
Сбор донатов на неделю с 3 постами в день и без рекламы
Привет! Меня зовут Артемий, я автор этого канала. Занимаюсь искусственным интеллектом в геофизике (кстати скоро поделюсь своим новым местом работы) и в свободное время пишу заметки и освещаю интересные, на мой взгляд, новости нашей отрасли.
Что бы не терять мотивацию, я иногда продаю рекламу в этом канале. В связи с чем, у меня есть предложение:
Если мы соберём нужную сумму, то я обещаю неделю в этом канале без рекламы и с 3 качественными постами в день.
💰ЗАДОНАТИТЬ АРТЕМИЮ 💰
Привет! Меня зовут Артемий, я автор этого канала. Занимаюсь искусственным интеллектом в геофизике (кстати скоро поделюсь своим новым местом работы) и в свободное время пишу заметки и освещаю интересные, на мой взгляд, новости нашей отрасли.
Что бы не терять мотивацию, я иногда продаю рекламу в этом канале. В связи с чем, у меня есть предложение:
Если мы соберём нужную сумму, то я обещаю неделю в этом канале без рекламы и с 3 качественными постами в день.
💰ЗАДОНАТИТЬ АРТЕМИЮ 💰
Masked Autoencoders that Listen
Вышла новая работа от Meta Research, в которой исследуется следующая идея для работы со звуком:
* переводим звук в спектрограмму (двухмерное отображение звука, где по оси x - время, а по оси y - частота)
* делим спектрограмму на патчи
* прячем патчи в случайном порядке
* просим автоэнкодер предсказать спрятанные куски
Таким образом получили self-supervised Masked Autoencoder (MAE) для звука.
Эмпирически Audio-MAE показывает новые SOTA результаты в шести задачах классификации аудио и речи, превосходя другие недавние модели, в том числе обученные с учителем.
🐙 код 📖 статья
Вышла новая работа от Meta Research, в которой исследуется следующая идея для работы со звуком:
* переводим звук в спектрограмму (двухмерное отображение звука, где по оси x - время, а по оси y - частота)
* делим спектрограмму на патчи
* прячем патчи в случайном порядке
* просим автоэнкодер предсказать спрятанные куски
Таким образом получили self-supervised Masked Autoencoder (MAE) для звука.
Эмпирически Audio-MAE показывает новые SOTA результаты в шести задачах классификации аудио и речи, превосходя другие недавние модели, в том числе обученные с учителем.
🐙 код 📖 статья
Forwarded from DLStories | Нейронные сети и ИИ
Mood Board Search: ML-powered тулза от Google для создания мудбордов.
Мудборд — это набор изображений, которые отражают какую-либо идею или концепт. Например, это могут быть картинки, подходящие под ваше понимание "свободы", "умиротворенности" или "дуализма". Мудборды часто используют фотографы для подготовки к съемкам: ищут в интернете фотографии, которые наиболее соответствуют их задумке.
И Гугл придумал тулзу, которая поможет найти больше картинок для вашего мудборда.
Работает это так:
- загружаете несколько картинок, подходящих под ваш концепт. При этом можно отранжировать картинки по значимости, а также добавить "антикартинки": те, которые отражают противоположность нужному концепту. Это сделает поиск точнее.
- система ищет картинки, концептуально наиболее похожие на ваши;
- далее вы можете добавить какие-то из найденных картинок в ваш мудборд и снова запустить поиск. Так он станет еще точнее.
Работает это чудо на эмбеддингах из предобученных нейросетей для классификации картинок GoogLeNet/MobileNet и такой штуке, как Concept Activation Vectors (CAVs).
CAV — это такой способ анализа эмбеддингов предобученной нейросети, способ анализа того, как нейросеть "думает". С помощью CAV можно понимать, насколько присутствие того или иного паттерна на картинке влияет на результат классификации картинки нейросетью. Например, насколько сильно наличие черно-белых полос подталкивает нейросеть к тому, чтобы классифицировать картинку, как Зебру.
И вот, оказывается, как идею для interpretability можно использовать для создания полезного инструмента =)
Ссылки:
Блогпост о Mood Board Search в Google AI Blog
Демка
Код на GitHub (тут есть интро в то, как CAV работает)
Статья о CAV на arxiv
Мудборд — это набор изображений, которые отражают какую-либо идею или концепт. Например, это могут быть картинки, подходящие под ваше понимание "свободы", "умиротворенности" или "дуализма". Мудборды часто используют фотографы для подготовки к съемкам: ищут в интернете фотографии, которые наиболее соответствуют их задумке.
И Гугл придумал тулзу, которая поможет найти больше картинок для вашего мудборда.
Работает это так:
- загружаете несколько картинок, подходящих под ваш концепт. При этом можно отранжировать картинки по значимости, а также добавить "антикартинки": те, которые отражают противоположность нужному концепту. Это сделает поиск точнее.
- система ищет картинки, концептуально наиболее похожие на ваши;
- далее вы можете добавить какие-то из найденных картинок в ваш мудборд и снова запустить поиск. Так он станет еще точнее.
Работает это чудо на эмбеддингах из предобученных нейросетей для классификации картинок GoogLeNet/MobileNet и такой штуке, как Concept Activation Vectors (CAVs).
CAV — это такой способ анализа эмбеддингов предобученной нейросети, способ анализа того, как нейросеть "думает". С помощью CAV можно понимать, насколько присутствие того или иного паттерна на картинке влияет на результат классификации картинки нейросетью. Например, насколько сильно наличие черно-белых полос подталкивает нейросеть к тому, чтобы классифицировать картинку, как Зебру.
И вот, оказывается, как идею для interpretability можно использовать для создания полезного инструмента =)
Ссылки:
Блогпост о Mood Board Search в Google AI Blog
Демка
Код на GitHub (тут есть интро в то, как CAV работает)
Статья о CAV на arxiv
Google запускает квантовую виртуальную машину
Несколько десятилетий назад квантовые компьютеры были лишь концепцией - далекой идеей, обсуждаемой в основном в лекционных залах. В настоящее время идет гонка за создание отказоустойчивых квантовых компьютеров и открытие новых алгоритмов для их полезного применения.
Сегодня Гугл выпустили на рынок квантовую виртуальную машину, которая эмулирует опыт и результаты программирования одного из гугловых квантовых компьютеров. В компании считают, что эмулятор облегчит исследователям создание прототипов новых алгоритмов и поможет студентам научиться программировать квантовый компьютер.
💡Статья
Несколько десятилетий назад квантовые компьютеры были лишь концепцией - далекой идеей, обсуждаемой в основном в лекционных залах. В настоящее время идет гонка за создание отказоустойчивых квантовых компьютеров и открытие новых алгоритмов для их полезного применения.
Сегодня Гугл выпустили на рынок квантовую виртуальную машину, которая эмулирует опыт и результаты программирования одного из гугловых квантовых компьютеров. В компании считают, что эмулятор облегчит исследователям создание прототипов новых алгоритмов и поможет студентам научиться программировать квантовый компьютер.
💡Статья
DALL·E Now Available in Beta
С сегодняшнего дня пользователи получают полные права на коммерческое использование изображений, созданных ими с помощью DALL-E, включая право на перепечатку, продажу и мерчандайзинг. Сюда входят изображения, созданные ими во время предварительного просмотра.
Пользователи сообщили OpenAI, что планируют использовать изображения DALL-E для коммерческих проектов, таких как иллюстрации для детских книг, иллюстрации для информационных бюллетеней, концепт-арт и персонажи для игр, moodboards для дизайнерских консультаций и раскадровки для фильмов.
анонс
С сегодняшнего дня пользователи получают полные права на коммерческое использование изображений, созданных ими с помощью DALL-E, включая право на перепечатку, продажу и мерчандайзинг. Сюда входят изображения, созданные ими во время предварительного просмотра.
Пользователи сообщили OpenAI, что планируют использовать изображения DALL-E для коммерческих проектов, таких как иллюстрации для детских книг, иллюстрации для информационных бюллетеней, концепт-арт и персонажи для игр, moodboards для дизайнерских консультаций и раскадровки для фильмов.
анонс
Forwarded from Graph Machine Learning
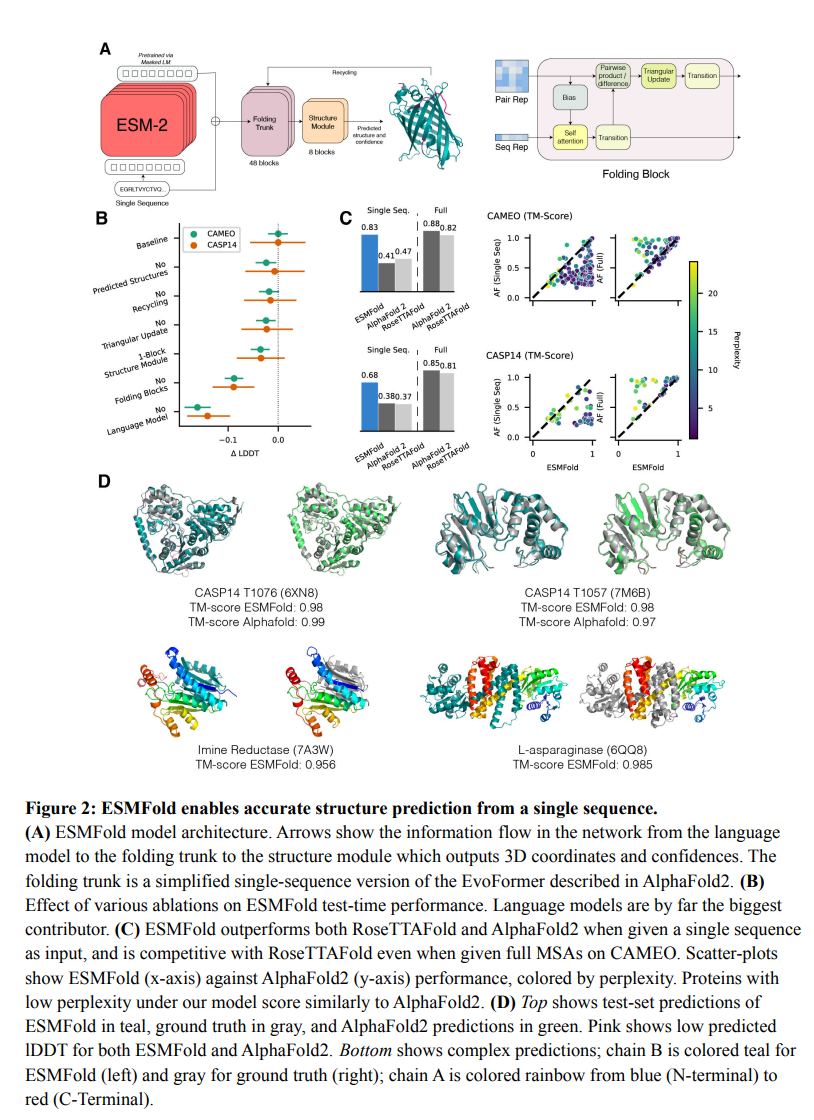
ESMFold: Protein Language Models Solve Folding, Too
Today, Meta AI Protein Team announced ESMFold - a protein folding model that uses representations right from a protein LM. Meta AI has been working on BERT-style protein language models for a while, e.g., they created a family of ESM models that are currently SOTA in masked protein sequence prediction tasks.
“A key difference between ESMFold and AlphaFold2 is the use of language model representations to remove the need for explicit homologous sequences (in the form of an MSA) as input.”
To this end, the authors design a new family of protein LMs ESM-2. ESM-2 are much more parameter efficient compared to ESM-1b, e.g., 150M ESM-2 is on par with 650M ESM-1b, and 15B ESM-2 leaves all ESM-1 models far behind. Having pre-trained an LM, ESMFold applies Folding Trunk blocks (simplified EvoFormer blocks from AlphaFold 2) and yields 3D predictions.
ESMFold outperforms AlphaFold and RoseTTAFold when only given a single-sequence input w/o MSAs and also much faster! Check out the attached illustration with architecture and charts.
“On a single NVIDIA V100 GPU, ESMFold makes a prediction on a protein with 384 residues in 14.2 seconds, 6X faster than a single AlphaFold2 model. On shorter sequences we see a ~60X improvement. … ESMFold can be run reasonably quickly on CPU, and an Apple M1 Macbook Pro makes the same prediction in just over 5 minutes.”
Finally, ESMFold shows remarkable scaling properties:
“We see non-linear improvements in protein structure predictions as a function of model
scale, and observe a strong link between how well the language model understands a sequence (as measured by perplexity) and the structure prediction that emerges.”
Are you already converted to the church of Scale Is All You Need - AGI Is Coming? 😉
Today, Meta AI Protein Team announced ESMFold - a protein folding model that uses representations right from a protein LM. Meta AI has been working on BERT-style protein language models for a while, e.g., they created a family of ESM models that are currently SOTA in masked protein sequence prediction tasks.
“A key difference between ESMFold and AlphaFold2 is the use of language model representations to remove the need for explicit homologous sequences (in the form of an MSA) as input.”
To this end, the authors design a new family of protein LMs ESM-2. ESM-2 are much more parameter efficient compared to ESM-1b, e.g., 150M ESM-2 is on par with 650M ESM-1b, and 15B ESM-2 leaves all ESM-1 models far behind. Having pre-trained an LM, ESMFold applies Folding Trunk blocks (simplified EvoFormer blocks from AlphaFold 2) and yields 3D predictions.
ESMFold outperforms AlphaFold and RoseTTAFold when only given a single-sequence input w/o MSAs and also much faster! Check out the attached illustration with architecture and charts.
“On a single NVIDIA V100 GPU, ESMFold makes a prediction on a protein with 384 residues in 14.2 seconds, 6X faster than a single AlphaFold2 model. On shorter sequences we see a ~60X improvement. … ESMFold can be run reasonably quickly on CPU, and an Apple M1 Macbook Pro makes the same prediction in just over 5 minutes.”
Finally, ESMFold shows remarkable scaling properties:
“We see non-linear improvements in protein structure predictions as a function of model
scale, and observe a strong link between how well the language model understands a sequence (as measured by perplexity) and the structure prediction that emerges.”
Are you already converted to the church of Scale Is All You Need - AGI Is Coming? 😉
{kind=link}
What Do We Maximize in Self-Supervised Learning?
Вышла статья за авторством в том числе Лекуна, в которой рассуждают о том что такое self-supervised learning (#SSL) и почему оно работает.
В статье рассматриваются методы SSL обучения, в частности VICReg. Делают следующее:
1. Демонстрируют, как SSL можно сделать для детерминированной сети, предлагая возможную альтернативу предыдущим работам, которые полагаются на стохастические модели.
2. Это позволяет авторам нам продемонстрировать, как VICReg может быть (пере)обнаружен из первых принципов и его предположений о распределении данных.
3. Эмпирически демонстрируют обоснованность своих предположений, подтверждая понимание VICReg.
4. Постулируют что их метод может быть обобщен на многие другие методы SSL, открывая новые пути для теоретического и практического понимания SSL и transfer learning.
Другое дело, что пусть сначала продемонстрируют, а там и поговорим :)
Статья
(1) Изображение сгенерировано проектом Simulacra
(2) За наводку спасибо @j_links
Вышла статья за авторством в том числе Лекуна, в которой рассуждают о том что такое self-supervised learning (#SSL) и почему оно работает.
В статье рассматриваются методы SSL обучения, в частности VICReg. Делают следующее:
1. Демонстрируют, как SSL можно сделать для детерминированной сети, предлагая возможную альтернативу предыдущим работам, которые полагаются на стохастические модели.
2. Это позволяет авторам нам продемонстрировать, как VICReg может быть (пере)обнаружен из первых принципов и его предположений о распределении данных.
3. Эмпирически демонстрируют обоснованность своих предположений, подтверждая понимание VICReg.
4. Постулируют что их метод может быть обобщен на многие другие методы SSL, открывая новые пути для теоретического и практического понимания SSL и transfer learning.
Другое дело, что пусть сначала продемонстрируют, а там и поговорим :)
Статья
(1) Изображение сгенерировано проектом Simulacra
(2) За наводку спасибо @j_links
Почему древовидные модели все еще превосходят глубокое обучение на табличных данных?
Нейросети не очень хорошо умеют в табличные данные.
Авторы статьи провели тестирование стандартных и новых методов глубокого обучения, а также моделей на основе деревьев, таких как XGBoost и Random Forests, на большом количестве наборов данных и комбинаций гиперпараметров. Они определили стандартный набор из 45 наборов данных из различных областей с четкими характеристиками табличных данных и методологию бенчмаркинга, учитывающую как подгонку моделей, так и поиск хороших гиперпараметров.
Результаты показывают, что модели на основе деревьев работают лучше на данных среднего размера (∼10K выборок) даже без учета их скорости.
Авторы задают вопрос - почему так? Чем деревья лучше нейронок? И сами же на него отвечают. NN для таблиц должны стать:
1. Более устойчивыми к неинформативным признакам,
2. сохранять ориентацию данных и
3. Более способными легко обучаться нерегулярным функциям.
📖Статья
Нейросети не очень хорошо умеют в табличные данные.
Авторы статьи провели тестирование стандартных и новых методов глубокого обучения, а также моделей на основе деревьев, таких как XGBoost и Random Forests, на большом количестве наборов данных и комбинаций гиперпараметров. Они определили стандартный набор из 45 наборов данных из различных областей с четкими характеристиками табличных данных и методологию бенчмаркинга, учитывающую как подгонку моделей, так и поиск хороших гиперпараметров.
Результаты показывают, что модели на основе деревьев работают лучше на данных среднего размера (∼10K выборок) даже без учета их скорости.
Авторы задают вопрос - почему так? Чем деревья лучше нейронок? И сами же на него отвечают. NN для таблиц должны стать:
1. Более устойчивыми к неинформативным признакам,
2. сохранять ориентацию данных и
3. Более способными легко обучаться нерегулярным функциям.
📖Статья
Сколько вам лет?
Anonymous Poll
1%
10-15
11%
16-20
33%
21-25
23%
26-30
14%
31-35
9%
36-40
4%
41-45
2%
46-50
3%
50+
Forwarded from gonzo-обзоры ML статей
Generative AI
Последние месяцы на поляне Generative AI праздник за праздником.
Начнём с генерации картинок.
Пока OpenAI со своим DALLE-2 медленно распиаривался, под боком возник быстрорастущий офигенный сервис Midjourney, забивший на сайт, API и всё такое, и предоставивший доступ к своим моделям через бота в Discord. Midjourney очень правильно начал работать с коммьюнити, набрал популярность и вышел в законодатели мод на этом рынке.
В отличие от OpenAI, Midjourney не требовал исключительных прав на все творения, оставляя все права пользователю и беря себе лицензию на их использование. Midjourney также разрешил коммерческое использование творений. У них есть пара оговорок касающихся бесплатного плана, а также компаний с выручкой больше $1M, но это всё очень reasonable. Оно у них, конечно, менялось и уточнялось по ходу дела, но явно было более либерально в отличие от terms OpenAI, где всё их, только private use, и всё такое.
И это кстати отдельный интересный вопрос этического плана — нормально ли, что система, обученная на результатах труда множества людей, присваивает весь производный результат себе, включая кстати и труд других людей по придумыванию правильных prompt'ов и селекции результатов. Где тот современный Маркс, который напишет Капитал 2.0?
Midjourney на днях вышел из закрытой беты в открытую https://www.facebook.com/intentoco/photos/a.1093842744008324/5486357671423454/) и OpenAI вынужден был последовать той же дорогой -- сразу прекратили играть в тщательно фильтруемые инвайты и тоже вышли в public beta, а также изменили terms на более коммерчески пригодные (https://www.facebook.com/intentoco/photos/a.1093842744008324/5493404720718749/).
Если бы не Midjourney, уверен, OpenAI бы ещё полгода свою илитность эксплуатировали. Конкуренция -- это прекрасно. И это только начало.
Также из области генерации картинок недавно широко разошлась новость (https://www.facebook.com/story.php?story_fbid=pfbid035HKtaMKL9ibTW2BH66cMecbCvj7RCXusf7w5yGkFP9xVHpg64Y4BcYCmv4Ea7x7Fl&id=4) про мартовскую работу Make-A-Scene (https://arxiv.org/abs/2203.13131), где при генерации картинки дополнительно к тексту можно давать эскиз с семантической маской. Это позволяет точно контролировать где на картинке что должно быть. В каком-то смысле это продолжение истории с аналогичным графическим редактором от Nvidia.
В генерации текстов тоже большое достижение -- опубликована модель BLOOM (https://www.facebook.com/intentoco/posts/pfbid02TEHE1sQYf78pXu9ZWEXcbfJ1DfZKQrCVSnB5PFEntSSQRFJW98CCSevGegWYCib2l) проекта BigScience и HuggingFace. Модель полностью открытая, на 176B параметров, мультиязычная с поддержкой 46 человеческих и 13 программистских языков.
Кстати, OpenAI Codex вроде ещё в private beta, инвайты как-то продолжают раздавать, мне даже с месяц назад прислали. Но зато можно попробовать построенный на нём GitHub Copilot (https://github.com/features/copilot/). А также в июне вышел Amazon CodeWhisperer (https://aws.amazon.com/blogs/machine-learning/introducing-amazon-codewhisperer-the-ml-powered-coding-companion/). Интересно, насколько BLOOM здесь будет хорош.
По части мультиязычности большое достижение — это публикация модели NLLB-200, способной переводить напрямую между 200 языками (https://www.facebook.com/intentoco/photos/a.1093842744008324/5452925358100019/).
Также сравнительно недавно Яндекс выпустил в опенсорс свою YaLM на 100B параметров (https://www.facebook.com/intentoco/posts/pfbid02MNduVaBTRv2ZnBgjEiWyuSst7zFnpRbXxcDXQ5oKWENtFmNdvvx8JFkshwgxgmEul), на тот момент самую большую опенсорсную GPT-like модель.
А ещё до этого Гугл выложил в опенсорс (https://www.facebook.com/intentoco/photos/a.1093842744008324/5409287722463783/) свой Switch Transformer на 1.6T параметров (https://t.me/gonzo_ML/472).
В общем, поляна расцветает буйным цветом. Bessemer Venture Partners недавно опубликовали хороший пост про то, что generative AI — это новая платформенная революция (https://www.bvp.com/atlas/is-ai-generation-the-next-platform-shift).
Последние месяцы на поляне Generative AI праздник за праздником.
Начнём с генерации картинок.
Пока OpenAI со своим DALLE-2 медленно распиаривался, под боком возник быстрорастущий офигенный сервис Midjourney, забивший на сайт, API и всё такое, и предоставивший доступ к своим моделям через бота в Discord. Midjourney очень правильно начал работать с коммьюнити, набрал популярность и вышел в законодатели мод на этом рынке.
В отличие от OpenAI, Midjourney не требовал исключительных прав на все творения, оставляя все права пользователю и беря себе лицензию на их использование. Midjourney также разрешил коммерческое использование творений. У них есть пара оговорок касающихся бесплатного плана, а также компаний с выручкой больше $1M, но это всё очень reasonable. Оно у них, конечно, менялось и уточнялось по ходу дела, но явно было более либерально в отличие от terms OpenAI, где всё их, только private use, и всё такое.
И это кстати отдельный интересный вопрос этического плана — нормально ли, что система, обученная на результатах труда множества людей, присваивает весь производный результат себе, включая кстати и труд других людей по придумыванию правильных prompt'ов и селекции результатов. Где тот современный Маркс, который напишет Капитал 2.0?
Midjourney на днях вышел из закрытой беты в открытую https://www.facebook.com/intentoco/photos/a.1093842744008324/5486357671423454/) и OpenAI вынужден был последовать той же дорогой -- сразу прекратили играть в тщательно фильтруемые инвайты и тоже вышли в public beta, а также изменили terms на более коммерчески пригодные (https://www.facebook.com/intentoco/photos/a.1093842744008324/5493404720718749/).
Если бы не Midjourney, уверен, OpenAI бы ещё полгода свою илитность эксплуатировали. Конкуренция -- это прекрасно. И это только начало.
Также из области генерации картинок недавно широко разошлась новость (https://www.facebook.com/story.php?story_fbid=pfbid035HKtaMKL9ibTW2BH66cMecbCvj7RCXusf7w5yGkFP9xVHpg64Y4BcYCmv4Ea7x7Fl&id=4) про мартовскую работу Make-A-Scene (https://arxiv.org/abs/2203.13131), где при генерации картинки дополнительно к тексту можно давать эскиз с семантической маской. Это позволяет точно контролировать где на картинке что должно быть. В каком-то смысле это продолжение истории с аналогичным графическим редактором от Nvidia.
В генерации текстов тоже большое достижение -- опубликована модель BLOOM (https://www.facebook.com/intentoco/posts/pfbid02TEHE1sQYf78pXu9ZWEXcbfJ1DfZKQrCVSnB5PFEntSSQRFJW98CCSevGegWYCib2l) проекта BigScience и HuggingFace. Модель полностью открытая, на 176B параметров, мультиязычная с поддержкой 46 человеческих и 13 программистских языков.
Кстати, OpenAI Codex вроде ещё в private beta, инвайты как-то продолжают раздавать, мне даже с месяц назад прислали. Но зато можно попробовать построенный на нём GitHub Copilot (https://github.com/features/copilot/). А также в июне вышел Amazon CodeWhisperer (https://aws.amazon.com/blogs/machine-learning/introducing-amazon-codewhisperer-the-ml-powered-coding-companion/). Интересно, насколько BLOOM здесь будет хорош.
По части мультиязычности большое достижение — это публикация модели NLLB-200, способной переводить напрямую между 200 языками (https://www.facebook.com/intentoco/photos/a.1093842744008324/5452925358100019/).
Также сравнительно недавно Яндекс выпустил в опенсорс свою YaLM на 100B параметров (https://www.facebook.com/intentoco/posts/pfbid02MNduVaBTRv2ZnBgjEiWyuSst7zFnpRbXxcDXQ5oKWENtFmNdvvx8JFkshwgxgmEul), на тот момент самую большую опенсорсную GPT-like модель.
А ещё до этого Гугл выложил в опенсорс (https://www.facebook.com/intentoco/photos/a.1093842744008324/5409287722463783/) свой Switch Transformer на 1.6T параметров (https://t.me/gonzo_ML/472).
В общем, поляна расцветает буйным цветом. Bessemer Venture Partners недавно опубликовали хороший пост про то, что generative AI — это новая платформенная революция (https://www.bvp.com/atlas/is-ai-generation-the-next-platform-shift).
Facebook
Log in or sign up to view
See posts, photos and more on Facebook.
Awesome self-supervised learning
С увеличением количества немаркированных данных в Интернете, появляется множество преимуществ в разработке методов, которые позволяют нам использовать немаркированные данные. Self-supervised learning (#SSL) - один из таких методов.
Нашёл хороший репозиторий, в котором собраны статьи, блоги и доклады по SSL.
С увеличением количества немаркированных данных в Интернете, появляется множество преимуществ в разработке методов, которые позволяют нам использовать немаркированные данные. Self-supervised learning (#SSL) - один из таких методов.
Нашёл хороший репозиторий, в котором собраны статьи, блоги и доклады по SSL.
GitHub
GitHub - jason718/awesome-self-supervised-learning: A curated list of awesome self-supervised methods
A curated list of awesome self-supervised methods. Contribute to jason718/awesome-self-supervised-learning development by creating an account on GitHub.
Forwarded from DLStories | Нейронные сети и ИИ
У ребят из Сберлоги очень часто бывают интересные онлайн-семинары по data science и биоинформатике: я тут как-то уже писала об одном из выступлений. И в этот четверг у них будет очередной интересный доклад о применении нейронок в генетике.
Тема: «DeepCT: Cell type-specific interpretation of noncoding variants using deep learning methods»
Спикеры: М. Синдеева и Н. Чеканов (Институт искусственного интеллекта AIRI)
Время: 28.07, четверг, 18:00 МСК
Анонс:
В последнее время все большую популярность приобретают ML-подходы, способные предсказать эпигенетические свойства клеток на основе последовательности ДНК. Новейшие модели Google и университета Стэндфорда, опубликованные за последний год, показывают высокую точность и могут использоваться для предсказания эффектов геномных вариантов некодирующих последовательностей ДНК. Однако эти подходы не могут обобщать предсказания по типам клеток, и применяются только к тем клеткам, в которых данные уже были получены экспериментально. Мы поговорим о новом подходе к задаче предсказания эпигенетических изменений, который позволяет выучить сложные зависимости между несколькими эпигенетическими характеристиками и предсказать их для любого входа, одновременно с этим выучив биологически значимые векторные представления типов клеток.
Ссылка на зум будет доступна на канале: @sberlogabig перед началом доклада. Там же можно найти записи предыдущих выступлений, и следить за анонсами будущих семинаров.
Тема: «DeepCT: Cell type-specific interpretation of noncoding variants using deep learning methods»
Спикеры: М. Синдеева и Н. Чеканов (Институт искусственного интеллекта AIRI)
Время: 28.07, четверг, 18:00 МСК
Анонс:
В последнее время все большую популярность приобретают ML-подходы, способные предсказать эпигенетические свойства клеток на основе последовательности ДНК. Новейшие модели Google и университета Стэндфорда, опубликованные за последний год, показывают высокую точность и могут использоваться для предсказания эффектов геномных вариантов некодирующих последовательностей ДНК. Однако эти подходы не могут обобщать предсказания по типам клеток, и применяются только к тем клеткам, в которых данные уже были получены экспериментально. Мы поговорим о новом подходе к задаче предсказания эпигенетических изменений, который позволяет выучить сложные зависимости между несколькими эпигенетическими характеристиками и предсказать их для любого входа, одновременно с этим выучив биологически значимые векторные представления типов клеток.
Ссылка на зум будет доступна на канале: @sberlogabig перед началом доклада. Там же можно найти записи предыдущих выступлений, и следить за анонсами будущих семинаров.
Курс "Нейронные сети и их применение в научных исследованиях" (весна 2022) выложен в открытый доступ
Этой весной, я читал в МГУ свой собственный курс, теперь он полностью в открытом доступе под лицензией CC0.
В настоящее время, одним из самых перспективных методов машинного обучения считается глубокое обучение (нейронные сети). За последние несколько лет глубокое обучение нашло применение практически во всех областях науки, от биологии и физики до лингвистики и философии.
Этот курс из 12 лекций даст студентам высокоуровневый обзор современных методов искусственного интеллекта и их применения в различных научных областях. Изучив курс, студенты смогут разобраться, что возможно в настоящее время и что, вероятно, будет возможно в ближайшем будущем.
🎥 Смотреть курс тут
Буду признателен за максимальное распространение, я потратил много времени и усилий и мне будет очень приятно, если курс увидит как можно больше людей!
Этой весной, я читал в МГУ свой собственный курс, теперь он полностью в открытом доступе под лицензией CC0.
В настоящее время, одним из самых перспективных методов машинного обучения считается глубокое обучение (нейронные сети). За последние несколько лет глубокое обучение нашло применение практически во всех областях науки, от биологии и физики до лингвистики и философии.
Этот курс из 12 лекций даст студентам высокоуровневый обзор современных методов искусственного интеллекта и их применения в различных научных областях. Изучив курс, студенты смогут разобраться, что возможно в настоящее время и что, вероятно, будет возможно в ближайшем будущем.
🎥 Смотреть курс тут
Буду признателен за максимальное распространение, я потратил много времени и усилий и мне будет очень приятно, если курс увидит как можно больше людей!
Если у вас есть огроменный
Почему? Читайте в этой заметке
tar архив используйте флаг -P для его разархивации за разумное время. Почему? Читайте в этой заметке
Forwarded from Neural Shit
А вот это нереально круто ❤️!
Персонажи Южного парка на максималках.
Сгенерированно в midjourney.
(не моё, нашел в твитторе)
Персонажи Южного парка на максималках.
Сгенерированно в midjourney.
(не моё, нашел в твитторе)