
How We Improved Our Monitoring Stack With Only a Few Small Changes
В этом посте рассказ о процессе совершенствования системы мониторинга в компании Riskified (на примере улучшений в Prometheus). Читать дальше.
В этом посте рассказ о процессе совершенствования системы мониторинга в компании Riskified (на примере улучшений в Prometheus). Читать дальше.
OpenTelemetry — Understanding SLI and SLO with OpenTelemetry Demo
Даже если вы не предполагаете, что вам не нужны или даже не используете Service Level Objectives (SLO), вы так или иначе используете их. В этой статье на примере приложения электронной коммерции из OpenTelemetry Demo показан анализ и визуализация реального сценария с использованием SLIs и SLOs. Читать дальше.
Даже если вы не предполагаете, что вам не нужны или даже не используете Service Level Objectives (SLO), вы так или иначе используете их. В этой статье на примере приложения электронной коммерции из OpenTelemetry Demo показан анализ и визуализация реального сценария с использованием SLIs и SLOs. Читать дальше.
{kind=link}
Monitoring Kubernetes layers: Key metrics to know
Метрики Kubernetes можно извлекать из службы kube-state-metrics, которая слушает сервер Kubernetes control plane/API и генерирует метрики о задействованных ресурсах или объектах. Как и в случае с другими видами мониторинга, можно использовать собранную информацию для оповещения команды о том, что происходит внутри системы. Создание алертов по определенным метрикам также может предупредить о приближающихся сбоях, что поможет сократить время решения проблемы. В этой статье в блоге Grafana разобраны 5 типов метрик k8s, которые рекомендуется отслеживать. Читать дальше.
Метрики Kubernetes можно извлекать из службы kube-state-metrics, которая слушает сервер Kubernetes control plane/API и генерирует метрики о задействованных ресурсах или объектах. Как и в случае с другими видами мониторинга, можно использовать собранную информацию для оповещения команды о том, что происходит внутри системы. Создание алертов по определенным метрикам также может предупредить о приближающихся сбоях, что поможет сократить время решения проблемы. В этой статье в блоге Grafana разобраны 5 типов метрик k8s, которые рекомендуется отслеживать. Читать дальше.
{kind=link}
Analyzing Kubernetes Traffic with Kubeshark
Kubeshark — это веб-инструмент, который позволяет захватывать и анализировать сетевой трафик в кластере Kubernetes. Он интегрируется с Wireshark, фильтровать и анализировать сетевые пакеты в режиме реального времени. Kubeshark также предоставляет удобный интерфейс для визуализации сетевого трафика, облегчая понимание сетевых потоков и выявление потенциальных проблем.
Kubeshark построен на базе Cilium, Kubernetes-нативной сетевой платформы и платформы безопасности, которая обеспечивает расширенные возможности применения сетевых политик и наблюдения. Cilium использует технологию eBPF для перехвата сетевого трафика на уровне ядра, что обеспечивает низкоуровневую видимость сетевых потоков без значительных накладных расходов на кластер. Читать статью.
Репыч на Гитхабе.
Kubeshark — это веб-инструмент, который позволяет захватывать и анализировать сетевой трафик в кластере Kubernetes. Он интегрируется с Wireshark, фильтровать и анализировать сетевые пакеты в режиме реального времени. Kubeshark также предоставляет удобный интерфейс для визуализации сетевого трафика, облегчая понимание сетевых потоков и выявление потенциальных проблем.
Kubeshark построен на базе Cilium, Kubernetes-нативной сетевой платформы и платформы безопасности, которая обеспечивает расширенные возможности применения сетевых политик и наблюдения. Cilium использует технологию eBPF для перехвата сетевого трафика на уровне ядра, что обеспечивает низкоуровневую видимость сетевых потоков без значительных накладных расходов на кластер. Читать статью.
Репыч на Гитхабе.
{kind=link}
How to find unused Prometheus metrics using mimirtool
В этой статье рассказывается, как с помощью mimirtool определить, какие метрики используются Prometheus, а какие нет. Читать дальше.
В этой статье рассказывается, как с помощью mimirtool определить, какие метрики используются Prometheus, а какие нет. Читать дальше.
Medium
How to find unused Prometheus metrics using mimirtool
In this article, I will explain how I used mimirtool to identify which metrics were used on the platform, and which wasn’t.
В сервис добавили сканер уязвимостей в Yandex Container Registry
Платформа Yandex Cloud открыла общий доступ к сканеру, который до этого был доступен только в режиме превью.
С помощью него вы можете:
— проводить анализ контейнерных образов на предмет уязвимостей;
— использовать крупнейшую базу уязвимостей;
— сканировать образы при непрерывном развёртывании приложений;
— создавать CI-сценарии для проверки безопасности.
Из нового — теперь можно сканировать контейнерные образы автоматически при загрузке.
Сканер уязвимостей работает только с образами из Container Registry.
Подробнее о сканере уязвимостей ➡️
Платформа Yandex Cloud открыла общий доступ к сканеру, который до этого был доступен только в режиме превью.
С помощью него вы можете:
— проводить анализ контейнерных образов на предмет уязвимостей;
— использовать крупнейшую базу уязвимостей;
— сканировать образы при непрерывном развёртывании приложений;
— создавать CI-сценарии для проверки безопасности.
Из нового — теперь можно сканировать контейнерные образы автоматически при загрузке.
Сканер уязвимостей работает только с образами из Container Registry.
Подробнее о сканере уязвимостей ➡️
Prometheus’ performance and cardinality in practice
В этой статье рассказано, как я проанализировать и настроить Prometheus, чтобы значительно снизить использование ресурсов. Читать дальше.
В этой статье рассказано, как я проанализировать и настроить Prometheus, чтобы значительно снизить использование ресурсов. Читать дальше.
{kind=link}
Unpacking Observability: The Observability Stack
"Наш текущий стек Observability выглядит как набор различных продуктов с открытым исходным кодом, в результате того, что команда X хотела использовать инструмент A, а команда Y хотела использовать инструмент B. В итоге мы получили стек, включающий кучу различных инструментов, собранных вместе в надежде обеспечить Observability. В последний год или около того я внимательно следил за развитием Observability, и я был уверен, что мы можем уменьшить этот стек в разы."
В этой статье разбирается кейс уменьшения набора решений для Observability. Читать дальше.
"Наш текущий стек Observability выглядит как набор различных продуктов с открытым исходным кодом, в результате того, что команда X хотела использовать инструмент A, а команда Y хотела использовать инструмент B. В итоге мы получили стек, включающий кучу различных инструментов, собранных вместе в надежде обеспечить Observability. В последний год или около того я внимательно следил за развитием Observability, и я был уверен, что мы можем уменьшить этот стек в разы."
В этой статье разбирается кейс уменьшения набора решений для Observability. Читать дальше.
{kind=link}
An overview of metrics in Prometheus
В этой статье вы найдете обзор типов метрик, которые есть в Prometheus, включая назначение каждого типа метрик. Читать дальше.
В этой статье вы найдете обзор типов метрик, которые есть в Prometheus, включая назначение каждого типа метрик. Читать дальше.
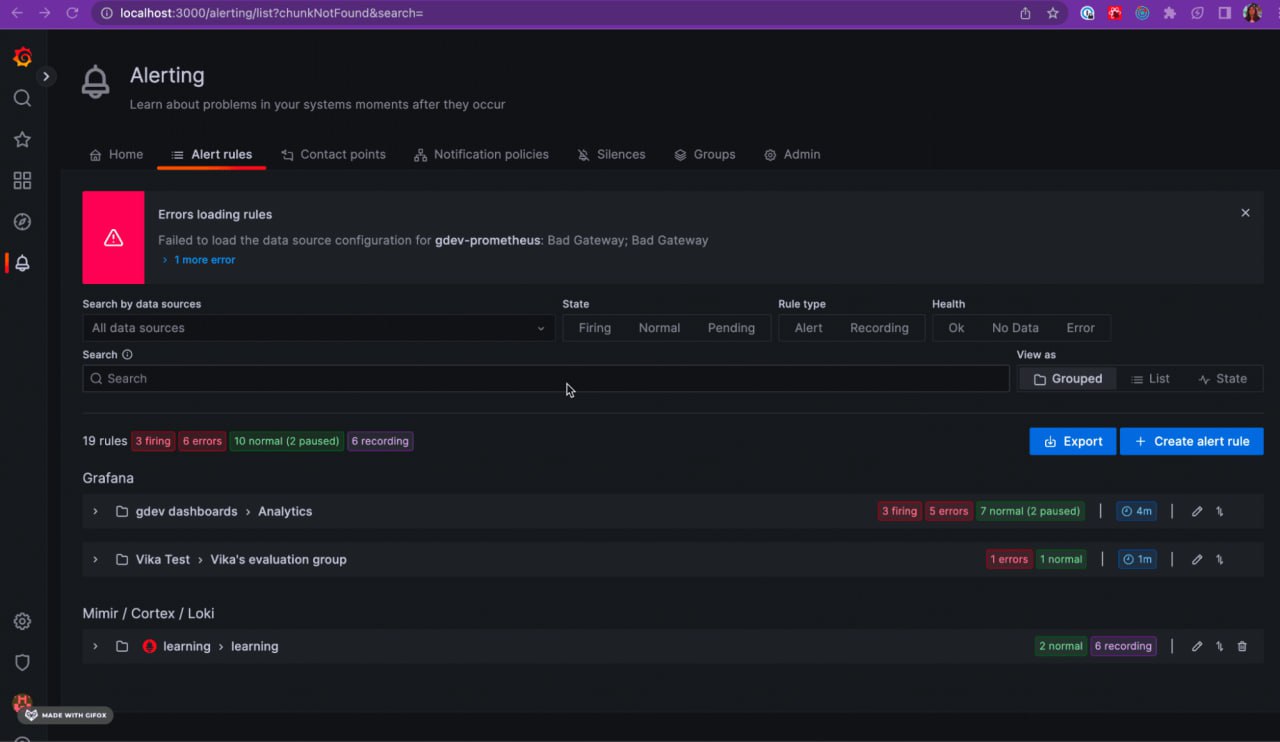
Grafana Alerting: Searching for Grafana alerts just got faster, easier, and more accurate
Управление сотнями, если не тысячами, правил оповещения в Grafana является обычным явлением и становится все более нетривиальным для пользователей.
Чтобы решить эту проблему, в Grafana внедрена поисковая система, призванная помочь пользователям быстро выполнять поиск по оповещениям и упростить управление большим количеством правил и сложными воркфлоу. Читать дальше.
Управление сотнями, если не тысячами, правил оповещения в Grafana является обычным явлением и становится все более нетривиальным для пользователей.
Чтобы решить эту проблему, в Grafana внедрена поисковая система, призванная помочь пользователям быстро выполнять поиск по оповещениям и упростить управление большим количеством правил и сложными воркфлоу. Читать дальше.
26 апреля вышла Grafana 9.5
В этом посте рассмотрим пару ключевых улучшений.
Обновление алертов
В Grafana Alerting появился поиск правил оповещения для нескольких источников данных, доступ к правилам оповещений непосредственно из дашбордов, а также переход к соответствующим дашбордам или панели управления правилами оповещения. Также внесены обновления в настройки правил оповещения и политики уведомлений, которые помогают уменьшить количество шумовых оповещений.
Появились саппорт бандлы
Теперь можно быстро собрать набор файлов с настройками Grafana для того, чтобы, например, поделиться ими с коллегами.
и несколько других улучшений. Читать в блоге Grafana.
В этом посте рассмотрим пару ключевых улучшений.
Обновление алертов
В Grafana Alerting появился поиск правил оповещения для нескольких источников данных, доступ к правилам оповещений непосредственно из дашбордов, а также переход к соответствующим дашбордам или панели управления правилами оповещения. Также внесены обновления в настройки правил оповещения и политики уведомлений, которые помогают уменьшить количество шумовых оповещений.
Появились саппорт бандлы
Теперь можно быстро собрать набор файлов с настройками Grafana для того, чтобы, например, поделиться ими с коллегами.
и несколько других улучшений. Читать в блоге Grafana.
{kind=link}
Integrate Zabbix with your data pipelines by configuring real-time metric and event streaming
До версии 6.4 метрики можно было экспортировать в файлы в формате JSON. С выходом Zabbix 6.4 метрики, собранные Zabbix, и события, сгенерированные на основе триггеров, могут быть переданы во внешние системы с помощью новой функции потоковой передачи метрик и событий в режиме реального времени. Чтобы передавать только необходимые метрики или события, их можно фильтровать по тегам. Данные передаются в формате JSON. Самый, наверное, популярный use case этой новой функции может заключаться в передаче исторических данных во внешние озера данных для целей аналитики, машинного обучения и прочих модных слов.
Читать статью в блоге Zabbix.
До версии 6.4 метрики можно было экспортировать в файлы в формате JSON. С выходом Zabbix 6.4 метрики, собранные Zabbix, и события, сгенерированные на основе триггеров, могут быть переданы во внешние системы с помощью новой функции потоковой передачи метрик и событий в режиме реального времени. Чтобы передавать только необходимые метрики или события, их можно фильтровать по тегам. Данные передаются в формате JSON. Самый, наверное, популярный use case этой новой функции может заключаться в передаче исторических данных во внешние озера данных для целей аналитики, машинного обучения и прочих модных слов.
Читать статью в блоге Zabbix.
{kind=link}
Мониторинг: измеряем потери пакетов с помощью C++
Всем хорош Zabbix, за исключением маленьких таймаутов для встроенных и внешних проверок. В файле конфигурации сервера указан максимальный таймаут 30 секунд, чего совершенно недостаточно, например, для пинга с использованием 10 000 пакетов, даже если мы установим интервал в 100 мс. Как мы знаем, по российским нормативам потери пакетов в сетях связи не должны превышать один пакет на тысячу. Особо требовательные заказчики трактуют эту цифру по-своему: всё что больше или равно 0,05% можно округлить до тех самых 0,1% или одного пакета на тысячу. Поэтому автор этой статьи решил для самых критичных узлов, особенно при поступлении заявки, использовать внешнюю программу (назовём её losshd), которая будет в несколько потоков измерять потери пакетов и записывать результаты в базу, а для Zabbix использовать простую утилиту (назовём её getloss), которая быстро вытащит из базы необходимое значение. Читать дальше.
Всем хорош Zabbix, за исключением маленьких таймаутов для встроенных и внешних проверок. В файле конфигурации сервера указан максимальный таймаут 30 секунд, чего совершенно недостаточно, например, для пинга с использованием 10 000 пакетов, даже если мы установим интервал в 100 мс. Как мы знаем, по российским нормативам потери пакетов в сетях связи не должны превышать один пакет на тысячу. Особо требовательные заказчики трактуют эту цифру по-своему: всё что больше или равно 0,05% можно округлить до тех самых 0,1% или одного пакета на тысячу. Поэтому автор этой статьи решил для самых критичных узлов, особенно при поступлении заявки, использовать внешнюю программу (назовём её losshd), которая будет в несколько потоков измерять потери пакетов и записывать результаты в базу, а для Zabbix использовать простую утилиту (назовём её getloss), которая быстро вытащит из базы необходимое значение. Читать дальше.
{kind=link}
Jaeger для трассировки в микросервисной архитектуре
Рассмотрим, как работает Jaeger, один из популярных инструментов, который помогает расследовать инциденты и находить узкие места в производительности в микросервисной архитектуре. Разберём, как правильно настроить трассировку и с какими проблемами можно столкнуться в процессе. Эта статья не для джунов: от должности джуна до состояния, когда можно осознанно подойти к пониманию observability, к OpenTelemetry-стандарту и Jaeger, может пройти несколько лет. До этого нужно дорасти. Читать дальше.
Рассмотрим, как работает Jaeger, один из популярных инструментов, который помогает расследовать инциденты и находить узкие места в производительности в микросервисной архитектуре. Разберём, как правильно настроить трассировку и с какими проблемами можно столкнуться в процессе. Эта статья не для джунов: от должности джуна до состояния, когда можно осознанно подойти к пониманию observability, к OpenTelemetry-стандарту и Jaeger, может пройти несколько лет. До этого нужно дорасти. Читать дальше.
{kind=link}
Symfony + Filebeat + Elasticsearch
Observability (и, как следствие, сбор логов) — это важная составляющая материальных средств, без которой было бы очень трудно исследовать баги или обнаруживать брутфорс-атаки. Обычно приложение выводит логи в специальный файл журнала или стандартный вывод системы (stdout). Это, конечно, уже что-то, но отсюда вытекает несколько проблем:
⚡️Работа с логами в текстовой форме и в зачастую огромных файлах сложна и не очень удобна.
⚡️Необходимо иметь доступа к машине с логами (в случае, если логи хранятся в файлах журналов).
⚡️Коррелирование таких логов не представляется возможным.
К счастью, существуют решения, облегчающие централизацию и работу с логами приложений (Elastic, Grafana Loki и т.д.). Читать дальше.
Observability (и, как следствие, сбор логов) — это важная составляющая материальных средств, без которой было бы очень трудно исследовать баги или обнаруживать брутфорс-атаки. Обычно приложение выводит логи в специальный файл журнала или стандартный вывод системы (stdout). Это, конечно, уже что-то, но отсюда вытекает несколько проблем:
⚡️Работа с логами в текстовой форме и в зачастую огромных файлах сложна и не очень удобна.
⚡️Необходимо иметь доступа к машине с логами (в случае, если логи хранятся в файлах журналов).
⚡️Коррелирование таких логов не представляется возможным.
К счастью, существуют решения, облегчающие централизацию и работу с логами приложений (Elastic, Grafana Loki и т.д.). Читать дальше.
{kind=link}
Как сделать мониторинг инженерной инфраструктуры ЦОД на примере DataLine
В этой статье рассмотрены основные задачи системы мониторинга ЦОД и подводные камни, которые помогут создать или улучшить собственную систему мониторинга, опираясь на опыт специалистов DataLine. Читать дальше.
В этой статье рассмотрены основные задачи системы мониторинга ЦОД и подводные камни, которые помогут создать или улучшить собственную систему мониторинга, опираясь на опыт специалистов DataLine. Читать дальше.
{kind=link}
«Карманный синоптик за час». Пишем Telegram-бота для мониторинга погоды на Python
Мониторинг погоды — тоже мониторинг. Из этой статьи вы узнаете, как написать своего Telegram-бота для получения данных о погоде в любом городе нашей планеты. Детально рассмотрена работа с API, парсинг JSON и показано как написать бота на асинхронной библиотеке aiogram. А после — загрузка его на виртуальный сервер и запуск. Читать дальше.
Мониторинг погоды — тоже мониторинг. Из этой статьи вы узнаете, как написать своего Telegram-бота для получения данных о погоде в любом городе нашей планеты. Детально рассмотрена работа с API, парсинг JSON и показано как написать бота на асинхронной библиотеке aiogram. А после — загрузка его на виртуальный сервер и запуск. Читать дальше.
{kind=link}
SLOs should be easy, say hi to Sloth
Sloth генерирует понятные, единообразные и надежные SLO для Prometheus.
Статья с описанием
Репыч на Гитхабе
Sloth генерирует понятные, единообразные и надежные SLO для Prometheus.
Статья с описанием
Репыч на Гитхабе
{kind=link}
Как в Yandex Cloud сделали незаметную капчу?
Как сделать так, чтобы капча работала и отсеивала ботов, а пользователям не приходилось вводить текст с картинки? На этот вопрос отвечают разработчики Yandex SmartCaptcha — в статье они делятся историей создания сервиса, рассказывают про изменение кода, рефакторинг архитектуры, невидимую для пользователя проверку и заботу о людях.
Читайте статью в новом блоге Yandex Cloud и Yandex Infrastructure на Хабре, и не забудьте подписаться, чтобы не пропустить истории о том, как строится инфраструктура Яндекса и делается публичная облачная платформа.
Как сделать так, чтобы капча работала и отсеивала ботов, а пользователям не приходилось вводить текст с картинки? На этот вопрос отвечают разработчики Yandex SmartCaptcha — в статье они делятся историей создания сервиса, рассказывают про изменение кода, рефакторинг архитектуры, невидимую для пользователя проверку и заботу о людях.
Читайте статью в новом блоге Yandex Cloud и Yandex Infrastructure на Хабре, и не забудьте подписаться, чтобы не пропустить истории о том, как строится инфраструктура Яндекса и делается публичная облачная платформа.
Why You Shouldn’t Fear to Adopt Opentelemetry for Observability
В этой статье автор делится своим опытом внедрения Otel в очень сложную архитектуру с нулевым временем простоя для конечных пользователей. Читать дальше.
В этой статье автор делится своим опытом внедрения Otel в очень сложную архитектуру с нулевым временем простоя для конечных пользователей. Читать дальше.
{kind=link}