
Узнал вчера про существование проекта для предобработки текста Tremor. Продукт нишевый и нужен только в определенных ситуациях. Это аналог Logstash, который входит в состав ELK. Я Logstash достаточно часто использую. В целом, привык к нему и к его языку парсинга в виде grok фильтров. Значительный минус Logstash - он очень требователен к ресурсам. Такое тяжелое Java приложение. Первого запуска достаточно, чтобы понять, какой он тормозной. Запускается секунд 5-7 даже без нагрузки.
Для тех, кто совсем не понимает, о чём идёт речь, кратко поясню. С помощью подобных инструментов можно брать исходные логи любого формата и приводить их к тому виду, какой вам нужен. Например, с помощью Logstash и его grok фильтров парсится лог веб сервера. Из строк вычленяются ip адреса, урлы, даты и т.д. Все эти данные конвертируются из строковых значений в свои форматы - число, ip адрес, дата и т.д. Далее эти распарсенные и сконвертированные данные можно использовать в построении графиков, отчётах, можно делать агрегации и т.д.
Tremor якобы более легкий и удобный инструмент. У него свой скриптовый язык tremor-script, что лично меня смущает. Хотя в документации говорится, что он более удобен и эффективен. Grok - универсальный фильтр для парсинга, используется много где, а не только в Logstash. А учить новый синтаксис только под один продукт как-то лениво.
Написал эту заметку, чтобы поделиться с вами новым для меня продуктом, а заодно спросить, есть ли тут кто-то, кто использовал Tremor. Имеет смысл его изучать и пробовать как замену Logstash? Я в свое время смотрел на Loki, как более легковесную замену всего ELK в простых ситуациях, но так и не начал пользоваться, так как привык к ELK и неплохо его знаю. Не захотелось распыляться и изучать два продукта. Но этого монстра хотелось бы как-то облегчить.
https://github.com/tremor-rs/tremor-runtime
https://www.tremor.rs/
#devops #elk
Для тех, кто совсем не понимает, о чём идёт речь, кратко поясню. С помощью подобных инструментов можно брать исходные логи любого формата и приводить их к тому виду, какой вам нужен. Например, с помощью Logstash и его grok фильтров парсится лог веб сервера. Из строк вычленяются ip адреса, урлы, даты и т.д. Все эти данные конвертируются из строковых значений в свои форматы - число, ip адрес, дата и т.д. Далее эти распарсенные и сконвертированные данные можно использовать в построении графиков, отчётах, можно делать агрегации и т.д.
Tremor якобы более легкий и удобный инструмент. У него свой скриптовый язык tremor-script, что лично меня смущает. Хотя в документации говорится, что он более удобен и эффективен. Grok - универсальный фильтр для парсинга, используется много где, а не только в Logstash. А учить новый синтаксис только под один продукт как-то лениво.
Написал эту заметку, чтобы поделиться с вами новым для меня продуктом, а заодно спросить, есть ли тут кто-то, кто использовал Tremor. Имеет смысл его изучать и пробовать как замену Logstash? Я в свое время смотрел на Loki, как более легковесную замену всего ELK в простых ситуациях, но так и не начал пользоваться, так как привык к ELK и неплохо его знаю. Не захотелось распыляться и изучать два продукта. Но этого монстра хотелось бы как-то облегчить.
https://github.com/tremor-rs/tremor-runtime
https://www.tremor.rs/
#devops #elk
{kind=link}
У меня было очень много заметок на канале про #мониторинг. При этом я всегда обходил стороной такой популярный продукт как The Dude. Надо это исправить. Авторами The Dude является всем известная компания Mikrotik. Основное её отличие - простота настройки и неприхотливость в плане ресурсов . Её очень легко установить и запустить в работу. Не нужны специальные знания и время на изучение продукта. Базовая настройка проста и интуитивна.
Сервер The Dude можно установить только на RouterOS. Так что вам нужно либо устройство Mikrotik, либо виртуальная машина с CHR (Cloud Hosted Router). Если будете ставить на роутер, имейте ввиду, что свою базу данных мониторинг будет хранить тоже локально, а значит будет постоянно что-то писать на устройство хранения. Для этого лучше сразу выделить sd карту или usb накопитель, чтобы не исчерпать ресурс записи встроенной памяти. Идеально поставить на CHR. У меня есть одна лицензия для различных тестов конфигураций микротов. Удобно это делать на виртуалке.
The Dude умеет автоматически сканировать сеть и добавлять в мониторинг все найденные устройства. Далее вы сможете их сами расположить на карте сети. Отдельно отмечу, что The Dude умеет мониторить и находить не только устройства Mikrotik, а и всё остальное, что доступно по сети. Например, для Windows у него есть свой агент, который можно установить для сбора метрик. А в общем случае он собирает метрики по snmp, в том числе и с Linux машин.
Писать много не буду, так как продукт достаточно известный. В сети много руководств по его настройке. Если вам нужен простой мониторинг и вы используете у себя Mikrotik, попробуйте The Dude. Он необычен и выделяется на фоне других систем мониторинга. При этом весьма удобен и популярен.
#монитоинг #mikrotik
Сервер The Dude можно установить только на RouterOS. Так что вам нужно либо устройство Mikrotik, либо виртуальная машина с CHR (Cloud Hosted Router). Если будете ставить на роутер, имейте ввиду, что свою базу данных мониторинг будет хранить тоже локально, а значит будет постоянно что-то писать на устройство хранения. Для этого лучше сразу выделить sd карту или usb накопитель, чтобы не исчерпать ресурс записи встроенной памяти. Идеально поставить на CHR. У меня есть одна лицензия для различных тестов конфигураций микротов. Удобно это делать на виртуалке.
The Dude умеет автоматически сканировать сеть и добавлять в мониторинг все найденные устройства. Далее вы сможете их сами расположить на карте сети. Отдельно отмечу, что The Dude умеет мониторить и находить не только устройства Mikrotik, а и всё остальное, что доступно по сети. Например, для Windows у него есть свой агент, который можно установить для сбора метрик. А в общем случае он собирает метрики по snmp, в том числе и с Linux машин.
Писать много не буду, так как продукт достаточно известный. В сети много руководств по его настройке. Если вам нужен простой мониторинг и вы используете у себя Mikrotik, попробуйте The Dude. Он необычен и выделяется на фоне других систем мониторинга. При этом весьма удобен и популярен.
#монитоинг #mikrotik
{kind=link}
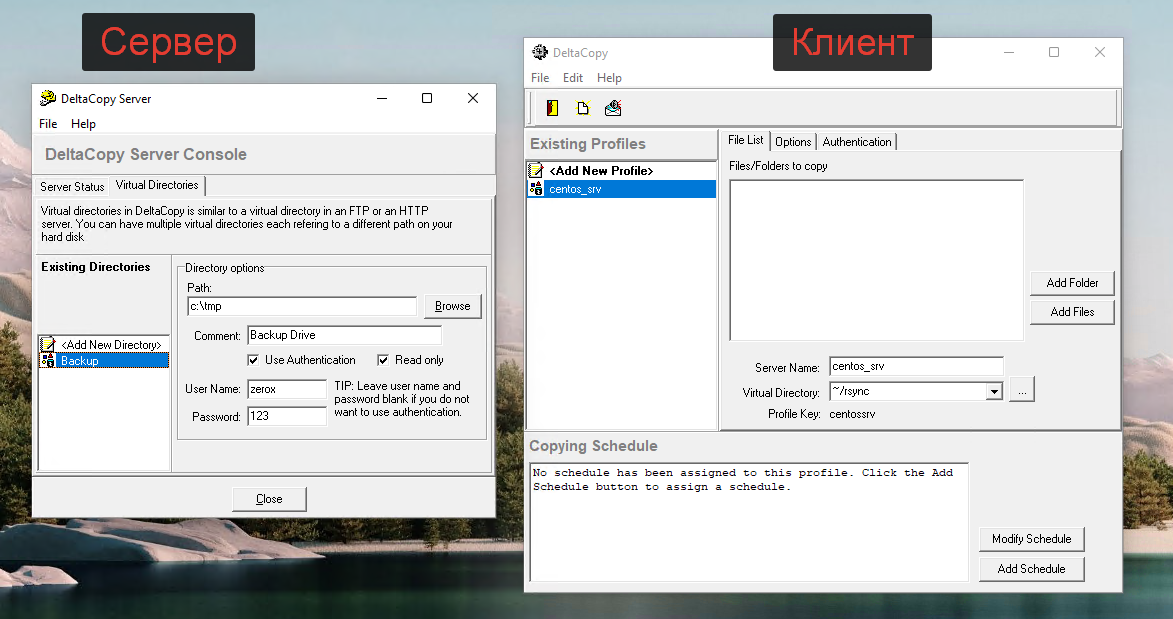
Если вы любите rsync так же, как и я, и при этом хотите с его помощью бэкапить windows машины, то помочь вам в этом может программа DeltaCopy. Эта программа стала для меня настоящим открытием. Раньше я уже писал про rsync под windows. Там я описывал старую программу, о которой практически не осталось упоминаний в интернете. Нет сайта программы, нет обновлений. На текущий момент она брошена.
DeltaCopy вполне себе живая. Есть сайт, где можно скачать последнюю версию дистрибутива, есть исходники. Да и в целом мне эта программа понравилась за свою простоту и функциональность. Она состоит из двух независимых частей - клиента и сервера.
Клиент вам нужен будет, если вы хотите забирать по расписанию данные с другого Rsync сервера. Мне обычно это не нужно. Сервера чаще всего под Linux и именно с них хочется забирать данные Windows машин. Для этого используется серверная часть. У неё минимум настроек и все через интерфейс программы.
Для того, чтобы начать забирать данные с Windows через Rsync надо в серверной части настроить директорию с источником файлов. Если нужна встроенная авторизация, добавить пользователя и пароль. DeltaCopy сформирует простейший конфиг rsync:
Далее запускаем DeltaCopy как службу и не забываем настроить фаерволл. Надо открыть стандартный порт rsync - tcp 873. Перемещаемся на Linux сервер и забираем оттуда данные:
И всё. Работает четко и просто. Я попробовал, буду теперь использовать DeltaCopy для rsync на Windows.
#windows #backup #rsync
DeltaCopy вполне себе живая. Есть сайт, где можно скачать последнюю версию дистрибутива, есть исходники. Да и в целом мне эта программа понравилась за свою простоту и функциональность. Она состоит из двух независимых частей - клиента и сервера.
Клиент вам нужен будет, если вы хотите забирать по расписанию данные с другого Rsync сервера. Мне обычно это не нужно. Сервера чаще всего под Linux и именно с них хочется забирать данные Windows машин. Для этого используется серверная часть. У неё минимум настроек и все через интерфейс программы.
Для того, чтобы начать забирать данные с Windows через Rsync надо в серверной части настроить директорию с источником файлов. Если нужна встроенная авторизация, добавить пользователя и пароль. DeltaCopy сформирует простейший конфиг rsync:
use chroot = falsestrict modes = false[Backup] path = /cygdrive/c/tmp comment = Backup Drive read only = true auth users = zerox secrets file = /cygdrive/c/DeltaCopy/secrets/Backup.secretДалее запускаем DeltaCopy как службу и не забываем настроить фаерволл. Надо открыть стандартный порт rsync - tcp 873. Перемещаемся на Linux сервер и забираем оттуда данные:
# rsync -avz zerox@10.20.1.57::Backup /mnt/backupИ всё. Работает четко и просто. Я попробовал, буду теперь использовать DeltaCopy для rsync на Windows.
#windows #backup #rsync
{kind=link}
В последнее время системы статистики посещаемости сайтов, такие как Яндекс.Мертика и Google Analytics превратились в настоящих монстров. Они собирают тонны информации о посетителях, грузя свои скрипты им в сеансы. Я бы очень хотел от них избавиться, но не могу себе этого позволить по двум причинам:
1. У меня почти весь трафик поисковой.
2. У меня крутится реклама от этих компаний.
Без их аналитики я рискую уменьшить поток поискового трафика и снизить релевантность рекламы. Если у вас сайт или приложение, для которых не критичны эти вещи, вы не хотите ставить себе тяжелейшие метрики публичных сервисов, которые шпионят за пользователями, но при этом есть желание получать аналитику по посетителям, посмотрите в сторону проекта counter.dev.
Это легкий (написан на GO), бесплатный счётчик для сайта или веб приложения.
https://github.com/ihucos/counter.dev
https://counter.dev/
Демка - https://counter.dev/dashboard.html?demo=1 Проект работает как сервис. То есть вы ставите их код и вся статистика хранится на серверах проекта. В репозитории отмечено, что при желании, можно поднять сервер у себя, но готовой инструкции о том, как это сделать, я не увидел.
#website
1. У меня почти весь трафик поисковой.
2. У меня крутится реклама от этих компаний.
Без их аналитики я рискую уменьшить поток поискового трафика и снизить релевантность рекламы. Если у вас сайт или приложение, для которых не критичны эти вещи, вы не хотите ставить себе тяжелейшие метрики публичных сервисов, которые шпионят за пользователями, но при этом есть желание получать аналитику по посетителям, посмотрите в сторону проекта counter.dev.
Это легкий (написан на GO), бесплатный счётчик для сайта или веб приложения.
https://github.com/ihucos/counter.dev
https://counter.dev/
Демка - https://counter.dev/dashboard.html?demo=1 Проект работает как сервис. То есть вы ставите их код и вся статистика хранится на серверах проекта. В репозитории отмечено, что при желании, можно поднять сервер у себя, но готовой инструкции о том, как это сделать, я не увидел.
#website
{kind=link}
Недавно рассказывал про то, как команды выполняются в оболочке Linux. А так же про утилиту type, которая позволяет точно узнать, какая программа будет выполнена при вводе команды в консоли. В продолжении этой темы расскажу про утилиту hash, которая дополняет всю эту историю с командами.
Для начала узнаем, что это вообще такое:
Hash встроена в оболочку bash. С ее помощью можно посмотреть кэш путей к исполняемым файлам, который хранится до перезапуска оболочки. Возможно где-то в инструкциях в интернете по настройке чего-либо вы видели запуск этой команды для очистки кэша путей. Иногда это нужно сделать при установке нового софта, когда изменился по какой-то причине путь к исполняемому файлу, который вы ранее уже запускали в консоли в текущем сеансе.
Покажу на практике, как и на что влияет hash.
Я запустил htop, он уехал в кэш с путём /usr/bin/htop. Потом я его перенёс в /usr/local/bin/htop и не смог запустить через консоль, пока не очистил кэш команды. На практике заниматься подобным обычно не приходится, но у меня были иногда ситуации, когда этот кэш нужно было почистить. Так что лучше про него знать.
Впервые с hash я познакомился еще во freebsd. Там часто в руководствах после установки чего-то из портов предлагалось очистить hash оболочки командой:
В bash на linux аналог этой команды:
Вы можете отключить или снова включить использование кэша исполняемых команд:
#bash #terminal
Для начала узнаем, что это вообще такое:
# type -a hashhash is a shell builtinHash встроена в оболочку bash. С ее помощью можно посмотреть кэш путей к исполняемым файлам, который хранится до перезапуска оболочки. Возможно где-то в инструкциях в интернете по настройке чего-либо вы видели запуск этой команды для очистки кэша путей. Иногда это нужно сделать при установке нового софта, когда изменился по какой-то причине путь к исполняемому файлу, который вы ранее уже запускали в консоли в текущем сеансе.
Покажу на практике, как и на что влияет hash.
# htop# hashhits command 1 /usr/bin/htop# mv /usr/bin/htop /usr/local/bin# htop-bash: /usr/bin/htop: No such file or directory# hash -r# htop# hashhits command 1 /usr/local/bin/htopЯ запустил htop, он уехал в кэш с путём /usr/bin/htop. Потом я его перенёс в /usr/local/bin/htop и не смог запустить через консоль, пока не очистил кэш команды. На практике заниматься подобным обычно не приходится, но у меня были иногда ситуации, когда этот кэш нужно было почистить. Так что лучше про него знать.
Впервые с hash я познакомился еще во freebsd. Там часто в руководствах после установки чего-то из портов предлагалось очистить hash оболочки командой:
# rehashВ bash на linux аналог этой команды:
# hash -rВы можете отключить или снова включить использование кэша исполняемых команд:
# set +h# hash-bash: hash: hashing disabled# set -h#bash #terminal
{kind=link}
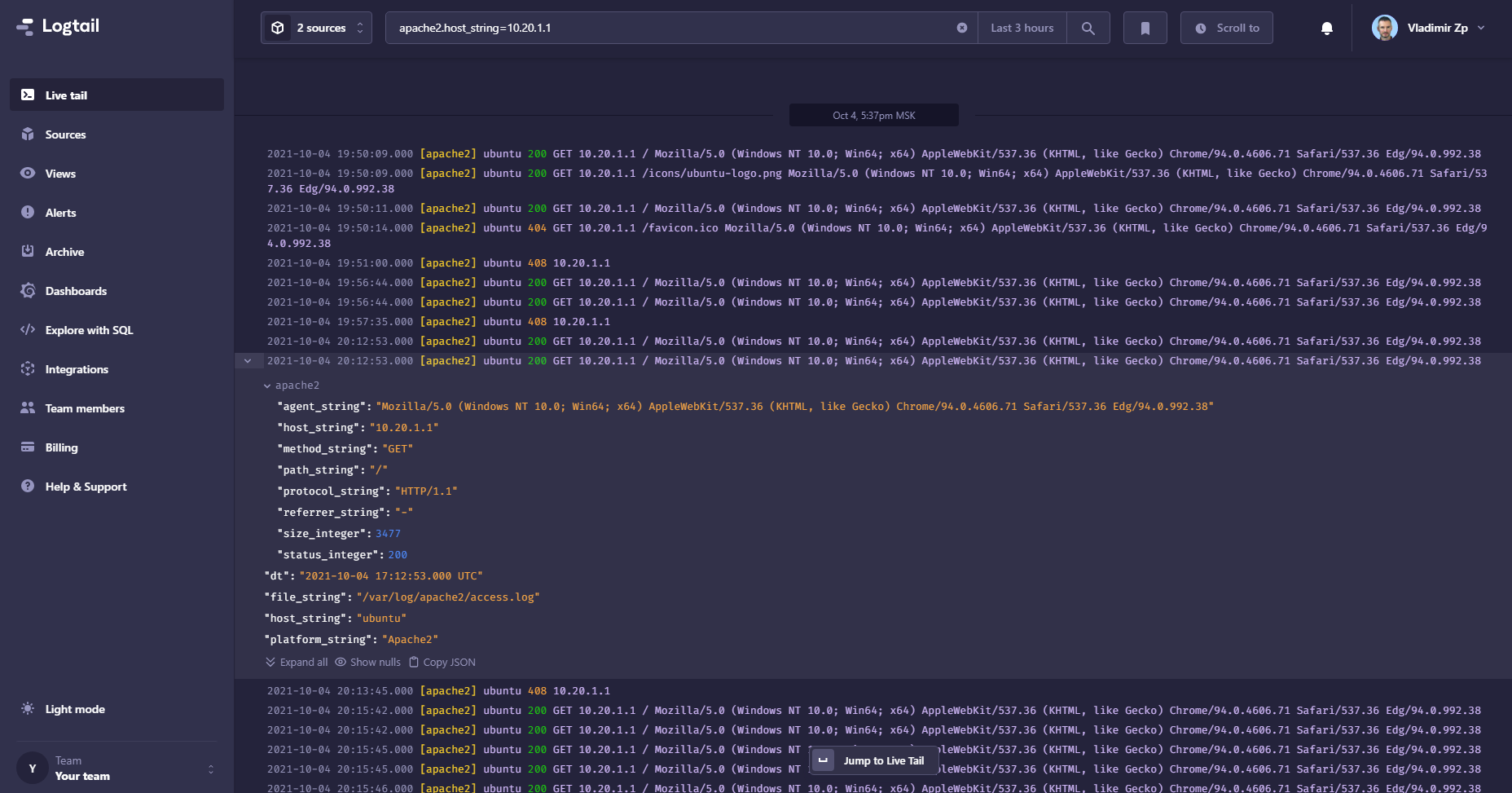
Делюсь с вами полезным сервисом с функциональным бесплатным тарифом. Речь пойдёт про logtail.com. С его помощью можно собирать различные логи. Так как он поставляется в качестве сервиса, вам самим практически ничего делать не надо, только логи к нему направить. Дальше он сам их распарсит, представит удобный вид для просмотра, настроит дашборды. Поддерживает практически все современные приложения и их формат логов (apache, nginx, docker, syslog, kuber, heroku и т.д.)
Сервис платный, но есть бесплатный тариф со следующими ограничениями:
◽ 1 Гб трафика в месяц
◽ 3 дня хранения логов
То есть в таком виде эта штука подходит для разбора текущих инцидентов небольшого проекта, без хранения исторических данных. Для регистрации достаточно только email. Карту вводить не надо.
Логи сервис собирает с помощью своего сборщика под названием Vector. С ним проще всего, так представлены готовые настройки под него с зашитым вашим токеном, так что настраивать руками ничего не надо. Достаточно скачать конфиг и подсунуть сборщику, если вам подойдут дефолтные настройки. Если не нравится Vector, можете отправлять своими Fluentd, Logstash или Rsyslog.
Я для тестов погонял сборку логов с nginx и apache. Ставил на centos и ubuntu. Настройка элементарная, все работает из коробки. Все инструкции и руководства вам предложат в процессе настройки в личном кабинете, так что не буду на этом останавливаться. В целом, процесс похож на настройку сбора логов в elk stack.
Сервис простой и интуитивный, настраивается через copy-past. Всё сделано для того, чтобы девопсы не отвлекались на всякую ерунду, типа настройки сбора логов. Для них прям готовые консольные команды в руководстве, чтобы не ошибиться при ручном наборе 😃:
Всё сделано для удобства современной разработки.
#сервис #бесплатно #devops
Сервис платный, но есть бесплатный тариф со следующими ограничениями:
◽ 1 Гб трафика в месяц
◽ 3 дня хранения логов
То есть в таком виде эта штука подходит для разбора текущих инцидентов небольшого проекта, без хранения исторических данных. Для регистрации достаточно только email. Карту вводить не надо.
Логи сервис собирает с помощью своего сборщика под названием Vector. С ним проще всего, так представлены готовые настройки под него с зашитым вашим токеном, так что настраивать руками ничего не надо. Достаточно скачать конфиг и подсунуть сборщику, если вам подойдут дефолтные настройки. Если не нравится Vector, можете отправлять своими Fluentd, Logstash или Rsyslog.
Я для тестов погонял сборку логов с nginx и apache. Ставил на centos и ubuntu. Настройка элементарная, все работает из коробки. Все инструкции и руководства вам предложат в процессе настройки в личном кабинете, так что не буду на этом останавливаться. В целом, процесс похож на настройку сбора логов в elk stack.
Сервис простой и интуитивный, настраивается через copy-past. Всё сделано для того, чтобы девопсы не отвлекались на всякую ерунду, типа настройки сбора логов. Для них прям готовые консольные команды в руководстве, чтобы не ошибиться при ручном наборе 😃:
# curl -1sLf \'https://repositories.timber.io/public/vector/cfg/setup/bash.deb.sh' \| sudo -E bashВсё сделано для удобства современной разработки.
#сервис #бесплатно #devops
{kind=link}
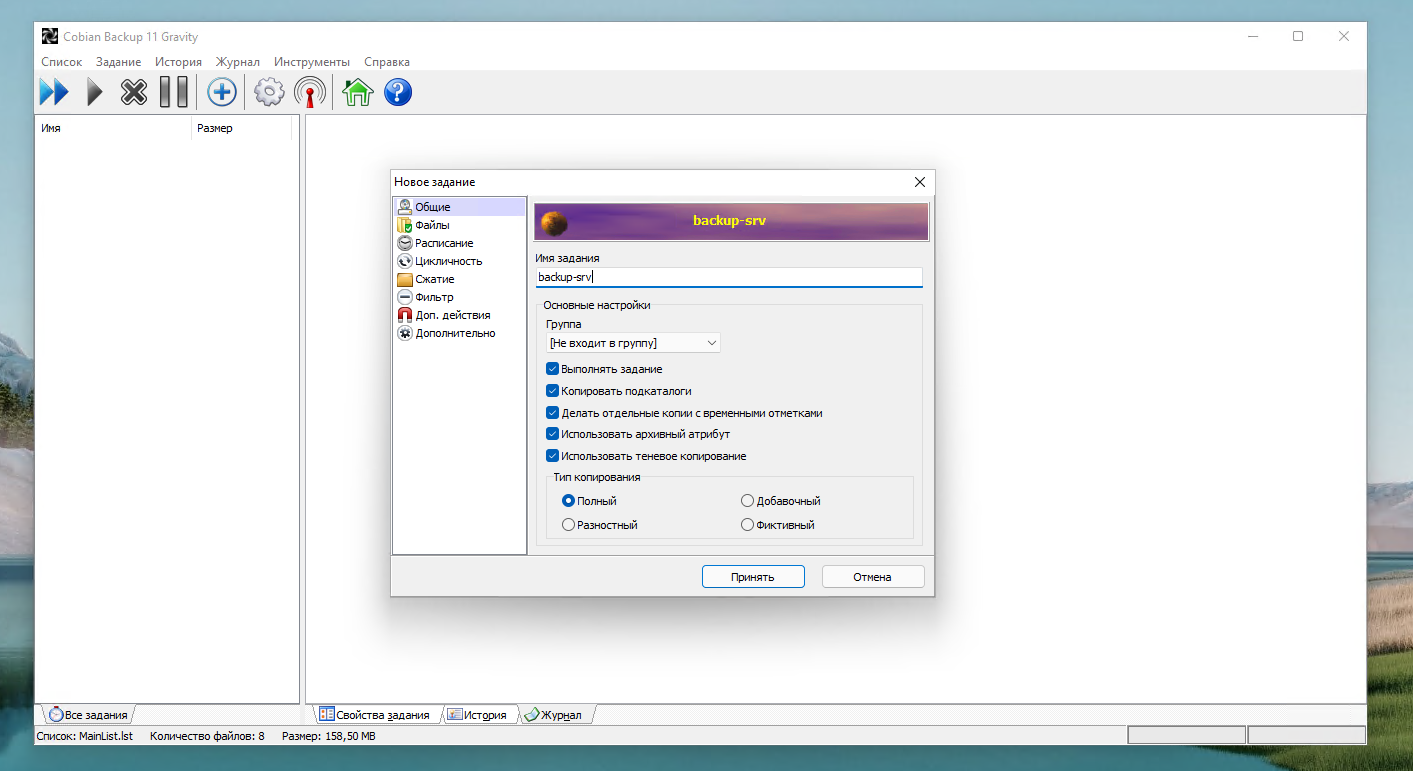
Существует очень старая и известная программа для бэкапа систем под управлением Windows - Cobian Backup. Она полностью бесплатна и весьма функциональна для нулевой стоимости. Я проверил её работу на Windows 11. Несмотря на то, что программа старая, нормально работает даже на самой последней версии винды. Надо только .Net Framework 3.5 поставить.
Основные возможности программы:
◽ Умеет работать как служба, использует расписание.
◽ Использует shadow copy для создания бэкапов.
◽ Поддерживает различные схемы бэкапа: полный, инкрементный, разностный.
◽ Умеет сжимать архивы с помощью zip или 7zip, а также шифровать их.
◽ Может запускать скрипты перед или после бэкапа.
◽ Поддерживает управление через командную строку.
◽ Нормальный русский язык в интерфейсе.
◽ Подробный лог выполнения задач.
В общем, для бесплатной программы она очень удобна и функциональна. Бэкапить может только локально, либо на сетевые диски. А также на ftp. Не знаю, кто еще ftp использует в наши дни. Тем не менее, возможность есть. Если сравнивать с тем же бесплатным Veeam Agent for Microsoft Windows FREE, то Cobian Backup более функциональна.
Настройки программы простые и тривиальные. Разбираться много не придётся, тем более читать какую-то документацию (кто её вообще читает?). После установки сразу настроите бэкап и запустите.
Сайт программы - https://www.cobiansoft.com/cobianbackup.html
#windows #backup
Основные возможности программы:
◽ Умеет работать как служба, использует расписание.
◽ Использует shadow copy для создания бэкапов.
◽ Поддерживает различные схемы бэкапа: полный, инкрементный, разностный.
◽ Умеет сжимать архивы с помощью zip или 7zip, а также шифровать их.
◽ Может запускать скрипты перед или после бэкапа.
◽ Поддерживает управление через командную строку.
◽ Нормальный русский язык в интерфейсе.
◽ Подробный лог выполнения задач.
В общем, для бесплатной программы она очень удобна и функциональна. Бэкапить может только локально, либо на сетевые диски. А также на ftp. Не знаю, кто еще ftp использует в наши дни. Тем не менее, возможность есть. Если сравнивать с тем же бесплатным Veeam Agent for Microsoft Windows FREE, то Cobian Backup более функциональна.
Настройки программы простые и тривиальные. Разбираться много не придётся, тем более читать какую-то документацию (кто её вообще читает?). После установки сразу настроите бэкап и запустите.
Сайт программы - https://www.cobiansoft.com/cobianbackup.html
#windows #backup
{kind=link}
В работе с современными информационными системами мы постоянно сталкиваемся с шифрованной передачей данных. В этой процедуре очень много нюансов. Я постараюсь своими словами кратко рассказать про протокол TLS, который постоянно обновляется, из-за чего системные администраторы вечно испытывают проблемы в первую очередь со старым оборудованием, которое новый протокол не поддерживает.
TLS - криптографический протокол, обеспечивающий защиту передаваемых данных в первую очередь по сети интернет. Его предшественника звали SSL, поэтому по привычке часто продолжают называть сертификаты, которые используют эти протоколы, SSL сертификатами, хотя по факту они сейчас TLS. Протокол SSL уже давно считается небезопасным и не поддерживается.
В настоящий момент актуальная и всеми поддерживаемая версия TLS 1.3. Все остальные версии SSL и TLS признаны устаревшими. Что же с ними происходит такого, что они устаревают? В момент подключения клиента к серверу с использованием TLS происходит согласование хэш-функций и алгоритмов шифрования, на основе которых будут зашифровываться передаваемые данные.
В первую очередь небезопасными становятся алгоритмы и хэш-функции старых версий, а так же процедуры их согласования. Например, в TLS 1.1 использовались хэш-функции MD5 и SHA-1, которые устарели. Их заменили на SHA-256, которые используются до сих пор в 1.3. То же самое происходит с алгоритмами шифрования. Например, в версии 1.3 убрали поддержку шифров AES-CBC, DES, RC4.
В момент подключения клиента к серверу происходит согласование поддерживаемых шифров и хэш-функций. Соответственно, всё старое ПО, что не поддерживает новый протокол с его шифрами и хэш-функциями, которых еще не было на момент создания, не может установить соединение.
На текущий момент, TLS 1.3 поддерживает следующий набор шифров, состоящих из алгоритмов шифрования и хэш-функций:
◽ TLS_AES_256_GCM_SHA384
◽ TLS_CHACHA20_POLY1305_SHA256
◽ TLS_AES_128_GCM_SHA256
◽ TLS_AES_128_CCM_8_SHA256
◽ TLS_AES_128_CCM_SHA256
Набор поддерживаемых шифров в TLS 1.3 меньше, чем в предыдущих версиях. Возможно это позволит ему оставаться актуальным большее количество времени, по сравнению с предшественниками.
TLS - криптографический протокол, обеспечивающий защиту передаваемых данных в первую очередь по сети интернет. Его предшественника звали SSL, поэтому по привычке часто продолжают называть сертификаты, которые используют эти протоколы, SSL сертификатами, хотя по факту они сейчас TLS. Протокол SSL уже давно считается небезопасным и не поддерживается.
В настоящий момент актуальная и всеми поддерживаемая версия TLS 1.3. Все остальные версии SSL и TLS признаны устаревшими. Что же с ними происходит такого, что они устаревают? В момент подключения клиента к серверу с использованием TLS происходит согласование хэш-функций и алгоритмов шифрования, на основе которых будут зашифровываться передаваемые данные.
В первую очередь небезопасными становятся алгоритмы и хэш-функции старых версий, а так же процедуры их согласования. Например, в TLS 1.1 использовались хэш-функции MD5 и SHA-1, которые устарели. Их заменили на SHA-256, которые используются до сих пор в 1.3. То же самое происходит с алгоритмами шифрования. Например, в версии 1.3 убрали поддержку шифров AES-CBC, DES, RC4.
В момент подключения клиента к серверу происходит согласование поддерживаемых шифров и хэш-функций. Соответственно, всё старое ПО, что не поддерживает новый протокол с его шифрами и хэш-функциями, которых еще не было на момент создания, не может установить соединение.
На текущий момент, TLS 1.3 поддерживает следующий набор шифров, состоящих из алгоритмов шифрования и хэш-функций:
◽ TLS_AES_256_GCM_SHA384
◽ TLS_CHACHA20_POLY1305_SHA256
◽ TLS_AES_128_GCM_SHA256
◽ TLS_AES_128_CCM_8_SHA256
◽ TLS_AES_128_CCM_SHA256
Набор поддерживаемых шифров в TLS 1.3 меньше, чем в предыдущих версиях. Возможно это позволит ему оставаться актуальным большее количество времени, по сравнению с предшественниками.
{kind=link}
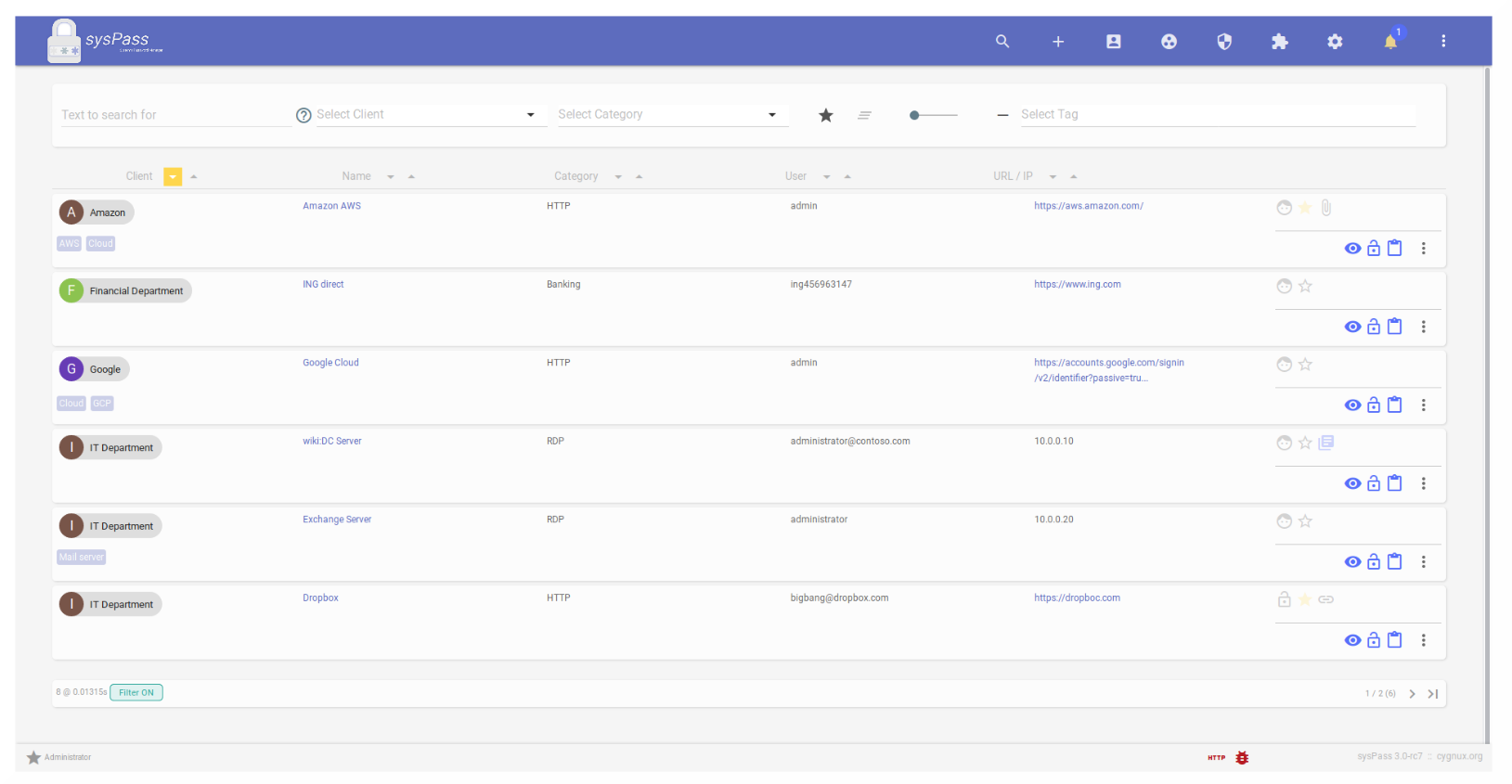
Ранее я касался темы менеджеров паролей, когда рассказывал про TeamPass и Bitwarden. В комментариях надавали кучу ссылок и других продуктов из этой же тематики. Наконец-то дошли руки, и я решил рассмотреть их все. Речь пойдет о менеджерах паролей для командной работы.
Начну с Syspass. Это бесплатная система управлением паролями, написанная на php. Код открыт и доступен на github. Основной функционал, который требуется от подобной системы есть: шифрование, двухфакторная авторизация, управление пользователями и группами, интеграция с ad и ldap, api, аудит событий. На вид система вполне зрелая, большое сообщество. Доступен импорт паролей из KeePass! Есть русский язык.
📌 Ссылки:
Сайт - https://www.syspass.org/
Github - https://github.com/nuxsmin/sysPass
Документация - https://syspass-doc.readthedocs.io/
Demo - https://demo.syspass.org/
Для знакомства проще всего запустить всё в докере. Есть готовый docker-compose (также есть deb и rpm пакеты):
# wget https://raw.githubusercontent.com/nuxsmin/docker-syspass/master/docker-compose.yml
# docker-compose -p syspass up -d
После запуска переходим на порт 49154 по https и создаём админскую учётку. В качестве пароля бд используется syspass, адрес сервера бд - syspass-db, по имени запущенного контейнера с базой данных.
Можно логиниться в систему и настраивать ее. Русский интерфейс неинтуитивен, лучше английскую версию использовать. Есть поддержка плагинов, но я не понял, где их можно взять.
#password
Начну с Syspass. Это бесплатная система управлением паролями, написанная на php. Код открыт и доступен на github. Основной функционал, который требуется от подобной системы есть: шифрование, двухфакторная авторизация, управление пользователями и группами, интеграция с ad и ldap, api, аудит событий. На вид система вполне зрелая, большое сообщество. Доступен импорт паролей из KeePass! Есть русский язык.
📌 Ссылки:
Сайт - https://www.syspass.org/
Github - https://github.com/nuxsmin/sysPass
Документация - https://syspass-doc.readthedocs.io/
Demo - https://demo.syspass.org/
Для знакомства проще всего запустить всё в докере. Есть готовый docker-compose (также есть deb и rpm пакеты):
# wget https://raw.githubusercontent.com/nuxsmin/docker-syspass/master/docker-compose.yml
# docker-compose -p syspass up -d
После запуска переходим на порт 49154 по https и создаём админскую учётку. В качестве пароля бд используется syspass, адрес сервера бд - syspass-db, по имени запущенного контейнера с базой данных.
Можно логиниться в систему и настраивать ее. Русский интерфейс неинтуитивен, лучше английскую версию использовать. Есть поддержка плагинов, но я не понял, где их можно взять.
#password
{kind=link}
Кто-нибудь в наше время еще использует факсы? Я последний раз видел работающий факс лет 5-6 назад, когда одну компанию переводил на voip. С факсом, как это обычно бывает, возникли проблемы. Им хоть и не пользовались уже на тот момент, но меня попросили как-то решить с ним вопрос. Сейчас даже не вспомню, что в итоге сделал. Вроде бы какой-то сервис в интернете нашёл по приёму факсов в качестве резерва, а текущий подключил через voip шлюз. Решил, что если заглючит что-то, то разбираться уже не буду, а перейду полностью на сервис.
С тех пор этим факсом никто так и не пользовался, а я с ними не взаимодействовал вообще. А вот когда я начинал свою работу, факсы еще были в ходу. Покупали плёнку к ним, секретари рассылали и принимали факсы.
В тему небольшой юмористический ролик на тему факсов в наше время:
https://www.youtube.com/watch?v=HCalMnX5QpY
Спасибо одному из подписчиков, который поделился ссылкой. На этом канале есть интересные видео. Посмотрел немного.
#юмор #видео
С тех пор этим факсом никто так и не пользовался, а я с ними не взаимодействовал вообще. А вот когда я начинал свою работу, факсы еще были в ходу. Покупали плёнку к ним, секретари рассылали и принимали факсы.
В тему небольшой юмористический ролик на тему факсов в наше время:
https://www.youtube.com/watch?v=HCalMnX5QpY
Спасибо одному из подписчиков, который поделился ссылкой. На этом канале есть интересные видео. Посмотрел немного.
#юмор #видео
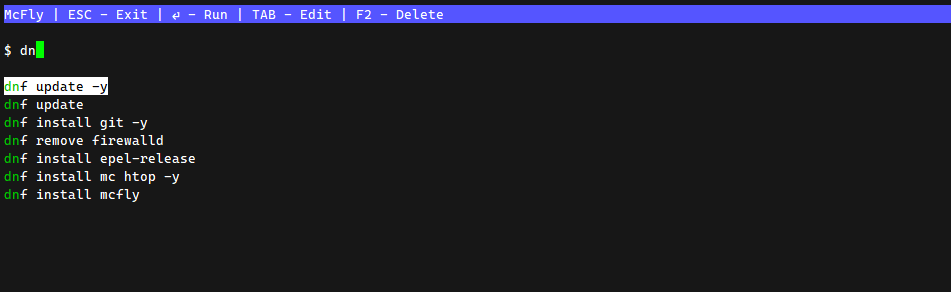
Тот, кто часто работает в Bash, наверняка пользуется поиском по истории команд, которую можно вызвать сочетанием клавиш Ctrl+R. Как по мне, пользоваться этим функционалом не очень удобно, поэтому я редко к нему прибегаю.
Но есть замечательная утилита McFly, которая перехватывает это сочетание клавиш и дальше сама управляет поиском по истории. Словами трудно описать, в чём удобство. Надо просто попробовать. Я как увидел, сразу влюбился в эту утилиту. С ней очень удобно работать с историей.
В репозиториях дистрибутивов программы нет. Поставить можно через github. Достаточно скачать и запустить бинарник из репы - https://github.com/cantino/mcfly. Для ленивых есть простенький скрипт, который сам это сделает и положит нужный под вашу систему бинарник в /usr/local/bin. Это путь для отважных и смелых:
# curl -LSfs https://raw.githubusercontent.com/cantino/mcfly/master/ci/install.sh | sh -s -- --git cantino/mcfly
Далее добавьте в свой ~/.bashrc строку:
и перезайдите.
Нажимайте Ctrl+R и наслаждайтесь красотой и удобством. Теперь работать с историей команд будет намного проще. При первом запуске вы увидите список наиболее часто используемых команд. После начала набора текста, когда будет ясно, какая команда вам нужна, откроется история запуска именной этой команды.
McFly не ломает работу встроенной history. Все свои данные хранит в отдельной sqlite базе в ~/.mcfly. Так что если станет не нужна, просто отключите ее в .bashrc и удалите бинарник.
#bash #terminal
Но есть замечательная утилита McFly, которая перехватывает это сочетание клавиш и дальше сама управляет поиском по истории. Словами трудно описать, в чём удобство. Надо просто попробовать. Я как увидел, сразу влюбился в эту утилиту. С ней очень удобно работать с историей.
В репозиториях дистрибутивов программы нет. Поставить можно через github. Достаточно скачать и запустить бинарник из репы - https://github.com/cantino/mcfly. Для ленивых есть простенький скрипт, который сам это сделает и положит нужный под вашу систему бинарник в /usr/local/bin. Это путь для отважных и смелых:
# curl -LSfs https://raw.githubusercontent.com/cantino/mcfly/master/ci/install.sh | sh -s -- --git cantino/mcfly
Далее добавьте в свой ~/.bashrc строку:
eval "$(mcfly init bash)"и перезайдите.
Нажимайте Ctrl+R и наслаждайтесь красотой и удобством. Теперь работать с историей команд будет намного проще. При первом запуске вы увидите список наиболее часто используемых команд. После начала набора текста, когда будет ясно, какая команда вам нужна, откроется история запуска именной этой команды.
McFly не ломает работу встроенной history. Все свои данные хранит в отдельной sqlite базе в ~/.mcfly. Так что если станет не нужна, просто отключите ее в .bashrc и удалите бинарник.
#bash #terminal
{kind=link}
Недавнее крупное падение Facebook и зависящих от неё сервисов подсветило некоторые неочевидные проблемы. Я обратил внимание на проскочившую новость о том, что сотрудники компании не могли попасть в нужные помещения, потому что у них не работали пропуска. А если бы это был пожар и пропуска так же отказали бы?
Как можно системы контроля доступа строить поверх обычных ethernet сетей, да еще зависящих от работы dns или чего-то еще? Они, как и системы пожаротушения, экстренного оповещения, должны быть отдельными автономными контурами на базе своих каналов связи. Но, как я понимаю, в целях экономии последнее время всё строят поверх существующих ethernet сетей, потому что проще и дешевле.
Давно еще я работал в компании, продающей промышленные системы в том числе аварийного оповещения на производстве. И они работали в своих независимых сетях. Нужно было только под них прокладывать отдельные кабельные сети. Из-за этого итоговая стоимость построения и обслуживания такой системы была достаточно высока. На рынке появлялись конкуренты, которые подобные системы строили поверх существующих сетей ethernet. Естественно, они были дешевле. Не знаю, какова сейчас судьба подобных независимых систем, но мне кажется, что их выдавили с рынка более дешёвые аналоги, которые просто не сработают в случае серьезных проблем.
У меня складывается впечатление, что последнее время как-то много негатива про Facebook в масс медиа. Такое ощущение, что этого технологического гиганта и почти монополиста в некоторых сферах кто-то планомерно и методично топит. Что думаете по этому поводу?
#мысли
Как можно системы контроля доступа строить поверх обычных ethernet сетей, да еще зависящих от работы dns или чего-то еще? Они, как и системы пожаротушения, экстренного оповещения, должны быть отдельными автономными контурами на базе своих каналов связи. Но, как я понимаю, в целях экономии последнее время всё строят поверх существующих ethernet сетей, потому что проще и дешевле.
Давно еще я работал в компании, продающей промышленные системы в том числе аварийного оповещения на производстве. И они работали в своих независимых сетях. Нужно было только под них прокладывать отдельные кабельные сети. Из-за этого итоговая стоимость построения и обслуживания такой системы была достаточно высока. На рынке появлялись конкуренты, которые подобные системы строили поверх существующих сетей ethernet. Естественно, они были дешевле. Не знаю, какова сейчас судьба подобных независимых систем, но мне кажется, что их выдавили с рынка более дешёвые аналоги, которые просто не сработают в случае серьезных проблем.
У меня складывается впечатление, что последнее время как-то много негатива про Facebook в масс медиа. Такое ощущение, что этого технологического гиганта и почти монополиста в некоторых сферах кто-то планомерно и методично топит. Что думаете по этому поводу?
#мысли
{kind=link}
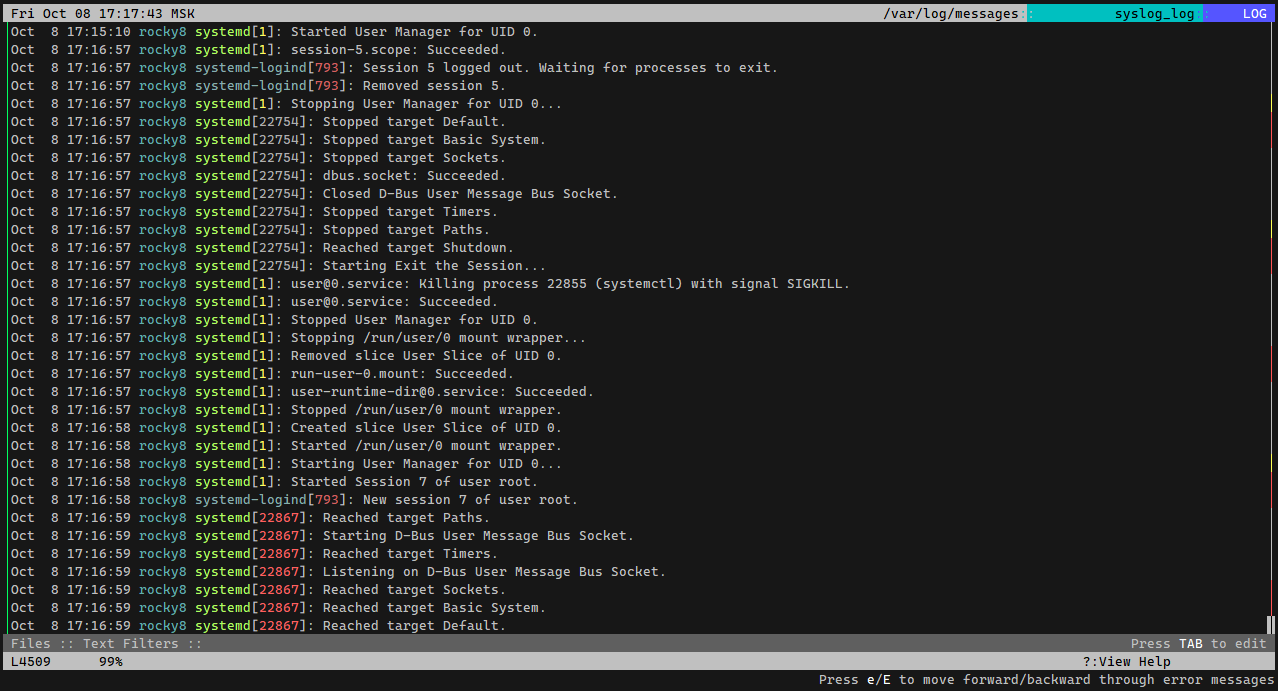
Существует крутой консольный просмотрщик логов Lnav. Он умеет объединять логи из разных источников, подсвечивать их, распаковывать из архивов, фильтровать по регуляркам и многое другое. При этом пользоваться им достаточно просто. Не надо изучать и вникать в работу. Всё интуитивно и максимально просто.
Lnav это просто одиночный бинарник, который можно загрузить из github - https://github.com/tstack/lnav/releases.
# wget https://github.com/tstack/lnav/releases/download/v0.10.0/lnav-0.10.0-musl-64bit.zip
# unzip lnav-0.10.0-musl-64bit.zip
# mv lnav-0.10.0/lnav /usr/local/bin
Теперь, к примеру, можно разом посмотреть все логи /var/log/messages, в том числе и сжатые, ротированные файлы:
Можно неудобочитаемый вывод journalctl направить в lnav:
При просмотре логов автоматически работает всторенная навигация на перемещение к ошибкам по горячей клавише e (error) или предупреждениям по клавише w (warning). Новые строки логов автоматически отображаются, то есть lnav можно использовать вместо tail -f.
Для корректной работы lnav нужен 256 цветный терминал. Если у вас используется обычный term, то надо добавить в ~/.bashrc и перезайти:
Сайт программы - https://lnav.org На нём описаны все возможности этой утилиты.
#утилита #terminal
Lnav это просто одиночный бинарник, который можно загрузить из github - https://github.com/tstack/lnav/releases.
# wget https://github.com/tstack/lnav/releases/download/v0.10.0/lnav-0.10.0-musl-64bit.zip
# unzip lnav-0.10.0-musl-64bit.zip
# mv lnav-0.10.0/lnav /usr/local/bin
Теперь, к примеру, можно разом посмотреть все логи /var/log/messages, в том числе и сжатые, ротированные файлы:
# lnav /var/log/messages*Можно неудобочитаемый вывод journalctl направить в lnav:
# journalctl | lnavПри просмотре логов автоматически работает всторенная навигация на перемещение к ошибкам по горячей клавише e (error) или предупреждениям по клавише w (warning). Новые строки логов автоматически отображаются, то есть lnav можно использовать вместо tail -f.
Для корректной работы lnav нужен 256 цветный терминал. Если у вас используется обычный term, то надо добавить в ~/.bashrc и перезайти:
export TERM=xterm-256colorСайт программы - https://lnav.org На нём описаны все возможности этой утилиты.
#утилита #terminal
{kind=link}
На прошлой неделе рассказывал про игру Human Resource Machine. У неё есть продолжение - 7 Billion Humans. Причём, судя по отзывам и рейтингу, еще лучше чем первая часть.
ОБ ЭТОЙ ИГРЕ:
Автоматизируйте толпы офисных работников для решения головоломок внутри вашего собственного распараллеленного компьютера, сделанного из людей. Захватывающее продолжение удостоенного наградами Human Resource Machine. Теперь людей в разы больше!
Игра в Steam - https://store.steampowered.com/app/792100/7_Billion_Humans/
Официальный трейлер - https://www.youtube.com/watch?v=1OqaU7CutsY
Геймплей (366 тыщ просмотров!!!) - https://www.youtube.com/watch?v=40HawFJYNOk
Отзывы:
Вот это нужно на уроках информатики использовать,а не Паскаль и тд. Ведь это будет не только развлечение,но и обучение программированию.
+Хорошая головоломка
+Приятная графика
+Не требовательна к железу
+Будет полезна при обучении программированию
Просыпаюсь, наливаю чаёк и неспешно прохожу несколько уровней, закусывая печенькой или глазированнным сырком. Удовольствие невероятное!
Прекрасная головоломка в направлении программирования.
Если первая часть была очень похожа на Ассемблер. То здесь авторы пошли дальше и теперь знакомят нас с многопоточностью. Если вы разработчик, вы легко узнаете родные дедлоки и синхронизаторы. Очень советую всем кому понравилась первая часть. А так же всем, кто интересуется кодом и разработкой, Вы окажетесь в родной среде =).
#игра
ОБ ЭТОЙ ИГРЕ:
Автоматизируйте толпы офисных работников для решения головоломок внутри вашего собственного распараллеленного компьютера, сделанного из людей. Захватывающее продолжение удостоенного наградами Human Resource Machine. Теперь людей в разы больше!
Игра в Steam - https://store.steampowered.com/app/792100/7_Billion_Humans/
Официальный трейлер - https://www.youtube.com/watch?v=1OqaU7CutsY
Геймплей (366 тыщ просмотров!!!) - https://www.youtube.com/watch?v=40HawFJYNOk
Отзывы:
Вот это нужно на уроках информатики использовать,а не Паскаль и тд. Ведь это будет не только развлечение,но и обучение программированию.
+Хорошая головоломка
+Приятная графика
+Не требовательна к железу
+Будет полезна при обучении программированию
Просыпаюсь, наливаю чаёк и неспешно прохожу несколько уровней, закусывая печенькой или глазированнным сырком. Удовольствие невероятное!
Прекрасная головоломка в направлении программирования.
Если первая часть была очень похожа на Ассемблер. То здесь авторы пошли дальше и теперь знакомят нас с многопоточностью. Если вы разработчик, вы легко узнаете родные дедлоки и синхронизаторы. Очень советую всем кому понравилась первая часть. А так же всем, кто интересуется кодом и разработкой, Вы окажетесь в родной среде =).
#игра
{kind=link}
Я на прошлой неделе возился дома с домашней лабой на proxmox. Обновил старый nettop, который лежал без дела. Поставил в него ssd диск и 16 gb памяти. Решил добавить к кластеру proxmox. Для тестовых vm будет самое то - не шумит, мало места занимает, электричества крохи ест.
Но вот незадача. Стандартный драйвер Realtek в ядре Linux не заработал со встроенной сетевухой. Пришлось качать альтернативный и собирать его локально. Основная сложность в том, что когда не работает сеть, ты как без рук. Я уже отвык от такого режима работы. Пришлось файлы и репозитории на флешке таскать на этот nettop и вспоминать, как работать на сервере без сети.
Сначала хотел плюнуть и забить на это дело. Поставить на неттоп винду и оставить его как рабочую станцию. Но потом всё-таки решил разобраться. В итоге всё получилось. Написал статью, чтобы не забыть и другим помочь. Судя по гуглению, проблема популярная.
https://serveradmin.ru/r8169-rtl_rxtx_empty_cond-0-loop-42-delay-100/
#proxmox #ошибка
Но вот незадача. Стандартный драйвер Realtek в ядре Linux не заработал со встроенной сетевухой. Пришлось качать альтернативный и собирать его локально. Основная сложность в том, что когда не работает сеть, ты как без рук. Я уже отвык от такого режима работы. Пришлось файлы и репозитории на флешке таскать на этот nettop и вспоминать, как работать на сервере без сети.
Сначала хотел плюнуть и забить на это дело. Поставить на неттоп винду и оставить его как рабочую станцию. Но потом всё-таки решил разобраться. В итоге всё получилось. Написал статью, чтобы не забыть и другим помочь. Судя по гуглению, проблема популярная.
https://serveradmin.ru/r8169-rtl_rxtx_empty_cond-0-loop-42-delay-100/
#proxmox #ошибка
Server Admin
R8169 rtl_rxtx_empty_cond == 0 (loop: 42, delay: 100) | serveradmin.ru
[01448.532276] r8169 0000:09:00.0 enp3s0: rtl_rxtx_empty_cond == 0 (loop: 42, delay: 100). [01458.532277] r8169 0000:09:00.0 enp3s0: rtl_rxtx_empty_cond == 0 (loop: 42, delay: 100). [01468.532278]...
Media is too big
VIEW IN TELEGRAM
Гиперконвергенция? Фичи? Баги? Cупергерой ГИПЕРМЕН расскажет вам обо всём! Смотрите и следите за новыми приключениями.
👉 https://clck.ru/XzEL9
#реклама #гипермен
👉 https://clck.ru/XzEL9
#реклама #гипермен
Multi-page dashboards в Zabbix.
Данный функционал появился в версии 5.4. Настраиваем следующим образом:
1. Открываем любой дашборд и нажимаем "Изменить панель".
2. Рядом с кнопкой "Добавить" жмем на стрелку и выбираем "Добавить страницу".
3. Указываем название новой страницы дашборда.
4. Кликаем мышкой в любом месте новой страницы и добавляем виджет.
5. Возвращаемся на первую страницу, жмём на значок с тремя точками любого виджета и выбираем "Копировать".
6. Переходим на вторую страницу, кликаем в любое свободное место мышкой и выбираем "Вставить виджет". Таким образом можно копировать виджеты со страницы на страницу.
7. Кликаем на шестерёнку дашборда, чтобы открыть его настройки. Ставим галочку "Запускать слайд-шоу автоматически".
8. Применяем изменения дашборда, выходим из режима редактирования.
9. Теперь дашборд будет автоматически переключать страницы через заданный интервал.
https://www.youtube.com/watch?v=czA-nbP_nKI
#zabbix #мониторинг
Данный функционал появился в версии 5.4. Настраиваем следующим образом:
1. Открываем любой дашборд и нажимаем "Изменить панель".
2. Рядом с кнопкой "Добавить" жмем на стрелку и выбираем "Добавить страницу".
3. Указываем название новой страницы дашборда.
4. Кликаем мышкой в любом месте новой страницы и добавляем виджет.
5. Возвращаемся на первую страницу, жмём на значок с тремя точками любого виджета и выбираем "Копировать".
6. Переходим на вторую страницу, кликаем в любое свободное место мышкой и выбираем "Вставить виджет". Таким образом можно копировать виджеты со страницы на страницу.
7. Кликаем на шестерёнку дашборда, чтобы открыть его настройки. Ставим галочку "Запускать слайд-шоу автоматически".
8. Применяем изменения дашборда, выходим из режима редактирования.
9. Теперь дашборд будет автоматически переключать страницы через заданный интервал.
https://www.youtube.com/watch?v=czA-nbP_nKI
#zabbix #мониторинг
YouTube
Zabbix Handy Tips: Multi-page dashboards
Zabbix Handy Tips - is byte-sized news for busy techies, focused on one particular topic. In this video, we will take a look at Zabbix multipage Dashboards and how they have replaced Screens in Zabbix 5.4. We will guide you through the creation of a multipage…
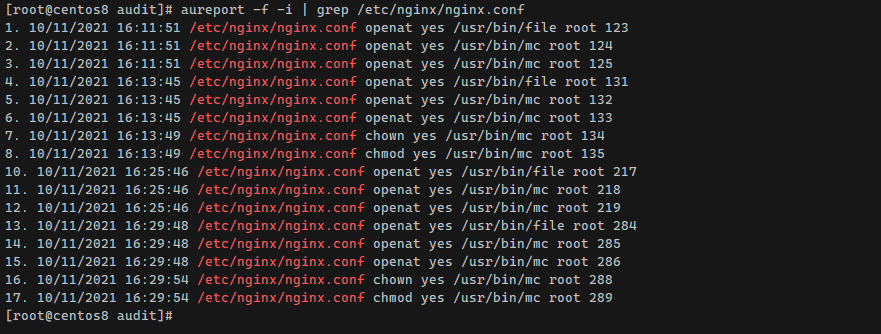
Если вы хотите сохранять информацию о том, кто получает доступ к тому или иному файлу в ОС Linux, читайте далее, как это сделать. Допустим, у вас есть конфиг nginx в файле /etc/nginx/nginx.conf и вы хотите знать, кто его открывает на чтение или изменяет. Сделать это можно с помощью встроенной подсистемы аудита Linux.
Для этого понадобится утилита auditctl. Чаще всего она уже присутствует в системе. Если это не так, то ее легко установить:
Дальше создаем отдельное правило для контроля за конкретным файлом. Так будет проще потом делать выборку:
rwa - чтение (r), запись (w), изменение атрибута (a)
nginx_conf - название правила аудита
Проверим текущий список правил auditctl и убедимся, что появилось новое:
Удалить правила можно командой:
Теперь можно что-то сделать с указанным в правиле файлом. После этого есть несколько способов посмотреть результат аудита.
Эта утилита покажет список событий, связанных с правилом, включающим в себя конфиг nginx.conf. В списке будет информация о пользователе, программе, с помощью которой был доступ к файлу, дата события и т.д.
Более подробную информацию по срабатыванию правила можно увидеть с помощью другой утилиты:
Конкретизировать вывод только событиями записи файла можно с помощью grep:
У ausearch много встроенных ключей для фильтрации событий, так что чаще всего нужную информацию можно получить с их помощью и без grep.
События аудита записываются в обычный лог файл. Чаще всего это /var/log/audit/audit.log. Для того, чтобы изменения этого файла не привели к потери важных событий имеет смысл дополнительно настроить отправку событий на удаленный сервер хранения логов.
#terminal #security
Для этого понадобится утилита auditctl. Чаще всего она уже присутствует в системе. Если это не так, то ее легко установить:
# dnf install auditctl# apt install auditctlДальше создаем отдельное правило для контроля за конкретным файлом. Так будет проще потом делать выборку:
# auditctl -w /etc/nginx/nginx.conf -p rwa -k nginx_confrwa - чтение (r), запись (w), изменение атрибута (a)
nginx_conf - название правила аудита
Проверим текущий список правил auditctl и убедимся, что появилось новое:
# auditctl -lУдалить правила можно командой:
# auditctl -DТеперь можно что-то сделать с указанным в правиле файлом. После этого есть несколько способов посмотреть результат аудита.
# aureport -f -i | grep /etc/nginx/nginx.confЭта утилита покажет список событий, связанных с правилом, включающим в себя конфиг nginx.conf. В списке будет информация о пользователе, программе, с помощью которой был доступ к файлу, дата события и т.д.
Более подробную информацию по срабатыванию правила можно увидеть с помощью другой утилиты:
# ausearch -i -k nginx_confКонкретизировать вывод только событиями записи файла можно с помощью grep:
# ausearch -i -k nginx_conf | grep O_WRONLYУ ausearch много встроенных ключей для фильтрации событий, так что чаще всего нужную информацию можно получить с их помощью и без grep.
События аудита записываются в обычный лог файл. Чаще всего это /var/log/audit/audit.log. Для того, чтобы изменения этого файла не привели к потери важных событий имеет смысл дополнительно настроить отправку событий на удаленный сервер хранения логов.
#terminal #security
{kind=link}
Написал статью по настройке Elastic Enterprise Search. Это отдельная служба, которая работает на базе ELK Stack и может быть установлена и интегрирована в указанную инфраструктуру. Но при этом остается независимым, отдельным компонентом.
Если я не ошибаюсь, то когда-то этот продукт был только в платной версии. Почему-то отложилась информация, но нигде не нашёл подтверждения. На текущий момент денег не просит, ставится свободно. Enterprise Search часто используют для настройки продвинутого поиска на большом сайте.
Так как для подключения Enterprise Search необходимо настроить авторизацию через xpack.security, а так же TLS, вынес эти настройки в отдельные подразделы статьи. Они могут быть полезны сами по себе. Я в простых случаях закрываю доступ к ELK через Firewall, а к Kibana на nginx proxy с помощью basic_auth. Это более простое решение, но понятно, что не такое гибкое, как встроенные средства ELK. Но EES хочет видеть настроенными встроенные инструменты, так что пришлось сделать.
https://serveradmin.ru/ustanovka-elastic-enterprise-search/
#elk #devops #статья
Если я не ошибаюсь, то когда-то этот продукт был только в платной версии. Почему-то отложилась информация, но нигде не нашёл подтверждения. На текущий момент денег не просит, ставится свободно. Enterprise Search часто используют для настройки продвинутого поиска на большом сайте.
Так как для подключения Enterprise Search необходимо настроить авторизацию через xpack.security, а так же TLS, вынес эти настройки в отдельные подразделы статьи. Они могут быть полезны сами по себе. Я в простых случаях закрываю доступ к ELK через Firewall, а к Kibana на nginx proxy с помощью basic_auth. Это более простое решение, но понятно, что не такое гибкое, как встроенные средства ELK. Но EES хочет видеть настроенными встроенные инструменты, так что пришлось сделать.
https://serveradmin.ru/ustanovka-elastic-enterprise-search/
#elk #devops #статья
Server Admin
Установка Elastic Enterprise Search | serveradmin.ru
xpack.security.enabled: true После этого перезапустите службу elasticsearch: # systemctl restart elasticsearch Теперь сгенерируем пароли к встроенным учётным записям (built-in users) elastic. Для...
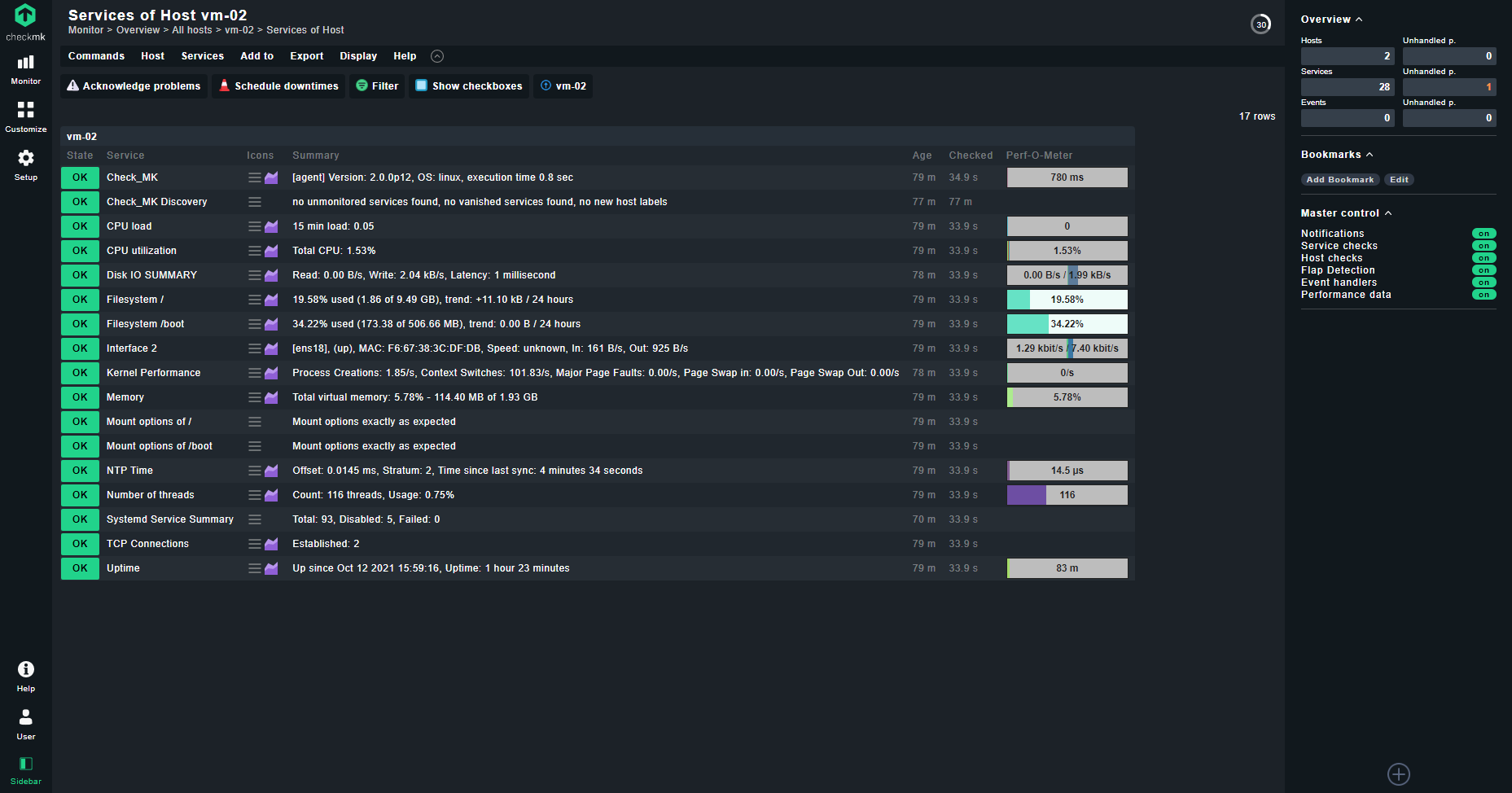
Попробовал вчера интересную систему мониторинга checkmk. Думал очередная система, по которой быстро напишу заметку и забуду, как это обычно бывает. Но на деле получилось немного не так.
Система мне очень понравилась. Я установил ее, посмотрел. Добавил пару агентов, изучил функционал. Как я понял, checkmk построена на базе nagios, но сильно доработана. Расскажу по порядку, на что конкретно обратил внимание.
Для теста систему можно запустить в докер. Всё упаковано в один контейнер.
# docker container run -dit -p 8080:5000 --tmpfs /opt/omd/sites/cmk/tmp:uid=1000,gid=1000 -v/omd/sites --name monitoring -v/etc/localtime:/etc/localtime:ro --restart always checkmk/check-mk-raw:2.0.0-latest
После запуска надо посмотреть пароль для доступа в web интерфейс. Он отобразится в логах запуска контейнера:
# docker logs monitoring
Переходим в веб интерфейс http://192.168.13.171:8080, логин cmkadmin, пароль из лога. Интерфейс лично мне понравился. Особенно его идея, когда ты сначала вносишь изменения, а потом подтверждаешь их. Пока не подтвердишь, изменения не применяются, как в некоторых сетевых устройствах.
На самом сервере хранятся пакеты для агентов. Для того, чтобы добавить новый хост, достаточно просто установить пакет, примерно так:
# rpm -ivh http://192.168.13.171:8080/cmk/check_mk/agents/check-mk-agent-2.0.0p12-1.noarch.rpm
На самом хосте больше делать ничего не надо. Идём на сервер и добавляем новый хост по ip. Checkmk автоматом к нему подключается, делает базовые проверки, выставляет метки. Например, контейнер lxc он распознал и повесил две метки - Container, Linux. Так же он сам находит службы на хосте по своим встроенным правилам Discovery. Вы тут же смотрите список служб и выбираете, какие хотите поставить на мониторинг.
Мой итог такой. Система простая, удобная и функциональная. Я в течении часа ее развернул, добавил хосты, поизучал, посмотрел на графики, дашборды и т.д. То есть порог входа очень низкий. Разобраться сможет почти любой. Это одна из немногих систем, которые я рассматривал и которая мне реально понравилась. Из форков nagios показалась самой интересной.
Сайт - https://checkmk.com/
Gihub - https://github.com/tribe29/checkmk/
Dockerhub - https://hub.docker.com/r/checkmk/check-mk-raw/
#мониторинг
Система мне очень понравилась. Я установил ее, посмотрел. Добавил пару агентов, изучил функционал. Как я понял, checkmk построена на базе nagios, но сильно доработана. Расскажу по порядку, на что конкретно обратил внимание.
Для теста систему можно запустить в докер. Всё упаковано в один контейнер.
# docker container run -dit -p 8080:5000 --tmpfs /opt/omd/sites/cmk/tmp:uid=1000,gid=1000 -v/omd/sites --name monitoring -v/etc/localtime:/etc/localtime:ro --restart always checkmk/check-mk-raw:2.0.0-latest
После запуска надо посмотреть пароль для доступа в web интерфейс. Он отобразится в логах запуска контейнера:
# docker logs monitoring
Переходим в веб интерфейс http://192.168.13.171:8080, логин cmkadmin, пароль из лога. Интерфейс лично мне понравился. Особенно его идея, когда ты сначала вносишь изменения, а потом подтверждаешь их. Пока не подтвердишь, изменения не применяются, как в некоторых сетевых устройствах.
На самом сервере хранятся пакеты для агентов. Для того, чтобы добавить новый хост, достаточно просто установить пакет, примерно так:
# rpm -ivh http://192.168.13.171:8080/cmk/check_mk/agents/check-mk-agent-2.0.0p12-1.noarch.rpm
На самом хосте больше делать ничего не надо. Идём на сервер и добавляем новый хост по ip. Checkmk автоматом к нему подключается, делает базовые проверки, выставляет метки. Например, контейнер lxc он распознал и повесил две метки - Container, Linux. Так же он сам находит службы на хосте по своим встроенным правилам Discovery. Вы тут же смотрите список служб и выбираете, какие хотите поставить на мониторинг.
Мой итог такой. Система простая, удобная и функциональная. Я в течении часа ее развернул, добавил хосты, поизучал, посмотрел на графики, дашборды и т.д. То есть порог входа очень низкий. Разобраться сможет почти любой. Это одна из немногих систем, которые я рассматривал и которая мне реально понравилась. Из форков nagios показалась самой интересной.
Сайт - https://checkmk.com/
Gihub - https://github.com/tribe29/checkmk/
Dockerhub - https://hub.docker.com/r/checkmk/check-mk-raw/
#мониторинг
{kind=link}
Предлагаю к просмотру обзор программы для анализа и мониторинга сетевого трафика - Noction Flow Analyzer. Она принимает, обрабатывает данные NetFlow, sFlow, IPFIX, NetStream и BGP и визуализирует их.
Я настроил анализ трафика в своей тестовой лаборатории и разобрал основной функционал программы. Знаю, что мониторинг того, что происходит в сети - востребованный функционал. Периодически вижу вопросы на тему того, как лучше и удобнее решать эту задачу. NFA как раз делает это быстро и просто.
Для тех, кто не понимает полностью, о чем идёт речь, поясню. С помощью указанной программы можно с точностью до пакета узнать, кто, куда и что именно отправлял по сети. То есть берём какой-то конкретный ip адрес и смотрим куда и что он отправлял, какую пропускную полосу занимал. Всё это можно агрегировать по разным признакам, визуализировать, настраивать предупреждения о превышении каких-то заданных сетевых метрик.
Noction Flow Analyzer устанавливается локально с помощью deb или rpm пакетов из репозитория разработчиков. Никакой хипстоты, контейнеров, кубернетисов, облаков и saas. Программа платная с ежемесячной подпиской. Есть триал на 30 дней. Под капотом - Yandex ClickHouse.
https://serveradmin.ru/analiz-setevogo-trafika-v-noction-flow-analyzer/
#gateway #статья #netflow
Я настроил анализ трафика в своей тестовой лаборатории и разобрал основной функционал программы. Знаю, что мониторинг того, что происходит в сети - востребованный функционал. Периодически вижу вопросы на тему того, как лучше и удобнее решать эту задачу. NFA как раз делает это быстро и просто.
Для тех, кто не понимает полностью, о чем идёт речь, поясню. С помощью указанной программы можно с точностью до пакета узнать, кто, куда и что именно отправлял по сети. То есть берём какой-то конкретный ip адрес и смотрим куда и что он отправлял, какую пропускную полосу занимал. Всё это можно агрегировать по разным признакам, визуализировать, настраивать предупреждения о превышении каких-то заданных сетевых метрик.
Noction Flow Analyzer устанавливается локально с помощью deb или rpm пакетов из репозитория разработчиков. Никакой хипстоты, контейнеров, кубернетисов, облаков и saas. Программа платная с ежемесячной подпиской. Есть триал на 30 дней. Под капотом - Yandex ClickHouse.
https://serveradmin.ru/analiz-setevogo-trafika-v-noction-flow-analyzer/
#gateway #статья #netflow
Server Admin
Анализ сетевого трафика в Noction Flow Analyzer | serveradmin.ru
Подробная статья с установкой и настройкой программы для мониторинга и анализа сетевого трафика Noction Flow Analyzer.