
Попал сегодня в неожиданную ситуацию, о которой хочу вас предупредить. Речь пойдет о systemd-mount в linux. Вообще, systemd должен был упростить жизнь системных администраторов. По факту, все не так однозначно. Как известно, у systemd есть свой планировщик (timer), свой ntp клиент (timesyncd). Как я сегодня узнал, еще и свое средство для монтирования разделов.
Узнал я вот о нем как. Есть облачный хостинг, который позволяет подключать к серверам высокопроизводительные сетевые диски. Я ими активно пользуюсь. Мне нужно было один диск заменить на другой и прицепить его к той же точке монтирования, что и старый.
Никаких проблем. Создаю второй диск, подключаю к серверу. Останавливаю приложение и копирую (!важно, лучше всегда копировать, а потом удалять, не переносить) данные на новый диск. Потом отключаю старый и монтирую новый в ту же точку монтирования. Запускаю приложение и убеждаюсь, что все нормально работает. А дальше самое неожиданное.
Иду в панель управления хостера и отключаю старый диск от сервера. Напоминаю, что в системе я его предварительно уже отмонтировал. Диск как-то подозрительно долго не отключался. Иду в системный лог сервера посмотреть, отключился ли диск. И вижу там очень неожиданную информацию.
Идут постоянные попытки от systemd отмонтировать раздел, к которому подмонтирован уже НОВЫЙ диск. То есть у него записано где-то (я нашел в /run/systemd/generator), что к этой точке монтирования подключен старый диск. Софт хостера по управлению ресурсами просит systemd отключить старый диск от его точки монтирования, хотя по факту она уже занята другим диском.
В общем, я в итоге не пострадал, так как приложение активно писало на диск и не дало его отмонтировать. В итоге systemd отстал и отключил диск принудительно. Будьте внимательны с systemd. Он уже не первый раз преподносит мне сюрприз.
#systemd
Узнал я вот о нем как. Есть облачный хостинг, который позволяет подключать к серверам высокопроизводительные сетевые диски. Я ими активно пользуюсь. Мне нужно было один диск заменить на другой и прицепить его к той же точке монтирования, что и старый.
Никаких проблем. Создаю второй диск, подключаю к серверу. Останавливаю приложение и копирую (!важно, лучше всегда копировать, а потом удалять, не переносить) данные на новый диск. Потом отключаю старый и монтирую новый в ту же точку монтирования. Запускаю приложение и убеждаюсь, что все нормально работает. А дальше самое неожиданное.
Иду в панель управления хостера и отключаю старый диск от сервера. Напоминаю, что в системе я его предварительно уже отмонтировал. Диск как-то подозрительно долго не отключался. Иду в системный лог сервера посмотреть, отключился ли диск. И вижу там очень неожиданную информацию.
Идут постоянные попытки от systemd отмонтировать раздел, к которому подмонтирован уже НОВЫЙ диск. То есть у него записано где-то (я нашел в /run/systemd/generator), что к этой точке монтирования подключен старый диск. Софт хостера по управлению ресурсами просит systemd отключить старый диск от его точки монтирования, хотя по факту она уже занята другим диском.
В общем, я в итоге не пострадал, так как приложение активно писало на диск и не дало его отмонтировать. В итоге systemd отстал и отключил диск принудительно. Будьте внимательны с systemd. Он уже не первый раз преподносит мне сюрприз.
#systemd
{kind=link}
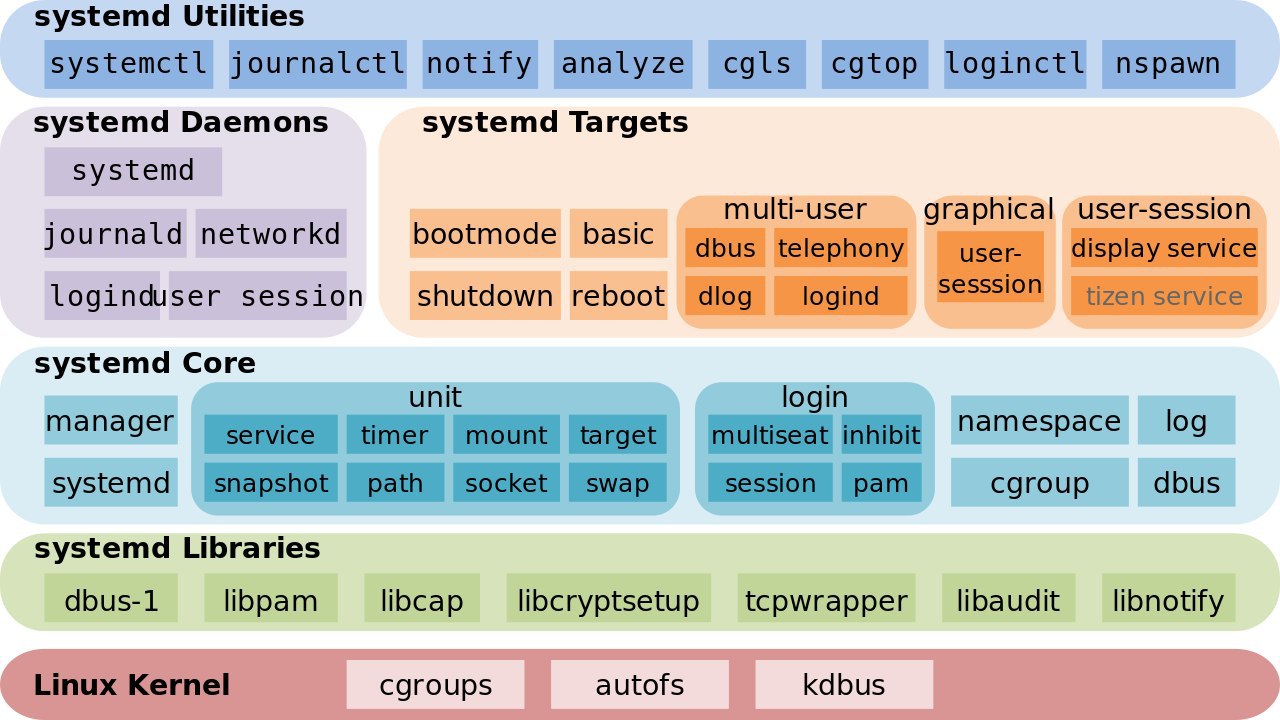
Когда работаешь в консоли Linux, постоянно приходится использовать команду systemctl для управления службами systemd. Решил собрать наиболее популярные команды в шпаргалку, чтобы удобно было сохранить и пользоваться.
Запустить службу. После внедрения systemd постоянно путался и сначала писал имя службы, а потом команду start. Сейчас уже переучился.
Добавить в автозагрузку:
Добавить сервис в автозагрузку и сразу запустить. Заменяет две предыдущие команды. Я не так давно узнал и стал использовать именно объединённую команду:
Перечитать настройки служб. Обязательно нужно выполнить после того, как изменили какие-то настройки юнитов systemd.
Список всех unit-files, а так же их состояний:
Список выше можно ограничить по типам:
Посмотреть статус конкретной службы:
Проверить статус автозапуска:
Посмотреть конфигурацию юнита:
Перечислил основное, с чем самому приходится сталкиваться. Если пропустил какую-то популярную и полезную команду, дайте знать, добавлю в список. Про stop, restart, reload, status не стал писать. Очевидные команды. Есть еще is-active и try-restart, но на практике я их вообще не использую.
Добавлю еще, что с помощью systemctl можно перезагружать и завершать работу системы, но лично я по старинке использую старые команды reboot и shutdown.
#terminal #systemd
Запустить службу. После внедрения systemd постоянно путался и сначала писал имя службы, а потом команду start. Сейчас уже переучился.
systemctl start mysqlДобавить в автозагрузку:
systemctl enable nginxДобавить сервис в автозагрузку и сразу запустить. Заменяет две предыдущие команды. Я не так давно узнал и стал использовать именно объединённую команду:
systemctl enable --now mariadbПеречитать настройки служб. Обязательно нужно выполнить после того, как изменили какие-то настройки юнитов systemd.
systemctl daemon-reloadСписок всех unit-files, а так же их состояний:
systemctl list-unit-filesСписок выше можно ограничить по типам:
systemctl -t servicesystemctl -t timersystemctl -t mountПосмотреть статус конкретной службы:
systemctl | grep sshПроверить статус автозапуска:
systemctl is-enabled nginxПосмотреть конфигурацию юнита:
systemctl cat sshdПеречислил основное, с чем самому приходится сталкиваться. Если пропустил какую-то популярную и полезную команду, дайте знать, добавлю в список. Про stop, restart, reload, status не стал писать. Очевидные команды. Есть еще is-active и try-restart, но на практике я их вообще не использую.
Добавлю еще, что с помощью systemctl можно перезагружать и завершать работу системы, но лично я по старинке использую старые команды reboot и shutdown.
systemctl poweroffsystemctl reboot#terminal #systemd
{kind=link}
Подсистема инициализации и управления службами в Linux под названием Systemd плотно вошла в нашу повседневную рутину по управлению серверами. Есть в ней отдельный компонент Timers, который служит заменой классического планировщика мира Unix - cron.
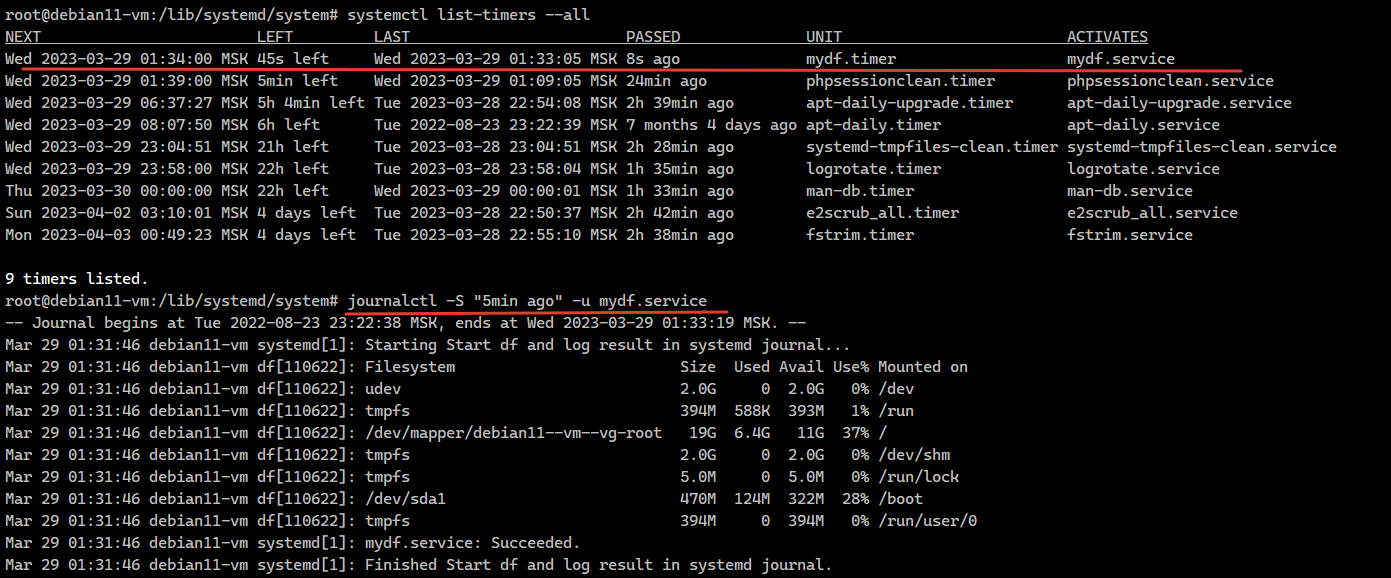
Хочешь не хочешь, но с Timers работать придётся. В том же Debian 11 все повторяющиеся действия реализованы через timers и продублированы в старом cron. Список можно посмотреть вот так:
Увидите там logrotate.timer, man-db.timer, apt-daily.timer, apt-daily-upgrade.timer и т.д. Если установить php, certbot, то они также добавят свои таймеры наравне с записями в классический cron. Я так подозреваю, что в какой-то момент в обычном cron они исчезнут.
Можно по-разному относиться к нововведениям, но лично мне в таком виде они не нравятся. Это как в Windows функции размазались по Настройкам и Панели управления. В итоге приходится тратить больше времени на настройку и проверять всё в двух местах. Если уж переехали на таймеры, то в cron зачем дублировать? Там всё равно стоят проверки и если уже есть таймер для задачи, то cron ничего не делает. Но проверять приходится.
Когда я познакомился с Unix, его cron был одним из тех инструментов, который мне понравился больше всего. Простота и гибкость настройки подкупали. Все задания в одном файле. Просто скопировал и перенёс его на любой другой сервер, то есть очень простой бэкап всех заданий. Я даже на Windows устанавливал порт крона.
Смотрим на таймеры. Из удобств лично я увидел более гибкий планировщик, который может быть не только календарным, как в cron, но и событийным. Например, можно задать интервал на запуск через 10 минут после загрузки системы и потом повторять каждые 3 часа. Вроде удобно, но лично у меня никогда не было задачи, которой бы требовалось такое расписание. Ни разу не возникло ситуации, когда планировщик cron не справился бы. Максимум, иногда в скрипт добавишь sleep, но это редко бывает. Стараюсь так не делать, потому что костыль.
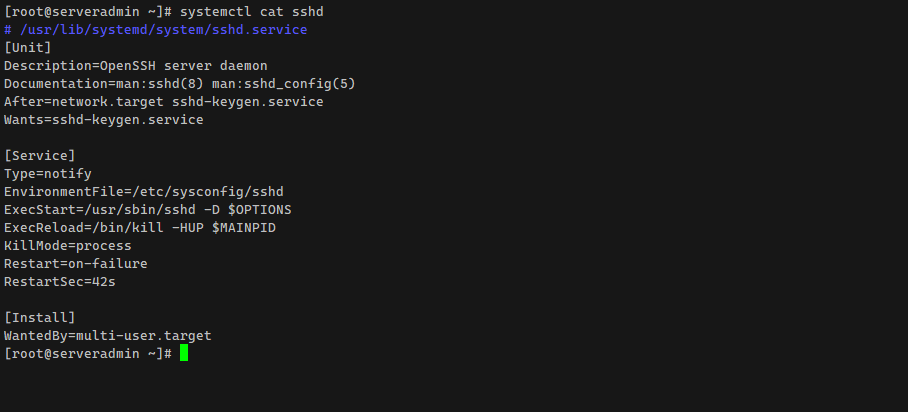
Вторым плюсом можно отметить логирование каждого отдельного таймера. Это удобно, но не сказать, что очень сильно надо. Grep общего лога cron с таким же успехом покажет все события отдельной задачи. В таймерах смотрим лог вот так:
Ещё одним несомненным плюсом таймеров является возможность настройки зависимостей задач от других служб. Это реально удобно и в обычном cron никак не реализуется. Только если закладывать логику проверки в сам скрипт. Также таймеры могут быть присоединены к разным cgroups.
Я решил написать эту заметку, потому что на днях возникла простая задача. Надо было настроить периодический перезапуск службы 1С на Linux сервере. Прикинул, как это можно сделать через Timers. Получилась такая схема:
1. Создаём отдельную службу, которая перезапускает процесс srv1cv83.
2. Создаём таймер, который запускает эту службу.
Второй вариант, в описание самой службы srv1cv83 добавить параметр WatchdogSec, который будет автоматически перезапускать службу через заданный промежуток времени. Но так трудно попасть в конкретное время. Можно рано или поздно в середине рабочего дня перезапуститься.
Мне показалось, что проще просто добавить в crontab:
и перезапускать службу каждое воскресенье в 6:55. На этом решении в итоге и остановился.
А вы используете systemd timers? Какие задачи решаете? Может я туплю и не понимаю, как красиво и просто перезапускать в нужное время существующую работающую службу, управляемую systemd?
#linux #systemd #cron
Хочешь не хочешь, но с Timers работать придётся. В том же Debian 11 все повторяющиеся действия реализованы через timers и продублированы в старом cron. Список можно посмотреть вот так:
# systemctl list-timersУвидите там logrotate.timer, man-db.timer, apt-daily.timer, apt-daily-upgrade.timer и т.д. Если установить php, certbot, то они также добавят свои таймеры наравне с записями в классический cron. Я так подозреваю, что в какой-то момент в обычном cron они исчезнут.
Можно по-разному относиться к нововведениям, но лично мне в таком виде они не нравятся. Это как в Windows функции размазались по Настройкам и Панели управления. В итоге приходится тратить больше времени на настройку и проверять всё в двух местах. Если уж переехали на таймеры, то в cron зачем дублировать? Там всё равно стоят проверки и если уже есть таймер для задачи, то cron ничего не делает. Но проверять приходится.
Когда я познакомился с Unix, его cron был одним из тех инструментов, который мне понравился больше всего. Простота и гибкость настройки подкупали. Все задания в одном файле. Просто скопировал и перенёс его на любой другой сервер, то есть очень простой бэкап всех заданий. Я даже на Windows устанавливал порт крона.
Смотрим на таймеры. Из удобств лично я увидел более гибкий планировщик, который может быть не только календарным, как в cron, но и событийным. Например, можно задать интервал на запуск через 10 минут после загрузки системы и потом повторять каждые 3 часа. Вроде удобно, но лично у меня никогда не было задачи, которой бы требовалось такое расписание. Ни разу не возникло ситуации, когда планировщик cron не справился бы. Максимум, иногда в скрипт добавишь sleep, но это редко бывает. Стараюсь так не делать, потому что костыль.
Вторым плюсом можно отметить логирование каждого отдельного таймера. Это удобно, но не сказать, что очень сильно надо. Grep общего лога cron с таким же успехом покажет все события отдельной задачи. В таймерах смотрим лог вот так:
# journalctl -u logrotate.timerЕщё одним несомненным плюсом таймеров является возможность настройки зависимостей задач от других служб. Это реально удобно и в обычном cron никак не реализуется. Только если закладывать логику проверки в сам скрипт. Также таймеры могут быть присоединены к разным cgroups.
Я решил написать эту заметку, потому что на днях возникла простая задача. Надо было настроить периодический перезапуск службы 1С на Linux сервере. Прикинул, как это можно сделать через Timers. Получилась такая схема:
1. Создаём отдельную службу, которая перезапускает процесс srv1cv83.
2. Создаём таймер, который запускает эту службу.
Второй вариант, в описание самой службы srv1cv83 добавить параметр WatchdogSec, который будет автоматически перезапускать службу через заданный промежуток времени. Но так трудно попасть в конкретное время. Можно рано или поздно в середине рабочего дня перезапуститься.
Мне показалось, что проще просто добавить в crontab:
55 6 * * 7 root /usr/bin/systemctl restart srv1cv83и перезапускать службу каждое воскресенье в 6:55. На этом решении в итоге и остановился.
А вы используете systemd timers? Какие задачи решаете? Может я туплю и не понимаю, как красиво и просто перезапускать в нужное время существующую работающую службу, управляемую systemd?
#linux #systemd #cron
Одна из особенностей Unix систем, которая меня сразу привлекла по сравнению с Windows, это наличие там CRON. По мне так это очень крутой, простой, удобный инструмент для управления периодическими задачами.
На своих серверах я привык все задачи писать в системный crontab, чтобы всё было в одном месте. Мне так удобнее управлять заданиями. Не надо проверять разные файлы. После планировщика Windows юниксовый cron очень понравился.
Сейчас на смену cron пришли systemd timers. Мне не особо нравится формат работы с ними, но приходится мириться и использовать, потому что всё больше софта по умолчанию свои задачи хранит там. Timers предлагают более широкий функционал по сравнению с cron и более гибкие настройки. Так что надо привыкать и пользоваться. Для этого решил сделать для себя шпаргалку и сразу поделиться с вами.
Сначала поясню, что умеют таймеры из того, что не умеет cron. Например, запустить какую-то задачу через заданное время после какого-то события. Для cron такое событие, насколько мне известно, может быть только — @reboot. Таймер же может запуститься, например, через некоторое время после завершения работы какого-то сервиса, возможно тоже вызванного по таймеру.
Таймер может проверять зависимости от других служб и не запускать задание, если какая-то служба недоступна. В случае cron подобную логику приходится реализовывать в самих скриптах. Например, проверять монтирование диска при бэкапе на удалённое хранилище.
Для каждого таймера systemd ведёт отдельный журнал, что удобно для отладки или анализа работы. Не надо грепать общий лог крона, или вообще системный лог, если по умолчанию cron не имеет отдельного журнала, как, например, в Debian. Я обычно это исправляю сразу же после установки системы.
В целом, удобство timers очевидно, хотя лично я ещё ни разу не сталкивался с ситуацией, где бы мне было проще и быстрее добавить таймер, а не воспользоваться cron. Для запуска скриптов крона вполне хватает. А с таймерами приходится взаимодействовать, когда настраиваешь какой-то софт. Например, certbot. Или смотришь системные залачи.
Посмотреть список всех таймеров:
Только активных:
Более подробная информация:
Пример создания таймера, который выполняет команду df -h. Сначала создаём конфигурацию сервиса в файле /etc/systemd/system/mydf.service:
Запустим и проверим результат. По умолчанию, вывод пишется в журнал systemd.
После нескольких запусков журнал можно посмотреть вот так:
Добавим задачу в планировщик, создав для неё минутный таймер в файле /etc/systemd/system/mydf.timer
Запускаем таймер:
Через несколько минут проверяем:
Если лог очень большой, его имеет смысл ограничить:
Формат systemd.time, в том числе и для таймеров, можно посмотреть в документации (сразу приведу шаблон DOW YYYY-MM-DD HH:MM:SS). Чаще всего при просмотре логов используется сокращение today или yesterday. То, что таймер пишет вывод в лог, удобно, но имейте ввиду, что за этим выводом стоит следить, если он большой.
Добавляем таймер в автозагрузку:
Удаляем из автозагрузки и останавливаем:
Примеры служб и таймеров удобно посмотреть в уже готовых системных, в директории /lib/systemd/system. Показательны примеры для apt-daily и apt-daily-upgrade. Там и зависимости, и запуск одного после другого. Ну и про документацию не забываем.
#systemd #terminal #linux
На своих серверах я привык все задачи писать в системный crontab, чтобы всё было в одном месте. Мне так удобнее управлять заданиями. Не надо проверять разные файлы. После планировщика Windows юниксовый cron очень понравился.
Сейчас на смену cron пришли systemd timers. Мне не особо нравится формат работы с ними, но приходится мириться и использовать, потому что всё больше софта по умолчанию свои задачи хранит там. Timers предлагают более широкий функционал по сравнению с cron и более гибкие настройки. Так что надо привыкать и пользоваться. Для этого решил сделать для себя шпаргалку и сразу поделиться с вами.
Сначала поясню, что умеют таймеры из того, что не умеет cron. Например, запустить какую-то задачу через заданное время после какого-то события. Для cron такое событие, насколько мне известно, может быть только — @reboot. Таймер же может запуститься, например, через некоторое время после завершения работы какого-то сервиса, возможно тоже вызванного по таймеру.
Таймер может проверять зависимости от других служб и не запускать задание, если какая-то служба недоступна. В случае cron подобную логику приходится реализовывать в самих скриптах. Например, проверять монтирование диска при бэкапе на удалённое хранилище.
Для каждого таймера systemd ведёт отдельный журнал, что удобно для отладки или анализа работы. Не надо грепать общий лог крона, или вообще системный лог, если по умолчанию cron не имеет отдельного журнала, как, например, в Debian. Я обычно это исправляю сразу же после установки системы.
В целом, удобство timers очевидно, хотя лично я ещё ни разу не сталкивался с ситуацией, где бы мне было проще и быстрее добавить таймер, а не воспользоваться cron. Для запуска скриптов крона вполне хватает. А с таймерами приходится взаимодействовать, когда настраиваешь какой-то софт. Например, certbot. Или смотришь системные залачи.
Посмотреть список всех таймеров:
# systemctl list-timers --allТолько активных:
# systemctl list-timersБолее подробная информация:
# systemctl status *timerПример создания таймера, который выполняет команду df -h. Сначала создаём конфигурацию сервиса в файле /etc/systemd/system/mydf.service:
[Unit]Description=Start df and log result in systemd journalWants=mydf.service[Service]Type=oneshotExecStart=/usr/bin/df -h[Install]WantedBy=multi-user.targetЗапустим и проверим результат. По умолчанию, вывод пишется в журнал systemd.
# systemctl start mydf.service# systemctl status mydf.serviceПосле нескольких запусков журнал можно посмотреть вот так:
# journalctl -u mydf.serviceДобавим задачу в планировщик, создав для неё минутный таймер в файле /etc/systemd/system/mydf.timer
[Unit]Description=Log df results every minuteRequires=mydf.service[Timer]Unit=mydf.serviceOnCalendar=*-*-* *:*:00[Install]WantedBy=timers.targetЗапускаем таймер:
# systemctl start mydf.timerЧерез несколько минут проверяем:
# journalctl -u mydf.serviceЕсли лог очень большой, его имеет смысл ограничить:
# journalctl -S "5min ago" -u mydf.serviceФормат systemd.time, в том числе и для таймеров, можно посмотреть в документации (сразу приведу шаблон DOW YYYY-MM-DD HH:MM:SS). Чаще всего при просмотре логов используется сокращение today или yesterday. То, что таймер пишет вывод в лог, удобно, но имейте ввиду, что за этим выводом стоит следить, если он большой.
Добавляем таймер в автозагрузку:
# systemctl enable mydf.timerУдаляем из автозагрузки и останавливаем:
# systemctl disable mydf.timer# systemctl stop mydf.timerПримеры служб и таймеров удобно посмотреть в уже готовых системных, в директории /lib/systemd/system. Показательны примеры для apt-daily и apt-daily-upgrade. Там и зависимости, и запуск одного после другого. Ну и про документацию не забываем.
#systemd #terminal #linux
{kind=link}
В systemd есть удобный механизм автозапуска сервиса в случае его завершения работы по той или иной причине. Какой-то стандартный софт имеет эту настройку в том или ином виде по умолчанию, например, Mariadb в Debian, какой-то нет, и это нужно сделать вручную.
Автозапуском сервиса управляет параметр
◽always — перезапускать всегда, когда сервис был остановлен корректно (exit code 0), с кодом ошибки или завис по таймауту
◽on-success — перезапускать, только если служба завершилась без ошибок (exit code 0)
◽on-failure — перезапускать, только если код завершения был не нулевым, был прибит одним из сигналов принудительного завершения работы (например SIGKILL), завис по таймауту
◽on-abnormal — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы или завис по таймауту
◽on-abort — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы
◽on-watchdog — перезапускать только если наступил настроенный для сервиса watchdog timeout
◽no — автоматического перезапуска нет
Надеюсь нигде не наврал. Перевёл кратенько отрывок документации, чтобы не притащить чьи-то ошибки. Так то в инете много статей по этой теме. По умолчанию, если явно не указан параметр, он принимает значение
Для того, чтобы настроить автоматический запуск сервиса, не надо редактировать его основной unit файл. Сделайте отдельный файл изменений
Добавьте туда:
После изменений надо перечитать настройки служб:
Теперь можно прибить Nginx и убедиться, что через 5 секунд он поднимется снова:
К автозапуску процессов надо подходить с умом. Не стоит для всех подряд его настраивать. Особенное внимание надо уделить службам СУБД. После аварийного завершения работы может запускаться очень ресурсоёмкая процедура восстановления данных, которая в нагруженном сервере может быть прибита oom killer и так по кругу. Это может привести к более серьезным последствиям или потере данных.
То же самое касается каких-то кластерных служб. Они могут падать и подниматься в цикле и приводить к рассинхронизации или каким-то ещё проблемам. Например, elasticsearch может подниматься очень долго на слабом железе. Иногда приходится стандартные таймауты systemd увеличивать, чтобы он удачно стартовал. Если настроить автозапуск, он может в цикле прибивать службу по таймауту.
А тот же самый Nginx, Postfix, Dovecot, Apache, Zabbix Agent можно спокойно ставить в автозапуск в случае падений. Проблем быть не должно.
У автозапуска есть более тонкие настройки и зависимости. Я описал только основной функционал, который нужен чаще всего. Более подробно всё описано в документации. Там настраиваются таймауты, различные статусы завершения работы, которые стоит считать успешными, количество попыток перезапуска, прежде чем они прекратятся и т.д. Можно слать оповещения на почту в случае падения и перезапуска службы. Это делается через параметр
Табличку себе сохраните на память для настройки. Без неё неочевидно, какой параметр лучше использовать. Например, Mariadb по умолчанию имеет настройку
#systemd #linux
Автозапуском сервиса управляет параметр
Restart в разделе [Service]. Он может принимать следующие значения:◽always — перезапускать всегда, когда сервис был остановлен корректно (exit code 0), с кодом ошибки или завис по таймауту
◽on-success — перезапускать, только если служба завершилась без ошибок (exit code 0)
◽on-failure — перезапускать, только если код завершения был не нулевым, был прибит одним из сигналов принудительного завершения работы (например SIGKILL), завис по таймауту
◽on-abnormal — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы или завис по таймауту
◽on-abort — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы
◽on-watchdog — перезапускать только если наступил настроенный для сервиса watchdog timeout
◽no — автоматического перезапуска нет
Надеюсь нигде не наврал. Перевёл кратенько отрывок документации, чтобы не притащить чьи-то ошибки. Так то в инете много статей по этой теме. По умолчанию, если явно не указан параметр, он принимает значение
no.Для того, чтобы настроить автоматический запуск сервиса, не надо редактировать его основной unit файл. Сделайте отдельный файл изменений
override.conf и положите его в директорию сервиса со специальным именем. Для nginx оно будет такое: /etc/systemd/system/nginx.service.d/override.conf.Добавьте туда:
[Service]Restart=alwaysRestartSec=5sПосле изменений надо перечитать настройки служб:
# systemctl daemon-reloadТеперь можно прибить Nginx и убедиться, что через 5 секунд он поднимется снова:
# systemctl status nginx ; смотрим pid корневого процесса (Main PID)# kill -9 1910155# systemctl status nginxК автозапуску процессов надо подходить с умом. Не стоит для всех подряд его настраивать. Особенное внимание надо уделить службам СУБД. После аварийного завершения работы может запускаться очень ресурсоёмкая процедура восстановления данных, которая в нагруженном сервере может быть прибита oom killer и так по кругу. Это может привести к более серьезным последствиям или потере данных.
То же самое касается каких-то кластерных служб. Они могут падать и подниматься в цикле и приводить к рассинхронизации или каким-то ещё проблемам. Например, elasticsearch может подниматься очень долго на слабом железе. Иногда приходится стандартные таймауты systemd увеличивать, чтобы он удачно стартовал. Если настроить автозапуск, он может в цикле прибивать службу по таймауту.
А тот же самый Nginx, Postfix, Dovecot, Apache, Zabbix Agent можно спокойно ставить в автозапуск в случае падений. Проблем быть не должно.
У автозапуска есть более тонкие настройки и зависимости. Я описал только основной функционал, который нужен чаще всего. Более подробно всё описано в документации. Там настраиваются таймауты, различные статусы завершения работы, которые стоит считать успешными, количество попыток перезапуска, прежде чем они прекратятся и т.д. Можно слать оповещения на почту в случае падения и перезапуска службы. Это делается через параметр
OnFailure. Табличку себе сохраните на память для настройки. Без неё неочевидно, какой параметр лучше использовать. Например, Mariadb по умолчанию имеет настройку
on-abort.#systemd #linux
{kind=link}
В современных дистрибутивах Linux почти везде вместо традиционных текстовых логов средствами syslog используются бинарные логи journald. Они также, как и текстовые логи, иногда разрастаются до больших размеров, так что необходимо заниматься чисткой. Вот об этом и будет заметка. На днях пришлось на одном сервере этим заняться, поэтому решил сразу оформить заметку. Написана она будет по мотивам Debian 11.
Смотрим, сколько логи занимают места:
Обычно они хранятся в директории
Настройки ротации логов могут быть заданы в файле
Параметров, относящихся к настройке хранения логов намного больше, но эти два основные, которых достаточно для простого ограничения размера. Первый параметр ограничивает суммарный размер логов, а второй размер отдельного лог файла. Journald автоматически разделяет логи на файлы определённого размера. После изменения параметров, надо перезапустить службу:
Так же вы можете обрезать логи в режиме реального времени. Примерно так:
В первом случае обрезали старые логи, чтобы их осталось не больше 1024 мегабайт. Во втором обрезали все логи, старше 7-ми дней.
Кстати, если вы не хотите связываться с настройками journald, то можете команды выше просто в cron добавить на регулярное выполнение. Это тоже будет решение по ротации логов.
По умолчанию journald может занимать до 10% объёма раздела, на котором он находится. Но не более 4 Гб. На деле именно с ограничением в 4 Гб я чаще всего и сталкивался. Если у вас общий системный диск 40+ Гб, то как раз логи в 4 Гб у вас и будут.
Если у вас в логи спамит какая-то конкретная служба, то имеет смысл для неё отдельно настроить ограничение, выделив её логи в отдельный namespace. Для этого в unit службы в раздел
Добавляем:
Создаём в директории
Перезапускаем службу:
Смотрим его логи отдельно:
Я, кстати, по старинке, всегда запускаю текстовые логи через syslog. Просто привык к ним. В итоге у меня и бинарные логи в journal, и текстовые в syslog. Примерно как с cron и timers. Через systemd больше функциональности и настройки гибче, но старые инструменты проще и быстрее в настройке.
#linux #logs #systemd #journal
Смотрим, сколько логи занимают места:
# journalctl --disk-usageОбычно они хранятся в директории
/var/log/journal. Настройки ротации логов могут быть заданы в файле
/etc/systemd/journald.conf. Управляются они следующими параметрами:[Journal]SystemMaxUse=1024MSystemMaxFileSize=50MПараметров, относящихся к настройке хранения логов намного больше, но эти два основные, которых достаточно для простого ограничения размера. Первый параметр ограничивает суммарный размер логов, а второй размер отдельного лог файла. Journald автоматически разделяет логи на файлы определённого размера. После изменения параметров, надо перезапустить службу:
# systemctl restart systemd-journald.serviceТак же вы можете обрезать логи в режиме реального времени. Примерно так:
# journalctl --vacuum-size=1024M# journalctl --vacuum-time=7dВ первом случае обрезали старые логи, чтобы их осталось не больше 1024 мегабайт. Во втором обрезали все логи, старше 7-ми дней.
Кстати, если вы не хотите связываться с настройками journald, то можете команды выше просто в cron добавить на регулярное выполнение. Это тоже будет решение по ротации логов.
По умолчанию journald может занимать до 10% объёма раздела, на котором он находится. Но не более 4 Гб. На деле именно с ограничением в 4 Гб я чаще всего и сталкивался. Если у вас общий системный диск 40+ Гб, то как раз логи в 4 Гб у вас и будут.
Если у вас в логи спамит какая-то конкретная служба, то имеет смысл для неё отдельно настроить ограничение, выделив её логи в отдельный namespace. Для этого в unit службы в раздел
[Service] добавьте отдельное пространство логов. Покажу на примере ssh. Запускаем редактирования юнита. # systemctl edit sshДобавляем:
[Service]LogNamespace=sshСоздаём в директории
/etc/systemd/ отдельный конфиг для этого namespace journald@ssh.conf со своими параметрами:[Journal]SystemMaxUse=20MПерезапускаем службу:
# systemctl restart sshСмотрим его логи отдельно:
# journalctl --namespace sshЯ, кстати, по старинке, всегда запускаю текстовые логи через syslog. Просто привык к ним. В итоге у меня и бинарные логи в journal, и текстовые в syslog. Примерно как с cron и timers. Через systemd больше функциональности и настройки гибче, но старые инструменты проще и быстрее в настройке.
#linux #logs #systemd #journal
В systemd есть все необходимые инструменты для централизованного сбора логов. Вот они:
▪ systemd-journal-remote — служба, принимающая или забирающая записи журналов на центральном сервере
▪ systemd-journal-upload — служба, отправляющая локальные журналы на центральный сервер
Всё это позволяет без сторонних инструментов настроить централизованный сбор логов со множества серверов в одном месте. В Debian эти службы устанавливаются одним пакетом
После этого можно подготовить конфиг службы. Если нет нужды, то можно отключить работу по https, чтобы не заморачиваться с сертификатом, если сбор логов идёт по закрытым каналам связи. Для этого копируем системный unit в
Заменили ключ
Служба запустится на tcp порту 19532.
Перемещаемся на сервер, который будет отправлять логи и устанавливаем туда этот же пакет. Затем идём в конфигурационный файл
Запускаем службу и проверяем, что она успешно начала отправку логов:
Если ошибок нет, то можно идти на центральный сервер и там смотреть логи от удалённого сервера.
Сами логи будут лежать в отдельных файлах с ip адресом отправляющего сервера в названии. Примерно так:
Для этих логов действуют те же правила фильтрации, что и для локальных. Смотрим все логи юнита ssh:
Или только сообщения ядра:
Если я правильно понял, то ротация удалённых логов будет производиться по тем же правилам и настройкам, что и всего системного журнала journald. Я рассказывал об этом. Отдельно настраивать не нужно.
С помощью systemd-journal удобно собирать логи в одно место с множества хостов без установки на них стороннего софта. А потом уже централизованно отправить в любую другую систему хранения логов на обработку. Я ещё забыл упомянуть, что systemd-journal-remote можно настроить так, что он сам будет ходить по серверам и забирать с них логи.
#linux #logs #systemd #journal
▪ systemd-journal-remote — служба, принимающая или забирающая записи журналов на центральном сервере
▪ systemd-journal-upload — служба, отправляющая локальные журналы на центральный сервер
Всё это позволяет без сторонних инструментов настроить централизованный сбор логов со множества серверов в одном месте. В Debian эти службы устанавливаются одним пакетом
systemd-journal-remote. # apt install systemd-journal-remoteПосле этого можно подготовить конфиг службы. Если нет нужды, то можно отключить работу по https, чтобы не заморачиваться с сертификатом, если сбор логов идёт по закрытым каналам связи. Для этого копируем системный unit в
/etc/systemd/system и меняем параметр ExecStart:# cp /lib/systemd/system/systemd-journal-remote.service \/etc/systemd/system/systemd-journal-remote.service[Service]ExecStart=/lib/systemd/systemd-journal-remote --listen-http=-3 --output=/var/log/journal/remote/Заменили ключ
--listen-https на --listen-http. Если захотите использовать https, то сертификат надо будет прописать в /etc/systemd/journal-remote.conf. Далее достаточно создать необходимую директорию, назначить права и запустить службу:# mkdir -p /var/log/journal/remote# chown systemd-journal-remote:systemd-journal-remote /var/log/journal/remote# systemctl daemon-reload# systemctl start systemd-journal-remoteСлужба запустится на tcp порту 19532.
Перемещаемся на сервер, который будет отправлять логи и устанавливаем туда этот же пакет. Затем идём в конфигурационный файл
/etc/systemd/journal-upload.conf и добавляем туда путь к серверу:[Upload]URL=http://10.20.1.36:19532Запускаем службу и проверяем, что она успешно начала отправку логов:
# systemctl start systemd-journal-upload# systemctl status systemd-journal-uploadЕсли ошибок нет, то можно идти на центральный сервер и там смотреть логи от удалённого сервера.
# journalctl -D /var/log/journal/remote -fСами логи будут лежать в отдельных файлах с ip адресом отправляющего сервера в названии. Примерно так:
remote-10.20.1.56.journal. Можно посмотреть конкретный файл:# journalctl --file=remote-10.20.1.56.journal -n 100Для этих логов действуют те же правила фильтрации, что и для локальных. Смотрим все логи юнита ssh:
# journalctl --file=remote-10.20.1.56.journal -u sshИли только сообщения ядра:
# journalctl --file=remote-10.20.1.56.journal -kЕсли я правильно понял, то ротация удалённых логов будет производиться по тем же правилам и настройкам, что и всего системного журнала journald. Я рассказывал об этом. Отдельно настраивать не нужно.
С помощью systemd-journal удобно собирать логи в одно место с множества хостов без установки на них стороннего софта. А потом уже централизованно отправить в любую другую систему хранения логов на обработку. Я ещё забыл упомянуть, что systemd-journal-remote можно настроить так, что он сам будет ходить по серверам и забирать с них логи.
#linux #logs #systemd #journal
Ещё одна заметка про systemd и его встроенные инструменты для работы с логами. Есть служба systemd-journal-gatewayd, с помощью которой можно смотреть логи systemd через браузер. Причём настраивается она максимально просто, буквально в пару действий. Показываю на примере Debian.
Устанавливаем пакет systemd-journal-remote:
Запускаем службу:
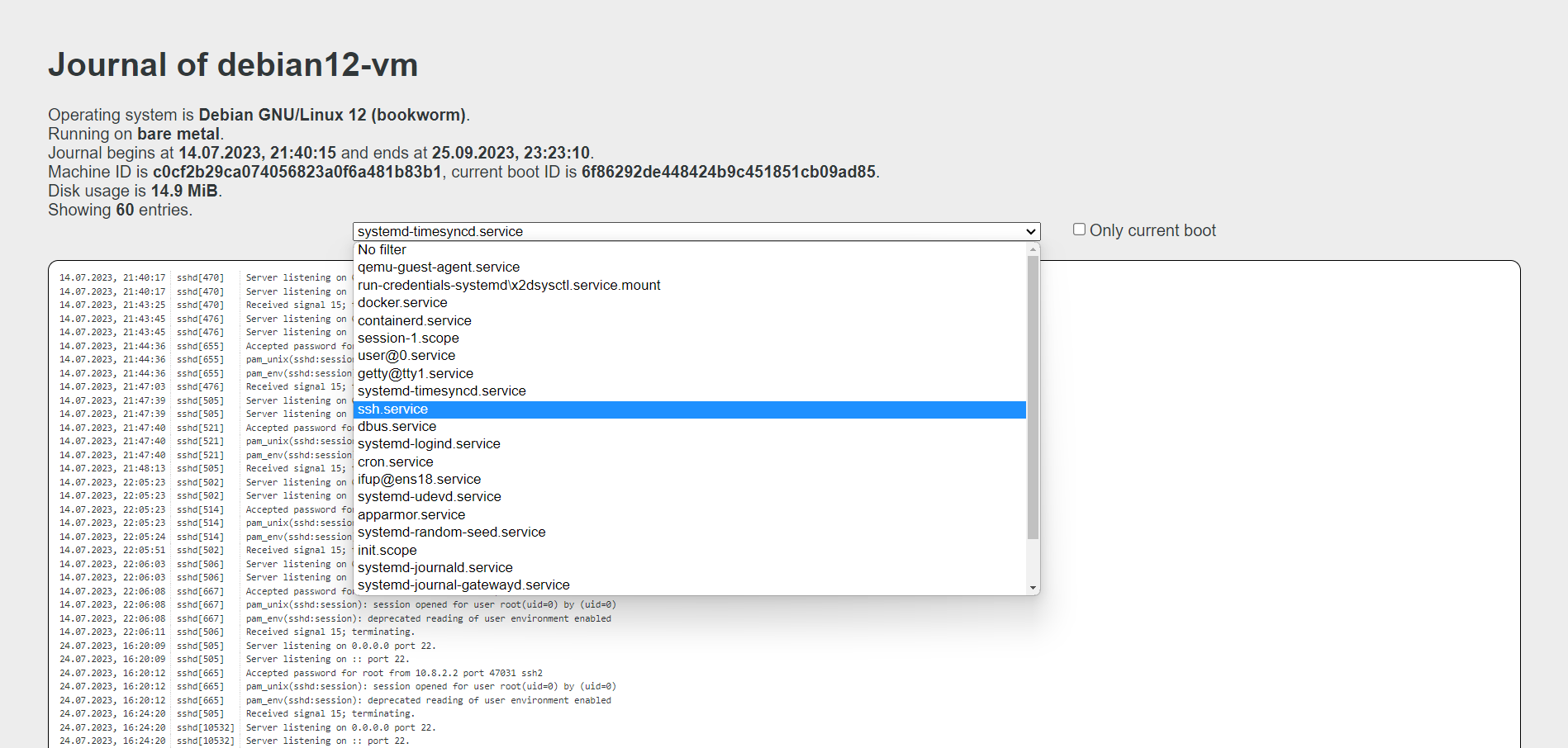
Порт по умолчанию 19531. Идём смотреть логи в браузер: http://10.20.1.36:19531/browse. Это обзорный url. Тут в выпадающем списке можно выбирать любой лог.
Можно посмотреть логи только текущей загрузки: http://10.20.1.36:19531/entries?boot.
Можно через curl забирать эти же логи в json формате. Примерно так для юнита ssh:
Все параметры и возможности описаны в документации. Обращаю внимание, что можно не только локальные логи открывать для доступа, но и собранные с удалённых машин. Если вы настроили такой сбор по моей вчерашней заметке, то директорию с логами для systemd-journal-gatewayd можно указать отдельно. Параметр
#linux #logs #systemd #journal
Устанавливаем пакет systemd-journal-remote:
# apt install systemd-journal-remoteЗапускаем службу:
# systemctl start systemd-journal-gatewayd.serviceПорт по умолчанию 19531. Идём смотреть логи в браузер: http://10.20.1.36:19531/browse. Это обзорный url. Тут в выпадающем списке можно выбирать любой лог.
Можно посмотреть логи только текущей загрузки: http://10.20.1.36:19531/entries?boot.
Можно через curl забирать эти же логи в json формате. Примерно так для юнита ssh:
# curl --silent -H 'Accept: application/json' \ 'http://10.20.1.36:19531/entries?UNIT=ssh.service'Все параметры и возможности описаны в документации. Обращаю внимание, что можно не только локальные логи открывать для доступа, но и собранные с удалённых машин. Если вы настроили такой сбор по моей вчерашней заметке, то директорию с логами для systemd-journal-gatewayd можно указать отдельно. Параметр
-D DIR, --directory=DIR.#linux #logs #systemd #journal
{kind=link}
В Linux есть любопытный бинарник
Бинарник этот по своей сути программа-пустышка. Он делает одну простую вещь - завершается с нулевым кодом выхода. То есть означает успешно выполненную команду. Используют её обычно для каких-то целей в скриптах.
Изначально true был обычным shell скриптом в unix вот такого содержания:
По сути это пустой скрипт, который, если его запустить, ничего не делает, но завершается с нулевым кодом выхода. И вот этот скрипт компания AT&T запатентовала. Для того, чтобы его можно было использовать в Linux, пришлось написать то же самое на C и скомпилировать. Поэтому в Linux не скрипт, а бинарник, который делает то же самое, что и задумывалось изначально.
Аналогичной утилитой, только возвращающей код ошибки является
Код выхода у неё ошибочный, то есть 1.
Узнал про
Вообще не понятно, к чему всё это и почему при этом служба работает корректно. Как она запускается? Оказалось, что для управления работой postfix используются шаблоны systemd. И рядом лежит файл
В итоге, сначала запускается основной unit, в котором прописана команда /bin/true, успешно отрабатывает, а потом то, что описано шаблоном.
Если честно, я не совсем понял, зачем для postfix используют шаблон. Они обычно нужны для удобного управления пулом запущенных сервисов единой командой. Когда у вас через шаблон запущены процессы, их все остановить или запустить можно одной командой. Но postfix обычно работает одним экземпляром на сервере.
Потом уже почитал ещё немного, увидел режим multiple Postfix instances в рамках одного хоста. Не буду на этом останавливаться подробно, но смысл в том, что можно запускать несколько экземпляров postfix, которые будут использовать разные файлы конфигураций и рабочие директории. Сам никогда подобное не настраивал и не вижу особо смысла в современных реалиях.
#postfix #systemd
/bin/true, про который я узнал случайно. Стал искать подробности и наткнулся на интересную информацию про него. Сначала про него расскажу, а потом как я на него наткнулся. Бинарник этот по своей сути программа-пустышка. Он делает одну простую вещь - завершается с нулевым кодом выхода. То есть означает успешно выполненную команду. Используют её обычно для каких-то целей в скриптах.
Изначально true был обычным shell скриптом в unix вот такого содержания:
# Copyright (c) 1984 AT&T # All Rights Reserved # THIS IS UNPUBLISHED PROPRIETARY SOURCE CODE OF AT&T # The copyright notice above does not evidence any # actual or intended publication of such source code. #ident "@(#)cmd/true.sh 50.1"По сути это пустой скрипт, который, если его запустить, ничего не делает, но завершается с нулевым кодом выхода. И вот этот скрипт компания AT&T запатентовала. Для того, чтобы его можно было использовать в Linux, пришлось написать то же самое на C и скомпилировать. Поэтому в Linux не скрипт, а бинарник, который делает то же самое, что и задумывалось изначально.
Аналогичной утилитой, только возвращающей код ошибки является
/bin/false:# /bin/false# echo $?1Код выхода у неё ошибочный, то есть 1.
Узнал про
/bin/true я случайно, когда в Debian смотрел systemd unit от postfix /lib/systemd/system/postfix.service. Открываю, а там такое:[Unit]Description=Postfix Mail Transport AgentConflicts=sendmail.service exim4.serviceConditionPathExists=/etc/postfix/main.cf[Service]Type=oneshotRemainAfterExit=yesExecStart=/bin/trueExecReload=/bin/true[Install]WantedBy=multi-user.targetВообще не понятно, к чему всё это и почему при этом служба работает корректно. Как она запускается? Оказалось, что для управления работой postfix используются шаблоны systemd. И рядом лежит файл
postfix@.service, где уже описаны все параметры запуска конкретного экземпляра почтового сервера. При этом в /etc/systemd/system/multi-user.target.wants есть символьная ссылка только на postfix.service, поэтому сразу не очевидно, что там зависимые юниты есть.В итоге, сначала запускается основной unit, в котором прописана команда /bin/true, успешно отрабатывает, а потом то, что описано шаблоном.
Если честно, я не совсем понял, зачем для postfix используют шаблон. Они обычно нужны для удобного управления пулом запущенных сервисов единой командой. Когда у вас через шаблон запущены процессы, их все остановить или запустить можно одной командой. Но postfix обычно работает одним экземпляром на сервере.
Потом уже почитал ещё немного, увидел режим multiple Postfix instances в рамках одного хоста. Не буду на этом останавливаться подробно, но смысл в том, что можно запускать несколько экземпляров postfix, которые будут использовать разные файлы конфигураций и рабочие директории. Сам никогда подобное не настраивал и не вижу особо смысла в современных реалиях.
#postfix #systemd
Постоянно использую systemctl, чтобы посмотреть статус службы:
И никогда не приходило в голову, что без указания службы эта команда тоже работает:
Заметил случайно, когда забыл указать службу. Удивился выводу, так как увидел впервые. Причём в самом начале было указано и подсвечено красным:
Стал разбираться, о чём тут идёт речь. Что там за сфейлившийся юнит:
Оказалось, что это
Тут уже увидел конкретную ошибку в логе службы. Не загрузился один из модулей ядра, перечисленных в
Помимо ошибок запуска юнитов, команда
◽количество запущенных Units
◽uptime самой systemd
◽версию systemd
◽иерархический список запущенных служб
При этом список служб представлен в удобном виде. Более наглядно, чем в том же htop с иерархическим отображением. Так что команду надо запомнить и пользоваться.
#systemd
# systemctl status mariadbИ никогда не приходило в голову, что без указания службы эта команда тоже работает:
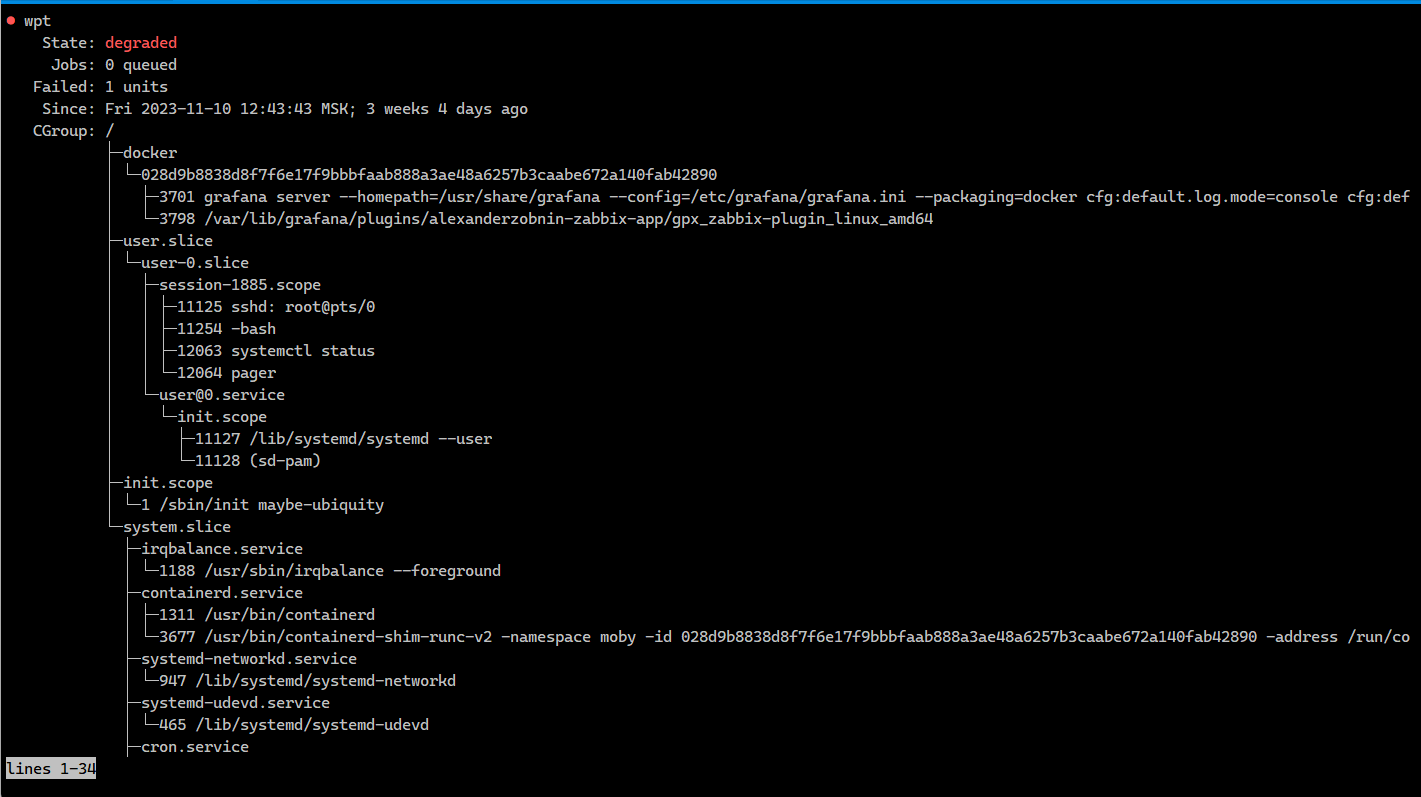
# systemctl status Заметил случайно, когда забыл указать службу. Удивился выводу, так как увидел впервые. Причём в самом начале было указано и подсвечено красным:
State: degradedFailed: 1 unitsСтал разбираться, о чём тут идёт речь. Что там за сфейлившийся юнит:
# systemctl list-units --failedОказалось, что это
systemd-modules-load.service юнит сфейлился на этапах ACTIVE и SUB. Мне это вообще ни о чём не сказало, поэтому стал разбираться дальше:# systemctl status systemd-modules-load.service# journalctl -u systemd-modules-load.serviceТут уже увидел конкретную ошибку в логе службы. Не загрузился один из модулей ядра, перечисленных в
/etc/modules-load.d. Когда-то настроил и забыл об этом. Он и не нужен уже, но при этом он и не грузился, потому что добавил его с ошибкой 😎.Помимо ошибок запуска юнитов, команда
systemctl status покажет:◽количество запущенных Units
◽uptime самой systemd
◽версию systemd
◽иерархический список запущенных служб
При этом список служб представлен в удобном виде. Более наглядно, чем в том же htop с иерархическим отображением. Так что команду надо запомнить и пользоваться.
#systemd
{kind=link}
Я делал несколько заметок на тему systemd, где встроенные возможности этой системы управления службами заменяют функциональность других линуксовых программ и утилит:
◽Systemd timers как замена Cron
◽Journald как замена Syslog
◽Systemd-journal-remote - централизованное хранение логов
◽Systemd-journal-gatewayd - просмотр логов через браузер
◽Systemd-mount для монтирования дисков
◽Есть ещё timesyncd как замена ntp или chrony.
Сегодня расскажу про ещё одну такую службу, которая заменяет локальный кэширующий DNS сервер - systemd-resolved. Изначально я научился настраивать DNS сервер Bind ещё в те времена, когда было привычным делом держать свою зону на своих серверах. Везде использовал его, даже в простых случаях, где нужно простое кэширование без поддержки своих зон. Потом познакомился с Dnsmasq и для обычного кэширования стал использовать его, так как настроить быстрее и проще. На пути к упрощению решил попробовать systemd-resolved. Он выступает в роли локального кэширующего сервера, то есть обрабатывает только запросы сервера, где он установлен, и его приложений.
В каких-то дистрибутивах systemd-resolved может быть в составе systemd. В Debian 12 это не так, поэтому придётся поставить отдельно:
Далее открываем конфиг
Это минимальный набор настроек для локального кэширующего сервера. Сервера из списка FallbackDNS будут использоваться в случае недоступности основного списка.
Перезапускаем службу:
После установки systemd-resolved удаляет
или так:
То есть локальный DNS сервис имеет адрес 127.0.0.54. Он же и указан в виде
Посмотреть статус службы можно так:
Если захотите посмотреть подробности работы службы, например, увидеть сами запросы и узнать сервера, к которым они были переадресованы, то можно включить режим отладки.
Добавляем параметр:
Перезапускаем службу и смотрим логи:
Если ответа нет в кэше, то вы увидите информацию о том, что был запрос к публичному DNS серверу. Если в кэше есть запись об этом домене, то увидите строку:
Посмотреть статистику по запросам:
Очистить локальный кэш:
В принципе, простой и эффективный инструмент. Можно пользоваться, особенно если он идёт в комплекте с systemd. Было бы интересно его приспособить и для удалённых запросов. Например, поставить на гипервизор и обслуживать запросы виртуальных машин. Но как я понял, он так не умеет и не предназначен для этого.
#systemd #dns
◽Systemd timers как замена Cron
◽Journald как замена Syslog
◽Systemd-journal-remote - централизованное хранение логов
◽Systemd-journal-gatewayd - просмотр логов через браузер
◽Systemd-mount для монтирования дисков
◽Есть ещё timesyncd как замена ntp или chrony.
Сегодня расскажу про ещё одну такую службу, которая заменяет локальный кэширующий DNS сервер - systemd-resolved. Изначально я научился настраивать DNS сервер Bind ещё в те времена, когда было привычным делом держать свою зону на своих серверах. Везде использовал его, даже в простых случаях, где нужно простое кэширование без поддержки своих зон. Потом познакомился с Dnsmasq и для обычного кэширования стал использовать его, так как настроить быстрее и проще. На пути к упрощению решил попробовать systemd-resolved. Он выступает в роли локального кэширующего сервера, то есть обрабатывает только запросы сервера, где он установлен, и его приложений.
В каких-то дистрибутивах systemd-resolved может быть в составе systemd. В Debian 12 это не так, поэтому придётся поставить отдельно:
# apt install systemd-resolvedДалее открываем конфиг
/etc/systemd/resolved.conf и приводим его примерно к такому виду:[Resolve]DNS=77.88.8.1 1.1.1.1 8.8.8.8FallbackDNS=77.88.8.8 8.8.4.4Cache=yesЭто минимальный набор настроек для локального кэширующего сервера. Сервера из списка FallbackDNS будут использоваться в случае недоступности основного списка.
Перезапускаем службу:
# systemctl restart systemd-resolvedПосле установки systemd-resolved удаляет
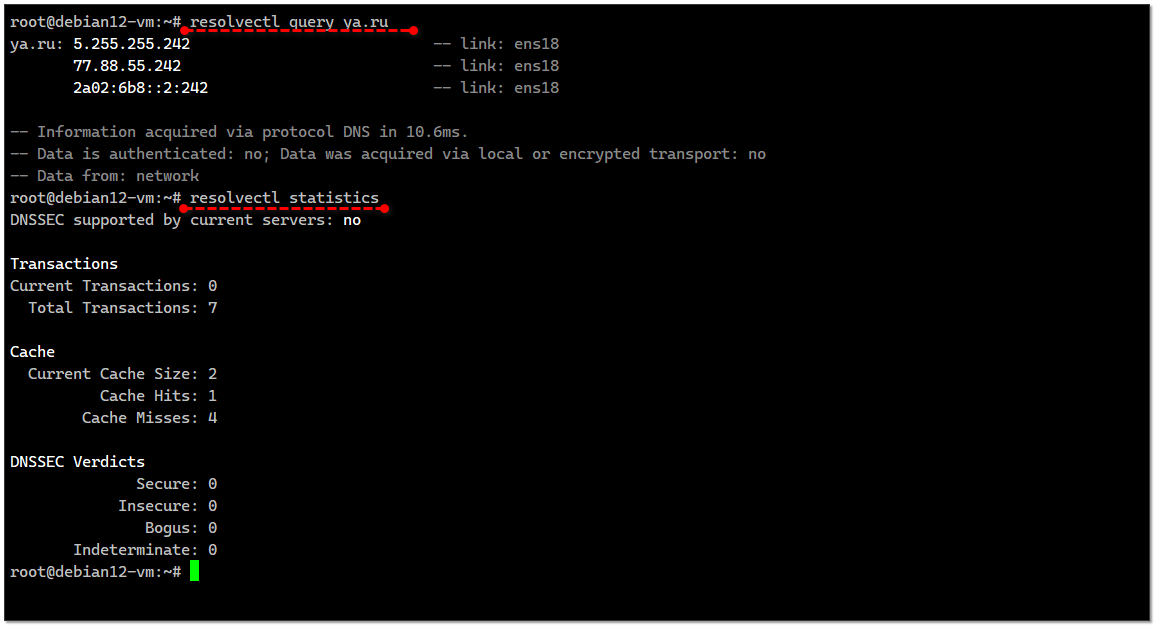
/etc/resolv.conf и заменяет ссылкой на /run/systemd/resolve/stub-resolv.conf. Проверить работу службы можно разными способами. Например так:# resolvectl query ya.ruили так:
# dig @127.0.0.54 ya.ruТо есть локальный DNS сервис имеет адрес 127.0.0.54. Он же и указан в виде
nameserver 127.0.0.53 в resolv.conf. Посмотреть статус службы можно так:
# resolvectl statusЕсли захотите посмотреть подробности работы службы, например, увидеть сами запросы и узнать сервера, к которым они были переадресованы, то можно включить режим отладки.
# systemctl edit systemd-resolvedДобавляем параметр:
[Service]Environment=SYSTEMD_LOG_LEVEL=debugПерезапускаем службу и смотрим логи:
# systemctl restart systemd-resolved# journalctl -f -u systemd-resolvedЕсли ответа нет в кэше, то вы увидите информацию о том, что был запрос к публичному DNS серверу. Если в кэше есть запись об этом домене, то увидите строку:
Positive cache hit for example.com IN AПосмотреть статистику по запросам:
# resolvectl statisticsОчистить локальный кэш:
# resolvectl flush-cachesВ принципе, простой и эффективный инструмент. Можно пользоваться, особенно если он идёт в комплекте с systemd. Было бы интересно его приспособить и для удалённых запросов. Например, поставить на гипервизор и обслуживать запросы виртуальных машин. Но как я понял, он так не умеет и не предназначен для этого.
#systemd #dns
{kind=link}
Короткая справочная заметка. С недавних пор (последние ~два года) для просмотра информации о системе использую простую команду:
Потихоньку ушёл от всех других вариантов. Раньше пользовался:
Уже забывать всё это стал. Hostnamectl даёт всю базовую информацию сразу, так что никуда заглядывать больше не надо. Тут и имя системы, и версия ОС, и ядро. Сразу видно, виртуальная машина это или контейнер. Если контейнер, то будет показан его тип: docker, lxc или openvz. Если VM, то тип виртуализации.
#systemd
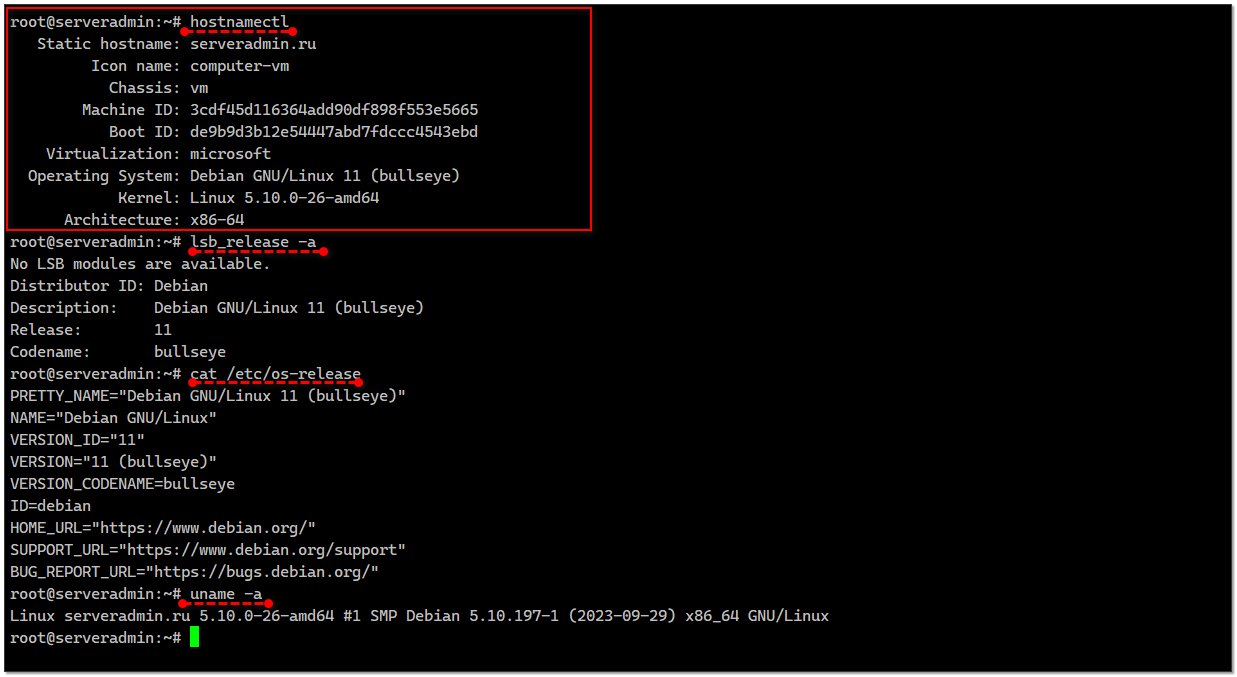
# hostnamectlStatic hostname: serveradmin.ruIcon name: computer-vmChassis: vmMachine ID: 3cdf45d116364add90df898f553e5665Boot ID: de9b9d3b12e54447abd7fdccc4543ebdVirtualization: microsoftOperating System: Debian GNU/Linux 11 (bullseye)Kernel: Linux 5.10.0-26-amd64Architecture: x86-64Потихоньку ушёл от всех других вариантов. Раньше пользовался:
# lsb_release -a# uname -a# cat /etc/os-release# cat /etc/redhat-releaseУже забывать всё это стал. Hostnamectl даёт всю базовую информацию сразу, так что никуда заглядывать больше не надо. Тут и имя системы, и версия ОС, и ядро. Сразу видно, виртуальная машина это или контейнер. Если контейнер, то будет показан его тип: docker, lxc или openvz. Если VM, то тип виртуализации.
#systemd
{kind=link}
Я делал уже много заметок на тему systemd, где эта изначально система инициализации и управления службами стала заменять старые компоненты системы Linux. Повествование не будет полным без рассказа о монтировании файловых систем с помощью systemd. Сейчас этот механизм встречается повсеместно, особенно у облачных провайдеров, так что знать о нём необходимо.
Давно уже рассказывал, как попал в неприятную ситуацию с облачной виртуалкой, где нужно было заменить диск. Я не учёл момент, что провайдер напрямую управляет монтированием внутри пользовательских виртуалок через systemd, из-за чего я чуть не потерял все данные.
Монтирование файловых систем с помощью systemd обладает явными преимуществами перед привычным fstab:
1️⃣ Есть возможность автомонтирования при обращении и отключения устройства по заданным параметрам.
2️⃣ Можно автоматически создавать директории для точек монтирования. За их наличием не обязательно следить.
3️⃣ Можно настроить таймаут подключения устройства. Если оно не доступно, это не заблокирует загрузку системы, как это бывает с fstab.
4️⃣ Можно настраивать зависимость монтирования от других служб. Актуально для монтирования после подключения по VPN, либо запуска какого-то специального софта для работы с диском.
Самый простой пример монтирования локального диска в
На диске должен быть создан раздел с файловой системой ext4. Если раздела нет, то создайте с помощью
Uuid диска смотрим с помощью blkid:
Перечитываем содержание юнитов и монтируем файловую систему:
Если всё в порядке, можно добавить в автозагрузку:
Теперь покажу пример юнита автомонтирования на примере диска NFS, который доступен только после подключения по openvpn с помощью локального клиента. Он будет автоматически подключаться при обращении к точке монтирования и отключаться в случае отсутствия активности в течении 60 секунд. У него должно быть расширение .automount. Для этого мы должны создать обычный юнит
mnt-backup.mount:
mnt-backup.automount:
Добавляем автомонтирование в автозагрузку:
Теперь при старте системы ничего монтироваться не будет. При обращении к точке монтирования /mnt/backup будет предпринята попытка примонтировать сетевой диск при условии запущенной службы openvpn@client.service. Если служба будет отключена, диск принудительно будет отмонтирован, так как .automount жёстко привязан не только к запуску службы, но и к её работе.
Документация по mount и automount:
- systemd.mount — Mount unit configuration
- systemd.automount — Automount unit configuration
📌 Полезные ссылки по теме systemd:
◽️Systemd timers как замена Cron
◽️Journald как замена Syslog
◽️Systemd-journal-remote - централизованное хранение логов
◽️Systemd-journal-gatewayd - просмотр логов через браузер
◽️Hostnamectl для просмотра информации о системе
◽️Systemd-resolved - кэширующий DNS сервер
#systemd
Давно уже рассказывал, как попал в неприятную ситуацию с облачной виртуалкой, где нужно было заменить диск. Я не учёл момент, что провайдер напрямую управляет монтированием внутри пользовательских виртуалок через systemd, из-за чего я чуть не потерял все данные.
Монтирование файловых систем с помощью systemd обладает явными преимуществами перед привычным fstab:
1️⃣ Есть возможность автомонтирования при обращении и отключения устройства по заданным параметрам.
2️⃣ Можно автоматически создавать директории для точек монтирования. За их наличием не обязательно следить.
3️⃣ Можно настроить таймаут подключения устройства. Если оно не доступно, это не заблокирует загрузку системы, как это бывает с fstab.
4️⃣ Можно настраивать зависимость монтирования от других служб. Актуально для монтирования после подключения по VPN, либо запуска какого-то специального софта для работы с диском.
Самый простой пример монтирования локального диска в
/mnt/backup со стандартными настройками. Создаём юнит в /etc/systemd/system с именем mnt-backup.mount:[Unit]Description=Disk for backups[Mount]What=/dev/disk/by-uuid/f774fad3-2ba0-47d1-a20b-0b1c2ae1b7d6Where=/mnt/backupType=ext4Options=defaults[Install]WantedBy=multi-user.targetНа диске должен быть создан раздел с файловой системой ext4. Если раздела нет, то создайте с помощью
cfdisk. Если нет файловой системы, то создайте: # mkfs -t ext4 /dev/sdb1Uuid диска смотрим с помощью blkid:
# blkid/dev/sdb1: UUID="f774fad3-2ba0-47d1-a20b-0b1c2ae1b7d6" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="a6242d02-8cff-fd44-99ce-a37c654c446c"Перечитываем содержание юнитов и монтируем файловую систему:
# systemctl daemon-reload# systemctl start mnt-backup.mountЕсли всё в порядке, можно добавить в автозагрузку:
# systemctl enable mnt-backup.mountТеперь покажу пример юнита автомонтирования на примере диска NFS, который доступен только после подключения по openvpn с помощью локального клиента. Он будет автоматически подключаться при обращении к точке монтирования и отключаться в случае отсутствия активности в течении 60 секунд. У него должно быть расширение .automount. Для этого мы должны создать обычный юнит
mnt-backup.mount, но не включать его автозагрузку, и к нему добавить mnt-backup.automount.mnt-backup.mount:
[Unit]Description=NFS share[Mount]What=srv.example.com:/backup/nfs_shareWhere=/mnt/backupType=nfs4Options=rwTimeoutSec=15mnt-backup.automount:
[Unit]Description=NFS shareRequires=network-online.targetBindsTo=openvpn@client.service After=openvpn@client.service[Automount]Where=/mnt/backupTimeoutIdleSec=60[Install]WantedBy=graphical.targetДобавляем автомонтирование в автозагрузку:
# systemctl daemon-reload# systemctl enable --now mnt-backup.automountТеперь при старте системы ничего монтироваться не будет. При обращении к точке монтирования /mnt/backup будет предпринята попытка примонтировать сетевой диск при условии запущенной службы openvpn@client.service. Если служба будет отключена, диск принудительно будет отмонтирован, так как .automount жёстко привязан не только к запуску службы, но и к её работе.
Документация по mount и automount:
- systemd.mount — Mount unit configuration
- systemd.automount — Automount unit configuration
📌 Полезные ссылки по теме systemd:
◽️Systemd timers как замена Cron
◽️Journald как замена Syslog
◽️Systemd-journal-remote - централизованное хранение логов
◽️Systemd-journal-gatewayd - просмотр логов через браузер
◽️Hostnamectl для просмотра информации о системе
◽️Systemd-resolved - кэширующий DNS сервер
#systemd
Недавно делал заметку про ограничение использования диска при создании дампов базы данных, чтобы не вызывать замедление всех остальных процессов в системе. Использовал утилиту pv. Способ простой и рабочий, я его внедрил и оставил. Поставленную задачу решает.
Тем не менее, захотелось сделать это более изящно через использование приоритетов. Если диск не нагружен, то неплохо было бы его использовать с максимальной производительностью. А если нагружен, то отдать приоритет другим процесса. Это был бы наиболее рациональный и эффективный способ.
Я знаю утилиту ionice, которая в большинстве дистрибутивов есть по умолчанию. Она как раз существует для решения именно этой задачи. У неё не так много параметров, так что пользоваться ей просто. Приоритет можно передать через ключи. Для этого нужно задать режим работы:
◽Idle - идентификатор 1, процесс работает с диском только тогда, когда он не занят
◽Best effort - идентификатор 2, стандартный режим работы с возможностью выставления приоритета от 0 до 7 (0 - максимальный)
◽Real time - режим работы реального времени тоже с возможностью задавать приоритет от 0 до 7
На практике это выглядит примерно так:
Скопировали tempfile в домашний каталог в режиме idle. По идее, это то, что нужно. На практике этот приоритет не работает. Провёл разные тесты и убедился в том, что в Debian 12 ionice не работает вообще. Стал копать, почему так.
В Linux системах существуют разные планировщики процессов в отношении ввода-вывода. Раньше использовался Cfq, и ionice работает только с ним. В современных системах используется более эффективный планировщик Deadline. Проверить планировщик можно так:
Принципиальная разница этих планировщиков в том, что cfq равномерно распределяет процессы с операциями ввода-вывода, и это нормально подходит для hdd, а deadline отдаёт приоритет чтению в ущерб записи, что в целом уменьшает отклик для ssd дисков. С ними использовать его более рационально. Можно заставить работать ionice, но тогда придётся вернуть планировщик cfq, что не хочется делать, если у вас ssd диски.
Для планировщика deadline не смог найти простого и наглядного решения приоритизации процессов записи на диск. Стандартным решением по ограничению скорости, по типу того, что делает pv, является использование параметров systemd:
- IOReadBandwidthMax - объём данных, который сервису разрешается прочитать с блочных устройств за одну секунду;
- IOWriteBandwidthMax - объём данных, который сервису разрешается записать на блочные устройства за одну секунду.
Причём у него есть также параметр IODeviceWeight, что является примерно тем же самым, что и приоритет. Но работает он тоже только с cfq.
Для того, чтобы ограничить скорость записи на диск с помощью systemd, необходимо создать юнит для этого. Покажу на примере создания тестового файла с помощью dd с ограничением скорости записи в 20 мегабайт в секунду.
Запускаем:
Проверяем:
Это можно использовать как заготовку для реального задания. Если хочется потестировать в консоли, то запускайте так:
Простое рабочее решение без использования дополнительных утилит. Обращаю внимание, что если сработает кэширование записи, то визуально ограничение можно не увидеть. Я это наблюдал. И только с флагом sync её хорошо сразу же видно.
#systemd
Тем не менее, захотелось сделать это более изящно через использование приоритетов. Если диск не нагружен, то неплохо было бы его использовать с максимальной производительностью. А если нагружен, то отдать приоритет другим процесса. Это был бы наиболее рациональный и эффективный способ.
Я знаю утилиту ionice, которая в большинстве дистрибутивов есть по умолчанию. Она как раз существует для решения именно этой задачи. У неё не так много параметров, так что пользоваться ей просто. Приоритет можно передать через ключи. Для этого нужно задать режим работы:
◽Idle - идентификатор 1, процесс работает с диском только тогда, когда он не занят
◽Best effort - идентификатор 2, стандартный режим работы с возможностью выставления приоритета от 0 до 7 (0 - максимальный)
◽Real time - режим работы реального времени тоже с возможностью задавать приоритет от 0 до 7
На практике это выглядит примерно так:
# ionice -c 3 cp tempfile ~/Скопировали tempfile в домашний каталог в режиме idle. По идее, это то, что нужно. На практике этот приоритет не работает. Провёл разные тесты и убедился в том, что в Debian 12 ionice не работает вообще. Стал копать, почему так.
В Linux системах существуют разные планировщики процессов в отношении ввода-вывода. Раньше использовался Cfq, и ionice работает только с ним. В современных системах используется более эффективный планировщик Deadline. Проверить планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineПринципиальная разница этих планировщиков в том, что cfq равномерно распределяет процессы с операциями ввода-вывода, и это нормально подходит для hdd, а deadline отдаёт приоритет чтению в ущерб записи, что в целом уменьшает отклик для ssd дисков. С ними использовать его более рационально. Можно заставить работать ionice, но тогда придётся вернуть планировщик cfq, что не хочется делать, если у вас ssd диски.
Для планировщика deadline не смог найти простого и наглядного решения приоритизации процессов записи на диск. Стандартным решением по ограничению скорости, по типу того, что делает pv, является использование параметров systemd:
- IOReadBandwidthMax - объём данных, который сервису разрешается прочитать с блочных устройств за одну секунду;
- IOWriteBandwidthMax - объём данных, который сервису разрешается записать на блочные устройства за одну секунду.
Причём у него есть также параметр IODeviceWeight, что является примерно тем же самым, что и приоритет. Но работает он тоже только с cfq.
Для того, чтобы ограничить скорость записи на диск с помощью systemd, необходимо создать юнит для этого. Покажу на примере создания тестового файла с помощью dd с ограничением скорости записи в 20 мегабайт в секунду.
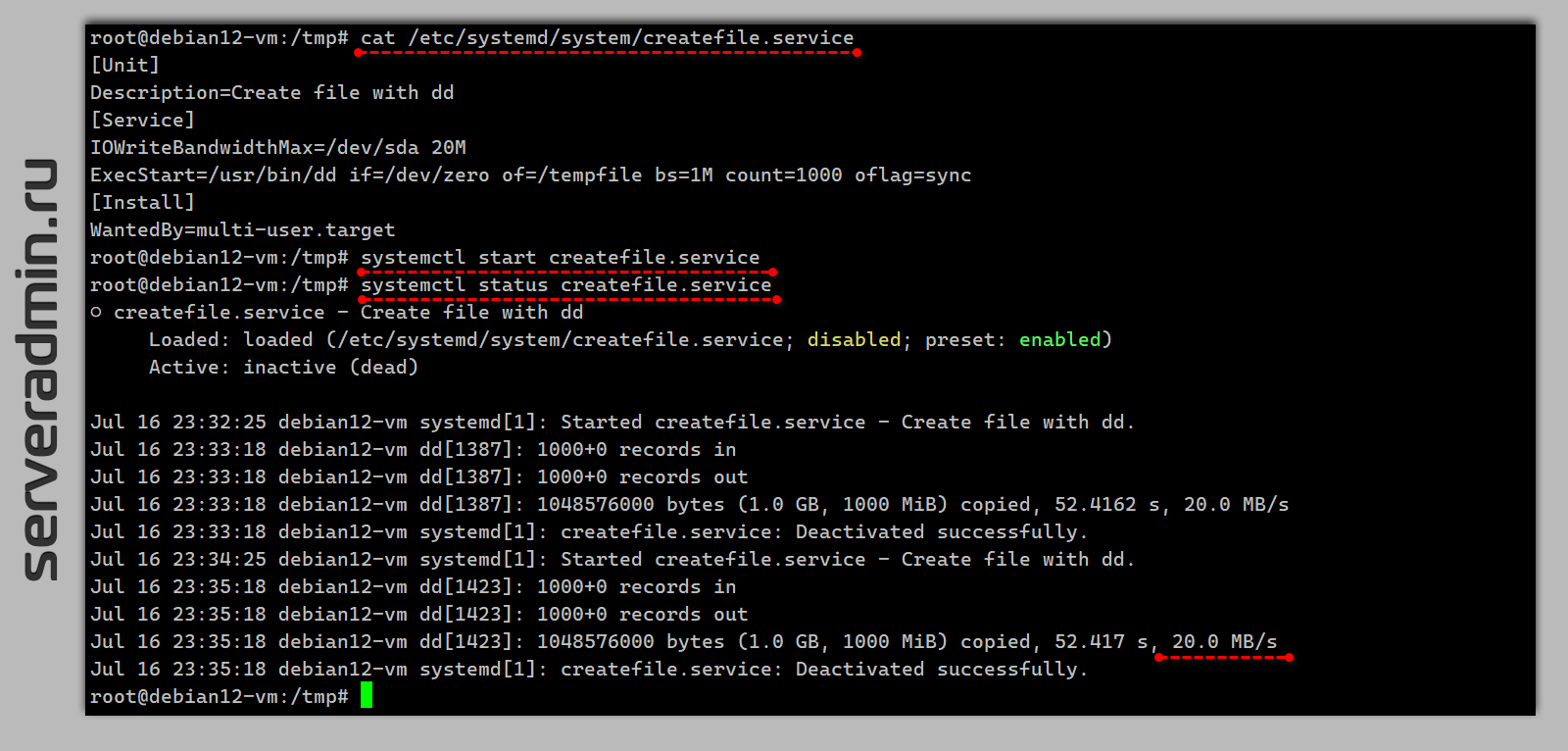
[Unit]Description=Create file with dd[Service]IOWriteBandwidthMax=/dev/sda 20MExecStart=/usr/bin/dd if=/dev/zero of=/tempfile bs=1M count=1000 oflag=sync[Install]WantedBy=multi-user.targetЗапускаем:
# systemctl start createfile.serviceПроверяем:
# systemctl status createfile.servicesystemd[1]: Started createfile.service - Create file with dd.dd[1423]: 1000+0 records indd[1423]: 1000+0 records outdd[1423]: 1048576000 bytes (1.0 GB, 1000 MiB) copied, 52.417 s, 20.0 MB/ssystemd[1]: createfile.service: Deactivated successfully.Это можно использовать как заготовку для реального задания. Если хочется потестировать в консоли, то запускайте так:
# systemd-run --scope -p IOWriteBandwidthMax='/dev/sda 20M' dd status=progress if=/dev/zero of=/tempfile bs=1M count=1000 oflag=syncПростое рабочее решение без использования дополнительных утилит. Обращаю внимание, что если сработает кэширование записи, то визуально ограничение можно не увидеть. Я это наблюдал. И только с флагом sync её хорошо сразу же видно.
#systemd
{kind=link}
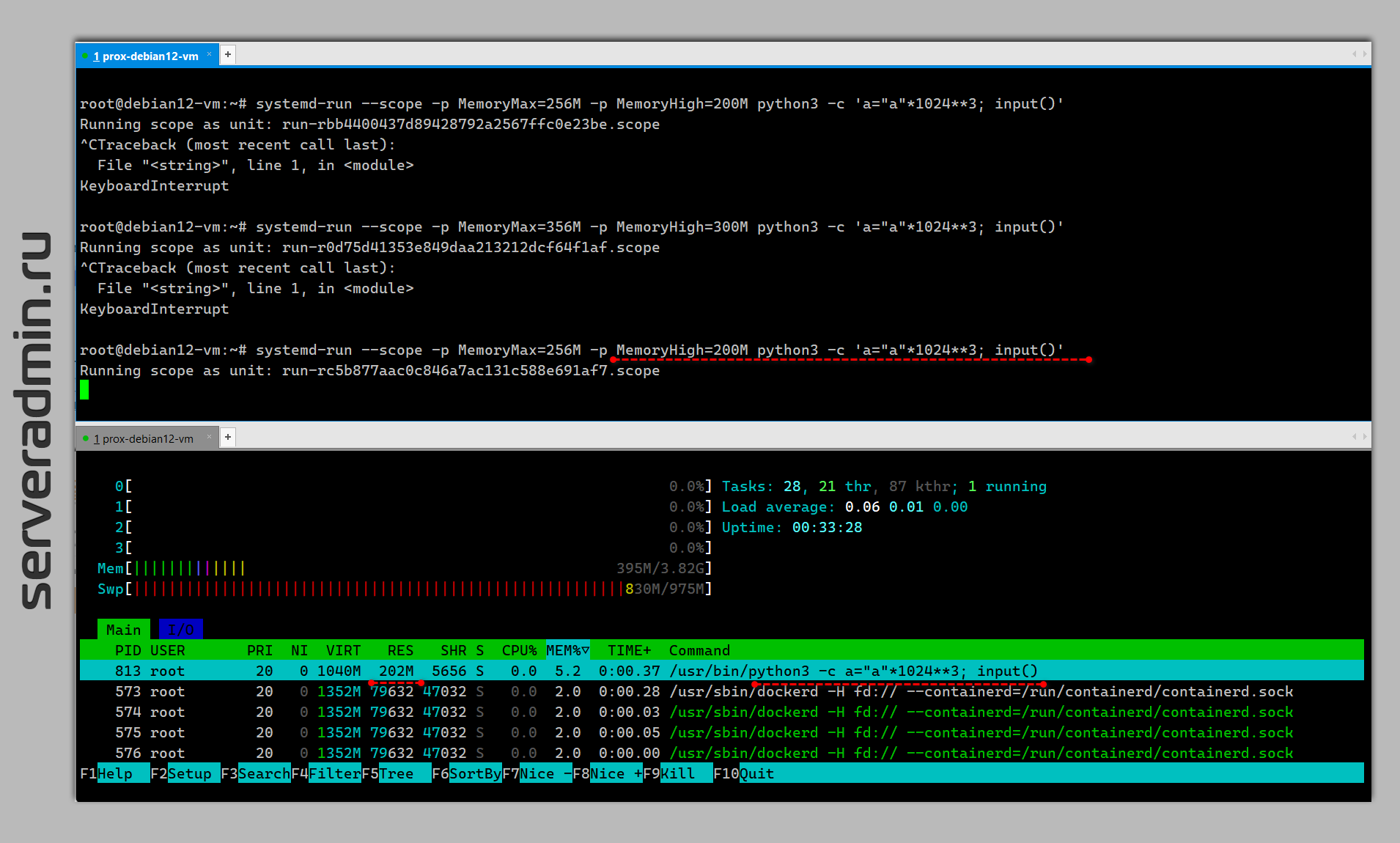
Если вам нужно ограничить процессу потребление памяти, то с systemd это сделать очень просто. Причём там есть гибкие варианты настройки. Вообще, все варианты ограничения ресурсов с помощью systemd описаны в документации. Там внушительный список. Покажу на примере памяти, какие настройки за что отвечают.
◽MemoryAccounting=1
Включение подсчёта памяти (Turn on process and kernel memory accounting for this unit)
◽MemoryHigh=16G
Это основной механизм ограничения потребления памяти (This is the main mechanism to control memory usage of a unit). Указанный лимит может быть превышен, если это необходимо, но процесс при этом будет замедляться, а память у него активно забираться назад.
◽MemoryMax=20G
Жёсткий лимит по потреблению памяти. Если процесс до него дойдет, то он будет завершён OOM Killer. В общем случае этот лимит лучше не использовать, только в крайних случаях, чтобы сохранить работоспособность системы.
◽MemorySwapMax=3G
Ограничение по использованию swap.
◽Restart=on-abnormal
Параметр не имеет отношения к потреблению памяти, но добавил сюда для справки. Если хотите, чтобы процесс перезапускался автоматически после того, как его прибьют по превышению MemoryMax, то используйте этот параметр.
◽OOMPolicy=stop
Тоже косвенный параметр, который устанавливает то, как OOM Killer будет останавливать процесс. Либо это будет попытка корректно остановить процесс через stop, либо он его просто прибьёт через kill. Выбирайте в зависимости от того, что ограничиваете. Если у процесса жор памяти означает, что он завис и его надо прибить, то ставьте kill. А если он ещё живой и может быть остановлен, тогда stop.
Параметры эти описываются в секции юнита [Service] примерно так:
Потестировать лимиты можно в консоли. Для примера возьмём python и съедим гигабайт памяти:
Команда будет висеть без ошибок, по По
Теперь зажимаем её:
Процесс работает, но потребляет разрешённые ему 200M. На практике чуть меньше. Смотрим через pmap:
Значения в килобайтах. Первое - виртуальная память (VSZ), сколько процесс запросил, столько получил. Занял весь гигабайт. Второе значение - RSS, что условно соответствует реальному потреблению физической памяти, и тут уже работает лимит. Реальной памяти процесс потребляет не больше лимита.
RSS можно ещё вот так быстро глянуть:
Вообще, с памятью у Linux всё непросто. Кому интересно, я как-то пытался в этом разобраться и рассказать простым языком.
Systemd удобный инструмент в плане управления лимитами процессов. Легко настраивать и управлять.
Считаю, что эта заметка достойна того, чтобы быть сохранённой в избранном.
#systemd
◽MemoryAccounting=1
Включение подсчёта памяти (Turn on process and kernel memory accounting for this unit)
◽MemoryHigh=16G
Это основной механизм ограничения потребления памяти (This is the main mechanism to control memory usage of a unit). Указанный лимит может быть превышен, если это необходимо, но процесс при этом будет замедляться, а память у него активно забираться назад.
◽MemoryMax=20G
Жёсткий лимит по потреблению памяти. Если процесс до него дойдет, то он будет завершён OOM Killer. В общем случае этот лимит лучше не использовать, только в крайних случаях, чтобы сохранить работоспособность системы.
◽MemorySwapMax=3G
Ограничение по использованию swap.
◽Restart=on-abnormal
Параметр не имеет отношения к потреблению памяти, но добавил сюда для справки. Если хотите, чтобы процесс перезапускался автоматически после того, как его прибьют по превышению MemoryMax, то используйте этот параметр.
◽OOMPolicy=stop
Тоже косвенный параметр, который устанавливает то, как OOM Killer будет останавливать процесс. Либо это будет попытка корректно остановить процесс через stop, либо он его просто прибьёт через kill. Выбирайте в зависимости от того, что ограничиваете. Если у процесса жор памяти означает, что он завис и его надо прибить, то ставьте kill. А если он ещё живой и может быть остановлен, тогда stop.
Параметры эти описываются в секции юнита [Service] примерно так:
[Unit]Description=Python ScriptAfter=network.target[Service]WorkingDirectory=/opt/runExecStart=/opt/run/scrape.pyRestart=on-abnormalMemoryAccounting=1MemoryHigh=16GMemoryMax=20GMemorySwapMax=3GOOMPolicy=stop[Install]WantedBy=multi-user.targetПотестировать лимиты можно в консоли. Для примера возьмём python и съедим гигабайт памяти:
# python3 -c 'a="a"*1024**3; input()'Команда будет висеть без ошибок, по По
ps или free -m будет видно, что скушала 1G оперативы. Теперь зажимаем её:
# systemd-run --scope -p MemoryMax=256M -p MemoryHigh=200M python3 -c 'a="a"*1024**3; input()'Процесс работает, но потребляет разрешённые ему 200M. На практике чуть меньше. Смотрим через pmap:
# ps ax | grep python 767 pts/0 S+ 0:00 /usr/bin/python3 -c a="a"*1024**3; input()# pmap 767 -x | grep totaltotal kB 1065048 173992 168284Значения в килобайтах. Первое - виртуальная память (VSZ), сколько процесс запросил, столько получил. Занял весь гигабайт. Второе значение - RSS, что условно соответствует реальному потреблению физической памяти, и тут уже работает лимит. Реальной памяти процесс потребляет не больше лимита.
RSS можно ещё вот так быстро глянуть:
# ps -e -o rss,args --sort -rssВообще, с памятью у Linux всё непросто. Кому интересно, я как-то пытался в этом разобраться и рассказать простым языком.
Systemd удобный инструмент в плане управления лимитами процессов. Легко настраивать и управлять.
Считаю, что эта заметка достойна того, чтобы быть сохранённой в избранном.
#systemd
{kind=link}