
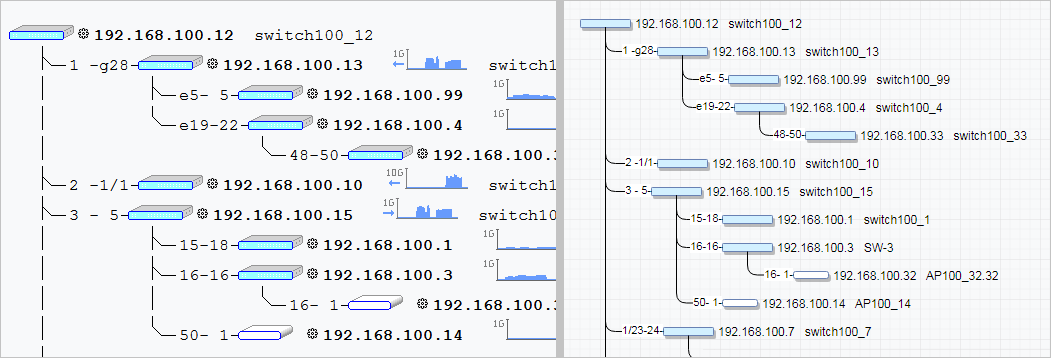
Маленькая простая программа для выполнения одной задачи - рисование топологии локальной сети, построенной на коммутаторах с включённой службой snmp - LanTopoLog. Я её знаю очень давно, ещё в бытность работы в техподдержке.
Программа не требует установки, но при желании может работать в качестве службы Windows. Работает, соответственно, только под Windows. По качеству работы эта программа одна из лучших именно для автоматического построения карты сети. Она использует snmp запросы к коммутаторам для получения и сопоставления информации. Так что для её корректной работы включение snmp обязательно на всех коммутаторах. С Микротиками, кстати, тоже нормально работает.
Программа условно-бесплатная. Без лицензии через некоторое время после запуска, отключается часть возможностей. Для разового просмотра схемы не критично. А если захотите пользоваться постоянно, то придётся купить лицензию. Благо она бессрочная, включает все последующие обновления и стоит 50$ для физиков или 9070₽ для юр. лиц.
📌 Помимо построения схемы, имеет другие возможности:
◽может публиковать схему на веб сервере;
◽следит за доступностью узлов и может уведомлять об этом в telegram или email;
◽отображает скорость портов коммутаторов, утилизацию канала;
◽умеет экспортировать схему в Draw.io;
🔥отслеживает все MAC адреса подключенных к коммутаторам устройств, осуществляет поиск по ним.
Описание можно послушать от админа, который реально пользуется этой программой на работе: https://www.youtube.com/watch?v=Js8N70nmYIg Смотрел раньше все видео с канала этого админа, но он что-то забросил его.
Программа, кстати, от нашего соотечественника. До сих пор поддерживается и обновляется, хотя ей уже 17 лет.
⇨ Сайт
#network #отечественное
Программа не требует установки, но при желании может работать в качестве службы Windows. Работает, соответственно, только под Windows. По качеству работы эта программа одна из лучших именно для автоматического построения карты сети. Она использует snmp запросы к коммутаторам для получения и сопоставления информации. Так что для её корректной работы включение snmp обязательно на всех коммутаторах. С Микротиками, кстати, тоже нормально работает.
Программа условно-бесплатная. Без лицензии через некоторое время после запуска, отключается часть возможностей. Для разового просмотра схемы не критично. А если захотите пользоваться постоянно, то придётся купить лицензию. Благо она бессрочная, включает все последующие обновления и стоит 50$ для физиков или 9070₽ для юр. лиц.
📌 Помимо построения схемы, имеет другие возможности:
◽может публиковать схему на веб сервере;
◽следит за доступностью узлов и может уведомлять об этом в telegram или email;
◽отображает скорость портов коммутаторов, утилизацию канала;
◽умеет экспортировать схему в Draw.io;
🔥отслеживает все MAC адреса подключенных к коммутаторам устройств, осуществляет поиск по ним.
Описание можно послушать от админа, который реально пользуется этой программой на работе: https://www.youtube.com/watch?v=Js8N70nmYIg Смотрел раньше все видео с канала этого админа, но он что-то забросил его.
Программа, кстати, от нашего соотечественника. До сих пор поддерживается и обновляется, хотя ей уже 17 лет.
⇨ Сайт
#network #отечественное
{kind=link}
Напомню тем, кто не знает. У Grafana есть облачный сервис по мониторингу и сбору логов с бесплатным тарифным планом. Называется, как нетрудно догадаться - Grafana Cloud. Для регистрации не надо ничего, кроме адреса почты. Есть бесплатный тарифный план с комфортными ограничениями: 50 GB логов в месяц, 10k метрик.
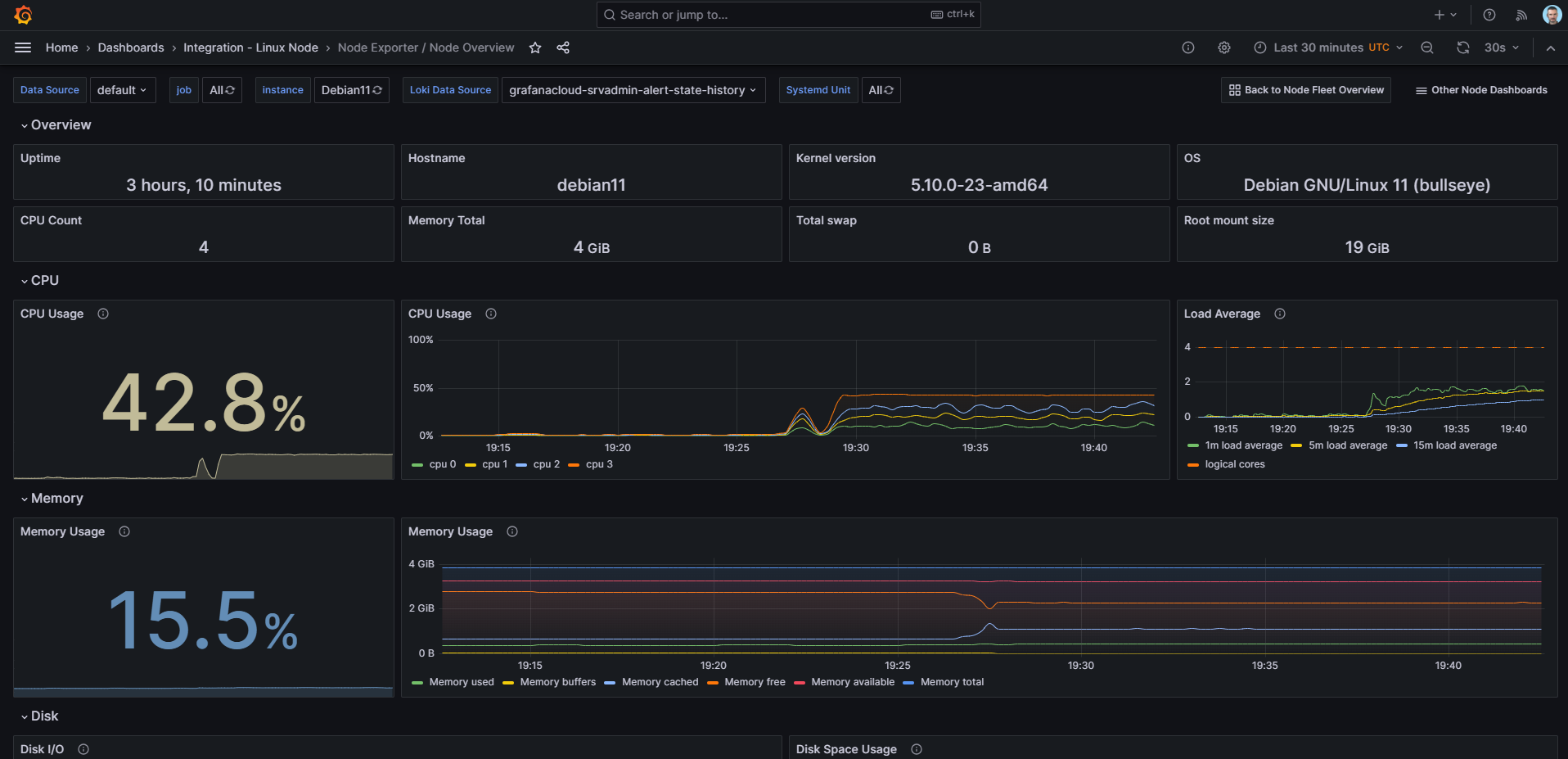
Это отличный способ оценить все возможности системы. Например, хотите посмотреть, как работает мониторинг Linux хоста. Идёте в раздел Connections, добавляете новое соединение типа Linux Server. Открывается готовая инструкция по добавлению хоста:
1️⃣ Устанавливаете Grafana Agent: выбираете тип системы и архитектуру, создаёте API токен, копируете команду для установки агента с интегрированным токеном, запускаете её на хосте. Дожидаетесь установки, проверяете соединение.
2️⃣ Настраиваете интеграцию с облаком — добавляете в конфигурацию агента информацию по сбору метрик и логов. Всё, что необходимо добавить, копируете в готовом виде. Перезапускаете агента на хосте.
3️⃣ Устанавливаете необходимые дашборды. Достаточно жмакнуть на кнопку Install. Всё само установится.
4️⃣ Идёте в раздел Dashboards и смотрите необходимые панели, выбирая в выпадающем списке добавленный хост.
5️⃣ Для просмотра логов (он автоматом все подтягивает из journald и /var/log) идёте в раздел Explore, выбираете в выпадающем списке источник данных с окончанием -log и смотрите логи. Можно как текстовые логи из файлов смотреть, так и systemd с разбивкой на сервисы, уровни важности и т.д.
Таким образом в полуавтоматическом режиме можно добавить все поддерживаемые системы и сервисы: Docker, Nginx, MySQL, Redis, Ceph и т.д. Список огромный.
Grafana - это давно уже не только графики и дашборды, но и полноценная система мониторинга и сбора логов. И всё это в одном месте. Выглядит очень круто и удобно. Если честно, мне всё труднее и труднее объяснить кому-нибудь зачем ему Zabbix. Глядя на Графану, понимаешь, каким простым, красивым и удобным может быть мониторинг. Zabbix удерживает только безграничными возможностями привычного велосипедостроения. Если мониторить что-то типовое, то он давно уже не лучший вариант.
#мониторинг #grafana
Это отличный способ оценить все возможности системы. Например, хотите посмотреть, как работает мониторинг Linux хоста. Идёте в раздел Connections, добавляете новое соединение типа Linux Server. Открывается готовая инструкция по добавлению хоста:
1️⃣ Устанавливаете Grafana Agent: выбираете тип системы и архитектуру, создаёте API токен, копируете команду для установки агента с интегрированным токеном, запускаете её на хосте. Дожидаетесь установки, проверяете соединение.
2️⃣ Настраиваете интеграцию с облаком — добавляете в конфигурацию агента информацию по сбору метрик и логов. Всё, что необходимо добавить, копируете в готовом виде. Перезапускаете агента на хосте.
3️⃣ Устанавливаете необходимые дашборды. Достаточно жмакнуть на кнопку Install. Всё само установится.
4️⃣ Идёте в раздел Dashboards и смотрите необходимые панели, выбирая в выпадающем списке добавленный хост.
5️⃣ Для просмотра логов (он автоматом все подтягивает из journald и /var/log) идёте в раздел Explore, выбираете в выпадающем списке источник данных с окончанием -log и смотрите логи. Можно как текстовые логи из файлов смотреть, так и systemd с разбивкой на сервисы, уровни важности и т.д.
Таким образом в полуавтоматическом режиме можно добавить все поддерживаемые системы и сервисы: Docker, Nginx, MySQL, Redis, Ceph и т.д. Список огромный.
Grafana - это давно уже не только графики и дашборды, но и полноценная система мониторинга и сбора логов. И всё это в одном месте. Выглядит очень круто и удобно. Если честно, мне всё труднее и труднее объяснить кому-нибудь зачем ему Zabbix. Глядя на Графану, понимаешь, каким простым, красивым и удобным может быть мониторинг. Zabbix удерживает только безграничными возможностями привычного велосипедостроения. Если мониторить что-то типовое, то он давно уже не лучший вариант.
#мониторинг #grafana
{kind=link}
На неделе попался забавный мем, который сохранил себе. Понимая, как работают некоторые информационные системы, приходится реально подстраховывать себя.
Например, я всегда храню у себя в бумажном виде всё лечение зубов, все снимки и манипуляции, что мне делали (к сожалению, обширная практика 😔). Хотя лечусь всегда в одной клинике, у которой база данных клиентов и там всё хранится. Но зная, как там это обслуживается, я понимаю, что в один прекрасный момент всё может пропасть.
Я храню все платёжки по ЖКХ, штрафам, оплатам за детей и т.д. Всё, что можно сохранить после оплаты в pdf, сохраняю и кладу в папочку. Уже не раз меня это выручало. И видел, как страдали другие в поисках своих платежей, кто не делает так же. Мне же достаточно был отправить pdf.
Билеты, купленные в онлайн, в обязательном порядке всегда печатаю. Ну и т.д. В общем, этот мем мне очень близок и понятен. Хотя допускаю, что кому-то это может показаться духотой или паранойей. Но мне так комфортнее.
#мем
Например, я всегда храню у себя в бумажном виде всё лечение зубов, все снимки и манипуляции, что мне делали (к сожалению, обширная практика 😔). Хотя лечусь всегда в одной клинике, у которой база данных клиентов и там всё хранится. Но зная, как там это обслуживается, я понимаю, что в один прекрасный момент всё может пропасть.
Я храню все платёжки по ЖКХ, штрафам, оплатам за детей и т.д. Всё, что можно сохранить после оплаты в pdf, сохраняю и кладу в папочку. Уже не раз меня это выручало. И видел, как страдали другие в поисках своих платежей, кто не делает так же. Мне же достаточно был отправить pdf.
Билеты, купленные в онлайн, в обязательном порядке всегда печатаю. Ну и т.д. В общем, этот мем мне очень близок и понятен. Хотя допускаю, что кому-то это может показаться духотой или паранойей. Но мне так комфортнее.
#мем
Недавно в новостях проскочила информация о сервисе windowsupdaterestored.com. Группа энтузиастов задалась целью восстановить работу системы обновления для Windows архивных моделей: 95, NT, 98, Millennium, 2000, XP, Server 2003, Vista. Сразу поясню, что это не новые обновления для старых систем. Это всё те же обновления, что выпускала Microsoft в прошлом, а сейчас просто закрыла сайты с обновлениями для этих систем.
Пока полная поддержка только до XP, то есть работают версии Windows Update v3.1 и v4. У меня есть виртуалка с Windosw XP. Решил попробовать на ней этот сервис. Для неё нужна версия Windows Update v5, поддержка которой ещё не полная. Нужно выполнить некоторые манипуляции на самой системе. Я немного повозился, почти всё получилось, служба заработала в итоге, но обновления так и не пошли. Надо подождать, когда доделают. Хотя на сайте есть ролик, где уже всё работает. Но у меня почему-то не получилось.
Зачем всё это нужно сейчас, я не знаю. Чисто для развлечения. Новых обновлений всё равно нет. Можно найти где-нибудь образы со всеми последними обновлениями и использовать их для установки, если уж понадобится система.
А так сайт прикольный. Прям старина. Мне нравится иногда загрузить старую систему и там потыкать. XP на современном железе в виртуалке просто летает. Так непривычно нажать на ярлык Internet Explorer, и он загружается мгновенно. Быстрее, чем современный браузер на современном компьютере. Хотя я помню, как IE раньше тормозил при первом запуске и меня это жутко раздражало.
Прям даже как-то обидно за прогресс. Параметры железа растут, а отклик приложений падает. Понятно, что возможности софта тоже заметно выросли. Но хотелось бы всё равно увидеть что-то быстрое, пусть и совсем простое, без наворотов. Какой-нибудь браузер на быстром движке, чтобы просто отображать страницы, без дополнительных сервисов, интеграций, виджетов, плагинов и т.д.
#windows
Пока полная поддержка только до XP, то есть работают версии Windows Update v3.1 и v4. У меня есть виртуалка с Windosw XP. Решил попробовать на ней этот сервис. Для неё нужна версия Windows Update v5, поддержка которой ещё не полная. Нужно выполнить некоторые манипуляции на самой системе. Я немного повозился, почти всё получилось, служба заработала в итоге, но обновления так и не пошли. Надо подождать, когда доделают. Хотя на сайте есть ролик, где уже всё работает. Но у меня почему-то не получилось.
Зачем всё это нужно сейчас, я не знаю. Чисто для развлечения. Новых обновлений всё равно нет. Можно найти где-нибудь образы со всеми последними обновлениями и использовать их для установки, если уж понадобится система.
А так сайт прикольный. Прям старина. Мне нравится иногда загрузить старую систему и там потыкать. XP на современном железе в виртуалке просто летает. Так непривычно нажать на ярлык Internet Explorer, и он загружается мгновенно. Быстрее, чем современный браузер на современном компьютере. Хотя я помню, как IE раньше тормозил при первом запуске и меня это жутко раздражало.
Прям даже как-то обидно за прогресс. Параметры железа растут, а отклик приложений падает. Понятно, что возможности софта тоже заметно выросли. Но хотелось бы всё равно увидеть что-то быстрое, пусть и совсем простое, без наворотов. Какой-нибудь браузер на быстром движке, чтобы просто отображать страницы, без дополнительных сервисов, интеграций, виджетов, плагинов и т.д.
#windows
{kind=link}
Когда настраиваешь мониторинг на ненагруженных машинах, хочется дать какую-то среднюю нагрузку, чтобы посмотреть, как выглядят получившиеся графики и дашборды. Для стресс тестов есть специальные утилиты, типа stress. Но чаще всего не хочется что-то устанавливать для этого.
Для этих целей в Linux часто используют псевдоустройства
Получилась универсальная нагрузка, которая идёт как на дисковую подсистему, так и на процессор. Изменяя размер файла (30M) и степень сжатия (-9) можно регулировать эту нагрузку. Чем больше размер файла, тем больше нагрузка на диск, чем больше уровень сжатия, тем больше нагрузка на процессор.
Можно только диски нагрузить и проверить скорость записи. Эту команду я постоянно использую, чтобы быстро оценить, с какими дисками я имею дело:
Увеличивая размер блока данных (1M) или количество этих блоков (1024) можно управлять характером нагрузки и итоговым объёмом записываемых файлов.
Если хотите нагрузить только CPU, то достаточно вот такой простой конструкции:
Она загрузит только одно ядро. Для двух можно запустить их в паре:
Процессы запустятся в фоне, по нажатию Enter в консоли, завершатся. Если у вас нет pkill, используйте killall. Процессор нагрузить проще всего. Можно также использовать что-то типа такого:
Это так же нагрузит одно ядро. Для нескольких, запускайте параллельно в фоне несколько процессов расчёта. Вот ещё один вариант нагрузки на 4 ядра с ограничением времени. В данном случае 10 секунд:
Причём эта нагрузка будет в большей степени в пространстве ядра. А показанная выше с sha1sum в пространстве пользователя. Пример на 2 ядра:
Если убрать timeout, то нагрузка будет длиться до тех пор, пока вы сами её не остановите по Ctrl-C.
Для загрузки памяти в консоли быстрее всего воспользоваться python3:
Съели 1G памяти.
#bash #linux #terminal
Для этих целей в Linux часто используют псевдоустройства
/dev/urandom или /dev/zero, направляя куда-нибудь их вывод. Вот простой пример:# while true; do dd if=/dev/urandom count=30M bs=1 \| bzip2 -9 > /tmp/tempfile ; rm -f /tmp/tempfile ; done Получилась универсальная нагрузка, которая идёт как на дисковую подсистему, так и на процессор. Изменяя размер файла (30M) и степень сжатия (-9) можно регулировать эту нагрузку. Чем больше размер файла, тем больше нагрузка на диск, чем больше уровень сжатия, тем больше нагрузка на процессор.
Можно только диски нагрузить и проверить скорость записи. Эту команду я постоянно использую, чтобы быстро оценить, с какими дисками я имею дело:
# sync; dd if=/dev/zero of=/tmp/tempfile bs=1M count=1024; syncУвеличивая размер блока данных (1M) или количество этих блоков (1024) можно управлять характером нагрузки и итоговым объёмом записываемых файлов.
Если хотите нагрузить только CPU, то достаточно вот такой простой конструкции:
# dd if=/dev/zero of=/dev/nullОна загрузит только одно ядро. Для двух можно запустить их в паре:
# cpuload() { dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null & }; \cpuload; read; pkill ddПроцессы запустятся в фоне, по нажатию Enter в консоли, завершатся. Если у вас нет pkill, используйте killall. Процессор нагрузить проще всего. Можно также использовать что-то типа такого:
# sha1sum /dev/zeroЭто так же нагрузит одно ядро. Для нескольких, запускайте параллельно в фоне несколько процессов расчёта. Вот ещё один вариант нагрузки на 4 ядра с ограничением времени. В данном случае 10 секунд:
# seq 4 | xargs -P0 -n1 timeout 10 yes > /dev/nullПричём эта нагрузка будет в большей степени в пространстве ядра. А показанная выше с sha1sum в пространстве пользователя. Пример на 2 ядра:
# seq 2 | xargs -P0 -n1 timeout 10 sha1sum /dev/zeroЕсли убрать timeout, то нагрузка будет длиться до тех пор, пока вы сами её не остановите по Ctrl-C.
Для загрузки памяти в консоли быстрее всего воспользоваться python3:
# python3 -c 'a="a"*1024**3; input()'Съели 1G памяти.
#bash #linux #terminal
Могу посоветовать необычную связку для доступа извне к внутренним ресурсам без необходимости настройки VPN или программных клиентов. Всё будет работать через браузер. Подход нестандартный, но вполне рабочий. Я реализовывал лично на одиночном сервере для безопасного и простого доступа к виртуалкам.
Задача стояла настроить на Proxmox несколько виртуальных машин: Windows Server для работы с 1С, Debian для PostgreSQL + 1С сервер, Debian для локальных изолированных бэкапов. Плюс я добавил сюда одну служебную виртуалку для шлюза с iptables. Задача была максимально упростить доступ клиентов к 1С без дополнительных настроек, но при этом обезопасить его.
В итоге что я сделал. На служебной виртуалке, которая являлась шлюзом в интернет для остальных виртуальных машин, настроил связку:
1️⃣ Labean — простой сервис, который при обнаружении открытия определённого url на установленном рядом веб сервере, добавляет временное или постоянное правило в iptables. Для настройки надо уметь работать с iptables.
2️⃣ Apache Guacamole — шлюз удалённых подключений, через который с помощью браузера можно по RDP или SSH попасть на сервер.
Работает всё это очень просто. Пользователю отправляются две ссылки. При переходе по первой ссылке labean создаёт правило в iptables для ip адреса клиента, разрешающее ему подключиться к Apache Guacamole. А вторая ссылка ведёт к веб интерфейсу Apache Guacamole, куда пользователю открылся доступ. В Apache Guacamole настраивается учётка для каждого пользователя, где добавлены сервера, к которым ему можно подключаться.
Ссылки для labean настраиваются вручную с не словарными путями, которые невозможно подобрать. Нужно точно знать URL. В данном случае Apache Guacamole выступает для удобства подключения пользователей. Если они готовы настраивать себе клиенты RDP, то можно в labean настраивать сразу проброс по RDP. А можно и то и другое. И каждый сам решает, как он хочется зайти: через RDP клиент или через браузер. Работа в браузере накладывает свои ограничения и не всем подходит.
Вместо labean можно использовать port knocking или настроить HTTP доступ через nginx proxy, закрыв его basic auth. Лично мне реализация через url для labean кажется наиболее простой и удобной для конечного пользователя.
Разумеется, помимо labean, должен быть ещё какой-то путь попасть на эти сервера для управления. Белые списки IP или тот же VPN. Администратору, думаю, будет не трудно настроить себе VPN. Я, кстати, на данном сервере в том числе настроил и OpenVPN для тех, кто готов им пользоваться в обход описанной выше схемы.
#security #gateway #network
Задача стояла настроить на Proxmox несколько виртуальных машин: Windows Server для работы с 1С, Debian для PostgreSQL + 1С сервер, Debian для локальных изолированных бэкапов. Плюс я добавил сюда одну служебную виртуалку для шлюза с iptables. Задача была максимально упростить доступ клиентов к 1С без дополнительных настроек, но при этом обезопасить его.
В итоге что я сделал. На служебной виртуалке, которая являлась шлюзом в интернет для остальных виртуальных машин, настроил связку:
1️⃣ Labean — простой сервис, который при обнаружении открытия определённого url на установленном рядом веб сервере, добавляет временное или постоянное правило в iptables. Для настройки надо уметь работать с iptables.
2️⃣ Apache Guacamole — шлюз удалённых подключений, через который с помощью браузера можно по RDP или SSH попасть на сервер.
Работает всё это очень просто. Пользователю отправляются две ссылки. При переходе по первой ссылке labean создаёт правило в iptables для ip адреса клиента, разрешающее ему подключиться к Apache Guacamole. А вторая ссылка ведёт к веб интерфейсу Apache Guacamole, куда пользователю открылся доступ. В Apache Guacamole настраивается учётка для каждого пользователя, где добавлены сервера, к которым ему можно подключаться.
Ссылки для labean настраиваются вручную с не словарными путями, которые невозможно подобрать. Нужно точно знать URL. В данном случае Apache Guacamole выступает для удобства подключения пользователей. Если они готовы настраивать себе клиенты RDP, то можно в labean настраивать сразу проброс по RDP. А можно и то и другое. И каждый сам решает, как он хочется зайти: через RDP клиент или через браузер. Работа в браузере накладывает свои ограничения и не всем подходит.
Вместо labean можно использовать port knocking или настроить HTTP доступ через nginx proxy, закрыв его basic auth. Лично мне реализация через url для labean кажется наиболее простой и удобной для конечного пользователя.
Разумеется, помимо labean, должен быть ещё какой-то путь попасть на эти сервера для управления. Белые списки IP или тот же VPN. Администратору, думаю, будет не трудно настроить себе VPN. Я, кстати, на данном сервере в том числе настроил и OpenVPN для тех, кто готов им пользоваться в обход описанной выше схемы.
#security #gateway #network
{kind=link}
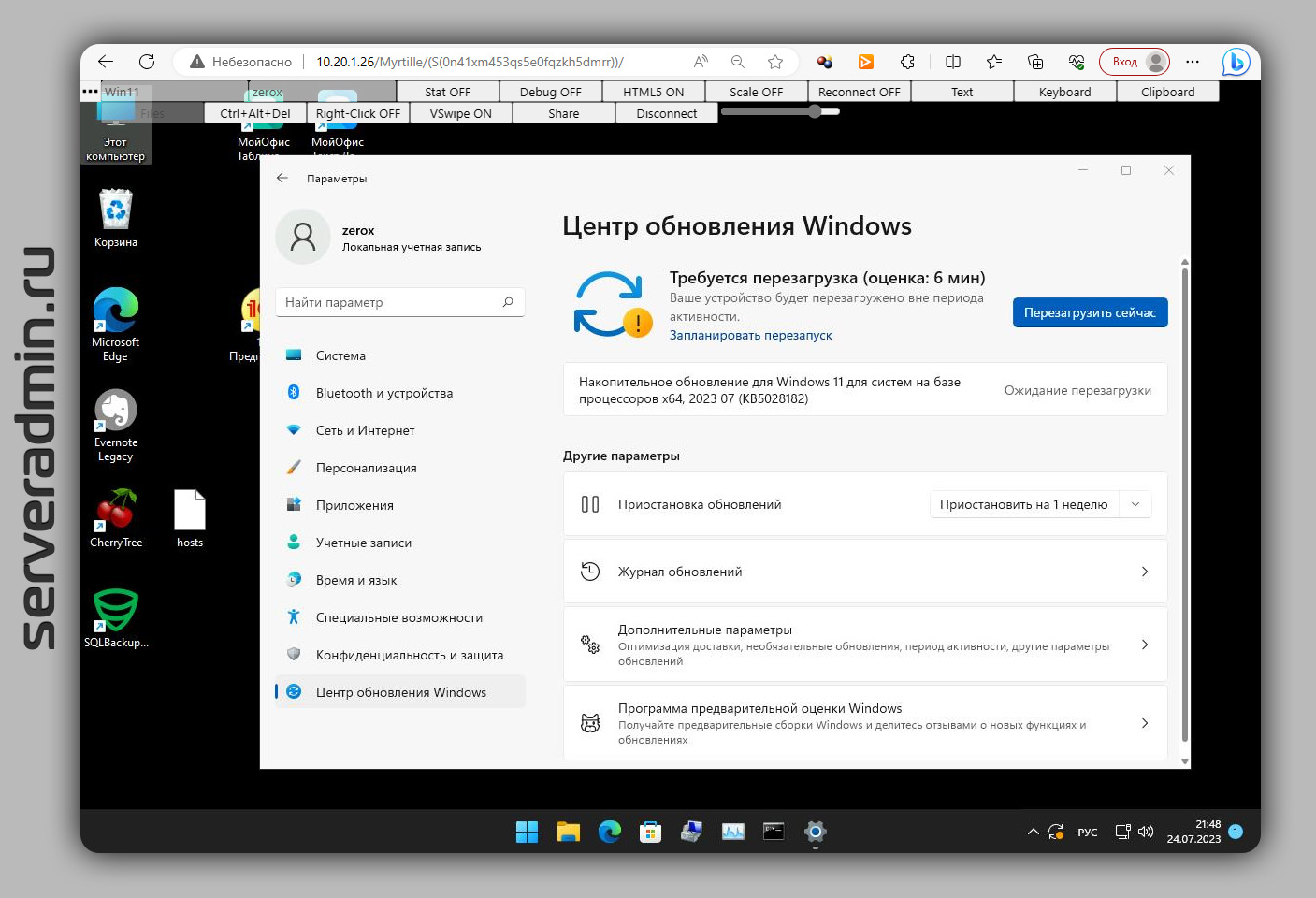
Продолжаю тему RDP и SSH клиентов в браузере. Представляю вам аналог Apache Guacamole, только под Windows — Myrtille. Я давно про неё слышал, ещё когда делал первую заметку про Guacamole, но руки дошли попробовать только сейчас.
Я установил и настроил Myrtille у себя на Windows Server 2019. Достаточно скачать и установить небольшой (46 Мб) msi пакет. Он всё сделал сам. В процессе установки вам предложат указать сервер API и ещё какие-то параметры. Я ничего не указывал. Просто оставил эти поля пустыми. Использовал все параметры по умолчанию.
Потом перезагрузил сервер и зашёл в браузере на страницу
⇨ https://10.20.1.26/Myrtille/
Myrtille выпускает самоподписанный сертификат. Работает программа на базе IIS.
Вас встречает RDP клиент на базе технологии HTML4 или HTML5. Достаточно ввести IP адрес машины, логин, пароль. И вы подключитесь по RDP. Принцип работы такой же, как у Apache Guacamole. В целом, мне понравился этот продукт. Прежде всего простотой настройки. Guacamole пока настроишь, пуд соли съешь: куча пакетов, конфигов, параметров. А тут мышкой клац-клац и всё работает.
У Myrtille куча возможностей. Отмечу некоторые из них:
◽Есть возможность подготовить URL, в котором будут зашиты параметры подключения (сервер, логин, пароль и т.д.). Переходите по ссылке и сразу попадаете на нужную машину. Есть возможность сделать её одноразовой. Подключиться можно будет только один раз.
◽Во время вашей активной сессии можно подготовить ссылку и отправить её другому человеку, чтобы он подключился в ваш сеанс с полными правами, или только для просмотра. Ссылка также будет одноразовой.
◽Если установить Myrtille на гипервизор Hyper-V, есть возможность напрямую подключаться к консоли виртуальных машин.
◽В URL можно зашить программу, которая автоматом запустится после подключения пользователя.
◽Есть REST API, интеграция с Active Directory, Multi-factor аутентификация.
Сразу дам несколько подсказок тем, кто будет тестировать. Учётка по умолчанию: admin / admin. Попасть в интерфейс управления можно либо сразу по ссылке https://10.20.1.26/Myrtille/?mode=admin, либо из основного интерфейса клиента, нажав на ссылку Hosts management. Я не сразу это заметил, поэтому провозился какое-то время, пока нашёл. Параметры подключений в файле C:\Program Files (x86)\Myrtille\js\config.js. Описание параметров в документации.
По умолчанию запускается версия без возможности создания пользователей и групп, чтобы назначать им преднастроенные соединения. То есть либо они ручками подключаются, используют HTTP клиент и заполняя все параметры подключения, либо используют подготовленные заранее ссылки. По умолчанию будет доступен только один пользователь admin, которому можно добавить настроенные соединения. Чтобы это изменить, надо запустить программу в режиме Enterprise Mode. Как это сделать, описано в документации. Я так понял, что для этого нужен AD.
В целом, полезная программа. Если использовать её для себя в административных целях, то вообще никакой настройки не надо. Достаточно веб интерфейс скрыть от посторонних глаз каким-либо способом.
Полезные ссылки, некоторые тоже пришлось поискать:
⇨ Сайт / Исходники / Загрузка / Документация
#remote #windows
Я установил и настроил Myrtille у себя на Windows Server 2019. Достаточно скачать и установить небольшой (46 Мб) msi пакет. Он всё сделал сам. В процессе установки вам предложат указать сервер API и ещё какие-то параметры. Я ничего не указывал. Просто оставил эти поля пустыми. Использовал все параметры по умолчанию.
Потом перезагрузил сервер и зашёл в браузере на страницу
⇨ https://10.20.1.26/Myrtille/
Myrtille выпускает самоподписанный сертификат. Работает программа на базе IIS.
Вас встречает RDP клиент на базе технологии HTML4 или HTML5. Достаточно ввести IP адрес машины, логин, пароль. И вы подключитесь по RDP. Принцип работы такой же, как у Apache Guacamole. В целом, мне понравился этот продукт. Прежде всего простотой настройки. Guacamole пока настроишь, пуд соли съешь: куча пакетов, конфигов, параметров. А тут мышкой клац-клац и всё работает.
У Myrtille куча возможностей. Отмечу некоторые из них:
◽Есть возможность подготовить URL, в котором будут зашиты параметры подключения (сервер, логин, пароль и т.д.). Переходите по ссылке и сразу попадаете на нужную машину. Есть возможность сделать её одноразовой. Подключиться можно будет только один раз.
◽Во время вашей активной сессии можно подготовить ссылку и отправить её другому человеку, чтобы он подключился в ваш сеанс с полными правами, или только для просмотра. Ссылка также будет одноразовой.
◽Если установить Myrtille на гипервизор Hyper-V, есть возможность напрямую подключаться к консоли виртуальных машин.
◽В URL можно зашить программу, которая автоматом запустится после подключения пользователя.
◽Есть REST API, интеграция с Active Directory, Multi-factor аутентификация.
Сразу дам несколько подсказок тем, кто будет тестировать. Учётка по умолчанию: admin / admin. Попасть в интерфейс управления можно либо сразу по ссылке https://10.20.1.26/Myrtille/?mode=admin, либо из основного интерфейса клиента, нажав на ссылку Hosts management. Я не сразу это заметил, поэтому провозился какое-то время, пока нашёл. Параметры подключений в файле C:\Program Files (x86)\Myrtille\js\config.js. Описание параметров в документации.
По умолчанию запускается версия без возможности создания пользователей и групп, чтобы назначать им преднастроенные соединения. То есть либо они ручками подключаются, используют HTTP клиент и заполняя все параметры подключения, либо используют подготовленные заранее ссылки. По умолчанию будет доступен только один пользователь admin, которому можно добавить настроенные соединения. Чтобы это изменить, надо запустить программу в режиме Enterprise Mode. Как это сделать, описано в документации. Я так понял, что для этого нужен AD.
В целом, полезная программа. Если использовать её для себя в административных целях, то вообще никакой настройки не надо. Достаточно веб интерфейс скрыть от посторонних глаз каким-либо способом.
Полезные ссылки, некоторые тоже пришлось поискать:
⇨ Сайт / Исходники / Загрузка / Документация
#remote #windows
{kind=link}
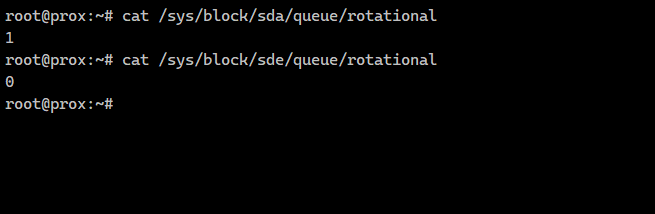
Очень простой и быстрый способ в Linux узнать, какой тип диска у вас в системе, HDD или SSD:
Диск sda — HDD, sde — SSD. Это работает только для железных серверов. То есть параметр буквально указывает, что первый диск с вращением, а второй — без. На основе этих данных ядро системы по возможности избегает одиночного поиска, чтобы лишний раз не дёргать диск. Вместо этого выстраивает запросы в очередь. Для SSD этот механизм становится неактуальным.
В виртуальных машинах могут быть разные значения. Чаще всего они будут показывать, что работают на HDD, если в гипервизоре специально не настроена эмуляция SSD. В Proxmox за это отвечает один из параметров диска — SSD Emulation. Если поставить соответствующую галочку, то виртуалка будет понимать, что работает на SSD. Это имеет смысл делать, хоть и не критично.
Возникает закономерный вопрос, начнёт ли работать технология trim в виртуальной машине, если включена эмуляция SSD. Насколько я смог понять, поискав информацию на эту тему, нет. Включенная эмуляция влияет только на rotational. Trim в виртуальной машине работать по-прежнему не будет.
#железо
# cat /sys/block/sda/queue/rotational1# cat /sys/block/sde/queue/rotational0Диск sda — HDD, sde — SSD. Это работает только для железных серверов. То есть параметр буквально указывает, что первый диск с вращением, а второй — без. На основе этих данных ядро системы по возможности избегает одиночного поиска, чтобы лишний раз не дёргать диск. Вместо этого выстраивает запросы в очередь. Для SSD этот механизм становится неактуальным.
В виртуальных машинах могут быть разные значения. Чаще всего они будут показывать, что работают на HDD, если в гипервизоре специально не настроена эмуляция SSD. В Proxmox за это отвечает один из параметров диска — SSD Emulation. Если поставить соответствующую галочку, то виртуалка будет понимать, что работает на SSD. Это имеет смысл делать, хоть и не критично.
Возникает закономерный вопрос, начнёт ли работать технология trim в виртуальной машине, если включена эмуляция SSD. Насколько я смог понять, поискав информацию на эту тему, нет. Включенная эмуляция влияет только на rotational. Trim в виртуальной машине работать по-прежнему не будет.
#железо
{kind=link}
Вчера слушал вебинар Rebrain по поводу бэкапов MySQL. Мне казалось, что я в целом всё знаю по этой теме. Это так и оказалось, кроме одного маленького момента. Существует более продвинутый аналог mysqldump для создания логических бэкапов — mydumper. Решил сразу сделать про него заметку, чтобы не забыть и самому запомнить инструмент.
Как вы, наверное, знаете, существуют два типа бэкапов MySQL:
1️⃣ Логические, или дампы, как их ещё называют. Это текстовые данные в виде sql команд, которые при восстановлении просто выполняются на сервере. Их обычно делают с помощью утилиты Mysqldump, которая идёт в комплекте с MySQL сервером. Их отличает простота создания и проверки. Из минусов — бэкапы только полные, долго создаются и долго восстанавливаются. В какой-то момент, в зависимости от размера базы и возможностей железа, их делать становится практически невозможно. (моя статья по теме)
2️⃣ Бинарные бэкапы на уровне непосредственно файлов базы данных. Наиболее популярное бесплатное средство для создания таких бэкапов — Percona XtraBackup. Позволяет делать полные и инкрементные бэкапы баз данных и всего сервера СУБД в целом. (моя статья по теме)
Mysqldump делает бэкапы в один поток и на выходе создаёт один файл дампа. Можно это обойти, делая скриптом бэкап таблиц по отдельности, но при таком подходе могут быть проблемы с целостностью итоговой базы. Отдельно таблицу из полного дампа можно вытянуть с помощью sed или awk. Пример потабличного бэкапа базы или вытаскивания отдельной таблицы из полного дампа я делал в заметке.
Так вот, с чего я начал. Есть утилита MyDumper, которая работает чуть лучше Mysqldump. Она делает логический дамп базы данных в несколько потоков и сразу складывает его в отдельные файлы по таблицам. И при этом контролирует целостность итогового бэкапа базы данных. Восстановление такого бэкапа выполняется с помощью MyLoader и тоже в несколько потоков.
Такой подход позволяет выполнять бэкап и восстановление базы в разы быстрее, чем с помощью Mysqldump, если, конечно, позволяет дисковая подсистема сервера. Использовать MyDumper не сложнее, чем Mysqldump. Это та же консольная утилита, которой можно передать параметры в виде ключей или заранее задать в конфигурационном файле. Примеры есть в репозитории.
Я не знал про существовании этой утилиты, хотя почти все свои сервера MySQL бэкаплю в виде логических бэкапов Mysqldump. Надо будет переходить на MyDumper.
#mysql #backup
Как вы, наверное, знаете, существуют два типа бэкапов MySQL:
1️⃣ Логические, или дампы, как их ещё называют. Это текстовые данные в виде sql команд, которые при восстановлении просто выполняются на сервере. Их обычно делают с помощью утилиты Mysqldump, которая идёт в комплекте с MySQL сервером. Их отличает простота создания и проверки. Из минусов — бэкапы только полные, долго создаются и долго восстанавливаются. В какой-то момент, в зависимости от размера базы и возможностей железа, их делать становится практически невозможно. (моя статья по теме)
2️⃣ Бинарные бэкапы на уровне непосредственно файлов базы данных. Наиболее популярное бесплатное средство для создания таких бэкапов — Percona XtraBackup. Позволяет делать полные и инкрементные бэкапы баз данных и всего сервера СУБД в целом. (моя статья по теме)
Mysqldump делает бэкапы в один поток и на выходе создаёт один файл дампа. Можно это обойти, делая скриптом бэкап таблиц по отдельности, но при таком подходе могут быть проблемы с целостностью итоговой базы. Отдельно таблицу из полного дампа можно вытянуть с помощью sed или awk. Пример потабличного бэкапа базы или вытаскивания отдельной таблицы из полного дампа я делал в заметке.
Так вот, с чего я начал. Есть утилита MyDumper, которая работает чуть лучше Mysqldump. Она делает логический дамп базы данных в несколько потоков и сразу складывает его в отдельные файлы по таблицам. И при этом контролирует целостность итогового бэкапа базы данных. Восстановление такого бэкапа выполняется с помощью MyLoader и тоже в несколько потоков.
Такой подход позволяет выполнять бэкап и восстановление базы в разы быстрее, чем с помощью Mysqldump, если, конечно, позволяет дисковая подсистема сервера. Использовать MyDumper не сложнее, чем Mysqldump. Это та же консольная утилита, которой можно передать параметры в виде ключей или заранее задать в конфигурационном файле. Примеры есть в репозитории.
Я не знал про существовании этой утилиты, хотя почти все свои сервера MySQL бэкаплю в виде логических бэкапов Mysqldump. Надо будет переходить на MyDumper.
#mysql #backup
{kind=link}
Просматривал список необычных утилит Linux, и зацепился взгляд за броское название — fakeroot. Сразу стало интересно, что это за фейковый рут. Впервые услышал это название. Причём утилита старая, есть в базовых репах. Немного почитал про неё, но не сразу въехал, что это в итоге такое и зачем надо.
Покажу сразу на примере. После установки:
Можно запустить:
И вы как будто сделали sudo su. Появилось приветствие в консоли root:
Создаём новый файл и проверяем его права:
Как будто мы работаем под root, создавая файлы с соответствующими правами. При этом, если выйти из fakeroot и проверить права этого файла, окажется, что они как у обычного пользователя, под которым мы подключены:
Fakeroot перехватывает системные вызовы и возвращает их программе, как будто они выполняются под root. Это может быть полезно только в одном случае. Программа из-за нехватки прав завершает работу с ошибкой. Но при этом нам бы хотелось, чтобы она продолжила свою работу, так как отсутствие некоторых прав для нас некритично.
Поясню на простом примере. Вы делаете бэкап каких-то каталогов и там попадаются файлы, к которым у вас вообще нет прав, даже на чтение. Программа, которая делает бэкап, может остановиться с ошибкой, ругнувшись на отсутствие прав. В таком случае её можно запустить в fakeroot. Она будет считать, что имеет доступ ко всему, что ей надо, хотя реально она не прочитает те файлы, к которым у неё нет доступа, но не узнает об этом.
Я, кстати, с этой ситуацией неоднократно сталкивался. Только мне не нужно было пропускать эти файлы, а наоборот — дать права на чтение, чтобы в архив они в итоге попали. Я специально отслеживал такие моменты. Ну а кому-то нужно было их пропускать. В итоге появилась утилита fakeroot.
⇨ Описание FakeRoot на сайте Debian
#linux #terminal
Покажу сразу на примере. После установки:
# apt install fakerootМожно запустить:
# fakerootИ вы как будто сделали sudo su. Появилось приветствие в консоли root:
root@T480:~#Создаём новый файл и проверяем его права:
# touch file.txt# ls -la file.txt-rw-r--r-- 1 root root 0 Jul 26 00:55 file.txtКак будто мы работаем под root, создавая файлы с соответствующими правами. При этом, если выйти из fakeroot и проверить права этого файла, окажется, что они как у обычного пользователя, под которым мы подключены:
# exit# ls -la file.txt-rw-r--r-- 1 zerox zerox 0 Jul 26 00:55 file.txtFakeroot перехватывает системные вызовы и возвращает их программе, как будто они выполняются под root. Это может быть полезно только в одном случае. Программа из-за нехватки прав завершает работу с ошибкой. Но при этом нам бы хотелось, чтобы она продолжила свою работу, так как отсутствие некоторых прав для нас некритично.
Поясню на простом примере. Вы делаете бэкап каких-то каталогов и там попадаются файлы, к которым у вас вообще нет прав, даже на чтение. Программа, которая делает бэкап, может остановиться с ошибкой, ругнувшись на отсутствие прав. В таком случае её можно запустить в fakeroot. Она будет считать, что имеет доступ ко всему, что ей надо, хотя реально она не прочитает те файлы, к которым у неё нет доступа, но не узнает об этом.
Я, кстати, с этой ситуацией неоднократно сталкивался. Только мне не нужно было пропускать эти файлы, а наоборот — дать права на чтение, чтобы в архив они в итоге попали. Я специально отслеживал такие моменты. Ну а кому-то нужно было их пропускать. В итоге появилась утилита fakeroot.
⇨ Описание FakeRoot на сайте Debian
#linux #terminal
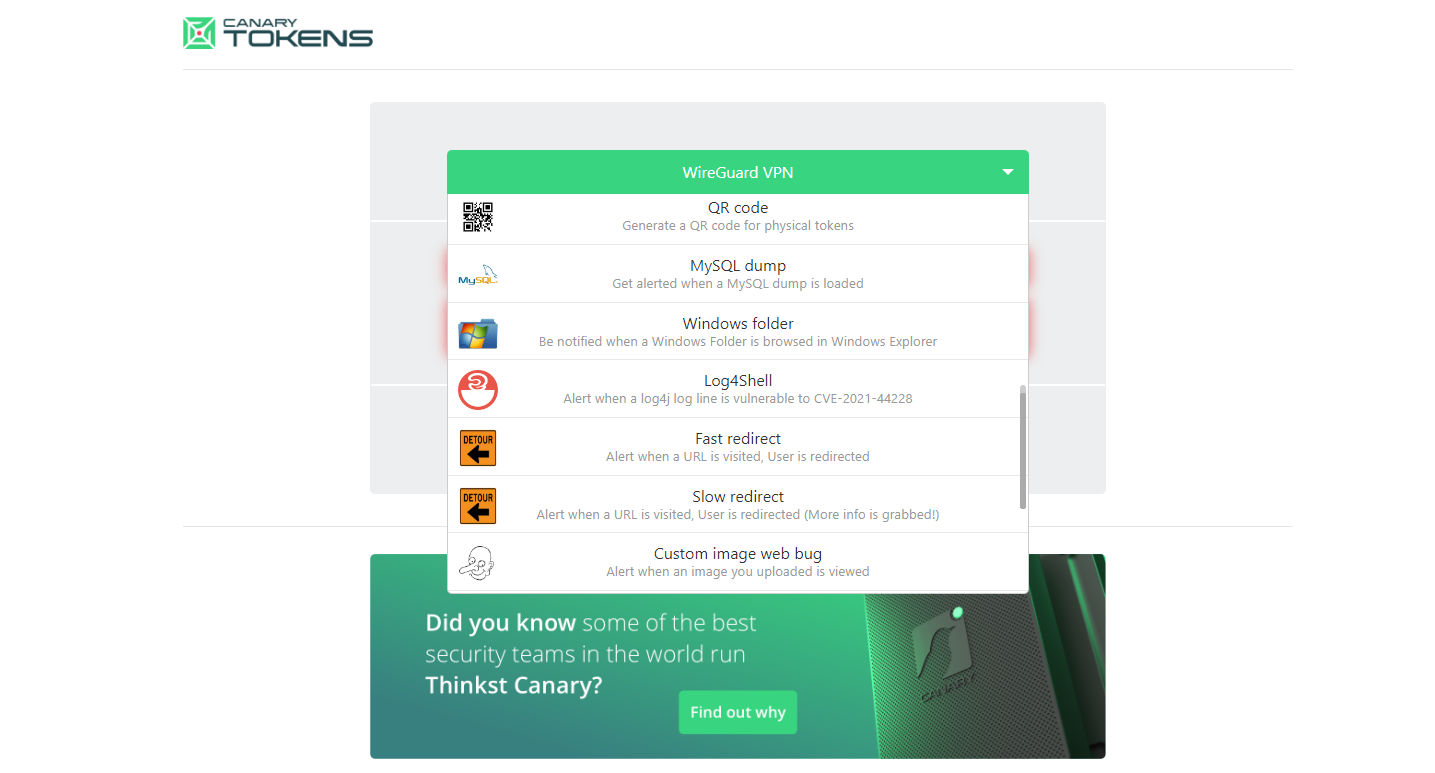
Необычный бесплатный сервис для обеспечения дополнительной безопасности какого-то периметра — canarytokens.org. С его помощью можно создавать "ловушки", которые сработают, когда кто-то выполнит то или иное действие. Покажу сразу на самом наглядном примере.
Вы можете с помощью сервиса создать документ Word или Exсel, указав свой email адрес. Сервис сгенерирует вам документ, открыв который пользователь увидит пустой лист. При этом о факте открытия вам придёт уведомление на почту с IP адресом того человека, который открыл этот файл.
Конкретно эта проверка с файлом Word работает следующим образом. Документ подписывается сертификатом. Он проверяется при открытии. В сертификате указан список отозванных сертификатов (CRL) на внешнем урле. Офис идёт туда за списком и это обращение отслеживается. Вам тут же приходит уведомление на почту с информацией о том, кто обращался к урлу с CRL списком из вашего документа.
И таких проверок у этого сервиса много. Например, можете сгенерировать URL и получать уведомления, когда кто-то по нему пройдёт. А можете отслеживать даже не переходы, а DNS резолвы поддомена этого урла. Вы увидите информацию о конечном DNS сервере, который обратился за резолвом этого домена. Я проверил эту тему, реально работает проверка с DNS. Можете делать ловушки для подключений Wireguard, для выполнения SQL запросов на MSSQL сервере, для сканирования QR кода и т.д.
Для чего всё это нужно? А тут уже каждый сам может придумать, где и как ему пользоваться. Можете куда-то в свои важные документы положить word файл с именем passwords.docx и следить за ним. Если кто-то откроет этот файл, значит у вас проблемы с безопасностью ваших файлов.
Можете в почту зашить url к какой-нибудь картинке и отследить, когда кто-то откроет это письмо. Или в виндовый файл desktop.ini, в котором хранятся настройки каталога, можно зашить путь к адресу иконки где-то на внешнем сервере. Когда кто-то будет проводником открывать вашу директорию, будете получать уведомления.
В общем, вариантов использования этого сервиса очень много. Посмотрите сами его возможности. Можно использовать как готовый сервис по указанному в начале публикации адресу, так и поднять его у себя. Он open source.
⇨ Сайт / Исходники
#security #сервис
Вы можете с помощью сервиса создать документ Word или Exсel, указав свой email адрес. Сервис сгенерирует вам документ, открыв который пользователь увидит пустой лист. При этом о факте открытия вам придёт уведомление на почту с IP адресом того человека, который открыл этот файл.
Конкретно эта проверка с файлом Word работает следующим образом. Документ подписывается сертификатом. Он проверяется при открытии. В сертификате указан список отозванных сертификатов (CRL) на внешнем урле. Офис идёт туда за списком и это обращение отслеживается. Вам тут же приходит уведомление на почту с информацией о том, кто обращался к урлу с CRL списком из вашего документа.
И таких проверок у этого сервиса много. Например, можете сгенерировать URL и получать уведомления, когда кто-то по нему пройдёт. А можете отслеживать даже не переходы, а DNS резолвы поддомена этого урла. Вы увидите информацию о конечном DNS сервере, который обратился за резолвом этого домена. Я проверил эту тему, реально работает проверка с DNS. Можете делать ловушки для подключений Wireguard, для выполнения SQL запросов на MSSQL сервере, для сканирования QR кода и т.д.
Для чего всё это нужно? А тут уже каждый сам может придумать, где и как ему пользоваться. Можете куда-то в свои важные документы положить word файл с именем passwords.docx и следить за ним. Если кто-то откроет этот файл, значит у вас проблемы с безопасностью ваших файлов.
Можете в почту зашить url к какой-нибудь картинке и отследить, когда кто-то откроет это письмо. Или в виндовый файл desktop.ini, в котором хранятся настройки каталога, можно зашить путь к адресу иконки где-то на внешнем сервере. Когда кто-то будет проводником открывать вашу директорию, будете получать уведомления.
В общем, вариантов использования этого сервиса очень много. Посмотрите сами его возможности. Можно использовать как готовый сервис по указанному в начале публикации адресу, так и поднять его у себя. Он open source.
⇨ Сайт / Исходники
#security #сервис
{kind=link}
Если вам нужно заблокировать какую-то страну, чтобы ограничить доступ к вашим сервисам, например, с помощью iptables или nginx, потребуется список IP адресов по странам.
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
Тут я создаю список IP адресов для ipset, а потом использую его в iptables:
Если в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
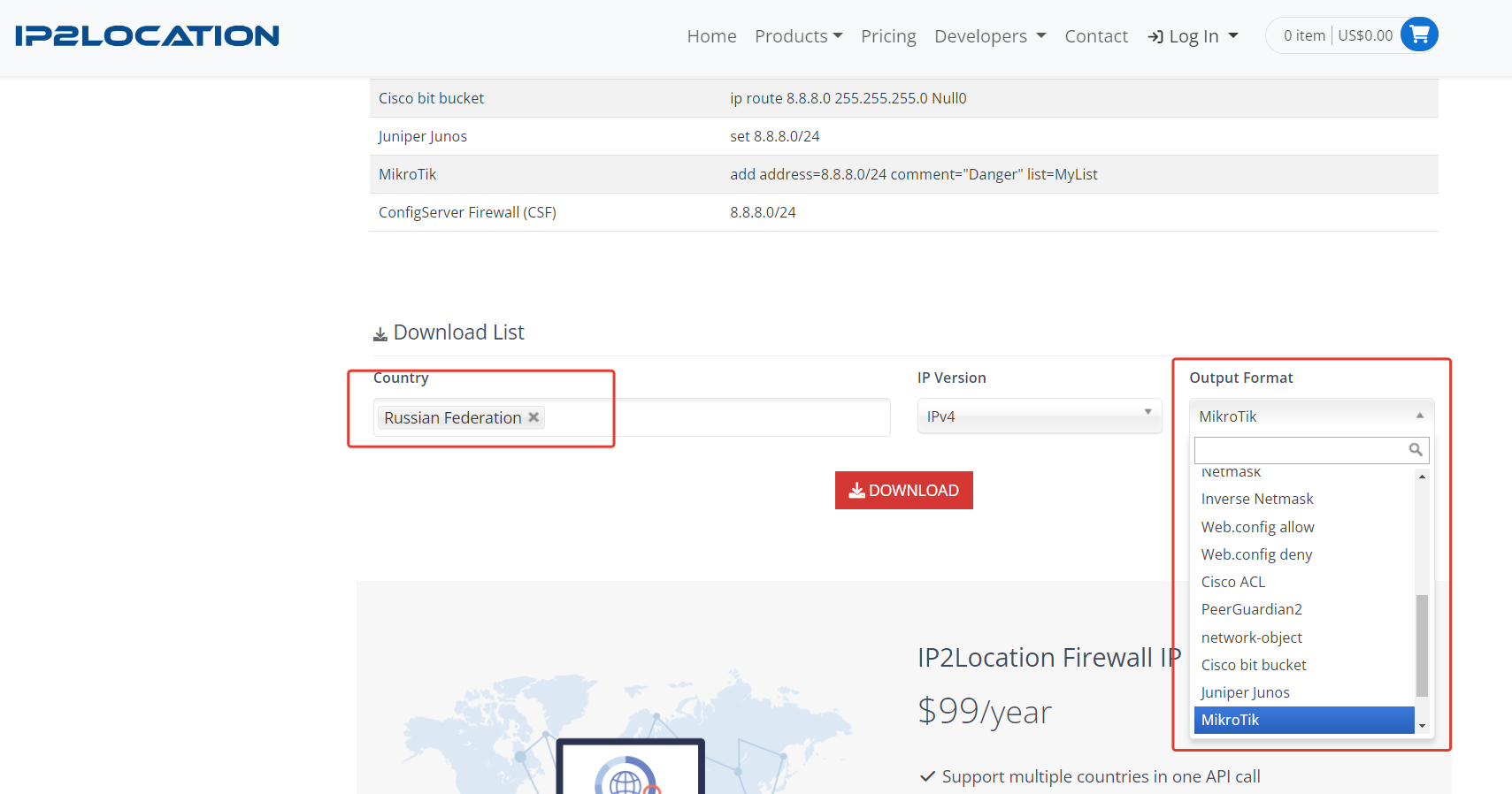
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
#!/bin/bash# Удаляем список, если он уже естьipset -X whitelist# Создаем новый списокipset -N whitelist nethash# Скачиваем файлы тех стран, что нас интересуют и сразу объединяем в единый списокwget -O netwhite http://www.ipdeny.com/ipblocks/data/countries/{ru,ua,kz,by,uz,md,kg,de,am,az,ge,ee,tj,lv}.zoneecho -n "Загружаем белый список в IPSET..."# Читаем список сетей и построчно добавляем в ipsetlist=$(cat netwhite)for ipnet in $list do ipset -A whitelist $ipnet doneecho "Завершено"# Выгружаем созданный список в файл для проверки составаipset -L whitelist > w-exportТут я создаю список IP адресов для ipset, а потом использую его в iptables:
iptables -A INPUT -i $WAN -m set --match-set whitenet src -p tcp --dport 80 -j ACCEPTЕсли в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
{kind=link}
У Zabbix вчера была рассылка с новостями. Давно ничего не писал про него, потому что новостей особо не было. Буднично проходили новости об очередных обновлениях и конференциях в разных странах. А в этот раз они немного подробностей дали по поводу новой версии 7.0, у которой уже 3-я альфа вышла. Так что работа идёт и релиз всё ближе.
Команда Zabbix показала новые виджеты дашборда, которые будут в новой версии. Можете оценить на прикреплённой картинке. Впечатления двоякие. Вроде бы прикольно, но выглядит как-то колхозно всё это. Не получается им к какому-то единому стилю прийти из-за того, что обновления сильно растянуты. Сначала интерфейс обновили, потом частично графики в виджетах, потом новые виджеты стали добавлять, при этом часть графиков так и осталась в старом дизайне, которому уже около 10-ти лет. Мне кажется, им стоило один раз собраться и в каком-то релизе выкатить полное обновление интерфейса и графиков. А то это так и будет вечно продолжаться.
Помимо новых визуализаций, появится виджет с топом триггеров. Я так понял, что это виджет из отчёта 100 наиболее активных триггеров (в русском интерфейсе). Он показывает триггеры, которые чаще всего меняли своё состояние (срабатывали) за указанный период времени. Кстати, удобный отчёт, который позволяет подредактировать триггеры, которые слишком часто срабатывают.
Из тех обновлений, что точно будут в 7.0, отмечу:
◽увеличится поддержка версий до MySQL 8.1 MariaDB 11
◽появится шаблон для мониторинга за PostgreSQL через ODBC
◽появится шаблон для Cisco SD-WAN
◽появится возможность выполнения удалённых команд при активных проверках
◽некоторые настройки переедут в модальные окна (способы оповещений, скрипты и т.д.)
◽увеличат возможности обработки в aggregation functions
Вот и всё наиболее значимое, что было объявлено в последних трех релизах альфы. Пока как-то негусто изменений. По обещанному обновлению модуля инвентаризации, поддержке сторонних TSDB, асинхронному сбору данных не сделано ничего в тех версиях, что опубликованы.
#zabbix
Команда Zabbix показала новые виджеты дашборда, которые будут в новой версии. Можете оценить на прикреплённой картинке. Впечатления двоякие. Вроде бы прикольно, но выглядит как-то колхозно всё это. Не получается им к какому-то единому стилю прийти из-за того, что обновления сильно растянуты. Сначала интерфейс обновили, потом частично графики в виджетах, потом новые виджеты стали добавлять, при этом часть графиков так и осталась в старом дизайне, которому уже около 10-ти лет. Мне кажется, им стоило один раз собраться и в каком-то релизе выкатить полное обновление интерфейса и графиков. А то это так и будет вечно продолжаться.
Помимо новых визуализаций, появится виджет с топом триггеров. Я так понял, что это виджет из отчёта 100 наиболее активных триггеров (в русском интерфейсе). Он показывает триггеры, которые чаще всего меняли своё состояние (срабатывали) за указанный период времени. Кстати, удобный отчёт, который позволяет подредактировать триггеры, которые слишком часто срабатывают.
Из тех обновлений, что точно будут в 7.0, отмечу:
◽увеличится поддержка версий до MySQL 8.1 MariaDB 11
◽появится шаблон для мониторинга за PostgreSQL через ODBC
◽появится шаблон для Cisco SD-WAN
◽появится возможность выполнения удалённых команд при активных проверках
◽некоторые настройки переедут в модальные окна (способы оповещений, скрипты и т.д.)
◽увеличат возможности обработки в aggregation functions
Вот и всё наиболее значимое, что было объявлено в последних трех релизах альфы. Пока как-то негусто изменений. По обещанному обновлению модуля инвентаризации, поддержке сторонних TSDB, асинхронному сбору данных не сделано ничего в тех версиях, что опубликованы.
#zabbix
{kind=link}
🎉 Сегодня оказывается день системного администратора. Я и не знал. Не слежу за этим праздником и никогда его не отмечал. Если бы тут в чате не написали, я бы и не вспомнил. Вот шуфутинов день я почему-то никогда не забываю.
Тем не менее, всех сисадминов любителей праздников поздравляю 😁. Вот пример того, как его можно провести (смотреть до конца)
⇨ https://www.youtube.com/watch?v=IhMYtA7ZPLM
По этому поводу предлагаю посмотреть немного развлекательного видео. В разное время мне попадались ролики на тему дня сисадмина. Один из любимых вот этот. Почему-то сразу его вспомнил. Он вроде и не праздничный, но снят хорошо и темы прикольные:
SysAdmin Day 2016
⇨ https://www.youtube.com/watch?v=3XliP_OTjuk
И вот ещё прикольное видео от них же:
This AI can do ANYTHING (SysAdmin Day 2022)
⇨ https://www.youtube.com/watch?v=KuvOwbtSeHk
История про друга айтишника, готового всегда прийти на помощь:
⇨ https://www.youtube.com/watch?v=VFHHbBV9nlo
Переозвучка на тему IT. Там все, и программисты, и сисадмины:
⇨ https://www.youtube.com/watch?v=NuKREeAnm1s
Ещё про программистов вспомнилось прикольное видео. Как на самом деле пишется и проверяется код в больших технологичных компаниях?
⇨ https://www.youtube.com/watch?v=rR4n-0KYeKQ
Помимо дня сисадмина, стоит помнить и про день электрика. А то может случиться вот что:
⇨ https://www.youtube.com/watch?v=9xYrJKYen8Y
Прикольный плейлист с сериями мини сериала на тему A Day in the Life of a SysAdmin. Я все серии смотрел в своё время. Не помню, делал ли заметки об этом. Вроде нет.
⇨ https://www.youtube.com/watch?v=Bo-6lBocYSU&list=PLjRDUUDcXg2GwKQIgNkAe45nkq9tBIXUZ
Не забывайте про сайт https://geekprank.com, когда захотите кого-нибудь разыграть по айтишной теме. Сделано классно.
📌 Ну и для настроения в завершении анекдот:
Умер системный администратор, и попал на небо к Богу. Бог посмотрел на него и говорит, мол ты себя при жизни вел хорошо, грехов немного и поэтому сам выберешь, куда тебе отправляться, в рай или ад. Админ выбирает рай.
Заводит Бог сисадмина в одно помещение, а там стоят крутые сервера, навороченные рабочие станции, быстрая сетка, и говорит: "Это рай, здесь ты будешь жить и развлекаться в свое довольствие, и будешь ты простым пользователем".
У админа глаза заблестели, но из любопытства он все равно просит Бога показать и ад. Бог отвечает: "Ад - это тоже здесь, только тогда ты будешь системным администраторoм".
#юмор
Тем не менее, всех сисадминов любителей праздников поздравляю 😁. Вот пример того, как его можно провести (смотреть до конца)
⇨ https://www.youtube.com/watch?v=IhMYtA7ZPLM
По этому поводу предлагаю посмотреть немного развлекательного видео. В разное время мне попадались ролики на тему дня сисадмина. Один из любимых вот этот. Почему-то сразу его вспомнил. Он вроде и не праздничный, но снят хорошо и темы прикольные:
SysAdmin Day 2016
⇨ https://www.youtube.com/watch?v=3XliP_OTjuk
И вот ещё прикольное видео от них же:
This AI can do ANYTHING (SysAdmin Day 2022)
⇨ https://www.youtube.com/watch?v=KuvOwbtSeHk
История про друга айтишника, готового всегда прийти на помощь:
⇨ https://www.youtube.com/watch?v=VFHHbBV9nlo
Переозвучка на тему IT. Там все, и программисты, и сисадмины:
⇨ https://www.youtube.com/watch?v=NuKREeAnm1s
Ещё про программистов вспомнилось прикольное видео. Как на самом деле пишется и проверяется код в больших технологичных компаниях?
⇨ https://www.youtube.com/watch?v=rR4n-0KYeKQ
Помимо дня сисадмина, стоит помнить и про день электрика. А то может случиться вот что:
⇨ https://www.youtube.com/watch?v=9xYrJKYen8Y
Прикольный плейлист с сериями мини сериала на тему A Day in the Life of a SysAdmin. Я все серии смотрел в своё время. Не помню, делал ли заметки об этом. Вроде нет.
⇨ https://www.youtube.com/watch?v=Bo-6lBocYSU&list=PLjRDUUDcXg2GwKQIgNkAe45nkq9tBIXUZ
Не забывайте про сайт https://geekprank.com, когда захотите кого-нибудь разыграть по айтишной теме. Сделано классно.
📌 Ну и для настроения в завершении анекдот:
Умер системный администратор, и попал на небо к Богу. Бог посмотрел на него и говорит, мол ты себя при жизни вел хорошо, грехов немного и поэтому сам выберешь, куда тебе отправляться, в рай или ад. Админ выбирает рай.
Заводит Бог сисадмина в одно помещение, а там стоят крутые сервера, навороченные рабочие станции, быстрая сетка, и говорит: "Это рай, здесь ты будешь жить и развлекаться в свое довольствие, и будешь ты простым пользователем".
У админа глаза заблестели, но из любопытства он все равно просит Бога показать и ад. Бог отвечает: "Ад - это тоже здесь, только тогда ты будешь системным администраторoм".
#юмор
{kind=link}
🎓 Сделал серию заметок про бесплатные курсы на платформе stepik.org и как-то забыл про неё. Там много хороших и полезных курсов, так что продолжу. Если у вас тоже есть на примете хорошие бесплатные курсы, поделитесь информацией.
Регулярные выражения в Python
⇨ https://stepik.org/course/107335/
Здесь вы научитесь составлять и использовать регулярные выражения для решения повседневных задач. В курсе пройдёмся по всем функциям модуля re, разберём работу с группами, изучим флаги, и поймём для чего нужны регулярные выражения.
Рекомендацию на этот курс я получал неоднократно в заметках про регулярки. Перебирал свои записи и вспомнил про него.
Интерактивный тренажер по SQL
⇨ https://stepik.org/course/63054/
В курсе большинство шагов — это практические задания на создание SQL-запросов. Каждый шаг включает минимальные теоретические аспекты по базам данных или языку SQL, примеры похожих запросов и пояснение к реализации.
Админам и девопсам с SQL приходится взаимодействовать постоянно. Базовый синтаксис очень желательно знать. Я немного знаю, но всё равно по шпаргалкам всё делаю, когда надо таблицу создать или запрос выполнить.
Go (Golang) - первое знакомство
⇨ https://stepik.org/course/100208/
Это курс по языку программирования Go (Golang) для самых маленьких. Почему? Потому что показаны будут прежде всего азы (хотя и не только), при этом в достаточно краткой форме.
Go, как и Python, активно используется для создания вспомогательных утилит и сервисов в обслуживании и эксплуатации систем. Знать его хоть чуть-чуть в современном IT будет полезно всем. Я, к сожалению, совсем не знаю.
А может вам просто надоело обслуживание и вы хотите перейти в разработку? Вот пример человека, который из тех поддержки стал программистом на Go.
#обучение #бесплатно
Регулярные выражения в Python
⇨ https://stepik.org/course/107335/
Здесь вы научитесь составлять и использовать регулярные выражения для решения повседневных задач. В курсе пройдёмся по всем функциям модуля re, разберём работу с группами, изучим флаги, и поймём для чего нужны регулярные выражения.
Рекомендацию на этот курс я получал неоднократно в заметках про регулярки. Перебирал свои записи и вспомнил про него.
Интерактивный тренажер по SQL
⇨ https://stepik.org/course/63054/
В курсе большинство шагов — это практические задания на создание SQL-запросов. Каждый шаг включает минимальные теоретические аспекты по базам данных или языку SQL, примеры похожих запросов и пояснение к реализации.
Админам и девопсам с SQL приходится взаимодействовать постоянно. Базовый синтаксис очень желательно знать. Я немного знаю, но всё равно по шпаргалкам всё делаю, когда надо таблицу создать или запрос выполнить.
Go (Golang) - первое знакомство
⇨ https://stepik.org/course/100208/
Это курс по языку программирования Go (Golang) для самых маленьких. Почему? Потому что показаны будут прежде всего азы (хотя и не только), при этом в достаточно краткой форме.
Go, как и Python, активно используется для создания вспомогательных утилит и сервисов в обслуживании и эксплуатации систем. Знать его хоть чуть-чуть в современном IT будет полезно всем. Я, к сожалению, совсем не знаю.
А может вам просто надоело обслуживание и вы хотите перейти в разработку? Вот пример человека, который из тех поддержки стал программистом на Go.
#обучение #бесплатно
Stepik: online education
Регулярные выражения в Python
Здесь вы научитесь научитесь составлять и использовать регулярные выражения для решения повседневных задач. В курсе пройдёмся по всем функциям модуля re, разберём работу с группами, изучим флаги, и поймём для чего нужны регулярные выражения ❤️
Меня часто спрашивают, каким образом можно объединить несколько интернет каналов в один общий. То есть настроить не резервирование, не переключение, не балансировку, а именно одновременное использование нескольких каналов для увеличения суммарной пропускной способности. При этом сами каналы чаще всего разного типа. То есть это не то же самое, что объединить порты на свитчах.
У меня никогда не было опыта подобной настройки. Я понимаю, что технически это сложная задача, как логически, так и архитектурно. Честное суммирование каналов будет приводить к явным проблемам. Например, у клиента канал 1000 мегабит, а у сервиса 3 канала по 100 мегабит. Клиент на полной скорости пытается забрать контент с сервера, который вынужден будет для максимальной скорости утилизировать все 3 канала одновременно. Получается один клиент будет забирать контент с трёх разных маршрутов с разными метриками, откликами, source ip шлюзов и т.д.
Ну и в обратную сторону те же самые проблемы, когда у клиента 3 канала, а у сервиса один. Всё это нужно как-то собирать в единую последовательность, чтобы данные не превращались в кашу. А есть ещё привязки аутентификаций и кук к IP. Что с ними будет?
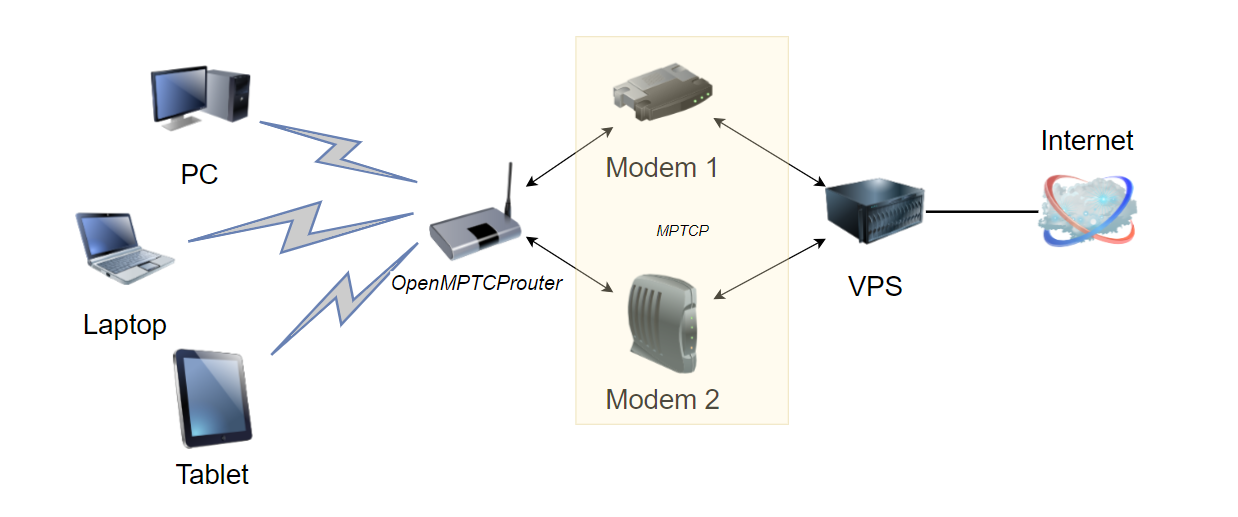
К чему я всё это? Если у вас возникнет подобная задача (постарайтесь от неё отмахнуться), то дам вам подсказку в виде бесплатного OpenMPTCProuter. Это open source проект программного роутера, который умеет честно суммировать интернет каналы. Для этого он состоит из двух частей. Одна клиентская, которую вы ставите там, где суммируете каналы. А вторая часть располагается где-то в интернете для объединения подключений со всех интернет каналов. Только такая схема может обеспечить реальное объединение каналов и возможность приложениям нормально работать при такой схеме без потери пакетов и разрыва соединений.
Клиентская часть, где будут подключены интернет каналы, может быть установлена на обычный x86, x86_64 Linux, Raspberry PI 2B/3B/3B+/4B, Linksys WRT3200ACM/WRT32X, Teltonika RUTX12, Banana PI BPI-R2. Она построена на базе OpenWRT. Суммирующий сервер может быть развёрнут в интернете на обычном VPS на базе Debian или Ubuntu.
Настройка, на удивление для такого продукта, не сложная. Я сам не пробовал, но есть руководство на сайте и инструкции в интернете. Настраивается суммирующий сервер с помощью готового скрипта. Потом поднимаем из образа клиентскую часть. Через веб интерфейс настраиваем интернет каналы и указываем настройки подключения к суммирующему серверу. Этого минимума будет достаточно, чтобы всё заработало.
Это единственное бесплатное решение, которое мне знакомо по данной задаче. Все другие входят в состав дорогих коммерческих продуктов. Из не очень дорогого я когда-то видел коробочку с несколькими USB модемами, но не уверен, что там было честное объединение, а не резервирование и переключение. Да и то название забыл.
Если кто-то пользовался подобными или конкретно этой системой, то дайте обратную связь. Как на практике работает объединение каналов? Тут же куча сопутствующих проблем возникает от банальной настройки файрвола до проброса портов. Не понятно, как это должно работать в таких схемах.
#network
У меня никогда не было опыта подобной настройки. Я понимаю, что технически это сложная задача, как логически, так и архитектурно. Честное суммирование каналов будет приводить к явным проблемам. Например, у клиента канал 1000 мегабит, а у сервиса 3 канала по 100 мегабит. Клиент на полной скорости пытается забрать контент с сервера, который вынужден будет для максимальной скорости утилизировать все 3 канала одновременно. Получается один клиент будет забирать контент с трёх разных маршрутов с разными метриками, откликами, source ip шлюзов и т.д.
Ну и в обратную сторону те же самые проблемы, когда у клиента 3 канала, а у сервиса один. Всё это нужно как-то собирать в единую последовательность, чтобы данные не превращались в кашу. А есть ещё привязки аутентификаций и кук к IP. Что с ними будет?
К чему я всё это? Если у вас возникнет подобная задача (постарайтесь от неё отмахнуться), то дам вам подсказку в виде бесплатного OpenMPTCProuter. Это open source проект программного роутера, который умеет честно суммировать интернет каналы. Для этого он состоит из двух частей. Одна клиентская, которую вы ставите там, где суммируете каналы. А вторая часть располагается где-то в интернете для объединения подключений со всех интернет каналов. Только такая схема может обеспечить реальное объединение каналов и возможность приложениям нормально работать при такой схеме без потери пакетов и разрыва соединений.
Клиентская часть, где будут подключены интернет каналы, может быть установлена на обычный x86, x86_64 Linux, Raspberry PI 2B/3B/3B+/4B, Linksys WRT3200ACM/WRT32X, Teltonika RUTX12, Banana PI BPI-R2. Она построена на базе OpenWRT. Суммирующий сервер может быть развёрнут в интернете на обычном VPS на базе Debian или Ubuntu.
Настройка, на удивление для такого продукта, не сложная. Я сам не пробовал, но есть руководство на сайте и инструкции в интернете. Настраивается суммирующий сервер с помощью готового скрипта. Потом поднимаем из образа клиентскую часть. Через веб интерфейс настраиваем интернет каналы и указываем настройки подключения к суммирующему серверу. Этого минимума будет достаточно, чтобы всё заработало.
Это единственное бесплатное решение, которое мне знакомо по данной задаче. Все другие входят в состав дорогих коммерческих продуктов. Из не очень дорогого я когда-то видел коробочку с несколькими USB модемами, но не уверен, что там было честное объединение, а не резервирование и переключение. Да и то название забыл.
Если кто-то пользовался подобными или конкретно этой системой, то дайте обратную связь. Как на практике работает объединение каналов? Тут же куча сопутствующих проблем возникает от банальной настройки файрвола до проброса портов. Не понятно, как это должно работать в таких схемах.
#network
{kind=link}
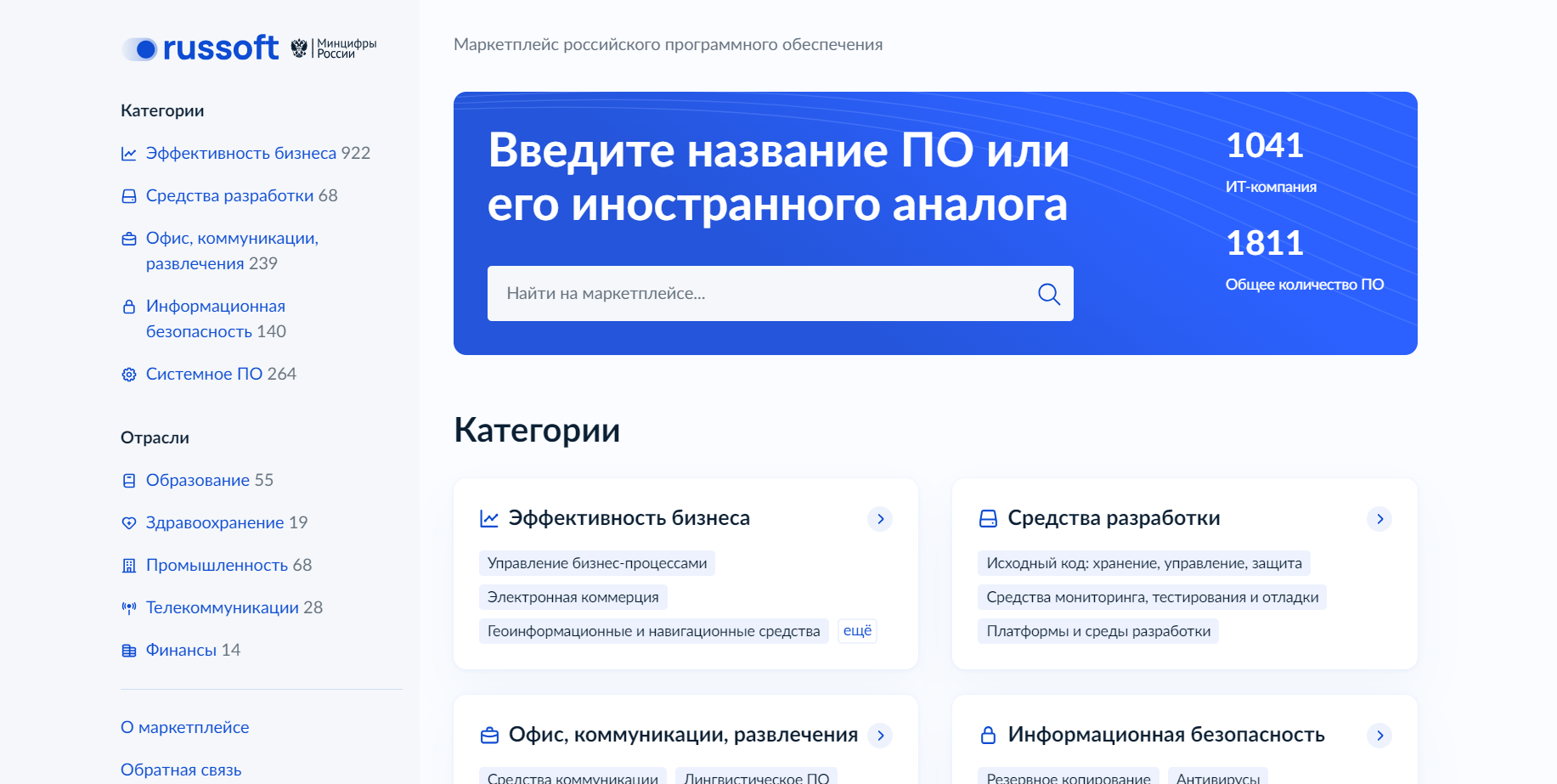
Минцифры давно уже запустило маркетплейс российского ПО. Выглядит он удобно и содержательно:
⇨ https://russoft.ru
Только сразу прошу, не надо обсуждать политику, чиновников, импортозамещение и прочее. Это не имеет смысла. Я просто делюсь информацией о хорошо организованном каталоге. Даже и не знал, что существует столько отечественного ПО.
Например, идём в Системное ПО ⇨ Управление IT-инфраструктурой. Видим 17 продуктов, про большую часть которых я даже не слышал. Тут сразу указана примерная стоимость и есть ссылка на сайт продукта. Немного изучил список. Привлекло внимание название Управление IT-отделом 8. Посмотрел, а это help desk и инвентаризация на базе платформы 1С. Причём там и веб интерфейс есть, и интеграция с Telegram ботами. 1С, как ни крути, мощная платформа. На её базе всё, что угодно можно делать.
К каждому ПО указан список иностранных аналогов. Так что если вы ищите замену чему-либо, можно сразу по этому продукту искать. Для примера забил Zabbix и увидел список ПО для мониторинга. Вообще ни один продукт из этого списка не знаком.
Почитал новости о релизе этого каталога. Обещали в будущем сделать рейтинг и отзывы, но пока ничего этого нет. А последние новости на сайте от марта этого года. Такое ощущение, что портал сделали, бюджет кончился и его заморозили. Надеюсь, что разморозят и продолжат развивать. Идея хорошая.
#отечественное
⇨ https://russoft.ru
Только сразу прошу, не надо обсуждать политику, чиновников, импортозамещение и прочее. Это не имеет смысла. Я просто делюсь информацией о хорошо организованном каталоге. Даже и не знал, что существует столько отечественного ПО.
Например, идём в Системное ПО ⇨ Управление IT-инфраструктурой. Видим 17 продуктов, про большую часть которых я даже не слышал. Тут сразу указана примерная стоимость и есть ссылка на сайт продукта. Немного изучил список. Привлекло внимание название Управление IT-отделом 8. Посмотрел, а это help desk и инвентаризация на базе платформы 1С. Причём там и веб интерфейс есть, и интеграция с Telegram ботами. 1С, как ни крути, мощная платформа. На её базе всё, что угодно можно делать.
К каждому ПО указан список иностранных аналогов. Так что если вы ищите замену чему-либо, можно сразу по этому продукту искать. Для примера забил Zabbix и увидел список ПО для мониторинга. Вообще ни один продукт из этого списка не знаком.
Почитал новости о релизе этого каталога. Обещали в будущем сделать рейтинг и отзывы, но пока ничего этого нет. А последние новости на сайте от марта этого года. Такое ощущение, что портал сделали, бюджет кончился и его заморозили. Надеюсь, что разморозят и продолжат развивать. Идея хорошая.
#отечественное
{kind=link}
Я активно использую как в работе, так и в личных целях, Яндекс.Диск. У него очень низкая стоимость хранения данных. В Linux использую либо API для загрузки данных, либо rclone.
Для Windows использовал либо родной клиент, что не очень удобно, либо монтировал сетевой диск в Linux и там с ним работал. Не знал, что полнофункциональный rclone нормально работает в Windows, причём абсолютно так же, как в Linux. Настройка 1 в 1.
Установить можно как вручную, так и с помощью winget:
Через winget не сразу понял, куда он был установлен. Оказалось, что в директорию C:\Users\User\AppData\Local\Microsoft\WinGet\Packages\Rclone.Rclone_Microsoft.Winget.Source_8wekyb3d8bbwe\rclone-v1.63.1-windows-amd64.
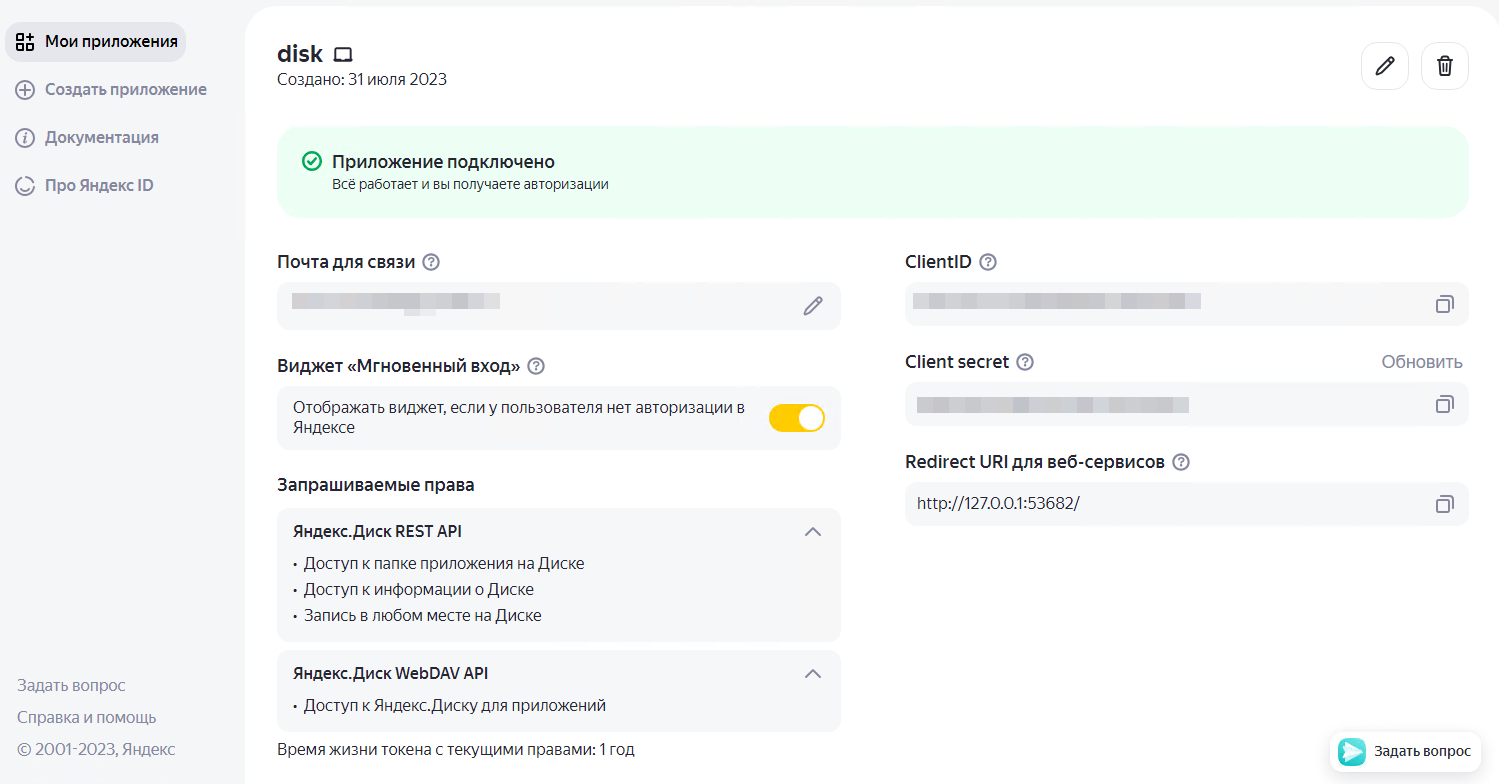
Для настройки работы rclone с Яндекс диском нужно получить токен. Как это сделать, я описывал в заметке по работе с API. Единственное отличие — нужно предоставить побольше прав:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
▪ Запись в любом месте на Диске
▪ Доступ к Яндекс.Диску для приложений
А в качестве Redirect URI использовать ссылку: http://127.0.0.1:53682/
После этого запускаете в консоли команду:
Выбираете New remote ⇨ указываете название, например yandex ⇨ номер 48, соответствующий хранилищу Яндекс диск ⇨ client_id и client_secret оставляете пустыми ⇨ выполняете запрос токена ⇨ сохраняете конфиг.
У вас появится файл в C:\Users\User\AppData\Roaming\rclone\rclone.conf примерно следующего содержания:
[yandex]
type = yandex
client_id =
client_secret =
token = {"access_token":"y0_AgAAAABvmXfPAALEtgAAAAKpIA8y2bb-M0IiRFu068gJJKvzSOGoBBs","token_type":"OAuth","refresh_token":"1:p0NRuhts1VI1N7Sq:NWEoGv963fVVGSpE_k8Mftn6Pd8AKsFcte2WGqv77mKgWaoer36TX4irbubWTfCgk9_Gxh5NLBzkWA:b_dCjrHMIEMkKeH-oOFrFQ","expiry":"2024-07-30T20:45:05.4991551+03:00"}
Теперь можно через консоль загружать туда файлы:
Положили в корень диска файл test.txt
Помимо загрузки файлов, rclone умеет монтировать внешние хранилища как локальные или сетевые диски. Для этого ему нужна программа winfsp. Поставить можно тоже через winget:
Монтируем яндекс диск в режиме чтения:
Или в режиме записи:
Яндекс диск смонтирован в виде локального диска X. Подробнее о монтировании в Windows, о правах доступа и прочих нюансах можно прочитать в документации.
Если для вас всё это слишком замороченно и хочется попроще, то вот набор программ, которые реализуют то же самое. Это платные программы, с ограниченными бесплатными версиями. Они удобны и популярны, так что при желании, вы найдёте репаки платных версий, но аккуратнее с ними. Я лично давно уже опасаюсь использовать ломаный софт.
🔹Air Explorer — двухпанельный файловый менеджер, который позволяет работать с облачными сервисами как с локальными директориями. Поддерживает и Яндекс.Диск, и диск от Mail ru.
🔹Air Live Drive — программа от того же производителя, которая позволят монтировать облачные диски как локальные.
🔹RaiDrive — писал об этой программе ранее. Позволяет подключать различные облачные сервисы как локальные диски.
#windows #rclone #backup
Для Windows использовал либо родной клиент, что не очень удобно, либо монтировал сетевой диск в Linux и там с ним работал. Не знал, что полнофункциональный rclone нормально работает в Windows, причём абсолютно так же, как в Linux. Настройка 1 в 1.
Установить можно как вручную, так и с помощью winget:
> winget install rcloneЧерез winget не сразу понял, куда он был установлен. Оказалось, что в директорию C:\Users\User\AppData\Local\Microsoft\WinGet\Packages\Rclone.Rclone_Microsoft.Winget.Source_8wekyb3d8bbwe\rclone-v1.63.1-windows-amd64.
Для настройки работы rclone с Яндекс диском нужно получить токен. Как это сделать, я описывал в заметке по работе с API. Единственное отличие — нужно предоставить побольше прав:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
▪ Запись в любом месте на Диске
▪ Доступ к Яндекс.Диску для приложений
А в качестве Redirect URI использовать ссылку: http://127.0.0.1:53682/
После этого запускаете в консоли команду:
> rclone configВыбираете New remote ⇨ указываете название, например yandex ⇨ номер 48, соответствующий хранилищу Яндекс диск ⇨ client_id и client_secret оставляете пустыми ⇨ выполняете запрос токена ⇨ сохраняете конфиг.
У вас появится файл в C:\Users\User\AppData\Roaming\rclone\rclone.conf примерно следующего содержания:
[yandex]
type = yandex
client_id =
client_secret =
token = {"access_token":"y0_AgAAAABvmXfPAALEtgAAAAKpIA8y2bb-M0IiRFu068gJJKvzSOGoBBs","token_type":"OAuth","refresh_token":"1:p0NRuhts1VI1N7Sq:NWEoGv963fVVGSpE_k8Mftn6Pd8AKsFcte2WGqv77mKgWaoer36TX4irbubWTfCgk9_Gxh5NLBzkWA:b_dCjrHMIEMkKeH-oOFrFQ","expiry":"2024-07-30T20:45:05.4991551+03:00"}
Теперь можно через консоль загружать туда файлы:
> rclone copy C:\Users\User\Downloads\test.txt yandex:/Положили в корень диска файл test.txt
Помимо загрузки файлов, rclone умеет монтировать внешние хранилища как локальные или сетевые диски. Для этого ему нужна программа winfsp. Поставить можно тоже через winget:
> winget install winfspМонтируем яндекс диск в режиме чтения:
> rclone mount yandex:/ X:Или в режиме записи:
> rclone mount yandex:/ X: --vfs-cache-mode writesЯндекс диск смонтирован в виде локального диска X. Подробнее о монтировании в Windows, о правах доступа и прочих нюансах можно прочитать в документации.
Если для вас всё это слишком замороченно и хочется попроще, то вот набор программ, которые реализуют то же самое. Это платные программы, с ограниченными бесплатными версиями. Они удобны и популярны, так что при желании, вы найдёте репаки платных версий, но аккуратнее с ними. Я лично давно уже опасаюсь использовать ломаный софт.
🔹Air Explorer — двухпанельный файловый менеджер, который позволяет работать с облачными сервисами как с локальными директориями. Поддерживает и Яндекс.Диск, и диск от Mail ru.
🔹Air Live Drive — программа от того же производителя, которая позволят монтировать облачные диски как локальные.
🔹RaiDrive — писал об этой программе ранее. Позволяет подключать различные облачные сервисы как локальные диски.
#windows #rclone #backup
{kind=link}
В Linux можно на ходу уменьшать или увеличивать количество используемой оперативной памяти. Единственное условие - если уменьшаете активную оперативную память, она должна быть свободна. Покажу на примерах.
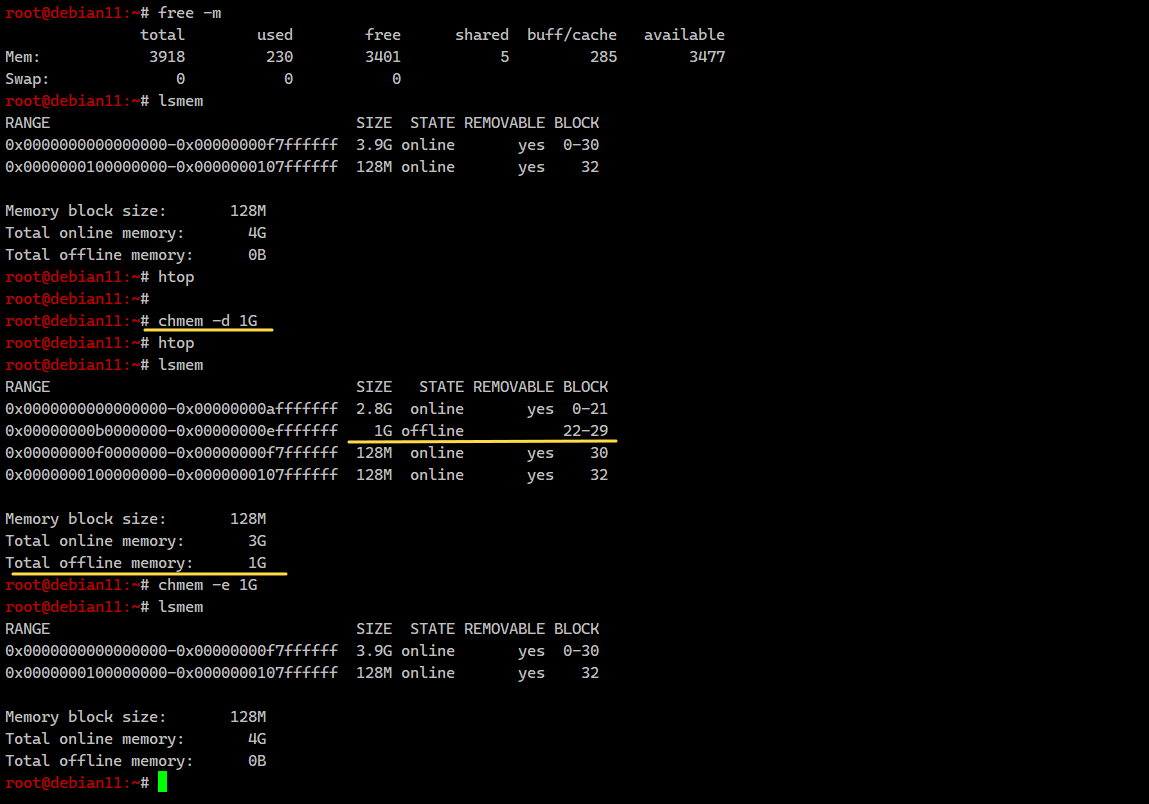
Для начала воспользуемся командой lsmem для просмотра информации об использовании оперативной памяти. Команда, кстати, полезная. Рекомендую запомнить и использовать. С её помощью можно быстро посмотреть полную информацию об оперативе сервера:
Команда показывает в том числе блоки оперативной памяти, на которые её разбивает ядро. Вот с этими блоками и можно работать. Видим, что у нас 32 блока по 128M, а всего 4G памяти и вся она активна. Отключим 1G c помощью chmem.
или отключим 8 произвольных блоков:
Утилита пройдётся по всем блокам памяти. Те, что могут быть освобождены, она отключит. Процесс может занимать много времени, так как утилита будет пытаться перемещать информацию по памяти, чтобы высвободить заданный объём.
Проверяем, что получилось:
Возвращаем всё как было:
Вряд ли вам часто может быть нужна эта возможность. Но иногда может пригодиться, так что стоит знать о ней. Например, в некоторых системах виртуализации, добавленная на ходу память добавляется как offline и её нужно вручную активировать.
Ещё вариант, если вы точно знаете диапазон битой памяти. Вы можете отключить содержащий её блок с помощью chmem и какое-то время сервер ещё поработает.
#linux #terminal
Для начала воспользуемся командой lsmem для просмотра информации об использовании оперативной памяти. Команда, кстати, полезная. Рекомендую запомнить и использовать. С её помощью можно быстро посмотреть полную информацию об оперативе сервера:
# lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x00000000f7ffffff 3.9G online yes 0-300x0000000100000000-0x0000000107ffffff 128M online yes 32Memory block size: 128MTotal online memory: 4GTotal offline memory: 0BКоманда показывает в том числе блоки оперативной памяти, на которые её разбивает ядро. Вот с этими блоками и можно работать. Видим, что у нас 32 блока по 128M, а всего 4G памяти и вся она активна. Отключим 1G c помощью chmem.
# chmem -d 1Gили отключим 8 произвольных блоков:
# chmem -d -b 22-29Утилита пройдётся по всем блокам памяти. Те, что могут быть освобождены, она отключит. Процесс может занимать много времени, так как утилита будет пытаться перемещать информацию по памяти, чтобы высвободить заданный объём.
Проверяем, что получилось:
# lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x00000000afffffff 2.8G online yes 0-210x00000000b0000000-0x00000000efffffff 1G offline 22-290x00000000f0000000-0x00000000f7ffffff 128M online yes 300x0000000100000000-0x0000000107ffffff 128M online yes 32Memory block size: 128MTotal online memory: 3GTotal offline memory: 1GВозвращаем всё как было:
# chmem -e 1GВряд ли вам часто может быть нужна эта возможность. Но иногда может пригодиться, так что стоит знать о ней. Например, в некоторых системах виртуализации, добавленная на ходу память добавляется как offline и её нужно вручную активировать.
Ещё вариант, если вы точно знаете диапазон битой памяти. Вы можете отключить содержащий её блок с помощью chmem и какое-то время сервер ещё поработает.
#linux #terminal
{kind=link}
Объясню простыми словами отличия современных систем контейнеризации. Для тех, кто с ними постоянно не работает, не очевидно, что они могут различаться принципиально по областям применения. Акцент сделаю на наиболее популярных Docker и LXC, а в конце немного по остальным пройдусь.
Все контейнеры используют одно и то же ядро операционной системы Linux и работают в его рамках. Это принципиальное отличие от виртуальных машин. А принципиальное отличие Docker от LXC в том, что Docker ориентируется на запуск приложений, а LXC на запуск системы.
Поясню на конкретном примере. Допустим, вам надо запустить в работу веб сервер. Если вы будете делать это с помощью Docker, то на хостовой машине запустите контейнер с Nginx, контейнер с Php-fpm, создадите на хосте локальные директории с файлами сайта и конфигурациями сервисов и пробросите их внутрь контейнеров, чтобы у них был доступ к ним. В самих контейнерах кроме непосредственно сервисов Nginx и Php-fpm практически ничего не будет.
Если ту же задачу решать с помощью LXC, то вы просто запустите контейнер с нужной базовой системой внутри. Зайдёте внутрь контейнера и настроите там всё, как обычно это делаете на отдельной виртуальной машине. То есть LXC максимально повторяет работу полноценной системы, только работает на базе ядра хоста.
☝ Docker - это один контейнер, одна служба, LXC - набор служб для решения конкретной задачи. При этом в образ Docker тоже можно поместить практически полноценную систему, но так обычно никто не делает, хотя и есть исключения.
Исходя из этих пояснений, становятся понятны плюсы и минусы каждого подхода. Плюсы Docker:
◽минимальный объём образов, соответственно, максимальная скорость запуска нужных сервисов;
◽для бэкапа достаточно сохранить непосредственно данные, образы можно опустить, так как они типовые.
Минусы:
◽более сложная настройка по сравнению с обычной виртуальной машиной, особенно что касается сети и диагностики в целом.
Плюсы LXC:
◽настройка практически такая же, как на обычной VM, заходишь внутрь контейнера по SSH и настраиваешь.
Минусы LXC:
◽итоговые образы бОльшего объёма, так как содержат всё окружение стандартных систем.
◽сложнее автоматизировать и стандартизировать разворачивание масштабных сервисов.
LXC отлично подходит как замена полноценной VM. Его удобно настроить, забэкапить в единый образ и развернуть в том же виде в другом месте. Docker идеален для максимальной плотности сервисов на одном сервере. Думаю именно за это он стал так популярен. На больших масштабах это заметная экономия средств, поэтому крупные компании его активно используют и продвигают.
Аналогом Docker в плане подхода в виде запуска отдельных служб в контейнерах является Podman. Там есть незначительные отличия в реализации, но в целом они очень похожи. Это продукт компании RedHat, и они его всячески продвигают.
Ещё упомяну про LXD, который иногда сравнивают с LXC, хотя это разные вещи. По сути, LXD - надстройка над LXC, предоставляющая REST API для работы с контейнерами LXC. Она упрощает работу с ними, стандартизирует и даёт удобные инструменты управления. При этом LXD может работать не только с контейнерами LXC, но и с виртуальными машинами QEMU.
Надеюсь ничего нигде не напутал. Писал своими словами по памяти, так как с Docker и LXC практически постоянно работаю и примерно представляю, как они устроены.
#docker #lxc
Все контейнеры используют одно и то же ядро операционной системы Linux и работают в его рамках. Это принципиальное отличие от виртуальных машин. А принципиальное отличие Docker от LXC в том, что Docker ориентируется на запуск приложений, а LXC на запуск системы.
Поясню на конкретном примере. Допустим, вам надо запустить в работу веб сервер. Если вы будете делать это с помощью Docker, то на хостовой машине запустите контейнер с Nginx, контейнер с Php-fpm, создадите на хосте локальные директории с файлами сайта и конфигурациями сервисов и пробросите их внутрь контейнеров, чтобы у них был доступ к ним. В самих контейнерах кроме непосредственно сервисов Nginx и Php-fpm практически ничего не будет.
Если ту же задачу решать с помощью LXC, то вы просто запустите контейнер с нужной базовой системой внутри. Зайдёте внутрь контейнера и настроите там всё, как обычно это делаете на отдельной виртуальной машине. То есть LXC максимально повторяет работу полноценной системы, только работает на базе ядра хоста.
☝ Docker - это один контейнер, одна служба, LXC - набор служб для решения конкретной задачи. При этом в образ Docker тоже можно поместить практически полноценную систему, но так обычно никто не делает, хотя и есть исключения.
Исходя из этих пояснений, становятся понятны плюсы и минусы каждого подхода. Плюсы Docker:
◽минимальный объём образов, соответственно, максимальная скорость запуска нужных сервисов;
◽для бэкапа достаточно сохранить непосредственно данные, образы можно опустить, так как они типовые.
Минусы:
◽более сложная настройка по сравнению с обычной виртуальной машиной, особенно что касается сети и диагностики в целом.
Плюсы LXC:
◽настройка практически такая же, как на обычной VM, заходишь внутрь контейнера по SSH и настраиваешь.
Минусы LXC:
◽итоговые образы бОльшего объёма, так как содержат всё окружение стандартных систем.
◽сложнее автоматизировать и стандартизировать разворачивание масштабных сервисов.
LXC отлично подходит как замена полноценной VM. Его удобно настроить, забэкапить в единый образ и развернуть в том же виде в другом месте. Docker идеален для максимальной плотности сервисов на одном сервере. Думаю именно за это он стал так популярен. На больших масштабах это заметная экономия средств, поэтому крупные компании его активно используют и продвигают.
Аналогом Docker в плане подхода в виде запуска отдельных служб в контейнерах является Podman. Там есть незначительные отличия в реализации, но в целом они очень похожи. Это продукт компании RedHat, и они его всячески продвигают.
Ещё упомяну про LXD, который иногда сравнивают с LXC, хотя это разные вещи. По сути, LXD - надстройка над LXC, предоставляющая REST API для работы с контейнерами LXC. Она упрощает работу с ними, стандартизирует и даёт удобные инструменты управления. При этом LXD может работать не только с контейнерами LXC, но и с виртуальными машинами QEMU.
Надеюсь ничего нигде не напутал. Писал своими словами по памяти, так как с Docker и LXC практически постоянно работаю и примерно представляю, как они устроены.
#docker #lxc
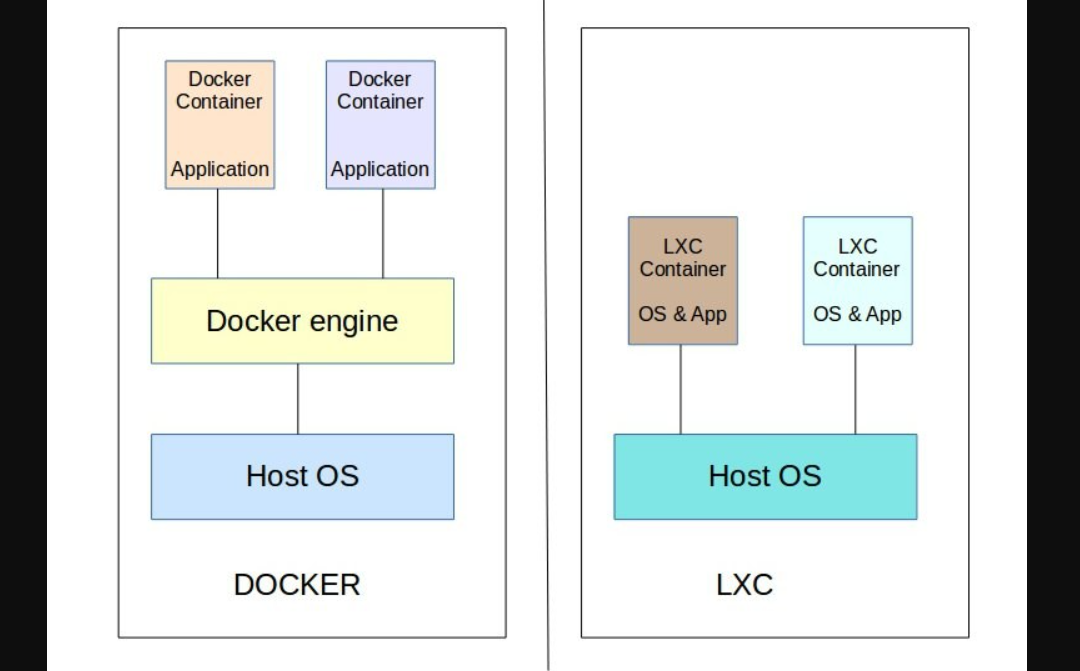{kind=link}
🔝Чуть не забыл про очередной топ постов за прошедший месяц. Надо будет попробовать собрать похожую информацию за прошедшее полугодие. И в целом сформировать какой-то список наиболее интересных и полезных заметок. Пока думаю, как это всё оформить. Написано уже море всего и какую-то часть я сам забываю. Приходится использовать поиск по каналу, чтобы не писать об одном и том же. Как же быстро летит время. Вроде недавно начал вести канал, а на самом деле прошло уже много лет и написаны тысячи заметок.
📌 Больше всего просмотров:
◽️Видео "Веселенький денек у сисадмина" (7381)
◽️Облачный сервис Grafana Cloud (7320)
◽️Списки IP адресов Google и Yandex (7301)
📌 Больше всего комментариев:
◽️Мифы про Astra Linux (154)
◽️Обновление Proxmox 7 до 8 (121)
◽️Заметка про бумажные копии электронных документов (69)
📌 Больше всего пересылок:
◽️Списки IP адресов по странам (489)
◽️Сервис уведомлений ntfy.sh (392)
◽️Создание ловушек с помощью canarytokens.org (372)
📌 Больше всего реакций:
◽️Мифы про Astra Linux (205)
◽️Заметка про бумажные копии электронных документов (180)
◽️Маркетплейс российского ПО от Минцифры (162)
◽️Расследование внезапной перезагрузки сервера (148)
#топ
📌 Больше всего просмотров:
◽️Видео "Веселенький денек у сисадмина" (7381)
◽️Облачный сервис Grafana Cloud (7320)
◽️Списки IP адресов Google и Yandex (7301)
📌 Больше всего комментариев:
◽️Мифы про Astra Linux (154)
◽️Обновление Proxmox 7 до 8 (121)
◽️Заметка про бумажные копии электронных документов (69)
📌 Больше всего пересылок:
◽️Списки IP адресов по странам (489)
◽️Сервис уведомлений ntfy.sh (392)
◽️Создание ловушек с помощью canarytokens.org (372)
📌 Больше всего реакций:
◽️Мифы про Astra Linux (205)
◽️Заметка про бумажные копии электронных документов (180)
◽️Маркетплейс российского ПО от Минцифры (162)
◽️Расследование внезапной перезагрузки сервера (148)
#топ