
LLD Filtering with Macros
В этой статье я рассказано, как пользовательские макросы и регулярные выражения используются в LLD для фильтрации результатов обнаружения. В качестве примера я использован шаблон Network Generic Device by SNMP. Читать дальше.
В этой статье я рассказано, как пользовательские макросы и регулярные выражения используются в LLD для фильтрации результатов обнаружения. В качестве примера я использован шаблон Network Generic Device by SNMP. Читать дальше.
{kind=link}
Managing Grafana Dashboards With Terraform
Ручное управление дашбордами в Grafana имеет некоторые недостатки, например, случайное удаление графиков, люди "тестируют" изменения и забывают их убрать. В этой статье разобран подход Config as Code относительно Grafana. Читать дальше.
Ручное управление дашбордами в Grafana имеет некоторые недостатки, например, случайное удаление графиков, люди "тестируют" изменения и забывают их убрать. В этой статье разобран подход Config as Code относительно Grafana. Читать дальше.
{kind=link}
Logging Best Practices: Proven Techniques for Services
При правильном подходе логирование может дать ценные сведения о производительности и использовании приложения, что поможет повысить общую надежность и улучшить пользовательский опыт. В этой статье о подходах к логированию. Читать дальше.
При правильном подходе логирование может дать ценные сведения о производительности и использовании приложения, что поможет повысить общую надежность и улучшить пользовательский опыт. В этой статье о подходах к логированию. Читать дальше.
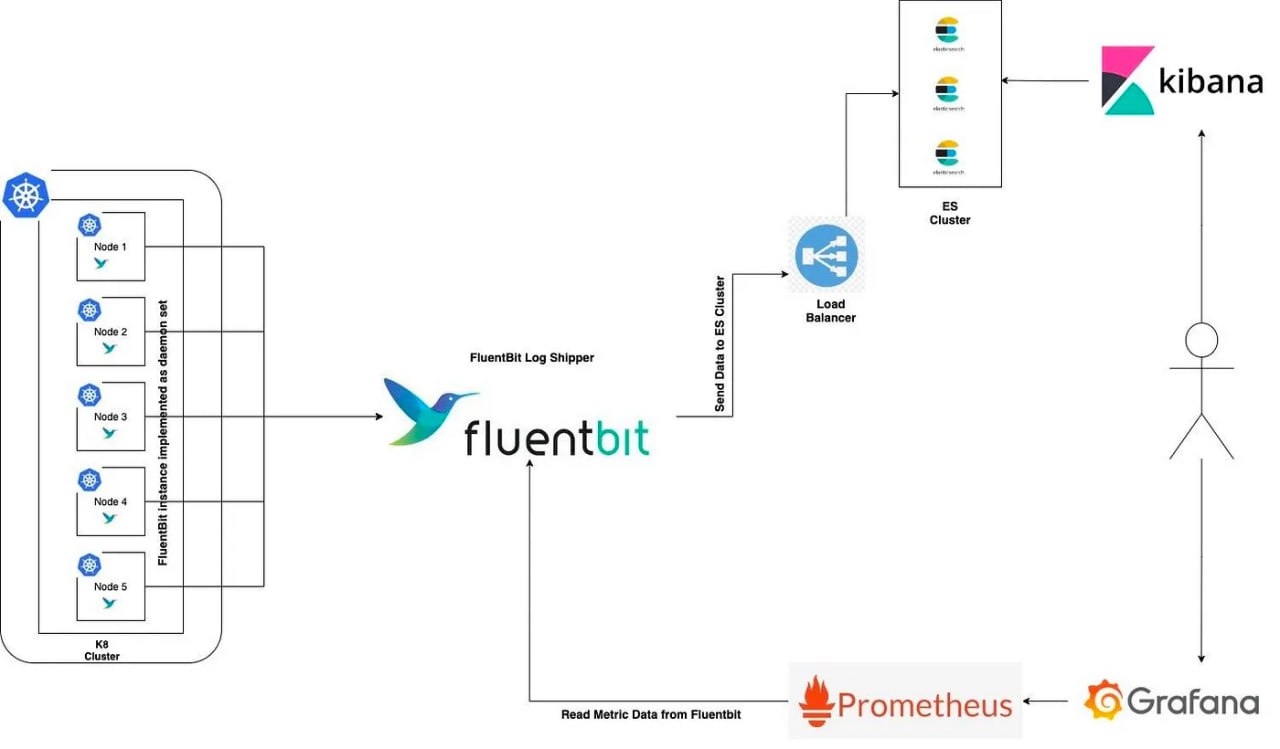
Kubernetes Logging essentials with EFK — Elasticsearch Fluentbit Kibana
Логирование - неотъемлемая часть любого приложения. В этой статье разбирается сбор логов из кластера Kubernetes при помощи EFK. Читать дальше.
Логирование - неотъемлемая часть любого приложения. В этой статье разбирается сбор логов из кластера Kubernetes при помощи EFK. Читать дальше.
{kind=link}
Повышаем производительность и безопасность мониторингом логов и метрик
В этой статье разбирается роль мониторинга в наблюдаемости, особенно его связь с безопасностью, производительностью и надёжностью. Мониторинг необходим для выявления происходящих в продакшене проблем и выбросов, он позволяет командам DevSecOps выявлять и устранять проблемы до того, как они нанесут серьёзный урон. Мониторинг снижения производительности или подозрительной активности может вызывать алерты и автоматическое реагирование для изоляции потенциальных проблем или атак. Читать дальше.
В этой статье разбирается роль мониторинга в наблюдаемости, особенно его связь с безопасностью, производительностью и надёжностью. Мониторинг необходим для выявления происходящих в продакшене проблем и выбросов, он позволяет командам DevSecOps выявлять и устранять проблемы до того, как они нанесут серьёзный урон. Мониторинг снижения производительности или подозрительной активности может вызывать алерты и автоматическое реагирование для изоляции потенциальных проблем или атак. Читать дальше.
{kind=link}
Real Life Business Service Monitoring (статья из блога Zabbix)
С помощью мониторинга бизнес-услуг можно увидеть, что именно происходит с вашим бизнесом, в зависимости от состояния каждой отдельной части вашей инфраструктуры. Это позволяет нам, администраторам и владельцам сервисов, понять, что на самом деле означает поломка оборудования или недоступность устройства. С помощью мониторинга бизнес-услуг мы видим, что именно влияет на наш бизнес и насколько серьезна ситуация, включая расчет SLA (соглашение об уровне обслуживания) и его оценку в сравнении с определенным SLO (целевой уровень обслуживания). Читать дальше.
С помощью мониторинга бизнес-услуг можно увидеть, что именно происходит с вашим бизнесом, в зависимости от состояния каждой отдельной части вашей инфраструктуры. Это позволяет нам, администраторам и владельцам сервисов, понять, что на самом деле означает поломка оборудования или недоступность устройства. С помощью мониторинга бизнес-услуг мы видим, что именно влияет на наш бизнес и насколько серьезна ситуация, включая расчет SLA (соглашение об уровне обслуживания) и его оценку в сравнении с определенным SLO (целевой уровень обслуживания). Читать дальше.
{kind=link}
Измеряем команду с JIRA и Grafana: sprint reports, грейдирование и не только
Мы работаем с JIRA. Теоретически, можно сделать отдельный JIRA report, но у нас практически нет Java-разработчиков, да и это займет время. Но зато есть Grafana и доступ к реплике БД JIRA. Поэтому мой выбор пал на связку Grafana + Jira. Нужно было лишь разобраться во внутреннем устройстве БД JIRA. Особо рекомендую обратить внимание на историю изменений и кастомные поля. Читать дальше.
Мы работаем с JIRA. Теоретически, можно сделать отдельный JIRA report, но у нас практически нет Java-разработчиков, да и это займет время. Но зато есть Grafana и доступ к реплике БД JIRA. Поэтому мой выбор пал на связку Grafana + Jira. Нужно было лишь разобраться во внутреннем устройстве БД JIRA. Особо рекомендую обратить внимание на историю изменений и кастомные поля. Читать дальше.
{kind=link}
Creating Time Series Plots in Grafana
В этой статье пример того, как построить график временного ряда в Grafana на основе данных из MySQL, показывающий температуру и влажность. Читать дальше.
В этой статье пример того, как построить график временного ряда в Grafana на основе данных из MySQL, показывающий температуру и влажность. Читать дальше.
{kind=link}
Monitor your databases with Open Source tools
В этом видео с Fosdem 2023 вы узнаете о технологиях мониторинга БД PostgreSQL при помощи PMM (Percona Monitoring and Management). Выступающая Edith Puclla — технический специалист из Percona.
PMM поддерживает мониторинг MySQL, MariaDB PostgreSQL, MongoDB. Построен на базе Grafana, VictoriaMetrics/Prometheus, ClickHouse, PostgreSQL и Docker. Удобное и завершенное решение для мониторинга поддерживаемых БД.
Посмотреть запись
Репыч на Гитхабе
В этом видео с Fosdem 2023 вы узнаете о технологиях мониторинга БД PostgreSQL при помощи PMM (Percona Monitoring and Management). Выступающая Edith Puclla — технический специалист из Percona.
PMM поддерживает мониторинг MySQL, MariaDB PostgreSQL, MongoDB. Построен на базе Grafana, VictoriaMetrics/Prometheus, ClickHouse, PostgreSQL и Docker. Удобное и завершенное решение для мониторинга поддерживаемых БД.
Посмотреть запись
Репыч на Гитхабе
{kind=link}
Create GeoIP dashboards in Grafana from iptables logs
Существует множество решений, как сопоставить IP-адреса с географическим местоположением, например, с помощью логов веб-сервера. Существует также множество вариантов их отображения с помощью различных решений для мониторинга. Однако если у вас есть несколько служб, которые создают журналы, может оказаться утомительным настраивать их все для сопоставления логов доступа с GeoIP. Когда вы можете брать IP-адреса непосредственно из брандмауэра, получить всю необходимую информацию можно в одном месте.
В этой статье о настройке Grafana для отображения информации о GeoIP, поступающей из журналов iptables. Читать дальше.
Существует множество решений, как сопоставить IP-адреса с географическим местоположением, например, с помощью логов веб-сервера. Существует также множество вариантов их отображения с помощью различных решений для мониторинга. Однако если у вас есть несколько служб, которые создают журналы, может оказаться утомительным настраивать их все для сопоставления логов доступа с GeoIP. Когда вы можете брать IP-адреса непосредственно из брандмауэра, получить всю необходимую информацию можно в одном месте.
В этой статье о настройке Grafana для отображения информации о GeoIP, поступающей из журналов iptables. Читать дальше.
{kind=link}
Developing Dashboards Using Grafana
В этой статье приведены два примера визуализации данных в Grafana из различных источников: MySQL и Web API. Если с первым более менее понятно, то со вторым всё гораздо интереснее. Здесь приведен пример создания бэкэнда с REST API и использования плагина Simplejson от Grafana. Читать дальше.
В этой статье приведены два примера визуализации данных в Grafana из различных источников: MySQL и Web API. Если с первым более менее понятно, то со вторым всё гораздо интереснее. Здесь приведен пример создания бэкэнда с REST API и использования плагина Simplejson от Grafana. Читать дальше.
{kind=link}
Open-Source Tracing Tools: Jaeger Vs. Zipkin Vs. Grafana Tempo
Трассировка вызовов в распределенном приложении очень важна для мониторинга. В этой статье рассматриваются три наиболее популярных инструмента трассировки с открытым исходным кодом: Jaeger, Zipkin и Grafana Tempo, а также приводится их сравнение в виде таблицы. Читать дальше.
Трассировка вызовов в распределенном приложении очень важна для мониторинга. В этой статье рассматриваются три наиболее популярных инструмента трассировки с открытым исходным кодом: Jaeger, Zipkin и Grafana Tempo, а также приводится их сравнение в виде таблицы. Читать дальше.
{kind=link}
Django Monitoring with Prometheus and Grafana
Prometheus Package для Django обеспечивает отличную интеграцию с Prometheus, но коробочным дашбордам и оповещениям не хватает некоторых собираемых данных. Дашборды в Grafana не использует большую часть метрик, предоставляемых пакетом Django-Prometheus, кроме того, отсутствуют фильтры для представлений, методов, заданий и пространств имен. В этой статье представлен Django-mixin - набор правил Prometheus и дашбордов Grafana для Django. Дашборды и оповещения реализуют представление информации о примененных/непримененных миграциях, метриках RED (запросы в секунду, процент ошибок в запросе, задержках для каждого запроса), операциях с базой данных и частоте попадания в кэш. Читать дальше.
Prometheus Package для Django обеспечивает отличную интеграцию с Prometheus, но коробочным дашбордам и оповещениям не хватает некоторых собираемых данных. Дашборды в Grafana не использует большую часть метрик, предоставляемых пакетом Django-Prometheus, кроме того, отсутствуют фильтры для представлений, методов, заданий и пространств имен. В этой статье представлен Django-mixin - набор правил Prometheus и дашбордов Grafana для Django. Дашборды и оповещения реализуют представление информации о примененных/непримененных миграциях, метриках RED (запросы в секунду, процент ошибок в запросе, задержках для каждого запроса), операциях с базой данных и частоте попадания в кэш. Читать дальше.
{kind=link}
6 Best Practices for Effective Monitoring Alerts
В этой статье обзор лучших практик для создания эффективных оповещений мониторинга, которые обеспечат бесперебойную работу систем, а также тех, которые этого не сделают. Думаю, вы в курсе всех этих лучших практик, однако, эту статью можно использовать как чек лист, чтобы ещё раз взглянуть на свои алерты.
Ключевые моменты:
1. Prioritized Alerts
2. Actionable Alerts
3. Documentation Attached
4. Alerts != Incident Management
5. Don’t limit your notifications channels
6. Use complex conditions to refine alerts
Читать дальше.
В этой статье обзор лучших практик для создания эффективных оповещений мониторинга, которые обеспечат бесперебойную работу систем, а также тех, которые этого не сделают. Думаю, вы в курсе всех этих лучших практик, однако, эту статью можно использовать как чек лист, чтобы ещё раз взглянуть на свои алерты.
Ключевые моменты:
1. Prioritized Alerts
2. Actionable Alerts
3. Documentation Attached
4. Alerts != Incident Management
5. Don’t limit your notifications channels
6. Use complex conditions to refine alerts
Читать дальше.
18 Kubernetes Metrics to Monitor for Optimal Cluster Performance
В этой статье рассказано о 18 метриках Kubernetes, которые можно использовать как в on-prem так и в облачных средах. Читать дальше.
В этой статье рассказано о 18 метриках Kubernetes, которые можно использовать как в on-prem так и в облачных средах. Читать дальше.
Locust Real-Time Monitoring with Grafana
Во время нагрузочного тестирования хочется мгновенно увидеть результаты по нужным метрикам. Каждый нагрузочный тест может потребовать сосредоточиться на разных метриках. Соответственно, нужно иметь возможность редактировать эти метрики по желанию и настраивать их.
В этой статье рассказывается как проводить нагрузочные тесты с помощью locust, мгновенно экспортировать метрики с помощью Prometheus и отображать нужные метрики в Grafana. Читать дальше.
Во время нагрузочного тестирования хочется мгновенно увидеть результаты по нужным метрикам. Каждый нагрузочный тест может потребовать сосредоточиться на разных метриках. Соответственно, нужно иметь возможность редактировать эти метрики по желанию и настраивать их.
В этой статье рассказывается как проводить нагрузочные тесты с помощью locust, мгновенно экспортировать метрики с помощью Prometheus и отображать нужные метрики в Grafana. Читать дальше.
{kind=link}
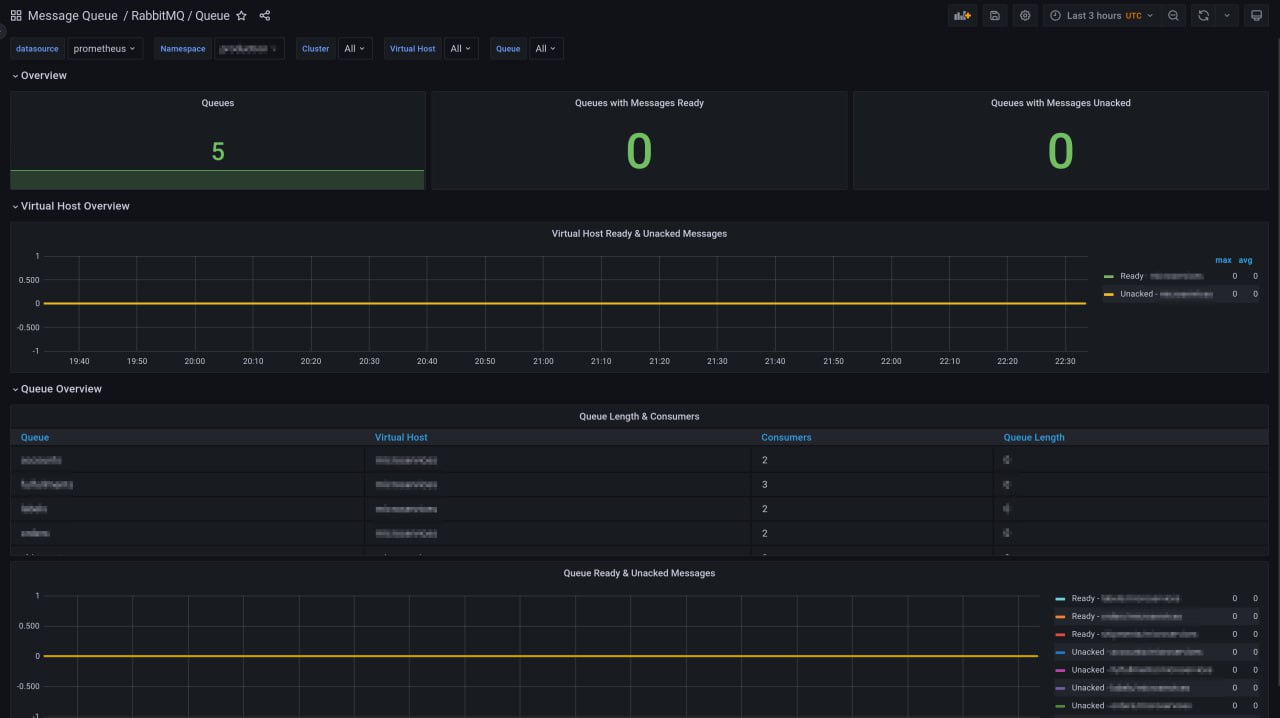
RabbitMQ Per Queue Monitoring
RabbitMQ имеет встроенный плагин Prometheus, и по умолчанию в нем отключены гранулярные метрики. Гранулярные метрики означают метрики по очередям и хостам — подробные метрики, которые предоставляют информацию о задержке сообщений и потребителях на основе очередей и хостов. Вы можете включить гранулярные метрики по объектам, но это не рекомендуется, так как плагин становится намного медленнее на большом кластере, а частота сбора метрик для базы данных временных рядов может стать высокой.
Для решения этой проблемы можно использовать неофициальный OSS экспортер RabbitMQ, написанный kbudde, который позволит включить гранулярные метрики, а также отключить специфические метрики, которые предоставляет родной плагин Prometheus. Неофициальный экспортер относится к смешанному подходу, когда вы используете неофициальный экспортер для детальных метрик, отключаете все остальные метрики и используете родной плагин RabbitMQ Prometheus для всех остальных метрик.
Однако недавно в родном плагине RabbitMQ Prometheus был добавлен еще один эндпоинт, предоставляющий подробные метрики, которые можно настраивать и детализировать. Это позволяет избежать использования двух экспортеров и не беспокоиться о дубликатах метрик, именовании меток, нескольких источниках данных для приборных панелей и других проблемах. Это также не требует включения метрик для каждого объекта для всего плагина Prometheus, что является медленным и может привести к высокой частоте сбора метрик. В этом посте мы рассмотрено, как собирать подробные метрики, а также создавать дашборды и оповещения для этих метрик. Читать дальше.
RabbitMQ имеет встроенный плагин Prometheus, и по умолчанию в нем отключены гранулярные метрики. Гранулярные метрики означают метрики по очередям и хостам — подробные метрики, которые предоставляют информацию о задержке сообщений и потребителях на основе очередей и хостов. Вы можете включить гранулярные метрики по объектам, но это не рекомендуется, так как плагин становится намного медленнее на большом кластере, а частота сбора метрик для базы данных временных рядов может стать высокой.
Для решения этой проблемы можно использовать неофициальный OSS экспортер RabbitMQ, написанный kbudde, который позволит включить гранулярные метрики, а также отключить специфические метрики, которые предоставляет родной плагин Prometheus. Неофициальный экспортер относится к смешанному подходу, когда вы используете неофициальный экспортер для детальных метрик, отключаете все остальные метрики и используете родной плагин RabbitMQ Prometheus для всех остальных метрик.
Однако недавно в родном плагине RabbitMQ Prometheus был добавлен еще один эндпоинт, предоставляющий подробные метрики, которые можно настраивать и детализировать. Это позволяет избежать использования двух экспортеров и не беспокоиться о дубликатах метрик, именовании меток, нескольких источниках данных для приборных панелей и других проблемах. Это также не требует включения метрик для каждого объекта для всего плагина Prometheus, что является медленным и может привести к высокой частоте сбора метрик. В этом посте мы рассмотрено, как собирать подробные метрики, а также создавать дашборды и оповещения для этих метрик. Читать дальше.
{kind=link}
{kind=link}
What is Grafana Mimir?
Обзорная статья. Grafana Mimir — это инструмент масштабируемого долговременного хранение данных для Prometheus. Благодаря простоте установки и обслуживания, масштабируемости, глобальному представлению метрик, дешевому и долговечному хранилищу, высокой доступности и многопользовательскому режиму, Grafana Mimir является мощным дополнением к Prometheus. Читать дальше.
Обзорная статья. Grafana Mimir — это инструмент масштабируемого долговременного хранение данных для Prometheus. Благодаря простоте установки и обслуживания, масштабируемости, глобальному представлению метрик, дешевому и долговечному хранилищу, высокой доступности и многопользовательскому режиму, Grafana Mimir является мощным дополнением к Prometheus. Читать дальше.
{kind=link}
Observability strategies to not overload engineering teams — OpenTelemetry Strategy
В этой статье о том как собирать метрики и трассировки из python-сервиса без изменений кода. Читать дальше.
В этой статье о том как собирать метрики и трассировки из python-сервиса без изменений кода. Читать дальше.
{kind=link}