
Forwarded from Denis Sexy IT 🤖
Крутой новый алгоритм от DeepMind в сотрудничестве с Венецианским университетом, который восстанавливает, размечает и даже помогает найти дату создания древне-греческих текстов, используя ИИ и умы историков.
Нейронку назвали Ithaca, и в Nature можно подробно прочитать ее презентацию. Так вот, по оценкам Ithaca достигает 62% точности при восстановлении поврежденных текстов, 71% точности при определении их первоначального местоположения и датирует их с точностью +/- 30 лет от их истинных дат написания.
Алгоритм обучали на большом наборе данных греческих надписей, а именно на порядке появления слов в предложениях и связях между ними, это формирует контекст и смысл. Для примера фраза «Когда-то давным давно» имеет больше смысла, чем отдельные слова в ней. Части фраз, конечно, утеряна безвозвратно, поэтому и отдельные символы тоже подверглись анализу.
Сам алгоритм не выдает конечный результат, мол вот тебе текст, а по факту предлагает несколько гипотез и прогнозов, дабы уже историки подключали свой опыт и формулировали конечный результат – очень крутой пример AI как инструмента в узкой теме. Теперь интересные факты о «man vs machine» — эксперты достигли 25%-точности при самостоятельной работе по восстановлению текста, когда как Ithaca достиг 72%, а это очень крутой результат и потенциал совместного сотрудничества.
Новые данные уже работаю и уже показали результаты: ряд афинских указов, которые раньше датировали 446/445 годами до н. э. теперь относят к 420-м годам до н. э., вроде не значительно, но значение имеет фундаментальное.
Вот тут выложили исходный код, а тут интерактивную версию Ithaca, и это отличный повод проверить вырезанные на склепе греческие буквы из моего недавнего поста (в этом канале руны есть, древние греческие символы есть, кажется я Лара Крофт почти).
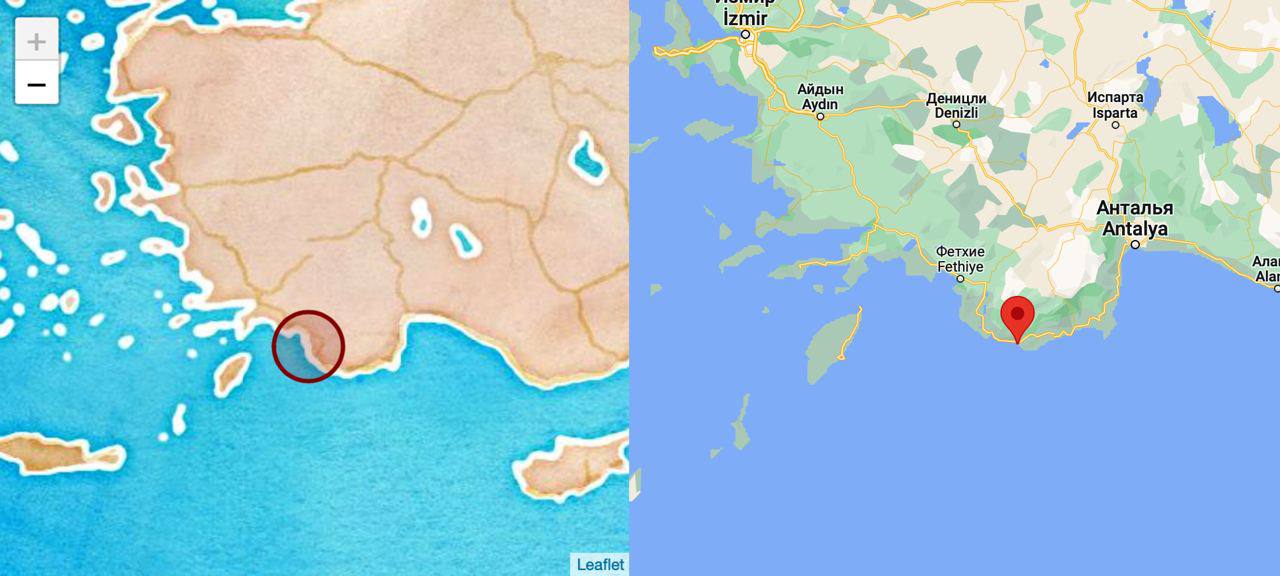
Я немного офигел, потому что нейронка максимально точно показала месторасположение надписей где я их сканировал (внизу скриншот), и дату их написания определила — 260-270 гг. н. э., ваще.
А еще, кому интересно, вот тут нашел много греческих текстов, с которыми можно поиграться алгоритмом.
Нейронку назвали Ithaca, и в Nature можно подробно прочитать ее презентацию. Так вот, по оценкам Ithaca достигает 62% точности при восстановлении поврежденных текстов, 71% точности при определении их первоначального местоположения и датирует их с точностью +/- 30 лет от их истинных дат написания.
Алгоритм обучали на большом наборе данных греческих надписей, а именно на порядке появления слов в предложениях и связях между ними, это формирует контекст и смысл. Для примера фраза «Когда-то давным давно» имеет больше смысла, чем отдельные слова в ней. Части фраз, конечно, утеряна безвозвратно, поэтому и отдельные символы тоже подверглись анализу.
Сам алгоритм не выдает конечный результат, мол вот тебе текст, а по факту предлагает несколько гипотез и прогнозов, дабы уже историки подключали свой опыт и формулировали конечный результат – очень крутой пример AI как инструмента в узкой теме. Теперь интересные факты о «man vs machine» — эксперты достигли 25%-точности при самостоятельной работе по восстановлению текста, когда как Ithaca достиг 72%, а это очень крутой результат и потенциал совместного сотрудничества.
Новые данные уже работаю и уже показали результаты: ряд афинских указов, которые раньше датировали 446/445 годами до н. э. теперь относят к 420-м годам до н. э., вроде не значительно, но значение имеет фундаментальное.
Вот тут выложили исходный код, а тут интерактивную версию Ithaca, и это отличный повод проверить вырезанные на склепе греческие буквы из моего недавнего поста (в этом канале руны есть, древние греческие символы есть, кажется я Лара Крофт почти).
Я немного офигел, потому что нейронка максимально точно показала месторасположение надписей где я их сканировал (внизу скриншот), и дату их написания определила — 260-270 гг. н. э., ваще.
А еще, кому интересно, вот тут нашел много греческих текстов, с которыми можно поиграться алгоритмом.
{kind=link}
Мы выложили вторую лекцию из курса «Нейронные сети и их применение в научных исследованиях».
В лекции обсудили: как учат машины, что такое нейрон, как вообще нейросети работают и конечно же примеры из разных областей науки 🧬
🎥 Лекция 1. Новая суперспособность науки
🎥 Лекция 2. Как учить машины
В лекции обсудили: как учат машины, что такое нейрон, как вообще нейросети работают и конечно же примеры из разных областей науки 🧬
🎥 Лекция 1. Новая суперспособность науки
🎥 Лекция 2. Как учить машины
Forwarded from See All
> Россия почти как :vim:
> Тоже приходится гуглить, как выйти.
> Тоже приходится гуглить, как выйти.
Открываем жанр History porn.
Андрей Карпати из Tesla решил повторить ту самую сетку Яна ЛеКа(у)на из 1989 года и написал об этом пост (🔥), который читается как смесь исторического детектива и стендап для гиков одновременно.
Короткие выводы основанные на путешествии во времени на 33 года назад: Что бы подумал путешественник во времени из 2055 года о производительности современных сетей?
Нейронные сети 2055 года на макроуровне практически не отличаются от нейронных сетей 2022 года, разве что они больше.
Наши сегодняшние наборы данных и модели выглядят как шутка. И то, и другое где-то в 10 000 000 000 раз больше.
Современные модели 2022 года можно обучить за ~1 минуту, обучаясь на своем персональном вычислительном устройстве в качестве развлекательного проекта на выходных.
Наши наборы данных слишком малы, и скромный выигрыш можно получить только за счет расширения набора данных.
🔥Пост
Андрей Карпати из Tesla решил повторить ту самую сетку Яна ЛеКа(у)на из 1989 года и написал об этом пост (🔥), который читается как смесь исторического детектива и стендап для гиков одновременно.
Короткие выводы основанные на путешествии во времени на 33 года назад: Что бы подумал путешественник во времени из 2055 года о производительности современных сетей?
Нейронные сети 2055 года на макроуровне практически не отличаются от нейронных сетей 2022 года, разве что они больше.
Наши сегодняшние наборы данных и модели выглядят как шутка. И то, и другое где-то в 10 000 000 000 раз больше.
Современные модели 2022 года можно обучить за ~1 минуту, обучаясь на своем персональном вычислительном устройстве в качестве развлекательного проекта на выходных.
Наши наборы данных слишком малы, и скромный выигрыш можно получить только за счет расширения набора данных.
🔥Пост
ChemicalX - это библиотека на основе PyTorch и TorchDrug для оценки пар лекарств, которая предсказывает лекарственные взаимодействия, побочные эффекты полифармацевтики и возможные синергические эффекты, как в биологическом, так и в химическом контексте.
🖥 Код
#ScientificML, #chemistry, #bio
🖥 Код
#ScientificML, #chemistry, #bio
GitHub
GitHub - AstraZeneca/chemicalx: A PyTorch and TorchDrug based deep learning library for drug pair scoring. (KDD 2022)
A PyTorch and TorchDrug based deep learning library for drug pair scoring. (KDD 2022) - GitHub - AstraZeneca/chemicalx: A PyTorch and TorchDrug based deep learning library for drug pair scoring. (K...
Мы выложили 3 лекцию из курса «Нейронные сети и их применение в научных исследованиях».
В лекции обсудили: линейные слои, эмбеддинги, word2vec и применения таких сетей в литературных и исторических задачах.
🎥 Лекция 1. Новая суперспособность науки
🎥 Лекция 2. Как учить машины
🎥 Лекция 3. Линейные модели
В лекции обсудили: линейные слои, эмбеддинги, word2vec и применения таких сетей в литературных и исторических задачах.
🎥 Лекция 1. Новая суперспособность науки
🎥 Лекция 2. Как учить машины
🎥 Лекция 3. Линейные модели
Интересное интервью про то, как вернуть биологию в нейронные сети: https://youtu.be/smxwT82o40Y
YouTube
Active Dendrites avoid catastrophic forgetting - Interview with the Authors
#multitasklearning #biology #neuralnetworks
This is an interview with the paper's authors: Abhiram Iyer, Karan Grewal, and Akash Velu!
Paper Review Video: https://youtu.be/O_dJ31T01i8
Check out Zak's course on Graph Neural Networks (discount with this link):…
This is an interview with the paper's authors: Abhiram Iyer, Karan Grewal, and Akash Velu!
Paper Review Video: https://youtu.be/O_dJ31T01i8
Check out Zak's course on Graph Neural Networks (discount with this link):…
3 вещи которые нужно знать про Visual Transformers:
1. Residual слои ViT можно эффективно распараллелить, на точности это практически не скажется
2. Для адаптации ViT к более высокому разрешению и к другим задачам классификации достаточно файнтюнинга слоев внимания.
3. Добавление слоев предварительной обработки патчей на основе MLP улучшает self-supervised обучение по типу BERT (на основе маскировки патчей)
📝 Статья
#transformer #vit
1. Residual слои ViT можно эффективно распараллелить, на точности это практически не скажется
2. Для адаптации ViT к более высокому разрешению и к другим задачам классификации достаточно файнтюнинга слоев внимания.
3. Добавление слоев предварительной обработки патчей на основе MLP улучшает self-supervised обучение по типу BERT (на основе маскировки патчей)
📝 Статья
#transformer #vit
Многие студенты (и не только) совершенно не умеют презентовать графики. Отличный тред с объяснением как надо: https://twitter.com/jbhuang0604/status/1506101759911116809?s=21
Twitter
Jia-Bin Huang
How to present a line plot? Line plots are effective for describing the relationship between two variables of interests. Unfortunately, most junior students would simply copy&paste the figure from the paper in their talk and cause much confusion. 😕 Let's…
This media is not supported in your browser
VIEW IN TELEGRAM
Мы выложили 4 лекцию из курса «Нейронные сети и их применение в научных исследованиях».
В лекции поговорили про то как работают сверточные сети (CNN), почему их круто применять для изображений, как с их помощью можно производить детекцию и сегментацию объектов и даже разобрались, как такие сети помогли определить возраст поверхности Марса!
🎥 Лекция 1. Новая суперспособность науки
🎥 Лекция 2. Как учить машины
🎥 Лекция 3. Линейные модели
🎥 Лекция 4. Сверточные сети
В лекции поговорили про то как работают сверточные сети (CNN), почему их круто применять для изображений, как с их помощью можно производить детекцию и сегментацию объектов и даже разобрались, как такие сети помогли определить возраст поверхности Марса!
🎥 Лекция 1. Новая суперспособность науки
🎥 Лекция 2. Как учить машины
🎥 Лекция 3. Линейные модели
🎥 Лекция 4. Сверточные сети
Не знаю какую чёрную магию они туда прикрутили, но их генеративная модель (да, это нарисовала нейросеть) выглядит на порядок стильнее, чем все, что мы видели до этого! И вроде как пускают тестить бету
#text2image
#text2image
Roadmap for Information Retrieval
Поиск информации (IR), задача поиска и доступа к соответствующим знаниям, вероятно, является одной из наиболее определяющих проблем информационного века. Люди используют IR каждый день, чтобы найти книги в электронной библиотеке, обувь в интернет-магазине, песни в стриминговом музыкальном сервисе и многое другое.
Нейронные модели - отличный метод для решения этой задачи, благодаря их способности глубоко понимать язык. Подобно тому, как людям, занятым на наукоемких работах, обычно приходится обращаться к знаниям в Интернете, нейронные сети должны эффективно искать более масштабные источники знаний. В последнее время исследователи добились больших успехов в повышении точности и эффективности предварительно обученных языковых моделей.
Почитать о том, что они придумали можно в блоге одной «экстремистской организации» 🤦♂️.
#information #text
Поиск информации (IR), задача поиска и доступа к соответствующим знаниям, вероятно, является одной из наиболее определяющих проблем информационного века. Люди используют IR каждый день, чтобы найти книги в электронной библиотеке, обувь в интернет-магазине, песни в стриминговом музыкальном сервисе и многое другое.
Нейронные модели - отличный метод для решения этой задачи, благодаря их способности глубоко понимать язык. Подобно тому, как людям, занятым на наукоемких работах, обычно приходится обращаться к знаниям в Интернете, нейронные сети должны эффективно искать более масштабные источники знаний. В последнее время исследователи добились больших успехов в повышении точности и эффективности предварительно обученных языковых моделей.
Почитать о том, что они придумали можно в блоге одной «экстремистской организации» 🤦♂️.
#information #text
Facebook
Advances toward ubiquitous neural information retrieval
Today, we’re sharing cutting-edge dense retrieval models that will help pave the way for ubiquitous neural information retrieval. This work will not only improve search as we currently use it, but also enable smarter AI agents of the future.
Я понимаю, что мы тут всякими продвинутыми штуками занимаемся. Но… вы во сколько лет узнали? (Я в сейчас лет )
Tim Urban: Научите меня чему-то интересному используя один комментарий
Buddha and Dog: Компьютеры используют бинарный код, и эта картинка содержит в себе и 0, и 1 (бинарные числа). Вкл и Выкл. 1 и 0.
Источник
Tim Urban: Научите меня чему-то интересному используя один комментарий
Buddha and Dog: Компьютеры используют бинарный код, и эта картинка содержит в себе и 0, и 1 (бинарные числа). Вкл и Выкл. 1 и 0.
Источник
Пока я пишу статьи и делаю свой курс, кто-то (я первый раз про этих чуваков слышу) уже успел написать целую книжку про машинное обучение в изучении других планет!
📖 Книжка
#ScientificMl
📖 Книжка
#ScientificMl
Мы выложили 5ую лекцию из курса «Нейронные сети и их применение в научных исследованиях».
В лекции поговорили про Рекуррентные сети (RNN). Разобрали, что такое последовательности; как с ними работать; и почему для работы с ними применяются именно RNN. В третей части лекции, как обычно, крутые научные примеры!
🎥 Лекция 5. Рекуррентные сети
В лекции поговорили про Рекуррентные сети (RNN). Разобрали, что такое последовательности; как с ними работать; и почему для работы с ними применяются именно RNN. В третей части лекции, как обычно, крутые научные примеры!
🎥 Лекция 5. Рекуррентные сети
YouTube
«Нейронные сети и их применение в научных исследованиях». Лекция 5: Рекуррентные сети
Пятое занятие на МФК-курсе «Нейронные сети и их применение в научных исследованиях» для студентов МГУ.
Преподаватель: Артемий Новоселов
0:00 В предыдущих сериях
1:45 Часть 1
1:54 Последовательности
3:32 1D
5:28 Hidden state
6:52 Recurrent Neural Network…
Преподаватель: Артемий Новоселов
0:00 В предыдущих сериях
1:45 Часть 1
1:54 Последовательности
3:32 1D
5:28 Hidden state
6:52 Recurrent Neural Network…
Обновился блокнот DiscoDiffusion по генерации чумовых картинок и видео.
- Turbo Mode from @zippy731
- Smoother video init
- 3D rotation params are now in degrees rather than radians
- diffusion_sampling_mode allows selection of DDIM vs PLMS
Играть тут
#text2image
- Turbo Mode from @zippy731
- Smoother video init
- 3D rotation params are now in degrees rather than radians
- diffusion_sampling_mode allows selection of DDIM vs PLMS
Играть тут
#text2image
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
За последний год, методы инверсии GAN в сочетании с CLIP позволили редактировать фотографии на совершенно новом уровне. Однако их применение в продакшене все еще затруднено из-за ограниченных возможностей инверсии GAN. Вместо GAN можно использовать DiffusionCLIP, который выполняет редактирование изображений с помощью текста с использованием диффузионных моделей и делает это лучше.
🖥 Colab
📎 Статья
🐙 Git
#diffusion #text2image
За последний год, методы инверсии GAN в сочетании с CLIP позволили редактировать фотографии на совершенно новом уровне. Однако их применение в продакшене все еще затруднено из-за ограниченных возможностей инверсии GAN. Вместо GAN можно использовать DiffusionCLIP, который выполняет редактирование изображений с помощью текста с использованием диффузионных моделей и делает это лучше.
🖥 Colab
📎 Статья
🐙 Git
#diffusion #text2image