
📝 Alibaba открыла код распределённой СУБД PolarDB, основанной на PostgreSQL
Несколько месяцев назад Alibaba Cloud открыла исходный код PolarDB PostgreSQL, которая на 100% совместима с PostgreSQL и расширяет ее возможности средствами для распределённого хранения данных с обеспечением целостности и поддержкой ACID-транзакций в контексте всей глобальной базы данных, разнесённой по разным узлам кластера.
PolarDB поддерживает распределённую обработку SQL-запросов, обеспечение отказоустойчивости и избыточное хранение данных для восполнения информации после выхода из строя одного или нескольких узлов. Архитектуру и основные возожности PolarDB прикрепили к посту.
Код: https://github.com/ApsaraDB/PolarDB-for-PostgreSQL
@sqlhub
Несколько месяцев назад Alibaba Cloud открыла исходный код PolarDB PostgreSQL, которая на 100% совместима с PostgreSQL и расширяет ее возможности средствами для распределённого хранения данных с обеспечением целостности и поддержкой ACID-транзакций в контексте всей глобальной базы данных, разнесённой по разным узлам кластера.
PolarDB поддерживает распределённую обработку SQL-запросов, обеспечение отказоустойчивости и избыточное хранение данных для восполнения информации после выхода из строя одного или нескольких узлов. Архитектуру и основные возожности PolarDB прикрепили к посту.
Код: https://github.com/ApsaraDB/PolarDB-for-PostgreSQL
@sqlhub
{kind=link}
👍4
Forwarded from Kali Linux
Тестирование на проникновение MSSQL
Эта шпаргалка предназначена для Red Teamers и пентестеров. Она разработан таким образом, что новички могут понять основы, а профессионалы могут освежить свои навыки с помощью расширенных опций.
https://github.com/Ignitetechnologies/MSSQL-Pentest-Cheatsheet
@linuxkalii
Эта шпаргалка предназначена для Red Teamers и пентестеров. Она разработан таким образом, что новички могут понять основы, а профессионалы могут освежить свои навыки с помощью расширенных опций.
https://github.com/Ignitetechnologies/MSSQL-Pentest-Cheatsheet
@linuxkalii
❤4
Арифметика с DATETIME
#tsql #datetime
Статья 1: Получите удовольствие от арифметики с DATETIME
Статья 2: Еще больше удовольствия с арифметикой DATETIME
Автор данных статей приводит способы использования "математики" для манипуляции со значениями типа datetime с целью эффективной генерации, вычислений и отображения интервалов.
#tsql #datetime
Статья 1: Получите удовольствие от арифметики с DATETIME
Статья 2: Еще больше удовольствия с арифметикой DATETIME
Автор данных статей приводит способы использования "математики" для манипуляции со значениями типа datetime с целью эффективной генерации, вычислений и отображения интервалов.
{kind=link}
👍9
Малоизвестные инструменты разработки: gRPC и SQL Syntax Intellisense
Описываем три инструмента разработки, которые малоизвестны, но очень полезны: gRPC, Protobuf и SQL Syntax Intellisense.
https://tproger.ru/articles/maloizvestnye-no-ochen-poleznye-instrumenty-dlja-razrabotki/
@sqlhub
Описываем три инструмента разработки, которые малоизвестны, но очень полезны: gRPC, Protobuf и SQL Syntax Intellisense.
https://tproger.ru/articles/maloizvestnye-no-ochen-poleznye-instrumenty-dlja-razrabotki/
@sqlhub
Tproger
Инструменты разработки: gRPC, Protobuf и SQL Syntax Intellisense
Описываем три инструмента разработки, которые малоизвестны, но очень полезны: gRPC, Protobuf и SQL Syntax Intellisense.
👍6
Выберите правильный ответ касательно SQL оператора CASE.
Anonymous Quiz
63%
Способ установления IF-THEN-ELSE в SQL.
8%
Способ создания цикла (loop) в SQL.
15%
Способ создания определения данных в SQL.
14%
Все вышеперечисленные.
👍8
Производительность запросов в SQL
Использование OR внутри оператора JOIN или WHERE для нескольких столбцов.
SQL Server может эффективно обрабатывать набор данных, если используется оператор WHERE или любая комбинация фильтров, разделенных AND. Будучи исключающими, эти операторы берут данные и нарезают их на все более мелкие части, пока не останется нужный набор данных.
Оператор OR – совсем другая история. SQL Server не может обработать его за одну операцию. Вместо этого каждый компонент OR рассмотривается отдельно. Когда каждая такая затратная операция завершена, результаты объединяются.
Сценарий, в котором OR работает хуже всего, – это когда задействовано несколько столбцов или таблиц. Даже если используется всего несколько таблиц или столбцов, производительность может стать крайне низкой.
Давайте рассмотрим простой пример использования OR, который приводит к плохой производительности:
SELECT DISTINCT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.ProductID = DETAIL.ProductID
OR PRODUCT.rowguid = DETAIL.rowguid;
Читать дальше
@sqlhub
Использование OR внутри оператора JOIN или WHERE для нескольких столбцов.
SQL Server может эффективно обрабатывать набор данных, если используется оператор WHERE или любая комбинация фильтров, разделенных AND. Будучи исключающими, эти операторы берут данные и нарезают их на все более мелкие части, пока не останется нужный набор данных.
Оператор OR – совсем другая история. SQL Server не может обработать его за одну операцию. Вместо этого каждый компонент OR рассмотривается отдельно. Когда каждая такая затратная операция завершена, результаты объединяются.
Сценарий, в котором OR работает хуже всего, – это когда задействовано несколько столбцов или таблиц. Даже если используется всего несколько таблиц или столбцов, производительность может стать крайне низкой.
Давайте рассмотрим простой пример использования OR, который приводит к плохой производительности:
SELECT DISTINCT
PRODUCT.ProductID,
PRODUCT.Name
FROM Production.Product PRODUCT
INNER JOIN Sales.SalesOrderDetail DETAIL
ON PRODUCT.ProductID = DETAIL.ProductID
OR PRODUCT.rowguid = DETAIL.rowguid;
Читать дальше
@sqlhub
{kind=link}
👍10
Трюк дня. COALESCE() для перезаписи NULL
При помощи функции COALESCE() можно перезаписать NULL на другое значение:
Запрос вернёт значение ‘missing‘ для всех строк таблицы, где null_var IS NULL
В mssql это делает функция isnull(null_var,'missing')
#tips
@sqlhub
При помощи функции COALESCE() можно перезаписать NULL на другое значение:
SELECT
id,
null_var,
COALESCE(null_var, 'missing') AS recode_null_var
FROM
current_table
ORDER BY idЗапрос вернёт значение ‘missing‘ для всех строк таблицы, где null_var IS NULL
В mssql это делает функция isnull(null_var,'missing')
#tips
@sqlhub
👍9
Друзья, для тех из вас кто хочет проверить свои знания в SQL запросах - у наших друзей из @sqlquestions сейчас как раз идет марафон SQL-задач.
Приходите, решайте задачи и общайтесь с любителями SQL.
Решай задачи
Приходите, решайте задачи и общайтесь с любителями SQL.
Решай задачи
Telegram
SQL задачи
Друзья, мы начинаем SQL марафон - серию задач по SQL.
Будет 15 задач.
1 задача в неделю.
Свои решения присылайте в комментариях к задачам. По итогу 15 задач, каждый увидит, сколько он смог решить правильно сам.
Мы создали для вас небольшой снипет(отрывок)…
Будет 15 задач.
1 задача в неделю.
Свои решения присылайте в комментариях к задачам. По итогу 15 задач, каждый увидит, сколько он смог решить правильно сам.
Мы создали для вас небольшой снипет(отрывок)…
👍6
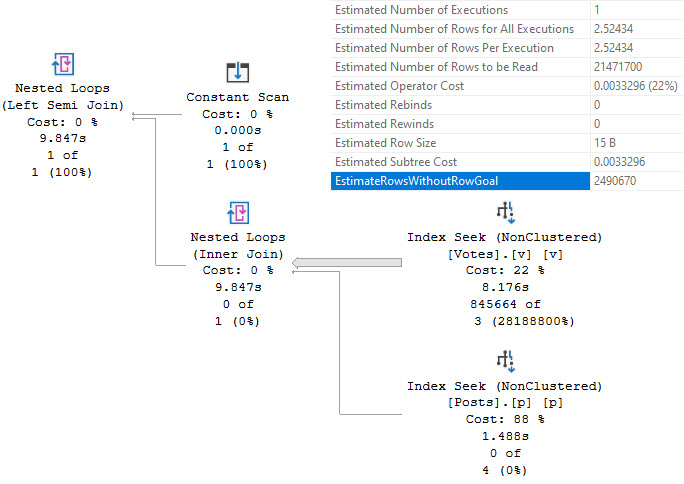
Проблемы производительности запросов с EXISTS
Мне на самом деле нравится EXISTS и NOT EXISTS. Правда. Они решают множество проблем.
Эта публикация не является их общей критикой, и я ни в коем случае не призываю вас отказаться от них. Я бы посоветовал вам даже использовать их почаще.
Но есть некоторые моменты, о которых вам следует знать, когда вы их используете, будь то в логике потока управления или в запросах.
Если вы будете помнить о них, у вас все будет хорошо.
Читать дальше
@sqlhub
Мне на самом деле нравится EXISTS и NOT EXISTS. Правда. Они решают множество проблем.
Эта публикация не является их общей критикой, и я ни в коем случае не призываю вас отказаться от них. Я бы посоветовал вам даже использовать их почаще.
Но есть некоторые моменты, о которых вам следует знать, когда вы их используете, будь то в логике потока управления или в запросах.
Если вы будете помнить о них, у вас все будет хорошо.
Читать дальше
@sqlhub
{kind=link}
👍4🥰1
Какой запрос возвратит работников с зарплатой >=2500 и <=4500?
Anonymous Quiz
56%
SELECT * FROM employees WHERE salary BETWEEN 2500 AND 4500;
6%
SELECT * FROM employees WHERE salary > 2499 AND < 4501;
12%
SELECT * FROM employees WHERE salary IN (2500, 4500);
19%
SELECT * FROM employees WHERE salary > 2499 AND salary < 4501;
8%
Посмотреть ответы
👍10
Трюк дня. Агрегирование записей в PostgreSQL
Таблица
Разница между датой окончания (
Напишите запрос, возвращающий даты начала и окончания каждого проекта, а также количество дней, затраченных на его выполнение. Расположите их в порядке возрастания продолжительности проекта, а в случае равенства - по возрастанию даты начала.
Код создания view исходной таблицы projects здесь.
Решение будет вечером.
#tips
Таблица
projects содержит три столбца: task_id, start_date и end_date. Разница между датой окончания (
end_date) и датой начала (start_date) составляет 1 день для каждой строки таблицы. Если даты окончания задач последовательны, они являются частью одного проекта. Даты проектов не пересекаются.Напишите запрос, возвращающий даты начала и окончания каждого проекта, а также количество дней, затраченных на его выполнение. Расположите их в порядке возрастания продолжительности проекта, а в случае равенства - по возрастанию даты начала.
Код создания view исходной таблицы projects здесь.
Решение будет вечером.
#tips
👍3
Трюк дня. Агрегирование записей в PostgreSQL. Решение
WITH projects (task_id, start_date, end_date)
AS (VALUES
(1, CAST('10-01-20' AS date), CAST('10-02-20' AS date)),
(2, CAST('10-02-20' AS date), CAST('10-03-20' AS date)),
(3, CAST('10-03-20' AS date), CAST('10-04-20' AS date)),
(4, CAST('10-13-20' AS date), CAST('10-14-20' AS date)),
(5, CAST('10-14-20' AS date), CAST('10-15-20' AS date)),
(6, CAST('10-28-20' AS date), CAST('10-29-20' AS date)),
(7, CAST('10-30-20' AS date), CAST('10-31-20' AS date))),
-- получим такие даты начала, которых не существует в колонке даты окончания (это 'настоящие' даты начала проекта)
t1 AS (
SELECT start_date
FROM projects
WHERE start_date NOT IN (SELECT end_date FROM projects) ),
-- получим такие даты окончания, которые не существуют в колонке дат начала (это 'настоящие' даты окончания проекта)
t2 AS (
SELECT end_date
FROM projects
WHERE end_date NOT IN (SELECT start_date FROM projects) ),
--отфильтруем допустимые пары начало-окончание (начало < окончание), затем найдем правильную дату окончания для каждой даты начала (минимальная дата окончания, поскольку нет пересекающихся проектов)
t3 AS (
SELECT
start_date,
MIN(end_date) AS end_date
FROM t1, t2
WHERE start_date < end_date
GROUP BY 1 )
SELECT
*,
end_date - start_date AS project_duration
FROM t3
ORDER BY 3, 1
#tips🥰2🤔2😢1
Какой оператор нужно вставить вместо [?], чтобы создать временную таблицу?
Anonymous Quiz
34%
TEMP
8%
37%
TEMPORARY
2%
ошибка
19%
ничего из перечисленного
👍8
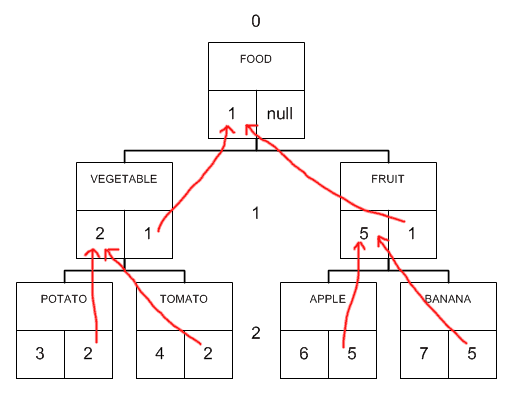
Иерархические структуры данных и Doctrine
Хранение иерархических данных (или попросту — деревьев) в реляционных структурах задача довольно нетривиальная и вызывает некоторые проблемы, когда разработчики сталкиваются с подобной задачей.
В первую очередь, это связано с тем, что реляционные базы не приспособлены к хранению иерархических структур (как, например, XML-файлы), структура реляционных таблиц представляет из себя простые списки. Иерархические же данные имеют связь родитель-наследники, которая не реализована в реляционной структуре.
Тем не менее, задача хранить деревья в базе данных рано или поздно возникает перед любым разработчиком.
Ниже мы подробно рассмотрим, какие существуют подходы в организации хранения деревьев в реляционных БД, а также рассмотрим инструментарий, который нам предоставляет ORM Doctrine для работы с такими структурами.
Читать дальше
@sqlhub
Хранение иерархических данных (или попросту — деревьев) в реляционных структурах задача довольно нетривиальная и вызывает некоторые проблемы, когда разработчики сталкиваются с подобной задачей.
В первую очередь, это связано с тем, что реляционные базы не приспособлены к хранению иерархических структур (как, например, XML-файлы), структура реляционных таблиц представляет из себя простые списки. Иерархические же данные имеют связь родитель-наследники, которая не реализована в реляционной структуре.
Тем не менее, задача хранить деревья в базе данных рано или поздно возникает перед любым разработчиком.
Ниже мы подробно рассмотрим, какие существуют подходы в организации хранения деревьев в реляционных БД, а также рассмотрим инструментарий, который нам предоставляет ORM Doctrine для работы с такими структурами.
Читать дальше
@sqlhub
{kind=link}
👍7