
Написал запланированную статью по настройке интеграции Lynis и Zabbix для оповещения о результатах аудита безопасности системы:
Мониторинг безопасности сервера с помощью Lynis и Zabbix
⇨ https://serveradmin.ru/monitoring-bezopasnosti-servera-s-pomoshhyu-lynis-i-zabbix
В статье постарался максимально подробно раскрыть тему. Приложил весь необходимый материал: скрипт, шаблон.
Решение получилось немного корявое, так как неудобно делать раскатку на много хостов. Приходится добавлять скрипты, настраивать таймер, собирать логи. Плюс, настройки самого Lynis могут быть разные на разных хостах. Менять приходится вручную.
Мне больше нравится, когда всё реализовано с помощью инструментов сервера мониторинга, а все настройки хранятся в шаблоне и управляются макросами. Но для данной задачи я не смог придумать более красивой реализации.
#zabbix #security
Мониторинг безопасности сервера с помощью Lynis и Zabbix
⇨ https://serveradmin.ru/monitoring-bezopasnosti-servera-s-pomoshhyu-lynis-i-zabbix
В статье постарался максимально подробно раскрыть тему. Приложил весь необходимый материал: скрипт, шаблон.
Решение получилось немного корявое, так как неудобно делать раскатку на много хостов. Приходится добавлять скрипты, настраивать таймер, собирать логи. Плюс, настройки самого Lynis могут быть разные на разных хостах. Менять приходится вручную.
Мне больше нравится, когда всё реализовано с помощью инструментов сервера мониторинга, а все настройки хранятся в шаблоне и управляются макросами. Но для данной задачи я не смог придумать более красивой реализации.
#zabbix #security
Server Admin
Мониторинг безопасности сервера с помощью Lynis и Zabbix |...
Интеграция системы проверки безопасности Linux сервера Lynis с системой мониторинга Zabbix. Оповещения об уязвимых пакетах.
Чем отличаются утилиты traceroute, tracert и tracepath? Какую и когда лучше использовать? Заметка будет об этом.
Думаю, все системные администраторы Linux знают команду traceroute. Она очень похожа на аналогичную программу в Windows — tracert. Я часто их путаю и в разных системах набираю разные названия, потом исправляю. С их помощью можно быстро увидеть маршрут следования пакета до конечного хоста. При этом отображаются сведения обо всех промежуточных маршрутизаторах, если там специально не настроена блокировка ответов на подобные запросы.
Отмечу, что хоть traceroute и tracert похожи, но у них есть существенное отличие. Traceroute по умолчанию использует UDP протокол, а tracert — ICMP. При этом в первой можно выбирать протокол, во второй нет. Вот пример запуска traceroute с разными протоколами (UDP и ICMP):
Лично у меня результаты разные, потому что разные протоколы могут иметь разные маршруты, либо где-то по пути следования какой-то из протоколов может быть заблокирован. Чаще это случается с UDP. ICMP обычно не блокируют.
Утилита tracepath очень похожа на traceroute в плане базовой трассировки. Она тоже использует UDP протокол. Но у неё есть важное и полезное отличие. Она сразу же показывает MTU пакетов. И если этот размер где-то по пути меняется, отображает это. На картинке снизу будет пример трассировки с изменением MTU по пути следования пакета. Я специально его уменьшил в VPN туннеле, чтобы показать работу tracepath. Иногда эта информация очень нужна и tracepath помогает быстро увидеть проблему. Возьмите на вооружение.
#network
Думаю, все системные администраторы Linux знают команду traceroute. Она очень похожа на аналогичную программу в Windows — tracert. Я часто их путаю и в разных системах набираю разные названия, потом исправляю. С их помощью можно быстро увидеть маршрут следования пакета до конечного хоста. При этом отображаются сведения обо всех промежуточных маршрутизаторах, если там специально не настроена блокировка ответов на подобные запросы.
Отмечу, что хоть traceroute и tracert похожи, но у них есть существенное отличие. Traceroute по умолчанию использует UDP протокол, а tracert — ICMP. При этом в первой можно выбирать протокол, во второй нет. Вот пример запуска traceroute с разными протоколами (UDP и ICMP):
# traceroute mail.ru# traceroute -I mail.ruЛично у меня результаты разные, потому что разные протоколы могут иметь разные маршруты, либо где-то по пути следования какой-то из протоколов может быть заблокирован. Чаще это случается с UDP. ICMP обычно не блокируют.
Утилита tracepath очень похожа на traceroute в плане базовой трассировки. Она тоже использует UDP протокол. Но у неё есть важное и полезное отличие. Она сразу же показывает MTU пакетов. И если этот размер где-то по пути меняется, отображает это. На картинке снизу будет пример трассировки с изменением MTU по пути следования пакета. Я специально его уменьшил в VPN туннеле, чтобы показать работу tracepath. Иногда эта информация очень нужна и tracepath помогает быстро увидеть проблему. Возьмите на вооружение.
#network
{kind=link}
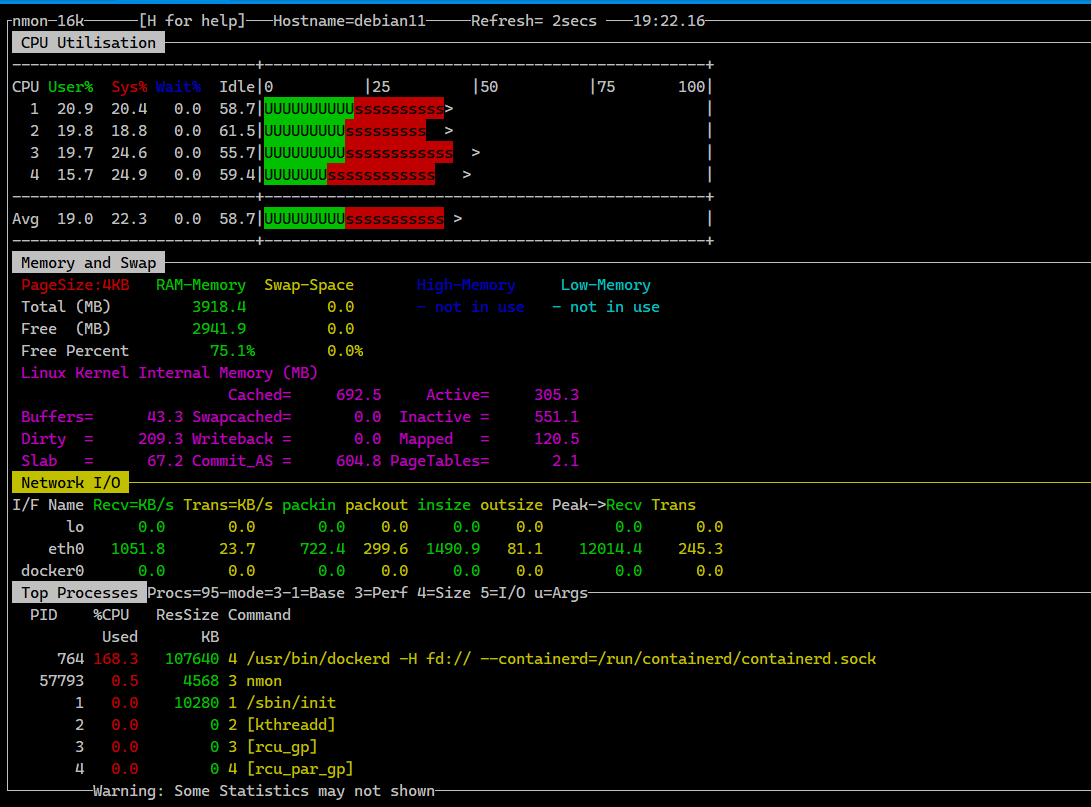
Представляю вашему вниманию очень старую, прямо таки олдскульную программу для анализа нагрузки Linux сервера — nmon. Она периодически всплывает в обсуждениях, рекомендациях. Я почему-то был уверен, что писал о ней. Но поиск по каналу неумолим — ни одного упоминания в заметках. Хотя программа известная, удобная и актуальная по сей день. Не заброшена, развивается, есть в репозиториях популярных дистрибутивов.
По своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
# apt install nmonПо своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
{kind=link}
🔝Традиционный топ постов за прошедший месяц. Как обычно, больше всего просмотров у мемасиков, обсуждений у Микротик, пересылок и сохранений у bash скриптов и бесплатных курсов.
Мне интересно, эти bash скрипты кто-то использует или просто сохраняет? А обучение проходят или тоже на когда-нибудь потом откладывают, как я? Обычно то, что не надо прямо сейчас в работе, откладывается на вечное потом.
📌 Больше всего просмотров:
◽️Мемчик с блатным шансоном для админа (10250)
◽️Песни группы the CI/CD band (10073)
◽️Настройка заголовков в веб сервере (9500)
📌 Больше всего комментариев:
◽️Новый Mikrotik L009UiGS-2HaxD-IN (239)
◽️Мем с удалением базы данных (84)
◽️Записи в DNS для почтового сервера (65)
📌 Больше всего пересылок:
◽️Скрипт topdiskconsumer (634)
◽️Бесплатные курсы по Linux на stepik.org (448)
◽️Тюнинг сетевого стека (365)
📌 Больше всего реакций:
◽️История убийства БД по совету ChatGPT (168)
◽️Скрипт topdiskconsumer (151)
◽️Шаринг консоли с помощью screen (145)
◽️Программа SophiApp для быстрой настройки Windows (132)
#топ
Мне интересно, эти bash скрипты кто-то использует или просто сохраняет? А обучение проходят или тоже на когда-нибудь потом откладывают, как я? Обычно то, что не надо прямо сейчас в работе, откладывается на вечное потом.
📌 Больше всего просмотров:
◽️Мемчик с блатным шансоном для админа (10250)
◽️Песни группы the CI/CD band (10073)
◽️Настройка заголовков в веб сервере (9500)
📌 Больше всего комментариев:
◽️Новый Mikrotik L009UiGS-2HaxD-IN (239)
◽️Мем с удалением базы данных (84)
◽️Записи в DNS для почтового сервера (65)
📌 Больше всего пересылок:
◽️Скрипт topdiskconsumer (634)
◽️Бесплатные курсы по Linux на stepik.org (448)
◽️Тюнинг сетевого стека (365)
📌 Больше всего реакций:
◽️История убийства БД по совету ChatGPT (168)
◽️Скрипт topdiskconsumer (151)
◽️Шаринг консоли с помощью screen (145)
◽️Программа SophiApp для быстрой настройки Windows (132)
#топ
На днях история с неработающим OpenVPN наделала шума. Я регулярно новости не читаю, поэтому даже не сразу понял, о чём идёт речь, когда разные люди стали писать по этой теме. Для тех, кто не в курсе, о чём идёт речь, немного ссылок по теме: habr, securitylab, tproger.
У меня много где используется OpenVPN. Это основная технология для построения VPN, которую я использую, как на работе, так и в личных целях. Когда узнал про блокировки, проверил у себя, проблем не нашлось. К серверу в USA без проблем подключился. Позже вечером заметил, что дома не работает обход блокировок. Там Mikrotik подключается по TCP. Подключение не работало, хотя по UDP из этой же квартиры без проблем подключался. Подумал, что вот оно, я тоже столкнулся. Но на самом деле нет. Пошёл на сервер и увидел, что TCP туннель пару дней назад упал по какой-то причине. Буду с этим отдельно разбираться. По факту всё работает, даже через упоминаемую в новостях Yota.
❓Что это на самом деле было — не знаю. Может банальный сбой, может тестирование блокировки openvpn, может тестирование чего-то другого, что косвенно задело vpn. Информации нет, так что остаётся только гадать на кофейной гуще. Больше всего похоже на разовую акцию для информационного шума. Уж больно лихо все СМИ подхватили эту тему.
Я думаю, что блокировка VPN за пределы РФ, как и многих популярных иностранных сервисов типа youtube, в итоге состоится. Нарастающая логика происходящий событий такова. Это вопрос времени. Внутри РФ, думаю, что VPN работать будет. Возможно, нас ещё раньше на той стороне заблокируют. Там же свобода и рыночная экономика.
Варианты обхода этих блокировок, думаю, тоже будут, но не для массового пользователя. Несколько лет назад у меня сотрудники ездили в командировку в Китай. У них там работал OpenVPN для связи с московским офисом. Хотя я думал, что не будет. Все же знают про великий китайский файрвол. Как он на самом деле работает, точной информации не видел. Везде в основном слухи.
✅ Как минимум у нас останется вариант с маскировкой под HTTPS. Можно будет поднять OpenConnect или SSTP, который умеет поднимать тот же SoftEther VPN. Их трафик трудноотличим от обычного web трафика. Для тех, кому жизненно важно подстраховаться, рекомендую поднять что-то подобное на случай реальной блокировки.
✅ Много раз слышал, что плохо детектится и блокируется технология Shadowsocks. Легко и быстро настраивается, клиенты есть под все платформы. На её базе работает Outline VPN, Shadowsocks for Windows и многие другие программы. Легко гуглятся, пока гугл не заблокирован. Думаю, до него не дойдёт, хотя кто знает.
✅ Ещё один вариант — завернуть весь VPN трафик в Udp2raw-tunnel. Он умеет маскировать трафик, добавляя фейковые заголовки пакетам. Если блокировка идёт без разбора содержимого пакетов, то может помочь.
Расскажите, столкнулись ли вы с блокировкой OpenVPN. Если да, то как это выглядело и какие параметры канала были. Какой протокол и порт использовался, включено ли сжатие трафика.
#vpn
У меня много где используется OpenVPN. Это основная технология для построения VPN, которую я использую, как на работе, так и в личных целях. Когда узнал про блокировки, проверил у себя, проблем не нашлось. К серверу в USA без проблем подключился. Позже вечером заметил, что дома не работает обход блокировок. Там Mikrotik подключается по TCP. Подключение не работало, хотя по UDP из этой же квартиры без проблем подключался. Подумал, что вот оно, я тоже столкнулся. Но на самом деле нет. Пошёл на сервер и увидел, что TCP туннель пару дней назад упал по какой-то причине. Буду с этим отдельно разбираться. По факту всё работает, даже через упоминаемую в новостях Yota.
❓Что это на самом деле было — не знаю. Может банальный сбой, может тестирование блокировки openvpn, может тестирование чего-то другого, что косвенно задело vpn. Информации нет, так что остаётся только гадать на кофейной гуще. Больше всего похоже на разовую акцию для информационного шума. Уж больно лихо все СМИ подхватили эту тему.
Я думаю, что блокировка VPN за пределы РФ, как и многих популярных иностранных сервисов типа youtube, в итоге состоится. Нарастающая логика происходящий событий такова. Это вопрос времени. Внутри РФ, думаю, что VPN работать будет. Возможно, нас ещё раньше на той стороне заблокируют. Там же свобода и рыночная экономика.
Варианты обхода этих блокировок, думаю, тоже будут, но не для массового пользователя. Несколько лет назад у меня сотрудники ездили в командировку в Китай. У них там работал OpenVPN для связи с московским офисом. Хотя я думал, что не будет. Все же знают про великий китайский файрвол. Как он на самом деле работает, точной информации не видел. Везде в основном слухи.
✅ Как минимум у нас останется вариант с маскировкой под HTTPS. Можно будет поднять OpenConnect или SSTP, который умеет поднимать тот же SoftEther VPN. Их трафик трудноотличим от обычного web трафика. Для тех, кому жизненно важно подстраховаться, рекомендую поднять что-то подобное на случай реальной блокировки.
✅ Много раз слышал, что плохо детектится и блокируется технология Shadowsocks. Легко и быстро настраивается, клиенты есть под все платформы. На её базе работает Outline VPN, Shadowsocks for Windows и многие другие программы. Легко гуглятся, пока гугл не заблокирован. Думаю, до него не дойдёт, хотя кто знает.
✅ Ещё один вариант — завернуть весь VPN трафик в Udp2raw-tunnel. Он умеет маскировать трафик, добавляя фейковые заголовки пакетам. Если блокировка идёт без разбора содержимого пакетов, то может помочь.
Расскажите, столкнулись ли вы с блокировкой OpenVPN. Если да, то как это выглядело и какие параметры канала были. Какой протокол и порт использовался, включено ли сжатие трафика.
#vpn
Нашёл забавное видео, где на всем известный ролик с испанцем, наложили титры с шуткой над коллегой линуксоидом. Он в качестве текстового редактора использовал nano, и ему сделали алиас
Linux User Plays Cruelest Joke EVER on Coworker
⇨ https://www.youtube.com/watch?v=AaESGrylj7k
Само наполнение ролика я оценил на троечку. Больше понравились комментарии, где люди поделились своими шутками над коллегами. Перевожу вам некоторые из них.
📌 Мой босс случайно заметил, что директор по маркетингу ушла и не заблокировала комп. Он добавил правило автозамены в Outlook, которое меняет "ты" (you) на "я" (me). Прошёл месяц, прежде чем она поняла, что каждая фраза "спасибо вам" (thank you) заменялась на "спасибо мне" (thank me).
🔥На одном из серверов я сделал алиас ls='cat /dev/urandom'. Видели бы вы выражение лица моего коллеги, когда он запустил ls.
📌 Ему повезло, что редактор не заменили на ed. (p.s. попробуйте выйти из него 😀)
📌 Было время, когда мои публичные скрипты использовали nano для того, чтобы ввести сообщение для git commit. Мне было лень их править, я добавил в публичное репо алиас на vi. А локально у меня был алиас с vi на vim. Один коллега, который был новичком, захотел себе такие же настройки терминала, как у меня. Скопировал себе все конфиги из репы, в том числе и с алиасом. Мне об этом не сказал. Два дня промучался, прежде чем пришёл ко мне с вопросом, что происходит.
💡 Однажды я сделал нечто подобное. Добавил симлинк на vi, сделал алиас для apt install nano, который запускал подготовленный скрипт с echo, а в фоне устанавливал vi.
📌 Однажды я подшутил над коллегой. Он работал допоздна. Перед уходом я заменил утилиту more программой, которая по мере чтения текста начинала перемещать буквы со своего места в нижнюю часть экрана, пока не образовывалась огромная куча букв. Он в панике позвонил мне, так как думал, что систему взломали. Эх, какие это были деньки. Старые добрые терминалы 80-х.
#юмор #видео
alias nano='vi'. Дальше обыгрывается эта тема:Linux User Plays Cruelest Joke EVER on Coworker
⇨ https://www.youtube.com/watch?v=AaESGrylj7k
Само наполнение ролика я оценил на троечку. Больше понравились комментарии, где люди поделились своими шутками над коллегами. Перевожу вам некоторые из них.
📌 Мой босс случайно заметил, что директор по маркетингу ушла и не заблокировала комп. Он добавил правило автозамены в Outlook, которое меняет "ты" (you) на "я" (me). Прошёл месяц, прежде чем она поняла, что каждая фраза "спасибо вам" (thank you) заменялась на "спасибо мне" (thank me).
🔥На одном из серверов я сделал алиас ls='cat /dev/urandom'. Видели бы вы выражение лица моего коллеги, когда он запустил ls.
📌 Ему повезло, что редактор не заменили на ed. (p.s. попробуйте выйти из него 😀)
📌 Было время, когда мои публичные скрипты использовали nano для того, чтобы ввести сообщение для git commit. Мне было лень их править, я добавил в публичное репо алиас на vi. А локально у меня был алиас с vi на vim. Один коллега, который был новичком, захотел себе такие же настройки терминала, как у меня. Скопировал себе все конфиги из репы, в том числе и с алиасом. Мне об этом не сказал. Два дня промучался, прежде чем пришёл ко мне с вопросом, что происходит.
💡 Однажды я сделал нечто подобное. Добавил симлинк на vi, сделал алиас для apt install nano, который запускал подготовленный скрипт с echo, а в фоне устанавливал vi.
📌 Однажды я подшутил над коллегой. Он работал допоздна. Перед уходом я заменил утилиту more программой, которая по мере чтения текста начинала перемещать буквы со своего места в нижнюю часть экрана, пока не образовывалась огромная куча букв. Он в панике позвонил мне, так как думал, что систему взломали. Эх, какие это были деньки. Старые добрые терминалы 80-х.
#юмор #видео
YouTube
Linux User Plays Cruelest Joke EVER on Coworker
A Linux admin shares a story about a cruel joke that he played on one of his coworkers. The story-teller does not speak English so I am translating his story...
WANT TO SUPPORT THE CHANNEL?
💰 Patreon: https://www.patreon.com/distrotube
💳 Paypal: http…
WANT TO SUPPORT THE CHANNEL?
💰 Patreon: https://www.patreon.com/distrotube
💳 Paypal: http…
🎓 Немного необычная тема для моего канала, хотя косвенно я иногда её затрагиваю. Предлагаю вашему вниманию бесплатный курс на stepik.org на тему написания IT статей:
Статьи для IT: как объяснять и распространять значимые идеи
⇨ https://stepik.org/course/101672/
Я люблю писать большие статьи, мне близка эта тема. Хотя давно уже не занимался ею. В прошлом я много писал статей для сайта, а также по заказу на тот же хабр, или просто коммерческие обзоры. Сейчас не занимаюсь этой деятельностью, потому что получить желаемых доход написанием статей у меня не получилось. Рассматривал варианты стать техническим писателем, но все предложения, что получал, по деньгам очень грустные. Они не сопоставимы с практический деятельность по настройке.
На курсе люди учат грамотно писать статьи. Уклон там в IT, но в целом база даётся для любого направления. Я самоучка в этой области, но частично применял те вещи, что рассказываются. Например, я всегда изучал предметную область, собирал проблемы по теме и вопросы, на которые будут ответы в статье, готовил контент план, подбирал хороший заголовок, продумывал оглавление. Все большие статьи на сайте, которые набрали более 100 тыс. просмотров, готовились очень серьёзно. Чтобы получить хорошие охваты, надо чётко понимать проблему, рассмотреть все сопутствующие подпроблемы и предложить решение. На подготовку уходило больше времени, чем на непосредственно написание текста. Когда у тебя всё подготовлено: заголовок, структура, вопросы, лаба, написать сам текст наиболее простая задача, чисто техническая, не творческая.
К чему я всё это. Если хотите научиться хорошо писать материалы по IT, рекомендую этот курс. Там помимо теории, даётся очень много полезных ссылок на различные ресурсы, блоги, площадки, авторов, книги и т.д. Прямо таки кладезь хороших технических текстов.
#обучение #бесплатно
Статьи для IT: как объяснять и распространять значимые идеи
⇨ https://stepik.org/course/101672/
Я люблю писать большие статьи, мне близка эта тема. Хотя давно уже не занимался ею. В прошлом я много писал статей для сайта, а также по заказу на тот же хабр, или просто коммерческие обзоры. Сейчас не занимаюсь этой деятельностью, потому что получить желаемых доход написанием статей у меня не получилось. Рассматривал варианты стать техническим писателем, но все предложения, что получал, по деньгам очень грустные. Они не сопоставимы с практический деятельность по настройке.
На курсе люди учат грамотно писать статьи. Уклон там в IT, но в целом база даётся для любого направления. Я самоучка в этой области, но частично применял те вещи, что рассказываются. Например, я всегда изучал предметную область, собирал проблемы по теме и вопросы, на которые будут ответы в статье, готовил контент план, подбирал хороший заголовок, продумывал оглавление. Все большие статьи на сайте, которые набрали более 100 тыс. просмотров, готовились очень серьёзно. Чтобы получить хорошие охваты, надо чётко понимать проблему, рассмотреть все сопутствующие подпроблемы и предложить решение. На подготовку уходило больше времени, чем на непосредственно написание текста. Когда у тебя всё подготовлено: заголовок, структура, вопросы, лаба, написать сам текст наиболее простая задача, чисто техническая, не творческая.
К чему я всё это. Если хотите научиться хорошо писать материалы по IT, рекомендую этот курс. Там помимо теории, даётся очень много полезных ссылок на различные ресурсы, блоги, площадки, авторов, книги и т.д. Прямо таки кладезь хороших технических текстов.
#обучение #бесплатно
Stepik: online education
Статьи для IT: как объяснять и распространять значимые идеи
Для тех, кто любит качественные IT-публикации и хочет научиться интересно писать о программировании и собственных IT-проектах
Последнее время стала актуальна тема VPN. Расскажу вам по этому поводу про интересный open source проект — Nebula. Авторы называют его scalable overlay networking tool, что для меня затруднительно однозначно перевести. В общем случае это программа для построения связной виртуальной сети поверх физической, в том числе и через интернет.
Термин overlay обычно применяют для больших виртуальных сетей, построенный как бы над обычными. Есть физические сети underlay и виртуальные overlay. В Nebula используется агент, который устанавливается на каждый хост и в зависимости от своих настроек, подключается к тем или иным хостам. Соединения образуются между хостами напрямую (p2p), то есть получается mesh сеть. В этом основное отличие от традиционных VPN сетей, где используются туннели между шлюзами, а все остальные хосты общаются друг с другом посредством шлюзов.
Nebula разработали в Slack и потом выложили в открытый доступ. Авторы инструмента открыли свою компанию, saas сервис, занимаются внедрением и поддержкой. У них, кстати, есть бесплатный тарифный план.
Развернуть Nebula у себя не представляет большой сложности. Простейшая инструкция для запуска есть в самом репозитории. Аутентификация хостов происходит посредством сертификатов, как в openvpn. Так что придётся поднять свой CA и выпускать для клиентов сертификаты. У Nebula всё это есть в комплекте, так что не придётся прибегать к сторонним инструментам.
Пример выпуска CA:
Сертификата для клиента:
Тут сразу идёт функциональная привязка к выпущенному сертификату, так что продумать структуру сети нужно до выпуска сертификатов. Потом клиенту передаётся конфиг с сертификатом, где указан IP адрес одного или группы хостов, которые выступают в роли управляющего сервера. Точкой обмена трафиком они не будут. В зависимости от своих настроек, хосты обмениваются трафиком между собой напрямую. Даже если оба клиента находятся за NAT, управляющая нода соединит их напрямую посредством технологии UDP hole punching.
Если я правильно понял принцип работы Nebula, VPN туннели поднимаются динамически между хостами в случае необходимости. При этом используется своя технология на базе обмена ключами Диффи-Хеллмана (ECDH) и шифре AES-256-GCM. То есть это не надстройка над каким-нибудь wireguard или чем-то аналогичным. И всё это создано для построения очень больших сетей из сотен и тысяч хостов.
Nebula немного похожа на Tailscale, только у неё изначально всё готово для установки на своём железе. Нет привязки к облачному сервису. Для Tailscale тоже есть подобный сервер — Headscale. Но его развивают и поддерживают другие люди, не разработчики.
⇨ Сайт / Исходники / Документация / Обзор
#vpn
Термин overlay обычно применяют для больших виртуальных сетей, построенный как бы над обычными. Есть физические сети underlay и виртуальные overlay. В Nebula используется агент, который устанавливается на каждый хост и в зависимости от своих настроек, подключается к тем или иным хостам. Соединения образуются между хостами напрямую (p2p), то есть получается mesh сеть. В этом основное отличие от традиционных VPN сетей, где используются туннели между шлюзами, а все остальные хосты общаются друг с другом посредством шлюзов.
Nebula разработали в Slack и потом выложили в открытый доступ. Авторы инструмента открыли свою компанию, saas сервис, занимаются внедрением и поддержкой. У них, кстати, есть бесплатный тарифный план.
Развернуть Nebula у себя не представляет большой сложности. Простейшая инструкция для запуска есть в самом репозитории. Аутентификация хостов происходит посредством сертификатов, как в openvpn. Так что придётся поднять свой CA и выпускать для клиентов сертификаты. У Nebula всё это есть в комплекте, так что не придётся прибегать к сторонним инструментам.
Пример выпуска CA:
# ./nebula-cert ca -name "Myorganization, Inc"Сертификата для клиента:
# ./nebula-cert sign -name "laptop" -ip "192.168.100.2/24" \-groups "laptop,home,ssh"Тут сразу идёт функциональная привязка к выпущенному сертификату, так что продумать структуру сети нужно до выпуска сертификатов. Потом клиенту передаётся конфиг с сертификатом, где указан IP адрес одного или группы хостов, которые выступают в роли управляющего сервера. Точкой обмена трафиком они не будут. В зависимости от своих настроек, хосты обмениваются трафиком между собой напрямую. Даже если оба клиента находятся за NAT, управляющая нода соединит их напрямую посредством технологии UDP hole punching.
Если я правильно понял принцип работы Nebula, VPN туннели поднимаются динамически между хостами в случае необходимости. При этом используется своя технология на базе обмена ключами Диффи-Хеллмана (ECDH) и шифре AES-256-GCM. То есть это не надстройка над каким-нибудь wireguard или чем-то аналогичным. И всё это создано для построения очень больших сетей из сотен и тысяч хостов.
Nebula немного похожа на Tailscale, только у неё изначально всё готово для установки на своём железе. Нет привязки к облачному сервису. Для Tailscale тоже есть подобный сервер — Headscale. Но его развивают и поддерживают другие люди, не разработчики.
⇨ Сайт / Исходники / Документация / Обзор
#vpn
{kind=link}
Решил немного развить тему с развлечением в терминале. Сегодня как раз подходящий день для этого. Ниже будет подборка приколов и просто забавных приложений для терминала. А вечером подборка игр.
▪Cmatrix. Визитная карточка фильма Матрица — набор символов, падающих как водопад, сверху вниз. Эта утилита воспроизводит его у вас в терминале. Живёт в стандартных репах:
Почитайте man, там много ключей для видоизменения эффектов. Выглядит прикольно, хоть и не так, как в кино. Посмотреть.
▪MapSCII. Карта мира в терминале. Написана на JS, поэтому живёт в репах nodejs.
В убунте через snap можно поставить:
Выглядит необычно и подробно для такого рода программы. Вплоть до отдельных улиц городов можно увидеть. Посмотреть.
▪Aafire. Разжигает терминальный ASCII огонь. Живёт в репах:
Поджигаем:
После этого огня у меня все символы в терминале становятся серыми. Не понял, это так задумано или какой-то глюк. Релогин сбрасывает эффект.
▪Toilet. Преобразует введённые слова в большие символы ASCII. Совершенно не понятно, почему у утилиты такое странное название. Живёт в репах:
Посмотреть.
▪Cowsay. С помощью этой утилиты вы можете попросить ASCII корову сказать любую фразу:
Посмотреть. Похожие программы: cowthink, ponysay.
▪Cal. Терминальный календарь. Рассказывал о нём отдельно. Полноценный календарь. В rpm дистрибутивах пакет называется cal, в deb — ncal:
Утилита без всяких шуток может быть полезной. В Centos вроде бы в базовой установке была. Даже устанавливать не надо было. Посмотреть месяц назад, текущий и будущий:
▪Rev. Отображает введённый текст в обратном порядке. В Debian присутствует по умолчанию в минимальной установке.
▪Sl. Паровозик в терминале. Писал о нём не так давно.
По полям, по полям, ASCII-паровозик едет к нам... (поймут только отцы)
▪Рождественская ёлочка от хостера scaleway в виде bash скрипта. Посмотреть.
▪Пасхалка в apt-get и apt:
▪Пасхалка в who:
#linux #terminal
▪Cmatrix. Визитная карточка фильма Матрица — набор символов, падающих как водопад, сверху вниз. Эта утилита воспроизводит его у вас в терминале. Живёт в стандартных репах:
# apt install cmatrixПочитайте man, там много ключей для видоизменения эффектов. Выглядит прикольно, хоть и не так, как в кино. Посмотреть.
▪MapSCII. Карта мира в терминале. Написана на JS, поэтому живёт в репах nodejs.
# npm install -g mapsciiВ убунте через snap можно поставить:
# snap install mapsciiВыглядит необычно и подробно для такого рода программы. Вплоть до отдельных улиц городов можно увидеть. Посмотреть.
▪Aafire. Разжигает терминальный ASCII огонь. Живёт в репах:
# apt install libaa-binПоджигаем:
# aafireПосле этого огня у меня все символы в терминале становятся серыми. Не понял, это так задумано или какой-то глюк. Релогин сбрасывает эффект.
▪Toilet. Преобразует введённые слова в большие символы ASCII. Совершенно не понятно, почему у утилиты такое странное название. Живёт в репах:
# apt install toilet# toilet туалетПосмотреть.
▪Cowsay. С помощью этой утилиты вы можете попросить ASCII корову сказать любую фразу:
# apt install cowsay# /usr/games/cowsay HiПосмотреть. Похожие программы: cowthink, ponysay.
▪Cal. Терминальный календарь. Рассказывал о нём отдельно. Полноценный календарь. В rpm дистрибутивах пакет называется cal, в deb — ncal:
# apt install ncalУтилита без всяких шуток может быть полезной. В Centos вроде бы в базовой установке была. Даже устанавливать не надо было. Посмотреть месяц назад, текущий и будущий:
# cal -A 1 -B 1▪Rev. Отображает введённый текст в обратном порядке. В Debian присутствует по умолчанию в минимальной установке.
# revserveradminnimdarevres▪Sl. Паровозик в терминале. Писал о нём не так давно.
# apt install slПо полям, по полям, ASCII-паровозик едет к нам... (поймут только отцы)
▪Рождественская ёлочка от хостера scaleway в виде bash скрипта. Посмотреть.
▪Пасхалка в apt-get и apt:
# apt moo▪Пасхалка в who:
# who is GOD?#linux #terminal
{kind=link}
Подборка консольных игр в Linux. Начнём с классики. Интересно, с этими играми знакомы те, кому сейчас до 25 лет? Я в эти игры играл ещё на приставках, типа денди, и на отдельных карманных устройствах на батарейках с монохромным дисплеем.
◽Тетрис. Его придумал Алексей Леонидович Пажитнов в 1984 году, работавший в Вычислительном центре Академии наук СССР.
Не удержался, и сыграл раунд после написания этих строк 😎
◽Pacman. Классический pacman. В обычной консоли выглядит немного узко, но играбельно.
Напомню, кто не знает. Задача скушать все звёздочки и не встретиться с другими движущимися символами.
◽Snake. Классическая змейка.
Стартовая скорость очень низкая. Захотелось на кнопку Turbo нажать. Когда я программировал что-то подобное в школе на turbo basic, это ускоряло исполнение кода примерно в два раза. Очень любил эту игру на телефоне Nokia 3310.
📌 Переходим к менее массовым играм.
◽2048. Математическая игра, где сдвигая плитки нужно добиться их объединения с увеличением номинала.
Немного непривычно и непонятно. Пришлось пару раз возвращаться к правилам, пока не понял, как тут играть.
◽Moon Buggy. Очень простая и залипательная игрушка, где особо не надо думать. Вы управляете машинкой, которая едет по луне. Нужно перепрыгивать ямы разной длины.
◽Ascii-patrol. Очень навороченная и красивая консольная игра. Автор упаковал её в snap, предлагает устанавливать оттуда:
Либо можете в html версию поиграть.
◽Space Invader. Вам надо управлять корабликом, стрелять по вражеским кораблям и уворачиваться от их выстрелов.
◽ZAngband. Терминальная rpg. Очень навороченная, где куча классов, специальностей. Надо качать персонажа, улучшать навыки. Лазить по подземелью, собирать предметы, улучшать оружие и т.д.
В универе сокурсник постоянно играл в эту игру на парах по Linux и программированию. Я не мог понять, как эта консольная штука может быть игрой, да ещё интересной.
◽BSD games. Куча старых консольных игр, портированных из BSD систем.
Там есть аналог змейки - worm, аналог тетриса - tetris-bsd, монополия - monop, пасьянс - canfield, нарды - backgammon и другие.
◽Sudoku. Классическая Судоку, которую часто печатают во всяких сборниках и журналах.
#игра #подборка
◽Тетрис. Его придумал Алексей Леонидович Пажитнов в 1984 году, работавший в Вычислительном центре Академии наук СССР.
# apt install bastetНе удержался, и сыграл раунд после написания этих строк 😎
◽Pacman. Классический pacman. В обычной консоли выглядит немного узко, но играбельно.
# apt install pacman4consoleНапомню, кто не знает. Задача скушать все звёздочки и не встретиться с другими движущимися символами.
◽Snake. Классическая змейка.
# apt install nsnakeСтартовая скорость очень низкая. Захотелось на кнопку Turbo нажать. Когда я программировал что-то подобное в школе на turbo basic, это ускоряло исполнение кода примерно в два раза. Очень любил эту игру на телефоне Nokia 3310.
📌 Переходим к менее массовым играм.
◽2048. Математическая игра, где сдвигая плитки нужно добиться их объединения с увеличением номинала.
# apt install 2048Немного непривычно и непонятно. Пришлось пару раз возвращаться к правилам, пока не понял, как тут играть.
◽Moon Buggy. Очень простая и залипательная игрушка, где особо не надо думать. Вы управляете машинкой, которая едет по луне. Нужно перепрыгивать ямы разной длины.
# apt install moon-buggy◽Ascii-patrol. Очень навороченная и красивая консольная игра. Автор упаковал её в snap, предлагает устанавливать оттуда:
# snap install ascii-patrolЛибо можете в html версию поиграть.
◽Space Invader. Вам надо управлять корабликом, стрелять по вражеским кораблям и уворачиваться от их выстрелов.
# apt install ninvaders◽ZAngband. Терминальная rpg. Очень навороченная, где куча классов, специальностей. Надо качать персонажа, улучшать навыки. Лазить по подземелью, собирать предметы, улучшать оружие и т.д.
# apt install zangband (нужен non-free репозиторй)В универе сокурсник постоянно играл в эту игру на парах по Linux и программированию. Я не мог понять, как эта консольная штука может быть игрой, да ещё интересной.
◽BSD games. Куча старых консольных игр, портированных из BSD систем.
# apt install bsdgamesТам есть аналог змейки - worm, аналог тетриса - tetris-bsd, монополия - monop, пасьянс - canfield, нарды - backgammon и другие.
◽Sudoku. Классическая Судоку, которую часто печатают во всяких сборниках и журналах.
# apt install sudoku#игра #подборка
{kind=link}
В операционной системе на базе Linux существуют два разных способа назначения прав доступа к файлам. Не все начинающие администраторы об этом знают. Недавно один читатель попросил помочь настроить права доступа к файловой шаре samba. Он описал задачу на основе того, как привык раздавать права на директории в Windows. В Linux у него не получалось настроить так же в рамках стандартных прав доступа через локальных пользователей, групп и утилит
В Linux, помимо основных прав доступа, которые вы видите при просмотре директории с помощью
После установки данного пакета у вас появятся две основные утилиты, которые будут нужны для управления доступом:
Я не буду сейчас подробно расписывать как всем этим пользоваться. В интернете масса руководств. Просто знайте, что в Linux правами на файлы и директории можно управлять практически точно так же, как в домене Windows. Есть нюансы и различия, но в базовых случаях несущественные. Если добавить Linux сервер с Samba и ACL в домен, то через систему Windows можно будет управлять доступом к файлами через её свойства папки с галочками и списками групп.
Пример того, как всё это может выглядеть, есть в моей статье:
⇨ https://serveradmin.ru/nastroyka-samba-s-integratsiey-v-ad/
Она очень старая и скорее всего уже неактуальна в технической части. Я сам давно файловые сервера в Linux в домене не настраивал и не эксплуатировал. Но общее понимание картины можно получить. Соответственно, вместо Microsoft AD может выступать любой другой LDAP каталог пользователей и групп.
Подскажите, кто скрещивает Linux с Windows. На текущий момент нет проблем с добавлением Linux в AD под управлением свежих Windows Server? Интеграция упростилась или усложнилась? Давно уже не слежу за этой темой. Я где-то видел новость, что Ubuntu для платных подписчиков выпустила какой-то свой инструмент для упрощения работы в AD.
#linux #fileserver
chown, chmod. В Linux, помимо основных прав доступа, которые вы видите при просмотре директории с помощью
ls -l, существуют дополнительные списки доступа ACL (access control list). Они позволяют очень гибко управлять доступом. По умолчанию инструменты для управления этими списками в минимальной установке Debian отсутствуют. Устанавливаются так:# apt install aclПосле установки данного пакета у вас появятся две основные утилиты, которые будут нужны для управления доступом:
getfacl - посмотреть права доступа, setfacl - установить права доступа. Я не буду сейчас подробно расписывать как всем этим пользоваться. В интернете масса руководств. Просто знайте, что в Linux правами на файлы и директории можно управлять практически точно так же, как в домене Windows. Есть нюансы и различия, но в базовых случаях несущественные. Если добавить Linux сервер с Samba и ACL в домен, то через систему Windows можно будет управлять доступом к файлами через её свойства папки с галочками и списками групп.
Пример того, как всё это может выглядеть, есть в моей статье:
⇨ https://serveradmin.ru/nastroyka-samba-s-integratsiey-v-ad/
Она очень старая и скорее всего уже неактуальна в технической части. Я сам давно файловые сервера в Linux в домене не настраивал и не эксплуатировал. Но общее понимание картины можно получить. Соответственно, вместо Microsoft AD может выступать любой другой LDAP каталог пользователей и групп.
Подскажите, кто скрещивает Linux с Windows. На текущий момент нет проблем с добавлением Linux в AD под управлением свежих Windows Server? Интеграция упростилась или усложнилась? Давно уже не слежу за этой темой. Я где-то видел новость, что Ubuntu для платных подписчиков выпустила какой-то свой инструмент для упрощения работы в AD.
#linux #fileserver
{kind=link}
В комментариях как-то раз увидел упоминание утилиты f*ck. Заинтересовался. Думаю, что это может быть, ни разу не слышал. Прям так и загуглил со звёздочкой. Оказалось, что речь идёт об open source проекте The Fuck.
Было очень любопытно, что же скрывается под таким неговорящим названием. Причём явно что-то популярное и полезное, потому что 77.7k звёзд на гитхабе. Оказалось, что это утилита для исправления опечаток или неполностью набранных команд.
Показываю сразу на примерах. Допустим, вы устанавливаете софт через пакетный менеджер и забыли написать sudo:
Появляется ошибка:
Вы расстраиваетесь и материтесь, потому что нервы у айтишников никудышные. Сидячая работа, стрессы, кофе и т.д. Пишите в консоль с досады:
TheFuck понимает ошибку и предлагает выполнить команду с учётом исправления.
TheFuck распознаёт популярные ошибки, опечатки, не только в командах, но и в их ключах, параметрах. Например:
То есть запустили гит пуш, забыли обязательные параметры, fuck добавил дефолтные параметры для этой команды.
Ещё больше примеров можно в репе посмотреть. Все исправления описаны правилами, которые лежат в соответствующей директории. Правила написаны на python, можете изменить готовые или написать свои. Например, есть правило для chmod. Если в консоли запускается скрипт через ./ и в выводе появляется сообщение
Больше всего правил написано для git. Судя по всему этот инструмент писался для разработчиков и немного девопсов, поэтому так много звёзд на гитхаб.
Если будете пробовать в Debian, утилита живёт в стандартных репах:
Автор пакет заботливо отключил все правила для sudo. На всякий случай. По умолчанию бинарники ставятся в
Если что, матершину не одобряю. Сам не матерюсь.
#linux #консоль
Было очень любопытно, что же скрывается под таким неговорящим названием. Причём явно что-то популярное и полезное, потому что 77.7k звёзд на гитхабе. Оказалось, что это утилита для исправления опечаток или неполностью набранных команд.
Показываю сразу на примерах. Допустим, вы устанавливаете софт через пакетный менеджер и забыли написать sudo:
# apt install mcПоявляется ошибка:
E: Could not open lock file /var/lib/dpkg/lock - open (13: Permission denied)Вы расстраиваетесь и материтесь, потому что нервы у айтишников никудышные. Сидячая работа, стрессы, кофе и т.д. Пишите в консоль с досады:
# fuckTheFuck понимает ошибку и предлагает выполнить команду с учётом исправления.
# sudo apt-get install mcTheFuck распознаёт популярные ошибки, опечатки, не только в командах, но и в их ключах, параметрах. Например:
# git pushfatal: The current branch master has no upstream branch.# fuck# git push --set-upstream origin masterТо есть запустили гит пуш, забыли обязательные параметры, fuck добавил дефолтные параметры для этой команды.
Ещё больше примеров можно в репе посмотреть. Все исправления описаны правилами, которые лежат в соответствующей директории. Правила написаны на python, можете изменить готовые или написать свои. Например, есть правило для chmod. Если в консоли запускается скрипт через ./ и в выводе появляется сообщение
permission denied, что типично, если у файла нет прав на исполнение, fuck исправляет это, добавяля права через chmod +x. Больше всего правил написано для git. Судя по всему этот инструмент писался для разработчиков и немного девопсов, поэтому так много звёзд на гитхаб.
Если будете пробовать в Debian, утилита живёт в стандартных репах:
# apt install thefuckАвтор пакет заботливо отключил все правила для sudo. На всякий случай. По умолчанию бинарники ставятся в
$HOME/.local/bin, поэтому надо добавить этот путь в PATH:# export PATH="$PATH:$HOME/.local/bin"Если что, матершину не одобряю. Сам не матерюсь.
#linux #консоль
{kind=link}
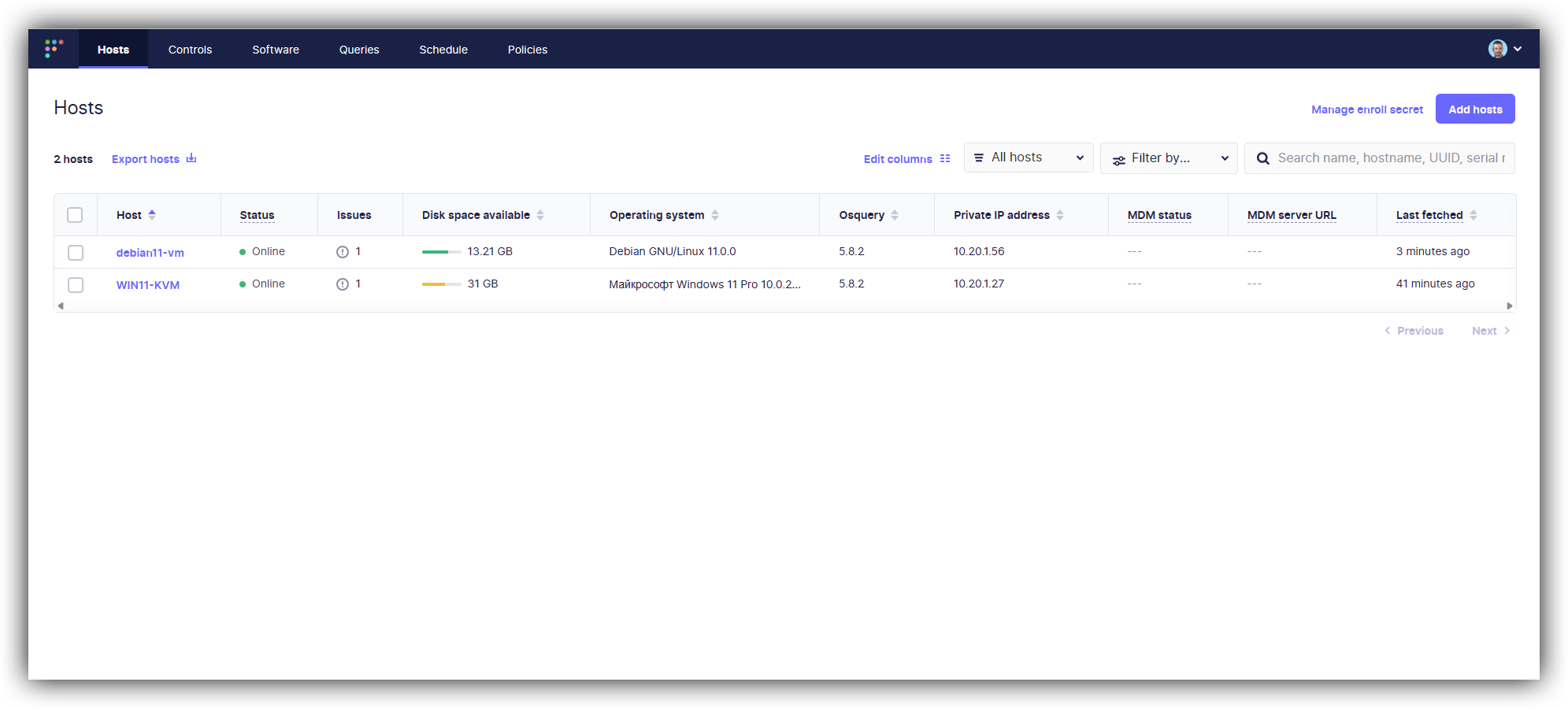
Сегодня расскажу вам про современный функциональный инструмент для управления парком рабочих станций и серверов с разными ОС. Речь пойдёт про Fleetdm. В рунете вообще не нашёл не то что информации по настройке, но даже упоминаний. Во всём разбирался сам на основе документации. Установил себе сервер и два управляемых хоста: Windows и Linux.
Fleetdm — это open source клиент-серверное приложение. Устанавливаете сервер, на управляемые хосты агенты. Поддерживаются системы: Windows, Linux, Macos. Раскатка агентов максимально простая — заранее готовится преднастроенный установщик. Далее он устанавливается на хост и тот появляется в панели управления.
С помощью Fleetdm можно управлять настройками хостов и проверять всё установленное ПО на наличие уязвимостей. Для выборки используется известный open source язык запросов osquery, который разработан специально для этих целей. С его помощью можно делать всевозможные выборки и к ним применять какие-то действия или политики. Вот простой пример, как это работает. Допустим, вы хотите найти все хосты и учётные записи, где установлена оболочка bash. Запрос выглядит так:
Для Windows запросы схожи. К примеру, найдём всех, у кого разрешён SMB1 на клиенте:
Описание запросов хорошо документировано. Писать их с помощью подсказок не сложно.
Бесплатная версия Fleetdm не предполагает встроенных средств для автоматизации выставления настроек или обновления уязвимого ПО. Вы можете создавать политики, которые будут в режиме реального времени проверять хосты. И если находят расхождения в политиках или уязвимое ПО, уведомляют об этом. С помощью API и вебхуков вы можете сами решать проблемы, например с помощью Ansible. Либо автоматически создавать задачи в Jira и Zendesk. В бесплатной версии настроены эти интеграции.
Теперь постараюсь кратко рассказать, как это всё быстро развернуть в тестовой среде, чтобы получилось быстро. В продуктив лучше поставить руками, есть подробная инструкция. Для работы сервера обязательно нужен TLS сертификат. Желательно валидный. С этим я провозился дольше всего, так как настраивал всё в локалке с использованием самоподписанного сертификата. Подготовим его:
Теперь берём минимально необходимый набор софта (Mysql+Redis) и запускаем Fleetdm через docker-compose (возьмите свежую 2-ю версию):
Дожидаемся запуска, идём на fleet.example.com:8080, создаём учётку. На всех управляемых хостах имя fleet.example.com должно резолвиться в IP адрес. Это важно.
Теперь качаем fleetctl последней версии под Linux. Это утилита, которая генерирует установщик для хостов. Распаковываем и создаём установщики под deb и windows. Используем тот же сертификат сервера, secret смотрим в веб интерфейсе, в разделе hosts.
Передаём установщики на целевые хосты. Я запустил http сервер и скачал пакеты:
После установки пакетов на целевые хосты, через пару минут они появятся в веб интерфейсе. Дальше с ними можно работать.
Программа мне понравилась, достойна полноценной статьи. Может напишу. Бесплатную, мультисистемную, с похожей функциональностью не припоминаю.
⇨ Сайт / Исходники
#управление #security #devops
Fleetdm — это open source клиент-серверное приложение. Устанавливаете сервер, на управляемые хосты агенты. Поддерживаются системы: Windows, Linux, Macos. Раскатка агентов максимально простая — заранее готовится преднастроенный установщик. Далее он устанавливается на хост и тот появляется в панели управления.
С помощью Fleetdm можно управлять настройками хостов и проверять всё установленное ПО на наличие уязвимостей. Для выборки используется известный open source язык запросов osquery, который разработан специально для этих целей. С его помощью можно делать всевозможные выборки и к ним применять какие-то действия или политики. Вот простой пример, как это работает. Допустим, вы хотите найти все хосты и учётные записи, где установлена оболочка bash. Запрос выглядит так:
SELECT * FROM users WHERE shell='/bin/bash';Для Windows запросы схожи. К примеру, найдём всех, у кого разрешён SMB1 на клиенте:
SELECT 1 FROM windows_optional_features \WHERE name = 'SMB1Protocol-Client' AND state != 1;Описание запросов хорошо документировано. Писать их с помощью подсказок не сложно.
Бесплатная версия Fleetdm не предполагает встроенных средств для автоматизации выставления настроек или обновления уязвимого ПО. Вы можете создавать политики, которые будут в режиме реального времени проверять хосты. И если находят расхождения в политиках или уязвимое ПО, уведомляют об этом. С помощью API и вебхуков вы можете сами решать проблемы, например с помощью Ansible. Либо автоматически создавать задачи в Jira и Zendesk. В бесплатной версии настроены эти интеграции.
Теперь постараюсь кратко рассказать, как это всё быстро развернуть в тестовой среде, чтобы получилось быстро. В продуктив лучше поставить руками, есть подробная инструкция. Для работы сервера обязательно нужен TLS сертификат. Желательно валидный. С этим я провозился дольше всего, так как настраивал всё в локалке с использованием самоподписанного сертификата. Подготовим его:
# mkdir fleet# openssl req -x509 -newkey rsa:4096 -sha256 -days 3650 -nodes \-keyout fleet/server.key -out fleet/server.cert -subj "/CN=fleet.example.com" \-addext "subjectAltName=DNS:fleet.example.com"# chown -R 100:101 fleet/Теперь берём минимально необходимый набор софта (Mysql+Redis) и запускаем Fleetdm через docker-compose (возьмите свежую 2-ю версию):
# docker-compose upДожидаемся запуска, идём на fleet.example.com:8080, создаём учётку. На всех управляемых хостах имя fleet.example.com должно резолвиться в IP адрес. Это важно.
Теперь качаем fleetctl последней версии под Linux. Это утилита, которая генерирует установщик для хостов. Распаковываем и создаём установщики под deb и windows. Используем тот же сертификат сервера, secret смотрим в веб интерфейсе, в разделе hosts.
# wget https://github.com/fleetdm/fleet/releases/download/fleet-v4.32.0/fleetctl_v4.32.0_linux.tar.gz# tar xzvf fleetctl_v4.32.0_linux.tar.gz# cd fleetctl_v4.32.0_linux# ./fleetctl package --type=msi --fleet-url=https://fleet.example.com:8080 \--enroll-secret=jlBXb1LUMo4/0Pn1cHXnVKqziMo87CgN --fleet-certificate=server.cert# ./fleetctl package --type=deb --fleet-url=https://fleet.example.com:8080 \--enroll-secret=jlBXb1LUMo4/0Pn1cHXnVKqziMo87CgN --fleet-certificate=server.certПередаём установщики на целевые хосты. Я запустил http сервер и скачал пакеты:
# python3 -m http.server 8181После установки пакетов на целевые хосты, через пару минут они появятся в веб интерфейсе. Дальше с ними можно работать.
Программа мне понравилась, достойна полноценной статьи. Может напишу. Бесплатную, мультисистемную, с похожей функциональностью не припоминаю.
⇨ Сайт / Исходники
#управление #security #devops
{kind=link}
Буквально на днях узнал, что в bash квадратная скобка [ и утилита test это одно и то же. Точнее, я вообще не знал, что существует эта встроенная утилита. Всегда и везде в скриптах видел и сам использовал именно скобку.
Синтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
Сделаем проверку, что он существует, как я обычно это делаю:
А теперь то же самое, только через test:
Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
# type testtest is a shell builtin# type [[ is a shell builtinСинтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
# touch file.txtСделаем проверку, что он существует, как я обычно это делаю:
#!/bin/bashif [ -e file.txt]then echo "File exist"else echo "There is no testfile"А теперь то же самое, только через test:
#!/bin/bashif test -e file.txtthen echo "File exist"else echo "There is no testfile"Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
Разбираю ещё один документ от CIS с рекомендациями по настройке Docker. Напомню, что ранее я уже делал выжимки по настройке Nginx, MySQL, Apache, Debian 11. Используя эти руководства нелишним будет освежить свои инструкции и принять некоторую информацию к сведению.
📌 Директорию для информации
📌 У Docker высокие полномочия для доступа к хостовой системе. Следите за тем, чтобы в системной группе docker не было лишних пользователей.
📌 Для повышения безопасности рекомендуется настроить аудит службы docker, например с помощью auditd. Ставим службу:
Добавляем правило в
Перезапускаем службу:
Для повышенной безопасности можно настроить аудит и за файлами и директориями Docker, за конфигурационными файлами, за юнитом systemd, за сокетом. Это общая рекомендация для служб, которые работают с правами root.
📌 Разделяйте контейнеры по отдельным сетям для межконтейнерного взаимодействия. Если этого не делать, они будут взаимодействовать через общий системный бридж, который docker создаёт по умолчанию.
📌 Включите уровень логирования службы "info", добавив в файл конфигурации
Для повышения безопасности логи имеет смысл хранить где-то во вне. Их можно направить по syslog. Пример:
📌 Если используете подключение к службе Docker по TCP, не забудьте настроить аутентификацию по TLS и ограничьте сетевой доступ.
📌 Используйте параметр no-new-privileges при создании контейнеров, либо добавьте этот параметр в настройку службы по умолчанию.
Это предотвратит повышение привилегий в контейнере от пользователя до root. Подробнее тут.
📌 Включите параметр live-restore:
Это позволит не останавливать контейнеры в случае остановки самой службы docker, что позволит обновлять её без остановки сервисов. По умолчанию он отключен.
📌 Отключите использование userland-proxy.
В подавляющем большинстве случаев для проброса портов в контейнеры используется NAT. Отключение прокси уменьшает вектор атак.
📌 Чаще всего файл с настройками
📌 Не используйте без крайней необходимости в контейнерах пользователя root. Хорошая практика запускать всё от обычного пользователя.
📌 Ограничивайте использование памяти контейнерами так, чтобы они не могли использовать всю доступную память хоста. Для этого запускайте их с параметром
📌 Ограничивайте количество попыток перезапуска контейнера в случае ошибок. То есть не запускайте их с параметром
Было много советов по написанию DockerFile. Не стал их разбирать, так как мне кажется, это отдельная тема, которая к самой службе не имеет отношения. Также было много советов по запуску контейнеров. Например, не запускать там службу sshd, не монтировать системные директории и т.д. Это тоже отдельная тема, пропускал такие рекомендации.
К данной заметке будет актуальна ссылка на автоматическую проверку контейнеров с помощью Trivy и исправление с помощью Copacetic. Я написал небольшую статью:
⇨ Проверка безопасности Docker образов с помощью Trivy
Данный список составил на основе переработки вот этого документа: CIS Docker Benchmark v1.5.0 - 12-28-2022. Там подробное описание с обоснованием всех рекомендаций.
#cis #docker
📌 Директорию для информации
/var/lib/docker рекомендуется вынести на отдельный раздел. Docker постоянно потребляет свободное место, так что переполнение раздела нередкое явление. 📌 У Docker высокие полномочия для доступа к хостовой системе. Следите за тем, чтобы в системной группе docker не было лишних пользователей.
📌 Для повышения безопасности рекомендуется настроить аудит службы docker, например с помощью auditd. Ставим службу:
# apt install auditdДобавляем правило в
/etc/audit/rules.d/audit.rules:-w /usr/bin/dockerd -k dockerПерезапускаем службу:
# systemctl restart auditdДля повышенной безопасности можно настроить аудит и за файлами и директориями Docker, за конфигурационными файлами, за юнитом systemd, за сокетом. Это общая рекомендация для служб, которые работают с правами root.
📌 Разделяйте контейнеры по отдельным сетям для межконтейнерного взаимодействия. Если этого не делать, они будут взаимодействовать через общий системный бридж, который docker создаёт по умолчанию.
📌 Включите уровень логирования службы "info", добавив в файл конфигурации
/etc/docker/daemon.json параметр:"log-level": "info"Для повышения безопасности логи имеет смысл хранить где-то во вне. Их можно направить по syslog. Пример:
{ "log-driver": "syslog", "log-opts": { "syslog-address": "tcp://192.xxx.xxx.xxx" }}📌 Если используете подключение к службе Docker по TCP, не забудьте настроить аутентификацию по TLS и ограничьте сетевой доступ.
📌 Используйте параметр no-new-privileges при создании контейнеров, либо добавьте этот параметр в настройку службы по умолчанию.
"no-new-privileges": trueЭто предотвратит повышение привилегий в контейнере от пользователя до root. Подробнее тут.
📌 Включите параметр live-restore:
"live-restore": trueЭто позволит не останавливать контейнеры в случае остановки самой службы docker, что позволит обновлять её без остановки сервисов. По умолчанию он отключен.
📌 Отключите использование userland-proxy.
"userland-proxy": falseВ подавляющем большинстве случаев для проброса портов в контейнеры используется NAT. Отключение прокси уменьшает вектор атак.
📌 Чаще всего файл с настройками
/etc/docker/daemon.json по умолчанию отсутствует и вы его создаёте сами, когда нужно задать те или иные параметры. Проследите, чтобы доступ на запись к нему имел только root (root:root 644). 📌 Не используйте без крайней необходимости в контейнерах пользователя root. Хорошая практика запускать всё от обычного пользователя.
📌 Ограничивайте использование памяти контейнерами так, чтобы они не могли использовать всю доступную память хоста. Для этого запускайте их с параметром
--memory и задайте объём, к примеру, 1024m. 📌 Ограничивайте количество попыток перезапуска контейнера в случае ошибок. То есть не запускайте их с параметром
--restart=always. Используйте вместо этого --restart=on-failure:5. Будет сделано 5 попыток запуска в случае ошибки. Было много советов по написанию DockerFile. Не стал их разбирать, так как мне кажется, это отдельная тема, которая к самой службе не имеет отношения. Также было много советов по запуску контейнеров. Например, не запускать там службу sshd, не монтировать системные директории и т.д. Это тоже отдельная тема, пропускал такие рекомендации.
К данной заметке будет актуальна ссылка на автоматическую проверку контейнеров с помощью Trivy и исправление с помощью Copacetic. Я написал небольшую статью:
⇨ Проверка безопасности Docker образов с помощью Trivy
Данный список составил на основе переработки вот этого документа: CIS Docker Benchmark v1.5.0 - 12-28-2022. Там подробное описание с обоснованием всех рекомендаций.
#cis #docker
{kind=link}
❓Вы когда-нибудь задумывались, чем в Unix отличаются директории /bin, /sbin, /usr/bin, /usr/sbin, /usr/local/{bin,sbin}? Я давно задавался этим вопросом. Точно помню, что несколько лет назад разбирался с этой темой, но уже забыл, к чему пришёл. Решил ещё раз поднять её и поделиться с вами, чтобы и самому запомнить.
Отдельно ещё стоит директория /usr/loca/etc. Я начинал изучение Unix с Freebsd. Все конфиги установленных программ по умолчанию были в /usr/loca/etc. Это было удобно. Так как всё системное в /etc, а всё, что поставил ты, в /usr/loca/etc. Потом непривычно было на Linux переходить, где директория /usr/loca/etc вообще не используется.
Вообще, на эту тему есть много различных мнений. В том же Debian можно запустить:
И прочитать про иерархию файловой системы. Там сказано:
▪ /bin - каталог, содержащий исполняемые программы, необходимые для работы в однопользовательском режиме и для запуска или ремонта системы.
▪ /sbin - как и /bin, содержит команды, необходимые для запуска системы, но, как правило, не запускаемые обычными пользователями.
▪ /usr/bin - основной каталог для исполняемых программ. Большая часть программ, не требующихся для загрузки или для ремонта системы, не устанавливаемых локально и запускаемых обычными пользователями, должна быть помещена в этот каталог.
▪ /usr/sbin - каталог, содержащий исполняемые программы для системного администрирования, не относящиеся к процессу загрузки, запуску /usr или ремонту системы.
▪ /usr/local/bin - локальные исполняемые файлы.
▪ /usr/local/sbin - локальные программы для системного администрирования.
Вроде объяснили, но всё равно не понятно, а почему именно такая иерархия. Есть такое мнение на этот счёт. Разработчики Unix в далёком 71-м году в какой-то момент проапгрейдили комп и получили 2 диска вместо одного. Когда ОС разрослась и перестала помещаться на первый диск, часть данных решили перенести на второй диск, где хранились данные пользователей, поэтому раздел назвали /usr (от слова user). Они продублировали на этом разделе все необходимые для ОС директории, в том числе bin и sbin. И всё новое складывали на новый диск, так как на старом не осталось места. Но при этом, чтобы во время загрузки иметь возможность смонтировать диск с /usr, программы типа mount обязательно жили в /bin на первом диске.
Такая есть история появления раздела /usr. С директорией /usr/local уже более ли менее понятно по смыслу. Туда кладётся всё то, что относится к конкретной локальной системе, а не дистрибутиву. В Freebsd именно так и было и это удобно. В Linux почему-то это не поддержали. Там обычно каталог /usr/local пустой.
В Debian 11 /bin и /sbin это символьные ссылки на /usr/bin и /usr/sbin. В rpm дистрибутивах то же самое уже давно. Так что в целом вся эта историческая иерархия фактически не поддерживается. Па факту всё живет в /usr. Было бы неплохо, если бы это всё привели к какому-то единому виду и распрощались с анахронизмами. А то неудобно с кучей каталогов, в которых уже не осталось смысла. Единственное, я бы идею с local поддержал и распространил.
#linux
Отдельно ещё стоит директория /usr/loca/etc. Я начинал изучение Unix с Freebsd. Все конфиги установленных программ по умолчанию были в /usr/loca/etc. Это было удобно. Так как всё системное в /etc, а всё, что поставил ты, в /usr/loca/etc. Потом непривычно было на Linux переходить, где директория /usr/loca/etc вообще не используется.
Вообще, на эту тему есть много различных мнений. В том же Debian можно запустить:
# man hierИ прочитать про иерархию файловой системы. Там сказано:
▪ /bin - каталог, содержащий исполняемые программы, необходимые для работы в однопользовательском режиме и для запуска или ремонта системы.
▪ /sbin - как и /bin, содержит команды, необходимые для запуска системы, но, как правило, не запускаемые обычными пользователями.
▪ /usr/bin - основной каталог для исполняемых программ. Большая часть программ, не требующихся для загрузки или для ремонта системы, не устанавливаемых локально и запускаемых обычными пользователями, должна быть помещена в этот каталог.
▪ /usr/sbin - каталог, содержащий исполняемые программы для системного администрирования, не относящиеся к процессу загрузки, запуску /usr или ремонту системы.
▪ /usr/local/bin - локальные исполняемые файлы.
▪ /usr/local/sbin - локальные программы для системного администрирования.
Вроде объяснили, но всё равно не понятно, а почему именно такая иерархия. Есть такое мнение на этот счёт. Разработчики Unix в далёком 71-м году в какой-то момент проапгрейдили комп и получили 2 диска вместо одного. Когда ОС разрослась и перестала помещаться на первый диск, часть данных решили перенести на второй диск, где хранились данные пользователей, поэтому раздел назвали /usr (от слова user). Они продублировали на этом разделе все необходимые для ОС директории, в том числе bin и sbin. И всё новое складывали на новый диск, так как на старом не осталось места. Но при этом, чтобы во время загрузки иметь возможность смонтировать диск с /usr, программы типа mount обязательно жили в /bin на первом диске.
Такая есть история появления раздела /usr. С директорией /usr/local уже более ли менее понятно по смыслу. Туда кладётся всё то, что относится к конкретной локальной системе, а не дистрибутиву. В Freebsd именно так и было и это удобно. В Linux почему-то это не поддержали. Там обычно каталог /usr/local пустой.
В Debian 11 /bin и /sbin это символьные ссылки на /usr/bin и /usr/sbin. В rpm дистрибутивах то же самое уже давно. Так что в целом вся эта историческая иерархия фактически не поддерживается. Па факту всё живет в /usr. Было бы неплохо, если бы это всё привели к какому-то единому виду и распрощались с анахронизмами. А то неудобно с кучей каталогов, в которых уже не осталось смысла. Единственное, я бы идею с local поддержал и распространил.
#linux
{kind=link}
Утилиту lsof в дистрибутивах Linux чаще всего используют для просмотра открытых файлов. Я и сам так делаю, и много материалов на эту тему видел. Да и название у неё говорящее. Оно как раз образовано от фразы list open files.
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
или так:
▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
▪ Смотрим открытые файлы конкретного пользователя:
Часто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
А теперь то же самое, только наоборот исключим открытые файлы пользователя:
Рассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
▪ Список TCP соединений к конкретному IP адресу:
▪ Список TCP соединений конкретного пользователя:
▪ Помимо TCP, можно и UDP соединения смотреть:
Публикацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
# lsof | grep '(deleted)'или так:
# lsof +L1▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
# lsof +D /var/log▪ Смотрим открытые файлы конкретного пользователя:
# lsof -u userЧасто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
# lsof -u user | wc -lА теперь то же самое, только наоборот исключим открытые файлы пользователя:
# lsof -u^user | wc -lРассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
# kill -9 `lsof -t -u user`▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
# lsof -p 94169▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
# lsof -ni▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
# lsof -ni TCP:80 ▪ Список TCP соединений к конкретному IP адресу:
# lsof -ni TCP@172.29.139.228▪ Список TCP соединений конкретного пользователя:
# lsof -ai -u nginx▪ Помимо TCP, можно и UDP соединения смотреть:
# lsof -iUDPПубликацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Вчера немного успел застать вебинара Ребрейн про OpenVPN. Попал на самый конец, но всё равно успел получить очень полезную для себя информацию, которой поделюсь с вами.
1️⃣ Первое прям открытие для меня — параметр ccd-exclusive. Если установлен этот параметр, то пользователь даже при наличие актуального сертификата сможет пройти аутентификацию только в том случае, если для него существует файл конфигурации пользователя в директории, заданной параметром client-config-dir.
Объясняю, зачем это может понадобиться. Чтобы запретить подключения какому-то пользователю, необходимо отозвать его сертификат, подготовить файл отозванных сертификатов и прописать их в конфигурации сервера с помощью параметра crl-verify. И после каждого отзыва файл надо перезаписывать.
С помощью ccd-exclusive можно отключать пользователей, просто удаляя их файл конфигурации. Я лично их почти всегда использую. Даже если там нет отдельных параметров, привык создавать эти файлы пустыми, чтобы для каждого пользователя был его файл конфигурации. На основе этих файлов делаю мониторинг подключений openvpn.
Да, сертификаты отключенных пользователей всё равно надо отзывать. Так правильно. Но можно это делать разово по регламенту, к примеру, раз в месяц. А если надо просто отключить пользователя, удаляем ему файл конфигурации и всё. Это намного проще и удобнее. Потом можно его снова вернуть и пользователь сможет подключиться с тем же сертификатом.
Лет 10 активно использую openvpn, а этот параметр никогда не попадался на глаза. Не знал, что так можно было сделать.
2️⃣ Работы по переводу OpenVPN из контекста пользователя в ядро Linux ведутся. Более того, модуль ядра уже написан и он реально работает. Пока ещё его не добавили в популярные дистрибутивы. Скорее всего это рано или поздно состоится. Уже сейчас можно скачать исходники модуля, скомпилировать их и всё заработает с некоторыми ограничениями по параметрам. К примеру, при обработке ядром не работает сжатие.
Поясню, в чём тут проблема. OpenVPN работает в пространстве пользователя, в отличите от WireGuard, которая обрабатывается напрямую в ядре Linux. Этим объясняется её быстродействие. Разработчики OpenVPN озадачились и решили тоже перенести обработку в ядро и написали свой модуль для этого. Так что в скором времени большой разницы в скоростях между OpenVPN и Wireguard не должно быть.
#openvpn
1️⃣ Первое прям открытие для меня — параметр ccd-exclusive. Если установлен этот параметр, то пользователь даже при наличие актуального сертификата сможет пройти аутентификацию только в том случае, если для него существует файл конфигурации пользователя в директории, заданной параметром client-config-dir.
Объясняю, зачем это может понадобиться. Чтобы запретить подключения какому-то пользователю, необходимо отозвать его сертификат, подготовить файл отозванных сертификатов и прописать их в конфигурации сервера с помощью параметра crl-verify. И после каждого отзыва файл надо перезаписывать.
С помощью ccd-exclusive можно отключать пользователей, просто удаляя их файл конфигурации. Я лично их почти всегда использую. Даже если там нет отдельных параметров, привык создавать эти файлы пустыми, чтобы для каждого пользователя был его файл конфигурации. На основе этих файлов делаю мониторинг подключений openvpn.
Да, сертификаты отключенных пользователей всё равно надо отзывать. Так правильно. Но можно это делать разово по регламенту, к примеру, раз в месяц. А если надо просто отключить пользователя, удаляем ему файл конфигурации и всё. Это намного проще и удобнее. Потом можно его снова вернуть и пользователь сможет подключиться с тем же сертификатом.
Лет 10 активно использую openvpn, а этот параметр никогда не попадался на глаза. Не знал, что так можно было сделать.
2️⃣ Работы по переводу OpenVPN из контекста пользователя в ядро Linux ведутся. Более того, модуль ядра уже написан и он реально работает. Пока ещё его не добавили в популярные дистрибутивы. Скорее всего это рано или поздно состоится. Уже сейчас можно скачать исходники модуля, скомпилировать их и всё заработает с некоторыми ограничениями по параметрам. К примеру, при обработке ядром не работает сжатие.
Поясню, в чём тут проблема. OpenVPN работает в пространстве пользователя, в отличите от WireGuard, которая обрабатывается напрямую в ядре Linux. Этим объясняется её быстродействие. Разработчики OpenVPN озадачились и решили тоже перенести обработку в ядро и написали свой модуль для этого. Так что в скором времени большой разницы в скоростях между OpenVPN и Wireguard не должно быть.
#openvpn
{kind=link}
С памятью в Linux всё сложно. Многие не понимают, как в принципе её смотреть и на какое конкретно значение обращать внимание. Особенно тяжело разбираться в этом после такого родного и понятного диспетчера задач в Windows, который чётко показывает, сколько у тебя памяти использовано и сколько свободно. В Linux использование памяти процессами — сложный вопрос. Вы не сможете просто запустить какую-то программу и сразу понять, что у нас с памятью процесса.
В заметке речь пойдёт о том, как посмотреть, что конкретно занимает память в каком то процессе. Возьмём для примера Nginx или Php-fpm. У них много модулей, поэтому бывает интересно заглянуть, а сколько каждый из них может потреблять памяти.
Для этого сначала посмотрим PID материнского процесса:
А теперь смотрим потребление памяти с помощью pmap. Эта утилита обычно есть в стандартном системном наборе.
Если я правильно понимаю, то данная команда в самом низу показывает всю виртуальную память процесса (VSZ или VIRT), которая включает в себя в том числе и библиотеки, которые могут быть разделены между разными процессами, а также то, что в swap. То есть эта такая условная метрика, с которой не понятно, что делать. Мастер процесс Nginx и все его рабочие процессы будут занимать одну и ту же виртуальную память.
Если использовать ключ
Это память процесса без swap, включает в себя память, занимаемую разделяемыми библиотеками, но только ту, что реально находится в оперативной памяти и используется в данный момент. Это уже больше похоже на реальное потребление процесса, но всё равно не точно, потому что если у процесса есть форки, то они все будут занимать одинаковое количество RSS памяти. Сумма занимаемой ими памяти не будет соответствовать тому, что реально занято в оперативе.
Ключ
Вот это уже можно считать памятью, которую потребляет конкретный процесс, без общих библиотек. Эта цифра важна, когда вы подбираете максимальное число процессов php-fpm или apache, которые будут автоматически запускаться. Вам надо понимать, сколько реально процессов вытянет сервер по памяти, чтобы не занять её всю и не повстречаться с oomkiller. Но всё равно не так просто правильно рассчитать количество процессов. В зависимости от того, что он делает, будет требоваться разное количество памяти. Так что придётся искать какое-то усреднённое значение с запасом.
Информацию pmap берёт из
Если я в чём то заблуждаюсь или вам есть чем дополнить данную заметку, поделитесь информацией. Тема с памятью в Linux замороченная, так что иногда мне кажется, что не понимаю, как там всё устроено и просто забиваю на это, добавив память виртуалке, или явно ограничив какой-то сервис.
#linux #terminal
В заметке речь пойдёт о том, как посмотреть, что конкретно занимает память в каком то процессе. Возьмём для примера Nginx или Php-fpm. У них много модулей, поэтому бывает интересно заглянуть, а сколько каждый из них может потреблять памяти.
Для этого сначала посмотрим PID материнского процесса:
# ps ax | grep nginxА теперь смотрим потребление памяти с помощью pmap. Эта утилита обычно есть в стандартном системном наборе.
# pmap 1947 -pЕсли я правильно понимаю, то данная команда в самом низу показывает всю виртуальную память процесса (VSZ или VIRT), которая включает в себя в том числе и библиотеки, которые могут быть разделены между разными процессами, а также то, что в swap. То есть эта такая условная метрика, с которой не понятно, что делать. Мастер процесс Nginx и все его рабочие процессы будут занимать одну и ту же виртуальную память.
Если использовать ключ
-x, то увидим ещё и резидентную память (RES или RSS). # pmap 1947 -xЭто память процесса без swap, включает в себя память, занимаемую разделяемыми библиотеками, но только ту, что реально находится в оперативной памяти и используется в данный момент. Это уже больше похоже на реальное потребление процесса, но всё равно не точно, потому что если у процесса есть форки, то они все будут занимать одинаковое количество RSS памяти. Сумма занимаемой ими памяти не будет соответствовать тому, что реально занято в оперативе.
Ключ
-d добавляет ещё одну метрику writeable/private:# pmap 1947 -dВот это уже можно считать памятью, которую потребляет конкретный процесс, без общих библиотек. Эта цифра важна, когда вы подбираете максимальное число процессов php-fpm или apache, которые будут автоматически запускаться. Вам надо понимать, сколько реально процессов вытянет сервер по памяти, чтобы не занять её всю и не повстречаться с oomkiller. Но всё равно не так просто правильно рассчитать количество процессов. В зависимости от того, что он делает, будет требоваться разное количество памяти. Так что придётся искать какое-то усреднённое значение с запасом.
Информацию pmap берёт из
/proc/PID/smaps и превращает её в удобочитаемый формат.Если я в чём то заблуждаюсь или вам есть чем дополнить данную заметку, поделитесь информацией. Тема с памятью в Linux замороченная, так что иногда мне кажется, что не понимаю, как там всё устроено и просто забиваю на это, добавив память виртуалке, или явно ограничив какой-то сервис.
#linux #terminal
Увидел на неделе вот этот мем с девопсом. Не знаю почему, но в голове сразу же возникла идея, что тут не хватает продолжения со словом девопёс. Решил реализовать.
Сохранил картинку и когда появилось время, расчехлил фотошоп. Сначала думал какой-нибудь маленький мозг поместить, но потом вспомнилась эта собачка. Долго ковырялся, получилось вот так. Мне нравится, надеюсь вам тоже.
Я всегда думаю, кто те люди, которые сами придумывают мемы. Никого не знаю, кто бы это делал. Вижу только, как все репостят одно и то же друг у друга. Но кто генерирует всё это в товарных количествах, не понимаю. Может уже давно ИИ это делает, а не люди? Откуда все эти мемы берутся в пабликах и группах?
#мем
Сохранил картинку и когда появилось время, расчехлил фотошоп. Сначала думал какой-нибудь маленький мозг поместить, но потом вспомнилась эта собачка. Долго ковырялся, получилось вот так. Мне нравится, надеюсь вам тоже.
Я всегда думаю, кто те люди, которые сами придумывают мемы. Никого не знаю, кто бы это делал. Вижу только, как все репостят одно и то же друг у друга. Но кто генерирует всё это в товарных количествах, не понимаю. Может уже давно ИИ это делает, а не люди? Откуда все эти мемы берутся в пабликах и группах?
#мем
🎓 Рекомендую вам очередной бесплатный курс по Stepik. Я его увидел в резюме одного системного администратора. За курс дают именной сертификат и он его решил добавить к себе. Я уже как-то говорил, что это не такая плохая идея, если у тебя есть какие-то другие, более значимые сертификаты с экзаменами. Разбавить его другими для подтверждения знания предметной области, думаю, лишним не будет.
⇨ Введение в базы данных
Курс ориентирован на начинающих программистов, но системным администраторам очень полезно, а зачастую жизненно необходимо, разбираться в SQL и в работе СУБД. С ними приходится сталкиваться повсеместно. Ну и написание простых SQL запросов тоже лишним не будет. Не так уж и редко приходится это делать. В простых случаях можно спастись поиском готовых выражений, но даже в этом случае лучше понимать, что ты делаешь.
Особенное внимание рекомендую уделить индексам. Я как-то писал о них заметку. Иногда проблему с производительностью СУБД можно решить добавлением индексов, про которые просто все забыли, либо разработчиков давно уже нет и за базой никто не следит. В общем случае индексы делают разработчики сами. Это если понимают, что это такое.
В курсе также немного захватывают NoSQL базы: Redis и MongoDB, что сейчас администраторам и девопсам очень актуально, так как эти базы популярны не менее SQL.
#обучение #бесплатно
⇨ Введение в базы данных
Курс ориентирован на начинающих программистов, но системным администраторам очень полезно, а зачастую жизненно необходимо, разбираться в SQL и в работе СУБД. С ними приходится сталкиваться повсеместно. Ну и написание простых SQL запросов тоже лишним не будет. Не так уж и редко приходится это делать. В простых случаях можно спастись поиском готовых выражений, но даже в этом случае лучше понимать, что ты делаешь.
Особенное внимание рекомендую уделить индексам. Я как-то писал о них заметку. Иногда проблему с производительностью СУБД можно решить добавлением индексов, про которые просто все забыли, либо разработчиков давно уже нет и за базой никто не следит. В общем случае индексы делают разработчики сами. Это если понимают, что это такое.
В курсе также немного захватывают NoSQL базы: Redis и MongoDB, что сейчас администраторам и девопсам очень актуально, так как эти базы популярны не менее SQL.
#обучение #бесплатно
Stepik: online education
Введение в базы данных
Знакомство с методами структурированного хранения данных, основами SQL, принципами использования баз данных в приложениях, обзор нереляционных способов хранения данных