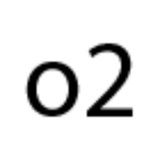
This media is not supported in your browser
VIEW IN TELEGRAM
навайбкодил. Питон, ни одной строчки руками не набрал. Но я знаю как должно работать внутри, все по моей инструкции. Страшно 🥲 или нет?
CodeGraphViewerTool.zip
166 KB
тулзу на питоне сгенерировал почти без ручных правок кода. Сгенеренный код довольно хорош. В целом llm с питоном и раньше справлялся лучше чем с С++, но тут я бы сам отревьюил код как "хороший"
помогать приходилось обильно, все классические грабли - что-то llm забывает, что-то делает не верно. Но в целом я действительно давал инструкции и у меня получилось слепить тулзу
другое дело что моя идея с физическим разрешением зависимостей мягко говоря провалилась, но об этом чуть позже
приложу архивчик с сорцами, если интересно
помогать приходилось обильно, все классические грабли - что-то llm забывает, что-то делает не верно. Но в целом я действительно давал инструкции и у меня получилось слепить тулзу
другое дело что моя идея с физическим разрешением зависимостей мягко говоря провалилась, но об этом чуть позже
приложу архивчик с сорцами, если интересно
большой проблемой стала проихводительность питона. Дело в том, что я пытался анализировать свой рабочий проект - игру homescapes. Она довольно большая )
и если тестовый пример с десятью сущностями работали прекрасно, то на 10 тысячах стало все прям печально.
хорошая новость в том, что через llm получилось ускорить на порядки. Местами конечно очевидные оптимизации, местами приходилось подсказывать, но например прикрутить jit компиляцию он предложил сам, а так же несколько либ ускоряющих перфоманс. Что порадовало
плохая новость в том, что кадр все равно обсчитывает очень долго - полторы секунды - и тулза совсем бесполезна
поэтому я пошел на следующую итерацию, сделать тулзу на С++
и если тестовый пример с десятью сущностями работали прекрасно, то на 10 тысячах стало все прям печально.
хорошая новость в том, что через llm получилось ускорить на порядки. Местами конечно очевидные оптимизации, местами приходилось подсказывать, но например прикрутить jit компиляцию он предложил сам, а так же несколько либ ускоряющих перфоманс. Что порадовало
плохая новость в том, что кадр все равно обсчитывает очень долго - полторы секунды - и тулза совсем бесполезна
поэтому я пошел на следующую итерацию, сделать тулзу на С++
и здесь я сразу решил с ноги зайти и просто написать что за тулзу я хочу. Да да, одним промтом, вот прям из коробки.
За основу я взял демо-проект imgui со своим прикрученным профайлером
Вот первый промт:
За основу я взял демо-проект imgui со своим прикрученным профайлером
Вот первый промт:
я хочу сделать графическую утилиту, которая сканирует исходники С++ в нескольких папках, строит зависимости, и отображает с помощью imgui в графическом виде эти зависимости. Графически эти зависимости кластеризуют связанные сущности (исходники), с помощью физических законов. Сущности представлены в виде цветных кружков, зависимости (или связи) в виде линий.
Зависимости строятся на 2х уровнях:
- иерархия папок и подпапок: для каждой директории создается сущность директории, дочерняя директория зависит от родительской. Внутри директории есть список сущностей - файлов в ней
- зависимости между исходниками С++ через #include: из каждого исходника парсится список инклюдов, ищутся файлы-исходники по путям и между ними создается связь
Работа физики:
- для этого сущности расположены в 2д мире, у каждого есть позиция
- между ними есть зависимости- связи, которые задают некое расстояние между сущностями
- сущности стараются оттолкнуться от билзлижащих сущностей
- используется интеграция верле и разрешение связей как в научной работе якобсена из hitman codename 47
- при зажимании левой кнопки мыши умеет захватывать сущность чтобы ее перемещать вслед за курсором
Графика:
- используется imgui Для отображения. В текущем исходнике Main.cpp создается дополнительное окно, в котором отображается вся графика: сущности и связи
- сущности - это разноцветные круги
- связи - это линнии между ними
- существует камера, которой можно управлять: скролл (перемещение) с зажатой правой кнопкой мыши, зум с помощью колесика
- наведение курсора на сущность включает ее подсветку: отображается имя исходника, а так же связь с родителем и детьми
- для профилирования используется nano profiler: работа физики и графики
что нужно сделать:
- завести json конфиг с параметрами: исходные директории для сканирования, настройки графики и физики. Работает как отдельный класс
- сделать класс парсера исходников с многопоточностью: берет исходные директории из json конфига и рекурсивно сканирует их в поисках C++ исходников .h/.cpp, парсит #include, связывает сущности, создает сущности для всех директорий
- физический движок, оптимизированный для вычисления 10000 сущностей и 30000 связей. Инициализируется из парсера исходников, сохраняя ссылки на исходные сущности. ПРоводит симуляцию мира и физики: интегрирует позиции, разрешает связи, расталкивает близлижащие сущности
- графическое отображение. Содержит камеру, обрабатывает инпут пользователя, отображает сущности и связи
- главный класс утилиты: читает конфиг, парсит исходники, инициализирует физику и графику, запускает игровой цикл апдейта фрейма - обонвление физики, обработка инпута и отрисовка
Разделяй вышеописанное на классы в разных файлах, рядом с Main.cpp. Используй для всего стандартную библиотеку stl и imgui. Не используй ничего кастомного, никаких скриптов, только С++
GitHub
GitHub - zenkovich/imgui_perfmon: Simple performance widget for ImGUI
Simple performance widget for ImGUI. Contribute to zenkovich/imgui_perfmon development by creating an account on GitHub.
cursor_c.md
767.4 KB
иии... тулза сгенерилась и скомпилилась сразу. Но естественно не совсем так, как хотелось.
Поэтому дальше допиливалось напильником, правился код стайл, в общем вот вся история общения с С++ версией
Проблемы были все те же: что-то забывал, что-то делал не так, но в код руками я почти не лез
Поэтому дальше допиливалось напильником, правился код стайл, в общем вот вся история общения с С++ версией
Проблемы были все те же: что-то забывал, что-то делал не так, но в код руками я почти не лез
This media is not supported in your browser
VIEW IN TELEGRAM
В результате получилась тулза, значительно быстрее по перфомансу, FPS получается в районе 20ти, что неплохо для 10 тыс сущностей, 30к связей и полумиллиона пар расталкивания
Здесь я практически не просил оптимизировать, некоторые алгоритмы llm выдал сразу оптимизированными. Например, для расталкивания сразу применил кластеризацию пространства, чтобы искать близко лежащие пары сущностей
Но сама тулза в итоге бесполезна. Физическая система не справляется с разрешением противоречий в системе зависимостей, в итоге она либо взрывается, либо уплывает куда-то в сторону. Думаю это все можно доработать, но уже не очень много смысла в этом, проще посмотреть структуру папок и директорий чтобы понять структуру.
Идея была в том, чтобы связать и кластеризовать зависящие друг от друга логические куски игры. Но, оказалось что все связано со всем, и все превращается в кашу
Здесь я практически не просил оптимизировать, некоторые алгоритмы llm выдал сразу оптимизированными. Например, для расталкивания сразу применил кластеризацию пространства, чтобы искать близко лежащие пары сущностей
Но сама тулза в итоге бесполезна. Физическая система не справляется с разрешением противоречий в системе зависимостей, в итоге она либо взрывается, либо уплывает куда-то в сторону. Думаю это все можно доработать, но уже не очень много смысла в этом, проще посмотреть структуру папок и директорий чтобы понять структуру.
Идея была в том, чтобы связать и кластеризовать зависящие друг от друга логические куски игры. Но, оказалось что все связано со всем, и все превращается в кашу
Ах да, что в итоге с gpt-5. Честно говоря я не увидел особых отличий в лучшую сторону от claude-4, который использовал все последнее время. Честно говоря даже местами получается хуже. Я пробовал и на других задачах, буквальо спрашивая одно и то же у двух моделей, и claude был понятнее, предсказуемее и... быстрее! gpt-5 очень долго думает, около минуты, чтобы предпринять действие. Честно говоря мне и самому минуты хватает чтобы разобраться, особенно в хорошо знакомом мне коде
Поэтому, пока что откатываюсь к более старой и проверенной claude
Поэтому, пока что откатываюсь к более старой и проверенной claude
Порой в реальных проектах классы становятся сложными, в них много полей и даже бывает что они просто плохо написаны их сложно смотреть при отладке. Тебе нужно увидеть значение какой-нибудь переменной, а до нее листать и листать, или разворачивать кучу вложенностей
Поверх этого еще могут быть оптимизационные ухищрения - кастомные коллекции, union'ы и другие страшные штуки, которые в отладке просто не читаемы
Еще бывают довольно простые типы, например математические вектора (x, y, z), цвет (RGBA), UID и тд, в общем что-то простое, но чтобы узнать содержимое - нужно разворачивать. Хотя данные можно было бы уместить в одну строку удобным образом
Поверх этого еще могут быть оптимизационные ухищрения - кастомные коллекции, union'ы и другие страшные штуки, которые в отладке просто не читаемы
Еще бывают довольно простые типы, например математические вектора (x, y, z), цвет (RGBA), UID и тд, в общем что-то простое, но чтобы узнать содержимое - нужно разворачивать. Хотя данные можно было бы уместить в одну строку удобным образом
Для всего этого есть специальные форматтеры, подключаемые к IDE, чтобы упростить вывод сложных объектов. Они говорят IDE в каком виде представлять ту или иную структуру, условное форматирование и форматирование превью объекта - то что может вывести XYZ или RGBA прямо в строке переменной.
Это и есть те самые natvis и lldb formatters. Есть и другие, но я пока использовал только их, поэтому расскажу про них 😁
- natvis - это инструмент чисто под msvs. Работает как конфиг, оперирующий полями объекта. Синтаксис довольно не простой, но возможности довольно обширные: условное форматирование, разворачивание сложных коллекций а-ля деревья/списки
- lldb formatters - это api для python, который позволяет писать скрипты для форматирования отображения в lldb. Тут все просто - пишешь скрипт под определенное API отладчика, внутри делаешь что хочешь. Но есть проблемы с перфомансом
Это и есть те самые natvis и lldb formatters. Есть и другие, но я пока использовал только их, поэтому расскажу про них 😁
- natvis - это инструмент чисто под msvs. Работает как конфиг, оперирующий полями объекта. Синтаксис довольно не простой, но возможности довольно обширные: условное форматирование, разворачивание сложных коллекций а-ля деревья/списки
- lldb formatters - это api для python, который позволяет писать скрипты для форматирования отображения в lldb. Тут все просто - пишешь скрипт под определенное API отладчика, внутри делаешь что хочешь. Но есть проблемы с перфомансом
Вывод краткого описания
Полезно для каких-то простых структур, содержимое которых можно уместить в одной строке: цвет RGBA, координаты вектора XYZ, интернированные строки и т.п.
в natvis это делается через тег
Так же можно задавать условие отображения того или иного варианта, что весьма удобно. Вот классический пример для умного указателя: если поинтер не пустой, то показываем его, иначе "empty"
в lldb formatter'ах чуть сложнее. Сначала нужно зарегать хендлер для типа:
затем реализовать его:
Относительно xml это выглядит понятнее и гибче
Полезно для каких-то простых структур, содержимое которых можно уместить в одной строке: цвет RGBA, координаты вектора XYZ, интернированные строки и т.п.
в natvis это делается через тег
DisplayString, внутри которого можно форматировать строку из доступных полей класса:<Type Name="o2::Vertex">
<DisplayString>{{ x: { x } y: { y } z: { z } c: { color } u: { tu } v: { tv }}</DisplayString>
</Type>
Так же можно задавать условие отображения того или иного варианта, что весьма удобно. Вот классический пример для умного указателя: если поинтер не пустой, то показываем его, иначе "empty"
<DisplayString Condition="(mPtr != 0)">{ mPtr }</DisplayString>
<DisplayString Condition="(mPtr == 0)">empty</DisplayString>в lldb formatter'ах чуть сложнее. Сначала нужно зарегать хендлер для типа:
debugger.HandleCommand('type summary add -F o2_lldb_formatters.vertex_summary "o2::Vertex"')затем реализовать его:
def get_child_value(valobj, name):
"""Helper to safely get child value"""
try:
child = valobj.GetChildMemberWithName(name)
if child.IsValid():
return child.GetValue()
return "?"
except:
return "?"
def vertex_summary(valobj, internal_dict):
"""Format o2::Vertex"""
x = get_child_value(valobj, "x")
y = get_child_value(valobj, "y")
z = get_child_value(valobj, "z")
color = get_child_value(valobj, "color")
tu = get_child_value(valobj, "tu")
tv = get_child_value(valobj, "tv")
return f"{{ x: {x} y: {y} z: {z} c: {color} u: {tu} v: {tv} }}"
Относительно xml это выглядит понятнее и гибче
Построение дочерних нод и структуры
Когда нужно какие-то поля показать, а какие-то нет. Использовать более читаемые слова или изменить порядок
В natvis это делается с помощью тегов <Expand>, <Synthetic> и <Item>:
-
-
-
-
Рассмотри пару примеров. Здесь просто перечисляем некоторые поля класса. Обратите внимание на само описание типа - оно задается для шаблонного типа, через
Или вот пример посложнее с синтезированными полями. Здесь описан тип меша с кастомными коллекциями вершин и индексов. IDE передаются два параметра: Size - размер коллекции, и ValuePointer - откуда начинать отсчет
В целом, формат хоть и немного упоротый, но с ним можно легко разобраться, особенно в эру ИИ, которые справляются с этим на ура.
Здесь в моем движке лежит список .natvis описаний типов, там есть довольно сложные описания типа актора
https://github.com/o2-engine/o2/blob/master/Framework/Platforms/Windows/Framework.natvis
Когда нужно какие-то поля показать, а какие-то нет. Использовать более читаемые слова или изменить порядок
В natvis это делается с помощью тегов <Expand>, <Synthetic> и <Item>:
-
<Expand> - список полей при разворачивании-
<Item> - конкретное поле класса-
<Synthetic> - сложное синтезированное поле класса, которое может быть коллекцией-
<ExpandedItem> - развернутые поля определенного дочернего поля классаРассмотри пару примеров. Здесь просто перечисляем некоторые поля класса. Обратите внимание на само описание типа - оно задается для шаблонного типа, через
<*> (да, вот такой вот незамысловатый формат с кодированием угловых скобок в xml)<Type Name="o2::FieldInfo<*>">
<DisplayString>{{ name={ mName } value={ mFieldRef } }}</DisplayString>
<Expand>
<Item Name="name">mName</Item>
<Item Name="value">mFieldRef</Item>
<Item Name="owner">mOwner</Item>
</Expand>
</Type>
Или вот пример посложнее с синтезированными полями. Здесь описан тип меша с кастомными коллекциями вершин и индексов. IDE передаются два параметра: Size - размер коллекции, и ValuePointer - откуда начинать отсчет
<Type Name="o2::Mesh">
<DisplayString>{{ vertx = { vertexCount }/{ mMaxVertexCount } poly = { polyCount }/{ mMaxPolyCount } tex = { mTexture.mTexture } }}</DisplayString>
<Expand>
<Item Name="texture" ExcludeView="simple">mTexture.mTexture</Item
<Synthetic Name="verticies">
<DisplayString>{ vertexCount }/{ mMaxVertexCount }</DisplayString>
<Expand>
<ArrayItems>
<Size>vertexCount</Size>
<ValuePointer>vertices</ValuePointer>
</ArrayItems>
</Expand>
</Synthetic
<Synthetic Name="indexes">
<DisplayString>{ polyCount }/{ mMaxPolyCount }</DisplayString>
<Expand>
<ArrayItems>
<Size>polyCount*3</Size>
<ValuePointer>indexes</ValuePointer>
</ArrayItems>
</Expand>
</Synthetic
</Expand>
</Type>
В целом, формат хоть и немного упоротый, но с ним можно легко разобраться, особенно в эру ИИ, которые справляются с этим на ура.
Здесь в моем движке лежит список .natvis описаний типов, там есть довольно сложные описания типа актора
https://github.com/o2-engine/o2/blob/master/Framework/Platforms/Windows/Framework.natvis
Для lldb все сильно проще - пишется скрипт, который формирует нужную структуру и отображение. Но у меня не получилось это хорошо завести из-за проблем перфоманса. Эти форматтеры вешали отладчик намертво, в итоге остались только простые summary обработчики
https://github.com/o2-engine/o2/blob/master/Framework/Platforms/o2_lldb_formatters.py
https://github.com/o2-engine/o2/blob/master/Framework/Platforms/o2_lldb_formatters.py