
fastText-модели на RusVectōrēs выложены для скачивания в нативном формате Gensim.
Библиотека Gensim активно обновляется. В частности, в последних релизах была существенно изменена логика работы с генерацией векторов для слов, отсутствующих в словаре (теперь она больше соответствует исходной реализации fastText от Facebook). Соответственно, немного изменился и формат хранения моделей.
TL:DR: если вы используете скачанные с нашего сайта fastText-модели, то скачайте их ещё раз прямо сейчас, их формат изменился. Также убедитесь, что вы используете свежий релиз Gensim (на сегодня это 3.7.2). Иначе корректная работа моделей не гарантируется, и мы умываем руки :)
Напоминаем, что процесс локальной работы с нашими моделями подробно описан в тьюториале: https://github.com/akutuzov/webvectors/blob/master/preprocessing/rusvectores_tutorial.ipynb
Библиотека Gensim активно обновляется. В частности, в последних релизах была существенно изменена логика работы с генерацией векторов для слов, отсутствующих в словаре (теперь она больше соответствует исходной реализации fastText от Facebook). Соответственно, немного изменился и формат хранения моделей.
TL:DR: если вы используете скачанные с нашего сайта fastText-модели, то скачайте их ещё раз прямо сейчас, их формат изменился. Также убедитесь, что вы используете свежий релиз Gensim (на сегодня это 3.7.2). Иначе корректная работа моделей не гарантируется, и мы умываем руки :)
Напоминаем, что процесс локальной работы с нашими моделями подробно описан в тьюториале: https://github.com/akutuzov/webvectors/blob/master/preprocessing/rusvectores_tutorial.ipynb
Сегодня мы представляем вам обзор статьи "Dark personalities on Facebook: harmful online behavior and language" (https://www.sciencedirect.com/science/article/pii/S0747563217305587), написанной коллективом авторов под руководством Ольги Боголюбовой. В этом исследовании авторы изучают взаимосвязь между негативными чертами личности, склонностью к вредоносному поведению в сети и языковыми характеристиками человека.
Для исследования при помощи специальной онлайн-платформы были опрошены более 6 тысяч русскоязычных пользователей социальной сети Фейсбук. Опрос включал в себя самооценку личностных черт, и вопросы об участии в кибербуллинге, троллинге и других негативных онлайн-практиках. Помимо этого, пользователи соглашались на обработку их текстовых записей в Фейсбуке.
Исследователей особенно интересовало, как взаимосвязаны черты личности из так называемой dark triad - нарциссизм, психопатия, склонность к манипуляциям - и лексические характеристики записей в соцсети. Для семантического анализа текстов авторы использовали нашу модель RusVectores на основе НКРЯ. Вектора слов, извлеченные из модели, были кластеризованы, и затем авторы подсчитали корреляцию между использованием слов из того или иного кластера и наличием одной из негативных черт личности.
Результатом исследования стало несколько интересных находок. Так, манипуляторы не склонны говорить о социальных взаимодействиях и эмпатии и не употребляют прилагательные, описывающие эмоции. Люди, заявившие о своей психопатии, говорят о базовых потребностях, таких как еда и финансы, а также о политике.
Основным недостатком исследования является тот факт, что все черты личности были описаны самими участниками, и неясно, насколько можно этому верить. Тем не менее, данное исследование очень интересно с точки зрения использования семантических моделей для анализа текстов и поведения в соцсетях.
Для исследования при помощи специальной онлайн-платформы были опрошены более 6 тысяч русскоязычных пользователей социальной сети Фейсбук. Опрос включал в себя самооценку личностных черт, и вопросы об участии в кибербуллинге, троллинге и других негативных онлайн-практиках. Помимо этого, пользователи соглашались на обработку их текстовых записей в Фейсбуке.
Исследователей особенно интересовало, как взаимосвязаны черты личности из так называемой dark triad - нарциссизм, психопатия, склонность к манипуляциям - и лексические характеристики записей в соцсети. Для семантического анализа текстов авторы использовали нашу модель RusVectores на основе НКРЯ. Вектора слов, извлеченные из модели, были кластеризованы, и затем авторы подсчитали корреляцию между использованием слов из того или иного кластера и наличием одной из негативных черт личности.
Результатом исследования стало несколько интересных находок. Так, манипуляторы не склонны говорить о социальных взаимодействиях и эмпатии и не употребляют прилагательные, описывающие эмоции. Люди, заявившие о своей психопатии, говорят о базовых потребностях, таких как еда и финансы, а также о политике.
Основным недостатком исследования является тот факт, что все черты личности были описаны самими участниками, и неясно, насколько можно этому верить. Тем не менее, данное исследование очень интересно с точки зрения использования семантических моделей для анализа текстов и поведения в соцсетях.
Sciencedirect
Dark personalities on Facebook: Harmful online behaviors and language
The goal of this paper was to assess the connection between dark personality traits and engagement in harmful online behaviors in a sample of Russian …
Vec2graph - визуализация связей слов в векторных моделях
Дружественный RusVectōrēs коллектив студентов магистратуры НИУ ВШЭ разработал python-библиотеку vec2graph. Она позволяет визуализировать эмбеддинги слов в виде динамических интерактивных графов и сохранять их в HTML-файлы, которые легко переносить или публиковать на сайтах. Библиотека очень проста в использовании и рассчитана на пользователей с минимальными навыками программирования. Уже послезавтра, 19 июля, она будет представлена на конференции AIST #aistconf, которая проходит в эти дни в Казани.
Принцип работы vec2graph заключается в том, что пользователь задаёт слово запроса, а библиотека визуализирует отношения этого слова с его ближайшими соседями в векторной модели (а также отношения соседей друг с другом). Каждое слово - это узел в графе, а веса на ребрах (и длина ребра) определяются косинусной близостью между словами. Можно задать определенный порог косинусной близости, ниже которого ребра между узлами визуализироваться не будут. Это помогает увидеть структуру семантического поля, заданного словом запроса и его соседями; также это полезно для анализа многозначных слов.
Vec2graph можно легко установить при помощи pip и сразу применить её к любой векторной модели, с которой умеет работать Gensim:
Например,
Мы надеемся, что vec2graph поможет вам в повседневных задачах, связанных с векторными представлениями слов. Кроме того, мы планируем добавить vec2graph-визуализации в интерфейс RusVectōrēs.
Дружественный RusVectōrēs коллектив студентов магистратуры НИУ ВШЭ разработал python-библиотеку vec2graph. Она позволяет визуализировать эмбеддинги слов в виде динамических интерактивных графов и сохранять их в HTML-файлы, которые легко переносить или публиковать на сайтах. Библиотека очень проста в использовании и рассчитана на пользователей с минимальными навыками программирования. Уже послезавтра, 19 июля, она будет представлена на конференции AIST #aistconf, которая проходит в эти дни в Казани.
Принцип работы vec2graph заключается в том, что пользователь задаёт слово запроса, а библиотека визуализирует отношения этого слова с его ближайшими соседями в векторной модели (а также отношения соседей друг с другом). Каждое слово - это узел в графе, а веса на ребрах (и длина ребра) определяются косинусной близостью между словами. Можно задать определенный порог косинусной близости, ниже которого ребра между узлами визуализироваться не будут. Это помогает увидеть структуру семантического поля, заданного словом запроса и его соседями; также это полезно для анализа многозначных слов.
Vec2graph можно легко установить при помощи pip и сразу применить её к любой векторной модели, с которой умеет работать Gensim:
pip install --upgrade vec2graph
from vec2graph import visualize
visualize(OUTPUT_DIR, MODEL, WORD)
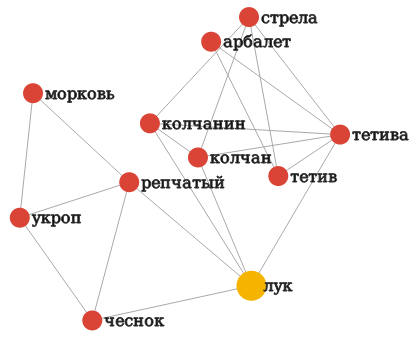
где OUTPUT_DIR - это каталог для сохранения выходных файлов с графами, MODEL - векторная модель, загруженная через Gensim, WORD - слово запроса.Например,
visualize(graph_directory, my_model, лук, threshold=0.55). Результат показан на картинке https://raw.githubusercontent.com/lizaku/vec2graph/master/vec2graph/data/luk.pngМы надеемся, что vec2graph поможет вам в повседневных задачах, связанных с векторными представлениями слов. Кроме того, мы планируем добавить vec2graph-визуализации в интерфейс RusVectōrēs.
{kind=link}
Контекстуализированные модели ELMo на RusVectōrēs
Сервис RusVectōrēs предоставляет множество семантических векторных моделей, обученных при помощи старых добрых дистрибутивных алгоритмов Continuous Bag-of-Words, Continuous Skipgram и fastText. Эти модели достаточно хорошо отражают семантическое пространство русского языка и успешно используются в разнообразных практических задачах. Однако технологии не стоят на месте, и приходит время двигаться дальше.
Один из существенных недостатков всех перечисленных моделей - их "статичность". Что это значит? В word2vec, GloVe, fastText и других "статических" алгоритмах у каждого слова (последовательности символов) после обучения есть ровно один вектор. В каком бы контексте в ваших данных не встретилось это слово, предобученная модель всегда будет сопоставлять ему одну-единственную репрезентацию. Именно поэтому на RusVectōrēs вы можете просто ввести одно слово и получить его вектор.
Почему это проблема? Конечно же, из-за неоднозначности, которая пронизывает любой человеческий язык. Говорить о лексической семантике без контекста - всегда упрощение.
У слова "коса" в русском есть как минимум три не связанных друг с другом значения: прическа, часть берега и инструмент.
У слова "бор" два нарицательных значения (сосновый бор и химический элемент бор), а ведь ещё есть физик Нильс Бор.
Дистрибутивным моделям приходится "втискивать" все эти значения в один вектор, и это не всегда получается хорошо.
Решить эту проблему пытались как минимум с 2015 года (в том числе одной из первых попыток стал алгоритм AdaGram Сергея Бартунова и других). Сейчас господствующая парадигма в NLP такова: необходимо учитывать контекст не только при обучении моделей, но и при генерации векторов в практических приложениях. Ведь мы, люди, решаем, в каком именно значении употреблено слово, на основании других слов вокруг него (и общего контекста беседы, конечно).
То есть, на вход модели должно поступать не одно изолированное слово, а последовательность слов (например, предложение). Модель обрабатывает его целиком и генерирует для каждого слова его вектор, учитывая текущий контекст. Таким образом, в предложениях "Она заплела свою длинную косу" и "Возьми косу, коси траву!" для слова "косу" будут сгенерированы два разных вектора.
Подобные модели называются "контекстуализированными" (contextualized embeddings) и являются сейчас новым стандартом в автоматической обработке текста. Поэтому сегодня мы представляем две таких модели для русского языка, которые вы можете скачать вместе с нашими прошлыми моделями. Эти модели обучены при помощи алгоритма Embeddings from Language Models (ELMo), который описан в ныне уже классической статье Мэттью Петерса и других "Deep contextualized word representations" (NAACL-2018) и основан на двуслойной BiLSTM.
Обучающим корпусом послужила русская Википедия за декабрь 2018 года, объединенная с полным НКРЯ (всего около миллиарда слов). Доступны два варианта модели: обученная на сырых словах (ruwikiruscorpora_tokens_elmo_1024_2019) и на леммах (ruwikiruscorpora_lemmas_elmo_1024_2019). В целом, для ELMo лемматизация не так критична, как, например, для word2vec, поскольку на входе модель анализирует символы внутри слова, и похожие по форме токены в любом случае получат схожие репрезентации. Тем не менее, в наших экспериментах модель, обученная на леммах, всё же работала несколько лучше на некоторых задачах. Вы можете самостоятельно определить, что подходит именно вам.
Сервис RusVectōrēs предоставляет множество семантических векторных моделей, обученных при помощи старых добрых дистрибутивных алгоритмов Continuous Bag-of-Words, Continuous Skipgram и fastText. Эти модели достаточно хорошо отражают семантическое пространство русского языка и успешно используются в разнообразных практических задачах. Однако технологии не стоят на месте, и приходит время двигаться дальше.
Один из существенных недостатков всех перечисленных моделей - их "статичность". Что это значит? В word2vec, GloVe, fastText и других "статических" алгоритмах у каждого слова (последовательности символов) после обучения есть ровно один вектор. В каком бы контексте в ваших данных не встретилось это слово, предобученная модель всегда будет сопоставлять ему одну-единственную репрезентацию. Именно поэтому на RusVectōrēs вы можете просто ввести одно слово и получить его вектор.
Почему это проблема? Конечно же, из-за неоднозначности, которая пронизывает любой человеческий язык. Говорить о лексической семантике без контекста - всегда упрощение.
У слова "коса" в русском есть как минимум три не связанных друг с другом значения: прическа, часть берега и инструмент.
У слова "бор" два нарицательных значения (сосновый бор и химический элемент бор), а ведь ещё есть физик Нильс Бор.
Дистрибутивным моделям приходится "втискивать" все эти значения в один вектор, и это не всегда получается хорошо.
Решить эту проблему пытались как минимум с 2015 года (в том числе одной из первых попыток стал алгоритм AdaGram Сергея Бартунова и других). Сейчас господствующая парадигма в NLP такова: необходимо учитывать контекст не только при обучении моделей, но и при генерации векторов в практических приложениях. Ведь мы, люди, решаем, в каком именно значении употреблено слово, на основании других слов вокруг него (и общего контекста беседы, конечно).
То есть, на вход модели должно поступать не одно изолированное слово, а последовательность слов (например, предложение). Модель обрабатывает его целиком и генерирует для каждого слова его вектор, учитывая текущий контекст. Таким образом, в предложениях "Она заплела свою длинную косу" и "Возьми косу, коси траву!" для слова "косу" будут сгенерированы два разных вектора.
Подобные модели называются "контекстуализированными" (contextualized embeddings) и являются сейчас новым стандартом в автоматической обработке текста. Поэтому сегодня мы представляем две таких модели для русского языка, которые вы можете скачать вместе с нашими прошлыми моделями. Эти модели обучены при помощи алгоритма Embeddings from Language Models (ELMo), который описан в ныне уже классической статье Мэттью Петерса и других "Deep contextualized word representations" (NAACL-2018) и основан на двуслойной BiLSTM.
Обучающим корпусом послужила русская Википедия за декабрь 2018 года, объединенная с полным НКРЯ (всего около миллиарда слов). Доступны два варианта модели: обученная на сырых словах (ruwikiruscorpora_tokens_elmo_1024_2019) и на леммах (ruwikiruscorpora_lemmas_elmo_1024_2019). В целом, для ELMo лемматизация не так критична, как, например, для word2vec, поскольку на входе модель анализирует символы внутри слова, и похожие по форме токены в любом случае получат схожие репрезентации. Тем не менее, в наших экспериментах модель, обученная на леммах, всё же работала несколько лучше на некоторых задачах. Вы можете самостоятельно определить, что подходит именно вам.
RusVectores
RusVectōrēs: модели
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
Важно, что контекстуализированные модели устроены радикально иначе, чем "статические", и многие понятия из привычного мира word2vec теряют здесь смысл. Как уже было сказано, здесь нет "вектора слова X", есть только "вектор слова X в предложении Z". Отсутствует в чистом виде и "словарь модели": обработано будет любое слово, состоящее из стандартных символов. Соответственно, нет смысла и усложнять входные данные, добавляя к ним частеречные тэги (как сделано в большинстве старых моделей на RusVectōrēs). В большинстве случаев ELMo может самостоятельно разобраться, на какую часть речи больше похоже текущее слово в текущем предложении.
Ценой за обработку многозначности становятся повышенные требования к вычислительным ресурсам. Теперь модель - это уже не просто таблица векторов, а полноценная рекуррентная нейронная сеть, проходящая по предложениям на входе. Привычная многим библиотека Gensim не умеет работать с ELMo, поэтому мы подготовили минимальный код на Python и Tensorflow, достаточный для извлечения векторов из моделей.
Пока возможно только скачать модели с нашего сервера для локальной работы с ними, но в ближайшие несколько месяцев мы планируем интегрировать их в веб-интерфейс RusVectōrēs (если у вас есть идеи по этому поводу - пишите нам!). Будут и новые модели, обученные на более крупных корпусах. Также скоро ожидается jupyter notebook с тьюториалом по работе с ELMo.
Stay tuned!
Ценой за обработку многозначности становятся повышенные требования к вычислительным ресурсам. Теперь модель - это уже не просто таблица векторов, а полноценная рекуррентная нейронная сеть, проходящая по предложениям на входе. Привычная многим библиотека Gensim не умеет работать с ELMo, поэтому мы подготовили минимальный код на Python и Tensorflow, достаточный для извлечения векторов из моделей.
Пока возможно только скачать модели с нашего сервера для локальной работы с ними, но в ближайшие несколько месяцев мы планируем интегрировать их в веб-интерфейс RusVectōrēs (если у вас есть идеи по этому поводу - пишите нам!). Будут и новые модели, обученные на более крупных корпусах. Также скоро ожидается jupyter notebook с тьюториалом по работе с ELMo.
Stay tuned!
GitHub
GitHub - ltgoslo/simple_elmo: Simple library to work with pre-trained ELMo models in TensorFlow
Simple library to work with pre-trained ELMo models in TensorFlow - ltgoslo/simple_elmo
Продолжаем тему про ELMo-модели, которые мы выложили на днях. У многих мог возникнуть закономерный вопрос: а как оценить качество этих моделей? Стандартные способы из мира статических эмбеддингов (ранжирование пар слов по семантической близости или решение аналогий) тут не подходят, ведь они принимают на вход изолированные слова. Для ELMo же имеет смысл обработка только целых фраз. Поэтому ры решили использовать в качестве базовой оценки качество решения задачи word sense disambiguation (разрешение лексической неоднозначности в контексте). В конце концов, ведь в этом основной смысл контекстуализированных эмбеддингов!
Порядок действий тут очень простой. Допустим, имеется многозначное русское слово "лук". У нас есть 10 предложений, где это слово употреблено в значении "оружие", 10 в значении "овощ" и 5 в значении "внешний вид". Слово одно, но контексты вокруг него разные. Соответственно, ELMo (предположительно) сгенерирует существенно различные репрезентации для слова "лук" в существенно разных контекстах. Мы берём эти 25 эмбеддингов (10 как "оружие", 10 как "овощ" и 5 как "внешний вид") и обучаем простейший классификатор на логистической регрессии, используя вектора "лука" как входные данные, а три значения - как три метки или три класса. Разделяем данные на обучающий и тестовый сеты, обучаемся, оцениваем качество классификации. Чем оно лучше - тем больше в репрезентациях данной модели информации о том, в каком из многих значений слово "лук" употреблено в данном конкретном предложении. Метрика оценки - макро-усредненная F1 score (то есть, каждый смысл одинаково важен, даже если он редкий).
Размеченные данные мы взяли с соревнования RUSSE'18 (недавно почищенный датасет выложила Яндекс-Толока). Изначально он содержал 20 многозначных слов, но чтобы честным образом сравнить лемматизированные и не-лемматизированные модели, мы убрали слова "байка" и "гвоздика", у которых неоднозначность проявляется только в некоторых словоизменительных формах. Таким образом, осталось 18 слов, каждому из которых в среднем сопоставлено около 126 предложений (точнее, кусков текста) и метки соответствующих значений.
Наши модели мы сравнивали с двумя известными нам публичными ELMo для русского: HIT-SCIR ElmoForManyLangs и DeepPavlov. Также на всякий случай мы сравнились с традиционными статическими word2vec-эмбеддингами (в этом случае на вход классификатору подавался средний вектор всех слов в предложении). Итоги такие (чем выше F1 score, тем лучше модель):
- word2vec (lemmas): 0.85
- ElmoForManyLangs: 0.74
- DeepPavlov: 0.88
- RusVectores (tokens): 0.88
- RusVectores (lemmas): 0.91
Как и предполагалось, ELMo существенно лучше в разрешении лексической неоднозначности, чем статические эмбеддинги. Правда, это не касается ElmoForManyLangs, обученной коллегами из Харбина. Их модели (в том числе для русского) использовали очень небольшой корпус, и, скорее всего, просто не успели в достаточной степени выучить семантику. Поэтому эта модель проигрывает даже word2vec (что не помешало этим же моделям выиграть соревнование по синтаксическому парсингу CONLL2018).
По сравнению с ELMo от DeepPavlov, наша модель на токенах находится на том же уровне, а модель на леммах слегка обгоняет. При этом модели с RusVectōrēs в два раза легче, и, соответственно, быстрее. Причина в том, что мы использовали размерность LSTM 2048, вместо значения по умолчанию 4096. Как мы видим, это не приводит к ухудшению качества (по крайней мере, на задаче разрешения неоднозначности).
На этом мы заканчиваем сегодняшний рассказ про ELMo и желаем вам интересных экспериментов! В следующих постах мы расскажем о других аспектах наших новых контекстуализированных эмбеддингов. Пока!
Порядок действий тут очень простой. Допустим, имеется многозначное русское слово "лук". У нас есть 10 предложений, где это слово употреблено в значении "оружие", 10 в значении "овощ" и 5 в значении "внешний вид". Слово одно, но контексты вокруг него разные. Соответственно, ELMo (предположительно) сгенерирует существенно различные репрезентации для слова "лук" в существенно разных контекстах. Мы берём эти 25 эмбеддингов (10 как "оружие", 10 как "овощ" и 5 как "внешний вид") и обучаем простейший классификатор на логистической регрессии, используя вектора "лука" как входные данные, а три значения - как три метки или три класса. Разделяем данные на обучающий и тестовый сеты, обучаемся, оцениваем качество классификации. Чем оно лучше - тем больше в репрезентациях данной модели информации о том, в каком из многих значений слово "лук" употреблено в данном конкретном предложении. Метрика оценки - макро-усредненная F1 score (то есть, каждый смысл одинаково важен, даже если он редкий).
Размеченные данные мы взяли с соревнования RUSSE'18 (недавно почищенный датасет выложила Яндекс-Толока). Изначально он содержал 20 многозначных слов, но чтобы честным образом сравнить лемматизированные и не-лемматизированные модели, мы убрали слова "байка" и "гвоздика", у которых неоднозначность проявляется только в некоторых словоизменительных формах. Таким образом, осталось 18 слов, каждому из которых в среднем сопоставлено около 126 предложений (точнее, кусков текста) и метки соответствующих значений.
Наши модели мы сравнивали с двумя известными нам публичными ELMo для русского: HIT-SCIR ElmoForManyLangs и DeepPavlov. Также на всякий случай мы сравнились с традиционными статическими word2vec-эмбеддингами (в этом случае на вход классификатору подавался средний вектор всех слов в предложении). Итоги такие (чем выше F1 score, тем лучше модель):
- word2vec (lemmas): 0.85
- ElmoForManyLangs: 0.74
- DeepPavlov: 0.88
- RusVectores (tokens): 0.88
- RusVectores (lemmas): 0.91
Как и предполагалось, ELMo существенно лучше в разрешении лексической неоднозначности, чем статические эмбеддинги. Правда, это не касается ElmoForManyLangs, обученной коллегами из Харбина. Их модели (в том числе для русского) использовали очень небольшой корпус, и, скорее всего, просто не успели в достаточной степени выучить семантику. Поэтому эта модель проигрывает даже word2vec (что не помешало этим же моделям выиграть соревнование по синтаксическому парсингу CONLL2018).
По сравнению с ELMo от DeepPavlov, наша модель на токенах находится на том же уровне, а модель на леммах слегка обгоняет. При этом модели с RusVectōrēs в два раза легче, и, соответственно, быстрее. Причина в том, что мы использовали размерность LSTM 2048, вместо значения по умолчанию 4096. Как мы видим, это не приводит к ухудшению качества (по крайней мере, на задаче разрешения неоднозначности).
На этом мы заканчиваем сегодняшний рассказ про ELMo и желаем вам интересных экспериментов! В следующих постах мы расскажем о других аспектах наших новых контекстуализированных эмбеддингов. Пока!
Russian Semantic Evaluation
Russian Word Sense Induction Evaluation
The RUSSE competition will perform a systematic comparison and evaluation of the baseline and the most recent approaches to word sense induction and disambiguation.
На arxiv.org опубликована наша статья, посвященная оценке моделей ELMo на задаче word sense disambiguation. В конце сентября мы представим эту статью на воркшопе конференции NODALIDA 2019, посвященном глубокому обучению в задачах обработки естественного языка.
Forwarded from Системный Блокъ
Семантические сети: как представить значения слов в виде графа
Команда компьютерных лингвистов из школы лингвистики НИУ ВШЭ, университета Тренто и университета Осло под руководством Андрея Кутузова представила на конференции AIST библиотеку vec2graph для Python. Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели.
«Системный Блокъ» уже рассказывал о том, что в основе дистрибутивной семантики — простая идея: близкие по значению слова будут встречаться в похожих контекстах. Чтобы передать знание о контекстной близости слов компьютеру, ученые и инженеры обучают векторные семантические модели — например, с помощью word2vec.
Но как отображать семантические близости из векторной модели так, чтобы они снова стали понятны человеку? Самый простой вариант — выдавать для любого слова столбик ближайших к нему «семантических ассоциатов».
Можно попытаться сжать многомерное векторное пространство модели обратно в двумерное. Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество.
Третья альтернатива — использовать сети (они же графы). Для каждого слова можно строить сеть из его семантических ассоциатов. При этом сам показатель близости отображать, например, через длину линии: чем короче связь — тем ближе слово в векторной модели. Именно такие визуализации делает vec2graph.
https://sysblok.ru/nlp/semanticheskie-seti-kak-predstavit-znachenija-slov-v-vide-grafa/
Команда компьютерных лингвистов из школы лингвистики НИУ ВШЭ, университета Тренто и университета Осло под руководством Андрея Кутузова представила на конференции AIST библиотеку vec2graph для Python. Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели.
«Системный Блокъ» уже рассказывал о том, что в основе дистрибутивной семантики — простая идея: близкие по значению слова будут встречаться в похожих контекстах. Чтобы передать знание о контекстной близости слов компьютеру, ученые и инженеры обучают векторные семантические модели — например, с помощью word2vec.
Но как отображать семантические близости из векторной модели так, чтобы они снова стали понятны человеку? Самый простой вариант — выдавать для любого слова столбик ближайших к нему «семантических ассоциатов».
Можно попытаться сжать многомерное векторное пространство модели обратно в двумерное. Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество.
Третья альтернатива — использовать сети (они же графы). Для каждого слова можно строить сеть из его семантических ассоциатов. При этом сам показатель близости отображать, например, через длину линии: чем короче связь — тем ближе слово в векторной модели. Именно такие визуализации делает vec2graph.
https://sysblok.ru/nlp/semanticheskie-seti-kak-predstavit-znachenija-slov-v-vide-grafa/
RusVectōrēs
Скоро ждите в веб-интерфейсе RusVectōrēs!
Всем привет! Месяц назад мы писали о библиотеке графовой визуализации векторных пространств vec2graph.
Как и было обещано, сегодня мы представляем интеграцию этих визуализаций в веб-интерфейс RusVectōrēs и во фреймворк WebVectors. Динамические интерактивные графы ближайших соседей доступны на главной странице сайта и на страницах отдельных слов (например, тут).
Они могут быть полезны для анализа кластеров соседей у многозначных слов и просто для демонстрации семантических сетей в естественных языках.
Интеграция vec2graph в веб-интерфейс проделана силами нашего волонтёра Анастасии Лисицыной, за что ей большое спасибо!
Как и было обещано, сегодня мы представляем интеграцию этих визуализаций в веб-интерфейс RusVectōrēs и во фреймворк WebVectors. Динамические интерактивные графы ближайших соседей доступны на главной странице сайта и на страницах отдельных слов (например, тут).
Они могут быть полезны для анализа кластеров соседей у многозначных слов и просто для демонстрации семантических сетей в естественных языках.
Интеграция vec2graph в веб-интерфейс проделана силами нашего волонтёра Анастасии Лисицыной, за что ей большое спасибо!
PyPI
vec2graph
Mini-library for producing graph visualizations from embedding models
Мы давно не рассказывали вам об исследованиях, которые в качестве инструментов используют модели RusVectōrēs. Сегодня мы возобновим эту славную традицию и познакомим вас со статьей Полины Паничевой и Татьяны Литвиновой "Semantic Coherence in Schizophrenia in Russian Written Texts". Это исследование использует методы author profiling по отношению к текстам людей, страдающих шизофренией. Главный вопрос исследования - можно ли отличить тексты людей, больных шизофренией, от текстов здоровых людей? Основной признак, по которому сравниваются данные - semantic coherence (семантическая связность).
Семантическая связность определяется как средний коэффициент косинусной близости двух векторов слов, подсчитанный для определенных n-грамм. Например, в предложении "Снесла курочка яичко, да не простое, а золотое" коэффициент семантической связности для триграммы "Снесла курочка яичко" (окно размера 3) подсчитывается как средний коэффициент косинусной близости между векторами слов "снесла" и "курочка", "курочка" и "яичко". Каждый текст характеризуется последовательностью таких коэффициентов для всех n-грамм (в нашем примере выше мы использовали триграммы). Авторы выделяют несколько метрик, с помощью которых можно сравнивать тексты: минимальное и максимальное значения коэффициента семантической связности, среднее значение коэффициента, стандартное отклонение и др. Для вычисления косинусной близости между векторами слов в тексте авторы используют модель RusVectōrēs с идентификатором ruwikiruscorpora_upos_skipgram_300_2_2018.
Исследование показало, что между текстами людей, больных шизофренией, и текстами здоровых людей имеются существенные различия. Авторы добились точности от 0.72 до 0.88 при автоматическом опредлении принадлежности текста к той или иной группе данных. В то же время, анализ результатов для русского языка противоречит исследованиям, проведенным для английского языка. Например, минимальный коэффициент семантической связности оказывается ниже для текстов здоровых людей, в то время как в английском языке прослеживалась обратная тенденция.
В целом, нам кажется, что это интересное исследование демонстрирует, как разнообразны сферы NLP, в которых применимы модели векторной семантики. Успехов авторам, а мы надеемся прочесть ещё множество замечательных статей, где в качестве инструментов используются модели RusVectōrēs!
Семантическая связность определяется как средний коэффициент косинусной близости двух векторов слов, подсчитанный для определенных n-грамм. Например, в предложении "Снесла курочка яичко, да не простое, а золотое" коэффициент семантической связности для триграммы "Снесла курочка яичко" (окно размера 3) подсчитывается как средний коэффициент косинусной близости между векторами слов "снесла" и "курочка", "курочка" и "яичко". Каждый текст характеризуется последовательностью таких коэффициентов для всех n-грамм (в нашем примере выше мы использовали триграммы). Авторы выделяют несколько метрик, с помощью которых можно сравнивать тексты: минимальное и максимальное значения коэффициента семантической связности, среднее значение коэффициента, стандартное отклонение и др. Для вычисления косинусной близости между векторами слов в тексте авторы используют модель RusVectōrēs с идентификатором ruwikiruscorpora_upos_skipgram_300_2_2018.
Исследование показало, что между текстами людей, больных шизофренией, и текстами здоровых людей имеются существенные различия. Авторы добились точности от 0.72 до 0.88 при автоматическом опредлении принадлежности текста к той или иной группе данных. В то же время, анализ результатов для русского языка противоречит исследованиям, проведенным для английского языка. Например, минимальный коэффициент семантической связности оказывается ниже для текстов здоровых людей, в то время как в английском языке прослеживалась обратная тенденция.
В целом, нам кажется, что это интересное исследование демонстрирует, как разнообразны сферы NLP, в которых применимы модели векторной семантики. Успехов авторам, а мы надеемся прочесть ещё множество замечательных статей, где в качестве инструментов используются модели RusVectōrēs!
Анонс от наших коллег:
Мы рады сообщить Вам, что в 2019-2020 году впервые будет проходить соревнование по автоматическому предсказанию гиперонимов для русского языка в рамках 26-й Международной конференции DIALOGUE 2020.
Цель данного соревнования -- автоматически обогатить существующую таксономию (ruWordNet) новыми словами, связав их отношениями гиперонимии с существующими. Для слова, не включенного в тезаурус, необходимо предсказать ранжированный список из 10 синсетов, которые с наибольшей вероятностью могли бы быть гиперонимами для данного слова (гиперонимов может быть больше, чем 1).
Мы полагаем, что современные контекстуальные векторные представления слов, такие как ELMo и BERT, будут особенно эффективны в при поиске гиперонимов, и будем рады увидеть решения, использующие данные подходы (или любые другие) в нашем соревновании. В качестве базовых решений мы предоставим реализации, основанные на дистрибутивной семантике и нейросетевых языковых моделях.
Важные даты:
Начало соревнования: 15 декабря 2019
Публикация тренировочных данных: 15 декабря 2019
Публикация тестовых данных: 31 января 2020
Последний день для отправки решений: 14 февраля 2020
Результаты дорожки: 28 февраля 2020
Контакты для связи с организаторами:
Irina.Nikishina@skoltech.ru
v.logacheva@skoltech.ru
Группа для обсуждения дорожки в Telegram
Мы рады сообщить Вам, что в 2019-2020 году впервые будет проходить соревнование по автоматическому предсказанию гиперонимов для русского языка в рамках 26-й Международной конференции DIALOGUE 2020.
Цель данного соревнования -- автоматически обогатить существующую таксономию (ruWordNet) новыми словами, связав их отношениями гиперонимии с существующими. Для слова, не включенного в тезаурус, необходимо предсказать ранжированный список из 10 синсетов, которые с наибольшей вероятностью могли бы быть гиперонимами для данного слова (гиперонимов может быть больше, чем 1).
Мы полагаем, что современные контекстуальные векторные представления слов, такие как ELMo и BERT, будут особенно эффективны в при поиске гиперонимов, и будем рады увидеть решения, использующие данные подходы (или любые другие) в нашем соревновании. В качестве базовых решений мы предоставим реализации, основанные на дистрибутивной семантике и нейросетевых языковых моделях.
Важные даты:
Начало соревнования: 15 декабря 2019
Публикация тренировочных данных: 15 декабря 2019
Публикация тестовых данных: 31 января 2020
Последний день для отправки решений: 14 февраля 2020
Результаты дорожки: 28 февраля 2020
Контакты для связи с организаторами:
Irina.Nikishina@skoltech.ru
v.logacheva@skoltech.ru
Группа для обсуждения дорожки в Telegram
Всем привет!
На RusVectōrēs появилась новая контекстуализированная ELMo-модель tayga_lemmas_elmo_2048_2019. В отличие от предыдущих, она обучена на большом корпусе Taiga (использовалась лемматизированная версия). Начиная с этого релиза, мы вкладываем в архивы кроме собственно модели в формате HDF5, ещё и исходные TensorFlow-чекпойнты, на случай, если они вам понадобятся (например, если вы собираетесь заниматься language modeling).
Кроме того, в новой модели в два раза больше размерность LSTM (2048x2=4096). Результат налицо: на задаче word sense disambiguation качество (макро-F1 на датасете RUSSE'18) поднялось с 0.91 (модель ruwikiruscorpora_lemmas_elmo_1024_2019) до 0.93. Между прочим, это выше, чем результат RuBERT на той же задаче (0.92), хотя наша модель в два раза легче. Так что BERT побеждает не всегда.
Чтобы не ограничиваться только снятием лексической неоднозначности, мы теперь также тестируем ELMo-модели на задаче детектирования парафразов (фактически - классификация пар документов на три класса). Для этого используется корпус проекта ParaPhraser. Вот F1-метрики наших трёх моделей (и RuBERT для сравнения):
- ruwikiruscorpora_tokens_elmo_1024_2019: 0.55
- ruwikiruscorpora_lemmas_elmo_1024_2019: 0.57
- tayga_lemmas_elmo_2048_2019: 0.54
- ruBERT: 0.35
Интересно, что в этой задаче НКРЯ+Википедия оказывается более полезным обучающим корпусом, чем "Тайга", в отличие от WSD.
Наконец, мы допилили простой код для работы с ELMo-моделями: проект Simple ELMo. С помощью скриптов из этого репозитория вы легко сможете подавать на вход нашим моделям тексты и получать контекстуализированные репрезентации отдельных слов или целых документов. Есть и функции, воспроизводящие нашу оценку на детектировании парафразов. Требуется TensorFlow не ниже 1.15.
С нетерпением ждём ваших комментариев и вопросов!
На RusVectōrēs появилась новая контекстуализированная ELMo-модель tayga_lemmas_elmo_2048_2019. В отличие от предыдущих, она обучена на большом корпусе Taiga (использовалась лемматизированная версия). Начиная с этого релиза, мы вкладываем в архивы кроме собственно модели в формате HDF5, ещё и исходные TensorFlow-чекпойнты, на случай, если они вам понадобятся (например, если вы собираетесь заниматься language modeling).
Кроме того, в новой модели в два раза больше размерность LSTM (2048x2=4096). Результат налицо: на задаче word sense disambiguation качество (макро-F1 на датасете RUSSE'18) поднялось с 0.91 (модель ruwikiruscorpora_lemmas_elmo_1024_2019) до 0.93. Между прочим, это выше, чем результат RuBERT на той же задаче (0.92), хотя наша модель в два раза легче. Так что BERT побеждает не всегда.
Чтобы не ограничиваться только снятием лексической неоднозначности, мы теперь также тестируем ELMo-модели на задаче детектирования парафразов (фактически - классификация пар документов на три класса). Для этого используется корпус проекта ParaPhraser. Вот F1-метрики наших трёх моделей (и RuBERT для сравнения):
- ruwikiruscorpora_tokens_elmo_1024_2019: 0.55
- ruwikiruscorpora_lemmas_elmo_1024_2019: 0.57
- tayga_lemmas_elmo_2048_2019: 0.54
- ruBERT: 0.35
Интересно, что в этой задаче НКРЯ+Википедия оказывается более полезным обучающим корпусом, чем "Тайга", в отличие от WSD.
Наконец, мы допилили простой код для работы с ELMo-моделями: проект Simple ELMo. С помощью скриптов из этого репозитория вы легко сможете подавать на вход нашим моделям тексты и получать контекстуализированные репрезентации отдельных слов или целых документов. Есть и функции, воспроизводящие нашу оценку на детектировании парафразов. Требуется TensorFlow не ниже 1.15.
С нетерпением ждём ваших комментариев и вопросов!
RusVectores
RusVectōrēs: модели
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
Всем привет! Анонс от наших коллег:
Social Media Mining for Health Application workshop (SMM4H) 2020: Дорожка по извлечению упоминаний побочных эффектов из твитов на русском языке
В этом году впервые будет проходить соревнование по автоматическому извлечению упоминаний о побочных эффектах из текстов твитов на русском языке в рамках SMM4H. SMM4H - это ежегодная встреча исследователей, заинтересованных в автоматических методах сбора, извлечения и анализа текстовых данных социальных сетей по теме медицины. В этом году воркшоп будет проходить совместно с конференцией COLING 2020.
Важные даты:
Публикация тренировочных данных: 15 января 2020
Публикация тестовых данных: 2 апреля 2020
Последний день для отправки решений: 5 апреля 2020
Подача статей с описанием решения: 5 мая 2020
Уведомление о принятии статьи с описанием решения: 10 июня 2020
Финальная версия статей: 30 июня 2020
SMM4H воркшоп: 13 сентября 2020
Для участия в дорожке отправьте письмо организаторам на Ivan.Flores@Pennmedicine.upenn.edu со следующей информацией:
(1) имя
(2) аффилиация
(3) ваша электронная почта
(4) имена и электронные почты участников вашей команды
(5) название команды в системе CodaLab
(6) номер дорожки.
Подробная информация:
https://healthlanguageprocessing.org/smm4h-sharedtask-2020/
Social Media Mining for Health Application workshop (SMM4H) 2020: Дорожка по извлечению упоминаний побочных эффектов из твитов на русском языке
В этом году впервые будет проходить соревнование по автоматическому извлечению упоминаний о побочных эффектах из текстов твитов на русском языке в рамках SMM4H. SMM4H - это ежегодная встреча исследователей, заинтересованных в автоматических методах сбора, извлечения и анализа текстовых данных социальных сетей по теме медицины. В этом году воркшоп будет проходить совместно с конференцией COLING 2020.
Важные даты:
Публикация тренировочных данных: 15 января 2020
Публикация тестовых данных: 2 апреля 2020
Последний день для отправки решений: 5 апреля 2020
Подача статей с описанием решения: 5 мая 2020
Уведомление о принятии статьи с описанием решения: 10 июня 2020
Финальная версия статей: 30 июня 2020
SMM4H воркшоп: 13 сентября 2020
Для участия в дорожке отправьте письмо организаторам на Ivan.Flores@Pennmedicine.upenn.edu со следующей информацией:
(1) имя
(2) аффилиация
(3) ваша электронная почта
(4) имена и электронные почты участников вашей команды
(5) название команды в системе CodaLab
(6) номер дорожки.
Подробная информация:
https://healthlanguageprocessing.org/smm4h-sharedtask-2020/
HLP @ Cedars-Sinai Computational Biomedicine
Social Media Mining for Health Applications (#SMM4H) Shared Task 2020
Call For Participation – Shared Task (Click here for the #SMM4H ’20 Call For Papers – Workshop, or click here for the #SMM4H ’19 Shared Task.) The Social Media Mining for Health Applications (#SMM4…
Как векторные семантические модели используются для отслеживания семантических сдвигов во времени:
Forwarded from Системный Блокъ
Семантические сдвиги и предсказание военных конфликтов — в интервью с Андреем Кутузовым
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
{kind=link}
На RusVectōrēs временно отключены индивидуальные странички слов (на которые можно попасть, кликнув на слово, например, в списке ближайших соседей).
Причина в том, что кто-то начал неистово обкачивать эти страницы с разных ip-адресов, игнорируя правила из robots.txt. Это серьёзно замедляло работу всего сервиса в целом.
Мы надеемся, что это временная мера. Если вы знаете, кто занимается автоматизированным краулингом RusVectōrēs - пожалуйста, попросите их связаться с нами. Возможно, мы найдём разумное решение.
Причина в том, что кто-то начал неистово обкачивать эти страницы с разных ip-адресов, игнорируя правила из robots.txt. Это серьёзно замедляло работу всего сервиса в целом.
Мы надеемся, что это временная мера. Если вы знаете, кто занимается автоматизированным краулингом RusVectōrēs - пожалуйста, попросите их связаться с нами. Возможно, мы найдём разумное решение.
Индивидуальные страницы слов вернулись к жизни.
Вот, например, страничка слова "спам" в модели, обученной на НКРЯ и Википедии:
https://rusvectores.org/ru/ruwikiruscorpora_upos_skipgram_300_2_2019/%D1%81%D0%BF%D0%B0%D0%BC/
Вот, например, страничка слова "спам" в модели, обученной на НКРЯ и Википедии:
https://rusvectores.org/ru/ruwikiruscorpora_upos_skipgram_300_2_2019/%D1%81%D0%BF%D0%B0%D0%BC/
RusVectores
Слова, семантически связанные с спам
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания