
Forwarded from Vox mediaevistae
Только что закончилась последняя сессия IMC в Лидсе. На этот слот пришлась и наша с @verbaliquida секция. Я сделала доклад дистанционно, потому что мой паспорт все еще в заложниках в британском визовом центре. Это ужасно обидно: и денег жаль, и всех невстреченных. В этом году в IMC очно участвовало четыре члена редколлегии Вокса, невиданное дело.
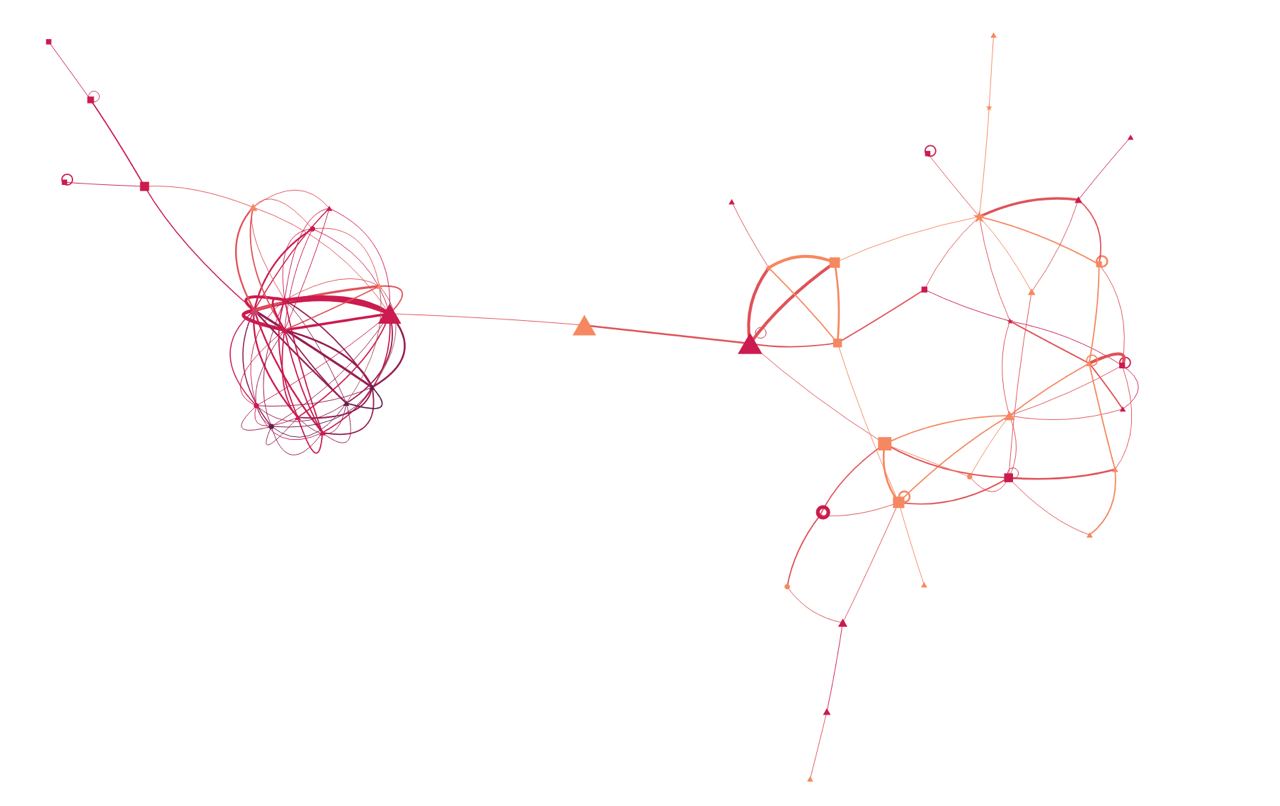
Я рассказала про эксперименты с построением сетей рукописей, в которых циркулировал Breviloquium. Вот визуализация, которой горжусь: на ней узлы — это рукописи, которые, помимо Breviloquium’а, делят с соседями еще хотя бы два других текста. Размер узла пропорционален его степени посредничества, а его форма указывает на размер сборника (в точках меньше 5 тектов, в треугольниках — от 5 до 10, в квадратах — от 15 до 25, и так далее, по мере нарастания углов у фигур). Цвет указывает на век создания рукописи (фиолетовые — XIII век, желтые — XVI).
На этом графе видно, что есть два плотных кластера, один относится к XIII-XIV вв., эти рукописи происходят из Франции и северной Италии, в них содержатся преимущественно сочинения Иоанна Уэльского, видимо, они связаны с францисканскими интеллектуальными центрами. Второй кластер происходит из Богемии и Германии, в этих рукописях можно найти младшую редакцию Breviloquium’а, контаминированную трактатом Якопо да Чессоле об игре в шахматы. А объединяет их рукопись из Кортоны, в которой, среди прочего, содержится единственное дошедшее до наших дней житие Иоанна. О житие я в докладе сказать не успела, но деталь эта трогательная, по-моему.
Код посмотреть и порассматривать сетки можно тут.
Я рассказала про эксперименты с построением сетей рукописей, в которых циркулировал Breviloquium. Вот визуализация, которой горжусь: на ней узлы — это рукописи, которые, помимо Breviloquium’а, делят с соседями еще хотя бы два других текста. Размер узла пропорционален его степени посредничества, а его форма указывает на размер сборника (в точках меньше 5 тектов, в треугольниках — от 5 до 10, в квадратах — от 15 до 25, и так далее, по мере нарастания углов у фигур). Цвет указывает на век создания рукописи (фиолетовые — XIII век, желтые — XVI).
На этом графе видно, что есть два плотных кластера, один относится к XIII-XIV вв., эти рукописи происходят из Франции и северной Италии, в них содержатся преимущественно сочинения Иоанна Уэльского, видимо, они связаны с францисканскими интеллектуальными центрами. Второй кластер происходит из Богемии и Германии, в этих рукописях можно найти младшую редакцию Breviloquium’а, контаминированную трактатом Якопо да Чессоле об игре в шахматы. А объединяет их рукопись из Кортоны, в которой, среди прочего, содержится единственное дошедшее до наших дней житие Иоанна. О житие я в докладе сказать не успела, но деталь эта трогательная, по-моему.
Код посмотреть и порассматривать сетки можно тут.
{kind=link}
👍7❤3👏3
Forwarded from Vox mediaevistae
manuscripts_network_strong_edges.html
722.9 KB
А вот файл, который можно позумить и потрогать.
Нужно знать, что Акакий Акакиевич изъяснялся большею частью предлогами, наречиями и, наконец, такими частицами, которые решительно не имеют никакого значения.
“Дельта Берроуза”, — догадался Штирлиц.
😁20🤣9❤3
RAntiquity
Photo
История получила продолжение; за усовершенствованный токенайзер спасибо agricolamz.
Telegram
Antibarbari HSE
Несколько лет назад антиварвары читали платоновского «Филеба» (плейлист), и все это время пользовались русским переводом Н.В. Самсонова, вошедшим в четырехтомник под редакцией А.Ф. Лосева. Сравнительно недавно, однако, нам удалось узнать кое-что новое и о…
🔥5🥰4❤2
Дорогие друзья, ушла в отпуск; ближе к сентябрю канал снова оживет! Пока набираюсь сил и идей для новых проектов.
👍27❤🔥10🐳4☃1
Forwarded from Boris Orekhov
Демонтаж красноречия
Разминулись
Был такой важный человек для современной науки о компьютерной атрибуции, Винценты Лютославский. Это он, по всей видимости, придумал слово «стилометрия». Учился одновременно на химика и философа, и вообще был мыслителем нетривиальным. В связи с платоновским…
👍3❤1🔥1
Boris Orekhov
https://schonenrede.hypotheses.org/305
Началось все с того, что Лютославский, оказывается был учеником Тейхмюллера, учился у него в Дерпте (Тарту), тогда это была территория Российской империи. У Тейхмюллера была большая семья, 9 детей, в Базеле ему было тяжело их обеспечивать, а в Дерпте ему предложили хорошие условия.
В моем сознании Тейхмюллер как исследователь Платона и Аристотеля и Лютославский как “стилометрист” до сих пор существовали отдельно. Но все намного сложнее: как выясняется, их объединяют в Юрьевскую школу неолейбницианства, которая оказала влияние, например, на Лосского.
(Простите, я и правда в отпуске, но такой интересный сюжет).
В моем сознании Тейхмюллер как исследователь Платона и Аристотеля и Лютославский как “стилометрист” до сих пор существовали отдельно. Но все намного сложнее: как выясняется, их объединяют в Юрьевскую школу неолейбницианства, которая оказала влияние, например, на Лосского.
(Простите, я и правда в отпуске, но такой интересный сюжет).
🔥9⚡1❤🔥1
Свежий обзор новейших МО-штуковин для древних языков: https://direct.mit.edu/coli/article/49/3/703/116160/Machine-Learning-for-Ancient-Languages-A-Survey
вникать буду позже, пока чтобы не потерять
вникать буду позже, пока чтобы не потерять
👀10👍4
Forwarded from aGricolaMZ
Дорогие все, вышел мой онлайн курс "Введение в анализ данных на R для гуманитарных и социальных наук" (https://openedu.ru/course/hse/IDAR/). Основная его концепция: только
- возможные продолжения дразнилки "Жадина-говядина" из исследования N+1
- роман Ф. М. Достоевского “Бесы”
- эпистолярные романы
- данные кладов Римских монет (https://chre.ashmus.ox.ac.uk/)
- время работы библиотек России
- высота и ширина утерянных или похищенных картин из музеев России
- многоязычие в Дагестане
- количество человек с злокачественными новообразованиями
- описания и рецепты из онлайн-магазина китайского чая
- и другие
Все формулировки заданий и код с решениями у меня в quarto занимают 20 тысяч строк.
Из смешного: одна из идей про датасет библиотек России так и не вылилась в задание на курсе, но вылилась в мою первую data-driven задачку.
Структуру курса я уже поменять не смогу, но если вы найдете опечатки или стилистические огрехи на сайте курса — пишите, я буду очень рад.
tidyverse и ноль программирования: я ставил себе цель, чтобы слушатели после окончания курса, получив данные, могли их обозреть и получить какие-то первые инсайты. Статистики в курсе всего одна неделя из девяти. К сожалению, я узнал, что Вышка дает посмотреть только две недели бесплатно, а потом просит денег (я даже увижу какую-то долю этих денег, если продолжу работать в Вышке). Но я не унываю, потому что в целом смотреть на видео как я блею на самом деле не очень интересно. Ведь я почти доделал онлайн ноутбук (https://agricolamz.github.io/daR4hs/) с комментариями и всем кодом, и он полностью открыт. Cейчас не хватает только последнего раздела про quarto. Для онлайн курса я подготовил достаточно большой пул заданий. Большинство заданий предполагает анализ какого-то датасета (и я потратил много времени, чтобы их собрать и сделать удобными ля заданий), поэтому я предлагаю оценить разброс:- возможные продолжения дразнилки "Жадина-говядина" из исследования N+1
- роман Ф. М. Достоевского “Бесы”
- эпистолярные романы
- данные кладов Римских монет (https://chre.ashmus.ox.ac.uk/)
- время работы библиотек России
- высота и ширина утерянных или похищенных картин из музеев России
- многоязычие в Дагестане
- количество человек с злокачественными новообразованиями
- описания и рецепты из онлайн-магазина китайского чая
- и другие
Все формулировки заданий и код с решениями у меня в quarto занимают 20 тысяч строк.
Из смешного: одна из идей про датасет библиотек России так и не вылилась в задание на курсе, но вылилась в мою первую data-driven задачку.
Структуру курса я уже поменять не смогу, но если вы найдете опечатки или стилистические огрехи на сайте курса — пишите, я буду очень рад.
agricolamz.github.io
Введение в анализ данных на R для гуманитарных и социальных наук
🔥19❤6👍2
RAntiquity
Дорогие все, вышел мой онлайн курс "Введение в анализ данных на R для гуманитарных и социальных наук" (https://openedu.ru/course/hse/IDAR/). Основная его концепция: только tidyverse и ноль программирования: я ставил себе цель, чтобы слушатели после окончания…
Часто спрашивают, где же “всему этому” научиться. Вот. Георгий Мороз записал новый онлайн-курс по R, и это должно быть очень хорошо. Записываемся, ставим лайки.
❤14🔥6
Forwarded from Гуманитарии в цифре
Восьмая школа по гуманитарной информатике в Калининграде
12–14 декабря 2024 года на базе БФУ имени И. Канта пройдет VIII школа по гуманитарной информатике (KDH2024).
Принять участие в Школе можно в качестве слушателя, докладчика или спикера. К участию приглашаются студенты и молодые ученые, использующие в своей научной или учебной деятельности математические методы и цифровые технологии.
В программе мастер-классы, семинары и лекции по тематикам:
→ Количественные методы в исторических исследованиях и компьютерное источниковедение
→ Оцифровка исторических источников и виртуальная реконструкция историко-культурного наследия (3D-моделирование, фотограмметрия)
→ Базы данных и (гео)информационные системы в гуманитарных исследованиях и образовании
→ Компьютерная и корпусная лингвистика, цифровая филология
→ Анализ данных, нейросетевые и другие технологии искусственного интеллекта в прикладном аспекте.
⏳🔴 Заявки на участие в Школе принимаются до 1 октября 2024 года по ссылке
⏳🔴 Статьи для публикации в сборнике Школы (РИНЦ) принимаются до 10 октября 2024 года на digitalbfu2017@gmail.com
Подробная информация будет публиковаться в официальной группе Школы
#KDH2024 #KDH
12–14 декабря 2024 года на базе БФУ имени И. Канта пройдет VIII школа по гуманитарной информатике (KDH2024).
Принять участие в Школе можно в качестве слушателя, докладчика или спикера. К участию приглашаются студенты и молодые ученые, использующие в своей научной или учебной деятельности математические методы и цифровые технологии.
В программе мастер-классы, семинары и лекции по тематикам:
→ Количественные методы в исторических исследованиях и компьютерное источниковедение
→ Оцифровка исторических источников и виртуальная реконструкция историко-культурного наследия (3D-моделирование, фотограмметрия)
→ Базы данных и (гео)информационные системы в гуманитарных исследованиях и образовании
→ Компьютерная и корпусная лингвистика, цифровая филология
→ Анализ данных, нейросетевые и другие технологии искусственного интеллекта в прикладном аспекте.
⏳
⏳
Подробная информация будет публиковаться в официальной группе Школы
#KDH2024 #KDH
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6
Forwarded from Boris Orekhov
Всем привет!
В пятницу, 16 августа в 14:00 (по МСК) встретимся в прямом эфире Moscow Python Podcast с Борисом Ореховым, кандидатом филологических наук и доцентом факультета гуманитарных наук НИУ ВШЭ. В выпуске мы обсудим:
🟡 в чём особенности обучения программированию гуманитариев;
🟡 что общего между естественным языком и языком программирования;
🟡 какие библиотеки востребованы у гуманитариев;
🟡 зачем кандидату филологических наук изучать программирование.
➡️ Когда: 16 августа в 14:00 по Москве.
➡️ Где: онлайн и в записи по ссылке.
В пятницу, 16 августа в 14:00 (по МСК) встретимся в прямом эфире Moscow Python Podcast с Борисом Ореховым, кандидатом филологических наук и доцентом факультета гуманитарных наук НИУ ВШЭ. В выпуске мы обсудим:
Please open Telegram to view this post
VIEW IN TELEGRAM
YouTube
Зачем гуманитариям изучать Python?
Спонсор подкаста: Learn Python Advanced — курсы по Python-разработке для тех, кто уже знаком с веб-разработкой — https://learn.python.ru/advanced
Ведущие – Григорий Петров и Михаил Корнеев
Ссылки выпуска:
Курс Learn Python — https://learn.python.ru/advanced…
Ведущие – Григорий Петров и Михаил Корнеев
Ссылки выпуска:
Курс Learn Python — https://learn.python.ru/advanced…
🔥6❤🔥1
RAntiquity
Вопрос о распределениях слов в стихе получил развитие на форуме Cross Validated. 1️⃣ T-test в целом может использоваться на дискретных данных, если распределение унимодально и симметрично. Вообще непрерывные данные даже в случае с ростом (который приводится…
История с распределением слов в гекзаметре получила продолжение: https://t.me/antibarbari/2509
Будет развитие, ждем #гомер
Будет развитие, ждем #гомер
Telegram
Antibarbari HSE
Есть ли разница между гекзаметром, предназначенным для устного исполнения, и гекзаметром, предназначенным для чтения?
Подсчеты показали: при метрической и тематической схожести «Илиады» Гомера и «Аргонавтики» Аполлония Родосского в поэме Гомера на один стих…
Подсчеты показали: при метрической и тематической схожести «Илиады» Гомера и «Аргонавтики» Аполлония Родосского в поэме Гомера на один стих…
❤4
Недавно @aGricolaMZ обратил мое внимание на то, что в пакете
Пока разработчик пакета не собирается обновлять модели и предлагает их доучивать самостоятельно. Для этого у него есть даже очень подробная инструкция.
В общем, я забрала из репозитория Perseus свеженький трибанк и обучила модель, ее можно скачать в формате udpipe вот здесь. На это ушло примерно 8 часов. Точность на картинке; это далеко от идеала, но (по итогам ручного сравнения выборки в 100 слов) в большинстве случае лучше, чем perseus 2.5.
Но самое интересное там оказалось внутри…⬇️
udpipe модели устаревшие: например, для латыни это Perseus 2.5, хотя трибанки доступны уже 2.12 и 2.13. Пока разработчик пакета не собирается обновлять модели и предлагает их доучивать самостоятельно. Для этого у него есть даже очень подробная инструкция.
В общем, я забрала из репозитория Perseus свеженький трибанк и обучила модель, ее можно скачать в формате udpipe вот здесь. На это ушло примерно 8 часов. Точность на картинке; это далеко от идеала, но (по итогам ручного сравнения выборки в 100 слов) в большинстве случае лучше, чем perseus 2.5.
Но самое интересное там оказалось внутри…
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4
(Продолжение о латинском парсере⬆️ )
Вот некоторые изменения:
- появилась метка dep_rel для ablativus absolutus (
- исправлены аннотации для супина (
- добавлен тип для местоимения (
Возможность различать указательные и относительные местоимения — это очень круто (несмотря на ошибки).
Но герундив и герундий новая модель не различает и даже не пытается. Это не баг, как говорится, а фича. В статье по ссылке выше для этого дается развернутое обоснование, из которого следует, что герундий — это вариант герундива, а последний рассматривается как причастие будущего времени пассивного залога. В общем, нау иц офишал: нет таких форм.
Так что задумайтесь, прежде чем ставить двойки студентам, которые так и не научились различать два “ерундива”🤷♀️
Вот некоторые изменения:
- появилась метка dep_rel для ablativus absolutus (
advcl:abs);- исправлены аннотации для супина (
VerbForm=Conv, Aspect=Prosp), а также герундия и герундива (VerbForm=Part, Aspect=Prosp);- добавлен тип для местоимения (
PronType) и вид для глагола (Aspect) и др. Возможность различать указательные и относительные местоимения — это очень круто (несмотря на ошибки).
Но герундив и герундий новая модель не различает и даже не пытается. Это не баг, как говорится, а фича. В статье по ссылке выше для этого дается развернутое обоснование, из которого следует, что герундий — это вариант герундива, а последний рассматривается как причастие будущего времени пассивного залога. В общем, нау иц офишал: нет таких форм.
Так что задумайтесь, прежде чем ставить двойки студентам, которые так и не научились различать два “ерундива”
Please open Telegram to view this post
VIEW IN TELEGRAM
😁9❤2
RAntiquity
Недавно @aGricolaMZ обратил мое внимание на то, что в пакете udpipe модели устаревшие: например, для латыни это Perseus 2.5, хотя трибанки доступны уже 2.12 и 2.13. Пока разработчик пакета не собирается обновлять модели и предлагает их доучивать самостоятельно.…
В общем, Perseus 2.13 при ближайшем рассмотрении оказался не так хорош. Так что учу вот эту малышку, пожелайте удачи. Неделю я возилась с конфликтами версий, нехваткой ума памяти -- и вот, кажется, дело пошло! До первой ошибки 😂
Очень хочется хороший латинский парсер. А так как с облаком не сложилось, буду без компьютера несколько дней (или недель).
А потом вернусь жаловаться, что все сломалось🐈
Очень хочется хороший латинский парсер. А так как с облаком не сложилось, буду без компьютера несколько дней (или недель).
А потом вернусь жаловаться, что все сломалось
Please open Telegram to view this post
VIEW IN TELEGRAM
GitHub
GitHub - ufal/evalatin2024-latinpipe: LatinPipe – the winning entry to parsing task of EvaLatin 2024
LatinPipe – the winning entry to parsing task of EvaLatin 2024 - ufal/evalatin2024-latinpipe
🔥6
RAntiquity
В общем, Perseus 2.13 при ближайшем рассмотрении оказался не так хорош. Так что учу вот эту малышку, пожелайте удачи. Неделю я возилась с конфликтами версий, нехваткой ума памяти -- и вот, кажется, дело пошло! До первой ошибки 😂 Очень хочется хороший…
1. Модель LatinPipe у меня дообучилась. В итоге пришлось заплатить Яндексу за GPU, примерно два дня я разбиралась в DataShere и осваивала Jupyter Lab, а потом за 8 часов все посчиталось. В целом оно того стоит (стоит недешево, кстати, но спасает родное железо).
2. На входе модель, как выяснилось, хочет готовый conllu, поэтому о воркфлоу я еще подумаю. Но по моим ощущениям результат намного лучше, чем дают и предобученные, и самостоятельно обученные модели udpipe.
…Что неудивительно: чехи построили очень сложную архитектуру из нескольких нейросетей, которые обучаются сразу на десятке латинских трибанков. То есть за 8 часов эта крошка выучила всю латынь, включая Данте и Фому.
Это какая-то, знаете, фантастика. Подробный отчет будет, но позже, мне надо прийти в себя от этих чудес техники и наконец выспаться.
2. На входе модель, как выяснилось, хочет готовый conllu, поэтому о воркфлоу я еще подумаю. Но по моим ощущениям результат намного лучше, чем дают и предобученные, и самостоятельно обученные модели udpipe.
…Что неудивительно: чехи построили очень сложную архитектуру из нескольких нейросетей, которые обучаются сразу на десятке латинских трибанков. То есть за 8 часов эта крошка выучила всю латынь, включая Данте и Фому.
Это какая-то, знаете, фантастика. Подробный отчет будет, но позже, мне надо прийти в себя от этих чудес техники и наконец выспаться.
GitHub
GitHub - ufal/evalatin2024-latinpipe: LatinPipe – the winning entry to parsing task of EvaLatin 2024
LatinPipe – the winning entry to parsing task of EvaLatin 2024 - ufal/evalatin2024-latinpipe
🔥9