
⚡️ Аналитика данных с SQL- блог ведущего Дата саентиста, работющего с данными в Uber, одного из авторов🔥 Machine Learning. Материал канала поможет реально вырасти до профессионала по работе с данными и получить самую высокоплачиваю ит-профессию.
1 канал вместо тысячи учебников и курсов, подписывайтесь: 👇👇👇
@data_analysis_ml
1 канал вместо тысячи учебников и курсов, подписывайтесь: 👇👇👇
@data_analysis_ml
🚀 Советы по производительности оператора SQL TOP
Оператор TOP используется для ограничения числа строк, которые извлекаются или обновляются в одной или нескольких таблицах. Это ограничение на число строк можно задать как фиксированным значением, так и процентом строк в таблице. Например, следующий запрос вернет первые 10 случайных строк из таблицы Production.
SELECT TOP 10 Name,ProductNumber,SafetyStockLevel FROM Production.Product
Читать дальше
@sqlhub
Оператор TOP используется для ограничения числа строк, которые извлекаются или обновляются в одной или нескольких таблицах. Это ограничение на число строк можно задать как фиксированным значением, так и процентом строк в таблице. Например, следующий запрос вернет первые 10 случайных строк из таблицы Production.
SELECT TOP 10 Name,ProductNumber,SafetyStockLevel FROM Production.Product
Читать дальше
@sqlhub
Какого строкового типа данных нет в SQL:
Anonymous Quiz
6%
VARCHAR
46%
STRING
9%
CHAR
31%
TEXT
8%
Посмотреть ответ
С помощью какого запроса можно получить пользователей, в email которых содержится более двух точек?
Anonymous Quiz
26%
SELECT * FROM users WHERE email COUNT(".") > 2;
21%
SELECT * FROM users WHERE "." IN email MATCHES > 2;
41%
SELECT * FROM users WHERE email LIKE "%.%.%.%";
11%
Узнать ответ
DBeaver – Бесплатный, мультиплатформенный инструмент баз данных для разработчиков, SQL программистов, администраторов баз данных и аналитиков.
Поддерживает любую базу данных, которая имеет драйвер JDBC (что означает - почти любую базу данных).
Также поддерживаются базы не на основе драйверов JDBC, такие как MongoDB, Cassandra, Couchbase, Redis, BigTable, DynamoDB и т. д.
DBeaver меет множество функций, включая редактор метаданных, редактор SQL, rich data editor, ERD, экспорт/импорт/миграцию данных, планы выполнения SQL и т. д.
@sqlhub | #Java #Database #SQL
Поддерживает любую базу данных, которая имеет драйвер JDBC (что означает - почти любую базу данных).
Также поддерживаются базы не на основе драйверов JDBC, такие как MongoDB, Cassandra, Couchbase, Redis, BigTable, DynamoDB и т. д.
DBeaver меет множество функций, включая редактор метаданных, редактор SQL, rich data editor, ERD, экспорт/импорт/миграцию данных, планы выполнения SQL и т. д.
@sqlhub | #Java #Database #SQL
{kind=link}
Обзор полезных инструкций SQL, которые помогут оптимизировать рабочий процесс.
https://nuancesprog.ru/p/15071/
@sqlhub #SQL
https://nuancesprog.ru/p/15071/
@sqlhub #SQL
Immudb – самая быстрая в мире неизменная база данных, построенная на модели нулевого доверия
Immudb - это база данных со встроенной криптографической проверкой. Она отслеживает изменения в конфиденциальных данных, и целостность истории будет защищена клиентами без необходимости доверять самой базе. Она может работать как хранилище ключей и значений, так и/или как реляционная база данных (SQL).
#GitHub | #SQL #Data
@sqlhub
Immudb - это база данных со встроенной криптографической проверкой. Она отслеживает изменения в конфиденциальных данных, и целостность истории будет защищена клиентами без необходимости доверять самой базе. Она может работать как хранилище ключей и значений, так и/или как реляционная база данных (SQL).
#GitHub | #SQL #Data
@sqlhub
Интеллектуальный анализ кэша планов SQL Server - атрибуты плана
Кэш планов выполнения в SQL Server является кладезью информации о запросах, которые выполнялись за последнее время. Помимо текста запроса и деталей плана выполнения доступны для исследования разнообразная статистика, опции и параметры. Эта информация, возможно, не всегда нужна для настройки производительности, но, когда она есть, знание куда обратиться и как её использовать, может сэкономить массу времени.
В этой статье рассматриваются атрибуты, хранящиеся в кэше планов, и их структурирование в легко воспринимаемый формат. Это может помочь для исследования поведения необычных запросов, например, обладающих плохой производительностью, частой перекомпиляции или аномальных результатов.
Читать дальше
@sqlhub
Кэш планов выполнения в SQL Server является кладезью информации о запросах, которые выполнялись за последнее время. Помимо текста запроса и деталей плана выполнения доступны для исследования разнообразная статистика, опции и параметры. Эта информация, возможно, не всегда нужна для настройки производительности, но, когда она есть, знание куда обратиться и как её использовать, может сэкономить массу времени.
В этой статье рассматриваются атрибуты, хранящиеся в кэше планов, и их структурирование в легко воспринимаемый формат. Это может помочь для исследования поведения необычных запросов, например, обладающих плохой производительностью, частой перекомпиляции или аномальных результатов.
Читать дальше
@sqlhub
Для чего используется LIMIT: select * from Orders limit 10
Anonymous Quiz
16%
необходим, чтобы показать рандомные 10 записей в запрос
73%
необходим, чтобы показать первых 10 записей в запросе
1%
необходим, чтобы показать все заказы, содержащие цифру 10
4%
Все варианты неверные
7%
Узнать ответ
Статья дня. Индексы в PostgreSQL
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Содержание:
1. Предназначение индексов
2. Индексы в PostgreSQL
3. B-tree
4. GiST и SP-GiST
5. и т.д.
Читать дальше
@sqlhub
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Содержание:
1. Предназначение индексов
2. Индексы в PostgreSQL
3. B-tree
4. GiST и SP-GiST
5. и т.д.
Читать дальше
@sqlhub
Tproger
Индексы в PostgreSQL
На примере PostgreSQL коротко рассматриваем несколько разных типов индексов и классов задач, для которых они применимы.
Что покажет следующий запрос:
select concat(`index`," ", `city`) AS delivery_address from Orders;
select concat(`index`," ", `city`) AS delivery_address from Orders;
Anonymous Quiz
18%
ничего, запрос составлен неверно
5%
покажет уникальные значения индексов и адресов из таблицы Orders
73%
соединит поля с индексом и адресом из таблицы Orders и покажет их с псевдонимом delivery_address
4%
соединит поля с индексом и адресом из таблицы Orders, но покажет их без псевдонима
Forwarded from Анализ данных (Data analysis)
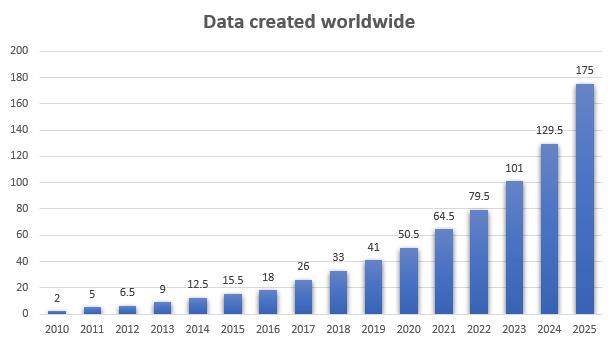
➕ SQL-запросы, о которых должен знать каждый дата-инженер. Гайд по по работе с SQL в Data Science.
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
{kind=link}