
2019 DS / ML digest 9
Highlights of the week
- Stack Overlow survey;
- Unsupervised STT (ofc not!);
- A mix between detection and semseg?;
https://spark-in.me/post/2019_ds_ml_digest_09
#digest
#deep_learning
Highlights of the week
- Stack Overlow survey;
- Unsupervised STT (ofc not!);
- A mix between detection and semseg?;
https://spark-in.me/post/2019_ds_ml_digest_09
#digest
#deep_learning
Spark in me
2019 DS/ML digest 09
2019 DS/ML digest 09
Статьи автора - http://spark-in.me/author/snakers41
Блог - http://spark-in.me
Статьи автора - http://spark-in.me/author/snakers41
Блог - http://spark-in.me
Tricky rsync flags
Rsync is the best program ever.
I find these flags the most useful
Sometimes first three flags get confusing.
#linux
Rsync is the best program ever.
I find these flags the most useful
--ignore-existing (ignores existing files)
--update (updates to newer versions of files based on ts)
--size-only (uses file-size to compare files)
-e 'ssh -p 22 -i /path/to/private/key' (use custom ssh identity)
Sometimes first three flags get confusing.
#linux
Forwarded from Yuri Baburov
Вторая экспериментальная гостевая лекция курса.
Один из семинаристов курса, Юрий Бабуров, расскажет о распознавании речи и работе с аудио.
1-го мая в 8:40 Мск (12:40 Нск, 10:40 вечера 30-го апреля по PST).
Deep Learning на пальцах 11 - Аудио и Speech Recognition (Юрий Бабуров)
https://www.youtube.com/watch?v=wm4H2Ym33Io
Один из семинаристов курса, Юрий Бабуров, расскажет о распознавании речи и работе с аудио.
1-го мая в 8:40 Мск (12:40 Нск, 10:40 вечера 30-го апреля по PST).
Deep Learning на пальцах 11 - Аудио и Speech Recognition (Юрий Бабуров)
https://www.youtube.com/watch?v=wm4H2Ym33Io
Spark in me
Вторая экспериментальная гостевая лекция курса. Один из семинаристов курса, Юрий Бабуров, расскажет о распознавании речи и работе с аудио. 1-го мая в 8:40 Мск (12:40 Нск, 10:40 вечера 30-го апреля по PST). Deep Learning на пальцах 11 - Аудио и Speech Recognition…
YouTube
Deep Learning на пальцах 11 - Аудио и распознавание речи (Юрий Бабуров)
Курс: http://dlcourse.ai
Слайды: https://www.dropbox.com/s/tv3cv0ihq2l0u9f/Lecture%2011%20-%20Audio%20and%20Speech.pdf?dl=0
Слайды: https://www.dropbox.com/s/tv3cv0ihq2l0u9f/Lecture%2011%20-%20Audio%20and%20Speech.pdf?dl=0
Poor man's computing cluster
So, when I last checked, Amazon's p3.4xlarge instances cost around US$12 per hour (unless you reserve them for a year). A tower supercomputer from Nvidia costs probably US$40-50k or more (it was announced at around US$69k).
It is not difficult to crunch the numbers and see, that 1 month of renting such a machine would cost at least US$8-10k. Also there will the additional cost / problem of actually storing your large datasets. When I last used Amazon - their cheap storage was sloooooow, and fast storage was prohibitively expensive.
So, why I am saying this?
Let's assume (according to my miner friends' experience) - that consumer Nvidia GPUs can work 2-3 years non-stop given proper cooling and care (test before buying!). Also let's assume that 4xTesla V100 is roughly the same as 7-8 * 1080Ti.
Yeah, I know that you will point out at least one reason why this does not hold, but for practical purposes this is fine (yes, I know that Teslas have some cool features like Nvlink).
Now let me drop the ball - modern professional motherboards often boast 2-3 Ethernet ports. And sometimes you can even get 2x10Gbit/s ports (!!!).
It means, that you actually can connect at least 2 (or maybe you can daisy chain them?) machines into a computing cluster.
Now let's crunch the numbers
According to quotes I collected through the years, you can build a cluster roughly equivalent to Amazon's p3.4xlarge for US$10k (but with storage!) with used GPUs (miners sell them like crazy now). If you buy second market drives, motherboards, CPUs and processors you can lower the cost to US$5k or less.
So, a cluster, that would serve you at least one year (if you test everything properly and take care of it) costing US$10k is roughly equivalent to:
- 20-25% of DGX desktop;
- 1 month of renting on Amazon;
Assuming that all the hardware will just break in a year:
- It is 4-5x cheaper than buying from Nvidia;
- It is 10x cheaper than renting;
If you buy everything used, then it is 10x and 20x cheaper!
I would buy that for a dollar!
Ofc you have to invest your free time.
See my calculations here:
http://bit.ly/spark00001
#deep_learning
#hardware
So, when I last checked, Amazon's p3.4xlarge instances cost around US$12 per hour (unless you reserve them for a year). A tower supercomputer from Nvidia costs probably US$40-50k or more (it was announced at around US$69k).
It is not difficult to crunch the numbers and see, that 1 month of renting such a machine would cost at least US$8-10k. Also there will the additional cost / problem of actually storing your large datasets. When I last used Amazon - their cheap storage was sloooooow, and fast storage was prohibitively expensive.
So, why I am saying this?
Let's assume (according to my miner friends' experience) - that consumer Nvidia GPUs can work 2-3 years non-stop given proper cooling and care (test before buying!). Also let's assume that 4xTesla V100 is roughly the same as 7-8 * 1080Ti.
Yeah, I know that you will point out at least one reason why this does not hold, but for practical purposes this is fine (yes, I know that Teslas have some cool features like Nvlink).
Now let me drop the ball - modern professional motherboards often boast 2-3 Ethernet ports. And sometimes you can even get 2x10Gbit/s ports (!!!).
It means, that you actually can connect at least 2 (or maybe you can daisy chain them?) machines into a computing cluster.
Now let's crunch the numbers
According to quotes I collected through the years, you can build a cluster roughly equivalent to Amazon's p3.4xlarge for US$10k (but with storage!) with used GPUs (miners sell them like crazy now). If you buy second market drives, motherboards, CPUs and processors you can lower the cost to US$5k or less.
So, a cluster, that would serve you at least one year (if you test everything properly and take care of it) costing US$10k is roughly equivalent to:
- 20-25% of DGX desktop;
- 1 month of renting on Amazon;
Assuming that all the hardware will just break in a year:
- It is 4-5x cheaper than buying from Nvidia;
- It is 10x cheaper than renting;
If you buy everything used, then it is 10x and 20x cheaper!
I would buy that for a dollar!
Ofc you have to invest your free time.
See my calculations here:
http://bit.ly/spark00001
#deep_learning
#hardware
Google Docs
computing_cluster
config
Server,Part,Approx quote,Quote date,Price, USD,Comment,RUR/USD,65,Yes, I know that you should have historical exchange rates
1,Thermaltake Core X9 Black,12,220,11/22/2018,188
1,Gigabyte X399 AORUS XTREMESocket TR4, AMD X399, 8xDDR-4, 7.1CH, 2x1000…
Server,Part,Approx quote,Quote date,Price, USD,Comment,RUR/USD,65,Yes, I know that you should have historical exchange rates
1,Thermaltake Core X9 Black,12,220,11/22/2018,188
1,Gigabyte X399 AORUS XTREMESocket TR4, AMD X399, 8xDDR-4, 7.1CH, 2x1000…
Russian Open Speech To Text (STT/ASR) Dataset
4000 hours of STT data in Russian
Made by us. Yes, really. I am not joking.
It was a lot of work.
The dataset:
https://github.com/snakers4/open_stt/
Accompanying post:
https://spark-in.me/post/russian-open-stt-part1
TLDR:
- On third release, we have ~4000 hours;
- Contributors and help wanted;
- Let's bring the Imagenet moment in STT closer together!;
Please repost this as much as you can.
#stt
#asr
#data_science
#deep_learning
4000 hours of STT data in Russian
Made by us. Yes, really. I am not joking.
It was a lot of work.
The dataset:
https://github.com/snakers4/open_stt/
Accompanying post:
https://spark-in.me/post/russian-open-stt-part1
TLDR:
- On third release, we have ~4000 hours;
- Contributors and help wanted;
- Let's bring the Imagenet moment in STT closer together!;
Please repost this as much as you can.
#stt
#asr
#data_science
#deep_learning
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
PyTorch
PyTorch 1.1
https://github.com/pytorch/pytorch/releases/tag/v1.1.0
- Tensorboard (beta);
- DistributedDataParallel new functionality and tutorials;
- Multi-headed attention;
- EmbeddingBag enhancements;
- Other cool, but more niche features:
-
-
#deep_learning
PyTorch 1.1
https://github.com/pytorch/pytorch/releases/tag/v1.1.0
- Tensorboard (beta);
- DistributedDataParallel new functionality and tutorials;
- Multi-headed attention;
- EmbeddingBag enhancements;
- Other cool, but more niche features:
-
nn.SyncBatchNorm;-
optim.lr_scheduler.CyclicLR;#deep_learning
GitHub
Release Official TensorBoard Support, Attributes, Dicts, Lists and User-defined types in JIT / TorchScript, Improved Distributed…
Note: CUDA 8.0 is no longer supported
Highlights
TensorBoard (currently experimental)
First-class and native support for visualization and model debugging with TensorBoard, a web application suite ...
Highlights
TensorBoard (currently experimental)
First-class and native support for visualization and model debugging with TensorBoard, a web application suite ...
PyTorch DP / DDP / model parallel
Finally they made proper tutorials:
- https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
Model parallel = have parts of the same model on different devices
Data Parallel (DP) = wrapper to use multi-GPU withing a single parent process
Distributed Data Parallel = multiple processes are spawned across cluster / on the same machine
#deep_learning
Finally they made proper tutorials:
- https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
Model parallel = have parts of the same model on different devices
Data Parallel (DP) = wrapper to use multi-GPU withing a single parent process
Distributed Data Parallel = multiple processes are spawned across cluster / on the same machine
#deep_learning
The State of ML, eof 2018 in Russian
Quite down-to-earth and clever lecture
https://www.youtube.com/watch?v=l6djLCYnOKw
Some nice examples for TTS and some interesting forecasts (some of them happened already).
#deep_learning
Quite down-to-earth and clever lecture
https://www.youtube.com/watch?v=l6djLCYnOKw
Some nice examples for TTS and some interesting forecasts (some of them happened already).
#deep_learning
YouTube
Сергей Марков: "Искусственный интеллект и машинное обучение: итоги 2018 года."
Лекция состоялась в научно-популярном лектории центра "Архэ" (http://arhe.msk.ru) 16 января 2019 года.
Лектор: Сергей Марков — автор одной из сильнейших российских шахматных программ, специалист по методам машинного обучения и основатель портала XX2 ВЕК…
Лектор: Сергей Марков — автор одной из сильнейших российских шахматных программ, специалист по методам машинного обучения и основатель портала XX2 ВЕК…
Habr.com / TowardsDataScience post for our dataset
In addition to a github release and a medium post, we also made habr.com post:
- https://habr.com/ru/post/450760/
Also our post was accepted to an editor's pick part of TDS:
- http://bit.ly/ru_open_stt
Share / give us a star / clap if you have not already!
Original release
https://github.com/snakers4/open_stt/
#deep_learning
#data_science
#dataset
In addition to a github release and a medium post, we also made habr.com post:
- https://habr.com/ru/post/450760/
Also our post was accepted to an editor's pick part of TDS:
- http://bit.ly/ru_open_stt
Share / give us a star / clap if you have not already!
Original release
https://github.com/snakers4/open_stt/
#deep_learning
#data_science
#dataset
Хабр
Огромный открытый датасет русской речи
Специалистам по распознаванию речи давно не хватало большого открытого корпуса устной русской речи, поэтому только крупные компании могли позволить себе заниматься этой задачей, но они не...
2019 DS / ML digest 10
Highlights of the week(s)
- New MobileNet;
- New PyTorch release;
- Practical GANs?;
https://spark-in.me/post/2019_ds_ml_digest_10
#digest
#deep_learning
Highlights of the week(s)
- New MobileNet;
- New PyTorch release;
- Practical GANs?;
https://spark-in.me/post/2019_ds_ml_digest_10
#digest
#deep_learning
Forwarded from Just links
PyTorch
Stochastic Weight Averaging in PyTorch
In this blogpost we describe the recently proposed Stochastic Weight Averaging (SWA) technique [1, 2], and its new implementation in torchcontrib. SWA is a simple procedure that improves generalization in deep learning over Stochastic Gradient Descent (SGD)…
New in our Open STT dataset
https://github.com/snakers4/open_stt#updates
- An
- A torrent for
- A torrent for the original
- Benchmarks on the public dataset / files with "poor" annotation marked;
#deep_learning
#data_science
#dataset
https://github.com/snakers4/open_stt#updates
- An
mp3 version of the dataset;- A torrent for
mp3 dataset;- A torrent for the original
wav dataset;- Benchmarks on the public dataset / files with "poor" annotation marked;
#deep_learning
#data_science
#dataset
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
Really working in the wild audio noise reduction libraries
Spectral gating
https://github.com/timsainb/noisereduce
It works. But you need a sample of your noise.
Will work well out of box for larger files / files with gaps where you can pay attention to each file and select a part of file that would act as noise example.
RNNoise: Learning Noise Suppression
Works with any arbitrary noise. Just feed your file.
It works more like adative equalizer.
It filters noise when there is no speech.
But it mostly does not change audio when speech is present.
As authors explain, it improves snr overall and makes sound less "tiring" to listen.
Description / blog posts
- https://people.xiph.org/~jm/demo/rnnoise/
- https://github.com/xiph/rnnoise
Step-by-step instructions in python
- https://github.com/xiph/rnnoise/issues/69
#audio
#deep_learning
Spectral gating
https://github.com/timsainb/noisereduce
It works. But you need a sample of your noise.
Will work well out of box for larger files / files with gaps where you can pay attention to each file and select a part of file that would act as noise example.
RNNoise: Learning Noise Suppression
Works with any arbitrary noise. Just feed your file.
It works more like adative equalizer.
It filters noise when there is no speech.
But it mostly does not change audio when speech is present.
As authors explain, it improves snr overall and makes sound less "tiring" to listen.
Description / blog posts
- https://people.xiph.org/~jm/demo/rnnoise/
- https://github.com/xiph/rnnoise
Step-by-step instructions in python
- https://github.com/xiph/rnnoise/issues/69
#audio
#deep_learning
GitHub
GitHub - timsainb/noisereduce: Noise reduction in python using spectral gating (speech, bioacoustics, audio, time-domain signals)
Noise reduction in python using spectral gating (speech, bioacoustics, audio, time-domain signals) - timsainb/noisereduce
Forwarded from Neural Networks Engineering (nne_controll_bot)
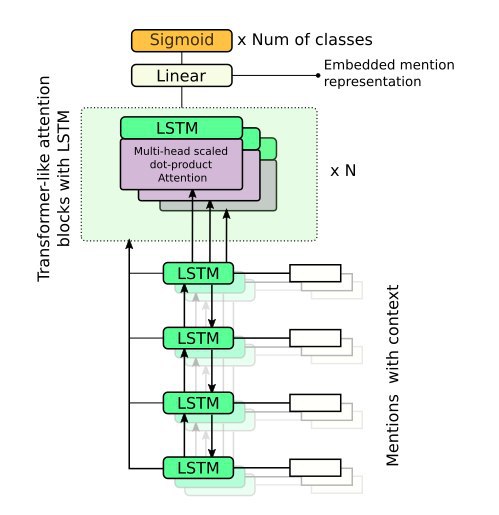
Have finished building demo and landing page for my project on mention classification. The idea of this project is to create a model which can assign some labels to objects based on their mentions in context. Right now it works only for people mentions, but if I find interest in this work, I will extend the model to other types like organizations or events. For now, you can check out the online demo of the neural network.
The current implementation can take account of several mentions at a time, so it can distinguish relevant parts of the context, not just averaging prediction.
It's also open sourced, and built with AllenNLP framework from training to serving. Take a look at it.
More technical details of implementation coming later.
The current implementation can take account of several mentions at a time, so it can distinguish relevant parts of the context, not just averaging prediction.
It's also open sourced, and built with AllenNLP framework from training to serving. Take a look at it.
More technical details of implementation coming later.
{kind=link}
2019 DS / ML digest 11
Highlights of the week(s)
- New attention block for CV;
- Reducing the amount of data for CV 10x?;
- Brain-to-CNN interfaces start popping up in the mainstream;
https://spark-in.me/post/2019_ds_ml_digest_11
#digest
#deep_learning
Highlights of the week(s)
- New attention block for CV;
- Reducing the amount of data for CV 10x?;
- Brain-to-CNN interfaces start popping up in the mainstream;
https://spark-in.me/post/2019_ds_ml_digest_11
#digest
#deep_learning