
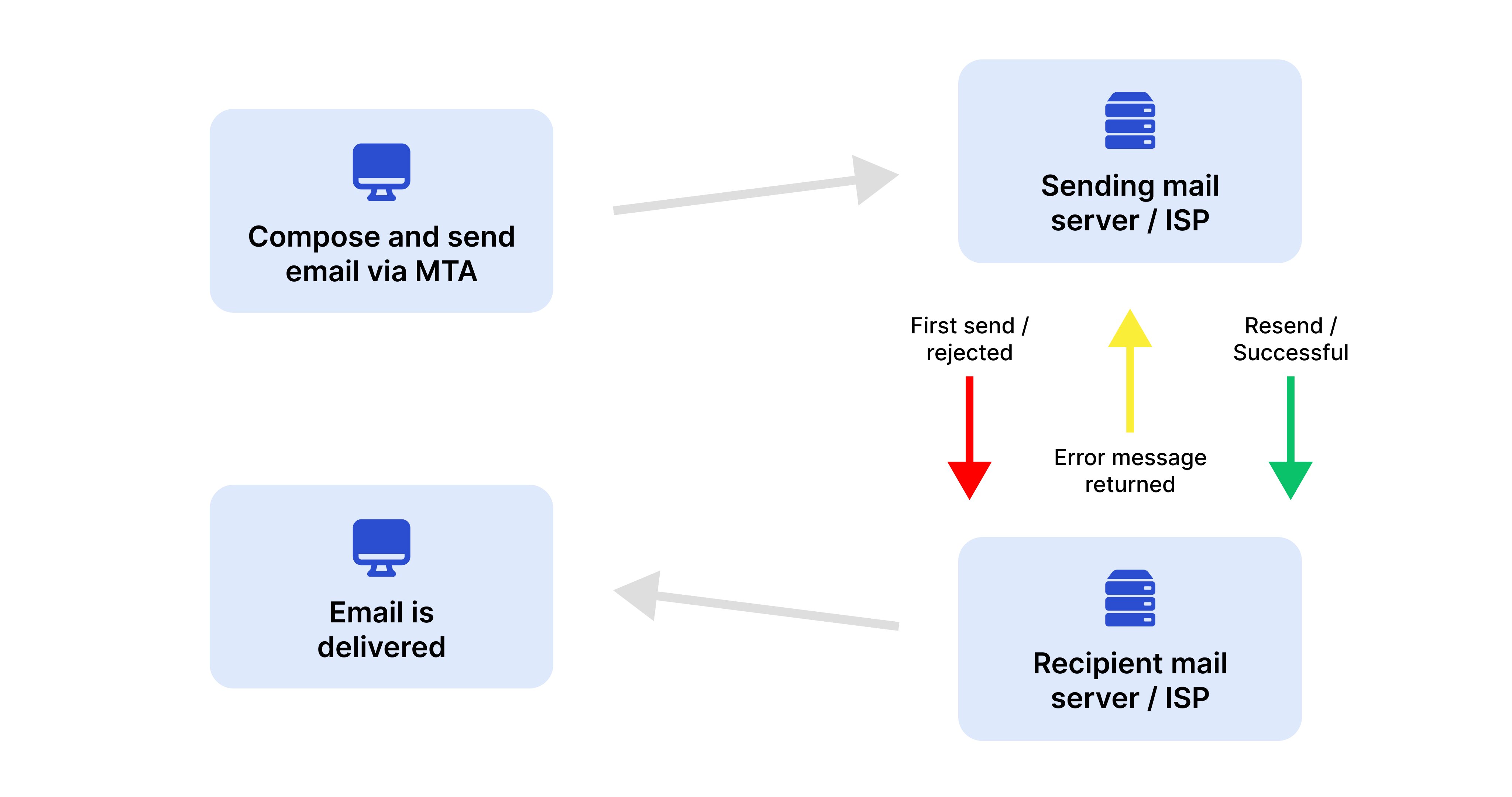
Существует простой и эффективный метод борьбы со спамом — Greylisting. Его переводят на русский как серый список. Расскажу вам простыми словами, как он работает, а также поделюсь своим опытом его использования.
Принцип работы Greylisting очень прост. Когда на сервер поступает письмо от нового адресата, с которым он ещё не взаимодействовал, письмо отклоняется с временным кодом ошибки 4ХХ, обычно 450. Согласно rfc5321, отправитель, получив такую ошибку, должен выполнить повторную отправку через некоторое время. В rfc оно указано как не менее 30 минут, если я правильно понял (the retry interval SHOULD be at least 30 minutes). На практике обычно это время меньше. В postfix по умолчанию оно равно 3 минутам.
Вот тут и кроется главная проблема. Не все серверы делают повторную отправку через 3 минуты. Это всё может настраиваться индивидуально, а rfc не указывает конкретные значения. В итоге может так получиться, что пользователь в течении 10-20 минут не сможет получить письмо от нового контрагента, что очень раздражает. Случается такое не часто, но бывает.
Способ реально простой и рабочий. Отсекает спам эффективно, так как спамеры обычно не обрабатывают коды ошибок и не держат у себя очередь, так как это накладно. Рассылка идёт по сотням тысяч адресов с каких-то взломанных машин или временных почтовых серверов. Надо за короткий промежуток времени разослать как можно больше почты, пока тебя не забанили. Поэтому обработкой ошибок обычно не занимаются.
Так что Greylisting очень дешёвый и эффективный способ борьбы со спамом, который не требует особых настроек. Достаточно где-то хранить список всех серверов, с которых вы уже получали почту и принимать от них её сразу. А всем остальным на первый раз выдавать 450 ошибку. Если они повторно делают отправку к вам, то принимается письмо, а сервер добавляется в этот список.
Во многих готовых почтовый сборках этот механизм включён по умолчанию. Например в Iredmail или Mail-in-a-Box. Я лично всегда его отключают, потому что даже задержка письма на 5-10 минут хотя бы раз в месяц вынудит пользователя сообщить поддержке, что с доставкой какие-то проблемы. И надо будет разбираться, объяснять в чём тут дело. Популярна ситуация, когда пользователь разговаривает с кем-то по телефону и тут же обменивается почтой. И письмо не приходит сразу. Для разговора в режиме реального времени задержка в 3 минуты значительна и раздражает. Приходится ждать, обновлять ящик, отправлять ещё раз и т.д.
Если для вас это не критично, то рекомендую обратить внимание на Greylisting. Он один способен отсечь большую часть спама. И не нужно будет разбираться с другими системами, особенно бальными, где надо поначалу тратить время на калибровку системы. Конкретных реализаций подхода Greylisting много. Под каждый почтовый сервер написаны свои. В каких-то сборках это собственным решением реализовано. На Postfix легко гуглится настройка.
#mailserver
Принцип работы Greylisting очень прост. Когда на сервер поступает письмо от нового адресата, с которым он ещё не взаимодействовал, письмо отклоняется с временным кодом ошибки 4ХХ, обычно 450. Согласно rfc5321, отправитель, получив такую ошибку, должен выполнить повторную отправку через некоторое время. В rfc оно указано как не менее 30 минут, если я правильно понял (the retry interval SHOULD be at least 30 minutes). На практике обычно это время меньше. В postfix по умолчанию оно равно 3 минутам.
Вот тут и кроется главная проблема. Не все серверы делают повторную отправку через 3 минуты. Это всё может настраиваться индивидуально, а rfc не указывает конкретные значения. В итоге может так получиться, что пользователь в течении 10-20 минут не сможет получить письмо от нового контрагента, что очень раздражает. Случается такое не часто, но бывает.
Способ реально простой и рабочий. Отсекает спам эффективно, так как спамеры обычно не обрабатывают коды ошибок и не держат у себя очередь, так как это накладно. Рассылка идёт по сотням тысяч адресов с каких-то взломанных машин или временных почтовых серверов. Надо за короткий промежуток времени разослать как можно больше почты, пока тебя не забанили. Поэтому обработкой ошибок обычно не занимаются.
Так что Greylisting очень дешёвый и эффективный способ борьбы со спамом, который не требует особых настроек. Достаточно где-то хранить список всех серверов, с которых вы уже получали почту и принимать от них её сразу. А всем остальным на первый раз выдавать 450 ошибку. Если они повторно делают отправку к вам, то принимается письмо, а сервер добавляется в этот список.
Во многих готовых почтовый сборках этот механизм включён по умолчанию. Например в Iredmail или Mail-in-a-Box. Я лично всегда его отключают, потому что даже задержка письма на 5-10 минут хотя бы раз в месяц вынудит пользователя сообщить поддержке, что с доставкой какие-то проблемы. И надо будет разбираться, объяснять в чём тут дело. Популярна ситуация, когда пользователь разговаривает с кем-то по телефону и тут же обменивается почтой. И письмо не приходит сразу. Для разговора в режиме реального времени задержка в 3 минуты значительна и раздражает. Приходится ждать, обновлять ящик, отправлять ещё раз и т.д.
Если для вас это не критично, то рекомендую обратить внимание на Greylisting. Он один способен отсечь большую часть спама. И не нужно будет разбираться с другими системами, особенно бальными, где надо поначалу тратить время на калибровку системы. Конкретных реализаций подхода Greylisting много. Под каждый почтовый сервер написаны свои. В каких-то сборках это собственным решением реализовано. На Postfix легко гуглится настройка.
#mailserver
{kind=link}
Для быстрой и простой проверки Docker образов на уязвимости существует популярный Open Source инструмент — Trivy. Я покажу на примере, как им пользоваться. Получится готовая мини инструкция по установке и использованию.
Установить Trivy можно разными способами: из репозитория с пакетами, собрать с помощью Nix, воспользоваться bash скриптом, запустить в Docker. Все способы описаны в документации. Я установлю в Debian из репозитория.
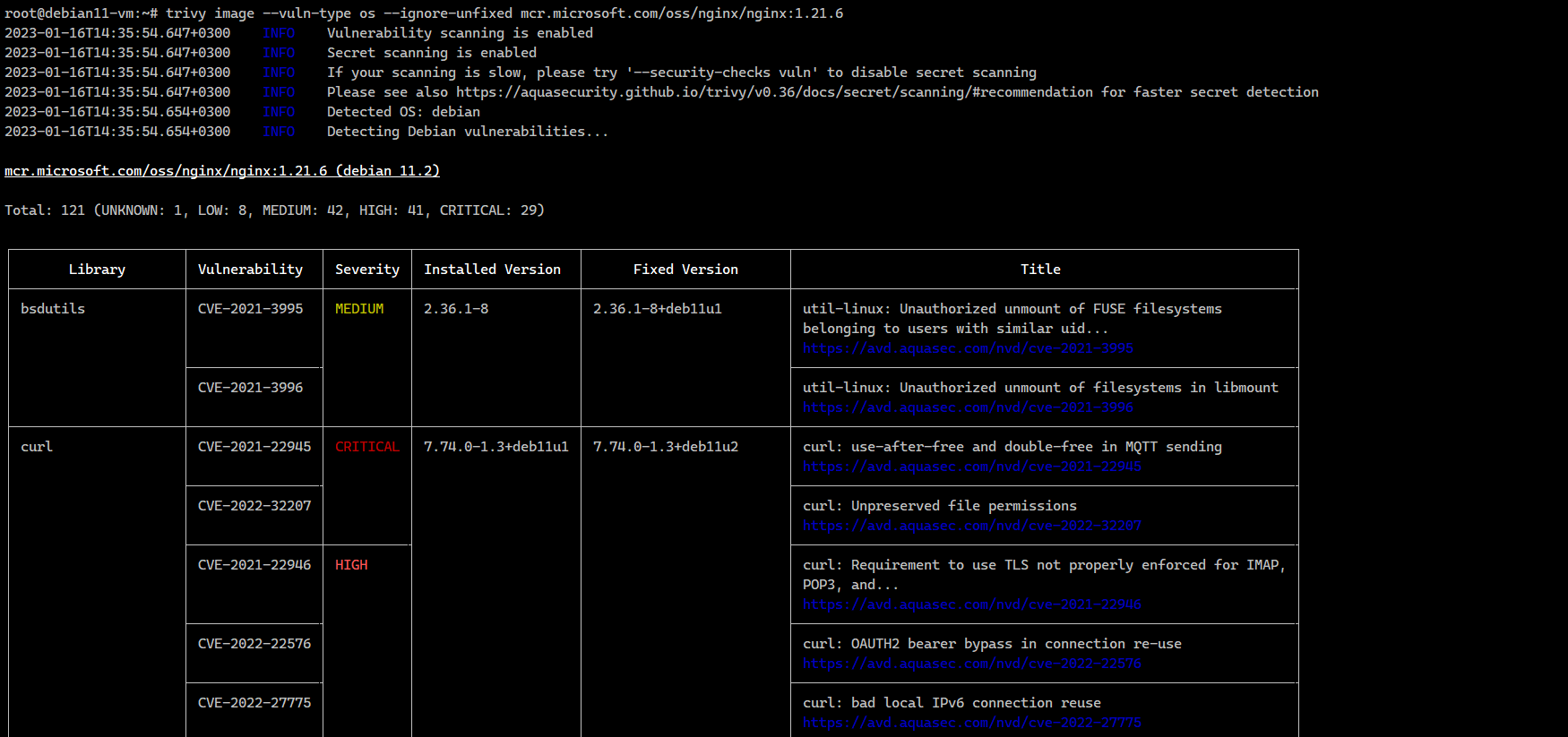
Теперь скачиваем любой образ и проверяем его на уязвимости. Покажу на примере заведомо уязвимого образа.
Результат проверки будет в файле nginx.1.21.6.json, что удобно для последующего автоматического анализа. Можно наглядно посмотреть результат в консоли:
Trivy отлично подходит для автоматической проверки образов перед их отправкой в registry. Да и просто для быстрого анализа созданного или скачанного образа. Помимо проверки образов, он умеет сканировать git репозитории, файлы с зависимостями (Gemfile.lock, Pipfile.lock, composer.lock, package-lock.json, yarn.lock, Cargo.lock).
Следующей будет заметка с описанием автоматического исправления уязвимостей в образах на основе отчётов trivy.
⇨ Сайт / Исходники
#security #docker #devops
Установить Trivy можно разными способами: из репозитория с пакетами, собрать с помощью Nix, воспользоваться bash скриптом, запустить в Docker. Все способы описаны в документации. Я установлю в Debian из репозитория.
# apt install wget apt-transport-https gnupg lsb-release# wget -qO - https://aquasecurity.github.io/trivy-repo/deb/public.key \| gpg --dearmor | tee /usr/share/keyrings/trivy.gpg > /dev/null# echo "deb [signed-by=/usr/share/keyrings/trivy.gpg] \ https://aquasecurity.github.io/trivy-repo/deb $(lsb_release -sc) main" \| tee -a /etc/apt/sources.list.d/trivy.list# apt update# apt install trivyТеперь скачиваем любой образ и проверяем его на уязвимости. Покажу на примере заведомо уязвимого образа.
# docker pull mcr.microsoft.com/oss/nginx/nginx:1.21.6# trivy image --vuln-type os --ignore-unfixed \-f json -o nginx.1.21.6.json mcr.microsoft.com/oss/nginx/nginx:1.21.6Результат проверки будет в файле nginx.1.21.6.json, что удобно для последующего автоматического анализа. Можно наглядно посмотреть результат в консоли:
# trivy image --vuln-type os \--ignore-unfixed mcr.microsoft.com/oss/nginx/nginx:1.21.6Trivy отлично подходит для автоматической проверки образов перед их отправкой в registry. Да и просто для быстрого анализа созданного или скачанного образа. Помимо проверки образов, он умеет сканировать git репозитории, файлы с зависимостями (Gemfile.lock, Pipfile.lock, composer.lock, package-lock.json, yarn.lock, Cargo.lock).
Следующей будет заметка с описанием автоматического исправления уязвимостей в образах на основе отчётов trivy.
⇨ Сайт / Исходники
#security #docker #devops
{kind=link}
Хотите научиться работать в DevSecOps проектах?
⚡️ Приглашаем 19 января в 20:00 мск на бесплатный вебинар «Сервисная сетка на базе Istio в Kubernetes».
На занятии мы:
✅ Рассмотрим один из базовых инструментов для обеспечения безопасности Kubernetes-кластеров — сервисная сетка (service mesh) на базе opensource-инструмента Istio.
✅ Посмотрим, из каких компонентов состоит сервисная сетка, как устроен инструмент Istio (control и data plane, sidecar, envoy), как осуществляется и внедряется термин наблюдаемости (observability).
✅ Продемонстрируем, как развернуть k3d-кластер, проинсталировать Istio и добавить в сервисную сетку свое первое приложение, развернутое в Kubernetes-кластер.
👉🏻 Регистрация на вебинар: https://otus.pw/GYpK/
⚡️ Приглашаем 19 января в 20:00 мск на бесплатный вебинар «Сервисная сетка на базе Istio в Kubernetes».
На занятии мы:
✅ Рассмотрим один из базовых инструментов для обеспечения безопасности Kubernetes-кластеров — сервисная сетка (service mesh) на базе opensource-инструмента Istio.
✅ Посмотрим, из каких компонентов состоит сервисная сетка, как устроен инструмент Istio (control и data plane, sidecar, envoy), как осуществляется и внедряется термин наблюдаемости (observability).
✅ Продемонстрируем, как развернуть k3d-кластер, проинсталировать Istio и добавить в сервисную сетку свое первое приложение, развернутое в Kubernetes-кластер.
👉🏻 Регистрация на вебинар: https://otus.pw/GYpK/
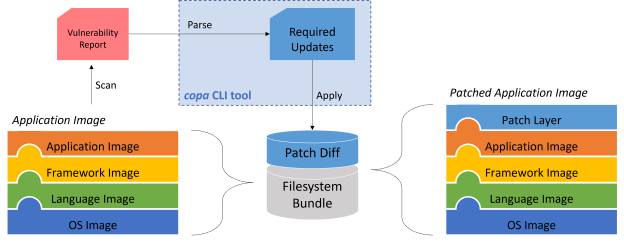
Продолжаю тему безопасности Docker контейнеров. С помощью Trivy можно проверить образ на уязвимости. Теперь расскажу, как их автоматически исправить. Для этого нам понадобится Copacetic. Он будет брать информацию из отчётов Trivy. Для запуска copa cli нам нужно:
1️⃣ Установить Go v1.19 или новее.
2️⃣ Собрать и установить runc.
3️⃣ Установить buildkit v0.10.5 или новее.
4️⃣ Собрать и установить copa.
Я кратко без пояснений покажу как это сделать на примере Debian. Все подробности есть в самих репозиториях программ.
✅ Устанавливаем GO.
✅ Устанавливаем runc.
✅ Устанавливаем buildkit.
✅ Устанавливаем copacetic.
Все необходимые компоненты установили. Теперь патчим уязвимый контейнер. Для этого предварительно в фоне запускаем buildkitd:
Copa не перезаписывает старый образ, а создаёт новый с тэгом patched. Можете сразу его посмотреть и проверить:
Ну и убедиться, что он нормально запускается:
Copa, используя информацию о версиях пакетов из отчёта Trivy, обновила все уязвимые системные пакеты в образе. Можете проверить уже пропатченный образ:
Я показал набор софта и пример обновления контейнера. Получилась готовая инструкция, которую я лично проверил. Используя эту информацию и информацию из репозиториев, можно настроить подобные обновления для своей среды.
⇨ Исходники Copacetic
#security #docker #devops
1️⃣ Установить Go v1.19 или новее.
2️⃣ Собрать и установить runc.
3️⃣ Установить buildkit v0.10.5 или новее.
4️⃣ Собрать и установить copa.
Я кратко без пояснений покажу как это сделать на примере Debian. Все подробности есть в самих репозиториях программ.
✅ Устанавливаем GO.
# wget https://go.dev/dl/go1.19.5.linux-amd64.tar.gz# tar -C /usr/local -xzf go1.19.5.linux-amd64.tar.gz# ln -s /usr/local/go/bin/go /usr/bin/go# go version✅ Устанавливаем runc.
# apt install make git gcc build-essential pkgconf libtool libsystemd-dev \libprotobuf-c-dev libcap-dev libseccomp-dev libyajl-dev libgcrypt20-dev \go-md2man autoconf python3 automake# git clone https://github.com/opencontainers/runc# cd runc# make# make install✅ Устанавливаем buildkit.
# wget https://github.com/moby/buildkit/releases/download/v0.11.0/buildkit-v0.11.0.linux-amd64.tar.gz# tar -C /usr -xzf buildkit-v0.11.0.linux-amd64.tar.gz✅ Устанавливаем copacetic.
# git clone https://github.com/project-copacetic/copacetic# cd copacetic# make# mv dist/linux_amd64/release/copa /usr/local/bin/Все необходимые компоненты установили. Теперь патчим уязвимый контейнер. Для этого предварительно в фоне запускаем buildkitd:
# buildkitd &# copa patch -i mcr.microsoft.com/oss/nginx/nginx:1.21.6 -r nginx.1.21.6.json -t 1.21.6-patchedCopa не перезаписывает старый образ, а создаёт новый с тэгом patched. Можете сразу его посмотреть и проверить:
# docker images# docker history mcr.microsoft.com/oss/nginx/nginx:1.21.6-patchedНу и убедиться, что он нормально запускается:
# docker run -it --rm --name nginx-test mcr.microsoft.com/oss/nginx/nginx:1.21.6-patchedCopa, используя информацию о версиях пакетов из отчёта Trivy, обновила все уязвимые системные пакеты в образе. Можете проверить уже пропатченный образ:
# trivy image --vuln-type os --ignore-unfixed mcr.microsoft.com/oss/nginx/nginx:1.21.6-patchedЯ показал набор софта и пример обновления контейнера. Получилась готовая инструкция, которую я лично проверил. Используя эту информацию и информацию из репозиториев, можно настроить подобные обновления для своей среды.
⇨ Исходники Copacetic
#security #docker #devops
{kind=link}
Все или почти все системные администраторы знают такой инструмент как Nmap. Если не знаете, познакомьтесь. Я сам не раз писал о нём на канале. Основной его минус — медленное сканирование. Есть альтернативная программа — Zmap, где проблема скорости решена, но и функционал у программы намного беднее.
А если хочется сканировать ещё быстрее? Чем вообще сканируют весь интернет? Сейчас это обычное дело. Для этого используют тоже open source программу — masscan. Она написана изначально под Linux, но можно собрать и под другую систему. В репозитории нет готовых сборок, но, к примеру, в Debian, поставить можно из стандартного репозитория:
Дополнительно понадобится библиотека Libpcap для анализа сетевых пакетов:
Masscan очень быстрый за счёт того, что использует свой собственный TCP/IP стек. Из-за этого он не может ничего делать, кроме как выполнять простое сканирование. В противном случае будут возникать проблемы с локальным TCP/IP стеком операционной системы. Для быстрого сканирования используются массовые асинхронные SYN пакеты только для обнаружения. А чтобы собирать полноценную информацию, как умеет Nmap, нужно устанавливать полноценные TCP соединения и ждать информацию.
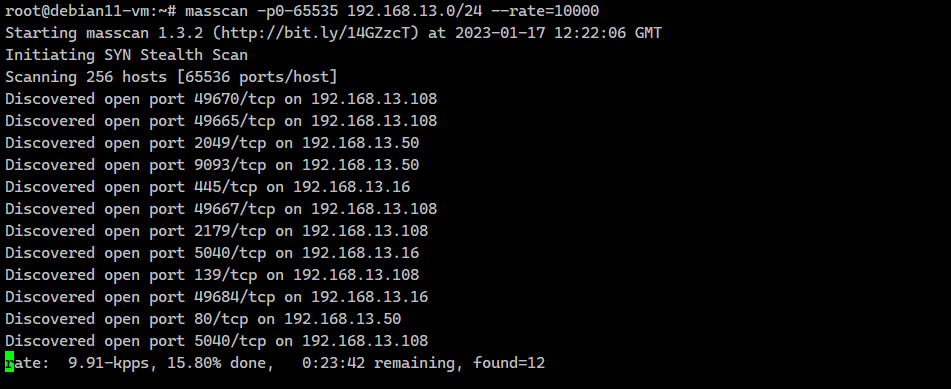
Вот пример сканирования в сети 80-го порта с ограничением в 100 пакетов в секунду:
Вся сеть просканирована за пару секунд. А теперь немного ускоримся до 10000 пакетов в секунду и просканируем весь диапазон портов в той же сети:
На это уйдёт примерно 30 минут. Нагрузка на железо будет значительная, так что аккуратнее. Лучше начинать с более низких значений. Виртуалка на Proxmox без проблем переварила 10000 пакетов в секунду, а вот если запустить на рабочем ноуте в виртуалке HyperV, то начинает подтормаживать хостовая система.
Процесс сканирования можно в любой момент прервать по CTRL + C. Результат будет сохранён в файл paused.conf. Возобновить сканирование можно следующим образом:
Если получите ошибку
то это баг более старой версии. В репах Debian именно она. Строку с nocapture = servername надо просто удалить из файла и всё заработает.
Если будете сканировать через NAT, то не забудьте, что существует ограничение на количество возможных одновременных соединений в роутере. Это если надумаете сканировать весь интернет с домашнего компьютера😀 Быстро всё равно не получится. За обещанные 5 минут не уложитесь. Если вы всё же настроены просканировать весь интернет, то в отдельной доке есть подсказки, как это лучше сделать.
Я первый раз попробовал masscan, хотя знал про него давно. Быстро просканировать всю локалку и найти вообще все открытые порты действительно удобно и быстро по сравнению с тем же Nmap.
После сканирования хорошо бы было как-то автоматически все открытые порты скормить в nmap для более детального анализа. Но пока не прорабатывал этот вопрос. Если у кого-то есть готовые решения по этой теме, поделитесь.
#network
А если хочется сканировать ещё быстрее? Чем вообще сканируют весь интернет? Сейчас это обычное дело. Для этого используют тоже open source программу — masscan. Она написана изначально под Linux, но можно собрать и под другую систему. В репозитории нет готовых сборок, но, к примеру, в Debian, поставить можно из стандартного репозитория:
# apt install masscanДополнительно понадобится библиотека Libpcap для анализа сетевых пакетов:
# apt install libpcap-devMasscan очень быстрый за счёт того, что использует свой собственный TCP/IP стек. Из-за этого он не может ничего делать, кроме как выполнять простое сканирование. В противном случае будут возникать проблемы с локальным TCP/IP стеком операционной системы. Для быстрого сканирования используются массовые асинхронные SYN пакеты только для обнаружения. А чтобы собирать полноценную информацию, как умеет Nmap, нужно устанавливать полноценные TCP соединения и ждать информацию.
Вот пример сканирования в сети 80-го порта с ограничением в 100 пакетов в секунду:
# masscan -p80 192.168.13.0/24 --rate=100Scanning 256 hosts [1 port/host]Discovered open port 80/tcp on 192.168.13.2 Discovered open port 80/tcp on 192.168.13.50Вся сеть просканирована за пару секунд. А теперь немного ускоримся до 10000 пакетов в секунду и просканируем весь диапазон портов в той же сети:
# masscan -p0-65535 192.168.13.0/24 --rate=10000На это уйдёт примерно 30 минут. Нагрузка на железо будет значительная, так что аккуратнее. Лучше начинать с более низких значений. Виртуалка на Proxmox без проблем переварила 10000 пакетов в секунду, а вот если запустить на рабочем ноуте в виртуалке HyperV, то начинает подтормаживать хостовая система.
Процесс сканирования можно в любой момент прервать по CTRL + C. Результат будет сохранён в файл paused.conf. Возобновить сканирование можно следующим образом:
# masscan --resume paused.confЕсли получите ошибку
CONF: unknown config option: nocapture=servernameто это баг более старой версии. В репах Debian именно она. Строку с nocapture = servername надо просто удалить из файла и всё заработает.
Если будете сканировать через NAT, то не забудьте, что существует ограничение на количество возможных одновременных соединений в роутере. Это если надумаете сканировать весь интернет с домашнего компьютера😀 Быстро всё равно не получится. За обещанные 5 минут не уложитесь. Если вы всё же настроены просканировать весь интернет, то в отдельной доке есть подсказки, как это лучше сделать.
Я первый раз попробовал masscan, хотя знал про него давно. Быстро просканировать всю локалку и найти вообще все открытые порты действительно удобно и быстро по сравнению с тем же Nmap.
После сканирования хорошо бы было как-то автоматически все открытые порты скормить в nmap для более детального анализа. Но пока не прорабатывал этот вопрос. Если у кого-то есть готовые решения по этой теме, поделитесь.
#network
{kind=link}
Почти любой пользователь Linux знаком с консольной командой cat, соавтором которой является легендарный Richard Matthew Stallman. Хочу рассказать об одной небольшой возможности этой программы, про которую не все знают. Более того, чаще всего люди как раз об этом не знают.
Cat может выступать как простой текстовый редактор. С помощью неё можно быстро создать пустой файл, либо добавить в конец новые строки. Создаём файл:
Проверяем:
Создавать пустые файлы с помощью cat не имеет большого смысла, так как то же самое делает команда touch:
Я обычно создаю файлы с её помощью.
С помощью cat можно сразу добавить несколько строк в файл, как в новый, так и в существующий.
Записали в файл строку testfile и вышли из редактора. Проверяем:
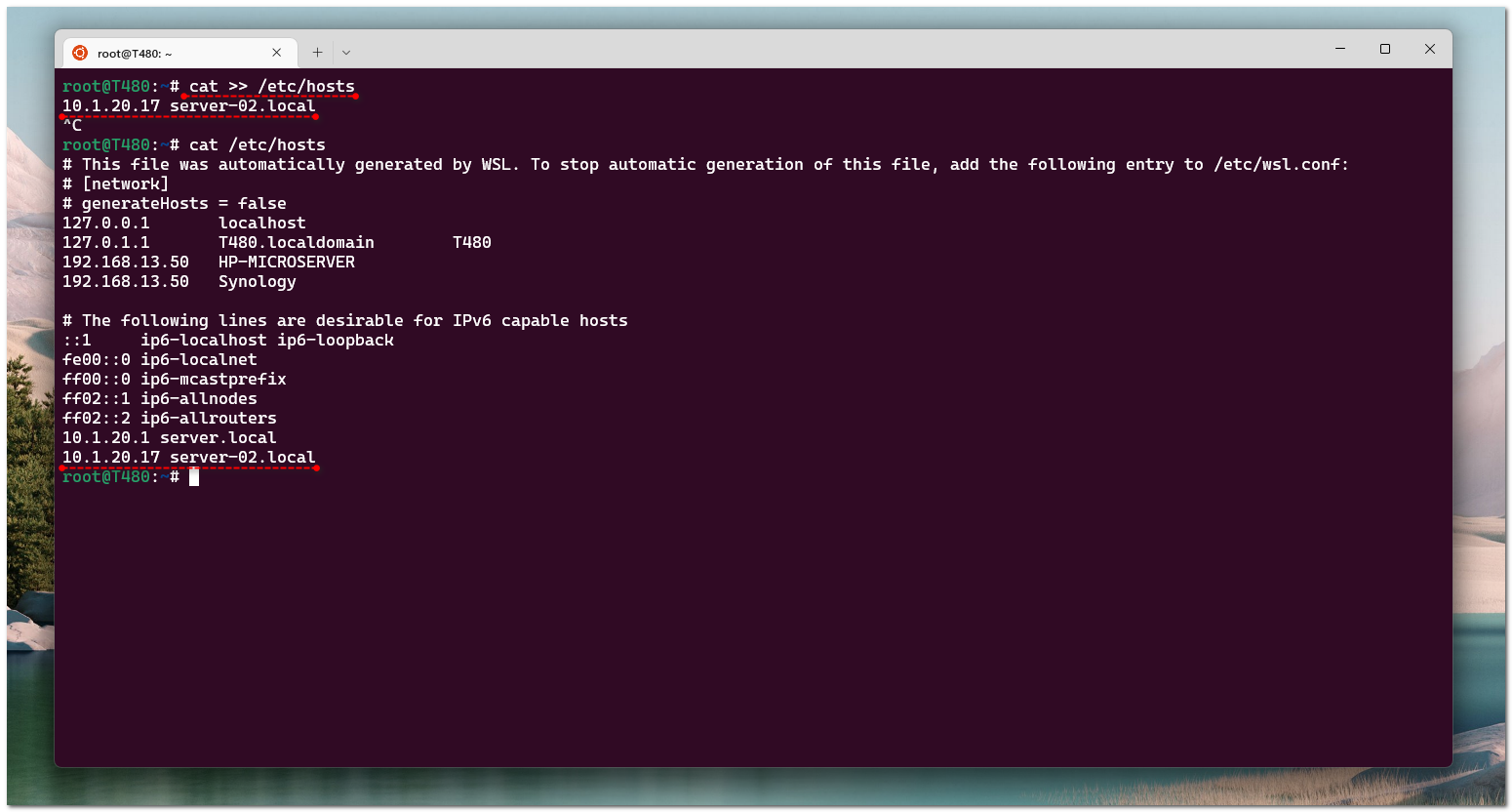
Cat может не только записать что-то в новый файл, но и добавить в конец уже существующего. А вот это уже удобно в некоторых случаях. Например, нужно добавить новую запись в hosts. С помощью cat это удобно сделать:
Добавили в конец файла новую строку
И в завершение напомню, что с помощью cat удобно объединить несколько файлов в один:
Интересно узнать, вы знали, что cat позволяет редактировать файлы? Обычно его используют только для просмотра.
#terminal
Cat может выступать как простой текстовый редактор. С помощью неё можно быстро создать пустой файл, либо добавить в конец новые строки. Создаём файл:
# cat > file1CTRL + CПроверяем:
# ls -lh file1-rw-r--r-- 1 root root 0 Jan 16 16:24 file1Создавать пустые файлы с помощью cat не имеет большого смысла, так как то же самое делает команда touch:
# touch file2Я обычно создаю файлы с её помощью.
С помощью cat можно сразу добавить несколько строк в файл, как в новый, так и в существующий.
# cat > file3testfileCTRL + CЗаписали в файл строку testfile и вышли из редактора. Проверяем:
# cat file3testfileCat может не только записать что-то в новый файл, но и добавить в конец уже существующего. А вот это уже удобно в некоторых случаях. Например, нужно добавить новую запись в hosts. С помощью cat это удобно сделать:
# cat >> /etc/hosts10.1.20.1 server.localCTRL + CДобавили в конец файла новую строку
10.1.20.1 server.local. Нет необходимости открывать файл в текстовом редакторе. Не забудьте добавить сразу переход на новую строку. И главное не перепутать и поставить два перенаправления ввода >>, а не одно >. С одним просто перезапишите файл, что тоже иногда случается 😁 Если не уверены в своей внимательности, не пользуйтесь.И в завершение напомню, что с помощью cat удобно объединить несколько файлов в один:
# cat file1 file2 > file_1_2Интересно узнать, вы знали, что cat позволяет редактировать файлы? Обычно его используют только для просмотра.
#terminal
{kind=link}
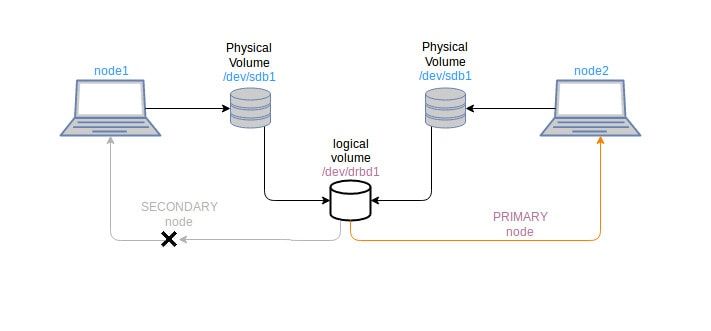
Расскажу про простую схему построения отказоустойчивой системы на уровне файлового хранения с помощью DRBD (Distributed Replicated Block Device — распределённое реплицируемое блочное устройство). Это очень простое и известное решение в том числе из-за того, что поддержка DRBD входит в стандартное ядро Linux.
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
/dev/sdb будут использоваться под DRBD. Запускаете инициализацию и получаете новое блочное устройство на каждом сервере, которое автоматически синхронизируется.Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
{kind=link}
Открытый практикум DevOps by Rebrain: Развёртывание kubernetes на своих машинках с помощью kubeadm
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
🗓 24 Января (Вторник) в 20:00 по МСК
Программа практикума:
🔹Зачем нужен карманный kubernetes?
🔹Популярные альтернативы kubeadm (MicroK8s, Docker Desktop)
🔹Kubernetes за десять минут, первый сервис за одну
Кто ведет?
Павел Фискович - Инженер с 2009. Мечтатель. Отец. He/him
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
🗓 24 Января (Вторник) в 20:00 по МСК
Программа практикума:
🔹Зачем нужен карманный kubernetes?
🔹Популярные альтернативы kubeadm (MicroK8s, Docker Desktop)
🔹Kubernetes за десять минут, первый сервис за одну
Кто ведет?
Павел Фискович - Инженер с 2009. Мечтатель. Отец. He/him
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Отследить сетевую активность конкретного приложения Linux, а также сетевые адреса, куда оно стучится, не тривиальная задача. Мне на ум не приходят какие-то известные простые программы. Решения по наблюдению за сетевым трафиком обычно оперируют IP адресами хостов и портами служб, но не локальными приложениями, потому что берут трафик со шлюзов.
Если вам нужно собирать на машине сетевую активность приложений, то можно воспользоваться open source утилитой picosnitch. Она позволяет через простой веб интерфейс просматривать статистику с группировкой по приложению, порту или удалённому IP адресу. Выбирая приложение, можно посмотреть, на какие IP адреса оно стучалось и посмотреть статистику по конкретному адресу.
Picosnitch создаёт впечатления простого pet проекта, но тем не менее заявленный функционал выполняется. Я протестировал. Автор поддерживает репозиторий пакетов для Ubuntu. Я же пробовал на Debian. Установка возможна через pip. Дополнительно понадобятся пакеты для работы с BPF.
Веб интерфейс запускается отдельной командой:
По умолчанию он работает на http://localhost:5100. Чтобы иметь доступ по сети к веб интерфейсу, задаётся IP адрес сервера через переменную окружения HOST перед запуском интерфейса. Примерно так:
На первый взгляд веб интерфейс выглядит как-то коряво и непривычно. Я даже подумал, что работает криво и не выводит информацию. Надо немного разобраться и понять логику работы. На самом деле всё работает. Можно выбрать конкретное приложение, IP адрес, домен, порт. Например, для того, чтобы посмотреть к каким IP адресам обращается какое-то приложение, необходимо выбрать группировку по Destination IP, в условии указать Where Process Name и в выпадающем списке выбрать приложение. Получите его статистику.
Picosnitch хранит информацию в SQLite базе. Сама база, настройки и лог файл лежит в директории пользователя (не root) ~/.config/picosnitch. Можно настроить глубину хранения статистики в днях. Все параметры подробно описаны в репозитории. Дополнительно программа умеет оповещать о том, что какое-то приложение полезло в сеть, либо изменился его исполняемый файл.
Для просмотра сетевой активности приложений в терминале, можно воспользоваться программой sniffer, которую я уже описывал ранее. Она более простая, без веб интерфейса и хранения статистики.
⇨ Исходники
#network
Если вам нужно собирать на машине сетевую активность приложений, то можно воспользоваться open source утилитой picosnitch. Она позволяет через простой веб интерфейс просматривать статистику с группировкой по приложению, порту или удалённому IP адресу. Выбирая приложение, можно посмотреть, на какие IP адреса оно стучалось и посмотреть статистику по конкретному адресу.
Picosnitch создаёт впечатления простого pet проекта, но тем не менее заявленный функционал выполняется. Я протестировал. Автор поддерживает репозиторий пакетов для Ubuntu. Я же пробовал на Debian. Установка возможна через pip. Дополнительно понадобятся пакеты для работы с BPF.
# apt install python3-pip bpfcc-tools libbpfcc libbpfcc-dev \linux-headers-$(uname -r)# pip3 install "picosnitch[full]" --upgrade --user# picosnitch systemd# systemctl start picosnitchВеб интерфейс запускается отдельной командой:
# picosnitch dashПо умолчанию он работает на http://localhost:5100. Чтобы иметь доступ по сети к веб интерфейсу, задаётся IP адрес сервера через переменную окружения HOST перед запуском интерфейса. Примерно так:
# export HOST='172.27.51.252'# picosnitch dashНа первый взгляд веб интерфейс выглядит как-то коряво и непривычно. Я даже подумал, что работает криво и не выводит информацию. Надо немного разобраться и понять логику работы. На самом деле всё работает. Можно выбрать конкретное приложение, IP адрес, домен, порт. Например, для того, чтобы посмотреть к каким IP адресам обращается какое-то приложение, необходимо выбрать группировку по Destination IP, в условии указать Where Process Name и в выпадающем списке выбрать приложение. Получите его статистику.
Picosnitch хранит информацию в SQLite базе. Сама база, настройки и лог файл лежит в директории пользователя (не root) ~/.config/picosnitch. Можно настроить глубину хранения статистики в днях. Все параметры подробно описаны в репозитории. Дополнительно программа умеет оповещать о том, что какое-то приложение полезло в сеть, либо изменился его исполняемый файл.
Для просмотра сетевой активности приложений в терминале, можно воспользоваться программой sniffer, которую я уже описывал ранее. Она более простая, без веб интерфейса и хранения статистики.
⇨ Исходники
#network
{kind=link}
Вчера один человек попросил посоветовать простенький, максимально легкий и простой в настройке мониторинг для одиночного сервера. Задача быстро настроить и смотреть красивые картинки в веб интерфейсе. Я быстро накидал вариантов, про которые вспомнил. Решил их оформить отдельным постом. Думаю, будет полезно не только ему.
🔥 Munin — очень простой мониторинг одиночного или небольшой группы серверов на perl. Данные хранятся в rrdtool. Настраивается очень просто и быстро, за что его любят некоторые разработчики, устанавливая на свои сервера для каких-то собственных проектов. Munin используют разработчики BitrixEnv, включили его в комплект своего окружения. А также авторы Mail-in-a-Box.
🟡 Monitorix — похожий на Munin мониторинг и тоже на основе perl и rrdtool. Подойдёт для одиночного сервера. Отличительная черта в том, что он потребляет очень мало ресурсов. Графики рендерятся сразу в png картинки. Помимо базовых системных и сетевых метрик, из коробки поддерживает мониторинг наиболее популярного софта - postfix, exim, apache, nginx, php-fpm, nfs, zfs, mysql, postgresql, redis и т.д.
🟡 Monit — похож на Munin и Monitorix. Такой же легковесный с акцентом на мониторинг одиночного сервера. Умеет не только мониторить, но и выполнять какие-то заскриптованные действия. Данные хранит в SQLite. Monit для тех, кто просто хочет мониторить свой локалхост, получать алерты, перезапускать сервисы, когда они падают. И при этом тратить минимум ресурсов. Писать oldschool конфиги без учёта отступов, пробелов, скобок.
🟡 Monitoror — очень простой мониторинг, который состоит всего лишь из одного бинарника и конфигурационного файла к нему. Отдельным конфигом настраивается web интерфейс. Используется формат json. Настраивать проверки быстро и просто. Monitoror отличает простота парсинга и сбора текстовых данных по http с возможностью их вывести в плитках на дашбодр. Это отличный инструмент для всяких чисел, получаемых из API.
🟡 Netdata — мониторинг с очень простой установкой и настройкой. Скрипт сам в автоматическом режиме развернёт сервер на Linux машине. Работает на основе агентов и коллекторов, которые ставятся очень просто, автоматически регистрируют себя на сервере и начинают отправлять данные. Это не легковесный вариант мониторинга локалхоста, но за счёт простоты установки и настройки, а так же готовых дашбордов в комплекте, добавил его в эту подборку. Для одиночного сервера он тоже подойдёт.
🟡 Glances — не совсем мониторинг, но для обозначенных в заметке задач может подойти. Это продвинутый монитор системных ресурсов с возможностью вывода информации через веб сервер. Эдакий прокачанный диспетчер ресурсов и процессов с веб интерфейсом и экспортёрами метрик в prometheus или elasticsearch.
Если забыл что-то интересное и полезное, то поделитесь в комментариях.
#мониторинг #подборка
🔥 Munin — очень простой мониторинг одиночного или небольшой группы серверов на perl. Данные хранятся в rrdtool. Настраивается очень просто и быстро, за что его любят некоторые разработчики, устанавливая на свои сервера для каких-то собственных проектов. Munin используют разработчики BitrixEnv, включили его в комплект своего окружения. А также авторы Mail-in-a-Box.
🟡 Monitorix — похожий на Munin мониторинг и тоже на основе perl и rrdtool. Подойдёт для одиночного сервера. Отличительная черта в том, что он потребляет очень мало ресурсов. Графики рендерятся сразу в png картинки. Помимо базовых системных и сетевых метрик, из коробки поддерживает мониторинг наиболее популярного софта - postfix, exim, apache, nginx, php-fpm, nfs, zfs, mysql, postgresql, redis и т.д.
🟡 Monit — похож на Munin и Monitorix. Такой же легковесный с акцентом на мониторинг одиночного сервера. Умеет не только мониторить, но и выполнять какие-то заскриптованные действия. Данные хранит в SQLite. Monit для тех, кто просто хочет мониторить свой локалхост, получать алерты, перезапускать сервисы, когда они падают. И при этом тратить минимум ресурсов. Писать oldschool конфиги без учёта отступов, пробелов, скобок.
🟡 Monitoror — очень простой мониторинг, который состоит всего лишь из одного бинарника и конфигурационного файла к нему. Отдельным конфигом настраивается web интерфейс. Используется формат json. Настраивать проверки быстро и просто. Monitoror отличает простота парсинга и сбора текстовых данных по http с возможностью их вывести в плитках на дашбодр. Это отличный инструмент для всяких чисел, получаемых из API.
🟡 Netdata — мониторинг с очень простой установкой и настройкой. Скрипт сам в автоматическом режиме развернёт сервер на Linux машине. Работает на основе агентов и коллекторов, которые ставятся очень просто, автоматически регистрируют себя на сервере и начинают отправлять данные. Это не легковесный вариант мониторинга локалхоста, но за счёт простоты установки и настройки, а так же готовых дашбордов в комплекте, добавил его в эту подборку. Для одиночного сервера он тоже подойдёт.
🟡 Glances — не совсем мониторинг, но для обозначенных в заметке задач может подойти. Это продвинутый монитор системных ресурсов с возможностью вывода информации через веб сервер. Эдакий прокачанный диспетчер ресурсов и процессов с веб интерфейсом и экспортёрами метрик в prometheus или elasticsearch.
Если забыл что-то интересное и полезное, то поделитесь в комментариях.
#мониторинг #подборка
{kind=link}
⚠ Я долго это терпел, но не выдержал. Надоело то, что не грузятся аватарки в youtube. Для всех других сайтов обходился редким включением VPN, так как не часто хожу по запрещёнке. Но ютубом пользуюсь каждый день.
✅ В итоге настроил:
◽ OpenVPN сервер на американском VPS.
◽ Подключил его к домашнему Микротику.
◽ Создал Address List со списком доменов, запросы к которым хочу заворачивать в VPN туннель.
◽ Промаркировал все запросы к этому списку.
◽ Настроил в routes маршрут через OpenVPN туннель для всех промаркированных запросов.
И о чудо, спустя почти год я постоянно вижу все картинки с ютуба.
Подробно весь процесс настройки показан вот в этом видео:
Wireguard + Mikrotik. Частичное перенаправление трафика
⇨ https://www.youtube.com/watch?v=RA8mICgGcs0
Единственное отличие — у автора уже RouterOS 7 и настроен WireGuard. Мне пока не хочется экспериментов с 7-й версией, поэтому я до сих пор везде использую 6-ю. А там поддержки WG нет, поэтому подключаюсь по OpenVPN.
#vpn #mikrotik
✅ В итоге настроил:
◽ OpenVPN сервер на американском VPS.
◽ Подключил его к домашнему Микротику.
◽ Создал Address List со списком доменов, запросы к которым хочу заворачивать в VPN туннель.
◽ Промаркировал все запросы к этому списку.
◽ Настроил в routes маршрут через OpenVPN туннель для всех промаркированных запросов.
И о чудо, спустя почти год я постоянно вижу все картинки с ютуба.
Подробно весь процесс настройки показан вот в этом видео:
Wireguard + Mikrotik. Частичное перенаправление трафика
⇨ https://www.youtube.com/watch?v=RA8mICgGcs0
Единственное отличие — у автора уже RouterOS 7 и настроен WireGuard. Мне пока не хочется экспериментов с 7-й версией, поэтому я до сих пор везде использую 6-ю. А там поддержки WG нет, поэтому подключаюсь по OpenVPN.
#vpn #mikrotik
YouTube
Wireguard + Mikrotik. Частичное перенаправление трафика
Ссылка на первый выпуск о Wireguard https://youtu.be/inx_dVfjadI
Мой сайт https://matiashov.ru
Телеграм канал https://t.me/amatyashov
Мой телеграм бот: https://t.me/amatyashov_bot
Добро пожаловать на мой канал, друзья! Здесь я делюсь информацией в разных…
Мой сайт https://matiashov.ru
Телеграм канал https://t.me/amatyashov
Мой телеграм бот: https://t.me/amatyashov_bot
Добро пожаловать на мой канал, друзья! Здесь я делюсь информацией в разных…
В операционной системе Linux существует полезная утилита touch, которую по моим наблюдениям чаще всего используют не по её прямому назначению. Когда-то давно я увидел, что с её помощью можно создать пустой файл. Запомнил это и сам постоянно её использую, хотя есть способы проще. А изначально touch была создана для обновления информации о времени изменения и доступа к файлу. Об этом прямо написано в man этой утилиты: Update the access and modification times of each FILE to the current time.
С помощью touch можно создать пустой файл или несколько файлов сразу:
А с помощью дополнительных ключей можно обновить информацию о времени последнего доступа к файлу:
Посмотрели старое время доступа, обновили его до актуального и посмотрели ещё раз. Время будет обновлено.
То же самое для времени изменения файла:
Несмотря на то, что сам файл мы не меняли, его метка о времени изменения обновилась на текущее время, когда выполнялась команда.
Подобный функционал с изменением меток времени можно использовать в скриптах, когда нужно после выполнения какого-то действия явно указать, что изменения произошли, даже если файлы не поменялись. Например, взять какой-то файл за образец того, когда выполнялся последний бэкап и перед его выполнением менять дату доступа к файлу. Отслеживая изменение этого файла можно следить за выполнением процесса синхронизации. Это пример того, как я сам использую подобный функционал. Суть в том, что если файлы в неизменном виде приезжают на бэкап сервер со своими исходными метками доступа и изменения, то в случае если в источнике файлы не изменились за время между бэкапами, на приёмнике трудно понять, а была ли реально выполнена синхронизация. Может файлы не изменились, а может и копирования не было. А если вы какой-то файл на источнике принудительно пометите с помощью touch, то проверив его изменение на приёмнике вы хотя бы будете знать, что синхронизация реально произошла, просто файлы не изменились.
Также с помощью touch можно явно указать дату изменения файла. Можно его существенно состарить:
Установили дату изменения файла - 21 марта 2019 года 16:55. Формат даты в команде - YYMMDDhhmm. Данный приём активно использую всякие зловреды на сайтах, чтобы затеряться среди старых файлов. Обычно когда разбираются во взломе, первым делом ищут все недавно изменённые файлы. А после такого изменения файл может разом состариться на пару лет.
Но если внимательно посмотреть на изменяемый файл с помощью stat, то можно увидеть время его создания и изменения атрибутов (change и birth):
Наверное их тоже можно поменять, но я не разбирался с этим. Если кто-то знает, как это сделать, подскажите.
#linux #bash
С помощью touch можно создать пустой файл или несколько файлов сразу:
# touch file01.txt# touch file01.txt file02.txt file03.txt# touch file0{1,2,3}.txtА с помощью дополнительных ключей можно обновить информацию о времени последнего доступа к файлу:
# ls -l file01.txt --time=atime# touch -a file01.txt# ls -l file01.txt --time=atimeПосмотрели старое время доступа, обновили его до актуального и посмотрели ещё раз. Время будет обновлено.
То же самое для времени изменения файла:
# ls -l file01.txt# touch -m file01.txt# ls -l file01.txtНесмотря на то, что сам файл мы не меняли, его метка о времени изменения обновилась на текущее время, когда выполнялась команда.
Подобный функционал с изменением меток времени можно использовать в скриптах, когда нужно после выполнения какого-то действия явно указать, что изменения произошли, даже если файлы не поменялись. Например, взять какой-то файл за образец того, когда выполнялся последний бэкап и перед его выполнением менять дату доступа к файлу. Отслеживая изменение этого файла можно следить за выполнением процесса синхронизации. Это пример того, как я сам использую подобный функционал. Суть в том, что если файлы в неизменном виде приезжают на бэкап сервер со своими исходными метками доступа и изменения, то в случае если в источнике файлы не изменились за время между бэкапами, на приёмнике трудно понять, а была ли реально выполнена синхронизация. Может файлы не изменились, а может и копирования не было. А если вы какой-то файл на источнике принудительно пометите с помощью touch, то проверив его изменение на приёмнике вы хотя бы будете знать, что синхронизация реально произошла, просто файлы не изменились.
Также с помощью touch можно явно указать дату изменения файла. Можно его существенно состарить:
# touch -t 201903211655 file01.txt # ls -l file01.txt-rw-r--r-- 1 root root 0 Mar 21 2019 file01.txtУстановили дату изменения файла - 21 марта 2019 года 16:55. Формат даты в команде - YYMMDDhhmm. Данный приём активно использую всякие зловреды на сайтах, чтобы затеряться среди старых файлов. Обычно когда разбираются во взломе, первым делом ищут все недавно изменённые файлы. А после такого изменения файл может разом состариться на пару лет.
Но если внимательно посмотреть на изменяемый файл с помощью stat, то можно увидеть время его создания и изменения атрибутов (change и birth):
# stat file01.txt File: file01.txt Size: 0 Blocks: 0 IO Block: 4096 regular empty fileDevice: 802h/2050d Inode: 790197 Links: 1Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)Access: 2019-03-21 16:55:00.000000000 +0300Modify: 2019-03-21 16:55:00.000000000 +0300Change: 2023-01-19 01:09:17.084405177 +0300 Birth: 2023-01-19 00:50:59.789606107 +0300Наверное их тоже можно поменять, но я не разбирался с этим. Если кто-то знает, как это сделать, подскажите.
#linux #bash
Хочу дать вам очень простой, но может быть для кого-то крайне полезный совет. Сам я его получил где-то год-два назад и очень рад, что со мной поделились полезной информацией.
В нашей профессии постоянно приходится взаимодействовать с англоязычными источниками. Я вполне могу осмысленно прочитать английский текст и перевести его практически полностью. Но если хочется быстро понять о чём написано, пробежав по началам абзацев, то я его прогоняю через переводчик.
По привычке много лет пользовался бесплатным переводчиком от Google. Мне казалось, что он самый лучший, так как у гугла огромные ресурсы для его развития. Но оказывается, есть более качественный автоматический переводчик — deepl.com. С тех пор как попробовал его, пользуюсь только им.
Попробуйте, может вы тоже до сих пор пользуетесь translate.google.ru, который переводит не так хорошо. С deepl я понял, что совсем скоро изучать иностранные языки для тех, кто не собирается общаться на них, потеряет смысл. Просто перевести текст или видео можно будет совсем без знания языка. Уже сейчас видео в режиме реального времени неплохо переводит Яндекс.Браузер, а deepl текст и вовсе хорошо, даже технической направленности.
💡 И ещё дам один совет по поводу автоматических переводов. Когда ищите какую-то информацию в Википедии, особенно про исторические события или персоналии, посмотрите текст на разных языках. Там иногда представлена либо дополненная информация, либо вообще другая по смыслу. Это позволяет лучше разобраться в событии или понять, что за человек описан. Причём перевод имеет смысл смотреть не только с английского, а чаще даже именно с других языков. Там может оказаться много всего нового и полезного.
#разное
В нашей профессии постоянно приходится взаимодействовать с англоязычными источниками. Я вполне могу осмысленно прочитать английский текст и перевести его практически полностью. Но если хочется быстро понять о чём написано, пробежав по началам абзацев, то я его прогоняю через переводчик.
По привычке много лет пользовался бесплатным переводчиком от Google. Мне казалось, что он самый лучший, так как у гугла огромные ресурсы для его развития. Но оказывается, есть более качественный автоматический переводчик — deepl.com. С тех пор как попробовал его, пользуюсь только им.
Попробуйте, может вы тоже до сих пор пользуетесь translate.google.ru, который переводит не так хорошо. С deepl я понял, что совсем скоро изучать иностранные языки для тех, кто не собирается общаться на них, потеряет смысл. Просто перевести текст или видео можно будет совсем без знания языка. Уже сейчас видео в режиме реального времени неплохо переводит Яндекс.Браузер, а deepl текст и вовсе хорошо, даже технической направленности.
💡 И ещё дам один совет по поводу автоматических переводов. Когда ищите какую-то информацию в Википедии, особенно про исторические события или персоналии, посмотрите текст на разных языках. Там иногда представлена либо дополненная информация, либо вообще другая по смыслу. Это позволяет лучше разобраться в событии или понять, что за человек описан. Причём перевод имеет смысл смотреть не только с английского, а чаще даже именно с других языков. Там может оказаться много всего нового и полезного.
#разное
{kind=link}
Для профессиональной работы с документацией есть open source продукт Antora. С её помощью можно автоматически генерировать статический сайт с документацией в формате AsciiDoc. При этом вся информация для сайта хранится в git репозиториях.
Как я уже сказал, Antora стоит рассматривать, если вам нужна документация профессионального уровня с различными продуктами, ветками, версиями. Это инструмент для технических писателей. Хотя ничего особо сложного там нет, просто нужно будет погрузиться в продукт и немного его изучить, прежде чем начать пользоваться. Это посложнее, чем та же wiki разметка.
У Antora свой язык разметки и взаимосвязей, с которым нужно будет ознакомиться, чтобы создавать и поддерживать более ли менее сложную документацию. Всё это описано в документации Анторы. Там же приведён Demo репозиторий, на основе которого можно собрать документацию и посмотреть, как работает генерация, и как потом выглядит сам сайт.
Я установил себе на Debian всё необходимо и сгенерировал сайт с документацией на основе Demo репозитория. На Debian 11 это выглядит следующим образом.
Ставим nodejs и npm:
В Debian в репах слишком старая версия nodejs, поэтому поставим nvm и с её помощью более свежую версию nodejs. Возможно предыдущий шаг не нужен, но я на всякий случай всё равно установил сначала старую версию, чтобы минимизировать возможные проблемы с какими-то зависимостями.
Смотрим версию:
Всё ОК.
Устанавливаем Antora.
Проверяем установленную версию:
Установка завершена. Теперь можно сгенерировать сайт на основе существующих репозиториев. Формат конфигурации antora - yaml. Вот примерный конфиг:
Взяли два разных источника в git, разные версии и ветки. Анторе достаточно доступа для чтения. Запускаем генерацию сайта:
В директории build/site находятся статические файлы сайта. Можете скопировать директорию к себе и запустить локально, либо установить nginx и скопировать содержимое этой директории в дефолтную директорию /var/www/html и посмотреть содержимое.
В принципе, большого смысла устанавливать Andora у себя нет, так как её достаточно один раз запустить и сгенерировать сайт. Можно воспользоваться готовым Docker контейнером.
Структура и формат такой документации прост, удобен и функционален. Документация самой Antora сделана с её же помощью, так что можно оценить функционал.
Напомню, что ранее я уже делал обзоры на популярные системы для ведения документации:
▪️ Mermaid — известный и популярный инструмент для создания визуализаций и диаграмм на основе написанного кода.
▪️ MkDocs — инструмент для генерации документации в виде статического сайта на базе текстовых файлов в формате markdown.
▪️ BookStack — open source платформа для создания документации и вики-контента.
▪️ Wiki.js — готовая wiki платформа с поддержкой редакторов wiki, markdown, wysiwyg.
⇨ Сайт / Исходники
#docs
Как я уже сказал, Antora стоит рассматривать, если вам нужна документация профессионального уровня с различными продуктами, ветками, версиями. Это инструмент для технических писателей. Хотя ничего особо сложного там нет, просто нужно будет погрузиться в продукт и немного его изучить, прежде чем начать пользоваться. Это посложнее, чем та же wiki разметка.
У Antora свой язык разметки и взаимосвязей, с которым нужно будет ознакомиться, чтобы создавать и поддерживать более ли менее сложную документацию. Всё это описано в документации Анторы. Там же приведён Demo репозиторий, на основе которого можно собрать документацию и посмотреть, как работает генерация, и как потом выглядит сам сайт.
Я установил себе на Debian всё необходимо и сгенерировал сайт с документацией на основе Demo репозитория. На Debian 11 это выглядит следующим образом.
Ставим nodejs и npm:
# apt install nodejs npmВ Debian в репах слишком старая версия nodejs, поэтому поставим nvm и с её помощью более свежую версию nodejs. Возможно предыдущий шаг не нужен, но я на всякий случай всё равно установил сначала старую версию, чтобы минимизировать возможные проблемы с какими-то зависимостями.
# curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh \| bash# source .bashrc# nvm install --ltsСмотрим версию:
# node --versionv18.13.0Всё ОК.
Устанавливаем Antora.
# mkdir docs-site && cd docs-site# node -e "fs.writeFileSync('package.json', '{}')"# npm i -D -E @antora/cli@3.1 @antora/site-generator@3.1# npm i -g @antora/cli@3.1 @antora/site-generator@3.1Проверяем установленную версию:
# antora -v@antora/cli: 3.1.2@antora/site-generator: 3.1.2Установка завершена. Теперь можно сгенерировать сайт на основе существующих репозиториев. Формат конфигурации antora - yaml. Вот примерный конфиг:
site: title: Antora Docs start_page: component-b::index.adoc content: sources: - url: https://gitlab.com/antora/demo/demo-component-a.git branches: HEAD - url: https://gitlab.com/antora/demo/demo-component-b.git branches: [v2.0, v1.0] start_path: docsui: bundle: url: https://gitlab.com/antora/antora-ui-default/-/jobs/artifacts/HEAD/raw/build/ui-bundle.zip?job=bundle-stable snapshot: trueВзяли два разных источника в git, разные версии и ветки. Анторе достаточно доступа для чтения. Запускаем генерацию сайта:
# antora --fetch antora-playbook.ymlВ директории build/site находятся статические файлы сайта. Можете скопировать директорию к себе и запустить локально, либо установить nginx и скопировать содержимое этой директории в дефолтную директорию /var/www/html и посмотреть содержимое.
В принципе, большого смысла устанавливать Andora у себя нет, так как её достаточно один раз запустить и сгенерировать сайт. Можно воспользоваться готовым Docker контейнером.
Структура и формат такой документации прост, удобен и функционален. Документация самой Antora сделана с её же помощью, так что можно оценить функционал.
Напомню, что ранее я уже делал обзоры на популярные системы для ведения документации:
▪️ Mermaid — известный и популярный инструмент для создания визуализаций и диаграмм на основе написанного кода.
▪️ MkDocs — инструмент для генерации документации в виде статического сайта на базе текстовых файлов в формате markdown.
▪️ BookStack — open source платформа для создания документации и вики-контента.
▪️ Wiki.js — готовая wiki платформа с поддержкой редакторов wiki, markdown, wysiwyg.
⇨ Сайт / Исходники
#docs
{kind=link}
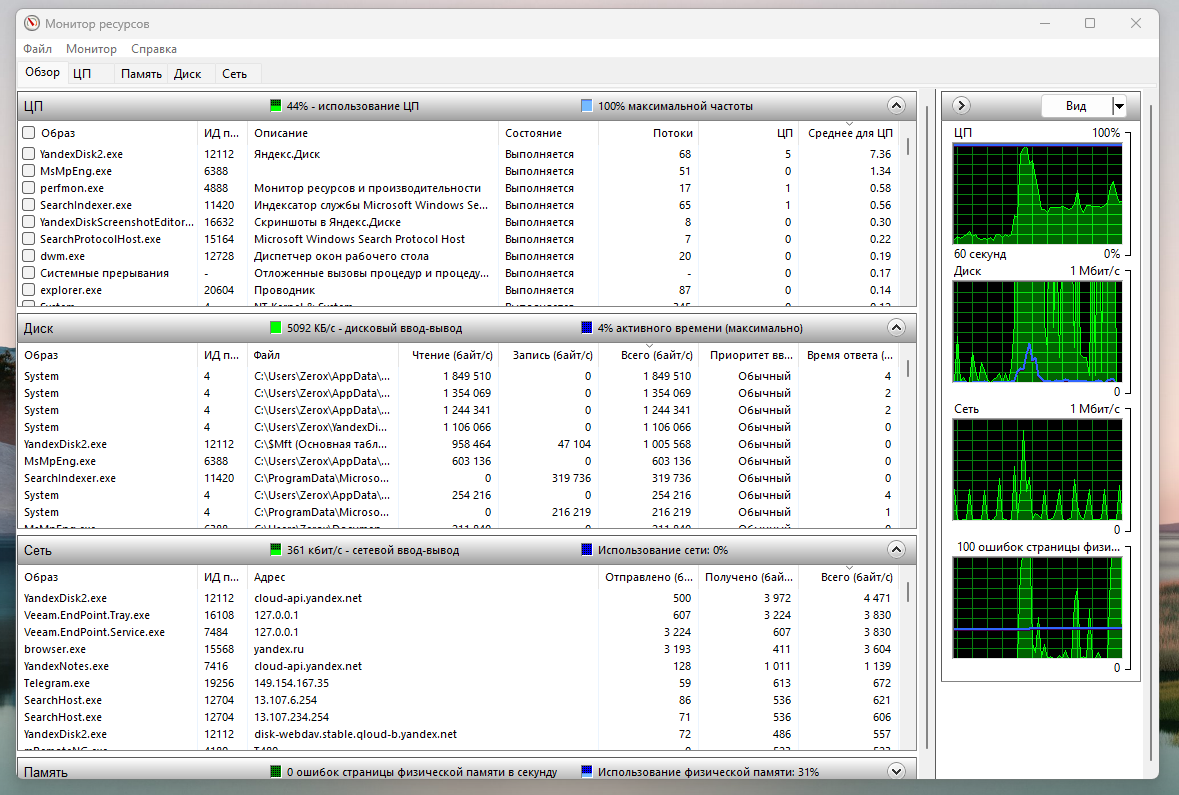
Недавно делал обзор простых систем мониторинга для одиночного сервера Linux. Меня один человек спросил, а есть ли что-то похожее для Windows. Я призадумался и понял, что ничего подобного не знаю. Под Windows судя по всему не принято писать подобные программы. Возможно это связано с тем, что там есть встроенный Системный монитор (perfmon), в котором можно собрать всевозможные счётчики и метрики.
Заменой простого мониторинга в Windows часто выступают виджеты рабочего стола, которые то появляются в какой-то редакции, то исчезают в следующей. Не знаю, зачем это делают. Я помню, что когда-то давно активно использовал виджеты, выводя на рабочий стол основные системные метрики. Сейчас, к примеру, есть довольно популярный open source продукт на эту тему — rainmeter.
Также для Windows существует много программ с отображением системных метрик и датчиков в режиме реального времени. Например, Open Hardware Monitor и другие подобные программы. Её консольную версию, кстати, удобно использовать для своего мониторинга, забирая нужные метрики.
Всё это, конечно, не тянет на полноценный мониторинг, потому что не хватает хранения исторических данных и оповещений. Я потратил немного времени и поискал что-то на подобии Munin, только для Windows. И не нашёл. Хотя по идее, потребность в этом должна быть. Я и видел, и настраивал много одиночных Windows серверов под тот же терминал, 1С или файловый сервер, где не было централизованной системы мониторинга. Было бы неплохо поставить что-то локально и хотя бы собирать исторические данные, чтобы посмотреть среднюю нагрузку на систему, к примеру, на прошлой недели. Как это быстро реализовать для одиночного сервера?
#windows
Заменой простого мониторинга в Windows часто выступают виджеты рабочего стола, которые то появляются в какой-то редакции, то исчезают в следующей. Не знаю, зачем это делают. Я помню, что когда-то давно активно использовал виджеты, выводя на рабочий стол основные системные метрики. Сейчас, к примеру, есть довольно популярный open source продукт на эту тему — rainmeter.
Также для Windows существует много программ с отображением системных метрик и датчиков в режиме реального времени. Например, Open Hardware Monitor и другие подобные программы. Её консольную версию, кстати, удобно использовать для своего мониторинга, забирая нужные метрики.
Всё это, конечно, не тянет на полноценный мониторинг, потому что не хватает хранения исторических данных и оповещений. Я потратил немного времени и поискал что-то на подобии Munin, только для Windows. И не нашёл. Хотя по идее, потребность в этом должна быть. Я и видел, и настраивал много одиночных Windows серверов под тот же терминал, 1С или файловый сервер, где не было централизованной системы мониторинга. Было бы неплохо поставить что-то локально и хотя бы собирать исторические данные, чтобы посмотреть среднюю нагрузку на систему, к примеру, на прошлой недели. Как это быстро реализовать для одиночного сервера?
#windows
{kind=link}
Обновил и полностью актуализировал популярную статью на своём сайте на тему отправки уведомлений из Zabbix в Telegram. Обновил некоторые картинки, проверил все описанные способы. Всё актуально и в рабочем состоянии. Если аккуратно повторить по статье, то всё получится.
Отправка уведомлений и графиков из zabbix в telegram
⇨ https://serveradmin.ru/nastroyka-opoveshheniy-zabbix-v-telegram
🟢 В статье описаны три способа отправки оповещений:
1️⃣ Стандартный шаблон, отправляющий сообщения через webhook. Максимально простая и быстрая настройка. Шаблон идёт стандартный вместе с сервером. Если обновлялись со старых релизов и шаблона у вас нет, то взять его можно в репозитории Zabbix. Функционал очень простой — отправлять можно только текст, без какого-либо форматирования или графиков.
2️⃣ Использование скрипта от известного автора ableev (Ilia Ableev). Это внешний скрипт на Python, который нужно отдельно настроить, а потом интегрировать в Zabbix. Тут всё придётся настроить самостоятельно, начиная от настройки самого скрипта, до создания способа оповещения с его помощью. Скрипт умеет отправлять графики в отдельном от текста сообщении.
3️⃣ Третий способ через ещё один внешний скрипт от xxsokolov (Dmitry Sokolov). Там немного сложнее настройка, но функционал скрипта чуть побольше. Основное преимущество над предыдущим скриптом — умеет отправлять графики вместе с текстом в одном сообщении. Так удобнее воспринимать информацию. Плюс настроек по оформлению побольше.
Я в разное время использовал все три способа. Сейчас ещё раз их проверил — работают нормально. Если лень заморачиваться, то использую первый способ. Если для себя делаю, то настраиваю второй или третий.
Статья довольно популярная. И в комментариях море вопросов и ошибок. И все они от невнимательности. Если аккуратно и вдумчиво повторять, то всё получится.
Помимо непосредственно отправки оповещений, в статье показываю, как реализуются различные схемы уведомлений на разные события разным пользователям и группам. Одни получают оповещения по почте, вторые только конкретные сообщения в личку телеграм, третьи оповещения летят в общую группу.
#zabbix
Отправка уведомлений и графиков из zabbix в telegram
⇨ https://serveradmin.ru/nastroyka-opoveshheniy-zabbix-v-telegram
🟢 В статье описаны три способа отправки оповещений:
1️⃣ Стандартный шаблон, отправляющий сообщения через webhook. Максимально простая и быстрая настройка. Шаблон идёт стандартный вместе с сервером. Если обновлялись со старых релизов и шаблона у вас нет, то взять его можно в репозитории Zabbix. Функционал очень простой — отправлять можно только текст, без какого-либо форматирования или графиков.
2️⃣ Использование скрипта от известного автора ableev (Ilia Ableev). Это внешний скрипт на Python, который нужно отдельно настроить, а потом интегрировать в Zabbix. Тут всё придётся настроить самостоятельно, начиная от настройки самого скрипта, до создания способа оповещения с его помощью. Скрипт умеет отправлять графики в отдельном от текста сообщении.
3️⃣ Третий способ через ещё один внешний скрипт от xxsokolov (Dmitry Sokolov). Там немного сложнее настройка, но функционал скрипта чуть побольше. Основное преимущество над предыдущим скриптом — умеет отправлять графики вместе с текстом в одном сообщении. Так удобнее воспринимать информацию. Плюс настроек по оформлению побольше.
Я в разное время использовал все три способа. Сейчас ещё раз их проверил — работают нормально. Если лень заморачиваться, то использую первый способ. Если для себя делаю, то настраиваю второй или третий.
Статья довольно популярная. И в комментариях море вопросов и ошибок. И все они от невнимательности. Если аккуратно и вдумчиво повторять, то всё получится.
Помимо непосредственно отправки оповещений, в статье показываю, как реализуются различные схемы уведомлений на разные события разным пользователям и группам. Одни получают оповещения по почте, вторые только конкретные сообщения в личку телеграм, третьи оповещения летят в общую группу.
#zabbix
Server Admin
Настройка оповещений zabbix в telegram
Несколько способов отправки оповещений из zabbix в telegram. В том числе пример с отправкой графиков вместе с событиями.
У меня основная рабочая система Windows 11, поэтому периодически пишу заметки по её настройке. Кстати, 11-ю версию не советую ставить. В ней есть неприятные баги. Например, аутентификация по RDP не работает, если использовать в качестве имени пользователя Администратор по-русски. Проблема исключительно с этим именем. Английский Administrator нормально проходит аутентификацию. У меня есть сервера с русским администратором и меня напрягает решать каждый раз эту задачу. Если кто-то сталкивался и решил проблему, дайте знать. Я не смог найти решение. Перепробовал всё, что только нашёл по ней.
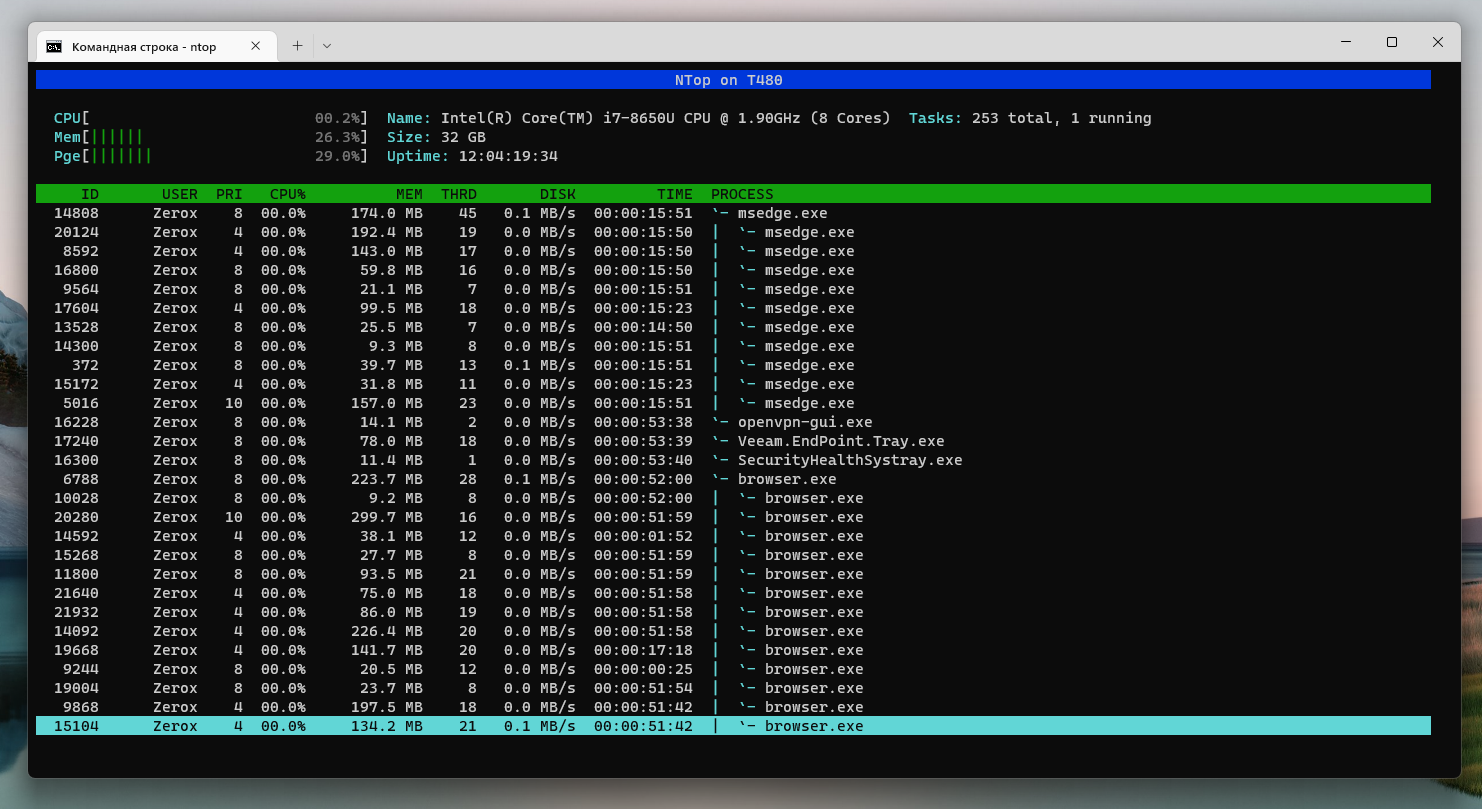
Рассказать я хотел не об этом. Когда искал что-то на github для Windows, попался в поиске репозиторий с NTop. Заинтересовало название, поэтому решил посмотреть, что это такое. Оказалось, что это попытка сделать клон линуксового диспетчера задач htop, который лично я ставлю на все сервера под своим управлением. Мне нравится эта программа.
NTop есть в виндовом магазине приложений. Так что поставить его просто:
Консоль должна быть запущена с правами администратора.
После этого можно запускать аналог htop в консоли Windows. Она у меня почти всегда запущена, так что довольно удобно получается. Этот диспетчер более легкий и информативный для беглого просмотра списка процессов. Так что я себе установил и буду пользоваться.
Функционал у NTop беднее, чем у htop. Практически ничего не реализовано, кроме базового просмотра процессов, их завершение и различная сортировка на основе потребления памяти или cpu. Также поддерживается древовидное отображение процессов, что удобно и более информативно по сравнению с встроенным диспетчером задач.
Попробуйте, может вам тоже понравится.
⇨ Исходники
#windows
Рассказать я хотел не об этом. Когда искал что-то на github для Windows, попался в поиске репозиторий с NTop. Заинтересовало название, поэтому решил посмотреть, что это такое. Оказалось, что это попытка сделать клон линуксового диспетчера задач htop, который лично я ставлю на все сервера под своим управлением. Мне нравится эта программа.
NTop есть в виндовом магазине приложений. Так что поставить его просто:
> winget install ntopКонсоль должна быть запущена с правами администратора.
После этого можно запускать аналог htop в консоли Windows. Она у меня почти всегда запущена, так что довольно удобно получается. Этот диспетчер более легкий и информативный для беглого просмотра списка процессов. Так что я себе установил и буду пользоваться.
Функционал у NTop беднее, чем у htop. Практически ничего не реализовано, кроме базового просмотра процессов, их завершение и различная сортировка на основе потребления памяти или cpu. Также поддерживается древовидное отображение процессов, что удобно и более информативно по сравнению с встроенным диспетчером задач.
Попробуйте, может вам тоже понравится.
⇨ Исходники
#windows
{kind=link}
На днях по новостным лентам пролетела новость на тему рекомендаций по безопасной настройки Linux от ФСТЭК. Думаю, многие из вас её видели. Меня заинтересовал документ, и я его внимательно прочитал и постарался осмыслить.
⇨ Сразу приведу ссылку на оригинал
В целом, документ показался полезным, так как на русском языке таких материалов довольно мало. Где-то половину рекомендаций я не понял, особенно связанных с настройками ядер и загрузчика. Нужно погружаться в тему. А то, что касается пользователей, прав доступа к бинарникам и задачам из cron всё по делу. Также понятны рекомендации отключить некоторый функционал ядра, если он не используется (user_namespaces, vsyscall и т.д.).
Я бы обратил ваше внимание и взял на вооружение, как лист проверки при настройке системы первые несколько разделов:
▪ Настройка авторизации в операционных системах Linux
▪ Ограничение механизмов получения привилегий
▪ Настройка прав доступа к объектам файловой системы
По ним также полезно пройтись после взлома вашей системы, если нет возможности её переустановить, а стоит задача вернуть работоспособность.
В документе очень не хватает подробностей про вектора атаки. Некоторые рекомендации по ядру не понятны даже с учётом того, что ты понимаешь смысл настроек.
Также я совершенно не понял, почему не уделили внимание настройке firewall. Какая может быть безопасность сервера, если к его сервисам не ограничили доступ на уровне брендмауэера. Для безопасности как минимум нужно упомянуть о том, что по умолчанию должен быть включен режим работы нормально закрытый. При этом виде настройки firewall всё запрещено, что не разрешено явно.
Практика подобных рекомендаций от гос. структур распространена в мире. Можете для общего развития или из любопытства посмотреть похожие рекомендации от гос. органов USA и UK:
⇨ https://ncp.nist.gov/checklist/909
⇨ https://security-guidance.service.justice.gov.uk/system-lockdown-and-hardening-standard/
У американцев сразу представлены готовые плейбуки ansible для применения на системах RHEL. А у англичан текстом перечислены прямо на странице. Интересно было ознакомиться. Про сеть там, кстати, не забыли:
◽ An application firewall shall be installed. The firewall shall be configured to ‘allow only essential services’, log firewall activity, and operate in ‘stealth mode’ (undiscoverable).
◽ ICMP redirects shall be disabled.
◽ Idle connections shall be disconnected after a default period; normally less than 30 minutes.
⚡️И ещё вам в копилочку очень подробный англоязычный материал на тему повышения безопасности в ОС на базе ядра Linux - Linux Hardening Guide. У неё любопытное начало: Linux is not a secure operating system. И дальше представлены шаги, следуя которым это можно исправить.
Если кто-то ознакомился и увидел явно вредные советы или скрытые неочевидные проблемы от настроек в документе ФСТЭК, поделитесь информацией. У меня появилось желание оформить это как-то более подробно в отдельную статью. Думаю, это было бы полезно.
#security
⇨ Сразу приведу ссылку на оригинал
В целом, документ показался полезным, так как на русском языке таких материалов довольно мало. Где-то половину рекомендаций я не понял, особенно связанных с настройками ядер и загрузчика. Нужно погружаться в тему. А то, что касается пользователей, прав доступа к бинарникам и задачам из cron всё по делу. Также понятны рекомендации отключить некоторый функционал ядра, если он не используется (user_namespaces, vsyscall и т.д.).
Я бы обратил ваше внимание и взял на вооружение, как лист проверки при настройке системы первые несколько разделов:
▪ Настройка авторизации в операционных системах Linux
▪ Ограничение механизмов получения привилегий
▪ Настройка прав доступа к объектам файловой системы
По ним также полезно пройтись после взлома вашей системы, если нет возможности её переустановить, а стоит задача вернуть работоспособность.
В документе очень не хватает подробностей про вектора атаки. Некоторые рекомендации по ядру не понятны даже с учётом того, что ты понимаешь смысл настроек.
Также я совершенно не понял, почему не уделили внимание настройке firewall. Какая может быть безопасность сервера, если к его сервисам не ограничили доступ на уровне брендмауэера. Для безопасности как минимум нужно упомянуть о том, что по умолчанию должен быть включен режим работы нормально закрытый. При этом виде настройки firewall всё запрещено, что не разрешено явно.
Практика подобных рекомендаций от гос. структур распространена в мире. Можете для общего развития или из любопытства посмотреть похожие рекомендации от гос. органов USA и UK:
⇨ https://ncp.nist.gov/checklist/909
⇨ https://security-guidance.service.justice.gov.uk/system-lockdown-and-hardening-standard/
У американцев сразу представлены готовые плейбуки ansible для применения на системах RHEL. А у англичан текстом перечислены прямо на странице. Интересно было ознакомиться. Про сеть там, кстати, не забыли:
◽ An application firewall shall be installed. The firewall shall be configured to ‘allow only essential services’, log firewall activity, and operate in ‘stealth mode’ (undiscoverable).
◽ ICMP redirects shall be disabled.
◽ Idle connections shall be disconnected after a default period; normally less than 30 minutes.
⚡️И ещё вам в копилочку очень подробный англоязычный материал на тему повышения безопасности в ОС на базе ядра Linux - Linux Hardening Guide. У неё любопытное начало: Linux is not a secure operating system. И дальше представлены шаги, следуя которым это можно исправить.
Если кто-то ознакомился и увидел явно вредные советы или скрытые неочевидные проблемы от настроек в документе ФСТЭК, поделитесь информацией. У меня появилось желание оформить это как-то более подробно в отдельную статью. Думаю, это было бы полезно.
#security
{kind=link}
В дистрибутивах на базе Linux по умолчанию нет никакой корзины, куда бы попадали файлы после обычного удаления, как это происходит в Windows. Мне кажется, что механизм корзины очень удобен. Можно было бы по умолчанию в каком-то виде его реализовать. В некоторых десктопных системах это решается тем или иными способом. Я вам хочу предложить самый простой и очевидный подход, который я придумал просто в лоб.
Создаём скрипт trash.sh в домашней директории пользователя примерно следующего содержания:
Создайте директорию для корзины:
Добавьте в .bashrc новый алиас:
Перечитайте .bashrc:
Теперь при удалении файла:
он будет помещаться в /tmp/trash, а к имени будет добавляться маска с датой и временем:
Вы можете её указать, как вам удобно. Варианты формата date я показывал в отдельной заметке.
#linux #terminal #script #bash
Создаём скрипт trash.sh в домашней директории пользователя примерно следующего содержания:
#!/bin/shTRASH_DIR="/tmp/trash"TIMESTAMP=`date +'%d-%b-%Y-%H:%M:%S'`for i in $*; do FILE=`basename $i` mv $i ${TRASH_DIR}/${FILE}.${TIMESTAMP}doneСоздайте директорию для корзины:
# mkdir /tmp/trashДобавьте в .bashrc новый алиас:
alias rm='sh ~/trash.sh'Перечитайте .bashrc:
# source ~/.bashrcТеперь при удалении файла:
# rm filename.txtон будет помещаться в /tmp/trash, а к имени будет добавляться маска с датой и временем:
filename.txt.26-Jan-2023-17:38:01Вы можете её указать, как вам удобно. Варианты формата date я показывал в отдельной заметке.
#linux #terminal #script #bash
{kind=link}
Когда только начинал писать скрипты на Linux, в начале скрипта на автомате всегда ставил строку
SH, BASH и DASH — это всё программные оболочки, которые принимают команды, интерпретируют их и передают операционной системе для обработки. Условно их можно назвать интерфейсом между пользователем и операционной системой. В современных дистрибутивах Unix, а также на базе ядра Linux, почти всегда присутствует оболочка SH, чаще всего есть и BASH, а на Debian или Ubuntu есть ещё и DASH.
◽ SH — Bourne Shell, поддерживает стандарт POSIX
◽ BASH — Bourne Again Shell, по умолчанию не совместим с POSIX
◽ DASH — Debian Almquist Shell, поддерживает стандарт POSIX
Скажу кратко, чем они различаются. SH имеет минимальный набор возможностей. BASH включает в себя всё, что умеет SH и добавляет сверху дополнительный функционал. После появления BASH, эта оболочка стала фактически стандартом для большинства операционных систем. Даже если в системе присутствует SH, скорее всего это будет символьная ссылка на BASH. Поэтому в большинстве случаев не имеет значения, какую оболочку вы укажите в скрипте, исполнена она будет в BASH.
Отдельно стоит оболочка DASH, которую можно встретить в дистрибутивах на базе Debian. В них символьная ссылка SH ведёт на DASH.
DASH это тоже Bourne Shell совместимая оболочка, только более легковесная по сравнению с BASH. Соответственно и функционала у неё меньше. На обычных скриптах разницу между BASH и DASH вы вряд ли заметите. А вот если у вас циклы на тысячи или десятки тысяч операций, разница будет существенна. DASH может отработать быстрее в несколько раз.
❗️Поддержка стандарта POSIX означает, что скрипт в любой оболочке, поддерживающей этот стандарт, будет выполнен корректно и одинаково. Что, как вы понимаете, для BASH будет не так. Хотя у него есть отдельный ключ, включающий исполнение кода в соответствии с POSIX.
Я для себя сделал вывод, что проще всего везде явно указывать BASH, потому что во всех системах, с которыми я работаю, есть эта оболочка. Если вы точно знаете, что функционала SH будет достаточно, а скрипт будет выполняться часто, например, как в скрипте с реализацией корзины, то можно явно указать SH или DASH. Отклик на команду будет чуть меньше, чем в BASH, что в некоторых случаях может быть заметно. Также, если вам нужен код, который будет одинаково работать на максимально возможном количестве систем, имеет смысл писать его сразу в SH.
#terminal #linux #bash
#!/bin/sh без особого понимания, для чего это. Потом заметил в других скриптах, что у кого-то там стоит #!/bin/bash. Пришлось разобраться с этой темой. Недавно случайно заметил, когда перешёл на Debian, что там используется dash. Раньше вообще не припоминаю, чтобы сталкивался с таким названием оболочки. Постараюсь своими словами рассказать вам, что всё это значит. SH, BASH и DASH — это всё программные оболочки, которые принимают команды, интерпретируют их и передают операционной системе для обработки. Условно их можно назвать интерфейсом между пользователем и операционной системой. В современных дистрибутивах Unix, а также на базе ядра Linux, почти всегда присутствует оболочка SH, чаще всего есть и BASH, а на Debian или Ubuntu есть ещё и DASH.
◽ SH — Bourne Shell, поддерживает стандарт POSIX
◽ BASH — Bourne Again Shell, по умолчанию не совместим с POSIX
◽ DASH — Debian Almquist Shell, поддерживает стандарт POSIX
Скажу кратко, чем они различаются. SH имеет минимальный набор возможностей. BASH включает в себя всё, что умеет SH и добавляет сверху дополнительный функционал. После появления BASH, эта оболочка стала фактически стандартом для большинства операционных систем. Даже если в системе присутствует SH, скорее всего это будет символьная ссылка на BASH. Поэтому в большинстве случаев не имеет значения, какую оболочку вы укажите в скрипте, исполнена она будет в BASH.
Отдельно стоит оболочка DASH, которую можно встретить в дистрибутивах на базе Debian. В них символьная ссылка SH ведёт на DASH.
# ls -l /bin/shlrwxrwxrwx 1 root root 4 Dec 6 21:51 /bin/sh -> dashDASH это тоже Bourne Shell совместимая оболочка, только более легковесная по сравнению с BASH. Соответственно и функционала у неё меньше. На обычных скриптах разницу между BASH и DASH вы вряд ли заметите. А вот если у вас циклы на тысячи или десятки тысяч операций, разница будет существенна. DASH может отработать быстрее в несколько раз.
❗️Поддержка стандарта POSIX означает, что скрипт в любой оболочке, поддерживающей этот стандарт, будет выполнен корректно и одинаково. Что, как вы понимаете, для BASH будет не так. Хотя у него есть отдельный ключ, включающий исполнение кода в соответствии с POSIX.
Я для себя сделал вывод, что проще всего везде явно указывать BASH, потому что во всех системах, с которыми я работаю, есть эта оболочка. Если вы точно знаете, что функционала SH будет достаточно, а скрипт будет выполняться часто, например, как в скрипте с реализацией корзины, то можно явно указать SH или DASH. Отклик на команду будет чуть меньше, чем в BASH, что в некоторых случаях может быть заметно. Также, если вам нужен код, который будет одинаково работать на максимально возможном количестве систем, имеет смысл писать его сразу в SH.
#terminal #linux #bash
{kind=link}
Решил начать новую рубрику на канале с мемасиками. Я сам не особо люблю, когда постоянно публикуются картинки в каналах. Тем не менее, я их иногда смотрю, и что-то нравится, вызывает улыбку. Так что, думаю, одной картинки в неделю по пятницам будет достаточно. Публиковать буду то, что сам видел в течении недели и то, что показалось наиболее интересным.
Если у вас есть желание поделиться чем-то прикольным, то можно это делать в комментариях. К подобным постам это будет уместно. Мультик из мема недавно просматривал с детьми. Очень клёвый, рекомендую.
#мем
Если у вас есть желание поделиться чем-то прикольным, то можно это делать в комментариях. К подобным постам это будет уместно. Мультик из мема недавно просматривал с детьми. Очень клёвый, рекомендую.
#мем