
Jenkins: СI/CD для DevOps и разработчиков
6 сентября стартует курс по Jenkins от Кирилла Борисова, Infrastructure Engineer технологического центра Deutsche Bank. В курсе будет много кейсов и примеров из практики спикера.
Вы научитесь:
- Автоматизировать процесс интеграции и поставки
- Ускорять цикл разработки и внедрять полезные инструменты
- Настраивать плагины и создавать пайплайны Jenkins as a code
- Работать с Jenkins Shared Library
Что вас ждёт на курсе:
📌 «Живые» уроки со спикером. Они проходят два раза в неделю по вторникам и четвергам. На них спикер объясняет теорию и показывает, как выполнять практические задания. В конце каждого урока предусмотрена QA-сессия, где можно задать вопросы.
📌 Много практики. После каждого урока вы получаете домашнее задание по теме. Для выполнения вам будут предоставлены настоящие сервера Selectel, предварительно настроенные для практики. Задания максимально приближены к реальным задачам, с которыми вы можете столкнуться в работе.
📌 Закрытый чат со спикером. На время потока мы создадим чат, где вы сможете задать Кириллу любой вопрос по Jenkins и оперативно получить ответ. После окончания курса чат будет закрыт, но вы всё равно сможете перечитать сообщения и освежить нужный диалог в памяти.
📌 Итоговое задание. Задание включает все темы, рассмотренные в рамках курса. Чтобы решить его, понадобится применить полученные знания в комплексе.
Здесь можно ознакомиться с подробной программой и занять местечко 👉 https://slurm.club/3aL4gSE
Ждём всех, кто хочет получить фундаментальные знания по работе с Jenkins и не тратить время на изобретение решений😈
#реклама
6 сентября стартует курс по Jenkins от Кирилла Борисова, Infrastructure Engineer технологического центра Deutsche Bank. В курсе будет много кейсов и примеров из практики спикера.
Вы научитесь:
- Автоматизировать процесс интеграции и поставки
- Ускорять цикл разработки и внедрять полезные инструменты
- Настраивать плагины и создавать пайплайны Jenkins as a code
- Работать с Jenkins Shared Library
Что вас ждёт на курсе:
📌 «Живые» уроки со спикером. Они проходят два раза в неделю по вторникам и четвергам. На них спикер объясняет теорию и показывает, как выполнять практические задания. В конце каждого урока предусмотрена QA-сессия, где можно задать вопросы.
📌 Много практики. После каждого урока вы получаете домашнее задание по теме. Для выполнения вам будут предоставлены настоящие сервера Selectel, предварительно настроенные для практики. Задания максимально приближены к реальным задачам, с которыми вы можете столкнуться в работе.
📌 Закрытый чат со спикером. На время потока мы создадим чат, где вы сможете задать Кириллу любой вопрос по Jenkins и оперативно получить ответ. После окончания курса чат будет закрыт, но вы всё равно сможете перечитать сообщения и освежить нужный диалог в памяти.
📌 Итоговое задание. Задание включает все темы, рассмотренные в рамках курса. Чтобы решить его, понадобится применить полученные знания в комплексе.
Здесь можно ознакомиться с подробной программой и занять местечко 👉 https://slurm.club/3aL4gSE
Ждём всех, кто хочет получить фундаментальные знания по работе с Jenkins и не тратить время на изобретение решений😈
#реклама
Много раз уже мельком в тематических заметках упоминал про инструмент, которым постоянно пользуюсь. Решил оформить отдельной заметкой, чтобы больше людей обратило внимание. Речь пойдёт о JSONPath Online Evaluator, который есть в виде публичного сервиса, и в виде исходников для установки где-то у себя.
Это простой и наглядный сервис для работы с JSON. Мне он нужен ровно для одной цели - вытаскивать значения с помощью JSONPath для предобработки в Zabbix. JSON очень популярный формат, так что работать с ним приходится постоянно. Возможность предобработки в Zabbix очень сильно упростила настройку мониторинга.
Раньше всё это обрабатывать в скриптах приходилось, но времена сие давно прошли, хотя куча скриптов с тех времён так и осталась. Но сейчас, если настраиваю что-то новое, то по максимум использую встроенную предобработку.
Если есть что-то лучше для этих же задач, поделитесь информацией.
#json
Это простой и наглядный сервис для работы с JSON. Мне он нужен ровно для одной цели - вытаскивать значения с помощью JSONPath для предобработки в Zabbix. JSON очень популярный формат, так что работать с ним приходится постоянно. Возможность предобработки в Zabbix очень сильно упростила настройку мониторинга.
Раньше всё это обрабатывать в скриптах приходилось, но времена сие давно прошли, хотя куча скриптов с тех времён так и осталась. Но сейчас, если настраиваю что-то новое, то по максимум использую встроенную предобработку.
Если есть что-то лучше для этих же задач, поделитесь информацией.
#json
{kind=link}
Если вы когда-нибудь сталкивались со взломом серверов, то наверняка видели скрипты с абракадаброй, которые таинственным образом то и дело всплывают в cron, либо запускаются раз за разом, хотя вы их прибиваете, а файлы удаляете. Моя рекомендация по любому взлому - переустановка системы. Это всегда быстрее, проще, надёжнее, чем пытаться вылечить. Но рассказать хотел не об этом.
Существует множество инструментов по обфускации кода, то есть превращение его в нечитаемую кашу, чтобы невозможно было однозначно понять, что он делает. Один из инструментов для bash - Bashfuscator. Он превращает bash код в абракадабру. Когда изучал его, повеселил один из комментариев на Reddit по поводу этого софта. Примерный перевод такой:
Разве для bash нужен обфускатор? Его и так невозможно понять.
На что разработчик ответил:
Это правда. До написания Bashfuscator я не очень хорошо понимал bash. Для непосвящённых он выглядит как случайный набор символов, но тем не менее до Perl ему далеко.
Bashfuscator написан на Python, ставится так:
Бинарник будет в директории ~/Bashfuscator/bashfuscator/bin.
Использовать примерно так:
Знаете, что я первым делом проверил этим обфускатором? Команду:
Обфусцированный код исполнился без всяких предупреждений и грохнул систему. Только не надо это повторять и кому-то вредить. Просто знайте, что может случиться вот такая ситуация. Будьте с таким кодом предельно аккуратны, если кто-то пошутит и пришлёт.
Для себя не могу придумать ситуации, где бы мне пригодился подобный обфускатор. Остался непонятен самый главный вопрос. Можно ли такой обфусцированный код превратить обратно в читаемый? По идее, простого способа не существует. Вариант только один - как-то отслеживать выполнение и на основе этого предполагать исходный код. Кто-то знает на практике как это реализуется?
Исходники / Документация / Reddit
#bash #security
Существует множество инструментов по обфускации кода, то есть превращение его в нечитаемую кашу, чтобы невозможно было однозначно понять, что он делает. Один из инструментов для bash - Bashfuscator. Он превращает bash код в абракадабру. Когда изучал его, повеселил один из комментариев на Reddit по поводу этого софта. Примерный перевод такой:
Разве для bash нужен обфускатор? Его и так невозможно понять.
На что разработчик ответил:
Это правда. До написания Bashfuscator я не очень хорошо понимал bash. Для непосвящённых он выглядит как случайный набор символов, но тем не менее до Perl ему далеко.
Bashfuscator написан на Python, ставится так:
# apt install python3 python3-pip python3-argcomplete xclip# git clone https://github.com/Bashfuscator/Bashfuscator# cd Bashfuscator# python3 setup.py install --userБинарник будет в директории ~/Bashfuscator/bashfuscator/bin.
Использовать примерно так:
# ./bashfuscator -c "cat /etc/passwd"Знаете, что я первым делом проверил этим обфускатором? Команду:
# rm -rf / --no-preserve-rootОбфусцированный код исполнился без всяких предупреждений и грохнул систему. Только не надо это повторять и кому-то вредить. Просто знайте, что может случиться вот такая ситуация. Будьте с таким кодом предельно аккуратны, если кто-то пошутит и пришлёт.
Для себя не могу придумать ситуации, где бы мне пригодился подобный обфускатор. Остался непонятен самый главный вопрос. Можно ли такой обфусцированный код превратить обратно в читаемый? По идее, простого способа не существует. Вариант только один - как-то отслеживать выполнение и на основе этого предполагать исходный код. Кто-то знает на практике как это реализуется?
Исходники / Документация / Reddit
#bash #security
{kind=link}
Немного пятничного юмора. Давно ничего не находил интересного, а тут испанец в рекомендациях выскочил. С ним трудно совсем не интересно сделать, так что получилось в целом нормально. Мне понравилось, особенно в самом конце про русских хакеров и ошибок в сети.
Испанец о методах быстрого и эффективного решения проблем:
https://www.youtube.com/watch?v=0K9I9o6YByY
Если кратко, то там о том, как искали баг в коде и по ошибке залили изменения не на dev, а на prod. Потом откатили.
Поделитесь хорошим юмором в видео на тему IT, сделаю как-нибудь подборку. У меня на канале уже много всего было, но давно публиковалось. Наверняка большинство не видели.
#юмор
Испанец о методах быстрого и эффективного решения проблем:
https://www.youtube.com/watch?v=0K9I9o6YByY
Если кратко, то там о том, как искали баг в коде и по ошибке залили изменения не на dev, а на prod. Потом откатили.
Поделитесь хорошим юмором в видео на тему IT, сделаю как-нибудь подборку. У меня на канале уже много всего было, но давно публиковалось. Наверняка большинство не видели.
#юмор
YouTube
Испанец о методах быстрого и эффективного решения проблем
Испанец рассказывает о методах быстрого и эффективного решения проблем.
В этом видео перед испанцем опять встала сложная задача. На продакшене случилась непредвиденная проблема и ее нужно было срочно решать. Что предпримет испанец и как найдет выход из сложившейся…
В этом видео перед испанцем опять встала сложная задача. На продакшене случилась непредвиденная проблема и ее нужно было срочно решать. Что предпримет испанец и как найдет выход из сложившейся…
Полезно всё-таки смотреть чужие вебинары, где человек что-то на практике делает и показывает на своём окружении. И желательно, если он всё делает с нуля. Я всегда ставил Docker по одной и той же схеме - гуглил "docker install distrolinux" и неизменно попадал в официальную доку докера, где надо было в несколько кликов попасть на нужную тебе инструкцию. Потом скачать ключ, подключить репу, обновить пакеты и поставить то, что тебе нужно.
Мне и в голову не приходило действовать как-то иначе. А докер приходится ставить часто. Практически постоянно. Можно сэкономить кучу времени, если ставить его вот так:
Будет сделано всё то же самое, только автоматически. Систему скрипт определит сам. Просто сохраните эту команду и используйте для ручной установки докера.
Если хочется сначала посмотреть, что за скрипт, то сохраните его, не запуская:
Если добавить опцию DRY_RUN, то можно посмотреть, что скрипт будет делать, но не выполнять ничего:
Так что для общего образования рекомендую иногда посматривать обучающие вебинары, даже если особой потребности в этом нет. Я чисто из любопытства смотрю. Не могу сказать, что они прям как-то сильно помогают. Обычно если сам что-то не делаешь, то от просмотра толку никакого нет. А тут написал заметку и запомнил, сохранил себе. Если бы не сделал этого, то опять бы гуглить продолжал.
#docker
Мне и в голову не приходило действовать как-то иначе. А докер приходится ставить часто. Практически постоянно. Можно сэкономить кучу времени, если ставить его вот так:
# curl -o - https://get.docker.com | bash -Будет сделано всё то же самое, только автоматически. Систему скрипт определит сам. Просто сохраните эту команду и используйте для ручной установки докера.
Если хочется сначала посмотреть, что за скрипт, то сохраните его, не запуская:
# curl https://get.docker.com -o get-docker.shЕсли добавить опцию DRY_RUN, то можно посмотреть, что скрипт будет делать, но не выполнять ничего:
# DRY_RUN=1 sh ./get-docker.shТак что для общего образования рекомендую иногда посматривать обучающие вебинары, даже если особой потребности в этом нет. Я чисто из любопытства смотрю. Не могу сказать, что они прям как-то сильно помогают. Обычно если сам что-то не делаешь, то от просмотра толку никакого нет. А тут написал заметку и запомнил, сохранил себе. Если бы не сделал этого, то опять бы гуглить продолжал.
#docker
{kind=link}
3 причины подписаться на канал Импортозамещение здорового человека 🔥
1. Честно о возможностях и проблемах российского железа простым языком.
2. Трибуна для импортозаместителей, которые любят свое дело.
3. Эксперты-разработчики отвечают на вопросы подписчиков.
Будет полезно — подписывайся на @aerodisk_official
#реклама
1. Честно о возможностях и проблемах российского железа простым языком.
2. Трибуна для импортозаместителей, которые любят свое дело.
3. Эксперты-разработчики отвечают на вопросы подписчиков.
Будет полезно — подписывайся на @aerodisk_official
#реклама
Посмотрел интересное выступление с HighLoad++ 2021, которое весной выложили в открытый доступ - Есть ли жизнь без ELK? Как снизить стоимость Log Management:
https://www.youtube.com/watch?v=BOVuwr43ZTE
Автор детально разбирает тему хранения логов с помощью современных инструментов. Прикидывает нагрузку, стоимость решения. Перебирает различные варианты и в итоге рассказывает, к какому решению пришли сами.
Они решили для экономии денег и ресурсов собрать систему сбора логов самостоятельно на базе сборщика логов Vector (по их тестам он оказался быстрее FluentD), парсинг делают им же, обработка с помощью Kafka, данные хранят в ClickHouse, визуализируют с помощью Grafana.
Если вам интересная данная тема, то рекомендую. Я, например, про Vector вообще впервые услышал. Всегда думал, что оптимальный парсер и доставщик логов это FluentD. Обычно его рекомендуют вместо тормозного Filebeat.
#видео #elk #logs
https://www.youtube.com/watch?v=BOVuwr43ZTE
Автор детально разбирает тему хранения логов с помощью современных инструментов. Прикидывает нагрузку, стоимость решения. Перебирает различные варианты и в итоге рассказывает, к какому решению пришли сами.
Они решили для экономии денег и ресурсов собрать систему сбора логов самостоятельно на базе сборщика логов Vector (по их тестам он оказался быстрее FluentD), парсинг делают им же, обработка с помощью Kafka, данные хранят в ClickHouse, визуализируют с помощью Grafana.
Если вам интересная данная тема, то рекомендую. Я, например, про Vector вообще впервые услышал. Всегда думал, что оптимальный парсер и доставщик логов это FluentD. Обычно его рекомендуют вместо тормозного Filebeat.
#видео #elk #logs
YouTube
Есть ли жизнь без ELK? Как снизить стоимость Log Management / Денис Безкоровайный
Приглашаем на конференцию HighLoad++ 2024, которая пройдет 2 и 3 декабря в Москве!
Программа, подробности и билеты по ссылке: https://clck.ru/3DD4yb
--------
Профессиональная конференция разработчиков высоконагруженных систем
20 и 21 сентября 2021. Санкт…
Программа, подробности и билеты по ссылке: https://clck.ru/3DD4yb
--------
Профессиональная конференция разработчиков высоконагруженных систем
20 и 21 сентября 2021. Санкт…
Ранее мне уже приходилось рассказывать о различных неожиданностях, которые можно получить от хостера при управлении виртуальной машиной. Сейчас расскажу ещё один пример, с которым столкнулся впервые.
На одной из VM случайно обнаружил, что нет моих правил в iptables. Остались только цепочки, что добавляет fail2ban, а остальных правил нет. Стал разбираться и выяснил, в чём дело.
На VM через панель управления был добавлен дополнительный внешний IP. А у хостера каким-то образом реализовано автоматическое применение сетевых настроек. Мало того, что они сразу же на VM применились, был отредактирован файл /etc/network/interfaces. В Debian там по умолчанию хранятся сетевые настройки. Мой файл был заменён на новый с дополнительным IP.
У меня давняя привычка применять правила iptables при поднятии сетевого интерфейса. Реализовано это так:
После добавления адреса я вручную отредактировал firewall, добавил новые правила, связанные с изменениями, применил их. Перезагрузка не потребовалась. А через какое-то время я VM перезагрузил. Стартанула она уже с новыми сетевыми настройками, где в interfaces моей настройки с загрузкой правил iptables уже не было.
В данном случае никаких проблем не возникло, так как ни один лишний сервис запущен не был. Правила были дежурные и только одно нужное с белым списком ip адресов для доступа к ssh. Но это не проблема, если он будет доступен через интернет. Я всегда всё закрываю белыми списками, к чему не нужен публичный доступ. Привычка такая.
Вот похожая история на тему управления VM со стороны хостера при добавлении и удалении диска через панель управления:
https://t.me/srv_admin/371
Чуть не остался без подмонтированного диска и всех данных.
Попадали в похожие истории?
#хостинг
На одной из VM случайно обнаружил, что нет моих правил в iptables. Остались только цепочки, что добавляет fail2ban, а остальных правил нет. Стал разбираться и выяснил, в чём дело.
На VM через панель управления был добавлен дополнительный внешний IP. А у хостера каким-то образом реализовано автоматическое применение сетевых настроек. Мало того, что они сразу же на VM применились, был отредактирован файл /etc/network/interfaces. В Debian там по умолчанию хранятся сетевые настройки. Мой файл был заменён на новый с дополнительным IP.
У меня давняя привычка применять правила iptables при поднятии сетевого интерфейса. Реализовано это так:
allow-hotplug eth0iface eth0 inet dhcppre-up iptables-restore < /etc/iptables_rulesПосле добавления адреса я вручную отредактировал firewall, добавил новые правила, связанные с изменениями, применил их. Перезагрузка не потребовалась. А через какое-то время я VM перезагрузил. Стартанула она уже с новыми сетевыми настройками, где в interfaces моей настройки с загрузкой правил iptables уже не было.
В данном случае никаких проблем не возникло, так как ни один лишний сервис запущен не был. Правила были дежурные и только одно нужное с белым списком ip адресов для доступа к ssh. Но это не проблема, если он будет доступен через интернет. Я всегда всё закрываю белыми списками, к чему не нужен публичный доступ. Привычка такая.
Вот похожая история на тему управления VM со стороны хостера при добавлении и удалении диска через панель управления:
https://t.me/srv_admin/371
Чуть не остался без подмонтированного диска и всех данных.
Попадали в похожие истории?
#хостинг
📍Есть большое количество поводов подписаться на канал сети дата-центров 3data и вот парочка из них:
✅ Рассказывают самые интересные новости из мира дата-центра!
Как работают дата-центры в период санкций, есть ли вероятность того, что ЦОДы вообще перестанут работать, и мы больше не сможем хранить все наши воспоминания в компьютерах и телефонах?
✅ Занимаются исследованием актуальных отраслевых вопросов.
Например, об изменениях спроса и предложения на услуги colocation, проведенное совместно с iKS-Consulting.
✅ Делятся интересными фактами о дата-центрах и их работе.
О ЦОДе на Луне, дата-центрах как объектах искусства и самых крупных сделках отрасли.
✅ Публикуют крутой развлекательный контент, где вы сможете найти подборку с интересными фильмами, сериалами и многое другое.
И это далеко не всё!😉
Подписывайтесь на канал 3data и узнавайте много полезной информации.
✅ Рассказывают самые интересные новости из мира дата-центра!
Как работают дата-центры в период санкций, есть ли вероятность того, что ЦОДы вообще перестанут работать, и мы больше не сможем хранить все наши воспоминания в компьютерах и телефонах?
✅ Занимаются исследованием актуальных отраслевых вопросов.
Например, об изменениях спроса и предложения на услуги colocation, проведенное совместно с iKS-Consulting.
✅ Делятся интересными фактами о дата-центрах и их работе.
О ЦОДе на Луне, дата-центрах как объектах искусства и самых крупных сделках отрасли.
✅ Публикуют крутой развлекательный контент, где вы сможете найти подборку с интересными фильмами, сериалами и многое другое.
И это далеко не всё!😉
Подписывайтесь на канал 3data и узнавайте много полезной информации.
{kind=link}
Какой системный администратор Linux не любит хорошенько грепнуть? Это очень полезный навык, который осваиваешь практически сразу, как начинаешь работать в консоли и тем более писать какие-то скрипты. Но есть формат json, который бессмысленно грепать, потому что с большой вероятностью получишь не то, что тебе надо, так как там все данные либо в одной строке, либо построчно иерархически разбиты.
Какой-то добрый человек решил спасти системных администраторов из прошлого и придумал утилиту, которая позволяет успешно грепать json - gron. Лозунг программы - Make JSON greppable!
Покажу на примере, зачем она может понадобиться. У меня есть статья по мониторингу посещаемости сайтов, где данные берутся из Яндекс.Метрики в формате json. Беру обрезанный кусок json, для наглядного примера:
Вам надо выхватить все значения из data Так просто их не грепнешь в один присест. А через gron очень просто:
Получили список всех значений data в построчном формате. При желании грепается любое конкретное значение (не забываем про экранирование):
Эта утилита для тех, кто по какой-то причине не может или не хочет использовать jsonpath в jq. С его помощью какое-то одно конкретное значение вытащить гораздо проще:
Конкретно в данном примере gron не особо нужен. Это просто первое, что в голову пришло. Им будет удобно грепнуть очень большую лапшу json, которая прилетит к вам в терминал. А это обычное дело. Например, когда я настраивал мониторинг ZONT, мне в консоль вываливалась такая лапша, что на экран не помещалась.
Также с помощью gron удобно сравнить два json:
Исходники - https://github.com/tomnomnom/gron
#json
Какой-то добрый человек решил спасти системных администраторов из прошлого и придумал утилиту, которая позволяет успешно грепать json - gron. Лозунг программы - Make JSON greppable!
Покажу на примере, зачем она может понадобиться. У меня есть статья по мониторингу посещаемости сайтов, где данные берутся из Яндекс.Метрики в формате json. Беру обрезанный кусок json, для наглядного примера:
{ "query" : { "ids" : [ 23506456 ], "dimensions" : [ "ym:s:searchEngine" ], "metrics" : [ "ym:s:users", "ym:s:visits", "ym:s:pageviews" ], "sort" : [ "-ym:s:users" ],},"data" : [ { "dimensions" : [ "ym:s:searchEngine" ], "metrics" : [ 2117.0, 2450.0, 3211.0 ] } ]}Вам надо выхватить все значения из data Так просто их не грепнешь в один присест. А через gron очень просто:
# curl ....... | gron | grep datajson.data = [];json.data[0] = {};json.data[0].dimensions = ["ym:s:searchEngine"];json.data[0].metrics = [];json.data[0].metrics[0] = 2147.0;json.data[0].metrics[1] = 2489.0;json.data[0].metrics[2] = 3271.0;json.data_lag = 0;Получили список всех значений data в построчном формате. При желании грепается любое конкретное значение (не забываем про экранирование):
# curl ....... | gron | grep "data\[0\].metrics\[2\]"json.data[0].metrics[2] = 3271.0;Эта утилита для тех, кто по какой-то причине не может или не хочет использовать jsonpath в jq. С его помощью какое-то одно конкретное значение вытащить гораздо проще:
# curl ....... | jq '.data[].metrics[2]'3271.0Конкретно в данном примере gron не особо нужен. Это просто первое, что в голову пришло. Им будет удобно грепнуть очень большую лапшу json, которая прилетит к вам в терминал. А это обычное дело. Например, когда я настраивал мониторинг ZONT, мне в консоль вываливалась такая лапша, что на экран не помещалась.
Также с помощью gron удобно сравнить два json:
# diff <(gron first.json) <(gron second.json)7c3< json.data[0].metrics[2] = 3271.0;---> json.data[0].metrics[2] = 3531.0;Исходники - https://github.com/tomnomnom/gron
#json
Есть много способов защитить подключение из интернета к Windows серверу по RDP. Приведу наиболее известные:
1️⃣ Самое надёжное и очевидное - настроить клиентам VPN, а доступ к серверу разрешить только через этот тоннель. Самый главный минус тут один - клиентам надо у себя на компьютерах настраивать VPN соединение. Где-то оно может блокироваться или работать ненадёжно.
2️⃣ Настроить шлюз Remote Desktop Gateway на базе Windows Server и осуществлять подключение через него. Это простое и удобное для пользователей решение, так как им не нужно делать никаких дополнительных настроек у себя, кроме добавления лишнего параметра в настройки RDP соединения. Я не знаю точно, насколько это безопасное решение. Не припоминаю, чтобы у RDG находили какие-то серьезные уязвимости.
3️⃣ Настроить подключение по RDP через браузер с помощью Apache Guacamole. С одной стороны удобно работать через браузер, так как не надо вообще ничего настраивать на клиенте, но с другой стороны при работе через браузер есть много нюансов с пробросом горячих клавиш, буфера обмена, с подключением принтеров. Подходит не всегда и не всем, но лично я настраивал подобные подключения и людей устраивало. Подобные подключения можно проксировать через Nginx, анализировать логи подключений с помощью fail2ban, добавлять basic auth и т.д.
4️⃣ Первые три способа я пробовал лично. Расскажу про ещё один, о котором узнал от знакомого. Есть софт, похожий на Apache Guacamole, только под Windows - Myrtille (open source). Настраивать сильно проще, чем AG (с этим есть объективные сложности, надо немного разбираться в теме). Обычный виндовый инсталлятор «Далее - Далее - ОК». Затем открываем браузер, заходим по адресу приложения и настраиваем. Поддерживает RDP, SSH и доступ к виртуальным машинам под Hyper-V. Веб клиент реализован на базе HTML5. Подключения можно также проксировать через Nginx, подключить сертификат, добавить basic auth и т.д. Myrtille поддерживает и печать, и передачу файлов.
5️⃣ Для полноты картины упомяну еще пару способов, которые сам не использовал, но знаю, что так можно. Проксировать RDP соединения напрямую умеет Nginx с помощью stream. Также шлюзом для RDP соединений может выступать HAProxy. Причём он умеет идентифицировать RDP, парсить rdp_cookie. Например, для запоминания связки "имя пользователя - сервер" и подключать пользователя к одному и тому же серверу. Актуально, если у вас HAProxy балансирует подключения на несколько RDP серверов.
А вы какой способ используете для защиты RDP? Может есть ещё что-то простое и удобное?
#windows #rdp #security
1️⃣ Самое надёжное и очевидное - настроить клиентам VPN, а доступ к серверу разрешить только через этот тоннель. Самый главный минус тут один - клиентам надо у себя на компьютерах настраивать VPN соединение. Где-то оно может блокироваться или работать ненадёжно.
2️⃣ Настроить шлюз Remote Desktop Gateway на базе Windows Server и осуществлять подключение через него. Это простое и удобное для пользователей решение, так как им не нужно делать никаких дополнительных настроек у себя, кроме добавления лишнего параметра в настройки RDP соединения. Я не знаю точно, насколько это безопасное решение. Не припоминаю, чтобы у RDG находили какие-то серьезные уязвимости.
3️⃣ Настроить подключение по RDP через браузер с помощью Apache Guacamole. С одной стороны удобно работать через браузер, так как не надо вообще ничего настраивать на клиенте, но с другой стороны при работе через браузер есть много нюансов с пробросом горячих клавиш, буфера обмена, с подключением принтеров. Подходит не всегда и не всем, но лично я настраивал подобные подключения и людей устраивало. Подобные подключения можно проксировать через Nginx, анализировать логи подключений с помощью fail2ban, добавлять basic auth и т.д.
4️⃣ Первые три способа я пробовал лично. Расскажу про ещё один, о котором узнал от знакомого. Есть софт, похожий на Apache Guacamole, только под Windows - Myrtille (open source). Настраивать сильно проще, чем AG (с этим есть объективные сложности, надо немного разбираться в теме). Обычный виндовый инсталлятор «Далее - Далее - ОК». Затем открываем браузер, заходим по адресу приложения и настраиваем. Поддерживает RDP, SSH и доступ к виртуальным машинам под Hyper-V. Веб клиент реализован на базе HTML5. Подключения можно также проксировать через Nginx, подключить сертификат, добавить basic auth и т.д. Myrtille поддерживает и печать, и передачу файлов.
5️⃣ Для полноты картины упомяну еще пару способов, которые сам не использовал, но знаю, что так можно. Проксировать RDP соединения напрямую умеет Nginx с помощью stream. Также шлюзом для RDP соединений может выступать HAProxy. Причём он умеет идентифицировать RDP, парсить rdp_cookie. Например, для запоминания связки "имя пользователя - сервер" и подключать пользователя к одному и тому же серверу. Актуально, если у вас HAProxy балансирует подключения на несколько RDP серверов.
А вы какой способ используете для защиты RDP? Может есть ещё что-то простое и удобное?
#windows #rdp #security
Есть одна вещь, которая мне не нравится в Debian. Я всегда выполняю одну и ту же настройку сразу после установки системы. Не понимаю, кто придумал по умолчанию логи cron писать в общий системный лог /var/log/syslog. Это при том, что настройка для отдельного ведения журнала cron уже есть в конфиге rsyslog, но почему-то закомментирована. И настройка для логирования файла /var/log/cron.log уже есть в logrotate.
Если вы так же, как и я, любите, когда логи cron хранятся в отдельном файле, то сделайте следующее. Открываете на редактирование /etc/rsyslog.conf и раскомментируете строку:
Далее отключаем запись логов в общий файл. Добавляем cron.none в следующую строку:
Перезапускаем rsyslog и cron:
Проверяем, появился ли файл с логом.
На всякий случай проверьте файл /etc/logrotate.d/rsyslog. Есть ли там строка с упоминанием файла /var/log/cron.log. Вроде должна быть. Не помню, чтобы я руками добавлял.
Мне кажется реально удобно, когда логи крона живут отдельно. Их довольно часто используешь, так как cron популярный инструмент. Хотя его сейчас активно вытесняют таймеры systemd. Надо про них отдельно написать.
Я подзабыл, а в Ubuntu тоже логи cron в наследство от Debian пишутся в общий syslog? Кто-то делает подобную настройку или это мой бзик? Я после Centos никак не могу привыкнуть, что по дефолту нет этого лога.
#debian
Если вы так же, как и я, любите, когда логи cron хранятся в отдельном файле, то сделайте следующее. Открываете на редактирование /etc/rsyslog.conf и раскомментируете строку:
cron.* /var/log/cron.logДалее отключаем запись логов в общий файл. Добавляем cron.none в следующую строку:
*.*;auth,authpriv.none,cron.none -/var/log/syslogПерезапускаем rsyslog и cron:
# systemctl restart rsyslog cronПроверяем, появился ли файл с логом.
# ls -l /var/log/cron.logНа всякий случай проверьте файл /etc/logrotate.d/rsyslog. Есть ли там строка с упоминанием файла /var/log/cron.log. Вроде должна быть. Не помню, чтобы я руками добавлял.
Мне кажется реально удобно, когда логи крона живут отдельно. Их довольно часто используешь, так как cron популярный инструмент. Хотя его сейчас активно вытесняют таймеры systemd. Надо про них отдельно написать.
Я подзабыл, а в Ubuntu тоже логи cron в наследство от Debian пишутся в общий syslog? Кто-то делает подобную настройку или это мой бзик? Я после Centos никак не могу привыкнуть, что по дефолту нет этого лога.
#debian
Продолжу вчерашнюю тему про RDP. Судя по комментариям, есть немало людей, которые просто ставят аналог fail2ban, только под Windows. Я ранее рассказывал про подобные решения:
▪ RDP Defender - https://t.me/srv_admin/1168
▪ EvlWatcher - https://t.me/srv_admin/1680
▪ IP Ban - https://t.me/srv_admin/1657
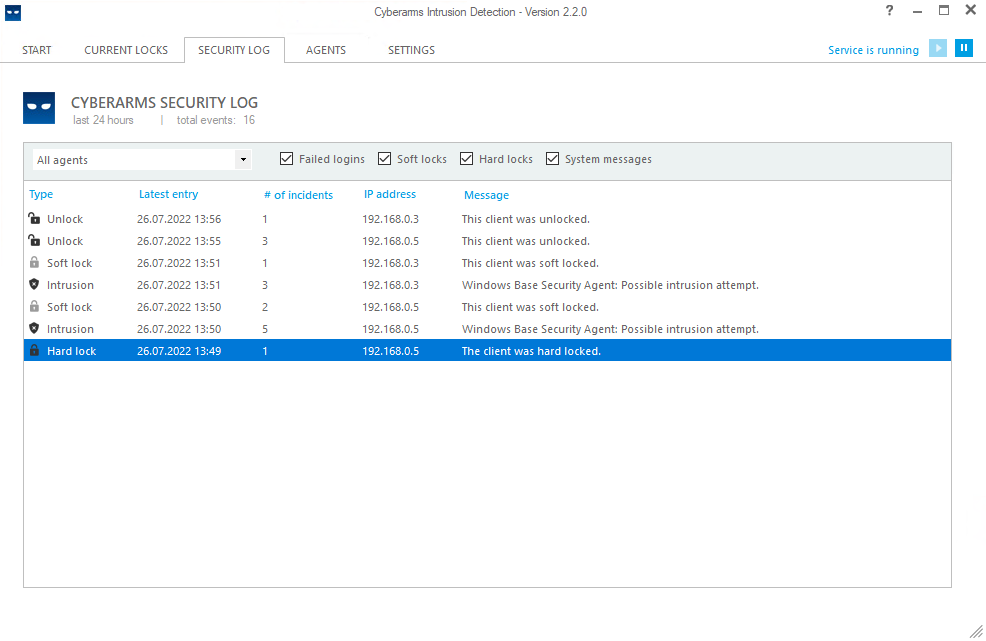
Мне лично RDP Defender больше всего нравится. Но есть ещё один бесплатный продукт, который раньше был популярен - Cyberarms IDDS. А сейчас у него даже сайт не открывается. Тем не менее, на github хранятся исходники и скомпилированная версия - https://github.com/EFTEC/Cyberarms Обновлений не было 5 лет. Я решил проверить, он вообще рабочий или уже нет.
Установил на Windows Server 2019, без проблем запустился. Всё работает. По функционалу и удобству он лучше всех перечисленных выше. У него настроек больше, они гибче, плюс уведомления по smtp отправлять умеет. Помимо подключений по RDP, может следить за виндовыми службами: ftp, smtp, sql server и некоторыми другими. Для каждой службы свой агент.
Принцип работы у Cyberarms IDDS примерно такой же, как у всех. Устанавливает свою службу, создаёт правило во встроенном брандмауэре, заполняет правило ip адресами. Перед установкой надо поставить в систему пакет Microsoft Visual C++ 2010 x64. Без него не установится. И агент, отвечающий за авторизацию по RDP называется Windows Base Security Agent. Во всех инструкциях в сети почему-то запускают другого агента - TLS/SSL Security Agent. С ним у меня ничего не работало.
Хочу напоминать, что подобного рода защита от перебора учёток решает только одну задачу. На моей памяти было как минимум две уязвимости в протоколе RDP, которые позволяли получить доступ к серверу в обход механизма аутентификации. То есть подобного рода программы никак вас от этого не защитят. Так что смотрящий напрямую в интернет RDP порт это очень небезопасно. До очередной найденной уязвимости. Сначала прокатится волна взломов, потом будет выяснено, через какую уязвимость они прошли. И только потом выпустят обновление, закрывающее эту уязвимость.
#windows #rdp #security
▪ RDP Defender - https://t.me/srv_admin/1168
▪ EvlWatcher - https://t.me/srv_admin/1680
▪ IP Ban - https://t.me/srv_admin/1657
Мне лично RDP Defender больше всего нравится. Но есть ещё один бесплатный продукт, который раньше был популярен - Cyberarms IDDS. А сейчас у него даже сайт не открывается. Тем не менее, на github хранятся исходники и скомпилированная версия - https://github.com/EFTEC/Cyberarms Обновлений не было 5 лет. Я решил проверить, он вообще рабочий или уже нет.
Установил на Windows Server 2019, без проблем запустился. Всё работает. По функционалу и удобству он лучше всех перечисленных выше. У него настроек больше, они гибче, плюс уведомления по smtp отправлять умеет. Помимо подключений по RDP, может следить за виндовыми службами: ftp, smtp, sql server и некоторыми другими. Для каждой службы свой агент.
Принцип работы у Cyberarms IDDS примерно такой же, как у всех. Устанавливает свою службу, создаёт правило во встроенном брандмауэре, заполняет правило ip адресами. Перед установкой надо поставить в систему пакет Microsoft Visual C++ 2010 x64. Без него не установится. И агент, отвечающий за авторизацию по RDP называется Windows Base Security Agent. Во всех инструкциях в сети почему-то запускают другого агента - TLS/SSL Security Agent. С ним у меня ничего не работало.
Хочу напоминать, что подобного рода защита от перебора учёток решает только одну задачу. На моей памяти было как минимум две уязвимости в протоколе RDP, которые позволяли получить доступ к серверу в обход механизма аутентификации. То есть подобного рода программы никак вас от этого не защитят. Так что смотрящий напрямую в интернет RDP порт это очень небезопасно. До очередной найденной уязвимости. Сначала прокатится волна взломов, потом будет выяснено, через какую уязвимость они прошли. И только потом выпустят обновление, закрывающее эту уязвимость.
#windows #rdp #security
{kind=link}
У меня накопилось много заметок по поводу работы с JSON. Решил сделать подборку, что собрать информацию в одном месте. С этим форматом постоянно приходится работать, так что, думаю, будет полезно. Можно в закладки забрать.
◽ обзорная статья по работе с json в zabbix
◽ jq - утилита для преобразования однострочных json в удобочитаемый вид, а также для получения значений через jsonpath
◽ онлайн сервис JSONLint для проверки синтаксиса
◽ форматирование json в удобочитаемый вид с помощью python
◽ онлайн сервис hcl2json для конвертации форматов json, yaml и hcl друг в друга
◽ jo - консольная утилита, создаёт json из поданных в неё данных. Умеет, к примеру, список файлов в директории оборачивать в json или вывод какой-нибудь консольной команды, типа ps.
◽ онлайн сервис JSONPath для извлечения данных из json
◽ gron - консольная утилита, которая превращает json в текст, к которому можно эффективно применить утилиту grep. То есть делает json грепабельным.
#json
◽ обзорная статья по работе с json в zabbix
◽ jq - утилита для преобразования однострочных json в удобочитаемый вид, а также для получения значений через jsonpath
◽ онлайн сервис JSONLint для проверки синтаксиса
◽ форматирование json в удобочитаемый вид с помощью python
◽ онлайн сервис hcl2json для конвертации форматов json, yaml и hcl друг в друга
◽ jo - консольная утилита, создаёт json из поданных в неё данных. Умеет, к примеру, список файлов в директории оборачивать в json или вывод какой-нибудь консольной команды, типа ps.
◽ онлайн сервис JSONPath для извлечения данных из json
◽ gron - консольная утилита, которая превращает json в текст, к которому можно эффективно применить утилиту grep. То есть делает json грепабельным.
#json
Постоянно пользуюсь утилитой rclone для загрузки данных в S3 хранилище. Вспомнил, что ни разу не писал про неё отдельно. Решил исправить. Думаю, многие знают про неё, так как программа старая, удобная, популярная. Она есть под все известные ОС: Windows, macOS, Linux, FreeBSD, NetBSD, OpenBSD, Plan9, Solaris.
Я использую её исключительно в консоли Linux. Она есть в базовых репозиториях, так что ставится стандартно:
Самую свежую версию можно поставить вот так:
Далее рисуем простой конфиг в файле ~/.config/rclone/rclone.conf:
Это пример для S3 хранилища от Selectel. Все учётные данные получите в ЛК. Я давно им пользуюсь. Когда выбирал, он был самым дешёвым. Сейчас не знаю как, не сравнивал. Для объёмов до 100 Гб там цены небольшие. За этот объём заплатите рублей 300 примерно (стандартное хранилище, холодное ещё дешевле), так что не критично. Рекомендую дублировать бэкапы сайтов, магазинов в S3. У меня это всегда второе, холодное хранилище, куда уезжают полные архивы с определённой периодичностью.
Бэкап директории /mnt/backup/day делается следующим образом:
Я обычно делаю 3 контейнера: day, week, month с настройкой хранения копий 7, 30 дней и бессрочно. Контейнер с месячными архивами чищу вручную время от времени, либо вообще не чищу. А первые два очищаются самостоятельно в соответствии со своими настройками. Следить самому за этим не надо. Если у вас это будет единственное хранилище, то очистку лучше настроить не по времени, а по количеству файлов в контейнере. Иначе если не уследите за бэкапами и они по какой-то причине не будут выполняться, через какое-то время все старые будут удалены, а новые не приедут.
В S3 от Selectel данные заходят очень быстро. Скорость до Гигабита в секунду. Скачивать редко приходится, так что не знаю, какая там реальная скорость, но проблем никогда не было. Думаю тоже что-то в районе гигабита, обычно сам интернет медленнее, куда грузить будете. Можно через панель управления зайти и открыть веб доступ к какому-нибудь файлу, сделать одноразовую ссылку. Также доступ к файлам есть через личный кабинет напрямую в браузере, либо по FTP. Я для визуального контроля и загрузки файлов обычно по FTP захожу.
Сайт - https://rclone.org
#backup #s3
Я использую её исключительно в консоли Linux. Она есть в базовых репозиториях, так что ставится стандартно:
# apt install rclone# dnf install rcloneСамую свежую версию можно поставить вот так:
# curl https://rclone.org/install.sh | bashДалее рисуем простой конфиг в файле ~/.config/rclone/rclone.conf:
[selectel]type = swiftuser = 79167_usernamekey = uO6GdPZ97auth = https://api.selcdn.ru/v3tenant = 79167_usernameauth_version = 3endpoint_type = publicЭто пример для S3 хранилища от Selectel. Все учётные данные получите в ЛК. Я давно им пользуюсь. Когда выбирал, он был самым дешёвым. Сейчас не знаю как, не сравнивал. Для объёмов до 100 Гб там цены небольшие. За этот объём заплатите рублей 300 примерно (стандартное хранилище, холодное ещё дешевле), так что не критично. Рекомендую дублировать бэкапы сайтов, магазинов в S3. У меня это всегда второе, холодное хранилище, куда уезжают полные архивы с определённой периодичностью.
Бэкап директории /mnt/backup/day делается следующим образом:
# /usr/bin/rclone copy /mnt/backup/day selectel:websrv-dayЯ обычно делаю 3 контейнера: day, week, month с настройкой хранения копий 7, 30 дней и бессрочно. Контейнер с месячными архивами чищу вручную время от времени, либо вообще не чищу. А первые два очищаются самостоятельно в соответствии со своими настройками. Следить самому за этим не надо. Если у вас это будет единственное хранилище, то очистку лучше настроить не по времени, а по количеству файлов в контейнере. Иначе если не уследите за бэкапами и они по какой-то причине не будут выполняться, через какое-то время все старые будут удалены, а новые не приедут.
В S3 от Selectel данные заходят очень быстро. Скорость до Гигабита в секунду. Скачивать редко приходится, так что не знаю, какая там реальная скорость, но проблем никогда не было. Думаю тоже что-то в районе гигабита, обычно сам интернет медленнее, куда грузить будете. Можно через панель управления зайти и открыть веб доступ к какому-нибудь файлу, сделать одноразовую ссылку. Также доступ к файлам есть через личный кабинет напрямую в браузере, либо по FTP. Я для визуального контроля и загрузки файлов обычно по FTP захожу.
Сайт - https://rclone.org
#backup #s3
{kind=link}
Когда у вас много независимых друг от друга мониторингов, возникает проблема за контролем всего этого хозяйства. Лично я для Zabbix использую интеграцию с Grafana и делаю на последней дашборд с выводом триггеров с нескольких Zabbix серверов. Меня вполне устраивает такое решение для быстрого просмотра состояния нескольких (у меня 6) серверов мониторинга.
Подозреваю, что для Prometheus и его Alertmanager тоже должно быть что-то похоже на базе Grafana, но я сегодня хочу вам рассказать про другой дашборд, который может объединять в себе события от нескольких Alertmanager. Это программа под названием Karma - https://github.com/prymitive/karma, которая как раз представляет из себя Alert dashboard для Prometheus Alertmanager.
У Karma плиточный интерфейс с возможностью настройки под свой вкус. В примерах из репозитория он разукрашен, как новогодняя ёлка. Лично мне не кажется это удобным и наглядным, но это дело вкуса. Можно брать цвета одного оттенка. Внешний вид оптимизирован для отображения на смартфонах.
Конфиг у Karma, как не трудно догадаться, в формате yaml и в общем случае довольно простой. В репозитории есть пример с подключением локального alertmanager. Для удалённых просто uri будет отличаться и их будет несколько. Для самой простой настройки достаточно их подключить в режиме readonly:
Для аутентификации в Karma есть 2 способа: basic auth или передача учётных данных через header в запросе. А для авторизации - ACL списки. То есть этот продукт подходит для работы различных команд с разграничением доступа к поступающим оповещениям. Ограничение доступа работает не на просмотр, а на возможность подавления оповещения.
Demo - https://karma-demo.herokuapp.com
Исходники - https://github.com/prymitive/karma
Обзор и пример настройки - https://www.youtube.com/watch?v=pLI8-gHgedA
#prometheus #мониторинг #devops
Подозреваю, что для Prometheus и его Alertmanager тоже должно быть что-то похоже на базе Grafana, но я сегодня хочу вам рассказать про другой дашборд, который может объединять в себе события от нескольких Alertmanager. Это программа под названием Karma - https://github.com/prymitive/karma, которая как раз представляет из себя Alert dashboard для Prometheus Alertmanager.
У Karma плиточный интерфейс с возможностью настройки под свой вкус. В примерах из репозитория он разукрашен, как новогодняя ёлка. Лично мне не кажется это удобным и наглядным, но это дело вкуса. Можно брать цвета одного оттенка. Внешний вид оптимизирован для отображения на смартфонах.
Конфиг у Karma, как не трудно догадаться, в формате yaml и в общем случае довольно простой. В репозитории есть пример с подключением локального alertmanager. Для удалённых просто uri будет отличаться и их будет несколько. Для самой простой настройки достаточно их подключить в режиме readonly:
servers: - name: prod uri: https://user:password@prod.alert.example.com timeout: 20s proxy: false readonly: true - name: dev uri: https://user:password@dev.alert.example.com timeout: 20s proxy: false readonly: trueДля аутентификации в Karma есть 2 способа: basic auth или передача учётных данных через header в запросе. А для авторизации - ACL списки. То есть этот продукт подходит для работы различных команд с разграничением доступа к поступающим оповещениям. Ограничение доступа работает не на просмотр, а на возможность подавления оповещения.
Demo - https://karma-demo.herokuapp.com
Исходники - https://github.com/prymitive/karma
Обзор и пример настройки - https://www.youtube.com/watch?v=pLI8-gHgedA
#prometheus #мониторинг #devops
{kind=link}
Недавно в блоге Zabbix вышла любопытная заметка на тему мониторинга веб сайта и создания скриншота по событию. Меня заинтересовала эта тема, так что решил немного разобраться.
В статье автор предлагает использовать фреймворк Selenium для создания скриншота сайта. Для его использования он написал небольшой скрипт на Python и опубликовал его в виде картинки 🤦
Дальше он предлагает добавить этот скрипт в Zabbix и использовать в каких-то действиях. Например, в триггере для мониторинга сайта. Если получаем ошибку мониторинга, то делаем автоматом скриншот. Скрипту url сайта передаём через макрос триггера {TRIGGER.URL}, так что не забудьте этот url указать в триггере.
Идея мне понравилась, только не захотелось возиться с Selenium. Я его вообще никогда не использовал. А ещё и скрипт набирать бы пришлось с картинки. В комментариях один человек посоветовал использовать утилиту cutycapt. И тут началось...
У меня тестовый Zabbix Server работает на базе Oracle Linux 8. Cutycapt старая утилита и для 8-й версии её вообще нет. Попытался собрать из исходников, не получилось, так как для сборки надо qt4, а он давно снят с поддержки и в репах его нет. Есть только qt5, но под ним не собирается. Долго я мучался со сборкой и установкой пакетов. Потом плюнул и просто установил пакет от 7-й версии, который взял в epel7. И на удивление, всё получилось. В зависимостях там qt5, которые подтянулись из epel8.
Также понадобился пакет Xvfb для запуска Cutycapt на сервере без графического окружения. В итоге скриншот сайта делается вот так:
Единственная проблема, которую так и не победил, как ни пытался - не смог выставить желаемое разрешение экрана. Какие бы параметры не ставил, не применялись. В итоге скриншот делается, как-будто ты зашёл через мобильный браузер. В целом, это не имеет большого значения. Может даже и лучше, так как мобильный трафик сейчас зачастую превышает десктопный.
Помимо привязки к триггеру, можно сделать ручной запуск скрипта через веб интерфейс. А скриншот добавить на дашборд в виджет. Я так понял, что подобный виджет появился в версии 6.2, так как в 6.0 у себя не нашёл его.
В общем, интересный функционал. Возьмите на вооружение, кому актуально. Мне кажется, неплохая идея автоматически делать скриншот сайта в момент каких-то проблем. Можно сразу на почту картинку отправить, вместе с оповещением. Утилита CutyCapt тоже понравилась. Может пригодиться и в других ситуациях. Надо будет по ней отдельную заметку сделать.
#zabbix #website
В статье автор предлагает использовать фреймворк Selenium для создания скриншота сайта. Для его использования он написал небольшой скрипт на Python и опубликовал его в виде картинки 🤦
Дальше он предлагает добавить этот скрипт в Zabbix и использовать в каких-то действиях. Например, в триггере для мониторинга сайта. Если получаем ошибку мониторинга, то делаем автоматом скриншот. Скрипту url сайта передаём через макрос триггера {TRIGGER.URL}, так что не забудьте этот url указать в триггере.
Идея мне понравилась, только не захотелось возиться с Selenium. Я его вообще никогда не использовал. А ещё и скрипт набирать бы пришлось с картинки. В комментариях один человек посоветовал использовать утилиту cutycapt. И тут началось...
У меня тестовый Zabbix Server работает на базе Oracle Linux 8. Cutycapt старая утилита и для 8-й версии её вообще нет. Попытался собрать из исходников, не получилось, так как для сборки надо qt4, а он давно снят с поддержки и в репах его нет. Есть только qt5, но под ним не собирается. Долго я мучался со сборкой и установкой пакетов. Потом плюнул и просто установил пакет от 7-й версии, который взял в epel7. И на удивление, всё получилось. В зависимостях там qt5, которые подтянулись из epel8.
Также понадобился пакет Xvfb для запуска Cutycapt на сервере без графического окружения. В итоге скриншот сайта делается вот так:
# xvfb-run CutyCapt --url=https://serveradmin.ru --out=serveradmin.pngЕдинственная проблема, которую так и не победил, как ни пытался - не смог выставить желаемое разрешение экрана. Какие бы параметры не ставил, не применялись. В итоге скриншот делается, как-будто ты зашёл через мобильный браузер. В целом, это не имеет большого значения. Может даже и лучше, так как мобильный трафик сейчас зачастую превышает десктопный.
Помимо привязки к триггеру, можно сделать ручной запуск скрипта через веб интерфейс. А скриншот добавить на дашборд в виджет. Я так понял, что подобный виджет появился в версии 6.2, так как в 6.0 у себя не нашёл его.
В общем, интересный функционал. Возьмите на вооружение, кому актуально. Мне кажется, неплохая идея автоматически делать скриншот сайта в момент каких-то проблем. Можно сразу на почту картинку отправить, вместе с оповещением. Утилита CutyCapt тоже понравилась. Может пригодиться и в других ситуациях. Надо будет по ней отдельную заметку сделать.
#zabbix #website
{kind=link}