
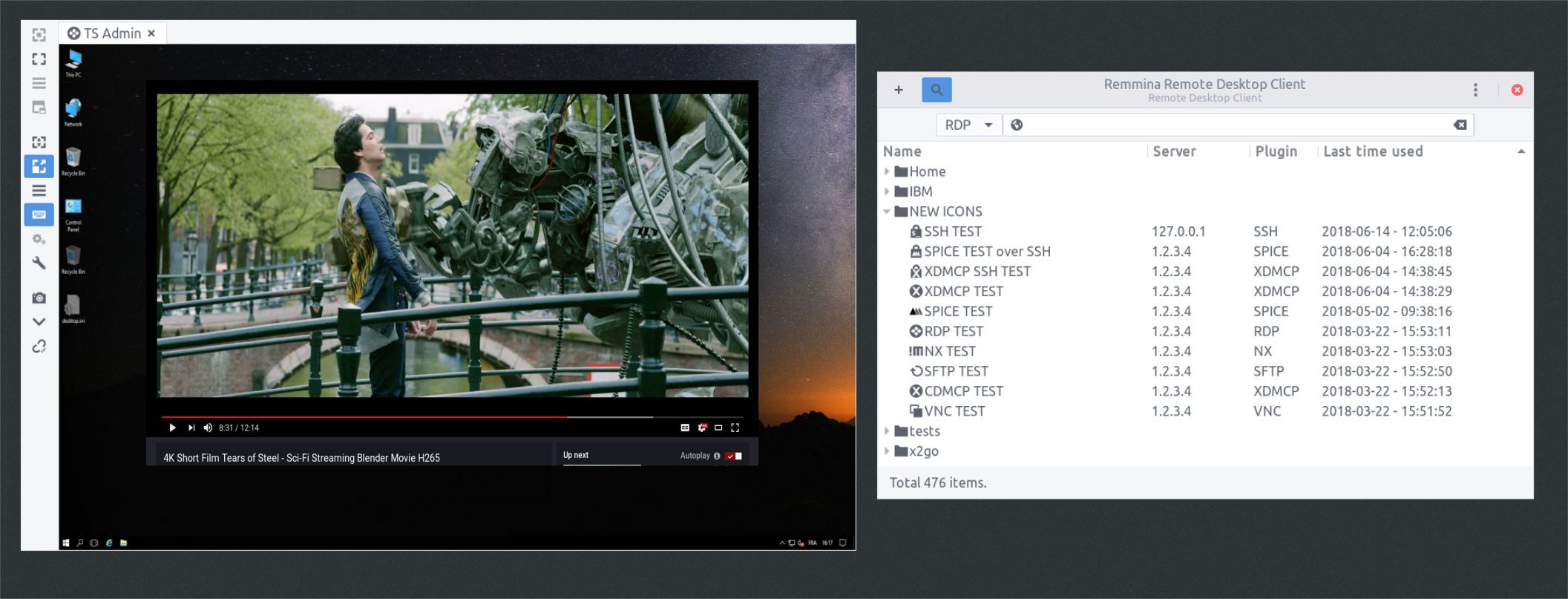
Я давно принял решение, что следующий купленный ноутбук для работы будет на Linux. С Windows буду потихоньку прощаться по целому ряду причин, которые может быть перечислю как-нибудь отдельным постом. Сегодня хотел рассказать про программу-клиент для подключения к удалённому рабочему столу по различным протоколам Remmina.
Это один из немногих примеров программ, про которые спрашивают пользователи Linux, когда вынуждены использовать Windows: "Какой есть аналог Remmina под виндой?" Обычно под виндой полно всякого софта и подобные вопросы задают в обратную сторону, переползая на Linux.
Лично я знаю два подобных аналога: MobaXterm и Remote Desktop Manager. Но с одной существенной разницей - они коммерческие. Про обе эти программы я писал ранее. Есть ещё одна, но как по мне похуже этих двух - mRemoteNG. Надо будет сделать про неё отдельный пост. Remmina существует только под Linux и умеет примерно всё то же самое, только абсолютно бесплатно и без ограничений, так как это Open Source и распространяется под лицензией GPLv2+.
Как я уже сказал, Remmina работает под Linux и позволяет получить удаленный доступ к Windows, MacOS и Linux с помощью протоколов RDP, SSH, SPICE, VNC, X2Go, HTTP/HTTPS. Программа популярна и есть в стандартных репозиториях всех известных дистрибутивов, либо имеет свой отдельный репозиторий, который можно подключить.
Если есть большое желание использовать Remmina под Windows, то можно запустить её под WSL. Эта возможность упомянута и продемонстрирована отдельной статьёй на официальном сайте.
В свете того, что многим из нас в ближайшее время придётся переходить на "отечественные ОС", которые все на базе Linux, имеет смысл подбирать подходящий софт под это дело. Я не придумал тэг для программ этой категории. Как думаете, какой для них будет актуален? #remote уже занят для всяких энидексов и им подобным.
Сайт - https://remmina.org
Исходники - https://gitlab.com/Remmina/Remmina
#linux #менеджеры_подключений
Это один из немногих примеров программ, про которые спрашивают пользователи Linux, когда вынуждены использовать Windows: "Какой есть аналог Remmina под виндой?" Обычно под виндой полно всякого софта и подобные вопросы задают в обратную сторону, переползая на Linux.
Лично я знаю два подобных аналога: MobaXterm и Remote Desktop Manager. Но с одной существенной разницей - они коммерческие. Про обе эти программы я писал ранее. Есть ещё одна, но как по мне похуже этих двух - mRemoteNG. Надо будет сделать про неё отдельный пост. Remmina существует только под Linux и умеет примерно всё то же самое, только абсолютно бесплатно и без ограничений, так как это Open Source и распространяется под лицензией GPLv2+.
Как я уже сказал, Remmina работает под Linux и позволяет получить удаленный доступ к Windows, MacOS и Linux с помощью протоколов RDP, SSH, SPICE, VNC, X2Go, HTTP/HTTPS. Программа популярна и есть в стандартных репозиториях всех известных дистрибутивов, либо имеет свой отдельный репозиторий, который можно подключить.
Если есть большое желание использовать Remmina под Windows, то можно запустить её под WSL. Эта возможность упомянута и продемонстрирована отдельной статьёй на официальном сайте.
В свете того, что многим из нас в ближайшее время придётся переходить на "отечественные ОС", которые все на базе Linux, имеет смысл подбирать подходящий софт под это дело. Я не придумал тэг для программ этой категории. Как думаете, какой для них будет актуален? #remote уже занят для всяких энидексов и им подобным.
Сайт - https://remmina.org
Исходники - https://gitlab.com/Remmina/Remmina
#linux #менеджеры_подключений
{kind=link}
🚑 Скорая помощь по Zabbix и Elastic Stack
Консультации через Zoom сертифицированными специалистами:
🔥 Оперативная помощь с траблшутингом проблем с Zabbix или Elastic Stack (все штатные компоненты)
🔥 Работы по миграции с версии на версию Zabbix/Elastic Stack
🔥 Разработка шаблонов мониторинга в Zabbix/правил обработки данных в Elastic Stack
🔥 Тюнинг производительности Zabbix/Elastic Stack
🔥 Услуги удаленного администрирования и удаленной поддержки на постоянной основе Zabbix/Elastic Stack
🔥 Семинары-инструктажи по Zabbix/Elastic Stack
Для оперативной связи @galssoftware. Подробнее о наших услугах на gals.software
#реклама
Консультации через Zoom сертифицированными специалистами:
🔥 Оперативная помощь с траблшутингом проблем с Zabbix или Elastic Stack (все штатные компоненты)
🔥 Работы по миграции с версии на версию Zabbix/Elastic Stack
🔥 Разработка шаблонов мониторинга в Zabbix/правил обработки данных в Elastic Stack
🔥 Тюнинг производительности Zabbix/Elastic Stack
🔥 Услуги удаленного администрирования и удаленной поддержки на постоянной основе Zabbix/Elastic Stack
🔥 Семинары-инструктажи по Zabbix/Elastic Stack
Для оперативной связи @galssoftware. Подробнее о наших услугах на gals.software
#реклама
Во вчерашней заметке вскользь упомянул про утилиту truncate. Решил рассказать про неё поподробнее, так как сам иногда использую. С её помощью можно усечь текстовый файл, либо полностью обнулить, не удаляя его. Это удобно, когда нужно очистить лог файл, но не хочется его удалять, создавать заново, выставлять права доступа и перезапускать сервис, который его использовал.
Утилита truncate чаще всего входит в базовый состав системных утилит, которые идут в комплекте с дистрибутивом Linux. Если её нет, то можно установить пакет coreutils, она скорее всего будет там.
Вообще, самый простой способ обнулить файл, это сделать вот так:
Это в оболочке bash. В каких-то других может не сработать и нужно будет какую-то команду типа echo -n или cat /dev/null добавить перед перенаправлением. С truncate очистка файла выглядит так:
Truncate позволяет не только полностью обнулить файл, но и сохранить какую-то его часть, что актуально для логов. Если у вас образовался огромный лог файл от веб сервера, который вам точно не нужен, но вы хотите что-то поискать в его начале, то просто обрежьте его до нужного размера:
Конец будет отсечён до нового размера файла в 10 мегабайт. Обращаю внимание, что обрезается хвост файла, а не начало. Это принципиальный момент, так как truncate не читает файл, а просто отсекает лишнее, поэтому работает очень быстро на любых объемах. Мне как-то нужно было удалить именно начало большого файла, оставив конец. С удивлением обнаружил, что это не так просто сделать. Так и не придумал простого и удобного решения. Использовал tail -n и перенаправление в новый файл.
Другой возможностью truncate является создание файлов заданного размера. На практике лично мне это никогда не было нужно и я не знаю, где может пригодиться. Только если в каких-то тестах. Тем не менее с truncate это сделать проще всего. Создаём файл:
Получили файл в 10 мегабайт, заполненный нулями.
Также с truncate удобно увеличивать размер файла порциями. Есть какой-то файл, его надо увеличить на 10 мегабайт:
Если использовать вместо плюса минус, файл будет уменьшен на 10 мегабайт. Это может быть полезно, когда тестируется какой-то триггер в мониторинге на контроль размера файла. Например, если дамп sql базы слишком маленький, нужно обратить на это внимание.
#terminal #bash
Утилита truncate чаще всего входит в базовый состав системных утилит, которые идут в комплекте с дистрибутивом Linux. Если её нет, то можно установить пакет coreutils, она скорее всего будет там.
Вообще, самый простой способ обнулить файл, это сделать вот так:
# > access.logЭто в оболочке bash. В каких-то других может не сработать и нужно будет какую-то команду типа echo -n или cat /dev/null добавить перед перенаправлением. С truncate очистка файла выглядит так:
# truncate -s 0 access.logTruncate позволяет не только полностью обнулить файл, но и сохранить какую-то его часть, что актуально для логов. Если у вас образовался огромный лог файл от веб сервера, который вам точно не нужен, но вы хотите что-то поискать в его начале, то просто обрежьте его до нужного размера:
# truncate -s 10M access.logКонец будет отсечён до нового размера файла в 10 мегабайт. Обращаю внимание, что обрезается хвост файла, а не начало. Это принципиальный момент, так как truncate не читает файл, а просто отсекает лишнее, поэтому работает очень быстро на любых объемах. Мне как-то нужно было удалить именно начало большого файла, оставив конец. С удивлением обнаружил, что это не так просто сделать. Так и не придумал простого и удобного решения. Использовал tail -n и перенаправление в новый файл.
Другой возможностью truncate является создание файлов заданного размера. На практике лично мне это никогда не было нужно и я не знаю, где может пригодиться. Только если в каких-то тестах. Тем не менее с truncate это сделать проще всего. Создаём файл:
# truncate -s 10M file.txtПолучили файл в 10 мегабайт, заполненный нулями.
Также с truncate удобно увеличивать размер файла порциями. Есть какой-то файл, его надо увеличить на 10 мегабайт:
# truncate -s +10M file.txtЕсли использовать вместо плюса минус, файл будет уменьшен на 10 мегабайт. Это может быть полезно, когда тестируется какой-то триггер в мониторинге на контроль размера файла. Например, если дамп sql базы слишком маленький, нужно обратить на это внимание.
#terminal #bash
В закладочках нашёл любопытный сервис, который очень полезен линуксоидам - конструктор для консольной команды FIND. Это такая типичная линуксовая утилита, у которой 100500 параметров и возможностей, ключи которой невозможно запомнить раз и навсегда. У меня огромная шпаргалка по find на все случаи жизни, чтобы не приходилось заново вспоминать, как реализовать тот или иной поиск.
Кое-что необычное по find уже публиковал на канале:
- очистка старых файлов
- поиск дубликатов файлов
- утилита fd для упрощения поиска через find
Сервис называется find-command-generator. С его помощью узнал, что find очень просто может находить файлы, которые принадлежат несуществующему пользователю или группе, или обоим одновременно. Бывает нужно такие найти:
Программисты любят ставить 777 без разбора. Постоянно с этим сталкиваюсь. Когда у них что-то работает не так, они первым делом права доступа 777 ставят, а потом дальше разбираются.
#bash #terminal #find
Кое-что необычное по find уже публиковал на канале:
- очистка старых файлов
- поиск дубликатов файлов
- утилита fd для упрощения поиска через find
Сервис называется find-command-generator. С его помощью узнал, что find очень просто может находить файлы, которые принадлежат несуществующему пользователю или группе, или обоим одновременно. Бывает нужно такие найти:
# find . -nogroup -nouser
Сервис пригодится, когда нужно найти что-то с параметрами, типа ограничения по датам изменения или доступа, размеру, правам доступа и т.д. Типичная история, когда надо проверить директорию веб сервера и снять с файлов все права на исполнение:# find /web/site/www -type f -name "*" -perm u+x -exec chmod 664 {} \; Программисты любят ставить 777 без разбора. Постоянно с этим сталкиваюсь. Когда у них что-то работает не так, они первым делом права доступа 777 ставят, а потом дальше разбираются.
#bash #terminal #find
В Zabbix 6.0 появились дашборды с географическими картами. Я посмотрел, как всё это работает и решил поделиться с вами информацией.
Реализовано всё достаточно просто и удобно. Для начала вам нужно в свойствах хоста, в инвентаризации, указать широту и долготу. Посмотреть их можно на любой публичной карте.
Затем надо добавить на Дашборд новый виджет - Геокарта. В настройках виджета указать узлы сети, которые будут помещены на карту. Вот и всё. Сохраняете виджет и наблюдаете узлы на карте. В свойствах виджета можно настроить начальный вид и приближение, чтобы каждый раз не скролить при поиске хостов.
В разделе Администрирование -> Общие -> Географические карты можно выбрать сервис, с помощью которого будет отображаться карта. Я видел отзывы, что не у всех все эти сервисы нормально работают. Сам попробовал несколько, всё нормально.
Наглядно посмотреть, как эти карты настраиваются и потом выглядят можно в ролике на официальном канале Zabbix:
https://www.youtube.com/watch?v=rjl9QLYBGRs
Мне понравилась реализация. Классно сделали.
#zabbix
Реализовано всё достаточно просто и удобно. Для начала вам нужно в свойствах хоста, в инвентаризации, указать широту и долготу. Посмотреть их можно на любой публичной карте.
Затем надо добавить на Дашборд новый виджет - Геокарта. В настройках виджета указать узлы сети, которые будут помещены на карту. Вот и всё. Сохраняете виджет и наблюдаете узлы на карте. В свойствах виджета можно настроить начальный вид и приближение, чтобы каждый раз не скролить при поиске хостов.
В разделе Администрирование -> Общие -> Географические карты можно выбрать сервис, с помощью которого будет отображаться карта. Я видел отзывы, что не у всех все эти сервисы нормально работают. Сам попробовал несколько, всё нормально.
Наглядно посмотреть, как эти карты настраиваются и потом выглядят можно в ролике на официальном канале Zabbix:
https://www.youtube.com/watch?v=rjl9QLYBGRs
Мне понравилась реализация. Классно сделали.
#zabbix
{kind=link}
Продолжаю ваc знакомить с утилитами командной стоки Linux, которыми пользуюсь сам. На днях вспомнил про SPLIT. С её помощью можно делить файлы на части. Чаще всего это нужно для больших архивов, которые требуется разбиться на части перед передачей по интернету. Так проще передать большой файл.
Я не помню, чтобы мне приходилось когда-нибудь ставить split отдельно. Обычно она есть в стандартном системном наборе во всех дистрибутивах, с которыми приходится работать.
Конкретно я split использую, когда нужно отправить в S3 хранилище какой-то большой архив. Во многих инструкциях по S3 указывается, что большие файлы отправлять не рекомендуется. Под большими подразумевается что-то больше 2-3 Гигабайт. Так что такие файлы приходится разбивать.
В общем случае разбить файл с помощью split можно следующим образом:
На выходе получим некоторый набор файлов в зависимости от размера исходного. Имена у файлов будут вида xaa, xab, xaс и т.д., что явно неудобно. Поэтому на практике лучше сразу указать маску, по которой будут создаваться новые файлы:
Мы указали длину префикса 2 и использование чисел. На выходе будут файлы file_00, file_01, file_02 и т.д., что мне видится удобнее дефолтных масок.
Собрать файлы обратно можно следующим образом:
Если вы просто хотите разделить файл на 5 частей вне зависимости от того, какого они будут размера, то делается это следующим образом:
Вот пример использования split на бэкапе большого сайта для дальнейшей передачи его в S3. Пример условный, так как вынул его из большого скрипта и все переменные указал явно. То есть это не мой окончательный рабочий вариант, а адаптированный пример:
Отдельно отмечу, что подобные бэкапы обязательно нужно проверять. У меня S3 это не основной бэкап, а холодное хранилище для них. Эти же бэкапы хранятся где-то ещё, разворачиваются и проверяются, так как туда ещё и дамп базы обычно кладётся, чтобы всё в одном месте было.
#terminal #bash
Я не помню, чтобы мне приходилось когда-нибудь ставить split отдельно. Обычно она есть в стандартном системном наборе во всех дистрибутивах, с которыми приходится работать.
Конкретно я split использую, когда нужно отправить в S3 хранилище какой-то большой архив. Во многих инструкциях по S3 указывается, что большие файлы отправлять не рекомендуется. Под большими подразумевается что-то больше 2-3 Гигабайт. Так что такие файлы приходится разбивать.
В общем случае разбить файл с помощью split можно следующим образом:
# split -b 100M fileНа выходе получим некоторый набор файлов в зависимости от размера исходного. Имена у файлов будут вида xaa, xab, xaс и т.д., что явно неудобно. Поэтому на практике лучше сразу указать маску, по которой будут создаваться новые файлы:
# split -b 2M file file_ -a 2 -dМы указали длину префикса 2 и использование чисел. На выходе будут файлы file_00, file_01, file_02 и т.д., что мне видится удобнее дефолтных масок.
Собрать файлы обратно можно следующим образом:
# cat file_* > fileЕсли вы просто хотите разделить файл на 5 частей вне зависимости от того, какого они будут размера, то делается это следующим образом:
# split -n 5 file file_ -a 2 -dВот пример использования split на бэкапе большого сайта для дальнейшей передачи его в S3. Пример условный, так как вынул его из большого скрипта и все переменные указал явно. То есть это не мой окончательный рабочий вариант, а адаптированный пример:
# Делаем архив с относительным путём внутри/usr/bin/tar --exclude='cache/*' \-czvf /mnt/backup/site.ru_`date +"%Y-%m-%d_%H-%M"`.tar.gz \-C /web/sites/site.ru www# Разбиваем архив на части/usr/bin/split -b 2048m \/mnt/backup/site.ru_`date +"%Y-%m-%d_%H-%M"`.tar.gz \"/mnt/backup/site.ru_`date +"%Y-%m-%d_%H-%M"`.tar.gz-part-"# Удаляем исходный файл/usr/bin/rm -rf /mnt/backup/site.ru_`date +"%Y-%m-%d_%H-%M"`.tar.gz# Заливаем в S3/usr/bin/rclone copy /mnt/backup s3storage:week# Чистим локальный бэкап от старых архивов/usr/bin/find /mnt/backup -type f -mtime +7 -exec rm {} \;Отдельно отмечу, что подобные бэкапы обязательно нужно проверять. У меня S3 это не основной бэкап, а холодное хранилище для них. Эти же бэкапы хранятся где-то ещё, разворачиваются и проверяются, так как туда ещё и дамп базы обычно кладётся, чтобы всё в одном месте было.
#terminal #bash
Мне очень не нравятся счётчики Яндекс.Метрика и Google Analytics для сайтов. Они собирают тонну информации, которая лично мне не нужна. При этом заметно замедляют рендеринг страниц. Приходится с этим мириться, потому что существует популярное мнение, что наличие этих счётчиков улучшает ранжирование сайта, так как у поисковых систем появляется больше информации о нём. И хотя нигде открыто об этом не говорится, но очевидно, что это так и есть. Иначе зачем делать такие масштабные highload системы с метрикой бесплатными и доступными всем. Для поисковиков это полезная информация и очевидно, что они будут понижать в выдаче тех, кто не захочет их установить.
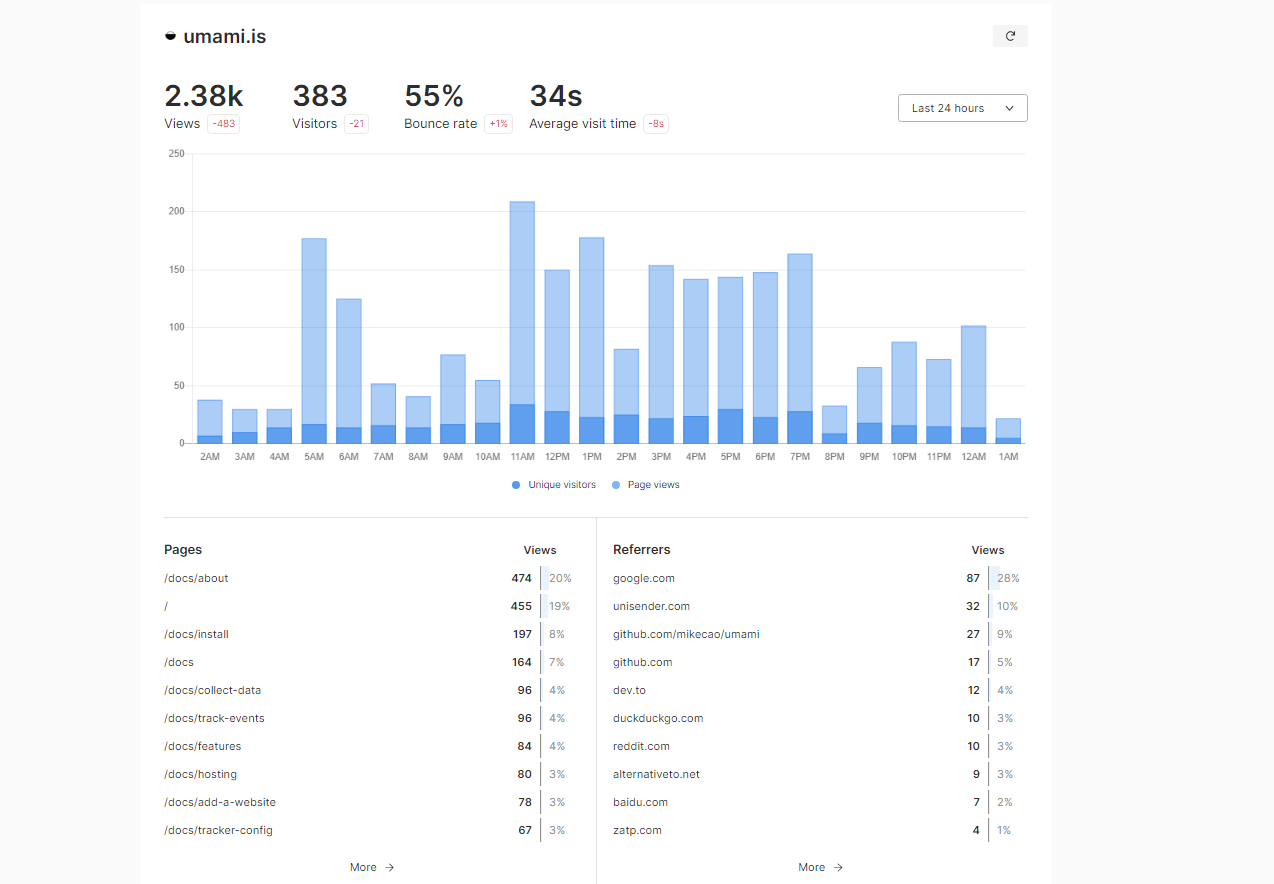
Для тех, кому описанная выше проблема не критична, существуют другие более простые и быстрые решения по сбору статистики. Ранее я уже рассказывал про одно из таких решений - counter.dev. Сейчас добавлю только одно - разработчик этой системы сбора статистики живёт в Киеве. Последние коммиты можете сами посмотреть. Я познакомился с похожим аналогом, который мне понравился больше - umami.is.
Это тоже Open Source система. Umami понравилась за очень простой, лаконичный и быстрый веб интерфейс. Написана на Node.js, использует базу MySQL или Postgresql для хранения статистики. Код скрипта сбора данных всего 2KB. Статистику можно сделать публичной при желании. Есть встроенное API, что удобно, если есть желание забирать метрики в мониторинг.
Бонусом использования подобной системы сбора статистики может стать учёт пользователей с блокировщиками рекламы, так как хостится она локально и повода для блокировки особо не имеет, хотя зная усердия некоторых фильтров не уверен в этом. Но в любом случае упомянутые в начале метрика и аналитика блокируются почти у всех.
Сайт - https://umami.is/
Исходники - https://github.com/mikecao/umami
Демо - https://app.umami.is/share/8rmHaheU/umami.is
#website
Для тех, кому описанная выше проблема не критична, существуют другие более простые и быстрые решения по сбору статистики. Ранее я уже рассказывал про одно из таких решений - counter.dev. Сейчас добавлю только одно - разработчик этой системы сбора статистики живёт в Киеве. Последние коммиты можете сами посмотреть. Я познакомился с похожим аналогом, который мне понравился больше - umami.is.
Это тоже Open Source система. Umami понравилась за очень простой, лаконичный и быстрый веб интерфейс. Написана на Node.js, использует базу MySQL или Postgresql для хранения статистики. Код скрипта сбора данных всего 2KB. Статистику можно сделать публичной при желании. Есть встроенное API, что удобно, если есть желание забирать метрики в мониторинг.
Бонусом использования подобной системы сбора статистики может стать учёт пользователей с блокировщиками рекламы, так как хостится она локально и повода для блокировки особо не имеет, хотя зная усердия некоторых фильтров не уверен в этом. Но в любом случае упомянутые в начале метрика и аналитика блокируются почти у всех.
Сайт - https://umami.is/
Исходники - https://github.com/mikecao/umami
Демо - https://app.umami.is/share/8rmHaheU/umami.is
#website
{kind=link}
Я вчера был на конференции, организованной компанией TrueConf. Была недавно на канале реклама этого мероприятия. Сразу скажу, что этот пост у меня никто не заказывал и не просил написать. Это моя инициатива. Он просто хорошо ложится в канву импортозамещения и перехода на отечественные продукты.
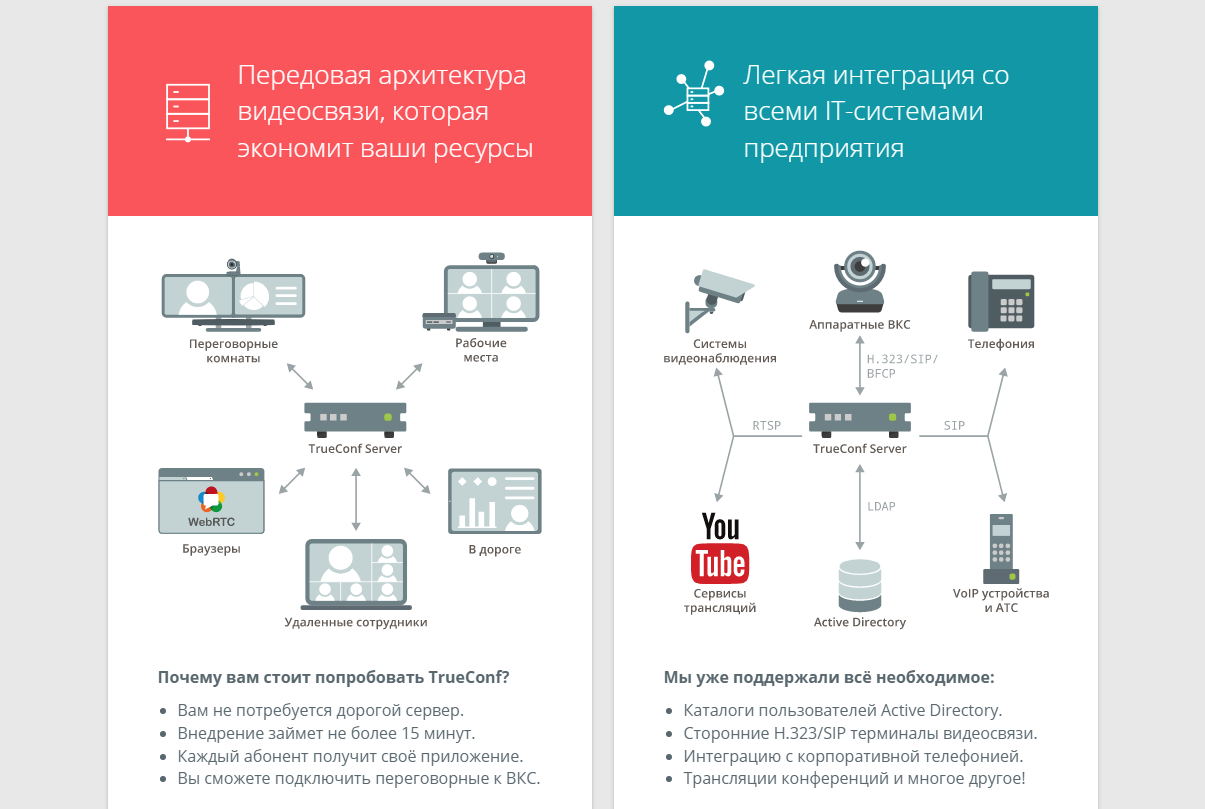
TrueConf - это платформа для видеоконференций и онлайн общения, которая конкурирует с известными мировыми брендами, такими как Zoom, Teams, Webex и т.д. Причём конкурирует давно и не только на отечественном рынке. Основное отличие и оно же преимущество - возможность купить продукт в формате On-premise или Box. То есть вы можете установить ПО на своё железо и оплачивать его по ежегодной подписке или купить бессрочную лицензию.
Я не буду подробно описывать все возможности TrueConf, так как это известная компания с большой линейкой продуктов, пытающаяся покрыть все потребности бизнеса в коммуникациях (видеоконференции через PC клиенты, через аппаратные устройства для переговорок, через аппаратные терминалы для sip/h323, свой транскодирующий сервер и т.д.) Всё это рассчитано на очень большие масштабы.
Отмечу кратко то, на что сам обратил внимание из полученной информации:
◽ Некоторое время назад было масштабное обновление ПО, в том числе клиентского. Сейчас клиент позиционируется в том числе как чат для корпоративного общения. Замена Telegram, WhatsApp и т.д. То есть не только звонилка для видеопереговоров.
◽ Разработка старается конкурировать с мировыми лидерами Zoom, Teams и т.д. Пытаются брать лучшие практики и улучшать их. Речь о функционале и удобстве.
◽ Решение, установленное на своих серверах, позволяет хранить у себя всю аналитику по использованию, в том числе статистику, видеозаписи и т.д. Это становится очень актуально в последнее время, так как явно виден тренд на сегментирование интернета и риски SaaS продуктов.
◽ TrueConf Server можно установить на любое типовое железо, так что производительность и объёмы дисков зависят только от ваших потребностей.
◽ У TrueConf есть поддержка SIP. То есть этот продукт пытается совместить в себе основные коммуникации бизнеса - чат, видео, телефония.
Отдельно отмечу, что сам я TrueConf никогда не использовал. Была пара тестирований, когда поднимал сервер, но внедрения не делал и активно не использовал. Так что всё написал со слов докладчиков и маркетинговой информации.
❗️У TrueConf Server есть бесплатная версия на 10 абонентов, где можно протестировать основной функционал, в том числе запись конференций. Сервер есть под Windows и Linux, клиенты под все популярные стационарные и мобильные системы. Поддерживаются в том числе все отечественные системы (Asta, ROSA, Alt и т.д.) Ещё раз отмечу, что сервер можно установить у себя автономно в том числе в закрытых сетях.
ps Отдельно хочу отметить, что хотя официально на поставки иностранного оборудования наложены ссанкции, сами производители в них не заинтересованы и реально оборудование поступает и доступно для заказа.
Сайт - https://trueconf.ru/
Реестр ПО - https://reestr.digital.gov.ru/reestr/301405/
#отечественное #videoserver #chat
TrueConf - это платформа для видеоконференций и онлайн общения, которая конкурирует с известными мировыми брендами, такими как Zoom, Teams, Webex и т.д. Причём конкурирует давно и не только на отечественном рынке. Основное отличие и оно же преимущество - возможность купить продукт в формате On-premise или Box. То есть вы можете установить ПО на своё железо и оплачивать его по ежегодной подписке или купить бессрочную лицензию.
Я не буду подробно описывать все возможности TrueConf, так как это известная компания с большой линейкой продуктов, пытающаяся покрыть все потребности бизнеса в коммуникациях (видеоконференции через PC клиенты, через аппаратные устройства для переговорок, через аппаратные терминалы для sip/h323, свой транскодирующий сервер и т.д.) Всё это рассчитано на очень большие масштабы.
Отмечу кратко то, на что сам обратил внимание из полученной информации:
◽ Некоторое время назад было масштабное обновление ПО, в том числе клиентского. Сейчас клиент позиционируется в том числе как чат для корпоративного общения. Замена Telegram, WhatsApp и т.д. То есть не только звонилка для видеопереговоров.
◽ Разработка старается конкурировать с мировыми лидерами Zoom, Teams и т.д. Пытаются брать лучшие практики и улучшать их. Речь о функционале и удобстве.
◽ Решение, установленное на своих серверах, позволяет хранить у себя всю аналитику по использованию, в том числе статистику, видеозаписи и т.д. Это становится очень актуально в последнее время, так как явно виден тренд на сегментирование интернета и риски SaaS продуктов.
◽ TrueConf Server можно установить на любое типовое железо, так что производительность и объёмы дисков зависят только от ваших потребностей.
◽ У TrueConf есть поддержка SIP. То есть этот продукт пытается совместить в себе основные коммуникации бизнеса - чат, видео, телефония.
Отдельно отмечу, что сам я TrueConf никогда не использовал. Была пара тестирований, когда поднимал сервер, но внедрения не делал и активно не использовал. Так что всё написал со слов докладчиков и маркетинговой информации.
❗️У TrueConf Server есть бесплатная версия на 10 абонентов, где можно протестировать основной функционал, в том числе запись конференций. Сервер есть под Windows и Linux, клиенты под все популярные стационарные и мобильные системы. Поддерживаются в том числе все отечественные системы (Asta, ROSA, Alt и т.д.) Ещё раз отмечу, что сервер можно установить у себя автономно в том числе в закрытых сетях.
ps Отдельно хочу отметить, что хотя официально на поставки иностранного оборудования наложены ссанкции, сами производители в них не заинтересованы и реально оборудование поступает и доступно для заказа.
Сайт - https://trueconf.ru/
Реестр ПО - https://reestr.digital.gov.ru/reestr/301405/
#отечественное #videoserver #chat
{kind=link}
Как организовать видеоконференцсвязь, когда приходится отказываться от импортного ПО и оборудования?
Об этом пойдёт речь на вебинаре Logitech и NBCom Group – «Как обеспечить видеоконференцсвязь в современных реалиях».
Дата и время: 14 апреля, 11:00 по МСК
Зарегистрироваться и узнать подробности здесь.
Об этом пойдёт речь на вебинаре Logitech и NBCom Group – «Как обеспечить видеоконференцсвязь в современных реалиях».
Дата и время: 14 апреля, 11:00 по МСК
Зарегистрироваться и узнать подробности здесь.
MikroTik Newsletter Апрель 2022
Основная новость для нас - Mikrotik отозвал все тренерские сертификаты из РФ, остановил программу обучения и официально прекратил поставки оборудования. Тем не менее, в продаже оно есть и скоро на канале будет реклама поставщиков этого оборудования. Законы капитализма нерушимы - деньги превыше всего. Пожалуй сейчас это единственная ситуация, когда данный принцип я могу оценить положительно.
Остальные новости вендора:
◽ Новая модель свитча CRS504-4XQ-IN за $799. Особенности: 2 hot-swap блока питания, 4х100 gigabit QSFP28 порта!!! Обзор на Youtube. Я думал такие скорости стоят значительно дороже, а оказывается 100 гигабит можно за 800 баксов заиметь.
◽ Новый уличный топовый LTE модем LHG LTE18 kit за $279. Пригодится там, где очень слабый сигнал и обычными устройствами он не ловится. Питаться может через PoE-in, связь через Gigabit Ethernet порт. Внутри dual-core ARM CPU, так что если сигнал хороший, то модем может агрегировать каналы и выдавать скорость LTE соединения до одного гигабита в секунду. Обзор на Youtube.
◽ Новый маршрутизатор CCR2004-16G-2S+PC за $465. Особенности: 16xGigabit Ethernet портов (по 8 на каждый switch чип), 2x10G SFP+ портов, 4-х ядерный процессор, консольный порт RG-45, пассивное охлаждение!. Устройство позиционируется как бесшумный роутер для установки прямо в офисе или дома (для богатеньких 😎). Обзор на Youtube.
◽ Вышла RouterOS v7.2 Stable. "Remember to keep your devices updated for the best performance and maximum security!" Все обновились? 😄
Там ещё новые вентиляторы и крепления вышли, но это не так интересно. Отдельно стоит упомянуть, что Mikrotik обновил логотип. Новый в прикреплённом изображении ниже. Побуду занудой, но мне старый нравится больше. А вам как?
Newsletter PDF
#mikrotik
Основная новость для нас - Mikrotik отозвал все тренерские сертификаты из РФ, остановил программу обучения и официально прекратил поставки оборудования. Тем не менее, в продаже оно есть и скоро на канале будет реклама поставщиков этого оборудования. Законы капитализма нерушимы - деньги превыше всего. Пожалуй сейчас это единственная ситуация, когда данный принцип я могу оценить положительно.
Остальные новости вендора:
◽ Новая модель свитча CRS504-4XQ-IN за $799. Особенности: 2 hot-swap блока питания, 4х100 gigabit QSFP28 порта!!! Обзор на Youtube. Я думал такие скорости стоят значительно дороже, а оказывается 100 гигабит можно за 800 баксов заиметь.
◽ Новый уличный топовый LTE модем LHG LTE18 kit за $279. Пригодится там, где очень слабый сигнал и обычными устройствами он не ловится. Питаться может через PoE-in, связь через Gigabit Ethernet порт. Внутри dual-core ARM CPU, так что если сигнал хороший, то модем может агрегировать каналы и выдавать скорость LTE соединения до одного гигабита в секунду. Обзор на Youtube.
◽ Новый маршрутизатор CCR2004-16G-2S+PC за $465. Особенности: 16xGigabit Ethernet портов (по 8 на каждый switch чип), 2x10G SFP+ портов, 4-х ядерный процессор, консольный порт RG-45, пассивное охлаждение!. Устройство позиционируется как бесшумный роутер для установки прямо в офисе или дома (для богатеньких 😎). Обзор на Youtube.
◽ Вышла RouterOS v7.2 Stable. "Remember to keep your devices updated for the best performance and maximum security!" Все обновились? 😄
Там ещё новые вентиляторы и крепления вышли, но это не так интересно. Отдельно стоит упомянуть, что Mikrotik обновил логотип. Новый в прикреплённом изображении ниже. Побуду занудой, но мне старый нравится больше. А вам как?
Newsletter PDF
#mikrotik
{kind=link}
Rsync - мощная консольная утилита и служба для быстрого копирования файлов. Отличает её в первую очередь скорость сравнения директорий с огромным количеством файлов. К примеру, если вам нужно будет сравнить и привести к единому содержимому два разнесённых по сети хранилища с миллионом файлов внутри, то rsync для этого подойдёт лучше, чем что-либо другое.
Я сам лично до сих пор для бэкапов использую преимущественно голый rsync, но не всегда и не везде. Если нужно обязательно копировать файлы как есть, без упаковки, сжатия, дедупликации, то как раз в этом случае выберу его. Пример подхода с использованием rsync давно описал в статье, которая нисколько не устарела, так как сам rsync, его возможности и параметры не изменились вообще.
Для тех, кто не хочет колхозить автоматизацию бэкапов с помощью самодельных скриптов, есть готовые системы на базе Rsync. Я постарался рассмотреть практически все более ли менее известные. Вот они:
▪ Butterfly Backup - консольная утилита Linux.
▪ Rsnapshot - консольная утилита Linux.
▪ ElkarBackup - сервис для бэкапов, написанный на PHP, настройка через браузер.
▪ BackupPC - сервис для бэкапов, написанный на PERL, настройка через браузер.
▪ Burp - сервис под Linux, более простой аналог Bacula.
▪ cwRsyncServer Программа под Windows.
▪ DeltaCopy Программа под Windows.
Забирайте в закладки. Rsnapshot, DeltaCopy постоянно использую сам.
#rsync #backup
Я сам лично до сих пор для бэкапов использую преимущественно голый rsync, но не всегда и не везде. Если нужно обязательно копировать файлы как есть, без упаковки, сжатия, дедупликации, то как раз в этом случае выберу его. Пример подхода с использованием rsync давно описал в статье, которая нисколько не устарела, так как сам rsync, его возможности и параметры не изменились вообще.
Для тех, кто не хочет колхозить автоматизацию бэкапов с помощью самодельных скриптов, есть готовые системы на базе Rsync. Я постарался рассмотреть практически все более ли менее известные. Вот они:
▪ Butterfly Backup - консольная утилита Linux.
▪ Rsnapshot - консольная утилита Linux.
▪ ElkarBackup - сервис для бэкапов, написанный на PHP, настройка через браузер.
▪ BackupPC - сервис для бэкапов, написанный на PERL, настройка через браузер.
▪ Burp - сервис под Linux, более простой аналог Bacula.
▪ cwRsyncServer Программа под Windows.
▪ DeltaCopy Программа под Windows.
Забирайте в закладки. Rsnapshot, DeltaCopy постоянно использую сам.
#rsync #backup
{kind=link}
Когда я только начинал администрировать Linux сервера, первые несколько лет регулярно использовал панель управления Webmin для одной единственной цели - просмотр всевозможных логов. Мне нравился там модуль для этого дела. С его помощью можно было удобно грепать логи, что-то искать, копировать и т.д.
Особенно это было актуально для почтовых серверов на базе postfix. Там постоянно нужно было лазить в лог и что-то проверять: почему письмо не дошло, подключался ли данный клиент, какой был ответ сервера и т.д. Мне было удобно в Webmin задать ID письма или IP сервера и посмотреть всю информацию о них в логах. Обычно там все сильно разбросано по лог файлу, потому что куча повторяющихся и новых событий происходят, а Webmin помогал упорядочить.
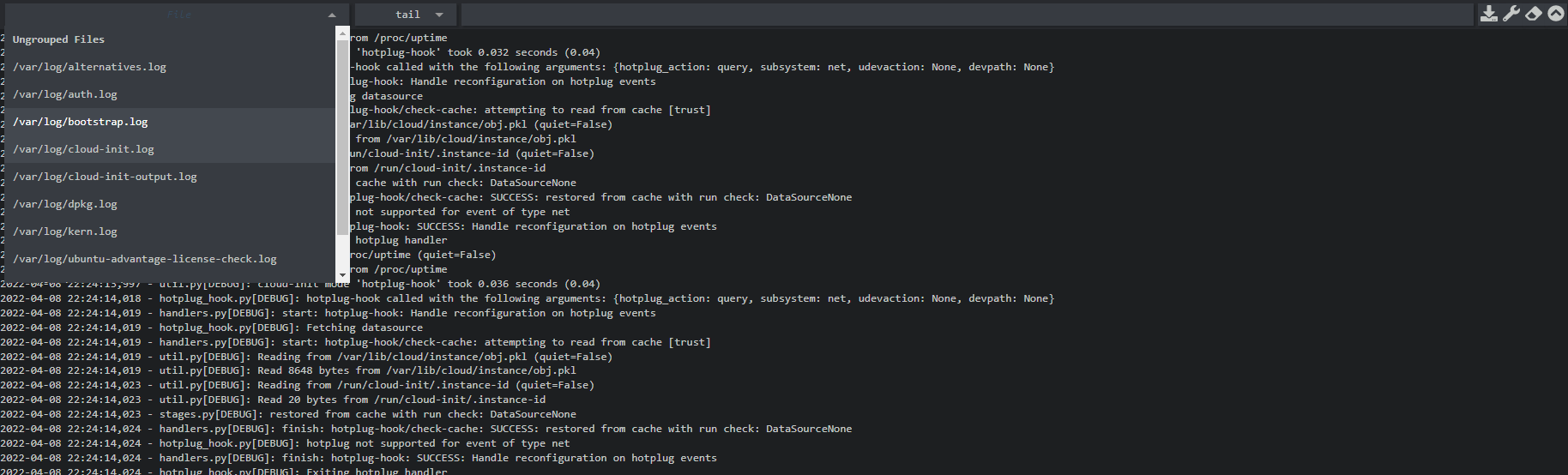
Со временем отказался от Webmin, так как ставить такого монстра только для логов было излишним. Недавно наткнулся на удобную утилиту, которая позволяет делать примерно то же самое - удобно просматривать логи через браузер. Речь идёт про tailon (https://github.com/gvalkov/tailon).
Это маленькая утилита, состоящая из одного бинарника, который можно скачать из репозитория и запустить. Она состоит из веб сервера, который открывает заданные логи, чтобы вы могли посмотреть их через браузер. Поддерживается не только просмотр, но и обработка прямо в браузере стандартными утилитами grep, awk, sed. Сделано всё простенько, но функционально.
Можно сразу все логи директории отправить в браузер, например так:
И выбирать, какой из них открыть на просмотр в веб интерфейсе. Сервер по умолчанию поднимается на порту 8080.
Если вы новичок в Linux и работать в консоли ещё не привыкли, то попробуйте, может понравится инструмент. Да и просто на время отладки может пригодиться, или анализа логов веб сервера в режиме реального времени. В общем, полезная штука.
#linux #logs
Особенно это было актуально для почтовых серверов на базе postfix. Там постоянно нужно было лазить в лог и что-то проверять: почему письмо не дошло, подключался ли данный клиент, какой был ответ сервера и т.д. Мне было удобно в Webmin задать ID письма или IP сервера и посмотреть всю информацию о них в логах. Обычно там все сильно разбросано по лог файлу, потому что куча повторяющихся и новых событий происходят, а Webmin помогал упорядочить.
Со временем отказался от Webmin, так как ставить такого монстра только для логов было излишним. Недавно наткнулся на удобную утилиту, которая позволяет делать примерно то же самое - удобно просматривать логи через браузер. Речь идёт про tailon (https://github.com/gvalkov/tailon).
Это маленькая утилита, состоящая из одного бинарника, который можно скачать из репозитория и запустить. Она состоит из веб сервера, который открывает заданные логи, чтобы вы могли посмотреть их через браузер. Поддерживается не только просмотр, но и обработка прямо в браузере стандартными утилитами grep, awk, sed. Сделано всё простенько, но функционально.
Можно сразу все логи директории отправить в браузер, например так:
# ./tailon /var/log/*.logИ выбирать, какой из них открыть на просмотр в веб интерфейсе. Сервер по умолчанию поднимается на порту 8080.
Если вы новичок в Linux и работать в консоли ещё не привыкли, то попробуйте, может понравится инструмент. Да и просто на время отладки может пригодиться, или анализа логов веб сервера в режиме реального времени. В общем, полезная штука.
#linux #logs
{kind=link}
Типовая ситуация, в которую часто попадаю при аренде выделенных серверов с SSD - нехватка места на дисках. Расширить его зачастую невозможно. Приходится придумывать какие-то другие варианты. Наиболее простым и бюджетным является перенос части холодных данных на S3.
Сделать это можно с помощью софта s3fs-fuse: https://github.com/s3fs-fuse/s3fs-fuse
Он обычно есть в стандартных репозиториях:
Далее необходимо создать файл с учётными данными для подключения к облаку:
И можно монтировать:
Показал на примере S3 хранилища в Selectel. Я обычно им пользуюсь, потому что дёшево.
#s3
Сделать это можно с помощью софта s3fs-fuse: https://github.com/s3fs-fuse/s3fs-fuse
Он обычно есть в стандартных репозиториях:
# dnf install s3fs-fuse# apt install s3fsДалее необходимо создать файл с учётными данными для подключения к облаку:
# echo user:password > ~/.passwd-s3fs# chmod 600 ~/.passwd-s3fsИ можно монтировать:
# s3fs mybucket /mnt/s3 -o passwd_file=~/.passwd-s3fs \-o url=https://s3.storage.selcloud.ru \-o use_path_request_styleПоказал на примере S3 хранилища в Selectel. Я обычно им пользуюсь, потому что дёшево.
#s3
GitHub
GitHub - s3fs-fuse/s3fs-fuse: FUSE-based file system backed by Amazon S3
FUSE-based file system backed by Amazon S3. Contribute to s3fs-fuse/s3fs-fuse development by creating an account on GitHub.
Типичная картина переноса сайта с дедика, где все ресурсы принадлежат только ему, на арендованную VPS. Это скриншот с дефолтного мониторинга сайта средствами Zabbix Server.
Упала и скорость доступа к сайту, и отклик сайта вырос и стал рваный, потому что хост принадлежит не только тебе. Сколько на нём работает виртуалок, можно только гадать.
Причём переезд осуществлён на VPS, где ресурсы арендованы с большим запасом. И сам хостинг не дешманский. Но спрогнозировать отклик всё равно невозможно. Это основная причина, почему при возможности лучше арендовать выделенный сервер, а не виртуальную машину.
В данном случае было не критично, поэтому решили сэкономить деньги. VPS купили ровно в 2 раза дешевле дедика. Так что надо в каждом конкретном случае решать, что важнее - деньги или скорость сайта. В этом примере производительность всё равно хорошая, но до этого была идеальная.
#webserver #zabbix #мониторинг
Упала и скорость доступа к сайту, и отклик сайта вырос и стал рваный, потому что хост принадлежит не только тебе. Сколько на нём работает виртуалок, можно только гадать.
Причём переезд осуществлён на VPS, где ресурсы арендованы с большим запасом. И сам хостинг не дешманский. Но спрогнозировать отклик всё равно невозможно. Это основная причина, почему при возможности лучше арендовать выделенный сервер, а не виртуальную машину.
В данном случае было не критично, поэтому решили сэкономить деньги. VPS купили ровно в 2 раза дешевле дедика. Так что надо в каждом конкретном случае решать, что важнее - деньги или скорость сайта. В этом примере производительность всё равно хорошая, но до этого была идеальная.
#webserver #zabbix #мониторинг
Я узнал про шикарную программу для автоматизации рутинных задач - xStarter. Мне кажется, для типичного офисного системного администратора с широким спектром задач это отличный инструмент. Посмотрел описание и возможности программы и сходу придумал несколько ситуаций, где эта программа может быть полезна:
1️⃣ Создание бэкапа на каком-то одиночном сервере. Например, вам нужно локально сделать выгрузку базы 1С в dt, куда-то её скопировать и удалить старые копии. В xStarter это можно сделать, создав на каждое действие свой шаг: запуск конфигуратора с параметрами командной строки для выгрузки в dt, копирование бэкапа, удаление старых версий.
2️⃣ Выполнение каких-либо действий при появлении файлов в определённой директории. Тут вообще широкое поле для деятельности. Можно на печать эти файлы отправлять, можно куда-то по почте или на ftp загружать, можно жать их и куда-то ещё копировать и т.д. Можно разные действия на разные маски файлов делать.
3️⃣ Сделать одиночный экзешник, который при запуске будет пинговать какой-то хост определёнными пакетами, а на хосте будет настроен port knocking для открытия rdp порта. После этого будет запускаться rdp клиент с какими-то параметрами и подключаться к серверу. Экзешник можно юзеру отдать.
4️⃣ Проверка какого-то почтового ящика на наличие писем с вложениями, сохранение вложения из присланного письма в какую-то локальную папку.
Чего только xStrater не умеет. Есть преднастроенные типовые действия, можно писать полностью свои сценарии. Какие-то примеры можно посмотреть на форуме.
Программа старая, но при этом нормально работает до сих пор. Я проверил на Windows 11. Для русскоязычных пользователей xStarter полностью бесплатна. Если кто-то пользовался, напишите, какие задачи решали.
Сайт - https://www.xstarter.com/rus/
#windows
1️⃣ Создание бэкапа на каком-то одиночном сервере. Например, вам нужно локально сделать выгрузку базы 1С в dt, куда-то её скопировать и удалить старые копии. В xStarter это можно сделать, создав на каждое действие свой шаг: запуск конфигуратора с параметрами командной строки для выгрузки в dt, копирование бэкапа, удаление старых версий.
2️⃣ Выполнение каких-либо действий при появлении файлов в определённой директории. Тут вообще широкое поле для деятельности. Можно на печать эти файлы отправлять, можно куда-то по почте или на ftp загружать, можно жать их и куда-то ещё копировать и т.д. Можно разные действия на разные маски файлов делать.
3️⃣ Сделать одиночный экзешник, который при запуске будет пинговать какой-то хост определёнными пакетами, а на хосте будет настроен port knocking для открытия rdp порта. После этого будет запускаться rdp клиент с какими-то параметрами и подключаться к серверу. Экзешник можно юзеру отдать.
4️⃣ Проверка какого-то почтового ящика на наличие писем с вложениями, сохранение вложения из присланного письма в какую-то локальную папку.
Чего только xStrater не умеет. Есть преднастроенные типовые действия, можно писать полностью свои сценарии. Какие-то примеры можно посмотреть на форуме.
Программа старая, но при этом нормально работает до сих пор. Я проверил на Windows 11. Для русскоязычных пользователей xStarter полностью бесплатна. Если кто-то пользовался, напишите, какие задачи решали.
Сайт - https://www.xstarter.com/rus/
#windows
{kind=link}
Неоднократно видел в интернете истории на тему случайного удаления /dev/null. Так как эта штука часто используется в командах bash или скриптах, достаточно перепутать какие-то аргументы или места в командах и удалено будет не то, что ожидается.
Конкретно с /dev/null никаких проблем не будет. Можно просто перезагрузить систему, либо выполнить без перезагрузки:
Если я не ошибаюсь, то /dev устройства создаются динамически при каждой загрузке устройства и следит за этим udev.
/dev/null - символьное псевдоустройство. Ключ "c" в команде mknod как раз указывает на это (b - блочный, c - символьный). Кстати, если удалить /dev/null и создать вместо него текстовый файл, то можно посмотреть, кто и как использует это псевдоустройство. Я чисто из любопытства это сделал:
Дальше можно выполнять какие-то действия: логиниться в систему, обновлять пакеты, останавливать службы и т.д. Будет видно, как в /dev/null постоянно кто-то что-то отправляет и делает truncate потом, так что файл будет всегда нулевого размера и без tail посмотреть, что туда пишут, не получится.
#terminal #linux
Конкретно с /dev/null никаких проблем не будет. Можно просто перезагрузить систему, либо выполнить без перезагрузки:
# mknod -m 666 /dev/null c 1 3Если я не ошибаюсь, то /dev устройства создаются динамически при каждой загрузке устройства и следит за этим udev.
/dev/null - символьное псевдоустройство. Ключ "c" в команде mknod как раз указывает на это (b - блочный, c - символьный). Кстати, если удалить /dev/null и создать вместо него текстовый файл, то можно посмотреть, кто и как использует это псевдоустройство. Я чисто из любопытства это сделал:
# rm -f /dev/null# touch /dev/null# chmod 0666 /dev/null# tail -f /dev/nullДальше можно выполнять какие-то действия: логиниться в систему, обновлять пакеты, останавливать службы и т.д. Будет видно, как в /dev/null постоянно кто-то что-то отправляет и делает truncate потом, так что файл будет всегда нулевого размера и без tail посмотреть, что туда пишут, не получится.
#terminal #linux
Существует рекомендация не восстанавливать Контроллеры Домена Windows из бэкапов. Якобы это может положить весь домен. На практике мне никогда не приходилось проверять данное утверждение. Я всегда делаю строго 2 контроллера домена в одном сегменте. Бэкаплю состояние сервера встроенной архивацией Windows и саму виртуальную машину на уровне гипервизора.
Некоторое время назад столкнулся с ситуацией, что после аварийного завершения работы сервера (скачок электричества ребутнул часть устройств за работающими упсами, а сами упсы даже не зарегистрировали его) не поднялись некоторые VM, в том числе с КД. Благо второй сервер с запасным КД поднялся нормально и каких-то серьезных проблем не возникло. Было время спокойно решить проблему.
У меня был бэкап всей VM, сделанный Veeam. Нашёл в одной из статей информацию о том, что Veeam умеет корректно поднимать упавший КД:
В большинстве сценариев восстановления вам потребуется режим non-authoritative, поскольку в среде имеется несколько контроллеров домена. (Кроме того, authoritative восстановление может привести к новым проблемам.) Именно на этом основана логика Veeam Backup & Replication: по умолчанию выполняется non-authoritative восстановление, поскольку считается, что инфраструктура выстроена с избыточностью и включает в себя несколько контроллеров.
В итоге всё равно не рискнул восстанавливать эту VM. Смогли починить на месте контроллер. Что конкретно с ним делали, не знаю, не я занимался. Вторым вариантом рассматривали забить на этот КД и поднять новый, завести его в домен. Но мне не хотелось этим заниматься, так как от старого КД в DNS остаётся куча записей. Я не знал, как корректно их оттуда все вычистить.
У кого есть практический опыт по данному вопросу? Как корректно разрулить ситуацию с полностью умершим одним из контроллеров домена? Восстановление из бэкапа реально положит весь домен? Я понимаю, что можно разом поднять вообще все КД, тогда конфликта быть не должно. Но в данном случае серверов много, все их поднимать было точно не вариант. Да и бэкапы в разное время были сделаны, а не одномоментно.
#windows
Некоторое время назад столкнулся с ситуацией, что после аварийного завершения работы сервера (скачок электричества ребутнул часть устройств за работающими упсами, а сами упсы даже не зарегистрировали его) не поднялись некоторые VM, в том числе с КД. Благо второй сервер с запасным КД поднялся нормально и каких-то серьезных проблем не возникло. Было время спокойно решить проблему.
У меня был бэкап всей VM, сделанный Veeam. Нашёл в одной из статей информацию о том, что Veeam умеет корректно поднимать упавший КД:
В большинстве сценариев восстановления вам потребуется режим non-authoritative, поскольку в среде имеется несколько контроллеров домена. (Кроме того, authoritative восстановление может привести к новым проблемам.) Именно на этом основана логика Veeam Backup & Replication: по умолчанию выполняется non-authoritative восстановление, поскольку считается, что инфраструктура выстроена с избыточностью и включает в себя несколько контроллеров.
В итоге всё равно не рискнул восстанавливать эту VM. Смогли починить на месте контроллер. Что конкретно с ним делали, не знаю, не я занимался. Вторым вариантом рассматривали забить на этот КД и поднять новый, завести его в домен. Но мне не хотелось этим заниматься, так как от старого КД в DNS остаётся куча записей. Я не знал, как корректно их оттуда все вычистить.
У кого есть практический опыт по данному вопросу? Как корректно разрулить ситуацию с полностью умершим одним из контроллеров домена? Восстановление из бэкапа реально положит весь домен? Я понимаю, что можно разом поднять вообще все КД, тогда конфликта быть не должно. Но в данном случае серверов много, все их поднимать было точно не вариант. Да и бэкапы в разное время были сделаны, а не одномоментно.
#windows
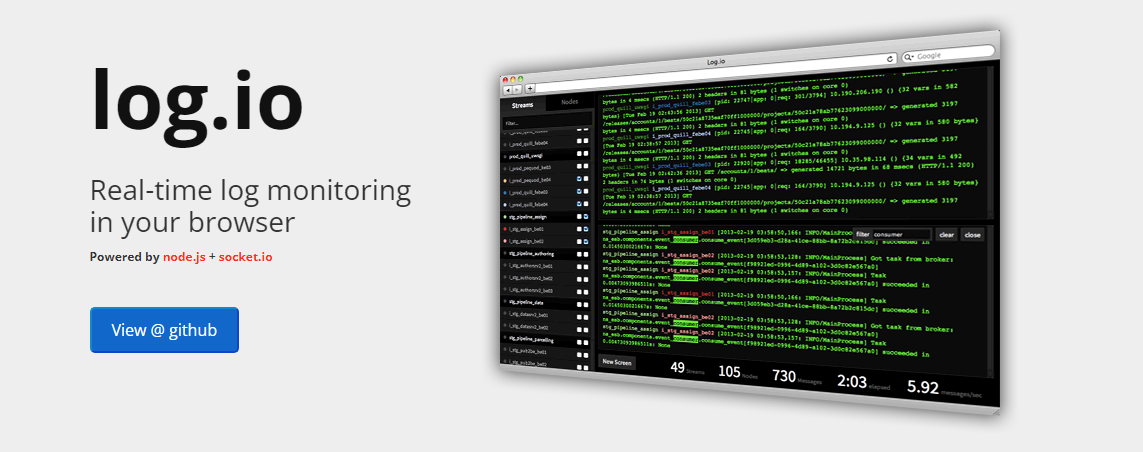
Продолжаю тему просмотра логов. Нашёл ещё один полезный и популярный проект для просмотра логов в браузере в режиме реального времени - log.io. Написан на Node.js с использованием Socket.io. Ставится через nmp в одну команду. Конфиги хранит в формате json.
Архитектура у приложения клиент серверная. Отдельно ставится сервер приёма сообщений и http сервер. Отдельно ставятся клиенты для отправки логов. Log.io может работать в рамках одного сервера.
Установка и настройка очень простая. Описана целиком на главной сайта с примером конфигурации. Не буду сюда это дублировать.
Встроенный веб сервер log.io сам поддерживает http basic auth, так что можно ограничить доступ без применения проксирующего сервера. Как я уже сказал, проект известный, поэтому в сети найдёте много руководств с примерами по установке и настройке. Лично мне хватило информации из документации на guthub.
Обращаю внимание, что сам домен log.io, как я понял, к описываемому продукту не имеет отношения и редиректит на сайт какой-то другой компании.
Сайт - http://logio.org/
Исходники - https://github.com/NarrativeScience/log.io
#logs
Архитектура у приложения клиент серверная. Отдельно ставится сервер приёма сообщений и http сервер. Отдельно ставятся клиенты для отправки логов. Log.io может работать в рамках одного сервера.
Установка и настройка очень простая. Описана целиком на главной сайта с примером конфигурации. Не буду сюда это дублировать.
Встроенный веб сервер log.io сам поддерживает http basic auth, так что можно ограничить доступ без применения проксирующего сервера. Как я уже сказал, проект известный, поэтому в сети найдёте много руководств с примерами по установке и настройке. Лично мне хватило информации из документации на guthub.
Обращаю внимание, что сам домен log.io, как я понял, к описываемому продукту не имеет отношения и редиректит на сайт какой-то другой компании.
Сайт - http://logio.org/
Исходники - https://github.com/NarrativeScience/log.io
#logs
{kind=link}
На днях в комментариях зашёл разговор о ситуации, когда с утилиты chmod сняли бит исполнения. Эта утилита как раз предназначена для того, чтобы этот бит ставить. Теоретически получается тупиковая ситуация. Это, кстати, отличная безобидная шутка для начинающего Linux админа:
К сожалению, сейчас решение очень легко находится через поиск. А вот когда-то давно это могло стать хорошим испытанием на сообразительность. Выходов из сложившейся ситуации много. Вот несколько примеров:
1️⃣ Используем утилиту setfacl. По умолчанию её может не быть в системе, но не проблема установить.
2️⃣ Можно запустить утилиту chmod, передав её явно динамическому компоновщику. В контексте данной заметки считайте компоновщик интерпретатором для программы chmod. В разных дистрибутивах он может иметь разное название и расположение. Пример для Debian 11:
3️⃣ Можно скопировать права с любого исполняемого файла и записать содержимое утилиты chmod в этот файл. Получается рабочая копия chmod.
Создаём пустой файл с правами утилиты ls.
Копируем содержимое утилиты chmod в созданный файл:
Можно использовать:
4️⃣ Почти то же самое что и предыдущий вариант только проще:
или так:
5️⃣ Если умеете программировать на какой-то языке, то можно с его помощью вернуть бит исполнения. Пример с python:
Если знаете ещё какие-то интересные и необычные решения данной проблемы, делитесь в комментариях.
#terminal #linux #юмор
# chmod -x chmodК сожалению, сейчас решение очень легко находится через поиск. А вот когда-то давно это могло стать хорошим испытанием на сообразительность. Выходов из сложившейся ситуации много. Вот несколько примеров:
1️⃣ Используем утилиту setfacl. По умолчанию её может не быть в системе, но не проблема установить.
# setfacl -m u::rwx,g::rx,o::x /usr/bin/chmod2️⃣ Можно запустить утилиту chmod, передав её явно динамическому компоновщику. В контексте данной заметки считайте компоновщик интерпретатором для программы chmod. В разных дистрибутивах он может иметь разное название и расположение. Пример для Debian 11:
# /usr/lib64/ld-linux-x86-64.so.2 /usr/bin/chmod +x /usr/bin/chmod3️⃣ Можно скопировать права с любого исполняемого файла и записать содержимое утилиты chmod в этот файл. Получается рабочая копия chmod.
Создаём пустой файл с правами утилиты ls.
# cp --attributes-only /usr/bin/ls ./new_chmodКопируем содержимое утилиты chmod в созданный файл:
# cat /usr/bin/chmod > ./new_chmodМожно использовать:
# ./new_chmod +x /usr/bin/chmod4️⃣ Почти то же самое что и предыдущий вариант только проще:
# install -m 755 /usr/bin/chmod ./new_chmodили так:
# rsync --chmod=ugo+x /usr/bin/chmod ./new_chmod5️⃣ Если умеете программировать на какой-то языке, то можно с его помощью вернуть бит исполнения. Пример с python:
python -c "import os;os.chmod('/usr/bin/chmod', 0755)"Если знаете ещё какие-то интересные и необычные решения данной проблемы, делитесь в комментариях.
#terminal #linux #юмор
Давно не затрагивал тему мониторинга, потому что все известные продукты так или иначе обозревал ранее в заметках. Посмотреть их можно по соответствующим тэгам. В этот раз хочу познакомить вас с интересным продуктом, ранее который я не обозревал и вообще сам не был с ним знаком. Речь пойдёт о комплексной системе для мониторинга, визуализации и инвентаризации компьютерного оборудования Algorius.
Сразу перечислю основные особенности Algorius:
◽ устанавливается на Windows систему через типовой установщик;
◽ максимально простая и быстрая настройка, в том числе с автоматическим обнаружением устройств в сети;
◽ вся настройка выполняется мышкой в окне программы, никакие конфиги править не надо, долго разбираться и читать документацию тоже, всё интуитивно понятно;
◽ в качестве БД использует SQLite.
А теперь основное по функционалу:
▪ Клиент-серверный доступ к информации. На сервере можно настроить, к каким данным может получать доступ тот или иной клиент. Клиентом выступает отдельное Windows приложение.
▪ В Algorius можно рисовать красивые и наглядные схемы сети с различной разбивкой по сегментам. Можно описать до каждого устройства локальную сеть, а потом все сети описать в общей навигационной карте. Есть поддержка географической карты OpenStreetMap.
▪ Поиск и идентификация устройств могут проходить автоматически с использованием различных механизмов и технологий - ARP, Ping, Netbios, TCP, UDP, SNMP, WMI.
▪ Для устройств можно заполнять инвентарные данные, а также собирать их автоматически отдельным агентом.
▪ Схемы сетей можно импортировать/экспортировать в формат Visio.
Поставил программу, немного посмотрел на неё. Она реально очень проста в настройке. Автоматически просканила сеть, нашла некоторые компы и сервера. Чтобы поставить объект на мониторинг, достаточно открыть его свойства, добавить ip адрес и сенсор, который будет использоваться (ping, tcp или udp запрос на какой-то порт, snmp, arp и т.д.).
Функционал относительно простой, если сравнивать с какими-то серьезными системами мониторинга. Но зато всё целостное, понятное и легко настраивается. Есть возможность использовать внешние проверки и устанавливать плагины. Не думаю, что найдётся большой выбор этих плагинов, кроме тех, что написали сами разработчики.
Algorius платная программа, не Open Source. Есть бесплатная версия с ограничениями:
- 25 хостов мониторинга;
- 5 одновременно открытых карт сетей;
- хранение отчётов 1 месяц;
Если покупать, то цены очень доступные. Мониторинг 500 хостов без каких-либо других ограничений стоит всего 10000р. в год. А 100 всего 2000р.
Сайт - https://algorius.ru
#мониторинг #управление #ITSM
Сразу перечислю основные особенности Algorius:
◽ устанавливается на Windows систему через типовой установщик;
◽ максимально простая и быстрая настройка, в том числе с автоматическим обнаружением устройств в сети;
◽ вся настройка выполняется мышкой в окне программы, никакие конфиги править не надо, долго разбираться и читать документацию тоже, всё интуитивно понятно;
◽ в качестве БД использует SQLite.
А теперь основное по функционалу:
▪ Клиент-серверный доступ к информации. На сервере можно настроить, к каким данным может получать доступ тот или иной клиент. Клиентом выступает отдельное Windows приложение.
▪ В Algorius можно рисовать красивые и наглядные схемы сети с различной разбивкой по сегментам. Можно описать до каждого устройства локальную сеть, а потом все сети описать в общей навигационной карте. Есть поддержка географической карты OpenStreetMap.
▪ Поиск и идентификация устройств могут проходить автоматически с использованием различных механизмов и технологий - ARP, Ping, Netbios, TCP, UDP, SNMP, WMI.
▪ Для устройств можно заполнять инвентарные данные, а также собирать их автоматически отдельным агентом.
▪ Схемы сетей можно импортировать/экспортировать в формат Visio.
Поставил программу, немного посмотрел на неё. Она реально очень проста в настройке. Автоматически просканила сеть, нашла некоторые компы и сервера. Чтобы поставить объект на мониторинг, достаточно открыть его свойства, добавить ip адрес и сенсор, который будет использоваться (ping, tcp или udp запрос на какой-то порт, snmp, arp и т.д.).
Функционал относительно простой, если сравнивать с какими-то серьезными системами мониторинга. Но зато всё целостное, понятное и легко настраивается. Есть возможность использовать внешние проверки и устанавливать плагины. Не думаю, что найдётся большой выбор этих плагинов, кроме тех, что написали сами разработчики.
Algorius платная программа, не Open Source. Есть бесплатная версия с ограничениями:
- 25 хостов мониторинга;
- 5 одновременно открытых карт сетей;
- хранение отчётов 1 месяц;
Если покупать, то цены очень доступные. Мониторинг 500 хостов без каких-либо других ограничений стоит всего 10000р. в год. А 100 всего 2000р.
Сайт - https://algorius.ru
#мониторинг #управление #ITSM
{kind=link}
Liefting_Zabbix-5-IT-Infrastructure-Monitoring-Cookbook_RuLi.pdf
12.6 MB
На днях Zabbix в своём блоге анонсировал новую редакцию книги Zabbix 6 IT Infrastructure Monitoring Cookbook. Купить можно в Amazon и Packtpub. Не уверен, что из РФ можно будет оплатить.
Поискал предыдущую редакцию книги, нашлась очень быстро. Её и приложил к посту. Книга кажется объёмной, но реально она не очень большая. Я её всю пролистал и могу посоветовать тем, кто хочет изучить Zabbix.
Рассказано очень доступно с большим количеством скриншотов из веб интерфейса. Из-за этого объём большой. Текстовый материал компактно оформлен по всем основным возможностям системы мониторинга Zabbix.
В 6-й версии есть отличия от 5-й, но не сказать, что прям сильно критичные. Основное - новый синтаксис шаблонов и триггеров. Если вы сами не пишите шаблоны, то для вас это будет не принципиально. Сама установка и настройка осталась плюс-минус такой же.
#zabbix
Поискал предыдущую редакцию книги, нашлась очень быстро. Её и приложил к посту. Книга кажется объёмной, но реально она не очень большая. Я её всю пролистал и могу посоветовать тем, кто хочет изучить Zabbix.
Рассказано очень доступно с большим количеством скриншотов из веб интерфейса. Из-за этого объём большой. Текстовый материал компактно оформлен по всем основным возможностям системы мониторинга Zabbix.
В 6-й версии есть отличия от 5-й, но не сказать, что прям сильно критичные. Основное - новый синтаксис шаблонов и триггеров. Если вы сами не пишите шаблоны, то для вас это будет не принципиально. Сама установка и настройка осталась плюс-минус такой же.
#zabbix