
Смотрите, какая интересная коллекция приёмов на bash для выполнения различных обработок строк, массивов, файлов и т.д.:
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
Использовать следующим образом:
Примерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
Используем для примера:
Понятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
lower() { printf '%s\n' "${1,,}"}Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
#!/bin/bashlower() { printf '%s\n' "${1,,}"}lower "$1"Использовать следующим образом:
# ./lower.sh HELLOhelloПримерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
#!/bin/bashbasename() { local tmp tmp=${1%"${1##*[!/]}"} tmp=${tmp##*/} tmp=${tmp%"${2/"$tmp"}"} printf '%s\n' "${tmp:-/}"}Используем для примера:
# ./basename.sh /var/log/syslog.2.gzsyslog.2.gzПонятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
basename и dirname для вычленения имени файла или пути директории, в котором лежит файл. Но это будут внешние зависимости к отдельным бинарникам, а не код на bash.Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
{kind=link}
Media is too big
VIEW IN TELEGRAM
▶️ Когда речь заходит о юмористических видео, неизменно всплывает в комментариях Веселенький денек у сисадмина (The Website is Down). Кто не смотрел, завидую. Сам пересмотрю в очередной раз.
Возможно не все знают, но авторы этого видео снимали и другие ролики. Они похуже самого первого, но посмотреть можно.
The Website is Down #2: Excel Hell
⇨ https://www.youtube.com/watch?v=1SNxaJlicEU
🔥The Website is Down #3: Remain Calm
⇨ https://www.youtube.com/watch?v=1XjKnxOcaO0
The Website is Down Episode #4: Sales Demolition (NSFW)
⇨ https://www.youtube.com/watch?v=v0mwT3DkG4w
Episode #4.5: Chipadmin
⇨ https://www.youtube.com/watch?v=s8QjArjcjbQ
#юмор
Возможно не все знают, но авторы этого видео снимали и другие ролики. Они похуже самого первого, но посмотреть можно.
The Website is Down #2: Excel Hell
⇨ https://www.youtube.com/watch?v=1SNxaJlicEU
🔥The Website is Down #3: Remain Calm
⇨ https://www.youtube.com/watch?v=1XjKnxOcaO0
The Website is Down Episode #4: Sales Demolition (NSFW)
⇨ https://www.youtube.com/watch?v=v0mwT3DkG4w
Episode #4.5: Chipadmin
⇨ https://www.youtube.com/watch?v=s8QjArjcjbQ
#юмор
Некоторое время назад вернулся к использованию RSS. Стал выбирать читалку для этого дела. Перепробовал кучу известных сервисов и приложений, а пользоваться в итоге стал Thunderbird. Я давно и постоянно использую её для работы с почтой. Случайно узнал, что там есть встроенный RSS ридер. Он мне показался вполне удобным, так что перетащил все ленты туда.
Не могу сказать, что в Thunderbird всё очень удобно, но так как всё равно её использую, то нормально. Если кто-то тоже будет выбирать отдельное приложение, то могу порекомендовать QuiteRSS. Мне она понравилась больше всего. Она каким-то образом умеет находить прямую ссылку на RSS на сайте, даже если сам её найти не можешь. Не знаю, как она это делает. Когда не могу найти RSS ленту, скармливаю ссылку сайта в QuiteRSS, а потом уже url ленты в Thunderbird добавляю.
Если захотите в RSS добавить Telegram каналы, то для этого можно воспользоваться сервисом https://rsshub.app. Ссылка на мой канал будет такой:
⇨ https://rsshub.app/telegram/channel/srv_admin
Причём этот сервис можно развернуть и у себя. Я писал когда-то о нём. С его помощью можно обернуть контент в RSS, если у него нет готового потока для этого.
#разное
Не могу сказать, что в Thunderbird всё очень удобно, но так как всё равно её использую, то нормально. Если кто-то тоже будет выбирать отдельное приложение, то могу порекомендовать QuiteRSS. Мне она понравилась больше всего. Она каким-то образом умеет находить прямую ссылку на RSS на сайте, даже если сам её найти не можешь. Не знаю, как она это делает. Когда не могу найти RSS ленту, скармливаю ссылку сайта в QuiteRSS, а потом уже url ленты в Thunderbird добавляю.
Если захотите в RSS добавить Telegram каналы, то для этого можно воспользоваться сервисом https://rsshub.app. Ссылка на мой канал будет такой:
⇨ https://rsshub.app/telegram/channel/srv_admin
Причём этот сервис можно развернуть и у себя. Я писал когда-то о нём. С его помощью можно обернуть контент в RSS, если у него нет готового потока для этого.
#разное
{kind=link}
Давно не поднимал тему обычных бэкапов, так как всё более ли менее известное уже упоминал на канале. Посмотреть можно по тэгу #backup. Но сегодня у меня есть кое-что новое в том числе и для меня самого.
Есть известная и популярная консольная программа для бэкапа в Linux — borg. Основные возможности следующие:
◽простая установка, есть в репозиториях
◽поддержка дедупликации
◽работает по ssh, без агентов
◽бэкапы монтируются с помощью fuse
В общем, это такая простая и надёжная утилита, которую можно сравнить с rsync по удобству консольных велосипедов, только с хранением файлов не в исходном виде, а в своих дедуплицированных архивах. Очень похожа на restic.
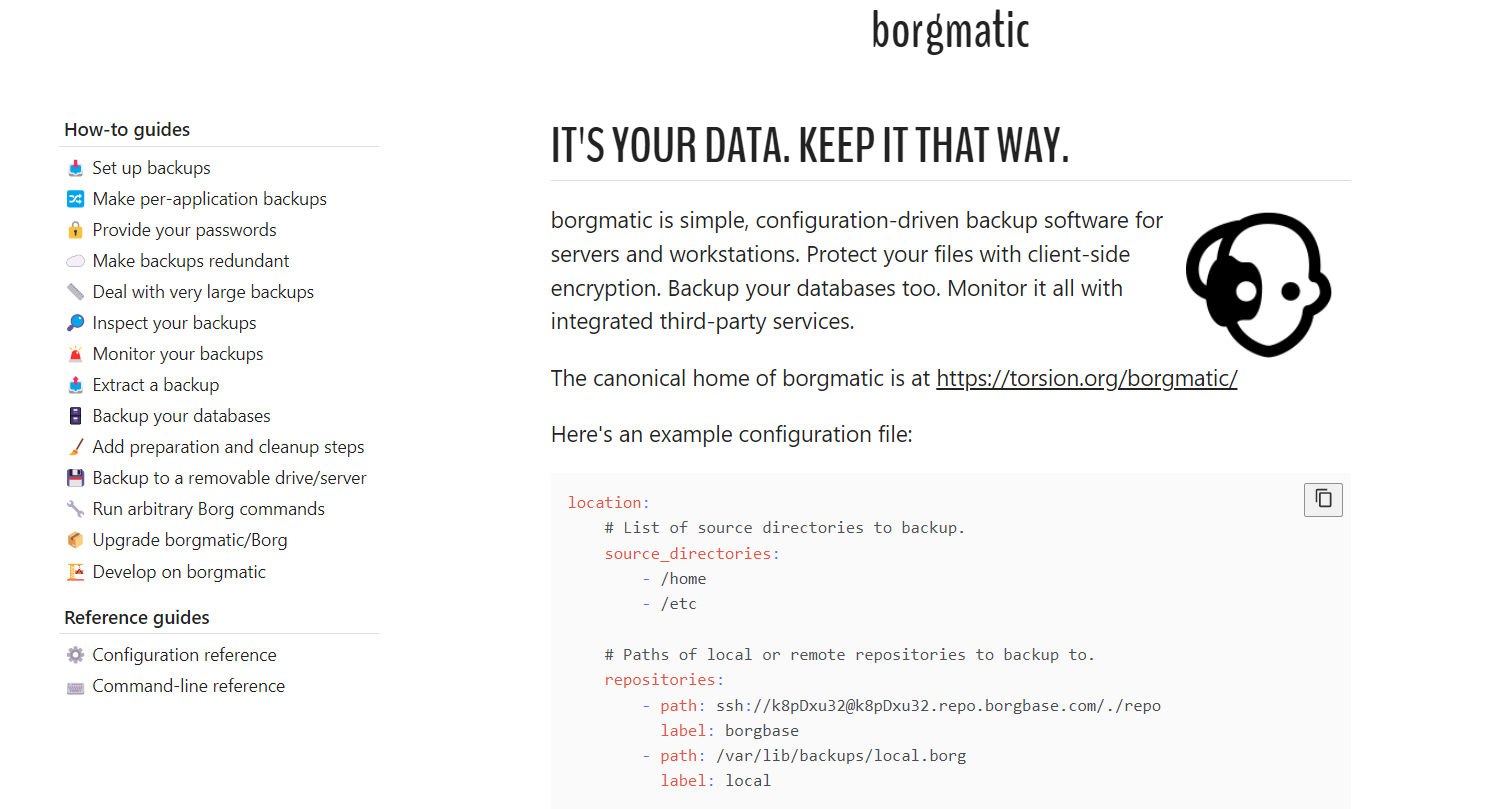
Так вот, для borg есть обёртка в виде borgmatic. С её помощью можно описывать бэкапы для borg в формате yaml. Это упрощает и делает более универсальной настройку бэкапов. С помощью borgmatic можно полностью описать все параметры бэкапа в едином конфиге, а не ключами запуска, как это делается в оригинальном borg. Сразу настраиваем источники, исключения, время жизни архива и т.д.
Вот основные возможности borgmatic, расширяющие функциональность borg:
▪ сохранение бэкапа сразу в несколько репозиториев;
▪ поддержка хуков и оповещений на события бэкапа (успешно, ошибка и т.д.);
▪ поддержка хуков на pre и post события бэкапа;
▪ встроенная поддержка создания дампов баз данных (PostgreSQL, MySQL/MariaDB, MongoDB, и SQLite);
▪ возможность передачи секретов (пароль архива, доступ к БД) через переменные.
Borgmatic написан на python, поставить можно через pip:
Пример использования можно посмотреть в скринкасте. Если нравится borg, то не вижу смысла не использовать borgmatic. С ним банально удобнее.
⇨ Сайт / Исходники
Напомню, что все бесплатные программы для бэкапа, которые я упоминал на канале, собраны для удобства в единую статью на сайте:
⇨ https://serveradmin.ru/top-12-besplatnyh-programm-dlya-bekapa
#backup
Есть известная и популярная консольная программа для бэкапа в Linux — borg. Основные возможности следующие:
◽простая установка, есть в репозиториях
# apt install borgbackup◽поддержка дедупликации
◽работает по ssh, без агентов
◽бэкапы монтируются с помощью fuse
В общем, это такая простая и надёжная утилита, которую можно сравнить с rsync по удобству консольных велосипедов, только с хранением файлов не в исходном виде, а в своих дедуплицированных архивах. Очень похожа на restic.
Так вот, для borg есть обёртка в виде borgmatic. С её помощью можно описывать бэкапы для borg в формате yaml. Это упрощает и делает более универсальной настройку бэкапов. С помощью borgmatic можно полностью описать все параметры бэкапа в едином конфиге, а не ключами запуска, как это делается в оригинальном borg. Сразу настраиваем источники, исключения, время жизни архива и т.д.
Вот основные возможности borgmatic, расширяющие функциональность borg:
▪ сохранение бэкапа сразу в несколько репозиториев;
▪ поддержка хуков и оповещений на события бэкапа (успешно, ошибка и т.д.);
▪ поддержка хуков на pre и post события бэкапа;
▪ встроенная поддержка создания дампов баз данных (PostgreSQL, MySQL/MariaDB, MongoDB, и SQLite);
▪ возможность передачи секретов (пароль архива, доступ к БД) через переменные.
Borgmatic написан на python, поставить можно через pip:
# pip3 install borgmaticПример использования можно посмотреть в скринкасте. Если нравится borg, то не вижу смысла не использовать borgmatic. С ним банально удобнее.
⇨ Сайт / Исходники
Напомню, что все бесплатные программы для бэкапа, которые я упоминал на канале, собраны для удобства в единую статью на сайте:
⇨ https://serveradmin.ru/top-12-besplatnyh-programm-dlya-bekapa
#backup
{kind=link}
Небольшой полезный сайт в закладки. Если хотите узнать, когда кончается поддержка того или иного программного продукта, то проще и быстрее всего зайти на сайт endoflife.date. Тут прям всё есть в одном месте, и софт, и операционные системы.
Пишем в поиск CentOS и видим время окончания поддержки последних версий. Напомню, что 7-я версия всё ещё поддерживается. Сайт нам это подсказывает: Ends in 11 months (30 Jun 2024). Частенько бывает, надо посмотреть, когда EOL какой-нибудь версии PHP. До сих пор активно используемая версия 7.4 уже больше года не поддерживается: Ended 7 months ago (28 Nov 2022).
В общем, тут есть всё, в одном месте и удобно оформлено: debian, proxmox, mysql и т.д. Сайт однозначно в закладки. Его, кстати, берут за основу многие программы по проверки актуальности версий пакетов, контейнеров с программами и т.д.
#security
Пишем в поиск CentOS и видим время окончания поддержки последних версий. Напомню, что 7-я версия всё ещё поддерживается. Сайт нам это подсказывает: Ends in 11 months (30 Jun 2024). Частенько бывает, надо посмотреть, когда EOL какой-нибудь версии PHP. До сих пор активно используемая версия 7.4 уже больше года не поддерживается: Ended 7 months ago (28 Nov 2022).
В общем, тут есть всё, в одном месте и удобно оформлено: debian, proxmox, mysql и т.д. Сайт однозначно в закладки. Его, кстати, берут за основу многие программы по проверки актуальности версий пакетов, контейнеров с программами и т.д.
#security
{kind=link}
На днях потратил кучу времени, чтобы настроить загрузку файлов на Яндекс.Диск через REST API. Больше всего провозился с настройкой доступа и получением токена. Текущего личного кабинета и документации недостаточно, чтобы успешно выполнить задачу. Пришлось разбираться. У Яндекс.Диска очень дешёвое хранилище. Активно его использую и для себя, и по работе.
1️⃣ С этим этапом я провозился больше всего. Если посмотреть документацию, то там предлагают пойти по ссылке https://yandex.ru/dev/oauth/ и создать приложение. Но в созданном через ЛК приложении у вас не будет возможности указать права для Яндекс.Диска. Это какой-то косяк очередного обновления сервиса. Раньше этой проблемы точно не было, так как я много раз получал токены для других нужд.
Правильная ссылка — https://oauth.yandex.ru/client/new По ней сразу можно создать приложение с нужными правами. Нужны будут следующие права:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
2️⃣ После создания приложения получите для него токен. Для этого откройте в браузере ссылку: https://oauth.yandex.ru/authorize?response_type=token&client_id=717284f34ab94558702c94345ac01829
В конце подставьте свой client_id от созданного приложения.
3️⃣ Прежде чем отправить файл в Яндекс.Диск, нужно получить ссылку для загрузки. Сделаем это с помощью curl:
curl -s -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://cloud-api.yandex.net:443/v1/disk/resources/upload/?path=app:/testfile.gz&overwrite=true
y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k — ваш токен
app:/testfile.gz — путь, куда будет загружен файл testfile.gz. В таком формате пути у вас в корне диска будет директория Приложения, в ней директория с именем приложения, а в ней уже файл.
В ответ вы получите url для загрузки.
4️⃣ Используя полученный url, загружаем файл:
curl -s -T ~/testfile.gz -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://uploader6g.disk.yandex.net:443/upload-target/20230711T030316.348.utd.cbcacvszdm46g8j68kttgwnuq-k6g.8149437
Теперь всё это можно обернуть в какой-то скрипт в зависимости от ваших потребностей. Я свой скрипт не буду приводить, он слишком длинный. Примеры можете посмотреть в статье Backup с помощью Yandex Disk REST API. Там подробно расписаны несколько вариантов.
#bash #backup
1️⃣ С этим этапом я провозился больше всего. Если посмотреть документацию, то там предлагают пойти по ссылке https://yandex.ru/dev/oauth/ и создать приложение. Но в созданном через ЛК приложении у вас не будет возможности указать права для Яндекс.Диска. Это какой-то косяк очередного обновления сервиса. Раньше этой проблемы точно не было, так как я много раз получал токены для других нужд.
Правильная ссылка — https://oauth.yandex.ru/client/new По ней сразу можно создать приложение с нужными правами. Нужны будут следующие права:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
2️⃣ После создания приложения получите для него токен. Для этого откройте в браузере ссылку: https://oauth.yandex.ru/authorize?response_type=token&client_id=717284f34ab94558702c94345ac01829
В конце подставьте свой client_id от созданного приложения.
3️⃣ Прежде чем отправить файл в Яндекс.Диск, нужно получить ссылку для загрузки. Сделаем это с помощью curl:
curl -s -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://cloud-api.yandex.net:443/v1/disk/resources/upload/?path=app:/testfile.gz&overwrite=true
y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k — ваш токен
app:/testfile.gz — путь, куда будет загружен файл testfile.gz. В таком формате пути у вас в корне диска будет директория Приложения, в ней директория с именем приложения, а в ней уже файл.
В ответ вы получите url для загрузки.
4️⃣ Используя полученный url, загружаем файл:
curl -s -T ~/testfile.gz -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://uploader6g.disk.yandex.net:443/upload-target/20230711T030316.348.utd.cbcacvszdm46g8j68kttgwnuq-k6g.8149437
Теперь всё это можно обернуть в какой-то скрипт в зависимости от ваших потребностей. Я свой скрипт не буду приводить, он слишком длинный. Примеры можете посмотреть в статье Backup с помощью Yandex Disk REST API. Там подробно расписаны несколько вариантов.
#bash #backup
{kind=link}
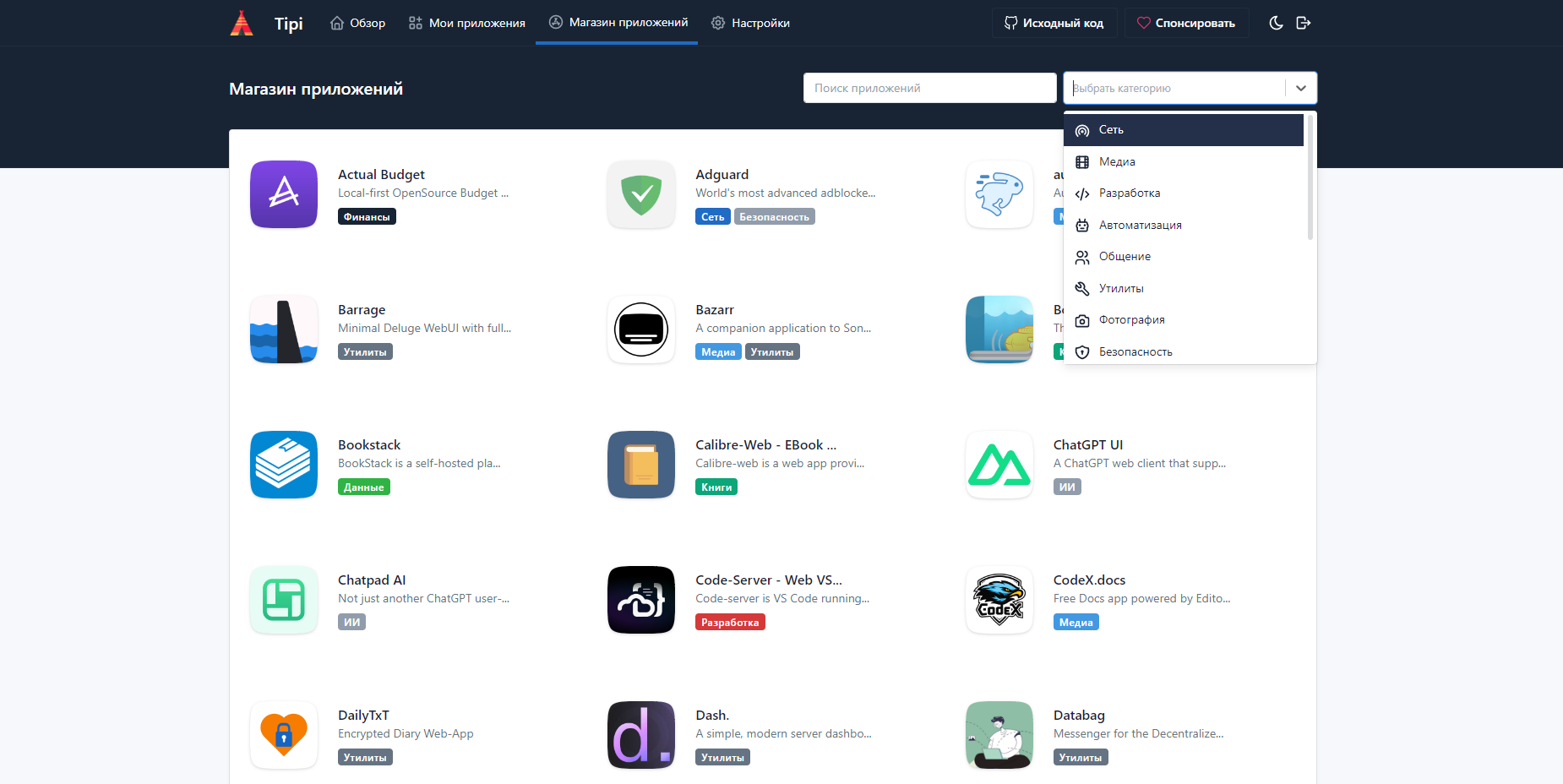
Рекомендую очень простой и удобный портал для управления запущенными сервисами на Linux — Runtipi. Он позиционирует себя для домашнего использования, что подтверждает набор сервисов. Позволяет очень просто и быстро запускать приложения. А тем, кто с Linux на ВЫ, позволит без особых усилий пощупать руками его возможности в плане использования готовых сервисов.
По своей сути Runtipi обычная веб панель для запуска Docker контейнеров. У неё минимум возможностей и настроек. Есть магазин приложений, которые устанавливаются в пару кликов. Каждое приложение запускается на своём порту, а вы с помощью дашборда Runtipi легко их открываете, запускаете, устанавливаете, делаете базовую настройку, обновляете.
Я развернул у себя и запустил, попробовал. Реально удобно. Под капотом обычный Docker и контейнеры, которые пишет не сам автор, а использует готовые либо от разработчиков, либо от каких-то доверенных издателей, типа linuxserver.io.
Список поддерживаемых приложений можно посмотреть на отдельной странице. Сейчас их там 132 штуки. Некоторые примеры, про которые я писал: Adguard, Pi-Hole, Duplicati, File Browser, Gitea, Grafana, Joplin Server, Minio, n8n, Nextcloud, Portainer, Revolt Chat, Syncthing, Uptime Kuma, ZeroTier, Wireguard.
Все эти приложения легко развернуть, попробовать, удалить и т.д. Я хотел быстренько попробовать клиента для ChatGPT (там есть для него приложение). К сожалению, доступ к API у меня был заблокирован. Возвращает 404 ошибку. Похоже надо прокси использовать. Подскажите, кто как работает с ChatGPT с территории РФ.
⇨ Сайт / Исходники
#docker #linux
По своей сути Runtipi обычная веб панель для запуска Docker контейнеров. У неё минимум возможностей и настроек. Есть магазин приложений, которые устанавливаются в пару кликов. Каждое приложение запускается на своём порту, а вы с помощью дашборда Runtipi легко их открываете, запускаете, устанавливаете, делаете базовую настройку, обновляете.
Я развернул у себя и запустил, попробовал. Реально удобно. Под капотом обычный Docker и контейнеры, которые пишет не сам автор, а использует готовые либо от разработчиков, либо от каких-то доверенных издателей, типа linuxserver.io.
Список поддерживаемых приложений можно посмотреть на отдельной странице. Сейчас их там 132 штуки. Некоторые примеры, про которые я писал: Adguard, Pi-Hole, Duplicati, File Browser, Gitea, Grafana, Joplin Server, Minio, n8n, Nextcloud, Portainer, Revolt Chat, Syncthing, Uptime Kuma, ZeroTier, Wireguard.
Все эти приложения легко развернуть, попробовать, удалить и т.д. Я хотел быстренько попробовать клиента для ChatGPT (там есть для него приложение). К сожалению, доступ к API у меня был заблокирован. Возвращает 404 ошибку. Похоже надо прокси использовать. Подскажите, кто как работает с ChatGPT с территории РФ.
⇨ Сайт / Исходники
#docker #linux
{kind=link}
Я неоднократно получал вопрос от тех, кто настраивал почтовый сервер по моей статье, о том, как закрыть почтовые алиасы от спама. Поясню, о чём идёт речь.
Допустим, у вас есть почтовый алиас all@firma.ru, куда входят все сотрудники компании. Их может быть очень много. Подобные алиасы удобно использовать для рассылок внутри компании. Обычно делаю общий алиас для всей компании и для каждого отдела. Остальное уже по потребностям.
Подобные адреса очень удобно использовать спамерам. Отправил одно письмо на all@firma.ru и его получили все сотрудники. Логично было бы ограничить возможность отправки на эти адреса. Я в своё время сам разбирал эту задачу и придумал решение. Нигде его не записал, поэтому каждый раз приходилось вспоминать, как я делал. Так что решил хотя бы заметкой оформить.
Чем мне нравится postfix, так это своей гибкостью и механизмом restrictions, на основе которых можно много всего придумать. Я задачу решил так. Взял параметр smtpd_recipient_restrictions и добавил туда дополнительную проверку:
Это строки из конфигурационного файла postfix main.cf. Текстовый файл maillist_access выглядит примерно так:
Одна строка, один адрес.
Суть тут в чём. Мы в ограничениях получателя указываем, что люди из mynetworks и sasl_authenticated не имеют никаких ограничений на отправку. Это все люди из белых списков локальных сетей (не рекомендую их использовать, только в крайних случаях) и прошедшие аутентификацию, то есть наши сотрудники и пользователи почтового сервера. А все остальные попадают на проверку check_recipient_access, где в файле указано действие для получателя all@firma.ru — давать REJECT. Вот и всё.
Основное неудобство в том, что файл maillist_access придётся заполнять вручную. Если это критично, то можно и автоматизировать каким-то образом. Например, настроить проверку из базы mysql, а там завести какую-то отдельную таблицу для таких алиасов, в которую по какому-то признаку скрипт будет перетаскивать записи из общей таблицы алиасов. Например, по наличию какого-то слова в описании. У меня не было задачи с автоматизацией, поэтому не занимался вопросом. Массовых алиасов не так много, можно и вручную один раз составить список.
Возможно есть какое-то другое решение этой задачи, может быть проще и удобнее. Я настроил так и везде использовал.
#postfix #mailserver
Допустим, у вас есть почтовый алиас all@firma.ru, куда входят все сотрудники компании. Их может быть очень много. Подобные алиасы удобно использовать для рассылок внутри компании. Обычно делаю общий алиас для всей компании и для каждого отдела. Остальное уже по потребностям.
Подобные адреса очень удобно использовать спамерам. Отправил одно письмо на all@firma.ru и его получили все сотрудники. Логично было бы ограничить возможность отправки на эти адреса. Я в своё время сам разбирал эту задачу и придумал решение. Нигде его не записал, поэтому каждый раз приходилось вспоминать, как я делал. Так что решил хотя бы заметкой оформить.
Чем мне нравится postfix, так это своей гибкостью и механизмом restrictions, на основе которых можно много всего придумать. Я задачу решил так. Взял параметр smtpd_recipient_restrictions и добавил туда дополнительную проверку:
.....................................smtpd_recipient_restrictions = permit_mynetworks, permit_sasl_authenticated, check_recipient_access hash:/etc/postfix/maillist_access..................................Это строки из конфигурационного файла postfix main.cf. Текстовый файл maillist_access выглядит примерно так:
all@firma.ru REJECTОдна строка, один адрес.
Суть тут в чём. Мы в ограничениях получателя указываем, что люди из mynetworks и sasl_authenticated не имеют никаких ограничений на отправку. Это все люди из белых списков локальных сетей (не рекомендую их использовать, только в крайних случаях) и прошедшие аутентификацию, то есть наши сотрудники и пользователи почтового сервера. А все остальные попадают на проверку check_recipient_access, где в файле указано действие для получателя all@firma.ru — давать REJECT. Вот и всё.
Основное неудобство в том, что файл maillist_access придётся заполнять вручную. Если это критично, то можно и автоматизировать каким-то образом. Например, настроить проверку из базы mysql, а там завести какую-то отдельную таблицу для таких алиасов, в которую по какому-то признаку скрипт будет перетаскивать записи из общей таблицы алиасов. Например, по наличию какого-то слова в описании. У меня не было задачи с автоматизацией, поэтому не занимался вопросом. Массовых алиасов не так много, можно и вручную один раз составить список.
Возможно есть какое-то другое решение этой задачи, может быть проще и удобнее. Я настроил так и везде использовал.
#postfix #mailserver
Server Admin
Настройка почтового сервера на Debian: postfix + dovecot + web...
Подробная пошаговая установка и настройка почтового сервера на Debian (postfix + dovecot): от подготовки DNS записей до запуска служб.
Я регулярно читаю рассылку от компании Onlyoffice. Кто про них не знает, поясню, что это компания с российскими корнями, которая разработала собственный движок для работы с документами онлайн, а также платформу для совместной работы. Яндекс в своих онлайн документах использует их движок. Также у них есть бесплатные десктопные редакторы, совместимые с документами Microsoft Office.
У них активно ведётся доработка, обновление продуктов, а также выпуск новых. Например, недавно появился сервис DocSpace (selfhosted версии пока нет, но обещают) для создания комнат с набором документов для совместной работы, доступ к которым можно настраивать.
Onlyoffice имеет некоторые продукты с открытым кодом, которые можно развернуть у себя и успешно использовать. К сожалению, они всё это замаскировали на сайте. Если не знаешь, где и что искать, то можешь даже не догадаться, что оно есть. Ну и с инструкциями по установке этих продуктов тоже всё очень запутанно, так что разобраться с нуля трудно. Поэтому и решил сделать заметку, чтобы тем, кому всё это нужно, смог бы быстро установить и попробовать продукты.
Сразу приведу ссылки, чтобы вы могли сами посмотреть, о чём идёт речь:
⇨ Страничка продукта ONLYOFFICE Workspace Community
⇨ Инструкции по ручной установке и запуску в Docker
⇨ Общая инструкция по установке ONLYOFFICE Workspace
Можете сами оценить ссылки с инструкциями. Там сходу как-то трудно понять, что тебе надо использовать, когда ты хочешь запустить у себя бесплатную версию. Так что если хотите попробовать портал для групповой работы с онлайн редактором документов, следуйте простой инструкции:
На вопрос установки через Docker ответьте утвердительно, а на запрос установки почтового сервера ответьте отказом. В общем случае не рекомендую ставить почтовый сервер в составе Workspace, так как в этом нет большого смысла. Лучше поднять его отдельно или использовать внешний сервер. А в Workspace можно подключать ящики по imap и отправлять по smtp. Там полноценный веб клиент есть.
❗️Основное ограничение community версии портала — 20 одновременных подключений к серверу работы с документами. Общее количество пользователей не ограничено. Достаточно солидный запас. Коллектив в 40-50 человек может спокойно работать с этим сервером, если будет закрывать документы, когда они не нужны.
После установки идёте по IP адресу сервера и выполняете начальную настройку. Если в процессе тестирования поймёте, что продукт вам подходит, тогда уже можно более детально разобраться в установке: поменять все дефолтные учётки в скриптах, вынести отдельные директории на нужные диски и т.д. Есть возможность разворачивать продукт через deb пакеты, но я не рекомендую. Лучше в Docker. Это надёжнее и проще в обновлении. У onlyoffice куча зависимостей и поддерживать всё это довольно хлопотно.
Также в прод рекомендую ставить без TLS, а шифрование настроить на Nginx в режиме proxy_pass. Так тоже проще настраивать и потом управлять доступом.
У меня есть статья Установка и настройка Onlyoffice. Она сильно устарела. Когда писал её, продукт ONLYOFFICE Workspace, который актуален сейчас, назывался по-другому — ONLYOFFICE Community Server. В названиях пакетов и репозиториях сохранилось это название, что дополнительно добавляет путаницы.
Из бесплатных редакторов документов ONLYOFFICE мне нравится больше всего. Я его успешно использую уже лет 5-6. Сейчас есть 2 портала в управлении. Так что можно задавать конкретные вопросы, если что-то интересует.
#onlyoffice #docs
У них активно ведётся доработка, обновление продуктов, а также выпуск новых. Например, недавно появился сервис DocSpace (selfhosted версии пока нет, но обещают) для создания комнат с набором документов для совместной работы, доступ к которым можно настраивать.
Onlyoffice имеет некоторые продукты с открытым кодом, которые можно развернуть у себя и успешно использовать. К сожалению, они всё это замаскировали на сайте. Если не знаешь, где и что искать, то можешь даже не догадаться, что оно есть. Ну и с инструкциями по установке этих продуктов тоже всё очень запутанно, так что разобраться с нуля трудно. Поэтому и решил сделать заметку, чтобы тем, кому всё это нужно, смог бы быстро установить и попробовать продукты.
Сразу приведу ссылки, чтобы вы могли сами посмотреть, о чём идёт речь:
⇨ Страничка продукта ONLYOFFICE Workspace Community
⇨ Инструкции по ручной установке и запуску в Docker
⇨ Общая инструкция по установке ONLYOFFICE Workspace
Можете сами оценить ссылки с инструкциями. Там сходу как-то трудно понять, что тебе надо использовать, когда ты хочешь запустить у себя бесплатную версию. Так что если хотите попробовать портал для групповой работы с онлайн редактором документов, следуйте простой инструкции:
# wget https://download.onlyoffice.com/install/workspace-install.sh# bash workspace-install.shНа вопрос установки через Docker ответьте утвердительно, а на запрос установки почтового сервера ответьте отказом. В общем случае не рекомендую ставить почтовый сервер в составе Workspace, так как в этом нет большого смысла. Лучше поднять его отдельно или использовать внешний сервер. А в Workspace можно подключать ящики по imap и отправлять по smtp. Там полноценный веб клиент есть.
❗️Основное ограничение community версии портала — 20 одновременных подключений к серверу работы с документами. Общее количество пользователей не ограничено. Достаточно солидный запас. Коллектив в 40-50 человек может спокойно работать с этим сервером, если будет закрывать документы, когда они не нужны.
После установки идёте по IP адресу сервера и выполняете начальную настройку. Если в процессе тестирования поймёте, что продукт вам подходит, тогда уже можно более детально разобраться в установке: поменять все дефолтные учётки в скриптах, вынести отдельные директории на нужные диски и т.д. Есть возможность разворачивать продукт через deb пакеты, но я не рекомендую. Лучше в Docker. Это надёжнее и проще в обновлении. У onlyoffice куча зависимостей и поддерживать всё это довольно хлопотно.
Также в прод рекомендую ставить без TLS, а шифрование настроить на Nginx в режиме proxy_pass. Так тоже проще настраивать и потом управлять доступом.
У меня есть статья Установка и настройка Onlyoffice. Она сильно устарела. Когда писал её, продукт ONLYOFFICE Workspace, который актуален сейчас, назывался по-другому — ONLYOFFICE Community Server. В названиях пакетов и репозиториях сохранилось это название, что дополнительно добавляет путаницы.
Из бесплатных редакторов документов ONLYOFFICE мне нравится больше всего. Я его успешно использую уже лет 5-6. Сейчас есть 2 портала в управлении. Так что можно задавать конкретные вопросы, если что-то интересует.
#onlyoffice #docs
{kind=link}
У меня на канале было много заметок на тему Help Desk систем. Я рассматривал в основном бесплатные продукты. При этом в комментариях не раз видел упоминание и советы посмотреть Okdesk. Причём не только у себя, но и в других каналах.
Не знаю, сколько времени я бы откладывал знакомство, но разработчики сами на меня вышли и предложили написать обзор в виде полноценной статьи. Я согласился, написал и предлагаю вам познакомиться:
⇨ Обзор Okdesk: удобная help desk система с широкими возможностями
Статья в основном обзорная, так как сервис продаётся по подписке (saas). Запустить у себя в работу и проверить мне банально негде. Я изучил личный кабинет, описание, документацию. На основе этого написал статью.
Основные возможности системы:
◽многофункциональная тикет-система (мультиканальный приём заявок, клиентский портал, мобильное приложение, API и т.д.)
◽автоматизация процессов (назначение ответственных, чек-листы для заявок, парсинг email и т.д.)
◽модуль CRM (база клиентов, договоров, оплат и т.д.)
◽аналитика и отчёты (десятки готовых отчётов, интеграция с Power BI и Яндекс Data Lens)
◽учёт договоров, платежей, стоимости работ
◽шаблоны документов и автозаполнение
◽календарное планирование
◽учёт трудозатрат
Okdesk — отличное решение для ИТ-аутсорсинговых компаний. Изначально под неё она и создавалась. Но сейчас может быть адаптирована и под другие отрасли: собственный ИТ отдел компании, техническая поддержка продукта, сервиса и т.д.
Моё краткое резюме такое. Okdesk предлагает удобный сервис с простым, интуитивно понятным интерфейсом и очень широкими возможностями. Авторы программы — разработчики больших, корпоративных продуктов для решения задач технической поддержки. Весь свой опыт они перенесли в свой сервис, который разработали с нуля. Из-за гибкой ценовой политики этот продукт доступен малому и среднему бизнесу. Стартовый тариф - 6000 р. в месяц. За эти деньги вы получите удобную Help Desk систему под ключ для 5 сотрудников техподдержки.
#helpdesk #отечественное
Не знаю, сколько времени я бы откладывал знакомство, но разработчики сами на меня вышли и предложили написать обзор в виде полноценной статьи. Я согласился, написал и предлагаю вам познакомиться:
⇨ Обзор Okdesk: удобная help desk система с широкими возможностями
Статья в основном обзорная, так как сервис продаётся по подписке (saas). Запустить у себя в работу и проверить мне банально негде. Я изучил личный кабинет, описание, документацию. На основе этого написал статью.
Основные возможности системы:
◽многофункциональная тикет-система (мультиканальный приём заявок, клиентский портал, мобильное приложение, API и т.д.)
◽автоматизация процессов (назначение ответственных, чек-листы для заявок, парсинг email и т.д.)
◽модуль CRM (база клиентов, договоров, оплат и т.д.)
◽аналитика и отчёты (десятки готовых отчётов, интеграция с Power BI и Яндекс Data Lens)
◽учёт договоров, платежей, стоимости работ
◽шаблоны документов и автозаполнение
◽календарное планирование
◽учёт трудозатрат
Okdesk — отличное решение для ИТ-аутсорсинговых компаний. Изначально под неё она и создавалась. Но сейчас может быть адаптирована и под другие отрасли: собственный ИТ отдел компании, техническая поддержка продукта, сервиса и т.д.
Моё краткое резюме такое. Okdesk предлагает удобный сервис с простым, интуитивно понятным интерфейсом и очень широкими возможностями. Авторы программы — разработчики больших, корпоративных продуктов для решения задач технической поддержки. Весь свой опыт они перенесли в свой сервис, который разработали с нуля. Из-за гибкой ценовой политики этот продукт доступен малому и среднему бизнесу. Стартовый тариф - 6000 р. в месяц. За эти деньги вы получите удобную Help Desk систему под ключ для 5 сотрудников техподдержки.
#helpdesk #отечественное
Server Admin
Обзор Okdesk: удобная help desk система с широкими возможностями
Обзор российской help desk системы Okdesk для организации технической поддержки под ключ.
В нашем IT сообществе до сих пор популярен миф на тему того, что Astra Linux это какая-то поделка на базе Debian с переклеенными шильдиками и устаревшими пакетами. Я сам хоть и не использую нигде Астру, но подобное слушать не люблю, потому что это неправда. Сейчас поясню на пальцах, что такое ОС Astra Linux.
Сейчас существует только один дистрибутив Астры - Astra Linux Special Edition. У него есть несколько релизов, в названиях которых присутствуют города России: Орёл, Воронеж, Смоленск. Они отличаются наличием сертификации и системы мандатного управления доступом. В Воронеже и Смоленске она есть. Что это за система?
Институт системного программирования им. В.П. Иванникова Российской академии наук (ИСП РАН) разработал мандатную сущностно-ролевую модель управления доступом и информационными потоками в ОС семейства Linux. Назвал её МРОСЛ ДП-модель. Она описана на языке формального метода Event-B. Программная реализация модели называется PARSEC. Она используется в Astra Linux Special Edition. PARSEC — это условно аналог AppArmor и SELinux, которые реализуют другие математические модели. Подробное описание и сравнение PARSEC, AppArmor и SELinux можно почитать в статье на хабре.
Для работы с системой PARSEC весь софт патчится для поддержки мандатного доступа. То есть всё, что есть в репозиториях Астры. После осознания этого становится понятно, зачем им своё графическое окружение Fly. Его написали для того, чтобы не зависеть от других продуктов. Регулярно патчить Gnome или KDE очень трудозатратно. Также становится понятно, почему такой устаревший софт в репозиториях. Регулярное обновление требует больших ресурсов. Разработчики астры выполняют его по своим регламентам с некоторой периодичностью.
Подводя итог можно сказать, что компания Astra выполняют серьезную самостоятельную работу по разработке и поддержке своих операционных систем, содержащих самостоятельно разработанные средства защиты информации.
#linux #отечественное
Сейчас существует только один дистрибутив Астры - Astra Linux Special Edition. У него есть несколько релизов, в названиях которых присутствуют города России: Орёл, Воронеж, Смоленск. Они отличаются наличием сертификации и системы мандатного управления доступом. В Воронеже и Смоленске она есть. Что это за система?
Институт системного программирования им. В.П. Иванникова Российской академии наук (ИСП РАН) разработал мандатную сущностно-ролевую модель управления доступом и информационными потоками в ОС семейства Linux. Назвал её МРОСЛ ДП-модель. Она описана на языке формального метода Event-B. Программная реализация модели называется PARSEC. Она используется в Astra Linux Special Edition. PARSEC — это условно аналог AppArmor и SELinux, которые реализуют другие математические модели. Подробное описание и сравнение PARSEC, AppArmor и SELinux можно почитать в статье на хабре.
Для работы с системой PARSEC весь софт патчится для поддержки мандатного доступа. То есть всё, что есть в репозиториях Астры. После осознания этого становится понятно, зачем им своё графическое окружение Fly. Его написали для того, чтобы не зависеть от других продуктов. Регулярно патчить Gnome или KDE очень трудозатратно. Также становится понятно, почему такой устаревший софт в репозиториях. Регулярное обновление требует больших ресурсов. Разработчики астры выполняют его по своим регламентам с некоторой периодичностью.
Подводя итог можно сказать, что компания Astra выполняют серьезную самостоятельную работу по разработке и поддержке своих операционных систем, содержащих самостоятельно разработанные средства защиты информации.
#linux #отечественное
{kind=link}
Дошли наконец-то руки проверить обновление Proxmox VE с 7 на 8-ю версию. Написал сразу статью, так как серверов таких много, обновлять рано или поздно придётся.
⇨ https://serveradmin.ru/obnovlenie-proxmox-7-do-8
Нюансов вообще никаких нет. Всё проходит штатно. Обращаю внимание только на один момент. Я и сам много раз сталкивался, и меня в комментариях постоянно спрашивали. Если увидите во время обновления ошибку:
Upgrade wants to remove package 'proxmox-ve'
То не пугайтесь. Она возникает у тех, кто накатывал Proxmox поверх Debian. Я часто это делаю, чтобы поставить гипервизор на mdadm. Так что ошибку эту знаю. Она возникает из-за конфликта пакетов proxmox-ve и linux-image-amd64, который остаётся от Debian. Его нужно просто удалить. Этот пакет относится к ядру Linux, а у Proxmox VE он свой, поэтому оригинальный не нужен.
Имя пакета может различаться из-за разных версий ядра.
Изменений в новой версии немного. Так что спешить с обновлением не обязательно. Как минимум, можно подождать выхода 8.1.
#proxmox
⇨ https://serveradmin.ru/obnovlenie-proxmox-7-do-8
Нюансов вообще никаких нет. Всё проходит штатно. Обращаю внимание только на один момент. Я и сам много раз сталкивался, и меня в комментариях постоянно спрашивали. Если увидите во время обновления ошибку:
Upgrade wants to remove package 'proxmox-ve'
То не пугайтесь. Она возникает у тех, кто накатывал Proxmox поверх Debian. Я часто это делаю, чтобы поставить гипервизор на mdadm. Так что ошибку эту знаю. Она возникает из-за конфликта пакетов proxmox-ve и linux-image-amd64, который остаётся от Debian. Его нужно просто удалить. Этот пакет относится к ядру Linux, а у Proxmox VE он свой, поэтому оригинальный не нужен.
# apt remove linux-image-amd64Имя пакета может различаться из-за разных версий ядра.
Изменений в новой версии немного. Так что спешить с обновлением не обязательно. Как минимум, можно подождать выхода 8.1.
#proxmox
Server Admin
Обновление Proxmox 7 до 8 | serveradmin.ru
Пошаговое описание с картинками процесса обновления системы виртуализации Proxmox VE с 7-й версии на 8-ю.
▶️ Для тех, кто не в курсе, расскажу, что на официальном канале дистрибутива SUSE есть классная подборка пародийных музыкальных клипов очень хорошего качества. Вот весь плейлист:
⇨ https://www.youtube.com/watch?v=Z9pCb110s7M&list=PL6sYHytyKN2-X93TurF3JptW8qSVm0DzA&index=1
Клипы реально классные, как по видеоряду, так и по музыке, содержанию. Я пару лет назад делал про них заметку. С тех пор клипов стало заметно больше. Они регулярно их выпускают. К сожалению, субъективно кажется, что чем позднее клипы, тем они хуже. Так что если будете слушать, начинайте с самых старых. Хотя недавний 🔥Are You Ready for Rancher прикольный.
🔝Мои самые любимые: Linus Said и SUSE. Yes Please.
Хороший тематический проект. Аналогов я даже и не знаю.
#музыка
⇨ https://www.youtube.com/watch?v=Z9pCb110s7M&list=PL6sYHytyKN2-X93TurF3JptW8qSVm0DzA&index=1
Клипы реально классные, как по видеоряду, так и по музыке, содержанию. Я пару лет назад делал про них заметку. С тех пор клипов стало заметно больше. Они регулярно их выпускают. К сожалению, субъективно кажется, что чем позднее клипы, тем они хуже. Так что если будете слушать, начинайте с самых старых. Хотя недавний 🔥Are You Ready for Rancher прикольный.
🔝Мои самые любимые: Linus Said и SUSE. Yes Please.
Хороший тематический проект. Аналогов я даже и не знаю.
#музыка
{kind=link}
▶️ Для новичков в системном администрировании, а также для тех, кто думает заняться этой темой, рекомендую интересное видео:
⇨ 1.5 Года работы Системным Администратором | Что это такое, и как им стать?
Автор на удивление просто и чётко разложил по полочкам особенности работы начинающего сисадмина. Как я понял, он сам за 1,5 года прошёл этот путь с нуля до 2-й линии техподдержки. И рассказал о своём опыте.
Он сравнил работу в маленькой и большой компании. Описал примерный рабочий день, с чем приходится работать. В общем и целом, он обрисовал реальную картину. Мне было интересно послушать. Этот ролик можно показывать тем, кто будет вас спрашивать, с чего начать и каково это на начальном этапе работать системным администратором.
У автора не ИТ канал. И просмотров там нет, кроме этого ролика, который судя по всему хорошо заходит смотрящим. Мне он в рекомендации попал и привлёк внимание. Смотреть можно на скорости 1,5 или 1,75.
⇨ 1.5 Года работы Системным Администратором | Что это такое, и как им стать?
Автор на удивление просто и чётко разложил по полочкам особенности работы начинающего сисадмина. Как я понял, он сам за 1,5 года прошёл этот путь с нуля до 2-й линии техподдержки. И рассказал о своём опыте.
Он сравнил работу в маленькой и большой компании. Описал примерный рабочий день, с чем приходится работать. В общем и целом, он обрисовал реальную картину. Мне было интересно послушать. Этот ролик можно показывать тем, кто будет вас спрашивать, с чего начать и каково это на начальном этапе работать системным администратором.
У автора не ИТ канал. И просмотров там нет, кроме этого ролика, который судя по всему хорошо заходит смотрящим. Мне он в рекомендации попал и привлёк внимание. Смотреть можно на скорости 1,5 или 1,75.
YouTube
1.5 Года работы Системным Администратором | Что это такое, и как им стать?
Прошло больше 1.5 лет с того дня как я устроился на работу в качестве системного администратора, и это видео рассказ о том что это за работа, какие задачи стоят перед типичным сисадмином, что необходимо выучить что-бы им стать, и стоит ли оно того.
Ключевые…
Ключевые…
Всем хорошего отдыха. Заметка будет не по теме канала, но, мне кажется, много кому может быть полезной. Речь пойдёт про пережатие самописных видеороликов.
У меня очень много семейных видеороликов, записанных на смартфоны или фотоаппараты. Думаю, тема знакома, у кого много детей. Праздники, утренники, да и просто прогулки. Всё это копится и занимает огромное количество места. Я только докупаю место на яндекс диске и харды для домашних бэкапов. Решение вопроса постоянно откладывал, хотя знал, что надо что-то делать.
Последней каплей стал видеоролик с выпускного из садика дочки. Прислали файл на 14 ГБ. Понял, что хватит это терпеть. В теме я вообще не разбираюсь. Ни про кодеки, ни про битрейты, ни про выравнивание и прочее ничего не знаю. Если вы такой же как я, и хотите просто решить вопрос без погружения в тему, то берите мой совет.
Я скачал бесплатную программу HandBrake. Это open source. Запустил со стандартными настройками. Ничего особо не менял. Стоял стандартный пресет Fast 1080p30. На вкладке видео указал качество 27 и кодек H.264. Не стал выбирать H.265. Он вроде лучше жмёт, но пока не везде поддерживается. И начал прогонять все свои ролики через эти настройки. На выходе файлы в 5-7 раз меньше. На глаз разницы в картинке я вообще не вижу.
Может в этой теме есть какие-то нюансы или варианты быстрее, проще все сделать (хотя куда проще), но я поступил вот так. Если не хотите заморачиваться и на ровном месте в разы сократить размер видеоархива, то попробуйте. Кстати, раньше, чтобы по-быстрому сжать видео, я заливал его на ютуб и скачивал обратно 😎
Домашний комп теперь круглые сутки жмёт видео. HandBrake позволяет создать очередь. Пережатие видео очень ресурсозатратный процесс. Тут я впервые ощутил, что неплохо бы заиметь железо помощнее. Хотя задача разовая, можно обойтись и без него.
⇨ Сайт / Исходники
#разное
У меня очень много семейных видеороликов, записанных на смартфоны или фотоаппараты. Думаю, тема знакома, у кого много детей. Праздники, утренники, да и просто прогулки. Всё это копится и занимает огромное количество места. Я только докупаю место на яндекс диске и харды для домашних бэкапов. Решение вопроса постоянно откладывал, хотя знал, что надо что-то делать.
Последней каплей стал видеоролик с выпускного из садика дочки. Прислали файл на 14 ГБ. Понял, что хватит это терпеть. В теме я вообще не разбираюсь. Ни про кодеки, ни про битрейты, ни про выравнивание и прочее ничего не знаю. Если вы такой же как я, и хотите просто решить вопрос без погружения в тему, то берите мой совет.
Я скачал бесплатную программу HandBrake. Это open source. Запустил со стандартными настройками. Ничего особо не менял. Стоял стандартный пресет Fast 1080p30. На вкладке видео указал качество 27 и кодек H.264. Не стал выбирать H.265. Он вроде лучше жмёт, но пока не везде поддерживается. И начал прогонять все свои ролики через эти настройки. На выходе файлы в 5-7 раз меньше. На глаз разницы в картинке я вообще не вижу.
Может в этой теме есть какие-то нюансы или варианты быстрее, проще все сделать (хотя куда проще), но я поступил вот так. Если не хотите заморачиваться и на ровном месте в разы сократить размер видеоархива, то попробуйте. Кстати, раньше, чтобы по-быстрому сжать видео, я заливал его на ютуб и скачивал обратно 😎
Домашний комп теперь круглые сутки жмёт видео. HandBrake позволяет создать очередь. Пережатие видео очень ресурсозатратный процесс. Тут я впервые ощутил, что неплохо бы заиметь железо помощнее. Хотя задача разовая, можно обойтись и без него.
⇨ Сайт / Исходники
#разное
{kind=link}
На прошлой неделе рассказал про сервер для групповой работы Onlyoffice Workspace. Подобного рода бесплатных продуктов не так много. Из тех, что я описывал ранее, где есть совместная работа с документами:
- Nextcloud
- Onlyoffice Workspace
- Univention Corporate Server (UCS)
Последний не совсем то же самое, что первые два, но в целом на его базе можно собрать сервер для групповой работы. Про те, что уже не поддерживаются и не обновляются, не пишу (Kopano). Отдельно отмечу продукты, про которые я не писал: Group office, Grommunio.
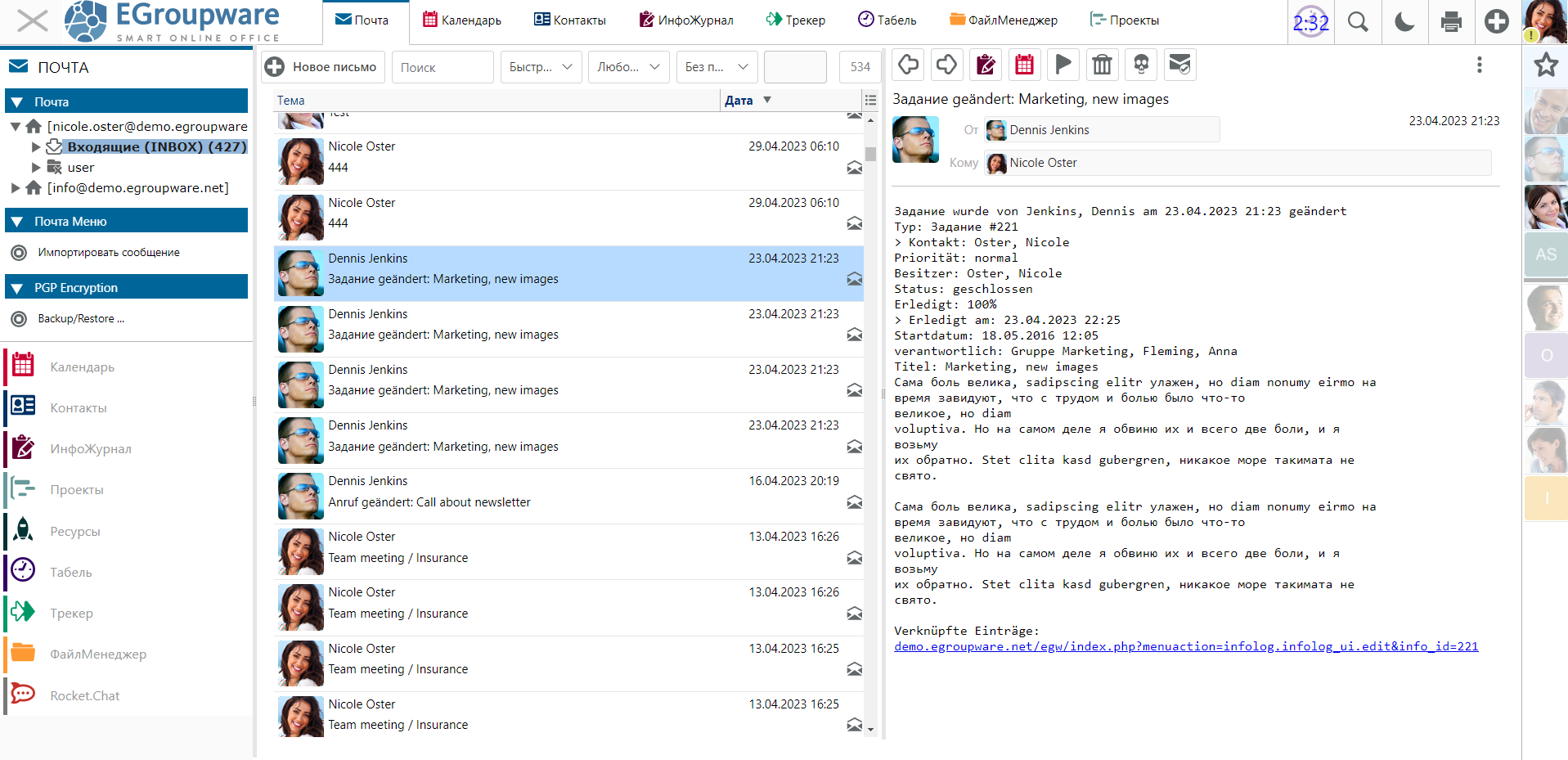
То есть в этой нише выбирать особо не из чего. Наиболее популярен сейчас, как мне кажется, Nextcloud. Он и Onlyoffice Workspace выглядят наиболее функционально и современно. Для полноты картины я решил рассмотреть ещё один open source проект, который активно развивается и поддерживается — EGroupware. Сразу скажу, что он мне не особо понравился. Но так как потратил время и получил информацию, поделюсь с вами.
Разворачивать у себя его не обязательно, так как есть Demo. Но я все равно развернул, чтобы посмотреть, как он устроен. Это сделать не трудно. Он хоть и работает на базе Docker, но при этом предоставляет свой репозиторий, где есть всё, что надо для установки. Сделано удобно. На Debian 11 поставил так:
Разворачивается Nginx в качестве прокси на самом хосте. А всё остальное живёт в Docker. Все данные вынесены в volumes для удобного бэкапа. Учётку для подключения смотреть в файле /var/lib/egroupware/egroupware-docker-install.log.
В целом, по возможностям, всё выглядит функционально и удобно. Плюс-минус как у всех - почтовый клиент, календарь, адресная книга, документы, проекты, интеграции и т.д. По умолчанию предлагает редактор документов Collabora Online в облачном сервисе, что стоит денег. Наверное можно как-то с бесплатной Collabora скрестить, но я не разбирался.
В публичной демке можно посмотреть, как Collabora Online работает, загрузить туда свои файлы. Кстати, хорошая возможность потестировать этот продукт. Он сильно отличается от Onlyoffice Docs как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняет на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice.
Мне не понравился внешний вид EGroupware. По нему сразу видно, что продукт из глубокого прошло (написан, кстати, на php). Интерфейс хоть и пытались освежить, но выглядит, как по мне, всё равно старовато. Ну не хочется им пользоваться. Хотя по настройкам и возможностям там всё очень хорошо. Добротный перевод на русский. Не возникло желания поскорее переключиться на английский язык. Более того, в настройках можно добавить свой перевод любой фразы и тут же применить изменения. Я попробовал, очень удобно. Перевёл один из пунктов меню по своему.
Из приятных особенностей EGroupware отмечу интеграцию с Rocket.Chat. По описанию все выглядит круто, но подозреваю, что будет куча нюансов. Надо будет ещё и Jitsi разворачивать, чтобы были видеозвонки. Я на практике знаю, что вся эта связка не так уж просто настраивается и обслуживается, особенно если работает за NAT и нужен доступ из интернета. Тем не менее, функционально всё это выглядит неплохо.
Если подыскиваете себе бесплатный groupware, то посмотрите EGroupware. Внешний вид — субъективный фактор. Возможно вам он будет некритичен.
⇨ Сайт / Исходники
#groupware #docs
- Nextcloud
- Onlyoffice Workspace
- Univention Corporate Server (UCS)
Последний не совсем то же самое, что первые два, но в целом на его базе можно собрать сервер для групповой работы. Про те, что уже не поддерживаются и не обновляются, не пишу (Kopano). Отдельно отмечу продукты, про которые я не писал: Group office, Grommunio.
То есть в этой нише выбирать особо не из чего. Наиболее популярен сейчас, как мне кажется, Nextcloud. Он и Onlyoffice Workspace выглядят наиболее функционально и современно. Для полноты картины я решил рассмотреть ещё один open source проект, который активно развивается и поддерживается — EGroupware. Сразу скажу, что он мне не особо понравился. Но так как потратил время и получил информацию, поделюсь с вами.
Разворачивать у себя его не обязательно, так как есть Demo. Но я все равно развернул, чтобы посмотреть, как он устроен. Это сделать не трудно. Он хоть и работает на базе Docker, но при этом предоставляет свой репозиторий, где есть всё, что надо для установки. Сделано удобно. На Debian 11 поставил так:
# echo 'deb http://download.opensuse.org/repositories/server:/eGroupWare/Debian_11/ /' \| tee /etc/apt/sources.list.d/server:eGroupWare.list# wget -nv https://download.opensuse.org/repositories/server:eGroupWare/Debian_11/Release.key -O - \| apt-key add - | tee /etc/apt/trusted.gpg.d/server:eGroupWare.asc# apt update && apt install egroupware-dockerРазворачивается Nginx в качестве прокси на самом хосте. А всё остальное живёт в Docker. Все данные вынесены в volumes для удобного бэкапа. Учётку для подключения смотреть в файле /var/lib/egroupware/egroupware-docker-install.log.
В целом, по возможностям, всё выглядит функционально и удобно. Плюс-минус как у всех - почтовый клиент, календарь, адресная книга, документы, проекты, интеграции и т.д. По умолчанию предлагает редактор документов Collabora Online в облачном сервисе, что стоит денег. Наверное можно как-то с бесплатной Collabora скрестить, но я не разбирался.
В публичной демке можно посмотреть, как Collabora Online работает, загрузить туда свои файлы. Кстати, хорошая возможность потестировать этот продукт. Он сильно отличается от Onlyoffice Docs как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняет на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice.
Мне не понравился внешний вид EGroupware. По нему сразу видно, что продукт из глубокого прошло (написан, кстати, на php). Интерфейс хоть и пытались освежить, но выглядит, как по мне, всё равно старовато. Ну не хочется им пользоваться. Хотя по настройкам и возможностям там всё очень хорошо. Добротный перевод на русский. Не возникло желания поскорее переключиться на английский язык. Более того, в настройках можно добавить свой перевод любой фразы и тут же применить изменения. Я попробовал, очень удобно. Перевёл один из пунктов меню по своему.
Из приятных особенностей EGroupware отмечу интеграцию с Rocket.Chat. По описанию все выглядит круто, но подозреваю, что будет куча нюансов. Надо будет ещё и Jitsi разворачивать, чтобы были видеозвонки. Я на практике знаю, что вся эта связка не так уж просто настраивается и обслуживается, особенно если работает за NAT и нужен доступ из интернета. Тем не менее, функционально всё это выглядит неплохо.
Если подыскиваете себе бесплатный groupware, то посмотрите EGroupware. Внешний вид — субъективный фактор. Возможно вам он будет некритичен.
⇨ Сайт / Исходники
#groupware #docs
{kind=link}
Недавно планово обновлял один из серверов 1С в связке с PostgreSQL, работающий на Debian. Сервер настроен примерно так же, как описано в моей статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
А обновление делал по этой статье:
⇨ Обновление Сервера 1С под Linux
Статьи в целом актуальны. Обновление сделал сначала на тестовом сервере клоне. Обновил, проверил работу сервера, баз. Всё нормально. Потом перешёл к рабочему. Обновил штатно, но начались проблемы.
Выражалось это в том, что раза в 2-3 возросла нагрузка по CPU. В целом, всё работало, но очень медленно. Через панель администрирования было видно большое количество фоновых задач. При этом они не висели, но выполнялись явно медленно, поэтому их было в списке аномально много. Больше обычного в несколько раз.
Какое-то время разбирался в проблеме, пытаясь понять, с чем это связано. Полный дублёр этого сервера не имел таких проблем. В итоге заглянул в лог postgresql и заметил, что там куча сообщений об исчерпании лимита доступных подключений, хотя в обычное время их достаточно. Судя по всему по какой-то причине на боевом сервере зависли соединения.
Остановил сервер 1С, перезапустил postgresql и запустил заново 1С сервер. Работа нормализовалась. Контроль соединений к базе данных — один из ключевых параметров, которые надо мониторить. Здесь это не было сделано. Пришло время настроить.
На что ещё обратить внимание при обновлении:
1️⃣ Периодически установщик 1С ставит дополнительные пакеты. Например, в этот раз заметил, что он установил Apache. Мне он был не нужен, удалил.
2️⃣ Проверьте, что вы точно удалили из автозапуска службу со старой версией 1С. Я в одном месте ошибся и удалил неправильно. Там немного отличаются команды. Например, остановка сервиса выполняется командой:
А удаление из автозапуска:
Окончания в названиях службы разные. Я в одном месте ошибся и после перезагрузки получил две запущенные службы 1С сервера. Старая запустилась в качестве сервера, а новая версия валилась в ошибки постоянно. Самое удивительное, что заметили это только через 3 дня, так как платформа 1С у клиентов автоматически использовала старую версию и никто не обратил на это внимание.
#1С
⇨ Установка и настройка 1С на Debian с PostgreSQL
А обновление делал по этой статье:
⇨ Обновление Сервера 1С под Linux
Статьи в целом актуальны. Обновление сделал сначала на тестовом сервере клоне. Обновил, проверил работу сервера, баз. Всё нормально. Потом перешёл к рабочему. Обновил штатно, но начались проблемы.
Выражалось это в том, что раза в 2-3 возросла нагрузка по CPU. В целом, всё работало, но очень медленно. Через панель администрирования было видно большое количество фоновых задач. При этом они не висели, но выполнялись явно медленно, поэтому их было в списке аномально много. Больше обычного в несколько раз.
Какое-то время разбирался в проблеме, пытаясь понять, с чем это связано. Полный дублёр этого сервера не имел таких проблем. В итоге заглянул в лог postgresql и заметил, что там куча сообщений об исчерпании лимита доступных подключений, хотя в обычное время их достаточно. Судя по всему по какой-то причине на боевом сервере зависли соединения.
Остановил сервер 1С, перезапустил postgresql и запустил заново 1С сервер. Работа нормализовалась. Контроль соединений к базе данных — один из ключевых параметров, которые надо мониторить. Здесь это не было сделано. Пришло время настроить.
На что ещё обратить внимание при обновлении:
1️⃣ Периодически установщик 1С ставит дополнительные пакеты. Например, в этот раз заметил, что он установил Apache. Мне он был не нужен, удалил.
2️⃣ Проверьте, что вы точно удалили из автозапуска службу со старой версией 1С. Я в одном месте ошибся и удалил неправильно. Там немного отличаются команды. Например, остановка сервиса выполняется командой:
# systemctl stop srv1cv8-8.3.22.1709@.defaultА удаление из автозапуска:
# systemctl disable srv1cv8-8.3.22.1709@.serviceОкончания в названиях службы разные. Я в одном месте ошибся и после перезагрузки получил две запущенные службы 1С сервера. Старая запустилась в качестве сервера, а новая версия валилась в ошибки постоянно. Самое удивительное, что заметили это только через 3 дня, так как платформа 1С у клиентов автоматически использовала старую версию и никто не обратил на это внимание.
#1С
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Расскажу вам небольшую историю про расследование внезапной перезагрузки сервера, которая вывела меня на самого себя. Попутно я наполню статью командами, которые конкретно мне не помогли, но могут пригодиться в похожей ситуации, чтобы статья получилась полезной шпаргалкой.
Случайно заметил, что один гипервизор Proxmox недавно перезагрузился. Причём это закрытый контур и доступ к нему сильно ограничен. Перезагрузка гипервизора всегда нештатная ситуация и просто так не делается. Более того, сам я редко их перезагружаю, только для необходимых обновлений. Ещё и время странное было — 2:17 ночи. Я сразу как-то напрягся.
Стал вспоминать, что я делал в тот день. Вспомнил, что работал с виртуалками на этом гипервизоре. Их как раз обновлял и перезагружал. Пошёл проверять мониторинг и заметил, что в нём перезагрузка гипервизора отражена. Но так как в тот день было много перезагрузок серверов, я не обратил на это внимание, а когда закончил работы, все сообщения мониторинга от этого сервера пометил прочитанными.
Первым делом пошёл в консоль гипервизора и посмотрел системный лог /var/log/syslog. Там как минимум увидел, что перезагрузка была штатная. Но в логе вообще никаких намёков на то, почему она произошла и кто её инициировал. Просто начали останавливаться службы. Если перезагрузка аварийная, или инициирована нажатием кнопки питания, то об этом в логе информация есть. Значит тут причина не в этом.
Далее я сразу же посмотрел лог SSH соединений в /var/log/auth.log. Увидел там авторизацию рутом, причём с IP адреса VPN сети. Проверил IP адрес — мой. Тут я немного расслабился, но до сих пор не понимал, что происходит. Запустил ещё пару команд для информации о последней перезагрузке:
Тут я начал понимать, что происходит. Проверил у себя в SSH клиенте лог подключений. Я одно время записывал содержимое всех сессий, но потом отключил, потому что хранится всё это в открытом виде. А в логе сессий много чувствительной информации. Решил, что лучше её не собирать. Да и нужно очень редко.
Глянул на сервере историю команд:
Тут уже всё понял. В общем, под конец работ, уже ночью, я перепутал сервера. И вместо очередной виртуальной машины обновил и перезагрузил гипервизор. Причём это была виртуалка дублёр без полезного функционала. Я просто зашёл и на автомате обновил. У неё было похожее имя с гипервизором.❗️Это, кстати, важный момент. Всегда следите за названиями серверов. Что самое интересное, когда я настроил этот сервер, по какой-то причине не смог нормально проименовать все виртуалки. Не придумал удобную схему и сделал в лоб. Получилось плохо. Я сразу это заметил, но стало лень переделывать, так как настроил мониторинг, сбор логов, документацию. В итоге это сыграло со мной злую шутку.
Ну и в целом ночью устаёшь уже. Это существенный минус работы в IT. Периодически приходится что-то делать ночью. Я очень это не люблю, но полностью обойтись без ночных работ не получается. Я на ночь специально не откладываю, стараюсь хотя бы вечером всё сделать. Но не всегда получается.
Ещё полезные команды по теме:
#linux #ошибка
Случайно заметил, что один гипервизор Proxmox недавно перезагрузился. Причём это закрытый контур и доступ к нему сильно ограничен. Перезагрузка гипервизора всегда нештатная ситуация и просто так не делается. Более того, сам я редко их перезагружаю, только для необходимых обновлений. Ещё и время странное было — 2:17 ночи. Я сразу как-то напрягся.
Стал вспоминать, что я делал в тот день. Вспомнил, что работал с виртуалками на этом гипервизоре. Их как раз обновлял и перезагружал. Пошёл проверять мониторинг и заметил, что в нём перезагрузка гипервизора отражена. Но так как в тот день было много перезагрузок серверов, я не обратил на это внимание, а когда закончил работы, все сообщения мониторинга от этого сервера пометил прочитанными.
Первым делом пошёл в консоль гипервизора и посмотрел системный лог /var/log/syslog. Там как минимум увидел, что перезагрузка была штатная. Но в логе вообще никаких намёков на то, почему она произошла и кто её инициировал. Просто начали останавливаться службы. Если перезагрузка аварийная, или инициирована нажатием кнопки питания, то об этом в логе информация есть. Значит тут причина не в этом.
Далее я сразу же посмотрел лог SSH соединений в /var/log/auth.log. Увидел там авторизацию рутом, причём с IP адреса VPN сети. Проверил IP адрес — мой. Тут я немного расслабился, но до сих пор не понимал, что происходит. Запустил ещё пару команд для информации о последней перезагрузке:
# who -b system boot 2023-07-14 02:17# last -x | headroot pts/0 10.20.140.6 Mon Jul 17 11:24 still logged inrunlevel (to lvl 5) 5.15.39-3-pve Fri Jul 14 02:17 still runningreboot system boot 5.15.39-3-pve Fri Jul 14 02:17 still runningshutdown system down 5.15.39-3-pve Fri Jul 14 02:16 - 02:17 (00:00)root pts/0 10.20.140.6 Fri Jul 14 00:58 - down (01:17)Тут я начал понимать, что происходит. Проверил у себя в SSH клиенте лог подключений. Я одно время записывал содержимое всех сессий, но потом отключил, потому что хранится всё это в открытом виде. А в логе сессий много чувствительной информации. Решил, что лучше её не собирать. Да и нужно очень редко.
Глянул на сервере историю команд:
# history 380 apt update 381 apt upgrade 382 w 383 rebootТут уже всё понял. В общем, под конец работ, уже ночью, я перепутал сервера. И вместо очередной виртуальной машины обновил и перезагрузил гипервизор. Причём это была виртуалка дублёр без полезного функционала. Я просто зашёл и на автомате обновил. У неё было похожее имя с гипервизором.❗️Это, кстати, важный момент. Всегда следите за названиями серверов. Что самое интересное, когда я настроил этот сервер, по какой-то причине не смог нормально проименовать все виртуалки. Не придумал удобную схему и сделал в лоб. Получилось плохо. Я сразу это заметил, но стало лень переделывать, так как настроил мониторинг, сбор логов, документацию. В итоге это сыграло со мной злую шутку.
Ну и в целом ночью устаёшь уже. Это существенный минус работы в IT. Периодически приходится что-то делать ночью. Я очень это не люблю, но полностью обойтись без ночных работ не получается. Я на ночь специально не откладываю, стараюсь хотя бы вечером всё сделать. Но не всегда получается.
Ещё полезные команды по теме:
# journalctl --list-boots# journalctl -b 0# last reboot#linux #ошибка
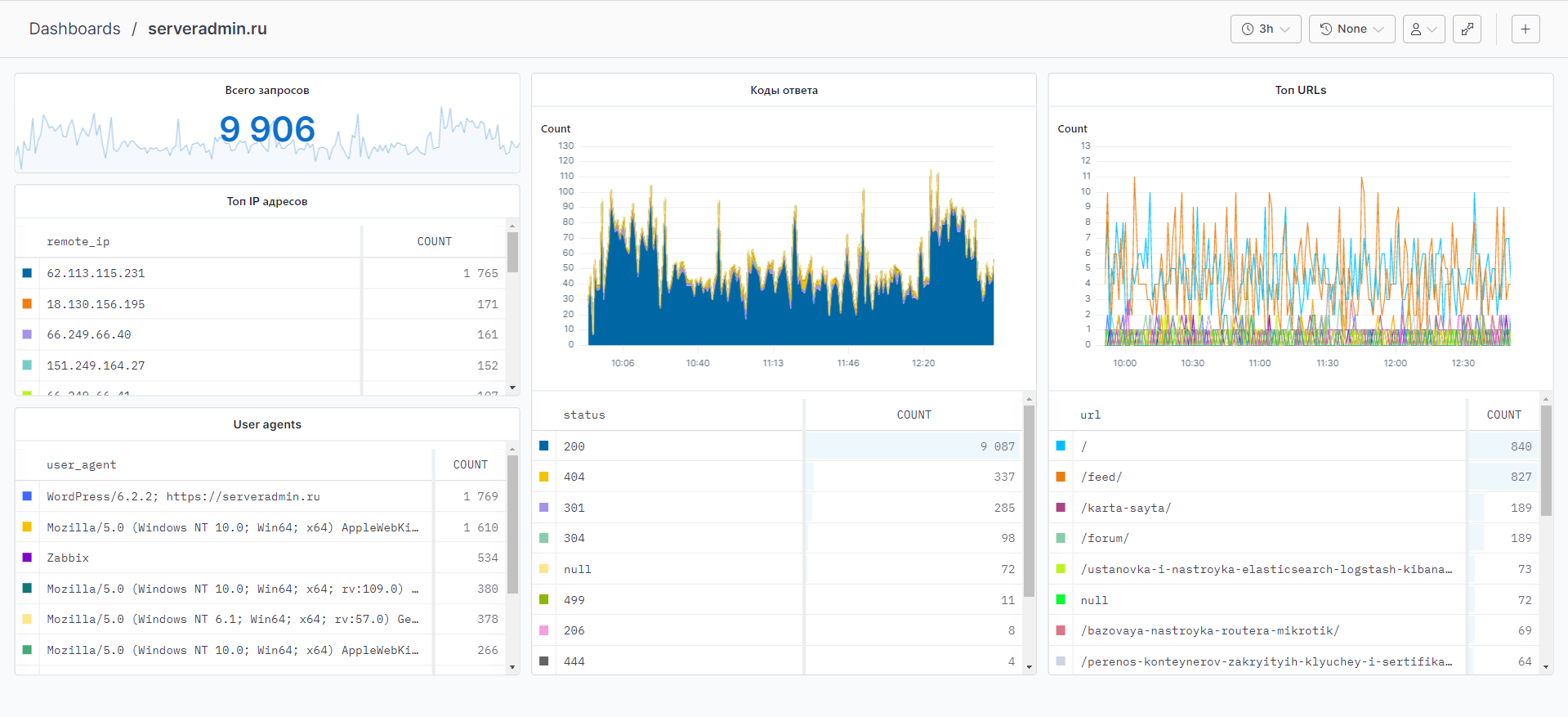
Некоторое время назад я рассказывал про программу Vector, с помощью которой удобно управлять потоками данных. Сейчас покажу, как с её помощью отправить логи Nginx в сервис axiom.co, где бесплатно можно хранить и обрабатывать до 500 ГБ в месяц. Это отличная возможность быстро собрать дашборд для анализа логов веб сервера.
Сначала зарегистрируйтесь в axiom.co. Там не нужны ни кредитки, ни какая-то ещё информация, кроме email. Сразу получите аккаунт с очень солидными бесплатными лимитами. Там же создайте новый Dataset и к нему API ключ. Это условный аналог облака Elastic на минималках. Я собственно, про него и хотел рассказать, но решил сразу на конкретном примере. К тому же у вектора не очень очевидная документация, особенно в плане преобразований. В своё время долго разбирался, как там парсинг json и grok фильтры правильно настраивать и описывать в конфигах.
Установите Vector любым удобным способом из документации. Настройте логи Nginx в формате json. Это можно не делать, но тогда понадобится grok фильтр для обработки access лога, что дольше и сложнее, чем использование сразу json. Рисуем конфиг для Vector.
У Vector есть готовая интеграция с axiom, что я и указал в sinks. Теперь запускайте Vector и идите в axiom.co. На вкладке Streams увидите свои логи в режиме реального времени.
Теперь можно зайти в Dashboards и собрать любой дашборд на основе данных лога Nginx. Чем более насыщенный лог, что настраивается в конфиге Nginx, тем больше данных для визуализации. Я для тестового сервера собрал дашборд буквально за 10 минут. Смотрите во вложении к заметке.
Такая вот заметка-инструкция получилась. Vector я уже рекомендовал, теперь советую посмотреть на описанный сервис. Меня никто не просил его рекламировать. Он просто удобный и есть функциональный бесплатный тарифный план. В него включены также 3 оповещения. Например, можно настроить, что если у вас в минуту будет больше 10 500-х ошибок сервера, прилетит оповещение. Или что-то ещё. Там большие возможности для насыщения, аггегации и других манипуляций с данными. Разобраться проще, чем в ELK или OpenSearch.
Для любителей grok, как я, покажу пример transforms в Vector своего формата логов Nginx. Вот пример формата лога, который я обычно использую, где есть всё, что мне надо:
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Вот grok фильтр в Vector:
[transforms.nginx_access_logs_parsed]
type = "remap"
inputs = ["nginx_access_logs"]
source = '''
. = parse_grok!(.message, "%{IPORHOST:remote_ip} - %{DATA:virt_host} \\[%{HTTPDATE:access_time}\\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}")
'''
#nginx #logs #devops
Сначала зарегистрируйтесь в axiom.co. Там не нужны ни кредитки, ни какая-то ещё информация, кроме email. Сразу получите аккаунт с очень солидными бесплатными лимитами. Там же создайте новый Dataset и к нему API ключ. Это условный аналог облака Elastic на минималках. Я собственно, про него и хотел рассказать, но решил сразу на конкретном примере. К тому же у вектора не очень очевидная документация, особенно в плане преобразований. В своё время долго разбирался, как там парсинг json и grok фильтры правильно настраивать и описывать в конфигах.
Установите Vector любым удобным способом из документации. Настройте логи Nginx в формате json. Это можно не делать, но тогда понадобится grok фильтр для обработки access лога, что дольше и сложнее, чем использование сразу json. Рисуем конфиг для Vector.
[sources.nginx_access_logs]type = "file"include = ["/var/log/nginx/access.log"][transforms.nginx_access_logs_parsed]type = "remap"inputs = ["nginx_access_logs"]source = '''. = parse_json!(.message)'''[sinks.axiom]inputs = ["nginx_access_logs_parsed"]type = "axiom"token = "xaat-36c1ff8f-447f-454e-99fd-abe804aeebf3"dataset = "webserver"У Vector есть готовая интеграция с axiom, что я и указал в sinks. Теперь запускайте Vector и идите в axiom.co. На вкладке Streams увидите свои логи в режиме реального времени.
Теперь можно зайти в Dashboards и собрать любой дашборд на основе данных лога Nginx. Чем более насыщенный лог, что настраивается в конфиге Nginx, тем больше данных для визуализации. Я для тестового сервера собрал дашборд буквально за 10 минут. Смотрите во вложении к заметке.
Такая вот заметка-инструкция получилась. Vector я уже рекомендовал, теперь советую посмотреть на описанный сервис. Меня никто не просил его рекламировать. Он просто удобный и есть функциональный бесплатный тарифный план. В него включены также 3 оповещения. Например, можно настроить, что если у вас в минуту будет больше 10 500-х ошибок сервера, прилетит оповещение. Или что-то ещё. Там большие возможности для насыщения, аггегации и других манипуляций с данными. Разобраться проще, чем в ELK или OpenSearch.
Для любителей grok, как я, покажу пример transforms в Vector своего формата логов Nginx. Вот пример формата лога, который я обычно использую, где есть всё, что мне надо:
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Вот grok фильтр в Vector:
[transforms.nginx_access_logs_parsed]
type = "remap"
inputs = ["nginx_access_logs"]
source = '''
. = parse_grok!(.message, "%{IPORHOST:remote_ip} - %{DATA:virt_host} \\[%{HTTPDATE:access_time}\\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}")
'''
#nginx #logs #devops
{kind=link}
По мотивам вчерашней заметки по поводу того, как я перепутал и перезагрузил не тот сервер. В комментариях много разных советов дали. Приведу 3 из них, которые мне показались наиболее простыми и эффективными.
1️⃣ Установить пакет molly-guard.
Он делает очень простую вещь. При попытке через консоль перезагрузить или выключить сервер, требует в качестве подтверждения ввести имя сервера. Я впервые услышал про эту утилиту. Надо её добавить в список софта, обязательного для установки. На мой взгляд это самый простой и эффективный способ себя подстраховать.
2️⃣ Разукрасить консоль серверов. К примеру, в гипервизорах раскрасить приветствие консоли в красный цвет. Для этого добавьте в
Получите стандартный терминал, только имя пользователя и сервера в нём будут написаны красным цветом.
3️⃣ Настройте разные цвета вкладок у вашего SSH клиента. Мой, кстати, это поддерживает. Для некоторых серверов я использовал разные цвета, но мне быстро надоело их назначать. У меня много SSH соединений (больше сотни), так что постоянно заниматься раскраской лениво, хотя и стоит это делать. Это не сложнее, чем ставить molly-guard или раскрашивать терминал. По идее, это наиболее простой способ, который не требует выполнять дополнительные действия на самом сервере.
#linux
1️⃣ Установить пакет molly-guard.
# apt install molly-guardОн делает очень простую вещь. При попытке через консоль перезагрузить или выключить сервер, требует в качестве подтверждения ввести имя сервера. Я впервые услышал про эту утилиту. Надо её добавить в список софта, обязательного для установки. На мой взгляд это самый простой и эффективный способ себя подстраховать.
2️⃣ Разукрасить консоль серверов. К примеру, в гипервизорах раскрасить приветствие консоли в красный цвет. Для этого добавьте в
.bashrc:PS1='\e[31m\u@\h:\e[31m\W\e[0m\$ 'Получите стандартный терминал, только имя пользователя и сервера в нём будут написаны красным цветом.
3️⃣ Настройте разные цвета вкладок у вашего SSH клиента. Мой, кстати, это поддерживает. Для некоторых серверов я использовал разные цвета, но мне быстро надоело их назначать. У меня много SSH соединений (больше сотни), так что постоянно заниматься раскраской лениво, хотя и стоит это делать. Это не сложнее, чем ставить molly-guard или раскрашивать терминал. По идее, это наиболее простой способ, который не требует выполнять дополнительные действия на самом сервере.
#linux
{kind=link}
И ещё одна заметка по мотивам прошлой, где я упоминал кодирование видео и программу HandBrake. Один человек, впечатлённый удобством HandBrake, создал веб интерфейс, очень похожий на интерфейс этой программы, только после выбора всех настроек, вы получаете консольную команду для ffmpeg. Что-то типа такого:
Ffmpeg очень мощная программа, которая умеет всё, что только может пожелать перекодировщик видео. Но разобраться в её ключах и настройках могут не только лишь все. Проект ffmpeg-commander помогает решить эту проблему.
Вы можете запустить его у себя, либо воспользоваться публичной веб версией:
⇨ https://alfg.dev/ffmpeg-commander
Это отличное решение для автоматизации процесса через скрипты. Удобно перекодировать видео и удалить исходник. Только надо каким-то образом проверить, что всё прошло успешно. А вот как это сделать автоматически, я не очень представляю. Стандартного выхода процесса кодирования без ошибки, мне кажется, в данном случае недостаточно для того, чтобы удалить исходник. Надо как-то подстраховаться.
Кстати, если воспользоваться другим проектом этого автора — ffmpegd, можно через веб интерфейс ffmpeg-commander выполнять непосредственно кодирование.
⇨ Сайт / Исходники
#разное
# ffmpeg -i movie.mp4 -c:v libx264 -b:v 3000 -c:a copy -pass 1 /dev/null \&& ffmpeg -i movie.mp4 -c:v libx264 -b:v 3000 -c:a copy -pass 2 output.mp4 Ffmpeg очень мощная программа, которая умеет всё, что только может пожелать перекодировщик видео. Но разобраться в её ключах и настройках могут не только лишь все. Проект ffmpeg-commander помогает решить эту проблему.
Вы можете запустить его у себя, либо воспользоваться публичной веб версией:
⇨ https://alfg.dev/ffmpeg-commander
Это отличное решение для автоматизации процесса через скрипты. Удобно перекодировать видео и удалить исходник. Только надо каким-то образом проверить, что всё прошло успешно. А вот как это сделать автоматически, я не очень представляю. Стандартного выхода процесса кодирования без ошибки, мне кажется, в данном случае недостаточно для того, чтобы удалить исходник. Надо как-то подстраховаться.
Кстати, если воспользоваться другим проектом этого автора — ffmpegd, можно через веб интерфейс ffmpeg-commander выполнять непосредственно кодирование.
⇨ Сайт / Исходники
#разное
{kind=link}