
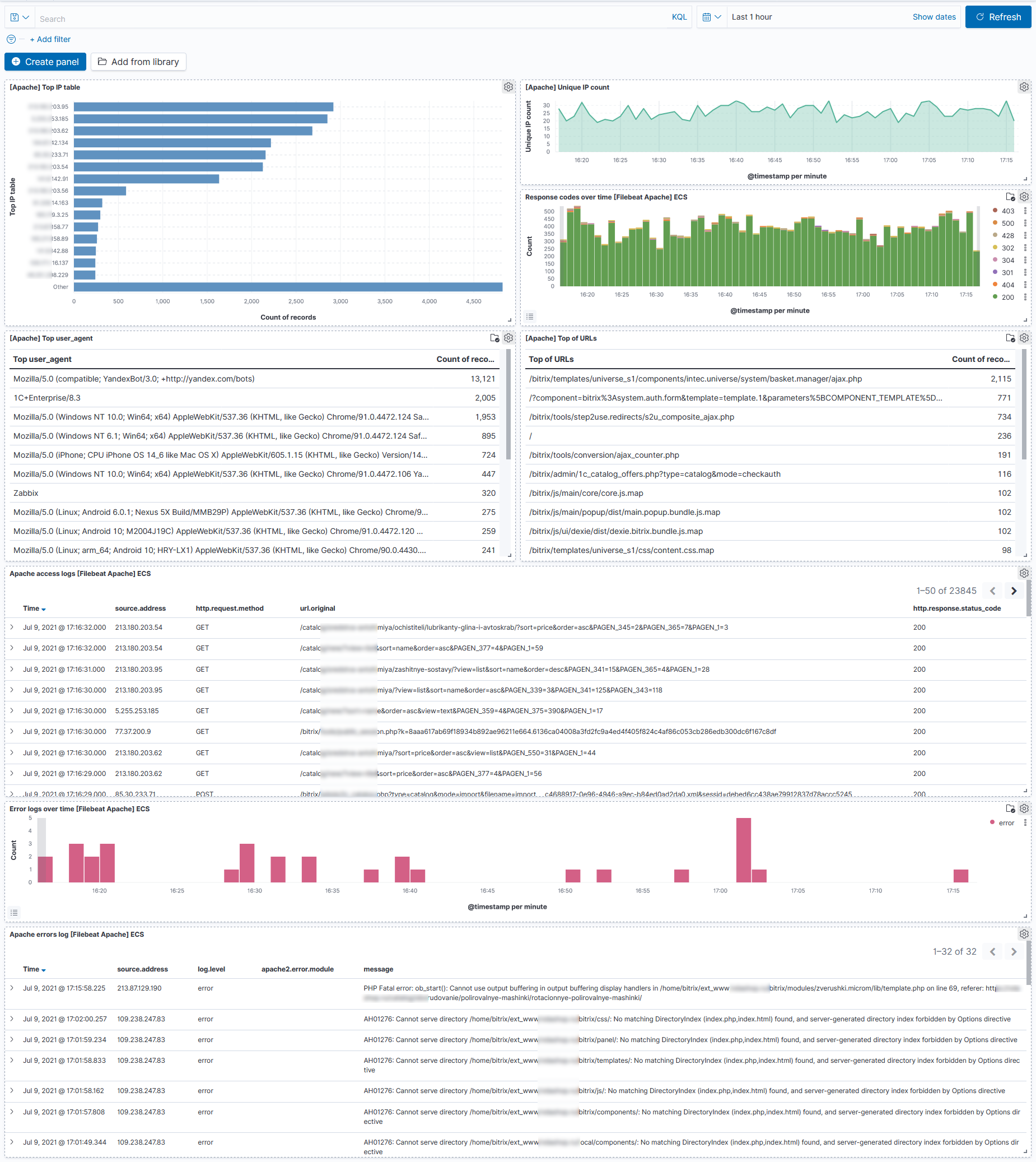
В пятницу пол дня настраивал сбор и анализ логов одного магазина на битриксе. Производительность потихоньку начала в потолок сервера упираться. Надо было внимательно посмотреть, что там происходит. Одного мониторинга уже не хватало.
Собрал вот такой типовой дашборд, основанный на своей практике. Тут есть всё, чтобы быстро оценить и проанализировать активность на сервере:
◽ Топ IP по количеству запросов.
◽ Запросы с уникальными ip на временной шкале.
◽ Коды ответов веб сервера.
◽ Топ юзер агентов.
◽ Топ урлов, к которым обращаются.
◽ Упрощенный лог файл.
◽ Ошибки веб сервера на временной шкале.
◽ Тексты ошибок веб сервера.
Всё это построено на базе elasticsearch + kibana и filebeat. Logstash не стал использовать, так как не было необходимости. Для тех, кто никогда не использовал подобные инструменты, поясню, как это работает.
На данном дашборде можно выбрать, к примеру, конкретный IP и увидите весь дашборд с фильтрацией по этому адресу. То есть все его урлы, что он посетил, все коды ответов, которые получил, все ошибки и т.д. И такая фильтрация работает по всем параметрам.
Еще пример. Вы можете выбрать код ошибки 404 и увидите всю информацию по запросам, клиентам, урлам, юзер агентам и т.д., которые получили ошибку 404. Это очень крутой и удобный инструмент. Правда разобраться с ним не так просто. Придётся потрудиться. Он еще и обновляется достаточно часто. Разница между версиями обычно значительная. Приходится каждый раз разбираться.
С помощью данного дашборда сразу же стало ясно, что основную нагрузку даёт бот Яндекса. Скорее всего от маркета. Я изначально предполагал, что какие-то боты парсеры долбят, но нет.
Некоторую информацию по настройке всего этого можно найти у меня на сайте в отдельном разделе.
#elk #devops
Собрал вот такой типовой дашборд, основанный на своей практике. Тут есть всё, чтобы быстро оценить и проанализировать активность на сервере:
◽ Топ IP по количеству запросов.
◽ Запросы с уникальными ip на временной шкале.
◽ Коды ответов веб сервера.
◽ Топ юзер агентов.
◽ Топ урлов, к которым обращаются.
◽ Упрощенный лог файл.
◽ Ошибки веб сервера на временной шкале.
◽ Тексты ошибок веб сервера.
Всё это построено на базе elasticsearch + kibana и filebeat. Logstash не стал использовать, так как не было необходимости. Для тех, кто никогда не использовал подобные инструменты, поясню, как это работает.
На данном дашборде можно выбрать, к примеру, конкретный IP и увидите весь дашборд с фильтрацией по этому адресу. То есть все его урлы, что он посетил, все коды ответов, которые получил, все ошибки и т.д. И такая фильтрация работает по всем параметрам.
Еще пример. Вы можете выбрать код ошибки 404 и увидите всю информацию по запросам, клиентам, урлам, юзер агентам и т.д., которые получили ошибку 404. Это очень крутой и удобный инструмент. Правда разобраться с ним не так просто. Придётся потрудиться. Он еще и обновляется достаточно часто. Разница между версиями обычно значительная. Приходится каждый раз разбираться.
С помощью данного дашборда сразу же стало ясно, что основную нагрузку даёт бот Яндекса. Скорее всего от маркета. Я изначально предполагал, что какие-то боты парсеры долбят, но нет.
Некоторую информацию по настройке всего этого можно найти у меня на сайте в отдельном разделе.
#elk #devops
{kind=link}
❓ Как думаете, в какую сторону стоит развиваться, чтобы обеспечить себе уверенность в завтрашнем дне и в своем будущем ближе к старости? Современный мир стремительно меняется, причём темп изменений нарастает с каждым годом. Поделюсь своими мыслями на этот счёт.
Иногда мне кажется, что было бы проще работать каким-нибудь плотником или водителем автобуса. Выучился один раз и всю жизнь работаешь. Пришел с работы вечером и отдыхаешь. При этом понимаю, что эта уверенность ложная. В ближайшее время куча специальностей будет невостребована, доход упадёт еще ниже. У меня по району уже сейчас пачками ездят автопилоты Яндекса. На типовых маршрутах они в скором времени заменят таксистов, водителей автобусов.
Для себя решил, чтобы быть уверенным в своём будущем, необходимо постоянно учиться, развиваться, познавать что-то новое. Причём, это относится не только к сфере IT. Я ощущаю в себе способности и возможности освоить много других специальностей. Сейчас для этого есть условия, лишь бы голова соображала и была мотивация к действиям.
В том числе, чтобы не киснуть и не сидеть в своем болоте, я веду этот канал и сайт. Они дают постоянный стимул к развитию, творчеству, изучению чего-то нового. Получается симбиоз полезности, дохода, самообучения. Я нашёл такой выход для себя. Мне просто это нравится и резонирует с внутренним состоянием. Но есть много других примеров, когда люди постоянно учатся и познают. Кто-то по стройке фанатеет, кто-то микроконтроллеры программирует, кто-то умный дом изучает и собирает, кто-то деревянную мебель придумывает и вырезает. Это всё примеры моих знакомых.
Мне кажется, что самый важный капитал, который пригодится в будущем - гибкость ума, открытого к познанию. Так что стоит в первую очередь работать в этом направлении, а остальное приложится. Следовательно, стоит бережно относиться к своим мозгам. Как минимум, не снижать их потенциал алкоголем и поддерживать здоровье всего организма, чтобы он мог на должном уровне обеспечивать кровоснабжение головы. Обычный ЗОЖ - здоровое питание и физкультура. Сейчас люди массово забивают на здоровье, так что достаточно просто немного следить за собой и держать курс в этом направлении, чтобы нормально существовать и быть конкурентным на рынке труда.
Я лично за себя не переживаю в этом плане. Плюс, вкладываю деньги, силы и время не в рынок ценных бумаг, недвигу и крипту, а своих детей.
#мысли
Иногда мне кажется, что было бы проще работать каким-нибудь плотником или водителем автобуса. Выучился один раз и всю жизнь работаешь. Пришел с работы вечером и отдыхаешь. При этом понимаю, что эта уверенность ложная. В ближайшее время куча специальностей будет невостребована, доход упадёт еще ниже. У меня по району уже сейчас пачками ездят автопилоты Яндекса. На типовых маршрутах они в скором времени заменят таксистов, водителей автобусов.
Для себя решил, чтобы быть уверенным в своём будущем, необходимо постоянно учиться, развиваться, познавать что-то новое. Причём, это относится не только к сфере IT. Я ощущаю в себе способности и возможности освоить много других специальностей. Сейчас для этого есть условия, лишь бы голова соображала и была мотивация к действиям.
В том числе, чтобы не киснуть и не сидеть в своем болоте, я веду этот канал и сайт. Они дают постоянный стимул к развитию, творчеству, изучению чего-то нового. Получается симбиоз полезности, дохода, самообучения. Я нашёл такой выход для себя. Мне просто это нравится и резонирует с внутренним состоянием. Но есть много других примеров, когда люди постоянно учатся и познают. Кто-то по стройке фанатеет, кто-то микроконтроллеры программирует, кто-то умный дом изучает и собирает, кто-то деревянную мебель придумывает и вырезает. Это всё примеры моих знакомых.
Мне кажется, что самый важный капитал, который пригодится в будущем - гибкость ума, открытого к познанию. Так что стоит в первую очередь работать в этом направлении, а остальное приложится. Следовательно, стоит бережно относиться к своим мозгам. Как минимум, не снижать их потенциал алкоголем и поддерживать здоровье всего организма, чтобы он мог на должном уровне обеспечивать кровоснабжение головы. Обычный ЗОЖ - здоровое питание и физкультура. Сейчас люди массово забивают на здоровье, так что достаточно просто немного следить за собой и держать курс в этом направлении, чтобы нормально существовать и быть конкурентным на рынке труда.
Я лично за себя не переживаю в этом плане. Плюс, вкладываю деньги, силы и время не в рынок ценных бумаг, недвигу и крипту, а своих детей.
#мысли
{kind=link}
Хотел написать заметку на тему бэкапов баз данных mysql с помощью mysqldump, но в итоге не удержался и написал полноценную статью. Как ни крути, а в рамках заметки дать нормальные инструкции и раскрыть тему невозможно.
В статье я рассматриваю три основных момента:
1️⃣ Параметры mysqldump, которые используются при дампе. Там есть важный нюанс, связанный с блокировкой таблиц в дефолтных настройках.
2️⃣ Делаю проверку дампа сразу после создания, анализируя начало и конец дампа. Результат записываю в лог. Привожу готовый скрипт для этого.
3️⃣ С помощью Zabbix настраиваю мониторинг этого лог файла и отправку оповещений, если он прошел с ошибкой.
Как обычно напоминаю, что делюсь своим опытом, который беру из реальных примеров в своей практике. Поиск оптимального решения и лучших практик не делал. Так что рад любым замечаниям, уточнения и подсказкам по существу.
https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
#backup #mysql #статья
В статье я рассматриваю три основных момента:
1️⃣ Параметры mysqldump, которые используются при дампе. Там есть важный нюанс, связанный с блокировкой таблиц в дефолтных настройках.
2️⃣ Делаю проверку дампа сразу после создания, анализируя начало и конец дампа. Результат записываю в лог. Привожу готовый скрипт для этого.
3️⃣ С помощью Zabbix настраиваю мониторинг этого лог файла и отправку оповещений, если он прошел с ошибкой.
Как обычно напоминаю, что делюсь своим опытом, который беру из реальных примеров в своей практике. Поиск оптимального решения и лучших практик не делал. Так что рад любым замечаниям, уточнения и подсказкам по существу.
https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
#backup #mysql #статья
Server Admin
Настройка mysqldump, проверка и мониторинг бэкапов mysql |...
Создание и проверка бэкапов MySQL с помощью mysqldump. Мониторинг бэкапов в Zabbix с уведомлением об ошибках создания.
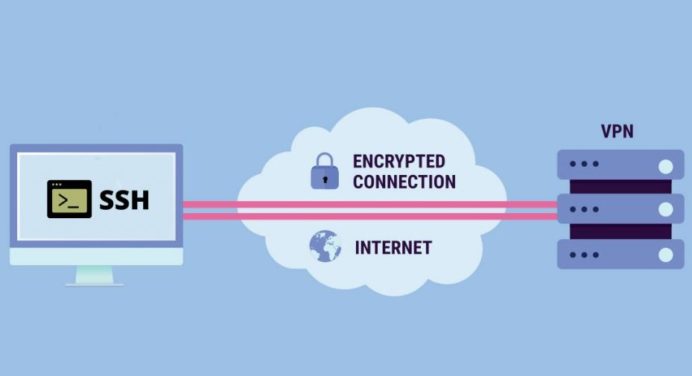
Ранее я уже рассказывал о полезных возможностях ssh. Речь была о SOCKS-прокси и переадресации портов через ssh. Сейчас расскажу о том, как настроить полноценный vpn туннель с помощью подключения по ssh.
Сразу отвечу на вопрос, зачем это вообще нужно, если есть куча других способов настроить vpn. Все дело в простоте и времени настройки. Обычно на сервере уже есть настроенный openssh сервер, так что ничего дополнительно устанавливать не надо. Берёте любой линукс сервер или виртуальную машину и организовываете через него vpn канал.
Для начала вам нужно включить параметр в конфиге /etc/ssh/sshd_config:
и перезапустить службу sshd.
Далее с клиента подключаетесь к серверу по ssh со следующими ключами:
w3:3 - имена tun интерфейсов, которые будут созданы на клиенте и сервере (в данном случае tun3). Обращаю внимание, что подобное подключение напрямую из Windows работать не будет. Я для этого подключаюсь через WSL.
После подобного ssh подключения, на сервере и клиенте поднимаются tun3 интерфейсы и фактически vpn канал уже создан. Дальше вам нужно вручную назначить им ip адреса и можно передавать информацию по зашифрованному vpn каналу поверх ssh подключения. Что-то вроде этого надо сделать:
Я взял подсеть 10.20.30.0 с маской 30, где всего 2 ip адреса и объединил клиента и сервера в рамках это подсети. Теперь можно пинговать по этим адресам друг друга с сервера или клиента.
Дальше есть разные варианты, как использовать это подключение. Если вы с клиента захотите увидеть локальную сеть за сервером, то на самом сервере нужно будет настроить ip_forward и nat для tun интерфейса, а на клиенте добавить маршрут в эту локалку через vpn канал. Всё точно так же, как и на других vpn туннелях.
Если тема заинтересовала без проблем нагуглите пошаговую инструкцию. Я просто дал информацию о том, что так можно сделать. Как-то объединял по быстрому два филиала через такой туннель. Автоматизировал всё через обычные bash скрипты. Один сервер стоял на базе какой-то готовой сборки с веб панелью управления. И всё это дремучей версии, непонятно кем и как настроенный. Я не захотел туда лазить, разбираться и что-то ставить дополнительно. Просто настроил vpn поверх ssh и закрыл вопрос.
#ssh #vpn
Сразу отвечу на вопрос, зачем это вообще нужно, если есть куча других способов настроить vpn. Все дело в простоте и времени настройки. Обычно на сервере уже есть настроенный openssh сервер, так что ничего дополнительно устанавливать не надо. Берёте любой линукс сервер или виртуальную машину и организовываете через него vpn канал.
Для начала вам нужно включить параметр в конфиге /etc/ssh/sshd_config:
PermitTunnel yesи перезапустить службу sshd.
Далее с клиента подключаетесь к серверу по ssh со следующими ключами:
ssh -p 22777 -w3:3 root@111.222.333.444w3:3 - имена tun интерфейсов, которые будут созданы на клиенте и сервере (в данном случае tun3). Обращаю внимание, что подобное подключение напрямую из Windows работать не будет. Я для этого подключаюсь через WSL.
После подобного ssh подключения, на сервере и клиенте поднимаются tun3 интерфейсы и фактически vpn канал уже создан. Дальше вам нужно вручную назначить им ip адреса и можно передавать информацию по зашифрованному vpn каналу поверх ssh подключения. Что-то вроде этого надо сделать:
server: ip a add 10.20.0.1/30 dev tun3server: ip link set dev tun3 upclient: ip a add 10.20.0.2/30 dev tun3client: ip link set dev tun3 upЯ взял подсеть 10.20.30.0 с маской 30, где всего 2 ip адреса и объединил клиента и сервера в рамках это подсети. Теперь можно пинговать по этим адресам друг друга с сервера или клиента.
Дальше есть разные варианты, как использовать это подключение. Если вы с клиента захотите увидеть локальную сеть за сервером, то на самом сервере нужно будет настроить ip_forward и nat для tun интерфейса, а на клиенте добавить маршрут в эту локалку через vpn канал. Всё точно так же, как и на других vpn туннелях.
Если тема заинтересовала без проблем нагуглите пошаговую инструкцию. Я просто дал информацию о том, что так можно сделать. Как-то объединял по быстрому два филиала через такой туннель. Автоматизировал всё через обычные bash скрипты. Один сервер стоял на базе какой-то готовой сборки с веб панелью управления. И всё это дремучей версии, непонятно кем и как настроенный. Я не захотел туда лазить, разбираться и что-то ставить дополнительно. Просто настроил vpn поверх ssh и закрыл вопрос.
#ssh #vpn
{kind=link}
На днях читал интересную статью в блоге Percona - MySQL/ZFS Performance Update.
https://www.percona.com/blog/mysql-zfs-performance-update/
Автор не первый раз проводит тестирование производительности Mysql сервера Percona на файловой системе zfs. В этот раз на текущих тестируемых версиях софта (Percona server 8.0.22, zfs 2.0, Debian 10) производительность на ext4 и zfs получилась примерно одинаковой, хотя еще 2 года назад это было не так. На zfs база работала заметно медленнее, о чем он напоминает.
То есть мы получаем все плюшки zfs (сжатие данных, дедупликация) и при этом сопоставимую производительность с ext4 или xfs. Автор в итоге делает такое заключение:
Было полезно провести очередное тестирование производительности Mysql на ZFS. В общем случае производительность находится на уровне работы на EXT4, но при этом предоставляются дополнительные возможности в виде сжатия данных, снепшотов и т.д. В следующих постах я протестирую облачные хранилища на базе zfs и посмотрю, какая будет производительность.
Как по мне, новость знаковая. Раньше я повсеместно видел в тестах падение производительности баз данных на zfs. Считалось, что это неподходящая файловая система для прода, где нужна максимальная производительность. Но сейчас это становится нет так. Так что можно потихоньку пробовать zfs не только под файловое хранилище холодных данных.
#mysql #zfs
https://www.percona.com/blog/mysql-zfs-performance-update/
Автор не первый раз проводит тестирование производительности Mysql сервера Percona на файловой системе zfs. В этот раз на текущих тестируемых версиях софта (Percona server 8.0.22, zfs 2.0, Debian 10) производительность на ext4 и zfs получилась примерно одинаковой, хотя еще 2 года назад это было не так. На zfs база работала заметно медленнее, о чем он напоминает.
То есть мы получаем все плюшки zfs (сжатие данных, дедупликация) и при этом сопоставимую производительность с ext4 или xfs. Автор в итоге делает такое заключение:
Было полезно провести очередное тестирование производительности Mysql на ZFS. В общем случае производительность находится на уровне работы на EXT4, но при этом предоставляются дополнительные возможности в виде сжатия данных, снепшотов и т.д. В следующих постах я протестирую облачные хранилища на базе zfs и посмотрю, какая будет производительность.
Как по мне, новость знаковая. Раньше я повсеместно видел в тестах падение производительности баз данных на zfs. Считалось, что это неподходящая файловая система для прода, где нужна максимальная производительность. Но сейчас это становится нет так. Так что можно потихоньку пробовать zfs не только под файловое хранилище холодных данных.
#mysql #zfs
{kind=link}
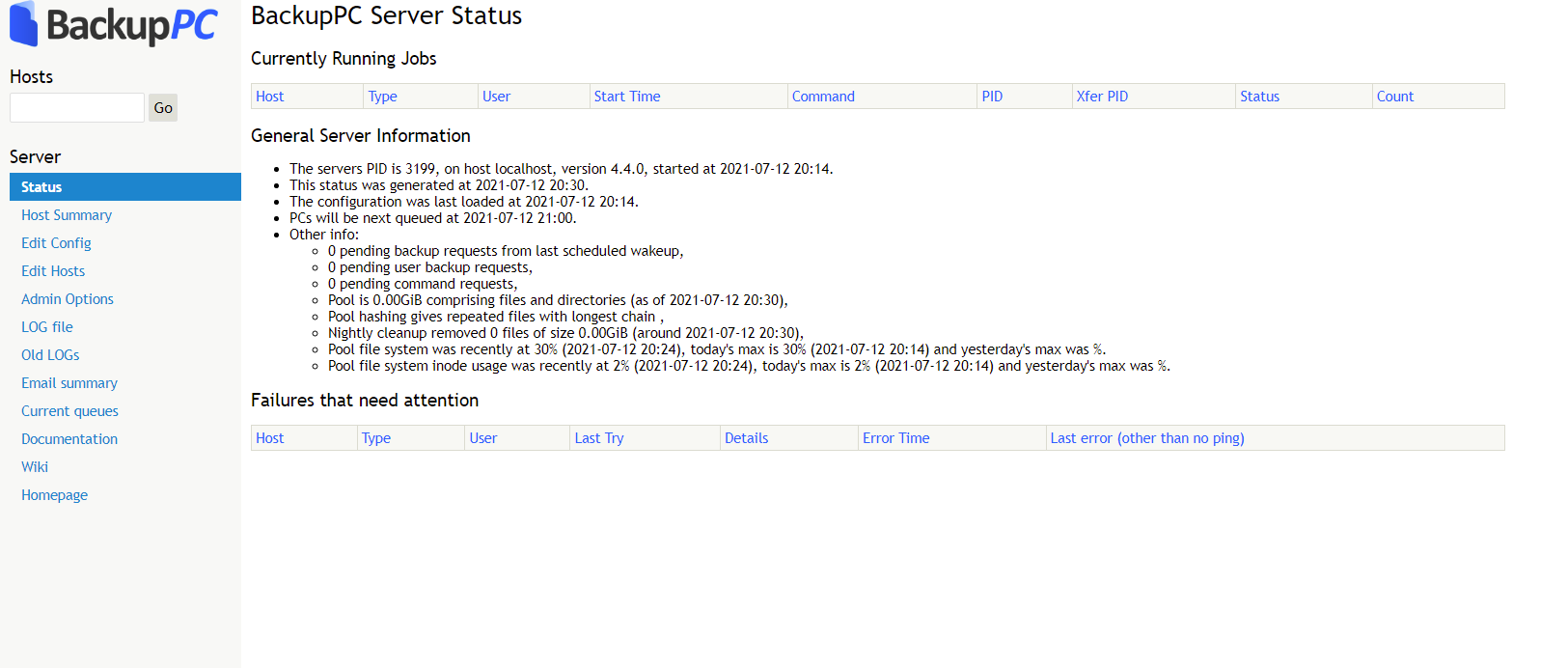
Потестировал любопытную систему для бэкапов - BackupPC. Основные её особенности следующие:
◽ Управление через встроенный веб интерфейс.
◽ Кроссплатформенный, написан на perl.
◽ Поддержка дедупликации и сжатия.
◽ Работает поверх ssh, в том числе с помощью rsync, агенты ставить не надо.
◽ Умеет сам работать по smb.
◽ В работе использует механизм жестких ссылок (hardlinks).
Поставить на Centos и попробовать можно из epel:
Вместе с backuppc прилетит apache с готовым конфигом. Надо будет только юзера добавить для авторизации. Подробная инструкция по установке есть тут. Я по ней поставил. А дальше полез в документацию и немного прифигел. Думал это небольшая утилитка, но по факту BackupPC достаточно крупная и зрелая система бэкапа, с которой надо разбираться.
Не сказать, что там что-то сложное. Плюс, всё делается через веб интерфейс. Вам надо раскидать по хостам ssh ключ, по которому BackupPC будет ходить по клиентам. Потом добавить хосты в систему, настроить задачи для бэкапа и потом поставить их в планировщик.
В целом, выглядит всё очень любопытно и полезно. Плюс, под капотом достаточно известные линуксовые утилиты. То есть никакой внутренней магии. Как я понял, эта система подойдет тем, кто не хочет связываться с Bacula/Bareos, но при этом уже вырос из самописных скриптов и нужна централизация и автоматизация.
Если у кого-то есть опыт эксплуатации BackupPC, прошу поделиться в комментариях. На первый взгляд система дельная.
http://backuppc.sourceforge.net/
https://github.com/backuppc/backuppc
#backup
◽ Управление через встроенный веб интерфейс.
◽ Кроссплатформенный, написан на perl.
◽ Поддержка дедупликации и сжатия.
◽ Работает поверх ssh, в том числе с помощью rsync, агенты ставить не надо.
◽ Умеет сам работать по smb.
◽ В работе использует механизм жестких ссылок (hardlinks).
Поставить на Centos и попробовать можно из epel:
dnf install epel-releasednf config-manager --set-enabled powertoolsdnf install backuppcВместе с backuppc прилетит apache с готовым конфигом. Надо будет только юзера добавить для авторизации. Подробная инструкция по установке есть тут. Я по ней поставил. А дальше полез в документацию и немного прифигел. Думал это небольшая утилитка, но по факту BackupPC достаточно крупная и зрелая система бэкапа, с которой надо разбираться.
Не сказать, что там что-то сложное. Плюс, всё делается через веб интерфейс. Вам надо раскидать по хостам ssh ключ, по которому BackupPC будет ходить по клиентам. Потом добавить хосты в систему, настроить задачи для бэкапа и потом поставить их в планировщик.
В целом, выглядит всё очень любопытно и полезно. Плюс, под капотом достаточно известные линуксовые утилиты. То есть никакой внутренней магии. Как я понял, эта система подойдет тем, кто не хочет связываться с Bacula/Bareos, но при этом уже вырос из самописных скриптов и нужна централизация и автоматизация.
Если у кого-то есть опыт эксплуатации BackupPC, прошу поделиться в комментариях. На первый взгляд система дельная.
http://backuppc.sourceforge.net/
https://github.com/backuppc/backuppc
#backup
{kind=link}
Помните, я на днях делал заметку про настройку анализа логов веб сервера с помощью elasticsearch? Проблему в итоге решили, но не с помощью логов. По ним стало понятно, что нет проблем с dos или какими-то другими паразитными нагрузками.
Стали еще раз внимательно смотреть мониторинг. Я с высокой точностью указал на дату, когда начались проблемы. Существенно выросла нагрузка на CPU. Стали внимательно вспоминать, кто и что делал в это время.
В итоге вспомнили, что примерно в эти дни начали использовать какой-то новый модуль для bitrix. Он на каждый хит выполнял какие-то действия. Я сам не вникал в эти подробности. Ну а в сумме это всё привело к серьезной нагрузке на сервер.
Таким образом, чтобы успешно администрировать любой веб проект, обязательно нужен мониторинг и анализатор логов. Вместе они позволяют даже не погружаясь глубоко в технические потроха, решить проблему. Не будь мониторинга, пришлось бы профилирование php и mysql делать. А это очень сложная техническая задача, так как у каждого веб приложения свои нюансы и профиль нагрузки. К примеру, я, глядя на запросы в mysql, которые генерирует битрикс, не смогу разобраться, в чем причина высокой нагрузки на базу.
А когда у тебя настроены вспомогательные инструменты, лезть глубоко в дебри не обязательно. Помимо мониторинга и анализа логов, так же эффективно помогают хорошие инкрементные бэкапы. Очень часто проблемы решаются банальным сопоставлением изменений в исходниках за какие-то даты. Сразу видно, кто и что менял в коде. На основе этого много раз решались похожие проблемы.
Так что настраиваем Zabbix, ELK, бэкапы и спим спокойно.
#webserver #bitrix
Стали еще раз внимательно смотреть мониторинг. Я с высокой точностью указал на дату, когда начались проблемы. Существенно выросла нагрузка на CPU. Стали внимательно вспоминать, кто и что делал в это время.
В итоге вспомнили, что примерно в эти дни начали использовать какой-то новый модуль для bitrix. Он на каждый хит выполнял какие-то действия. Я сам не вникал в эти подробности. Ну а в сумме это всё привело к серьезной нагрузке на сервер.
Таким образом, чтобы успешно администрировать любой веб проект, обязательно нужен мониторинг и анализатор логов. Вместе они позволяют даже не погружаясь глубоко в технические потроха, решить проблему. Не будь мониторинга, пришлось бы профилирование php и mysql делать. А это очень сложная техническая задача, так как у каждого веб приложения свои нюансы и профиль нагрузки. К примеру, я, глядя на запросы в mysql, которые генерирует битрикс, не смогу разобраться, в чем причина высокой нагрузки на базу.
А когда у тебя настроены вспомогательные инструменты, лезть глубоко в дебри не обязательно. Помимо мониторинга и анализа логов, так же эффективно помогают хорошие инкрементные бэкапы. Очень часто проблемы решаются банальным сопоставлением изменений в исходниках за какие-то даты. Сразу видно, кто и что менял в коде. На основе этого много раз решались похожие проблемы.
Так что настраиваем Zabbix, ELK, бэкапы и спим спокойно.
#webserver #bitrix
Telegram
ServerAdmin.ru
В пятницу пол дня настраивал сбор и анализ логов одного магазина на битриксе. Производительность потихоньку начала в потолок сервера упираться. Надо было внимательно посмотреть, что там происходит. Одного мониторинга уже не хватало.
Собрал вот такой типовой…
Собрал вот такой типовой…
Приветствую своих дорогих читателей. Пишу слово "дорогих" искренне, потому что если бы не было вас, не было бы и канала. Вчера случилась знаменательная для моего канала дата. Вас (подписчиков) стало 10 тысяч. Причём мне об этом напомнил совершенно искренне один из вас, незнакомый мне человек. Следил и заметил раньше меня :) Его скрин в закрепе снизу.
Этому каналу уже несколько лет, но осознанно вести и писать в него заметки я стал в начале 2020 года. До этого здесь были только анонсы статей с сайта. То есть по сути каналу в таком виде, как он есть, всего 1,5 года. Я практически не вкладывал деньги в рекламу, так как не умею и не знаю как это делать эффективно. Всё веду сам в одно лицо. Тем не менее, аудитория постоянно растёт и меня это очень радует. Значит то, что я делаю, действительно интересно и полезно людям.
По идее, в столь знаменательную дату имеет смысл провести какой-то конкурс с призами, медведями и балалайкой. Кто давно меня читает, наверное помнит, как я пытался экспериментировать и придумывать какие-то активности на канале. Всё бросил, потому что не умею. Внутри я как был так и остался обычным инженером. Так что хорошо писать получается только технические статьи. К тому же именно их мне писать нравится. Всё остальное через силу делал, но бросил.
Этот канал для меня коммерческий проект. Не буду лукавить и рассказывать, что всё ради людей, распространения знаний, развития и т.д. Если бы не было рекламы, канал не был бы таким, какой он есть. Реклама была и будет дальше примерно в таком же формате, как есть сейчас. Доход дает стимулы к развитию, движению вперёд, сосредоточенности и постоянному графику постов. Мне кажется, что получился удачный симбиоз пользы вам, мне, так как постоянно что-то узнаю и изучаю, и рекламодателям.
Как-то я уже говорил об этом отдельно - я пишу по два поста в день всё время на протяжении полутора лет. Не ложусь спать, пока не напишу их. Это очень дисциплинирует. Результат в любом деле следует из упорства и постоянства. Хотя, понятно, где-то и удача нужна, но на одной удаче не выехать.
Данный канал останется только про IT, как и сейчас. Очень хочу начать писать на посторонние темы, но пока просто не хватает времени. Скорее всего я буду это делать позже на втором канале, который сменит тематику с IT на общую. Там будет про жизнь, семью, детей, здоровье, стройку и т.д. Мне кажется, что есть о чем рассказать. Пока стройка не закончится и я не перееду в свой дом, времени на это не будет, но потом обязательно займусь. Так что оставайтесь на связи, кому это интересно.
Этому каналу уже несколько лет, но осознанно вести и писать в него заметки я стал в начале 2020 года. До этого здесь были только анонсы статей с сайта. То есть по сути каналу в таком виде, как он есть, всего 1,5 года. Я практически не вкладывал деньги в рекламу, так как не умею и не знаю как это делать эффективно. Всё веду сам в одно лицо. Тем не менее, аудитория постоянно растёт и меня это очень радует. Значит то, что я делаю, действительно интересно и полезно людям.
По идее, в столь знаменательную дату имеет смысл провести какой-то конкурс с призами, медведями и балалайкой. Кто давно меня читает, наверное помнит, как я пытался экспериментировать и придумывать какие-то активности на канале. Всё бросил, потому что не умею. Внутри я как был так и остался обычным инженером. Так что хорошо писать получается только технические статьи. К тому же именно их мне писать нравится. Всё остальное через силу делал, но бросил.
Этот канал для меня коммерческий проект. Не буду лукавить и рассказывать, что всё ради людей, распространения знаний, развития и т.д. Если бы не было рекламы, канал не был бы таким, какой он есть. Реклама была и будет дальше примерно в таком же формате, как есть сейчас. Доход дает стимулы к развитию, движению вперёд, сосредоточенности и постоянному графику постов. Мне кажется, что получился удачный симбиоз пользы вам, мне, так как постоянно что-то узнаю и изучаю, и рекламодателям.
Как-то я уже говорил об этом отдельно - я пишу по два поста в день всё время на протяжении полутора лет. Не ложусь спать, пока не напишу их. Это очень дисциплинирует. Результат в любом деле следует из упорства и постоянства. Хотя, понятно, где-то и удача нужна, но на одной удаче не выехать.
Данный канал останется только про IT, как и сейчас. Очень хочу начать писать на посторонние темы, но пока просто не хватает времени. Скорее всего я буду это делать позже на втором канале, который сменит тематику с IT на общую. Там будет про жизнь, семью, детей, здоровье, стройку и т.д. Мне кажется, что есть о чем рассказать. Пока стройка не закончится и я не перееду в свой дом, времени на это не будет, но потом обязательно займусь. Так что оставайтесь на связи, кому это интересно.
{kind=link}
Недавно увидел новость про то, что платформа CommuniGate Pro, которая включает в том числе почтовый сервер, научилась полноценно поддерживать кириллистические домены для почты.
https://www.cnews.ru/news/top/2021-07-01_v_rossii_poyavilsya_pervyj
Для тех, кто не в курсе, напомню, что до этого вы хоть и могли зарегистрировать кириллистический домен в зоне рф или рус (у меня там, кстати, домен есть - серверадмин.рус), но почта на них работать не будет. Почтовые серверы не поддерживают эти домены. А CommuniGate Pro теперь умеет.
Пишу эту заметку для того, чтобы понять, а кто вообще использует продукты CommuniGate Systems? Погуглил немного. Это очень старая компания, дата основания 91-й год, но я реально ни разу не сталкивался с ее продуктами нигде. И даже не знаком с людьми, которые бы ими управляли. А при этом среди пользователей CGS -TELE2 Швеция, 2 500 000 абонентов, British Airways, 100 000 абонентов и куча других огромных корпораций. Даже не понимаю, как этот софт прошёл мимо меня.
Я так понял из описаний, что это платформа для огромного бизнеса, но там обычно либо Exchange, либо Lotus Domino. Это из того, что я знаю. Про CommuniGate не слышал. Кто-нибудь видел этот почтовый сервер и инфраструктуру вокруг него? Что это за продукт? На сайте есть версии и для малого бизнеса, но не замечал, чтобы кто-то его использовал.
https://www.cnews.ru/news/top/2021-07-01_v_rossii_poyavilsya_pervyj
Для тех, кто не в курсе, напомню, что до этого вы хоть и могли зарегистрировать кириллистический домен в зоне рф или рус (у меня там, кстати, домен есть - серверадмин.рус), но почта на них работать не будет. Почтовые серверы не поддерживают эти домены. А CommuniGate Pro теперь умеет.
Пишу эту заметку для того, чтобы понять, а кто вообще использует продукты CommuniGate Systems? Погуглил немного. Это очень старая компания, дата основания 91-й год, но я реально ни разу не сталкивался с ее продуктами нигде. И даже не знаком с людьми, которые бы ими управляли. А при этом среди пользователей CGS -TELE2 Швеция, 2 500 000 абонентов, British Airways, 100 000 абонентов и куча других огромных корпораций. Даже не понимаю, как этот софт прошёл мимо меня.
Я так понял из описаний, что это платформа для огромного бизнеса, но там обычно либо Exchange, либо Lotus Domino. Это из того, что я знаю. Про CommuniGate не слышал. Кто-нибудь видел этот почтовый сервер и инфраструктуру вокруг него? Что это за продукт? На сайте есть версии и для малого бизнеса, но не замечал, чтобы кто-то его использовал.
CNews.ru
В России появился первый почтовый сервер с сертифицированной поддержкой кириллических адресов - CNews
Российская платформа унифицированных коммуникаций CommuniGate Pro теперь поддерживает кириллические доменные имена...
Если вы по какой-то причине до сих пор не изучили Git 😱, то можете попробовать изучить его с помощью бесплатного курса - https://ru.hexlet.io/courses/intro_to_git. Я там зарегистрировался и посмотрел уроки. Понравилось, как всё устроено. Никакие персональные данные платформа не вытягивает. Регистрация по почте. Немного на Stepik похоже.
Есть несколько бесплатных курсов для системных администраторов. Помимо Git может быть полезно пройти Основы командной строки Linux и Основы языка Python.
Отмечаю, что это не реклама данной платформы. У меня никто ее не заказывал. Я просто немного на нее посмотрел и мне показалась интересной. Очень много всевозможных курсов, в основном для программистов, но есть кое-что по devops и системному администрированию. При этом месячная подписка стоит 3900. Сравните это с другими курсами, которые у меня рекламируются.
Можете просто купить доступ на месяц и забрать себе все интересующие вас курсы, чтобы спокойно изучить потом. Очень доступно. Если есть реальное желание чему-то научиться, то можно это без особых проблем и финансовых затрат сделать.
#обучение #git
Есть несколько бесплатных курсов для системных администраторов. Помимо Git может быть полезно пройти Основы командной строки Linux и Основы языка Python.
Отмечаю, что это не реклама данной платформы. У меня никто ее не заказывал. Я просто немного на нее посмотрел и мне показалась интересной. Очень много всевозможных курсов, в основном для программистов, но есть кое-что по devops и системному администрированию. При этом месячная подписка стоит 3900. Сравните это с другими курсами, которые у меня рекламируются.
Можете просто купить доступ на месяц и забрать себе все интересующие вас курсы, чтобы спокойно изучить потом. Очень доступно. Если есть реальное желание чему-то научиться, то можно это без особых проблем и финансовых затрат сделать.
#обучение #git
ru.hexlet.io
Бесплатный курс: Введение в Git. Основы контроля версий
Курс по основам работы с системой контроля версий Git. Принципы работы Git, управление версиями кода, работа с ветками и слияниями. Бесплатное обучение поможет освоить все ключевые навыки, которые нужны начинающему разработчику
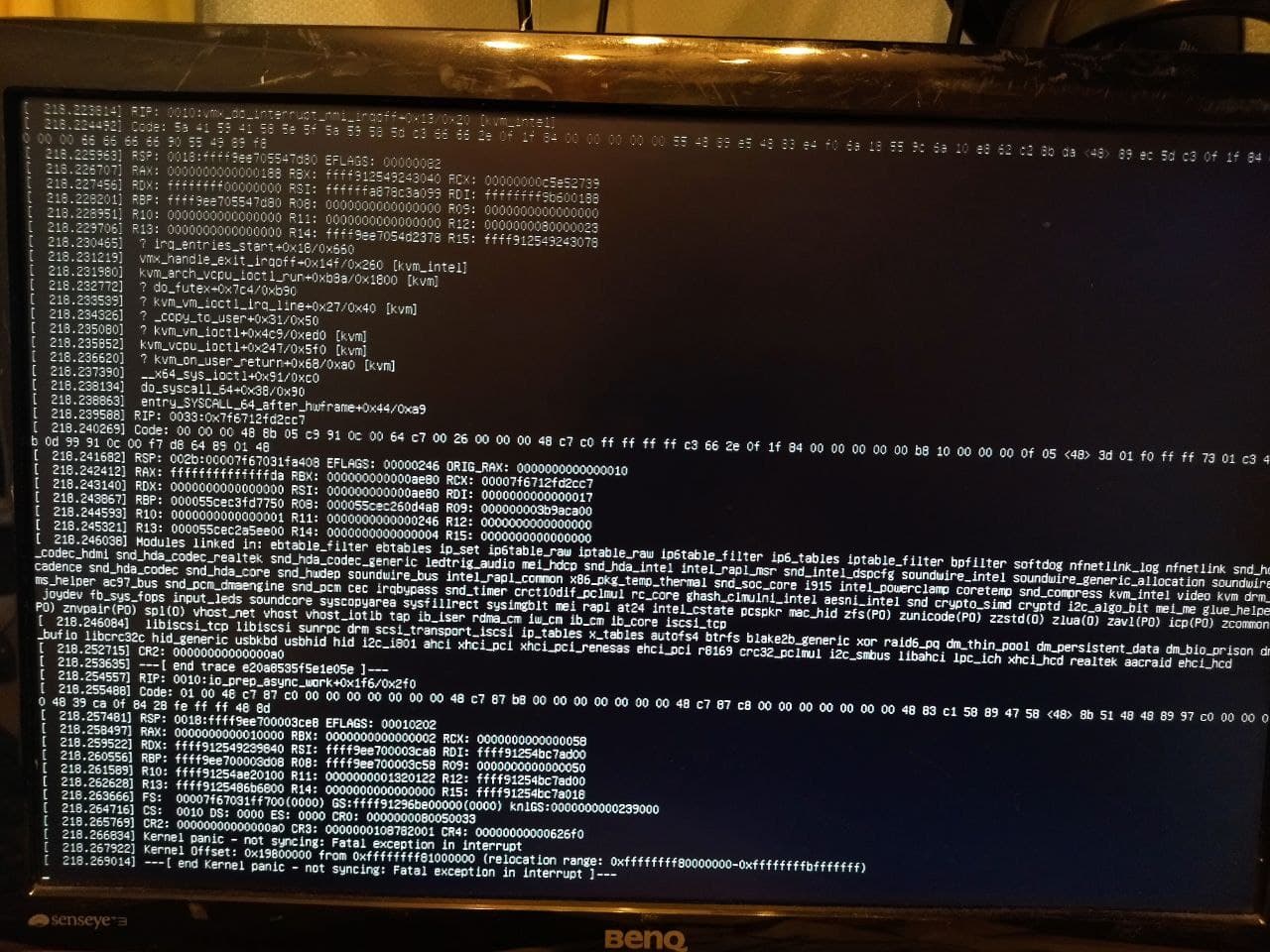
Важное техническое оповещение для тех, кто использует Proxmox и думает над обновлением до 7-й версии. Не обновляйтесь пока.
Я словил Kernel Panic и полный зависон тестового гипервизора, который обновил. Стал гуглить и нашел много похожих сообщений, появившихся в июле. Вот пример подобного обсуждения - https://forum.proxmox.com/threads/kernel-panic-whole-server-crashes-about-every-day.91803/
В моем случае пока не ясно, что является причиной проблемы. Гипервизор жестко зависает после запуска виртуалки с виндой и типом процессора [host]. Воспроизводимость глюка 100%.
Пока вернул настройки процессора в Default (kvm64), ни разу не завис. Но надо тестировать дальше. Зависает не только из-за настроек процессора. У некоторых при высокой нагрузке на диск гипервизор встаёт колом.
Я не стал дожидаться результатов своих тестов. Решил сразу предупредить, пока не спешить обновляться. Я буквально на днях пару гипервизоров в прод запускал. Еще думал, 7-ю версию ставить или пока на 6.4 остаться. Оставил 6-ю версию и не прогадал.
#proxmox
Я словил Kernel Panic и полный зависон тестового гипервизора, который обновил. Стал гуглить и нашел много похожих сообщений, появившихся в июле. Вот пример подобного обсуждения - https://forum.proxmox.com/threads/kernel-panic-whole-server-crashes-about-every-day.91803/
В моем случае пока не ясно, что является причиной проблемы. Гипервизор жестко зависает после запуска виртуалки с виндой и типом процессора [host]. Воспроизводимость глюка 100%.
Пока вернул настройки процессора в Default (kvm64), ни разу не завис. Но надо тестировать дальше. Зависает не только из-за настроек процессора. У некоторых при высокой нагрузке на диск гипервизор встаёт колом.
Я не стал дожидаться результатов своих тестов. Решил сразу предупредить, пока не спешить обновляться. Я буквально на днях пару гипервизоров в прод запускал. Еще думал, 7-ю версию ставить или пока на 6.4 остаться. Оставил 6-ю версию и не прогадал.
#proxmox
{kind=link}
Вчера погонял скрипт миграции Centos на RockyLinux. Процесс не быстрый. На голой системе Centos 8 переустанавливаются почти 700 пакетов. Минут 30 процесс длился. Все автоматически делается, можно и по ssh. Проблем не заметил при этом.
Оформил всё это в статью, хотя там просто запуск одного скрипта - migrate2rocky.sh. Никаких проблем или нюансов. По сути полностью переустанавливается вся система. Я по началу не так себе представлял этот процесс. Думал просто репы поменяются и пару каких-нибудь пакетов. На деле - нет. Переустанавливаются из новых репозиториев абсолютно все пакеты.
Надо будет ближе к делу погонять тесты с копиями боевых серверов. Такой длинный простой при переходе не очень нравится. Надо будет всё внимательно спланировать.
https://serveradmin.ru/migracziya-ili-konvertacziya-centos-8-v-rocky-linux-8/
#rockylinux #статья
Оформил всё это в статью, хотя там просто запуск одного скрипта - migrate2rocky.sh. Никаких проблем или нюансов. По сути полностью переустанавливается вся система. Я по началу не так себе представлял этот процесс. Думал просто репы поменяются и пару каких-нибудь пакетов. На деле - нет. Переустанавливаются из новых репозиториев абсолютно все пакеты.
Надо будет ближе к делу погонять тесты с копиями боевых серверов. Такой длинный простой при переходе не очень нравится. Надо будет всё внимательно спланировать.
https://serveradmin.ru/migracziya-ili-konvertacziya-centos-8-v-rocky-linux-8/
#rockylinux #статья
Server Admin
Миграция или конвертация Centos 8 в Rocky Linux 8 | serveradmin.ru
# wget https://raw.githubusercontent.com/rocky-linux/rocky-tools/main/migrate2rocky/migrate2rocky.sh # chmod +x migrate2rocky.sh Для того, чтобы начать переход с Centos на Rocky Linux, запускаем...
Ну что, друзья, сегодня пятница, да еще и вечер. Самое время задеплоить что-нибудь, пока никто не мешает. Ну или на худой конец обновления накатить.
Хуяк хуяк и в продакшн
https://www.youtube.com/watch?v=F2skk6RFFos
Я - инженер, и моя голова
Сразу забывает бесполезные слова.
Agile scrum? Fuck you, i'm russian.
Хуяк хуяк и в продакшн.
Особенно нравится вот эти строки:
Лет пять назад уже потерян всякий стыд -
Мы делаем дело. Пусть криво, но стоит.
Если что, такой подход к делу осуждаю, но песенка и клип нравятся очень даже :)
#юмор
Хуяк хуяк и в продакшн
https://www.youtube.com/watch?v=F2skk6RFFos
Я - инженер, и моя голова
Сразу забывает бесполезные слова.
Agile scrum? Fuck you, i'm russian.
Хуяк хуяк и в продакшн.
Особенно нравится вот эти строки:
Лет пять назад уже потерян всякий стыд -
Мы делаем дело. Пусть криво, но стоит.
Если что, такой подход к делу осуждаю, но песенка и клип нравятся очень даже :)
#юмор
YouTube
Научно-технический рэп - Хуяк хуяк и в продакшн
/!\ Канал не ведется участниками научно-технического рэпа /!\
Хуяк-хуяк и видео готово
Официальная ВК группа исполнителей: https://vk.com/nii_rap
--------------------------------
Текст:
(Таааак...
Плиз коммит ченджес иммидиатли асап.
Сумасандаран самалан…
Хуяк-хуяк и видео готово
Официальная ВК группа исполнителей: https://vk.com/nii_rap
--------------------------------
Текст:
(Таааак...
Плиз коммит ченджес иммидиатли асап.
Сумасандаран самалан…
На неделе была рассылка от Zabbix с новостями. На сайте нигде эта информация у них не отражена (искал, не нашёл), так что если не подписаны по почте на рассылку, то и посмотреть инфу негде. Я это исправляю. Рассказываю о том, что мне показалось интересным.
В первую очередь это новые шаблоны мониторинга:
◽ Новый шаблон для Systemd Units - https://www.zabbix.com/integrations/systemd
◽ Обновились шаблоны для Cisco - https://www.zabbix.com/integrations/cisco
◽ Обновились шаблоны для серверов Dell - https://www.zabbix.com/integrations/dell
◽ Обновились шаблоны для серверов HPE - https://www.zabbix.com/integrations/hp_enterprise
В блоге опубликована подробная статья про планировщик отчётов - https://blog.zabbix.com/scheduled-report-generation-in-zabbix-5-4/ Я их, кстати, так и не потестировал. Нужды нет в этом функционале, так что забыл про него, хотя выглядит интересно. Записал себе, чтобы проверить.
Как обычно запланированы семинары на русском языке. Я перестал их анонсить, потому что они крутят одни и те же темы. Раньше было разнообразнее и интереснее. Смотреть расписание тут - http://www.zabbix.com/webinars?language=russian#tab:upcoming Обращаю внимание там же на отдельную вкладку с записями вебинаров. Темы есть интересные, записи на английском языке.
Обновилась дорожная карта для Zabbix 6.0 LTS. Кому интересно посмотреть, что нас ждет нового, знакомьтесь - https://www.zabbix.com/roadmap Релиз к концу этого года готовится.
Pdf рассылки - https://yadi.sk/i/1d8_ziMlerqL4A
#zabbix
В первую очередь это новые шаблоны мониторинга:
◽ Новый шаблон для Systemd Units - https://www.zabbix.com/integrations/systemd
◽ Обновились шаблоны для Cisco - https://www.zabbix.com/integrations/cisco
◽ Обновились шаблоны для серверов Dell - https://www.zabbix.com/integrations/dell
◽ Обновились шаблоны для серверов HPE - https://www.zabbix.com/integrations/hp_enterprise
В блоге опубликована подробная статья про планировщик отчётов - https://blog.zabbix.com/scheduled-report-generation-in-zabbix-5-4/ Я их, кстати, так и не потестировал. Нужды нет в этом функционале, так что забыл про него, хотя выглядит интересно. Записал себе, чтобы проверить.
Как обычно запланированы семинары на русском языке. Я перестал их анонсить, потому что они крутят одни и те же темы. Раньше было разнообразнее и интереснее. Смотреть расписание тут - http://www.zabbix.com/webinars?language=russian#tab:upcoming Обращаю внимание там же на отдельную вкладку с записями вебинаров. Темы есть интересные, записи на английском языке.
Обновилась дорожная карта для Zabbix 6.0 LTS. Кому интересно посмотреть, что нас ждет нового, знакомьтесь - https://www.zabbix.com/roadmap Релиз к концу этого года готовится.
Pdf рассылки - https://yadi.sk/i/1d8_ziMlerqL4A
#zabbix
{kind=link}
Недавно решил обновить Windows Server 2012 r2 до 2016. Ранее никогда не проделывал такие обновления, потому что считаю их потенциально небезопасными с непрогнозируемым результатом. Но этот сервер мог постоять без дела какое-то время в случае проблем. Бэкапы все предварительно сделал.
В целом, у меня всё получилось в итоге. Но как и предполагал изначально - результат непрогнозируем. Сделал всё стандартно. Подмонтировал iso образ и запустил обновление. Какое-то время все это продолжалось (где-то час в сумме), система успешно обновилась и без проблем загрузилась.
А дальше начались проблемы. В логах много ошибок, но это ладно. Я особо не разбирался в них, так как не получались более важные дела. Система никак не хотела ставить обновления. Плюс, при подключении по rdp или локально у некоторых пользователей был черный экран, но при этом работала мышка. С этим не стал разбираться сразу, сфокусировался на проблеме с обновлениями.
Возился с этим сервером пару дней наверно. Он в целом работал, но обновления никак не хотели ставиться. Помогло в итоге самое простое и очевидное действие, с которого стоило начать сразу после обновления:
Последняя команда долго шуршала шестерёнками. В итоге после её успешного завершения поставились все обновления. Починился черный экран у юзеров и в логах ушли почти все ошибки. И сервер заработал нормально.
Так что в целом решение рабочее, но потенциально рискованное, так что я бы в проде не стал этого делать, а сделал все же миграцию на новую версию системы.
#windows
В целом, у меня всё получилось в итоге. Но как и предполагал изначально - результат непрогнозируем. Сделал всё стандартно. Подмонтировал iso образ и запустил обновление. Какое-то время все это продолжалось (где-то час в сумме), система успешно обновилась и без проблем загрузилась.
А дальше начались проблемы. В логах много ошибок, но это ладно. Я особо не разбирался в них, так как не получались более важные дела. Система никак не хотела ставить обновления. Плюс, при подключении по rdp или локально у некоторых пользователей был черный экран, но при этом работала мышка. С этим не стал разбираться сразу, сфокусировался на проблеме с обновлениями.
Возился с этим сервером пару дней наверно. Он в целом работал, но обновления никак не хотели ставиться. Помогло в итоге самое простое и очевидное действие, с которого стоило начать сразу после обновления:
sfc /scannowDISM /Online /Cleanup-Image /CheckHealthПоследняя команда долго шуршала шестерёнками. В итоге после её успешного завершения поставились все обновления. Починился черный экран у юзеров и в логах ушли почти все ошибки. И сервер заработал нормально.
Так что в целом решение рабочее, но потенциально рискованное, так что я бы в проде не стал этого делать, а сделал все же миграцию на новую версию системы.
#windows
{kind=link}
Для одного из веб проектов появилась возможность выделить отдельный гипервизор под регулярное автоматическое тестирование бэкапов - исходники + mysql база. До этого бэкапы просто делались и мониторилось их наличие.
Встала задача воссоздать прод. Так как до этого никому это не нужно было, никакой автоматизации не было. Достаточно было скопировать виртуалку. Но не получалось это сделать по двум причинам. На самом гипервизоре не было достаточно свободного места. Диск виртуалки был очень жирным для этого сервера (300 Гб). Из-за этого её нельзя было остановить и скопировать. Процесс продлился бы несколько часов.
Я не нашел ничего проще и быстрее, чем наживую скопировать диск работающей виртуалки. Процесс длился 1.5 часа. Сайт нормально работал. Я понимал, что может ничего не получиться, но хотелось поэкспериментировать. По факту никаких особых проблем не возникло.
После копирования диска на другой гипервизор, виртуалка ожидаемо не запустилась. Но решилось всё очень просто. Была всего лишь повреждена файловая система xfs. Починил ее простыми командами и всё завелось. Туда же успешно накатил бэкапы.
Более подробно всё описал в статье.
https://serveradmin.ru/metadata-corruption-detected-unmount-and-run-xfs_repair/
Если у кого-то есть идеи, как еще можно было бы выкрутиться, готов выслушать. Была мысль, подцепить внешнее хранилище по nfs и сделать бэкап на него. Но мне кажется, что когда-то давно я проводил такие эксперименты и всё равно на исходном гипервизоре должно быть достаточно свободного места, чтобы proxmox смог сделать бэкап на nfs storage.
#proxmox #статья
Встала задача воссоздать прод. Так как до этого никому это не нужно было, никакой автоматизации не было. Достаточно было скопировать виртуалку. Но не получалось это сделать по двум причинам. На самом гипервизоре не было достаточно свободного места. Диск виртуалки был очень жирным для этого сервера (300 Гб). Из-за этого её нельзя было остановить и скопировать. Процесс продлился бы несколько часов.
Я не нашел ничего проще и быстрее, чем наживую скопировать диск работающей виртуалки. Процесс длился 1.5 часа. Сайт нормально работал. Я понимал, что может ничего не получиться, но хотелось поэкспериментировать. По факту никаких особых проблем не возникло.
После копирования диска на другой гипервизор, виртуалка ожидаемо не запустилась. Но решилось всё очень просто. Была всего лишь повреждена файловая система xfs. Починил ее простыми командами и всё завелось. Туда же успешно накатил бэкапы.
Более подробно всё описал в статье.
https://serveradmin.ru/metadata-corruption-detected-unmount-and-run-xfs_repair/
Если у кого-то есть идеи, как еще можно было бы выкрутиться, готов выслушать. Была мысль, подцепить внешнее хранилище по nfs и сделать бэкап на него. Но мне кажется, что когда-то давно я проводил такие эксперименты и всё равно на исходном гипервизоре должно быть достаточно свободного места, чтобы proxmox смог сделать бэкап на nfs storage.
#proxmox #статья
Server Admin
Metadata corruption detected, unmount and run xfs_repair |...
# qemu-img check vm-102-disk-0.qcow2 # qemu-img check -r all vm-102-disk-0.qcow2 Ошибок на этом этапе не было. Но виртуалка всё равно не стартовала, так как судя по ошибке на скрине, была...
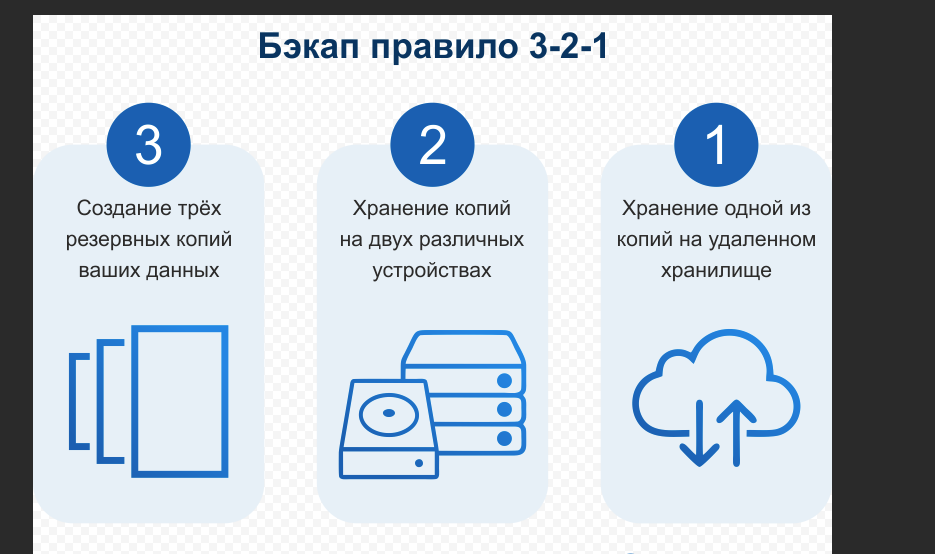
У меня на канале накопилось достаточно много содержательных заметок по какой-то конкретной тематике, которые не теряют актуальность со временем. Я решил периодически делать подборки постов по ним, чтобы удобнее было ориентироваться на канале и сохранять в закладки разом побольше полезной информации.
В этот раз будет подборка заметок об инструментах для бэкапа - #backup.
◽ Veeam Agent for Windows или Linux - известные бесплатные инструменты для бэкапа всей системы целиком или отдельных данных от одного из мировых лидеров в данной тематике.
◽ Rsync - утилита для синхронизации данных между разными хостами. Отличительной особенностью является быстродействие при работе с огромными списками исходных файлов. Я не знаю инструмента, который бы быстрее rsync сравнил 2 хоста с сотнями тысяч файлов и выдал разницу между ними для копирования только изменений.
◽ Kopia - кроссплатформенная система для бэкапа файлов (Win, Lin, Mac) c GUI. Может подключаться по ssh к хостам, поддерживает подключение к storage по S3,webdav, sftp. Простая и удобная система для тех, кто хочет всем управлять через GIU. В консоль лизить не обязательно.
◽ Burp - написан на C, использует как и rsync библиотеку librsync. Работает в режиме клиент - сервер. Умеет шифрование, дедупликацию, планировщик, оповещения и т.д. Облегченная версия Bacula/Bareos для тех, кто последнюю не осилил.
◽ Syncthing - утилита для синхронизации каталогов по сети, которая работает по принципу торрент клиентов. Можно автоматически синхронизировать данные в режиме реального времени на нескольких хостах.
◽ Borgbackup - кроссплатформенная утилита для бэкапа, состоящая из одного бинарника. При этом имеет обширный функционал - дедупликация, сжатие и т.д. Работает по ssh, клиенты не нужны. Отлично подходит для использования в скриптах. Хранит данные в бинарном формате.
◽ Rsnapshot - написан на perl, под капотом обычный rsync. По сути это скрипт для автоматизации бэкапов с помощью rsync. Он умеет делать инкрементные бэкапы, ротировать их и чистить устаревшие данные. Для экономии места хранилища использует hard links на одни и те же файлы в бэкапах.
◽ BackupPC - полноценная кроссплатформенная система бэкапов со своим GUI. Работает по ssh, в том числе с помощью rsync. Подойдет для тех, кто не осилил или ему не нужен весь функционал Bacula/Bareos.
Не забудьте забрать в закладки. Утилиты полезные.
#подборка #backup
В этот раз будет подборка заметок об инструментах для бэкапа - #backup.
◽ Veeam Agent for Windows или Linux - известные бесплатные инструменты для бэкапа всей системы целиком или отдельных данных от одного из мировых лидеров в данной тематике.
◽ Rsync - утилита для синхронизации данных между разными хостами. Отличительной особенностью является быстродействие при работе с огромными списками исходных файлов. Я не знаю инструмента, который бы быстрее rsync сравнил 2 хоста с сотнями тысяч файлов и выдал разницу между ними для копирования только изменений.
◽ Kopia - кроссплатформенная система для бэкапа файлов (Win, Lin, Mac) c GUI. Может подключаться по ssh к хостам, поддерживает подключение к storage по S3,webdav, sftp. Простая и удобная система для тех, кто хочет всем управлять через GIU. В консоль лизить не обязательно.
◽ Burp - написан на C, использует как и rsync библиотеку librsync. Работает в режиме клиент - сервер. Умеет шифрование, дедупликацию, планировщик, оповещения и т.д. Облегченная версия Bacula/Bareos для тех, кто последнюю не осилил.
◽ Syncthing - утилита для синхронизации каталогов по сети, которая работает по принципу торрент клиентов. Можно автоматически синхронизировать данные в режиме реального времени на нескольких хостах.
◽ Borgbackup - кроссплатформенная утилита для бэкапа, состоящая из одного бинарника. При этом имеет обширный функционал - дедупликация, сжатие и т.д. Работает по ssh, клиенты не нужны. Отлично подходит для использования в скриптах. Хранит данные в бинарном формате.
◽ Rsnapshot - написан на perl, под капотом обычный rsync. По сути это скрипт для автоматизации бэкапов с помощью rsync. Он умеет делать инкрементные бэкапы, ротировать их и чистить устаревшие данные. Для экономии места хранилища использует hard links на одни и те же файлы в бэкапах.
◽ BackupPC - полноценная кроссплатформенная система бэкапов со своим GUI. Работает по ssh, в том числе с помощью rsync. Подойдет для тех, кто не осилил или ему не нужен весь функционал Bacula/Bareos.
Не забудьте забрать в закладки. Утилиты полезные.
#подборка #backup
{kind=link}
Один мой знакомый написал подробную статью про установку и настройку PeerTube. Условно его можно назвать self-hosted аналогом youtube. Меня он заинтересовал в первую очередь тем, что туда можно грузить семейные записи видео и автоматически жать с разными настройками, чтобы уменьшить размер семейного архива.
Так же его можно шарить между другими членами семьи, организовав доступ бабушкам, дедушкам к просмотру видео с внуками. Я в итоге всё настроил у себя локально, чтобы супруга могла сама через веб интерфейс загружать и скачивать пережатые ролики.
Сама статья вот - https://sevo44.ru/peertube-ustanovka-na-centos/comment-page-1/ Настраивается всё практически копипастом. Но есть нюанс. Судя по всему, недавно поменялись зависимости пакетов и поставить ffmpeg на Centos 8 не получается. Я и так, и сяк подходил к вопросу, но так и не понял, как сейчас разрулить корректно зависимости - ffmpeg-lib хочет libaom одной версии, а в репах лежит другая версия. В итоге решил вопрос вот так:
Дальше всё копипастом по статье можно. Единственное, я не делал проксирующий сервер и не настраивал https. Сделал доступ просто по локальному IP. Мне для дома и так сойдет. Пришлось немного поправить конфиги самого peertube.
Интерфейс PeerTube приятный и понятный. Можно грузить ролики, обмениваться. При желании можно организовать публичный доступ к этой штуке. В общем, любопытный и масштабный проект. Рекомендую присмотреться, если нужно что-то подобное.
Так же его можно шарить между другими членами семьи, организовав доступ бабушкам, дедушкам к просмотру видео с внуками. Я в итоге всё настроил у себя локально, чтобы супруга могла сама через веб интерфейс загружать и скачивать пережатые ролики.
Сама статья вот - https://sevo44.ru/peertube-ustanovka-na-centos/comment-page-1/ Настраивается всё практически копипастом. Но есть нюанс. Судя по всему, недавно поменялись зависимости пакетов и поставить ffmpeg на Centos 8 не получается. Я и так, и сяк подходил к вопросу, но так и не понял, как сейчас разрулить корректно зависимости - ffmpeg-lib хочет libaom одной версии, а в репах лежит другая версия. В итоге решил вопрос вот так:
# dnf install libaom# dnf install ffmpeg --nobestДальше всё копипастом по статье можно. Единственное, я не делал проксирующий сервер и не настраивал https. Сделал доступ просто по локальному IP. Мне для дома и так сойдет. Пришлось немного поправить конфиги самого peertube.
Интерфейс PeerTube приятный и понятный. Можно грузить ролики, обмениваться. При желании можно организовать публичный доступ к этой штуке. В общем, любопытный и масштабный проект. Рекомендую присмотреться, если нужно что-то подобное.
сЭВО:эволюция работ
PeerTube установка на Rocky Linux - сЭВО:эволюция работ
Установим и настроим децентрализованную платформу для организации видеохостинга и видеовещания под названием PeerTube на систему Rocky Linux.
Расскажу своими словами про индексы в Mysql. Информация теоретическая и будет скорее всего актуальна и для других баз, но лично я из всех баз больше всего работаю с Mysql. Рассказать про индексы решил, так как знать их хотя бы немного необходимо и системному администратору, и devops инженеру. Я сам долгое время только примерно представлял, что это вообще такое, но в итоге разобрался со временем.
Индексы нужны, чтобы быстро находить данные в базе. Например, у вас есть таблица, где 10 тысяч строк и колонка с датами. Вам нужно быстро найти какую-то дату. Для этого придётся каждую колонку сравнить с искомой, чтобы найти совпадения. Это долго. Вы можете создать индекс для этой колонки, который выстроит даты по порядку. В таком случае с помощью поиска вы сразу же найдёте все совпадающие значения, так как они отсортированы по порядку. Не нужно будет перечитывать всю таблицу.
Индексы могут быть разные под разные типы данных. Также они могут быть составными из нескольких колонок. Общий смысл их один - упорядочить данные для быстрого поиска, сортировки, сравнения и т.д.
На первый взгляд может показаться, что если сделать индексы на все колонки, то база будет работать быстрее. Но это не так. Перестройка индексов после изменения данных ресурсоёмкая операция, так что индексы надо использовать именно там, где они больше всего нужны. Они ко всему прочему еще и место в базе занимают.
Зачем всё это нужно знать системному администратору? В каких-то простых случаях это помогает решать проблемы производительности. К примеру, база тормозит. Включаете slow-log и смотрите все запросы, которые выполняются дольше секунды. Если явно видите, что постоянно тормозит конкретный запрос, можете ускорить его, создав индекс по нужной колонке.
Не всегда удастся разобраться в запросах и понять, куда и какой индекс добавить. Но иногда это можно сделать, так что понимание индексов вам явно лишним не будет, если вы взаимодействуете с базами данных.
#mysql
Индексы нужны, чтобы быстро находить данные в базе. Например, у вас есть таблица, где 10 тысяч строк и колонка с датами. Вам нужно быстро найти какую-то дату. Для этого придётся каждую колонку сравнить с искомой, чтобы найти совпадения. Это долго. Вы можете создать индекс для этой колонки, который выстроит даты по порядку. В таком случае с помощью поиска вы сразу же найдёте все совпадающие значения, так как они отсортированы по порядку. Не нужно будет перечитывать всю таблицу.
Индексы могут быть разные под разные типы данных. Также они могут быть составными из нескольких колонок. Общий смысл их один - упорядочить данные для быстрого поиска, сортировки, сравнения и т.д.
На первый взгляд может показаться, что если сделать индексы на все колонки, то база будет работать быстрее. Но это не так. Перестройка индексов после изменения данных ресурсоёмкая операция, так что индексы надо использовать именно там, где они больше всего нужны. Они ко всему прочему еще и место в базе занимают.
Зачем всё это нужно знать системному администратору? В каких-то простых случаях это помогает решать проблемы производительности. К примеру, база тормозит. Включаете slow-log и смотрите все запросы, которые выполняются дольше секунды. Если явно видите, что постоянно тормозит конкретный запрос, можете ускорить его, создав индекс по нужной колонке.
Не всегда удастся разобраться в запросах и понять, куда и какой индекс добавить. Но иногда это можно сделать, так что понимание индексов вам явно лишним не будет, если вы взаимодействуете с базами данных.
#mysql
{kind=link}
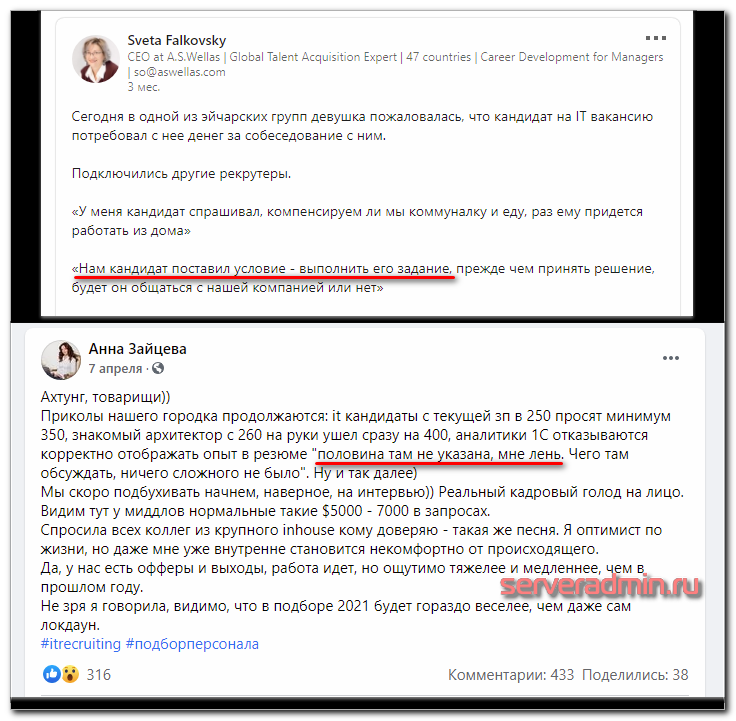
В шоу Холостяк давно должен участвовать айтишник. Напротив него будут сидеть 10 эйчарок из разных компаний, которые склоняют его к офферу. Он дарит розы первого впечатления от созвона и флирта в мессенджерах. Кому не досталось роз, её технарь награждает фразой «спасибо, не интересно, будем на связи».
В последней серии две леди показывают все прелести своих компаний. Одна молодая, перспективная, с красивым логотипом, манит современным стеком - стартапчик. Вторая успешная, богатая, пленит своей зарплатной вилкой - опытная госконтора. Главный герой сомневается, но после долгих раздумий выбор падает на первую.
В финальной сцене мы узнаём, что новой подругой айтишника оказывается его бывшая, которая сделала пластику. И из СберТеха он перешел работать в Сбер.
Мужчины и немногочисленные женщины из сферы IT. Настал наш звездный час. Зарплаты растут вместе с дефицитом кадров. Не упускайте своих возможностей... И учитесь программировать 😁
Диалоги на картинке реальные, я нашел их лично и перечитал. Было интересно.
https://clck.ru/WGVJN (linkedin)
https://clck.ru/WGVK9 (facebook)
В последней серии две леди показывают все прелести своих компаний. Одна молодая, перспективная, с красивым логотипом, манит современным стеком - стартапчик. Вторая успешная, богатая, пленит своей зарплатной вилкой - опытная госконтора. Главный герой сомневается, но после долгих раздумий выбор падает на первую.
В финальной сцене мы узнаём, что новой подругой айтишника оказывается его бывшая, которая сделала пластику. И из СберТеха он перешел работать в Сбер.
Мужчины и немногочисленные женщины из сферы IT. Настал наш звездный час. Зарплаты растут вместе с дефицитом кадров. Не упускайте своих возможностей... И учитесь программировать 😁
Диалоги на картинке реальные, я нашел их лично и перечитал. Было интересно.
https://clck.ru/WGVJN (linkedin)
https://clck.ru/WGVK9 (facebook)
{kind=link}
Недавно уже делал заметку о настройке mysqldump для бэкапа баз данных mysql. Продолжу тему и приведу еще несколько полезных примеров из практики.
Чаще всего база дампится целиком. Если вам нужно восстановить отдельную таблицу из полного дампа, то простого способа сделать это нет. Я решаю эту задачу в консоли с помощью линуксовых утилит.
cat dbase.sql | /usr/bin/awk '/CREATE TABLE `b_catalog_discount`/,/UNLOCK TABLES/' > /tmp/b_catalog_discount.sql
Ищу в дампе строку CREATE TABLE и UNLOCK TABLES и сохраняю все, что между этих строк. Такой способ сработает, если вы дампите с ключами add-locks и create-options. Если дампите без них, по посмотрите сами, какие строки окаймляют создание таблиц в дампе.
Если нужно сделать потабличный дамп баз данных, использую простой скрипт с циклом:
#!/bin/bash
USER='root'
PASS='pass'
MYSQL="mysql --user=$USER --password=$PASS --skip-column-names";
DIR="/tmp/backupdb"
for s in mysql `$MYSQL -e "SHOW DATABASES"`;
do
mkdir $DIR/$s;
for t in `$MYSQL -e "SHOW TABLES FROM $s"`;
do
/usr/bin/mysqldump --user="$USER" --password="$PASS" --opt $s $t |
/usr/bin/gzip -c > $DIR/$s/$t.sql.gz;
done
done
Данный скрипт сделает потабличный бэкап всех баз данных и положит каждую базу данных в отдельную директорию. Если вам нужна будет конкретная база данных, то замените конструкцию `$MYSQL -e "SHOW DATABASES"` на имя нужной базы данных.
Восстановить всю базу из потабличного бэкапа можно тоже скриптом:
#!/bin/bash
DB=dbase;
USER='root'
PASS=''pass
DIR="/tmp/backupdb/dbase"
for s in `ls -1 $DIR`;
do
echo "--> $s restoring... ";
zcat $DIR/$s | /usr/bin/mysql --user=$USER --password=$PASS $DB;
done
Удобнее не использовать в скриптах пользователя и пароль, а задавать их в ~/.my.cnf, обязательно ограничив доступ на чтение.
#mysql #backup #bash
Чаще всего база дампится целиком. Если вам нужно восстановить отдельную таблицу из полного дампа, то простого способа сделать это нет. Я решаю эту задачу в консоли с помощью линуксовых утилит.
cat dbase.sql | /usr/bin/awk '/CREATE TABLE `b_catalog_discount`/,/UNLOCK TABLES/' > /tmp/b_catalog_discount.sql
Ищу в дампе строку CREATE TABLE и UNLOCK TABLES и сохраняю все, что между этих строк. Такой способ сработает, если вы дампите с ключами add-locks и create-options. Если дампите без них, по посмотрите сами, какие строки окаймляют создание таблиц в дампе.
Если нужно сделать потабличный дамп баз данных, использую простой скрипт с циклом:
#!/bin/bash
USER='root'
PASS='pass'
MYSQL="mysql --user=$USER --password=$PASS --skip-column-names";
DIR="/tmp/backupdb"
for s in mysql `$MYSQL -e "SHOW DATABASES"`;
do
mkdir $DIR/$s;
for t in `$MYSQL -e "SHOW TABLES FROM $s"`;
do
/usr/bin/mysqldump --user="$USER" --password="$PASS" --opt $s $t |
/usr/bin/gzip -c > $DIR/$s/$t.sql.gz;
done
done
Данный скрипт сделает потабличный бэкап всех баз данных и положит каждую базу данных в отдельную директорию. Если вам нужна будет конкретная база данных, то замените конструкцию `$MYSQL -e "SHOW DATABASES"` на имя нужной базы данных.
Восстановить всю базу из потабличного бэкапа можно тоже скриптом:
#!/bin/bash
DB=dbase;
USER='root'
PASS=''pass
DIR="/tmp/backupdb/dbase"
for s in `ls -1 $DIR`;
do
echo "--> $s restoring... ";
zcat $DIR/$s | /usr/bin/mysql --user=$USER --password=$PASS $DB;
done
Удобнее не использовать в скриптах пользователя и пароль, а задавать их в ~/.my.cnf, обязательно ограничив доступ на чтение.
#mysql #backup #bash