
Media is too big
VIEW IN TELEGRAM
Синтетических биороботов научили размножаться
В начале прошлого года группа исследователей объявила о создании первых в мире живых машин - пучков стволовых клеток африканских когтистых лягушек (Xenopus laevis), которые можно запрограммировать на выполнение определенных задач. Клетки размером с песчинку могли успешно перемещать микроскопические объекты, перемещаться по чашкам Петри и даже самовосстанавливаться.
Ученые добились этого с помощью суперкомпьютера и эволюционного алгоритма: компьютер автоматически проектирует новые машины в симуляции, а затем лучшие конструкции прошедшие эволюционный отбор, собираются учеными в реальном мире.
С момента своего первого исследования команда работала над тем, чтобы использовать возможности этих крошечных роботов, названных "ксеноботами".
В новом исследовании команда объявила, что ксенороботы теперь могут размножаться способом, совершенно отличным от всех известных науке растений и животных: собирая свободно плавающие клетки в новые кластеры.
В начале прошлого года группа исследователей объявила о создании первых в мире живых машин - пучков стволовых клеток африканских когтистых лягушек (Xenopus laevis), которые можно запрограммировать на выполнение определенных задач. Клетки размером с песчинку могли успешно перемещать микроскопические объекты, перемещаться по чашкам Петри и даже самовосстанавливаться.
Ученые добились этого с помощью суперкомпьютера и эволюционного алгоритма: компьютер автоматически проектирует новые машины в симуляции, а затем лучшие конструкции прошедшие эволюционный отбор, собираются учеными в реальном мире.
С момента своего первого исследования команда работала над тем, чтобы использовать возможности этих крошечных роботов, названных "ксеноботами".
В новом исследовании команда объявила, что ксенороботы теперь могут размножаться способом, совершенно отличным от всех известных науке растений и животных: собирая свободно плавающие клетки в новые кластеры.
Мета выпустила переводчик на 200 языков.
Зацените новый прорыв Меты в области машинного перевода, о котором только что объявил Марк Цукерберг. Они создали и выложили в открытый доступ модель, с громким названием No language left behind (Ни один язык не останется за бортом), которая переводит с 200 различных языков.
Методы из этой работы были применены для улучшения переводов на Facebook, Instagram и даже Wikipedia.
📖 Статья
🗽 Код
Зацените новый прорыв Меты в области машинного перевода, о котором только что объявил Марк Цукерберг. Они создали и выложили в открытый доступ модель, с громким названием No language left behind (Ни один язык не останется за бортом), которая переводит с 200 различных языков.
Методы из этой работы были применены для улучшения переводов на Facebook, Instagram и даже Wikipedia.
📖 Статья
🗽 Код
This media is not supported in your browser
VIEW IN TELEGRAM
Сингулярность на пороге. Как ИИ проектирует GPU?
NVIDIA использует ИИ для разработки более компактных, быстрых и эффективных микросхем, обеспечивающих повышение производительности с каждым поколением чипов.
В работе PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning исследователи демонстрируют, что ИИ не только может научиться проектировать эти схемы с нуля, но и разработанные им схемы меньше и быстрее, чем схемы, разработанные современными инструментами автоматизации электронного проектирования (EDA). Новейшая архитектура NVIDIA Hopper GPU имеет почти 13 000 чипов, разработанных ИИ.
За наводку спасибо @j_links
NVIDIA использует ИИ для разработки более компактных, быстрых и эффективных микросхем, обеспечивающих повышение производительности с каждым поколением чипов.
В работе PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning исследователи демонстрируют, что ИИ не только может научиться проектировать эти схемы с нуля, но и разработанные им схемы меньше и быстрее, чем схемы, разработанные современными инструментами автоматизации электронного проектирования (EDA). Новейшая архитектура NVIDIA Hopper GPU имеет почти 13 000 чипов, разработанных ИИ.
За наводку спасибо @j_links
Вышла крупнейшая в мире открытая многоязычная языковая модель: BLOOM
Большие языковые модели (LLM) оказали значительное влияние на исследования в области ИИ. Эти мощные модели могут решать широкий спектр новых языковых задач на основе инструкций пользователя. Однако академическим кругам, некоммерческим организациям и исследовательским лабораториям небольших компаний сложно создавать, изучать или даже использовать LLM, поскольку полный доступ к ним имеют лишь несколько промышленных лабораторий, обладающих необходимыми ресурсами и эксклюзивными правами. Сегодня, международная коллаборация BigScience выпускает BLOOM, первую многоязычную LLM, обученную в условиях полной прозрачности.
BLOOM - результат крупнейшего сотрудничества исследователей ИИ, когда-либо участвовавших в одном исследовательском проекте.
Имея 176 миллиардов параметров, BLOOM способен генерировать текст на 46 естественных языках и 13 языках программирования. Почти для всех из них, таких как испанский, французский и арабский, BLOOM станет первой в истории языковой моделью с более чем 100 миллиардами параметров. Это кульминация года работы с участием более 1000 исследователей из 70+ стран и 250+ институтов, в результате которой модель BLOOM обучалась 117 дней (с 11 марта по 6 июля) на суперкомпьютере Jean Zay на юге Парижа, Франция.
Модель
Большие языковые модели (LLM) оказали значительное влияние на исследования в области ИИ. Эти мощные модели могут решать широкий спектр новых языковых задач на основе инструкций пользователя. Однако академическим кругам, некоммерческим организациям и исследовательским лабораториям небольших компаний сложно создавать, изучать или даже использовать LLM, поскольку полный доступ к ним имеют лишь несколько промышленных лабораторий, обладающих необходимыми ресурсами и эксклюзивными правами. Сегодня, международная коллаборация BigScience выпускает BLOOM, первую многоязычную LLM, обученную в условиях полной прозрачности.
BLOOM - результат крупнейшего сотрудничества исследователей ИИ, когда-либо участвовавших в одном исследовательском проекте.
Имея 176 миллиардов параметров, BLOOM способен генерировать текст на 46 естественных языках и 13 языках программирования. Почти для всех из них, таких как испанский, французский и арабский, BLOOM станет первой в истории языковой моделью с более чем 100 миллиардами параметров. Это кульминация года работы с участием более 1000 исследователей из 70+ стран и 250+ институтов, в результате которой модель BLOOM обучалась 117 дней (с 11 марта по 6 июля) на суперкомпьютере Jean Zay на юге Парижа, Франция.
Модель
huggingface.co
bigscience/bloom · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Forwarded from Love. Death. Transformers.
#чтивонаночь
RITA: a Study on Scaling Up Generative Protein Sequence Models
Есть классическая задача моделирования протеина,
которую очень хорошо решают трансформеры тк речь идет о вполне NLPшной последовательности.
- 280m протеиновых последовательностей в претрейне из сетов UniRef-100, MGnify и
Metaclust
- Rotary Positional Embeddings просто потому что это улучшает качество модели
- Претрейн как GPT3 с аналогичными гипараметрами в
следующих размерах: 85, 300, 680m и 1.2b соотвественно с seqlen 1024
- По метрикам обгонят PROTOGPT2
доступно в huggingaface простым
arxiv
github
Boosty если вы хотите помочь купить мне железа
RITA: a Study on Scaling Up Generative Protein Sequence Models
Есть классическая задача моделирования протеина,
которую очень хорошо решают трансформеры тк речь идет о вполне NLPшной последовательности.
- 280m протеиновых последовательностей в претрейне из сетов UniRef-100, MGnify и
Metaclust
- Rotary Positional Embeddings просто потому что это улучшает качество модели
- Претрейн как GPT3 с аналогичными гипараметрами в
следующих размерах: 85, 300, 680m и 1.2b соотвественно с seqlen 1024
- По метрикам обгонят PROTOGPT2
доступно в huggingaface простым
AutoModelForCausalLM.from_pretrained("lightonai/RITA_s", trust_remote_code=True)
датасет лежит тутarxiv
github
Boosty если вы хотите помочь купить мне железа
Mimesis: The Fake Data Generator
Mimesis - это генератор фальшивых данных для Python, который умеет синтезировать данные для различных целей на различных языках.
Фальшивые данные могут быть использованы для наполнения базы данных тестирования, создания фальшивых конечных точек API, создания JSON и XML файлов произвольной структуры, анонимизации данных, взятых из индустрии и т.д.
Mimesis - это генератор фальшивых данных для Python, который умеет синтезировать данные для различных целей на различных языках.
Фальшивые данные могут быть использованы для наполнения базы данных тестирования, создания фальшивых конечных точек API, создания JSON и XML файлов произвольной структуры, анонимизации данных, взятых из индустрии и т.д.
>>> from mimesis import Person
>>> from mimesis.locales import Locale
>>> person = Person(Locale.EN)
>>> person.full_name()
'Brande Sears'
>>> person.email(domains=['example.com'])
'roccelline1878@example.com'
🐙GitHubForwarded from эйай ньюз
CS25: Transformers United
Ух! Вышел курс чисто по Трансформерам от Стенфорда! Думаю, должно быть интересно.
Выложили уже 4 лекции. Го смотреть, прокачиваться.
🌐 Сайт
📺 Видео лекции
@ai_newz
Ух! Вышел курс чисто по Трансформерам от Стенфорда! Думаю, должно быть интересно.
Выложили уже 4 лекции. Го смотреть, прокачиваться.
🌐 Сайт
📺 Видео лекции
@ai_newz
Forwarded from Мишин Лернинг 🇺🇦🇮🇱
🧠 Andrej Karpathy станет независимым ресерчером и частью stability.ai, куда входят такие команды как: EleutherAI и LAION
Stability AI
AI by the people for the people. We are building the foundation to activate humanity's potential.
Out-of-Distribution Detection with Deep Nearest Neighbors
Обнаружение вне распределения (OOD) является важной задачей для применения машинного обучения в реальном мире с реальными данными.
В данной работе, авторы, исследуют эффективность непараметрического расстояния ближайшего соседа для обнаружения OOD.
🐙 Код 📖 Статья
Обнаружение вне распределения (OOD) является важной задачей для применения машинного обучения в реальном мире с реальными данными.
В данной работе, авторы, исследуют эффективность непараметрического расстояния ближайшего соседа для обнаружения OOD.
🐙 Код 📖 Статья
Набор данных WorldStrat: Открытые спутниковые снимки высокого разрешения с парными снимками низкого разрешения
Почти 10 000 км² бесплатных спутниковых снимков высокого разрешения и парных им снимков низкого разрешения уникальных мест, которые обеспечивают стратифицированное представление всех типов землепользования по всему миру: от сельского хозяйства до ледяных шапок, от лесов до урбана.
Эти места также обогащены типично недопредставленными местами представляющими гуманитарный интерес: местами незаконной добычи полезных ископаемых и поселениями лиц, подверженных риску.
Каждое изображение высокого разрешения (1,5 м/пиксель) поставляется с несколькими сопоставленными по времени изображениями низкого разрешения со спутников Sentinel-2 (10 м/пиксель), находящимися в свободном доступе.
🗺 Датасет
Почти 10 000 км² бесплатных спутниковых снимков высокого разрешения и парных им снимков низкого разрешения уникальных мест, которые обеспечивают стратифицированное представление всех типов землепользования по всему миру: от сельского хозяйства до ледяных шапок, от лесов до урбана.
Эти места также обогащены типично недопредставленными местами представляющими гуманитарный интерес: местами незаконной добычи полезных ископаемых и поселениями лиц, подверженных риску.
Каждое изображение высокого разрешения (1,5 м/пиксель) поставляется с несколькими сопоставленными по времени изображениями низкого разрешения со спутников Sentinel-2 (10 м/пиксель), находящимися в свободном доступе.
🗺 Датасет
Сбор донатов на неделю с 3 постами в день и без рекламы
Привет! Меня зовут Артемий, я автор этого канала. Занимаюсь искусственным интеллектом в геофизике (кстати скоро поделюсь своим новым местом работы) и в свободное время пишу заметки и освещаю интересные, на мой взгляд, новости нашей отрасли.
Что бы не терять мотивацию, я иногда продаю рекламу в этом канале. В связи с чем, у меня есть предложение:
Если мы соберём нужную сумму, то я обещаю неделю в этом канале без рекламы и с 3 качественными постами в день.
💰ЗАДОНАТИТЬ АРТЕМИЮ 💰
Привет! Меня зовут Артемий, я автор этого канала. Занимаюсь искусственным интеллектом в геофизике (кстати скоро поделюсь своим новым местом работы) и в свободное время пишу заметки и освещаю интересные, на мой взгляд, новости нашей отрасли.
Что бы не терять мотивацию, я иногда продаю рекламу в этом канале. В связи с чем, у меня есть предложение:
Если мы соберём нужную сумму, то я обещаю неделю в этом канале без рекламы и с 3 качественными постами в день.
💰ЗАДОНАТИТЬ АРТЕМИЮ 💰
Masked Autoencoders that Listen
Вышла новая работа от Meta Research, в которой исследуется следующая идея для работы со звуком:
* переводим звук в спектрограмму (двухмерное отображение звука, где по оси x - время, а по оси y - частота)
* делим спектрограмму на патчи
* прячем патчи в случайном порядке
* просим автоэнкодер предсказать спрятанные куски
Таким образом получили self-supervised Masked Autoencoder (MAE) для звука.
Эмпирически Audio-MAE показывает новые SOTA результаты в шести задачах классификации аудио и речи, превосходя другие недавние модели, в том числе обученные с учителем.
🐙 код 📖 статья
Вышла новая работа от Meta Research, в которой исследуется следующая идея для работы со звуком:
* переводим звук в спектрограмму (двухмерное отображение звука, где по оси x - время, а по оси y - частота)
* делим спектрограмму на патчи
* прячем патчи в случайном порядке
* просим автоэнкодер предсказать спрятанные куски
Таким образом получили self-supervised Masked Autoencoder (MAE) для звука.
Эмпирически Audio-MAE показывает новые SOTA результаты в шести задачах классификации аудио и речи, превосходя другие недавние модели, в том числе обученные с учителем.
🐙 код 📖 статья
Forwarded from DLStories
Mood Board Search: ML-powered тулза от Google для создания мудбордов.
Мудборд — это набор изображений, которые отражают какую-либо идею или концепт. Например, это могут быть картинки, подходящие под ваше понимание "свободы", "умиротворенности" или "дуализма". Мудборды часто используют фотографы для подготовки к съемкам: ищут в интернете фотографии, которые наиболее соответствуют их задумке.
И Гугл придумал тулзу, которая поможет найти больше картинок для вашего мудборда.
Работает это так:
- загружаете несколько картинок, подходящих под ваш концепт. При этом можно отранжировать картинки по значимости, а также добавить "антикартинки": те, которые отражают противоположность нужному концепту. Это сделает поиск точнее.
- система ищет картинки, концептуально наиболее похожие на ваши;
- далее вы можете добавить какие-то из найденных картинок в ваш мудборд и снова запустить поиск. Так он станет еще точнее.
Работает это чудо на эмбеддингах из предобученных нейросетей для классификации картинок GoogLeNet/MobileNet и такой штуке, как Concept Activation Vectors (CAVs).
CAV — это такой способ анализа эмбеддингов предобученной нейросети, способ анализа того, как нейросеть "думает". С помощью CAV можно понимать, насколько присутствие того или иного паттерна на картинке влияет на результат классификации картинки нейросетью. Например, насколько сильно наличие черно-белых полос подталкивает нейросеть к тому, чтобы классифицировать картинку, как Зебру.
И вот, оказывается, как идею для interpretability можно использовать для создания полезного инструмента =)
Ссылки:
Блогпост о Mood Board Search в Google AI Blog
Демка
Код на GitHub (тут есть интро в то, как CAV работает)
Статья о CAV на arxiv
Мудборд — это набор изображений, которые отражают какую-либо идею или концепт. Например, это могут быть картинки, подходящие под ваше понимание "свободы", "умиротворенности" или "дуализма". Мудборды часто используют фотографы для подготовки к съемкам: ищут в интернете фотографии, которые наиболее соответствуют их задумке.
И Гугл придумал тулзу, которая поможет найти больше картинок для вашего мудборда.
Работает это так:
- загружаете несколько картинок, подходящих под ваш концепт. При этом можно отранжировать картинки по значимости, а также добавить "антикартинки": те, которые отражают противоположность нужному концепту. Это сделает поиск точнее.
- система ищет картинки, концептуально наиболее похожие на ваши;
- далее вы можете добавить какие-то из найденных картинок в ваш мудборд и снова запустить поиск. Так он станет еще точнее.
Работает это чудо на эмбеддингах из предобученных нейросетей для классификации картинок GoogLeNet/MobileNet и такой штуке, как Concept Activation Vectors (CAVs).
CAV — это такой способ анализа эмбеддингов предобученной нейросети, способ анализа того, как нейросеть "думает". С помощью CAV можно понимать, насколько присутствие того или иного паттерна на картинке влияет на результат классификации картинки нейросетью. Например, насколько сильно наличие черно-белых полос подталкивает нейросеть к тому, чтобы классифицировать картинку, как Зебру.
И вот, оказывается, как идею для interpretability можно использовать для создания полезного инструмента =)
Ссылки:
Блогпост о Mood Board Search в Google AI Blog
Демка
Код на GitHub (тут есть интро в то, как CAV работает)
Статья о CAV на arxiv
Google запускает квантовую виртуальную машину
Несколько десятилетий назад квантовые компьютеры были лишь концепцией - далекой идеей, обсуждаемой в основном в лекционных залах. В настоящее время идет гонка за создание отказоустойчивых квантовых компьютеров и открытие новых алгоритмов для их полезного применения.
Сегодня Гугл выпустили на рынок квантовую виртуальную машину, которая эмулирует опыт и результаты программирования одного из гугловых квантовых компьютеров. В компании считают, что эмулятор облегчит исследователям создание прототипов новых алгоритмов и поможет студентам научиться программировать квантовый компьютер.
💡Статья
Несколько десятилетий назад квантовые компьютеры были лишь концепцией - далекой идеей, обсуждаемой в основном в лекционных залах. В настоящее время идет гонка за создание отказоустойчивых квантовых компьютеров и открытие новых алгоритмов для их полезного применения.
Сегодня Гугл выпустили на рынок квантовую виртуальную машину, которая эмулирует опыт и результаты программирования одного из гугловых квантовых компьютеров. В компании считают, что эмулятор облегчит исследователям создание прототипов новых алгоритмов и поможет студентам научиться программировать квантовый компьютер.
💡Статья
DALL·E Now Available in Beta
С сегодняшнего дня пользователи получают полные права на коммерческое использование изображений, созданных ими с помощью DALL-E, включая право на перепечатку, продажу и мерчандайзинг. Сюда входят изображения, созданные ими во время предварительного просмотра.
Пользователи сообщили OpenAI, что планируют использовать изображения DALL-E для коммерческих проектов, таких как иллюстрации для детских книг, иллюстрации для информационных бюллетеней, концепт-арт и персонажи для игр, moodboards для дизайнерских консультаций и раскадровки для фильмов.
анонс
С сегодняшнего дня пользователи получают полные права на коммерческое использование изображений, созданных ими с помощью DALL-E, включая право на перепечатку, продажу и мерчандайзинг. Сюда входят изображения, созданные ими во время предварительного просмотра.
Пользователи сообщили OpenAI, что планируют использовать изображения DALL-E для коммерческих проектов, таких как иллюстрации для детских книг, иллюстрации для информационных бюллетеней, концепт-арт и персонажи для игр, moodboards для дизайнерских консультаций и раскадровки для фильмов.
анонс
Forwarded from Graph Machine Learning
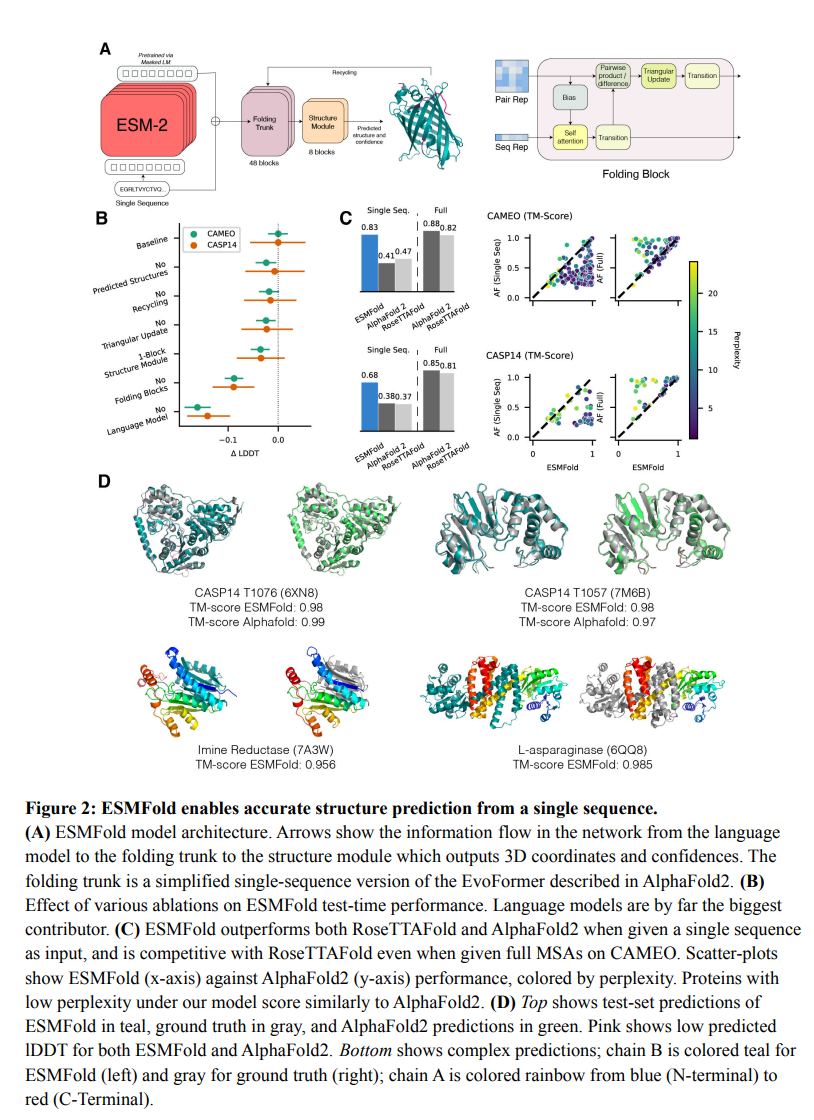
ESMFold: Protein Language Models Solve Folding, Too
Today, Meta AI Protein Team announced ESMFold - a protein folding model that uses representations right from a protein LM. Meta AI has been working on BERT-style protein language models for a while, e.g., they created a family of ESM models that are currently SOTA in masked protein sequence prediction tasks.
“A key difference between ESMFold and AlphaFold2 is the use of language model representations to remove the need for explicit homologous sequences (in the form of an MSA) as input.”
To this end, the authors design a new family of protein LMs ESM-2. ESM-2 are much more parameter efficient compared to ESM-1b, e.g., 150M ESM-2 is on par with 650M ESM-1b, and 15B ESM-2 leaves all ESM-1 models far behind. Having pre-trained an LM, ESMFold applies Folding Trunk blocks (simplified EvoFormer blocks from AlphaFold 2) and yields 3D predictions.
ESMFold outperforms AlphaFold and RoseTTAFold when only given a single-sequence input w/o MSAs and also much faster! Check out the attached illustration with architecture and charts.
“On a single NVIDIA V100 GPU, ESMFold makes a prediction on a protein with 384 residues in 14.2 seconds, 6X faster than a single AlphaFold2 model. On shorter sequences we see a ~60X improvement. … ESMFold can be run reasonably quickly on CPU, and an Apple M1 Macbook Pro makes the same prediction in just over 5 minutes.”
Finally, ESMFold shows remarkable scaling properties:
“We see non-linear improvements in protein structure predictions as a function of model
scale, and observe a strong link between how well the language model understands a sequence (as measured by perplexity) and the structure prediction that emerges.”
Are you already converted to the church of Scale Is All You Need - AGI Is Coming? 😉
Today, Meta AI Protein Team announced ESMFold - a protein folding model that uses representations right from a protein LM. Meta AI has been working on BERT-style protein language models for a while, e.g., they created a family of ESM models that are currently SOTA in masked protein sequence prediction tasks.
“A key difference between ESMFold and AlphaFold2 is the use of language model representations to remove the need for explicit homologous sequences (in the form of an MSA) as input.”
To this end, the authors design a new family of protein LMs ESM-2. ESM-2 are much more parameter efficient compared to ESM-1b, e.g., 150M ESM-2 is on par with 650M ESM-1b, and 15B ESM-2 leaves all ESM-1 models far behind. Having pre-trained an LM, ESMFold applies Folding Trunk blocks (simplified EvoFormer blocks from AlphaFold 2) and yields 3D predictions.
ESMFold outperforms AlphaFold and RoseTTAFold when only given a single-sequence input w/o MSAs and also much faster! Check out the attached illustration with architecture and charts.
“On a single NVIDIA V100 GPU, ESMFold makes a prediction on a protein with 384 residues in 14.2 seconds, 6X faster than a single AlphaFold2 model. On shorter sequences we see a ~60X improvement. … ESMFold can be run reasonably quickly on CPU, and an Apple M1 Macbook Pro makes the same prediction in just over 5 minutes.”
Finally, ESMFold shows remarkable scaling properties:
“We see non-linear improvements in protein structure predictions as a function of model
scale, and observe a strong link between how well the language model understands a sequence (as measured by perplexity) and the structure prediction that emerges.”
Are you already converted to the church of Scale Is All You Need - AGI Is Coming? 😉
{kind=link}