
Forwarded from Data Science by ODS.ai 🦜
DINOv2: Learning Robust Visual Features without Supervision
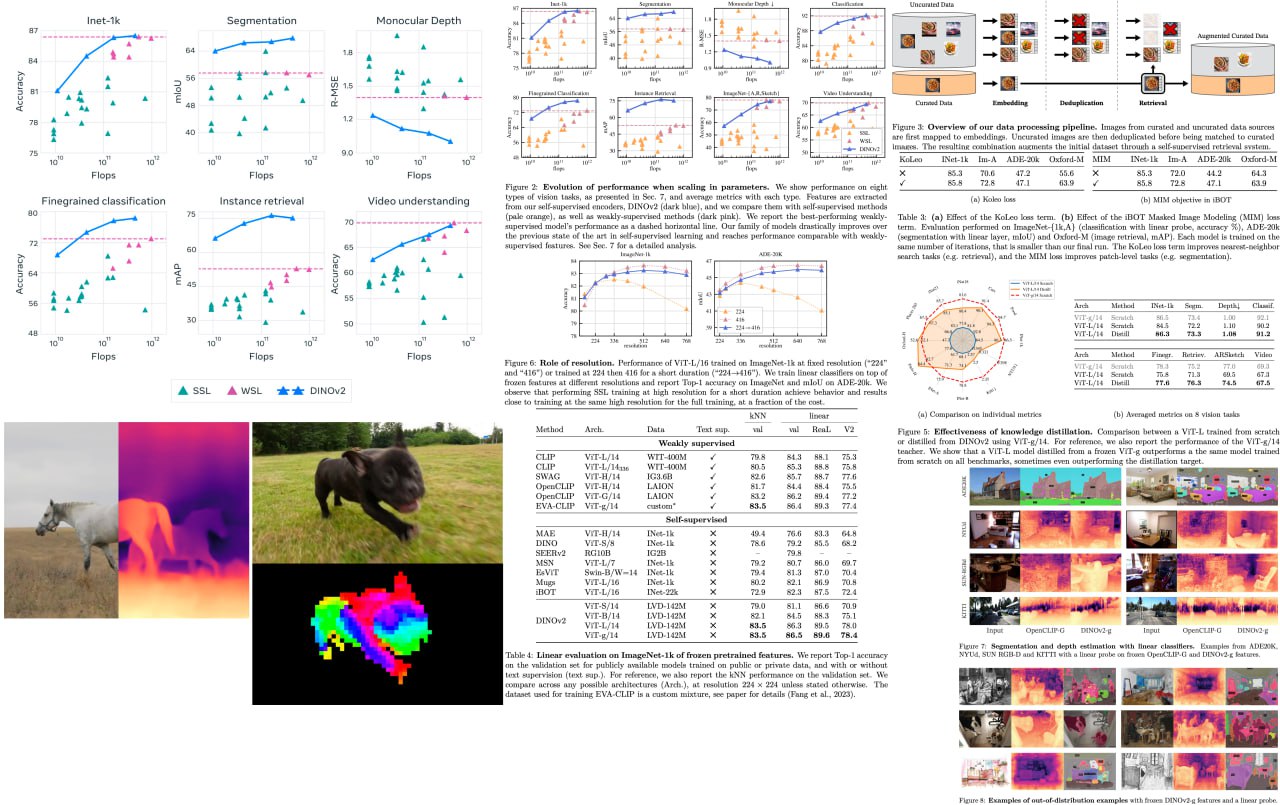
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
Spark in me
Stellar No BS Articles A ConvNet for the 2020s - https://arxiv.org/pdf/2201.03545.pdf #no_bs
InceptionNeXt: When Inception Meets ConvNeXt
https://arxiv.org/abs/2303.16900
https://github.com/sail-sg/inceptionnext/tree/main/models
https://arxiv.org/abs/2303.16900
https://github.com/sail-sg/inceptionnext/tree/main/models
GitHub
inceptionnext/models at main · sail-sg/inceptionnext
InceptionNeXt: When Inception Meets ConvNeXt (CVPR 2024) - sail-sg/inceptionnext
Собака лает — ветер носит, или решил ли Bark синтез речи?
Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой, который обычно сводится к тому, что задача X теперь уже решена и мы были в очередной раз по гроб облагодетельствованы.
Давайте разберемся так ли это, но теперь на примере синтеза речи:
- https://habr.com/ru/articles/731418/
Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой, который обычно сводится к тому, что задача X теперь уже решена и мы были в очередной раз по гроб облагодетельствованы.
Давайте разберемся так ли это, но теперь на примере синтеза речи:
- https://habr.com/ru/articles/731418/
Хабр
Собака лает — ветер носит, или решил ли Bark синтез речи?
Ну вы понимаете, да? Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой,...
https://arxiv.org/pdf/2304.09848.pdf
Also there is nothing in the LLM design that points to a particular web page or a source in the dataset, so I wonder how the citation mechanism works.
Do they run ... plain searches under the hood, or do they do plain search first, and then do the summarization part?
Also there is nothing in the LLM design that points to a particular web page or a source in the dataset, so I wonder how the citation mechanism works.
Do they run ... plain searches under the hood, or do they do plain search first, and then do the summarization part?
Leaked deck raises questions over Stability AI's Series A pitch to investors
https://sifted.eu/articles/stability-ai-fundraise-leak
Cannot prove or disprove it, but sound funny af
https://sifted.eu/articles/stability-ai-fundraise-leak
Cannot prove or disprove it, but sound funny af
Sifted
Leaked deck raises questions over Stability AI's Series A pitch to investors
The leaked material from June 2022 suggests that the company said it was "co-creating" products with rival company Midjourney
Forwarded from Логи внутренних диалогов
Ну, то есть:
1. Таможня торговала маркетинговыми данными. Практически с той же степенью детализации, что имелись у игроков рынка совершающих операции. Ничего не скрывала, ни что закупается и ввозится, ни кем.
2. Вообще, это немножко охренеть и с точки зрения защиты коммерческой тайны, и с точки зрения того, а как такая торговля устроена.
3. И после 24.02 — продолжила этим заниматься
4. И это тоже немного охренеть. А у нас много всяких "викторов бутов", а мы хотим чтоб их всех Штаты к себе выцепляли при первом же удобном поводе, что ли?
1. Таможня торговала маркетинговыми данными. Практически с той же степенью детализации, что имелись у игроков рынка совершающих операции. Ничего не скрывала, ни что закупается и ввозится, ни кем.
2. Вообще, это немножко охренеть и с точки зрения защиты коммерческой тайны, и с точки зрения того, а как такая торговля устроена.
3. И после 24.02 — продолжила этим заниматься
4. И это тоже немного охренеть. А у нас много всяких "викторов бутов", а мы хотим чтоб их всех Штаты к себе выцепляли при первом же удобном поводе, что ли?
Чуваки выдают базу по КД:
Фашизм при становлении паразитирует на революционных настроениях и выдает себя за социализм
Приход фашизма к власти означает слабость даже мнимых и театральных инстутов буржуазной демократии
В той или иной мере многие проявления начальной стадии прихода фашизма к власти сейчас наблюдаются во ВСЕХ буржуазных государствах
https://youtu.be/Y6Tu_GdN-Uk
Фашизм при становлении паразитирует на революционных настроениях и выдает себя за социализм
Приход фашизма к власти означает слабость даже мнимых и театральных инстутов буржуазной демократии
В той или иной мере многие проявления начальной стадии прихода фашизма к власти сейчас наблюдаются во ВСЕХ буржуазных государствах
https://youtu.be/Y6Tu_GdN-Uk
YouTube
Клим Жуков, Реми Майснер. Фашизм в современной повестке, как узнать фашиста.
Клим Жуков, Реми Майснер. Фашизм в современной повестке, как узнать фашиста.
Аудиоверсия - https://klimzhukov.mave.digital/ep-130
Подписка на спонср.ру - https://sponsr.ru/zhukov
Проект уроки истории - https://sponsr.ru/uzhukoffa_lessons/
Проект Юго-Восточная…
Аудиоверсия - https://klimzhukov.mave.digital/ep-130
Подписка на спонср.ру - https://sponsr.ru/zhukov
Проект уроки истории - https://sponsr.ru/uzhukoffa_lessons/
Проект Юго-Восточная…
Spark in me
Чуваки выдают базу по КД: Фашизм при становлении паразитирует на революционных настроениях и выдает себя за социализм Приход фашизма к власти означает слабость даже мнимых и театральных инстутов буржуазной демократии В той или иной мере многие проявления…
Но не всё так мрачно. Приведу пример с другой стороны - за несколько часов реально пройти KYC для эквайринга в боте в телеграме, оформить онлайн кассу и это все не отрывая жопу от стула.
Киберпанк как он есть. Рынок эквайринга сильно изменился, и не думаю, что со сбером так бы получилось (вообще ещё давно мы месяцами вели с ними переговоры), но тем не менее.
Даже почти все формы и регистрации были бесшовными.
Киберпанк как он есть. Рынок эквайринга сильно изменился, и не думаю, что со сбером так бы получилось (вообще ещё давно мы месяцами вели с ними переговоры), но тем не менее.
Даже почти все формы и регистрации были бесшовными.
Еще из интересного. Есть датасет Common Voice.
Вроде прекрасно, бесплатная датка.
Но есть один нюанс. Почему-то в языковых парах:
Русский - Белорусский
Татарский - Башкирский
Испанский - Каталонский
Лидирует менее популярный язык. И очень много эсперанто. Интересно, почему?)
Вроде прекрасно, бесплатная датка.
Но есть один нюанс. Почему-то в языковых парах:
Русский - Белорусский
Татарский - Башкирский
Испанский - Каталонский
Лидирует менее популярный язык. И очень много эсперанто. Интересно, почему?)
Forwarded from Data Science by ODS.ai 🦜
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
{kind=link}
Какая пушка 🙈
Наверное хорошо, что мы в школе на истории не изучали историю 20 века, точнее изучали ее галопом, а занимались математикой и физикой.
Наверное хорошо, что мы в школе на истории не изучали историю 20 века, точнее изучали ее галопом, а занимались математикой и физикой.
Forwarded from Мир Михаила Онуфриенко
Media is too big
VIEW IN TELEGRAM
Forwarded from gonzo-обзоры ML статей
TWIMC
string2string: A Modern Python Library for String-to-String Algorithms
https://arxiv.org/abs/2304.14395
We introduce string2string, an open-source library that offers a comprehensive suite of efficient algorithms for a broad range of string-to-string problems. It includes traditional algorithmic solutions as well as recent advanced neural approaches to tackle various problems in string alignment, distance measurement, lexical and semantic search, and similarity analysis -- along with several helpful visualization tools and metrics to facilitate the interpretation and analysis of these methods. Notable algorithms featured in the library include the Smith-Waterman algorithm for pairwise local alignment, the Hirschberg algorithm for global alignment, the Wagner-Fisher algorithm for edit distance, BARTScore and BERTScore for similarity analysis, the Knuth-Morris-Pratt algorithm for lexical search, and Faiss for semantic search. Besides, it wraps existing efficient and widely-used implementations of certain frameworks and metrics, such as sacreBLEU and ROUGE, whenever it is appropriate and suitable. Overall, the library aims to provide extensive coverage and increased flexibility in comparison to existing libraries for strings. It can be used for many downstream applications, tasks, and problems in natural-language processing, bioinformatics, and computational social sciences. It is implemented in Python, easily installable via pip, and accessible through a simple API. Source code, documentation, and tutorials are all available on our GitHub page:
https://github.com/stanfordnlp/string2string
string2string: A Modern Python Library for String-to-String Algorithms
https://arxiv.org/abs/2304.14395
We introduce string2string, an open-source library that offers a comprehensive suite of efficient algorithms for a broad range of string-to-string problems. It includes traditional algorithmic solutions as well as recent advanced neural approaches to tackle various problems in string alignment, distance measurement, lexical and semantic search, and similarity analysis -- along with several helpful visualization tools and metrics to facilitate the interpretation and analysis of these methods. Notable algorithms featured in the library include the Smith-Waterman algorithm for pairwise local alignment, the Hirschberg algorithm for global alignment, the Wagner-Fisher algorithm for edit distance, BARTScore and BERTScore for similarity analysis, the Knuth-Morris-Pratt algorithm for lexical search, and Faiss for semantic search. Besides, it wraps existing efficient and widely-used implementations of certain frameworks and metrics, such as sacreBLEU and ROUGE, whenever it is appropriate and suitable. Overall, the library aims to provide extensive coverage and increased flexibility in comparison to existing libraries for strings. It can be used for many downstream applications, tasks, and problems in natural-language processing, bioinformatics, and computational social sciences. It is implemented in Python, easily installable via pip, and accessible through a simple API. Source code, documentation, and tutorials are all available on our GitHub page:
https://github.com/stanfordnlp/string2string
GitHub
GitHub - stanfordnlp/string2string: String-to-String Algorithms for Natural Language Processing
String-to-String Algorithms for Natural Language Processing - stanfordnlp/string2string
> Western propaganda and ideology are just like the Devil: the greatest trick they ever played was to make us think they don’t exist. The very moment you believe they’re not there is the very moment you’re in the eye of the storm.
https://medium.com/@harolddegauche/western-propaganda-the-greatest-trick-the-devil-ever-pulled-99df373facd2
https://medium.com/@harolddegauche/western-propaganda-the-greatest-trick-the-devil-ever-pulled-99df373facd2
Medium
Western Propaganda — The Greatest Trick The Devil Ever Pulled …
Good propaganda doesn’t make you think, it makes you feel
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
https://lmsys.org/blog/2023-03-30-vicuna/
https://lmsys.org/blog/2023-03-30-vicuna/
lmsys.org
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality | LMSYS Org
<p>We introduce Vicuna-13B, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Preliminary evaluation ...