
#git
Ну что, сверяем ответы?
1. В чем отличие git от svn? Отличий достаточно много, но из основных можно выделить следующие:
– Git – распределенная система, а svn – нет. Это позволяет хранить репозиторий (его копию) у каждого разработчика, работающего с данной системой. Практически каждая операция выполняется с данными на локальном диске, что достаточно быстро и может быть выполнено в оффлайн режиме. Вы можете выполнять команды «commit», «diff», «log», «branch», «merge», создавать аннотации к файлам и многое другое, полностью в оффлайн режиме.
– Git сохраняет метаданные изменений, а svn целые файлы. Это экономит место и время.
– В git рабочий процесс не имеет единой точки отказа. Поскольку каждый разработчик, работающий над проектом, имеет по сути его резервную копию, потеря связи с серверами ничем ему не грозит.
2. Как взять удаленные изменения?
– С помощью команды «git fetch <url>», которая связывается с указанным удаленным проектом и забирает все те данные проекта, которых у вас еще нет. После выполнения команды должны появиться ссылки на все ветки из этого удалённого проекта, которые вы можете просмотреть или слить в любой момент.
3. Что делает «git stash»?
– Довольно часто при работе с git возникает ситуация, когда необходимо обновиться (сделать pull), но при этом коммитить сырой код не хочется. Команда «git stash» скрывает все сделанные изменения и переводит код в состояние HEAD. Последовательность команд в данном случае такая:
$ git stash
$ git pull
$ git stash apply
4. В чем отличие «git pull» от «git fetch»?
– «git pull» – это, по сути, команда «git fetch», после которой сразу же следует «git merge». «git fetch» получает изменения с сервера и сохраняет их в каталог refs/remotes/. Это никак не влияет на локальные ветки и текущие изменения. А «git merge» уже вливает все эти изменения в локальную копию.
5. В чем отличие «git merge» от «git rebase»?
– «git merge» – слияние изменений из одной ветки в другую. Независимо от того, созданы ли ветки для тестирования, исправления ошибок или по другим причинам, слияние фиксирует изменения в другом месте. Слияние принимает содержимое ветки источника и объединяет их с целевой веткой. В этом процессе изменяется только целевая ветка. История исходных веток остается неизменной. «git rebase» сжимает все изменения в один «патч». Затем он интегрирует патч в целевую ветку. В отличие от слияния, перемещение перезаписывает историю, потому что она передает завершенную работу из одной ветки в другую. В процессе устраняется нежелательная история.
6. В чем заключается стратегия Git Flow?
– Git Flow – одна из первых крупных стратегий ветвления, которая завоевала популярность. Git Flow описывает несколько веток для разработки, релизов и взаимодействия между ними: feature branches, release branches, hotfix branches.
Ну что, сверяем ответы?
1. В чем отличие git от svn? Отличий достаточно много, но из основных можно выделить следующие:
– Git – распределенная система, а svn – нет. Это позволяет хранить репозиторий (его копию) у каждого разработчика, работающего с данной системой. Практически каждая операция выполняется с данными на локальном диске, что достаточно быстро и может быть выполнено в оффлайн режиме. Вы можете выполнять команды «commit», «diff», «log», «branch», «merge», создавать аннотации к файлам и многое другое, полностью в оффлайн режиме.
– Git сохраняет метаданные изменений, а svn целые файлы. Это экономит место и время.
– В git рабочий процесс не имеет единой точки отказа. Поскольку каждый разработчик, работающий над проектом, имеет по сути его резервную копию, потеря связи с серверами ничем ему не грозит.
2. Как взять удаленные изменения?
– С помощью команды «git fetch <url>», которая связывается с указанным удаленным проектом и забирает все те данные проекта, которых у вас еще нет. После выполнения команды должны появиться ссылки на все ветки из этого удалённого проекта, которые вы можете просмотреть или слить в любой момент.
3. Что делает «git stash»?
– Довольно часто при работе с git возникает ситуация, когда необходимо обновиться (сделать pull), но при этом коммитить сырой код не хочется. Команда «git stash» скрывает все сделанные изменения и переводит код в состояние HEAD. Последовательность команд в данном случае такая:
$ git stash
$ git pull
$ git stash apply
4. В чем отличие «git pull» от «git fetch»?
– «git pull» – это, по сути, команда «git fetch», после которой сразу же следует «git merge». «git fetch» получает изменения с сервера и сохраняет их в каталог refs/remotes/. Это никак не влияет на локальные ветки и текущие изменения. А «git merge» уже вливает все эти изменения в локальную копию.
5. В чем отличие «git merge» от «git rebase»?
– «git merge» – слияние изменений из одной ветки в другую. Независимо от того, созданы ли ветки для тестирования, исправления ошибок или по другим причинам, слияние фиксирует изменения в другом месте. Слияние принимает содержимое ветки источника и объединяет их с целевой веткой. В этом процессе изменяется только целевая ветка. История исходных веток остается неизменной. «git rebase» сжимает все изменения в один «патч». Затем он интегрирует патч в целевую ветку. В отличие от слияния, перемещение перезаписывает историю, потому что она передает завершенную работу из одной ветки в другую. В процессе устраняется нежелательная история.
6. В чем заключается стратегия Git Flow?
– Git Flow – одна из первых крупных стратегий ветвления, которая завоевала популярность. Git Flow описывает несколько веток для разработки, релизов и взаимодействия между ними: feature branches, release branches, hotfix branches.
Глубокое обучение – это метод машинного обучения, который позволяет обучать нейронную сеть предсказывать результаты по набору входных данных. Ниже представлена демонстрация как раз такой нейросети.
#git
Интерес к теме, связанной с Git, не оставляет нам ничего, кроме рассмотрения данной темы более подробно. Давайте разберемся с тем, как использовать ветвление в Git: создание, обновление, удаление и многое другое.
https://proglib.io/sh/3gVS8YUWHn
Интерес к теме, связанной с Git, не оставляет нам ничего, кроме рассмотрения данной темы более подробно. Давайте разберемся с тем, как использовать ветвление в Git: создание, обновление, удаление и многое другое.
https://proglib.io/sh/3gVS8YUWHn
Библиотека программиста
Ветвление Git с примерами из реальной жизни
Разбираемся, как использовать ветвление: создание, обновление, удаление и прочие классные штуки.
#algorithm
Breadth-First Search(s) – Поиск в ширину
Алгоритм позволяет найти кратчайший (содержащий наименьшее число ребер) путь из одной вершины графа до всех остальных вершин. В нем сначала посещаются все вершины, смежные с текущей, а затем их потомки.
Breadth-First Search(s) – Поиск в ширину
Алгоритм позволяет найти кратчайший (содержащий наименьшее число ребер) путь из одной вершины графа до всех остальных вершин. В нем сначала посещаются все вершины, смежные с текущей, а затем их потомки.
Бесплатные митапы о блокчейн разработке в Казани!
28 января в ИТ-парке г. Казань пройдет встреча, посвященная финтех решениям на блокчейне для банков и крупного бизнеса. Расскажем об использовании технологии в различных бизнес-отраслях, а также покажем архитектуру типовых решений и познакомим с функциональными инструментами разработки и внедрения.
Регистрация по ссылке: http://leader-id.ru/event/41240/?utm_source=proglibrary
29 января в г. Иннополисе эксперты Университета Иннополис, а также компаний-разработчиков блокчейн решений Waves Enterprise и Soramitsu Lab расскажут о кейсах применения технологии на практике и ответят на технические вопросы о внедрении блокчейна.
Регистрация по ссылке: https://oez-innopolis.timepad.ru/event/1240660/?utm_source=proglibrary
28 января в ИТ-парке г. Казань пройдет встреча, посвященная финтех решениям на блокчейне для банков и крупного бизнеса. Расскажем об использовании технологии в различных бизнес-отраслях, а также покажем архитектуру типовых решений и познакомим с функциональными инструментами разработки и внедрения.
Регистрация по ссылке: http://leader-id.ru/event/41240/?utm_source=proglibrary
29 января в г. Иннополисе эксперты Университета Иннополис, а также компаний-разработчиков блокчейн решений Waves Enterprise и Soramitsu Lab расскажут о кейсах применения технологии на практике и ответят на технические вопросы о внедрении блокчейна.
Регистрация по ссылке: https://oez-innopolis.timepad.ru/event/1240660/?utm_source=proglibrary
{kind=link}
Новые мероприятия на конец января и первую половину февраля
Москва
– PyData Moscow Meetup, 01 февраля
– Forum.Digital AI. Будущее искусственного интеллекта, 05 февраля
– moscowcss №17, 06 февраля
– Хакатон Moscow Travel Hack, 08 февраля
– Хакатон Photo Hack, 15 февраля
Казань
– Митап «Финтех решения на базе блокчейн-платформы Waves Enterprise для банков и крупного бизнеса», 28 января
– MEET UP: «Эволюция блокчейн – основа цифровой трансформации», 29 января
– Отбор проектов в Бизнес-инкубатор ИТ-парка, 02 февраля
Санкт-Петербург
– Tender Hack.Spb, 01 февраля
Витебск
– Митап Miniq #22, 30 января
Минск
– Митап Minsk PostgreSQL, 12 февраля
Москва
– PyData Moscow Meetup, 01 февраля
– Forum.Digital AI. Будущее искусственного интеллекта, 05 февраля
– moscowcss №17, 06 февраля
– Хакатон Moscow Travel Hack, 08 февраля
– Хакатон Photo Hack, 15 февраля
Казань
– Митап «Финтех решения на базе блокчейн-платформы Waves Enterprise для банков и крупного бизнеса», 28 января
– MEET UP: «Эволюция блокчейн – основа цифровой трансформации», 29 января
– Отбор проектов в Бизнес-инкубатор ИТ-парка, 02 февраля
Санкт-Петербург
– Tender Hack.Spb, 01 февраля
Витебск
– Митап Miniq #22, 30 января
Минск
– Митап Minsk PostgreSQL, 12 февраля
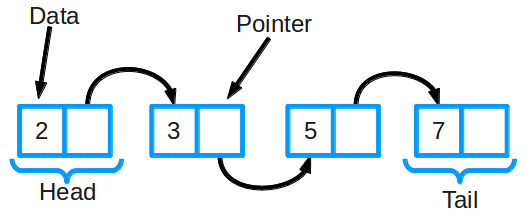
Структуры данных
Структуры данных являются важной частью разработки программного обеспечения и одной из наиболее распространенных тем для вопросов на собеседованиях с разработчиками. Давайте вспомним что из себя представляют структуры данных и начнем со связных списков.
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки.
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности. Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке. Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
Структуры данных являются важной частью разработки программного обеспечения и одной из наиболее распространенных тем для вопросов на собеседованиях с разработчиками. Давайте вспомним что из себя представляют структуры данных и начнем со связных списков.
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки.
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности. Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке. Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
{kind=link}
Окей, гуру! Каковы стоимость и риски автоматизации тестирования?
Гуру тестирования и тест-менеджер компании Luxoft Александр Александров рассказывает о себе и делится своими соображениями о преимущества и недостатках автоматизации тестирования.
1 часть: https://proglib.io/sh/pueanIlT9X
2 часть: https://proglib.io/sh/ZHYDfQtiUz
Гуру тестирования и тест-менеджер компании Luxoft Александр Александров рассказывает о себе и делится своими соображениями о преимущества и недостатках автоматизации тестирования.
1 часть: https://proglib.io/sh/pueanIlT9X
2 часть: https://proglib.io/sh/ZHYDfQtiUz
Библиотека программиста
Окей, гуру! Ты кто такой?
Дедушка русского тестирования и тест-менеджер компании Luxoft Александр Александров рассказывает о себе и своём опыте.
Стань специалистом по анализу данных: используй продвинутые методы и инструменты, чтобы автоматизировать рутину, работать быстрее или получить высокооплачиваемую профессию с высоким спросом.
Регистрация по ссылке: https://clc.to/EsNZRA.
💣 Ты научишься исследовать данные с помощью Python, восстанавливать отсутствующую информацию, находить аномалии.
💣 Построишь модели для реальных кейсов.
💣 Познакомишься с инструментами анализа данных — библиотеками Pandas и Matplotlib.
Занятия проведёт главный инженер Сбербанка Анастасия Борнева с 30 января по 1 февраля.
Регистрация по ссылке: https://clc.to/EsNZRA.
💣 Ты научишься исследовать данные с помощью Python, восстанавливать отсутствующую информацию, находить аномалии.
💣 Построишь модели для реальных кейсов.
💣 Познакомишься с инструментами анализа данных — библиотеками Pandas и Matplotlib.
Занятия проведёт главный инженер Сбербанка Анастасия Борнева с 30 января по 1 февраля.
#algorithm #sort
Quick sort (быстрая сортировка)
Быстрая сортировка - в целом это один из самых быстрых алгоритмов сортировки массивов, однако на практике он чаще всего применяется с разного рода модификациями. Является примером принципа «разделяй и властвуй».
Идея алгоритма заключается в том, что выбирается опорный элемент, относительно которого будет происходить сортировка. Равные и бОльшие элементы помещаются справа, меньшие – слева. Затем к полученным подмассивам рекурсивно применяются два первых пункта.
Quick sort (быстрая сортировка)
Быстрая сортировка - в целом это один из самых быстрых алгоритмов сортировки массивов, однако на практике он чаще всего применяется с разного рода модификациями. Является примером принципа «разделяй и властвуй».
Идея алгоритма заключается в том, что выбирается опорный элемент, относительно которого будет происходить сортировка. Равные и бОльшие элементы помещаются справа, меньшие – слева. Затем к полученным подмассивам рекурсивно применяются два первых пункта.
#job #interview
Практика прохождения собеседований
Большинство интервьюеров на собеседованиях не будут задавать вопросы о конкретных алгоритмах балансировки двоичного дерева или каких-то других сложных алгоритмах. Не исключено, что они сами их уже забыли, ведь такие вещи забываются сразу после окончания учебы.
Вам нужно знать основы и вы должны убедиться, что понимаете как их использовать и реализовывать, а также знаете их область применения, эффективность использования памяти и время выполнения. Вам могут задать вопрос как по теме из списка ниже (список не исчерпывающий, естественно), так и попросить реализовать какую-либо его модификацию.
Структуры данных:
- связные списки,
- бинарные деревья,
- графы,
- стеки,
- очереди,
- векторы/списки массивов,
- хеш-таблицы.
Алгоритмы:
- поиск в ширину и глубину,
- бинарный поиск,
- сортировка слиянием и быстрая сортировка,
- вставка в дерево.
Концепции:
- манипуляция битами,
- паттерн одиночка,
- паттерн фабричный метод.
- память (стек, куча),
- рекурсия,
- время порядка «О-большое».
Практика прохождения собеседований
Большинство интервьюеров на собеседованиях не будут задавать вопросы о конкретных алгоритмах балансировки двоичного дерева или каких-то других сложных алгоритмах. Не исключено, что они сами их уже забыли, ведь такие вещи забываются сразу после окончания учебы.
Вам нужно знать основы и вы должны убедиться, что понимаете как их использовать и реализовывать, а также знаете их область применения, эффективность использования памяти и время выполнения. Вам могут задать вопрос как по теме из списка ниже (список не исчерпывающий, естественно), так и попросить реализовать какую-либо его модификацию.
Структуры данных:
- связные списки,
- бинарные деревья,
- графы,
- стеки,
- очереди,
- векторы/списки массивов,
- хеш-таблицы.
Алгоритмы:
- поиск в ширину и глубину,
- бинарный поиск,
- сортировка слиянием и быстрая сортировка,
- вставка в дерево.
Концепции:
- манипуляция битами,
- паттерн одиночка,
- паттерн фабричный метод.
- память (стек, куча),
- рекурсия,
- время порядка «О-большое».
#logic
Новая головоломка. Задача о шести шахматных конях
Сегодня нам предстоит алгоритмическая задача с позиционным обменом двух типов объектов. Наглядно такое движение можно представить через перемещение шахматных коней.
После описания задачи идёт ответ на предыдущую головоломку о вирусе в колонии бактерий. Ответ и новая задача будут опубликованы в 14:00 в субботу.
https://proglib.io/sh/JmH5Ms16YL
Новая головоломка. Задача о шести шахматных конях
Сегодня нам предстоит алгоритмическая задача с позиционным обменом двух типов объектов. Наглядно такое движение можно представить через перемещение шахматных коней.
После описания задачи идёт ответ на предыдущую головоломку о вирусе в колонии бактерий. Ответ и новая задача будут опубликованы в 14:00 в субботу.
https://proglib.io/sh/JmH5Ms16YL
{kind=link}
ㅤ
Специально, для тех, кто ищет работу в сфере АйТи, был создан канал, где публикуют только качественные вакансии.
Больше не нужно бесконечно сёрфить в надежде найти что-то годное...всё уже собрано здесь!
Ссылка на канал с отборными вакансиями: https://t.me/joinchat/AAAAAFZEHKueTRHhpUEoww
Го сам и захвати друга 😉
Специально, для тех, кто ищет работу в сфере АйТи, был создан канал, где публикуют только качественные вакансии.
Больше не нужно бесконечно сёрфить в надежде найти что-то годное...всё уже собрано здесь!
Ссылка на канал с отборными вакансиями: https://t.me/joinchat/AAAAAFZEHKueTRHhpUEoww
Го сам и захвати друга 😉
#linux
9 занимательных вещей, которые позволят вам более виртуозно пользоваться командной оболочкой: https://proglib.io/p/interesting-shell/
9 занимательных вещей, которые позволят вам более виртуозно пользоваться командной оболочкой: https://proglib.io/p/interesting-shell/
Библиотека программиста
9 занимательных вещей о shell, о которых вы могли не знать
Очень сложно представить работу админа без использования терминала и командной оболочки. Сегодня мы поговорим о shell и тонкостях работы с ним.
Библиотека Rough.js позволяет научить компьютер рисовать «от руки» и внести некую шероховатость в ваши изображения. Знакомимся подробнее: https://proglib.io/sh/z0m3LtGYrs
Библиотека программиста
Rough.js: как заставить компьютер рисовать «от руки»
Слишком минималистичная, ровная графика может приедасться. Простой способ внести приятную шероховатость – библиотека Rough.js. Показываем примеры кода и применения.
Миграция на новую версию Elasticsearch с нулевым временем простоя
В статье рассмотрим реальный кейс по переходу на более современную версию Elasticsearch при соблюдении следующих ограничений: нулевое время простоя, отсутствие ошибок и потерь данных.
https://proglib.io/sh/YNnL2VtqW9
В статье рассмотрим реальный кейс по переходу на более современную версию Elasticsearch при соблюдении следующих ограничений: нулевое время простоя, отсутствие ошибок и потерь данных.
https://proglib.io/sh/YNnL2VtqW9
Библиотека программиста
Миграция на новую версию Elasticsearch с нулевым временем простоя
Доводилось ли вам переводить крупную систему на современную версию без потери данных и простоя? Рассматриваем пример реального проекта на Elasticsearch.
Мы решили один раз в конце каждого месяца рассказывать о работе, которую проводим на сайте. Подобного рода посты будут выступать путеводителем по самым значимым публикациям за прошедшее время.
У вас есть идеи и пожелания? Пишите в комментариях:
https://proglib.io/sh/MhvQGNu8rO
У вас есть идеи и пожелания? Пишите в комментариях:
https://proglib.io/sh/MhvQGNu8rO
Библиотека программиста
Наша работа над Proglib. Январь 2020
Подробный отчёт с гифками и ссылками. Что сделала команда Библиотеки программиста для своих читателей за первый месяц 2020 года.
#logic
Новая головоломка. Задача о беглеце
На рисунке приведён план одного из этажей тюрьмы. Найдите число различных кратчайших путей, которыми беглец может добраться по системе коридоров из точки
После описания задачи идёт ответ на предыдущую головоломку о шести шахматных конях. Ответ и новая задача будут опубликованы в 14:00 в среду.
https://proglib.io/sh/juLrpmAzDI
Новая головоломка. Задача о беглеце
На рисунке приведён план одного из этажей тюрьмы. Найдите число различных кратчайших путей, которыми беглец может добраться по системе коридоров из точки
A в точку B.После описания задачи идёт ответ на предыдущую головоломку о шести шахматных конях. Ответ и новая задача будут опубликованы в 14:00 в среду.
https://proglib.io/sh/juLrpmAzDI
{kind=link}
#stack
Структуры данных
Продолжим такую важную тему, как структуры данных. Сегодня на очереди стеки. Стек – это базовая структура данных, в которой вы можете только вставлять или удалять элементы в начале стека. Он напоминает стопку книг. Если вы хотите взглянуть на книгу в середине стека, вы сначала должны взять книги, лежащие сверху.
Стек считается LIFO (Last In First Out) – это означает, что последний элемент, который добавлен в стек, – это первый элемент, который из него выходит.
Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (называемый «push»), удаление элемента из стека (называемое «pop») и отображение содержимого стека (иногда называемого «pip»).
Структуры данных
Продолжим такую важную тему, как структуры данных. Сегодня на очереди стеки. Стек – это базовая структура данных, в которой вы можете только вставлять или удалять элементы в начале стека. Он напоминает стопку книг. Если вы хотите взглянуть на книгу в середине стека, вы сначала должны взять книги, лежащие сверху.
Стек считается LIFO (Last In First Out) – это означает, что последний элемент, который добавлен в стек, – это первый элемент, который из него выходит.
Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (называемый «push»), удаление элемента из стека (называемое «pop») и отображение содержимого стека (иногда называемого «pip»).
{kind=link}
Какое офомление вам нравится больше?
Anonymous Poll
63%
Тёмная тема
9%
Светлая тема
28%
Неважно, хочу интересный контент!
Разыскивается автор статей о языке Python в команду библиотеки программиста
Требования
— знаете стандартную библиотеку Python и популярные сторонние модули
— владеете терминами, принятыми в сообществе питонистов 🐍— любите объяснять новое, умеете разобраться в старом
— стремитесь увлечь читателя, но не во вред правде
— умеете организовать себя и выполнять задания в сжатые сроки
— уверенно читаете технические тексты на английским языке
— готовы писать не менее 2 материалов в неделю
Задачи
— готовить статьи о Python, популярных библиотеках и применениях
— переводить публикации с английского языка
— украшать тексты ссылками и 🖼 картинками
— составлять и проверять тесты для проверки знаний
— искать информацию, вникать и разбираться
— отвечать на комментарии ваших читателей
— делать работу над ошибками
Условия
— будем регулярно оплачивать труд 📅 дважды в месяц
— размер оплаты определяют только объем и сложность работы
— вы свободны в выборе материала, нам важно качество результата
— главный редактор знает Python и поможет освоиться в команде
— не оставим наедине с трудностями, если такие вдруг возникнут
Подробности здесь: https://proglib.io/vacancies/avtor-statey-o-yazyke-python-biblioteka-programmista-2020-01-14
Требования
— знаете стандартную библиотеку Python и популярные сторонние модули
— владеете терминами, принятыми в сообществе питонистов 🐍— любите объяснять новое, умеете разобраться в старом
— стремитесь увлечь читателя, но не во вред правде
— умеете организовать себя и выполнять задания в сжатые сроки
— уверенно читаете технические тексты на английским языке
— готовы писать не менее 2 материалов в неделю
Задачи
— готовить статьи о Python, популярных библиотеках и применениях
— переводить публикации с английского языка
— украшать тексты ссылками и 🖼 картинками
— составлять и проверять тесты для проверки знаний
— искать информацию, вникать и разбираться
— отвечать на комментарии ваших читателей
— делать работу над ошибками
Условия
— будем регулярно оплачивать труд 📅 дважды в месяц
— размер оплаты определяют только объем и сложность работы
— вы свободны в выборе материала, нам важно качество результата
— главный редактор знает Python и поможет освоиться в команде
— не оставим наедине с трудностями, если такие вдруг возникнут
Подробности здесь: https://proglib.io/vacancies/avtor-statey-o-yazyke-python-biblioteka-programmista-2020-01-14
{kind=link}