
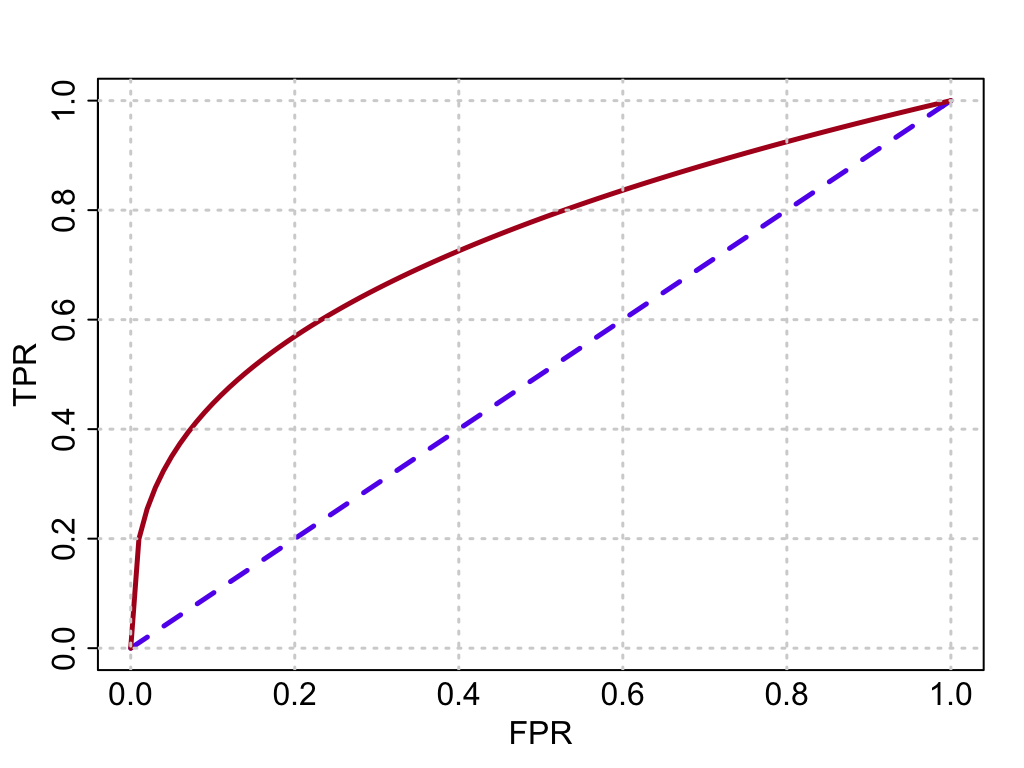
ROC-кривая
Рассмотрим задачу бинарной классификации. Для анализа точности будем использовать true positive rate (TPR) и false positive rate (FPR).
На практике часто встречается ситуация, когда один и тот же алгоритм должен работать в разных диапазонах TPR/FPR. Пусть у алгоритма классификации есть параметр t, изменяя который, можно менять баланс между TPR и FPR. У линейного классификатора таким параметром служит w₀, у сверточной сети — порог после softmax-слоя.
Нанесем на график точки, соответствующие разным значениям t. По оси x отложим FPR, по оси y — TPR. Полученная кривая называется ROC (receiver operating characteristic).
ROC-кривая проходит из точки (0, 0) в точку (1, 1). Чем выше ее положение, тем выше качество классификатора. Прямая, проходящая из (0, 0) в (1, 1), соответствует случайному угадыванию.
Если нужно охарактеризовать качество классификатора одним числом, используют площадь под ROC-кривой (area under curve, AUC). AUC = 1 соответствует идеальной классификации.
Рассмотрим задачу бинарной классификации. Для анализа точности будем использовать true positive rate (TPR) и false positive rate (FPR).
На практике часто встречается ситуация, когда один и тот же алгоритм должен работать в разных диапазонах TPR/FPR. Пусть у алгоритма классификации есть параметр t, изменяя который, можно менять баланс между TPR и FPR. У линейного классификатора таким параметром служит w₀, у сверточной сети — порог после softmax-слоя.
Нанесем на график точки, соответствующие разным значениям t. По оси x отложим FPR, по оси y — TPR. Полученная кривая называется ROC (receiver operating characteristic).
ROC-кривая проходит из точки (0, 0) в точку (1, 1). Чем выше ее положение, тем выше качество классификатора. Прямая, проходящая из (0, 0) в (1, 1), соответствует случайному угадыванию.
Если нужно охарактеризовать качество классификатора одним числом, используют площадь под ROC-кривой (area under curve, AUC). AUC = 1 соответствует идеальной классификации.
{kind=link}
Dataset augmentation
Современные архитектуры нейронных сетей содержат миллионы параметров. Чтобы обучить такие модели, нужны огромные объемы данных. При этом сбор данных и их разметка — чрезвычайно трудоемкий процесс.
Простой и эффективный способ увеличения объема тренировочной выборки называется dataset augmentation. Идея простая: нужно определить множество преобразований данных, не меняющих классы, и применить ко всем объектам выборки. Примером такого преобразования для классификации изображений кошек и собак будет отражение изображений по горизонтали. Классы при этом не поменяются (кошки останутся кошками, собаки — собаками), а объем данных увеличится в два раза.
Преобразования могут быть самыми разными: повороты изображений, отражения, гамма-коррекция, изменение яркости и контраста и т. д. Чем разнообразнее аугментация, тем лучше.
Современные архитектуры нейронных сетей содержат миллионы параметров. Чтобы обучить такие модели, нужны огромные объемы данных. При этом сбор данных и их разметка — чрезвычайно трудоемкий процесс.
Простой и эффективный способ увеличения объема тренировочной выборки называется dataset augmentation. Идея простая: нужно определить множество преобразований данных, не меняющих классы, и применить ко всем объектам выборки. Примером такого преобразования для классификации изображений кошек и собак будет отражение изображений по горизонтали. Классы при этом не поменяются (кошки останутся кошками, собаки — собаками), а объем данных увеличится в два раза.
Преобразования могут быть самыми разными: повороты изображений, отражения, гамма-коррекция, изменение яркости и контраста и т. д. Чем разнообразнее аугментация, тем лучше.
Leave-one-out cross-validation
Один из самых простых методов скользящего контроля — контроль по отдельным объектам (leave-one-out CV). Из исходной выборки по очереди исключается каждый из объектов и становится валидационным. Объединение всех оставшихся объектов становится обучающей подвыборкой. Если в исходной выборке N объектов, то на каждом из N шагов, модель обучается на (N − 1) объектах и проверяется на одном. Результаты всех N валидаций усредняются.
Минусом такого подхода является большая ресурсозатратность. Чтобы пройти один валидационный цикл, модель должна обучаться N раз.
Плюсом является то, что при каждом обучении выборка используется по максимуму — объем уменьшается всего на один объект.
В качестве примера рассмотрим настройку параметра k в k-NN классификаторе.
Работает такой классификатор очень просто.
1. Для объекта, который нужно классифицировать, находятся k ближайших к нему объектов (соседей) в обучающей выборке.
2. Объекту присваивается класс, представителей которого больше всего среди соседей.
Параметр k подбирается методом leave-one-out. Для каждого проверяемого значения k запускается цикл обучений/валидаций. Параметр с лучшим средним результатом на N валидациях фиксируется.
Заметим, что процесс обучения k-NN тривиален и заключается в простом сохранении обучающей выборки. Именно поэтому для этого классификатора leave-one-out очень эффективен.
Один из самых простых методов скользящего контроля — контроль по отдельным объектам (leave-one-out CV). Из исходной выборки по очереди исключается каждый из объектов и становится валидационным. Объединение всех оставшихся объектов становится обучающей подвыборкой. Если в исходной выборке N объектов, то на каждом из N шагов, модель обучается на (N − 1) объектах и проверяется на одном. Результаты всех N валидаций усредняются.
Минусом такого подхода является большая ресурсозатратность. Чтобы пройти один валидационный цикл, модель должна обучаться N раз.
Плюсом является то, что при каждом обучении выборка используется по максимуму — объем уменьшается всего на один объект.
В качестве примера рассмотрим настройку параметра k в k-NN классификаторе.
Работает такой классификатор очень просто.
1. Для объекта, который нужно классифицировать, находятся k ближайших к нему объектов (соседей) в обучающей выборке.
2. Объекту присваивается класс, представителей которого больше всего среди соседей.
Параметр k подбирается методом leave-one-out. Для каждого проверяемого значения k запускается цикл обучений/валидаций. Параметр с лучшим средним результатом на N валидациях фиксируется.
Заметим, что процесс обучения k-NN тривиален и заключается в простом сохранении обучающей выборки. Именно поэтому для этого классификатора leave-one-out очень эффективен.
Метод максимального правдоподобия
Метод максимального правдоподобия исходит из вероятностной постановки задачи машинного обучения. Любая модель, настраиваемая этим методом — вероятностная.
Таким образом выход логистической регрессии интерпретируется, как вероятность принадлежности классу (а не просто «привели к диапазону (0, 1)»). Выход softmax-слоя сети — тоже вероятность принадлежности классу. Выход линейной регрессии — наиболее вероятное значение зависимой переменной.
К сожалению:
1. Ни одна модель не может быть идеальной.
2. Объем данных для обучения ограничен.
3. Методы обучения редко приводят к оптимальному решению.
По этим причинам в реальных задачах вероятностный смысл выходов моделей получается использовать редко. Тем не менее этот смысл нужно понимать.
Метод максимального правдоподобия исходит из вероятностной постановки задачи машинного обучения. Любая модель, настраиваемая этим методом — вероятностная.
Таким образом выход логистической регрессии интерпретируется, как вероятность принадлежности классу (а не просто «привели к диапазону (0, 1)»). Выход softmax-слоя сети — тоже вероятность принадлежности классу. Выход линейной регрессии — наиболее вероятное значение зависимой переменной.
К сожалению:
1. Ни одна модель не может быть идеальной.
2. Объем данных для обучения ограничен.
3. Методы обучения редко приводят к оптимальному решению.
По этим причинам в реальных задачах вероятностный смысл выходов моделей получается использовать редко. Тем не менее этот смысл нужно понимать.
Параметрические и непараметрические методы
При вероятностной постановке, задача машинного обучения сводится к оценке плотностей распределений по имеющимся данным. Существует несколько подходов к оцениванию распределений.
Наиболее распространенный подход — параметрический. Сначала задается параметризованная модель плотностей, затем, по имеющимся данным, настраиваются параметры. К таким методам относятся линейная и логистическая регрессия, нейронные сети и многие другие алгоритмы.
Другой подход — непараметрический. Такие методы заключаются в непосредственном оценивании плотностей в окрестностях классифицируемых объектов. Фактически используется само определение плотности. К непараметрическим методам относятся k-NN, метод парзеновского окна, метод потенциальных функций и другие.
Пример. Допустим нужно восстановить распределение одной единственной переменной. Один из подходов — предположить, что распределение гауссово и найти параметры (выборочное матожидание и дисперсию). Второй — просто поделить весь диапазон изменения переменной на интервалы и построить гистограмму.
При вероятностной постановке, задача машинного обучения сводится к оценке плотностей распределений по имеющимся данным. Существует несколько подходов к оцениванию распределений.
Наиболее распространенный подход — параметрический. Сначала задается параметризованная модель плотностей, затем, по имеющимся данным, настраиваются параметры. К таким методам относятся линейная и логистическая регрессия, нейронные сети и многие другие алгоритмы.
Другой подход — непараметрический. Такие методы заключаются в непосредственном оценивании плотностей в окрестностях классифицируемых объектов. Фактически используется само определение плотности. К непараметрическим методам относятся k-NN, метод парзеновского окна, метод потенциальных функций и другие.
Пример. Допустим нужно восстановить распределение одной единственной переменной. Один из подходов — предположить, что распределение гауссово и найти параметры (выборочное матожидание и дисперсию). Второй — просто поделить весь диапазон изменения переменной на интервалы и построить гистограмму.
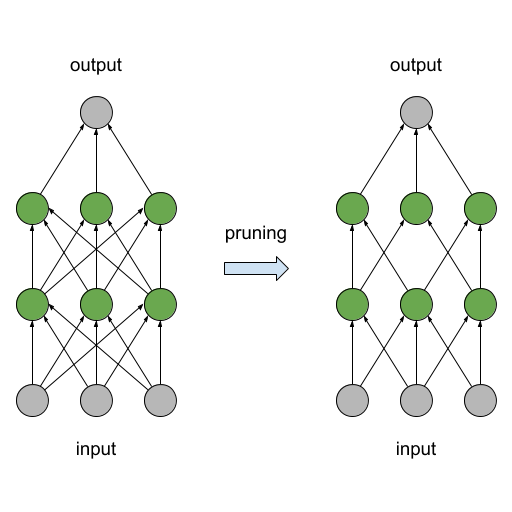
Weight pruning
Прореживание (weight pruning) — эффективный способ уменьшения размера модели нейронной сети и одновременно ускорения исполнения. Метод заключается в удалении связей с малыми весами из структуры сети. Прореживание выполняется в процессе тренировки. Это позволяет сети адаптироваться под изменения своей структуры.
Прореживание сетей теперь доступно в TensorFlow Model Optimization Toolkit.
Прореживание (weight pruning) — эффективный способ уменьшения размера модели нейронной сети и одновременно ускорения исполнения. Метод заключается в удалении связей с малыми весами из структуры сети. Прореживание выполняется в процессе тренировки. Это позволяет сети адаптироваться под изменения своей структуры.
Прореживание сетей теперь доступно в TensorFlow Model Optimization Toolkit.
{kind=link}
Translatotron
Исследователи Google представили первую в мире (как сами заявляют) speech-to-speech систему перевода устной речи.
Большинство современных система голосового перевода работают следующим образом:
1. Речь распознается и сохраняется в текстовом виде (voice ⇒ text).
2. Текст переводится с одного языка на другой (text ⇒ text).
3. На основе текста генерируется речь (text ⇒ voice).
В предлагаемом подходе нет промежуточных стадий преобразования звука в текст и обратно. Речь спикера переводится нейронной сетью с одного языка на другой напрямую, без работы с текстом. Интересно, что система может передавать голос спикера, интонацию и паузы.
Послушать примеры перевода и скачать оригинальную статью можно здесь.
Исследователи Google представили первую в мире (как сами заявляют) speech-to-speech систему перевода устной речи.
Большинство современных система голосового перевода работают следующим образом:
1. Речь распознается и сохраняется в текстовом виде (voice ⇒ text).
2. Текст переводится с одного языка на другой (text ⇒ text).
3. На основе текста генерируется речь (text ⇒ voice).
В предлагаемом подходе нет промежуточных стадий преобразования звука в текст и обратно. Речь спикера переводится нейронной сетью с одного языка на другой напрямую, без работы с текстом. Интересно, что система может передавать голос спикера, интонацию и паузы.
Послушать примеры перевода и скачать оригинальную статью можно здесь.
Формула Байеса в ML
Теорема Байеса — один из ключевых инструментов машинного обучения. Через нее выводятся алгоритмы обучения большинства ML-моделей: от линейной регрессии до глубоких нейронных сетей.
Формула:
p(w | D) = p(w) ⋅ p(D | w) / p(D),
где:
D — данные для обучения;
w — вектор параметров модели;
p(w) — априорная вероятность параметров (prior probability);
p(D) — вероятность данных (evidence);
p(D | w) — правдоподобие (likelihood);
p(w | D) — апостериорная вероятность параметров (posterior probability).
Теорема Байеса — один из ключевых инструментов машинного обучения. Через нее выводятся алгоритмы обучения большинства ML-моделей: от линейной регрессии до глубоких нейронных сетей.
Формула:
p(w | D) = p(w) ⋅ p(D | w) / p(D),
где:
D — данные для обучения;
w — вектор параметров модели;
p(w) — априорная вероятность параметров (prior probability);
p(D) — вероятность данных (evidence);
p(D | w) — правдоподобие (likelihood);
p(w | D) — апостериорная вероятность параметров (posterior probability).
Top-3 конференций по компьютерному зрению
Наш Top-3 конференций по компьютерному зрению и распознаванию образов. Прекрасно отражают происходящее в мире AI и ML.
1. Conference on Computer Vision and Pattern Recognition, CVPR.
2. International Conference on Computer Vision, ICCV.
3. European Conference on Computer Vision, ECCV.
В этом году пройдут две из них:
CVPR 2019. June 16th — June 20th, Long Beach, CA, USA.
http://cvpr2019.thecvf.com
ICCV 2019. October 27th — November 2th, Seoul, Korea.
http://iccv2019.thecvf.com
Наш Top-3 конференций по компьютерному зрению и распознаванию образов. Прекрасно отражают происходящее в мире AI и ML.
1. Conference on Computer Vision and Pattern Recognition, CVPR.
2. International Conference on Computer Vision, ICCV.
3. European Conference on Computer Vision, ECCV.
В этом году пройдут две из них:
CVPR 2019. June 16th — June 20th, Long Beach, CA, USA.
http://cvpr2019.thecvf.com
ICCV 2019. October 27th — November 2th, Seoul, Korea.
http://iccv2019.thecvf.com
Проклятие размерности
В машинном обучении объекты описываются своими характеристиками — признаками. В простейшем случае объект представляется точкой в N-мерном евклидовом пространстве. Кажется очевидным, что чем признаков больше, тем лучше. К сожалению, это не всегда так.
С ростом числа признаков (увеличением размерности пространства) начинают проявляться эффекты, получившие название «проклятия размерности» — термин ввёл в прошлом веке Ричард Беллман.
Одно из проявлений этого проклятия — экспоненциальный рост объёма данных.
Пример. Пусть каждый из признаков принимает значение от 0 до 1, и для оценки его распределения нужно всего 10 точек. Тогда для оценки распределения двух признаков нужно 100 точек. Для 10 признаков — уже 10^10.
Вот ещё одна особенность многомерных пространств. Внутри единичного гиперкуба (или гиперсферы) возьмём случайную опорную точку Q, а затем j случайных точек P₁...Pⱼ. Матожидание отношения наибольшего расстояния от Q до Pₓ к наименьшему будет стремиться к 1 при стремлении размерности к бесконечности.
E[maxdist(Q, Pₓ) / mindist(Q, Pₓ)] → 1
На практике это означает, что в пространствах высоких размерностей расстояния между большинством точек будут близки друг к другу. Все метрические методы в этом случае перестанут работать. Попробуйте при помощи k-NN классифицировать в лоб (каждый пиксел — это признак) изображения размером хотя бы 100×100.
Как бороться с проклятием размерности? Понижать размерность! Для этого есть множество методов: PCA (Principal Component Analysis — Метод Главных Компонент), отбор признаков и другие.
В машинном обучении объекты описываются своими характеристиками — признаками. В простейшем случае объект представляется точкой в N-мерном евклидовом пространстве. Кажется очевидным, что чем признаков больше, тем лучше. К сожалению, это не всегда так.
С ростом числа признаков (увеличением размерности пространства) начинают проявляться эффекты, получившие название «проклятия размерности» — термин ввёл в прошлом веке Ричард Беллман.
Одно из проявлений этого проклятия — экспоненциальный рост объёма данных.
Пример. Пусть каждый из признаков принимает значение от 0 до 1, и для оценки его распределения нужно всего 10 точек. Тогда для оценки распределения двух признаков нужно 100 точек. Для 10 признаков — уже 10^10.
Вот ещё одна особенность многомерных пространств. Внутри единичного гиперкуба (или гиперсферы) возьмём случайную опорную точку Q, а затем j случайных точек P₁...Pⱼ. Матожидание отношения наибольшего расстояния от Q до Pₓ к наименьшему будет стремиться к 1 при стремлении размерности к бесконечности.
E[maxdist(Q, Pₓ) / mindist(Q, Pₓ)] → 1
На практике это означает, что в пространствах высоких размерностей расстояния между большинством точек будут близки друг к другу. Все метрические методы в этом случае перестанут работать. Попробуйте при помощи k-NN классифицировать в лоб (каждый пиксел — это признак) изображения размером хотя бы 100×100.
Как бороться с проклятием размерности? Понижать размерность! Для этого есть множество методов: PCA (Principal Component Analysis — Метод Главных Компонент), отбор признаков и другие.
Обучение тождественной функции
В машинном обучении нужно различать две стадии: построение правильной модели и обучение этой модели. Выбор удачной, даже абсолютно правильной модели, не гарантирует, что она будет хорошо обучаться.
Пример: проблема обучения тождественной функции. Обычные полносвязные сети прямого распространения плохо учатся переводить вход в выход без изменений (y = f(x) = x). Попробуйте.
Решение проблемы довольно простое: нужно «пробросить» вход сети в обход полносвязных слоёв и сложить с выходом полносвязных слоев.
Была сеть вида:
y = f(x, w)
Стала:
y = f(x, w) + x
Такая сеть учится тождественной функции очень быстро.
В машинном обучении нужно различать две стадии: построение правильной модели и обучение этой модели. Выбор удачной, даже абсолютно правильной модели, не гарантирует, что она будет хорошо обучаться.
Пример: проблема обучения тождественной функции. Обычные полносвязные сети прямого распространения плохо учатся переводить вход в выход без изменений (y = f(x) = x). Попробуйте.
Решение проблемы довольно простое: нужно «пробросить» вход сети в обход полносвязных слоёв и сложить с выходом полносвязных слоев.
Была сеть вида:
y = f(x, w)
Стала:
y = f(x, w) + x
Такая сеть учится тождественной функции очень быстро.
Что почитать по машинному обучению на русском
Неплохие книги и лекции по машинному обучению на русском.
1. Бенджио И., Гудфеллоу Я., Курвилль А. Глубокое обучение. ДМК-Пресс, 2018.
2. Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. Питер, 2018.
3. Воронцов К. В. Лекции по машинному обучению. http://www.machinelearning.ru, 2004–2018.
Неплохие книги и лекции по машинному обучению на русском.
1. Бенджио И., Гудфеллоу Я., Курвилль А. Глубокое обучение. ДМК-Пресс, 2018.
2. Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. Питер, 2018.
3. Воронцов К. В. Лекции по машинному обучению. http://www.machinelearning.ru, 2004–2018.
Speech2Face
Ребята из MIT создали сеть, восстанавливающую лицо по голосу. Работа будет представлена на постерной секции CVPR 2019.
https://arxiv.org/abs/1905.09773
Ребята из MIT создали сеть, восстанавливающую лицо по голосу. Работа будет представлена на постерной секции CVPR 2019.
https://arxiv.org/abs/1905.09773
Решение задачи через усложнение
В машинном обучении есть множество задач с простой постановкой, которые сложно решить напрямую.
Пример: сказать, есть ли на изображении кошка. Это задача бинарной классификации — для каждого изображения нужно ответить «да» или «нет».
Кажется, что простая классификационная сеть с задачей легко справится. К сожалению это не так. Если изображения достаточно сложные, присутствуют различные объекты кроме кошек — алгоритм обучения просто «не поймёт», что от него хотят.
Решение простое: вместо того, чтобы решать задачу классификации (говорить есть ли кошка), можно решить задачу детекции (сказать где кошка). Переходом к задаче детекции, мы сообщаем алгоритму дополнительную информацию — подсказываем, что именно от него хотим. Само собой, для такого перехода придётся разметить всех кошек.
Таким образом, более простая (по постановке) задача может быть решена через более сложную.
В машинном обучении есть множество задач с простой постановкой, которые сложно решить напрямую.
Пример: сказать, есть ли на изображении кошка. Это задача бинарной классификации — для каждого изображения нужно ответить «да» или «нет».
Кажется, что простая классификационная сеть с задачей легко справится. К сожалению это не так. Если изображения достаточно сложные, присутствуют различные объекты кроме кошек — алгоритм обучения просто «не поймёт», что от него хотят.
Решение простое: вместо того, чтобы решать задачу классификации (говорить есть ли кошка), можно решить задачу детекции (сказать где кошка). Переходом к задаче детекции, мы сообщаем алгоритму дополнительную информацию — подсказываем, что именно от него хотим. Само собой, для такого перехода придётся разметить всех кошек.
Таким образом, более простая (по постановке) задача может быть решена через более сложную.
Две постановки задач классификации и регрессии
Существует как минимум две постановки задач классификации и регрессии.
1. Функциональная.
По доступным N парам {xⱼ, yⱼ}, необходимо восстановить неизвестную функцию y = f(x). Где:
x — вектор признаков;
y — ответ.
У такой постановки есть ряд недостатков. Например на практике одинаковым векторам признаков могут соответствовать разные ответы. В этом случае x и y не связаны функционально.
2. Вероятностная.
По доступным N парам {xⱼ, yⱼ}, необходимо восстановить неизвестную плотность совместного распределения p(x, y). Где:
x — вектор признаков;
y — ответ.
Такая постановка является более общей и допускает нефункциональную зависимость x и y.
Большинство современных методов машинного обучения, включая сверточные нейронные сети, исходят из вероятностной постановки задачи.
Существует как минимум две постановки задач классификации и регрессии.
1. Функциональная.
По доступным N парам {xⱼ, yⱼ}, необходимо восстановить неизвестную функцию y = f(x). Где:
x — вектор признаков;
y — ответ.
У такой постановки есть ряд недостатков. Например на практике одинаковым векторам признаков могут соответствовать разные ответы. В этом случае x и y не связаны функционально.
2. Вероятностная.
По доступным N парам {xⱼ, yⱼ}, необходимо восстановить неизвестную плотность совместного распределения p(x, y). Где:
x — вектор признаков;
y — ответ.
Такая постановка является более общей и допускает нефункциональную зависимость x и y.
Большинство современных методов машинного обучения, включая сверточные нейронные сети, исходят из вероятностной постановки задачи.
Байесовские нейронные сети не переобучаются?
Последнее время все чаще слышим утверждение, что байесовские нейронные сети не переобучаются. Не просто «меньше склонны к переобучению», а не переобучаются вообще. Вроде как при байесовском выводе даже такого понятия не существует.
Первоисточник утверждения найти не удалось. Если вдруг кто знает — поделитесь (контакт в описании канала).
Проясним ситуацию. Абсолютно все модели переобучаются. Это фундаментальная проблема машинного обучения.
Байесовский вывод действительно позволяет получить более корректные и точные (по сравнению с методом максимального правдоподобия) оценки вероятностей p(y | x). Тем не менее, эти оценки рассчитываются по ограниченной выборке. Очевидно, что они не могут тождественно совпасть с соответствующими значениями для генеральной совокупности.
Последнее время все чаще слышим утверждение, что байесовские нейронные сети не переобучаются. Не просто «меньше склонны к переобучению», а не переобучаются вообще. Вроде как при байесовском выводе даже такого понятия не существует.
Первоисточник утверждения найти не удалось. Если вдруг кто знает — поделитесь (контакт в описании канала).
Проясним ситуацию. Абсолютно все модели переобучаются. Это фундаментальная проблема машинного обучения.
Байесовский вывод действительно позволяет получить более корректные и точные (по сравнению с методом максимального правдоподобия) оценки вероятностей p(y | x). Тем не менее, эти оценки рассчитываются по ограниченной выборке. Очевидно, что они не могут тождественно совпасть с соответствующими значениями для генеральной совокупности.
Метод наименьших квадратов и метод наименьших модулей
Рассмотрим очень простую задачу. Есть вектор чисел x длиной N. Мы хотим аппроксимировать (приблизить) x другим вектором y, у которого все компоненты равны. Иначе говоря N исходных чисел мы хотим приблизить одним.
Запишем оптимизационную задачу:
∑ ℒ(xⱼ − y) → min
ℒ(xⱼ − y) — функция потерь.
Выберем квадратичную функцию потерь:
ℒ(xⱼ − y) = (xⱼ − y)²
Задача оптимизации:
∑ (y − xⱼ)² → min
Взяв производную по y и приравняв к нулю получим решение:
y = ∑ xⱼ / N = mean(x)
Теперь в качестве функции потерь возьмем модуль ошибки:
ℒ(xⱼ − y) = |xⱼ − y|
Задача оптимизации:
∑ |xⱼ − y| → min
Доопределив производную модуля, продифференцировав и приравняв к нулю, получим решение:
y = median(x)
Итак, при выборе двух разных функций потерь, в первом случае приходим к среднему исходных чисел, во втором — к медиане.
Замечательным свойством медианы (в отличие от среднего) является нечувствительность к выбросам — робастность. Единичные очень большие (или очень маленькие) значения xⱼ не приведут к увеличению (или уменьшению) y.
Все рассуждения легко применить и к гораздо более сложным моделям регрессии и классификации.
Вывод: робастность методов аппроксимации можно регулировать простым выбором функции потерь.
Рассмотрим очень простую задачу. Есть вектор чисел x длиной N. Мы хотим аппроксимировать (приблизить) x другим вектором y, у которого все компоненты равны. Иначе говоря N исходных чисел мы хотим приблизить одним.
Запишем оптимизационную задачу:
∑ ℒ(xⱼ − y) → min
ℒ(xⱼ − y) — функция потерь.
Выберем квадратичную функцию потерь:
ℒ(xⱼ − y) = (xⱼ − y)²
Задача оптимизации:
∑ (y − xⱼ)² → min
Взяв производную по y и приравняв к нулю получим решение:
y = ∑ xⱼ / N = mean(x)
Теперь в качестве функции потерь возьмем модуль ошибки:
ℒ(xⱼ − y) = |xⱼ − y|
Задача оптимизации:
∑ |xⱼ − y| → min
Доопределив производную модуля, продифференцировав и приравняв к нулю, получим решение:
y = median(x)
Итак, при выборе двух разных функций потерь, в первом случае приходим к среднему исходных чисел, во втором — к медиане.
Замечательным свойством медианы (в отличие от среднего) является нечувствительность к выбросам — робастность. Единичные очень большие (или очень маленькие) значения xⱼ не приведут к увеличению (или уменьшению) y.
Все рассуждения легко применить и к гораздо более сложным моделям регрессии и классификации.
Вывод: робастность методов аппроксимации можно регулировать простым выбором функции потерь.
Предобучение
Современные нейронные сети содержат миллионы параметров. Чтобы эффективно их обучать нужны огромные тренировочные наборы. К сожалению, для многих задач получение необходимого объема данных с разметкой проблематично.
Эффективным решением является предобучение. Первые слои сети предварительно обучаются на другой задаче, для которой данных достаточно. После этого вся сеть дотренировывается на целевом наборе.
Стандартный подход — предобучение на задаче классификации ImageNet. Как пример, многие state of the art архитектуры детекции текста претренировываются именно на нем.
#dainamicskills
Современные нейронные сети содержат миллионы параметров. Чтобы эффективно их обучать нужны огромные тренировочные наборы. К сожалению, для многих задач получение необходимого объема данных с разметкой проблематично.
Эффективным решением является предобучение. Первые слои сети предварительно обучаются на другой задаче, для которой данных достаточно. После этого вся сеть дотренировывается на целевом наборе.
Стандартный подход — предобучение на задаче классификации ImageNet. Как пример, многие state of the art архитектуры детекции текста претренировываются именно на нем.
#dainamicskills
Регуляризация и нехватка данных
Необходимость использования регуляризации — прямое следствие недостатка данных.
Разберем на примере L₁/L₂ регуляризации. Вспомним откуда она берётся.
Веса сети ищутся из условия максимизации апостериорной вероятности:
p(w | D) → max
где:
D — данные для обучения;
w — вектор параметров модели (веса сети).
Апостериорная вероятность выражается по формула Байеса:
p(w | D) = p(D | w) ⋅ p(w) / p(D)
p(D) не зависит от весов, поэтому из оптимизационной задачи её можно исключить:
p(w | D) ∝ p(D | w) ⋅ p(w) → max
Логарифмируем:
log p(D | w) + log p(w) → max
Второе слагаемое и есть регуляризатор. Если p(w) — гауссова функция, получаем L₂ регуляризацию. Если веса имеют распределение Лапласа, получаем L₁ регуляризацию.
Баланс между вкладами слагаемых log p(D | w) и log p(w) определяется «остротой» распределения p(w) и объемом данных D. Чем больше данных и/или чем «шире» априорное распределение, тем меньше значимость регуляризации.
#dainamicskills
Необходимость использования регуляризации — прямое следствие недостатка данных.
Разберем на примере L₁/L₂ регуляризации. Вспомним откуда она берётся.
Веса сети ищутся из условия максимизации апостериорной вероятности:
p(w | D) → max
где:
D — данные для обучения;
w — вектор параметров модели (веса сети).
Апостериорная вероятность выражается по формула Байеса:
p(w | D) = p(D | w) ⋅ p(w) / p(D)
p(D) не зависит от весов, поэтому из оптимизационной задачи её можно исключить:
p(w | D) ∝ p(D | w) ⋅ p(w) → max
Логарифмируем:
log p(D | w) + log p(w) → max
Второе слагаемое и есть регуляризатор. Если p(w) — гауссова функция, получаем L₂ регуляризацию. Если веса имеют распределение Лапласа, получаем L₁ регуляризацию.
Баланс между вкладами слагаемых log p(D | w) и log p(w) определяется «остротой» распределения p(w) и объемом данных D. Чем больше данных и/или чем «шире» априорное распределение, тем меньше значимость регуляризации.
#dainamicskills
Not Equal
ML ≠ AI
“Deconvolution” ≠ Deconvolution
“1×1 Convolution” ≠ 1×1 Convolution
“Tensor” ≠ Tensor
Inference ≠ Statistical Inference
TensorFlow Skills ≠ ML Skills
Naive Bayes Classifier ≠ Bayes Optimal Classifier
Bayesian Network ≠ Bayesian Neural Network
Deep Learning ≠ Machine Learning
p(y | x) ≠ softmax(f(x))
P ≠ NP
#dainamicskills
ML ≠ AI
“Deconvolution” ≠ Deconvolution
“1×1 Convolution” ≠ 1×1 Convolution
“Tensor” ≠ Tensor
Inference ≠ Statistical Inference
TensorFlow Skills ≠ ML Skills
Naive Bayes Classifier ≠ Bayes Optimal Classifier
Bayesian Network ≠ Bayesian Neural Network
Deep Learning ≠ Machine Learning
p(y | x) ≠ softmax(f(x))
P ≠ NP
#dainamicskills
Простое vs сложное
При решении задач машинного обучения часто не задумываясь просто берут модель посложнее (более общую). Логика такая: простая модель — частный случай более сложной, возьмём сложную, чтобы наверняка.
В ряде случаев подобный подход не оправдан. В качестве примера рассмотрим два популярных метода линейной классификации: линейный дискриминантный анализ (ЛДА) и логистическую регрессию.
На практике чаще используют логистическую регрессию, так как она исходит из более слабых предположений о распределении данных. Тем не менее, если предположения ЛДА о распределениях выполняются, он показывает лучшие результаты.
Простой пример, когда логистическая регрессия перестаёт работать — классы в обучающей выборке линейно разделимы. В этом случае веса регрессии устремляются в бесконечность. Такое часто происходит при нехватке обучающих прецедентов. ЛДА, благодаря более сильным предположениям о распределении данных, продолжает работать даже на малых обучающих выборках.
Вывод: чем больше информации о распределении данных учтено в модели — тем лучше.
#dainamicskills
При решении задач машинного обучения часто не задумываясь просто берут модель посложнее (более общую). Логика такая: простая модель — частный случай более сложной, возьмём сложную, чтобы наверняка.
В ряде случаев подобный подход не оправдан. В качестве примера рассмотрим два популярных метода линейной классификации: линейный дискриминантный анализ (ЛДА) и логистическую регрессию.
На практике чаще используют логистическую регрессию, так как она исходит из более слабых предположений о распределении данных. Тем не менее, если предположения ЛДА о распределениях выполняются, он показывает лучшие результаты.
Простой пример, когда логистическая регрессия перестаёт работать — классы в обучающей выборке линейно разделимы. В этом случае веса регрессии устремляются в бесконечность. Такое часто происходит при нехватке обучающих прецедентов. ЛДА, благодаря более сильным предположениям о распределении данных, продолжает работать даже на малых обучающих выборках.
Вывод: чем больше информации о распределении данных учтено в модели — тем лучше.
#dainamicskills