
Один подписчик вчера рассказал мне поучительную историю практически из первых уст от непосредственного участника. Была приложена вся первичка в виде технических подробностей и скринов, но я не буду на этом акцентировать ваше внимание, так как это второстепенная информация.
У человека был гипервизор Hyper-V, смотрящий напрямую в интернет. Встроенный брандмауэр включен, RDP порт открыт только по белым спискам IP. На хосте крутятся виртуалки, в одной из них установлена RouterOS (операционка от Микротик) со своим внешним IP. Все виртуалки в интернет ходят через неё. Соответственно, всё тоже закрыто, проброшены только нужные порты.
В какой-то момент на гипервизор установили Veeam Backup & Replication и не проконтролировали открытые порты. А он открыл для себя TCP 9401 на весь интернет. Через некоторое время через этот порт зашёл шифровальщик, всё зашифровал и оставил информацию, куда обращаться за расшифровкой.
Дальше пострадавшему повезло. Он зашёл в чат, рассказал, что денег нет и платить никто не будет, а сумма для него неподъёмная. И его почему-то пожалели и дали дешифратор. Он успешно всё расшифровал и заодно увидел в системе следы взлома в виде новой учётки с правами администратора. В чате на прощание парню дали подсказку, чтобы он обновил свой Veeam.
Он стал разбираться и нашёл относительно свежую уязвимость, через которую его скорее всего и взломали: CVE-2023-27532. The vulnerable process, Veeam.Backup.Service.exe (TCP 9401 by default), allows an unauthenticated user to request encrypted credentials.
❗️Лишний раз напоминаю, что следите за своими внешними IP адресами. Тут ошибка была в том, что гипервизор сидел на своём отдельном IP адресе напрямую во внешний интернет. Надо было его тоже закрыть Микротиком, раз он есть. Я всегда так делал, если есть отдельная виртуальная машина под шлюз. Пусть она закрывает всю виртуальную инфраструктуру и сам гипервизор. Главное, не забыть настроить её автозапуск, иначе после выключения доступа к гипервизору не будет.
В такой схеме обязательно нужен какой-то отдельный доступ к консоли гипервизора на случай непредвиденных ситуаций. Когда я часто настраивал по такой схеме гипервизоры, у меня всё было отлажено, так что я доступ к гипервизору не терял во время его перенастройки на работу через шлюз в виртуальной машине. В такой схеме ты намного защищённее и увереннее себя чувствуешь, так как весь доступ только через шлюз.
⚠ У меня тоже были ситуации, когда гипервизор по ошибке оказывался открыт со стороны интернета. Например, программно погасил интерфейс с внешним интернетом, сетевые настройки не прописывал. А в какой-то момент по неизвестной мне причине, этот интерфейс стал активен, а провайдер выдавал настройки внешнего IP по DHCP. Я очень удивился, когда обнаружил свой гипервизор вместе с RDP доступным из интернета. Просто в порядке профилактики просканировал все внешние IP адреса и заметил это.
Так что, если используете Veeam Backup & Replication, обновляйтесь. И не выставляйте в интернет то, чему там не место. За этим надо регулярно следить, так как от ошибок и случайностей никто не застрахован.
📌 Полезные ссылки по теме:
▪ Esxi: меня взломали! Лечим и понимаем причину
▪ Автоматическая проверка серверов с помощью OpenVAS
▪ Проверка хостов на CVE на открытых портах
▪ Регулярная проверка с помощью Nmap
▪ Сетевой сканер для поиска уязвимостей - Nessus Scanner
Заберите список в закладки. Что-нибудь наверняка пригодится.
#security
У человека был гипервизор Hyper-V, смотрящий напрямую в интернет. Встроенный брандмауэр включен, RDP порт открыт только по белым спискам IP. На хосте крутятся виртуалки, в одной из них установлена RouterOS (операционка от Микротик) со своим внешним IP. Все виртуалки в интернет ходят через неё. Соответственно, всё тоже закрыто, проброшены только нужные порты.
В какой-то момент на гипервизор установили Veeam Backup & Replication и не проконтролировали открытые порты. А он открыл для себя TCP 9401 на весь интернет. Через некоторое время через этот порт зашёл шифровальщик, всё зашифровал и оставил информацию, куда обращаться за расшифровкой.
Дальше пострадавшему повезло. Он зашёл в чат, рассказал, что денег нет и платить никто не будет, а сумма для него неподъёмная. И его почему-то пожалели и дали дешифратор. Он успешно всё расшифровал и заодно увидел в системе следы взлома в виде новой учётки с правами администратора. В чате на прощание парню дали подсказку, чтобы он обновил свой Veeam.
Он стал разбираться и нашёл относительно свежую уязвимость, через которую его скорее всего и взломали: CVE-2023-27532. The vulnerable process, Veeam.Backup.Service.exe (TCP 9401 by default), allows an unauthenticated user to request encrypted credentials.
❗️Лишний раз напоминаю, что следите за своими внешними IP адресами. Тут ошибка была в том, что гипервизор сидел на своём отдельном IP адресе напрямую во внешний интернет. Надо было его тоже закрыть Микротиком, раз он есть. Я всегда так делал, если есть отдельная виртуальная машина под шлюз. Пусть она закрывает всю виртуальную инфраструктуру и сам гипервизор. Главное, не забыть настроить её автозапуск, иначе после выключения доступа к гипервизору не будет.
В такой схеме обязательно нужен какой-то отдельный доступ к консоли гипервизора на случай непредвиденных ситуаций. Когда я часто настраивал по такой схеме гипервизоры, у меня всё было отлажено, так что я доступ к гипервизору не терял во время его перенастройки на работу через шлюз в виртуальной машине. В такой схеме ты намного защищённее и увереннее себя чувствуешь, так как весь доступ только через шлюз.
⚠ У меня тоже были ситуации, когда гипервизор по ошибке оказывался открыт со стороны интернета. Например, программно погасил интерфейс с внешним интернетом, сетевые настройки не прописывал. А в какой-то момент по неизвестной мне причине, этот интерфейс стал активен, а провайдер выдавал настройки внешнего IP по DHCP. Я очень удивился, когда обнаружил свой гипервизор вместе с RDP доступным из интернета. Просто в порядке профилактики просканировал все внешние IP адреса и заметил это.
Так что, если используете Veeam Backup & Replication, обновляйтесь. И не выставляйте в интернет то, чему там не место. За этим надо регулярно следить, так как от ошибок и случайностей никто не застрахован.
📌 Полезные ссылки по теме:
▪ Esxi: меня взломали! Лечим и понимаем причину
▪ Автоматическая проверка серверов с помощью OpenVAS
▪ Проверка хостов на CVE на открытых портах
▪ Регулярная проверка с помощью Nmap
▪ Сетевой сканер для поиска уязвимостей - Nessus Scanner
Заберите список в закладки. Что-нибудь наверняка пригодится.
#security
Распространённая ситуация (картинка внизу 👇), когда люди не понимают работу айтишников или не могут правильно её оценить. Из-за этого некоторые специалисты сознательно делают что-то плохо, растягивают дела, создают видимость работы. Они это объясняют тем, что иначе трудно убедить заказчика или работодателя платить определённую сумму. Он заплатит только за фактическое время, а потом скажет, что я сижу без дела и платить мне не обязательно. На практике так реально бывает. Кого-то даже увольняют, считая, что и так всё хорошо работает. Перебьёмся фрилансером, приезжающим по заявкам. Иногда перебиваются, иногда нет.
Я всегда решал подобные разногласия по-другому. Если я видел, что с руководителем могут возникать подобные разговоры, то просто скрупулёзно вёл список дел. И если меня кто-то спросит, чем я занимался в течении дня или на прошлой неделе, я спокойно покажу список дел. Если были какие-то аварии или настройка новых сервисов, то прямо об этом напишу. Тут все просто и понятно. Если не было чего-то особенного, а обычная рутина по обслуживанию, то оберну это примерно в такие формулировки:
◽Плановая проверка бэкапов, как по их наличию, так и возможности восстановления сохранённой информации
◽Анализ возможных уязвимостей используемого в инфраструктуре ПО, установка критических обновлений с предварительной проверкой их на тестовом стенде
◽Аудит потребления ресурсов сервером 1С. Присутствовали всплески потребления CPU, которые приводили к кратковременным задержкам в работе баз. Анализ вероятных причин и вариантов решения проблемы
Формулировки обтекаемые и человеку, который погружён в тему (шарит), понятно, что ему немного ездят по ушам. Но такие люди обычно и не спрашивают, чем занимается айтишник, итак понимают. А вот если человек не понимает его работу, то для него это сойдёт. К тому же, этот список не виртуальный, а реальный. Вы сможете его развернуть с подробностями, если у вас попросят. Вы же реально настроили бэкапы и проверяете их наличие и качество, просто автоматически. Но на создание этой системы ушло время, к тому же всё равно нужен контроль. То же самое с обновлениями. Так или иначе вы всё равно их регулярно ставите и если попросят подробности, то можно рассказать, что конкретно и зачем было обновлено. То же самое с сервером 1С. Подобная задача возникла, потому что от сервера 1С реально прилетали оповещения с мониторинга и приходилось как-то реагировать на них, тратить время.
Достаточно просто в конце дня подумать, чем ты занимался и оформить это в краткий список дел (3-5). Со временем это входит в привычку и занимает очень мало времени. Да и проверять эти списки чаще всего никто не будет, потому что на это надо время. У вас их проверят один-два раза, а потом либо вообще просить не будут, либо не будут проверять.
Подробный список задач поможет убедить нанять помощника, если у вас действительно не хватает времени на все свои задачи. Также на основе своих задач вы сможете объяснить, почему новая задача откладывается на какой-то срок, так как сейчас вы занимаетесь другой. Со списком задач вы можете более предметно обсуждать повышение зарплаты.
❗️Таким образом, записанный реальный список задач — это ваш надежный помощник, а не просто какая-то формальность, которая отнимает время. Причём не обязательно искать какой-то софт для них. Я в обычном текстовом формате их вёл и отправлял в основном по почте.
#мем
Я всегда решал подобные разногласия по-другому. Если я видел, что с руководителем могут возникать подобные разговоры, то просто скрупулёзно вёл список дел. И если меня кто-то спросит, чем я занимался в течении дня или на прошлой неделе, я спокойно покажу список дел. Если были какие-то аварии или настройка новых сервисов, то прямо об этом напишу. Тут все просто и понятно. Если не было чего-то особенного, а обычная рутина по обслуживанию, то оберну это примерно в такие формулировки:
◽Плановая проверка бэкапов, как по их наличию, так и возможности восстановления сохранённой информации
◽Анализ возможных уязвимостей используемого в инфраструктуре ПО, установка критических обновлений с предварительной проверкой их на тестовом стенде
◽Аудит потребления ресурсов сервером 1С. Присутствовали всплески потребления CPU, которые приводили к кратковременным задержкам в работе баз. Анализ вероятных причин и вариантов решения проблемы
Формулировки обтекаемые и человеку, который погружён в тему (шарит), понятно, что ему немного ездят по ушам. Но такие люди обычно и не спрашивают, чем занимается айтишник, итак понимают. А вот если человек не понимает его работу, то для него это сойдёт. К тому же, этот список не виртуальный, а реальный. Вы сможете его развернуть с подробностями, если у вас попросят. Вы же реально настроили бэкапы и проверяете их наличие и качество, просто автоматически. Но на создание этой системы ушло время, к тому же всё равно нужен контроль. То же самое с обновлениями. Так или иначе вы всё равно их регулярно ставите и если попросят подробности, то можно рассказать, что конкретно и зачем было обновлено. То же самое с сервером 1С. Подобная задача возникла, потому что от сервера 1С реально прилетали оповещения с мониторинга и приходилось как-то реагировать на них, тратить время.
Достаточно просто в конце дня подумать, чем ты занимался и оформить это в краткий список дел (3-5). Со временем это входит в привычку и занимает очень мало времени. Да и проверять эти списки чаще всего никто не будет, потому что на это надо время. У вас их проверят один-два раза, а потом либо вообще просить не будут, либо не будут проверять.
Подробный список задач поможет убедить нанять помощника, если у вас действительно не хватает времени на все свои задачи. Также на основе своих задач вы сможете объяснить, почему новая задача откладывается на какой-то срок, так как сейчас вы занимаетесь другой. Со списком задач вы можете более предметно обсуждать повышение зарплаты.
❗️Таким образом, записанный реальный список задач — это ваш надежный помощник, а не просто какая-то формальность, которая отнимает время. Причём не обязательно искать какой-то софт для них. Я в обычном текстовом формате их вёл и отправлял в основном по почте.
#мем
{kind=link}
🔝Как обычно, традиционный топ постов за прошедший месяц. Надеюсь, вам хорошо отдыхается в эти праздники. Я наконец-то уехал на дачу до 10-го мая. С того момента, как дети начали ходить в школу, это стало делать сложнее. До этого часто в начале мая уезжали до сентября из города. А в пандемийный год вообще с конца марта до сентября жили на даче.
📌 Больше всего просмотров:
◽️Утилита ioping для анализа дисков (8863)
◽️Бэкап реп из github или gitlab (8038)
◽️Self-hosted система анализа посещений сайта PostHog (7910)
📌 Больше всего комментариев:
◽️Замена бесплатной почты для домена от Яндекс (381)
◽️Бесплатный программный шлюз Sophos Firewall Home Edition (107)
◽️Почтовый сервер Tegu (103)
📌 Больше всего пересылок:
◽️Бэкап и перенос систем с помощью ReaR (457)
◽️Утилита ioping для анализа дисков (366)
◽️Советы по безопасности для Debian от CIS (318)
◽️Подборка обучающих игр (315)
📌 Больше всего реакций:
◽️Описание работы протокола DHCP (196)
◽️Бэкап и перенос систем с помощью ReaR (157)
◽️Баг и отключение Credential Guard в Windows 11 (152)
◽️За что вам, айтишникам, вообще платят? (147)
#топ
📌 Больше всего просмотров:
◽️Утилита ioping для анализа дисков (8863)
◽️Бэкап реп из github или gitlab (8038)
◽️Self-hosted система анализа посещений сайта PostHog (7910)
📌 Больше всего комментариев:
◽️Замена бесплатной почты для домена от Яндекс (381)
◽️Бесплатный программный шлюз Sophos Firewall Home Edition (107)
◽️Почтовый сервер Tegu (103)
📌 Больше всего пересылок:
◽️Бэкап и перенос систем с помощью ReaR (457)
◽️Утилита ioping для анализа дисков (366)
◽️Советы по безопасности для Debian от CIS (318)
◽️Подборка обучающих игр (315)
📌 Больше всего реакций:
◽️Описание работы протокола DHCP (196)
◽️Бэкап и перенос систем с помощью ReaR (157)
◽️Баг и отключение Credential Guard в Windows 11 (152)
◽️За что вам, айтишникам, вообще платят? (147)
#топ
Покажу на простом и наглядном примере методику защиты от типичных брутфорс атак (перебор учётных записей). Для этого возьму всем привычный инструмент nmap и популярный движок сайта Wordpress. Все настройки возьму с реально работающего сервера, где блокировка переборов паролей успешно работает.
Сайты на Wordpress брутят повсеместно. Из-за того, что этот движок очень легко установить, много установок, сделанных дилетантами (сеошники, блогеры и т.д.). О безопасности там никто особо не заботится, поэтому и вероятность взлома значительная, чтобы заинтересованные люди решили потратить на это своё время.
Для примера покажу, как легко и просто начать подбор паролей. Возьмём всем известный сетевой сканер nmap. Нам понадобится любой список паролей, по которому мы будем делать перебор. Можно взять для тестов простые списки в репозитории BruteX или огромный список в wordlist.
В составе nmap есть готовый скрипт для брута админки Wordpress. Достаточно указать адрес сайта, учётную запись, например, admin и список паролей для перебора. Запускаем перебор:
В логах веб сервера увидите POST запросы к
Теперь расскажу, как работает защита от такого перебора с помощью fail2ban. Устанавливаете его в систему и делаете очень простой фильтр
Он ищет все POST запросы к указанным url. Это защита от подборка учёток через wp-login и xmlrpc (последний лучше вообще отключить или закрыть доступ через nginx). Далее создаём настройку jail
Это пример настроек, когда используется iptables. Теперь, как только в логе access.log появится более 5 попыток POST запросов к wp-login.php или xmlrpc.php, IP адрес обратившегося будет забанен. Это удобно проверить с помощью скрипта для nmap.
Подобным образом можно настроить защиту от перебора учётных записей любого сервиса, который записывает информацию об аутентификации в текстовый лог файл. Главное не забыть очень важный момент. Лог файл не должен быть очень большим. Обязательно необходима ротация по размеру файла. Если лог становится очень большим, то fail2ban может сам повесить сервер. Он написан, если не ошибаюсь, на Python и работает не очень быстро. Если вас начинают ддосить и access лог разрастается за минуту до гигабайтов, fail2ban вам сам повесит сервер. Его надо оперативно выключать. В отдельной заметке расскажу, как сделать более универсальную защиту без необходимости парсить access.log.
Более подробно с примерами эта настройка описана у меня на сайте в статье: Защита админки wordpress с помощью fail2ban.
Отдельно отмечу, что для fail2ban есть веб интерфейс — fail2web
#security #webserver #wordpress #fail2ban
Сайты на Wordpress брутят повсеместно. Из-за того, что этот движок очень легко установить, много установок, сделанных дилетантами (сеошники, блогеры и т.д.). О безопасности там никто особо не заботится, поэтому и вероятность взлома значительная, чтобы заинтересованные люди решили потратить на это своё время.
Для примера покажу, как легко и просто начать подбор паролей. Возьмём всем известный сетевой сканер nmap. Нам понадобится любой список паролей, по которому мы будем делать перебор. Можно взять для тестов простые списки в репозитории BruteX или огромный список в wordlist.
В составе nmap есть готовый скрипт для брута админки Wordpress. Достаточно указать адрес сайта, учётную запись, например, admin и список паролей для перебора. Запускаем перебор:
# nmap example.com --script http-wordpress-brute --script-args \'user=admin, passdb=password.lst, http-wordpress-brute.thread=3, brute.firstonly=true'В логах веб сервера увидите POST запросы к
/wp-login.php от user_agent="Mozilla/5.0 (compatible; Nmap Scripting Engine; https://nmap.org/book/nse.html)". Этот скрипт удобно использовать для тестирования своей защиты. Теперь расскажу, как работает защита от такого перебора с помощью fail2ban. Устанавливаете его в систему и делаете очень простой фильтр
wp-login.conf, положив его в директорию /etc/fail2ban/filter.d:[Definition]failregex = <HOST>.*POST.*(wp-login\.php|xmlrpc\.php).*Он ищет все POST запросы к указанным url. Это защита от подборка учёток через wp-login и xmlrpc (последний лучше вообще отключить или закрыть доступ через nginx). Далее создаём настройку jail
wp-login.conf и кладём её в директорию /etc/fail2ban/jail.d:[wp-login]enabled = trueport = http,httpsaction = iptables-multiport[name=WP, port="http,https", protocol=tcp]filter = wp-loginlogpath = /var/log/nginx/example.com/access.logmaxretry = 5Это пример настроек, когда используется iptables. Теперь, как только в логе access.log появится более 5 попыток POST запросов к wp-login.php или xmlrpc.php, IP адрес обратившегося будет забанен. Это удобно проверить с помощью скрипта для nmap.
Подобным образом можно настроить защиту от перебора учётных записей любого сервиса, который записывает информацию об аутентификации в текстовый лог файл. Главное не забыть очень важный момент. Лог файл не должен быть очень большим. Обязательно необходима ротация по размеру файла. Если лог становится очень большим, то fail2ban может сам повесить сервер. Он написан, если не ошибаюсь, на Python и работает не очень быстро. Если вас начинают ддосить и access лог разрастается за минуту до гигабайтов, fail2ban вам сам повесит сервер. Его надо оперативно выключать. В отдельной заметке расскажу, как сделать более универсальную защиту без необходимости парсить access.log.
Более подробно с примерами эта настройка описана у меня на сайте в статье: Защита админки wordpress с помощью fail2ban.
Отдельно отмечу, что для fail2ban есть веб интерфейс — fail2web
#security #webserver #wordpress #fail2ban
Не надо вот так настраивать веб сервера. В тексте ошибки полная информация о системе. Всю техническую информацию о системе, веб сервере и его версии нужно отключать в настройках. Везде есть этот параметр. Например, в nginx это
И обязательно удаляйте или заменяйте стандартные заглушки от страниц с ошибками, особенно 404 и 502. Они иногда тоже выдают служебную информацию.
Кстати, если в поисковиках поискать что-то по подобным служебным строкам, то можно найти кучу сайтов с открытыми потрохами. Вот несколько примеров:
- http://www.zoonman.ru/files/
- https://gusto-ufa.ru/test.php
- https://neiroplus.ru/test/ (phpinfo в паблик вывалили)
Нашёл через Яндекс.
#webserver
server_tokens off. По умолчанию он в режиме on.И обязательно удаляйте или заменяйте стандартные заглушки от страниц с ошибками, особенно 404 и 502. Они иногда тоже выдают служебную информацию.
Кстати, если в поисковиках поискать что-то по подобным служебным строкам, то можно найти кучу сайтов с открытыми потрохами. Вот несколько примеров:
- http://www.zoonman.ru/files/
- https://gusto-ufa.ru/test.php
- https://neiroplus.ru/test/ (phpinfo в паблик вывалили)
Нашёл через Яндекс.
#webserver
Ещё один пример защиты веб сервера с помощью fail2ban. На этот раз пример будет более универсальный, который защитит не только от брута, но и от любых множественных подключений к серверу.
Для этого нам понадобятся модули nginx limit_req и limit_conn. С их помощью можно ограничить скорость обработки запросов с одного IP адреса. Для этого в основной конфигурации nginx, в разделе http, нужно добавить одну или несколько зон с максимальной скоростью обработки запросов или количеством числа соединений с одного IP. Я обычно использую несколько зон, чаще всего четыре. Одна для общего ограничения соединений, вторая для статики, третья для легких динамических запросов (обычные php страницы), четвёртая для тяжёлых динамических запросов (аутентификация, поиск, формирование большого каталога и т.д.).
Выглядят настройки примерно так:
Зону лучше называть по разрешённому лимиту, чтобы проще было использовать в настройках. Далее идём в конфиг виртуального хоста и там расставляем зоны в общей настройке server и разных locations. Примерно так:
Здесь главное без фанатизма использовать лимиты, особенно на общие страницы и статику, чтобы не блокировать поисковые системы или какие-то другие полезные боты. После настройки некоторое время понаблюдайте за ограничениями.
Сработанные ограничения будут отображаться в error.log nginx. Его мы и будем проверять с помощью fail2ban. Для этого добавляем в директорию
nginx-limit-conn.conf:
nginx-limit-req.conf:
И в
nginx-limit-conn.conf
nginx-limit-req.conf
Теперь нарушители лимитов будут отправляться в бан. При этом не так критично разрастание логов, так как error лог редко растёт быстро, даже если вас ддосят. Но всё равно не нужно забывать про его ротацию.
Все лимиты и реакции настраивайте в зависимости от вашей ситуации. Не надо брать мои значения из примера. Они сильно зависят от типа сайта и производительности сервера. Главное, как я уже сказал, без фанатизма. Лимиты должны быть комфортными для легитимных пользователей и систем.
Есть более простой в плане нагрузки способ блокировать тех, кто открывает слишком много соединений. Использовать системную информацию о подключениях, например, с помощью netstat и если превышен лимит, отправлять IP в бан. Я не очень люблю этот способ и редко использую, так как нет гибкой настройки по сайтам, урлам и т.д. Его стоит использовать, если вас ддосят и вам надо максимально быстро и дёшево по ресурсам блокировать атакующих. Иногда это помогает, если ддос не очень сильный и провайдер вас не отключает. Если интересно посмотреть эту реализацию, то напишите в комментах, я расскажу с примером.
#security #fail2ban #webserver #nginx
Для этого нам понадобятся модули nginx limit_req и limit_conn. С их помощью можно ограничить скорость обработки запросов с одного IP адреса. Для этого в основной конфигурации nginx, в разделе http, нужно добавить одну или несколько зон с максимальной скоростью обработки запросов или количеством числа соединений с одного IP. Я обычно использую несколько зон, чаще всего четыре. Одна для общего ограничения соединений, вторая для статики, третья для легких динамических запросов (обычные php страницы), четвёртая для тяжёлых динамических запросов (аутентификация, поиск, формирование большого каталога и т.д.).
Выглядят настройки примерно так:
limit_conn_zone $binary_remote_addr zone=perip:10m;limit_req_zone $binary_remote_addr zone=lim_50r:10m rate=50r/s;limit_req_zone $binary_remote_addr zone=lim_10r:10m rate=10r/s; limit_req_zone $binary_remote_addr zone=lim_3r:10m rate=3r/s;Зону лучше называть по разрешённому лимиту, чтобы проще было использовать в настройках. Далее идём в конфиг виртуального хоста и там расставляем зоны в общей настройке server и разных locations. Примерно так:
server { ... limit_conn perip 100; ...# поискlocation /?s= { limit_req zone=lim_3r burst=5 nodelay; ...}# динамика location ~ \.php$ { limit_req zone=lim_10r burst=15 nodelay; ...}# всё остальное location / { limit_req zone=lim_50r burst=65 nodelay; ...}}Здесь главное без фанатизма использовать лимиты, особенно на общие страницы и статику, чтобы не блокировать поисковые системы или какие-то другие полезные боты. После настройки некоторое время понаблюдайте за ограничениями.
Сработанные ограничения будут отображаться в error.log nginx. Его мы и будем проверять с помощью fail2ban. Для этого добавляем в директорию
/etc/fail2ban/filter.d два конфига.nginx-limit-conn.conf:
[Definition]failregex = ^\s*\[[a-z]+\] \d+#\d+: \*\d+ limiting connections by zone.*client: <HOST>ignoreregex =nginx-limit-req.conf:
[Definition]ngx_limit_req_zones = [^"]+failregex = ^\s*\[[a-z]+\] \d+#\d+: \*\d+ limiting requests, excess: [\d\.]+ by zone "(?:%(ngx_limit_req_zones)s)", client: <HOST>,ignoreregex = datepattern = {^LN-BEG}И в
/etc/fail2ban/jail.d два файла конфигурации:nginx-limit-conn.conf
[nginx-limit-conn]enabled = truefilter = nginx-limit-connport = httpaction = iptables-multiport[name=ConnLimit, port="http,https", protocol=tcp]logpath = /web/sites/*/logs/error.logbantime = 3600maxretry = 20nginx-limit-req.conf
[nginx-limit-req]enabled = truefilter = nginx-limit-reqaction = iptables-multiport[name=ReqLimit, port="http,https", protocol=tcp]logpath = /web/sites/*/logs/error.logbantime = 3600maxretry = 10Теперь нарушители лимитов будут отправляться в бан. При этом не так критично разрастание логов, так как error лог редко растёт быстро, даже если вас ддосят. Но всё равно не нужно забывать про его ротацию.
Все лимиты и реакции настраивайте в зависимости от вашей ситуации. Не надо брать мои значения из примера. Они сильно зависят от типа сайта и производительности сервера. Главное, как я уже сказал, без фанатизма. Лимиты должны быть комфортными для легитимных пользователей и систем.
Есть более простой в плане нагрузки способ блокировать тех, кто открывает слишком много соединений. Использовать системную информацию о подключениях, например, с помощью netstat и если превышен лимит, отправлять IP в бан. Я не очень люблю этот способ и редко использую, так как нет гибкой настройки по сайтам, урлам и т.д. Его стоит использовать, если вас ддосят и вам надо максимально быстро и дёшево по ресурсам блокировать атакующих. Иногда это помогает, если ддос не очень сильный и провайдер вас не отключает. Если интересно посмотреть эту реализацию, то напишите в комментах, я расскажу с примером.
#security #fail2ban #webserver #nginx
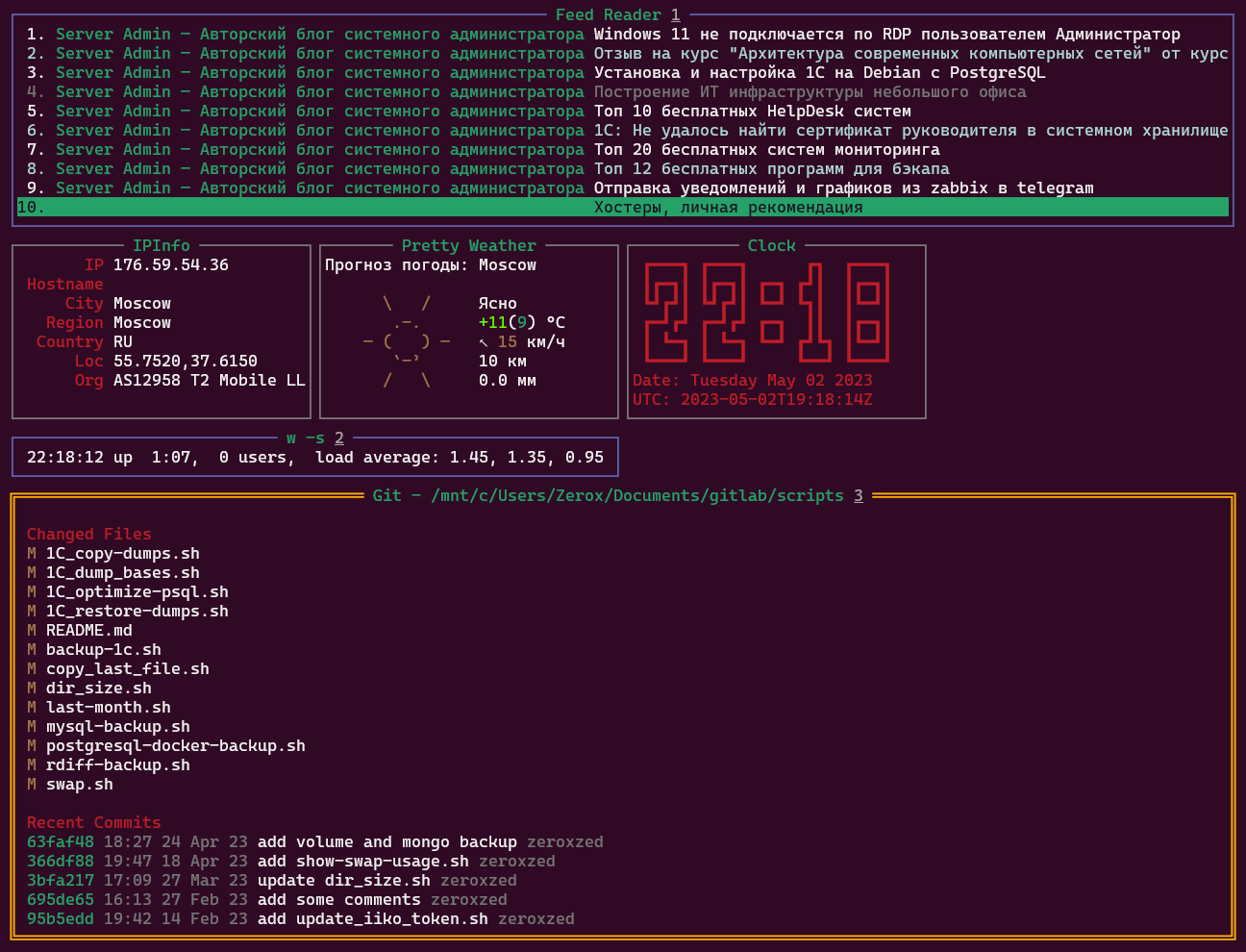
Рассказываю про практически бесполезную, но интересную программу на go, которая позволяет создавать в консоли дашборды с виджетами из разных сервисов. Речь пойдёт про wtfutil. Программа состоит из одного бинарника и конфигурационного файла в формате yaml.
Можете сразу посмотреть картинку к посту, чтобы понять, о чём пойдёт речь. Я собрал себе вот такой дашборд из модулей, которые не требуют внешних интеграций через API сервисов и токены. Там только локальные виджеты:
◽RSS ридер со статьями с моего сайта
◽Информация о моём внешнем IP
◽Погода в Москве
◽Цифровые часы
◽Аптайм ноутбука (попробовал виджет с любой консольной командой)
◽Обзор локальных репозиториев GIT
Некоторые виджеты, например с GIT или RSS, имеют отдельное управление. На них можно переключаться через tab, открывать ссылки или листать разные репозитории. Я добавил пару локальных для теста.
Wtfutil имеет довольно много модулей для интеграции с внешними сервисами. Например, может из google analytics показывать статистику по какому-то сайту, из todoist выводить список дел, из gitlab информацию о своих проектах, из UptimeRobot информацию о проверках, из google календаря информацию о событиях и т.д. Полный список можно посмотреть в документации. Для всех модулей есть примеры. Настраивается всё интуитивно и легко. Вот здесь подробно описаны некоторые модули сразу с картинками.
Я просто скачал бинарник и запустил wtfutil на ноуте в WSL2. Без проблем заработало. Шутка интересная, но не знаю, насколько может быть полезной. Мне по приколу было собрать этот дашборд. Думаю для тех, у кого Linux основная система это может оказаться полезным. Судя по тому, что программа живёт в Homebrew, написана она была скорее всего для маководов.
#linux #terminal
Можете сразу посмотреть картинку к посту, чтобы понять, о чём пойдёт речь. Я собрал себе вот такой дашборд из модулей, которые не требуют внешних интеграций через API сервисов и токены. Там только локальные виджеты:
◽RSS ридер со статьями с моего сайта
◽Информация о моём внешнем IP
◽Погода в Москве
◽Цифровые часы
◽Аптайм ноутбука (попробовал виджет с любой консольной командой)
◽Обзор локальных репозиториев GIT
Некоторые виджеты, например с GIT или RSS, имеют отдельное управление. На них можно переключаться через tab, открывать ссылки или листать разные репозитории. Я добавил пару локальных для теста.
Wtfutil имеет довольно много модулей для интеграции с внешними сервисами. Например, может из google analytics показывать статистику по какому-то сайту, из todoist выводить список дел, из gitlab информацию о своих проектах, из UptimeRobot информацию о проверках, из google календаря информацию о событиях и т.д. Полный список можно посмотреть в документации. Для всех модулей есть примеры. Настраивается всё интуитивно и легко. Вот здесь подробно описаны некоторые модули сразу с картинками.
Я просто скачал бинарник и запустил wtfutil на ноуте в WSL2. Без проблем заработало. Шутка интересная, но не знаю, насколько может быть полезной. Мне по приколу было собрать этот дашборд. Думаю для тех, у кого Linux основная система это может оказаться полезным. Судя по тому, что программа живёт в Homebrew, написана она была скорее всего для маководов.
#linux #terminal
{kind=link}
В systemd есть удобный механизм автозапуска сервиса в случае его завершения работы по той или иной причине. Какой-то стандартный софт имеет эту настройку в том или ином виде по умолчанию, например, Mariadb в Debian, какой-то нет, и это нужно сделать вручную.
Автозапуском сервиса управляет параметр
◽always — перезапускать всегда, когда сервис был остановлен корректно (exit code 0), с кодом ошибки или завис по таймауту
◽on-success — перезапускать, только если служба завершилась без ошибок (exit code 0)
◽on-failure — перезапускать, только если код завершения был не нулевым, был прибит одним из сигналов принудительного завершения работы (например SIGKILL), завис по таймауту
◽on-abnormal — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы или завис по таймауту
◽on-abort — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы
◽on-watchdog — перезапускать только если наступил настроенный для сервиса watchdog timeout
◽no — автоматического перезапуска нет
Надеюсь нигде не наврал. Перевёл кратенько отрывок документации, чтобы не притащить чьи-то ошибки. Так то в инете много статей по этой теме. По умолчанию, если явно не указан параметр, он принимает значение
Для того, чтобы настроить автоматический запуск сервиса, не надо редактировать его основной unit файл. Сделайте отдельный файл изменений
Добавьте туда:
После изменений надо перечитать настройки служб:
Теперь можно прибить Nginx и убедиться, что через 5 секунд он поднимется снова:
К автозапуску процессов надо подходить с умом. Не стоит для всех подряд его настраивать. Особенное внимание надо уделить службам СУБД. После аварийного завершения работы может запускаться очень ресурсоёмкая процедура восстановления данных, которая в нагруженном сервере может быть прибита oom killer и так по кругу. Это может привести к более серьезным последствиям или потере данных.
То же самое касается каких-то кластерных служб. Они могут падать и подниматься в цикле и приводить к рассинхронизации или каким-то ещё проблемам. Например, elasticsearch может подниматься очень долго на слабом железе. Иногда приходится стандартные таймауты systemd увеличивать, чтобы он удачно стартовал. Если настроить автозапуск, он может в цикле прибивать службу по таймауту.
А тот же самый Nginx, Postfix, Dovecot, Apache, Zabbix Agent можно спокойно ставить в автозапуск в случае падений. Проблем быть не должно.
У автозапуска есть более тонкие настройки и зависимости. Я описал только основной функционал, который нужен чаще всего. Более подробно всё описано в документации. Там настраиваются таймауты, различные статусы завершения работы, которые стоит считать успешными, количество попыток перезапуска, прежде чем они прекратятся и т.д. Можно слать оповещения на почту в случае падения и перезапуска службы. Это делается через параметр
Табличку себе сохраните на память для настройки. Без неё неочевидно, какой параметр лучше использовать. Например, Mariadb по умолчанию имеет настройку
#systemd #linux
Автозапуском сервиса управляет параметр
Restart в разделе [Service]. Он может принимать следующие значения:◽always — перезапускать всегда, когда сервис был остановлен корректно (exit code 0), с кодом ошибки или завис по таймауту
◽on-success — перезапускать, только если служба завершилась без ошибок (exit code 0)
◽on-failure — перезапускать, только если код завершения был не нулевым, был прибит одним из сигналов принудительного завершения работы (например SIGKILL), завис по таймауту
◽on-abnormal — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы или завис по таймауту
◽on-abort — перезапускать только если сервис был прибит одним из сигналов принудительного завершения работы
◽on-watchdog — перезапускать только если наступил настроенный для сервиса watchdog timeout
◽no — автоматического перезапуска нет
Надеюсь нигде не наврал. Перевёл кратенько отрывок документации, чтобы не притащить чьи-то ошибки. Так то в инете много статей по этой теме. По умолчанию, если явно не указан параметр, он принимает значение
no.Для того, чтобы настроить автоматический запуск сервиса, не надо редактировать его основной unit файл. Сделайте отдельный файл изменений
override.conf и положите его в директорию сервиса со специальным именем. Для nginx оно будет такое: /etc/systemd/system/nginx.service.d/override.conf.Добавьте туда:
[Service]Restart=alwaysRestartSec=5sПосле изменений надо перечитать настройки служб:
# systemctl daemon-reloadТеперь можно прибить Nginx и убедиться, что через 5 секунд он поднимется снова:
# systemctl status nginx ; смотрим pid корневого процесса (Main PID)# kill -9 1910155# systemctl status nginxК автозапуску процессов надо подходить с умом. Не стоит для всех подряд его настраивать. Особенное внимание надо уделить службам СУБД. После аварийного завершения работы может запускаться очень ресурсоёмкая процедура восстановления данных, которая в нагруженном сервере может быть прибита oom killer и так по кругу. Это может привести к более серьезным последствиям или потере данных.
То же самое касается каких-то кластерных служб. Они могут падать и подниматься в цикле и приводить к рассинхронизации или каким-то ещё проблемам. Например, elasticsearch может подниматься очень долго на слабом железе. Иногда приходится стандартные таймауты systemd увеличивать, чтобы он удачно стартовал. Если настроить автозапуск, он может в цикле прибивать службу по таймауту.
А тот же самый Nginx, Postfix, Dovecot, Apache, Zabbix Agent можно спокойно ставить в автозапуск в случае падений. Проблем быть не должно.
У автозапуска есть более тонкие настройки и зависимости. Я описал только основной функционал, который нужен чаще всего. Более подробно всё описано в документации. Там настраиваются таймауты, различные статусы завершения работы, которые стоит считать успешными, количество попыток перезапуска, прежде чем они прекратятся и т.д. Можно слать оповещения на почту в случае падения и перезапуска службы. Это делается через параметр
OnFailure. Табличку себе сохраните на память для настройки. Без неё неочевидно, какой параметр лучше использовать. Например, Mariadb по умолчанию имеет настройку
on-abort.#systemd #linux
{kind=link}
Дам маленький совет по настройке почтового сервера. Мне задали вопрос в комментариях к статье, который напомнил об одной небольшой ошибке. Хочу вас предостеречь от неё.
Как-то раз в одной компании настраивал локальный почтовый сервер. Развернул привычную связку на базе postfix + dovecot и сделал веб интерфейс roundcube. Настроил всё это на одном сервере. Для простоты настройки, сделал доменное имя сервера mail.example.com и для настройки почтовых клиентов, и для веб интерфейса. Сотрудники пользовались и тем, и другим, в зависимости от личных предпочтений. Доступ был из локальной сети.
Со временем появилась необходимость убрать веб интерфейс с почтового сервера на отдельный веб сервер. Парк сервисов и серверов увеличился, захотелось всё упорядочить. В общем случае я рекомендую веб интерфейс настраивать отдельно, не на самом почтовом сервере.
В итоге возникла проблема с тем, что все привыкли к адресу веб интерфейса mail.example.com, который резолвится в IP адрес почтового сервера, а веб сервер имеет другой IP. Пришлось сделать отдельное доменное имя для веб интерфейса - webmail.example.com, а на почтовом сервере оставить nginx с проксированием запросов к mail.example.com на новый веб сервер.
В целом, это некритичная мелочь, но всё равно неудобство. Лучше для почтового сервера выделить отдельное доменное имя и больше его нигде не использовать. Одна виртуалка, один сервис, одно доменное имя. Когда настраиваешь, думаешь, зачем заморачиваться с разными именами. Разные настройки, разные сертификаты получать и т.д. Удобно же, когда всё с одним именем. А на самом деле неудобно. Потом больше времени потеряешь, чтобы разделить сервисы.
#mailserver
Как-то раз в одной компании настраивал локальный почтовый сервер. Развернул привычную связку на базе postfix + dovecot и сделал веб интерфейс roundcube. Настроил всё это на одном сервере. Для простоты настройки, сделал доменное имя сервера mail.example.com и для настройки почтовых клиентов, и для веб интерфейса. Сотрудники пользовались и тем, и другим, в зависимости от личных предпочтений. Доступ был из локальной сети.
Со временем появилась необходимость убрать веб интерфейс с почтового сервера на отдельный веб сервер. Парк сервисов и серверов увеличился, захотелось всё упорядочить. В общем случае я рекомендую веб интерфейс настраивать отдельно, не на самом почтовом сервере.
В итоге возникла проблема с тем, что все привыкли к адресу веб интерфейса mail.example.com, который резолвится в IP адрес почтового сервера, а веб сервер имеет другой IP. Пришлось сделать отдельное доменное имя для веб интерфейса - webmail.example.com, а на почтовом сервере оставить nginx с проксированием запросов к mail.example.com на новый веб сервер.
В целом, это некритичная мелочь, но всё равно неудобство. Лучше для почтового сервера выделить отдельное доменное имя и больше его нигде не использовать. Одна виртуалка, один сервис, одно доменное имя. Когда настраиваешь, думаешь, зачем заморачиваться с разными именами. Разные настройки, разные сертификаты получать и т.д. Удобно же, когда всё с одним именем. А на самом деле неудобно. Потом больше времени потеряешь, чтобы разделить сервисы.
#mailserver
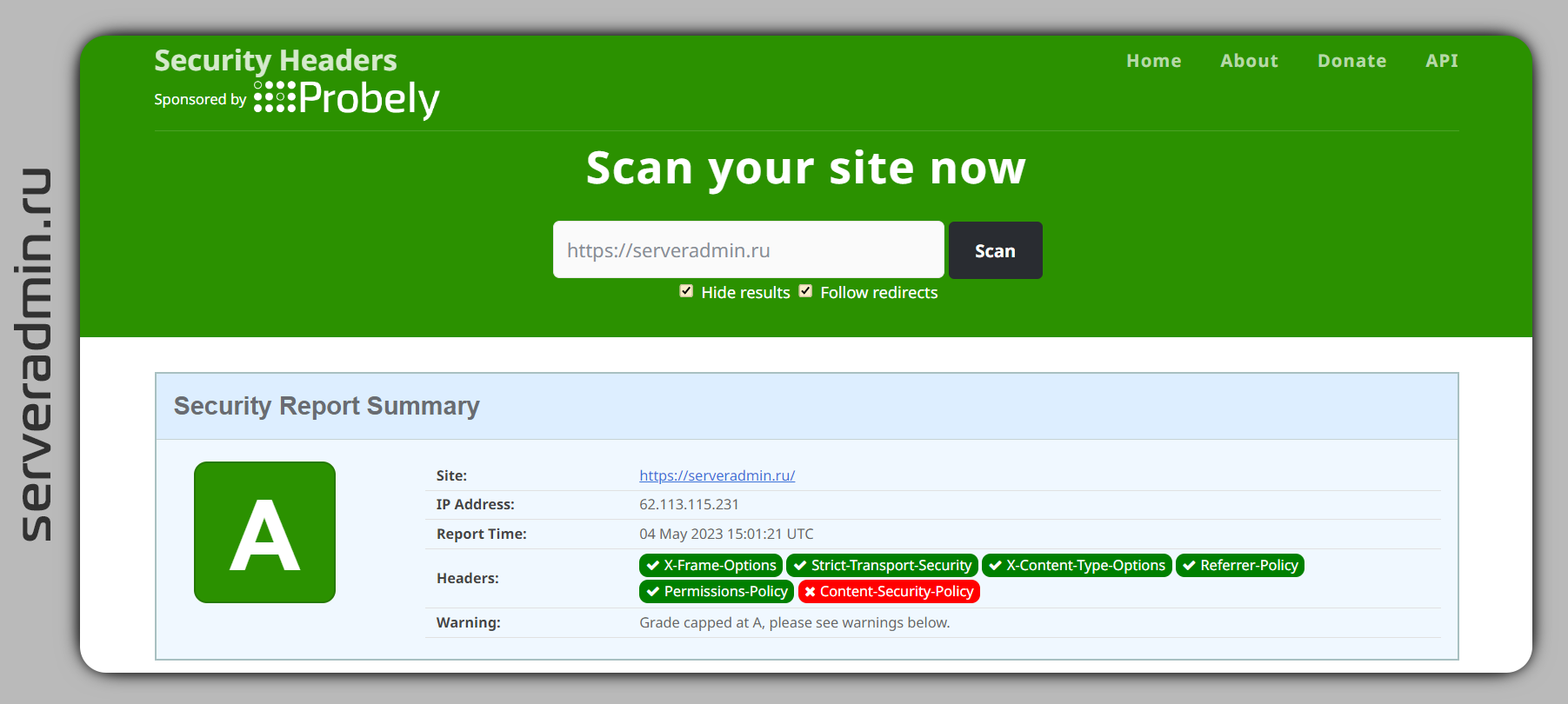
На днях в комментариях подсказали полезный ресурс для проверки настроек безопасности в заголовках веб сервера — securityheaders.com. Для теста проверил свой сайт, получилась неутешительная картинка. Многие полезные с точки зрения безопасности заголовки не настроены. Стал разбираться.
Ключевым заголовком в плане обеспечения безопасности является CSP (Content Security Policy). С его помощью можно указать, с каких доменов может загружаться контент при просмотре сайта. Значение этого заголовка передаётся браузеру. Если он видит, что какие-то скрипты или прочие объекты пытаются загрузится с домена, который не разрешён в CSP, то блокирует их. Подобная защита, к примеру, помогает от XSS (cross site scripting) атак.
На деле оказалось, что конкретно мне настроить CSP будет очень непросто. Сначала бодро взялся за написание правил, потом приуныл. У меня крутится реклама от Яндекса, счётчики от Яндекс Метрики и Google Analytics. Чтобы все их корректно разрешить, надо прилично заморочиться, чтобы ничего не упустить. Вот пример настроек для метрики и рекламной сети. Ошибку можно сразу не заметить, а это приведёт к некорректному сбору статистики или ошибок в ней. А у кого-то ещё и шрифты внешние грузятся, библиотеки. Надо всё аккуратно проверять и настраивать.
Пока отложил вопрос. Конкретно для моего блога это некритично, но если у вас коммерческий сайт, то рекомендую заморочить и всё аккуратно настроить. По остальным заголовкам в сервисе есть описание, можно настроить. Но они уже не так важны и настраиваются проще.
У меня в итоге получилось вот так:
#nginx #webserver
Ключевым заголовком в плане обеспечения безопасности является CSP (Content Security Policy). С его помощью можно указать, с каких доменов может загружаться контент при просмотре сайта. Значение этого заголовка передаётся браузеру. Если он видит, что какие-то скрипты или прочие объекты пытаются загрузится с домена, который не разрешён в CSP, то блокирует их. Подобная защита, к примеру, помогает от XSS (cross site scripting) атак.
На деле оказалось, что конкретно мне настроить CSP будет очень непросто. Сначала бодро взялся за написание правил, потом приуныл. У меня крутится реклама от Яндекса, счётчики от Яндекс Метрики и Google Analytics. Чтобы все их корректно разрешить, надо прилично заморочиться, чтобы ничего не упустить. Вот пример настроек для метрики и рекламной сети. Ошибку можно сразу не заметить, а это приведёт к некорректному сбору статистики или ошибок в ней. А у кого-то ещё и шрифты внешние грузятся, библиотеки. Надо всё аккуратно проверять и настраивать.
Пока отложил вопрос. Конкретно для моего блога это некритично, но если у вас коммерческий сайт, то рекомендую заморочить и всё аккуратно настроить. По остальным заголовкам в сервисе есть описание, можно настроить. Но они уже не так важны и настраиваются проще.
У меня в итоге получилось вот так:
add_header X-Frame-Options "SAMEORIGIN";add_header Strict-Transport-Security max-age=15768000;add_header X-Content-Type-Options "nosniff" always;add_header Referrer-Policy "origin-when-cross-origin";add_header Permissions-Policy "geolocation=(),midi=(),sync-xhr=(),\microphone=(),camera=(),magnetometer=(),gyroscope=(),fullscreen=*,payment=()";#nginx #webserver
{kind=link}
Очень понравился вот этот мемчик. Особенно злободневно про циску и сервера:
◽Cisco: Сегодня кент, а завтра...
◽Золотые сервера
Ну и про Zabbix тоже ничего:
◽Заббикс гонит порожняк
Автор не знаю кто, но явно что-то свежее. Увидел вот тут (хороший канал): https://t.me/mikrotikninja/1540
#мем
◽Cisco: Сегодня кент, а завтра...
◽Золотые сервера
Ну и про Zabbix тоже ничего:
◽Заббикс гонит порожняк
Автор не знаю кто, но явно что-то свежее. Увидел вот тут (хороший канал): https://t.me/mikrotikninja/1540
#мем
Для тех, кто ещё не знаком, рекомендую к прослушиванию песни классной группы the CI/CD band. Они поют каверы популярных песен с уклоном в IT тематику. Причём у них не только песни, но даже клип есть. Как по мне, исполнение очень классное, но просмотров на их канале неоправданно мало.
Вот список того, что мне нравится больше всего. Я в машине иногда слушаю их песни.
▪🔥Про девопса Валеру (видеоклип, кавер Игоря Растеряева "Комбайнёры")
▪ Прожка моя (Руки Вверх - Крошка моя)
▪ ❤️ Кодим сервачок (Гражданская оборона "Про дурачка")
▪ Я девопс (5'nizza "Я солдат")
▪ Залей в инсту (Ленинград "XXX")
Насыпте ребятам лайков и комментов. Они это заслужили. Мне очень резонирует их творчество. Растеряев мой любимый современный исполнитель. Единственные концерты, на которые хожу, это его. Руки Вверх это моя юность в 90-е, прям теплота на душе от этих песен. Гражданская оборона это моё студенчество. Играли на гитаре их песни, был один раз на концерте (это жесть, повторить не захотелось 😆).
Ну а деревенская тематика это вообще весь я. Несмотря на то, что родился и вырос в Москве, до 17 лет я каждое лето проводил в деревне. Скучаю и вспоминаю о ней, и искренне хотел бы там жить, но увы. Реальность такова, что современная политика вымыла из деревень центральной России и Поволжья большинство адекватных людей. И глядя на то, с кем придётся жить в деревне, понимаешь, что для детей это не лучший вариант. Пришлось остановиться на суррогате деревни в виде подмосковной деревушки в основном с дачниками горожанами, но и постоянно живущие тоже есть.
#музыка
Вот список того, что мне нравится больше всего. Я в машине иногда слушаю их песни.
▪🔥Про девопса Валеру (видеоклип, кавер Игоря Растеряева "Комбайнёры")
▪ Прожка моя (Руки Вверх - Крошка моя)
▪ ❤️ Кодим сервачок (Гражданская оборона "Про дурачка")
▪ Я девопс (5'nizza "Я солдат")
▪ Залей в инсту (Ленинград "XXX")
Насыпте ребятам лайков и комментов. Они это заслужили. Мне очень резонирует их творчество. Растеряев мой любимый современный исполнитель. Единственные концерты, на которые хожу, это его. Руки Вверх это моя юность в 90-е, прям теплота на душе от этих песен. Гражданская оборона это моё студенчество. Играли на гитаре их песни, был один раз на концерте (это жесть, повторить не захотелось 😆).
Ну а деревенская тематика это вообще весь я. Несмотря на то, что родился и вырос в Москве, до 17 лет я каждое лето проводил в деревне. Скучаю и вспоминаю о ней, и искренне хотел бы там жить, но увы. Реальность такова, что современная политика вымыла из деревень центральной России и Поволжья большинство адекватных людей. И глядя на то, с кем придётся жить в деревне, понимаешь, что для детей это не лучший вариант. Пришлось остановиться на суррогате деревни в виде подмосковной деревушки в основном с дачниками горожанами, но и постоянно живущие тоже есть.
#музыка
YouTube
Про девопса Валеру (Игорь Растеряев "Комбайнёры" cover)
#легендыбелорусскогоайтирока #the_cicd_band #potoksoznania_ru
Instagram: https://www.instagram.com/the_cicd_band/
Слушать песню на стриминговых сервисах (Spotify, Яндекс.Музыка, iTunes, Apple Music, Vk...) - https://links.freshtunes.com/zLU4J
живём под…
Instagram: https://www.instagram.com/the_cicd_band/
Слушать песню на стриминговых сервисах (Spotify, Яндекс.Музыка, iTunes, Apple Music, Vk...) - https://links.freshtunes.com/zLU4J
живём под…
Для бэкапа сетевых устройств существует не так много бесплатных продуктов. Наиболее известным из них является Oxidized. Это Open Source проект, который можно запустить у себя. Написан на Ruby. Я подробно писал о нём в отдельной заметке, так что не буду повторяться.
Сегодня хочу рассказать о коммерческом проекте Unimus, у которого есть бесплатная версия для бэкапа 5 сетевых устройств. Программу написал тренер по Mikrotik из США Tomas Kirnak (презентация программы на MUM: видео и доклад в pdf). Написана Unimus на Java, так что работает практически на любой операционной системе. Я попробовал на Windows, скачав Portable версию.
Unimus имеет очень простой и приятный веб интерфейс, хороший функционал. Там не только бэкап, но и управление (групповые операции, обновление и т.д.). Разработан в первую очередь под корпоративный рынок и большие сети, так что там многое автоматизировано. У автора была сеть из 1500 устройств Mikrotik, для которых он и написал программу. Так что максимальная поддержка устройств этого вендора там была изначально, но сейчас список значительно шире. Поддерживает всё популярное сетевое оборудование: Cisco, Huawei, HP, Fortinet и т.д. Есть оповещения по email.
Понятное дело, сейчас покупать такое не имеет никакого смысла, да и технически невозможно, хотя по мировым меркам цена очень скромная. Тем не менее, бесплатная версия нормально работает. Я без проблем запустил и забэкапил тестовый микротик. Не надо ни разбираться в установке, ни в настройке. Достаточно запустить, добавить устройство, настроить бэкап. Всё максимально просто и понятно.
⇨ Сайт
Другие варианты бэкапа микротиков:
- Oxidized
- Rancid
- eNMS
- Backup по SSH +diff
- Бэкап настроек на ftp сервер
- Отправка бэкапа настроек по email
#backup #mikrotik
Сегодня хочу рассказать о коммерческом проекте Unimus, у которого есть бесплатная версия для бэкапа 5 сетевых устройств. Программу написал тренер по Mikrotik из США Tomas Kirnak (презентация программы на MUM: видео и доклад в pdf). Написана Unimus на Java, так что работает практически на любой операционной системе. Я попробовал на Windows, скачав Portable версию.
Unimus имеет очень простой и приятный веб интерфейс, хороший функционал. Там не только бэкап, но и управление (групповые операции, обновление и т.д.). Разработан в первую очередь под корпоративный рынок и большие сети, так что там многое автоматизировано. У автора была сеть из 1500 устройств Mikrotik, для которых он и написал программу. Так что максимальная поддержка устройств этого вендора там была изначально, но сейчас список значительно шире. Поддерживает всё популярное сетевое оборудование: Cisco, Huawei, HP, Fortinet и т.д. Есть оповещения по email.
Понятное дело, сейчас покупать такое не имеет никакого смысла, да и технически невозможно, хотя по мировым меркам цена очень скромная. Тем не менее, бесплатная версия нормально работает. Я без проблем запустил и забэкапил тестовый микротик. Не надо ни разбираться в установке, ни в настройке. Достаточно запустить, добавить устройство, настроить бэкап. Всё максимально просто и понятно.
⇨ Сайт
Другие варианты бэкапа микротиков:
- Oxidized
- Rancid
- eNMS
- Backup по SSH +diff
- Бэкап настроек на ftp сервер
- Отправка бэкапа настроек по email
#backup #mikrotik
{kind=link}
Последнее время перестал следить за новостями Mikrotik, так как их устройства существенно подорожали, да и с наличием не всё так хорошо, как раньше. Хотя в целом все ходовые модели есть и при желании купить можно. Я знаю компании, которые по прежнему их закупают и активно используют в своей инфраструктуре.
Но мимо этой новости не смог пройти мимо. Для легендарной версии беспроводного роутера RB2011, который продаётся как раз с 2011 года практически в неизменном виде, вышло долгожданное обновление за ту же цену! Но при этом производительность в 4 раза выше, плюс другие полезные изменения. Я впервые впечатлился микротиками как раз при знакомстве с этим устройством. Он отлично подходил в роли шлюза для небольшого офиса и загородного дома, либо в качестве точки доступа, объединённой в единую сеть с помощью CAPsMAN.
На его замену за те же самые $129 выпустили L009UiGS-2HaxD-IN. Основные особенности этой модели:
◽Двухядерный ARM процессор и 512 мегабайт оперативной памяти с пассивным охлаждением всего этого хозяйства. Это примерно в 4 раза мощнее старого процессора mips.
◽Полноценный USB 3.0 порт, который можно использовать для LTE модема или внешнего хранилища. Это хранилище могут использовать контейнеры, работа которых поддерживается в RouterOS 7. Можно, к примеру, запустить контейнер с Pi-Hole или Adguard и резать рекламу, либо какую-то сетевую хранилку запустить, или даже простенький сайт захостить.
◽Все порты гигабитные. Со 2-го по 8-й подключены в единый свитч чип суммарной ёмкостью 2.5G. Первый порт обрабатывается напрямую процессором.
◽Есть отдельный консольный порт для управления, spf порт (поддерживает 2.5G).
◽Устройство может быть запитано по PoE через первый порт, а если питается от своего блока питания, то может выдать PoE-Out на 8-м порту.
◽Дизайн корпуса позволяет разместить 4 устройства в серверную стойку и занять 1U.
◽Есть поддержка Wi-Fi 6 на частоте 2.4 GHz, 5 GHz почему-то нет 🤷♂️ и это портит всё впечатление.
⇨ Обзор: https://www.youtube.com/watch?v=rIxkkNxsEhs
Устройство классное за свои деньги. В первую очередь в качестве шлюза. Аналогов нет и пока не предвидится. Странно, что за столько лет никто не попытался зайти в этот же сегмент и составить конкуренцию Микротикам. Часто называют Zyxel с серией Keenetic, но это всё равно не то. Функционал и удобство управление заметно хуже.
#mikrotik
Но мимо этой новости не смог пройти мимо. Для легендарной версии беспроводного роутера RB2011, который продаётся как раз с 2011 года практически в неизменном виде, вышло долгожданное обновление за ту же цену! Но при этом производительность в 4 раза выше, плюс другие полезные изменения. Я впервые впечатлился микротиками как раз при знакомстве с этим устройством. Он отлично подходил в роли шлюза для небольшого офиса и загородного дома, либо в качестве точки доступа, объединённой в единую сеть с помощью CAPsMAN.
На его замену за те же самые $129 выпустили L009UiGS-2HaxD-IN. Основные особенности этой модели:
◽Двухядерный ARM процессор и 512 мегабайт оперативной памяти с пассивным охлаждением всего этого хозяйства. Это примерно в 4 раза мощнее старого процессора mips.
◽Полноценный USB 3.0 порт, который можно использовать для LTE модема или внешнего хранилища. Это хранилище могут использовать контейнеры, работа которых поддерживается в RouterOS 7. Можно, к примеру, запустить контейнер с Pi-Hole или Adguard и резать рекламу, либо какую-то сетевую хранилку запустить, или даже простенький сайт захостить.
◽Все порты гигабитные. Со 2-го по 8-й подключены в единый свитч чип суммарной ёмкостью 2.5G. Первый порт обрабатывается напрямую процессором.
◽Есть отдельный консольный порт для управления, spf порт (поддерживает 2.5G).
◽Устройство может быть запитано по PoE через первый порт, а если питается от своего блока питания, то может выдать PoE-Out на 8-м порту.
◽Дизайн корпуса позволяет разместить 4 устройства в серверную стойку и занять 1U.
◽Есть поддержка Wi-Fi 6 на частоте 2.4 GHz, 5 GHz почему-то нет 🤷♂️ и это портит всё впечатление.
⇨ Обзор: https://www.youtube.com/watch?v=rIxkkNxsEhs
Устройство классное за свои деньги. В первую очередь в качестве шлюза. Аналогов нет и пока не предвидится. Странно, что за столько лет никто не попытался зайти в этот же сегмент и составить конкуренцию Микротикам. Часто называют Zyxel с серией Keenetic, но это всё равно не то. Функционал и удобство управление заметно хуже.
#mikrotik
{kind=link}
Наступила новая эпоха, а проблемы остались всё те же. Хочу рассказать вам одну поучительную историю, которую я узнал от подписчика. История банальна, так как там отсутствовали бэкапы и системный подход, но нова, потому что не обошлось без ChatGPT.
Как-то поздно вечером сел делать свои дела. Пишет незнакомый человек и очень просит помочь, потому что у него упала база данных Mysql, а он не знает, как починить. Да и база не его, а там много сайтов. Отчаяние сообщения сподвигло меня попробовать помочь. Подключаюсь к серверу и вижу там совершенно незнакомые мне ошибки, суть которых не очень понятна. В логе ошибок был backtrace и информация о том, что нарушен порядок транзакций. Как всё это чинить я совершенно не знал, а времени разбираться и погружаться в проблему не было, так что помочь ничем не смог.
Дальше мне рассказали историю проблемы. База данных очень сильно нагружала процессор. Автор вызвался помочь с решением проблемы, но не рассчитал свои силы. Он запустил mysqltuner.pl и получил некоторые рекомендации от него. Когда он их внёс, в логе были какие-то ошибки. Тогда он решил спросить по ним совета у ChatGPT, и он предложил переместить файлы ib_logfile0 и ib_logfile1, чтобы при запуске были созданы новые. После этих манипуляций база перестала вообще стартовать.
В этих файлах хранится журнал транзакций innodb. Тут я примерно понял, в чем скорее всего проблема. Вероятно эти файлы были переименованы при работающей субд, что и привело к расхождению в транзакциях. Это нарушило целостность баз данных, поэтому служба не стартовала. Как решать подобную проблему, я даже теоретически не знаю. Было бы любопытно узнать хотя бы теорию по восстановлению, если оно вообще возможно при таких вводных.
В итоге были обращения в платную поддержку хостера, но они тоже не помогли. Пришлось всё восстанавливать из частичных бэкапов, которые кое-где нашлись. На момент обращения ко мне была информация, что бэкапов нет. То есть перед началом всех манипуляций бэкапы сделаны не были.
☝Ругать автора всех этих манипуляций не надо, он и так всё понял. Понятно, что желающие это сделать и так всё знают и ошибок не совершают. Но есть другие люди и их много. Они пока ещё не научились, как делать правильно, так что эта заметка для них.
Когда вы выполняете какие-то манипуляции в работающих сервисах, всегда держите в голове мысль: "А что я будут делать, если после моих изменений сервис не запустится". Об этом нужно подумать заранее, даже если вы точно знаете, что будете делать. Вы можете банально ошибиться, перепутать консоли и грохнуть работающие базы. Это далеко не редкость, и я сам путал консоли неоднократно.
Перед любыми действиями как минимум делаем бэкап или убеждаемся, что у нас есть работающий бэкап. Потом в голове прокручиваем мысль с тем, как мы поступим, если всё упадёт. Есть ли у нас хотя бы в теории возможность всё быстро запустить из бэкапа. Если первое и второе не сделано и не продумано, то не начинайте что-то менять.
Я сам с чем только не сталкивался. И свои ошибки были, и ошибки разработчиков, которые всё уничтожали. И поддержка хостера роняла серваки, отключив сетевой кабель или питание, и диски не те меняли на развалившихся массивах. Всегда нужно держать в голове план восстановления и сразу же начинать его реализовывать, когда что-то пошло не так, а не сидеть и думать, что же теперь делать. Когда нет плана, это сильно бьёт по нервам и вообще отбивает желание работать в профессии.
#backup #история
Как-то поздно вечером сел делать свои дела. Пишет незнакомый человек и очень просит помочь, потому что у него упала база данных Mysql, а он не знает, как починить. Да и база не его, а там много сайтов. Отчаяние сообщения сподвигло меня попробовать помочь. Подключаюсь к серверу и вижу там совершенно незнакомые мне ошибки, суть которых не очень понятна. В логе ошибок был backtrace и информация о том, что нарушен порядок транзакций. Как всё это чинить я совершенно не знал, а времени разбираться и погружаться в проблему не было, так что помочь ничем не смог.
Дальше мне рассказали историю проблемы. База данных очень сильно нагружала процессор. Автор вызвался помочь с решением проблемы, но не рассчитал свои силы. Он запустил mysqltuner.pl и получил некоторые рекомендации от него. Когда он их внёс, в логе были какие-то ошибки. Тогда он решил спросить по ним совета у ChatGPT, и он предложил переместить файлы ib_logfile0 и ib_logfile1, чтобы при запуске были созданы новые. После этих манипуляций база перестала вообще стартовать.
В этих файлах хранится журнал транзакций innodb. Тут я примерно понял, в чем скорее всего проблема. Вероятно эти файлы были переименованы при работающей субд, что и привело к расхождению в транзакциях. Это нарушило целостность баз данных, поэтому служба не стартовала. Как решать подобную проблему, я даже теоретически не знаю. Было бы любопытно узнать хотя бы теорию по восстановлению, если оно вообще возможно при таких вводных.
В итоге были обращения в платную поддержку хостера, но они тоже не помогли. Пришлось всё восстанавливать из частичных бэкапов, которые кое-где нашлись. На момент обращения ко мне была информация, что бэкапов нет. То есть перед началом всех манипуляций бэкапы сделаны не были.
☝Ругать автора всех этих манипуляций не надо, он и так всё понял. Понятно, что желающие это сделать и так всё знают и ошибок не совершают. Но есть другие люди и их много. Они пока ещё не научились, как делать правильно, так что эта заметка для них.
Когда вы выполняете какие-то манипуляции в работающих сервисах, всегда держите в голове мысль: "А что я будут делать, если после моих изменений сервис не запустится". Об этом нужно подумать заранее, даже если вы точно знаете, что будете делать. Вы можете банально ошибиться, перепутать консоли и грохнуть работающие базы. Это далеко не редкость, и я сам путал консоли неоднократно.
Перед любыми действиями как минимум делаем бэкап или убеждаемся, что у нас есть работающий бэкап. Потом в голове прокручиваем мысль с тем, как мы поступим, если всё упадёт. Есть ли у нас хотя бы в теории возможность всё быстро запустить из бэкапа. Если первое и второе не сделано и не продумано, то не начинайте что-то менять.
Я сам с чем только не сталкивался. И свои ошибки были, и ошибки разработчиков, которые всё уничтожали. И поддержка хостера роняла серваки, отключив сетевой кабель или питание, и диски не те меняли на развалившихся массивах. Всегда нужно держать в голове план восстановления и сразу же начинать его реализовывать, когда что-то пошло не так, а не сидеть и думать, что же теперь делать. Когда нет плана, это сильно бьёт по нервам и вообще отбивает желание работать в профессии.
#backup #история
{kind=link}
Для ОС Windows со стародавних времён существуют различные твикеры, которые могут быть как безвредными и полезными, так и вредными и бесполезными. Я вас хочу познакомить с полезной программой такого рода, которая использует только встроенные возможности самой Windows, ничего принудительно не отключает и не удаляет, типа обновлений или Windows Defender. Это проект с большой историей и хорошей репутаций. Его можно считать помощником по настройке Windows 10 и 11. Речь пойдёт о наборе скриптов Sophia-Script-for-Windows и приложении SophiApp на его основе.
Как я уже сказал, эти программы работают на базе стандартных возможностей настройки ОС Windows с помощью PowerShell. Первая ссылка этот как раз скрипт на powershell, а вторая — приложение на C#, реализующее этот же функционал. Полностью историю создания и возможности можно узнать из статьи самого автора на хабре.
📌 Основные возможности программы:
▪ Быстрая настройка параметров конфиденциальности (телеметрия, сбор диагностических данных ОС, всевозможные настройки в браузере и т.д.)
▪ Настройка внешнего вида проводника (значки рабочего стола, флажки элементов, поиск, тема и т.д.)
▪ Некоторые системные настройки (очистка диска, гибернация, схема электропитания и т.д.)
▪ Удаление UWP приложений и игр, OneDrive.
▪ Управление планировщиком заданий (базовые задачи, которыми имеет смысл управлять пользователю)
▪ Некоторые настройки безопасности (аудит, песочница Windows, Defender и т.д.)
В настройках нет ничего такого, чего бы вы не смогли сделать вручную, перемещаясь по многочисленным настройкам Windows. Начиная с Windows 10 настройка системы реально усложнилась. Приходится тратить много времени, чтобы вспомнить и отыскать ту или иную настройку. Тут автор попытался собрать то, что посчитал наиболее полезным в единый интерфейс. Удалить Defender или отключить обновления с помощью SophiApp не получится.
❗️Уже предвижу комментарии, что подобные программы это дилетантство, колхоз и т.д. Не надо использовать подобные штуки на работе, особенно если у вас там AD. Но при этом её удобно использовать на своей домашней, семейной машине, в тестовых лабах, у родственников, на каких-то одиночных системах. Винда реально раскидала свои настройки по куче мест. Как минимум, есть две разные панели управления, настройки Edge и проводника. Я лично по ним всем прыгаю, когда надо настроить систему. И это действительно утомляет.
⇨ Sophia-Script-for-Windows / SophiApp
#windows
Как я уже сказал, эти программы работают на базе стандартных возможностей настройки ОС Windows с помощью PowerShell. Первая ссылка этот как раз скрипт на powershell, а вторая — приложение на C#, реализующее этот же функционал. Полностью историю создания и возможности можно узнать из статьи самого автора на хабре.
📌 Основные возможности программы:
▪ Быстрая настройка параметров конфиденциальности (телеметрия, сбор диагностических данных ОС, всевозможные настройки в браузере и т.д.)
▪ Настройка внешнего вида проводника (значки рабочего стола, флажки элементов, поиск, тема и т.д.)
▪ Некоторые системные настройки (очистка диска, гибернация, схема электропитания и т.д.)
▪ Удаление UWP приложений и игр, OneDrive.
▪ Управление планировщиком заданий (базовые задачи, которыми имеет смысл управлять пользователю)
▪ Некоторые настройки безопасности (аудит, песочница Windows, Defender и т.д.)
В настройках нет ничего такого, чего бы вы не смогли сделать вручную, перемещаясь по многочисленным настройкам Windows. Начиная с Windows 10 настройка системы реально усложнилась. Приходится тратить много времени, чтобы вспомнить и отыскать ту или иную настройку. Тут автор попытался собрать то, что посчитал наиболее полезным в единый интерфейс. Удалить Defender или отключить обновления с помощью SophiApp не получится.
❗️Уже предвижу комментарии, что подобные программы это дилетантство, колхоз и т.д. Не надо использовать подобные штуки на работе, особенно если у вас там AD. Но при этом её удобно использовать на своей домашней, семейной машине, в тестовых лабах, у родственников, на каких-то одиночных системах. Винда реально раскидала свои настройки по куче мест. Как минимум, есть две разные панели управления, настройки Edge и проводника. Я лично по ним всем прыгаю, когда надо настроить систему. И это действительно утомляет.
⇨ Sophia-Script-for-Windows / SophiApp
#windows
{kind=link}
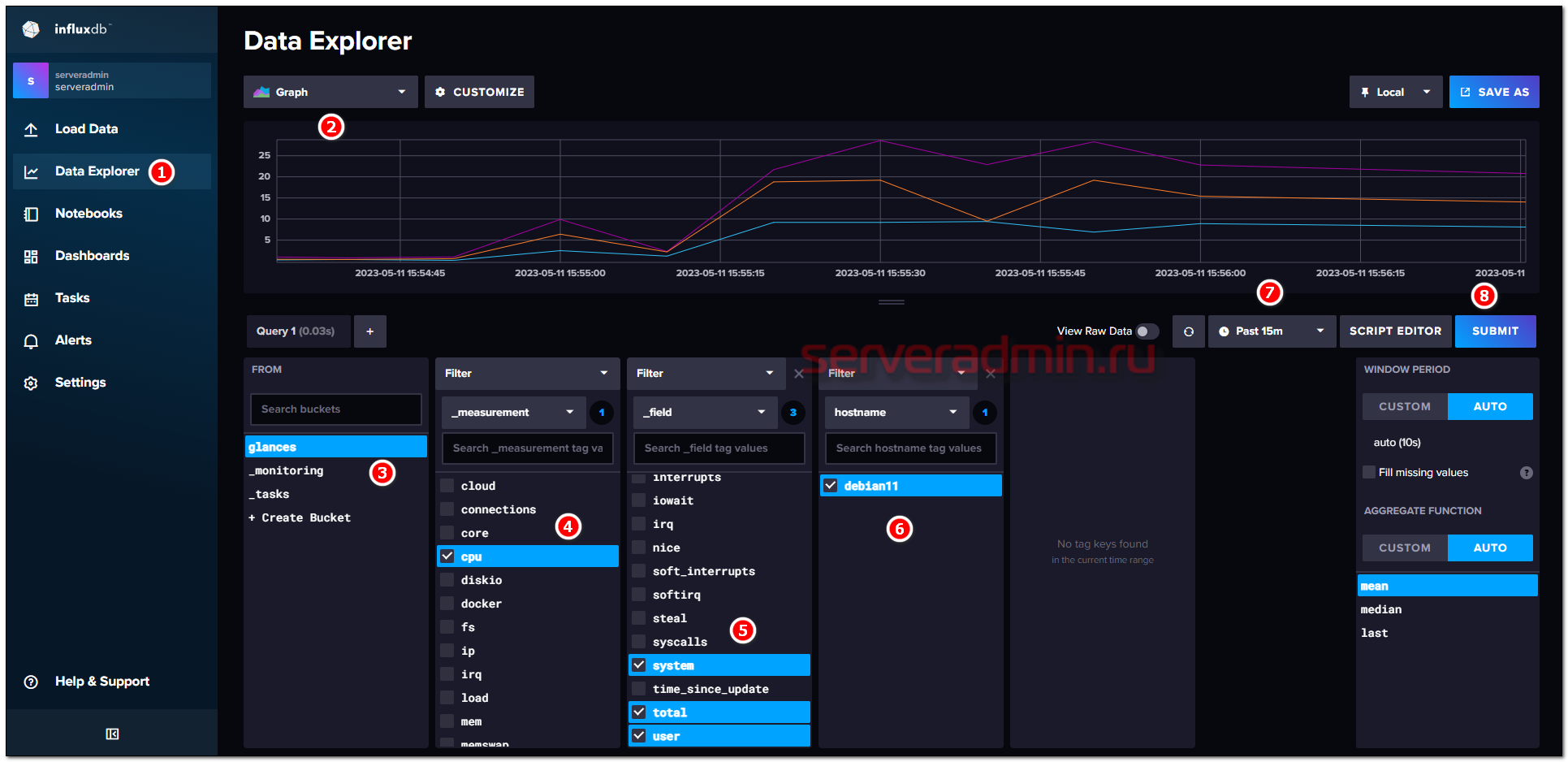
Расскажу про простой и современный способ быстро организовать временный мониторинг Linux сервера с возможностью посмотреть результаты в веб интерфейсе. Для этого нам понадобится утилита glances и influxdb.
Glances в консоли показывает нагрузку на сервер в режиме реального времени. Эта программа сама по себе неплоха, а конкретно в нашей задаче удобна тем, что умеет выгружать метрики в режиме реального времени в influxdb. Influxdb — СУБД для хранения временных рядов. Имеет свой собственный веб интерфейс, что тоже удобно для нашей задачи.
Всё манипуляции я буду проводить на Debian 11. Установим туда glances определённой версии через pip. В данном случае 3.2.5. В самой последней, судя по всему, какой-то баг с экспортом данных, она падает через несколько секунд после запуска. В 3.2.5 проблем не было.
Можете запустить glances в консоли и посмотреть, что она из себя представляет. Теперь запустим influxdb. Для простоты будем использовать docker. Запустить можете как локально, так и на любом другом хосте. Я запущу тут же, предварительно создав директорию для хранения данных:
Идём в консоль контейнера и инициализируем базу данных:
Теперь создадим токен для доступа к оrganization serveradmin:
В конце получите токен вида
Host укажите свой. Если запустили локально, то это localhost, если удалённо, то укажите реальный адрес. Теперь можно идти в web интерфейс influxdb по адресу http://172.25.225.173:8086 (измените ip на свой) и просматривать графики. Для этого перейдите в раздел Load Data ⇨ Buckets и выберите созданный бакет Glances. Дальше, думаю, разберётесь, как выводить данные. Пример ниже на картинке.
На хосте по сути ставится только glances, который можно остановить после окончания наблюдения. При этом собирается приличное количество метрик, часто достаточных, чтобы провести базовую диагностику. При желании influxdb очень просто подключить к grafana и смотреть метрики там.
Получилась законченная инструкция, которую можно сохранить на память, чтобы потом повторить описанное.
#мониторинг
Glances в консоли показывает нагрузку на сервер в режиме реального времени. Эта программа сама по себе неплоха, а конкретно в нашей задаче удобна тем, что умеет выгружать метрики в режиме реального времени в influxdb. Influxdb — СУБД для хранения временных рядов. Имеет свой собственный веб интерфейс, что тоже удобно для нашей задачи.
Всё манипуляции я буду проводить на Debian 11. Установим туда glances определённой версии через pip. В данном случае 3.2.5. В самой последней, судя по всему, какой-то баг с экспортом данных, она падает через несколько секунд после запуска. В 3.2.5 проблем не было.
# apt install python3-pip# pip install glances[all]==3.2.5# pip install influxdb-clientМожете запустить glances в консоли и посмотреть, что она из себя представляет. Теперь запустим influxdb. Для простоты будем использовать docker. Запустить можете как локально, так и на любом другом хосте. Я запущу тут же, предварительно создав директорию для хранения данных:
# mkdir ~/influxdb# docker run -d -p 8086:8086 \-v ~/influxdb:/var/lib/influxdb2 influxdb:latestИдём в консоль контейнера и инициализируем базу данных:
# docker exec -i -t 6ee6223a3ce3 bash# influx setup> Welcome to InfluxDB 2.0!? Please type your primary username serveradmin? Please type your password ***********? Please type your password again ***********? Please type your primary organization name serveradmin? Please type your primary bucket name glances? Please type your retention period in hours, or 0 for infinite 0? Setup with these parameters? Username: serveradmin Organization: serveradmin Bucket: glances Retention Period: infinite YesUser Organization Bucketserveradmin serveradmin glancesТеперь создадим токен для доступа к оrganization serveradmin:
influx auth create \ --org serveradmin --read-authorizations --write-authorizations \ --read-buckets --write-buckets --read-dashboards \ --write-dashboards --read-tasks --write-tasks \ --read-telegrafs --write-telegrafs --read-users \ --write-users --read-variables --write-variables \ --read-secrets --write-secrets --read-labels \ --write-labels --read-views --write-views --read-documents \ --write-documents --read-notificationRules --write-notificationRules \ --read-notificationEndpoints --write-notificationEndpoints \ --read-checks --write-checks --read-dbrp \ --write-dbrp --read-annotations --write-annotations \ --read-sources --write-sources --read-scrapers \ --write-scrapers --read-notebooks --write-notebooks \ --read-remotes --write-remotes --read-replications --write-replicationsВ конце получите токен вида
wEgrY0Y1wY1R1S-qCiKxA== (в оригинале он длиннее, сократил для удобства) Он будет нужен для конфигурации glances. Создаём её в директории ~/.config/glances/glances.conf[influxdb2]host=localhostport=8086protocol=httporg=serveradminbucket=glancestoken=wEgrY0Y1wY1R1S-qCiKxA==Host укажите свой. Если запустили локально, то это localhost, если удалённо, то укажите реальный адрес. Теперь можно идти в web интерфейс influxdb по адресу http://172.25.225.173:8086 (измените ip на свой) и просматривать графики. Для этого перейдите в раздел Load Data ⇨ Buckets и выберите созданный бакет Glances. Дальше, думаю, разберётесь, как выводить данные. Пример ниже на картинке.
На хосте по сути ставится только glances, который можно остановить после окончания наблюдения. При этом собирается приличное количество метрик, часто достаточных, чтобы провести базовую диагностику. При желании influxdb очень просто подключить к grafana и смотреть метрики там.
Получилась законченная инструкция, которую можно сохранить на память, чтобы потом повторить описанное.
#мониторинг
{kind=link}
Удаляли когда-нибудь рабочие базы данных? Я посидел, подумал, но не припоминаю такого. Вообще не помню, чтобы по ошибке удалял что-то нужное.
Вспомнилась другая история ещё в бытность тех. поддержки. У меня привычка до сих пор осталась, если вижу неочищенную корзину, очищаю. Ничего не могу с собой поделать.
Сел так как-то за комп к одному сотруднику и по привычке очистил корзину в Outlook. У него глаза на лоб полезли. Задёргался аж, говорит, зачем ты это сделал? Он там зачем-то нужные письма хранил. Восстановить я это уже никак не мог. Объяснил ему, что так делать не надо. В некоторых случаях корзина может и автоматически очиститься.
#мем
Вспомнилась другая история ещё в бытность тех. поддержки. У меня привычка до сих пор осталась, если вижу неочищенную корзину, очищаю. Ничего не могу с собой поделать.
Сел так как-то за комп к одному сотруднику и по привычке очистил корзину в Outlook. У него глаза на лоб полезли. Задёргался аж, говорит, зачем ты это сделал? Он там зачем-то нужные письма хранил. Восстановить я это уже никак не мог. Объяснил ему, что так делать не надо. В некоторых случаях корзина может и автоматически очиститься.
#мем
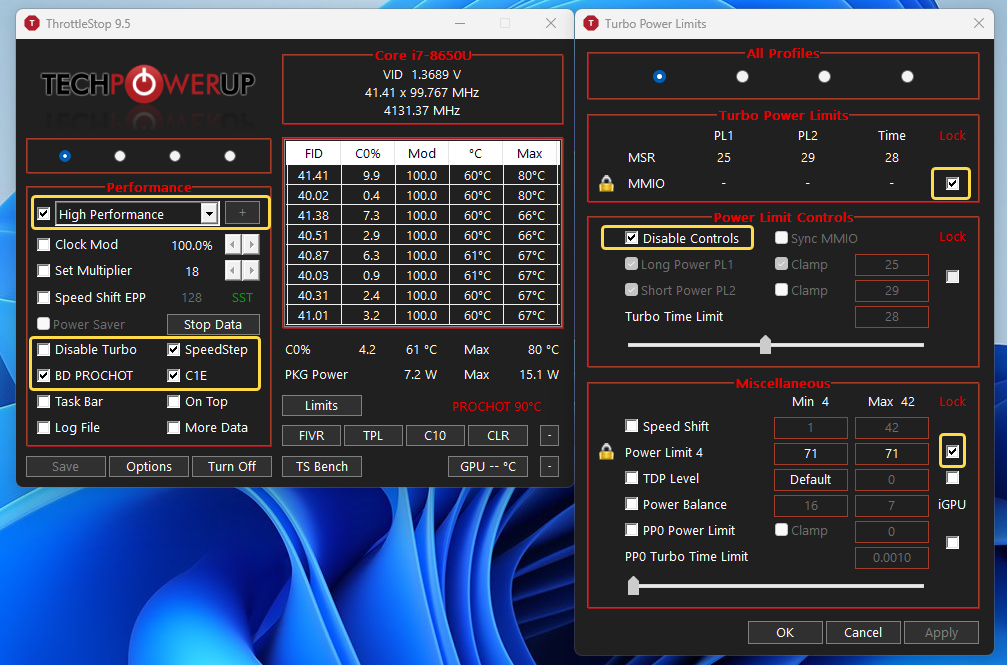
Заметка на тему современных ноутбуков. После того, как пересел на Thinkpad T480, всё устраивало в плане производительности, кроме одного момента. Иногда при быстром переключении межу приложениями по Alt+Tab ощущался небольшой подлаг, даже если никакой особой нагрузки нет. Не сильно мешало, но раздражало.
Причину такого поведения узнал случайно. Вывел на видное место информацию о частоте процессора и заметил, что когда нет нагрузки, частота сильно снижается и сразу же повышается, если начинаешь что-то делать. Я так понял, что работает какая-то оптимизация потребления энергии процессором. Я почти всегда работаю стационарно, так что никакой экономии заряда или электричества мне не надо. Игра с настройками электропитания ни к чему не привела. Так и не понял, как окончательно отключить такое поведение.
Решил вопрос бесплатной программой ThrottleStop. У неё уйма настроек, разбираться в которых нет ни желания, ни времени. Что конкретно мне помогло, уже не помню. Настроил по какой-то рекомендации на англоязычном ресурсе от владельца такого же ноута. Когда программа запущена, никаких подлагов нет, частота процессора не снижается.
Если работаю от аккумуляторов (в этом ноуте их 2), не запускаю ThrottleStop. В итоге работает задуманное вендором энергосбережение. Надеюсь кому-то это будет полезным. Сейчас во всё современное оборудование внедряют энергосбережение, которое не всегда уместно.
Ниже скриншоты моих настроек ThrottleStop, где я что-то менял. Всё остальное по умолчанию оставлено.
#железо
Причину такого поведения узнал случайно. Вывел на видное место информацию о частоте процессора и заметил, что когда нет нагрузки, частота сильно снижается и сразу же повышается, если начинаешь что-то делать. Я так понял, что работает какая-то оптимизация потребления энергии процессором. Я почти всегда работаю стационарно, так что никакой экономии заряда или электричества мне не надо. Игра с настройками электропитания ни к чему не привела. Так и не понял, как окончательно отключить такое поведение.
Решил вопрос бесплатной программой ThrottleStop. У неё уйма настроек, разбираться в которых нет ни желания, ни времени. Что конкретно мне помогло, уже не помню. Настроил по какой-то рекомендации на англоязычном ресурсе от владельца такого же ноута. Когда программа запущена, никаких подлагов нет, частота процессора не снижается.
Если работаю от аккумуляторов (в этом ноуте их 2), не запускаю ThrottleStop. В итоге работает задуманное вендором энергосбережение. Надеюсь кому-то это будет полезным. Сейчас во всё современное оборудование внедряют энергосбережение, которое не всегда уместно.
Ниже скриншоты моих настроек ThrottleStop, где я что-то менял. Всё остальное по умолчанию оставлено.
#железо
{kind=link}
Меня периодически просят рассказать, как я веду свои дела, с чем работаю, где нахожу заказчиков. Последнее наиболее актуально для вопрошающих. На все эти вопросы я в разное время так или иначе отвечал, поэтому и писать что-то новое не хочется и не имеет смысла.
Я очень консервативен в плане взаимоотношений с людьми и редко меняю что-то, если меня всё устраивает. Редко менял работу (всего две постоянных было, пока я не стал ИП), со всеми заказчиками работаю уже много лет. Последний новый заказчик появился 2 года назад. Так что изменений в этой сфере почти нет.
Вместо этого могу посоветовать свою старую статью про то, как я открыл ИП, для тех, кто её не видел. В конкретных деталях она устарела, так как с Adsense я уже не работаю, бухгалтерию веду не в Эльбе, порядок открытия в налоговой скорее всего поменялся и возможно стал ещё проще и быстрее. Полностью актуальны остались разделы Где брать клиентов и Заключение. Ну и коды ОКВЭД скорее всего не изменились.
Отдельно отмечу комментарии, где мне задали много вопросов, на которые я очень подробно ответил. Также некоторые люди написали интересные содержательные комментарии по данной теме.
❓Вот примерный список вопросов, на которые ответил я:
- Как Вы определяете цену за свою работу?
- Попадались ли ситуации, когда заказчик кидал с оплатой?
- Оформляются ли документы с заказчиком (договоры, ТЗ и пр.)?
- Как обстоят дела с лицензиями?
- Как Вы думаете, почему после собеседования тебя, как ИП, потом часто отказывают в сотрудничестве?
- Можешь вспомнить своего первого клиента после ухода с работы?
- Владимир, а ты работаешь один или у тебя есть сотрудники?
Ну и другие мелкие вопросы. Здесь не стал оформлять всё в отдельную публикацию, потому что по объёму будет превышение и влезет всего 2-3 вопроса с ответами. В комментариях на сайте удобнее будет всю переписку прочитать.
Если у кого-то будут вопросы, то лучше тоже там в комментариях задать. Я по возможности подробно отвечу, когда время будет. Всё это там лучше сохранится, а здесь в переписке затеряется. Для написания комментов не нужна регистрация.
⇨ https://serveradmin.ru/kak-sistemnomu-administratoru-otkryit-ip
#разное
Я очень консервативен в плане взаимоотношений с людьми и редко меняю что-то, если меня всё устраивает. Редко менял работу (всего две постоянных было, пока я не стал ИП), со всеми заказчиками работаю уже много лет. Последний новый заказчик появился 2 года назад. Так что изменений в этой сфере почти нет.
Вместо этого могу посоветовать свою старую статью про то, как я открыл ИП, для тех, кто её не видел. В конкретных деталях она устарела, так как с Adsense я уже не работаю, бухгалтерию веду не в Эльбе, порядок открытия в налоговой скорее всего поменялся и возможно стал ещё проще и быстрее. Полностью актуальны остались разделы Где брать клиентов и Заключение. Ну и коды ОКВЭД скорее всего не изменились.
Отдельно отмечу комментарии, где мне задали много вопросов, на которые я очень подробно ответил. Также некоторые люди написали интересные содержательные комментарии по данной теме.
❓Вот примерный список вопросов, на которые ответил я:
- Как Вы определяете цену за свою работу?
- Попадались ли ситуации, когда заказчик кидал с оплатой?
- Оформляются ли документы с заказчиком (договоры, ТЗ и пр.)?
- Как обстоят дела с лицензиями?
- Как Вы думаете, почему после собеседования тебя, как ИП, потом часто отказывают в сотрудничестве?
- Можешь вспомнить своего первого клиента после ухода с работы?
- Владимир, а ты работаешь один или у тебя есть сотрудники?
Ну и другие мелкие вопросы. Здесь не стал оформлять всё в отдельную публикацию, потому что по объёму будет превышение и влезет всего 2-3 вопроса с ответами. В комментариях на сайте удобнее будет всю переписку прочитать.
Если у кого-то будут вопросы, то лучше тоже там в комментариях задать. Я по возможности подробно отвечу, когда время будет. Всё это там лучше сохранится, а здесь в переписке затеряется. Для написания комментов не нужна регистрация.
⇨ https://serveradmin.ru/kak-sistemnomu-administratoru-otkryit-ip
#разное
Server Admin
Открытие ИП системным администратором
Подробная пошаговая инструкция для открытия и работы в качестве ИП системному администратору. Личный опыт автора.
▶️ Я уже рассказывал про классный мониторинг Uptime Kuma, который можно развернуть у себя. Он умеет мониторить сайты и всё, что с ними связано, а также делать простые icmp проверки, проверки tcp портов и Docker контейнеров.
На канале realmanual, автора которого вы часто можете видеть в комментариях к моим заметкам, вышло подробное видео на тему этого мониторинга. Там он рассказывает не только про установку и настройку, которые просты, но и углубляется в автоматизацию. С помощью API он настроил добавление и удаление мониторов.
Если не знакомы с Uptime Kuma, рекомендую обратить внимание. Очень приятный и удобный мониторинг доступности хостов и сервисов. Активно поддерживается и развивается. В видео подробно про него рассказано на примере уже настроенного большого мониторинга.
⇨ https://www.youtube.com/watch?v=7gN9_Ph-9Z4
#мониторинг #видео
На канале realmanual, автора которого вы часто можете видеть в комментариях к моим заметкам, вышло подробное видео на тему этого мониторинга. Там он рассказывает не только про установку и настройку, которые просты, но и углубляется в автоматизацию. С помощью API он настроил добавление и удаление мониторов.
Если не знакомы с Uptime Kuma, рекомендую обратить внимание. Очень приятный и удобный мониторинг доступности хостов и сервисов. Активно поддерживается и развивается. В видео подробно про него рассказано на примере уже настроенного большого мониторинга.
⇨ https://www.youtube.com/watch?v=7gN9_Ph-9Z4
#мониторинг #видео
{kind=link}