
На днях была рассылка от компании Onlyoffice. Они анонсировали бесплатный онлайн конвертер офисных документов разных форматов. Например, перевести pdf в word, xlsx в pdf, csv в xls и т.д.
Очевидно, что самым востребованным направлением является конвертация pdf во что-то другое. Например в doc или fb2 (для книг актуально, которые часто только в pdf формате есть). Я попробовал на нескольких примерах, работает нормально.
Не нужна регистрация, нет никакой рекламы. Всё работает быстро и чётко. Единственное ограничение - размер файла не более 5 Мб. Это мало, особенно для книг, но что есть, то есть.
Мне кажется, хороший ход сделали маркетологи. Подобный сервис реально востребован. Я сам иногда пользуюсь. В сети много клонов, но все они чаще всего с рекламой или ещё какой-то заманухой. А тут по сути сам сервис является рекламой своих продуктов, так что нет смысла его как-то монетизировать отдельно.
Даже если самому не надо, можно этот сервис предлагать каким-то знакомым, далёким от IT.
https://www.onlyoffice.com/ru/convert.aspx
#сервис
Очевидно, что самым востребованным направлением является конвертация pdf во что-то другое. Например в doc или fb2 (для книг актуально, которые часто только в pdf формате есть). Я попробовал на нескольких примерах, работает нормально.
Не нужна регистрация, нет никакой рекламы. Всё работает быстро и чётко. Единственное ограничение - размер файла не более 5 Мб. Это мало, особенно для книг, но что есть, то есть.
Мне кажется, хороший ход сделали маркетологи. Подобный сервис реально востребован. Я сам иногда пользуюсь. В сети много клонов, но все они чаще всего с рекламой или ещё какой-то заманухой. А тут по сути сам сервис является рекламой своих продуктов, так что нет смысла его как-то монетизировать отдельно.
Даже если самому не надо, можно этот сервис предлагать каким-то знакомым, далёким от IT.
https://www.onlyoffice.com/ru/convert.aspx
#сервис
{kind=link}
Вы в курсе, что знаменитую на весь мир игру тетрис придумал Алексей Леонидович Пажитнов в 1984 году, работавший в Вычислительном центре Академии наук СССР. Он вёл работу над искусственным интеллектом и распознаванием речи, или не вёл, а разрабатывал игру 🙂
У меня в детстве был тетрис в виде отдельного игрового устройства. Оказывается, тетрис есть даже в официальных репозиториях популярных дистрибутивов Linux:
Игра реально залипательная. Я минут 30 поиграл, прежде чем написал эту заметку. Мне показалось, что на Linux она чересчур сложная. Постоянно выходят не те фигуры, много повторов и совсем редко длинные палочки появляются. Из-за этого довольно быстро проигрывал, а за раунд удавалось сократить 3-5 полных линий и дальше всё.
Даже по картинке ниже видно, что у меня с начала игры вышли 7 белых квадратов (4 подряд были), по паре остальных фигур и ни одной палочки. Как тут выигрывать?
#игра
У меня в детстве был тетрис в виде отдельного игрового устройства. Оказывается, тетрис есть даже в официальных репозиториях популярных дистрибутивов Linux:
# apt install bastet# dnf install bastet# /usr/games/bastetИгра реально залипательная. Я минут 30 поиграл, прежде чем написал эту заметку. Мне показалось, что на Linux она чересчур сложная. Постоянно выходят не те фигуры, много повторов и совсем редко длинные палочки появляются. Из-за этого довольно быстро проигрывал, а за раунд удавалось сократить 3-5 полных линий и дальше всё.
Даже по картинке ниже видно, что у меня с начала игры вышли 7 белых квадратов (4 подряд были), по паре остальных фигур и ни одной палочки. Как тут выигрывать?
#игра
{kind=link}
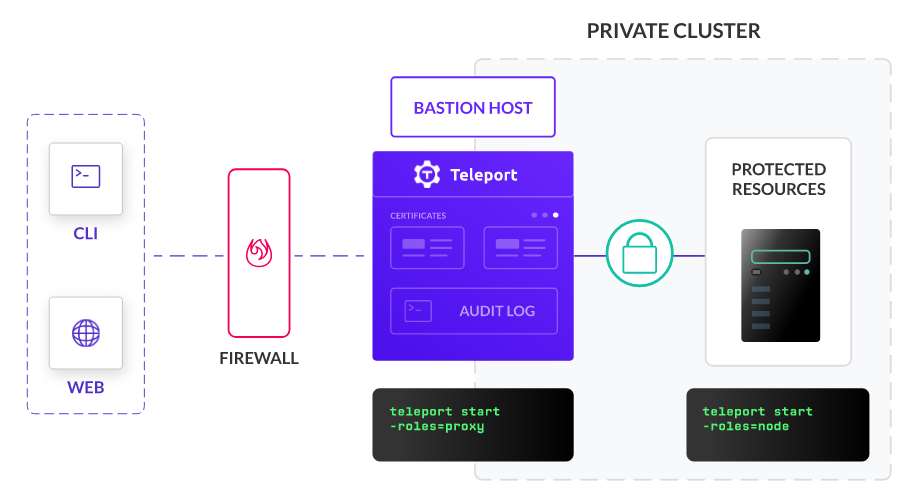
Расскажу вам про отличную бесплатную Open Source систему контроля доступа к сервисам и системам - Teleport. Она очень функциональная, кроссплатформенная, немного навороченная. Попробую кратко рассказать принцип работы.
Допустим, у вас есть какой-то веб сервис и полноценный сервер в закрытой сети. Вы не хотите открывать к ним доступ извне. Вам нужно точечно выдавать права к этим ресурсам различным пользователям. Есть вариант организовать это с помощью VPN, но это решение сетевого уровня. В то время как Teleport обеспечивает доступ на уровне сервисов.
Вы разворачиваете какой-то сервер в интернете, привязываете к нему DNS имя. Устанавливаете туда сервер Teleport. Добавляете все свои внутренние ресурсы, к которым хотите настроить доступ. Добавляете пользователей и назначаете им права доступа. Далее на целевых серверах ставите Teleport и связываете его с сервером и ресурсами, которые туда добавили.
Теперь централизованно можете управлять доступом к своим внутренним ресурсам. При этом ведётся лог подключений. В качестве ресурсов могут выступать: ssh подключения к серверам, доступ к kubernetes, к базам данных, к десктопным системам (в т.ч. windows по rdp), к отдельным приложениям (gitlab, grafana и т.д.).
Доступ к серверу Teleport и ресурсам осуществляется через браузер. Можно включить двухфакторную аутентификацию. Доступ к SSH может осуществляться как через web, так и с помощью локального приложения со своим cli. Выглядит это примерно так:
Я систему не разворачивал и не использовал. Изучил сайт, документацию, видео. На вид выглядит очень круто. Можно закрыть вопросы как подключений администраторов для управления всего и всем, так и пользователей к своим компьютерам и терминальным серверам. Компания, которая разработала и поддерживает Teleport, зарабатывает на поддержке и облачной версии. За счёт этого Community версия выглядит очень неплохо. Каких-то ограничений я не нашёл.
Аналог этой системы я описывал ранее - Trasa. Teleport показался более функциональным, удобным, с хорошей документацией.
Сайт - https://goteleport.com/
Исходники - https://github.com/gravitational/teleport
Обзор - https://www.youtube.com/watch?v=6ynLlAUipNE
#remote #управление #devops
Допустим, у вас есть какой-то веб сервис и полноценный сервер в закрытой сети. Вы не хотите открывать к ним доступ извне. Вам нужно точечно выдавать права к этим ресурсам различным пользователям. Есть вариант организовать это с помощью VPN, но это решение сетевого уровня. В то время как Teleport обеспечивает доступ на уровне сервисов.
Вы разворачиваете какой-то сервер в интернете, привязываете к нему DNS имя. Устанавливаете туда сервер Teleport. Добавляете все свои внутренние ресурсы, к которым хотите настроить доступ. Добавляете пользователей и назначаете им права доступа. Далее на целевых серверах ставите Teleport и связываете его с сервером и ресурсами, которые туда добавили.
Теперь централизованно можете управлять доступом к своим внутренним ресурсам. При этом ведётся лог подключений. В качестве ресурсов могут выступать: ssh подключения к серверам, доступ к kubernetes, к базам данных, к десктопным системам (в т.ч. windows по rdp), к отдельным приложениям (gitlab, grafana и т.д.).
Доступ к серверу Teleport и ресурсам осуществляется через браузер. Можно включить двухфакторную аутентификацию. Доступ к SSH может осуществляться как через web, так и с помощью локального приложения со своим cli. Выглядит это примерно так:
# tsh login --proxy=tp.site.com --user=sysadminЯ систему не разворачивал и не использовал. Изучил сайт, документацию, видео. На вид выглядит очень круто. Можно закрыть вопросы как подключений администраторов для управления всего и всем, так и пользователей к своим компьютерам и терминальным серверам. Компания, которая разработала и поддерживает Teleport, зарабатывает на поддержке и облачной версии. За счёт этого Community версия выглядит очень неплохо. Каких-то ограничений я не нашёл.
Аналог этой системы я описывал ранее - Trasa. Teleport показался более функциональным, удобным, с хорошей документацией.
Сайт - https://goteleport.com/
Исходники - https://github.com/gravitational/teleport
Обзор - https://www.youtube.com/watch?v=6ynLlAUipNE
#remote #управление #devops
{kind=link}
Сколько я себя знаю в профессии системного администратора, никаких прокси серверов, кроме Squid не доводилось ни видеть, ни настраивать. Если лет 15-20 назад он стоял почти везде (я даже себе домой ставил локально, когда модемом пользовался), так как трафик экономили.
Сейчас прокси ставят гораздо реже, но тем не менее используют. А в некоторых отраслях в обязательном порядке, но чаще какие-то готовые решения, типа шлюза ИКС или Ideco (и там, и там тоже squid). Я не раз получал заказы как на настройку, так и на перенос или обновление очень старых версий Squid. Люди до сих пор им пользуются, так как бесплатных альтернатив нет.
Squid полностью отвечает поставленным задачам, может быть поэтому и не возникло никаких альтернатив. Вопросы возникают только с управлением и просмотром статистики. Я видел и использовал огромное количество всевозможных решений. Начинал с SAMS. Это был отличный продукт как для управления, так и для статистики. Поддерживалась интеграция с AD. Это было очень удобно. Насколько я понимаю, этот проект давно мёртв.
Неплохой вариант для управления - Webmin. Можно выполнять настройки по добавлению пользователей, ограничению доступа, управлению списками и т.д. Всё через веб, лазить в консоль не надо. Можно научить кого-то далёкого от серверов. Но статистики нет. Для этого надо использовать отдельное решение.
Так же я настраивал работу squid на основе групп AD. Вручную создавались списки доступа в соответствии с группами в AD, потом людей просто по группам перемещали. Тоже управлять мог человек, далёкий от Linux и прокси серверов. Статистику делал с помощью lightsquid. Малофункциональная панель, мне не очень нравилась.
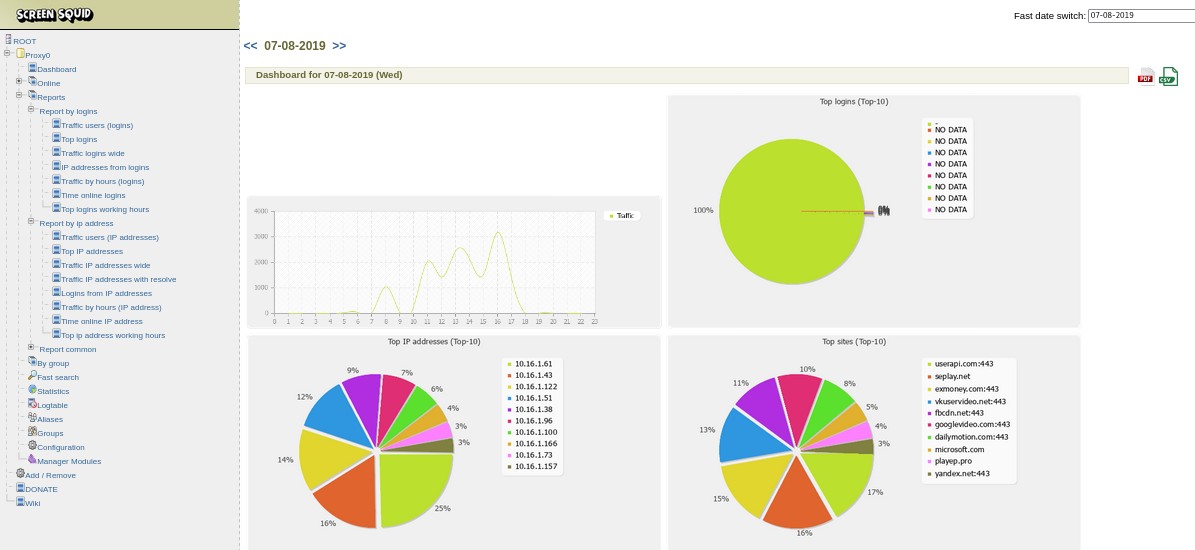
Как-то я издалека начал. Заметку хотел написать по поводу веб панели для формирования и просмотра статистики Squid - Screen Squid. Среди бесплатных решений она наиболее функциональна из тех, что знаю. Работает на базе стандартного стека php+perl+mysql. Проект не заброшен, в июне было очередное большое обновление. Автор панели помогает с настройкой в отдельном чате - https://t.me/screensquid.
Быстро посмотреть и попробовать Screen Squid можно в докере, чтобы не поднимать веб сервер вручную. Есть готовый docker-compose. Нужно понимать, что все логи Screen Squid хранит в SQL базе. При большом трафике будет большой объём базы. Нужно это отдельно продумать заранее. Есть вариант использовать PostgreSQL, вместо MySQL.
Если у кого-то есть Squid в хозяйстве, скажите, чем управляете и что используете для просмотра статистики.
Сайт - http://break-people.ru/cmsmade/?page=scriptology_screen_squid
Исходники - https://sourceforge.net/projects/screen-squid/
Docker - https://gitlab.com/dimonleonov/screensquid-compose
#squid #gateway
Сейчас прокси ставят гораздо реже, но тем не менее используют. А в некоторых отраслях в обязательном порядке, но чаще какие-то готовые решения, типа шлюза ИКС или Ideco (и там, и там тоже squid). Я не раз получал заказы как на настройку, так и на перенос или обновление очень старых версий Squid. Люди до сих пор им пользуются, так как бесплатных альтернатив нет.
Squid полностью отвечает поставленным задачам, может быть поэтому и не возникло никаких альтернатив. Вопросы возникают только с управлением и просмотром статистики. Я видел и использовал огромное количество всевозможных решений. Начинал с SAMS. Это был отличный продукт как для управления, так и для статистики. Поддерживалась интеграция с AD. Это было очень удобно. Насколько я понимаю, этот проект давно мёртв.
Неплохой вариант для управления - Webmin. Можно выполнять настройки по добавлению пользователей, ограничению доступа, управлению списками и т.д. Всё через веб, лазить в консоль не надо. Можно научить кого-то далёкого от серверов. Но статистики нет. Для этого надо использовать отдельное решение.
Так же я настраивал работу squid на основе групп AD. Вручную создавались списки доступа в соответствии с группами в AD, потом людей просто по группам перемещали. Тоже управлять мог человек, далёкий от Linux и прокси серверов. Статистику делал с помощью lightsquid. Малофункциональная панель, мне не очень нравилась.
Как-то я издалека начал. Заметку хотел написать по поводу веб панели для формирования и просмотра статистики Squid - Screen Squid. Среди бесплатных решений она наиболее функциональна из тех, что знаю. Работает на базе стандартного стека php+perl+mysql. Проект не заброшен, в июне было очередное большое обновление. Автор панели помогает с настройкой в отдельном чате - https://t.me/screensquid.
Быстро посмотреть и попробовать Screen Squid можно в докере, чтобы не поднимать веб сервер вручную. Есть готовый docker-compose. Нужно понимать, что все логи Screen Squid хранит в SQL базе. При большом трафике будет большой объём базы. Нужно это отдельно продумать заранее. Есть вариант использовать PostgreSQL, вместо MySQL.
Если у кого-то есть Squid в хозяйстве, скажите, чем управляете и что используете для просмотра статистики.
Сайт - http://break-people.ru/cmsmade/?page=scriptology_screen_squid
Исходники - https://sourceforge.net/projects/screen-squid/
Docker - https://gitlab.com/dimonleonov/screensquid-compose
#squid #gateway
{kind=link}
Если вам необходимо выполнить одновременно на нескольких хостах какую-то команду по SSH, можно воспользоваться очень удобным и простым инструментом для этого - orgalorg. Сразу скажу, что способов решения данной задачи очень много, начиная от простого однострочника на bash и заканчивая ClusterSSH или Ansible. Покажу в конце примеры.
Я пишу именно про orgalorg, потому что там это реализовано максимально просто и быстро. Для тех, кому нет нужды разбираться в настройках, разных подходах и тем более изучать ansible.
Основные возможности orgalorg:
◽ параллельное выполнение ssh команд на удалённых хостах
◽ одновременная загрузка файла на несколько удалённых хостов
◽ аутентификация как по ключам, так и интерактивно по паролю
◽ возможность выбрать файл как источник команд для удалённых хостов
Orgalorg написан на go и может быть установлен с его помощью:
В директории ~/go/bin будет собранный бинарник orgalorg.
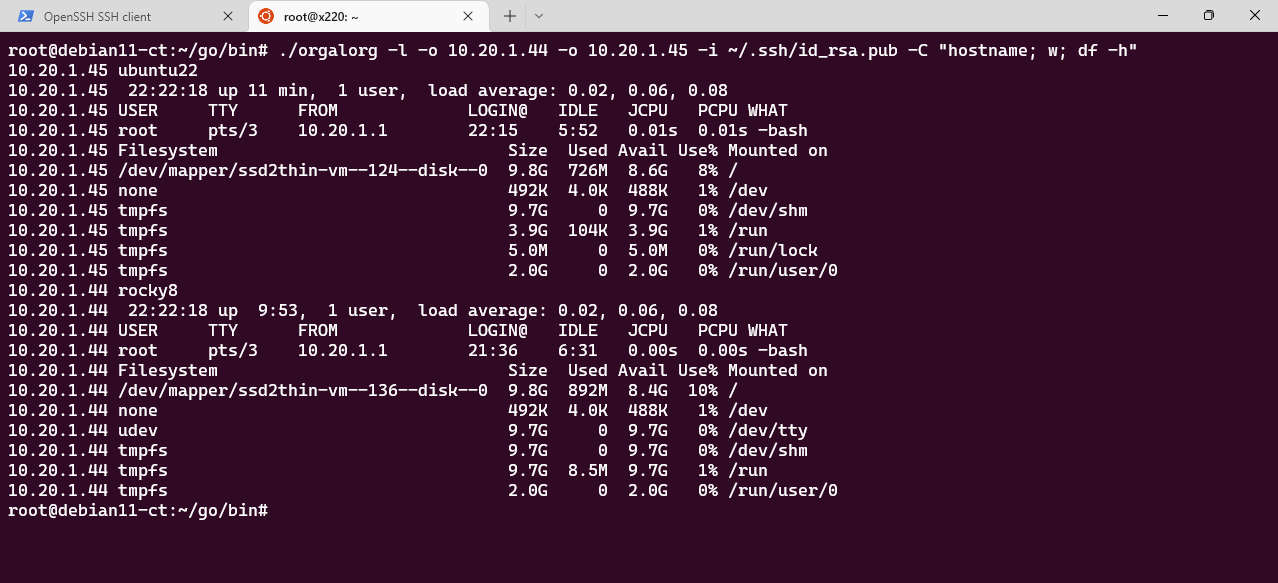
Одновременное выполнение команды uptime на двух хостах с аутентификацией через пароль:
С помощью orgalorg можно легко добавить свой публичный ключ на эти хосты:
После этого можно выполнять команды напрямую, минуя ключ -p и ввод пароля. Смотрим информацию о шлюзе по умолчанию на группе хостов:
Загрузим файл ~/file.txt с текущего хоста на два удалённых в директорию /tmp:
Orgalorg поддерживает много функций. Например, открытие интерактивного сеанса с удалённым хостом или отображение в режиме реального времени изменение одного и того же лог файла с разных хостов.
Если у вас рабочая система на Linux, то похожий функционал можно получить с помощью ClusterSSH. При выполнении команд на разных хостах, будут автоматом открываться терминалы с автоматическим подключением к ним. Это удобно в тестовой среде. Позволяет выполнить какую-то команду и тут же в терминале наблюдать за выполнением, а потом продолжить работу в этом терминале.
Всё описанное выше можно выполнить с помощью Ansible. Вот пример выполнения команды на нескольких хостах с интерактивной аутентификацией по паролю:
Файл host.txt с инвентарём должен быть следующего содержания:
А вот эта же задача решается с помощью однострочника на bash:
#bash
Я пишу именно про orgalorg, потому что там это реализовано максимально просто и быстро. Для тех, кому нет нужды разбираться в настройках, разных подходах и тем более изучать ansible.
Основные возможности orgalorg:
◽ параллельное выполнение ssh команд на удалённых хостах
◽ одновременная загрузка файла на несколько удалённых хостов
◽ аутентификация как по ключам, так и интерактивно по паролю
◽ возможность выбрать файл как источник команд для удалённых хостов
Orgalorg написан на go и может быть установлен с его помощью:
# apt install golang# go get github.com/reconquest/orgalorgВ директории ~/go/bin будет собранный бинарник orgalorg.
Одновременное выполнение команды uptime на двух хостах с аутентификацией через пароль:
# ./orgalorg -p -o 10.20.1.44 -o 10.20.1.45 -C uptimePassword: 10.20.1.45 12:46:49 up 18 min, 2 users, load average: 0.02, 0.03, 0.0610.20.1.44 12:46:49 up 18 min, 2 users, load average: 0.02, 0.03, 0.06С помощью orgalorg можно легко добавить свой публичный ключ на эти хосты:
# ./orgalorg -p -o 10.20.1.44 -o 10.20.1.45 \-i ~/.ssh/id_rsa.pub -C tee -a ~/.ssh/authorized_keysПосле этого можно выполнять команды напрямую, минуя ключ -p и ввод пароля. Смотрим информацию о шлюзе по умолчанию на группе хостов:
# ./orgalorg -o 10.20.1.43 -o 10.20.1.44 -o 10.20.1.45 \-i ~/.ssh/id_rsa.pub -C ip r | grep default10.20.1.45 default via 10.20.1.1 dev eth010.20.1.43 default via 10.20.1.1 dev eth0 10.20.1.44 default via 10.20.1.1 dev eth0Загрузим файл ~/file.txt с текущего хоста на два удалённых в директорию /tmp:
# ./orgalorg -o 10.20.1.44 -o 10.20.1.45 \-i ~/.ssh/id_rsa.pub -er /tmp -U ~/file.txtOrgalorg поддерживает много функций. Например, открытие интерактивного сеанса с удалённым хостом или отображение в режиме реального времени изменение одного и того же лог файла с разных хостов.
Если у вас рабочая система на Linux, то похожий функционал можно получить с помощью ClusterSSH. При выполнении команд на разных хостах, будут автоматом открываться терминалы с автоматическим подключением к ним. Это удобно в тестовой среде. Позволяет выполнить какую-то команду и тут же в терминале наблюдать за выполнением, а потом продолжить работу в этом терминале.
Всё описанное выше можно выполнить с помощью Ansible. Вот пример выполнения команды на нескольких хостах с интерактивной аутентификацией по паролю:
# ansible -k -u root -a "uptime" -i hosts.txt serversФайл host.txt с инвентарём должен быть следующего содержания:
[servers]10.20.1.4410.20.1.45А вот эта же задача решается с помощью однострочника на bash:
# hosts=('10.20.1.44' '10.20.1.45'); \for HOST in "${hosts[@]}"; \do ssh -f root@$HOST "uptime"; done#bash
{kind=link}
Информация для пользователей Windows. Хочу рассказать о небольшой программе, о которой случайно узнал и сразу же стал пользоваться. Очень её не хватало. Я даже не знал, что она существует.
Monitorian позволяет управлять яркостью одного или сразу нескольких мониторов. У меня как раз такой случай. Функции автояркости у моих мониторов нет, так что приходилось вручную подкручивать в разное время суток яркость и иногда контраст. С помощью Monitorian это делать очень удобно, причём сразу на обоих мониторах.
Поставить программу можно через магазин Windows:
После запуска она живёт в трее и позволяет ползунками управлять яркостью и контрастом всех подключенных мониторов. Это очень удобно. Теперь она всегда со мной ❤️.
Исходники - https://github.com/emoacht/Monitorian
#windows
Monitorian позволяет управлять яркостью одного или сразу нескольких мониторов. У меня как раз такой случай. Функции автояркости у моих мониторов нет, так что приходилось вручную подкручивать в разное время суток яркость и иногда контраст. С помощью Monitorian это делать очень удобно, причём сразу на обоих мониторах.
Поставить программу можно через магазин Windows:
# winget install MonitorianПосле запуска она живёт в трее и позволяет ползунками управлять яркостью и контрастом всех подключенных мониторов. Это очень удобно. Теперь она всегда со мной ❤️.
Исходники - https://github.com/emoacht/Monitorian
#windows
{kind=link}
На днях столкнулся с непривычным поведением dhcp клиента на разных дистрибутивах Linux. Точнее, неожиданным образом он себя повёл на Ubuntu 22. Пришлось потратить немного времени, чтобы разобраться.
Началось всё с того, что я на системе с Ubuntu заметил сетевые маршруты, которые не настраивал сам. Немного напрягся, так как ситуация неординарная. Лишние маршруты в системе не должны появляться. Выглядело это примерно так:
По описанию маршрутов видно, что пришли они по dhcp. Но и на dhcp сервере я не добавлял их. Начал проверять эти адреса. Оба европейские. PTR запись одного из них содержала в названии поддомен ntp. Тут я понял, что это адреса публичных серверов времени.
В качестве dhcp сервера и шлюза выступал Mikrotik. Зашёл в его настройки и увидел, что в настройках sntp client указаны как раз эти серверы, маршруты к которым были добавлены. Перепроверил все настройки dhcp сервера на микротике, нигде не увидел явной настройки, которая бы отвечала за передачу этих маршрутов клиентам.
Решил проверить в самой Ubuntu, какие настройки она получает по dhcp. Я всегда знал, что leases, которые получает dhcpclient, живут в директории /var/lib/dhcp в обычном текстовом файле. В Ubuntu там было пусто. Я специально запустил в этой же сетке Debian 11 и Rocky Linux 8, проверил, у них файл leases на указанном месте. И там есть параметр:
через него передаются настройки ntp. Я, кстати, не знал о том, что Mikrotik их передаёт. Но ни в Debian, ни в Rocky не добавляются новые маршруты к этим ntp серверам.
Стал дальше разбираться с Ubuntu. Оказывается, там leases переехали в /run/systemd/netif/leases и живут в файле с многозначительным именем 2, чтобы никто точно не запутался и сразу понял, о чём тут речь. Если я правильно понял, то управляет в том числе и клиентом dhcp теперь systemd. Настройки и статус хранит в своих потрохах.
Очевидно, что все настройки, полученные от dhcp сервера на Ubuntu аналогичны другим системам, но именно она почему-то добавила статические маршруты к ntp серверам. Совершенно не понял, зачем. Загрузил для проверки в этой же сети Ubuntu 20. Она маршруты не создаёт.
Беглый поиск в гугле по ключевым словам не помог найти ответ на свой вопрос - зачем стали добавляться статические маршруты до ntp серверов, полученных по dhcp и кто за эту настройку отвечает.
Это один из примеров, почему лично мне не очень нравится Ubuntu. Там постоянно что-то меняется и это часто мешает или тратит твоё время.
#linux
Началось всё с того, что я на системе с Ubuntu заметил сетевые маршруты, которые не настраивал сам. Немного напрягся, так как ситуация неординарная. Лишние маршруты в системе не должны появляться. Выглядело это примерно так:
# ip rdefault via 10.20.1.1 dev eth0 proto dhcp src 10.20.1.45 metric 1024 ...............................37.120.179.169 via 10.20.1.1 dev eth0 proto dhcp src 10.20.1.45 metric 1024 193.136.164.4 via 10.20.1.1 dev eth0 proto dhcp src 10.20.1.45 metric 1024По описанию маршрутов видно, что пришли они по dhcp. Но и на dhcp сервере я не добавлял их. Начал проверять эти адреса. Оба европейские. PTR запись одного из них содержала в названии поддомен ntp. Тут я понял, что это адреса публичных серверов времени.
В качестве dhcp сервера и шлюза выступал Mikrotik. Зашёл в его настройки и увидел, что в настройках sntp client указаны как раз эти серверы, маршруты к которым были добавлены. Перепроверил все настройки dhcp сервера на микротике, нигде не увидел явной настройки, которая бы отвечала за передачу этих маршрутов клиентам.
Решил проверить в самой Ubuntu, какие настройки она получает по dhcp. Я всегда знал, что leases, которые получает dhcpclient, живут в директории /var/lib/dhcp в обычном текстовом файле. В Ubuntu там было пусто. Я специально запустил в этой же сетке Debian 11 и Rocky Linux 8, проверил, у них файл leases на указанном месте. И там есть параметр:
option ntp-servers 193.136.164.4,37.120.179.169;через него передаются настройки ntp. Я, кстати, не знал о том, что Mikrotik их передаёт. Но ни в Debian, ни в Rocky не добавляются новые маршруты к этим ntp серверам.
Стал дальше разбираться с Ubuntu. Оказывается, там leases переехали в /run/systemd/netif/leases и живут в файле с многозначительным именем 2, чтобы никто точно не запутался и сразу понял, о чём тут речь. Если я правильно понял, то управляет в том числе и клиентом dhcp теперь systemd. Настройки и статус хранит в своих потрохах.
Очевидно, что все настройки, полученные от dhcp сервера на Ubuntu аналогичны другим системам, но именно она почему-то добавила статические маршруты к ntp серверам. Совершенно не понял, зачем. Загрузил для проверки в этой же сети Ubuntu 20. Она маршруты не создаёт.
Беглый поиск в гугле по ключевым словам не помог найти ответ на свой вопрос - зачем стали добавляться статические маршруты до ntp серверов, полученных по dhcp и кто за эту настройку отвечает.
Это один из примеров, почему лично мне не очень нравится Ubuntu. Там постоянно что-то меняется и это часто мешает или тратит твоё время.
#linux
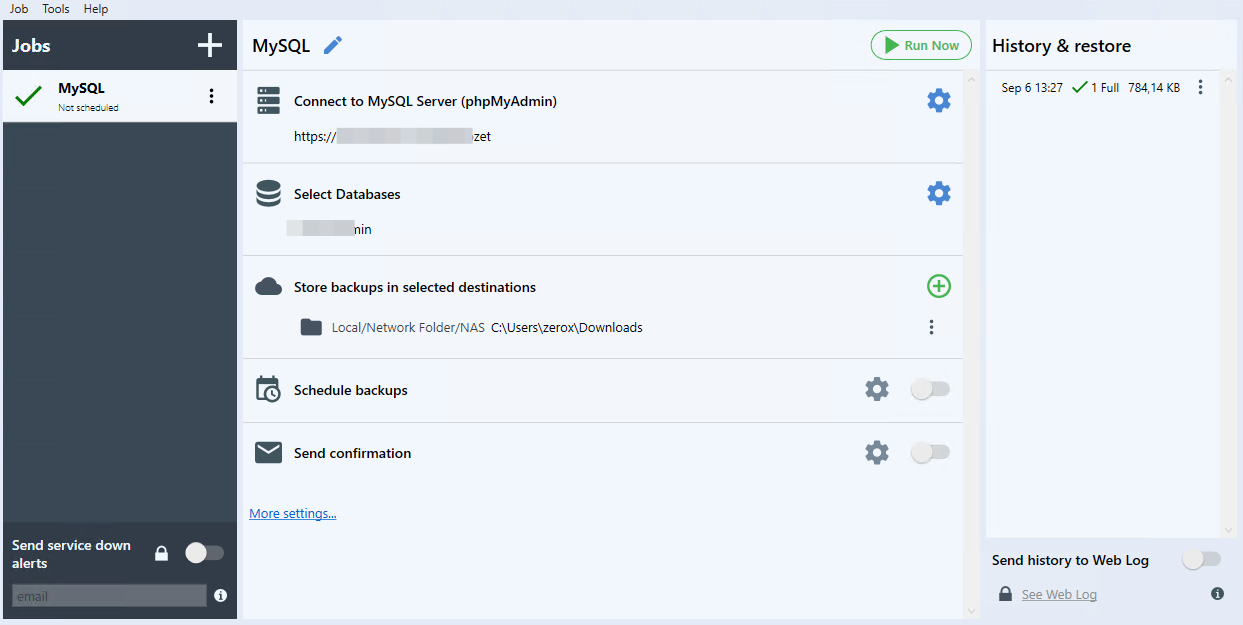
Хочу поделиться с вами очень приятной находкой в виде бесплатной программы для бэкапа SQL баз и обычных файлов - SQLBackupAndFTP. Программа работает под Windows и на самом деле платная, но есть функциональная бесплатная версия с некоторыми ограничениями.
SQLBackupAndFTP умеет:
◽ бэкапить вручную и по расписанию базы данных MSSQL, MySQL, PostgreSQL
◽ складывать бэкапы на FTP, SFTP, FTPS, локальную или сетевую папку, Yandex.Disk
◽ отправлять уведомления на почту
◽ писать лог выполняемых действий
◽ автоматически удалять старые бэкапы
◽ работать через прокси
◽ подключаться к sql серверу и выполнять там sql команды
Основное ограничение бесплатной версии - не более двух баз данных, добавленных в планировщик. Вручную запускать бэкапы можно для неограниченного количества баз. Ещё ограничения бесплатной версии: нет поддержки S3, только полные бэкапы, нет поддержки шифрования.
Я попробовал программу. Скачивается с сайта без всяких регистраций и других ужимок. Настройки очень простые и наглядные. Сама программа выглядит современно и удобно. Порадовала возможность снять бэкап mysql базы, подключившись к веб интерфейсу phpmyadmin. То есть не нужен прямой доступ к базе. Раньше нигде не видел такого функционала.
Программа оставила приятное впечатление. Если вам некритичны ограничения, то можно пользоваться. Уточню ещё раз, что вручную запускать бэкап можно неограниченного количества баз. Вы можете их добавить в интерфейс и запускать время от времени вручную по мере необходимости. Знаю людей, которые базы 1С вручную раз в неделю копируют на Яндекс.Диск. Эта программа может существенно упростить задачу, особенно людям, далёким от IT.
Сайт - https://sqlbackupandftp.com/
#backup #mysql #windows
SQLBackupAndFTP умеет:
◽ бэкапить вручную и по расписанию базы данных MSSQL, MySQL, PostgreSQL
◽ складывать бэкапы на FTP, SFTP, FTPS, локальную или сетевую папку, Yandex.Disk
◽ отправлять уведомления на почту
◽ писать лог выполняемых действий
◽ автоматически удалять старые бэкапы
◽ работать через прокси
◽ подключаться к sql серверу и выполнять там sql команды
Основное ограничение бесплатной версии - не более двух баз данных, добавленных в планировщик. Вручную запускать бэкапы можно для неограниченного количества баз. Ещё ограничения бесплатной версии: нет поддержки S3, только полные бэкапы, нет поддержки шифрования.
Я попробовал программу. Скачивается с сайта без всяких регистраций и других ужимок. Настройки очень простые и наглядные. Сама программа выглядит современно и удобно. Порадовала возможность снять бэкап mysql базы, подключившись к веб интерфейсу phpmyadmin. То есть не нужен прямой доступ к базе. Раньше нигде не видел такого функционала.
Программа оставила приятное впечатление. Если вам некритичны ограничения, то можно пользоваться. Уточню ещё раз, что вручную запускать бэкап можно неограниченного количества баз. Вы можете их добавить в интерфейс и запускать время от времени вручную по мере необходимости. Знаю людей, которые базы 1С вручную раз в неделю копируют на Яндекс.Диск. Эта программа может существенно упростить задачу, особенно людям, далёким от IT.
Сайт - https://sqlbackupandftp.com/
#backup #mysql #windows
{kind=link}
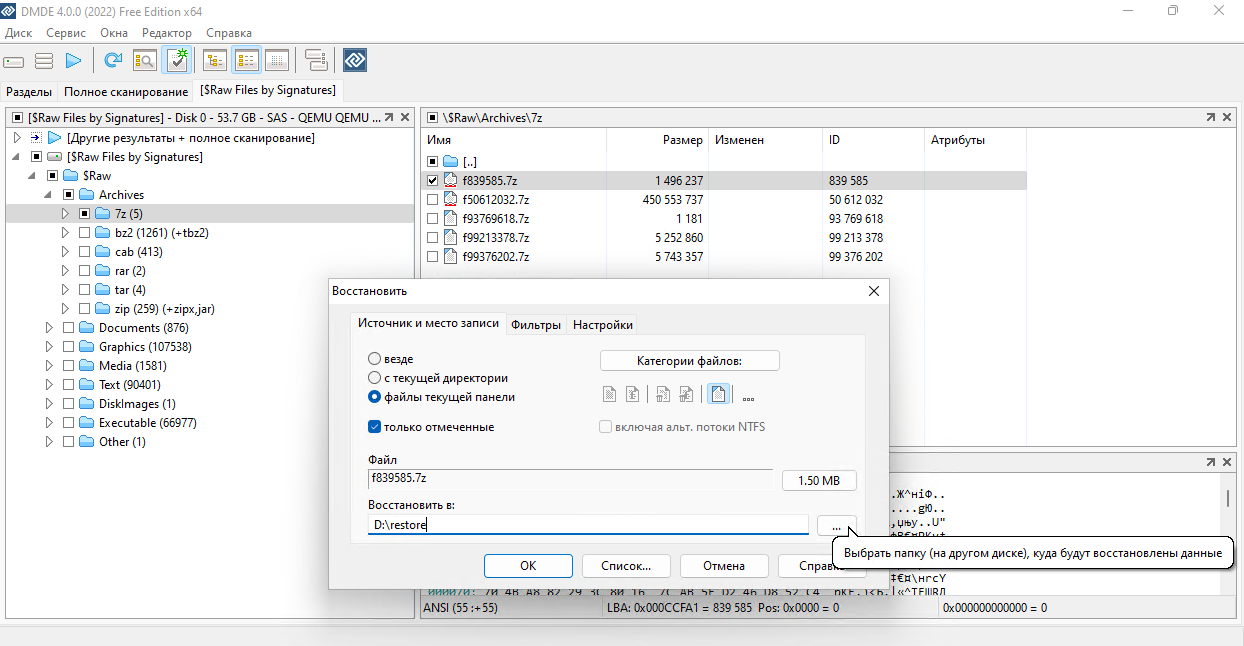
Практически ко всем заметкам с программами для восстановления данных были комментарии с упоминанием DMDE. Это платная программа, у которой есть бесплатная версия с несильно критичным ограничением - 4000 файлов за раз. Для восстановления случайно удалённых файлов это вообще не критично. Ограничение станет актуальным, если вы будете восстанавливать целый диск или раздел со всеми уничтоженными данными.
DMDE существует под все распространённые системы - Windows, MacOS, Linux (gui и cli версии). Она популярна и качественна, есть русская версия, да и сам автор русскоязычный - Дмитрий Сидоров. Для того, чтобы пользоваться, особо разбираться не надо. Всё интуитивно понятно, плюс в сети много руководств и видео на ютубе. Да и на самом сайте есть подробная инструкция на русском от автора.
📌 Основные возможности программы:
◽ портативный запуск без установки
◽ поддержка ФС NTFS, FAT12/16, FAT32, exFAT, ReFS, Ext2/Ext3/Ext4, btrfs, HFS+/HFSX,
APFS
◽ менеджер разделов с возможностью быстро восстановить удалённый или потерянный раздел
◽ клонирование и создание образов системы с пропуском нечитаемых секторов
Загрузка программы доступна на сайте без регистрации. Напомню, что другие популярные программы для восстановления данных вы можете посмотреть по соответствующему тэгу в конце заметки.
Сайт - https://dmde.ru
#restore
DMDE существует под все распространённые системы - Windows, MacOS, Linux (gui и cli версии). Она популярна и качественна, есть русская версия, да и сам автор русскоязычный - Дмитрий Сидоров. Для того, чтобы пользоваться, особо разбираться не надо. Всё интуитивно понятно, плюс в сети много руководств и видео на ютубе. Да и на самом сайте есть подробная инструкция на русском от автора.
📌 Основные возможности программы:
◽ портативный запуск без установки
◽ поддержка ФС NTFS, FAT12/16, FAT32, exFAT, ReFS, Ext2/Ext3/Ext4, btrfs, HFS+/HFSX,
APFS
◽ менеджер разделов с возможностью быстро восстановить удалённый или потерянный раздел
◽ клонирование и создание образов системы с пропуском нечитаемых секторов
Загрузка программы доступна на сайте без регистрации. Напомню, что другие популярные программы для восстановления данных вы можете посмотреть по соответствующему тэгу в конце заметки.
Сайт - https://dmde.ru
#restore
{kind=link}
Бэкапы в S3
Вчера в чате один читатель попросил совет на тему бесплатных решений для бэкапа шифрованных архивов в хранилище на базе S3. Я описывал много различных продуктов для бэкапа и довольно быстро нашёл именно те, что умеют в S3 складывать данные. Думаю, эта информация будет полезна всем, так что решил оформить в отдельную заметку.
🟢 Kopia. Поставил на первое место, так как это классное кроссплатформенное решение с управлением как через web, так и cli. Можно в одном месте собрать бэкапы с разных систем. Настраивается просто, функционал обширный. Я использовал этот софт лично, мне понравился.
🟢 Restic. Простая и быстрая консольная программа, состоящая из одного бинарника. Как и Kopia, есть под все системы. В Debian можно из базовой репы поставить. Есть поддержка снепшотов и дедупликации. Отличное решение под автоматизацию на базе самописных скриптов.
🟢 Duplicati. Очень популярная программа. Тоже кроссплатформенная, есть cli и веб интерфейс. Поддерживает много бэкендов в качестве хранилища, типа Dropbox, OneDrive, Google Drive и т.д. Умеет делать инкрементные бэкапы, поддерживает дедупликацию. Функционально и архитектурно похожа на Kopia.
🟢 Duplicity. Программа только под Linux с управлением через cli. Работает на базе библиотеки librsync, как и rsync, а значит синхронизирует данные очень быстро. Плюс поддерживает работу с rsync сервером. То есть вы можете поднять привычный rsync сервер и с помощью Duplicity забирать с него данные. Это удобно и функционально.
🟢 Rclone. Консольная программа под Linux. Она не совсем для бэкапов, а скорее просто для передачи данных. Я её использую, чтобы складывать в S3 уже подготовленные данные, например шифрованный дамп базы данных. Удобно использовать в своих скриптах.
💡 В дополнение отмечу, что если вам нужен свой сервер на базе S3, то рекомендую поднять его с помощью MinIO. Очень простой в настройке и функциональный продукт.
Если знаете и используете ещё какие-то хорошие продукты по данной тематике, поделитесь информацией. А этот пост рекомендую забрать в закладки.
#backup #S3 #подборка
Вчера в чате один читатель попросил совет на тему бесплатных решений для бэкапа шифрованных архивов в хранилище на базе S3. Я описывал много различных продуктов для бэкапа и довольно быстро нашёл именно те, что умеют в S3 складывать данные. Думаю, эта информация будет полезна всем, так что решил оформить в отдельную заметку.
🟢 Kopia. Поставил на первое место, так как это классное кроссплатформенное решение с управлением как через web, так и cli. Можно в одном месте собрать бэкапы с разных систем. Настраивается просто, функционал обширный. Я использовал этот софт лично, мне понравился.
🟢 Restic. Простая и быстрая консольная программа, состоящая из одного бинарника. Как и Kopia, есть под все системы. В Debian можно из базовой репы поставить. Есть поддержка снепшотов и дедупликации. Отличное решение под автоматизацию на базе самописных скриптов.
🟢 Duplicati. Очень популярная программа. Тоже кроссплатформенная, есть cli и веб интерфейс. Поддерживает много бэкендов в качестве хранилища, типа Dropbox, OneDrive, Google Drive и т.д. Умеет делать инкрементные бэкапы, поддерживает дедупликацию. Функционально и архитектурно похожа на Kopia.
🟢 Duplicity. Программа только под Linux с управлением через cli. Работает на базе библиотеки librsync, как и rsync, а значит синхронизирует данные очень быстро. Плюс поддерживает работу с rsync сервером. То есть вы можете поднять привычный rsync сервер и с помощью Duplicity забирать с него данные. Это удобно и функционально.
🟢 Rclone. Консольная программа под Linux. Она не совсем для бэкапов, а скорее просто для передачи данных. Я её использую, чтобы складывать в S3 уже подготовленные данные, например шифрованный дамп базы данных. Удобно использовать в своих скриптах.
💡 В дополнение отмечу, что если вам нужен свой сервер на базе S3, то рекомендую поднять его с помощью MinIO. Очень простой в настройке и функциональный продукт.
Если знаете и используете ещё какие-то хорошие продукты по данной тематике, поделитесь информацией. А этот пост рекомендую забрать в закладки.
#backup #S3 #подборка
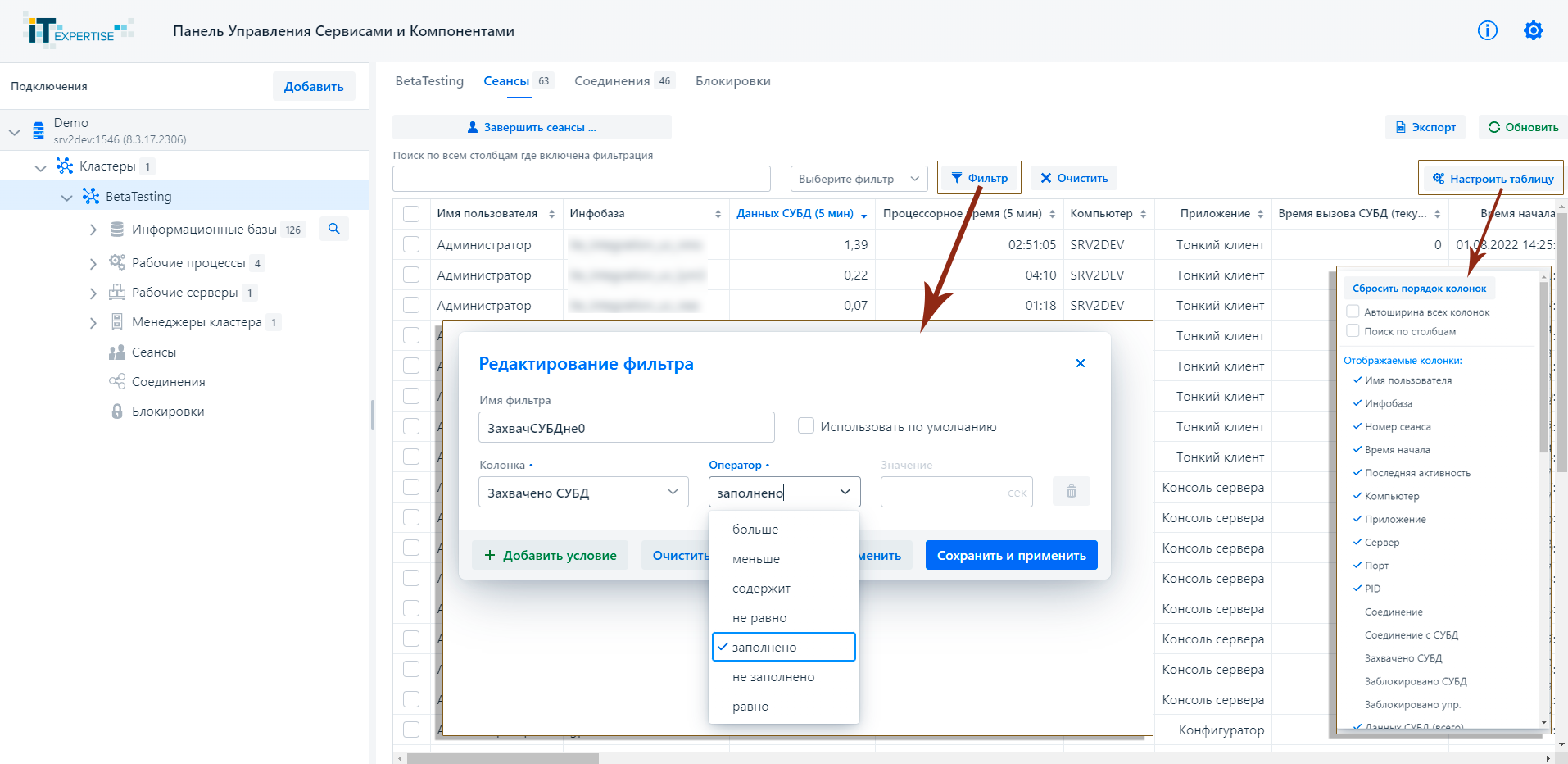
Знакомлю вас с необычным продуктом, аналогов которого я не видел. Речь пойдёт о веб панели для управления кластером 1С, причем не важно, где установленном, на Windows или Linux. У программы, на мой взгляд, не очень удачное название - Панель управления сервисами и компонентами (ПУСК). По нему совершенно не понятно, о чём идёт речь, плюс используется употребляемое в других значениях слово пуск.
Программа бесплатная, написана на Java. Внешний вид максимально приближённо копирует интерфейс штатной консоли для администрирования 1С. Для управления кластером используются стандартные возможности Сервера администрирования кластера (ras), который входит в поставку технологической платформы 1С:Предприятие 8.
С помощью ПУСК можно выполнять привычные действия:
◽ управление кластерами 1С (на различных серверах, с различными версиями платформы 1С);
◽ управление информационными базами 1С;
◽ управление сеансами и блокировками;
◽ управление рабочими процессами и серверами;
◽ управление менеджерами кластера;
◽ статистика использования лицензий.
Как я уже сказал, программа написана на Java, так что для запуска достаточно установить Java версии не ниже 17 и запустить jar файл. Ну и не забыть открыть на фаерволе 8080 порт. Дальше всё делается через браузер. Инструкция по установке есть в архиве с программой, в папке doc. Авторы программы русскоязычные, так что всё подробно описано.
❗️Программа пока находится в статусе беты. Идёт активная разработка. В ближайшем релизе ожидается доработка скриптов запуска, интерфейса, тёмная тема, возможно в этом, либо следующем релизе массовая обработка над информационными базами.
Сам я программу не пробовал, так как нет сейчас подходящего стенда под неё. Да и времени особо тестами заниматься тоже нет. Идея, как по мне, отличная. Если выйдет в релиз, точно буду пользоваться. Для серверов под Linux очень кстати будет.
Сайт - https://it-expertise.ru/pusk/
Обсуждение - https://infostart.ru/public/1713088/
#1С
Программа бесплатная, написана на Java. Внешний вид максимально приближённо копирует интерфейс штатной консоли для администрирования 1С. Для управления кластером используются стандартные возможности Сервера администрирования кластера (ras), который входит в поставку технологической платформы 1С:Предприятие 8.
С помощью ПУСК можно выполнять привычные действия:
◽ управление кластерами 1С (на различных серверах, с различными версиями платформы 1С);
◽ управление информационными базами 1С;
◽ управление сеансами и блокировками;
◽ управление рабочими процессами и серверами;
◽ управление менеджерами кластера;
◽ статистика использования лицензий.
Как я уже сказал, программа написана на Java, так что для запуска достаточно установить Java версии не ниже 17 и запустить jar файл. Ну и не забыть открыть на фаерволе 8080 порт. Дальше всё делается через браузер. Инструкция по установке есть в архиве с программой, в папке doc. Авторы программы русскоязычные, так что всё подробно описано.
❗️Программа пока находится в статусе беты. Идёт активная разработка. В ближайшем релизе ожидается доработка скриптов запуска, интерфейса, тёмная тема, возможно в этом, либо следующем релизе массовая обработка над информационными базами.
Сам я программу не пробовал, так как нет сейчас подходящего стенда под неё. Да и времени особо тестами заниматься тоже нет. Идея, как по мне, отличная. Если выйдет в релиз, точно буду пользоваться. Для серверов под Linux очень кстати будет.
Сайт - https://it-expertise.ru/pusk/
Обсуждение - https://infostart.ru/public/1713088/
#1С
{kind=link}
▶️ На прошлой неделе делал подборку бесплатных обучающих материалов и обратил внимание, что нет вообще ничего на тему Mikrotik. Ни разу не попадалось никаких курсов в свободном доступе по этой теме. Решил поискать в интернете специально, но так ничего похожего на какой-то целостный курс или набор материалов не увидел. Делюсь тем, что нашёл.
🟢 Официальный канал Mikrotik. Там очень много видео, так что найти что-то по настройке не так просто. Надо сразу перейти в плейлисты и выбрать MikroTips. Это как раз обучающие видео по конкретной настройке какого-то функционала. Там же есть плейлисты со всех MUM. Это хоть и не инструкции, но всё равно хороший и качественный материал по теории настройки.
🟢 Канал сертифицированного тренера Романа Козлова - Mikrotik Training. Этот канал мне уже знаком. Смотрел в прошлом несколько вебинаров по интересующим меня темам. Сразу вспомнил вот этот - Передача маршрутов удаленным VPN-клиентам. Автор востребованные темы рассматривает, подробно описывая настройку. Есть чему поучиться.
🟢 Канал сертифицированного тренера Дмитрия Скоромнова
- курсы-по-ит.рф. Я знаю его лично и проходил очное обучение. На канале только отдельные уроки с его платных курсов. Каждый урок рассматривает какую-то узкую тему. Где-то только теория, где-то практика с настройкой устройства. Самих уроков выложено много.
🟢 На англоязычном канале The Network Berg есть полный курс подготовки к MTCNA, который, кстати, тоже проходит на английском языке. Там же в плейлистах советую обратить внимание на лист MTCNA - EVE-NG Setup. Там рассказывается, как развернуть тестовую лабу с микротиками на EVE-NG.
🟢 Также нашёл репозиторий на Github, где представлены русскоязычные материалы по основным темам из MTCNA на русском языке в текстовом виде.
Больше чего-то более ли менее целостного и похожего на обучение по Микротик я не нашёл. Если у вас есть что-то на примете, то поделитесь информацией.
#обучение #mikrotik
🟢 Официальный канал Mikrotik. Там очень много видео, так что найти что-то по настройке не так просто. Надо сразу перейти в плейлисты и выбрать MikroTips. Это как раз обучающие видео по конкретной настройке какого-то функционала. Там же есть плейлисты со всех MUM. Это хоть и не инструкции, но всё равно хороший и качественный материал по теории настройки.
🟢 Канал сертифицированного тренера Романа Козлова - Mikrotik Training. Этот канал мне уже знаком. Смотрел в прошлом несколько вебинаров по интересующим меня темам. Сразу вспомнил вот этот - Передача маршрутов удаленным VPN-клиентам. Автор востребованные темы рассматривает, подробно описывая настройку. Есть чему поучиться.
🟢 Канал сертифицированного тренера Дмитрия Скоромнова
- курсы-по-ит.рф. Я знаю его лично и проходил очное обучение. На канале только отдельные уроки с его платных курсов. Каждый урок рассматривает какую-то узкую тему. Где-то только теория, где-то практика с настройкой устройства. Самих уроков выложено много.
🟢 На англоязычном канале The Network Berg есть полный курс подготовки к MTCNA, который, кстати, тоже проходит на английском языке. Там же в плейлистах советую обратить внимание на лист MTCNA - EVE-NG Setup. Там рассказывается, как развернуть тестовую лабу с микротиками на EVE-NG.
🟢 Также нашёл репозиторий на Github, где представлены русскоязычные материалы по основным темам из MTCNA на русском языке в текстовом виде.
Больше чего-то более ли менее целостного и похожего на обучение по Микротик я не нашёл. Если у вас есть что-то на примете, то поделитесь информацией.
#обучение #mikrotik
Заметка немного не формат канала, но выходные самое время для этого. Почти у каждого дома есть системный блок. У меня их несколько. На Aliexpress вылезла в рекомендациях очень полезная штуковина для него. Я даже не знал, что они существуют. Идея и реализация на 5 баллов.
Китайцы предлагают выдвижной ящик для слота 5,25 системного блока. В полноразмерном системнике их обычно несколько, а так как сидиромы почти не используются, они скорее всего не заняты. Можно это место использовать под флешки, внешние харды, какие-то провода type-c, micro-usb, зарядки для фитнес браслетов и т.д. У меня сейчас под эти дела занят один из ящиков тумбочки рабочего стола.
Дело даже не в том, что появляется дополнительное место, а в том, что оно именно там, где удобно хранить все эти штуки, потому что они тут же и подключаются в usb порты системного блока. Меньше шансов, что будут куда-то положены и забыты. Достал, попользовался и тут же убал.
Реализаций этих ящиков много. Если вам реально нужно, то, думаю, сами найдёте что-то подходящее. Искать по фразе Blank Drawer Rack 5.25. Вот пример.
#железо
Китайцы предлагают выдвижной ящик для слота 5,25 системного блока. В полноразмерном системнике их обычно несколько, а так как сидиромы почти не используются, они скорее всего не заняты. Можно это место использовать под флешки, внешние харды, какие-то провода type-c, micro-usb, зарядки для фитнес браслетов и т.д. У меня сейчас под эти дела занят один из ящиков тумбочки рабочего стола.
Дело даже не в том, что появляется дополнительное место, а в том, что оно именно там, где удобно хранить все эти штуки, потому что они тут же и подключаются в usb порты системного блока. Меньше шансов, что будут куда-то положены и забыты. Достал, попользовался и тут же убал.
Реализаций этих ящиков много. Если вам реально нужно, то, думаю, сами найдёте что-то подходящее. Искать по фразе Blank Drawer Rack 5.25. Вот пример.
#железо
{kind=link}
HackTheBox - одна из самых известных онлайн площадок для практики в тестировании и взломе информационных систем. Использовать её можно бесплатно, но с некоторыми ограничениями, которые могут быть сняты платным тарифным планом. Это отличный инструмент для прокачки своих навыков. При этом не обязательно быть специалистом по информационной безопасности. Системному администратору крайне полезно в общих чертах представлять, как взламывают информационные системы.
Идея HackTheBox следующая. Вы выбираете одну из доступных виртуальных машин, которую можно взломать. Ориентируетесь на описание и уровень сложности. Далее с помощью VPN подключаетесь в подсеть с этой виртуальной машиной и пытаетесь её взломать. Никаких подсказок нет.
Если у вас нет навыков по взлому, то довольно быстро сможете нагуглить описание прохождения и попробовать его повторить. Даже этого будет достаточно, чтобы понимать, к примеру, почему не стоит выставлять в общий доступ тот или иной софт, особенно без свежих обновлений. Хотя публикация прохождений заданий с HackTheBox запрещена правилами сервиса, они всё равно публикуются в сети.
Вот пример прохождения одного из заданий, а вот ещё один, более приближённый к практике. Там наглядно показано, почему нужно закрывать доступ к софту (redis и webmin) и своевременно обновлять его. Также прохождение различных машин в режиме реального времени можно найти на youtube. Мне кажется, это очень хороший формат для самообразования, причём совершенно бесплатный. От вас требуется только упорство и старание.
Сайт - https://hackthebox.com
#обучение #security
Идея HackTheBox следующая. Вы выбираете одну из доступных виртуальных машин, которую можно взломать. Ориентируетесь на описание и уровень сложности. Далее с помощью VPN подключаетесь в подсеть с этой виртуальной машиной и пытаетесь её взломать. Никаких подсказок нет.
Если у вас нет навыков по взлому, то довольно быстро сможете нагуглить описание прохождения и попробовать его повторить. Даже этого будет достаточно, чтобы понимать, к примеру, почему не стоит выставлять в общий доступ тот или иной софт, особенно без свежих обновлений. Хотя публикация прохождений заданий с HackTheBox запрещена правилами сервиса, они всё равно публикуются в сети.
Вот пример прохождения одного из заданий, а вот ещё один, более приближённый к практике. Там наглядно показано, почему нужно закрывать доступ к софту (redis и webmin) и своевременно обновлять его. Также прохождение различных машин в режиме реального времени можно найти на youtube. Мне кажется, это очень хороший формат для самообразования, причём совершенно бесплатный. От вас требуется только упорство и старание.
Сайт - https://hackthebox.com
#обучение #security
{kind=link}
Посмотрел выступление с митапа The Standoff Talks на тему использования Zabbix Server для взлома инфраструктуры - Абузим Zabbix заказчика, или Как бедолаге стать хозяином подконтрольных узлов.
https://youtu.be/ufSVRxdVNQU?t=9107
Если не хочется смотреть видео, то всё самое основное можно посмотреть в pdf презентации. Само выступление тем, кто хорошо знает Zabbix, будет не интересно, так как там подробно разбирается техническая часть - как всё устроено в Zabbix и как он работает.
В выступлении рассказывается, как имея частичный или полный доступ к веб интерфейсу Zabbix Server можно захватывать инфраструктуру, которая мониторится. Сразу скажу, что никаких катастрофических провалов в самом Zabbix Server в плане безопасности нет. Достаточно выполнять общие рекомендации по безопасности и всё будет в порядке.
⚡️ Основные векторы атаки:
▪ Перехват учётных данных для доступа к веб интерфейсу.
▪ Использование Zabbix API.
▪ Использование функционала по запуску удалённых команд через zabbix-agent.
▪ Использование ключей айтемов Zabbix, с помощью которых можно выполнять команды или собирать информацию с хостов: system.run, registry.data, system.hw.macaddr, wmi.get, vfs.file.exists, vfs.file.contents и т.д.
🛡 Основные рекомендации, которые помогут защититься от взлома (это мои соображения):
◽ Если нет необходимости, не выставляйте веб интерфейс Zabbix в общий доступ.
◽ Всегда используйте HTTPS соединение с веб интерфейсом.
◽ Если нет большой нужды, не разрешайте выполнение удалённых команд через zabbix-agent. Я часто ими пользуюсь, удобный функционал.
◽ Всегда настраивайте tls соединения между агентом и сервером.
◽ Не запускайте zabbix-agent под root. Я иногда запускаю, но знаю, что это плохая практика.
◽ Не сидите постоянно в веб интерфейсе под Super Admin и не раздавайте без необходимости эти права.
◽ Внимательно следите за содержимым скриптов для удалённого выполнения, если ими пользуетесь. Это основной вектор атак.
◽ Ограничивайте с помощью firewall доступ к серверу и агентам. Tcp порт 10051 сервера должен быть доступен только для агентов, а к портам 10050 агентов должен быть доступ только с сервера мониторинга.
Если следовать всем этим правилам, а это не так сложно, то проблем с безопасностью Zabbix Server вам не добавит.
#zabbix #security
https://youtu.be/ufSVRxdVNQU?t=9107
Если не хочется смотреть видео, то всё самое основное можно посмотреть в pdf презентации. Само выступление тем, кто хорошо знает Zabbix, будет не интересно, так как там подробно разбирается техническая часть - как всё устроено в Zabbix и как он работает.
В выступлении рассказывается, как имея частичный или полный доступ к веб интерфейсу Zabbix Server можно захватывать инфраструктуру, которая мониторится. Сразу скажу, что никаких катастрофических провалов в самом Zabbix Server в плане безопасности нет. Достаточно выполнять общие рекомендации по безопасности и всё будет в порядке.
⚡️ Основные векторы атаки:
▪ Перехват учётных данных для доступа к веб интерфейсу.
▪ Использование Zabbix API.
▪ Использование функционала по запуску удалённых команд через zabbix-agent.
▪ Использование ключей айтемов Zabbix, с помощью которых можно выполнять команды или собирать информацию с хостов: system.run, registry.data, system.hw.macaddr, wmi.get, vfs.file.exists, vfs.file.contents и т.д.
🛡 Основные рекомендации, которые помогут защититься от взлома (это мои соображения):
◽ Если нет необходимости, не выставляйте веб интерфейс Zabbix в общий доступ.
◽ Всегда используйте HTTPS соединение с веб интерфейсом.
◽ Если нет большой нужды, не разрешайте выполнение удалённых команд через zabbix-agent. Я часто ими пользуюсь, удобный функционал.
◽ Всегда настраивайте tls соединения между агентом и сервером.
◽ Не запускайте zabbix-agent под root. Я иногда запускаю, но знаю, что это плохая практика.
◽ Не сидите постоянно в веб интерфейсе под Super Admin и не раздавайте без необходимости эти права.
◽ Внимательно следите за содержимым скриптов для удалённого выполнения, если ими пользуетесь. Это основной вектор атак.
◽ Ограничивайте с помощью firewall доступ к серверу и агентам. Tcp порт 10051 сервера должен быть доступен только для агентов, а к портам 10050 агентов должен быть доступ только с сервера мониторинга.
Если следовать всем этим правилам, а это не так сложно, то проблем с безопасностью Zabbix Server вам не добавит.
#zabbix #security
{kind=link}
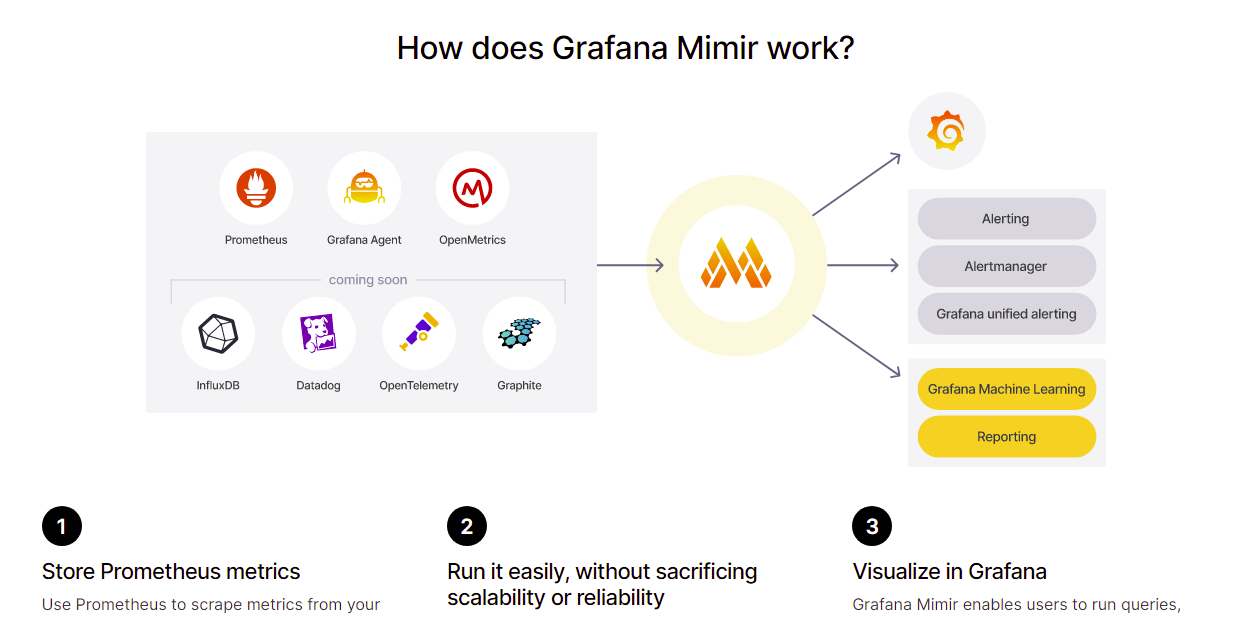
Долгосрочное хранение метрик всегда было одной из слабых сторон Prometheus. Изначально он был спроектирован для оперативного мониторинга, не подразумевающего хранение истории метрик на срок более двух недель. Сохранить в нём тренды месячных или годовых интервалов было отдельной задачей с привлечением внешних хранилищ и инструментов.
Весной Grafana анонсировала своё решение под названием Grafana Mimir, которое способно максимально просто, быстро и дёшево решить вопрос с долгосрочным хранением метрик в том числе с помощью S3 совместимого хранилища. В самом простом варианте может на файловую систему складывать данные. Одним из основных преимуществ указывается возможность быстро и просто настроить горизонтально масштабируемый high availability кластер хранения.
Настроить всё это дело реально очень просто.
1️⃣ Поднимаете в Docker сервер Mimir, указав в его конфиге бэкенд для хранения данных. В самом простом случае это может быть локальная директория.
2️⃣ Указываете в Prometheus в качестве remote_write сервер с Mimir.
3️⃣ В веб панели Grafana добавляете сервер Mimir в качестве Prometheus data source.
Авторы Mimir называют её самой производительной TSDB для долговременного хранения метрик Prometheus. Насколько это правда, трудно судить. Вот пример их нагрузочных тестов. Авторы конкурирующего хранилища из VictoriaMetrics собрали свои стенды с обоими продуктами и протестировали их производительность. В результате оказалось, что Mimir более требовательна к памяти, больше нагружает процессор и больше расходует места хранилища, но имеет ниже задержку в 50-м перцентиле и выше в 99-м. По результатам теста почти по всем параметрам Mimir хуже, причем с кратной разницей, что немного странно.
Ниже ссылка на get started, где в самом начале представлено наглядное видео по настройке связки Prometheus + Grafana + Mimir + MinIO.
Сайт - https://grafana.com/oss/mimir/
Исходники - https://github.com/grafana/mimir
Get started - https://grafana.com/docs/mimir/v2.3.x/operators-guide/get-started/
#prometheus #grafana #devops #мониторинг
Весной Grafana анонсировала своё решение под названием Grafana Mimir, которое способно максимально просто, быстро и дёшево решить вопрос с долгосрочным хранением метрик в том числе с помощью S3 совместимого хранилища. В самом простом варианте может на файловую систему складывать данные. Одним из основных преимуществ указывается возможность быстро и просто настроить горизонтально масштабируемый high availability кластер хранения.
Настроить всё это дело реально очень просто.
1️⃣ Поднимаете в Docker сервер Mimir, указав в его конфиге бэкенд для хранения данных. В самом простом случае это может быть локальная директория.
2️⃣ Указываете в Prometheus в качестве remote_write сервер с Mimir.
3️⃣ В веб панели Grafana добавляете сервер Mimir в качестве Prometheus data source.
Авторы Mimir называют её самой производительной TSDB для долговременного хранения метрик Prometheus. Насколько это правда, трудно судить. Вот пример их нагрузочных тестов. Авторы конкурирующего хранилища из VictoriaMetrics собрали свои стенды с обоими продуктами и протестировали их производительность. В результате оказалось, что Mimir более требовательна к памяти, больше нагружает процессор и больше расходует места хранилища, но имеет ниже задержку в 50-м перцентиле и выше в 99-м. По результатам теста почти по всем параметрам Mimir хуже, причем с кратной разницей, что немного странно.
Ниже ссылка на get started, где в самом начале представлено наглядное видео по настройке связки Prometheus + Grafana + Mimir + MinIO.
Сайт - https://grafana.com/oss/mimir/
Исходники - https://github.com/grafana/mimir
Get started - https://grafana.com/docs/mimir/v2.3.x/operators-guide/get-started/
#prometheus #grafana #devops #мониторинг
{kind=link}
Каждый, кто администрировал компании с количеством сетевых устройств от 100 и более знает, что по мере роста локальной сети начинаются проблемы с сегментацией. Точнее проблемы начинаются, если сегментацию не делать. А вот как её правильно сделать, вопрос дискуссионный. Каждый исходя их своих условий начинает соображать, как ему лучше сделать.
Отдельная головная боль, если компания растёт плавно и тебе приходится перестраиваться по ходу дела. Если есть возможность продумать и спроектировать заранее, то задача сильно упрощается.
Я в сети нашёл интересный репозиторий, где автор предлагает свои планы по сегментации типичной корпоративной сети с пользователями, разработчиками, с офисной и внешней инфраструктурой, в том числе с частичным управлением внешними подрядчиками.
Вначале бегло посмотрел и ничего не понял. Подумал, что ерунда какая-то, куча стрелок и квадратиков. Потом всё же задержался и внимательно изучил схемы. Они на самом деле интересные. Полезно посмотреть и проанализировать чужой опыт, наложить на свой и подумать, как лучше сделать.
Наиболее приближённые к обычной жизни первые две схемы. Первая вообще про обычную среднестатистическую компанию, где просто сделано хорошо с точки зрения сегментации и изоляции на основе здравого смысла и прямой логики. Вторая про такую же, но где сделано не только хорошо, но и с небольшим уклоном в безопасность. Добавили почтовый релей, побольше не связанных серверов времени, офисную сеть немного разделили и т.д.
Третий и четвертый вариант уже жёсткие для тех, у кого есть безопасники и все сопутствующие мероприятия с их участием. Там я не знаю, можно ли что-то советовать со стороны. Я так понимаю, тем же безопасникам сегментацию сети преподают на основе каких-то методик, и строят они её не на основе разумений системного или сетевого администратора.
У вас получалось когда-нибудь построить идеальную сеть такой, какой вы хотели бы её видеть? У меня никогда этого не получалось. Всегда приходилось идти на какие-то компромиссы из-за недостатка или ограничений железа, из-за лени, из-за невозможности найти технологическое окно или нежелания выполнить нормально настройку в нерабочее или ночное время. Так в итоге и откладываешь некоторые изменения на неопределённый срок. Вроде работает, да и ладно.
https://github.com/sergiomarotco/Network-segmentation-cheat-sheet
#обучение #network
Отдельная головная боль, если компания растёт плавно и тебе приходится перестраиваться по ходу дела. Если есть возможность продумать и спроектировать заранее, то задача сильно упрощается.
Я в сети нашёл интересный репозиторий, где автор предлагает свои планы по сегментации типичной корпоративной сети с пользователями, разработчиками, с офисной и внешней инфраструктурой, в том числе с частичным управлением внешними подрядчиками.
Вначале бегло посмотрел и ничего не понял. Подумал, что ерунда какая-то, куча стрелок и квадратиков. Потом всё же задержался и внимательно изучил схемы. Они на самом деле интересные. Полезно посмотреть и проанализировать чужой опыт, наложить на свой и подумать, как лучше сделать.
Наиболее приближённые к обычной жизни первые две схемы. Первая вообще про обычную среднестатистическую компанию, где просто сделано хорошо с точки зрения сегментации и изоляции на основе здравого смысла и прямой логики. Вторая про такую же, но где сделано не только хорошо, но и с небольшим уклоном в безопасность. Добавили почтовый релей, побольше не связанных серверов времени, офисную сеть немного разделили и т.д.
Третий и четвертый вариант уже жёсткие для тех, у кого есть безопасники и все сопутствующие мероприятия с их участием. Там я не знаю, можно ли что-то советовать со стороны. Я так понимаю, тем же безопасникам сегментацию сети преподают на основе каких-то методик, и строят они её не на основе разумений системного или сетевого администратора.
У вас получалось когда-нибудь построить идеальную сеть такой, какой вы хотели бы её видеть? У меня никогда этого не получалось. Всегда приходилось идти на какие-то компромиссы из-за недостатка или ограничений железа, из-за лени, из-за невозможности найти технологическое окно или нежелания выполнить нормально настройку в нерабочее или ночное время. Так в итоге и откладываешь некоторые изменения на неопределённый срок. Вроде работает, да и ладно.
https://github.com/sergiomarotco/Network-segmentation-cheat-sheet
#обучение #network
GitHub
GitHub - sergiomarotco/Network-segmentation-cheat-sheet: Best practices for segmentation of the corporate network of any company
Best practices for segmentation of the corporate network of any company - sergiomarotco/Network-segmentation-cheat-sheet
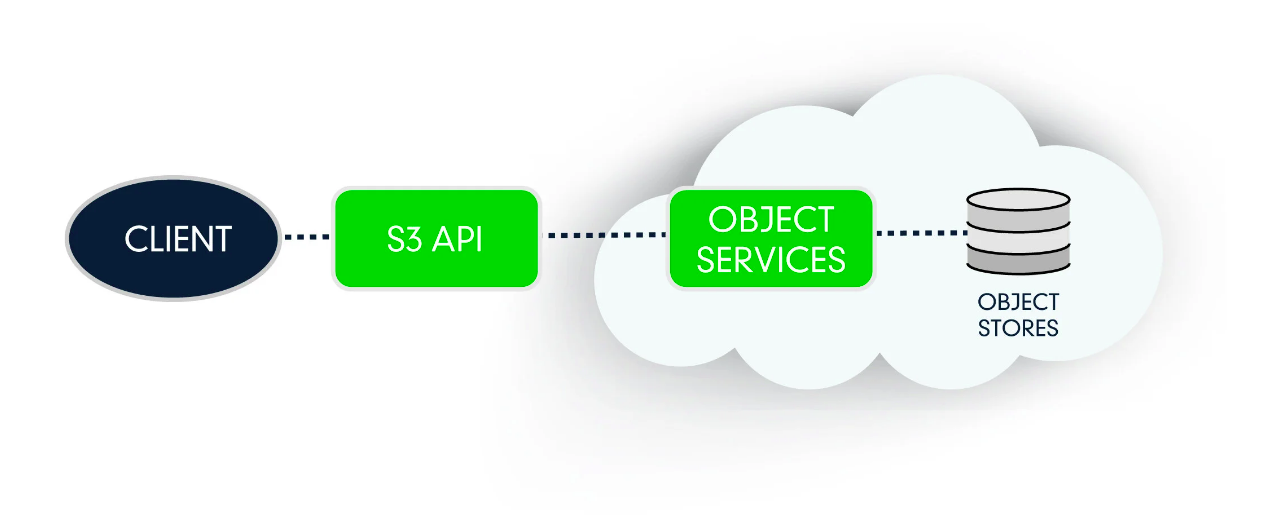
❓Неоднократно получал вопросы на тему современных S3 (Simple Storage Service) совместимых хранилищ. Для чего они нужны, почему такие популярные и чем лучше того же NFS или SMB?
Консерваторы считают это хипстерской поделкой для девопсов, которые не хотят и не умеют ни в чём разбираться, а хотят просто денежки чужие заплатить и получить результат, не прилагая усилий.
Я неоднократно в комментариях отвечал на этот вопрос, поэтому решил вынести его в отдельную заметку и своими словами пояснить, чем удобны подобные хранилища и за счёт чего завоевали популярность.
Замечал, что некоторые люди путают и считают, что когда речь идёт о S3 хранилище данных, подразумевается объектное хранилище Amazon S3. Да, Amazon придумал и внедрил подобное хранилище, оснастив его S3 RESTful API. Сейчас появилось огромное количество продуктов и сервисов, которые на 100% поддерживают S3 API. Именно их и называют S3 хранилищами. Можно выбирать на любой вкус и кошелёк. Практически у всех крупных провайдеров есть подобный сервис.
➕Преимущества объектного хранилища S3 (Object storage S3):
🟢 Возможность быстро обратиться к файлу по его идентификатору, получить его метаданные. При этом в бэкенде у хранилища может быть всё, что угодно, API запросов будет везде одинаковый.
🟢 Удобные для провайдера возможности тарификации в зависимости от активности клиентов. Это позволяет клиентам получать необходимый объём, линейно его изменяя, и платить только за потребляемые ресурсы: объём, трафик, количество запросов.
🟢 Данные могут храниться в отдельных контейнерах со своими настройками доступа, хранения, производительности и т.д. То есть их удобно структурировать и разделять информацию по различным типам.
🟢 Все объекты хранилища располагаются в плоском адресном пространстве, без иерархии, которая присутствует в обычной файловой системе. Это упрощает доступ и работу с файлами. Нет проблем с ограничением на длину пути к файлу или с именем файла.
➖Минусы:
🟠 Больше накладных расходов на хранение информации.
🟠 Ниже скорость работы с файлами по сравнению с блочными хранилищами.
Несмотря на то, что хранение файлов в объектных хранилищах дороже, чем в блочных или файловых, за счёт более гибкой и точной тарификации для клиента это всё равно выходит выгоднее, так как он платит только за то, что реально использовал. А минус в скорости работы компенсируется простотой горизонтального масштабирования S3 хранилищ.
❗️Нужно хорошо понимать, что S3 это не про скорость доступа, а про объём и унификацию.
Расписал всё своими словами. Надеюсь понятно объяснил. На практике S3 лучше всего подходит под хранение статических файлов больших сайтов, архивов видеонаблюдения, логов, бэкапов. Конкретно я именно для холодных бэкапов их использую. Обычно это бэкапы бэкапов, копируются с помощью rclone.
#s3
Консерваторы считают это хипстерской поделкой для девопсов, которые не хотят и не умеют ни в чём разбираться, а хотят просто денежки чужие заплатить и получить результат, не прилагая усилий.
Я неоднократно в комментариях отвечал на этот вопрос, поэтому решил вынести его в отдельную заметку и своими словами пояснить, чем удобны подобные хранилища и за счёт чего завоевали популярность.
Замечал, что некоторые люди путают и считают, что когда речь идёт о S3 хранилище данных, подразумевается объектное хранилище Amazon S3. Да, Amazon придумал и внедрил подобное хранилище, оснастив его S3 RESTful API. Сейчас появилось огромное количество продуктов и сервисов, которые на 100% поддерживают S3 API. Именно их и называют S3 хранилищами. Можно выбирать на любой вкус и кошелёк. Практически у всех крупных провайдеров есть подобный сервис.
➕Преимущества объектного хранилища S3 (Object storage S3):
🟢 Возможность быстро обратиться к файлу по его идентификатору, получить его метаданные. При этом в бэкенде у хранилища может быть всё, что угодно, API запросов будет везде одинаковый.
🟢 Удобные для провайдера возможности тарификации в зависимости от активности клиентов. Это позволяет клиентам получать необходимый объём, линейно его изменяя, и платить только за потребляемые ресурсы: объём, трафик, количество запросов.
🟢 Данные могут храниться в отдельных контейнерах со своими настройками доступа, хранения, производительности и т.д. То есть их удобно структурировать и разделять информацию по различным типам.
🟢 Все объекты хранилища располагаются в плоском адресном пространстве, без иерархии, которая присутствует в обычной файловой системе. Это упрощает доступ и работу с файлами. Нет проблем с ограничением на длину пути к файлу или с именем файла.
➖Минусы:
🟠 Больше накладных расходов на хранение информации.
🟠 Ниже скорость работы с файлами по сравнению с блочными хранилищами.
Несмотря на то, что хранение файлов в объектных хранилищах дороже, чем в блочных или файловых, за счёт более гибкой и точной тарификации для клиента это всё равно выходит выгоднее, так как он платит только за то, что реально использовал. А минус в скорости работы компенсируется простотой горизонтального масштабирования S3 хранилищ.
❗️Нужно хорошо понимать, что S3 это не про скорость доступа, а про объём и унификацию.
Расписал всё своими словами. Надеюсь понятно объяснил. На практике S3 лучше всего подходит под хранение статических файлов больших сайтов, архивов видеонаблюдения, логов, бэкапов. Конкретно я именно для холодных бэкапов их использую. Обычно это бэкапы бэкапов, копируются с помощью rclone.
#s3
{kind=link}
Давно не было заметок про чаты. Одно время обозревал все наиболее известные бесплатные решения с возможностью установки своего сервера. Посмотреть их можно по тэгу #chat.
Сегодня расскажу про ещё один бесплатный чат-сервер и клиент, который попробовал сам. Речь пойдёт про SimpleX Chat. Своими словами об особенностях, на которые я лично обратил внимание:
◽ возможность использовать свой сервер на Linux для соединения клиентов;
◽ возможность установить консольный клиент на Linux, общаться и передавать файлы на клиенты других платформ (MacOS, Windows, Android, iOS), десктопные клиенты только консольные;
◽ чат полностью независим от каких-либо внешних компонентов или сервисов, для регистрации и общения не нужно ничего указывать;
◽ можно совершать аудио и видео звонки;
◽ сообщения хранятся только на стороне пользователя.
🛡 SimpleX позиционирует себя как очень защищённая, приватная платформа для общения с двойным E2E шифрованием (End-to-End Encryption) всей передаваемой информацией. С учётом того, что можно использовать open source клиенты и серверы, скорее всего это так и есть.
На практике общение выглядит так. Вы устанавливаете клиенты на необходимые устройства. Например, на смартфон и сервер под Linux. Никаких регистраций нигде не надо, достаточно указать только имя, по которому вас будут видеть собеседники. Если не используете свой сервер для соединения, по умолчанию используется пул серверов от разработчиков на поддоменах simplex.im. Поменять сервер можно в настройках.
Чтобы связать два устройства между собой, необходимо на одном из них сформировать специальный код для подключения и передать его другому человеку. Можно в виде текста или qr кода. Этот человек добавляет новый контакт и указывает этот код. Теперь можно переписываться.
На практике я не знаю, кому может пригодиться подобная секретность или анонимность. Но параноиков сейчас масса, так что проект активно развивается, регулярно выходят обновления. Клиенты написаны на Haskell, Swift и Kotlin. Ещё раз отмечу, что десктопные клиенты только консольные. Подозреваю, что это временно, так как протокол общения открытый. Сервер можно развернуть из готовых шаблонов VM у крупных хостеров, например Linode или DigitalOcean.
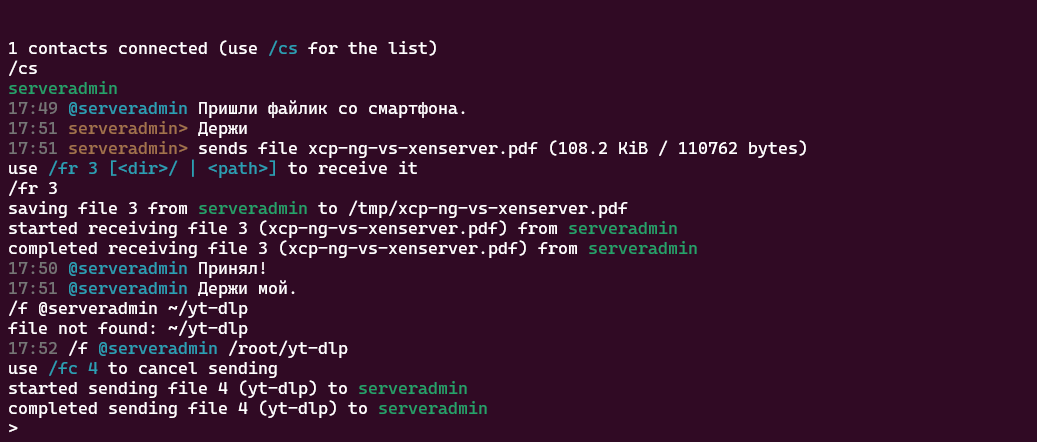
Лично мне показалось удобным перекидывать файлы через консольный клиент с сервера на смартфон или обратно. Поддерживается групповое общение. То есть можно создать группу серверов и через смартфон передавать туда какие-то файлы или наоборот. Всё это через свою инфраструктуру, без отсвечивания на сторонних сервисах. Можно заскриптовать какие-то действия.
Сайт - https://simplex.chat
Исходники клиента - https://github.com/simplex-chat/simplex-chat
Исходники сервера - https://github.com/simplex-chat/simplexmq
#chat
Сегодня расскажу про ещё один бесплатный чат-сервер и клиент, который попробовал сам. Речь пойдёт про SimpleX Chat. Своими словами об особенностях, на которые я лично обратил внимание:
◽ возможность использовать свой сервер на Linux для соединения клиентов;
◽ возможность установить консольный клиент на Linux, общаться и передавать файлы на клиенты других платформ (MacOS, Windows, Android, iOS), десктопные клиенты только консольные;
◽ чат полностью независим от каких-либо внешних компонентов или сервисов, для регистрации и общения не нужно ничего указывать;
◽ можно совершать аудио и видео звонки;
◽ сообщения хранятся только на стороне пользователя.
🛡 SimpleX позиционирует себя как очень защищённая, приватная платформа для общения с двойным E2E шифрованием (End-to-End Encryption) всей передаваемой информацией. С учётом того, что можно использовать open source клиенты и серверы, скорее всего это так и есть.
На практике общение выглядит так. Вы устанавливаете клиенты на необходимые устройства. Например, на смартфон и сервер под Linux. Никаких регистраций нигде не надо, достаточно указать только имя, по которому вас будут видеть собеседники. Если не используете свой сервер для соединения, по умолчанию используется пул серверов от разработчиков на поддоменах simplex.im. Поменять сервер можно в настройках.
Чтобы связать два устройства между собой, необходимо на одном из них сформировать специальный код для подключения и передать его другому человеку. Можно в виде текста или qr кода. Этот человек добавляет новый контакт и указывает этот код. Теперь можно переписываться.
На практике я не знаю, кому может пригодиться подобная секретность или анонимность. Но параноиков сейчас масса, так что проект активно развивается, регулярно выходят обновления. Клиенты написаны на Haskell, Swift и Kotlin. Ещё раз отмечу, что десктопные клиенты только консольные. Подозреваю, что это временно, так как протокол общения открытый. Сервер можно развернуть из готовых шаблонов VM у крупных хостеров, например Linode или DigitalOcean.
Лично мне показалось удобным перекидывать файлы через консольный клиент с сервера на смартфон или обратно. Поддерживается групповое общение. То есть можно создать группу серверов и через смартфон передавать туда какие-то файлы или наоборот. Всё это через свою инфраструктуру, без отсвечивания на сторонних сервисах. Можно заскриптовать какие-то действия.
Сайт - https://simplex.chat
Исходники клиента - https://github.com/simplex-chat/simplex-chat
Исходники сервера - https://github.com/simplex-chat/simplexmq
#chat
{kind=link}
Надо оживить рубрику с однострочниками на bash. Раньше регулярно публиковал, так как вижу очень большой отклик на подобные заметки. Да я и сам их люблю. С удовольствием читаю у других и забираю к себе в закладки то, что посчитаю полезным. У меня большая структурированная коллекция bash команд, разбитая по темам и приложениям. Пополняется уже лет 15. Складываю туда только то, что реально использую, а не всё подряд. Иначе смысл теряется. Рекомендую поступать так же.
Работа с файлами и директориями
📌 Создание сразу нескольких директорий dir1, dir2, dir3:
То же самое, только с файлами. Создаём 3 файла:
Переименовываем файл:
Удобный приём с оператором { }, можно использовать в различных командах.
📌 Смотрим файл конфигурации без комментариев (начинаются с ; или #) и пустых (^$) строк:
Этим постоянно приходится пользоваться, особенно в конфигах php, asterisk, postgresql.
📌 Удаляем комментарии и пустые строки и записываем чистый конфиг в новый файл:
Изменение параметра в конфиге post_max_size на новое значение:
Сначала запустите команду без ключа -i и проверьте результат. Файл не изменится.
📌 Сравниваем содержимое файлов двух директорий с выводом результата в файл:
Удобно для поиска изменений в файлах сайта после взлома. Сравниваете с бэкапом и сразу все изменения перед глазами.
📌 Считаем размер всех файлов определённого типа в директории.
Результат будет в байтах.
Вам было бы интересно увидеть разбор каких-то длинных и на первый взгляд непонятных конструкций на bash? Я хоть и не пишу сам ничего сложного, но всегда понимаю, что реально происходит в выполняемых конструкциях, даже если они очень длинные и кажутся обфусцированными.
#bash
Работа с файлами и директориями
📌 Создание сразу нескольких директорий dir1, dir2, dir3:
# mkdir -p -v /home/user/{dir1,dir2,dir3}То же самое, только с файлами. Создаём 3 файла:
# touch file0{1,2,3}Переименовываем файл:
# mv file.{old,new}Удобный приём с оператором { }, можно использовать в различных командах.
📌 Смотрим файл конфигурации без комментариев (начинаются с ; или #) и пустых (^$) строк:
# grep -E -v '^;|^#|^$' /etc/php.iniЭтим постоянно приходится пользоваться, особенно в конфигах php, asterisk, postgresql.
📌 Удаляем комментарии и пустые строки и записываем чистый конфиг в новый файл:
# sed '/^;\|^$\|^#/d' php.ini > php.ini.cleanИзменение параметра в конфиге post_max_size на новое значение:
# sed -i 's/^post_max_size =.*/post_max_size = 16M/g' php.iniСначала запустите команду без ключа -i и проверьте результат. Файл не изменится.
📌 Сравниваем содержимое файлов двух директорий с выводом результата в файл:
# diff -Naur /var/www/site.ru/ /mnt/backup/site.ru/ > ~/site.diffУдобно для поиска изменений в файлах сайта после взлома. Сравниваете с бэкапом и сразу все изменения перед глазами.
📌 Считаем размер всех файлов определённого типа в директории.
# i=0; for n in $(find /mnt/files -type f -name '*.iso' -print \| xargs stat --printf "%s "); do ((i+=n)); done; echo $iРезультат будет в байтах.
Вам было бы интересно увидеть разбор каких-то длинных и на первый взгляд непонятных конструкций на bash? Я хоть и не пишу сам ничего сложного, но всегда понимаю, что реально происходит в выполняемых конструкциях, даже если они очень длинные и кажутся обфусцированными.
#bash
{kind=link}
Очень простой и быстрый способ передать файлы с Linux сервера в любое другое место. Если никогда не слышали о нём, то наверняка оцените и заберёте в закладки. Всё, что нужно, это Python, который есть по умолчанию почти во всех дистрибутивах.
Идёте по адресу http://10.20.1.43:8181 и скачиваете нужные вам файлы. Потом возвращаетесь в консоль и завершаете работу временного веб сервера, нажатием Ctrl+C. Все обращения к веб серверу вы увидите в логе прямо в консоли.
Если у вас Windows и WSL, то тоже сработает. Таким образом передать файлы даже проще, чем по smb через расшаренную папку. Дома вообще красота перекинуть что-то жене или детям со своего ноута. Не надо ничего копировать и объяснять, достаточно прямую ссылку на файл скинуть.
#webserver
# cd /var/log# python3 -m http.server 8181Идёте по адресу http://10.20.1.43:8181 и скачиваете нужные вам файлы. Потом возвращаетесь в консоль и завершаете работу временного веб сервера, нажатием Ctrl+C. Все обращения к веб серверу вы увидите в логе прямо в консоли.
Если у вас Windows и WSL, то тоже сработает. Таким образом передать файлы даже проще, чем по smb через расшаренную папку. Дома вообще красота перекинуть что-то жене или детям со своего ноута. Не надо ничего копировать и объяснять, достаточно прямую ссылку на файл скинуть.
#webserver
{kind=link}