
Spark in me
Три наблюдения про CPM на YouTube Ютуб это 40% времени россиянина в интернете после всех событий. Отсюда понятно, почему кабели не режут, но непонятно, почему VK и Рутуб все ещё нигде, причем согласно блоггерам. Гипотеза - потому что нигде кроме Ютуба не…
Небольшой вброс про ВК
Во-первых, у ВК есть партнерская программа на показы рекламы (я не знал).
Случайно узнал у админа постов с приколами ВК со 150к подписоты, что ВК сейчас привлекает блоггеров из ТТ и инсты искусственно повышая им CPM в партнерке.
Но при этом это не аттракцион неслыханной щедрости, а идет пессимизация старых пабликов.
Простыми словами CPM условно был 10-15 рублей, а стал 2 рубля. Это неточно, проверяйте факты сами, если вам важно.
Во-первых, у ВК есть партнерская программа на показы рекламы (я не знал).
Случайно узнал у админа постов с приколами ВК со 150к подписоты, что ВК сейчас привлекает блоггеров из ТТ и инсты искусственно повышая им CPM в партнерке.
Но при этом это не аттракцион неслыханной щедрости, а идет пессимизация старых пабликов.
Простыми словами CPM условно был 10-15 рублей, а стал 2 рубля. Это неточно, проверяйте факты сами, если вам важно.
Did you use any Ada / Hopper GPUs for DL / calculations (not games)?
Anonymous Poll
7%
Yes, Ada
2%
Yes, Hopper
1%
Yes, but only for gaming
35%
No
62%
What is Ada / Hopper?
Только что обратил внимание, что Сбер живет на GitHub по данному адресу - https://github.com/ai-forever
Там ссылки ведут на Хабр и там слово Сбер капсом.
Интересно, почему их не снесли из-за санкций, ведь очевидно же, что это Сбер.
Там ссылки ведут на Хабр и там слово Сбер капсом.
Интересно, почему их не снесли из-за санкций, ведь очевидно же, что это Сбер.
GitHub
AI Forever
Creating ML for the future. AI projects you already know. We are non-profit organization with members from all over the world. - AI Forever
Spark in me
Про нормальные docker образы Astra Linux На Хабре кто-то заметил - https://habr.com/ru/post/693176/ Ни в коем случае НЕ КАЧАЙТЕ базовый образ ОС не с оф. сайта / аккаунта разработчиков ОС! Оказывается что есть уже просто папка с докер-образами Astra Linux…
https://vault.astralinux.ru/images/orel/docker/
У Астры был репозиторий с образами.
А сейчас он недоступен и статья на Хабре с ссылкой на него удалена.
Молодцы, делаете свою систему доступнее.
Понятно, что платная версия у вас платная, но зачем например удалили образы с бесплатной версией?
Так ваша ОС станет популярнее?
У Астры был репозиторий с образами.
А сейчас он недоступен и статья на Хабре с ссылкой на него удалена.
Молодцы, делаете свою систему доступнее.
Понятно, что платная версия у вас платная, но зачем например удалили образы с бесплатной версией?
Так ваша ОС станет популярнее?
Forwarded from Silero Bot News (Alexander)
This media is not supported in your browser
VIEW IN TELEGRAM
Рассылка дошла и до меня (опоздала на день).
Уже все люди с тонкой душевной организацией высказались, вот и я выскажусь.
Почему налогоплательщики должны платить за фильм, снятый на наши налоги?
Пиарите нашу космонавтику? Прекрасно! Пиарьте, но фильм нужно выложить на все хостинги, трекеры и утюги страны.
Уже все люди с тонкой душевной организацией высказались, вот и я выскажусь.
Почему налогоплательщики должны платить за фильм, снятый на наши налоги?
Пиарите нашу космонавтику? Прекрасно! Пиарьте, но фильм нужно выложить на все хостинги, трекеры и утюги страны.
Forwarded from Silero Bot News (Alexander)
This media is not supported in your browser
VIEW IN TELEGRAM
Мы добавили возможность переозвучки голосовух и кружков!
🎂 Ура. Мы долго готовились, и теперь наконец первая бета. Надеюсь я нигде не проспойлерил и это будет для вас сюрпризом!
🎭 Теперь боту можно посылать голосовухи и кружки, и он будет повторять за вами, копируя слова и интонацию, но другим голосом.
💣 Надеюсь вам понравится базовый набор голосов, и у нас есть несколько шаловливых идей, что можно добавить дальше.
🎮 Примеры и демонстрации будут дальше на канале новостей бота, а поиграться можно в боте. Подробная инструкция в боте под командой /revoice.
🎛 Обновили лимиты.
🎂 Ура. Мы долго готовились, и теперь наконец первая бета. Надеюсь я нигде не проспойлерил и это будет для вас сюрпризом!
🎭 Теперь боту можно посылать голосовухи и кружки, и он будет повторять за вами, копируя слова и интонацию, но другим голосом.
💣 Надеюсь вам понравится базовый набор голосов, и у нас есть несколько шаловливых идей, что можно добавить дальше.
🎮 Примеры и демонстрации будут дальше на канале новостей бота, а поиграться можно в боте. Подробная инструкция в боте под командой /revoice.
🎛 Обновили лимиты.
Forwarded from Silero Bot News (Alexander)
This media is not supported in your browser
VIEW IN TELEGRAM
🍿 Half-Life 2 + наша переозвучка голосом GladOS + кот
🔗 Источник видео
💬 Подробная инструкция - /revoice в боте.
🔗 Источник видео
💬 Подробная инструкция - /revoice в боте.
Просто оставлю это здесь без комментариев -
https://pikabu.ru/story/nas_vsegda_ubezhdali_chto_dzhentlmenyi_vsegda_igrayut_po_pravilam_10158233
Я бы написал много едких домыслов, но не буду. Факты говорят сами ярче за меня.
https://pikabu.ru/story/nas_vsegda_ubezhdali_chto_dzhentlmenyi_vsegda_igrayut_po_pravilam_10158233
Я бы написал много едких домыслов, но не буду. Факты говорят сами ярче за меня.
Пикабу
Нас всегда убеждали, что "джентльмены всегда играют по правилам"
Пост пикабушницы RoseWhite в сообществе Лига Политики
Forwarded from Data Science by ODS.ai 🦜
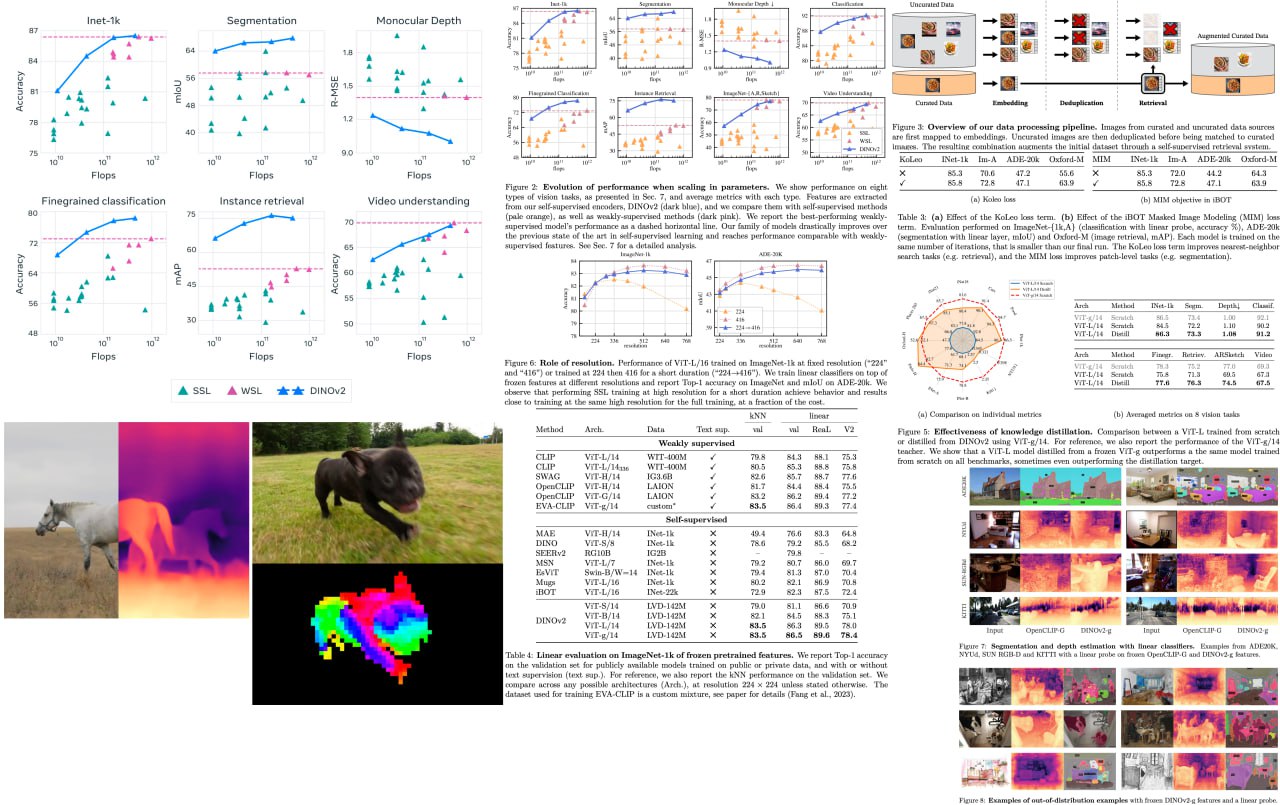
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
Spark in me
Stellar No BS Articles A ConvNet for the 2020s - https://arxiv.org/pdf/2201.03545.pdf #no_bs
InceptionNeXt: When Inception Meets ConvNeXt
https://arxiv.org/abs/2303.16900
https://github.com/sail-sg/inceptionnext/tree/main/models
https://arxiv.org/abs/2303.16900
https://github.com/sail-sg/inceptionnext/tree/main/models
GitHub
inceptionnext/models at main · sail-sg/inceptionnext
InceptionNeXt: When Inception Meets ConvNeXt (CVPR 2024) - sail-sg/inceptionnext
Собака лает — ветер носит, или решил ли Bark синтез речи?
Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой, который обычно сводится к тому, что задача X теперь уже решена и мы были в очередной раз по гроб облагодетельствованы.
Давайте разберемся так ли это, но теперь на примере синтеза речи:
- https://habr.com/ru/articles/731418/
Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой, который обычно сводится к тому, что задача X теперь уже решена и мы были в очередной раз по гроб облагодетельствованы.
Давайте разберемся так ли это, но теперь на примере синтеза речи:
- https://habr.com/ru/articles/731418/
Хабр
Собака лает — ветер носит, или решил ли Bark синтез речи?
Ну вы понимаете, да? Время от времени мне в личку присылают посты с телеграм-каналов, специализирующихся на "ИИ" хайпе. Обычно такие посты сопровождаются весьма сомнительного качества журналистикой,...
https://arxiv.org/pdf/2304.09848.pdf
Also there is nothing in the LLM design that points to a particular web page or a source in the dataset, so I wonder how the citation mechanism works.
Do they run ... plain searches under the hood, or do they do plain search first, and then do the summarization part?
Also there is nothing in the LLM design that points to a particular web page or a source in the dataset, so I wonder how the citation mechanism works.
Do they run ... plain searches under the hood, or do they do plain search first, and then do the summarization part?
Leaked deck raises questions over Stability AI's Series A pitch to investors
https://sifted.eu/articles/stability-ai-fundraise-leak
Cannot prove or disprove it, but sound funny af
https://sifted.eu/articles/stability-ai-fundraise-leak
Cannot prove or disprove it, but sound funny af
Sifted
Leaked deck raises questions over Stability AI's Series A pitch to investors
The leaked material from June 2022 suggests that the company said it was "co-creating" products with rival company Midjourney
Forwarded from Логи внутренних диалогов
Ну, то есть:
1. Таможня торговала маркетинговыми данными. Практически с той же степенью детализации, что имелись у игроков рынка совершающих операции. Ничего не скрывала, ни что закупается и ввозится, ни кем.
2. Вообще, это немножко охренеть и с точки зрения защиты коммерческой тайны, и с точки зрения того, а как такая торговля устроена.
3. И после 24.02 — продолжила этим заниматься
4. И это тоже немного охренеть. А у нас много всяких "викторов бутов", а мы хотим чтоб их всех Штаты к себе выцепляли при первом же удобном поводе, что ли?
1. Таможня торговала маркетинговыми данными. Практически с той же степенью детализации, что имелись у игроков рынка совершающих операции. Ничего не скрывала, ни что закупается и ввозится, ни кем.
2. Вообще, это немножко охренеть и с точки зрения защиты коммерческой тайны, и с точки зрения того, а как такая торговля устроена.
3. И после 24.02 — продолжила этим заниматься
4. И это тоже немного охренеть. А у нас много всяких "викторов бутов", а мы хотим чтоб их всех Штаты к себе выцепляли при первом же удобном поводе, что ли?
Чуваки выдают базу по КД:
Фашизм при становлении паразитирует на революционных настроениях и выдает себя за социализм
Приход фашизма к власти означает слабость даже мнимых и театральных инстутов буржуазной демократии
В той или иной мере многие проявления начальной стадии прихода фашизма к власти сейчас наблюдаются во ВСЕХ буржуазных государствах
https://youtu.be/Y6Tu_GdN-Uk
Фашизм при становлении паразитирует на революционных настроениях и выдает себя за социализм
Приход фашизма к власти означает слабость даже мнимых и театральных инстутов буржуазной демократии
В той или иной мере многие проявления начальной стадии прихода фашизма к власти сейчас наблюдаются во ВСЕХ буржуазных государствах
https://youtu.be/Y6Tu_GdN-Uk
YouTube
Клим Жуков, Реми Майснер. Фашизм в современной повестке, как узнать фашиста.
Клим Жуков, Реми Майснер. Фашизм в современной повестке, как узнать фашиста.
Аудиоверсия - https://klimzhukov.mave.digital/ep-130
Подписка на спонср.ру - https://sponsr.ru/zhukov
Проект уроки истории - https://sponsr.ru/uzhukoffa_lessons/
Проект Юго-Восточная…
Аудиоверсия - https://klimzhukov.mave.digital/ep-130
Подписка на спонср.ру - https://sponsr.ru/zhukov
Проект уроки истории - https://sponsr.ru/uzhukoffa_lessons/
Проект Юго-Восточная…
Spark in me
Чуваки выдают базу по КД: Фашизм при становлении паразитирует на революционных настроениях и выдает себя за социализм Приход фашизма к власти означает слабость даже мнимых и театральных инстутов буржуазной демократии В той или иной мере многие проявления…
Но не всё так мрачно. Приведу пример с другой стороны - за несколько часов реально пройти KYC для эквайринга в боте в телеграме, оформить онлайн кассу и это все не отрывая жопу от стула.
Киберпанк как он есть. Рынок эквайринга сильно изменился, и не думаю, что со сбером так бы получилось (вообще ещё давно мы месяцами вели с ними переговоры), но тем не менее.
Даже почти все формы и регистрации были бесшовными.
Киберпанк как он есть. Рынок эквайринга сильно изменился, и не думаю, что со сбером так бы получилось (вообще ещё давно мы месяцами вели с ними переговоры), но тем не менее.
Даже почти все формы и регистрации были бесшовными.
Еще из интересного. Есть датасет Common Voice.
Вроде прекрасно, бесплатная датка.
Но есть один нюанс. Почему-то в языковых парах:
Русский - Белорусский
Татарский - Башкирский
Испанский - Каталонский
Лидирует менее популярный язык. И очень много эсперанто. Интересно, почему?)
Вроде прекрасно, бесплатная датка.
Но есть один нюанс. Почему-то в языковых парах:
Русский - Белорусский
Татарский - Башкирский
Испанский - Каталонский
Лидирует менее популярный язык. И очень много эсперанто. Интересно, почему?)
Forwarded from Data Science by ODS.ai 🦜
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
{kind=link}