
Для чего используется LIMIT: select * from Orders limit 10
Anonymous Quiz
16%
необходим, чтобы показать рандомные 10 записей в запрос
73%
необходим, чтобы показать первых 10 записей в запросе
1%
необходим, чтобы показать все заказы, содержащие цифру 10
4%
Все варианты неверные
7%
Узнать ответ
👍10
Статья дня. Индексы в PostgreSQL
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Содержание:
1. Предназначение индексов
2. Индексы в PostgreSQL
3. B-tree
4. GiST и SP-GiST
5. и т.д.
Читать дальше
@sqlhub
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Содержание:
1. Предназначение индексов
2. Индексы в PostgreSQL
3. B-tree
4. GiST и SP-GiST
5. и т.д.
Читать дальше
@sqlhub
Tproger
Индексы в PostgreSQL
На примере PostgreSQL коротко рассматриваем несколько разных типов индексов и классов задач, для которых они применимы.
👍7
Что покажет следующий запрос:
select concat(`index`," ", `city`) AS delivery_address from Orders;
select concat(`index`," ", `city`) AS delivery_address from Orders;
Anonymous Quiz
18%
ничего, запрос составлен неверно
5%
покажет уникальные значения индексов и адресов из таблицы Orders
73%
соединит поля с индексом и адресом из таблицы Orders и покажет их с псевдонимом delivery_address
4%
соединит поля с индексом и адресом из таблицы Orders, но покажет их без псевдонима
👍8
Forwarded from Анализ данных (Data analysis)
➕ SQL-запросы, о которых должен знать каждый дата-инженер. Гайд по по работе с SQL в Data Science.
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
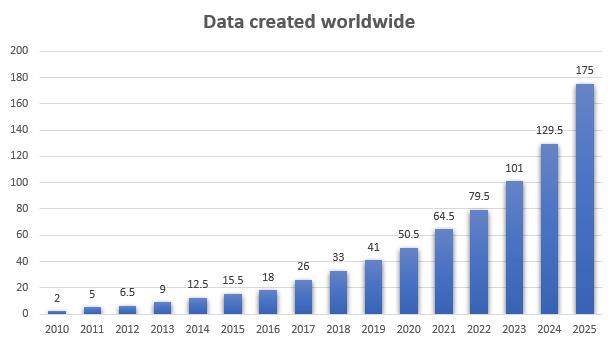
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
{kind=link}
👍7
100+ самых популярных вопросов и ответов на собеседовании по SQL
https://atesting.ru/100-samyh-popyliarnyh-voprosov-i-otvetov-na-sobesedovanii-po-sql/
@sqlhub
https://atesting.ru/100-samyh-popyliarnyh-voprosov-i-otvetov-na-sobesedovanii-po-sql/
@sqlhub
👍7🔥1
Какое значение вернёт следующий PostgreSQL запрос:
SELECT CEIL(53.2);
SELECT CEIL(53.2);
Anonymous Quiz
32%
53
20%
54
11%
53.0
11%
53.2
6%
Ничего из перечисленного
19%
Посмотреть ответы
👍9
Python FastAPI: OpenAPI, CRUD, PostgreSQL в Docker и внедрение зависимостей
https://nuancesprog.ru/p/14818/
@sqlhub
https://nuancesprog.ru/p/14818/
@sqlhub
NOP::Nuances of programming
Python FastAPI: OpenAPI, CRUD, PostgreSQL в Docker и внедрение зависимостей
Все шаги разработки первого приложения на FastAPI: настройка ORM SQLAlchemy, валидация схем Pydantic и менеджер пакетов Poetry.
👍5
Статья дня. Пошаговая инструкция создания SQL-сервера на Google Cloud Platform
Google Cloud Platform (сокр. GCP) – это набор облачных служб, которые выполняются на той же самой инфраструктуре, что и продукты Google. Кроме инструментов для управления, также предоставляется ряд модульных облачных служб, таких как облачные вычисления, хранение данных, анализ данных и машинное обучение. В этой структуре крутятся такие гиганты, как PayPal, eBay, Spotify и Twitter.
Читать
#sql #читать
Google Cloud Platform (сокр. GCP) – это набор облачных служб, которые выполняются на той же самой инфраструктуре, что и продукты Google. Кроме инструментов для управления, также предоставляется ряд модульных облачных служб, таких как облачные вычисления, хранение данных, анализ данных и машинное обучение. В этой структуре крутятся такие гиганты, как PayPal, eBay, Spotify и Twitter.
Читать
#sql #читать
Библиотека программиста
Пошаговая инструкция создания SQL-сервера на Google Cloud Platform
Воспользовались бесплатной годовой подпиской GCP, создали PostgreSQL-сервер (MySQL регистрируется аналогично) и сделали скриншоты, чтобы вы могли оценить, не пробуя без необходимости.
👍7
🐍📚 Создаем аналог LiveLib.ru на Flask. Часть 1: основы работы с SQLAlchemy
https://proglib.io/p/sozdaem-analog-livelib-ru-na-flask-chast-1-osnovy-raboty-s-sqlalchemy-2022-07-11
@sqlhub
https://proglib.io/p/sozdaem-analog-livelib-ru-na-flask-chast-1-osnovy-raboty-s-sqlalchemy-2022-07-11
@sqlhub
Библиотека программиста
🐍📚 Создаем аналог LiveLib.ru на Flask. Часть 1: основы работы с SQLAlchemy
Изучаем взаимодействие Flask с SQLAlchemy и WTForms, создавая веб-приложение — лайт-версию сервиса LiveLib.ru — для хранения информации о прочитанных книгах. Реализуем CRUD, пагинацию, фильтры и экспорт данных.
🔥6
Кручу, верчу логи при помощи SQL — облегчаем анализ данных
https://tproger.ru/articles/kruchu-verchu-logi-pri-pomoshhi-sql-oblegchaem-analiz-dannyh/
@sqlhub
https://tproger.ru/articles/kruchu-verchu-logi-pri-pomoshhi-sql-oblegchaem-analiz-dannyh/
@sqlhub
Tproger
Облегчаем анализ логов при помощи SQL
Рассказываем в виде пошагового гайда, как облегчить работу с большими логами при помощи SQL-скриптов и баз данных.
👍7🔥1
SQL HowTo: наперегонки со временем
В PostgreSQL несложно написать запрос, который уйдет в глубокую рекурсию или просто будет выполняться гораздо дольше, чем нам хотелось бы. Как от этого защититься?
А чтобы еще и полезную работу сделать? Например, набрать следующий сегмент данных при постраничной навигации со сложным условием фильтрации.
Читать дальше
@sqlhub
В PostgreSQL несложно написать запрос, который уйдет в глубокую рекурсию или просто будет выполняться гораздо дольше, чем нам хотелось бы. Как от этого защититься?
А чтобы еще и полезную работу сделать? Например, набрать следующий сегмент данных при постраничной навигации со сложным условием фильтрации.
Читать дальше
@sqlhub
👍8
✔️ Использование хэш-ключей вместо строковых индексов
Вашему приложению может потребоваться индекс на основе длинной строки символов или, что еще хуже, конкатенации двух строк или строки и одного-двух целых чисел. Для небольшой таблицы вы можете не заметить какого-либо отрицательного влияния такого индекса. Но если предположить, что рассматриваемая таблица содержит 50 миллионов записей? Теперь вы не сможете не заметить воздействия, которое скажется как на требованиях к хранению, так и к производительности поиска.
Однако вам не обязательно так поступать. Есть очень простая альтернатива, использующая то, что еще известно под названием хэш-блоков или хэш-ключей.
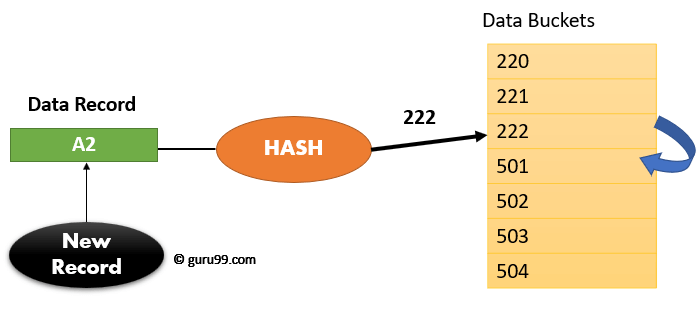
Что такое хэширование?
Говоря коротко, хэширование – это целочисленный результат алгоритма (известного как хэш-функция), применяемого к заданной строке. Вы передаете в алгоритм строку, а на выходе получаете целое число. Если Вы используете эффективную хэш-функцию, то вероятность того, что две различных строки дадут одно и то же значение хэш-функции, будет невелика. Такой случай известен под названием коллизии хэширования. Предположим, что Вы применили к этой статье алгоритм хэширования, затем изменили один символ в статье и повторили алгоритм: он возвратил бы другое целое число.
Хэш-ключи в проекте базы данных
Читать дальше
@sqlhub
Вашему приложению может потребоваться индекс на основе длинной строки символов или, что еще хуже, конкатенации двух строк или строки и одного-двух целых чисел. Для небольшой таблицы вы можете не заметить какого-либо отрицательного влияния такого индекса. Но если предположить, что рассматриваемая таблица содержит 50 миллионов записей? Теперь вы не сможете не заметить воздействия, которое скажется как на требованиях к хранению, так и к производительности поиска.
Однако вам не обязательно так поступать. Есть очень простая альтернатива, использующая то, что еще известно под названием хэш-блоков или хэш-ключей.
Что такое хэширование?
Говоря коротко, хэширование – это целочисленный результат алгоритма (известного как хэш-функция), применяемого к заданной строке. Вы передаете в алгоритм строку, а на выходе получаете целое число. Если Вы используете эффективную хэш-функцию, то вероятность того, что две различных строки дадут одно и то же значение хэш-функции, будет невелика. Такой случай известен под названием коллизии хэширования. Предположим, что Вы применили к этой статье алгоритм хэширования, затем изменили один символ в статье и повторили алгоритм: он возвратил бы другое целое число.
Хэш-ключи в проекте базы данных
Читать дальше
@sqlhub
{kind=link}
👍6