
После недавней заметки про Appflowy, в комментариях, как обычно, было бурное обсуждение. Очень активно советовали Obsidian. Я знаю про него, так как и раньше мне его тоже советовали, но попробовать руки дошли только сейчас. Остановился в итоге не на нём, но обо всё по порядку.
Obsidian реально удобное бесплатное для личного использования приложение. Очень много возможностей, большое сообщество, функционал расширяется плагинами, которых написано очень много. По всем параметрам это хороший продукт. Но чисто субъективно мне не очень понравился. По умолчанию разметка документа Markdown. Мне не нравится этот формат для локальных заметок. Посмотрел все настройки, так и не понял, как сделать так, чтобы выделенный текст можно было тут же сделать жирным или курсивом. Наверняка это решается, но я не стал сильно разбираться.
Второе, что не понравилось в Obsidian, это опять клиент на JavaScript. Не знаю, Electron там или что-то другое, но смысл тот же. Не очень отзывчивый интерфейс и в перспективе тормоза. Ещё обратил внимание на то, что в Obsidian акцент на связях всех и вся. Мне особо это не нужно. Привык структурировать данные сам по условным папкам или темам.
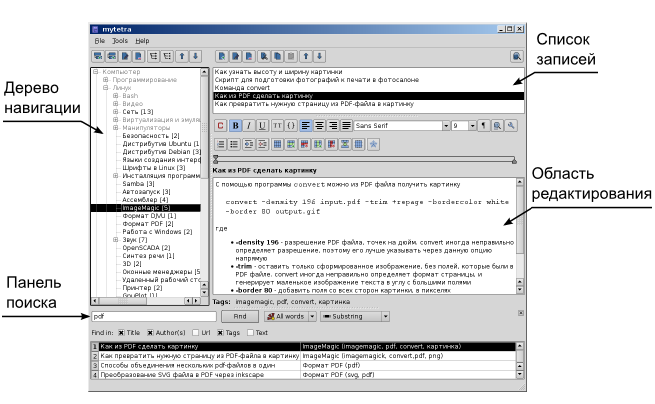
В итоге, я остановился на программе MyTetra. Привлёк старпёрский интерфейс и то, что написано на С++. Мне реально такой интерфейс, как в классических почтовых программах типа TheBat, Thunderbird (пользуюсь регулярно), Outlook и т.д., кажется удобным. Слева дерево, сверху список заметок, снизу текст. Всегда такой вид делал по умолчанию.
MyTetra умеет всё хранить локально, поддерживает шифрование. Просто положил её на Яндекс.Диск, так как программа портированная, установки не требует. Мобильного приложения нет, но мне и не надо. Никогда не пользовался заметками на смартфоне, не работаю с него, всё в ноуте. Иногда если сильно надо что-то посмотреть, по RDP подключался к виндовой машине.
Понемногу начал в MyTetra переносить заметки. Попользуюсь немного, посмотрю, как пойдёт. Если понравится, напишу более подробные впечатления и итог. Редактор в ней - WYSIWYG. Программа полностью бесплатна и пишется примерно 10 лет силами одного автора разработчика. Исходники есть на github. Никаких привязок к внешним сервисам и обновлениям нет. Программа полностью локальная.
⇨ Сайт / Исходники / Видеообзор / Обсуждение
#заметки
Obsidian реально удобное бесплатное для личного использования приложение. Очень много возможностей, большое сообщество, функционал расширяется плагинами, которых написано очень много. По всем параметрам это хороший продукт. Но чисто субъективно мне не очень понравился. По умолчанию разметка документа Markdown. Мне не нравится этот формат для локальных заметок. Посмотрел все настройки, так и не понял, как сделать так, чтобы выделенный текст можно было тут же сделать жирным или курсивом. Наверняка это решается, но я не стал сильно разбираться.
Второе, что не понравилось в Obsidian, это опять клиент на JavaScript. Не знаю, Electron там или что-то другое, но смысл тот же. Не очень отзывчивый интерфейс и в перспективе тормоза. Ещё обратил внимание на то, что в Obsidian акцент на связях всех и вся. Мне особо это не нужно. Привык структурировать данные сам по условным папкам или темам.
В итоге, я остановился на программе MyTetra. Привлёк старпёрский интерфейс и то, что написано на С++. Мне реально такой интерфейс, как в классических почтовых программах типа TheBat, Thunderbird (пользуюсь регулярно), Outlook и т.д., кажется удобным. Слева дерево, сверху список заметок, снизу текст. Всегда такой вид делал по умолчанию.
MyTetra умеет всё хранить локально, поддерживает шифрование. Просто положил её на Яндекс.Диск, так как программа портированная, установки не требует. Мобильного приложения нет, но мне и не надо. Никогда не пользовался заметками на смартфоне, не работаю с него, всё в ноуте. Иногда если сильно надо что-то посмотреть, по RDP подключался к виндовой машине.
Понемногу начал в MyTetra переносить заметки. Попользуюсь немного, посмотрю, как пойдёт. Если понравится, напишу более подробные впечатления и итог. Редактор в ней - WYSIWYG. Программа полностью бесплатна и пишется примерно 10 лет силами одного автора разработчика. Исходники есть на github. Никаких привязок к внешним сервисам и обновлениям нет. Программа полностью локальная.
⇨ Сайт / Исходники / Видеообзор / Обсуждение
#заметки
{kind=link}
Вы никогда не задавались вопросом, почему известный веб сервер в одних дистрибутивах именуется apache (Debian, Ubuntu), а в других httpd (Centos, RHEL, Fedora)? Меня всегда это интересовало, пока в итоге не разобрался, почему так. Поделюсь с вами.
Разработкой веб сервера занимается организация Apache Foundation, а сам продукт внутри организации называется Apache HTTP Server. Для краткости в Unix его стали называть Apache httpd (http daemon), добавив d на конец, как это происходит со многими службами (sshd, rsyslogd, crond и т.д.). В Debian и производных прижилось именование apache из первой части названия.
Название httpd появилось в системах от RedHat. Зачем они это сделали - не понятно. Я не нашёл информации на тему того, чем их не устроило уже имевшееся название программы в виде apache. Но если разобраться, то под брендом apache существует множество продуктов. Именование httpd выглядит более логичным, хотя и не строго, так как службы http тоже могут быть разными. В общем, тут есть предпосылки для разночтений.
Если я не ошибаюсь, то название пакета httpd есть и в MacOS. Возможно именно они первые стали использовать это имя, а RedHat подхватили. Выяснить наверняка не удалось.
Такая вот историческая справка. Я сначала сам путался, когда только начинал администрировать. Не сразу понял, что это одно и то же, хотя по структуре конфига понятно, что что-то похожее. И в комментариях к своим статьям с веб серверами видел вопросы на тему apache и httpd. Некоторые новички реально путаются и не понимают, что httpd это apache и есть.
#webserver #apache #httpd
Разработкой веб сервера занимается организация Apache Foundation, а сам продукт внутри организации называется Apache HTTP Server. Для краткости в Unix его стали называть Apache httpd (http daemon), добавив d на конец, как это происходит со многими службами (sshd, rsyslogd, crond и т.д.). В Debian и производных прижилось именование apache из первой части названия.
Название httpd появилось в системах от RedHat. Зачем они это сделали - не понятно. Я не нашёл информации на тему того, чем их не устроило уже имевшееся название программы в виде apache. Но если разобраться, то под брендом apache существует множество продуктов. Именование httpd выглядит более логичным, хотя и не строго, так как службы http тоже могут быть разными. В общем, тут есть предпосылки для разночтений.
Если я не ошибаюсь, то название пакета httpd есть и в MacOS. Возможно именно они первые стали использовать это имя, а RedHat подхватили. Выяснить наверняка не удалось.
Такая вот историческая справка. Я сначала сам путался, когда только начинал администрировать. Не сразу понял, что это одно и то же, хотя по структуре конфига понятно, что что-то похожее. И в комментариях к своим статьям с веб серверами видел вопросы на тему apache и httpd. Некоторые новички реально путаются и не понимают, что httpd это apache и есть.
#webserver #apache #httpd
Делюсь с вами информацией об очень полезной консольной утилите JC. С её помощью можно поток данных из стандартных команд Linux конвертировать в json. Покажу сразу на простом примере:
Вывод имеет смысл сразу через jq пропустить, чтобы было удобнее смотреть.
JC поддерживает большое количество утилит. Это делает её удобной для настройки мониторинга. Например, очень просто сделать мониторинг бэкапов в виде файлов.
Отправляем вывод на Zabbix Server и парсим с помощью JSONPath нужные данные. Например, имя файла, дату и размер. А дальше делаем нужные триггеры. Я раньше всё это на баше через grep, awk, sed и т.д. делал. Но тут намного удобнее.
В репозитории приведён полный список утилит, которые поддерживает jc. Написана программа на python, ставится через pip:
С помощью jc можно парсить вывод STDOUT у Ansible. В статье приведён простой и наглядный пример.
Утилита по нынешним временам очень актуальна и востребована. Рекомендую обратить внимание и сохранить информацию, если прямо сейчас не нужно.
⇨ Исходники / Много примеров
#json
# free | jc --freeВывод имеет смысл сразу через jq пропустить, чтобы было удобнее смотреть.
# free | jc --free | jq[ { "type": "Mem", "total": 1014640, "used": 197868, "free": 276000, "shared": 31280, "buff_cache": 540772, "available": 634004 }, { "type": "Swap", "total": 999996, "used": 175740, "free": 824256 }]JC поддерживает большое количество утилит. Это делает её удобной для настройки мониторинга. Например, очень просто сделать мониторинг бэкапов в виде файлов.
# ls -lh | jc --ls | jqОтправляем вывод на Zabbix Server и парсим с помощью JSONPath нужные данные. Например, имя файла, дату и размер. А дальше делаем нужные триггеры. Я раньше всё это на баше через grep, awk, sed и т.д. делал. Но тут намного удобнее.
В репозитории приведён полный список утилит, которые поддерживает jc. Написана программа на python, ставится через pip:
# pip3 install jcС помощью jc можно парсить вывод STDOUT у Ansible. В статье приведён простой и наглядный пример.
Утилита по нынешним временам очень актуальна и востребована. Рекомендую обратить внимание и сохранить информацию, если прямо сейчас не нужно.
⇨ Исходники / Много примеров
#json
{kind=link}
В рамках задачи по изучению бесплатных платформ для запуска чат-серверов нашёл интересный продукт, который помимо чата включает в себя остальные инструменты для совместной работы - онлайн документы, календарь, задачи. Речь пойдёт про Twake - open source продукт с монетизацией через продажу SaaS сервиса по подписке.
Сразу обращаю внимание на некоторые моменты, которые меня привлекли. Во-первых, сайт проекта представлен на английском, французском и русском языках. Во-вторых, на сайте явно указано, что Twake соответствует федеральному закону о персональных данных 152-ФЗ. Сама компания из Франции, но называет свою команду международной. Я так понял, что там есть какие-то связи с РФ, иначе про 152-ФЗ они вряд ли бы знали.
Twake называет сам себя бесплатной альтернативой Microsoft Teams, хотя лично мне он показался вообще непохожим на Teams. В качестве редактора документов там используется OnlyOffice, для видеозвонков Jitsi. Он скорее похож на Nextcloud или Kopano.
Twake расширяет свой функционал за счёт внешних интеграций, которые настраивать должно быть просто, так как архитектура приложения заточена под это. К примеру, уже есть готовая интеграция с n8n. Настройка показана в документации. Фронт написан на React (Javascript), бэкенд на PHP. Клиент, понятное дело, Electron. Ставить отдельно большого смысла нет, потому что он ничем не отличается от веб версии.
Попробовать Twake можно на бесплатном тарифном плане в облаке или развернуть у себя с помощью Docker. Все контейнеры уже собраны. Запустить так:
Только один нюанс. По умолчанию почему-то запускаются очень старые контейнеры еще от 2021 года. Я вручную заменил версию на последнюю 2022.Q4.1120 в файле docker-compose.yml. И ещё момент. Twake использует БД ScyllaBD, которой для работы нужны инструкции процессора pclmul и sse4_2. Без них не запустится. Пришлось в виртуалке на Proxmox, где её запускал, сделать тип процессора host для этой VM, иначе этих инструкций у неё не было.
Как сам чат Twake ничего особенного из себя не представляет. Всё примерно как у всех. Его стоит рассматривать именно как платформу для совместной работы. Заметно, что проект ещё молодой (первые версии от 2020 года) и сыроват. Акцент на готовую платформу для создания собственных интеграций выглядит перспективно и если всё получится, должно выйти дельное приложение. Пока ставить в прод рискованно. Документация слабая, популярность тоже небольшая. Надо наблюдать. Бесплатных продуктов подобного типа практически нет, так что и выбирать особо не из чего.
⇨ Сайт / Исходники
#chat #docs
Сразу обращаю внимание на некоторые моменты, которые меня привлекли. Во-первых, сайт проекта представлен на английском, французском и русском языках. Во-вторых, на сайте явно указано, что Twake соответствует федеральному закону о персональных данных 152-ФЗ. Сама компания из Франции, но называет свою команду международной. Я так понял, что там есть какие-то связи с РФ, иначе про 152-ФЗ они вряд ли бы знали.
Twake называет сам себя бесплатной альтернативой Microsoft Teams, хотя лично мне он показался вообще непохожим на Teams. В качестве редактора документов там используется OnlyOffice, для видеозвонков Jitsi. Он скорее похож на Nextcloud или Kopano.
Twake расширяет свой функционал за счёт внешних интеграций, которые настраивать должно быть просто, так как архитектура приложения заточена под это. К примеру, уже есть готовая интеграция с n8n. Настройка показана в документации. Фронт написан на React (Javascript), бэкенд на PHP. Клиент, понятное дело, Electron. Ставить отдельно большого смысла нет, потому что он ничем не отличается от веб версии.
Попробовать Twake можно на бесплатном тарифном плане в облаке или развернуть у себя с помощью Docker. Все контейнеры уже собраны. Запустить так:
# git clone https://github.com/linagora/Twake# cd Twake/twake# ./start.shТолько один нюанс. По умолчанию почему-то запускаются очень старые контейнеры еще от 2021 года. Я вручную заменил версию на последнюю 2022.Q4.1120 в файле docker-compose.yml. И ещё момент. Twake использует БД ScyllaBD, которой для работы нужны инструкции процессора pclmul и sse4_2. Без них не запустится. Пришлось в виртуалке на Proxmox, где её запускал, сделать тип процессора host для этой VM, иначе этих инструкций у неё не было.
Как сам чат Twake ничего особенного из себя не представляет. Всё примерно как у всех. Его стоит рассматривать именно как платформу для совместной работы. Заметно, что проект ещё молодой (первые версии от 2020 года) и сыроват. Акцент на готовую платформу для создания собственных интеграций выглядит перспективно и если всё получится, должно выйти дельное приложение. Пока ставить в прод рискованно. Документация слабая, популярность тоже небольшая. Надо наблюдать. Бесплатных продуктов подобного типа практически нет, так что и выбирать особо не из чего.
⇨ Сайт / Исходники
#chat #docs
{kind=link}
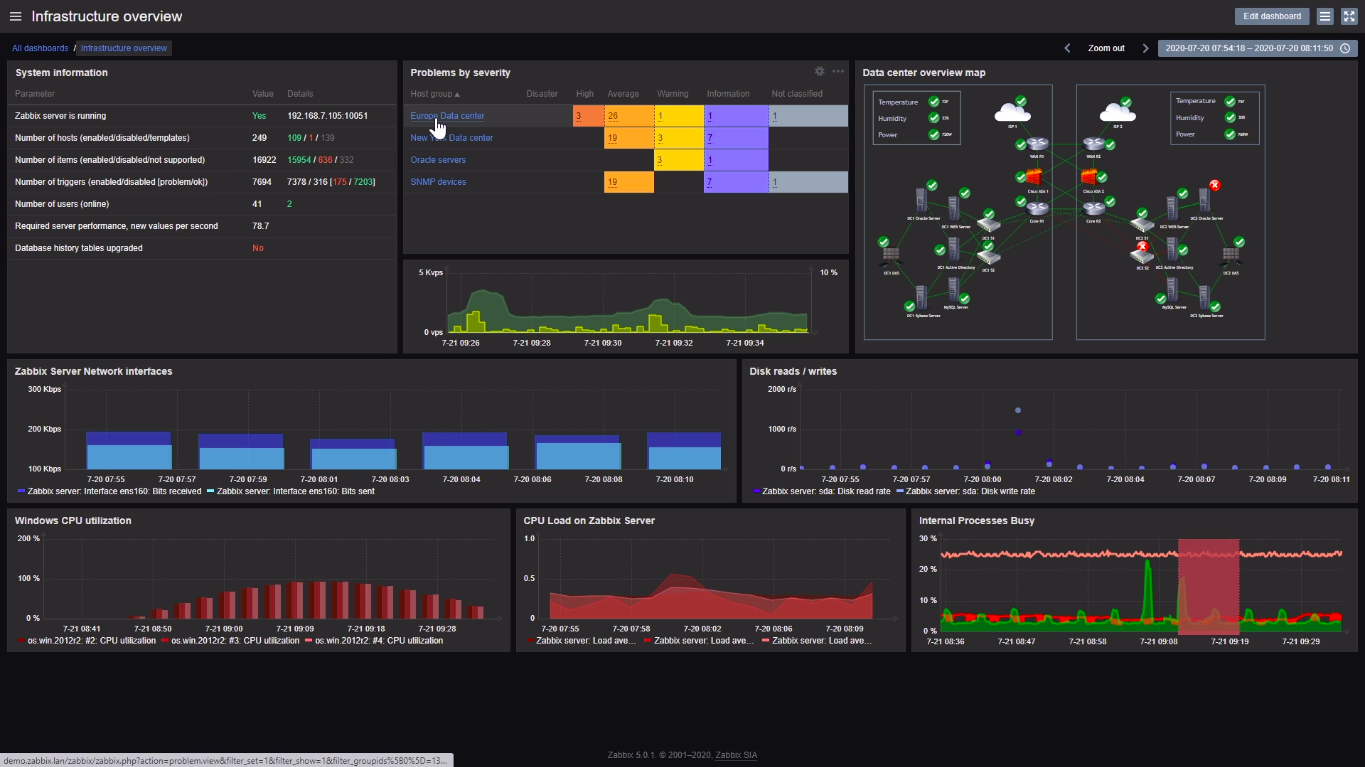
Для тех, кто не в курсе, напомню, что у Zabbix есть собственное очень хорошее обзорное видео, где максимально подробно и наглядно показаны все основные возможности системы мониторинга.
⇨ https://www.zabbix.com/ru/demo
Мне иногда пишут в личку вопросы на тему того, можно ли что-то реализовать через Zabbix, есть ли такой функционал и как это сделать. Если не очень хорошо знакомы с Zabbix, то посмотрите это обзорное видео. Там наглядно показаны возможности, особенно в плане визуализации.
Я лично не видел, чтобы кто-то заморачивался с дашбордами так, как это сделано в демонстрации. Выглядит красиво, но на практике не факт, что это будет удобно в работе. У меня обычно всё сильно проще. Особенно картам не уделяю много внимания. Всё равно в них никто не смотрит, а если что-то случилось, то информацию получаешь от оповещений триггеров.
p.s. Заметил, что у Zabbix продолжаются вебинары на русском языке. Записался на ближайший. Если посмотрю, дам обратную связь. Они там судя по плану регулярно проводятся.
#zabbix
⇨ https://www.zabbix.com/ru/demo
Мне иногда пишут в личку вопросы на тему того, можно ли что-то реализовать через Zabbix, есть ли такой функционал и как это сделать. Если не очень хорошо знакомы с Zabbix, то посмотрите это обзорное видео. Там наглядно показаны возможности, особенно в плане визуализации.
Я лично не видел, чтобы кто-то заморачивался с дашбордами так, как это сделано в демонстрации. Выглядит красиво, но на практике не факт, что это будет удобно в работе. У меня обычно всё сильно проще. Особенно картам не уделяю много внимания. Всё равно в них никто не смотрит, а если что-то случилось, то информацию получаешь от оповещений триггеров.
p.s. Заметил, что у Zabbix продолжаются вебинары на русском языке. Записался на ближайший. Если посмотрю, дам обратную связь. Они там судя по плану регулярно проводятся.
#zabbix
{kind=link}
Решил упростить себе задачу и подготовить список настроек, которые надо обязательно проверить при настройке одиночного mysql/mariadb сервера. Я не буду давать описания настроек и советовать какие-то значения, потому что это очень большой объём информации. Вы сами сможете её найти в интернете и подогнать под свою ситуацию.
Первое, что надо сделать - сбалансировать потребление памяти сервером. Не обязательно делать это вручную. Можно воспользоваться скриптом mysqltuner. Перечислю параметры Global + Thread, из которых складывается потребление памяти:
Global:
Эти значения просто суммируются.
Thread:
Эти значения суммируются и умножаются на
Как я уже сказал, не обязательно их все править. Можно воспользоваться mysqltuner или оставить дефолтные значения, а вручную указать наиболее критичные - innodb_buffer_pool_size, max_connections. Остальные параметры mysqltuner подскажет, как подогнать под основные. Innodb_buffer_pool_size подбирают таким образом, чтобы с учётом всех остальных параметров суммарное потребление оперативной памяти не выходило за отведённые для Mysql Server пределы.
Обязательно проверяю:
Если не требуются подключения извне, привязываю к localhost.
Проверяю расположение логов и чаще всего сразу добавляю лог медленных запросов:
Указываю нужную кодировку. Сейчас вроде бы везде utf8mb4 по умолчанию стоит, раньше utf8 ставили.
Важные параметры, которые заметно влияют на производительность:
Они привязаны к количеству соединений и таблиц в базе. Для того же Bitrix эти параметры имеют высокие значения и часто упираются в системные лимиты ОС для отдельного процесса. Их нужно тоже увеличить. Например вот так:
Содержимое файла:
Ещё один параметр, на который стоит обратить внимание:
Он регулирует размер и рост файла с временным табличным пространством. Этот файл иногда может вырастать до огромных размеров и вызывать нехватку свободного места. Имеет смысл его сразу ограничить до разумных пределов. Вот пример ограничения размера в 2 ГБ и роста частями по 12 Мб
Это основное, на что я обращаю внимание. Более детальные настройки делаются, если возникают какие-то проблемы.
#mysql
Первое, что надо сделать - сбалансировать потребление памяти сервером. Не обязательно делать это вручную. Можно воспользоваться скриптом mysqltuner. Перечислю параметры Global + Thread, из которых складывается потребление памяти:
Global:
innodb_buffer_pool_sizeinnodb_log_file_sizekey_buffer_sizeinnodb_log_buffer_sizequery_cache_sizearia_pagecache_buffer_sizeЭти значения просто суммируются.
Thread:
sort_buffer_sizejoin_buffer_sizeread_buffer_sizeread_rnd_buffer_sizemax_allowed_packetthread_stackЭти значения суммируются и умножаются на
max_connections. Как я уже сказал, не обязательно их все править. Можно воспользоваться mysqltuner или оставить дефолтные значения, а вручную указать наиболее критичные - innodb_buffer_pool_size, max_connections. Остальные параметры mysqltuner подскажет, как подогнать под основные. Innodb_buffer_pool_size подбирают таким образом, чтобы с учётом всех остальных параметров суммарное потребление оперативной памяти не выходило за отведённые для Mysql Server пределы.
Обязательно проверяю:
bind-address = 127.0.0.1Если не требуются подключения извне, привязываю к localhost.
Проверяю расположение логов и чаще всего сразу добавляю лог медленных запросов:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Указываю нужную кодировку. Сейчас вроде бы везде utf8mb4 по умолчанию стоит, раньше utf8 ставили.
character-set-server = utf8mb4collation-server = utf8mb4_general_ciВажные параметры, которые заметно влияют на производительность:
open_files_limittable_open_cache Они привязаны к количеству соединений и таблиц в базе. Для того же Bitrix эти параметры имеют высокие значения и часто упираются в системные лимиты ОС для отдельного процесса. Их нужно тоже увеличить. Например вот так:
# mkdir /etc/systemd/system/mysqld.service.d# touch limit.confСодержимое файла:
[Service]LimitNOFILE=65535Ещё один параметр, на который стоит обратить внимание:
innodb_temp_data_file_pathОн регулирует размер и рост файла с временным табличным пространством. Этот файл иногда может вырастать до огромных размеров и вызывать нехватку свободного места. Имеет смысл его сразу ограничить до разумных пределов. Вот пример ограничения размера в 2 ГБ и роста частями по 12 Мб
innodb_temp_data_file_path = ibtmp1:12M:autoextend:max:2GЭто основное, на что я обращаю внимание. Более детальные настройки делаются, если возникают какие-то проблемы.
#mysql
-50% на Akamai CDN в Selectel до конца ноября
Вы можете ускорять загрузку контента на сайте в два раза дешевле, чем раньше. Скидка действует, если вы подключаете Akamai CDN до конца ноября и оплачиваете услугу на 6 месяцев. Akamai — крупный CDN-провайдер, кэш-серверы которого расположены в более чем 135 странах.
Чем CDN может быть полезен:
▫️Ускоряя загрузку контента сайта, вы можете повлиять на его ранжирование в поисковой выдаче
▫️Используя CDN в работе, вы уменьшаете нагрузку на основную инфраструктуру.
▫️Сервис не боится растущих нагрузок, он без труда умеет под них адаптироваться. А если с одним из кэширующих серверов что-то случится, пользователи получат контент с другого ближайшего и не заметят нарушений.
Переходите по ссылке и подключайте Akamai CDN со скидкой на 6 месяцев: https://slc.tl/zdsoa
Реклама. ООО Селектел 2Vtzqwghymz
Вы можете ускорять загрузку контента на сайте в два раза дешевле, чем раньше. Скидка действует, если вы подключаете Akamai CDN до конца ноября и оплачиваете услугу на 6 месяцев. Akamai — крупный CDN-провайдер, кэш-серверы которого расположены в более чем 135 странах.
Чем CDN может быть полезен:
▫️Ускоряя загрузку контента сайта, вы можете повлиять на его ранжирование в поисковой выдаче
▫️Используя CDN в работе, вы уменьшаете нагрузку на основную инфраструктуру.
▫️Сервис не боится растущих нагрузок, он без труда умеет под них адаптироваться. А если с одним из кэширующих серверов что-то случится, пользователи получат контент с другого ближайшего и не заметят нарушений.
Переходите по ссылке и подключайте Akamai CDN со скидкой на 6 месяцев: https://slc.tl/zdsoa
Реклама. ООО Селектел 2Vtzqwghymz
Для тех, кто не в курсе, что такое прошивка для роутера DD-WRT, рекомендую хорошее обзорное видео. Я несколько лет пользовался обычным роутером Linksys, прошитым этой прошивкой, пока не начал использовать Mikrotik.
DD-WRT. Универсальная прошивка для роутера на примере Netgear R7000P. Обзор и установка
⇨ https://www.youtube.com/watch?v=Lzg8lMFK8Zk
Эта прошивка более дружественна к пользователям. С её настройками я разобрался без проблем. Не пришлось искать руководства и пояснения. Функционал сопоставим с Микротиками для soho устройств. Конкретно мне там нравилась возможность настройки OpenVPN сервера или клиента и написание правил в формате iptables. А также хоть и простое, но хранение статистики использования интернета.
Похоже, придётся опять возвращаться к истокам, так как завышенные цены на Mikrotik в России делают нецелесообразным их использование. Причём совершенно не понятно, почему именно они так подорожали. Многие другие роутеры остались плюс-минус по тем же ценам с поправкой на годовую инфляцию.
У меня только один вопрос возник после просмотра. DD-WRT вообще актуальна сейчас? На вид за 10 лет ничего не поменялось. Сложилось ощущение, что она уже давно устарела. Может есть что-то получше на сегодняшний день? Я не слышал.
#видео #ddwrt
DD-WRT. Универсальная прошивка для роутера на примере Netgear R7000P. Обзор и установка
⇨ https://www.youtube.com/watch?v=Lzg8lMFK8Zk
Эта прошивка более дружественна к пользователям. С её настройками я разобрался без проблем. Не пришлось искать руководства и пояснения. Функционал сопоставим с Микротиками для soho устройств. Конкретно мне там нравилась возможность настройки OpenVPN сервера или клиента и написание правил в формате iptables. А также хоть и простое, но хранение статистики использования интернета.
Похоже, придётся опять возвращаться к истокам, так как завышенные цены на Mikrotik в России делают нецелесообразным их использование. Причём совершенно не понятно, почему именно они так подорожали. Многие другие роутеры остались плюс-минус по тем же ценам с поправкой на годовую инфляцию.
У меня только один вопрос возник после просмотра. DD-WRT вообще актуальна сейчас? На вид за 10 лет ничего не поменялось. Сложилось ощущение, что она уже давно устарела. Может есть что-то получше на сегодняшний день? Я не слышал.
#видео #ddwrt
{kind=link}
Расскажу про технологию, которую возможно не все знают. Речь пойдёт про port knocking, который я иногда использую. Это очень простой способ защитить подключение к какому-то сервису через интернет.
Суть метода в том, что разрешающее правило на firewall создаётся после поступления определённой последовательности пакетов. Чаще всего в качестве такой последовательности выбирают icmp пакеты определённой длины. Но совсем не обязательно ограничиваться только этим. Тут можно придумать любую последовательность и использовать различные порты, протоколы, tcp флаги и т.д.
Вот простейший пример реализации port knocking на Mikrotik.
Создаём правило в firewall, которое будет на 30 минут добавлять в список winbox_remote все ip, откуда придёт пакет размером 144 байта по протоколу icmp.
Теперь разрешим всем ip адресам из этого списка подключаться по winbox:
Важно поставить эти два правила выше блокирующего правила для input. Теперь достаточно выполнить с любого устройства ping:
(размер пакета ставим 116, потому что 28 байт добавит заголовок)
И роутер откроет доступ к tcp порту 8291, чтобы можно было подключиться по winbox. Через 30 минут адрес будет удалён из списка и новое подключение будет сделать невозможно. По такому же принципу, можно сделать и закрывающее правило. Поработали, отправили определённую последовательность и очистили список winbox_remote.
Таким простым и нехитрым способом можно очень надёжно прикрыть какой-то сервис. Например, тот же rdp. Достаточно настроить port knocking на шлюзе, а пользователю дать батник, который будет сначала пинговать, а потом подключаться. Причём можно использовать более сложную последовательность действий из нескольких шагов. Подобный пример описан в статье. Я его реально применяю очень давно.
В Linux реализацию port knocking тоже настроить не сложно. Есть готовый софт для этого. Например, knockd. При желании, можно и вручную написать правила для iptables, если хорошо разбираетесь в них. Реализаций может быть тоже великое множество, в том числе с использованием списков ipset или более современных nftables. Тема легко гуглится и решается.
#mikrotik #security #gateway
Суть метода в том, что разрешающее правило на firewall создаётся после поступления определённой последовательности пакетов. Чаще всего в качестве такой последовательности выбирают icmp пакеты определённой длины. Но совсем не обязательно ограничиваться только этим. Тут можно придумать любую последовательность и использовать различные порты, протоколы, tcp флаги и т.д.
Вот простейший пример реализации port knocking на Mikrotik.
add action=add-src-to-address-list \address-list=winbox_remote \address-list-timeout=30m \chain=input comment="icmp port knocking" \in-interface=ether1-wan packet-size=144 protocol=icmpСоздаём правило в firewall, которое будет на 30 минут добавлять в список winbox_remote все ip, откуда придёт пакет размером 144 байта по протоколу icmp.
Теперь разрешим всем ip адресам из этого списка подключаться по winbox:
add action=accept chain=input \comment="accept winbox_remote" \dst-port=8291 in-interface=ether1-wan \protocol=tcp src-address-list=winbox_remoteВажно поставить эти два правила выше блокирующего правила для input. Теперь достаточно выполнить с любого устройства ping:
ping 1.2.3.4 -l 116 -n 1(размер пакета ставим 116, потому что 28 байт добавит заголовок)
И роутер откроет доступ к tcp порту 8291, чтобы можно было подключиться по winbox. Через 30 минут адрес будет удалён из списка и новое подключение будет сделать невозможно. По такому же принципу, можно сделать и закрывающее правило. Поработали, отправили определённую последовательность и очистили список winbox_remote.
Таким простым и нехитрым способом можно очень надёжно прикрыть какой-то сервис. Например, тот же rdp. Достаточно настроить port knocking на шлюзе, а пользователю дать батник, который будет сначала пинговать, а потом подключаться. Причём можно использовать более сложную последовательность действий из нескольких шагов. Подобный пример описан в статье. Я его реально применяю очень давно.
В Linux реализацию port knocking тоже настроить не сложно. Есть готовый софт для этого. Например, knockd. При желании, можно и вручную написать правила для iptables, если хорошо разбираетесь в них. Реализаций может быть тоже великое множество, в том числе с использованием списков ipset или более современных nftables. Тема легко гуглится и решается.
#mikrotik #security #gateway
{kind=link}
С выбором хостинг провайдера так и или иначе сталкиваются все, кто использует современные информационные системы. Меня постоянно спрашивают, какой хостинг могу порекомендовать. Чаще всего я ничего не рекомендую. Максимум могу сказать, кого сам использую, но это совершенно не показатель качества, так как причины выбрать того или иного хостера могут быть разные.
У меня давно есть список, по которому можно оценить того или иного хостера. Это не значит, что по нему получится на 100% выбрать лучшего, но отсеять неподходящие варианты можно. Или как минимум оценить риски и сопоставить их с ценой. Не всегда нужна максимальная надёжность.
1️⃣ У хостера есть юридическое лицо в РФ и оно явно указано на сайте. На это юр. лицо он должен принимать безналичную оплату или выдавать кассовый чек по 54-ФЗ. Так же стоит обратить внимание на возраст этого юр. лица и его историю, оквэды.
2️⃣ Наличие собственного, а не арендованного дата-центра. В идеале, чтобы он принадлежал тому же юр. лицу, что указано на сайте и принимает оплату. На этом, к примеру, погорели Ihor и Masterhost, когда лежали несколько дней. Они размещались в ДЦ, который им не принадлежал. Конфликт владельцев ДЦ и хостера привёл к огромным простоям.
3️⃣ Работа тех. поддержки. Можно просто зарегистрироваться и позадавать нестандартные вопросы. По ответам часто можно понять уровень поддержки. Она бывает сильно разной. Не говоря уже просто о времени реакции.
4️⃣ Прокачка бренда. Я склонен полагать, что тот, кто давно и регулярно вкладывается в развитие бренда, будет стремиться оказывать услуги хорошо. По моим наблюдениям в высококонкурентном рынке хостеров это имеет значение.
5️⃣ Наличие дополнительных сертификатов, типа Tier или нашего ФСТЭК явно идёт в плюс. Их получение непростая задача, так что если хостер заморочился, это косвенно может подтверждать его серьезное намерение долго работать на рынке.
6️⃣ Наличие физического офиса. В идеале в вашем регионе. Или хотя бы в стране. Это небольшой, но косвенный плюс к хостеру.
Понятно, что проверять этот список стоит, когда вы планируете тратить много денег. Например, арендовать или размещать свои сервера. Если вам нужно арендовать VPS за 500 р. в месяц, сильно заморачиваться не имеет смысла.
А вот когда у вас в аренде сервера на 50-100 т.р. или больше в месяц и хостер внезапно ложится и перестаёт отвечать на запросы, как было с Ihor, начинаешь переживать и суетиться. И думать, как в следующий раз подстраховать себя.
Например, в Ihor были люди, которые размещали свои сервера, а потом не могли получить к ним доступ. А какие-то вообще были украдены. В итоге оказалось, что у хостера было одно юр. лицо, оплата шла на другое, а ДЦ принадлежал третьему. То юр. лицо, что получало оплату в итоге и скрылось со всеми деньгами, оставив задолженность перед ДЦ. А когда владельцы серверов приезжали в ДЦ их забирать, им говорили, что обращайтесь к тем, кому вы платили, мы от них денег не видели, они нам должны остались.
#хостинг
У меня давно есть список, по которому можно оценить того или иного хостера. Это не значит, что по нему получится на 100% выбрать лучшего, но отсеять неподходящие варианты можно. Или как минимум оценить риски и сопоставить их с ценой. Не всегда нужна максимальная надёжность.
1️⃣ У хостера есть юридическое лицо в РФ и оно явно указано на сайте. На это юр. лицо он должен принимать безналичную оплату или выдавать кассовый чек по 54-ФЗ. Так же стоит обратить внимание на возраст этого юр. лица и его историю, оквэды.
2️⃣ Наличие собственного, а не арендованного дата-центра. В идеале, чтобы он принадлежал тому же юр. лицу, что указано на сайте и принимает оплату. На этом, к примеру, погорели Ihor и Masterhost, когда лежали несколько дней. Они размещались в ДЦ, который им не принадлежал. Конфликт владельцев ДЦ и хостера привёл к огромным простоям.
3️⃣ Работа тех. поддержки. Можно просто зарегистрироваться и позадавать нестандартные вопросы. По ответам часто можно понять уровень поддержки. Она бывает сильно разной. Не говоря уже просто о времени реакции.
4️⃣ Прокачка бренда. Я склонен полагать, что тот, кто давно и регулярно вкладывается в развитие бренда, будет стремиться оказывать услуги хорошо. По моим наблюдениям в высококонкурентном рынке хостеров это имеет значение.
5️⃣ Наличие дополнительных сертификатов, типа Tier или нашего ФСТЭК явно идёт в плюс. Их получение непростая задача, так что если хостер заморочился, это косвенно может подтверждать его серьезное намерение долго работать на рынке.
6️⃣ Наличие физического офиса. В идеале в вашем регионе. Или хотя бы в стране. Это небольшой, но косвенный плюс к хостеру.
Понятно, что проверять этот список стоит, когда вы планируете тратить много денег. Например, арендовать или размещать свои сервера. Если вам нужно арендовать VPS за 500 р. в месяц, сильно заморачиваться не имеет смысла.
А вот когда у вас в аренде сервера на 50-100 т.р. или больше в месяц и хостер внезапно ложится и перестаёт отвечать на запросы, как было с Ihor, начинаешь переживать и суетиться. И думать, как в следующий раз подстраховать себя.
Например, в Ihor были люди, которые размещали свои сервера, а потом не могли получить к ним доступ. А какие-то вообще были украдены. В итоге оказалось, что у хостера было одно юр. лицо, оплата шла на другое, а ДЦ принадлежал третьему. То юр. лицо, что получало оплату в итоге и скрылось со всеми деньгами, оставив задолженность перед ДЦ. А когда владельцы серверов приезжали в ДЦ их забирать, им говорили, что обращайтесь к тем, кому вы платили, мы от них денег не видели, они нам должны остались.
#хостинг
После публикации на тему port knocking один читатель поделился шикарной утилитой, с помощью которой можно похожим образом открывать доступ на основе HTTP запроса, что во многих случаях удобнее отправки пакетов. Программа называется labean. Автор русскоязычный, поэтому подобное название не случайно (кто не понял, читайте наоборот).
Идея подобного функционала у меня давно сидела в голове, но до реализации дело не дошло. А готовых инструментов я раньше не встречал и даже не слышал о них. Labean работает очень просто и эффективно. С его помощью можно выполнить любое действие при определённом http запросе. Например, обращаемся на url http://10.20.1.56/labean/tuktuk/ssh/on, а labean выполняет проброс порта на нужный сервер. То есть выполняет конкретное действие:
Я проверил работу labean, очень понравился результат. Настраивается быстро и легко. Рассказываю по шагам.
Сначала собираем утилиту из исходников. Написана на GO.
Копируем бинарник, конфиг и systemd unit.
Рисуем примерно такой конфиг:
Не буду все настройки описывать, можно в репозитории посмотреть. Я для теста сделал 2 сервиса и 2 разных действия для них. Первое действие добавляет правило в iptables, второе - запускает службу. Проверил оба примера, всё работает. Привожу для наглядности, чтобы вы понимали функционал. Labean может делать всё, что угодно, а не только правила firewall изменять.
Теперь для любого хоста, к которому мы будем обращаться, добавляем в конфиг nginx ещё один location. Я добавил прямо в default, чтобы по ip обращаться.
При желании можно добавить basic auth и закрыть паролем.
Перечитываем службы systemd и запускаем:
Идём по урлу http://10.20.1.56/labean/tuktuk/ssh/on и смотрим результат:
Зайдём в консоль сервера и посмотрим правила iptables:
Через 30 секунд правило исчезнет. За это отвечает параметр timeout. Если поставить 0, то само удаляться не будет, и нужно будет вручную зайти на закрывающий урл - http://10.20.1.56/labean/tuktuk/ssh/off.
Как вы уже поняли, обращение к url http://10.20.1.56/labean/tuktuk/postfix/on и http://10.20.1.56/labean/tuktuk/postfix/off будет запускать и останавливать службу postfix. Дергать эти адреса можно как в браузере, так и через curl.
В документации заявлена ещё одна возможность через дополнительный аргумент ?ip=123.56.78.9 указывать для обработки различные ip адреса, но у меня почему-то сходу не заработало. Пока не разбирался.
Вот такая простая и удобная программа. Рекомендую обратить внимание. Я точно буду пользоваться, так как это очень удобно. Заметка получилось полной инструкцией.
#security #gateway
Идея подобного функционала у меня давно сидела в голове, но до реализации дело не дошло. А готовых инструментов я раньше не встречал и даже не слышал о них. Labean работает очень просто и эффективно. С его помощью можно выполнить любое действие при определённом http запросе. Например, обращаемся на url http://10.20.1.56/labean/tuktuk/ssh/on, а labean выполняет проброс порта на нужный сервер. То есть выполняет конкретное действие:
iptables -t nat -A PREROUTING -p tcp --dport 31004 -i ens18 \-s 10.20.1.1 -j DNAT --to 10.30.51.4:22Я проверил работу labean, очень понравился результат. Настраивается быстро и легко. Рассказываю по шагам.
Сначала собираем утилиту из исходников. Написана на GO.
# apt install golang git nginx# git clone https://github.com/uprt/labean.git# cd labean# go buildКопируем бинарник, конфиг и systemd unit.
# cp labean /usr/sbin# cp examples/labean.conf.ex /etc/labean.conf# cp examples/labean.service.ex /etc/systemd/system/labean.serviceРисуем примерно такой конфиг:
{ "listen": "127.0.0.1:8080", "url_prefix": "tuktuk", "external_ip": "10.20.1.56", "real_ip_header": "X-Real-IP", "allow_explicit_ips": true, "tasks": [ { "name": "ssh", "timeout": 30, "on_command": "iptables -t nat -A PREROUTING -p tcp --dport 31004 -i ens18 -s {clientIP} -j DNAT --to 10.30.51.4:22", "off_command": "iptables -t nat -D PREROUTING -p tcp --dport 31004 -i ens18 -s {clientIP} -j DNAT --to 10.30.51.4:22" }, { "name": "postfix", "timeout": 0, "on_command": "systemctl start postfix", "off_command": "systemctl stop postfix" } ]}Не буду все настройки описывать, можно в репозитории посмотреть. Я для теста сделал 2 сервиса и 2 разных действия для них. Первое действие добавляет правило в iptables, второе - запускает службу. Проверил оба примера, всё работает. Привожу для наглядности, чтобы вы понимали функционал. Labean может делать всё, что угодно, а не только правила firewall изменять.
Теперь для любого хоста, к которому мы будем обращаться, добавляем в конфиг nginx ещё один location. Я добавил прямо в default, чтобы по ip обращаться.
location ~ ^/labean/(.*) { proxy_set_header X-Real-IP $remote_addr; proxy_pass http://127.0.0.1:8080/$1;}При желании можно добавить basic auth и закрыть паролем.
Перечитываем службы systemd и запускаем:
# systemctl daemon-reload# systemctl start nginx labeanИдём по урлу http://10.20.1.56/labean/tuktuk/ssh/on и смотрим результат:
{ "commandLine": "iptables -t nat -A PREROUTING -p tcp --dport 31004 -i ens18 -s 10.20.1.1 -j DNAT --to 10.30.51.4:22", "returnCode": 0, "timeoutInSeconds": 30, "clientIp": "10.20.1.1"}Зайдём в консоль сервера и посмотрим правила iptables:
# iptables -L -v -n -t nat | grep 31004 0 0 DNAT tcp -- ens18 * 10.20.1.1 0.0.0.0/0 tcp dpt:31004 to:10.30.51.4:22Через 30 секунд правило исчезнет. За это отвечает параметр timeout. Если поставить 0, то само удаляться не будет, и нужно будет вручную зайти на закрывающий урл - http://10.20.1.56/labean/tuktuk/ssh/off.
Как вы уже поняли, обращение к url http://10.20.1.56/labean/tuktuk/postfix/on и http://10.20.1.56/labean/tuktuk/postfix/off будет запускать и останавливать службу postfix. Дергать эти адреса можно как в браузере, так и через curl.
В документации заявлена ещё одна возможность через дополнительный аргумент ?ip=123.56.78.9 указывать для обработки различные ip адреса, но у меня почему-то сходу не заработало. Пока не разбирался.
Вот такая простая и удобная программа. Рекомендую обратить внимание. Я точно буду пользоваться, так как это очень удобно. Заметка получилось полной инструкцией.
#security #gateway
На днях разбирался с небольшой проблемой на voip сервере asterisk. Есть сервер, который настраивали очень давно. Его никто не трогает, он просто работает. Недавно купили новую серию телефонов. На них почему-то не проходили входящие звонки.
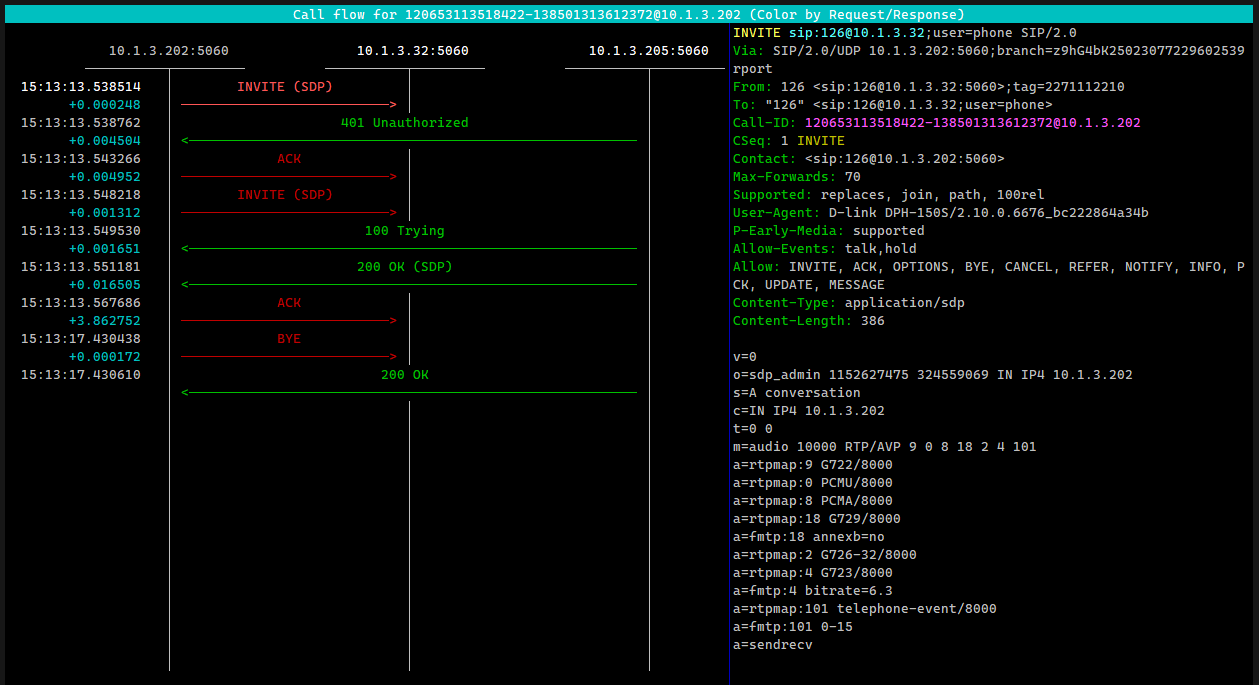
Ранее я уже рассказывал про утилиту sngrep, которая позволяет в удобном виде посмотреть всю информацию по sip трафику. Там в удобном виде собрано всё то, что вы можете увидеть, включив debug на asterisk, только в sngrep всё будет очень наглядно.
Я уже не особо разбираюсь в voip, так как давно ничего не настраивал. Решил не заниматься этим направлением. Но по старой памяти немного приглядываю за старыми серверами. Это сервер был с наследством в виде нескольких IP адресов. На новых аппаратах запрос шёл к одному из ip, который был указан в настройках, а ответ приходил от другого адреса. И телефон его не принимал.
Я не знаю, почему так происходило, и почему проблема появилась только сейчас и только на конкретных аппаратах. Но именно sngrep позволил буквально за 5 минут понять, в чем именно проблема. Просто поменяли ip адрес в телефоне на тот, с которого приходил ответ и всё заработало.
Написал это для тех, у кого есть в управлении сервера asterisk, чтобы лишний раз напомнить про sngrep. Она меня всегда выручала и выручает, когда надо быстро разобраться с какой-то проблемой с телефонией.
Сейчас, наверное, свой сервер asterisk, как и почтовый, это скорее экзотика. Все постепенно переползают на готовые сервисы. В чём-то это оправданно, так как с тем же voip разбираться довольно трудно, если нет специализации по этой теме.
ps. На картинке не дебаг проблемного звонка. На нём просто наглядно видно, что общение идёт с двумя ip адресами сервера. Во время звонка телефон не отвечал на invite от сервера.
#asterisk #voip
Ранее я уже рассказывал про утилиту sngrep, которая позволяет в удобном виде посмотреть всю информацию по sip трафику. Там в удобном виде собрано всё то, что вы можете увидеть, включив debug на asterisk, только в sngrep всё будет очень наглядно.
Я уже не особо разбираюсь в voip, так как давно ничего не настраивал. Решил не заниматься этим направлением. Но по старой памяти немного приглядываю за старыми серверами. Это сервер был с наследством в виде нескольких IP адресов. На новых аппаратах запрос шёл к одному из ip, который был указан в настройках, а ответ приходил от другого адреса. И телефон его не принимал.
Я не знаю, почему так происходило, и почему проблема появилась только сейчас и только на конкретных аппаратах. Но именно sngrep позволил буквально за 5 минут понять, в чем именно проблема. Просто поменяли ip адрес в телефоне на тот, с которого приходил ответ и всё заработало.
Написал это для тех, у кого есть в управлении сервера asterisk, чтобы лишний раз напомнить про sngrep. Она меня всегда выручала и выручает, когда надо быстро разобраться с какой-то проблемой с телефонией.
Сейчас, наверное, свой сервер asterisk, как и почтовый, это скорее экзотика. Все постепенно переползают на готовые сервисы. В чём-то это оправданно, так как с тем же voip разбираться довольно трудно, если нет специализации по этой теме.
ps. На картинке не дебаг проблемного звонка. На нём просто наглядно видно, что общение идёт с двумя ip адресами сервера. Во время звонка телефон не отвечал на invite от сервера.
#asterisk #voip
{kind=link}
Для IP адресов России часто стали встречаться блокировки доступа к репозиториям популярных продуктов. Первое, что вспоминается - Hashicorp, Elastic, Grafana и т. д. Для решения этих проблем становятся актуальны локальные репозитории. Я уже рассказывал про отдельные программы для deb и rpm репозиториев. Сегодня хочу рассказать про универсальный open source проект для организации локальных репозиториев различных типов - Nexus repository.
📌 Основные возможности Nexus repository:
◽ управление через браузер или api
◽ ролевая модель доступа к репозиториям
◽ интеграция с ldap
◽ может работать как локальный репозиторий или в режиме прокси
С помощью Nexus можно быстро поднять локальные репозитории огромного списка типов - rpm, deb, docker, helm и много других. Он поддерживает практически все современные репозитории. Запуск можно выполнить через готовый Docker образ:
После этого смотрим пароль пользователя admin в файле /var/lib/docker/volumes/nexus-data/_data/admin.password. Теперь можно идти в веб интерфейс и создавать репозитории. Сделать это очень просто. Например, создаёте репозиторий apt, генерируете gpg ключ, через браузер заливаете в репозиторий готовый пакет. Потом идёте в систему, импортируете ключ и подключаете репозиторий. Путь к нему можно посмотреть через веб интерфейс. Примерно так выглядит процедура для любого репозитория.
На все действия есть подсказки в веб интерфейсе или в документации. Так что продукт максимально дружелюбен к пользователю. А для автоматизации можно использовать API.
⇨ Сайт / Исходники / Документация / Docker / Обзор
#devops
📌 Основные возможности Nexus repository:
◽ управление через браузер или api
◽ ролевая модель доступа к репозиториям
◽ интеграция с ldap
◽ может работать как локальный репозиторий или в режиме прокси
С помощью Nexus можно быстро поднять локальные репозитории огромного списка типов - rpm, deb, docker, helm и много других. Он поддерживает практически все современные репозитории. Запуск можно выполнить через готовый Docker образ:
# docker volume create --name nexus-data# docker run -d -p 8081:8081 --name nexus \-v nexus-data:/nexus-data sonatype/nexus3После этого смотрим пароль пользователя admin в файле /var/lib/docker/volumes/nexus-data/_data/admin.password. Теперь можно идти в веб интерфейс и создавать репозитории. Сделать это очень просто. Например, создаёте репозиторий apt, генерируете gpg ключ, через браузер заливаете в репозиторий готовый пакет. Потом идёте в систему, импортируете ключ и подключаете репозиторий. Путь к нему можно посмотреть через веб интерфейс. Примерно так выглядит процедура для любого репозитория.
На все действия есть подсказки в веб интерфейсе или в документации. Так что продукт максимально дружелюбен к пользователю. А для автоматизации можно использовать API.
⇨ Сайт / Исходники / Документация / Docker / Обзор
#devops
{kind=link}
Существует очень простая утилита для сбора статистики по сетевой активности в Linux - vnStat. Она есть в стандартном репозитории Debian. Эта небольшая программа работает как служба, собирает информацию из ядра о сетевом трафике и хранит в своей локально базе данных.
С помощью vnStat можно посмотреть статистику загрузки сетевого интерфейса, разбитую по интервалам - 5 минут, час, день, неделя, месяц. Устанавливаете программу:
Ждёте 5 минут и смотрите статистику:
По мере накопления информации, можно смотреть более широкие интервалы. Так как программа не снифает трафик, а берёт его через /proc, к тому же потом агрегирует информацию, особой нагрузки на систему не оказывает, много места не занимает. Можно установить как службу, а потом, когда надо, посмотреть на средний трафик за какой-то интервал.
При желании, можно наблюдать за трафиком в режиме реального времени:
Или смотреть с псевдографическими графиками:
Если под вашу систему нет пакета, можно запустить vnStat в Docker. Он собран сразу с простеньким графическим интерфейсом для просмотра статистики:
По адресу 0.0.0.0:8685 можно смотреть статистику.
Простая, удобная, лёгкая программа для решения одной небольшой задачи. В лучшем стиле старых юниксовских программ, каковой она и является. Написана на православном С (папа может в Си).
⇨ Сайт / Исходники / Docker
#network
С помощью vnStat можно посмотреть статистику загрузки сетевого интерфейса, разбитую по интервалам - 5 минут, час, день, неделя, месяц. Устанавливаете программу:
# apt install vnstatЖдёте 5 минут и смотрите статистику:
# vnstat -5По мере накопления информации, можно смотреть более широкие интервалы. Так как программа не снифает трафик, а берёт его через /proc, к тому же потом агрегирует информацию, особой нагрузки на систему не оказывает, много места не занимает. Можно установить как службу, а потом, когда надо, посмотреть на средний трафик за какой-то интервал.
При желании, можно наблюдать за трафиком в режиме реального времени:
# vnstat -l -i ens18Или смотреть с псевдографическими графиками:
# vnstat -hgЕсли под вашу систему нет пакета, можно запустить vnStat в Docker. Он собран сразу с простеньким графическим интерфейсом для просмотра статистики:
docker run -d --restart=unless-stopped \ --network=host -e HTTP_PORT=8685 \ -v /etc/localtime:/etc/localtime:ro \ -v /etc/timezone:/etc/timezone:ro \ --name vnstat vergoh/vnstatПо адресу 0.0.0.0:8685 можно смотреть статистику.
Простая, удобная, лёгкая программа для решения одной небольшой задачи. В лучшем стиле старых юниксовских программ, каковой она и является. Написана на православном С (папа может в Си).
⇨ Сайт / Исходники / Docker
#network
{kind=link}
На днях в блоге Zabbix вышла полезная статья по бэкапу сервера мониторинга. Мне она показалась подробной и полезной, так что решил её законспектировать для вас. Я сам всё это знаю, но некоторые вещи, типа экспорта и импорта хостов долго не знал и не использовал, хотя это удобно.
1️⃣ Вся основная информация Zabbix Server живёт в базе данных. Так что если не хочется заморачиваться с бэкапом, просто сохраняй БД. Всё остальное так или иначе можно будет восстановить, но без БД придётся очень многое настраивать с нуля.
Если не нужны бэкапы исторических данных, а это основной объём БД, то можно пропустить таблицы с History, Trends и Events. Вот их список: history, history_uint, history_text, history_str, history_log, trends, trends_uint, events. Без них сервер мониторинга будет полностью восстановлен, но без накопленных данных. Часто это вполне приемлемый вариант, который уменьшает объем бэкапов на 90-95%.
2️⃣ К бэкапу БД стоит добавить файлы самого Zabbix Server и веб сервера Nginx или Apache. Это директории: /etc/nginx/, /etc/httpd/, /etc/apache2, /etc/zabbix/, /usr/lib/zabbix.
3️⃣ Если вам нет нужды бэкапить или переносить всю базу данных, Zabbix предоставляет возможность экспорта и импорта отдельных компонентов через веб интерфейс. Вы можете выгрузить в конфигурационные файлы следующие типы данных: Hosts, Templates, Media types, Maps, images, Host groups и Template groups только через API.
Я долгое время не обращал внимания на то, что можно экспортировать и импортировать хосты. Про шаблоны, понятное дело знал, без импрота их не добавить в систему. А вот про хосты не знал, хотя это иногда очень удобно. Например, хочется поднять мониторинг с нуля, с новыми шаблонами, настройками и т.д., так как иногда это проще, чем обновлять очень старый сервер. И тут очень поможет экспорт хостов. Сохраняем их на старом сервере и переносим на новый.
Рекомендую обратить внимание на такую возможность. Это бывает удобно как для переноса сервера, так и для каких-то тестов на втором сервере. Туда можно выгрузить часть хостов, добавить второй сервер в настройки агентов и протестировать какие-то новые шаблоны.
4️⃣ Бэкап перечисленных выше объектов в автоматическом режиме через API и метод configuration.export. Пример использования показан в документации.
Я в общем случае делаю бэкапы виртуальной машины и обязательно отдельно бэкап самой БД тем или иным способом. Если база небольшая, то обычным дампом, не забывая отключать блокировку таблиц при этом, иначе мониторинг во время снятия дампа тупит и спамит триггерами. Если большая, то другими инструментами в зависимости от типа БД.
#zabbix #backup
1️⃣ Вся основная информация Zabbix Server живёт в базе данных. Так что если не хочется заморачиваться с бэкапом, просто сохраняй БД. Всё остальное так или иначе можно будет восстановить, но без БД придётся очень многое настраивать с нуля.
Если не нужны бэкапы исторических данных, а это основной объём БД, то можно пропустить таблицы с History, Trends и Events. Вот их список: history, history_uint, history_text, history_str, history_log, trends, trends_uint, events. Без них сервер мониторинга будет полностью восстановлен, но без накопленных данных. Часто это вполне приемлемый вариант, который уменьшает объем бэкапов на 90-95%.
2️⃣ К бэкапу БД стоит добавить файлы самого Zabbix Server и веб сервера Nginx или Apache. Это директории: /etc/nginx/, /etc/httpd/, /etc/apache2, /etc/zabbix/, /usr/lib/zabbix.
3️⃣ Если вам нет нужды бэкапить или переносить всю базу данных, Zabbix предоставляет возможность экспорта и импорта отдельных компонентов через веб интерфейс. Вы можете выгрузить в конфигурационные файлы следующие типы данных: Hosts, Templates, Media types, Maps, images, Host groups и Template groups только через API.
Я долгое время не обращал внимания на то, что можно экспортировать и импортировать хосты. Про шаблоны, понятное дело знал, без импрота их не добавить в систему. А вот про хосты не знал, хотя это иногда очень удобно. Например, хочется поднять мониторинг с нуля, с новыми шаблонами, настройками и т.д., так как иногда это проще, чем обновлять очень старый сервер. И тут очень поможет экспорт хостов. Сохраняем их на старом сервере и переносим на новый.
Рекомендую обратить внимание на такую возможность. Это бывает удобно как для переноса сервера, так и для каких-то тестов на втором сервере. Туда можно выгрузить часть хостов, добавить второй сервер в настройки агентов и протестировать какие-то новые шаблоны.
4️⃣ Бэкап перечисленных выше объектов в автоматическом режиме через API и метод configuration.export. Пример использования показан в документации.
Я в общем случае делаю бэкапы виртуальной машины и обязательно отдельно бэкап самой БД тем или иным способом. Если база небольшая, то обычным дампом, не забывая отключать блокировку таблиц при этом, иначе мониторинг во время снятия дампа тупит и спамит триггерами. Если большая, то другими инструментами в зависимости от типа БД.
#zabbix #backup
Если вам нужен простой файловый сервер с доступом к файлам через браузер, то могу посоветовать хорошее решение для этого. Программа так и называется - File Browser. Это open source проект, доступный для установки на Linux, MacOS, Windows. Серверная часть представляет из себя один бинарник и базу данных в одном файле, где хранятся все настройки и пользователи.
Управление File Browser немного непривычное, так что покажу сразу на примере, как его запустить и попробовать. В документации всё это описано. Я там и посмотрел.
Установить File Browser можно через готовый скрипт. Он очень простой, и ничего особенного не делает, только скачивает бинарник и копирует его в системную директорию. Можете это сделать и вручную.
Теперь можно сразу запустить файловый сервер примерно так:
Он запустится на localhost, что не удобно, поэтому поступим по-другому. Создадим сразу готовый конфиг, где укажем некоторые параметры:
Я указал, что надо запуститься на внешнем IP и в качестве директории для обзора указал /var/log. Теперь добавим одного пользователя с полными правами:
serveradmin - имя пользователя, pass - пароль. В директории, где вы запускали команды, будет создан файл filebrowser.db, в котором хранятся все настройки. Можно запускать filebrowser с указанием пути к этому файлу. Все консольные команды по конфигурации и управлению пользователями описаны в документации.
Теперь можно идти http://85.143.175.246:8080, авторизовываться и просматривать файлы. Текстовые можно создавать и редактировать прямо в браузере. Также есть встроенный просмотр картинок.
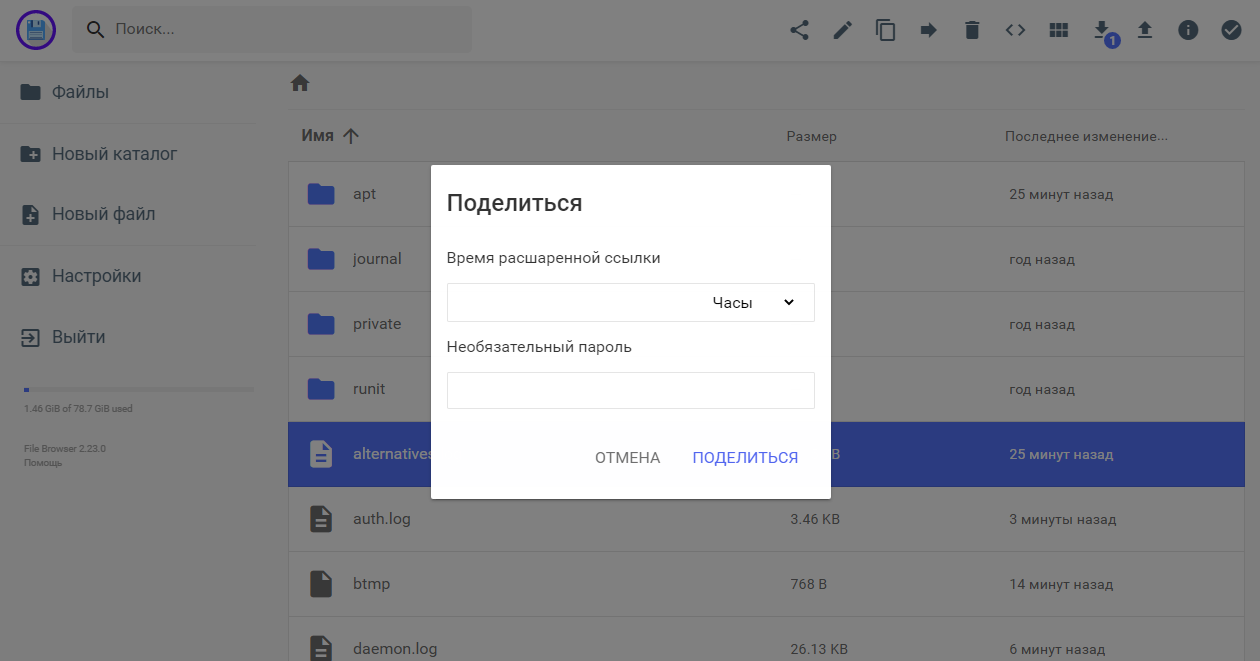
🔥 Для файлов можно открывать внешний доступ с ограничением по времени или доступом по паролю.
Filebrowser имеет простой и удобный веб интерфейс. Есть русский язык. В общем и целом оставляет приятное впечатление. Для работы с файлами через браузер отличный вариант, который легко и быстро запускается и настраивается. Рекомендую обратить внимание, если нужен подобный функционал.
⇨ Сайт / Исходники
#fileserver
Управление File Browser немного непривычное, так что покажу сразу на примере, как его запустить и попробовать. В документации всё это описано. Я там и посмотрел.
Установить File Browser можно через готовый скрипт. Он очень простой, и ничего особенного не делает, только скачивает бинарник и копирует его в системную директорию. Можете это сделать и вручную.
# curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh \| bashТеперь можно сразу запустить файловый сервер примерно так:
# filebrowser -r /path/to/your/filesОн запустится на localhost, что не удобно, поэтому поступим по-другому. Создадим сразу готовый конфиг, где укажем некоторые параметры:
# filebrowser config init --address 85.143.175.246 -r /var/logЯ указал, что надо запуститься на внешнем IP и в качестве директории для обзора указал /var/log. Теперь добавим одного пользователя с полными правами:
# filebrowser users add serveradmin pass --perm.adminserveradmin - имя пользователя, pass - пароль. В директории, где вы запускали команды, будет создан файл filebrowser.db, в котором хранятся все настройки. Можно запускать filebrowser с указанием пути к этому файлу. Все консольные команды по конфигурации и управлению пользователями описаны в документации.
Теперь можно идти http://85.143.175.246:8080, авторизовываться и просматривать файлы. Текстовые можно создавать и редактировать прямо в браузере. Также есть встроенный просмотр картинок.
🔥 Для файлов можно открывать внешний доступ с ограничением по времени или доступом по паролю.
Filebrowser имеет простой и удобный веб интерфейс. Есть русский язык. В общем и целом оставляет приятное впечатление. Для работы с файлами через браузер отличный вариант, который легко и быстро запускается и настраивается. Рекомендую обратить внимание, если нужен подобный функционал.
⇨ Сайт / Исходники
#fileserver
{kind=link}
Мне вчера несколько человек написали, что вышло обновление Proxmox VE 7.3. Я смотрю, это очень популярное решение, потому что по обновлениям VMware или Hyper-V мне никто ни разу не писал 🙂 Сама новость ничем особо не примечательна, так как Proxmox обновляется регулярно, что не может не радовать.
Хочу сразу предупредить, чтобы не торопились обновляться. Уже не раз бывало, что обновление приносит проблемы. Сталкивался сам и писал об этом на канале не единожды.
Второй момент, который привлек внимание - информация о приложении Proxmox Mobile. Я и не знал, что оно существует. Обычно если надо было через смартфон зайти, я просто открывал в браузере версию для PC. Вполне сносно работает, даже консоль сервера можно посмотреть, что-то изменить или перезапустить VM. Кто-то уже пробовал мобильное приложение? Есть там что-то полезное, ради чего его можно поставить?
⇨ Сама новость: ru и en.
#proxmox
Хочу сразу предупредить, чтобы не торопились обновляться. Уже не раз бывало, что обновление приносит проблемы. Сталкивался сам и писал об этом на канале не единожды.
Второй момент, который привлек внимание - информация о приложении Proxmox Mobile. Я и не знал, что оно существует. Обычно если надо было через смартфон зайти, я просто открывал в браузере версию для PC. Вполне сносно работает, даже консоль сервера можно посмотреть, что-то изменить или перезапустить VM. Кто-то уже пробовал мобильное приложение? Есть там что-то полезное, ради чего его можно поставить?
⇨ Сама новость: ru и en.
#proxmox
{kind=link}
Хочу вас познакомить с отличной современной программой по передаче текстовых данных из одних источников в другие. Речь пойдёт про Vector и проект vector.dev. Это пример простой и качественной программы, которая решает одну задачу - взять данные в одном месте, преобразовать их или оставить в неизменном виде и передать в другое место.
Мне она понравилась в первую очередь своим сайтом с подробной информацией обо всех возможностях и настройках. Буквально за несколько минут разобрался с настройками и запустил в работу.
С помощью Vector можно взять данные из источников: File, Docker logs, JournalD, Kafka, Kubernetes logs, Logstash и ещё 40 различных программ и положить их в один из 50-ти типов поддерживаемых приёмников, среди которых: Console, Elasticsearch, File, HTTP, Loki, Prometheus и т.д.
По пути Vector может делать преобразования. Для каждого источника, преобразования и приёмника есть пример конфигурации, как это можно реализовать. В итоге по частям настраивается полный маршрут.
Вот для примера конфиг для сбора логов JournalD и записи их в файл. Я прямо взял из документации конфиг для JournalD, конфиг для File и совместил их.
Ставим Vector (есть и пакеты, и docker образ):
Рисуем конфиг:
Всё просто и понятно - источник, приёмник, преобразование. Можно текст автоматом в json сконвертировать. Я оставил обычный формат.
Создаём дефолтную директорию для Vector и запускаем его:
В файле /tmp/ntp-%Y-%m-%d.log будет текстовый лог службы ntp, взятый из journald. По такому же принципу работают и другие направления.
Программа очень простая и удобная. По сути она заменяет более именитых и старых товарищей - fluentd, filebeat и т.д. Частично и logstash. Я принял решение использовать её для сбора логов и отправки в ELK.
⇨ Сайт / Исходники / Документация
#logs #devops
Мне она понравилась в первую очередь своим сайтом с подробной информацией обо всех возможностях и настройках. Буквально за несколько минут разобрался с настройками и запустил в работу.
С помощью Vector можно взять данные из источников: File, Docker logs, JournalD, Kafka, Kubernetes logs, Logstash и ещё 40 различных программ и положить их в один из 50-ти типов поддерживаемых приёмников, среди которых: Console, Elasticsearch, File, HTTP, Loki, Prometheus и т.д.
По пути Vector может делать преобразования. Для каждого источника, преобразования и приёмника есть пример конфигурации, как это можно реализовать. В итоге по частям настраивается полный маршрут.
Вот для примера конфиг для сбора логов JournalD и записи их в файл. Я прямо взял из документации конфиг для JournalD, конфиг для File и совместил их.
Ставим Vector (есть и пакеты, и docker образ):
# curl --proto '=https' --tlsv1.2 -sSf https://sh.vector.dev \| bashРисуем конфиг:
[sources.journal_ntp]type = "journald"current_boot_only = trueinclude_units = [ "ntp" ][sinks.log_ntp]type = "file"inputs = [ "journal_ntp" ]path = "/tmp/ntp-%Y-%m-%d.log"[sinks.log_ntp.encoding]codec = "text"Всё просто и понятно - источник, приёмник, преобразование. Можно текст автоматом в json сконвертировать. Я оставил обычный формат.
Создаём дефолтную директорию для Vector и запускаем его:
# mkdir /var/lib/vector/# vector --config /root/.vector/config/vector.tomlВ файле /tmp/ntp-%Y-%m-%d.log будет текстовый лог службы ntp, взятый из journald. По такому же принципу работают и другие направления.
Программа очень простая и удобная. По сути она заменяет более именитых и старых товарищей - fluentd, filebeat и т.д. Частично и logstash. Я принял решение использовать её для сбора логов и отправки в ELK.
⇨ Сайт / Исходники / Документация
#logs #devops
{kind=link}
Администраторам Linux постоянно приходится сталкиваться с регулярными выражениями. Разобраться в них - та ещё задача. Лично я не умею писать регулярки. Что-то простое, конечно, могу придумать, или расшифровать чужую, но не всегда. Как по мне, регулярки - настоящий вынос мозга. Я их просто записываю и собираю свою коллекцию.
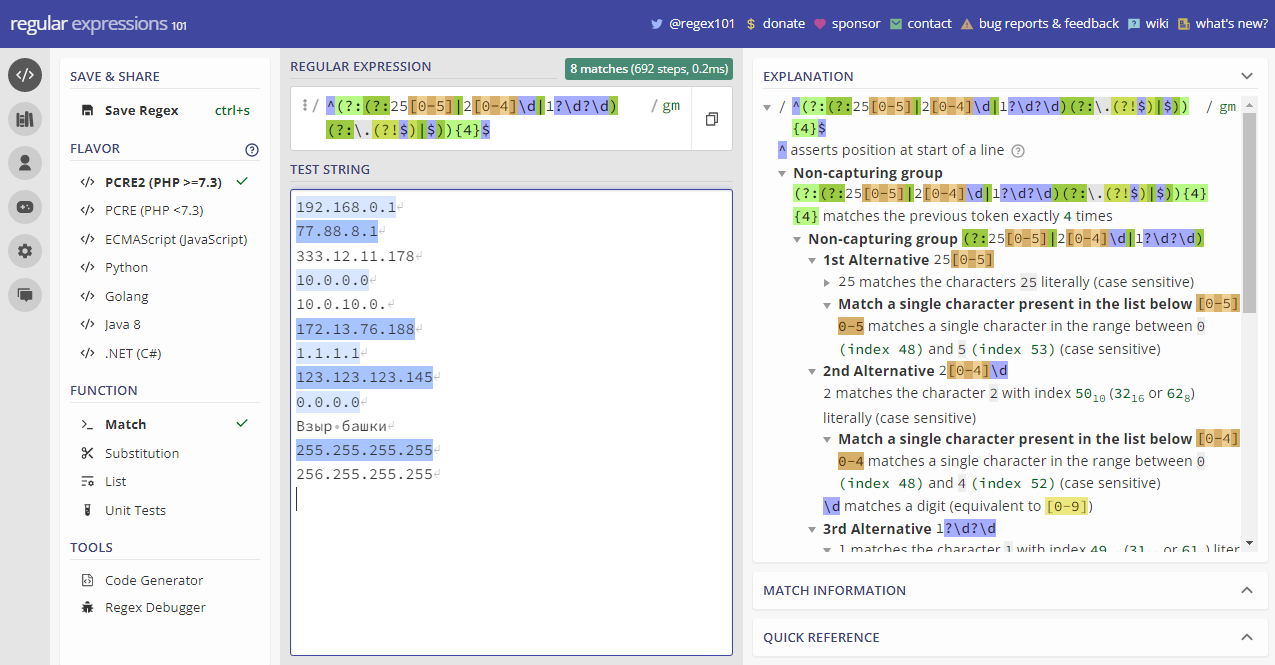
Упростить понимание и написание регулярок может старый известный сервис regex101.com. Рекомендую забрать его в закладки. Странно, что я ещё ни разу о нём не написал. Рассмотрим простой пример 😁
Есть хоть один вменяемый человек, который сможет понять, что это такое? Это же натуральная обфускация, чтобы никто не понял, о чём тут речь. Но на самом деле это регулярка для проверки IP адреса. Результат работы сервиса по этой регулярке можете посмотреть на картинке.
Помимо непосредственно проверки, в этом сервисе есть большая коллекция готовых выражений, по которой работает поиск. Там можно найти много полезных штук, которые не придётся придумывать самому или искать где-то ещё.
Один народный умелец так проникся этим сервисом, что упаковал его в офлайн приложение для PC под все системы:
⇨ https://github.com/nedrysoft/regex101
Кстати, у меня даже ни одного знакомого нет, кто мог бы написать какую-то более ли менее сложную регулярку. Либо я об этом не знаю. Это какое-то тайное знание, которое передаётся как магия из рук в руки между хранителями исходников.
❓Вы можете сами написать регулярку, наподобие той, что проверяет ip адреса?
#regex #сервис
Упростить понимание и написание регулярок может старый известный сервис regex101.com. Рекомендую забрать его в закладки. Странно, что я ещё ни разу о нём не написал. Рассмотрим простой пример 😁
^(?:(?:25[0-5]|2[0-4]\d|1?\d?\d)(?:\.(?!$)|$)){4}$Есть хоть один вменяемый человек, который сможет понять, что это такое? Это же натуральная обфускация, чтобы никто не понял, о чём тут речь. Но на самом деле это регулярка для проверки IP адреса. Результат работы сервиса по этой регулярке можете посмотреть на картинке.
Помимо непосредственно проверки, в этом сервисе есть большая коллекция готовых выражений, по которой работает поиск. Там можно найти много полезных штук, которые не придётся придумывать самому или искать где-то ещё.
Один народный умелец так проникся этим сервисом, что упаковал его в офлайн приложение для PC под все системы:
⇨ https://github.com/nedrysoft/regex101
Кстати, у меня даже ни одного знакомого нет, кто мог бы написать какую-то более ли менее сложную регулярку. Либо я об этом не знаю. Это какое-то тайное знание, которое передаётся как магия из рук в руки между хранителями исходников.
❓Вы можете сами написать регулярку, наподобие той, что проверяет ip адреса?
#regex #сервис
{kind=link}
На этой неделе познакомился с новым для меня авторским каналом по ИТ:
⇨ Pavel Zloi aka EvilFreelancer
Видео немного и выходят не часто, но материал интересный, особенно последний цикл, где автор собирает кластер Kubernetes на базе NanoPi NEO3. В качестве виртуализации использует Proxmox под виртуалки кластера. Всё как мы любим.
Там и другие видео заслуживают внимания. Например, про GNS3 или TeamPass, Syspass, Passman, KeeWeb. Автор рассмотрел несколько решений для хранилища паролей, и остановился в итоге на hashicorp vault.
#видео
⇨ Pavel Zloi aka EvilFreelancer
Видео немного и выходят не часто, но материал интересный, особенно последний цикл, где автор собирает кластер Kubernetes на базе NanoPi NEO3. В качестве виртуализации использует Proxmox под виртуалки кластера. Всё как мы любим.
Там и другие видео заслуживают внимания. Например, про GNS3 или TeamPass, Syspass, Passman, KeeWeb. Автор рассмотрел несколько решений для хранилища паролей, и остановился в итоге на hashicorp vault.
#видео
{kind=link}
Напоминаю, для тех, кто не в курсе, что Zabbix регулярно проводит вебинары. В том числе и на русском языке. У меня были сомнения насчёт того, актуально ли это в наше время. Записался на недавний вебинар и успешно его прослушал. Так что всё актуально.
Вебинары в основном обзорные и рассчитаны на новичков. Чаще всего по кругу крутят темы с обзором системы мониторинга и установкой. Но иногда добавляют что-то более информативное и сложное. После вебинара чаще всего можно задать свой вопрос.
Ближайшие анонсированные вебинары:
🗓 1 декабря, 11:00 Обзор системы мониторинга Zabbix
🗓 8 декабря, 11:00 Установите и настройте Zabbix за 5 минут
🗓 15 декабря, 11:00 Расширение возможностей Zabbix
Записаться можно на отдельной странице. Внимательно смотрите на часовой пояс. Его будет видно во время записи на мероприятие в Zoom. Он иногда меняется. Последний вебинар был по часовому поясу Хельсинки, разница с Москвой на час. Я пришёл раньше и думал, что пропустил уже. Не сразу сообразил, что он ещё просто не начался.
#zabbix
Вебинары в основном обзорные и рассчитаны на новичков. Чаще всего по кругу крутят темы с обзором системы мониторинга и установкой. Но иногда добавляют что-то более информативное и сложное. После вебинара чаще всего можно задать свой вопрос.
Ближайшие анонсированные вебинары:
🗓 1 декабря, 11:00 Обзор системы мониторинга Zabbix
🗓 8 декабря, 11:00 Установите и настройте Zabbix за 5 минут
🗓 15 декабря, 11:00 Расширение возможностей Zabbix
Записаться можно на отдельной странице. Внимательно смотрите на часовой пояс. Его будет видно во время записи на мероприятие в Zoom. Он иногда меняется. Последний вебинар был по часовому поясу Хельсинки, разница с Москвой на час. Я пришёл раньше и думал, что пропустил уже. Не сразу сообразил, что он ещё просто не начался.
#zabbix
{kind=link}