
Какой запрос возвратит работников с зарплатой >=2500 и <=4500?
Anonymous Quiz
56%
SELECT * FROM employees WHERE salary BETWEEN 2500 AND 4500;
6%
SELECT * FROM employees WHERE salary > 2499 AND < 4501;
12%
SELECT * FROM employees WHERE salary IN (2500, 4500);
19%
SELECT * FROM employees WHERE salary > 2499 AND salary < 4501;
8%
Посмотреть ответы
Трюк дня. Агрегирование записей в PostgreSQL
Таблица
Разница между датой окончания (
Напишите запрос, возвращающий даты начала и окончания каждого проекта, а также количество дней, затраченных на его выполнение. Расположите их в порядке возрастания продолжительности проекта, а в случае равенства - по возрастанию даты начала.
Код создания view исходной таблицы projects здесь.
Решение будет вечером.
#tips
Таблица
projects содержит три столбца: task_id, start_date и end_date. Разница между датой окончания (
end_date) и датой начала (start_date) составляет 1 день для каждой строки таблицы. Если даты окончания задач последовательны, они являются частью одного проекта. Даты проектов не пересекаются.Напишите запрос, возвращающий даты начала и окончания каждого проекта, а также количество дней, затраченных на его выполнение. Расположите их в порядке возрастания продолжительности проекта, а в случае равенства - по возрастанию даты начала.
Код создания view исходной таблицы projects здесь.
Решение будет вечером.
#tips
Трюк дня. Агрегирование записей в PostgreSQL. Решение
WITH projects (task_id, start_date, end_date)
AS (VALUES
(1, CAST('10-01-20' AS date), CAST('10-02-20' AS date)),
(2, CAST('10-02-20' AS date), CAST('10-03-20' AS date)),
(3, CAST('10-03-20' AS date), CAST('10-04-20' AS date)),
(4, CAST('10-13-20' AS date), CAST('10-14-20' AS date)),
(5, CAST('10-14-20' AS date), CAST('10-15-20' AS date)),
(6, CAST('10-28-20' AS date), CAST('10-29-20' AS date)),
(7, CAST('10-30-20' AS date), CAST('10-31-20' AS date))),
-- получим такие даты начала, которых не существует в колонке даты окончания (это 'настоящие' даты начала проекта)
t1 AS (
SELECT start_date
FROM projects
WHERE start_date NOT IN (SELECT end_date FROM projects) ),
-- получим такие даты окончания, которые не существуют в колонке дат начала (это 'настоящие' даты окончания проекта)
t2 AS (
SELECT end_date
FROM projects
WHERE end_date NOT IN (SELECT start_date FROM projects) ),
--отфильтруем допустимые пары начало-окончание (начало < окончание), затем найдем правильную дату окончания для каждой даты начала (минимальная дата окончания, поскольку нет пересекающихся проектов)
t3 AS (
SELECT
start_date,
MIN(end_date) AS end_date
FROM t1, t2
WHERE start_date < end_date
GROUP BY 1 )
SELECT
*,
end_date - start_date AS project_duration
FROM t3
ORDER BY 3, 1
#tipsКакой оператор нужно вставить вместо [?], чтобы создать временную таблицу?
Anonymous Quiz
35%
TEMP
8%
#NEW
36%
TEMPORARY
2%
ошибка
19%
ничего из перечисленного
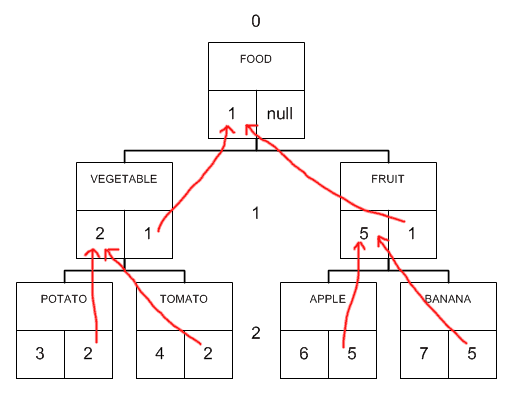
Иерархические структуры данных и Doctrine
Хранение иерархических данных (или попросту — деревьев) в реляционных структурах задача довольно нетривиальная и вызывает некоторые проблемы, когда разработчики сталкиваются с подобной задачей.
В первую очередь, это связано с тем, что реляционные базы не приспособлены к хранению иерархических структур (как, например, XML-файлы), структура реляционных таблиц представляет из себя простые списки. Иерархические же данные имеют связь родитель-наследники, которая не реализована в реляционной структуре.
Тем не менее, задача хранить деревья в базе данных рано или поздно возникает перед любым разработчиком.
Ниже мы подробно рассмотрим, какие существуют подходы в организации хранения деревьев в реляционных БД, а также рассмотрим инструментарий, который нам предоставляет ORM Doctrine для работы с такими структурами.
Читать дальше
@sqlhub
Хранение иерархических данных (или попросту — деревьев) в реляционных структурах задача довольно нетривиальная и вызывает некоторые проблемы, когда разработчики сталкиваются с подобной задачей.
В первую очередь, это связано с тем, что реляционные базы не приспособлены к хранению иерархических структур (как, например, XML-файлы), структура реляционных таблиц представляет из себя простые списки. Иерархические же данные имеют связь родитель-наследники, которая не реализована в реляционной структуре.
Тем не менее, задача хранить деревья в базе данных рано или поздно возникает перед любым разработчиком.
Ниже мы подробно рассмотрим, какие существуют подходы в организации хранения деревьев в реляционных БД, а также рассмотрим инструментарий, который нам предоставляет ORM Doctrine для работы с такими структурами.
Читать дальше
@sqlhub
{kind=link}
Forwarded from Анализ данных (Data analysis)
Автоматическое масштабирование БД в Kubernetes для MongoDB, MySQL и PostgreSQL
Читать
@data_analysis_ml
Читать
@data_analysis_ml
Telegraph
Автоматическое масштабирование БД в Kubernetes для MongoDB, MySQL и PostgreSQL
Автор оригинала: Dmitriy Kostiuk и Mykola Marzhan Стремясь к повышению производительности базы данных, вы можете столкнуться с ситуацией, когда оптимизации и настройки уже недостаточно. Если вы не можете заменить движок БД, а для настройки параметры рабочей…
Отличаются ли в SQL операторы AND и & (амперсанд)?
Anonymous Quiz
6%
AND имеет более низкий приоритет, чем &
17%
Между ними нет отличий
45%
Оператор & не поддерживается стандартом SQL
9%
AND имеет более высокий приоритет, чем &
23%
Посмотреть ответы
Колоночные базы данных
#nosql
"Колоночные базы данных позволяют эффективно делать сложные выборки на больших таблицах. Изменение структуры больших таблиц происходит мгновенно, а сжатие данных позволяет сэкономить кучу места. Однако не следует использовать колоночные базы для случаев с обычными выборками по ключу и известными структурами запросов. Для этого лучше подойдут обычные (строчные) СУБД."
Читать
@data_study
#nosql
"Колоночные базы данных позволяют эффективно делать сложные выборки на больших таблицах. Изменение структуры больших таблиц происходит мгновенно, а сжатие данных позволяет сэкономить кучу места. Однако не следует использовать колоночные базы для случаев с обычными выборками по ключу и известными структурами запросов. Для этого лучше подойдут обычные (строчные) СУБД."
Читать
@data_study
{kind=link}
5 полезных запросов для MS SQL
За 2 года работы с MS SQL у меня накопился перечень из 5 запросов: для поиска, отладки, агрегации и обработки множеств и таблиц.
https://tproger.ru/articles/5-poleznyh-zaprosov-dlja-ms-sql/
@sqlhub
За 2 года работы с MS SQL у меня накопился перечень из 5 запросов: для поиска, отладки, агрегации и обработки множеств и таблиц.
https://tproger.ru/articles/5-poleznyh-zaprosov-dlja-ms-sql/
@sqlhub
Tproger
5 полезных запросов MS SQL на каждый день
За 2 года работы с MS SQL у меня накопился перечень из 5 запросов: для поиска, отладки, агрегации и обработки множеств и таблиц.
Поясните разницу между кластерными и некластерными индексами
#вопросы_с_собеседований
Кластерный индекс используется для сортировки данных в строках по их ключевым значениям. Кластерный индекс напоминает телефонный справочник. Мы можем открыть справочник на David (например, в поисках «David, Thompson») и найти информацию обо всех Дэвидах, по порядку. Поскольку данные расположены друг за другом, это помогает выбирать их в запросах с указанием диапазона. Также кластерный индекс имеет отношение к тому, как, собственно, хранятся данные. В таблице может быть только один кластерный индекс.
Некластерный индекс хранит данные в одном месте, а индексы — в другом. Этот индекс имеет указатели на расположение данных. Поскольку индекс не хранится там же, где и данные, для каждой таблицы может существовать много некластерных индексов.
Давайте рассмотрим основные различия между кластерными и некластерными индексами.
@sqlhub
#вопросы_с_собеседований
Кластерный индекс используется для сортировки данных в строках по их ключевым значениям. Кластерный индекс напоминает телефонный справочник. Мы можем открыть справочник на David (например, в поисках «David, Thompson») и найти информацию обо всех Дэвидах, по порядку. Поскольку данные расположены друг за другом, это помогает выбирать их в запросах с указанием диапазона. Также кластерный индекс имеет отношение к тому, как, собственно, хранятся данные. В таблице может быть только один кластерный индекс.
Некластерный индекс хранит данные в одном месте, а индексы — в другом. Этот индекс имеет указатели на расположение данных. Поскольку индекс не хранится там же, где и данные, для каждой таблицы может существовать много некластерных индексов.
Давайте рассмотрим основные различия между кластерными и некластерными индексами.
@sqlhub
{kind=link}
Что такое SQL-инъекции и как им противостоять
SQL-инъекции (SQL injections, SQLi) — самый хорошо изученный и простой для понимания тип атаки на веб-сайт или веб-приложение. Тем не менее, он странным образом остается весьма распространенным и в наши дни. Организация OWASP (Open Web Application Security Project) упоминает SQL-инъекции в своем документе OWASP Top 10 2017 как угрозу номер один для безопасности веб-приложений, и вряд ли положение сильно изменилось за четыре года.
Читать
@sqlhub
SQL-инъекции (SQL injections, SQLi) — самый хорошо изученный и простой для понимания тип атаки на веб-сайт или веб-приложение. Тем не менее, он странным образом остается весьма распространенным и в наши дни. Организация OWASP (Open Web Application Security Project) упоминает SQL-инъекции в своем документе OWASP Top 10 2017 как угрозу номер один для безопасности веб-приложений, и вряд ли положение сильно изменилось за четыре года.
Читать
@sqlhub
{kind=link}
⚡️ Аналитика данных с SQL- блог ведущего Дата саентиста, работющего с данными в Uber, одного из авторов🔥 Machine Learning. Материал канала поможет реально вырасти до профессионала по работе с данными и получить самую высокоплачиваю ит-профессию.
1 канал вместо тысячи учебников и курсов, подписывайтесь: 👇👇👇
@data_analysis_ml
1 канал вместо тысячи учебников и курсов, подписывайтесь: 👇👇👇
@data_analysis_ml