
Forwarded from Mike Blazer (Mike Blazer)
Найдите статьи Википедии, нуждающиеся в цитировании!
Простое приложение для помощи в построении ссылок из Википедии, которое находит статьи, нуждающиеся в цитировании.
Вы можете использовать:
— Существующий контент
— Расширить существующий контент
— Создать новый контент для цитирования
Просто введите ключевое слово, чтобы увидеть все страницы, которые нуждаются в цитировании.
Удобная загрузка документа Word
Поделитесь с командой или сохраните результаты на потом!
Это приложение лучше всего подходит для устоявшихся веб-сайтов / компаний с ресурсами для написания хорошо изученных, качественных статей, которые могут быть процитированы.
Если все сделать правильно, то выиграют все.
Википедия получает высококачественное цитирование, а ваш сайт - обратную ссылку.
Расширение существующего контента - один из самых простых способов добиться цитирования, но если у вас нет ничего, что можно переработать, придется писать что-то новое.
Отсутствие цитирования может также указывать на нехватку контента, которую стоит изучить.
Посмотрите видео о том, как это работает, перейдя по этой ссылке.
Приложение: https://wikicite.streamlit.app/
Исходный код: https://github.com/searchsolved/search-solved-public-seo/tree/main/linking/wikipedia-citation-finder
Ссылки и инструкции: https://leefoot.co.uk/portfolio/free-streamlit-app-wikipedia-citation-needed-finder/
@MikeBlazerX
Простое приложение для помощи в построении ссылок из Википедии, которое находит статьи, нуждающиеся в цитировании.
Вы можете использовать:
— Существующий контент
— Расширить существующий контент
— Создать новый контент для цитирования
Просто введите ключевое слово, чтобы увидеть все страницы, которые нуждаются в цитировании.
Удобная загрузка документа Word
Поделитесь с командой или сохраните результаты на потом!
Это приложение лучше всего подходит для устоявшихся веб-сайтов / компаний с ресурсами для написания хорошо изученных, качественных статей, которые могут быть процитированы.
Если все сделать правильно, то выиграют все.
Википедия получает высококачественное цитирование, а ваш сайт - обратную ссылку.
Расширение существующего контента - один из самых простых способов добиться цитирования, но если у вас нет ничего, что можно переработать, придется писать что-то новое.
Отсутствие цитирования может также указывать на нехватку контента, которую стоит изучить.
Посмотрите видео о том, как это работает, перейдя по этой ссылке.
Приложение: https://wikicite.streamlit.app/
Исходный код: https://github.com/searchsolved/search-solved-public-seo/tree/main/linking/wikipedia-citation-finder
Ссылки и инструкции: https://leefoot.co.uk/portfolio/free-streamlit-app-wikipedia-citation-needed-finder/
@MikeBlazerX
{kind=link}
Forwarded from Dart: Product SEO Engineer (Dárt 検索)
Бесплатный кластеризатор по топам
Для собственных нужд, я сделал кластеризатор по похожести SERP. Побудило на создание меня следующее:
- Программы чаще всего сделаны под Windows.
- Сервисы обычно предоставляют услугу как дополнительную.
- На больших объемах не выгодно.
- Виснут на 100к+ ключевых слов, мне нужны большие объемы.
- ChatGPT предлагает кластеризацию, которая не справляется с большими объемами.
- Мне нужна была поддержка любых языков.
- Не требовательно к ресурсам.
Я подумал, что для URL не обязательно нужна векторизация. По сути топ это множество, а для множеств можно использовать другие формулы, поэтому сделал кластеризатор на основе Коэффициента Жаккара. Я опробовал и другие, например, Dice или Overlap, но они оказались хуже.
За репост буду благодарен! 🙏
Инструкция:
Сохраните себе копию данного файла на Google Drive через File, чтобы не сталкиваться каждый раз с предупреждением от Google Colab.
Внимание! Этот код только кластеризует, он не собирает выдачу. Собрать выдачу можно с помощью других сервисов, например, выгрузить Ahrefs с галочкой на Include top 10 positions from SERP for each keyword.
Для запуска необходимо нажать на кнопку play (▷) внизу и следовать инструкции.
1. Choose files. Загружаем CSV файл с, как минимум, 2-мя колонками: Keywords и URL.
2. Column delimiter. Вводим разделитель колонок. По умолчанию это запятая.
3. Keywords column label. Вводим заголовок колонки для поисковых фраз (чувствителен к регистру).
4. URL column label. Вводим заголовок колонки для URL (чувствителен к регистру).
5. Similarity threshold. Вводим порог похожести, я рекомендую 0,6.
6. Жмем кнопку Run.
7. После окончания работы нажимаем Save, чтобы сохранить в папку Downloads.
Файл результатов
1. Каждая группа в колонке Group имеет номер, начинающийся с 0.
2. Ключевые фразы, которые объеденены в один кластер, будут иметь один номер группы.
3. Если фраза не имеет общих групп с другими фразами, то она выделяется в отдельную группу.
4. Если фразы не имеют собранных URL, то они все выделяются в группу -1.
Внимание! В браузере Safari работает некорректно, необходимо использовать Chrome.
https://colab.research.google.com/drive/1QGNNuY7OSBErn5am-dS1lnubHr-65kSF?usp=sharing
Для собственных нужд, я сделал кластеризатор по похожести SERP. Побудило на создание меня следующее:
- Программы чаще всего сделаны под Windows.
- Сервисы обычно предоставляют услугу как дополнительную.
- На больших объемах не выгодно.
- Виснут на 100к+ ключевых слов, мне нужны большие объемы.
- ChatGPT предлагает кластеризацию, которая не справляется с большими объемами.
- Мне нужна была поддержка любых языков.
- Не требовательно к ресурсам.
Я подумал, что для URL не обязательно нужна векторизация. По сути топ это множество, а для множеств можно использовать другие формулы, поэтому сделал кластеризатор на основе Коэффициента Жаккара. Я опробовал и другие, например, Dice или Overlap, но они оказались хуже.
За репост буду благодарен! 🙏
Инструкция:
Сохраните себе копию данного файла на Google Drive через File, чтобы не сталкиваться каждый раз с предупреждением от Google Colab.
Внимание! Этот код только кластеризует, он не собирает выдачу. Собрать выдачу можно с помощью других сервисов, например, выгрузить Ahrefs с галочкой на Include top 10 positions from SERP for each keyword.
Для запуска необходимо нажать на кнопку play (▷) внизу и следовать инструкции.
1. Choose files. Загружаем CSV файл с, как минимум, 2-мя колонками: Keywords и URL.
2. Column delimiter. Вводим разделитель колонок. По умолчанию это запятая.
3. Keywords column label. Вводим заголовок колонки для поисковых фраз (чувствителен к регистру).
4. URL column label. Вводим заголовок колонки для URL (чувствителен к регистру).
5. Similarity threshold. Вводим порог похожести, я рекомендую 0,6.
6. Жмем кнопку Run.
7. После окончания работы нажимаем Save, чтобы сохранить в папку Downloads.
Файл результатов
1. Каждая группа в колонке Group имеет номер, начинающийся с 0.
2. Ключевые фразы, которые объеденены в один кластер, будут иметь один номер группы.
3. Если фраза не имеет общих групп с другими фразами, то она выделяется в отдельную группу.
4. Если фразы не имеют собранных URL, то они все выделяются в группу -1.
Внимание! В браузере Safari работает некорректно, необходимо использовать Chrome.
https://colab.research.google.com/drive/1QGNNuY7OSBErn5am-dS1lnubHr-65kSF?usp=sharing
Google
SERP-Similarity-Keyword-Clustering-by-Dart.ipynb
Colab notebook
Forwarded from Dart: Product SEO Engineer (Dárt 検索)
Кластеризатор массивных семантических ядер по схожести выдачи
Для огромных семантических ядер скорость и масштабирумость группировки может быть более важна, чем ее точность, поэтому для таких случаев у меня был в запасе другой алгоритм. Он является продолжением идеи кластеризации через меру Жаккара описанной в предыдущих постах (1, 2). В комментариях к постам и в личных сообщениях возник интерес к решениям для массивных семантических ядер, поэтому я переписал предыдущий скрипт для них.
За репост буду благодарен! 🙏
В алгоритме используется техника MinHash и LSH. Этот метод, основанный на хэшировании и индексации множеств, позволяет быстро искать частичные дубликаты на больших данных. Он также, как кластеризатор из предыдущих постов, менее ресурсоемкий, чем векторное преобразование и операции над матрицами.
В чем разница между мерой Жаккара и этим решением?
Точность vs. Эффективность: Коэффициент Жаккара обеспечивает точное значение схожести, но неэффективен для больших данных. MinHash и LSH предоставляют приближенное значение, но значительно более эффективны для обработки больших объемов данных.
Например, японское семантическое ядро в 480 тысяч ключевых фраз было сгруппировано за 30 минут. Конечный результат вполне устроил, учитывая, что метод на основе Жаккара считал такой объем более суток. Отлично подойдет для дорвейщиков!
Скачать можно здесь:
https://drive.google.com/file/d/1b01TbXmWINe3w0haneMcHVy-opFZkwqH/view?usp=share_link
Проект на Github:
https://github.com/dartseoengineer/keyword-clustering-minhash
Инструкция
Внимание! Этот скрипт только кластеризует, для сбора выдачи используйте сторонние программы, например, A-Parser.
1. Предварительно установите библиотеки pandas и tqdm.
2. Инструкция по использованию скрипта в командной строке:
Обязательные аргументы
input_file: Путь к входному CSV файлу.
output_file: Путь для сохранения выходного файла с кластеризованными ключевыми словами.
Необязательные аргументы
-s, --separator: Разделитель во входном файле (по умолчанию: `,`).
-k, --keyword_col: Название столбца с ключевыми словами во входном файле (по умолчанию: `Keyword`).
-u, --url_col: Название столбца с URL во входном файле (по умолчанию: `URL`).
-t, --similarity_threshold: Порог схожести (по умолчанию: `0.6`).
Пример команды в терминале
Файл результатов
1. Каждая группа в колонке Group имеет номер, начинающийся с 0.
2. Ключевые фразы, которые объеденены в один кластер, будут иметь один номер группы.
3. Если фраза не имеет общих групп с другими фразами, то она выделяется в отдельную группу.
4. Если фразы не имеют собранных URL, то они все выделяются в группу -1.
Для огромных семантических ядер скорость и масштабирумость группировки может быть более важна, чем ее точность, поэтому для таких случаев у меня был в запасе другой алгоритм. Он является продолжением идеи кластеризации через меру Жаккара описанной в предыдущих постах (1, 2). В комментариях к постам и в личных сообщениях возник интерес к решениям для массивных семантических ядер, поэтому я переписал предыдущий скрипт для них.
За репост буду благодарен! 🙏
В алгоритме используется техника MinHash и LSH. Этот метод, основанный на хэшировании и индексации множеств, позволяет быстро искать частичные дубликаты на больших данных. Он также, как кластеризатор из предыдущих постов, менее ресурсоемкий, чем векторное преобразование и операции над матрицами.
В чем разница между мерой Жаккара и этим решением?
Точность vs. Эффективность: Коэффициент Жаккара обеспечивает точное значение схожести, но неэффективен для больших данных. MinHash и LSH предоставляют приближенное значение, но значительно более эффективны для обработки больших объемов данных.
Например, японское семантическое ядро в 480 тысяч ключевых фраз было сгруппировано за 30 минут. Конечный результат вполне устроил, учитывая, что метод на основе Жаккара считал такой объем более суток. Отлично подойдет для дорвейщиков!
Скачать можно здесь:
https://drive.google.com/file/d/1b01TbXmWINe3w0haneMcHVy-opFZkwqH/view?usp=share_link
Проект на Github:
https://github.com/dartseoengineer/keyword-clustering-minhash
Инструкция
Внимание! Этот скрипт только кластеризует, для сбора выдачи используйте сторонние программы, например, A-Parser.
1. Предварительно установите библиотеки pandas и tqdm.
pip install pandas
pip install tqdm
pip install datasketch
2. Инструкция по использованию скрипта в командной строке:
Обязательные аргументы
input_file: Путь к входному CSV файлу.
output_file: Путь для сохранения выходного файла с кластеризованными ключевыми словами.
Необязательные аргументы
-s, --separator: Разделитель во входном файле (по умолчанию: `,`).
-k, --keyword_col: Название столбца с ключевыми словами во входном файле (по умолчанию: `Keyword`).
-u, --url_col: Название столбца с URL во входном файле (по умолчанию: `URL`).
-t, --similarity_threshold: Порог схожести (по умолчанию: `0.6`).
Пример команды в терминале
python minhash-cluster-cli.py for-clustering.csv clustered_keywords.csv -s ';' -k 'keyword' -u 'url' -t 0.6
Файл результатов
1. Каждая группа в колонке Group имеет номер, начинающийся с 0.
2. Ключевые фразы, которые объеденены в один кластер, будут иметь один номер группы.
3. Если фраза не имеет общих групп с другими фразами, то она выделяется в отдельную группу.
4. Если фразы не имеют собранных URL, то они все выделяются в группу -1.
Telegram
Advanced SEO
Бесплатный кластеризатор по топам
Для собственных нужд, я сделал кластеризатор по похожести SERP. Побудило на создание меня следующее:
- Программы чаще всего сделаны под Windows.
- Сервисы обычно предоставляют услугу как дополнительную.
- На больших объемах…
Для собственных нужд, я сделал кластеризатор по похожести SERP. Побудило на создание меня следующее:
- Программы чаще всего сделаны под Windows.
- Сервисы обычно предоставляют услугу как дополнительную.
- На больших объемах…
👍1🔥1👌1
Forwarded from Канал seo блоггера Евгения Молдовану
Написал парсер для получения ответов от Gemini (аналог ChatGPT) с помощью их API.
Скрипт позволяет получить данные из csv и из заголовков написать условия с шаблонами для запросов к чатботу.
Что можно делать с его помощью? Примеры:
1) Массово генерировать статьи с условиями
2) Генерировать Title и дескрипшионы
3) Анализировать данные (как в Excel) после ответа чатбота.
4) Получать LSI или слова задающие тематику для ключевых фраз
5) И так далее. Весь функционал который есть у чатботов.
Ссылка на проект https://github.com/Devvver/gemini_csv_parser
Там же условия использования и запуска.
Буду благодарен репосту за opensource решение.
Скрипт позволяет получить данные из csv и из заголовков написать условия с шаблонами для запросов к чатботу.
Что можно делать с его помощью? Примеры:
1) Массово генерировать статьи с условиями
2) Генерировать Title и дескрипшионы
3) Анализировать данные (как в Excel) после ответа чатбота.
4) Получать LSI или слова задающие тематику для ключевых фраз
5) И так далее. Весь функционал который есть у чатботов.
Ссылка на проект https://github.com/Devvver/gemini_csv_parser
Там же условия использования и запуска.
Буду благодарен репосту за opensource решение.
👍2
Forwarded from Канал seo блоггера Евгения Молдовану
🚨 Решение проблемы с индексацией RSS лент комментариев в WordPress 🚨
Google упорно пытается индексировать страницы, даже если они заблокированы в robots.txt. Особенно это касается RSS лент комментариев, которые не всегда нужны и могут попасть в дополнительный индекс, ухудшая ранжирование сайта.
💡 Как я решил проблему: Создал плагин для WordPress, который блокирует индексацию RSS лент комментариев, но сохраняет основную ленту и Яндекс Турбо.
Плагин: ссылка на скачивание
Прописывает 301 редирект с комментариев на посты.
Позволяет сохранить нужные RSS ленты.
Полный пост с описанием на моем блоге.
Google упорно пытается индексировать страницы, даже если они заблокированы в robots.txt. Особенно это касается RSS лент комментариев, которые не всегда нужны и могут попасть в дополнительный индекс, ухудшая ранжирование сайта.
💡 Как я решил проблему: Создал плагин для WordPress, который блокирует индексацию RSS лент комментариев, но сохраняет основную ленту и Яндекс Турбо.
Плагин: ссылка на скачивание
Прописывает 301 редирект с комментариев на посты.
Позволяет сохранить нужные RSS ленты.
Полный пост с описанием на моем блоге.
Forwarded from Mike Blazer (Mike Blazer)
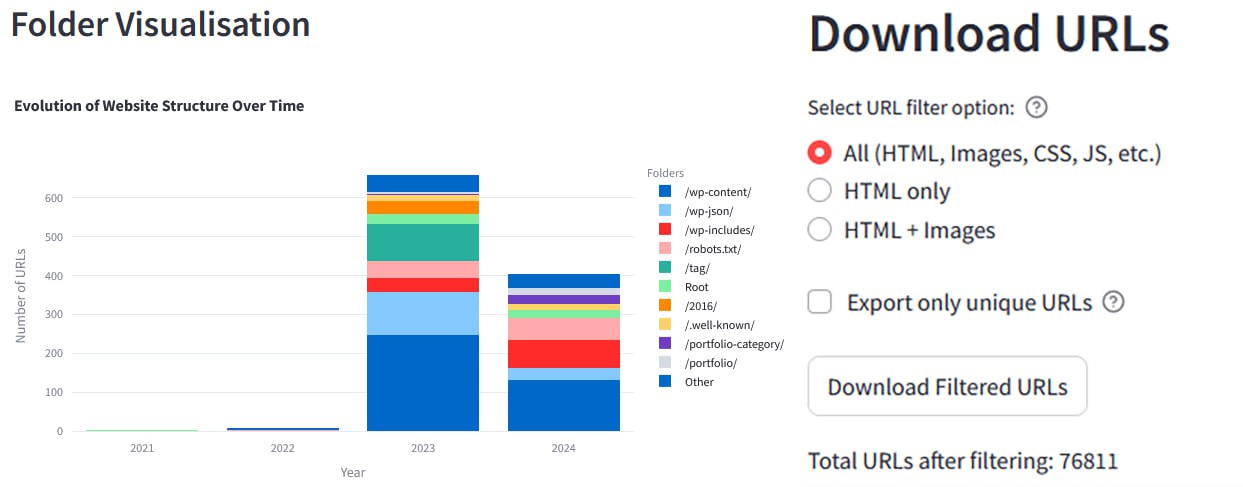
Бесплатная тулза: Анализатор и сборщик
Вам когда-нибудь требовалось выгрузить список урлов из Веб-Архива для анализа неудачной миграции, но не хватало подходящего инструмента?
Вот он, его фичи:
- Эволюция структуры сайта
- Эволюция статус-кодов
- Часто изменяемые страницы
- Изменения в
- Выгрузка
Посмотрите, как менялась структура сайта (эволюция папок) с течением времени.
Это позволит легко увидеть, когда сайт переезжал на новую платформу или имел проблемы в прошлом.
Выгружайте и проверяйте статус-коды страниц на лету.
Полезно для отслеживания частоты серверных ошибок, удаленных страниц, редиректов и страниц со статусом 200.
Удобно шпионить за наиболее часто меняющимися страницами конкурентов.
Отслеживайте эволюцию
Быстро восстанавливайте рабочую/историческую версию
Восстанавливайтесь после неудачных миграций и переездов на новые платформы.
Возможно, есть шанс повысить релевантность старых редиректов или настроить редиректы для старых
Приложение: https://wayback.streamlit.app
Исходник: https://github.com/searchsolved/search-solved-public-seo/tree/main/wayback-url-tool
@MikeBlazerX
URL-адресов с Wayback MachineВам когда-нибудь требовалось выгрузить список урлов из Веб-Архива для анализа неудачной миграции, но не хватало подходящего инструмента?
Вот он, его фичи:
- Эволюция структуры сайта
- Эволюция статус-кодов
- Часто изменяемые страницы
- Изменения в
robots.txt- Выгрузка
URL-овПосмотрите, как менялась структура сайта (эволюция папок) с течением времени.
Это позволит легко увидеть, когда сайт переезжал на новую платформу или имел проблемы в прошлом.
Выгружайте и проверяйте статус-коды страниц на лету.
Полезно для отслеживания частоты серверных ошибок, удаленных страниц, редиректов и страниц со статусом 200.
Удобно шпионить за наиболее часто меняющимися страницами конкурентов.
Отслеживайте эволюцию
robots.txt во времени и сравнивайте версии.Быстро восстанавливайте рабочую/историческую версию
robots.txt.Восстанавливайтесь после неудачных миграций и переездов на новые платформы.
Возможно, есть шанс повысить релевантность старых редиректов или настроить редиректы для старых
404-ых, которые были упущены в первый раз.Приложение: https://wayback.streamlit.app
Исходник: https://github.com/searchsolved/search-solved-public-seo/tree/main/wayback-url-tool
@MikeBlazerX
{kind=link}
Плагин для WordPress который показывает всплывающее окно с подпиской на Телеграм.
Скриншот.
Плюсы
1) Минимум библиотек
2) Возможность настройки текста
3) Установка задержки в секундах
Скриншот.
Плюсы
1) Минимум библиотек
2) Возможность настройки текста
3) Установка задержки в секундах
Media is too big
VIEW IN TELEGRAM
На видео процес установки Python и PyCharm на Windows.
Много кто из seo специалистов видят исходные коды проектов, но не совсем понимают как их запустить. На видео основа - как установить питон и среду разработки IDE. После можно будет выполнять код из нашего телеграм канала.
#python #pycharm
Много кто из seo специалистов видят исходные коды проектов, но не совсем понимают как их запустить. На видео основа - как установить питон и среду разработки IDE. После можно будет выполнять код из нашего телеграм канала.
#python #pycharm
🔥1
🚀 Как использовать KeyBERT для кластеризации ключевых слов 🔑
Ищете способ улучшить структуру контента и SEO-оптимизацию? В новой статье рассказываем, как применить KeyBERT — мощный инструмент для кластеризации ключевых слов с помощью машинного обучения.
🔍 Что вас ждет:
Обзор методов кластеризации.
Пошаговое руководство по использованию KeyBERT.
Примеры реальных данных и практическое применение.
Как повысить релевантность ваших ключевых слов для SEO.
🔗 Ознакомьтесь с полным гайдом по ссылке:
#SEO #python #Кластеризация #KeyBERT #Маркетинг
Ищете способ улучшить структуру контента и SEO-оптимизацию? В новой статье рассказываем, как применить KeyBERT — мощный инструмент для кластеризации ключевых слов с помощью машинного обучения.
🔍 Что вас ждет:
Обзор методов кластеризации.
Пошаговое руководство по использованию KeyBERT.
Примеры реальных данных и практическое применение.
Как повысить релевантность ваших ключевых слов для SEO.
🔗 Ознакомьтесь с полным гайдом по ссылке:
#SEO #python #Кластеризация #KeyBERT #Маркетинг
🔍 Парсинг поисковой выдачи Google по ключевым словам — подробный гайд (аналог вордстат в Google)
💡 Для SEO-специалистов и разработчиков: как создать свой инструмент для сбора данных из Keyword Planner API без дорогих сервисов на Python.
👉 В статье:
Как обойти ограничения Google и собрать 40+ тысяч ключевых слов.
Полный процесс работы с Google Ads API: от получения токена до обработки данных.
💬 "Наступает новая эпоха — без прямого обращения к API Google всё становится сложнее. Готовы заморочиться? Тогда получите доступ к сокровищнице данных и создайте свой Google Wordstat!"
📖 Читайте, чтобы узнать, как сэкономить сотни долларов и сделать мощный парсер своими руками. 🚀
https://habr.com/ru/articles/867876/
#Python #GoogleAPI #Google #CloudPlatform
💡 Для SEO-специалистов и разработчиков: как создать свой инструмент для сбора данных из Keyword Planner API без дорогих сервисов на Python.
👉 В статье:
Как обойти ограничения Google и собрать 40+ тысяч ключевых слов.
Полный процесс работы с Google Ads API: от получения токена до обработки данных.
💬 "Наступает новая эпоха — без прямого обращения к API Google всё становится сложнее. Готовы заморочиться? Тогда получите доступ к сокровищнице данных и создайте свой Google Wordstat!"
📖 Читайте, чтобы узнать, как сэкономить сотни долларов и сделать мощный парсер своими руками. 🚀
https://habr.com/ru/articles/867876/
#Python #GoogleAPI #Google #CloudPlatform
Хабр
Парсинг поисковой выдачи Google по ключевым словам — подробный гайд как сделать парсер Гугл (аналог вордстат в Гугл)
Любой SEO специалист знает, какая боль собирать семантику для Гугла. Одно дело, когда запросы можно пересчитать по пальцам, а когда они исчисляются тысячами, а не штуками? Как посмотреть количество...
👍2
Google Search Console Data Exporter
🚀 Google Search Console Data Exporter — это инструмент, созданный с использованием Streamlit, предназначенный для удобной выгрузки данных из Google Search Console в формате CSV.
Главное преимущество - позволяет за счет API получить больше запросов и данных, чем через интерфейс самого Google Console.
📊 Основные функции:
Получение информации о ключевых запросах (keywords).
Данные по связанным URL.
Статистика кликов и показов.
Определение средней позиции запроса в поисковой выдаче.
Экспорт данных в CSV для дальнейшего анализа.
💻 Простой и удобный интерфейс:
Ввод домена вашего сайта и выбор диапазона дат.
Отображение прогресса выполнения запросов.
Автоматическое создание таблицы с результатами и возможность экспорта в CSV.
🔧 Как использовать:
Введите домен сайта.
Выберите диапазон дат.
Нажмите на кнопку "Получить данные".
Ознакомьтесь с таблицей и скачайте данные в CSV.
📥 Получите полный отчет с ключевыми запросами, кликами, показами и позициями.
Код на github
🚀 Google Search Console Data Exporter — это инструмент, созданный с использованием Streamlit, предназначенный для удобной выгрузки данных из Google Search Console в формате CSV.
Главное преимущество - позволяет за счет API получить больше запросов и данных, чем через интерфейс самого Google Console.
📊 Основные функции:
Получение информации о ключевых запросах (keywords).
Данные по связанным URL.
Статистика кликов и показов.
Определение средней позиции запроса в поисковой выдаче.
Экспорт данных в CSV для дальнейшего анализа.
💻 Простой и удобный интерфейс:
Ввод домена вашего сайта и выбор диапазона дат.
Отображение прогресса выполнения запросов.
Автоматическое создание таблицы с результатами и возможность экспорта в CSV.
🔧 Как использовать:
Введите домен сайта.
Выберите диапазон дат.
Нажмите на кнопку "Получить данные".
Ознакомьтесь с таблицей и скачайте данные в CSV.
📥 Получите полный отчет с ключевыми запросами, кликами, показами и позициями.
Код на github
👍1
🔧 Скрипт для анализа каннибализации ключевых запросов
Этот скрипт позволяет анализировать данные из Google Search Console на предмет каннибализации ключевых запросов.
Он выявляет случаи, когда один запрос продвигается на нескольких URL, и предоставляет подробный отчет с указанием показов, кликов и позиций.
📥 Загрузите CSV, установите фильтры, и получите готовый анализ прямо в интерфейсе! Файл CSV можно получить из предыдущего скрипта.
📂 Экспортируйте результаты в удобном формате для дальнейшей работы.
Полезно для SEO-специалистов, которые хотят улучшить видимость своих страниц в поисковой выдаче.
Ссылка на Github
Этот скрипт позволяет анализировать данные из Google Search Console на предмет каннибализации ключевых запросов.
Он выявляет случаи, когда один запрос продвигается на нескольких URL, и предоставляет подробный отчет с указанием показов, кликов и позиций.
📥 Загрузите CSV, установите фильтры, и получите готовый анализ прямо в интерфейсе! Файл CSV можно получить из предыдущего скрипта.
📂 Экспортируйте результаты в удобном формате для дальнейшей работы.
Полезно для SEO-специалистов, которые хотят улучшить видимость своих страниц в поисковой выдаче.
Ссылка на Github
👍3
🔥 Расчет релевантности текстов с помощью нейронных сетей
Скрипт на Python использует LaBSE для оценки текстовой релевантности через косинусную близость. Это мощный инструмент для анализа запросов, статей и URL из выдачи.
📌 Как начать
1️⃣ Установите Python и PyCharm .
2️⃣ Скачайте код с GitHub.
3️⃣ Запустите. При первом старте загрузится нейронная сеть LaBSE (2 ГБ).
📊 Возможности
Проверка релевантности абзацев и заголовков, title.
Автоматическое скачивание текстов из сайтов и расчет семантической релевантности.
Полное описание запуска, работы и скриншотов на сайте
Скрипт на Python использует LaBSE для оценки текстовой релевантности через косинусную близость. Это мощный инструмент для анализа запросов, статей и URL из выдачи.
📌 Как начать
1️⃣ Установите Python и PyCharm .
2️⃣ Скачайте код с GitHub.
3️⃣ Запустите. При первом старте загрузится нейронная сеть LaBSE (2 ГБ).
📊 Возможности
Проверка релевантности абзацев и заголовков, title.
Автоматическое скачивание текстов из сайтов и расчет семантической релевантности.
Полное описание запуска, работы и скриншотов на сайте
🔥6
Обещанный скрипт для отлова ботов Google. Скрипт собирает все ip и юзерагенты зашедших на тестовую страницу. Работает даже с кешированными страницами.
В тестовой странице test.html в самом низу вставлен скрипт, который записывает ip и юзерагент в базу данных с помощью write.php.
Посмотреть записанные данные можно с помощью log.php.
В subnets.txt хранятся ip и подсети Google ботов (список не полный, можете редактировать)
Как протестировать.
В файлы write.php и log.php прописываем данные для подключения к базе данных Mysql.
Создаем с помощью FTP папку и заливаем туда файлы.
Создаем таблицу в базе данных (к примеру в Cpanel) заходим в Базы данных->PhpMyAdmin-> выбираем базу данных и переходим в вкладку SQL.
Выполняем код:
База создана, теперь у вас все должно работать. Проверяем:
1) Переходим по url https://mysite.com/papka/test.html
2) Заходим на https://mysite.com/papka/log.php и увидите свой ip и юзерагент.
3) Проводите эксперименты, привлекая бота на https://mysite.com/papka/test.html
Ссылка на архив.
Если будет интерес, доработаю функционал, тот который напрашивается больше всего - работа с WordPress, показ стран ip и другое.
В тестовой странице test.html в самом низу вставлен скрипт, который записывает ip и юзерагент в базу данных с помощью write.php.
Посмотреть записанные данные можно с помощью log.php.
В subnets.txt хранятся ip и подсети Google ботов (список не полный, можете редактировать)
Как протестировать.
В файлы write.php и log.php прописываем данные для подключения к базе данных Mysql.
Создаем с помощью FTP папку и заливаем туда файлы.
Создаем таблицу в базе данных (к примеру в Cpanel) заходим в Базы данных->PhpMyAdmin-> выбираем базу данных и переходим в вкладку SQL.
Выполняем код:
CREATE TABLE user_ip_data (
id INT(11) AUTO_INCREMENT PRIMARY KEY,
ip_address VARCHAR(45),
user_agent TEXT,
date_time DATETIME
);
База создана, теперь у вас все должно работать. Проверяем:
1) Переходим по url https://mysite.com/papka/test.html
2) Заходим на https://mysite.com/papka/log.php и увидите свой ip и юзерагент.
3) Проводите эксперименты, привлекая бота на https://mysite.com/papka/test.html
Ссылка на архив.
Если будет интерес, доработаю функционал, тот который напрашивается больше всего - работа с WordPress, показ стран ip и другое.
Lightshot
Screenshot
Captured with Lightshot
👍4🔥2
🔎 Проверка позиций сайта в Google за секунды! В любой стране с помощью php скрипта🚀
Определение позиций в Гугле через API Xmlriver ( примерно 25 центов USD за 1К запросов). Вводишь домен, список ключевых слов – мгновенно получаешь данные о позициях в поиске! 🔥
✅ Можно настроить регион, язык, мобильная или desktop выдача
✅ Можно переделать под Яндекс за 10 минут
✅ Без лишних действий, можно настроить дополнительно.
❌ Однопоточный
❌ Нет обработки в случае ошибок самого Xmlriver (такое бывает)
Для первого запуска:
Открываем файл process.php и вводим свой API и юзер_id (увидеть свой можно тут). Заливаем 2 файла index.html и process.php на свой сайт, желательно в папочку и открываем https://site.com/papka/index.html
⚡️ Как это работает?
1️⃣ Вводишь домен и ключевые слова.
2️⃣ Скрипт отправляет запрос к API xmlriver.
3️⃣ API возвращает XML с позициями сайта в поиске Google.
4️⃣ Результаты отображаются в удобной таблице прямо на сайте.
Скачать с Github.
Определение позиций в Гугле через API Xmlriver ( примерно 25 центов USD за 1К запросов). Вводишь домен, список ключевых слов – мгновенно получаешь данные о позициях в поиске! 🔥
✅ Можно настроить регион, язык, мобильная или desktop выдача
✅ Можно переделать под Яндекс за 10 минут
✅ Без лишних действий, можно настроить дополнительно.
❌ Однопоточный
❌ Нет обработки в случае ошибок самого Xmlriver (такое бывает)
Для первого запуска:
Открываем файл process.php и вводим свой API и юзер_id (увидеть свой можно тут). Заливаем 2 файла index.html и process.php на свой сайт, желательно в папочку и открываем https://site.com/papka/index.html
⚡️ Как это работает?
1️⃣ Вводишь домен и ключевые слова.
2️⃣ Скрипт отправляет запрос к API xmlriver.
3️⃣ API возвращает XML с позициями сайта в поиске Google.
4️⃣ Результаты отображаются в удобной таблице прямо на сайте.
Скачать с Github.
👍3
🚀 Проверка метрик PageSpeed Insights
Этот скрипт позволяет проверять производительность веб-страниц с помощью Google PageSpeed Insights API.
Поддерживает мобильную и десктопную проверку.
Можно получить:
FCP, LCP, TBT, CLS, Speed Index, TTFB и Score.
💡 Как пользоваться:
Введите свой API ключ Google PageSpeed. (Как его получить читайте тут)
Выберите стратегию (мобильная или десктопная).
Введите URL вручную или загрузите XML карту сайта.
Нажмите Проверить для получения результатов.
Получить результат можно в CSV и Excel.
Скачать с Github.
Этот скрипт позволяет проверять производительность веб-страниц с помощью Google PageSpeed Insights API.
Поддерживает мобильную и десктопную проверку.
Можно получить:
FCP, LCP, TBT, CLS, Speed Index, TTFB и Score.
💡 Как пользоваться:
Введите свой API ключ Google PageSpeed. (Как его получить читайте тут)
Выберите стратегию (мобильная или десктопная).
Введите URL вручную или загрузите XML карту сайта.
Нажмите Проверить для получения результатов.
Получить результат можно в CSV и Excel.
Скачать с Github.
👍2
🔍 RDAP-инструмент для проверки доменов !
Уже месяц как официально Whois перестали поддерживаться. Если вы где-то проверяете с помощью whois - это или поддержка старого API или данные получают с помощью RDAP и отдают вам.
🧠 Всё работает через официальный протокол RDAP, с выбором сервера на основе зоны домена (например, .com, .org и т.д.).
💡 Этот Python-скрипт дает возможность получить:
✅ Статус домена
📅 Даты регистрации и истечения
👥 Контакты и организации
🌐 DNS-серверы
📄 Примечания и источник данных (RDAP-ссылка)
Зачем это нужно - можно переделать под чекер времени до дропа, юзать для своих PBN или для перехвата освобождающихся доменов.
Ссылка на Гитхаб
Уже месяц как официально Whois перестали поддерживаться. Если вы где-то проверяете с помощью whois - это или поддержка старого API или данные получают с помощью RDAP и отдают вам.
🧠 Всё работает через официальный протокол RDAP, с выбором сервера на основе зоны домена (например, .com, .org и т.д.).
💡 Этот Python-скрипт дает возможность получить:
✅ Статус домена
📅 Даты регистрации и истечения
👥 Контакты и организации
🌐 DNS-серверы
📄 Примечания и источник данных (RDAP-ссылка)
Зачем это нужно - можно переделать под чекер времени до дропа, юзать для своих PBN или для перехвата освобождающихся доменов.
Ссылка на Гитхаб
👍6
🕷Получение карты XML и парсинг по полученным ссылкам.
Иногда нужно получить все ссылки конкурента (которые должны индексироваться) и спарсить какие то данные. Пример демонстрирует получение xml карты и реализацию однопоточного парсинга (заготовка).
Код на Python который:
🧨Загружает все ссылки из sitemap.xml ;
🧨Проверяет код ответа каждой страницы (200, 404, и т.д.);
🧨Автоматически открывает каждую ссылку через Selenium;
🧨Извлекает заголовок страницы (<title>) - сделано для демонстрации, парсить можно все что угодно;
Позволяет настроить свой User-Agent и задержку между запросами (для некоторых сайтов которые жестко следят за юзерагентом);
Отображает процесс работы: сколько осталось, сколько прошло времени ⏱️;
После завершения — позволяет скачать все результаты в CSV.
По традиции ссылка с исходным кодом на гитхаб.
Иногда нужно получить все ссылки конкурента (которые должны индексироваться) и спарсить какие то данные. Пример демонстрирует получение xml карты и реализацию однопоточного парсинга (заготовка).
Код на Python который:
🧨Загружает все ссылки из sitemap.xml ;
🧨Проверяет код ответа каждой страницы (200, 404, и т.д.);
🧨Автоматически открывает каждую ссылку через Selenium;
🧨Извлекает заголовок страницы (<title>) - сделано для демонстрации, парсить можно все что угодно;
Позволяет настроить свой User-Agent и задержку между запросами (для некоторых сайтов которые жестко следят за юзерагентом);
Отображает процесс работы: сколько осталось, сколько прошло времени ⏱️;
После завершения — позволяет скачать все результаты в CSV.
По традиции ссылка с исходным кодом на гитхаб.
🔥6🤡2👏1
Этот инструмент позволяет наглядно отобразить векторную семантическую близость между статьями. Он использует модель BERT (LaBSE) для оценки смысловой схожести текстов и визуализирует результат в виде интерактивного графа.
Как пользоваться:
Подготовьте CSV-файл с двумя колонками: Address (URL статьи) и H1-1 (заголовок) - экспорт из лягушки.
Загрузите файл в интерфейс Streamlit - простым перетаскиванием.
Инструмент автоматически скачает и распарсит текст каждой статьи.
Можно настраивать порог релевантности, выбирать отображение одиночных узлов и скачивать CSV со списком схожих пар.
Зачем нужно:
1) Найти малорелевантные страницы для улучшения siteEmbeddings, поможет увеличить тематический траст после удаления.
2) Найти страницы с 100% совпадением - каннибализация и дубли.
3) Найти наиболее семантически релевантные страницы для ручной перелинковки.
4) Можно проверять разные сайты - таким образом среди списка страниц разных доменов искать релевантные (для PBN).
Ссылка на Гитхаб.
Как пользоваться:
Подготовьте CSV-файл с двумя колонками: Address (URL статьи) и H1-1 (заголовок) - экспорт из лягушки.
Загрузите файл в интерфейс Streamlit - простым перетаскиванием.
Инструмент автоматически скачает и распарсит текст каждой статьи.
Можно настраивать порог релевантности, выбирать отображение одиночных узлов и скачивать CSV со списком схожих пар.
Зачем нужно:
1) Найти малорелевантные страницы для улучшения siteEmbeddings, поможет увеличить тематический траст после удаления.
2) Найти страницы с 100% совпадением - каннибализация и дубли.
3) Найти наиболее семантически релевантные страницы для ручной перелинковки.
4) Можно проверять разные сайты - таким образом среди списка страниц разных доменов искать релевантные (для PBN).
Ссылка на Гитхаб.
1🔥7