
Forwarded from Small Data Science for Russian Adventurers
#интересно
Построение эго-графа по Гугл-запросу вида « ... vs ... »... это же просто и гениально:
https://medium.com/applied-data-science/the-google-vs-trick-618c8fd5359f
Построение эго-графа по Гугл-запросу вида « ... vs ... »... это же просто и гениально:
https://medium.com/applied-data-science/the-google-vs-trick-618c8fd5359f
Medium
The Google ‘vs’ Trick
How ego graphs can help you learn about AI, play chess, eat healthier, buy a dog and find love.
ASCII diagrams
If you are writing technical docs, this is a nice service to create ASCII diagrams
http://asciiflow.com/
If you are writing technical docs, this is a nice service to create ASCII diagrams
http://asciiflow.com/
Ubuntu Snap Strings Attached
Ubuntu has its play store ... and when you install Ubuntu 20 server from scratch ... it offers you to pre-install Docker.
Do not do it. It comes with some app armor bs, which prevents you from using docker-compose and glitches with nvidia-docker.
Canonical forcing their app store too much, selling out or it is just early stage? I do not know. But their app store sucks compared to apt.
#linux
Ubuntu has its play store ... and when you install Ubuntu 20 server from scratch ... it offers you to pre-install Docker.
Do not do it. It comes with some app armor bs, which prevents you from using docker-compose and glitches with nvidia-docker.
Canonical forcing their app store too much, selling out or it is just early stage? I do not know. But their app store sucks compared to apt.
#linux
WSL2 with CUDA
WSL2 with CUDA support takes 18% longer than native Ubuntu to train an MNIST model on my Nvidia RTX 2080 Ti.
[Source]
WSL2 with CUDA support takes 18% longer than native Ubuntu to train an MNIST model on my Nvidia RTX 2080 Ti.
[Source]
Medium
Cuda on WSL2 for Deep Learning — First Impressions and Benchmarks
TLDR: It’s a little slower than native Ubuntu, but the future is bright!
2020 DS / ML Digest 10
Highlights:
- Ben Evans making his email digest a paid feature. RIP.
- A great review on what Tiktok is and how it works
- Fast Transformers with Clustered Attention
- New MLperf is out
- PyTorch 1.6
- Nvidia negotiating to buy ARM, lol
- Rumors that new Nvidia GPUS are not +25% performance, but +50% compared to last generation, also 20GB+ of memory
- A vector search library from Google
Please like / share / repost!
https://spark-in.me/post/2020_ds_ml_digest_10
#digest
Highlights:
- Ben Evans making his email digest a paid feature. RIP.
- A great review on what Tiktok is and how it works
- Fast Transformers with Clustered Attention
- New MLperf is out
- PyTorch 1.6
- Nvidia negotiating to buy ARM, lol
- Rumors that new Nvidia GPUS are not +25% performance, but +50% compared to last generation, also 20GB+ of memory
- A vector search library from Google
Please like / share / repost!
https://spark-in.me/post/2020_ds_ml_digest_10
#digest
Spark in me
A Small Social Experiment A small social experiment. Totally forgot about my account with TDS when publishing my first post about our research in STT. Since both of them put a lot of emphasis into authors actually owning their posts and they have canonical…
A Small Social Experiment - Update 2
Funnily enough all happened as I expected
- Very little traction on medium on TDS, despite being featured by their editor, lol
- HackerNoon did not review my draft, did not respond to my emails and in the end - my draft disappeared from their admin
Funnily enough all happened as I expected
- Very little traction on medium on TDS, despite being featured by their editor, lol
- HackerNoon did not review my draft, did not respond to my emails and in the end - my draft disappeared from their admin
Forwarded from DL in NLP (nlpcontroller_bot)
From English To Foreign Languages: Transferring Pre-trained Language Models
Tran [Amazon Alexa AI]
arxiv.org/abs/2002.07306
Когда ты видишь статью с одним автором - это либо полный трэш, либо что-то действительно интересное. В случае с этой статьёй:
With a single GPU, our approach can obtain a foreign BERTbase model within a day and a foreign BERTlarge within two days
Основная идея:
1. Инициализировать эмбеддинги нового языка (L2) с помощью эмбеддингов старого языка (L1). Каждый эмбеддинг L2 - это взвешенная сумма некоторых эмбеддингов L1. Веса находят либо с помощью word transition probability (см. статистический MT) либо с помощью unsupervised embedding alignment (см. Artexe 2018)
2. Обучить эмбеддинги BERT на данных L2 (остальные веса заморожены)
3. Обучить BERT на данных L1 + L2
Результаты заметно лучше mBERT на XNLI и немножко лучше на dependency parsing. Абляционные исследования показывают, что инициализация критически важна.
Tran [Amazon Alexa AI]
arxiv.org/abs/2002.07306
Когда ты видишь статью с одним автором - это либо полный трэш, либо что-то действительно интересное. В случае с этой статьёй:
With a single GPU, our approach can obtain a foreign BERTbase model within a day and a foreign BERTlarge within two days
Основная идея:
1. Инициализировать эмбеддинги нового языка (L2) с помощью эмбеддингов старого языка (L1). Каждый эмбеддинг L2 - это взвешенная сумма некоторых эмбеддингов L1. Веса находят либо с помощью word transition probability (см. статистический MT) либо с помощью unsupervised embedding alignment (см. Artexe 2018)
2. Обучить эмбеддинги BERT на данных L2 (остальные веса заморожены)
3. Обучить BERT на данных L1 + L2
Результаты заметно лучше mBERT на XNLI и немножко лучше на dependency parsing. Абляционные исследования показывают, что инициализация критически важна.
Найм в Условиях Киберпанка
Недавно у нас был такой процесс. Много инсайдов, забавных вещей, очарований и разочарований.
Совсем детали по ссылке в конце поста.
Немного капитанства:
(0)
Откуда приходили люди:
- Внезапно ОДС (слак) - 50%
- Внезапно этот канал или пошерили в телеге - 25%
- Профунктор джобс - 25%
(1)
Когда я работал в профи.ру, я обратил внимание, что там сильно более половины новых сотрудников перевозят из регионов (и не по той причине, о которой вы подумали). Внезапно как оказалось - у толковых людей не из Москвы сильно больше мотивации, как правило. Но очень немало людей, кто remote-first работу понимает как парт-тайм или вторую или третью работу.
(2)
Мы не разводили специальные олимпиады в духе решения задач у доски, но внезапно самые сильные решения не означают самых подходящих кандидатов. Sad but true.
(3)
Сильно больше ожидаемого - маркетинговой оптимизаций, ключевых слов, которых хватит на целый IT отдел, и всего такого. Тоже sad but true.
Полная статья тут. Много букв.
#hr
Недавно у нас был такой процесс. Много инсайдов, забавных вещей, очарований и разочарований.
Совсем детали по ссылке в конце поста.
Немного капитанства:
(0)
Откуда приходили люди:
- Внезапно ОДС (слак) - 50%
- Внезапно этот канал или пошерили в телеге - 25%
- Профунктор джобс - 25%
(1)
Когда я работал в профи.ру, я обратил внимание, что там сильно более половины новых сотрудников перевозят из регионов (и не по той причине, о которой вы подумали). Внезапно как оказалось - у толковых людей не из Москвы сильно больше мотивации, как правило. Но очень немало людей, кто remote-first работу понимает как парт-тайм или вторую или третью работу.
(2)
Мы не разводили специальные олимпиады в духе решения задач у доски, но внезапно самые сильные решения не означают самых подходящих кандидатов. Sad but true.
(3)
Сильно больше ожидаемого - маркетинговой оптимизаций, ключевых слов, которых хватит на целый IT отдел, и всего такого. Тоже sad but true.
Полная статья тут. Много букв.
#hr
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
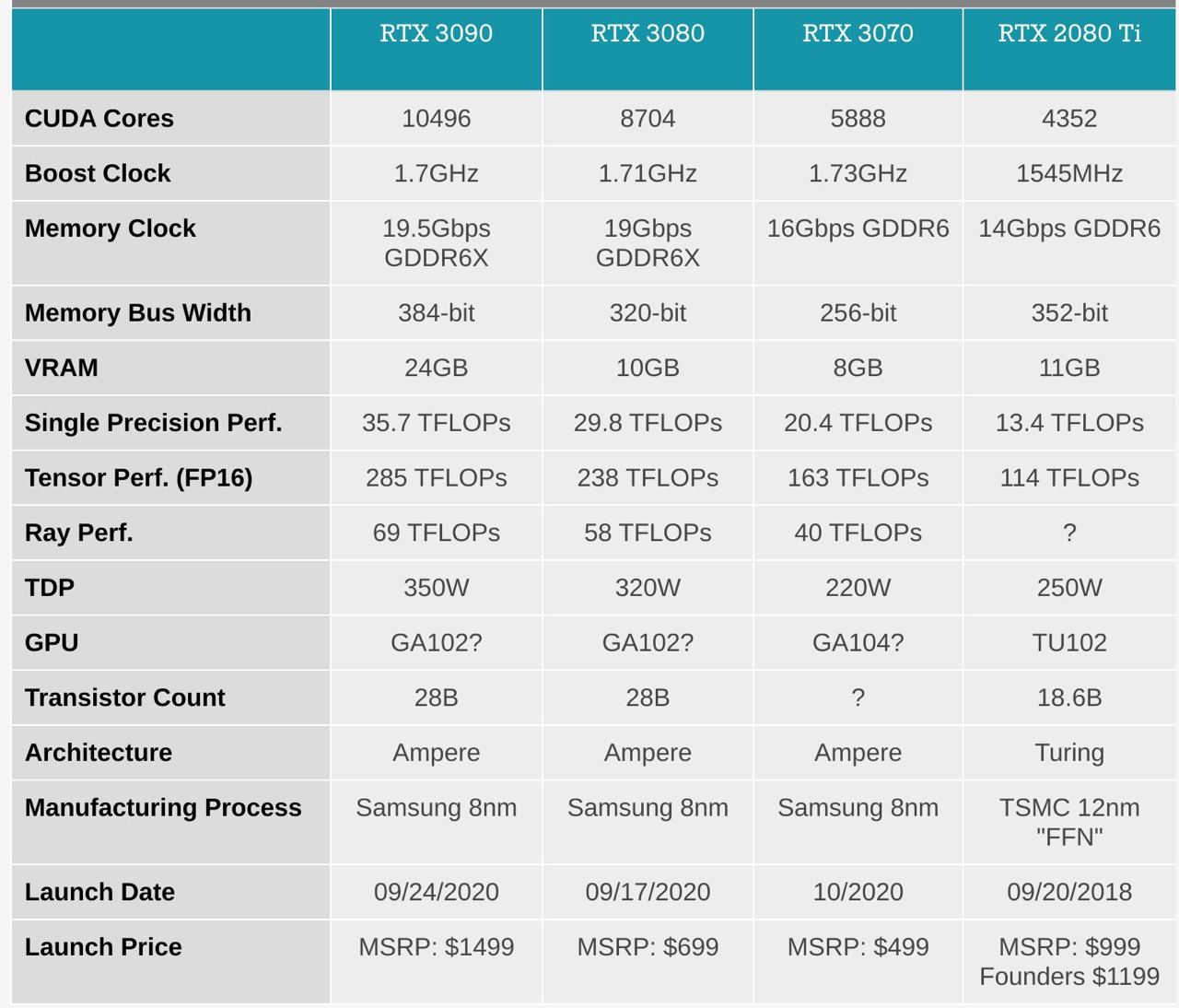
Nvidia announced new card RTX 3090
RTX 3090 is roughly 2 times more powerful than 2080.
There is probably no point in getting 3080 because RAM volume is only 10G.
But what really matters, is how it was presented. Purely technological product for mostly proffesionals, techheads and gamers was presented with absolute brialliancy. That is much more exciting then the release itself.
YouTube: https://www.youtube.com/watch?v=E98hC9e__Xs
#Nvidia #GPU #techstack
RTX 3090 is roughly 2 times more powerful than 2080.
There is probably no point in getting 3080 because RAM volume is only 10G.
But what really matters, is how it was presented. Purely technological product for mostly proffesionals, techheads and gamers was presented with absolute brialliancy. That is much more exciting then the release itself.
YouTube: https://www.youtube.com/watch?v=E98hC9e__Xs
#Nvidia #GPU #techstack
{kind=link}
RTX 3090 + Multi-Instance-GPU
So, ~2x faster than 2080 Ti, which is 30% faster than 1080Ti.
2x VRAM.
The only real question for me is, will it support Multi-Instance-GPU?
Let me explain why this is important. Now usually when you train a network, you increase your batch-size to fit the VRAM and monitor your IO and GPU load to ensure saturation.
But if a GPU has 2x VRAM and is 2-3x faster than 1080Ti, then maybe you can have multiple instances of your model on you GPU (that matters only for models that do not scale with large batch-sizes easily).
The only problem is that:
- You cannot use DDP in PyTorch (usually it is faster than DP for 4+ devices), because:
- So you will have to invent something / change your code / or maybe even use their bleeding edge RPC functions;
If this function is available on 3090 ... then you could turn your GPU into 2-3 virtual GPUs and use it accordingly? That would be truly epic, especially for production use-cases (yeah I know about their SLA)! Also would be great for teamworking.
#hardware
So, ~2x faster than 2080 Ti, which is 30% faster than 1080Ti.
2x VRAM.
The only real question for me is, will it support Multi-Instance-GPU?
Let me explain why this is important. Now usually when you train a network, you increase your batch-size to fit the VRAM and monitor your IO and GPU load to ensure saturation.
But if a GPU has 2x VRAM and is 2-3x faster than 1080Ti, then maybe you can have multiple instances of your model on you GPU (that matters only for models that do not scale with large batch-sizes easily).
The only problem is that:
- You cannot use DDP in PyTorch (usually it is faster than DP for 4+ devices), because:
DDP processes can be placed on the same machine or across machines, but GPU devices cannot be shared across processes.
- So you will have to invent something / change your code / or maybe even use their bleeding edge RPC functions;
If this function is available on 3090 ... then you could turn your GPU into 2-3 virtual GPUs and use it accordingly? That would be truly epic, especially for production use-cases (yeah I know about their SLA)! Also would be great for teamworking.
#hardware
NVIDIA Blog
What Is a Multi-Instance GPU? | NVIDIA Blog
The multi-instance GPU (MIG) technology in the NVIDIA Ampere architecture enables the NVIDIA A100 GPU to deliver up to 7x higher utilization compared to prior GPUs.
Notebooks + Spreadsheets
Notebooks and spreadsheets (Excel or Google Sheets) have always been two most useful and helpful instruments I have ever used. Whole companies were built based on pseudo-relational Excel databases (this is ofc does not scale well).
Now there is a new library in python that integrates some JS tables library seamlessly with ipywidgets and notebooks. It is news and predictably sucks a little bit (as most of interactive tables in JS).
It goes without saying that it opens up a lot of possibilities for ML annotation - you can essentially combine tables and ipywidgets easily.
As far as I see It does not have an option to embed some HTML code, but recently there just appeared and Audio widget in ipywidgets (buried in the release notes somewhere)
So you can just use this to load audio into ipysheet:
Notebooks and spreadsheets (Excel or Google Sheets) have always been two most useful and helpful instruments I have ever used. Whole companies were built based on pseudo-relational Excel databases (this is ofc does not scale well).
Now there is a new library in python that integrates some JS tables library seamlessly with ipywidgets and notebooks. It is news and predictably sucks a little bit (as most of interactive tables in JS).
It goes without saying that it opens up a lot of possibilities for ML annotation - you can essentially combine tables and ipywidgets easily.
As far as I see It does not have an option to embed some HTML code, but recently there just appeared and Audio widget in ipywidgets (buried in the release notes somewhere)
So you can just use this to load audio into ipysheet:
wavb = open('test.wav', "rb").read()
audio = Audio(value=wavb,
format='wav',
autoplay=False)
#data_scienceGitHub
GitHub - QuantStack/ipysheet: Jupyter handsontable integration
Jupyter handsontable integration. Contribute to QuantStack/ipysheet development by creating an account on GitHub.
Notes from captain obvious:
Сomparing two GPUs with Tensor Cores, one of the single best indicators for each GPU’s performance is their memory bandwidth;
Most computation time on GPUs is memory access;
A100 compared to the V100 is 1.70x faster for NLP and 1.45x faster for computer vision;
Tesla A100 compared to the V100 is 1.70x faster for NLP and 1.45x faster for computer vision;
3-Slot design of the RTX 3090 makes 4x GPU builds problematic. Possible solutions are 2-slot variants or the use of PCIe extenders;
4x RTX 3090 will need more power than any standard power supply unit on the market can provide right now (this is BS, but power connectors may be an issue - I have 2000W PSU);
With BF16 precision, training might be more stable than with FP16 precision while providing the same speedups;
The new fan design for the RTX 30sV series features both a blower fan and a push/pull fan;
350W TDP;
Compared to an RTX 2080 Ti, the RTX 3090 yields a speedup of 1.57x for convolutional networks and 1.5x for transformers while having a 15% higher release price. Thus the Ampere RTX 30s delivers a pretty substantial improvement over the Turing RTX 20s series;
PCIe 4.0 and PCIe lanes do not matter in 2x GPU setups. For 4x GPU setups, they still do not matter much;
NVLink is not useful. Only useful for GPU clusters;
No info about power connector. But I believe the first gaming gpus use 2*6 pin plus maybe some adapter;
Despite heroic software engineering efforts, AMD GPUs + ROCm will probably not be able to compete with NVIDIA due to lacking community and Tensor Core equivalent for at least 1-2 years;
You will need +50Gbits/s network cards to gain speedups if you want to parallelize across machines;
So if you expect to run deep learning models after 300 days, it is better to buy a desktop instead of using AWS spot instances (also fuck off AWS and Nvidia with sla about data centers);
Сomparing two GPUs with Tensor Cores, one of the single best indicators for each GPU’s performance is their memory bandwidth;
Most computation time on GPUs is memory access;
A100 compared to the V100 is 1.70x faster for NLP and 1.45x faster for computer vision;
Tesla A100 compared to the V100 is 1.70x faster for NLP and 1.45x faster for computer vision;
3-Slot design of the RTX 3090 makes 4x GPU builds problematic. Possible solutions are 2-slot variants or the use of PCIe extenders;
4x RTX 3090 will need more power than any standard power supply unit on the market can provide right now (this is BS, but power connectors may be an issue - I have 2000W PSU);
With BF16 precision, training might be more stable than with FP16 precision while providing the same speedups;
The new fan design for the RTX 30sV series features both a blower fan and a push/pull fan;
350W TDP;
Compared to an RTX 2080 Ti, the RTX 3090 yields a speedup of 1.57x for convolutional networks and 1.5x for transformers while having a 15% higher release price. Thus the Ampere RTX 30s delivers a pretty substantial improvement over the Turing RTX 20s series;
PCIe 4.0 and PCIe lanes do not matter in 2x GPU setups. For 4x GPU setups, they still do not matter much;
NVLink is not useful. Only useful for GPU clusters;
No info about power connector. But I believe the first gaming gpus use 2*6 pin plus maybe some adapter;
Despite heroic software engineering efforts, AMD GPUs + ROCm will probably not be able to compete with NVIDIA due to lacking community and Tensor Core equivalent for at least 1-2 years;
You will need +50Gbits/s network cards to gain speedups if you want to parallelize across machines;
So if you expect to run deep learning models after 300 days, it is better to buy a desktop instead of using AWS spot instances (also fuck off AWS and Nvidia with sla about data centers);
Spark in me
Nvidia announced new card RTX 3090 RTX 3090 is roughly 2 times more powerful than 2080. There is probably no point in getting 3080 because RAM volume is only 10G. But what really matters, is how it was presented. Purely technological product for mostly…
YouTube
Греет ли RTX 3080 память и кулер процессора? Моделирование воздушных потоков референсной RTX 3080.
RTX 3000 серии - https://www.e-katalog.ru/u/SCQd7w/a
Комплектующие - https://www.e-katalog.ru/u/znDHaL/a
В видео смотрим на то как RTX 3080 со сквозным вентилятором ведёт в себя в обычных и в необычных корпусах. замеряем температуры внутри корпуса на разных…
Комплектующие - https://www.e-katalog.ru/u/znDHaL/a
В видео смотрим на то как RTX 3080 со сквозным вентилятором ведёт в себя в обычных и в необычных корпусах. замеряем температуры внутри корпуса на разных…