
Накопилось открытых вкладок.
ML:
ML Feature Serving Infrastructure at Lyft
Flyte Joins LF AI & Data
7 steps to get started with large-scale labeling
Building Riviera: A Declarative Real-Time Feature Engineering Framework
Driving business decisions using data science and machine learning
DE:
How PayPal moves secure and encrypted data across security zones
Data Pipelines @ Samsara
Lessons Learned from Scaling Up Cloudflare’s Anomaly Detection Platform
Data movement for Google services at Netflix
Why Kafka Is so Fast
BigQuery delivers a modern view of materialized views
Прочее:
Gousto Data Team — Best of 2020
You should pick your org chart when looking at a position
ML:
ML Feature Serving Infrastructure at Lyft
Flyte Joins LF AI & Data
7 steps to get started with large-scale labeling
Building Riviera: A Declarative Real-Time Feature Engineering Framework
Driving business decisions using data science and machine learning
DE:
How PayPal moves secure and encrypted data across security zones
Data Pipelines @ Samsara
Lessons Learned from Scaling Up Cloudflare’s Anomaly Detection Platform
Data movement for Google services at Netflix
Why Kafka Is so Fast
BigQuery delivers a modern view of materialized views
Прочее:
Gousto Data Team — Best of 2020
You should pick your org chart when looking at a position
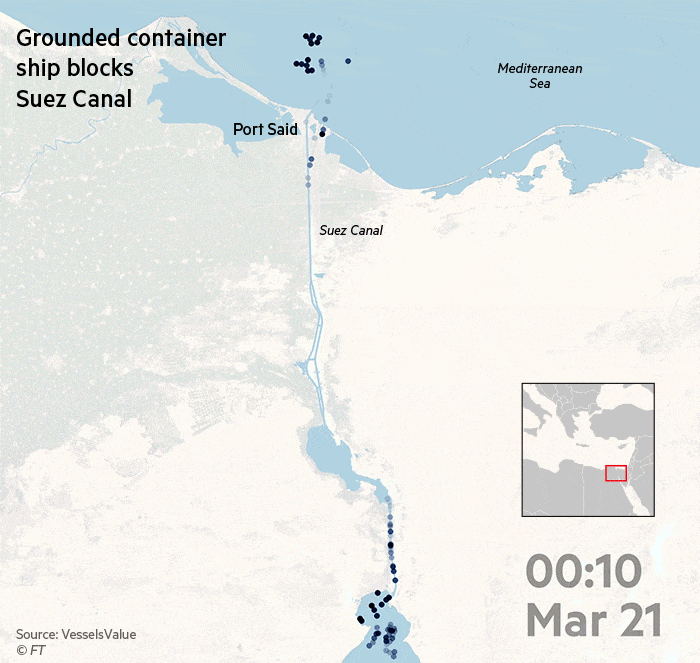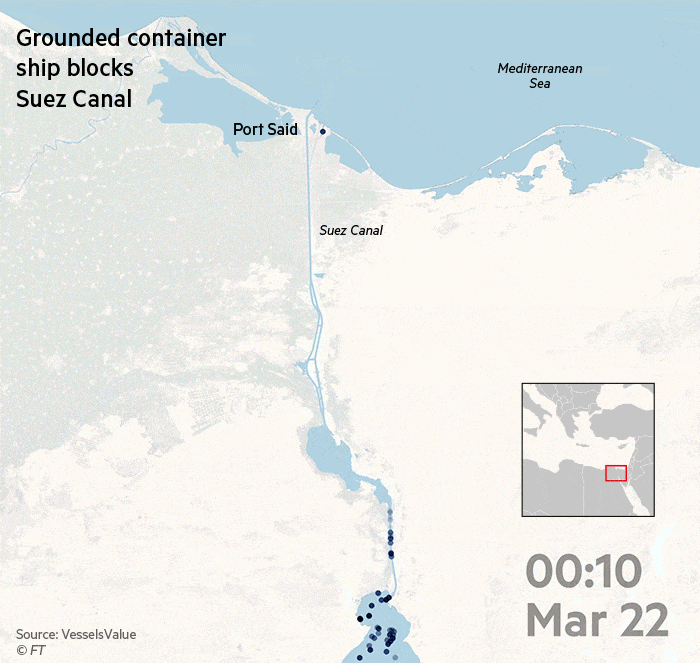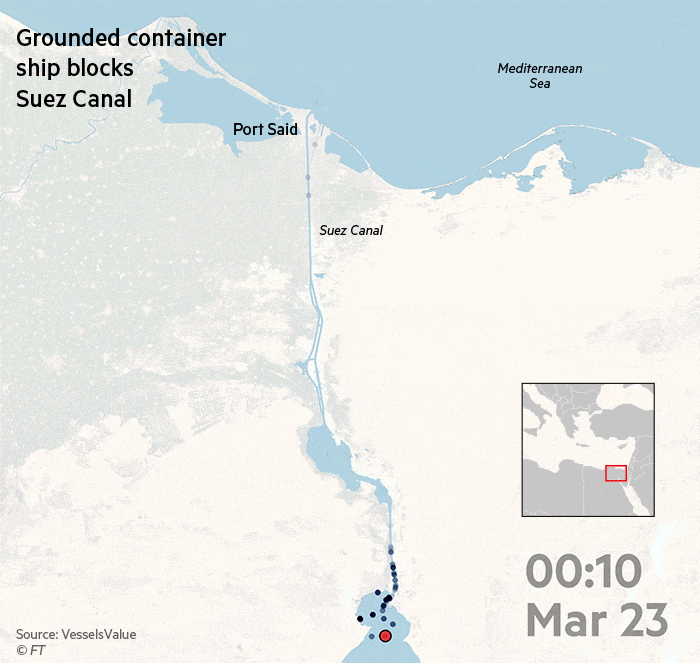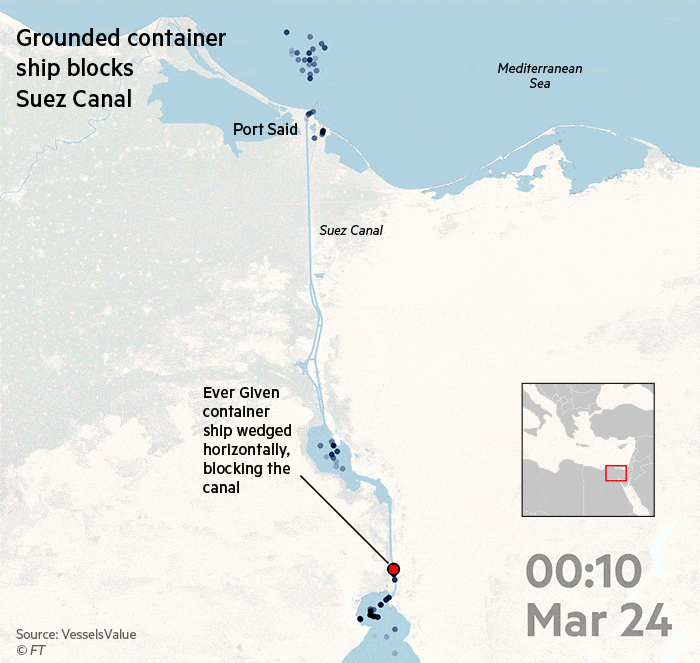
А вот визуализация от Financial Times про Суэйкций канал, который как вы знаете оказался заблокированным. https://www.ft.com/__origami/service/image/v2/images/raw/https%3A%2F%2Fd6c748xw2pzm8.cloudfront.net%2Fprod%2F8863f760-8cc9-11eb-8365-072a5bcc3510-standard.png?dpr=1&fit=scale-down&quality=highest&source=next&width=700
{kind=link}
Последние несколько дней были посвящены - Databricks. И я хочу вам еще порекомендовать 2 инверсных видео на русском от Dodo пицца. Я знал эту компанию раньше, когда с товарищем пытался создать франчайзинг meal prep по доставке еды. У Dodo даже есть книга про их бизнес. Они не только новаторы в России и в Мире по созданию сети пиццерий, но еще и новаторы в области аналитики и инжиниринг данных, и с удовольствием делятся опытом.
-> meetup 3 - Разбор реального проекта: E2E пайплайн данных, на котором они разбирают архитектуру решения на Azure Databricks и говорят про ML, CI/CD, Delta Lake. Мне очень понравилось, так как я сейчас чувствую, что “изобретаю велосипед” для своих проектов, но уже давно все сделали. Да еще и на русском рассказали:)
-> meetup 6 - Delta Lake — table format for large scale storage and analytics. (Запись почему-то пока пропала).
В общем интересные у них митапы, может посмотреть на другие видео.
-> meetup 3 - Разбор реального проекта: E2E пайплайн данных, на котором они разбирают архитектуру решения на Azure Databricks и говорят про ML, CI/CD, Delta Lake. Мне очень понравилось, так как я сейчас чувствую, что “изобретаю велосипед” для своих проектов, но уже давно все сделали. Да еще и на русском рассказали:)
-> meetup 6 - Delta Lake — table format for large scale storage and analytics. (Запись почему-то пока пропала).
В общем интересные у них митапы, может посмотреть на другие видео.
dodobrands.io
Додо Книга - Предисловие
Оглавление Глава 0 Не читай,а слушай. Эта книга в подкасте Как прыгать выше головы, ловить волну, двигать горы и менять мир
аудио Дорогой друг!
Мы счастливы приветствовать тебя среди читателей «Додо Книги». Каждый наш сотрудник, партнер или даже гость входит…
аудио Дорогой друг!
Мы счастливы приветствовать тебя среди читателей «Додо Книги». Каждый наш сотрудник, партнер или даже гость входит…
Forwarded from Smart Data (Denis Solovyov)
Всем привет!
В прошлом посте я начал описывать путь обучения и становления data-инженера. Контент получился подробный, и я решил разделить его на 2 части. В первой части я описал базовые навыки, которыми должен обладать data engineer, чтобы выполнять большую часть бизнес-задач и мог освоить практически любую технологию, связанную с интеграцией и обработкой данных.
Сегодня я опишу, на мой взгляд, уже более специфические навыки, связанные с конкретными инструментами и необходимые для отдельных бизнес-задач.
Итак, мы освоили базовую теорию баз данных, научились писать SQL-запросы, разобрались, что такое ETL, начали кодить на Python и деплоить наш код в production.
Что дальше?
1. Cloud Computing (облачные вычисления). Сейчас очень растёт популярность облачных технологий и всё в большем количестве вакансий в качестве требований для data-инженера отмечается опыт работы с одним из крупных облачных провайдеров - Amazon Web Services, Microsoft Azure и Google Cloud. Здесь, в первую очередь, нам нужно фундаментально понимать принципы облачных вычислений и знать основные модели предоставления услуг от облачных провайдеров: IaaS, PaaS, SaaS (есть ещё производные модели, такие как KaaS и FaaS). Для каждой модели каждый провайдер предоставляет соответствующие сервисы. В первую очередь это касается сервисов из группы Compute, которая составляет костяк любого облака.
После изучения принципов облачных вычислений, понимания основных моделей предоставления услуг и базового изучения инструментов, отвечающих за вычислительные возможности облака важно изучить продукты из группы Storage - второго основного элемента любого cloud. Здесь важно понимать, какие сервисы есть для SQL и NoSQL баз данных, что можно использовать в качестве файлового хранилища (Data Lake), а что в качестве хранилища данных (Data Warehouse).
Это база, которую нужно знать, чтобы понять возможности Cloud. Дальше вы уже можете более глубоко изучать инструменты, которые необходимы для конкретного проекта или задачи.
Очень часто вижу вопрос: "Какое облако учить?"
Мой ответ: всё зависит от того, какое облако чаще используют в вашей стране или какое облако используют компании, в которых вы хотели бы работать.
Лично у меня исторически сложилось так, что я начал работать с Google Cloud, так как я работаю с маркетинговыми данными, а у GCP много удобных бесшовных интеграций с различными маркетинговыми сервисами от Google.
Если же вы работаете или планируете работать с российским рынком, то хорошим вариантом будет Yandex Cloud. Насколько я знаю, в России есть строгие ограничения по хранению данных - данные географически должны храниться в рамках РФ. Т.е. вы не можете использовать сервера, которые находятся за пределами страны, а как раз такие сервера предоставляют 3 крупных провайдера (AWS, Azure и GCP). Yandex Cloud же может предоставить сервера внутри РФ, и вы не будете нарушать закон.
* Возможно, я чего-то не учёл здесь, поэтому поправьте меня в комментариях, если что.
Нужно знать главное - принципы у всех провайдеров одни и те же. Все делают одно и то же, просто сервисы немного отличаются. Но, если вы комфортно чувствуете себя с каким-то одним облаком, вам не составит огромного труда попробовать другое, так как вы будете понимать принципы. Поэтому, это не критически важно, какое конкретное облако вы выберете для изучения. Главное, не хватайтесь за все))Толку от такого изучения будет мало.
В прошлом посте я начал описывать путь обучения и становления data-инженера. Контент получился подробный, и я решил разделить его на 2 части. В первой части я описал базовые навыки, которыми должен обладать data engineer, чтобы выполнять большую часть бизнес-задач и мог освоить практически любую технологию, связанную с интеграцией и обработкой данных.
Сегодня я опишу, на мой взгляд, уже более специфические навыки, связанные с конкретными инструментами и необходимые для отдельных бизнес-задач.
Итак, мы освоили базовую теорию баз данных, научились писать SQL-запросы, разобрались, что такое ETL, начали кодить на Python и деплоить наш код в production.
Что дальше?
1. Cloud Computing (облачные вычисления). Сейчас очень растёт популярность облачных технологий и всё в большем количестве вакансий в качестве требований для data-инженера отмечается опыт работы с одним из крупных облачных провайдеров - Amazon Web Services, Microsoft Azure и Google Cloud. Здесь, в первую очередь, нам нужно фундаментально понимать принципы облачных вычислений и знать основные модели предоставления услуг от облачных провайдеров: IaaS, PaaS, SaaS (есть ещё производные модели, такие как KaaS и FaaS). Для каждой модели каждый провайдер предоставляет соответствующие сервисы. В первую очередь это касается сервисов из группы Compute, которая составляет костяк любого облака.
После изучения принципов облачных вычислений, понимания основных моделей предоставления услуг и базового изучения инструментов, отвечающих за вычислительные возможности облака важно изучить продукты из группы Storage - второго основного элемента любого cloud. Здесь важно понимать, какие сервисы есть для SQL и NoSQL баз данных, что можно использовать в качестве файлового хранилища (Data Lake), а что в качестве хранилища данных (Data Warehouse).
Это база, которую нужно знать, чтобы понять возможности Cloud. Дальше вы уже можете более глубоко изучать инструменты, которые необходимы для конкретного проекта или задачи.
Очень часто вижу вопрос: "Какое облако учить?"
Мой ответ: всё зависит от того, какое облако чаще используют в вашей стране или какое облако используют компании, в которых вы хотели бы работать.
Лично у меня исторически сложилось так, что я начал работать с Google Cloud, так как я работаю с маркетинговыми данными, а у GCP много удобных бесшовных интеграций с различными маркетинговыми сервисами от Google.
Если же вы работаете или планируете работать с российским рынком, то хорошим вариантом будет Yandex Cloud. Насколько я знаю, в России есть строгие ограничения по хранению данных - данные географически должны храниться в рамках РФ. Т.е. вы не можете использовать сервера, которые находятся за пределами страны, а как раз такие сервера предоставляют 3 крупных провайдера (AWS, Azure и GCP). Yandex Cloud же может предоставить сервера внутри РФ, и вы не будете нарушать закон.
* Возможно, я чего-то не учёл здесь, поэтому поправьте меня в комментариях, если что.
Нужно знать главное - принципы у всех провайдеров одни и те же. Все делают одно и то же, просто сервисы немного отличаются. Но, если вы комфортно чувствуете себя с каким-то одним облаком, вам не составит огромного труда попробовать другое, так как вы будете понимать принципы. Поэтому, это не критически важно, какое конкретное облако вы выберете для изучения. Главное, не хватайтесь за все))Толку от такого изучения будет мало.
Forwarded from Smart Data (Denis Solovyov)
Ресурсы для изучения:
AWS Cloud Practitioner Essentials
Data Analytics Fundamentals
Amazon Redshift - Getting Started Guide
Azure Fundamentals part 1: Describe core Azure concepts
Azure Fundamentals part 2: Describe core Azure services
Azure Fundamentals part 3: Describe core solutions and management tools on Azure
Data Engineering, Big Data, and Machine Learning on GCP
Серия постов по Google BigQuery
2. Работа с orchestration tools (или на русском - оркестраторами). Оркестратор - это инструмент, который позволяет объединить все наши этапы по извлечению, трансформации и загрузке данных в единую логическую цепочку, в единый data-пайплайн, чтобы весь ETL-процесс работал слаженно и бесперебойно. Такими инструментами могут выступать:
1) Специализированные решения для оркестрации по типу Apache Airflow, Apache NiFi или Luigi.
2) Готовые ETL-инструменты, такие как AWS Glue, Azure Data Factory, Google Cloud Dataflow, Matillion ETL, Fivetran и др.
Также возможности оркестрации есть в таком инструменте, как Data Build Tool (dbt), но этот инструмент предназначен только для трансформаций данных внутри хранилища данных. Т.е. в ETL он делает T - transform. За E - extract и L - load этот инструмент не отвечает.
Какой из этих инструментов учить зависит, опять-таки, от многих факторов: популярности отдельных инструментов в вашей стране, компании, в которой вы хотите работать, какого-то личного видения и т.д.
Лично я сейчас активно работаю с dbt и решения по типу Apache Airflow ещё не доводилось использовать. Но у меня у самого есть желание хорошо выучить какой-то инструмент для оркестрации всего ETL-процесса и, скорее всего, это будет Airflow, так это решение гибкое - оно не ограничивает вас каким-то одним вендором (как, например, Amazon Glue или Azure Data Factory) и позволяет использовать DevOps-практики. Вы можете развернуть его на локальном сервере или на любом облаке. Но, опять же, повторюсь, всё зависит от многих факторов и тут нужно выбрать инструмент, подходящий конкретно вам. Сразу все инструменты учить нет смысла - достаточно знать один.
3. Spark. Теперь переходим к Big Data. Когда вы работаете уже с очень большими объёмами данных, стандартных решений может быть недостаточно, и вы прибегаете к технологиям параллельной обработки больших массивов данных. Одной из таких технологий является Spark. Так как вы до этого учили Python, то и учить Spark я вам рекомендую, используя уже знакомый вам синтаксис. Этот фреймворк называется PySpark (использовать возможности Spark можно также, программируя на Java или Scala). Хорошим вариантом для изучения PySpark будет использование Databricks Community Edition. Он бесплатный, и там вы можете сразу запускать свой код на PySpark. В общем, очень удобно.
Ресурсы для изучения:
Introduction to PySpark
Big Data Fundamentals with PySpark
Cleaning Data with PySpark
Databricks Community Edition
В принципе, это основные навыки, которые нужны будут вам, чтобы шагнуть на новую ступеньку в развитии вас как data-инженера.
Здесь я не упомянул экосистему Hadoop и сделал это намеренно, так как считаю, что Hadoop - это больше legacy-штука и, со временем, его будут использовать всё реже и реже. Сейчас основной тренд в построении аналитической инфраструктуры направлен на облачные технологии. Это можно увидеть по большому количеству проектов, связанных с миграцией аналитики из on-premise в cloud. В принципе возможности Hadoop можно использовать и в облаке, но не совсем понимаю зачем, если, например, HDFS можно полностью заменить AWS S3, Cloud Storage или Delta Lake, а Hive или Impala - Redshift Spectrum или Google BigQuery.
В общем, я топлю за путь изучения с погружением в Cloud, но вы можете быть со мной не согласны.
После изучения вышеперечисленных технологий и применения их в коммерческих проектах, можно пойти дальше и начать изучать DevOps для data-инжиниринга. В принципе у вас уже есть некоторые знания DevOps-инженера - вы уже изучили Linux и командную строку, Git, Docker и это очень неплохой бекграунд. Теперь можно двигаться дальше и разобраться с более сложными штуками:
AWS Cloud Practitioner Essentials
Data Analytics Fundamentals
Amazon Redshift - Getting Started Guide
Azure Fundamentals part 1: Describe core Azure concepts
Azure Fundamentals part 2: Describe core Azure services
Azure Fundamentals part 3: Describe core solutions and management tools on Azure
Data Engineering, Big Data, and Machine Learning on GCP
Серия постов по Google BigQuery
2. Работа с orchestration tools (или на русском - оркестраторами). Оркестратор - это инструмент, который позволяет объединить все наши этапы по извлечению, трансформации и загрузке данных в единую логическую цепочку, в единый data-пайплайн, чтобы весь ETL-процесс работал слаженно и бесперебойно. Такими инструментами могут выступать:
1) Специализированные решения для оркестрации по типу Apache Airflow, Apache NiFi или Luigi.
2) Готовые ETL-инструменты, такие как AWS Glue, Azure Data Factory, Google Cloud Dataflow, Matillion ETL, Fivetran и др.
Также возможности оркестрации есть в таком инструменте, как Data Build Tool (dbt), но этот инструмент предназначен только для трансформаций данных внутри хранилища данных. Т.е. в ETL он делает T - transform. За E - extract и L - load этот инструмент не отвечает.
Какой из этих инструментов учить зависит, опять-таки, от многих факторов: популярности отдельных инструментов в вашей стране, компании, в которой вы хотите работать, какого-то личного видения и т.д.
Лично я сейчас активно работаю с dbt и решения по типу Apache Airflow ещё не доводилось использовать. Но у меня у самого есть желание хорошо выучить какой-то инструмент для оркестрации всего ETL-процесса и, скорее всего, это будет Airflow, так это решение гибкое - оно не ограничивает вас каким-то одним вендором (как, например, Amazon Glue или Azure Data Factory) и позволяет использовать DevOps-практики. Вы можете развернуть его на локальном сервере или на любом облаке. Но, опять же, повторюсь, всё зависит от многих факторов и тут нужно выбрать инструмент, подходящий конкретно вам. Сразу все инструменты учить нет смысла - достаточно знать один.
3. Spark. Теперь переходим к Big Data. Когда вы работаете уже с очень большими объёмами данных, стандартных решений может быть недостаточно, и вы прибегаете к технологиям параллельной обработки больших массивов данных. Одной из таких технологий является Spark. Так как вы до этого учили Python, то и учить Spark я вам рекомендую, используя уже знакомый вам синтаксис. Этот фреймворк называется PySpark (использовать возможности Spark можно также, программируя на Java или Scala). Хорошим вариантом для изучения PySpark будет использование Databricks Community Edition. Он бесплатный, и там вы можете сразу запускать свой код на PySpark. В общем, очень удобно.
Ресурсы для изучения:
Introduction to PySpark
Big Data Fundamentals with PySpark
Cleaning Data with PySpark
Databricks Community Edition
В принципе, это основные навыки, которые нужны будут вам, чтобы шагнуть на новую ступеньку в развитии вас как data-инженера.
Здесь я не упомянул экосистему Hadoop и сделал это намеренно, так как считаю, что Hadoop - это больше legacy-штука и, со временем, его будут использовать всё реже и реже. Сейчас основной тренд в построении аналитической инфраструктуры направлен на облачные технологии. Это можно увидеть по большому количеству проектов, связанных с миграцией аналитики из on-premise в cloud. В принципе возможности Hadoop можно использовать и в облаке, но не совсем понимаю зачем, если, например, HDFS можно полностью заменить AWS S3, Cloud Storage или Delta Lake, а Hive или Impala - Redshift Spectrum или Google BigQuery.
В общем, я топлю за путь изучения с погружением в Cloud, но вы можете быть со мной не согласны.
После изучения вышеперечисленных технологий и применения их в коммерческих проектах, можно пойти дальше и начать изучать DevOps для data-инжиниринга. В принципе у вас уже есть некоторые знания DevOps-инженера - вы уже изучили Linux и командную строку, Git, Docker и это очень неплохой бекграунд. Теперь можно двигаться дальше и разобраться с более сложными штуками:
Forwarded from Smart Data (Denis Solovyov)
4. CI/CD. В принципе, если вы, имея предыдущие навыки, успели поработать на больших коммерческих проектах, то, скорее всего, вы уже сталкивались с CI/CD и использовали специальные инструменты. CI/CD расшифровывается как Continuous Integration и Continuous Deployment. Это автоматический процесс компиляции, тестирования и деплоя вашего кода и приложений в production. Пример CI/CD пайплайна: вы написали код на Python для вашего ETL и сделали push этого кода через Git на GitHub. После этого запускается так называемый build, который запускает автоматический процесс тестирования и деплоймента вашего кода на рабочий сервер или в Docker-контейнер. Для запуска CI/CD пайплайнов используются специальные сервисы, такие как Jenkins, GitLab CI/CD, Bamboo, Circle CI. Облачные провайдеры имеют свои CI/CD сервисы, например, Google Cloud Build, Azure DevOps или AWS CodePipeline.
Что учить, опять-таки, зависит от компании и проекта. Я, например, в своей работе использую Cloud Build, так как тесно работаю с Google Cloud.
Полезные ресурсы здесь посоветовать сложнее, потому что я учил Cloud Build, просто разбираясь с ним на практике, читая разные статьи и справку Google Cloud. Знаю только хороший курс по Jenkins. Если вы до этого не имели опыта с CI/CD, могу рекомендовать этот курс, так как мне нравится как его автор подаёт материал.
5. Infrastructure as Code (IaC). Это когда мы поднимаем всю инфраструктуру, т.е. создаём сервера, группы серверов, load balancer, кластеры контейнеров, привязываем ip-адреса и т.д., через код. Это очень удобно, когда мы создаём отдельные ресурсы для разных сред (dev, test, prod) и хотим просто скопировать всю инфраструктуру на другой проект.
Сам с таким не работал, но хочу обязательно получить такой опыт)
Для IaC также используются свои сервисы, такие как Terraform, AWS CloudFormation, Ansible, Puppet и др. Часто слышу о первых 3-х. Какой из них изучать, снова-таки, зависит от компании и проекта.
Полезные ресурсы:
Курс по Terraform
Урок по AWS Cloud Formation
Думаю, на этом закончим. Как вы смогли увидеть, путь становления data-инженером высокого уровня длинный и интересный. Очень много различных технологий и инструментов. С таким скоупом не соскучишься:)
В следующих постах хочу рассказать о том, что учить и в каком порядке для других специализаций, опираясь на свой опыт и опыт коллег по рынку. Эти пути могут быть не менее интересными для вас:)
Что учить, опять-таки, зависит от компании и проекта. Я, например, в своей работе использую Cloud Build, так как тесно работаю с Google Cloud.
Полезные ресурсы здесь посоветовать сложнее, потому что я учил Cloud Build, просто разбираясь с ним на практике, читая разные статьи и справку Google Cloud. Знаю только хороший курс по Jenkins. Если вы до этого не имели опыта с CI/CD, могу рекомендовать этот курс, так как мне нравится как его автор подаёт материал.
5. Infrastructure as Code (IaC). Это когда мы поднимаем всю инфраструктуру, т.е. создаём сервера, группы серверов, load balancer, кластеры контейнеров, привязываем ip-адреса и т.д., через код. Это очень удобно, когда мы создаём отдельные ресурсы для разных сред (dev, test, prod) и хотим просто скопировать всю инфраструктуру на другой проект.
Сам с таким не работал, но хочу обязательно получить такой опыт)
Для IaC также используются свои сервисы, такие как Terraform, AWS CloudFormation, Ansible, Puppet и др. Часто слышу о первых 3-х. Какой из них изучать, снова-таки, зависит от компании и проекта.
Полезные ресурсы:
Курс по Terraform
Урок по AWS Cloud Formation
Думаю, на этом закончим. Как вы смогли увидеть, путь становления data-инженером высокого уровня длинный и интересный. Очень много различных технологий и инструментов. С таким скоупом не соскучишься:)
В следующих постах хочу рассказать о том, что учить и в каком порядке для других специализаций, опираясь на свой опыт и опыт коллег по рынку. Эти пути могут быть не менее интересными для вас:)
YouTube
Jenkins - Автоматизация CI/CD - Полный Курс на Простом Языке
#devops #девопс #jenkins #ityoutubersru
1-Jenkins - Автоматизация CI/CD
Если помог, поддержите парой баксов, хотябы Канадских :) https://www.paypal.me/DenisAstahov
1-Jenkins - Автоматизация CI/CD
Если помог, поддержите парой баксов, хотябы Канадских :) https://www.paypal.me/DenisAstahov
Мужик затронул очень важную тему - “Дети и карьера”. Для нас вроде как это нормально заводить детей и не откладывать это на потом. Мы не стремимся сделать карьеру, мы понимаем важность семьи, мы пользуемся помощью родителей (бабушек и дедушек). И наш род продолжается. Но в Северной Америке, да и в Европе наверно, все не так. Дети уходят от родителей в 18 лет. Еле еле сводят концы с концами, копят на первоначальный взнос, кредиты, карьерный рост, короткий декретный отпуск. Как результат, детей заводят после 35-40, если конечно здоровье к тому времени это позволяет. Люди предпочитают заводить собак и кошек. Институт семьи разрушается.В целом на мой взгляд ситуация не очень хорошая. Зато у иммигрантов из арабских стран, Индии и тп, дела обстоят иначе. У них очень сильны традиции, они перевозят родителей, родственников, которые помогают растить детей, пока молодишь учиться и работает. Мне кажется пропорция население в следующие лет 10 кардинально изменится, потому что белое население решает карьерные, ипотечные вопросы, гонится за развлечениями и откладывают создание семьи на потом. Еще решают вопросы связанные с diversity&inclusion, равные права и все в этом духе.
Возможно это мой bias, так как у меня есть 3ое детей, а вот у многих коллег в Amazon и Microsoft есть только питомцы, а про детей пока не особо задумываются. По опыту дети очень мотивируют и помогают принимать правильные решения, которые способствуют достижению карьерных целей, иметь хороший work life balance и не дают скучать, ну и от выгорания на работе помогают. Ну и конечно моей жене нужно памятник поставить за домашний уют и сытых/опрятных детей🥰
Возможно это мой bias, так как у меня есть 3ое детей, а вот у многих коллег в Amazon и Microsoft есть только питомцы, а про детей пока не особо задумываются. По опыту дети очень мотивируют и помогают принимать правильные решения, которые способствуют достижению карьерных целей, иметь хороший work life balance и не дают скучать, ну и от выгорания на работе помогают. Ну и конечно моей жене нужно памятник поставить за домашний уют и сытых/опрятных детей🥰
YouTube
Is Having Kids worth it...? (as a millionaire)
Ex-Google TechLead on having kids. 💵 [LIMITED TIME] Get 2 FREE Stocks on WeBull (Deposit $100 and get 2 stocks valued up to $1600): https://act.webull.com/k/S4oOH2yGOtHk/main
Join ex-Google/ex-Facebook engineers for my coding interview training: https://…
Join ex-Google/ex-Facebook engineers for my coding interview training: https://…
Forwarded from Reveal the Data
На этой неделе провёл небольшой мастер-класс про визуализацию личных данных в Вастрик Клубе:
— Показал примеры визуализаций про себя и где можно легко собирать свои личные данные;
— Сделал небольшой обзор Табло и показал как в нём создать простую визуализацию;
— Построили вместе с участниками дашборд про чатик в телеграмме и посмотрели свои перемещения на карте.
Было интересно выступить перед аудиторией не из тусовки датавиза и BI, и рассказать про визуализацию как хобби.
Презентация с ссылками
#выступление
— Показал примеры визуализаций про себя и где можно легко собирать свои личные данные;
— Сделал небольшой обзор Табло и показал как в нём создать простую визуализацию;
— Построили вместе с участниками дашборд про чатик в телеграмме и посмотрели свои перемещения на карте.
Было интересно выступить перед аудиторией не из тусовки датавиза и BI, и рассказать про визуализацию как хобби.
Презентация с ссылками
#выступление
YouTube
Роман Бунин — Bизуализация данных о себе без страха и кода (Мастер-класс)
Презентация тут: https://drive.google.com/file/d/1QEfnzAN0K1k3KMtGWMI3fKn-ZNun5rmW/view?usp=sharing
Сервисы собирают про нас огромное количество данных, но мы их с вами обычно не используем и не замечаем их. На мастер-классе мы поговорим о том, как можно…
Сервисы собирают про нас огромное количество данных, но мы их с вами обычно не используем и не замечаем их. На мастер-классе мы поговорим о том, как можно…
Сравнение форматов файлов для озера данных.https://medium.com/adaltas/storage-size-and-generation-time-in-popular-file-formats-48a23190c1da
Medium
Storage size and generation time in popular file formats
Performance comparison in terms of storage usage and generation time for popular file formats (ORC, Parquet, CSV, JSON, AVRO)
Все без изменений, Oracle обижен на Amazon, после того, как Амазон отказался от Oracle в качестве хранилища данных и backend для интернет магазина.
У AWS куча ресурсов, и они обязательно нагонят и обгонят лидеров рынка. Также как и Microsoft и Google. В 2018/2019 у снежинки было преимущество, но уже конкуренты догоняют.
21 год будет за Databricks, особенно если выйдут на IPO. А там дальше видно будет.
У AWS куча ресурсов, и они обязательно нагонят и обгонят лидеров рынка. Также как и Microsoft и Google. В 2018/2019 у снежинки было преимущество, но уже конкуренты догоняют.
21 год будет за Databricks, особенно если выйдут на IPO. А там дальше видно будет.
Завтра в 4:30 pm по Альберте, расскажу и покажу Snowflake+Tableau для их user group
https://lnkd.in/gNKeHxc
https://lnkd.in/gNKeHxc
Forwarded from Data Apps Design (Artemiy Kzr)
Ура! Новый пост.
2+ года dbt в продакшн в управлении Хранилищем Данных.
- Структура хранилища + бизнес-вертикали
- Оптимизация физического хранения в Redshift
- SQL + Jinja = Flexibility
- Macro: UDF, currency exchange
- Importing modules: calendar, external data, logging
- Deployment with dbt Cloud: Schedule + Webhooks, Slack notifications
Мультитул для управления Хранилищем Данных — кейс Wheely + dbt
2+ года dbt в продакшн в управлении Хранилищем Данных.
- Структура хранилища + бизнес-вертикали
- Оптимизация физического хранения в Redshift
- SQL + Jinja = Flexibility
- Macro: UDF, currency exchange
- Importing modules: calendar, external data, logging
- Deployment with dbt Cloud: Schedule + Webhooks, Slack notifications
Мультитул для управления Хранилищем Данных — кейс Wheely + dbt
Хабр
Мультитул для управления Хранилищем Данных — кейс Wheely + dbt
Уже более двух лет data build tool активно используется в компании Wheely для управления Хранилищем Данных. За это время накоплен немалый опыт, мы на тернистом пути проб и ошибок к совершенству в...
Forwarded from DataEng
Про data engineering для тех, кто не в теме: https://www.youtube.com/watch?v=qWru-b6m030
Классное вводное видео.
Классное вводное видео.
YouTube
How Data Engineering Works
So, the sole purpose of data engineering is to take data from the source and save it to make it available for analysis. Sounds simple, but it’s the matter of the system that works under the hood.
Watch our video to find out more about data engineering:
00:00…
Watch our video to find out more about data engineering:
00:00…
У Tableau есть свой онлайн магазин, и цены там совсем не высокие. https://bdasites.com/tableau/Main/Default
Конечно заказать в Россию не просто, но наверно возможно, через службы, которые делают вам американский адрес. Я себе маску Data Rock Star заказал, будут теперь из офиса работать, там нужно в маске сидеть.
Конечно заказать в Россию не просто, но наверно возможно, через службы, которые делают вам американский адрес. Я себе маску Data Rock Star заказал, будут теперь из офиса работать, там нужно в маске сидеть.
Анастасия записала урок 2 2го модуля. https://youtu.be/p2R8eK5ljAA
YouTube
ML-101 | Module 02 | Lesson 02 | Regression: Practice | Anastasia Rizzo
Курс Getting Started with Machine Learning and Data Science (ML-101).
В этом уроке мы сделаем практический регрессионный кейс.
⚠️ Для эффективного прохождения курса необходимо зарегистрироваться в Slack (наш чат) и читать гид на Github, в котором рассказывается…
В этом уроке мы сделаем практический регрессионный кейс.
⚠️ Для эффективного прохождения курса необходимо зарегистрироваться в Slack (наш чат) и читать гид на Github, в котором рассказывается…
Уже на следующей неделе пройдет первая в своем роде русскоязычная онлайн-конференция по продуктовой аналитике Aha!'21. Организаторы собрали убедительную программу:
- 20% - про монетизацию: из каких шагов состоит оптимальная воронка активации, как определить шаги (моменты) воронки, применение фреймворка от Reforge на практике и др.
- 20% - технологический стек - от работы с Power BI и Amplitude до Яндекс.Облака и Exasol.
- 20% - эксперименты: оценке долгосрочных эффектов после проведения эксперимента, этапам эволюции in-house системы экспериментов в любой компании, проверке качества систем сплитования трафика и мн. др.
- Много внимания уделено системам автоматического поиска инсайтов в данных, поиску, анализу и автоматизации процесса обнаружения аномалий, как находить инсайты по оптимизации монетизации. После этого, подходы к определению product market fit и обнаружению aha-моментов. Оргам удалось согласовать Q&A-сессию с вице-президентом Sequoia Capital (!!!) - самым успешным венчурным фондом в мире - они то уж точно знают что к чему в деньгах и продуктах + еще десяток тем и дискуссий. Подробная программа конференции.
🔥 Не пропускайте конференцию - промокод - LASTCALL - дает скидку 10% - регистрируйтесь!
❗️Важно! Все материалы — видео, презентации, мастер-классы, доступы в чаты - бессрочно доступны участникам в записи сразу после трансляции. Вещание студийного качества в формате FullHD, с возможностью поставить прямой эфир на паузу и потом ускорить. Если вы пропустили что-то в прямом эфире — не страшно! Вопросы к спикерам собираются в течение 1,5-2 недель и потом проводится общий Q&A Zoom со спикерами.
Помните - ничто не освобождает вас от знания матчасти!
- 20% - про монетизацию: из каких шагов состоит оптимальная воронка активации, как определить шаги (моменты) воронки, применение фреймворка от Reforge на практике и др.
- 20% - технологический стек - от работы с Power BI и Amplitude до Яндекс.Облака и Exasol.
- 20% - эксперименты: оценке долгосрочных эффектов после проведения эксперимента, этапам эволюции in-house системы экспериментов в любой компании, проверке качества систем сплитования трафика и мн. др.
- Много внимания уделено системам автоматического поиска инсайтов в данных, поиску, анализу и автоматизации процесса обнаружения аномалий, как находить инсайты по оптимизации монетизации. После этого, подходы к определению product market fit и обнаружению aha-моментов. Оргам удалось согласовать Q&A-сессию с вице-президентом Sequoia Capital (!!!) - самым успешным венчурным фондом в мире - они то уж точно знают что к чему в деньгах и продуктах + еще десяток тем и дискуссий. Подробная программа конференции.
🔥 Не пропускайте конференцию - промокод - LASTCALL - дает скидку 10% - регистрируйтесь!
❗️Важно! Все материалы — видео, презентации, мастер-классы, доступы в чаты - бессрочно доступны участникам в записи сразу после трансляции. Вещание студийного качества в формате FullHD, с возможностью поставить прямой эфир на паузу и потом ускорить. Если вы пропустили что-то в прямом эфире — не страшно! Вопросы к спикерам собираются в течение 1,5-2 недель и потом проводится общий Q&A Zoom со спикерами.
Помните - ничто не освобождает вас от знания матчасти!
matemarketing.timepad.ru
Aha! Лови момент / События на TimePad.ru
Aha! – международная практическая онлайн-конференция по продвинутой продуктовой аналитике. Среди спикеров конференции представители крупных российских и зарубежных компаний: Avito, Яндекс, Amplitude, Flo, MIRO и др. Целевая аудитория —продуктовые аналитики…