
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing (Microsoft)
Self-supervised learning (SSL) уже достигло больших успехов в распознавании речи. При этом в для других задач обработки речи были предприняты лишь ограниченные попытки. Поскольку речевой сигнал содержит многогранную информацию, включая личность диктора, паралингвистику, содержание речи и т.д., обучение универсальным представлениям для всех речевых задач является сложной задачей.
В этой статье авторы предлагают новую модель WavLM для решения речевых задач полного стека. WavLM построена на основе архитектуры HuBERT с акцентом на моделирование речевого контента и сохранение идентичности диктора.
📎 Статья
🖥 Код
#SSL #signals #speech #audio
Self-supervised learning (SSL) уже достигло больших успехов в распознавании речи. При этом в для других задач обработки речи были предприняты лишь ограниченные попытки. Поскольку речевой сигнал содержит многогранную информацию, включая личность диктора, паралингвистику, содержание речи и т.д., обучение универсальным представлениям для всех речевых задач является сложной задачей.
В этой статье авторы предлагают новую модель WavLM для решения речевых задач полного стека. WavLM построена на основе архитектуры HuBERT с акцентом на моделирование речевого контента и сохранение идентичности диктора.
📎 Статья
🖥 Код
#SSL #signals #speech #audio
AugMax: Adversarial Composition of Random Augmentations for Robust Training
Аугментация (дополнение) данных - это простой и эффективный способ улучшения генерализации глубоких нейронных сетей.
Авторы предлагают схему аугментации данных, названную AugMax (отсылка к AugMix). AugMax сначала случайным образом выбирает несколько операторов дополнения, а затем обучается состязательной смеси выбранных операторов.
📎 Статья
🖥 Код
#augmentation #training
Аугментация (дополнение) данных - это простой и эффективный способ улучшения генерализации глубоких нейронных сетей.
Авторы предлагают схему аугментации данных, названную AugMax (отсылка к AugMix). AugMax сначала случайным образом выбирает несколько операторов дополнения, а затем обучается состязательной смеси выбранных операторов.
📎 Статья
🖥 Код
#augmentation #training
Forwarded from N + 1
В сентябре математик Мартин Доуд выложил в открытый доступ свое решение одной из самых известных «задач тысячелетия» — доказательство P≠NP. Но торжества по этому поводу длились недолго. Задача, судя по всему, устояла: после ряда критических замечаний к работе Доуд снял ее с публикации. Математик Владимир Потапов рассказывает о задаче, которой бросил вызов его американский коллега, и том, что, по-видимому, пошло не так
n-pl.us/31093/t
n-pl.us/31093/t
MedMNIST v2 👩⚕️
Вышла большая MNIST-подобная коллекция стандартизированных биомедицинских изображений, включающая 12 наборов данных для 2D и 6 наборов данных для 3D. Все изображения предварительно обработаны в формат 28 x 28 (2D) или 28 x 28 x 28 (3D) с соответствующими классификационными метками.
Охватывая основные модальности данных в биомедицинских изображениях, MedMNIST v2 предназначен для выполнения классификации на легких 2D и 3D изображениях с различными масштабами данных (от 100 до 100 000) и разнообразными задачами (бинарные/многоклассовые, порядковые регрессии и мульти-метки). Полученный набор данных, состоящий из 708 069 2D-изображений и 10 214 3D-изображений в целом, может помочь в многочисленных исследовательских и образовательных целях в области анализа биомедицинских изображений, компьютерного зрения и машинного обучения.
Про предыдущую версию мы писали тут (оказалось что мы писали про второй medmnist, как мне верно напомнили).
🗂 Датасет
📎 Статья
#ScientificML #datasets #medicine #3d
Вышла большая MNIST-подобная коллекция стандартизированных биомедицинских изображений, включающая 12 наборов данных для 2D и 6 наборов данных для 3D. Все изображения предварительно обработаны в формат 28 x 28 (2D) или 28 x 28 x 28 (3D) с соответствующими классификационными метками.
Охватывая основные модальности данных в биомедицинских изображениях, MedMNIST v2 предназначен для выполнения классификации на легких 2D и 3D изображениях с различными масштабами данных (от 100 до 100 000) и разнообразными задачами (бинарные/многоклассовые, порядковые регрессии и мульти-метки). Полученный набор данных, состоящий из 708 069 2D-изображений и 10 214 3D-изображений в целом, может помочь в многочисленных исследовательских и образовательных целях в области анализа биомедицинских изображений, компьютерного зрения и машинного обучения.
Про предыдущую версию мы писали тут (оказалось что мы писали про второй medmnist, как мне верно напомнили).
🗂 Датасет
📎 Статья
#ScientificML #datasets #medicine #3d
Forwarded from Denis Sexy IT 🤖
OpenAI продолжает решать все новые и новые задачи своими нейронками, в этот раз они пришли за домашкой по математике – натренили нейронку которая умеет успешно решать 90% математических задачек.
Вот пример на основе реальной задачи из учебника, по ссылке есть больше примеров:
>У Энтони было 50 карандашей. Он отдал 1/2 своих карандашей Брэндону, а 3/5 оставшихся карандашей отдал Чарли. Оставшиеся карандаши он оставил себе. Сколько карандашей оставил себе Энтони?
Пока вы думаете, нейронка уже решила:
>Энтони отдал 50/2=25 карандашей Брэндону.
После того, как Брэндон отдал 25 карандашей, у Энтони осталось 50-25= 25 карандашей.
Энтони дал 25*3/5=15 карандашей Чарли.
После того, как Чарли отдал 15 карандашей, у Энтони осталось 25-15= 10 карандашей.
Поэтому Энтони оставил себе 10 карандашей.
Что же, ждем когда OpenAI придет за физикой и изобретет холодный синтез 🌚
Вот пример на основе реальной задачи из учебника, по ссылке есть больше примеров:
>У Энтони было 50 карандашей. Он отдал 1/2 своих карандашей Брэндону, а 3/5 оставшихся карандашей отдал Чарли. Оставшиеся карандаши он оставил себе. Сколько карандашей оставил себе Энтони?
Пока вы думаете, нейронка уже решила:
>Энтони отдал 50/2=25 карандашей Брэндону.
После того, как Брэндон отдал 25 карандашей, у Энтони осталось 50-25= 25 карандашей.
Энтони дал 25*3/5=15 карандашей Чарли.
После того, как Чарли отдал 15 карандашей, у Энтони осталось 25-15= 10 карандашей.
Поэтому Энтони оставил себе 10 карандашей.
Что же, ждем когда OpenAI придет за физикой и изобретет холодный синтез 🌚
Openai
Solving math word problems
We’ve trained a system that solves grade school math problems with nearly twice the accuracy of a fine-tuned GPT-3 model. It solves about 90% as many problems as real kids: a small sample of 9-12 year olds scored 60% on a test from our dataset, while our…
This media is not supported in your browser
VIEW IN TELEGRAM
Какие задачи должны обучаться вместе в многозадачных нейронных сетях?
Многие модели машинного обучения сосредоточены на обучении одной задаче за раз (например, языковые модели предсказывают вероятность следующего слова). Однако не сложно себе представить, одновременное обучение на нескольких связанных задачах может привести к лучшим результатам по каждой из них.
Например, при игре в пинг-понг часто бывает полезно оценить расстояние, вращение и предстоящую траекторию мяча для того, чтобы скорректировать свою руку и выстроить замах. Хотя каждая из этих задач уникальна, понимание того где мяч сейчас и как он крутится, вероятно, поможет вам лучше предсказывать его траекторию и наоборот.
Google придумал механизм, для изучения динамики обучения многозадачных сетей, что позволяет учить многозадачные сети лучше.
🔭 Блог-пост
📎 Статья
#training #multitasking
Многие модели машинного обучения сосредоточены на обучении одной задаче за раз (например, языковые модели предсказывают вероятность следующего слова). Однако не сложно себе представить, одновременное обучение на нескольких связанных задачах может привести к лучшим результатам по каждой из них.
Например, при игре в пинг-понг часто бывает полезно оценить расстояние, вращение и предстоящую траекторию мяча для того, чтобы скорректировать свою руку и выстроить замах. Хотя каждая из этих задач уникальна, понимание того где мяч сейчас и как он крутится, вероятно, поможет вам лучше предсказывать его траекторию и наоборот.
Google придумал механизм, для изучения динамики обучения многозадачных сетей, что позволяет учить многозадачные сети лучше.
🔭 Блог-пост
📎 Статья
#training #multitasking
Шутка от Andrew Car
Data science jokes for new dads
Where do data scientist go camping?
In random forests
Who do they bring along?
Their nearest neighbors
Where do they stop to fish?
A data lake
How do they stay on track?
Using the ridges
What do they do the second night?
Tell anova bad joke
Data science jokes for new dads
Where do data scientist go camping?
In random forests
Who do they bring along?
Their nearest neighbors
Where do they stop to fish?
A data lake
How do they stay on track?
Using the ridges
What do they do the second night?
Tell anova bad joke
Twitter
Andrew Carr
Data science jokes for new dads Where do data scientist go camping? In random forests Who do they bring along? Their nearest neighbors Where do they stop to fish? A data lake How do they stay on track? Using the ridges What do they do the second night? Tell…
Я про вас не забыл, но с переездами пока сложно что-то написать осмысленное. Думаю что выйду на нормальный режим уже завтра. Пока посмотрите TED Talk Джеффа Дина (главный по AI в Google): AI isn't as smart as you think — but it could be
Ted
Jeff Dean: AI isn't as smart as you think -- but it could be
What is AI, really? Jeff Dean, the head of Google's AI efforts, explains the underlying technology that enables artificial intelligence to do all sorts of things, from understanding language to diagnosing disease -- and presents a roadmap for building better…
Forwarded from Denis Sexy IT 🤖
This media is not supported in your browser
VIEW IN TELEGRAM
Опубликовали код этой нейронки которая делает 3D-сцену по фотографиям, го играться:
https://github.com/darglein/ADOP
✨
https://github.com/darglein/ADOP
✨
Forwarded from Мишин Лернинг 🇺🇦🇮🇱
🥑 DALL-E ждали? Всем ruDALL-E!
Высшая точка генерации по текстовому описанию: DALL-E, по факту это GPT, обученная генерировать картинки по текстовому запросу.
При обучении таких моделей большие изображения (256x256 или 512х512) сжимаются при помощи энкодеров dVAE или VQGAN до 32x32 последовательности визуальных токенов. GPT теперь может работать как и текстовыми, так и с визуальными токенами, как с одной последовательность (длинной строкой).
Потом GPT-like архитектура принимает текстовое описание и учится генерировать эти визуальные токены, которые потом “проявляются” в высоком разрешении при помощи декодеров dVAE или VQGAN.
Запустить колаб и получить свою генерацию очень просто! Достаточно прейти по ссылке и, вписав что-то свое в поле текст (вместо text = 'изображение радуги на фоне ночного города’), выбрать Runtime -> Run all (среда выполнения -> выполнить все).
🔮colab 💻Git
Высшая точка генерации по текстовому описанию: DALL-E, по факту это GPT, обученная генерировать картинки по текстовому запросу.
При обучении таких моделей большие изображения (256x256 или 512х512) сжимаются при помощи энкодеров dVAE или VQGAN до 32x32 последовательности визуальных токенов. GPT теперь может работать как и текстовыми, так и с визуальными токенами, как с одной последовательность (длинной строкой).
Потом GPT-like архитектура принимает текстовое описание и учится генерировать эти визуальные токены, которые потом “проявляются” в высоком разрешении при помощи декодеров dVAE или VQGAN.
Запустить колаб и получить свою генерацию очень просто! Достаточно прейти по ссылке и, вписав что-то свое в поле текст (вместо text = 'изображение радуги на фоне ночного города’), выбрать Runtime -> Run all (среда выполнения -> выполнить все).
🔮colab 💻Git
Feature extraction in torchvision
В обновлении torchvision (популярная надстройка к PyTorch) появились зачатки функционала Explainable AI (#XAI, запоминайте сокращение, будем его слышать все чаще и чаще).
Теперь, с помощью функции «из коробки», можно строить карты активации нейронов для сверточных сетей (не то что бы раньше было нельзя, но стало сильно удобнее).
🔭 Разбор и туториал
#explainability #images
В обновлении torchvision (популярная надстройка к PyTorch) появились зачатки функционала Explainable AI (#XAI, запоминайте сокращение, будем его слышать все чаще и чаще).
Теперь, с помощью функции «из коробки», можно строить карты активации нейронов для сверточных сетей (не то что бы раньше было нельзя, но стало сильно удобнее).
🔭 Разбор и туториал
#explainability #images
Forwarded from эйай ньюз
Наткнулся на твиттер-тред, где известный профессор (86k цитирований) по вычислительной биологии просто уничтожает критикой алгоритмы для уменьшения размерности, такие как t-SNE и UMAP, и призыввет их не использовать. Чувак приводит аргументы, почему они не работают, и примеры их фейлов на биологических данных (как на картинке выше, демонстрирующей фейлы UMAP).
Если хотите получше разобраться в алгоритмах для dimensionality reduction и в их плюсах и минусах, то могу порекомендовать видео Neighbour embeddings for scientific visualization by Dmitry Kobak.
От себя добавлю, я довольно много крутил t-SNE и колпулся в его имплементации (респект Диме Ульянову за его чудесную имплементацию Multicore-TSNE). И это правда, что, меняя параметры алгоритма и рандом сид, можно получить график желаемого вида, где будет кластеризовано то, что вам хочется.
Если хотите получше разобраться в алгоритмах для dimensionality reduction и в их плюсах и минусах, то могу порекомендовать видео Neighbour embeddings for scientific visualization by Dmitry Kobak.
От себя добавлю, я довольно много крутил t-SNE и колпулся в его имплементации (респект Диме Ульянову за его чудесную имплементацию Multicore-TSNE). И это правда, что, меняя параметры алгоритма и рандом сид, можно получить график желаемого вида, где будет кластеризовано то, что вам хочется.
Image Manipulation with Only Pretrained StyleGAN
StyleGAN позволяет манипулировать и редактировать изображения благодаря своему обширному латентному пространству.
В данной работе, авторы показывают, что с помощью предварительно обученного StyleGAN вместе с некоторыми операциями, без какой-либо дополнительной архитектуры, можно смешивать изображения, генерировать панорамы, применять стили и много другое. Look mum, no clip!
💻 Colab
📎 Статья
🖥 Код
#gan #images
StyleGAN позволяет манипулировать и редактировать изображения благодаря своему обширному латентному пространству.
В данной работе, авторы показывают, что с помощью предварительно обученного StyleGAN вместе с некоторыми операциями, без какой-либо дополнительной архитектуры, можно смешивать изображения, генерировать панорамы, применять стили и много другое. Look mum, no clip!
💻 Colab
📎 Статья
🖥 Код
#gan #images
NitroFE (Nitro Feature Engineering)
NitroFE - это конструктор функций на языке Python, который предоставляет множество модулей, предназначенных для внутреннего сохранения прошлых зависимых значений для обеспечения непрерывных расчетов.
Умеет работать с:
⏰ Time based features
🏔 Indicator based features
💘 Moving average based features
🖥 Код
#features
NitroFE - это конструктор функций на языке Python, который предоставляет множество модулей, предназначенных для внутреннего сохранения прошлых зависимых значений для обеспечения непрерывных расчетов.
Умеет работать с:
⏰ Time based features
🏔 Indicator based features
💘 Moving average based features
🖥 Код
#features
Forwarded from Denis Sexy IT 🤖
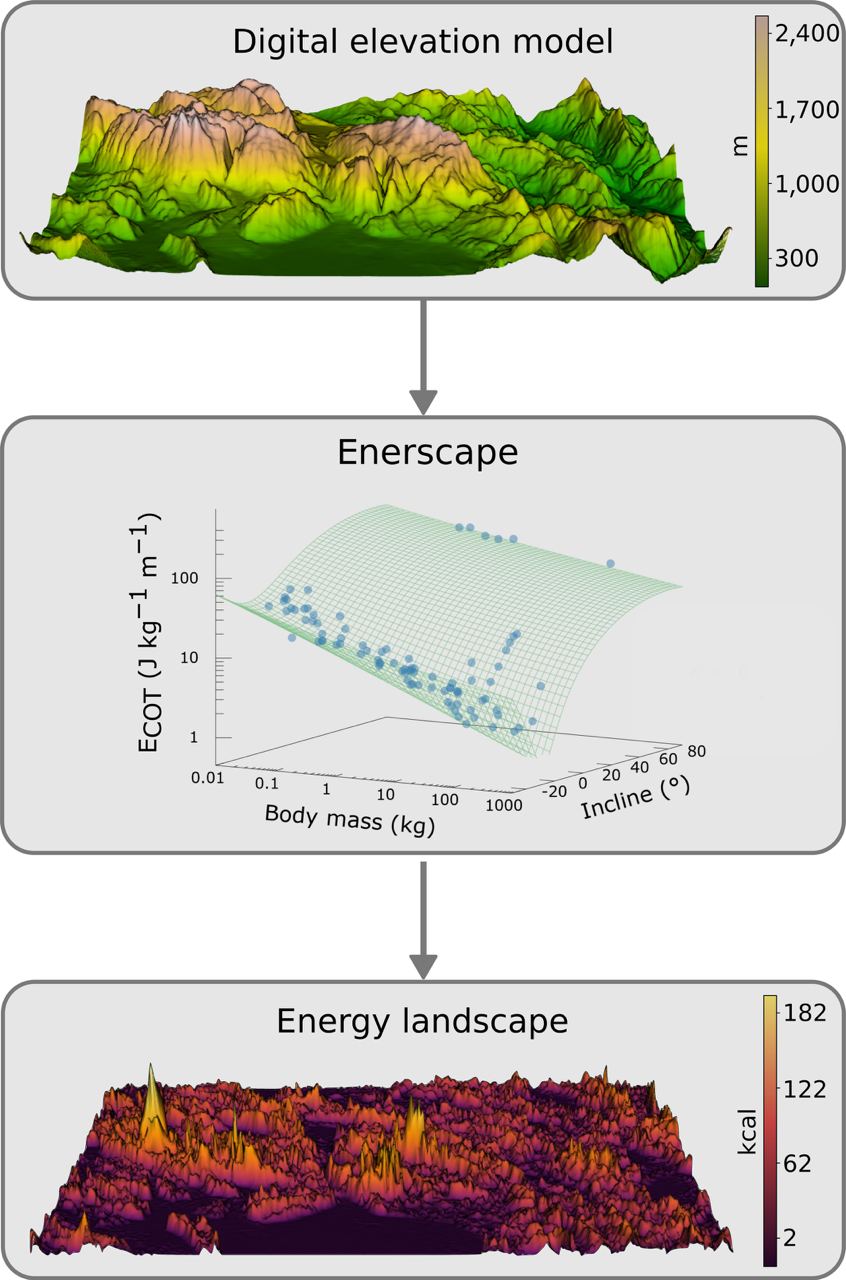
Новое ПО под названием «enerscape» сможет предсказать передвижения крупных животных, минимизируя их контакты с людьми. Вряд ли бы вы хотели, чтобы ваш маршрут пересекался с медвежьими и волчьими тропами.
Традиционно, все карты передвижений основаны на долгосрочных исследованиях данных, которые поступают с животных с датчиками, а составление таких карт отнимает много времени и слишком дорогое. А если радиосвязь в районе отсутствует, то маячок вообще бесполезен.
Enerscape поможет сделать такие карты легко и не дорого, да и и каких-то вводных данных она требует по минимуму. Вся суть в методологии — энергия, котороя животное затрачивает на свой маршрут, рассчитывается на основе его веса и общего поведения при передвижении. Затем эти затраты энергии интегрируются в топографическую информацию о местности и создаются так называемые «энергетические ландшафтные карты» как для отдельных особей, так и для разных групп животных.
ПО было протестировано в Италии в региональном парке Сиренте Велино, где обитает находящийся под угрозой исчезновения бурый медведь. Используя enerscape исследователи обнаружили, что медведи выбирают пути, требующие меньше энергетических затрат (умные медведи 🐻). А эти пути часто пересекаются с населенными пунктами, где столкновения с людьми заканчиваются фатально. Программа определила конфликтные и защитные зоны и проверила, достаточно ли хорошо связаны между собой элементы ландшафта, чтобы медведи могли беспрепятственно по нему перемещаться.
Благодаря тому, что enerscape написана на зыке «R», она может обрабатывать информацию из различных типов экосистем, поэтому учёные надеятся, что таких карт будет в разы больше – с ними легко работать.
На картинке пример создания такой карты, где в исходных данных, основанных на топографии, показывается какое количество калорий необходимо потратить, чтобы пройти по определенному участку местности (нижняя картинка).
Ну, взвешивать по фото, как мы знаем, уже решенная задача, так что алгоритм внезапно клевый.
Традиционно, все карты передвижений основаны на долгосрочных исследованиях данных, которые поступают с животных с датчиками, а составление таких карт отнимает много времени и слишком дорогое. А если радиосвязь в районе отсутствует, то маячок вообще бесполезен.
Enerscape поможет сделать такие карты легко и не дорого, да и и каких-то вводных данных она требует по минимуму. Вся суть в методологии — энергия, котороя животное затрачивает на свой маршрут, рассчитывается на основе его веса и общего поведения при передвижении. Затем эти затраты энергии интегрируются в топографическую информацию о местности и создаются так называемые «энергетические ландшафтные карты» как для отдельных особей, так и для разных групп животных.
ПО было протестировано в Италии в региональном парке Сиренте Велино, где обитает находящийся под угрозой исчезновения бурый медведь. Используя enerscape исследователи обнаружили, что медведи выбирают пути, требующие меньше энергетических затрат (умные медведи 🐻). А эти пути часто пересекаются с населенными пунктами, где столкновения с людьми заканчиваются фатально. Программа определила конфликтные и защитные зоны и проверила, достаточно ли хорошо связаны между собой элементы ландшафта, чтобы медведи могли беспрепятственно по нему перемещаться.
Благодаря тому, что enerscape написана на зыке «R», она может обрабатывать информацию из различных типов экосистем, поэтому учёные надеятся, что таких карт будет в разы больше – с ними легко работать.
На картинке пример создания такой карты, где в исходных данных, основанных на топографии, показывается какое количество калорий необходимо потратить, чтобы пройти по определенному участку местности (нижняя картинка).
Ну, взвешивать по фото, как мы знаем, уже решенная задача, так что алгоритм внезапно клевый.
{kind=link}
DeepMind регистрирует компанию по разработке лекарств
CEO DeepMind объявил о создании новой компании Alphabet - Isomorphic Labs - коммерческого предприятия с целью переосмыслить весь процесс открытия лекарств с нуля, используя подход, основанный на искусственном интеллекте, и, в конечном итоге, смоделировать и понять некоторые фундаментальные механизмы жизни.
«Сейчас мы переживаем захватывающий момент истории, когда эти техники и методы [машинное обучение] становятся достаточно мощными и сложными, чтобы их можно было применять для решения реальных проблем, включая научные открытия. Одно из самых важных применений ИИ, которое я могу себе представить, - это область биологических и медицинских исследований, и я страстно желал заняться этой областью в течение многих лет. Сейчас настало время продвигать эту область в темпе и с целевым вниманием и ресурсами, которые предоставит Isomorphic Labs.»
🕵🏻♂️ Интервью
CEO DeepMind объявил о создании новой компании Alphabet - Isomorphic Labs - коммерческого предприятия с целью переосмыслить весь процесс открытия лекарств с нуля, используя подход, основанный на искусственном интеллекте, и, в конечном итоге, смоделировать и понять некоторые фундаментальные механизмы жизни.
«Сейчас мы переживаем захватывающий момент истории, когда эти техники и методы [машинное обучение] становятся достаточно мощными и сложными, чтобы их можно было применять для решения реальных проблем, включая научные открытия. Одно из самых важных применений ИИ, которое я могу себе представить, - это область биологических и медицинских исследований, и я страстно желал заняться этой областью в течение многих лет. Сейчас настало время продвигать эту область в темпе и с целевым вниманием и ресурсами, которые предоставит Isomorphic Labs.»
🕵🏻♂️ Интервью