Версия CHR у меня тоже нормально работает, лицензия активна.
С одной стороны это говорит о том, что развитие 6-й версии фактически завершено. А с другой о том, что и дыр никаких за это время обнаружено не было, так что в обновлениях не было необходимости.
Как по мне, так это отлично для сетевых устройств. Чем меньше там дыр, обновлений и нововведений, тем лучше. Настроил один раз и забыл. При этом лично мне нововведения 7-й версии не нужны. Так что все устройства Mikrotik под моим управлением до сих пор на 6-й версии. Обновлять не планирую, пока не объявят прекращение поддержки этой версии.
#mikrotik
{kind=link}
Существует удобный инструмент для поддержания постоянного подключения по SSH - Autossh. Это бесплатная программа, которая есть в стандартных репозиториях популярных дистрибутивов.
Autossh отслеживает SSH соединение, и если оно разрывается, переподключает. Я не знаю, где это может быть полезно, кроме как в случаях использования туннелей или проброса портов через SSH. Покажу на примере, как это работает.
Допустим, у вас есть какой-то сервер в интернете с внешним IP адресом. И вы хотите превратить его в jump хост, подключаясь через него к другим серверам в закрытом сегменте без прямого доступа к ним через интернет.
Настраиваем доступ с закрытых хостов к внешнему серверу через ключи. Проверяем в ручном режиме, что они работают. Для SSH туннелей как на внешнем сервере, так и на внутренних, можно создать отдельного пользователя. Это необязательно, но так будет удобнее и безопаснее. Shell ему можно не назначать, указав nologin.
Сначала просто проверяем соединение:
Синтаксис тут один в один как у обычной службы sshd в том, что касается ssh соединения. То есть выполняем стандартный обратный проброс через ssh. Локальный порт 22 пробрасываем на удалённый хост 1.1.1.1 на порт 9033. Опции autossh можете посмотреть в его описании. Не буду на этом подробно останавливаться.
Теперь можно подключиться к внешнему серверу и на нём подключиться к внутреннему серверу:
Окажетесь на закрытом сервере, на котором запустили autossh.
Теперь сделаем всё красиво, запуская autossh через systemd под отдельной учётной записью. Создаём юнит
Запускаем и добавляем в автозагрузку:
Проверяем на внешнем сервере:
Всё работает. Заходим на внешний сервер и через его консоль подключаемся к закрытым серверам. Подобным образом можно настроить постоянное подключение NFS сервера по SSH.
По необходимости можно ограничивать разрешённые команды по ssh, либо настроить логирование действий.
#ssh
# apt install autosshAutossh отслеживает SSH соединение, и если оно разрывается, переподключает. Я не знаю, где это может быть полезно, кроме как в случаях использования туннелей или проброса портов через SSH. Покажу на примере, как это работает.
Допустим, у вас есть какой-то сервер в интернете с внешним IP адресом. И вы хотите превратить его в jump хост, подключаясь через него к другим серверам в закрытом сегменте без прямого доступа к ним через интернет.
Настраиваем доступ с закрытых хостов к внешнему серверу через ключи. Проверяем в ручном режиме, что они работают. Для SSH туннелей как на внешнем сервере, так и на внутренних, можно создать отдельного пользователя. Это необязательно, но так будет удобнее и безопаснее. Shell ему можно не назначать, указав nologin.
Сначала просто проверяем соединение:
# autossh -M 0 -N -p 22777 -f -q -i /home/userssh/.ssh/id_rsa \-o "ExitOnForwardFailure=yes" -o "ServerAliveInterval=30" \-o "ServerAliveCountMax=3" -R 9033:localhost:22 \userssh@1.1.1.1Синтаксис тут один в один как у обычной службы sshd в том, что касается ssh соединения. То есть выполняем стандартный обратный проброс через ssh. Локальный порт 22 пробрасываем на удалённый хост 1.1.1.1 на порт 9033. Опции autossh можете посмотреть в его описании. Не буду на этом подробно останавливаться.
Теперь можно подключиться к внешнему серверу и на нём подключиться к внутреннему серверу:
# ssh -p 9033 root@localhost Окажетесь на закрытом сервере, на котором запустили autossh.
Теперь сделаем всё красиво, запуская autossh через systemd под отдельной учётной записью. Создаём юнит
/etc/systemd/system/autossh.service:[Unit]Description=SSH Reverse TunnelAfter=network-online.target[Service]Type=forkingUser=usersshExecStart=/usr/bin/autossh -M 0 -N -p 22777 -f -q -i /home/userssh/.ssh/id_rsa -o "ExitOnForwardFailure=yes" -o "ServerAliveInterval=30" -o "ServerAliveCountMax=3" -R 9033:localhost:22 userssh@1.1.1.1ExecStop=/usr/bin/pkill -9 -u usersshRestartSec=5Restart=always[Install]WantedBy=multi-user.targetЗапускаем и добавляем в автозагрузку:
# systemctl daemon-reload# systemctl start autossh.service# systemctl enable autossh.serviceПроверяем на внешнем сервере:
# netstat -tulnp | grep 9033tcp 0 0 127.0.0.1:9033 0.0.0.0:* LISTEN 19814/sshd: usersshtcp6 0 0 ::1:9033 :::* LISTEN 19814/sshd: usersshВсё работает. Заходим на внешний сервер и через его консоль подключаемся к закрытым серверам. Подобным образом можно настроить постоянное подключение NFS сервера по SSH.
По необходимости можно ограничивать разрешённые команды по ssh, либо настроить логирование действий.
#ssh
Я всегда на одиночных веб серверах использую для отправки почты локальный Postfix. И хотя я не раз рассказывал про различные сервисы для отправки почты или специализированные серверы, которые можно развернуть у себя только для рассылок с сайта, сам я неизменно использую Postfix, потому что хорошо его знаю.
Назову несколько причин, почему отдаю предпочтение именно локальному Postfix.
1️⃣ У Postfix хорошее логирование. Всегда точно можно узнать, что, когда, кому было отправлено и какой статус получила эта отправка. Было ли письмо реально принято удалённой стороной или отклонено. Это особенно актуально для сайтов, где нет собственного логирования отправки, либо оно не очень информативное.
2️⃣ Вы без проблем можете направлять всю отправленную почту в отдельные ящики для аналитики, контроля или бэкапа. Всё делается средствами самого Postfix. Для разных сайтов и доменов можно настроить свои правила.
3️⃣ С помощью Postfix можно гибко управлять отправкой. Какую-то почту можно отправлять самостоятельно, какую-то направлять на отправку через внешний smtp сервер. Для каждого сайта, почтового домена или отдельного ящика можно настроить свои маршруты отправки.
4️⃣ Благодаря подробному логированию для Postfix легко настроить мониторинг, подсчёт статистики. Это позволит сразу заметить, если ваш сайт взломают и начнут рассылать через него спам, что случается не редко, если сайт не обслуживают и своевременно не обновляют. Много раз с этим сталкивался. Можно легко вычислить бота, который начнёт спамить в личку пользователям сайта. Им тут же полетят уведомления на почту. Статистика почты часто позволяет обнаружить проблемы быстрее всего. Советую использовать эту возможность.
5️⃣ Вы можете на ходу менять содержимое письма без участия непосредственно сайта, только средствами Postfix. Например, менять адрес отправителя или тему письма. Это снимет лишнюю задачу с разработчиков.
Ссылки на мои статьи по данной теме:
▪ Мониторинг postfix в zabbix
▪ Настройка маршрута отправки в зависимости от домена
▪ Как изменить тему письма и адрес отправителя через postfix
▪ Выбор сервера для отправки в зависимости от получателя
#postfix #mailserver #webserver
Назову несколько причин, почему отдаю предпочтение именно локальному Postfix.
1️⃣ У Postfix хорошее логирование. Всегда точно можно узнать, что, когда, кому было отправлено и какой статус получила эта отправка. Было ли письмо реально принято удалённой стороной или отклонено. Это особенно актуально для сайтов, где нет собственного логирования отправки, либо оно не очень информативное.
2️⃣ Вы без проблем можете направлять всю отправленную почту в отдельные ящики для аналитики, контроля или бэкапа. Всё делается средствами самого Postfix. Для разных сайтов и доменов можно настроить свои правила.
3️⃣ С помощью Postfix можно гибко управлять отправкой. Какую-то почту можно отправлять самостоятельно, какую-то направлять на отправку через внешний smtp сервер. Для каждого сайта, почтового домена или отдельного ящика можно настроить свои маршруты отправки.
4️⃣ Благодаря подробному логированию для Postfix легко настроить мониторинг, подсчёт статистики. Это позволит сразу заметить, если ваш сайт взломают и начнут рассылать через него спам, что случается не редко, если сайт не обслуживают и своевременно не обновляют. Много раз с этим сталкивался. Можно легко вычислить бота, который начнёт спамить в личку пользователям сайта. Им тут же полетят уведомления на почту. Статистика почты часто позволяет обнаружить проблемы быстрее всего. Советую использовать эту возможность.
5️⃣ Вы можете на ходу менять содержимое письма без участия непосредственно сайта, только средствами Postfix. Например, менять адрес отправителя или тему письма. Это снимет лишнюю задачу с разработчиков.
Ссылки на мои статьи по данной теме:
▪ Мониторинг postfix в zabbix
▪ Настройка маршрута отправки в зависимости от домена
▪ Как изменить тему письма и адрес отправителя через postfix
▪ Выбор сервера для отправки в зависимости от получателя
#postfix #mailserver #webserver
{kind=link}
⚠ Хочу предупредить всех, кто занимается поддержкой сайтов. Последнее время часто вижу взломанные сайты. Причём на первый взгляд с сайтами всё в порядке. Они нормально функционируют. Но ровно один раз новому посетителю они открывают вкладку с каким-то левым сайтом. При этом они отслеживают тех, кто пользуется админкой, и им рекламу не показывают. Вы можете быть в полном неведении о том, что у вас взломан сайт.
Я сам с этим сталкивался на одном из обслуживаемых мной сайтов. Хостеру прилетело уведомление от Роскомнадзора удалить ссылку на вредоносный сайт. Он мне переадресовал это. Я был очень удивлён, когда его увидел. Подумал, что какая-то ошибка. Не смог сходу найти проблему. Но потом немного разобрался и решил вопрос. Эту ссылку посетителям из поиска примерно 2 месяца подсовывали. При этом с сайтом каждый день работали человек 10 и не видели ничего подозрительного.
Самое главное, что тут ничего конкретного не посоветуешь. Сайты взламывают совершенно разные и через разные уязвимости. Меня сподвигло написать эту заметку, когда за один день я увидел 2 таких сайта. Причём один на Bitrix, а второй на MaxSite CMS, который вёл какой-то Linux админ. Я техническую статью там читал. А разок была история, что у меня заказывают рекламу, я иду на сайте рекламодателя, и мне открывают левую ссылку. Сайт был взломан, о чём я сразу сообщил. Проблема подтвердилась и её решили. А до этого, как и у меня, не замечали проблему.
Тут я даже не знаю, что можно посоветовать, чтобы гарантированно избежать таких проблем. Если используется какой-то публичный движок, то регулярно его обновляйте. И обязательно следите за тем, чтобы были бэкапы с достаточной глубиной архива. В идеале до года. Я и дольше храню, если есть возможность. Червь может сидеть несколько месяцев и не выдавать себя. Нужно иметь возможность получить незаражённую копию, чтобы наверняка вычистить сайт. Без чистой копии это сделать будет в разы труднее, чем с ней.
Как вариант, регулярно использовать какие-то сканеры сайтов, типа такого:
⇨ https://securityscan.getastra.com/malware-scanner
Но я не прорабатывал этот вопрос и не знаю хороших проверенных инструментов для проверки сайтов на вирусы. Один из вирусов, что я видел, был очень хитрый. Он открывал левую вкладку только тем, кто приходил из поиска. То есть все подобные сканеры ничего не видели, как и админы.
#security #webserver
Я сам с этим сталкивался на одном из обслуживаемых мной сайтов. Хостеру прилетело уведомление от Роскомнадзора удалить ссылку на вредоносный сайт. Он мне переадресовал это. Я был очень удивлён, когда его увидел. Подумал, что какая-то ошибка. Не смог сходу найти проблему. Но потом немного разобрался и решил вопрос. Эту ссылку посетителям из поиска примерно 2 месяца подсовывали. При этом с сайтом каждый день работали человек 10 и не видели ничего подозрительного.
Самое главное, что тут ничего конкретного не посоветуешь. Сайты взламывают совершенно разные и через разные уязвимости. Меня сподвигло написать эту заметку, когда за один день я увидел 2 таких сайта. Причём один на Bitrix, а второй на MaxSite CMS, который вёл какой-то Linux админ. Я техническую статью там читал. А разок была история, что у меня заказывают рекламу, я иду на сайте рекламодателя, и мне открывают левую ссылку. Сайт был взломан, о чём я сразу сообщил. Проблема подтвердилась и её решили. А до этого, как и у меня, не замечали проблему.
Тут я даже не знаю, что можно посоветовать, чтобы гарантированно избежать таких проблем. Если используется какой-то публичный движок, то регулярно его обновляйте. И обязательно следите за тем, чтобы были бэкапы с достаточной глубиной архива. В идеале до года. Я и дольше храню, если есть возможность. Червь может сидеть несколько месяцев и не выдавать себя. Нужно иметь возможность получить незаражённую копию, чтобы наверняка вычистить сайт. Без чистой копии это сделать будет в разы труднее, чем с ней.
Как вариант, регулярно использовать какие-то сканеры сайтов, типа такого:
⇨ https://securityscan.getastra.com/malware-scanner
Но я не прорабатывал этот вопрос и не знаю хороших проверенных инструментов для проверки сайтов на вирусы. Один из вирусов, что я видел, был очень хитрый. Он открывал левую вкладку только тем, кто приходил из поиска. То есть все подобные сканеры ничего не видели, как и админы.
#security #webserver
{kind=link}
Раньше часто писал на отвлечённые темы, а последний год в основном только про IT. Хотя у меня в жизни много чего происходит. Я постоянно в каких-то процессах, изменениях, экспериментах и т.д. Много внимания уделяю детям и воспитанию, семье в целом, но эту тему вообще не поднимаю, хотя она важнее и сложнее профессиональной деятельности.
Сейчас хотел бы вернуться к старой теме со сном, о которой когда-то давно я писал. Хочу обратить ваше внимание на неё, так как это сильно влияет на продуктивность и качество жизни в целом. Речь идёт про ранний подъём и ранний отход ко сну. Я недавно опять пытался перейти на этот режим и снова не получилось закрепить результат. И опять я убедился, что это очень продуктивный и полезный для жизни и здоровья режим сна. Рано или поздно я точно на него перейду.
Чтобы не повторяться, приведу свою старую публикацию. Там всё с подробностями описано.
Хочу рассказать про свой небольшой эксперимент. Чуть более месяца назад я решил регулярно вставать в 5 утра. Так как времени уже прошло прилично и появилась определенная привычка, можно подвести промежуточные итоги.
Мой график сна получается такой. Ложусь чаще всего в 21:00 одновременно с детьми. Засыпаю по-разному, но к 22 уже сплю. Встаю в интервале 5-5:30, сейчас даже без будильника. Самый главный плюс такого режима - мне хватает 7 часов, чтобы полноценно выспаться и встать бодрым. Раньше ложился позже, в 23 - 24, мне нужно было 8-9 часов чтобы выспаться. Четко это фиксировал, так как часто не высыпался и вставал разбитым.
Получается чистая экономия времени в 1-2 часа в сутки. При этом качество сна выше. Я лучше высыпаюсь. Утром встаю, пью много воды, съедаю что-то легкое, обычно фрукт и дальше занимаюсь различными делами. В основном что-то по работе делаю. Например, этот пост пишу, когда на часах 5:55. Домашние все спят где-то до 7-7:30.
И еще такое наблюдение. Часто, когда засиживаешься допоздна, занимаешься всякой фигней - читаешь что-нибудь на смарте или смотришь ютуб. Время улетает незаметно. Хоп, и уже полночь, а то и позже. Сейчас у меня правило - никакого смартфона перед сном. Всегда оставляю его на кухне по вечерам или где-то еще, но не в комнате, в которой сплю. Смартфон сильно снижает качество сна. Утром же мотивация и настроение другие. Тупить не хочется, настрой на созидательную деятельность, на что-то полезное. То есть без всяких усилий деградационные потребности сменились на созидательные автоматически.
Минусы такого режима, думаю, каждый сам видит. Темп современной жизни таков, что очень много процессов откладываются на поздний вечер. Те же посиделки в кафешках и т.д. Я в 22 уже зеваю, сплю и ничего не хочу (в новый год уснул в 21 и встал в 23:40). В целом, мне это не страшно, так как я особо никуда не хожу. Редко в это время бываю не дома.
Еще один минус - иногда приходится делать профилактические работы на серверах, связанные с простоями и ребутами. Это лучше делать вечером, чтобы было в запасе побольше времени. У меня уже был недавно один инцидент, который в течении ночи решил. Если бы делал все утром, вошел с проблемами в рабочий день.
Но в целом, нет проблемы иногда выйти из режима и лечь в двенадцать или чуть позже. Если это несистемно и не чаще 1-2 раза в неделю, то никаких проблем нет. Я просто не встаю в 5, а сплю до 7. На следующий день возвращаешься в обычный режим. Организм становится более устойчив к стрессам и недосыпам. Они проходят мягко.
Вот такой вот опыт. Думаю, кому-то будет полезно. Я все время экспериментирую, пробую что-то новое, чего и вам советую. Все люди разные, у всех свои нюансы. Ищите что-то лучшее для себя и не стойте на месте. У меня много было экспериментов с едой, но в итоге каких-то особых изменений для себя не заметил и вернулся к обычному рациону, к которому привык с детства. Давно уже не пью алкоголь и не курю, хотя плотно сидел на этих зависимостях лет до 30-ти. С ними рекомендую покончить каждому. Это деструктивные привычки, не дающие никаких плюсов, только минусы.
#разное
Сейчас хотел бы вернуться к старой теме со сном, о которой когда-то давно я писал. Хочу обратить ваше внимание на неё, так как это сильно влияет на продуктивность и качество жизни в целом. Речь идёт про ранний подъём и ранний отход ко сну. Я недавно опять пытался перейти на этот режим и снова не получилось закрепить результат. И опять я убедился, что это очень продуктивный и полезный для жизни и здоровья режим сна. Рано или поздно я точно на него перейду.
Чтобы не повторяться, приведу свою старую публикацию. Там всё с подробностями описано.
Хочу рассказать про свой небольшой эксперимент. Чуть более месяца назад я решил регулярно вставать в 5 утра. Так как времени уже прошло прилично и появилась определенная привычка, можно подвести промежуточные итоги.
Мой график сна получается такой. Ложусь чаще всего в 21:00 одновременно с детьми. Засыпаю по-разному, но к 22 уже сплю. Встаю в интервале 5-5:30, сейчас даже без будильника. Самый главный плюс такого режима - мне хватает 7 часов, чтобы полноценно выспаться и встать бодрым. Раньше ложился позже, в 23 - 24, мне нужно было 8-9 часов чтобы выспаться. Четко это фиксировал, так как часто не высыпался и вставал разбитым.
Получается чистая экономия времени в 1-2 часа в сутки. При этом качество сна выше. Я лучше высыпаюсь. Утром встаю, пью много воды, съедаю что-то легкое, обычно фрукт и дальше занимаюсь различными делами. В основном что-то по работе делаю. Например, этот пост пишу, когда на часах 5:55. Домашние все спят где-то до 7-7:30.
И еще такое наблюдение. Часто, когда засиживаешься допоздна, занимаешься всякой фигней - читаешь что-нибудь на смарте или смотришь ютуб. Время улетает незаметно. Хоп, и уже полночь, а то и позже. Сейчас у меня правило - никакого смартфона перед сном. Всегда оставляю его на кухне по вечерам или где-то еще, но не в комнате, в которой сплю. Смартфон сильно снижает качество сна. Утром же мотивация и настроение другие. Тупить не хочется, настрой на созидательную деятельность, на что-то полезное. То есть без всяких усилий деградационные потребности сменились на созидательные автоматически.
Минусы такого режима, думаю, каждый сам видит. Темп современной жизни таков, что очень много процессов откладываются на поздний вечер. Те же посиделки в кафешках и т.д. Я в 22 уже зеваю, сплю и ничего не хочу (в новый год уснул в 21 и встал в 23:40). В целом, мне это не страшно, так как я особо никуда не хожу. Редко в это время бываю не дома.
Еще один минус - иногда приходится делать профилактические работы на серверах, связанные с простоями и ребутами. Это лучше делать вечером, чтобы было в запасе побольше времени. У меня уже был недавно один инцидент, который в течении ночи решил. Если бы делал все утром, вошел с проблемами в рабочий день.
Но в целом, нет проблемы иногда выйти из режима и лечь в двенадцать или чуть позже. Если это несистемно и не чаще 1-2 раза в неделю, то никаких проблем нет. Я просто не встаю в 5, а сплю до 7. На следующий день возвращаешься в обычный режим. Организм становится более устойчив к стрессам и недосыпам. Они проходят мягко.
Вот такой вот опыт. Думаю, кому-то будет полезно. Я все время экспериментирую, пробую что-то новое, чего и вам советую. Все люди разные, у всех свои нюансы. Ищите что-то лучшее для себя и не стойте на месте. У меня много было экспериментов с едой, но в итоге каких-то особых изменений для себя не заметил и вернулся к обычному рациону, к которому привык с детства. Давно уже не пью алкоголь и не курю, хотя плотно сидел на этих зависимостях лет до 30-ти. С ними рекомендую покончить каждому. Это деструктивные привычки, не дающие никаких плюсов, только минусы.
#разное
{kind=link}