
В связи с последними событиями с отменой бесплатной почты для доменов от Яндекса, постоянно возникают вопросы насчёт настройки почтовых серверов, их выбора, переноса почты и т.д. Хочу напомнить по поводу переноса. Есть очень простое, проверенное временем средство для переноса почты из одного почтового ящика в другой по imap - imapsync.
Проект очень старый (знаю его лет 10), но по-прежнему развивается и нормально работает. С его помощью перенос почты между ящиками выглядит примерно следующим образом:
Где host1 это сервер, с которого переносим почту, а host2 - куда переносим. Дополнительные параметры (tls, ssl и т.д.) указываются отдельными ключами.
Imapsync написан на Perl и работает под Linux. Я его только на нём запускал, но если поискать информацию, то можно найти варианты, где люди и под Windows запускают. Есть официальная инструкция для этого, но выглядит всё это слишком сложно. Если уж совсем нет линукса, то проще всего в WSL запустить. Не важно, где будет проходить сама синхронизация. Подойдёт любой компьютер.
Imapsync может брать параметры подключения к ящикам из txt файла. То есть можно запускать массовый перенос почты. С этим надо быть аккуратным, чтобы не нарваться на какие-нибудь лимиты бесплатных сервисов, которые хоть и не озвучиваются, но всегда есть.
С помощью imapsync можно не только переносить почту между ящиками, но и выполнять бэкап почтового ящика. В репозитории есть примеры готовых скриптов для этого.
Для полноты картины ещё добавлю, что похожий функционал есть у утилиты imapcopy, которая живёт в репозиториях Debian. Она не так популярна, но задачу свою выполняет. Если не срастётся с imapsync, можете imapcopy попробовать.
⇨ Сайт / Исходники / DockerHub
#mailserver
Проект очень старый (знаю его лет 10), но по-прежнему развивается и нормально работает. С его помощью перенос почты между ящиками выглядит примерно следующим образом:
# imapsync \ --host1 test1.server.info --user1 test1 --password1 secret1 \ --host2 test2.server.info --user2 test2 --password2 secret2Где host1 это сервер, с которого переносим почту, а host2 - куда переносим. Дополнительные параметры (tls, ssl и т.д.) указываются отдельными ключами.
Imapsync написан на Perl и работает под Linux. Я его только на нём запускал, но если поискать информацию, то можно найти варианты, где люди и под Windows запускают. Есть официальная инструкция для этого, но выглядит всё это слишком сложно. Если уж совсем нет линукса, то проще всего в WSL запустить. Не важно, где будет проходить сама синхронизация. Подойдёт любой компьютер.
Imapsync может брать параметры подключения к ящикам из txt файла. То есть можно запускать массовый перенос почты. С этим надо быть аккуратным, чтобы не нарваться на какие-нибудь лимиты бесплатных сервисов, которые хоть и не озвучиваются, но всегда есть.
С помощью imapsync можно не только переносить почту между ящиками, но и выполнять бэкап почтового ящика. В репозитории есть примеры готовых скриптов для этого.
Для полноты картины ещё добавлю, что похожий функционал есть у утилиты imapcopy, которая живёт в репозиториях Debian. Она не так популярна, но задачу свою выполняет. Если не срастётся с imapsync, можете imapcopy попробовать.
⇨ Сайт / Исходники / DockerHub
#mailserver
{kind=link}
Расскажу своими словами про особенности и удобство сбора логов в ELK Stack или любое подобное хранилище на его основе. Продукт сложный и многокомпонентный. Те, кто с ним не работали, зачастую не понимают, что это такое и зачем оно нужно. Ведь логи можно хранить и просматривать много где. Зачем этот тяжелющий монстр? Я поясню своими словами на простом примере.
Вои пример фрагмента лога web сервера стандартного формата:
180.163.220.100 - travvels.ru [05/Sep/2021:14:45:52 +0300] "GET /assets/galleries/26/1.png HTTP/1.1" 304 0 "https://travvels.ru/ru/glavnaya/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
Он состоит из отдельных частей, каждая из которых содержит какую-то информацию - ip адрес, дата, тип запроса, url, метод, код ответа, количество переданных байт, реферер, user-agent. Это стандартный формат лога Nginx или Apache.
ELK Stack не просто собирает эти логи и хранит у себя. Он распознаёт каждое значение из каждой строки и индексирует эти данные, чтобы потом можно было быстро с ними работать. Например, подсчитать количество 500-х кодов ответов, или количество запросов к какому-то урлу. Для типовых форматов данных есть готовые фильтры парсинга. Но нет проблем написать и свои, хоть и не так просто, но посильно. Я в своё время разобрался, когда надо было. В частности, Logstash использует фильтры GROK.
Чтобы было удобно работать с логами, я обычно делаю следующее. Собираю дашборд, куда вывожу в виджетах информацию о топе урлов, к которым идут запросы, о топе ip адресов, с которых идут запросы, о топе user-agent, графики кодов ответов и т.д. В общем, всё, что может быть интересно.
Когда нужно разобраться с каким-нибудь инцидентом, этот дашборд очень выручает. Если честно, я так привык к ним, что даже не представляю, как обслуживать веб сервер без подобного сбора и анализа логов. Так вот, я открываю этот дашборд и вижу, к примеру, что к какому-то урлу идёт вал запросов. В поиске тут же в дашборде делаю группировку данных на основе этого урла и дашборд со всеми виджетами перестраивается, выводя информацию только по этому урлу.
В итоге я вижу все IP адреса, которые к нему обращались, все коды ответов, все user-agents и т.д. Например, я могу увидеть, что все запросы к этому урлу идут с одного и того же IP адреса и это какой-то бот. Можно его забанить. Также, например, можно заметить, что резко выросло количество 404 ошибок. Делаю группировку по ним и вижу, что все 404 коды ответов выдаются какому-то боту с отличительным user-agent, который занимается перебором. Баним его по user-agent.
Надеюсь, понятно объяснил принцип. Видя какую-то аномалию, мы без проблем можем детально её рассмотреть со всеми подробностями. Ещё актуальный пример из практики. В веб сервере сайта на Bitrix можно добавить ID сессии пользователя в лог веб сервера. Затем подредактировать стандартный фильтр парсинга Logstash, чтобы он индексировал и это поле. После этого вы сможете делать группировку логов по этой сессии. Очень удобно, когда надо просмотреть все действия пользователя. Эту настройку я описывал в отдельной статье.
Подводя итог скажу, что ELK Stack очень полезный инструмент даже в небольшой инфраструктуре. Не обязательно собирать кластер о хранить тонны логов. Даже логи с одного сайта очень помогут в его поддержке. Админам инфраструктуры на Windows тоже советую обратить внимание на ELK. С его помощью удобно разбирать журналы Windows, которые он тоже умеет парсить и индексировать. По винде я делал отдельную статью, где описывал принцип и показывал примеры.
Если захотите изучить ELK Stack и попробовать в работе, воспользуйтесь моей статьёй. С её помощью простым копипастом можно поднять весь стек и попробовать с ним поработать. Ничего супер сложного в этом нет. Когда я задался целью, то сам с нуля всё изучил, не ходил ни на какие курсы и никто мне не помогал. Просто сел и разобрался понемногу. Было тяжело, конечно, особенно с фильтрами, но дорогу осилит идущий.
#elk
Вои пример фрагмента лога web сервера стандартного формата:
180.163.220.100 - travvels.ru [05/Sep/2021:14:45:52 +0300] "GET /assets/galleries/26/1.png HTTP/1.1" 304 0 "https://travvels.ru/ru/glavnaya/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
Он состоит из отдельных частей, каждая из которых содержит какую-то информацию - ip адрес, дата, тип запроса, url, метод, код ответа, количество переданных байт, реферер, user-agent. Это стандартный формат лога Nginx или Apache.
ELK Stack не просто собирает эти логи и хранит у себя. Он распознаёт каждое значение из каждой строки и индексирует эти данные, чтобы потом можно было быстро с ними работать. Например, подсчитать количество 500-х кодов ответов, или количество запросов к какому-то урлу. Для типовых форматов данных есть готовые фильтры парсинга. Но нет проблем написать и свои, хоть и не так просто, но посильно. Я в своё время разобрался, когда надо было. В частности, Logstash использует фильтры GROK.
Чтобы было удобно работать с логами, я обычно делаю следующее. Собираю дашборд, куда вывожу в виджетах информацию о топе урлов, к которым идут запросы, о топе ip адресов, с которых идут запросы, о топе user-agent, графики кодов ответов и т.д. В общем, всё, что может быть интересно.
Когда нужно разобраться с каким-нибудь инцидентом, этот дашборд очень выручает. Если честно, я так привык к ним, что даже не представляю, как обслуживать веб сервер без подобного сбора и анализа логов. Так вот, я открываю этот дашборд и вижу, к примеру, что к какому-то урлу идёт вал запросов. В поиске тут же в дашборде делаю группировку данных на основе этого урла и дашборд со всеми виджетами перестраивается, выводя информацию только по этому урлу.
В итоге я вижу все IP адреса, которые к нему обращались, все коды ответов, все user-agents и т.д. Например, я могу увидеть, что все запросы к этому урлу идут с одного и того же IP адреса и это какой-то бот. Можно его забанить. Также, например, можно заметить, что резко выросло количество 404 ошибок. Делаю группировку по ним и вижу, что все 404 коды ответов выдаются какому-то боту с отличительным user-agent, который занимается перебором. Баним его по user-agent.
Надеюсь, понятно объяснил принцип. Видя какую-то аномалию, мы без проблем можем детально её рассмотреть со всеми подробностями. Ещё актуальный пример из практики. В веб сервере сайта на Bitrix можно добавить ID сессии пользователя в лог веб сервера. Затем подредактировать стандартный фильтр парсинга Logstash, чтобы он индексировал и это поле. После этого вы сможете делать группировку логов по этой сессии. Очень удобно, когда надо просмотреть все действия пользователя. Эту настройку я описывал в отдельной статье.
Подводя итог скажу, что ELK Stack очень полезный инструмент даже в небольшой инфраструктуре. Не обязательно собирать кластер о хранить тонны логов. Даже логи с одного сайта очень помогут в его поддержке. Админам инфраструктуры на Windows тоже советую обратить внимание на ELK. С его помощью удобно разбирать журналы Windows, которые он тоже умеет парсить и индексировать. По винде я делал отдельную статью, где описывал принцип и показывал примеры.
Если захотите изучить ELK Stack и попробовать в работе, воспользуйтесь моей статьёй. С её помощью простым копипастом можно поднять весь стек и попробовать с ним поработать. Ничего супер сложного в этом нет. Когда я задался целью, то сам с нуля всё изучил, не ходил ни на какие курсы и никто мне не помогал. Просто сел и разобрался понемногу. Было тяжело, конечно, особенно с фильтрами, но дорогу осилит идущий.
#elk
{kind=link}
Наконец-то закончил статью по настройке почтового сервера на Debian на базе postfix и dovecot. В качестве веб интерфейса использую roundcube. Хотел ещё и SOGo захватить, но статья слишком большая получается. Нужно разбивать на части. Может быть будет отдельным материалом, если найду время на это.
Со статьёй торопился, чтобы успеть к новогодним праздникам. Это удобное время, чтобы сделать миграцию, пока все отдыхают и до почты нет никому дела. Можно просто на весь день всё выключить и никто не заметит. Я крупные почтовые сервера всегда после нового года переносил.
В статье рассмотрел все основные моменты, чтобы получился свой собственный полноценный почтовый сервер. Настраивать всё можно простым копипастом. Все конфиги взял с реально настроенного сервера, который для себя делал. Надеюсь сильно нигде не ошибся. Проверить самому затруднительно, так как всё привязано к DNS записям. Нельзя просто взять и проверить статью по настройке почтового сервера на какой-то тестовой машине. Нужны реальные DNS записи и открытый 25-й порт в мир, который сейчас большинство провайдеров блокируют.
Статью писал где-то неделю по вечерам после работы. Ушло примерно часов 20. Рассказываю, потому что иногда в личку спрашивают, будет ли такая статья, почему так мало новых статей стало. А всё очень просто. У меня нет свободного времени на написание хорошей статьи. Сайт начинал ещё неженатым, было время и интерес. А с каждым годом забот всё больше, свободного времени всё меньше. Если оно появляется, трачу его на детей. Поэтому статьи появляются только те, которые мне самому помогают в работе и не требуют большой вовлечённости. В основном переработка старых материалов и актуализация под новые системы.
⇨ https://serveradmin.ru/nastrojka-postfix-dovecot-postfixadmin-roundcube-dkim-na-debian/
#mailserver
Со статьёй торопился, чтобы успеть к новогодним праздникам. Это удобное время, чтобы сделать миграцию, пока все отдыхают и до почты нет никому дела. Можно просто на весь день всё выключить и никто не заметит. Я крупные почтовые сервера всегда после нового года переносил.
В статье рассмотрел все основные моменты, чтобы получился свой собственный полноценный почтовый сервер. Настраивать всё можно простым копипастом. Все конфиги взял с реально настроенного сервера, который для себя делал. Надеюсь сильно нигде не ошибся. Проверить самому затруднительно, так как всё привязано к DNS записям. Нельзя просто взять и проверить статью по настройке почтового сервера на какой-то тестовой машине. Нужны реальные DNS записи и открытый 25-й порт в мир, который сейчас большинство провайдеров блокируют.
Статью писал где-то неделю по вечерам после работы. Ушло примерно часов 20. Рассказываю, потому что иногда в личку спрашивают, будет ли такая статья, почему так мало новых статей стало. А всё очень просто. У меня нет свободного времени на написание хорошей статьи. Сайт начинал ещё неженатым, было время и интерес. А с каждым годом забот всё больше, свободного времени всё меньше. Если оно появляется, трачу его на детей. Поэтому статьи появляются только те, которые мне самому помогают в работе и не требуют большой вовлечённости. В основном переработка старых материалов и актуализация под новые системы.
⇨ https://serveradmin.ru/nastrojka-postfix-dovecot-postfixadmin-roundcube-dkim-na-debian/
#mailserver
{kind=link}
В продолжение темы настройки почтовых серверов решил сделать подборку онлайн сервисов, которые помогут проверить все настройки DNS и самого сервера. Первыми двумя я сам постоянно пользуюсь, когда настраиваю почтовый сервер.
✅ mail-tester.com - отличный сервис по проверке работы почтового сервера. Достаточно отправить письмо со своего сервера на специально сформированный ящик и дальше смотреть отчет. Сервис проверяет следующие параметры:
◽️ Настройку DKIM, SPF, DMARC
◽️ Все необходимые DNS записи, в том числе PTR
◽️ Наличие вашего сервера в черных списках
◽️ Контекстные факторы (форматирование, картинки, наличие List-Unsubscribe и т.д.)
◽️ Анализ вашего письма с помощью SpamAssasin
По каждому пункту можно посмотреть комментарии и конкретную информацию по существу. Например, заголовки писем, ошибки в DNS записях и т.д. Если проблемы есть, они будут отражены, и этой информации будет достаточно для исправления.
✅ dkimcore - очень простой сервис для проверки DKIM. Имеет две проверки:
◽️Корректность публичного ключа, который вы будете записывать в DNS. Иногда, при копировании строки для DNS записи, туда могут попадать лишние символы, либо строку по ошибке обрежешь, и в итоге ключ становится недействительным. Можно потом долго соображать, почему же проверка DKIM не проходит. А просто ключ неверный записан.
◽️Корректность DNS записи. После того, как добавили TXT запись с публичным ключом, стоит подождать обновления DNS, а потом проверить с помощью сервиса корректность этой записи.
✅ checktls.com - с помощью этого сервиса можно выполнить проверку подключения к своему серверу. Он проверит основные этапы взаимодействия (подключение, ответ, шифрование и т.д.) и выведет весь лог smtp сессии в браузере. Это удобно для анализа работы сервера и проверки tls сертификатов.
✅ mxtoolbox.com - здесь огромное количество всевозможных проверок: DNS записи, сертификаты, чёрные списки и т.д. Можно получить сводный отчёт о своём сервере, если отправить письмо по адресу ping@tools.mxtoolbox.com. В ответ придёт отчёт с проверками.
Если знаете ещё хорошие сервисы, помогающие настраивать и проверять почтовые сервера, поделитесь в комментариях.
#mailserver #сервис
✅ mail-tester.com - отличный сервис по проверке работы почтового сервера. Достаточно отправить письмо со своего сервера на специально сформированный ящик и дальше смотреть отчет. Сервис проверяет следующие параметры:
◽️ Настройку DKIM, SPF, DMARC
◽️ Все необходимые DNS записи, в том числе PTR
◽️ Наличие вашего сервера в черных списках
◽️ Контекстные факторы (форматирование, картинки, наличие List-Unsubscribe и т.д.)
◽️ Анализ вашего письма с помощью SpamAssasin
По каждому пункту можно посмотреть комментарии и конкретную информацию по существу. Например, заголовки писем, ошибки в DNS записях и т.д. Если проблемы есть, они будут отражены, и этой информации будет достаточно для исправления.
✅ dkimcore - очень простой сервис для проверки DKIM. Имеет две проверки:
◽️Корректность публичного ключа, который вы будете записывать в DNS. Иногда, при копировании строки для DNS записи, туда могут попадать лишние символы, либо строку по ошибке обрежешь, и в итоге ключ становится недействительным. Можно потом долго соображать, почему же проверка DKIM не проходит. А просто ключ неверный записан.
◽️Корректность DNS записи. После того, как добавили TXT запись с публичным ключом, стоит подождать обновления DNS, а потом проверить с помощью сервиса корректность этой записи.
✅ checktls.com - с помощью этого сервиса можно выполнить проверку подключения к своему серверу. Он проверит основные этапы взаимодействия (подключение, ответ, шифрование и т.д.) и выведет весь лог smtp сессии в браузере. Это удобно для анализа работы сервера и проверки tls сертификатов.
✅ mxtoolbox.com - здесь огромное количество всевозможных проверок: DNS записи, сертификаты, чёрные списки и т.д. Можно получить сводный отчёт о своём сервере, если отправить письмо по адресу ping@tools.mxtoolbox.com. В ответ придёт отчёт с проверками.
Если знаете ещё хорошие сервисы, помогающие настраивать и проверять почтовые сервера, поделитесь в комментариях.
#mailserver #сервис
{kind=link}
Существуют разные подходы к мониторингу. Можно настраивать одну универсальную систему и всё замыкать на неё. Это удобно в том плане, что всё в одном месте. Но мониторинг каждого отдельного элемента будет не самым лучшим.
Другой подход - для каждого продукта использовать тот мониторинг, который заточен именно под него. Например, такой мониторинг есть для Nginx - NGINX Amplify. Или мониторинг для баз данных от Percona - Percona Monitoring and Management (PMM). Про последний я и хочу сегодня рассказать.
Percona Monitoring and Management - open source мониторинг для баз данных MySQL, PostgreSQL и MongoDB. Построен на базе своего PMM Server и PMM Agent. Визуализация метрик реализована через Grafana.
Благодаря тому, что это узкоспециализированный продукт, его очень легко установить и настроить. По сути и настраивать то нечего. Достаточно установить сервер, агенты на хосты с БД и дальше смотреть метрики в готовых дашбордах Графаны.
Это не сравнится с тем, что предлагает Zabbix по мониторингу баз данных. Да, все те же метрики в него тоже можно передать. Но настроить всё это в готовую систему с метриками, триггерами, оповещениями, графиками и дашбордами очень хлопотно. А в PMM всё это работает сразу после установки. Времени нужно минимум, чтобы запустить мониторинг.
В принципе, если для вас важны базы данных, подобные мониторинги можно и отдельно разворачивать рядом с основным, а потом события со всех мониторингов собирать в одном месте. Например, с помощью OnCall.
Как я уже сказал, установить PMM очень просто. Можете сами оценить сложность и трудозатраты - Install Percona Monitoring and Management. Буквально 10 минут копипасты: ставим сервер, ставим клиент, соединяем клиента с сервером, добавляем в базу пользователя для сбора метрик. Если я правильно понял, то PMM построен на базе prometheus и использует метрики с его exporters.
Как всё это выглядит, можете посмотреть в публичном Demo. Там даже аутентификация не нужна. Помимо метрик баз данных PMM может собирать типовые метрики сервера Linux, HAProxy, выполнять внешние проверки tcp портов или забирать метрики по http.
Проект относительно свежий (2019 год) и очень активно развивается.
⇨ Сайт / Установка / Demo / Исходники
#мониторинг #mysql #postgresql
Другой подход - для каждого продукта использовать тот мониторинг, который заточен именно под него. Например, такой мониторинг есть для Nginx - NGINX Amplify. Или мониторинг для баз данных от Percona - Percona Monitoring and Management (PMM). Про последний я и хочу сегодня рассказать.
Percona Monitoring and Management - open source мониторинг для баз данных MySQL, PostgreSQL и MongoDB. Построен на базе своего PMM Server и PMM Agent. Визуализация метрик реализована через Grafana.
Благодаря тому, что это узкоспециализированный продукт, его очень легко установить и настроить. По сути и настраивать то нечего. Достаточно установить сервер, агенты на хосты с БД и дальше смотреть метрики в готовых дашбордах Графаны.
Это не сравнится с тем, что предлагает Zabbix по мониторингу баз данных. Да, все те же метрики в него тоже можно передать. Но настроить всё это в готовую систему с метриками, триггерами, оповещениями, графиками и дашбордами очень хлопотно. А в PMM всё это работает сразу после установки. Времени нужно минимум, чтобы запустить мониторинг.
В принципе, если для вас важны базы данных, подобные мониторинги можно и отдельно разворачивать рядом с основным, а потом события со всех мониторингов собирать в одном месте. Например, с помощью OnCall.
Как я уже сказал, установить PMM очень просто. Можете сами оценить сложность и трудозатраты - Install Percona Monitoring and Management. Буквально 10 минут копипасты: ставим сервер, ставим клиент, соединяем клиента с сервером, добавляем в базу пользователя для сбора метрик. Если я правильно понял, то PMM построен на базе prometheus и использует метрики с его exporters.
Как всё это выглядит, можете посмотреть в публичном Demo. Там даже аутентификация не нужна. Помимо метрик баз данных PMM может собирать типовые метрики сервера Linux, HAProxy, выполнять внешние проверки tcp портов или забирать метрики по http.
Проект относительно свежий (2019 год) и очень активно развивается.
⇨ Сайт / Установка / Demo / Исходники
#мониторинг #mysql #postgresql
{kind=link}
▶️ Если для вас интересна тема CI/CD, вы уже специалист с некоторым опытом или только начинаете изучать devops, могу порекомендовать отличное по качеству обзорное видео с фундаментальным материалом:
Идеальный CI/CD pipeline. What is Continuous Integration / Continuous Delivery?
⇨ https://www.youtube.com/watch?v=wXJgB9oZsBo
Очень приятный формат подачи: атмосфера, качественная картинка, звук, презентации, временные метки. Участники внятно и содержательно общаются, хорошая дикция и ведение диалога.
Это первое видео от данного канала, которое я увидел. Даже удивился, что у них так мало просмотров и подписчиков. Мне кажется, с таким качеством материала, у них всего должно быть побольше.
Только есть одна проблема. Где найти свободное время, чтобы слушать такие длинные подкасты?
#видео #devops #cicd
Идеальный CI/CD pipeline. What is Continuous Integration / Continuous Delivery?
⇨ https://www.youtube.com/watch?v=wXJgB9oZsBo
Очень приятный формат подачи: атмосфера, качественная картинка, звук, презентации, временные метки. Участники внятно и содержательно общаются, хорошая дикция и ведение диалога.
Это первое видео от данного канала, которое я увидел. Даже удивился, что у них так мало просмотров и подписчиков. Мне кажется, с таким качеством материала, у них всего должно быть побольше.
Только есть одна проблема. Где найти свободное время, чтобы слушать такие длинные подкасты?
#видео #devops #cicd
{kind=link}
1С последнее время стала часто менять установщик сервера под Linux. Сначала с переходом на единый дистрибутив поменялся процесс обновления и установки сервера. А теперь по мере изменения версий в рамках единого установщика тоже происходят заметные изменения. То gnome на сервер автоматом ставит, а не так давно вместо скрипта запуска для init.d, появился unit для systemd.
Во время очередного обновления я немного затупил и решил записать актуальную пошаговую инструкцию по обновлению сервера 1С на Linux, чтобы просто на неё посмотреть и всё сделать, а не вспоминать, что делал в прошлый раз.
1️⃣ Останавливаем сервер 1С. В зависимости от установленной версии, команда будет выглядеть по-разному. До 8.3.21 вот так:
После 8.3.21 примерно так:
2️⃣ Я рекомендую сохранить настройки кластера из домашней директории /home/usr1cv8/.1cv8/1C/1cv8. Только текстовые файлы с настройками, больше ничего. У меня разок была ситуация, когда обновлял тестовый сервер, где .1cv8 была символьной ссылкой на другой том. По какой-то причине она была заменена на новую пустую директорию. Когда запустил сервер, очень удивился, что в списке баз пусто. А их там было штук 30. Сервер хоть и тестовый, я всегда сначала на нём проверял обновления, но всё равно перспектива добавления заново всех баз не радовала. Решил детальнее разобраться, что случилось и заметил, что символьная ссылка пропала. Вернул её на место и все базы восстановились.
Тем не менее, у меня были ситуации, когда я терял настройки сервера. Хоть и некритично, но всё равно неприятно. Лишняя работа. Рекомендую параметры сохранять перед обновлением.
3️⃣ Качаем дистрибутив единого установщика и копируем на сервер. Имя файла имеет примерно такой формат: server64_8_3_22_1709.tar.gz. Распаковываем:
Можно сразу запустить установщик
Установили компоненты: Сервер 1С, модуль расширения веб сервера, толстый клиент.
4️⃣ Если раньше был скрипт запуска в /etc/init.d/srv1cv83, удаляем его. Вместо него устанавливаем юнит systemd:
Добавляем в автозагрузку и запускаем:
Обращаю внимание, что команда на запуск изменилась. Нужно добавлять имя экземпляра сервера. По умолчанию - default. Так сделано для того, чтобы было удобно запускать несколько разных экземпляров сервера с разными настройками на одном хосте, повесив их на разные порты.
5️⃣ Напомню, что управлять кластером 1С можно с помощью бесплатной панели управления ПУСК. Если у вас оснастки администрирования установлены на Windows машине, не забудьте там обновить платформу и зарегистрировать утилиту администрирования новой версии, иначе не получится подключиться к обновлённому серверу. Я частенько забываю это сделать.
На этом с обновлением всё. Ничего сложного. 1С неплохо потрудились с переработкой установщика. С одной стороны выглядит как-то громоздко - один установщик под всем дистрибутивы, вместо пакетов. Но с другой стороны - процесс стал проще и одинаков под все системы.
#1с
Во время очередного обновления я немного затупил и решил записать актуальную пошаговую инструкцию по обновлению сервера 1С на Linux, чтобы просто на неё посмотреть и всё сделать, а не вспоминать, что делал в прошлый раз.
1️⃣ Останавливаем сервер 1С. В зависимости от установленной версии, команда будет выглядеть по-разному. До 8.3.21 вот так:
# systemctl stop srv1cv83После 8.3.21 примерно так:
# systemctl stop srv1cv8-8.3.21.1484@default2️⃣ Я рекомендую сохранить настройки кластера из домашней директории /home/usr1cv8/.1cv8/1C/1cv8. Только текстовые файлы с настройками, больше ничего. У меня разок была ситуация, когда обновлял тестовый сервер, где .1cv8 была символьной ссылкой на другой том. По какой-то причине она была заменена на новую пустую директорию. Когда запустил сервер, очень удивился, что в списке баз пусто. А их там было штук 30. Сервер хоть и тестовый, я всегда сначала на нём проверял обновления, но всё равно перспектива добавления заново всех баз не радовала. Решил детальнее разобраться, что случилось и заметил, что символьная ссылка пропала. Вернул её на место и все базы восстановились.
Тем не менее, у меня были ситуации, когда я терял настройки сервера. Хоть и некритично, но всё равно неприятно. Лишняя работа. Рекомендую параметры сохранять перед обновлением.
3️⃣ Качаем дистрибутив единого установщика и копируем на сервер. Имя файла имеет примерно такой формат: server64_8_3_22_1709.tar.gz. Распаковываем:
# tar xzvf server64_8_3_22_1709.tar.gzМожно сразу запустить установщик
./setup-full-8.3.22.1709-x86_64.run и интерактивно выбрать все настройки, либо запустить в пакетном режиме, указав необходимые настройки. Например:# ./setup-full-8.3.22.1709-x86_64.run --mode unattended \--enable-components server,ws,client_fullУстановили компоненты: Сервер 1С, модуль расширения веб сервера, толстый клиент.
4️⃣ Если раньше был скрипт запуска в /etc/init.d/srv1cv83, удаляем его. Вместо него устанавливаем юнит systemd:
# systemctl link /opt/1cv8/x86_64/8.3.22.1709/srv1cv8-8.3.22.1709@.serviceДобавляем в автозагрузку и запускаем:
# systemctl enable srv1cv8-8.3.22.1709@.service# systemctl start srv1cv8-8.3.22.1709@.defaultОбращаю внимание, что команда на запуск изменилась. Нужно добавлять имя экземпляра сервера. По умолчанию - default. Так сделано для того, чтобы было удобно запускать несколько разных экземпляров сервера с разными настройками на одном хосте, повесив их на разные порты.
5️⃣ Напомню, что управлять кластером 1С можно с помощью бесплатной панели управления ПУСК. Если у вас оснастки администрирования установлены на Windows машине, не забудьте там обновить платформу и зарегистрировать утилиту администрирования новой версии, иначе не получится подключиться к обновлённому серверу. Я частенько забываю это сделать.
На этом с обновлением всё. Ничего сложного. 1С неплохо потрудились с переработкой установщика. С одной стороны выглядит как-то громоздко - один установщик под всем дистрибутивы, вместо пакетов. Но с другой стороны - процесс стал проще и одинаков под все системы.
#1с
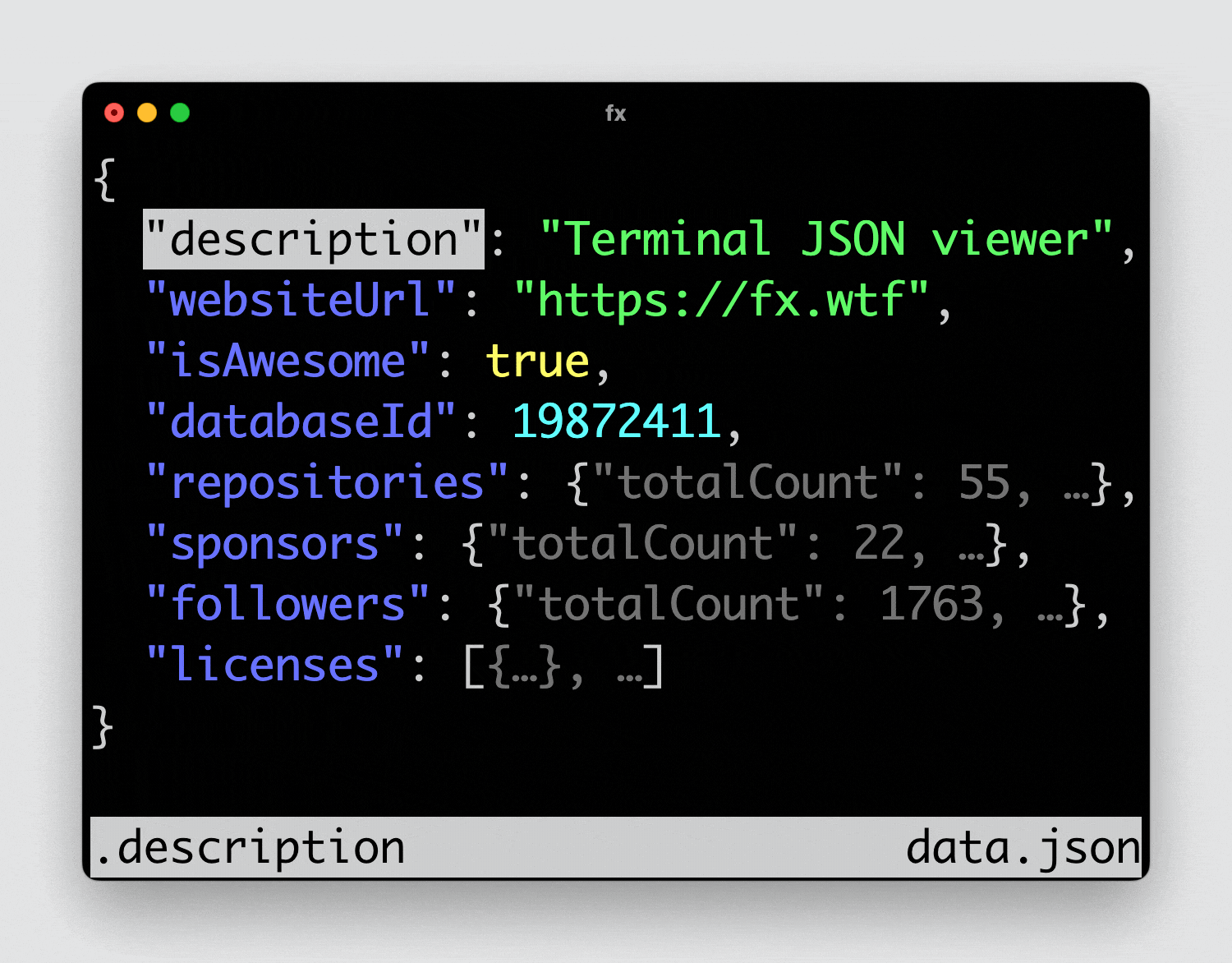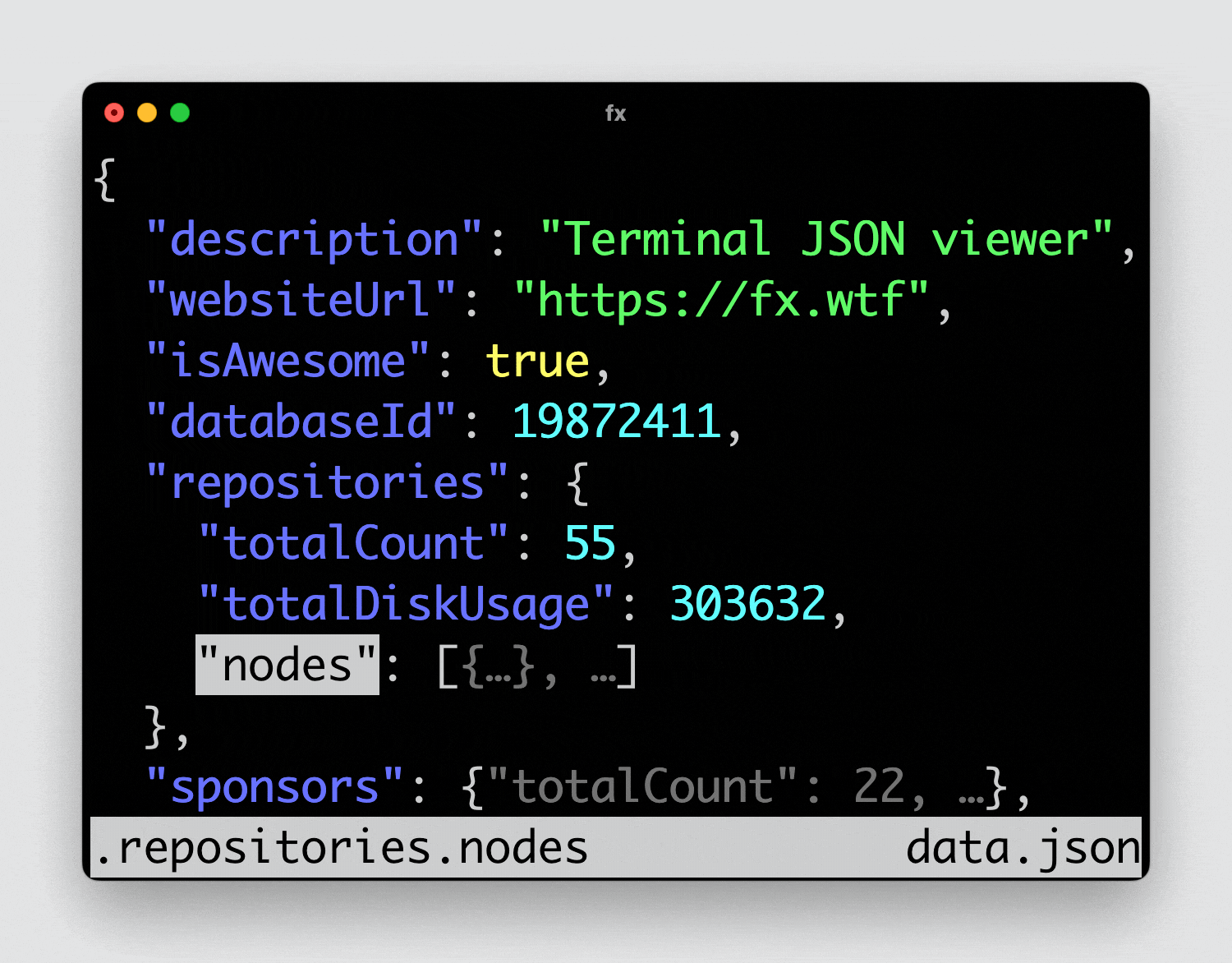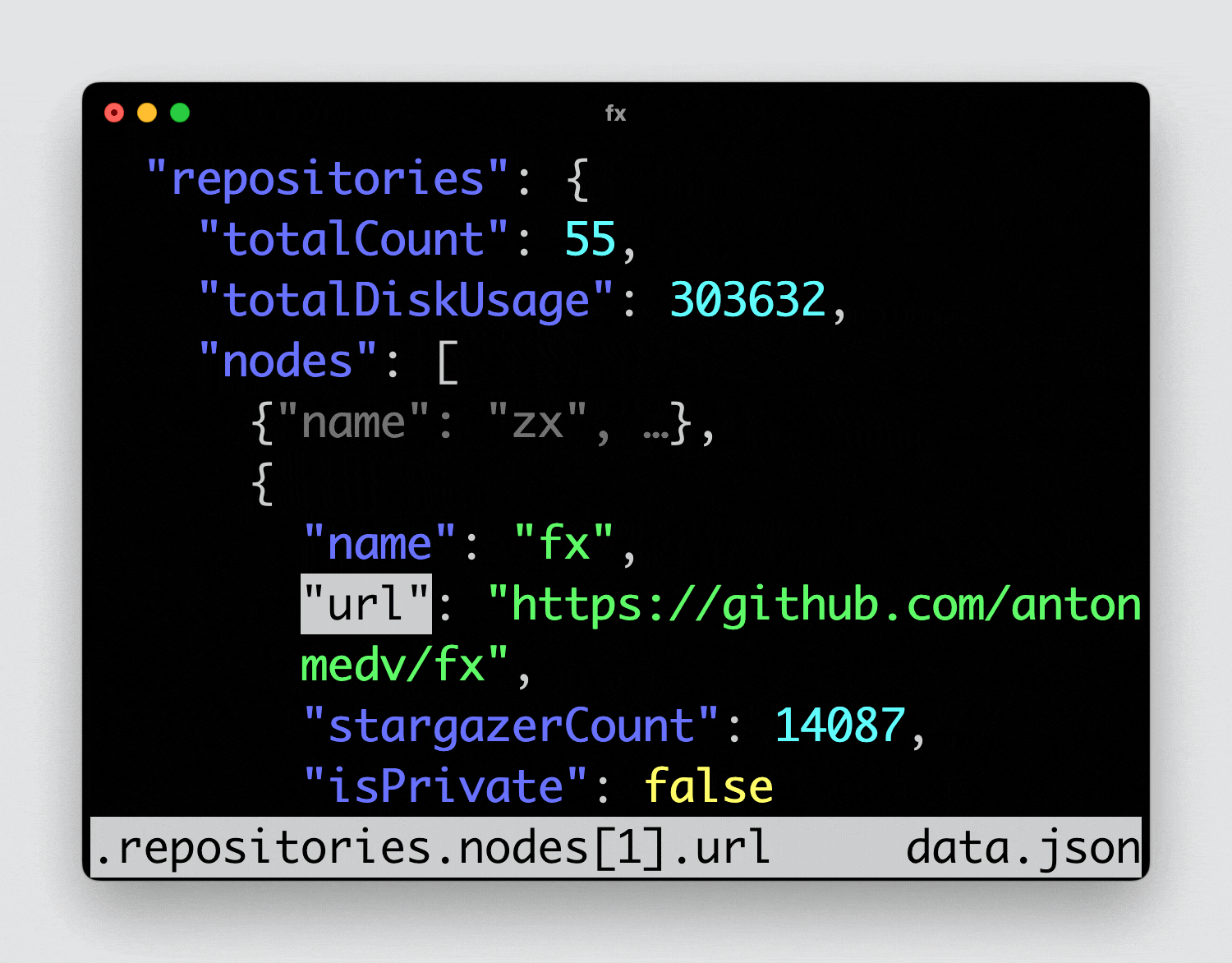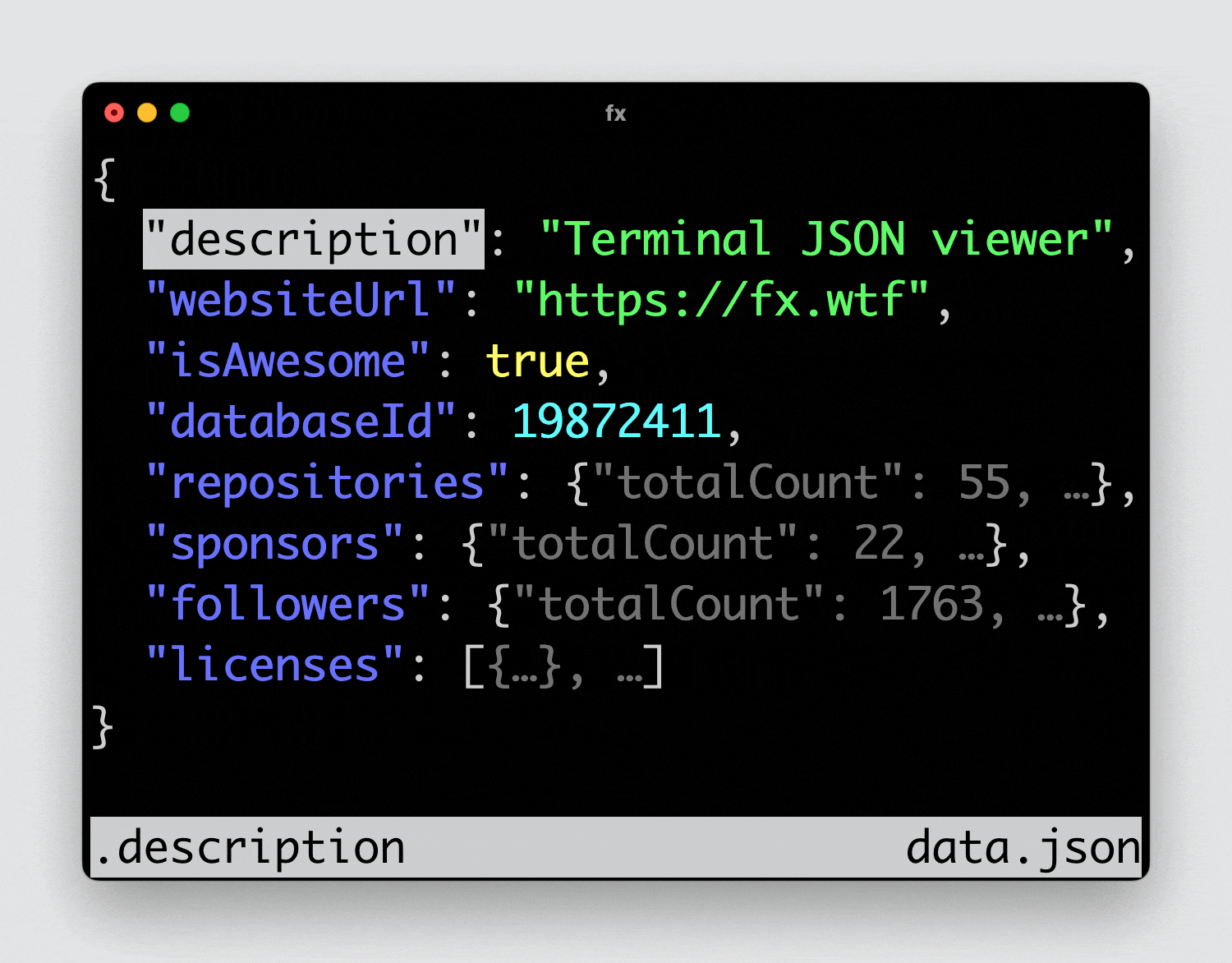
Простая и удобная утилита для работы в консоли с json - fx. Она умеет отображать данные в свёрнутом виде, раскрывая те ветки, что вам нужны. При этом поддерживает мышь. Настроек никаких нет, кроме выбора тем.
В некоторых системах fx есть в базовых репозиториях, например в MacOS, Ubuntu (snap), Arch, FreeBSD. Странно, что даже во фрюху заехала, но нет в rpm и deb репах. Можно просто скачать бинарник из репозитория.
Посмотреть, как fx работает, можно на тестовой публичной апишке:
Либо сохранить какой-нибудь здоровенный json в файл и посмотреть его:
Если много работаете с json, утилита точно пригодится.
⇨ Исходники
#json
В некоторых системах fx есть в базовых репозиториях, например в MacOS, Ubuntu (snap), Arch, FreeBSD. Странно, что даже во фрюху заехала, но нет в rpm и deb репах. Можно просто скачать бинарник из репозитория.
Посмотреть, как fx работает, можно на тестовой публичной апишке:
# curl https://reqres.in/api/users?page=2 | fxЛибо сохранить какой-нибудь здоровенный json в файл и посмотреть его:
# fx data.jsonЕсли много работаете с json, утилита точно пригодится.
⇨ Исходники
#json
{kind=link}
На днях заморочился и на своей рабочей системе добавил алиасы и функции для упрощения рутинных операций. Расскажу про них на примере сервиса по получению информации об IP адресах ifconfig.co.
Делаем простой алиас для проверки своего внешнего IP адреса. Нужно, в основном, когда пользуешься VPN, иногда для временного открытия доступа через свои фаерволы. Добавляем в ~/.bashrc:
Применяем изменения:
Проверяем:
Теперь сделаем алиас для получения информации о случайном IP адресе, который, к примеру, попался где-то в логе. Я иногда делаю уведомления от Zabbix о подключении к некоторым серверам по SSH, где не должно быть посторонних людей, и куда в принципе очень редко кто-то подключается напрямую. Как-то раз прилетает оповещение, проверяю IP и вижу, что это Сербия. Тут же блокирую доступ, начинаю смотреть, что сделано. Вижу какие-то изменения в исходниках, смысл которых не могу понять.
Через некоторое время пишет разработчик и говорит, что не может подключиться к серверу, а ему там надо срочно что-то поправить через консоль. Оказалось, что он временно уехал в Сербию и работает оттуда. Вернул ему доступ.
Чтобы быстро проверить страну IP адреса, надо использовать запрос вида:
То есть нам в алиас (например
Но алиасы не поддерживают передачу переменных. Для этого надо использовать функцию. Добавляем туда же, в .bashrc:
Проверяем:
Мне столько информации не надо, поэтому решил сделать пару функций. Одна выводит информацию только о стране, вторая полную информацию об IP, за исключением информации о user_agent. Я и так знаю, что это мой curl. В итоге получились две функции с использованием утилиты jq:
Проверяем:
Подобными подходами с помощью алиасов и функций можете упростить свои рутинные операции. Обычно это различные утилиты копирования сразу с ключами, создание новой директории и сразу же переход в неё и т.д. У каждого будет свой набор.
#bash
Делаем простой алиас для проверки своего внешнего IP адреса. Нужно, в основном, когда пользуешься VPN, иногда для временного открытия доступа через свои фаерволы. Добавляем в ~/.bashrc:
alias myip='curl ifconfig.co'Применяем изменения:
# source .bashrcПроверяем:
# myip195.196.228.171Теперь сделаем алиас для получения информации о случайном IP адресе, который, к примеру, попался где-то в логе. Я иногда делаю уведомления от Zabbix о подключении к некоторым серверам по SSH, где не должно быть посторонних людей, и куда в принципе очень редко кто-то подключается напрямую. Как-то раз прилетает оповещение, проверяю IP и вижу, что это Сербия. Тут же блокирую доступ, начинаю смотреть, что сделано. Вижу какие-то изменения в исходниках, смысл которых не могу понять.
Через некоторое время пишет разработчик и говорит, что не может подключиться к серверу, а ему там надо срочно что-то поправить через консоль. Оказалось, что он временно уехал в Сербию и работает оттуда. Вернул ему доступ.
Чтобы быстро проверить страну IP адреса, надо использовать запрос вида:
# curl 'https://ifconfig.co/json?ip=1.1.1.1'То есть нам в алиас (например
ipc) нужно передать значение из ввода консоли, примерно так:# ipc 1.1.1.1Но алиасы не поддерживают передачу переменных. Для этого надо использовать функцию. Добавляем туда же, в .bashrc:
function ipc { curl https://ifconfig.co/json?ip=$1 } Проверяем:
# ipc 1.1.1.1{ "ip": "1.1.1.1", "ip_decimal": 16843009, "country": "Australia", "country_iso": "AU", "country_eu": false, "latitude": -33.494, "longitude": 143.2104, "time_zone": "Australia/Sydney", "asn": "AS13335", "asn_org": "CLOUDFLARENET", "hostname": "one.one.one.one", "user_agent": { "product": "curl", "version": "7.81.0", "raw_value": "curl/7.81.0" }Мне столько информации не надо, поэтому решил сделать пару функций. Одна выводит информацию только о стране, вторая полную информацию об IP, за исключением информации о user_agent. Я и так знаю, что это мой curl. В итоге получились две функции с использованием утилиты jq:
function ipa { curl -s https://ifconfig.co/json?ip=$1 | jq 'del(.user_agent)' }function ipc { curl -s https://ifconfig.co/json?ip=$1 | jq '.country' }Проверяем:
# ipc 1.1.1.1"Australia"# ipa 1.1.1.1{ "ip": "1.1.1.1", "ip_decimal": 16843009, "country": "Australia", "country_iso": "AU", "country_eu": false, "latitude": -33.494, "longitude": 143.2104, "time_zone": "Australia/Sydney", "asn": "AS13335", "asn_org": "CLOUDFLARENET", "hostname": "one.one.one.one"}Подобными подходами с помощью алиасов и функций можете упростить свои рутинные операции. Обычно это различные утилиты копирования сразу с ключами, создание новой директории и сразу же переход в неё и т.д. У каждого будет свой набор.
#bash
{kind=link}
Во времена расцвета чёрной бухгалтерии были популярны всевозможные методы сокрытия серверов. Чего только не придумывали люди. На моём опыте это было и полное шифрование, и сокрытие серверной где-то в подсобных помещениях, и розетки с управлением по gsm, чтобы удалённо надёжно обесточить оборудование. Про удалённое выключение или управляемый обрыв связи вообще молчу. Сейчас всё это кануло в лету и почти все работают в белую.
С тех времён у меня осталась статья про удалённое выключение серверов на Linux и Windows с управляющей машиной под Windows. Ничего особенного я там не придумал, но тем не менее, когда упоминал об этих возможностях, люди спрашивали, как я это реализовывал. Да и у статьи довольно много просмотров и комментариев накопилось, так что я решил кратенько рассказать о методах. Может кому-то будет полезно. В бизнесе я уже не вижу, кому бы это было надо, а вот сам я такими же методами выключаю своё оборудование дома.
1️⃣ С Linux всё наиболее просто. Подключаемся по SSH любым способом и отправляем команду на выключение:
2️⃣ С Windows немного посложнее, так как нюансов больше. Я делал следующим образом. Создавал отдельного пользователя с правами на выключение системы. В автозапуск ему ставил скрипт, который выполняет
Подробности реализаций описаны в статье. Это не самые оптимальные способы. Я вообще не заморачивался над задачей. Сделал в лоб так, как пришло на ум. Наверняка многие из вас придумают что-то более простое и универсальное. Тем не менее, мои способы работали. Периодически в компании делали тестовые выключения. Да и сам я выключаю свои машины удалённо примерно так же. Добавил скрипты в Zabbix и прямо с карты выключаю их на ночь, если дома забыли выключить.
#разное #linux #windows
С тех времён у меня осталась статья про удалённое выключение серверов на Linux и Windows с управляющей машиной под Windows. Ничего особенного я там не придумал, но тем не менее, когда упоминал об этих возможностях, люди спрашивали, как я это реализовывал. Да и у статьи довольно много просмотров и комментариев накопилось, так что я решил кратенько рассказать о методах. Может кому-то будет полезно. В бизнесе я уже не вижу, кому бы это было надо, а вот сам я такими же методами выключаю своё оборудование дома.
1️⃣ С Linux всё наиболее просто. Подключаемся по SSH любым способом и отправляем команду на выключение:
shutdown -h now. Из под Windows это делается с помощью putty. Она поддерживает выполнение команд при подключении. Всё это можно обернуть в bat файл и автоматизировать, чтобы было достаточно запустить только этот скрипт. 2️⃣ С Windows немного посложнее, так как нюансов больше. Я делал следующим образом. Создавал отдельного пользователя с правами на выключение системы. В автозапуск ему ставил скрипт, который выполняет
shutdown /p /d p:0:0 /f. Далее настраивал rdp подключение под этим пользователем и тоже всё оборачивал в bat файл. В итоге при подключении этим пользователем, сервер выключался. Мне такой способ показался наиболее надёжным в плане исполнения, когда не все компьютеры в домене. С доменом всё проще. Подробности реализаций описаны в статье. Это не самые оптимальные способы. Я вообще не заморачивался над задачей. Сделал в лоб так, как пришло на ум. Наверняка многие из вас придумают что-то более простое и универсальное. Тем не менее, мои способы работали. Периодически в компании делали тестовые выключения. Да и сам я выключаю свои машины удалённо примерно так же. Добавил скрипты в Zabbix и прямо с карты выключаю их на ночь, если дома забыли выключить.
#разное #linux #windows
Server Admin
Удаленное выключение компьютера по сети
Два способа удаленного выключения windows и linux сервера по сети с помощью скриптов и консольных команд завершения работы.
Хочу поделиться информацией по поводу публикации баз 1С по HTTP. Регулярно получаю вопросы по этой теме, очень актуальная. Да и статьи писал не раз по этому поводу. У меня есть довольно большой практический опыт настройки и поддержки работы таких баз.
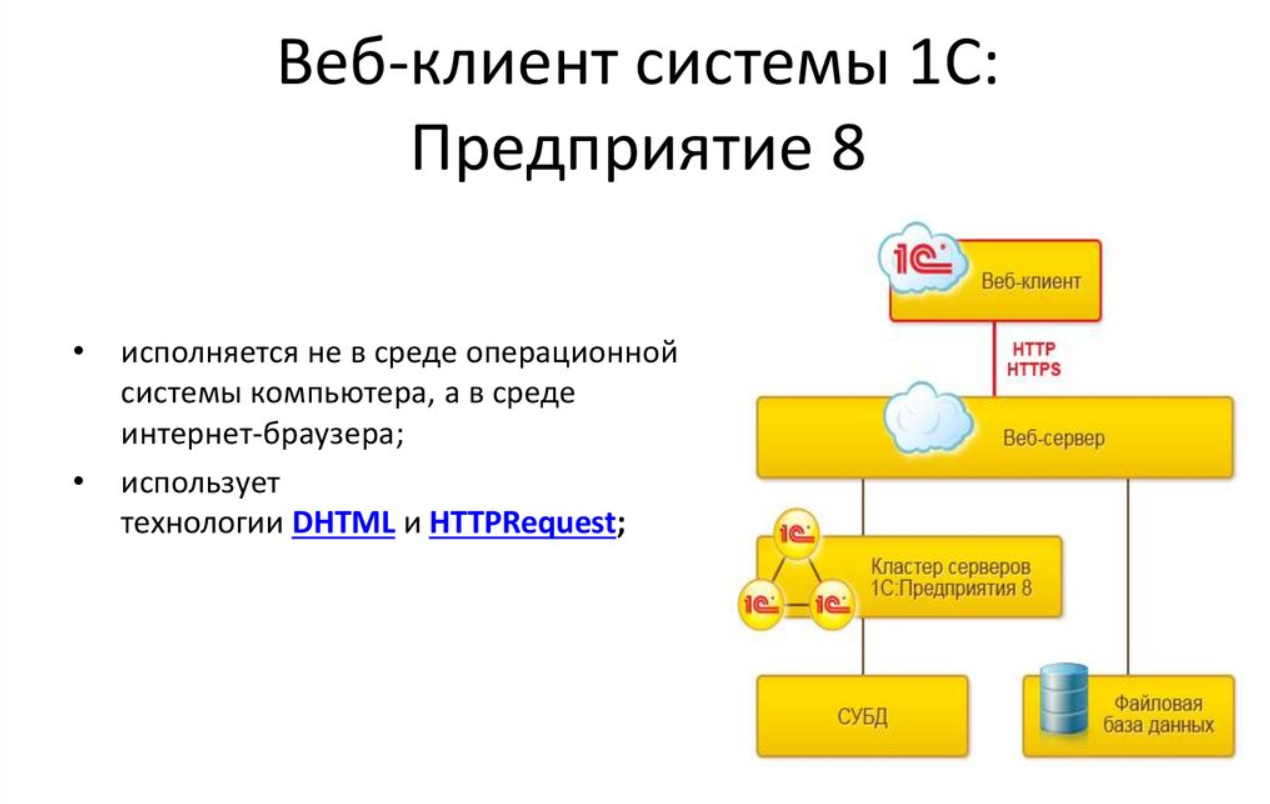
Работа с 1С через браузер выглядит очень заманчивой, так как сильно упрощает сопровождение пользователей. Им достаточно дать ссылку на сайт и пусть работают. На деле, к сожалению, не всё так просто.
Начну с того, что некоторый функционал по управлению базой в принципе не работает через веб клиент. Например, обновление конфигурации или создание резервной копии. Это актуально для небольших файловых баз, которые обновлять или бэкапить могут сами пользователи. Так как работа в браузере осуществляется через веб клиент, а клиент это не конфигуратор, то работа в нём через браузер тоже невозможна.
Ограничения это ладно, с ними можно разобраться, так как они известны. Но, к сожалению, через браузер иногда возникают проблемы с работой основного функционала. Это бывает не часто, но бывает. Я сталкивался не раз и не два. Например, обновляется Chrome и какой-то запрос при работе с базой начинает зацикливаться и блокироваться браузером. При этом в том же Firefox продолжает нормально работать. В следующем обновлении платформы или конфигурации это может быть исправлено, а может и нет. Также сталкивался с тем, что какие-то то ли формы, то ли отчёты или другой функционал не открывался через браузер. Ошибка появлялась тоже после очередного обновления. Решения тупо нет, надо сидеть и ждать, либо откатываться назад. Ситуация очень неприятная.
При этом, если использовать стандартную платформу и подключать в ней базу по HTTP, этих ошибок нет. Они возникают только при работе через браузер. Получается, что обслуживать машины пользователей всё равно придётся, обновляя им платформу и подключая базы.
💡 При всех этих минусах, публикация в веб решает другую важную задачу - доступ к базе без настройки доступа к самой инфраструктуре. Не нужны ни VPN, ни терминальный доступ, ни пробросы портов. Достаточно опубликовать базу в веб, закрыть её дополнительным паролем на уровне веб сервера и безопасно предоставить доступ внешним клиентам. Кого-то может и устроит работа в браузере, если он выполняет очень простые операции. Всем остальным можно поставить платформу и нормально работать, не забывая её обновлять вместе с сервером.
Если же у вас локальные пользователи, то не вижу смысла их подключать к базам через браузер. Работа в нём более медленна, отклик на действия пользователя дольше. Плюс, возникают нюансы с лицензиями и выполнением запросов. При больших нагрузках работа через веб публикацию будет значительно медленнее, чем классический доступ, так как веб сервер все запросы к одной базе выполняет последовательно от всех клиентов.
Подводя итог, скажу, что работа с базами 1С через веб клиент - это дополнительный инструмент для удобной работы удалённых клиентов, который не заменит основное прямое подключение через стандартную платформу.
#1С
Работа с 1С через браузер выглядит очень заманчивой, так как сильно упрощает сопровождение пользователей. Им достаточно дать ссылку на сайт и пусть работают. На деле, к сожалению, не всё так просто.
Начну с того, что некоторый функционал по управлению базой в принципе не работает через веб клиент. Например, обновление конфигурации или создание резервной копии. Это актуально для небольших файловых баз, которые обновлять или бэкапить могут сами пользователи. Так как работа в браузере осуществляется через веб клиент, а клиент это не конфигуратор, то работа в нём через браузер тоже невозможна.
Ограничения это ладно, с ними можно разобраться, так как они известны. Но, к сожалению, через браузер иногда возникают проблемы с работой основного функционала. Это бывает не часто, но бывает. Я сталкивался не раз и не два. Например, обновляется Chrome и какой-то запрос при работе с базой начинает зацикливаться и блокироваться браузером. При этом в том же Firefox продолжает нормально работать. В следующем обновлении платформы или конфигурации это может быть исправлено, а может и нет. Также сталкивался с тем, что какие-то то ли формы, то ли отчёты или другой функционал не открывался через браузер. Ошибка появлялась тоже после очередного обновления. Решения тупо нет, надо сидеть и ждать, либо откатываться назад. Ситуация очень неприятная.
При этом, если использовать стандартную платформу и подключать в ней базу по HTTP, этих ошибок нет. Они возникают только при работе через браузер. Получается, что обслуживать машины пользователей всё равно придётся, обновляя им платформу и подключая базы.
💡 При всех этих минусах, публикация в веб решает другую важную задачу - доступ к базе без настройки доступа к самой инфраструктуре. Не нужны ни VPN, ни терминальный доступ, ни пробросы портов. Достаточно опубликовать базу в веб, закрыть её дополнительным паролем на уровне веб сервера и безопасно предоставить доступ внешним клиентам. Кого-то может и устроит работа в браузере, если он выполняет очень простые операции. Всем остальным можно поставить платформу и нормально работать, не забывая её обновлять вместе с сервером.
Если же у вас локальные пользователи, то не вижу смысла их подключать к базам через браузер. Работа в нём более медленна, отклик на действия пользователя дольше. Плюс, возникают нюансы с лицензиями и выполнением запросов. При больших нагрузках работа через веб публикацию будет значительно медленнее, чем классический доступ, так как веб сервер все запросы к одной базе выполняет последовательно от всех клиентов.
Подводя итог, скажу, что работа с базами 1С через веб клиент - это дополнительный инструмент для удобной работы удалённых клиентов, который не заменит основное прямое подключение через стандартную платформу.
#1С
{kind=link}
▶️ Хочу с вами поделиться полезной информацией, которую можно извлечь из видео, предлагаемое к просмотру. Посмотрел его ещё на прошлой неделе, посчитал полезным. За наймом специалистов в своей сфере деятельности надо внимательно следить, чтобы получать доход по рыночной стоимости своих услуг. Это позволит предметно общаться с руководством на тему своей ЗП, либо не теряться при смене работы и чётко понимать, на какой доход ты можешь рассчитывать.
IT пузырь лопнул. Что делать junior разработчикам? / Мобильный разработчик
⇨ https://www.youtube.com/watch?v=1S_1MmOY0yY
Несмотря на то, что автор рассказывает про рынок разработки, к обслуживанию это имеет точно такое же отношение, так как инфраструктуру девопсы и сисадмины в современном IT строят и поддерживают чаще всего для результатов деятельности программистов.
📌 Основные тезисы:
1️⃣ Рынок IT падает во всём мире. Идут сокращения во многих крупных международных компаниях (facebook, microsoft, tesla, twitter и т.д.).
2️⃣ Насыщение рынка малоопытными сотрудниками произошло. Они больше не нужны, так как рост в ближайшем будущем не планируется, а будет сокращение.
3️⃣ В 2012-2014 годах в РФ после полугодовых курсов реально можно было устроиться в IT на хорошую зарплату в сравнении с другими специальностями. Все школы по инерции продолжают повторять эти тексты из прошлого, которые сейчас совершенно не актуальны.
4️⃣ На вакансию стажёра в течении часа-двух после публикации прилетает по 200-400 резюме. Конкуренция огромна. Пробиться без опыта очень сложно.
5️⃣ Сейчас, чтобы войти в IT, понадобится 2-3 года обучения и практики. Это становится сопоставимо со многими другими профессиями. Лёгкого входа больше нет. Трезво оценивайте свои возможности. Возможно IT вообще не для вас.
6️⃣ Всегда будут востребованы квалифицированные инженеры. Они нужны сейчас, они будут нужны в будущем. На них всегда дефицит, потому что это не каждому дано, это не массовая профессия. Ваша задача, чтобы быть востребованным, становиться профессионалом. Надо работать над собой, развиваться в своей сфере.
Какой отсюда можно сделать вывод? Трезво оценивайте свои возможности и вероятные доходы. Весь мир вкатывается в затяжной экономический кризис. Уровень жизни в среднем будет падать везде, поэтому придётся потихоньку мириться с тем фактом, что статистическое большинство людей по мере накопления профессионального опыта и компетенций не будут получать увеличение уровня жизни. Думаю, многие это замечают уже сейчас. Я лично заметил и с этим не просто мириться. Похоже на бег белки в колесе.
Если нет гарантированного трудоустройства на новом месте, не торопитесь покидать старое.
#разное
IT пузырь лопнул. Что делать junior разработчикам? / Мобильный разработчик
⇨ https://www.youtube.com/watch?v=1S_1MmOY0yY
Несмотря на то, что автор рассказывает про рынок разработки, к обслуживанию это имеет точно такое же отношение, так как инфраструктуру девопсы и сисадмины в современном IT строят и поддерживают чаще всего для результатов деятельности программистов.
📌 Основные тезисы:
1️⃣ Рынок IT падает во всём мире. Идут сокращения во многих крупных международных компаниях (facebook, microsoft, tesla, twitter и т.д.).
2️⃣ Насыщение рынка малоопытными сотрудниками произошло. Они больше не нужны, так как рост в ближайшем будущем не планируется, а будет сокращение.
3️⃣ В 2012-2014 годах в РФ после полугодовых курсов реально можно было устроиться в IT на хорошую зарплату в сравнении с другими специальностями. Все школы по инерции продолжают повторять эти тексты из прошлого, которые сейчас совершенно не актуальны.
4️⃣ На вакансию стажёра в течении часа-двух после публикации прилетает по 200-400 резюме. Конкуренция огромна. Пробиться без опыта очень сложно.
5️⃣ Сейчас, чтобы войти в IT, понадобится 2-3 года обучения и практики. Это становится сопоставимо со многими другими профессиями. Лёгкого входа больше нет. Трезво оценивайте свои возможности. Возможно IT вообще не для вас.
6️⃣ Всегда будут востребованы квалифицированные инженеры. Они нужны сейчас, они будут нужны в будущем. На них всегда дефицит, потому что это не каждому дано, это не массовая профессия. Ваша задача, чтобы быть востребованным, становиться профессионалом. Надо работать над собой, развиваться в своей сфере.
Какой отсюда можно сделать вывод? Трезво оценивайте свои возможности и вероятные доходы. Весь мир вкатывается в затяжной экономический кризис. Уровень жизни в среднем будет падать везде, поэтому придётся потихоньку мириться с тем фактом, что статистическое большинство людей по мере накопления профессионального опыта и компетенций не будут получать увеличение уровня жизни. Думаю, многие это замечают уже сейчас. Я лично заметил и с этим не просто мириться. Похоже на бег белки в колесе.
Если нет гарантированного трудоустройства на новом месте, не торопитесь покидать старое.
#разное
{kind=link}
При выборе упсов я всегда отдаю предпочтение фирме APC, несмотря на то, что чаще всего они дороже аналогов. А всё из-за небольшой программы apcupsd, которую я использую уже более 10-ти лет с упсами этого вендора. Расскажу про неё для тех, кто о ней не слышал.
Apcupsd - это небольшая программа, доступная под все популярные системы (Linux, Windows, Macos, Freebsd). В Linux она есть в стандартных репозиториях популярных дистрибутивов. С её помощью можно управлять поведением систем в зависимости от состояния упса. Поясню на простом примере.
Допустим, у вас есть стойка, в ней 5 сильно разных серверов и один мощный UPS. Все сервера запитаны от этого упса. Вам нужно настроить автоматические отключение серверов при пропадании электропитания. При этом желательно выбрать определённую последовательность, кто и когда выключается.
С apcupsd решить эту задачу очень просто. Подключаете UPS по USB к любому серверу. То есть упс может быть и без сетевой карты. Я обычно к Linux его подключаю, потому что туда никакие дополнительные драйвера ставить не нужно. Apcupsd сразу видит упс. Настраиваю его в качестве сервера и ставлю ему максимальное время жизни при отключенном электропитании. То есть указываю, что этот сервер отключится, когда останется 10% заряда или 5 минут жизни упс.
На остальных серверах настраиваю apcuspd в качестве клиента, который подключается к серверу по сети и получают информацию об упсе. На каждом сервере можно настроить любые условия, когда они начнут выключаться. Кого-то гасим сразу, как пропало электричество на минуту и более. А кому-то указываем отключаться при заряде батарей 50% и ниже. Таким образом просто и удобно управляется отключение серверов.
У программы всего один простой конфигурационный файл, который хорошо прокомментирован. Помимо параметров завершения работы, можно настроить выполнение каких-то скриптов. Для Windows у программы есть иконка в трее, а также можно настроить веб интерфейс. Apcupsd пишет всю информацию в текстовый лог, так что его очень легко парсить и забирать данные в Zabbix, что я тоже делаю.
С этой программой у меня было в разное время и в разном контексте несколько статей на сайте. Можете посмотреть, как её использовать. Если не знали про неё, рекомендую попробовать. Она мне нравится намного больше стандартных приложений вендора. В первую очередь за счёт простоты и гибкости настройки, а так же минимализма и возможности без проблем и с единым конфигом настроить под все поддерживаемые системы.
⇨ Сайт
#железо
Apcupsd - это небольшая программа, доступная под все популярные системы (Linux, Windows, Macos, Freebsd). В Linux она есть в стандартных репозиториях популярных дистрибутивов. С её помощью можно управлять поведением систем в зависимости от состояния упса. Поясню на простом примере.
Допустим, у вас есть стойка, в ней 5 сильно разных серверов и один мощный UPS. Все сервера запитаны от этого упса. Вам нужно настроить автоматические отключение серверов при пропадании электропитания. При этом желательно выбрать определённую последовательность, кто и когда выключается.
С apcupsd решить эту задачу очень просто. Подключаете UPS по USB к любому серверу. То есть упс может быть и без сетевой карты. Я обычно к Linux его подключаю, потому что туда никакие дополнительные драйвера ставить не нужно. Apcupsd сразу видит упс. Настраиваю его в качестве сервера и ставлю ему максимальное время жизни при отключенном электропитании. То есть указываю, что этот сервер отключится, когда останется 10% заряда или 5 минут жизни упс.
На остальных серверах настраиваю apcuspd в качестве клиента, который подключается к серверу по сети и получают информацию об упсе. На каждом сервере можно настроить любые условия, когда они начнут выключаться. Кого-то гасим сразу, как пропало электричество на минуту и более. А кому-то указываем отключаться при заряде батарей 50% и ниже. Таким образом просто и удобно управляется отключение серверов.
У программы всего один простой конфигурационный файл, который хорошо прокомментирован. Помимо параметров завершения работы, можно настроить выполнение каких-то скриптов. Для Windows у программы есть иконка в трее, а также можно настроить веб интерфейс. Apcupsd пишет всю информацию в текстовый лог, так что его очень легко парсить и забирать данные в Zabbix, что я тоже делаю.
С этой программой у меня было в разное время и в разном контексте несколько статей на сайте. Можете посмотреть, как её использовать. Если не знали про неё, рекомендую попробовать. Она мне нравится намного больше стандартных приложений вендора. В первую очередь за счёт простоты и гибкости настройки, а так же минимализма и возможности без проблем и с единым конфигом настроить под все поддерживаемые системы.
⇨ Сайт
#железо
{kind=link}
На днях делал публикацию на тему удалённого выключения компьютера. Не ожидал, что столько людей напишут о том, как они прятали приватную информацию компании от посторонних глаз. Решил сделать подборку наиболее оригинальных решений.
📌 В своё время было устройство с USB и LAN портам, которым пинговалось оборудование, роутеры и серваки. На USB порт вешалась релюшка на 5 вольт, и как только десяток пингов не проходили, на релюшку подавалось питание, и релюшка нажимала сброс на серваке или отключала питание роутера, в зависимости, куда подключили контакты реле.
📌 Мы вставляли флешку внутрь сервера с кроном, который должен был запустить скрипт с флешки который затирает нулями диск , запуск скрипта происходил по истечению 3 минут после запуска сервера. Свой человек должен был перед запуском эту флешку извлечь. Если сервак оказывался у других людей соответственно получали пустой диск.
📌 Помню были два девайса модные в то время. Один при несанкционированном извлечении из стойки устраивал электромагнитный коллапс дисковой полке. Если забыл отключить при проведении регламентных работ, то отправлял охапку дисков в помойку и радовался восстановлению из бэкапов. Другой был в виде промежуточного контроллера между диском и мат. платой, имел скрытую кнопочку в ножке компа. Если комп поднимали, контроллер, вооружённый собственной батарей, радостно затирал диск мусором, превращая содержимое в тыкву, пока черепашки-ниндзя везли трофей на экспертизы.
📌 У нас было полу-облачное решение! Но мы тогда круто потрудились.
На выделенном сервере в облаке или VDS крутился сервис, написанный хорошим человеком. Обращение к сервису было через кнопку на рабочем столе и в приложении на телефоне. По нажатию кнопки, творилась полная вакханалия. Выключались все сервера 1С. Выключались терминальные сервера. Ребутались компы для доступа к терминальной 1С. Отключались маршруты на коммутаторах и роутерах. И вообще много чего интересного ещё было.
📌 Помню делали запуск чудо "кнопки". Штука базировалась на центральной сигнализации на базе hikvision. По кнопке, которая отвечала за тревогу, блокировались некоторые двери и лифты, делали через реле подключенной в СКУД, далее она ещё звонила на нужные номера и запускала скрипты на сервере. Со звонками и СКУД было просто, там считай все аналогово настраивается. А вот со скриптами намучался. В итоге сделал скрипт, запускающийся при определенном событии от сетевого интерфейса, на который сигнал как раз и слала сигнализация. Оказалось, что IP пакеты помечаются кодами, на которые сценарий и повесил. А сам скрипт был на Powershell, так что там было просто и с паролями и самим сценарием.
📌 Была в одном месте еще такая фишка. Роутер на Linux пробрасывал порты через VPN на рабочие сервера. Но сделан был хитро. По умолчанию грузились правила iptables, которые вели к левым серверам, там тоже были базы, но с левым содержимым. После запуска роутера, админ удаленно выполнял скрипт, который переписывал правила iptables, и начинали работать настоящие сервера. В случае какого ахтунга, роутер просто надо было перезагрузить. И для маски-шоу вроде никакого криминала не было. Где базы? На сервере, сервер в датацентре в Москве. Вот, заходите, смотрите. Хотите - качайте. Локально нет ничего.
У нас оказывается было целое направление в IT - спрячь свои сервера и сервисы от проверок. Я сам лично сталкивался и со спрятанными стойками в скрытых помещениях, и с программными кнопками, удаляющими данные, и с ложными приложениями, в которых на самом деле открывались терминальные сессии с бухгалтерией, и с отдельными квартирами, где физически вырубали электричество, чтобы гарантированно разорвать связь. На деле всё это слабо помогало. До кого докапывались компетентные органы, в итоге всё равно своё получали. Возможно с меньшими последствиями.
Были времена... Хорошо, что прошли. Такой дичью занимались 😁
Я всегда сразу говорил, что могу настроить что угодно, но если меня спросят, всё расскажу, вилять не буду.
#разное #security
📌 В своё время было устройство с USB и LAN портам, которым пинговалось оборудование, роутеры и серваки. На USB порт вешалась релюшка на 5 вольт, и как только десяток пингов не проходили, на релюшку подавалось питание, и релюшка нажимала сброс на серваке или отключала питание роутера, в зависимости, куда подключили контакты реле.
📌 Мы вставляли флешку внутрь сервера с кроном, который должен был запустить скрипт с флешки который затирает нулями диск , запуск скрипта происходил по истечению 3 минут после запуска сервера. Свой человек должен был перед запуском эту флешку извлечь. Если сервак оказывался у других людей соответственно получали пустой диск.
📌 Помню были два девайса модные в то время. Один при несанкционированном извлечении из стойки устраивал электромагнитный коллапс дисковой полке. Если забыл отключить при проведении регламентных работ, то отправлял охапку дисков в помойку и радовался восстановлению из бэкапов. Другой был в виде промежуточного контроллера между диском и мат. платой, имел скрытую кнопочку в ножке компа. Если комп поднимали, контроллер, вооружённый собственной батарей, радостно затирал диск мусором, превращая содержимое в тыкву, пока черепашки-ниндзя везли трофей на экспертизы.
📌 У нас было полу-облачное решение! Но мы тогда круто потрудились.
На выделенном сервере в облаке или VDS крутился сервис, написанный хорошим человеком. Обращение к сервису было через кнопку на рабочем столе и в приложении на телефоне. По нажатию кнопки, творилась полная вакханалия. Выключались все сервера 1С. Выключались терминальные сервера. Ребутались компы для доступа к терминальной 1С. Отключались маршруты на коммутаторах и роутерах. И вообще много чего интересного ещё было.
📌 Помню делали запуск чудо "кнопки". Штука базировалась на центральной сигнализации на базе hikvision. По кнопке, которая отвечала за тревогу, блокировались некоторые двери и лифты, делали через реле подключенной в СКУД, далее она ещё звонила на нужные номера и запускала скрипты на сервере. Со звонками и СКУД было просто, там считай все аналогово настраивается. А вот со скриптами намучался. В итоге сделал скрипт, запускающийся при определенном событии от сетевого интерфейса, на который сигнал как раз и слала сигнализация. Оказалось, что IP пакеты помечаются кодами, на которые сценарий и повесил. А сам скрипт был на Powershell, так что там было просто и с паролями и самим сценарием.
📌 Была в одном месте еще такая фишка. Роутер на Linux пробрасывал порты через VPN на рабочие сервера. Но сделан был хитро. По умолчанию грузились правила iptables, которые вели к левым серверам, там тоже были базы, но с левым содержимым. После запуска роутера, админ удаленно выполнял скрипт, который переписывал правила iptables, и начинали работать настоящие сервера. В случае какого ахтунга, роутер просто надо было перезагрузить. И для маски-шоу вроде никакого криминала не было. Где базы? На сервере, сервер в датацентре в Москве. Вот, заходите, смотрите. Хотите - качайте. Локально нет ничего.
У нас оказывается было целое направление в IT - спрячь свои сервера и сервисы от проверок. Я сам лично сталкивался и со спрятанными стойками в скрытых помещениях, и с программными кнопками, удаляющими данные, и с ложными приложениями, в которых на самом деле открывались терминальные сессии с бухгалтерией, и с отдельными квартирами, где физически вырубали электричество, чтобы гарантированно разорвать связь. На деле всё это слабо помогало. До кого докапывались компетентные органы, в итоге всё равно своё получали. Возможно с меньшими последствиями.
Были времена... Хорошо, что прошли. Такой дичью занимались 😁
Я всегда сразу говорил, что могу настроить что угодно, но если меня спросят, всё расскажу, вилять не буду.
#разное #security
{kind=link}
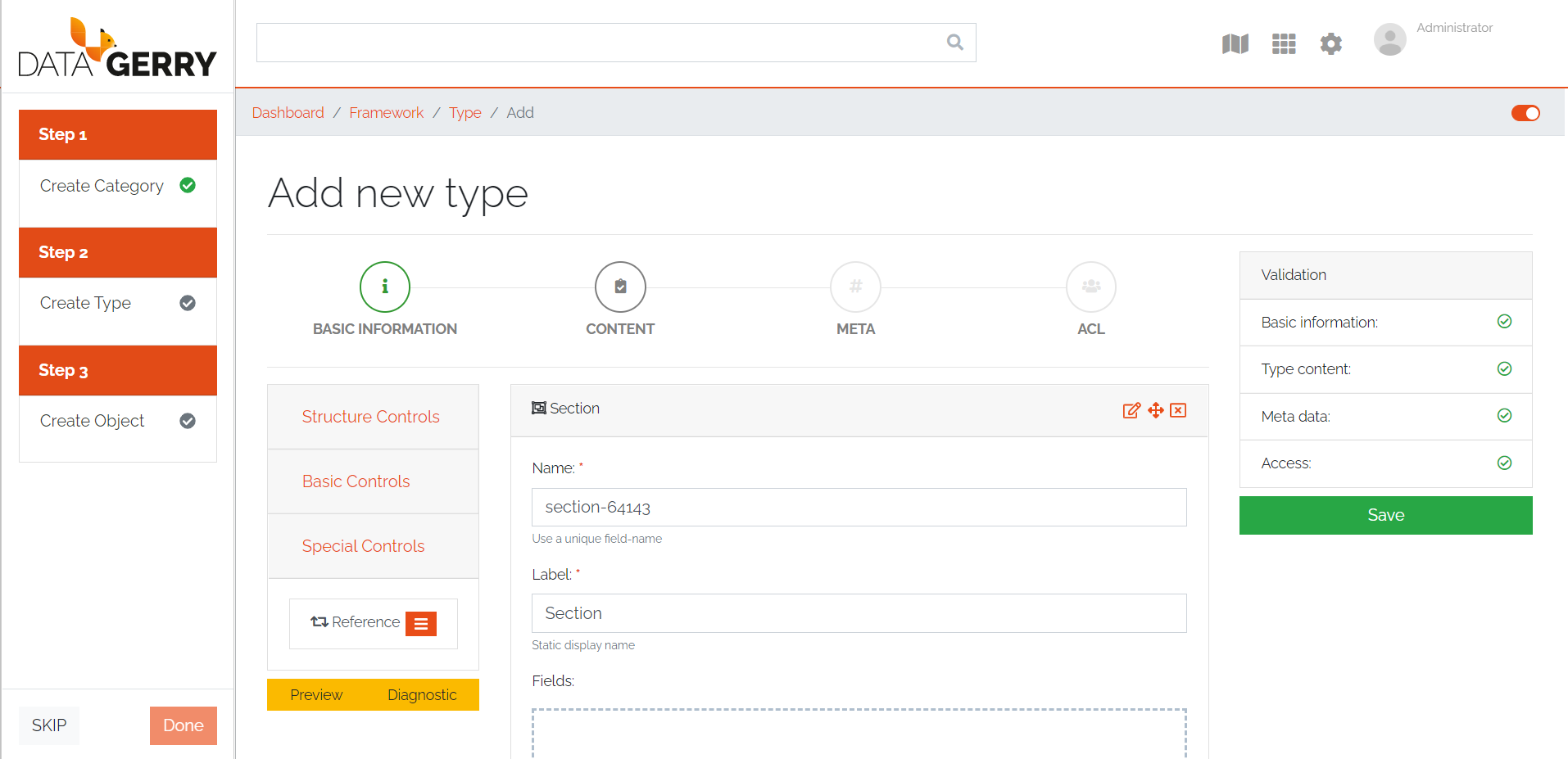
Хочу вас познакомить с необычным продуктом, который не будет подходить для массового использования. Но в каких-то нестандартных задачах он может оказаться настоящей находкой, так как позволяет как конструктор собрать то, что нужно именно вам. Речь пойдёт про open source CMDB систему DataGerry.
Чтобы сразу было понятно, о чём пойдёт речь, поясню, что это аналог таких продуктов, как i-doit, iTop, Ralph и т. д. Основное отличие от перечисленных бесплатных продуктов в том, что в DataGerry нет вообще никаких преднастроек. По своей сути это конструктор, который позволяет на базе CMDB (Configuration Management Database) собрать готовую систему под конкретную задачу.
В DataGerry вы сможете сами создавать категории, в них разные типы данных со своей структурой и параметрами, а на основании типов данных добавлять объекты. Это не готовая программа по учёту техники в офисе, серверов в стойках, лицензий ПО и т. д. Вы можете в ней хранить всё, что угодно. Описать структуру какого-то своего склада, своей системы управления.
У DataGerry есть встроенный API, с помощью которого можно настраивать интеграции с внешними системами. Аутентификация по API происходит с помощью токенов, доступ к системе через web настраивается либо с помощью локальных пользователей и групп, либо через интеграцию с LDAP.
Помимо API DataGerry умеет взаимодействовать с внешними системами через встроенные ExternalSystems. Это готовые экспортёры данных. Их можно писать самому в виде плагинов, либо использовать что-то из готового. Например, есть экспортёры inventory для Ansible, DNS записей для веб панели Cpanel, объектов в CVS файлы, объектов в MySQL базы и т.д. Список можно в документации посмотреть. Отдельно отмечу встроенную возможность экспорта хостов в бесплатную систему мониторинга OpenNMS.
Попробовать DataGerry очень просто. Есть готовый docker-compose.yml. Достаточно его запустить и идти в веб интерфейс на стандартный 80-й или 443-й порт. Учётка - admin / admin. При первом входе вам предложат пройти небольшое обучение, чтобы понять, как тут создавать объекты.
⇨ Сайт / Исходники
#управление #ITSM
Чтобы сразу было понятно, о чём пойдёт речь, поясню, что это аналог таких продуктов, как i-doit, iTop, Ralph и т. д. Основное отличие от перечисленных бесплатных продуктов в том, что в DataGerry нет вообще никаких преднастроек. По своей сути это конструктор, который позволяет на базе CMDB (Configuration Management Database) собрать готовую систему под конкретную задачу.
В DataGerry вы сможете сами создавать категории, в них разные типы данных со своей структурой и параметрами, а на основании типов данных добавлять объекты. Это не готовая программа по учёту техники в офисе, серверов в стойках, лицензий ПО и т. д. Вы можете в ней хранить всё, что угодно. Описать структуру какого-то своего склада, своей системы управления.
У DataGerry есть встроенный API, с помощью которого можно настраивать интеграции с внешними системами. Аутентификация по API происходит с помощью токенов, доступ к системе через web настраивается либо с помощью локальных пользователей и групп, либо через интеграцию с LDAP.
Помимо API DataGerry умеет взаимодействовать с внешними системами через встроенные ExternalSystems. Это готовые экспортёры данных. Их можно писать самому в виде плагинов, либо использовать что-то из готового. Например, есть экспортёры inventory для Ansible, DNS записей для веб панели Cpanel, объектов в CVS файлы, объектов в MySQL базы и т.д. Список можно в документации посмотреть. Отдельно отмечу встроенную возможность экспорта хостов в бесплатную систему мониторинга OpenNMS.
Попробовать DataGerry очень просто. Есть готовый docker-compose.yml. Достаточно его запустить и идти в веб интерфейс на стандартный 80-й или 443-й порт. Учётка - admin / admin. При первом входе вам предложат пройти небольшое обучение, чтобы понять, как тут создавать объекты.
⇨ Сайт / Исходники
#управление #ITSM
{kind=link}
▶️ Тема почтовых серверов приободрилась в последнее время, так что решил посмотреть выступление с linkmeetup, которое давно было в закладках (я их иногда всё же просматриваю).
Инженер из МойОфис рассказал про свои почтовые сервера - МойОфис Почта и Mailion. Так как оба продукта построены на базе Postfix и Dovecot, выступление получилось универсальным, из которого лично я вынес несколько полезных моментов. Например:
◽ Если вы хотите использовать аутентификацию через LDAP, но пользователи у вас в AD, с которой вы хотите уехать, есть Open Source сервер 389 Directory Server, на который можно перенести учётные записи с помощью RedHat sync utility Directory Server with Active Directory.
◽ В Dovecot есть свой собственный инструмент репликации для отказоустойчивой почтовой системы - dsync.
◽Альтернативой использования dsync может быть файловая система GlusterFS, которую разработчики МойОфис использовали в проде для почтового кластера.
◽ Для адресных книг и их синхронизации нет каких-то универсальных продуктов. Каждый решает это вопрос на месте.
Общая тема выступления - миграция с одних почтовых серверов, в том числе облачных, в другие. Рассказывается общая теория по процессу без привязки к каким-то конкретным решениям.
Импортозамещение почтового сервера. Андрей Колесников, руководитель инженерного отдела, МойОфис
⇨ https://www.youtube.com/watch?v=D_6pu-nd6cc
#видео #mailserver
Инженер из МойОфис рассказал про свои почтовые сервера - МойОфис Почта и Mailion. Так как оба продукта построены на базе Postfix и Dovecot, выступление получилось универсальным, из которого лично я вынес несколько полезных моментов. Например:
◽ Если вы хотите использовать аутентификацию через LDAP, но пользователи у вас в AD, с которой вы хотите уехать, есть Open Source сервер 389 Directory Server, на который можно перенести учётные записи с помощью RedHat sync utility Directory Server with Active Directory.
◽ В Dovecot есть свой собственный инструмент репликации для отказоустойчивой почтовой системы - dsync.
◽Альтернативой использования dsync может быть файловая система GlusterFS, которую разработчики МойОфис использовали в проде для почтового кластера.
◽ Для адресных книг и их синхронизации нет каких-то универсальных продуктов. Каждый решает это вопрос на месте.
Общая тема выступления - миграция с одних почтовых серверов, в том числе облачных, в другие. Рассказывается общая теория по процессу без привязки к каким-то конкретным решениям.
Импортозамещение почтового сервера. Андрей Колесников, руководитель инженерного отдела, МойОфис
⇨ https://www.youtube.com/watch?v=D_6pu-nd6cc
#видео #mailserver
{kind=link}
У команды VK Team в открытом доступе есть очень качественный курс по Linux. Записан и выложен он был 5 лет назад, но данная тематика не сильно меняется год от года, так что всё актуально и по сей день. Курс не для новичков, должна быть небольшая база.
⇨ Администрирование Linux (весна 2017)
Это не просто серия вебинаров с каким-то админом, а вполне серьезный курс, созданный на базе МФТИ (Московский физико-технический институт). Там же он и читался очно. К сожалению, в первой лекции нет записи консоли преподавателя, да и звук плохой, что немного смазывает впечатление о курсе, но потом это было исправлено.
В лекциях качественная подготовка и изложение материала. Видно, что лектор большой специалист в предметной области. Может и шуткануть по теме.
Программа курса:
◽ Основы (командная строка, bash скрипты и т.д.)
◽ Пользовательское окружение Linux
◽ Linux и сеть (основы)
◽ Управление пользовательским окружением
◽ Веб-сервисы
◽ Хранение данных
◽ Сервисы инфраструктуры
◽ Резервное копирование
◽ Инфраструктура электронной почты
◽ Распределение ресурсов системы
◽ Основы информационной безопасности
◽ Отказоустойчивость и масштабирование
Как я уже сказал, это курс не для новичков. Самые основы даются на другом их курсе на базе МГТУ им. Н. Э. Баумана - Администрирование Linux (осень 2015).
Оба эти курса можно использовать как базу для того, чтобы начать осваивать Linux. Меня очень часто спрашивают, с чего начать и что взять за основу. Это хороший пример основы.
#обучение
⇨ Администрирование Linux (весна 2017)
Это не просто серия вебинаров с каким-то админом, а вполне серьезный курс, созданный на базе МФТИ (Московский физико-технический институт). Там же он и читался очно. К сожалению, в первой лекции нет записи консоли преподавателя, да и звук плохой, что немного смазывает впечатление о курсе, но потом это было исправлено.
В лекциях качественная подготовка и изложение материала. Видно, что лектор большой специалист в предметной области. Может и шуткануть по теме.
Программа курса:
◽ Основы (командная строка, bash скрипты и т.д.)
◽ Пользовательское окружение Linux
◽ Linux и сеть (основы)
◽ Управление пользовательским окружением
◽ Веб-сервисы
◽ Хранение данных
◽ Сервисы инфраструктуры
◽ Резервное копирование
◽ Инфраструктура электронной почты
◽ Распределение ресурсов системы
◽ Основы информационной безопасности
◽ Отказоустойчивость и масштабирование
Как я уже сказал, это курс не для новичков. Самые основы даются на другом их курсе на базе МГТУ им. Н. Э. Баумана - Администрирование Linux (осень 2015).
Оба эти курса можно использовать как базу для того, чтобы начать осваивать Linux. Меня очень часто спрашивают, с чего начать и что взять за основу. Это хороший пример основы.
#обучение
{kind=link}
На моём канале не было ни одного упоминания про старую, самобытную систему мониторинга OpenNMS. Это open source проект из далёкого 1999 года. Она развивается и по сей день. Последний релиз был 14 декабря этого года.
OpenNMS делает упор на мониторинг сетевого оборудования, хотя не ограничивается только им. Метрики может собирать по SNMP, WinRM, XML, SQL, JMX, SFTP, FTP, JDBC, HTTP, HTTPS, JSON, VMware, WS-Management, Prometheus, плагины Nagios. Поддерживает протоколы учёта трафика NetFlow v5/v9, IPFIX, sFlow. Она вообще умеет очень много всего. Например, можно складывать NetFlow в ElasticSearch, а OpenNMS будет туда ходить, разбирать трафик и формировать какие-то события на основе того, что там найдёт. Система многогранная и функциональная. За столько лет она получила очень большое развитие.
Написана на Java, поэтому является кроссплатформенной. Данные хранит в PostgreSQL, метрики умеет в TSDB. Java может быть как минусом, так как в целом немного тормозная и требует много ресурсов, так и плюсом. OpenNMS легко запускается на любой системе, в том числе и на Windows. Не требуется какой-то особенной подготовки и настройки.
У OpenNMS есть интеграция с Grafana в виде готовых дашбордов, которые поддерживаются разработчиками. Как я уже упомянул, система умеет принимать данные с экспортёров Prometheus. Также есть интеграция с Kibana. То есть идёт в ногу со временем. Про неё можно много писать, но это уже не формат telegram заметок. Система старая, информации в интернете про неё много, в том числе и готовых руководств, и в том числе в виде видеороликов. Помимо этого есть хорошая документация.
Если подбираете себе готовую систему мониторинга сетевой инфраструктуры, где не хочется много костылить и пилить под себя, а хочется максимальной автоматизации и готовых решений, то обязательно попробуйте OpenNMS. Может вам зайдёт.
Отмечу бесплатные аналоги:
◽ Observium
◽ LibreNMS
◽ NetXMS
⇨ Сайт / Исходники
#мониторинг #network
OpenNMS делает упор на мониторинг сетевого оборудования, хотя не ограничивается только им. Метрики может собирать по SNMP, WinRM, XML, SQL, JMX, SFTP, FTP, JDBC, HTTP, HTTPS, JSON, VMware, WS-Management, Prometheus, плагины Nagios. Поддерживает протоколы учёта трафика NetFlow v5/v9, IPFIX, sFlow. Она вообще умеет очень много всего. Например, можно складывать NetFlow в ElasticSearch, а OpenNMS будет туда ходить, разбирать трафик и формировать какие-то события на основе того, что там найдёт. Система многогранная и функциональная. За столько лет она получила очень большое развитие.
Написана на Java, поэтому является кроссплатформенной. Данные хранит в PostgreSQL, метрики умеет в TSDB. Java может быть как минусом, так как в целом немного тормозная и требует много ресурсов, так и плюсом. OpenNMS легко запускается на любой системе, в том числе и на Windows. Не требуется какой-то особенной подготовки и настройки.
У OpenNMS есть интеграция с Grafana в виде готовых дашбордов, которые поддерживаются разработчиками. Как я уже упомянул, система умеет принимать данные с экспортёров Prometheus. Также есть интеграция с Kibana. То есть идёт в ногу со временем. Про неё можно много писать, но это уже не формат telegram заметок. Система старая, информации в интернете про неё много, в том числе и готовых руководств, и в том числе в виде видеороликов. Помимо этого есть хорошая документация.
Если подбираете себе готовую систему мониторинга сетевой инфраструктуры, где не хочется много костылить и пилить под себя, а хочется максимальной автоматизации и готовых решений, то обязательно попробуйте OpenNMS. Может вам зайдёт.
Отмечу бесплатные аналоги:
◽ Observium
◽ LibreNMS
◽ NetXMS
⇨ Сайт / Исходники
#мониторинг #network
{kind=link}
С завидной регулярностью появляются новости про взлом известной публичной облачной инфраструктуры по хранению паролей LastPass. Вот свежая:
Утечка резервных копий с данными пользователей LastPass
⇨ https://www.opennet.ru/opennews/art.shtml?num=58379
Было время, когда я тоже использовал этот сервис и хранил там свои пароли. А что, удобно. Пару кликов и пароль запомнен, а потом автоматически введён. Я иногда видел, как этим сервисом пользуются люди, которые проводили либо вебинары, либо обучение по IT. У них выскакивали эти надоедливые всплывающие информационные сообщения с предложением либо сохранить, либо заполнить веб формы.
Я быстро понял, что идея там хранить пароли плохая. Удалил учётку (лет 6-7 назад) и больше никогда не пользовался публичными сервисами для хранения паролей. Хочу это же посоветовать и вам. Мало ли, кто-то наверняка до сих пор пользуется LastPass или чем-то подобным. Я бы не рисковал. Да и удобство на самом деле сомнительное. Автозаполнение часто раздражает, а не помогает. Я и в браузере никогда не сохраняю важные пароли. Только всякую ерунду от незначительных сервисов.
Что там на самом деле своровали у LastPass после нескольких взломов - не известно. Правду всё равно не скажут, если реально что-то приватное утащили. Это похоронит сервис. Я для своих паролей использую локальный KeePass. А вы где храните пароли?
#security
Утечка резервных копий с данными пользователей LastPass
⇨ https://www.opennet.ru/opennews/art.shtml?num=58379
Было время, когда я тоже использовал этот сервис и хранил там свои пароли. А что, удобно. Пару кликов и пароль запомнен, а потом автоматически введён. Я иногда видел, как этим сервисом пользуются люди, которые проводили либо вебинары, либо обучение по IT. У них выскакивали эти надоедливые всплывающие информационные сообщения с предложением либо сохранить, либо заполнить веб формы.
Я быстро понял, что идея там хранить пароли плохая. Удалил учётку (лет 6-7 назад) и больше никогда не пользовался публичными сервисами для хранения паролей. Хочу это же посоветовать и вам. Мало ли, кто-то наверняка до сих пор пользуется LastPass или чем-то подобным. Я бы не рисковал. Да и удобство на самом деле сомнительное. Автозаполнение часто раздражает, а не помогает. Я и в браузере никогда не сохраняю важные пароли. Только всякую ерунду от незначительных сервисов.
Что там на самом деле своровали у LastPass после нескольких взломов - не известно. Правду всё равно не скажут, если реально что-то приватное утащили. Это похоронит сервис. Я для своих паролей использую локальный KeePass. А вы где храните пароли?
#security
{kind=link}
Существует старый и известный продукт на основе Linux по типу всё в одном - Zentyal. Он время от времени мелькает в комментариях и рекомендациях как замена AD или в качестве почтового сервера. Решил вам рассказать о нём, так как и то, и другое сейчас актуально.
Стоит сразу сказать, что Zentyal в первую очередь коммерческий продукт, продающийся по подписке. Но у него, как это часто бывает, есть бесплатная community версия, которую они в какой-то момент переименовали в Development Edition. Полное название бесплатной версии - Zentyal Server Development Edition.
У бесплатной версии сильно ограничен функционал, но всё основное есть. То есть его можно использовать в качестве контроллера домена для Windows машин и почтового сервера. Дистрибутив основан на ОС Ubuntu, установщик полностью от неё. После установки в консоль лазить не обязательно, всё управление через веб интерфейс. Причём стандартный установщик автоматически разворачивает графическое окружение и ставит браузер Firefox, так что управлять сервером можно сразу через консоль VM.
После установки настройка и управление осуществляются через веб интерфейс: https://ip_address:8443, учётка та, что была создана в качестве пользователя во время установки системы. Там вы сможете установить пакеты для:
▪ Контроллера домена на основе Samba 4.
▪ Почтового сервера на базе SOGo с поддержкой IMAP, Microsoft Exchange ActiveSync, CalDAV и CardDAV.
▪ Шлюза Linux с Firewall и NAT, DNS, DHCP, VPN и т.д.
Всё остальное не перечисляю, там уже не так интересно. Насколько всё это хорошо работает, трудно судить. В целом, домен работает. Много видел отзывов об этом в том числе и в комментариях к своим заметкам. Но нужно понимать, что это всё та же Samba и там могут быть проблемы. Но виндовые машины в домен зайдут и будет работать аутентификация, в том числе во все связанные сервисы (почта, файлы и т.д.). Можно будет файловые шары создать с доступом по пользователям и группам.
Сами разработчики позиционируют Zentyal как альтернатива Windows Server для малого и среднего бизнеса. Насколько я могу судить, это одна из самых удачных реализаций Linux all-in-box.
Аналоги:
◽ UCS
◽ ClearOS
⇨ Сайт / Исходники
#docs #fileserver #mailserver #ldap #samba
Стоит сразу сказать, что Zentyal в первую очередь коммерческий продукт, продающийся по подписке. Но у него, как это часто бывает, есть бесплатная community версия, которую они в какой-то момент переименовали в Development Edition. Полное название бесплатной версии - Zentyal Server Development Edition.
У бесплатной версии сильно ограничен функционал, но всё основное есть. То есть его можно использовать в качестве контроллера домена для Windows машин и почтового сервера. Дистрибутив основан на ОС Ubuntu, установщик полностью от неё. После установки в консоль лазить не обязательно, всё управление через веб интерфейс. Причём стандартный установщик автоматически разворачивает графическое окружение и ставит браузер Firefox, так что управлять сервером можно сразу через консоль VM.
После установки настройка и управление осуществляются через веб интерфейс: https://ip_address:8443, учётка та, что была создана в качестве пользователя во время установки системы. Там вы сможете установить пакеты для:
▪ Контроллера домена на основе Samba 4.
▪ Почтового сервера на базе SOGo с поддержкой IMAP, Microsoft Exchange ActiveSync, CalDAV и CardDAV.
▪ Шлюза Linux с Firewall и NAT, DNS, DHCP, VPN и т.д.
Всё остальное не перечисляю, там уже не так интересно. Насколько всё это хорошо работает, трудно судить. В целом, домен работает. Много видел отзывов об этом в том числе и в комментариях к своим заметкам. Но нужно понимать, что это всё та же Samba и там могут быть проблемы. Но виндовые машины в домен зайдут и будет работать аутентификация, в том числе во все связанные сервисы (почта, файлы и т.д.). Можно будет файловые шары создать с доступом по пользователям и группам.
Сами разработчики позиционируют Zentyal как альтернатива Windows Server для малого и среднего бизнеса. Насколько я могу судить, это одна из самых удачных реализаций Linux all-in-box.
Аналоги:
◽ UCS
◽ ClearOS
⇨ Сайт / Исходники
#docs #fileserver #mailserver #ldap #samba
{kind=link}
В преддверии праздников не хочется заниматься рабочими моментами. Решил с вами поделиться новостью, а также обсудить её. Я регулярно читаю блог Cloudflare, там иногда бывают интересные новости. Некоторыми я делился с вами ранее. Я заинтересовался вот этой:
⇨ Xata Workers: client-side database access without client-side secrets
Название не очень информативное. Речь там идёт о serverless базе данных с доступом к хранимой информации через API - Xata. Мне стало интересно, что это такое, поэтому сходил на сайт и ознакомился. Технология мне показалась похожей по своей сути на объектные хранилища S3, поэтому думаю, что она станет популярной через некоторое время.
Идея там такая. Есть некая конструкция для хранения данных. Конкретно в Xata это связка из Postgresql, Kafka, Elasticsearch. Если я правильно понял описание структуры хранения, то данные хранятся в кластере PostgreSQL, по репликам они раскладываются через очередь Kafka, а одной из реплик является Elasticsearch. Таким образом решается вопрос традиционного хранения данных в SQL базе и использование Elasticsearch для функций аналитики, быстрого поиска, машинного обучения и т.д.
Доступ к данным через RESTful API. Я посмотрел синтаксис, он простой, легко читается даже не программистами. Соответственно и использовать его не сложно. Сейчас Xata в бета тесте, поэтому пользоваться можно бесплатно с некоторыми ограничениями. Как я понял, потом также останется лимитированный бесплатный тарифный план. Я зарегистрировался и немного попользовался этой БД. Удобный интерфейс для управления через браузер, примерно как это сейчас реализовано в S3 хранилищах у провайдеров.
Лично мне эта идея и технология показались очень интересными и полезными. Не удивлюсь, если будет сформирован какой-то общепринятый API для работы с подобными базами, а что там будет в бэкенде для хранения - не так важно. Как и сейчас не важно, где хранятся файлы в S3. Главное, чтобы был отказоустойчивый кластер с заданными параметрами доступа.
Подобная технология хорошо ложится в канву iac и serverless подхода, доля которого растёт год от года. Используется какой-то безсерверный код в облаке, статика хранится в S3, а данные в подобной БД. Идеальная структура, к примеру, для Telegram бота. Или для статичного сайта с JavaScript, где все запросы к данным реализованы на уровне API прямо в коде сайте.
Я знаю, что в комментариях наверняка появятся люди, которые станут писать, что облака это всё развод на деньги и информацию, надо хранить данные у себя и т.д. Но дело не в том, где вы купите размещение, а в самом подходе. Всю эту инфраструктуру вы можете разместить и у себя локально. Подход к разработке при этом не изменится.
#разное #devops
⇨ Xata Workers: client-side database access without client-side secrets
Название не очень информативное. Речь там идёт о serverless базе данных с доступом к хранимой информации через API - Xata. Мне стало интересно, что это такое, поэтому сходил на сайт и ознакомился. Технология мне показалась похожей по своей сути на объектные хранилища S3, поэтому думаю, что она станет популярной через некоторое время.
Идея там такая. Есть некая конструкция для хранения данных. Конкретно в Xata это связка из Postgresql, Kafka, Elasticsearch. Если я правильно понял описание структуры хранения, то данные хранятся в кластере PostgreSQL, по репликам они раскладываются через очередь Kafka, а одной из реплик является Elasticsearch. Таким образом решается вопрос традиционного хранения данных в SQL базе и использование Elasticsearch для функций аналитики, быстрого поиска, машинного обучения и т.д.
Доступ к данным через RESTful API. Я посмотрел синтаксис, он простой, легко читается даже не программистами. Соответственно и использовать его не сложно. Сейчас Xata в бета тесте, поэтому пользоваться можно бесплатно с некоторыми ограничениями. Как я понял, потом также останется лимитированный бесплатный тарифный план. Я зарегистрировался и немного попользовался этой БД. Удобный интерфейс для управления через браузер, примерно как это сейчас реализовано в S3 хранилищах у провайдеров.
Лично мне эта идея и технология показались очень интересными и полезными. Не удивлюсь, если будет сформирован какой-то общепринятый API для работы с подобными базами, а что там будет в бэкенде для хранения - не так важно. Как и сейчас не важно, где хранятся файлы в S3. Главное, чтобы был отказоустойчивый кластер с заданными параметрами доступа.
Подобная технология хорошо ложится в канву iac и serverless подхода, доля которого растёт год от года. Используется какой-то безсерверный код в облаке, статика хранится в S3, а данные в подобной БД. Идеальная структура, к примеру, для Telegram бота. Или для статичного сайта с JavaScript, где все запросы к данным реализованы на уровне API прямо в коде сайте.
Я знаю, что в комментариях наверняка появятся люди, которые станут писать, что облака это всё развод на деньги и информацию, надо хранить данные у себя и т.д. Но дело не в том, где вы купите размещение, а в самом подходе. Всю эту инфраструктуру вы можете разместить и у себя локально. Подход к разработке при этом не изменится.
#разное #devops
{kind=link}