
Подборка консольных игр в Linux. Начнём с классики. Интересно, с этими играми знакомы те, кому сейчас до 25 лет? Я в эти игры играл ещё на приставках, типа денди, и на отдельных карманных устройствах на батарейках с монохромным дисплеем.
◽Тетрис. Его придумал Алексей Леонидович Пажитнов в 1984 году, работавший в Вычислительном центре Академии наук СССР.
Не удержался, и сыграл раунд после написания этих строк 😎
◽Pacman. Классический pacman. В обычной консоли выглядит немного узко, но играбельно.
Напомню, кто не знает. Задача скушать все звёздочки и не встретиться с другими движущимися символами.
◽Snake. Классическая змейка.
Стартовая скорость очень низкая. Захотелось на кнопку Turbo нажать. Когда я программировал что-то подобное в школе на turbo basic, это ускоряло исполнение кода примерно в два раза. Очень любил эту игру на телефоне Nokia 3310.
📌 Переходим к менее массовым играм.
◽2048. Математическая игра, где сдвигая плитки нужно добиться их объединения с увеличением номинала.
Немного непривычно и непонятно. Пришлось пару раз возвращаться к правилам, пока не понял, как тут играть.
◽Moon Buggy. Очень простая и залипательная игрушка, где особо не надо думать. Вы управляете машинкой, которая едет по луне. Нужно перепрыгивать ямы разной длины.
◽Ascii-patrol. Очень навороченная и красивая консольная игра. Автор упаковал её в snap, предлагает устанавливать оттуда:
Либо можете в html версию поиграть.
◽Space Invader. Вам надо управлять корабликом, стрелять по вражеским кораблям и уворачиваться от их выстрелов.
◽ZAngband. Терминальная rpg. Очень навороченная, где куча классов, специальностей. Надо качать персонажа, улучшать навыки. Лазить по подземелью, собирать предметы, улучшать оружие и т.д.
В универе сокурсник постоянно играл в эту игру на парах по Linux и программированию. Я не мог понять, как эта консольная штука может быть игрой, да ещё интересной.
◽BSD games. Куча старых консольных игр, портированных из BSD систем.
Там есть аналог змейки - worm, аналог тетриса - tetris-bsd, монополия - monop, пасьянс - canfield, нарды - backgammon и другие.
◽Sudoku. Классическая Судоку, которую часто печатают во всяких сборниках и журналах.
#игра #подборка
◽Тетрис. Его придумал Алексей Леонидович Пажитнов в 1984 году, работавший в Вычислительном центре Академии наук СССР.
# apt install bastetНе удержался, и сыграл раунд после написания этих строк 😎
◽Pacman. Классический pacman. В обычной консоли выглядит немного узко, но играбельно.
# apt install pacman4consoleНапомню, кто не знает. Задача скушать все звёздочки и не встретиться с другими движущимися символами.
◽Snake. Классическая змейка.
# apt install nsnakeСтартовая скорость очень низкая. Захотелось на кнопку Turbo нажать. Когда я программировал что-то подобное в школе на turbo basic, это ускоряло исполнение кода примерно в два раза. Очень любил эту игру на телефоне Nokia 3310.
📌 Переходим к менее массовым играм.
◽2048. Математическая игра, где сдвигая плитки нужно добиться их объединения с увеличением номинала.
# apt install 2048Немного непривычно и непонятно. Пришлось пару раз возвращаться к правилам, пока не понял, как тут играть.
◽Moon Buggy. Очень простая и залипательная игрушка, где особо не надо думать. Вы управляете машинкой, которая едет по луне. Нужно перепрыгивать ямы разной длины.
# apt install moon-buggy◽Ascii-patrol. Очень навороченная и красивая консольная игра. Автор упаковал её в snap, предлагает устанавливать оттуда:
# snap install ascii-patrolЛибо можете в html версию поиграть.
◽Space Invader. Вам надо управлять корабликом, стрелять по вражеским кораблям и уворачиваться от их выстрелов.
# apt install ninvaders◽ZAngband. Терминальная rpg. Очень навороченная, где куча классов, специальностей. Надо качать персонажа, улучшать навыки. Лазить по подземелью, собирать предметы, улучшать оружие и т.д.
# apt install zangband (нужен non-free репозиторй)В универе сокурсник постоянно играл в эту игру на парах по Linux и программированию. Я не мог понять, как эта консольная штука может быть игрой, да ещё интересной.
◽BSD games. Куча старых консольных игр, портированных из BSD систем.
# apt install bsdgamesТам есть аналог змейки - worm, аналог тетриса - tetris-bsd, монополия - monop, пасьянс - canfield, нарды - backgammon и другие.
◽Sudoku. Классическая Судоку, которую часто печатают во всяких сборниках и журналах.
# apt install sudoku#игра #подборка
{kind=link}
В операционной системе на базе Linux существуют два разных способа назначения прав доступа к файлам. Не все начинающие администраторы об этом знают. Недавно один читатель попросил помочь настроить права доступа к файловой шаре samba. Он описал задачу на основе того, как привык раздавать права на директории в Windows. В Linux у него не получалось настроить так же в рамках стандартных прав доступа через локальных пользователей, групп и утилит
В Linux, помимо основных прав доступа, которые вы видите при просмотре директории с помощью
После установки данного пакета у вас появятся две основные утилиты, которые будут нужны для управления доступом:
Я не буду сейчас подробно расписывать как всем этим пользоваться. В интернете масса руководств. Просто знайте, что в Linux правами на файлы и директории можно управлять практически точно так же, как в домене Windows. Есть нюансы и различия, но в базовых случаях несущественные. Если добавить Linux сервер с Samba и ACL в домен, то через систему Windows можно будет управлять доступом к файлами через её свойства папки с галочками и списками групп.
Пример того, как всё это может выглядеть, есть в моей статье:
⇨ https://serveradmin.ru/nastroyka-samba-s-integratsiey-v-ad/
Она очень старая и скорее всего уже неактуальна в технической части. Я сам давно файловые сервера в Linux в домене не настраивал и не эксплуатировал. Но общее понимание картины можно получить. Соответственно, вместо Microsoft AD может выступать любой другой LDAP каталог пользователей и групп.
Подскажите, кто скрещивает Linux с Windows. На текущий момент нет проблем с добавлением Linux в AD под управлением свежих Windows Server? Интеграция упростилась или усложнилась? Давно уже не слежу за этой темой. Я где-то видел новость, что Ubuntu для платных подписчиков выпустила какой-то свой инструмент для упрощения работы в AD.
#linux #fileserver
chown, chmod. В Linux, помимо основных прав доступа, которые вы видите при просмотре директории с помощью
ls -l, существуют дополнительные списки доступа ACL (access control list). Они позволяют очень гибко управлять доступом. По умолчанию инструменты для управления этими списками в минимальной установке Debian отсутствуют. Устанавливаются так:# apt install aclПосле установки данного пакета у вас появятся две основные утилиты, которые будут нужны для управления доступом:
getfacl - посмотреть права доступа, setfacl - установить права доступа. Я не буду сейчас подробно расписывать как всем этим пользоваться. В интернете масса руководств. Просто знайте, что в Linux правами на файлы и директории можно управлять практически точно так же, как в домене Windows. Есть нюансы и различия, но в базовых случаях несущественные. Если добавить Linux сервер с Samba и ACL в домен, то через систему Windows можно будет управлять доступом к файлами через её свойства папки с галочками и списками групп.
Пример того, как всё это может выглядеть, есть в моей статье:
⇨ https://serveradmin.ru/nastroyka-samba-s-integratsiey-v-ad/
Она очень старая и скорее всего уже неактуальна в технической части. Я сам давно файловые сервера в Linux в домене не настраивал и не эксплуатировал. Но общее понимание картины можно получить. Соответственно, вместо Microsoft AD может выступать любой другой LDAP каталог пользователей и групп.
Подскажите, кто скрещивает Linux с Windows. На текущий момент нет проблем с добавлением Linux в AD под управлением свежих Windows Server? Интеграция упростилась или усложнилась? Давно уже не слежу за этой темой. Я где-то видел новость, что Ubuntu для платных подписчиков выпустила какой-то свой инструмент для упрощения работы в AD.
#linux #fileserver
{kind=link}
В комментариях как-то раз увидел упоминание утилиты f*ck. Заинтересовался. Думаю, что это может быть, ни разу не слышал. Прям так и загуглил со звёздочкой. Оказалось, что речь идёт об open source проекте The Fuck.
Было очень любопытно, что же скрывается под таким неговорящим названием. Причём явно что-то популярное и полезное, потому что 77.7k звёзд на гитхабе. Оказалось, что это утилита для исправления опечаток или неполностью набранных команд.
Показываю сразу на примерах. Допустим, вы устанавливаете софт через пакетный менеджер и забыли написать sudo:
Появляется ошибка:
Вы расстраиваетесь и материтесь, потому что нервы у айтишников никудышные. Сидячая работа, стрессы, кофе и т.д. Пишите в консоль с досады:
TheFuck понимает ошибку и предлагает выполнить команду с учётом исправления.
TheFuck распознаёт популярные ошибки, опечатки, не только в командах, но и в их ключах, параметрах. Например:
То есть запустили гит пуш, забыли обязательные параметры, fuck добавил дефолтные параметры для этой команды.
Ещё больше примеров можно в репе посмотреть. Все исправления описаны правилами, которые лежат в соответствующей директории. Правила написаны на python, можете изменить готовые или написать свои. Например, есть правило для chmod. Если в консоли запускается скрипт через ./ и в выводе появляется сообщение
Больше всего правил написано для git. Судя по всему этот инструмент писался для разработчиков и немного девопсов, поэтому так много звёзд на гитхаб.
Если будете пробовать в Debian, утилита живёт в стандартных репах:
Автор пакет заботливо отключил все правила для sudo. На всякий случай. По умолчанию бинарники ставятся в
Если что, матершину не одобряю. Сам не матерюсь.
#linux #консоль
Было очень любопытно, что же скрывается под таким неговорящим названием. Причём явно что-то популярное и полезное, потому что 77.7k звёзд на гитхабе. Оказалось, что это утилита для исправления опечаток или неполностью набранных команд.
Показываю сразу на примерах. Допустим, вы устанавливаете софт через пакетный менеджер и забыли написать sudo:
# apt install mcПоявляется ошибка:
E: Could not open lock file /var/lib/dpkg/lock - open (13: Permission denied)Вы расстраиваетесь и материтесь, потому что нервы у айтишников никудышные. Сидячая работа, стрессы, кофе и т.д. Пишите в консоль с досады:
# fuckTheFuck понимает ошибку и предлагает выполнить команду с учётом исправления.
# sudo apt-get install mcTheFuck распознаёт популярные ошибки, опечатки, не только в командах, но и в их ключах, параметрах. Например:
# git pushfatal: The current branch master has no upstream branch.# fuck# git push --set-upstream origin masterТо есть запустили гит пуш, забыли обязательные параметры, fuck добавил дефолтные параметры для этой команды.
Ещё больше примеров можно в репе посмотреть. Все исправления описаны правилами, которые лежат в соответствующей директории. Правила написаны на python, можете изменить готовые или написать свои. Например, есть правило для chmod. Если в консоли запускается скрипт через ./ и в выводе появляется сообщение
permission denied, что типично, если у файла нет прав на исполнение, fuck исправляет это, добавяля права через chmod +x. Больше всего правил написано для git. Судя по всему этот инструмент писался для разработчиков и немного девопсов, поэтому так много звёзд на гитхаб.
Если будете пробовать в Debian, утилита живёт в стандартных репах:
# apt install thefuckАвтор пакет заботливо отключил все правила для sudo. На всякий случай. По умолчанию бинарники ставятся в
$HOME/.local/bin, поэтому надо добавить этот путь в PATH:# export PATH="$PATH:$HOME/.local/bin"Если что, матершину не одобряю. Сам не матерюсь.
#linux #консоль
{kind=link}
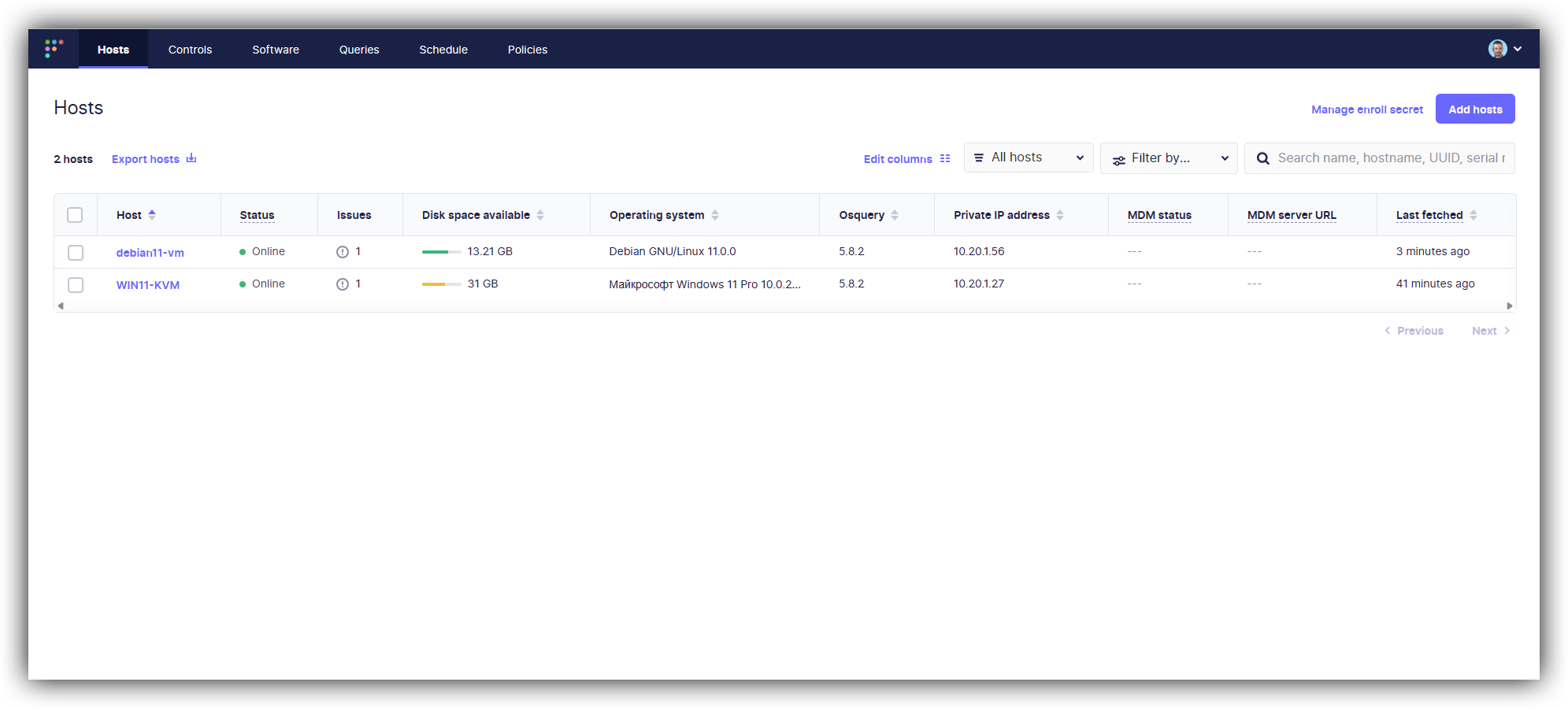
Сегодня расскажу вам про современный функциональный инструмент для управления парком рабочих станций и серверов с разными ОС. Речь пойдёт про Fleetdm. В рунете вообще не нашёл не то что информации по настройке, но даже упоминаний. Во всём разбирался сам на основе документации. Установил себе сервер и два управляемых хоста: Windows и Linux.
Fleetdm — это open source клиент-серверное приложение. Устанавливаете сервер, на управляемые хосты агенты. Поддерживаются системы: Windows, Linux, Macos. Раскатка агентов максимально простая — заранее готовится преднастроенный установщик. Далее он устанавливается на хост и тот появляется в панели управления.
С помощью Fleetdm можно управлять настройками хостов и проверять всё установленное ПО на наличие уязвимостей. Для выборки используется известный open source язык запросов osquery, который разработан специально для этих целей. С его помощью можно делать всевозможные выборки и к ним применять какие-то действия или политики. Вот простой пример, как это работает. Допустим, вы хотите найти все хосты и учётные записи, где установлена оболочка bash. Запрос выглядит так:
Для Windows запросы схожи. К примеру, найдём всех, у кого разрешён SMB1 на клиенте:
Описание запросов хорошо документировано. Писать их с помощью подсказок не сложно.
Бесплатная версия Fleetdm не предполагает встроенных средств для автоматизации выставления настроек или обновления уязвимого ПО. Вы можете создавать политики, которые будут в режиме реального времени проверять хосты. И если находят расхождения в политиках или уязвимое ПО, уведомляют об этом. С помощью API и вебхуков вы можете сами решать проблемы, например с помощью Ansible. Либо автоматически создавать задачи в Jira и Zendesk. В бесплатной версии настроены эти интеграции.
Теперь постараюсь кратко рассказать, как это всё быстро развернуть в тестовой среде, чтобы получилось быстро. В продуктив лучше поставить руками, есть подробная инструкция. Для работы сервера обязательно нужен TLS сертификат. Желательно валидный. С этим я провозился дольше всего, так как настраивал всё в локалке с использованием самоподписанного сертификата. Подготовим его:
Теперь берём минимально необходимый набор софта (Mysql+Redis) и запускаем Fleetdm через docker-compose (возьмите свежую 2-ю версию):
Дожидаемся запуска, идём на fleet.example.com:8080, создаём учётку. На всех управляемых хостах имя fleet.example.com должно резолвиться в IP адрес. Это важно.
Теперь качаем fleetctl последней версии под Linux. Это утилита, которая генерирует установщик для хостов. Распаковываем и создаём установщики под deb и windows. Используем тот же сертификат сервера, secret смотрим в веб интерфейсе, в разделе hosts.
Передаём установщики на целевые хосты. Я запустил http сервер и скачал пакеты:
После установки пакетов на целевые хосты, через пару минут они появятся в веб интерфейсе. Дальше с ними можно работать.
Программа мне понравилась, достойна полноценной статьи. Может напишу. Бесплатную, мультисистемную, с похожей функциональностью не припоминаю.
⇨ Сайт / Исходники
#управление #security #devops
Fleetdm — это open source клиент-серверное приложение. Устанавливаете сервер, на управляемые хосты агенты. Поддерживаются системы: Windows, Linux, Macos. Раскатка агентов максимально простая — заранее готовится преднастроенный установщик. Далее он устанавливается на хост и тот появляется в панели управления.
С помощью Fleetdm можно управлять настройками хостов и проверять всё установленное ПО на наличие уязвимостей. Для выборки используется известный open source язык запросов osquery, который разработан специально для этих целей. С его помощью можно делать всевозможные выборки и к ним применять какие-то действия или политики. Вот простой пример, как это работает. Допустим, вы хотите найти все хосты и учётные записи, где установлена оболочка bash. Запрос выглядит так:
SELECT * FROM users WHERE shell='/bin/bash';Для Windows запросы схожи. К примеру, найдём всех, у кого разрешён SMB1 на клиенте:
SELECT 1 FROM windows_optional_features \WHERE name = 'SMB1Protocol-Client' AND state != 1;Описание запросов хорошо документировано. Писать их с помощью подсказок не сложно.
Бесплатная версия Fleetdm не предполагает встроенных средств для автоматизации выставления настроек или обновления уязвимого ПО. Вы можете создавать политики, которые будут в режиме реального времени проверять хосты. И если находят расхождения в политиках или уязвимое ПО, уведомляют об этом. С помощью API и вебхуков вы можете сами решать проблемы, например с помощью Ansible. Либо автоматически создавать задачи в Jira и Zendesk. В бесплатной версии настроены эти интеграции.
Теперь постараюсь кратко рассказать, как это всё быстро развернуть в тестовой среде, чтобы получилось быстро. В продуктив лучше поставить руками, есть подробная инструкция. Для работы сервера обязательно нужен TLS сертификат. Желательно валидный. С этим я провозился дольше всего, так как настраивал всё в локалке с использованием самоподписанного сертификата. Подготовим его:
# mkdir fleet# openssl req -x509 -newkey rsa:4096 -sha256 -days 3650 -nodes \-keyout fleet/server.key -out fleet/server.cert -subj "/CN=fleet.example.com" \-addext "subjectAltName=DNS:fleet.example.com"# chown -R 100:101 fleet/Теперь берём минимально необходимый набор софта (Mysql+Redis) и запускаем Fleetdm через docker-compose (возьмите свежую 2-ю версию):
# docker-compose upДожидаемся запуска, идём на fleet.example.com:8080, создаём учётку. На всех управляемых хостах имя fleet.example.com должно резолвиться в IP адрес. Это важно.
Теперь качаем fleetctl последней версии под Linux. Это утилита, которая генерирует установщик для хостов. Распаковываем и создаём установщики под deb и windows. Используем тот же сертификат сервера, secret смотрим в веб интерфейсе, в разделе hosts.
# wget https://github.com/fleetdm/fleet/releases/download/fleet-v4.32.0/fleetctl_v4.32.0_linux.tar.gz# tar xzvf fleetctl_v4.32.0_linux.tar.gz# cd fleetctl_v4.32.0_linux# ./fleetctl package --type=msi --fleet-url=https://fleet.example.com:8080 \--enroll-secret=jlBXb1LUMo4/0Pn1cHXnVKqziMo87CgN --fleet-certificate=server.cert# ./fleetctl package --type=deb --fleet-url=https://fleet.example.com:8080 \--enroll-secret=jlBXb1LUMo4/0Pn1cHXnVKqziMo87CgN --fleet-certificate=server.certПередаём установщики на целевые хосты. Я запустил http сервер и скачал пакеты:
# python3 -m http.server 8181После установки пакетов на целевые хосты, через пару минут они появятся в веб интерфейсе. Дальше с ними можно работать.
Программа мне понравилась, достойна полноценной статьи. Может напишу. Бесплатную, мультисистемную, с похожей функциональностью не припоминаю.
⇨ Сайт / Исходники
#управление #security #devops
{kind=link}
Буквально на днях узнал, что в bash квадратная скобка [ и утилита test это одно и то же. Точнее, я вообще не знал, что существует эта встроенная утилита. Всегда и везде в скриптах видел и сам использовал именно скобку.
Синтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
Сделаем проверку, что он существует, как я обычно это делаю:
А теперь то же самое, только через test:
Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
# type testtest is a shell builtin# type [[ is a shell builtinСинтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
# touch file.txtСделаем проверку, что он существует, как я обычно это делаю:
#!/bin/bashif [ -e file.txt]then echo "File exist"else echo "There is no testfile"А теперь то же самое, только через test:
#!/bin/bashif test -e file.txtthen echo "File exist"else echo "There is no testfile"Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
Разбираю ещё один документ от CIS с рекомендациями по настройке Docker. Напомню, что ранее я уже делал выжимки по настройке Nginx, MySQL, Apache, Debian 11. Используя эти руководства нелишним будет освежить свои инструкции и принять некоторую информацию к сведению.
📌 Директорию для информации
📌 У Docker высокие полномочия для доступа к хостовой системе. Следите за тем, чтобы в системной группе docker не было лишних пользователей.
📌 Для повышения безопасности рекомендуется настроить аудит службы docker, например с помощью auditd. Ставим службу:
Добавляем правило в
Перезапускаем службу:
Для повышенной безопасности можно настроить аудит и за файлами и директориями Docker, за конфигурационными файлами, за юнитом systemd, за сокетом. Это общая рекомендация для служб, которые работают с правами root.
📌 Разделяйте контейнеры по отдельным сетям для межконтейнерного взаимодействия. Если этого не делать, они будут взаимодействовать через общий системный бридж, который docker создаёт по умолчанию.
📌 Включите уровень логирования службы "info", добавив в файл конфигурации
Для повышения безопасности логи имеет смысл хранить где-то во вне. Их можно направить по syslog. Пример:
📌 Если используете подключение к службе Docker по TCP, не забудьте настроить аутентификацию по TLS и ограничьте сетевой доступ.
📌 Используйте параметр no-new-privileges при создании контейнеров, либо добавьте этот параметр в настройку службы по умолчанию.
Это предотвратит повышение привилегий в контейнере от пользователя до root. Подробнее тут.
📌 Включите параметр live-restore:
Это позволит не останавливать контейнеры в случае остановки самой службы docker, что позволит обновлять её без остановки сервисов. По умолчанию он отключен.
📌 Отключите использование userland-proxy.
В подавляющем большинстве случаев для проброса портов в контейнеры используется NAT. Отключение прокси уменьшает вектор атак.
📌 Чаще всего файл с настройками
📌 Не используйте без крайней необходимости в контейнерах пользователя root. Хорошая практика запускать всё от обычного пользователя.
📌 Ограничивайте использование памяти контейнерами так, чтобы они не могли использовать всю доступную память хоста. Для этого запускайте их с параметром
📌 Ограничивайте количество попыток перезапуска контейнера в случае ошибок. То есть не запускайте их с параметром
Было много советов по написанию DockerFile. Не стал их разбирать, так как мне кажется, это отдельная тема, которая к самой службе не имеет отношения. Также было много советов по запуску контейнеров. Например, не запускать там службу sshd, не монтировать системные директории и т.д. Это тоже отдельная тема, пропускал такие рекомендации.
К данной заметке будет актуальна ссылка на автоматическую проверку контейнеров с помощью Trivy и исправление с помощью Copacetic. Я написал небольшую статью:
⇨ Проверка безопасности Docker образов с помощью Trivy
Данный список составил на основе переработки вот этого документа: CIS Docker Benchmark v1.5.0 - 12-28-2022. Там подробное описание с обоснованием всех рекомендаций.
#cis #docker
📌 Директорию для информации
/var/lib/docker рекомендуется вынести на отдельный раздел. Docker постоянно потребляет свободное место, так что переполнение раздела нередкое явление. 📌 У Docker высокие полномочия для доступа к хостовой системе. Следите за тем, чтобы в системной группе docker не было лишних пользователей.
📌 Для повышения безопасности рекомендуется настроить аудит службы docker, например с помощью auditd. Ставим службу:
# apt install auditdДобавляем правило в
/etc/audit/rules.d/audit.rules:-w /usr/bin/dockerd -k dockerПерезапускаем службу:
# systemctl restart auditdДля повышенной безопасности можно настроить аудит и за файлами и директориями Docker, за конфигурационными файлами, за юнитом systemd, за сокетом. Это общая рекомендация для служб, которые работают с правами root.
📌 Разделяйте контейнеры по отдельным сетям для межконтейнерного взаимодействия. Если этого не делать, они будут взаимодействовать через общий системный бридж, который docker создаёт по умолчанию.
📌 Включите уровень логирования службы "info", добавив в файл конфигурации
/etc/docker/daemon.json параметр:"log-level": "info"Для повышения безопасности логи имеет смысл хранить где-то во вне. Их можно направить по syslog. Пример:
{ "log-driver": "syslog", "log-opts": { "syslog-address": "tcp://192.xxx.xxx.xxx" }}📌 Если используете подключение к службе Docker по TCP, не забудьте настроить аутентификацию по TLS и ограничьте сетевой доступ.
📌 Используйте параметр no-new-privileges при создании контейнеров, либо добавьте этот параметр в настройку службы по умолчанию.
"no-new-privileges": trueЭто предотвратит повышение привилегий в контейнере от пользователя до root. Подробнее тут.
📌 Включите параметр live-restore:
"live-restore": trueЭто позволит не останавливать контейнеры в случае остановки самой службы docker, что позволит обновлять её без остановки сервисов. По умолчанию он отключен.
📌 Отключите использование userland-proxy.
"userland-proxy": falseВ подавляющем большинстве случаев для проброса портов в контейнеры используется NAT. Отключение прокси уменьшает вектор атак.
📌 Чаще всего файл с настройками
/etc/docker/daemon.json по умолчанию отсутствует и вы его создаёте сами, когда нужно задать те или иные параметры. Проследите, чтобы доступ на запись к нему имел только root (root:root 644). 📌 Не используйте без крайней необходимости в контейнерах пользователя root. Хорошая практика запускать всё от обычного пользователя.
📌 Ограничивайте использование памяти контейнерами так, чтобы они не могли использовать всю доступную память хоста. Для этого запускайте их с параметром
--memory и задайте объём, к примеру, 1024m. 📌 Ограничивайте количество попыток перезапуска контейнера в случае ошибок. То есть не запускайте их с параметром
--restart=always. Используйте вместо этого --restart=on-failure:5. Будет сделано 5 попыток запуска в случае ошибки. Было много советов по написанию DockerFile. Не стал их разбирать, так как мне кажется, это отдельная тема, которая к самой службе не имеет отношения. Также было много советов по запуску контейнеров. Например, не запускать там службу sshd, не монтировать системные директории и т.д. Это тоже отдельная тема, пропускал такие рекомендации.
К данной заметке будет актуальна ссылка на автоматическую проверку контейнеров с помощью Trivy и исправление с помощью Copacetic. Я написал небольшую статью:
⇨ Проверка безопасности Docker образов с помощью Trivy
Данный список составил на основе переработки вот этого документа: CIS Docker Benchmark v1.5.0 - 12-28-2022. Там подробное описание с обоснованием всех рекомендаций.
#cis #docker
{kind=link}
❓Вы когда-нибудь задумывались, чем в Unix отличаются директории /bin, /sbin, /usr/bin, /usr/sbin, /usr/local/{bin,sbin}? Я давно задавался этим вопросом. Точно помню, что несколько лет назад разбирался с этой темой, но уже забыл, к чему пришёл. Решил ещё раз поднять её и поделиться с вами, чтобы и самому запомнить.
Отдельно ещё стоит директория /usr/loca/etc. Я начинал изучение Unix с Freebsd. Все конфиги установленных программ по умолчанию были в /usr/loca/etc. Это было удобно. Так как всё системное в /etc, а всё, что поставил ты, в /usr/loca/etc. Потом непривычно было на Linux переходить, где директория /usr/loca/etc вообще не используется.
Вообще, на эту тему есть много различных мнений. В том же Debian можно запустить:
И прочитать про иерархию файловой системы. Там сказано:
▪ /bin - каталог, содержащий исполняемые программы, необходимые для работы в однопользовательском режиме и для запуска или ремонта системы.
▪ /sbin - как и /bin, содержит команды, необходимые для запуска системы, но, как правило, не запускаемые обычными пользователями.
▪ /usr/bin - основной каталог для исполняемых программ. Большая часть программ, не требующихся для загрузки или для ремонта системы, не устанавливаемых локально и запускаемых обычными пользователями, должна быть помещена в этот каталог.
▪ /usr/sbin - каталог, содержащий исполняемые программы для системного администрирования, не относящиеся к процессу загрузки, запуску /usr или ремонту системы.
▪ /usr/local/bin - локальные исполняемые файлы.
▪ /usr/local/sbin - локальные программы для системного администрирования.
Вроде объяснили, но всё равно не понятно, а почему именно такая иерархия. Есть такое мнение на этот счёт. Разработчики Unix в далёком 71-м году в какой-то момент проапгрейдили комп и получили 2 диска вместо одного. Когда ОС разрослась и перестала помещаться на первый диск, часть данных решили перенести на второй диск, где хранились данные пользователей, поэтому раздел назвали /usr (от слова user). Они продублировали на этом разделе все необходимые для ОС директории, в том числе bin и sbin. И всё новое складывали на новый диск, так как на старом не осталось места. Но при этом, чтобы во время загрузки иметь возможность смонтировать диск с /usr, программы типа mount обязательно жили в /bin на первом диске.
Такая есть история появления раздела /usr. С директорией /usr/local уже более ли менее понятно по смыслу. Туда кладётся всё то, что относится к конкретной локальной системе, а не дистрибутиву. В Freebsd именно так и было и это удобно. В Linux почему-то это не поддержали. Там обычно каталог /usr/local пустой.
В Debian 11 /bin и /sbin это символьные ссылки на /usr/bin и /usr/sbin. В rpm дистрибутивах то же самое уже давно. Так что в целом вся эта историческая иерархия фактически не поддерживается. Па факту всё живет в /usr. Было бы неплохо, если бы это всё привели к какому-то единому виду и распрощались с анахронизмами. А то неудобно с кучей каталогов, в которых уже не осталось смысла. Единственное, я бы идею с local поддержал и распространил.
#linux
Отдельно ещё стоит директория /usr/loca/etc. Я начинал изучение Unix с Freebsd. Все конфиги установленных программ по умолчанию были в /usr/loca/etc. Это было удобно. Так как всё системное в /etc, а всё, что поставил ты, в /usr/loca/etc. Потом непривычно было на Linux переходить, где директория /usr/loca/etc вообще не используется.
Вообще, на эту тему есть много различных мнений. В том же Debian можно запустить:
# man hierИ прочитать про иерархию файловой системы. Там сказано:
▪ /bin - каталог, содержащий исполняемые программы, необходимые для работы в однопользовательском режиме и для запуска или ремонта системы.
▪ /sbin - как и /bin, содержит команды, необходимые для запуска системы, но, как правило, не запускаемые обычными пользователями.
▪ /usr/bin - основной каталог для исполняемых программ. Большая часть программ, не требующихся для загрузки или для ремонта системы, не устанавливаемых локально и запускаемых обычными пользователями, должна быть помещена в этот каталог.
▪ /usr/sbin - каталог, содержащий исполняемые программы для системного администрирования, не относящиеся к процессу загрузки, запуску /usr или ремонту системы.
▪ /usr/local/bin - локальные исполняемые файлы.
▪ /usr/local/sbin - локальные программы для системного администрирования.
Вроде объяснили, но всё равно не понятно, а почему именно такая иерархия. Есть такое мнение на этот счёт. Разработчики Unix в далёком 71-м году в какой-то момент проапгрейдили комп и получили 2 диска вместо одного. Когда ОС разрослась и перестала помещаться на первый диск, часть данных решили перенести на второй диск, где хранились данные пользователей, поэтому раздел назвали /usr (от слова user). Они продублировали на этом разделе все необходимые для ОС директории, в том числе bin и sbin. И всё новое складывали на новый диск, так как на старом не осталось места. Но при этом, чтобы во время загрузки иметь возможность смонтировать диск с /usr, программы типа mount обязательно жили в /bin на первом диске.
Такая есть история появления раздела /usr. С директорией /usr/local уже более ли менее понятно по смыслу. Туда кладётся всё то, что относится к конкретной локальной системе, а не дистрибутиву. В Freebsd именно так и было и это удобно. В Linux почему-то это не поддержали. Там обычно каталог /usr/local пустой.
В Debian 11 /bin и /sbin это символьные ссылки на /usr/bin и /usr/sbin. В rpm дистрибутивах то же самое уже давно. Так что в целом вся эта историческая иерархия фактически не поддерживается. Па факту всё живет в /usr. Было бы неплохо, если бы это всё привели к какому-то единому виду и распрощались с анахронизмами. А то неудобно с кучей каталогов, в которых уже не осталось смысла. Единственное, я бы идею с local поддержал и распространил.
#linux
{kind=link}
Утилиту lsof в дистрибутивах Linux чаще всего используют для просмотра открытых файлов. Я и сам так делаю, и много материалов на эту тему видел. Да и название у неё говорящее. Оно как раз образовано от фразы list open files.
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
или так:
▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
▪ Смотрим открытые файлы конкретного пользователя:
Часто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
А теперь то же самое, только наоборот исключим открытые файлы пользователя:
Рассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
▪ Список TCP соединений к конкретному IP адресу:
▪ Список TCP соединений конкретного пользователя:
▪ Помимо TCP, можно и UDP соединения смотреть:
Публикацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
# lsof | grep '(deleted)'или так:
# lsof +L1▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
# lsof +D /var/log▪ Смотрим открытые файлы конкретного пользователя:
# lsof -u userЧасто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
# lsof -u user | wc -lА теперь то же самое, только наоборот исключим открытые файлы пользователя:
# lsof -u^user | wc -lРассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
# kill -9 `lsof -t -u user`▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
# lsof -p 94169▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
# lsof -ni▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
# lsof -ni TCP:80 ▪ Список TCP соединений к конкретному IP адресу:
# lsof -ni TCP@172.29.139.228▪ Список TCP соединений конкретного пользователя:
# lsof -ai -u nginx▪ Помимо TCP, можно и UDP соединения смотреть:
# lsof -iUDPПубликацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Вчера немного успел застать вебинара Ребрейн про OpenVPN. Попал на самый конец, но всё равно успел получить очень полезную для себя информацию, которой поделюсь с вами.
1️⃣ Первое прям открытие для меня — параметр ccd-exclusive. Если установлен этот параметр, то пользователь даже при наличие актуального сертификата сможет пройти аутентификацию только в том случае, если для него существует файл конфигурации пользователя в директории, заданной параметром client-config-dir.
Объясняю, зачем это может понадобиться. Чтобы запретить подключения какому-то пользователю, необходимо отозвать его сертификат, подготовить файл отозванных сертификатов и прописать их в конфигурации сервера с помощью параметра crl-verify. И после каждого отзыва файл надо перезаписывать.
С помощью ccd-exclusive можно отключать пользователей, просто удаляя их файл конфигурации. Я лично их почти всегда использую. Даже если там нет отдельных параметров, привык создавать эти файлы пустыми, чтобы для каждого пользователя был его файл конфигурации. На основе этих файлов делаю мониторинг подключений openvpn.
Да, сертификаты отключенных пользователей всё равно надо отзывать. Так правильно. Но можно это делать разово по регламенту, к примеру, раз в месяц. А если надо просто отключить пользователя, удаляем ему файл конфигурации и всё. Это намного проще и удобнее. Потом можно его снова вернуть и пользователь сможет подключиться с тем же сертификатом.
Лет 10 активно использую openvpn, а этот параметр никогда не попадался на глаза. Не знал, что так можно было сделать.
2️⃣ Работы по переводу OpenVPN из контекста пользователя в ядро Linux ведутся. Более того, модуль ядра уже написан и он реально работает. Пока ещё его не добавили в популярные дистрибутивы. Скорее всего это рано или поздно состоится. Уже сейчас можно скачать исходники модуля, скомпилировать их и всё заработает с некоторыми ограничениями по параметрам. К примеру, при обработке ядром не работает сжатие.
Поясню, в чём тут проблема. OpenVPN работает в пространстве пользователя, в отличите от WireGuard, которая обрабатывается напрямую в ядре Linux. Этим объясняется её быстродействие. Разработчики OpenVPN озадачились и решили тоже перенести обработку в ядро и написали свой модуль для этого. Так что в скором времени большой разницы в скоростях между OpenVPN и Wireguard не должно быть.
#openvpn
1️⃣ Первое прям открытие для меня — параметр ccd-exclusive. Если установлен этот параметр, то пользователь даже при наличие актуального сертификата сможет пройти аутентификацию только в том случае, если для него существует файл конфигурации пользователя в директории, заданной параметром client-config-dir.
Объясняю, зачем это может понадобиться. Чтобы запретить подключения какому-то пользователю, необходимо отозвать его сертификат, подготовить файл отозванных сертификатов и прописать их в конфигурации сервера с помощью параметра crl-verify. И после каждого отзыва файл надо перезаписывать.
С помощью ccd-exclusive можно отключать пользователей, просто удаляя их файл конфигурации. Я лично их почти всегда использую. Даже если там нет отдельных параметров, привык создавать эти файлы пустыми, чтобы для каждого пользователя был его файл конфигурации. На основе этих файлов делаю мониторинг подключений openvpn.
Да, сертификаты отключенных пользователей всё равно надо отзывать. Так правильно. Но можно это делать разово по регламенту, к примеру, раз в месяц. А если надо просто отключить пользователя, удаляем ему файл конфигурации и всё. Это намного проще и удобнее. Потом можно его снова вернуть и пользователь сможет подключиться с тем же сертификатом.
Лет 10 активно использую openvpn, а этот параметр никогда не попадался на глаза. Не знал, что так можно было сделать.
2️⃣ Работы по переводу OpenVPN из контекста пользователя в ядро Linux ведутся. Более того, модуль ядра уже написан и он реально работает. Пока ещё его не добавили в популярные дистрибутивы. Скорее всего это рано или поздно состоится. Уже сейчас можно скачать исходники модуля, скомпилировать их и всё заработает с некоторыми ограничениями по параметрам. К примеру, при обработке ядром не работает сжатие.
Поясню, в чём тут проблема. OpenVPN работает в пространстве пользователя, в отличите от WireGuard, которая обрабатывается напрямую в ядре Linux. Этим объясняется её быстродействие. Разработчики OpenVPN озадачились и решили тоже перенести обработку в ядро и написали свой модуль для этого. Так что в скором времени большой разницы в скоростях между OpenVPN и Wireguard не должно быть.
#openvpn
{kind=link}
С памятью в Linux всё сложно. Многие не понимают, как в принципе её смотреть и на какое конкретно значение обращать внимание. Особенно тяжело разбираться в этом после такого родного и понятного диспетчера задач в Windows, который чётко показывает, сколько у тебя памяти использовано и сколько свободно. В Linux использование памяти процессами — сложный вопрос. Вы не сможете просто запустить какую-то программу и сразу понять, что у нас с памятью процесса.
В заметке речь пойдёт о том, как посмотреть, что конкретно занимает память в каком то процессе. Возьмём для примера Nginx или Php-fpm. У них много модулей, поэтому бывает интересно заглянуть, а сколько каждый из них может потреблять памяти.
Для этого сначала посмотрим PID материнского процесса:
А теперь смотрим потребление памяти с помощью pmap. Эта утилита обычно есть в стандартном системном наборе.
Если я правильно понимаю, то данная команда в самом низу показывает всю виртуальную память процесса (VSZ или VIRT), которая включает в себя в том числе и библиотеки, которые могут быть разделены между разными процессами, а также то, что в swap. То есть эта такая условная метрика, с которой не понятно, что делать. Мастер процесс Nginx и все его рабочие процессы будут занимать одну и ту же виртуальную память.
Если использовать ключ
Это память процесса без swap, включает в себя память, занимаемую разделяемыми библиотеками, но только ту, что реально находится в оперативной памяти и используется в данный момент. Это уже больше похоже на реальное потребление процесса, но всё равно не точно, потому что если у процесса есть форки, то они все будут занимать одинаковое количество RSS памяти. Сумма занимаемой ими памяти не будет соответствовать тому, что реально занято в оперативе.
Ключ
Вот это уже можно считать памятью, которую потребляет конкретный процесс, без общих библиотек. Эта цифра важна, когда вы подбираете максимальное число процессов php-fpm или apache, которые будут автоматически запускаться. Вам надо понимать, сколько реально процессов вытянет сервер по памяти, чтобы не занять её всю и не повстречаться с oomkiller. Но всё равно не так просто правильно рассчитать количество процессов. В зависимости от того, что он делает, будет требоваться разное количество памяти. Так что придётся искать какое-то усреднённое значение с запасом.
Информацию pmap берёт из
Если я в чём то заблуждаюсь или вам есть чем дополнить данную заметку, поделитесь информацией. Тема с памятью в Linux замороченная, так что иногда мне кажется, что не понимаю, как там всё устроено и просто забиваю на это, добавив память виртуалке, или явно ограничив какой-то сервис.
#linux #terminal
В заметке речь пойдёт о том, как посмотреть, что конкретно занимает память в каком то процессе. Возьмём для примера Nginx или Php-fpm. У них много модулей, поэтому бывает интересно заглянуть, а сколько каждый из них может потреблять памяти.
Для этого сначала посмотрим PID материнского процесса:
# ps ax | grep nginxА теперь смотрим потребление памяти с помощью pmap. Эта утилита обычно есть в стандартном системном наборе.
# pmap 1947 -pЕсли я правильно понимаю, то данная команда в самом низу показывает всю виртуальную память процесса (VSZ или VIRT), которая включает в себя в том числе и библиотеки, которые могут быть разделены между разными процессами, а также то, что в swap. То есть эта такая условная метрика, с которой не понятно, что делать. Мастер процесс Nginx и все его рабочие процессы будут занимать одну и ту же виртуальную память.
Если использовать ключ
-x, то увидим ещё и резидентную память (RES или RSS). # pmap 1947 -xЭто память процесса без swap, включает в себя память, занимаемую разделяемыми библиотеками, но только ту, что реально находится в оперативной памяти и используется в данный момент. Это уже больше похоже на реальное потребление процесса, но всё равно не точно, потому что если у процесса есть форки, то они все будут занимать одинаковое количество RSS памяти. Сумма занимаемой ими памяти не будет соответствовать тому, что реально занято в оперативе.
Ключ
-d добавляет ещё одну метрику writeable/private:# pmap 1947 -dВот это уже можно считать памятью, которую потребляет конкретный процесс, без общих библиотек. Эта цифра важна, когда вы подбираете максимальное число процессов php-fpm или apache, которые будут автоматически запускаться. Вам надо понимать, сколько реально процессов вытянет сервер по памяти, чтобы не занять её всю и не повстречаться с oomkiller. Но всё равно не так просто правильно рассчитать количество процессов. В зависимости от того, что он делает, будет требоваться разное количество памяти. Так что придётся искать какое-то усреднённое значение с запасом.
Информацию pmap берёт из
/proc/PID/smaps и превращает её в удобочитаемый формат.Если я в чём то заблуждаюсь или вам есть чем дополнить данную заметку, поделитесь информацией. Тема с памятью в Linux замороченная, так что иногда мне кажется, что не понимаю, как там всё устроено и просто забиваю на это, добавив память виртуалке, или явно ограничив какой-то сервис.
#linux #terminal
Увидел на неделе вот этот мем с девопсом. Не знаю почему, но в голове сразу же возникла идея, что тут не хватает продолжения со словом девопёс. Решил реализовать.
Сохранил картинку и когда появилось время, расчехлил фотошоп. Сначала думал какой-нибудь маленький мозг поместить, но потом вспомнилась эта собачка. Долго ковырялся, получилось вот так. Мне нравится, надеюсь вам тоже.
Я всегда думаю, кто те люди, которые сами придумывают мемы. Никого не знаю, кто бы это делал. Вижу только, как все репостят одно и то же друг у друга. Но кто генерирует всё это в товарных количествах, не понимаю. Может уже давно ИИ это делает, а не люди? Откуда все эти мемы берутся в пабликах и группах?
#мем
Сохранил картинку и когда появилось время, расчехлил фотошоп. Сначала думал какой-нибудь маленький мозг поместить, но потом вспомнилась эта собачка. Долго ковырялся, получилось вот так. Мне нравится, надеюсь вам тоже.
Я всегда думаю, кто те люди, которые сами придумывают мемы. Никого не знаю, кто бы это делал. Вижу только, как все репостят одно и то же друг у друга. Но кто генерирует всё это в товарных количествах, не понимаю. Может уже давно ИИ это делает, а не люди? Откуда все эти мемы берутся в пабликах и группах?
#мем
🎓 Рекомендую вам очередной бесплатный курс по Stepik. Я его увидел в резюме одного системного администратора. За курс дают именной сертификат и он его решил добавить к себе. Я уже как-то говорил, что это не такая плохая идея, если у тебя есть какие-то другие, более значимые сертификаты с экзаменами. Разбавить его другими для подтверждения знания предметной области, думаю, лишним не будет.
⇨ Введение в базы данных
Курс ориентирован на начинающих программистов, но системным администраторам очень полезно, а зачастую жизненно необходимо, разбираться в SQL и в работе СУБД. С ними приходится сталкиваться повсеместно. Ну и написание простых SQL запросов тоже лишним не будет. Не так уж и редко приходится это делать. В простых случаях можно спастись поиском готовых выражений, но даже в этом случае лучше понимать, что ты делаешь.
Особенное внимание рекомендую уделить индексам. Я как-то писал о них заметку. Иногда проблему с производительностью СУБД можно решить добавлением индексов, про которые просто все забыли, либо разработчиков давно уже нет и за базой никто не следит. В общем случае индексы делают разработчики сами. Это если понимают, что это такое.
В курсе также немного захватывают NoSQL базы: Redis и MongoDB, что сейчас администраторам и девопсам очень актуально, так как эти базы популярны не менее SQL.
#обучение #бесплатно
⇨ Введение в базы данных
Курс ориентирован на начинающих программистов, но системным администраторам очень полезно, а зачастую жизненно необходимо, разбираться в SQL и в работе СУБД. С ними приходится сталкиваться повсеместно. Ну и написание простых SQL запросов тоже лишним не будет. Не так уж и редко приходится это делать. В простых случаях можно спастись поиском готовых выражений, но даже в этом случае лучше понимать, что ты делаешь.
Особенное внимание рекомендую уделить индексам. Я как-то писал о них заметку. Иногда проблему с производительностью СУБД можно решить добавлением индексов, про которые просто все забыли, либо разработчиков давно уже нет и за базой никто не следит. В общем случае индексы делают разработчики сами. Это если понимают, что это такое.
В курсе также немного захватывают NoSQL базы: Redis и MongoDB, что сейчас администраторам и девопсам очень актуально, так как эти базы популярны не менее SQL.
#обучение #бесплатно
Stepik: online education
Введение в базы данных
Знакомство с методами структурированного хранения данных, основами SQL, принципами использования баз данных в приложениях, обзор нереляционных способов хранения данных
На днях вышел релиз Debian 12 Bookworm. Для меня это не стало сюрпризом, так как недавно я уже смотрел эту версию и проверял, как проходит обновление с прошлого релиза. У меня уже довольно много серверов под управлением Debian, так что вопрос меня касается напрямую.
Решил не откладывать задачу на потом и сразу рассмотреть изменения новой версии. Я написал подробную статью с обновлением с 11-й версии на 12-ю. Постарался рассмотреть наиболее значимые моменты обновления в соответствии с рекомендациями самих разработчиков из заметки Upgrades from Debian 11 (bullseye).
⇨ https://serveradmin.ru/kak-obnovit-debian-11-do-debian-12-bookworm/
Из основных нововведений, помимо обновления пакетов, я отметил следующие:
◽В установочные образы включили некоторые прошивки из репозитория non-free. Это сделано для лучшей поддержки железа во время установки. Debian всегда очень внимательно относился к проприетарному софту, выделяя его в отдельный репозиторий non-free. В этом релизе решили сделать некоторые исключения. Поэтому добавлен ещё один репозиторий для проприетарных прошивок non-free-firmware.
◽В Debian 12 добавлен пакет ksmbd-tools, который реализует функциональность файлового сервера на базе протокола SMB3. Сервер работает на базе модуля ядра Linux. Подобная реализация более эффективна с точки зрения производительности, потребления памяти и интеграции с расширенными возможностями ядра. При этом ksmbd не претендует на полноценную замену Samba. Скорее как расширение для неё.
◽По умолчанию не используется rsyslog для записи системных логов. Вместо этого предлагают использовать journalctl для просмотра логов systemd. Если хотите (а мы хотим) по старинке системные логи в текстовом виде в /var/log, установите пакет system-log-daemon.
◽Из дистрибутива выпилили утилиту which, которая объявлена устаревшей. Вместо неё предлагают использовать type. Это приведёт к поломке многих скриптов, где часто используют which для определения полного пути к бинарнику. Не забудьте установить вручную whitch, если она у вас используется.
◽Из репозиториев убрали пакеты для Asterisk. Не нашлось желающих их поддерживать, а сами разработчики астера не занимаются поддержкой пакетов в принципе.
С полным списком можете ознакомиться в официальной новости или переводе на opennet. За что лично мне нравится Debian, так это за его стабильность. В нём мало каких-то революционных изменений ради изменений. К примеру, сколько я знаю Debian, ещё со времён 6-й версии, у него не менялся интерфейс установщика. В этом просто нет смысла. Всё, что нужно в плане функциональности, там есть. Нет смысла менять то, что хорошо работает.
Я один свой сервер уже обновил, всё прошло штатно. Остальной прод торопиться обновлять не буду. Подожду месячишко, другой.
Скоро наверное Proxmox свою новую версию выкатит. Он обычно подгоняет свои релизы под релизы Debian. Я уже видел инфу про появление 8-й беты.
#debian
Решил не откладывать задачу на потом и сразу рассмотреть изменения новой версии. Я написал подробную статью с обновлением с 11-й версии на 12-ю. Постарался рассмотреть наиболее значимые моменты обновления в соответствии с рекомендациями самих разработчиков из заметки Upgrades from Debian 11 (bullseye).
⇨ https://serveradmin.ru/kak-obnovit-debian-11-do-debian-12-bookworm/
Из основных нововведений, помимо обновления пакетов, я отметил следующие:
◽В установочные образы включили некоторые прошивки из репозитория non-free. Это сделано для лучшей поддержки железа во время установки. Debian всегда очень внимательно относился к проприетарному софту, выделяя его в отдельный репозиторий non-free. В этом релизе решили сделать некоторые исключения. Поэтому добавлен ещё один репозиторий для проприетарных прошивок non-free-firmware.
◽В Debian 12 добавлен пакет ksmbd-tools, который реализует функциональность файлового сервера на базе протокола SMB3. Сервер работает на базе модуля ядра Linux. Подобная реализация более эффективна с точки зрения производительности, потребления памяти и интеграции с расширенными возможностями ядра. При этом ksmbd не претендует на полноценную замену Samba. Скорее как расширение для неё.
◽По умолчанию не используется rsyslog для записи системных логов. Вместо этого предлагают использовать journalctl для просмотра логов systemd. Если хотите (а мы хотим) по старинке системные логи в текстовом виде в /var/log, установите пакет system-log-daemon.
◽Из дистрибутива выпилили утилиту which, которая объявлена устаревшей. Вместо неё предлагают использовать type. Это приведёт к поломке многих скриптов, где часто используют which для определения полного пути к бинарнику. Не забудьте установить вручную whitch, если она у вас используется.
◽Из репозиториев убрали пакеты для Asterisk. Не нашлось желающих их поддерживать, а сами разработчики астера не занимаются поддержкой пакетов в принципе.
С полным списком можете ознакомиться в официальной новости или переводе на opennet. За что лично мне нравится Debian, так это за его стабильность. В нём мало каких-то революционных изменений ради изменений. К примеру, сколько я знаю Debian, ещё со времён 6-й версии, у него не менялся интерфейс установщика. В этом просто нет смысла. Всё, что нужно в плане функциональности, там есть. Нет смысла менять то, что хорошо работает.
Я один свой сервер уже обновил, всё прошло штатно. Остальной прод торопиться обновлять не буду. Подожду месячишко, другой.
Скоро наверное Proxmox свою новую версию выкатит. Он обычно подгоняет свои релизы под релизы Debian. Я уже видел инфу про появление 8-й беты.
#debian
Server Admin
Обновление Debian 11 до 12 Bookworm
Подробное описание обновления Debian 11 до 12 Bookworm в соответствии с рекомендациями разработчиков системы.
Хочу дать пару простых советов, которые не все знают и используют, но они могут сильно упростить жизнь при работе со стандартными утилитами Unix в консоли.
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
Тут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
Получится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
В этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
А если c $, получим то, что надо:
Можно совместить:
А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
#bash #script
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
# grep -E -v '^#' nginx.confТут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
# grep -E -v '^ #' nginx.confПолучится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
# ls | grep ^errorerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngВ этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
# ls | grep .pngerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngА если c $, получим то, что надо:
# ls | grep .png$error-windows-10-share-110x75.pngerror-windows-10-share-150x150.pngМожно совместить:
# ls | grep ^error | grep png$А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
# grep -E -v '^#|^$' nginx.conf#bash #script
{kind=link}
В выходные просматривал тематические ролики из youtube, которых накопилось некоторое количество. В одном из них увидел упоминание веб интерфейса для Ansible. Речь идёт про ролик: This web UI for Ansible is so damn useful!. Я сразу обратил на него внимание и запомнил, чтобы посмотреть, когда будет время.
В видео речь идёт про Ansible Semaphore. Я видел недавно его упоминание в некоторых TG каналах. Подумал, что выкатили какой-то новый продукт, поэтому на него обратили внимание. Но на самом деле нет. Это старый open source проект из 2015 года. Ранее о нём не слышал, поэтому решил посмотреть, что это такое. Специально никогда не искал веб интерфейс для Ansible, как-то не было необходимости. Вообще не знаю ни одного бесплатного решения для этой задачи.
Как я уже сказал, Ansible Semaphore — open source проект, написанный на чистом Go, а веб интерфейс с примесью Vue. С его помощью можно создавать и запускать плейбуки, превращая всё это в подобие CI/CD системы на минималках. То есть это для тех, кому не надо GitLab или Jenkins, но хочется автоматизации на базе ansible.
Для понимания возможностей Ansible Semaphore, покажу, какие там реализованы сущности. Тогда станет понятно, что он умеет. Там реализованы:
◽Задачи, для запуска плейбуков.
◽Шаблоны для этих задач.
◽Репозитории для подключения кода плейбуков и приложений.
◽Инвентарь, то есть список серверов, для которых можно выполнять задачи.
◽Хранилище ssh ключей и переменных.
Посмотреть всё это можно в публичном demo:
⇨ https://demo.ansible-semaphore.com
Работает всё это как обычная CI/CD система. Подключаем репозиторий с приложением, репозиторий с плейбуками. Создаём задачу, которая следит за репозиторием приложения и в случае коммита выполняет какие-то плейбуки из репозитория с ними.
Настроить всё это дело в Ansible Semaphore легко. Настроек немного, можете ознакомиться сами в Demo. Я посмотрел видео, чуток почитал доков (там совсем немного, сразу понятна последовательность действий) и посмотрел, как это реализовано в демке.
Продукт мне понравился. Прям то, что надо для небольшой инфраструктуры, где что-то более масштабное будет избыточным. Удобно смотреть вывод плейбуков прямо в веб интерфейсе после запуска. Причём интерфейс адаптивен и нормально смотрится в смартфонах.
У меня для личного использования есть отдельная виртуалка с ansible, откуда я запускаю все свои плейбуки. Туда как раз будет уместно поставить Ansible Semaphore.
⇨ Сайт / Исходники
#ansible #devops
В видео речь идёт про Ansible Semaphore. Я видел недавно его упоминание в некоторых TG каналах. Подумал, что выкатили какой-то новый продукт, поэтому на него обратили внимание. Но на самом деле нет. Это старый open source проект из 2015 года. Ранее о нём не слышал, поэтому решил посмотреть, что это такое. Специально никогда не искал веб интерфейс для Ansible, как-то не было необходимости. Вообще не знаю ни одного бесплатного решения для этой задачи.
Как я уже сказал, Ansible Semaphore — open source проект, написанный на чистом Go, а веб интерфейс с примесью Vue. С его помощью можно создавать и запускать плейбуки, превращая всё это в подобие CI/CD системы на минималках. То есть это для тех, кому не надо GitLab или Jenkins, но хочется автоматизации на базе ansible.
Для понимания возможностей Ansible Semaphore, покажу, какие там реализованы сущности. Тогда станет понятно, что он умеет. Там реализованы:
◽Задачи, для запуска плейбуков.
◽Шаблоны для этих задач.
◽Репозитории для подключения кода плейбуков и приложений.
◽Инвентарь, то есть список серверов, для которых можно выполнять задачи.
◽Хранилище ssh ключей и переменных.
Посмотреть всё это можно в публичном demo:
⇨ https://demo.ansible-semaphore.com
Работает всё это как обычная CI/CD система. Подключаем репозиторий с приложением, репозиторий с плейбуками. Создаём задачу, которая следит за репозиторием приложения и в случае коммита выполняет какие-то плейбуки из репозитория с ними.
Настроить всё это дело в Ansible Semaphore легко. Настроек немного, можете ознакомиться сами в Demo. Я посмотрел видео, чуток почитал доков (там совсем немного, сразу понятна последовательность действий) и посмотрел, как это реализовано в демке.
Продукт мне понравился. Прям то, что надо для небольшой инфраструктуры, где что-то более масштабное будет избыточным. Удобно смотреть вывод плейбуков прямо в веб интерфейсе после запуска. Причём интерфейс адаптивен и нормально смотрится в смартфонах.
У меня для личного использования есть отдельная виртуалка с ansible, откуда я запускаю все свои плейбуки. Туда как раз будет уместно поставить Ansible Semaphore.
⇨ Сайт / Исходники
#ansible #devops
{kind=link}
Автор классного ютуб канала RomNero выпустил подробное видео с разбором чат-сервера на базе протокола [matrix]. Я делал по нему заметку пару лет назад, а лет пять назад тестировал и писал статью. Ссылку не даю, так как нет смысла. Она уже сильно устарела.
Тема чатов всегда актуальна и жива, так как в среде self-hosted решений нет явного лидера. Приходится выбирать из множества имён. Я делал подборку бесплатных вариантов самых известных решений.
Недавно я успешно внедрил в небольшой компании (60-70 сотрудников) Rocket.Chat. Уже накопился некоторый опыт по настройке, поддержке, обновлению, бэкапу и т.д. Думаю, ещё немного подожду и напишу подробную статью. У этого решения есть как плюсы, так и минусы. Я остановился на нём, потому что он популярен, отзывы в целом неплохие. Плюсов больше чем минусов. Субъективно, мне кажется это наиболее подходящим вариантом на текущий момент по совокупности факторов.
Возвращаюсь к видео: Matrix messenger. Лучшая, бесплатная и ДЕЦЕНТРАЛИЗОВАННАЯ сеть для общения. Я его посмотрел целиком, было интересно, хотя почти вся информация была мне известна. Но если вы не знакомы с этим решением, то рекомендую.
Автор объяснил принцип работы протокола Matrix и чат-сервера на его основе Synapse. Он подробно разобрал установку и настройку сервера и клиентов, начиная от создания DNS записей и заканчивая просмотром логов для решения проблем.
Со стороны решение на базе Matrix выглядит привлекательно. Лично меня останавливает от его использования мало реальных отзывов и личного опыта тех, кто его использовал. Не понятно, насколько в итоге это всё удобно за пределами тестовых лабораторий, стендов и заметок с обзорами. По конкурентам такие отзывы и опыт есть (Mattermost, Zulip, Rocket.Chat).
Если у вас есть опыт внедрения и использования этого чат-сервера, поделитесь информацией. Ну а если вы подбираете себе решение для внедрения, то обратите внимание на Matrix.
#chat
Тема чатов всегда актуальна и жива, так как в среде self-hosted решений нет явного лидера. Приходится выбирать из множества имён. Я делал подборку бесплатных вариантов самых известных решений.
Недавно я успешно внедрил в небольшой компании (60-70 сотрудников) Rocket.Chat. Уже накопился некоторый опыт по настройке, поддержке, обновлению, бэкапу и т.д. Думаю, ещё немного подожду и напишу подробную статью. У этого решения есть как плюсы, так и минусы. Я остановился на нём, потому что он популярен, отзывы в целом неплохие. Плюсов больше чем минусов. Субъективно, мне кажется это наиболее подходящим вариантом на текущий момент по совокупности факторов.
Возвращаюсь к видео: Matrix messenger. Лучшая, бесплатная и ДЕЦЕНТРАЛИЗОВАННАЯ сеть для общения. Я его посмотрел целиком, было интересно, хотя почти вся информация была мне известна. Но если вы не знакомы с этим решением, то рекомендую.
Автор объяснил принцип работы протокола Matrix и чат-сервера на его основе Synapse. Он подробно разобрал установку и настройку сервера и клиентов, начиная от создания DNS записей и заканчивая просмотром логов для решения проблем.
Со стороны решение на базе Matrix выглядит привлекательно. Лично меня останавливает от его использования мало реальных отзывов и личного опыта тех, кто его использовал. Не понятно, насколько в итоге это всё удобно за пределами тестовых лабораторий, стендов и заметок с обзорами. По конкурентам такие отзывы и опыт есть (Mattermost, Zulip, Rocket.Chat).
Если у вас есть опыт внедрения и использования этого чат-сервера, поделитесь информацией. Ну а если вы подбираете себе решение для внедрения, то обратите внимание на Matrix.
#chat
{kind=link}
Провёл небольшое исследование на тему того, чем в консоли bash быстрее всего удалить большое количество директорий и файлов. Думаю, не все знают, что очень много файлов могут стать большой проблемой. Пока с этим не столкнёшься, не думаешь об этом. Если у тебя сервер бэкапов на обычных дисках и надо удалить миллионы файлов, это может оказаться непростой задачей.
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
И последняя команда, ради которой всё затевалось:
Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
Создаю 500 000 файлов в цикле по 50 000 с помощью
и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
Для второго теста сделал такой скрипт:
Создаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
# rm -r test/# rm -r test/*# find test/ -type f -delete# cd test/ ; ls . | xargs -n 100 rm #только для файлов работаетИ последняя команда, ради которой всё затевалось:
# rsync -a --delete empty/ test/Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
#!/bin/bashmkdir testcount=1while test $count -le 10do touch test/file$count-{000..50000}count=$(( $count + 1 ))donels test | wc -lСоздаю 500 000 файлов в цикле по 50 000 с помощью
touch. Больше за раз не получается создать, touch ругается на слишком большой список аргументов. После этого запускаю приведённые выше команды с подсчётом времени их выполнения с помощью time:# time rm -r test/и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
rm -r test/* в какой-то момент перестанет работать и будет ругаться на большое количество аргументов.Для второго теста сделал такой скрипт:
#!/bin/bashcount=1while test $count -le 10do mkdir -p test/dir$count-{000..500}touch test/dir$count-{000..500}/file-{000..100}count=$(( $count + 1 ))donefind test/ | wc -lСоздаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Моя публикация про утилиты для трассировки получила много полезных комментариев, так что решил их все собрать и оформить в отдельную справочную заметку.
✅ Linux 🐧
◽traceroute - стандартная утилита Linux для трассировки маршрута. По умолчанию использует udp протокол. С icmp протоколом запускать вот так:
◽tracepath - похожа на traceroute, использует udp протокол, сразу же в выводе по умолчанию показывает значения mtu и маршрутизаторы, где оно меняется.
◽mtr - про эту утилиту делал отдельную заметку. Она совмещает функциональность ping и traceroute одновременно. Может использовать протоколы tcp, udp, icmp. В Windows тоже есть под названием Winmtr.
✅ Windows 💻
◽tracert - стандартная утилита в Windows для трассировки маршрута. Известна всем.
Использование:
◽pathping - это чисто виндовый аналог mtr со схожей функциональностью, но поддерживает только icmp запросы. Тоже сочетает в себе ping и tracert. Обычно есть в системе, ставить отдельно не надо.
Использование:
◽tracetcp - виндовая утилита, которая умеет делать tcp syn запросы по пути следования пакетов, чтобы проверить доступность того или иного порта. Позволяет узнать, где конкретно блокируется какой-то порт. Может делать проверки там, где icmp или udp заблокированы. Надо ставить вручную, скачав с сайта.
Использование:
Не знал, что есть программа с такой возможностью. Если где-то по пути порт будет заблокирован, она укажет на этот узел. На Linux аналога не знаю, хотя он бы не помешал.
#network
✅ Linux 🐧
◽traceroute - стандартная утилита Linux для трассировки маршрута. По умолчанию использует udp протокол. С icmp протоколом запускать вот так:
# traceroute -I ya.ru◽tracepath - похожа на traceroute, использует udp протокол, сразу же в выводе по умолчанию показывает значения mtu и маршрутизаторы, где оно меняется.
# tracepath ya.ru◽mtr - про эту утилиту делал отдельную заметку. Она совмещает функциональность ping и traceroute одновременно. Может использовать протоколы tcp, udp, icmp. В Windows тоже есть под названием Winmtr.
✅ Windows 💻
◽tracert - стандартная утилита в Windows для трассировки маршрута. Известна всем.
Использование:
> tracert ya.ru◽pathping - это чисто виндовый аналог mtr со схожей функциональностью, но поддерживает только icmp запросы. Тоже сочетает в себе ping и tracert. Обычно есть в системе, ставить отдельно не надо.
Использование:
> pathping ya.ru◽tracetcp - виндовая утилита, которая умеет делать tcp syn запросы по пути следования пакетов, чтобы проверить доступность того или иного порта. Позволяет узнать, где конкретно блокируется какой-то порт. Может делать проверки там, где icmp или udp заблокированы. Надо ставить вручную, скачав с сайта.
Использование:
> tracetcp ya.ru:443Не знал, что есть программа с такой возможностью. Если где-то по пути порт будет заблокирован, она укажет на этот узел. На Linux аналога не знаю, хотя он бы не помешал.
#network
Рассказываю вам про очень классную систему видеонаблюдения. Мне её посоветовали давно, когда я делал публикацию про свою систему видеонаблюдения, которую на даче настроил. И только сейчас дошли руки посмотреть insentry.io. Это в разы лучше того, что получилось у меня.
Insentry — большое коммерческое решение для видеонаблюдения и аналитики. Используется в крупных компаниях, в том числе государственных (например, метрополитен). При этом у них есть абсолютно бесплатная, без каких-либо ограничений лицензия на 16 камер. Доступна вся функциональность редакции Standart, в том числе распознавание номеров автомобилей и лиц людей. На это даётся 10 детекторов. Ограничения на размер хранилища нет.
Запустить сервер Insentry можно в Windows или Linux. В последнем есть готовый Docker образ, который я запустил. Делается всё буквально за 5 минут. Запускаем:
Идём в веб интерфейс на порт хоста 9200 и создаём нового пользователя. И сразу же оказываемся в веб интерфейсе. Я запустил его в компании, где используется платный видеосервер от LTV и подключил для теста одну камеру. Даже не заходил на неё. Указал IP и учётку. Insentry сам нашёл потоки и добавил их в систему. Через браузер стал возможен просмотр.
Выглядит всё это очень удобно и функционально для бесплатного решения. При этом не нужны никакие регистрации и лицензии. Просить её будут только тогда, когда добавите 17-ю камеру. Да и та стоит всего 1000 р. за лицензию.
На сервере по умолчанию есть интеграция с Telegram. А также мобильные клиенты. Я нигде не нашёл информации по поводу их платности, так что по идее должны работать и с бесплатным сервером.
У продукта аккуратная и небольшая документация, в которой всё по делу. Увидел руководство по установке на Raspberry Pi 4B. Судя по всему, ресурсов этому серверу надо не много, раз он готов работать на одноплатнике.
Программа есть в реестре отечественного ПО. В общем, со всех сторон приятное впечатление о продукте. Рекомендую. Для личных нужд или небольших компаний отличный вариант. Да и если покупать, то цена более чем доступная.
Напомню, что ранее рассказывал про ещё одно отечественное решение SecurOS Lite. Там тоже есть бесплатная версия на 32 камеры, но совсем без аналитики и без мобильных приложений. Там это только в платных редакциях. И сервер только под Windows. У Insentry меньше камер, зато аналитика есть в бесплатной лицензии и сервер под Win и Lin на выбор.
⇨ Сайт
#видеонаблюдение #отечественное
Insentry — большое коммерческое решение для видеонаблюдения и аналитики. Используется в крупных компаниях, в том числе государственных (например, метрополитен). При этом у них есть абсолютно бесплатная, без каких-либо ограничений лицензия на 16 камер. Доступна вся функциональность редакции Standart, в том числе распознавание номеров автомобилей и лиц людей. На это даётся 10 детекторов. Ограничения на размер хранилища нет.
Запустить сервер Insentry можно в Windows или Linux. В последнем есть готовый Docker образ, который я запустил. Делается всё буквально за 5 минут. Запускаем:
# docker volume create --name insentry-data# docker run \--name insentry_watch \--detach \--restart unless-stopped \--network host \--volume insentry-data:/var/lib \--volume /etc/timezone:/etc/timezone:ro \--volume /etc/localtime:/etc/localtime:ro \--stop-timeout 60 \cr.yandex/crp5a5q503oamalo3iou/insentry-watch/linux/amd64:23.1.0.27Идём в веб интерфейс на порт хоста 9200 и создаём нового пользователя. И сразу же оказываемся в веб интерфейсе. Я запустил его в компании, где используется платный видеосервер от LTV и подключил для теста одну камеру. Даже не заходил на неё. Указал IP и учётку. Insentry сам нашёл потоки и добавил их в систему. Через браузер стал возможен просмотр.
Выглядит всё это очень удобно и функционально для бесплатного решения. При этом не нужны никакие регистрации и лицензии. Просить её будут только тогда, когда добавите 17-ю камеру. Да и та стоит всего 1000 р. за лицензию.
На сервере по умолчанию есть интеграция с Telegram. А также мобильные клиенты. Я нигде не нашёл информации по поводу их платности, так что по идее должны работать и с бесплатным сервером.
У продукта аккуратная и небольшая документация, в которой всё по делу. Увидел руководство по установке на Raspberry Pi 4B. Судя по всему, ресурсов этому серверу надо не много, раз он готов работать на одноплатнике.
Программа есть в реестре отечественного ПО. В общем, со всех сторон приятное впечатление о продукте. Рекомендую. Для личных нужд или небольших компаний отличный вариант. Да и если покупать, то цена более чем доступная.
Напомню, что ранее рассказывал про ещё одно отечественное решение SecurOS Lite. Там тоже есть бесплатная версия на 32 камеры, но совсем без аналитики и без мобильных приложений. Там это только в платных редакциях. И сервер только под Windows. У Insentry меньше камер, зато аналитика есть в бесплатной лицензии и сервер под Win и Lin на выбор.
⇨ Сайт
#видеонаблюдение #отечественное
{kind=link}
Сегодня в обед прилёг хостер vdsina, на котором живёт мой сайт. Точнее его локация в Москве. Причём прилёг очень интересно. У него судя по всему проблемы с дисковой подсистемой. Виртуалка работает, но всё, что связано с дисковыми операциями записи, зависает. В итоге я спокойно захожу по SSH, открываю htop и смотрю LA > 50. Если пытаюсь что-то делать в консоли, то подключение зависает.
Я обычно жду час-полтора и если хостер не оживает, начинаю переезд. Мне кажется, что если за это время не починились, значит что-то серьёзное и сидеть ждать дальше уже опасно. Можно весь день прождать.
Как это обычно бывает, с переездом возникли проблемы. Расскажу, как у меня устроен бэкап и мониторинг сайта. Бэкапов к меня много:
◽в S3 хранилище дневные, недельные и месячные архивы
◽сервер дома, который сам по ssh ходит и забирает данные
◽копия бэкапов в яндекс.диске
◽копия бэкапов в Synology
Сайты занимают мало места, так что я особо не заморачиваюсь и храню побольше копий. Даже если где-то что-то сломается и не сохранится, то хоть какую-то копию можно достать. Причём данные у меня хранятся как в упакованных архивах, так и в виде сырых файлов. Настройки Nginx тоже сохраняю. Это важно, там много нюансов, которые долго вспоминать и восстанавливать.
Бэкапы у меня автоматически копируются на резервную виртуалку, там разворачиваются в полноценные сайты с БД. Далее Zabbix ходит на эту резервную виртуалку с веб проверками и смотрит, что сайт реально работает и там грузится главная страница с осмысленным содержимым, а не какая-нибудь заглушка веб сервера.
В такой схеме достаточно просто переключить DNS записи и всё заработает на новом сервере. Конечно, без веских причин делать это не хочется, потому что после этого придётся перенастраивать всю схему бэкапа, мониторинг и сбор логов. Это всё хлопотно, потому что не автоматизировано. А не автоматизировано, потому что виртуалки не точные копии друг друга, а используются в том числе и для других целей. Нельзя взять и автоматом накатить все настройки с одного сервера на другой.
В этот раз просто переключить DNS не получилось, потому что я ошибся и очень долго не замечал этого. После очередного переезда сайта, я забыл поменять скрипт восстановления на резервном сервере. И там очень долго жила абсолютно рабочая копия сайта, но старая. Первыми на ней протухли сертификаты, но мониторинг это не заметил, потому что проверки были сделаны с игнорированием ошибок сертификата. Раньше я не копировал сертификаты и проверку сайта делал без их учёта. Потом просто не добавил.
Проверка содержимого тоже никак не отреагировала на то, что сайт старый. Она не учитывала новизну материала, проверялся только подвал сайта на наличие там привычных строк для главной страницы. На устаревшем сайте протух набор статей, но внешне он выглядел вполне рабочим.
В итоге, когда надо было переключиться на резервный сервер, оказалось, что он не готов. У меня получилось вытащить сертификаты со старого сервера. Бэкап накатил из другого источника. Переключил DNS записи на этот временный сервер.
Моя схема бэкапа и мониторинга не прошла проверку практикой. Надо будет доработать. Организовать проверку TLS на запасном сервере и как-то продумать механизм определения актуальности сайта путём анализа главной страницы. Тут надо будет что-то наколхозить. Пока сходу нет идей, как это сделать. Можно по простоте не со стороны браузера это делать, а на уровне файлов. Проосто положить в исходники какой-то файл с меткой времени и на приёмнике смотреть это время.
А в целом, такая схема с доработками видится мне удобной и надёжной. Тут сразу и бэкапы проверяются, когда разворачиваются на резервном сервере, и под рукой всегда запасной работающий сервер с актуальной копией сайта. Его можно использовать для тестов или каких-то дополнительных проверок.
Если интересно, могу более подробно расписать всю эту схему, но тут надо будет целую серию заметок делать, так как материала будет много.
#webserver
Я обычно жду час-полтора и если хостер не оживает, начинаю переезд. Мне кажется, что если за это время не починились, значит что-то серьёзное и сидеть ждать дальше уже опасно. Можно весь день прождать.
Как это обычно бывает, с переездом возникли проблемы. Расскажу, как у меня устроен бэкап и мониторинг сайта. Бэкапов к меня много:
◽в S3 хранилище дневные, недельные и месячные архивы
◽сервер дома, который сам по ssh ходит и забирает данные
◽копия бэкапов в яндекс.диске
◽копия бэкапов в Synology
Сайты занимают мало места, так что я особо не заморачиваюсь и храню побольше копий. Даже если где-то что-то сломается и не сохранится, то хоть какую-то копию можно достать. Причём данные у меня хранятся как в упакованных архивах, так и в виде сырых файлов. Настройки Nginx тоже сохраняю. Это важно, там много нюансов, которые долго вспоминать и восстанавливать.
Бэкапы у меня автоматически копируются на резервную виртуалку, там разворачиваются в полноценные сайты с БД. Далее Zabbix ходит на эту резервную виртуалку с веб проверками и смотрит, что сайт реально работает и там грузится главная страница с осмысленным содержимым, а не какая-нибудь заглушка веб сервера.
В такой схеме достаточно просто переключить DNS записи и всё заработает на новом сервере. Конечно, без веских причин делать это не хочется, потому что после этого придётся перенастраивать всю схему бэкапа, мониторинг и сбор логов. Это всё хлопотно, потому что не автоматизировано. А не автоматизировано, потому что виртуалки не точные копии друг друга, а используются в том числе и для других целей. Нельзя взять и автоматом накатить все настройки с одного сервера на другой.
В этот раз просто переключить DNS не получилось, потому что я ошибся и очень долго не замечал этого. После очередного переезда сайта, я забыл поменять скрипт восстановления на резервном сервере. И там очень долго жила абсолютно рабочая копия сайта, но старая. Первыми на ней протухли сертификаты, но мониторинг это не заметил, потому что проверки были сделаны с игнорированием ошибок сертификата. Раньше я не копировал сертификаты и проверку сайта делал без их учёта. Потом просто не добавил.
Проверка содержимого тоже никак не отреагировала на то, что сайт старый. Она не учитывала новизну материала, проверялся только подвал сайта на наличие там привычных строк для главной страницы. На устаревшем сайте протух набор статей, но внешне он выглядел вполне рабочим.
В итоге, когда надо было переключиться на резервный сервер, оказалось, что он не готов. У меня получилось вытащить сертификаты со старого сервера. Бэкап накатил из другого источника. Переключил DNS записи на этот временный сервер.
Моя схема бэкапа и мониторинга не прошла проверку практикой. Надо будет доработать. Организовать проверку TLS на запасном сервере и как-то продумать механизм определения актуальности сайта путём анализа главной страницы. Тут надо будет что-то наколхозить. Пока сходу нет идей, как это сделать. Можно по простоте не со стороны браузера это делать, а на уровне файлов. Проосто положить в исходники какой-то файл с меткой времени и на приёмнике смотреть это время.
А в целом, такая схема с доработками видится мне удобной и надёжной. Тут сразу и бэкапы проверяются, когда разворачиваются на резервном сервере, и под рукой всегда запасной работающий сервер с актуальной копией сайта. Его можно использовать для тестов или каких-то дополнительных проверок.
Если интересно, могу более подробно расписать всю эту схему, но тут надо будет целую серию заметок делать, так как материала будет много.
#webserver
{kind=link}
Если вам нужно точно знать, кто и что делает в базе данных MySQL, то настроить это относительно просто. В MySQL и её популярных форках существует встроенный модуль Audit Plugin, с помощью которого можно все действия с сервером баз данных записывать в лог-файл.
Я покажу на примере системы Debian и СУБД MariaDB, как настроить аудит всех действий с сервером. Это будет полная инструкция, по которой копированием команд можно всё настроить.
Ставим сервер и выполняем начальную настройку:
Заходим в консоль Mysql:
Устанавливаем плагин:
В Debian этот плагин присутствует по умолчанию. Проверить можно в директории /usr/lib/mysql/plugin наличие файла server_audit.so.
Смотрим информацию о плагине и его настройки:
По умолчанию аудит в СУБД отключён. За это отвечает параметр server_audit_logging. Активируем его:
Теперь все действия на сервере СУБД будут записываться в лог файл, который по умолчанию будет создан в директории /var/lib/mysql в файле server_audit.log.
Записываться будут все действия для всех пользователей. Это можно изменить, задав явно параметр server_audit_events, который будет указывать, какие события записываем. Например так:
В этом параметре поддерживаются следующие значения: CONNECT, QUERY, TABLE, QUERY_DDL, QUERY_DML, QUERY_DCL, QUERY_DML_NO_SELECT.
Для пользователей можно настроить исключения. То есть указать, для какого пользователя мы не будем вести аудит. Список этих пользователей хранится в параметре server_audit_excl_users. Тут, в отличие от предыдущего параметра, мы указываем исключение. Управляется примерно так:
Все подробности по настройке плагина есть в официальной документации.
Дальше этот лог можно передать куда-то на хранение. Например в elasticsearch. Для него есть готовые grok фильтры для разбора лога аудита в Ingest ноде или Logstash. Вот пример подобного фильтра. После этого можно будет настроить какие-то оповещения в зависимости от ваших потребностей. Например, при превышении каким-то пользователем числа подключений или слишком больше количество каких-то операций в единицу времени.
Максимально просто и быстро мониторинг на события можно настроить и в Zabbix. К примеру, сделать отдельные айтемы для строк только с конкретными запросами, например UPDATE или DELETE, или записывать только коды выхода, отличные от 0. Далее для них настроить триггеры на превышение средних значений в интервал времени на какую-то величину. Если происходят всплески по этим строкам, получите уведомление. Но сразу предупрежу, что Zabbix не очень для этого подходит. Только если событий немного. Иначе лог аудита будет занимать очень много места в базе данных Zabbix. Это плохая практика.
Придумать тут можно много всего в зависимости от ваших потребностей. И всё это сделать относительно просто. Не нужны никакие дополнительные средства и программы.
#mysql #security
Я покажу на примере системы Debian и СУБД MariaDB, как настроить аудит всех действий с сервером. Это будет полная инструкция, по которой копированием команд можно всё настроить.
Ставим сервер и выполняем начальную настройку:
# apt install mariadb-server# mysql_secure_installationЗаходим в консоль Mysql:
# mysql -u root -pУстанавливаем плагин:
> install plugin server_audit soname 'server_audit.so';В Debian этот плагин присутствует по умолчанию. Проверить можно в директории /usr/lib/mysql/plugin наличие файла server_audit.so.
Смотрим информацию о плагине и его настройки:
> select * from information_schema.plugins where plugin_name='SERVER_AUDIT'\G> show global variables like 'server_audit%';По умолчанию аудит в СУБД отключён. За это отвечает параметр server_audit_logging. Активируем его:
> set global server_audit_logging=on;Теперь все действия на сервере СУБД будут записываться в лог файл, который по умолчанию будет создан в директории /var/lib/mysql в файле server_audit.log.
Записываться будут все действия для всех пользователей. Это можно изменить, задав явно параметр server_audit_events, который будет указывать, какие события записываем. Например так:
> set global server_audit_events='QUERY;В этом параметре поддерживаются следующие значения: CONNECT, QUERY, TABLE, QUERY_DDL, QUERY_DML, QUERY_DCL, QUERY_DML_NO_SELECT.
Для пользователей можно настроить исключения. То есть указать, для какого пользователя мы не будем вести аудит. Список этих пользователей хранится в параметре server_audit_excl_users. Тут, в отличие от предыдущего параметра, мы указываем исключение. Управляется примерно так:
> set global server_audit_excl_users='user01';Все подробности по настройке плагина есть в официальной документации.
Дальше этот лог можно передать куда-то на хранение. Например в elasticsearch. Для него есть готовые grok фильтры для разбора лога аудита в Ingest ноде или Logstash. Вот пример подобного фильтра. После этого можно будет настроить какие-то оповещения в зависимости от ваших потребностей. Например, при превышении каким-то пользователем числа подключений или слишком больше количество каких-то операций в единицу времени.
Максимально просто и быстро мониторинг на события можно настроить и в Zabbix. К примеру, сделать отдельные айтемы для строк только с конкретными запросами, например UPDATE или DELETE, или записывать только коды выхода, отличные от 0. Далее для них настроить триггеры на превышение средних значений в интервал времени на какую-то величину. Если происходят всплески по этим строкам, получите уведомление. Но сразу предупрежу, что Zabbix не очень для этого подходит. Только если событий немного. Иначе лог аудита будет занимать очень много места в базе данных Zabbix. Это плохая практика.
Придумать тут можно много всего в зависимости от ваших потребностей. И всё это сделать относительно просто. Не нужны никакие дополнительные средства и программы.
#mysql #security
{kind=link}