
Open-Source Tracing Tools: Jaeger Vs. Zipkin Vs. Grafana Tempo
Трассировка вызовов в распределенном приложении очень важна для мониторинга. В этой статье рассматриваются три наиболее популярных инструмента трассировки с открытым исходным кодом: Jaeger, Zipkin и Grafana Tempo, а также приводится их сравнение в виде таблицы. Читать дальше.
Трассировка вызовов в распределенном приложении очень важна для мониторинга. В этой статье рассматриваются три наиболее популярных инструмента трассировки с открытым исходным кодом: Jaeger, Zipkin и Grafana Tempo, а также приводится их сравнение в виде таблицы. Читать дальше.
{kind=link}
Django Monitoring with Prometheus and Grafana
Prometheus Package для Django обеспечивает отличную интеграцию с Prometheus, но коробочным дашбордам и оповещениям не хватает некоторых собираемых данных. Дашборды в Grafana не использует большую часть метрик, предоставляемых пакетом Django-Prometheus, кроме того, отсутствуют фильтры для представлений, методов, заданий и пространств имен. В этой статье представлен Django-mixin - набор правил Prometheus и дашбордов Grafana для Django. Дашборды и оповещения реализуют представление информации о примененных/непримененных миграциях, метриках RED (запросы в секунду, процент ошибок в запросе, задержках для каждого запроса), операциях с базой данных и частоте попадания в кэш. Читать дальше.
Prometheus Package для Django обеспечивает отличную интеграцию с Prometheus, но коробочным дашбордам и оповещениям не хватает некоторых собираемых данных. Дашборды в Grafana не использует большую часть метрик, предоставляемых пакетом Django-Prometheus, кроме того, отсутствуют фильтры для представлений, методов, заданий и пространств имен. В этой статье представлен Django-mixin - набор правил Prometheus и дашбордов Grafana для Django. Дашборды и оповещения реализуют представление информации о примененных/непримененных миграциях, метриках RED (запросы в секунду, процент ошибок в запросе, задержках для каждого запроса), операциях с базой данных и частоте попадания в кэш. Читать дальше.
{kind=link}
6 Best Practices for Effective Monitoring Alerts
В этой статье обзор лучших практик для создания эффективных оповещений мониторинга, которые обеспечат бесперебойную работу систем, а также тех, которые этого не сделают. Думаю, вы в курсе всех этих лучших практик, однако, эту статью можно использовать как чек лист, чтобы ещё раз взглянуть на свои алерты.
Ключевые моменты:
1. Prioritized Alerts
2. Actionable Alerts
3. Documentation Attached
4. Alerts != Incident Management
5. Don’t limit your notifications channels
6. Use complex conditions to refine alerts
Читать дальше.
В этой статье обзор лучших практик для создания эффективных оповещений мониторинга, которые обеспечат бесперебойную работу систем, а также тех, которые этого не сделают. Думаю, вы в курсе всех этих лучших практик, однако, эту статью можно использовать как чек лист, чтобы ещё раз взглянуть на свои алерты.
Ключевые моменты:
1. Prioritized Alerts
2. Actionable Alerts
3. Documentation Attached
4. Alerts != Incident Management
5. Don’t limit your notifications channels
6. Use complex conditions to refine alerts
Читать дальше.
18 Kubernetes Metrics to Monitor for Optimal Cluster Performance
В этой статье рассказано о 18 метриках Kubernetes, которые можно использовать как в on-prem так и в облачных средах. Читать дальше.
В этой статье рассказано о 18 метриках Kubernetes, которые можно использовать как в on-prem так и в облачных средах. Читать дальше.
Locust Real-Time Monitoring with Grafana
Во время нагрузочного тестирования хочется мгновенно увидеть результаты по нужным метрикам. Каждый нагрузочный тест может потребовать сосредоточиться на разных метриках. Соответственно, нужно иметь возможность редактировать эти метрики по желанию и настраивать их.
В этой статье рассказывается как проводить нагрузочные тесты с помощью locust, мгновенно экспортировать метрики с помощью Prometheus и отображать нужные метрики в Grafana. Читать дальше.
Во время нагрузочного тестирования хочется мгновенно увидеть результаты по нужным метрикам. Каждый нагрузочный тест может потребовать сосредоточиться на разных метриках. Соответственно, нужно иметь возможность редактировать эти метрики по желанию и настраивать их.
В этой статье рассказывается как проводить нагрузочные тесты с помощью locust, мгновенно экспортировать метрики с помощью Prometheus и отображать нужные метрики в Grafana. Читать дальше.
{kind=link}
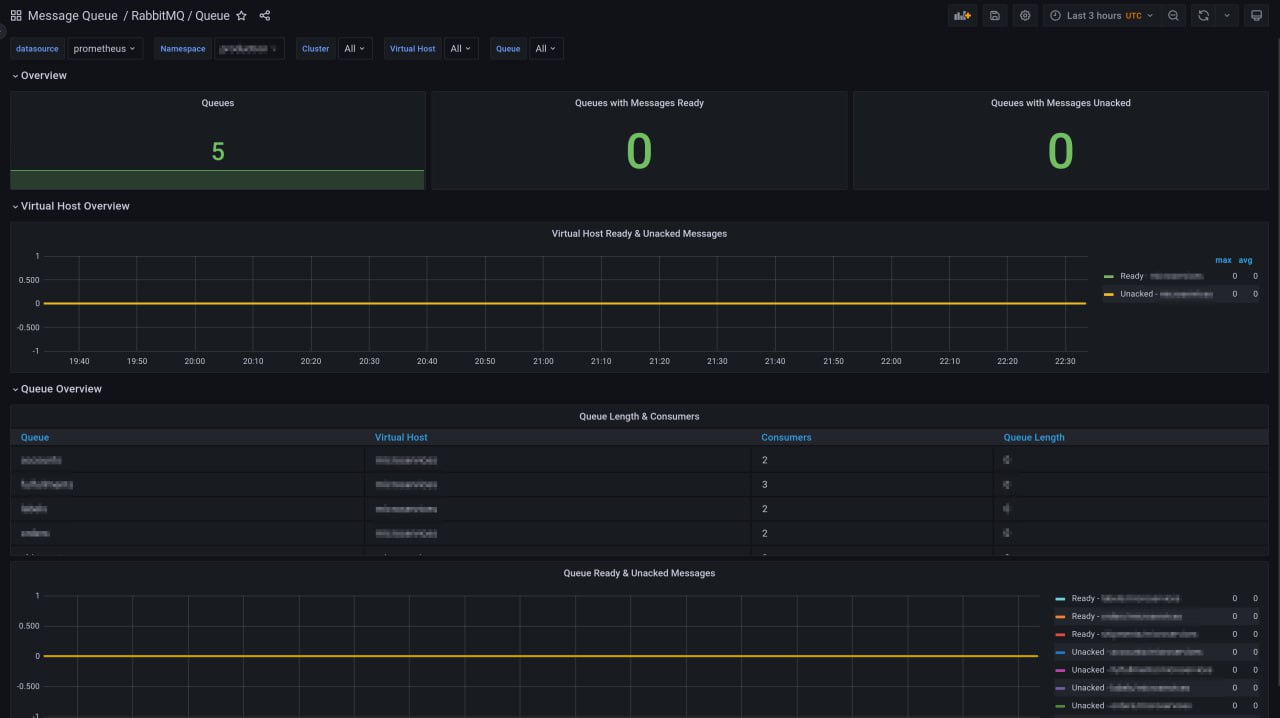
RabbitMQ Per Queue Monitoring
RabbitMQ имеет встроенный плагин Prometheus, и по умолчанию в нем отключены гранулярные метрики. Гранулярные метрики означают метрики по очередям и хостам — подробные метрики, которые предоставляют информацию о задержке сообщений и потребителях на основе очередей и хостов. Вы можете включить гранулярные метрики по объектам, но это не рекомендуется, так как плагин становится намного медленнее на большом кластере, а частота сбора метрик для базы данных временных рядов может стать высокой.
Для решения этой проблемы можно использовать неофициальный OSS экспортер RabbitMQ, написанный kbudde, который позволит включить гранулярные метрики, а также отключить специфические метрики, которые предоставляет родной плагин Prometheus. Неофициальный экспортер относится к смешанному подходу, когда вы используете неофициальный экспортер для детальных метрик, отключаете все остальные метрики и используете родной плагин RabbitMQ Prometheus для всех остальных метрик.
Однако недавно в родном плагине RabbitMQ Prometheus был добавлен еще один эндпоинт, предоставляющий подробные метрики, которые можно настраивать и детализировать. Это позволяет избежать использования двух экспортеров и не беспокоиться о дубликатах метрик, именовании меток, нескольких источниках данных для приборных панелей и других проблемах. Это также не требует включения метрик для каждого объекта для всего плагина Prometheus, что является медленным и может привести к высокой частоте сбора метрик. В этом посте мы рассмотрено, как собирать подробные метрики, а также создавать дашборды и оповещения для этих метрик. Читать дальше.
RabbitMQ имеет встроенный плагин Prometheus, и по умолчанию в нем отключены гранулярные метрики. Гранулярные метрики означают метрики по очередям и хостам — подробные метрики, которые предоставляют информацию о задержке сообщений и потребителях на основе очередей и хостов. Вы можете включить гранулярные метрики по объектам, но это не рекомендуется, так как плагин становится намного медленнее на большом кластере, а частота сбора метрик для базы данных временных рядов может стать высокой.
Для решения этой проблемы можно использовать неофициальный OSS экспортер RabbitMQ, написанный kbudde, который позволит включить гранулярные метрики, а также отключить специфические метрики, которые предоставляет родной плагин Prometheus. Неофициальный экспортер относится к смешанному подходу, когда вы используете неофициальный экспортер для детальных метрик, отключаете все остальные метрики и используете родной плагин RabbitMQ Prometheus для всех остальных метрик.
Однако недавно в родном плагине RabbitMQ Prometheus был добавлен еще один эндпоинт, предоставляющий подробные метрики, которые можно настраивать и детализировать. Это позволяет избежать использования двух экспортеров и не беспокоиться о дубликатах метрик, именовании меток, нескольких источниках данных для приборных панелей и других проблемах. Это также не требует включения метрик для каждого объекта для всего плагина Prometheus, что является медленным и может привести к высокой частоте сбора метрик. В этом посте мы рассмотрено, как собирать подробные метрики, а также создавать дашборды и оповещения для этих метрик. Читать дальше.
{kind=link}
{kind=link}
What is Grafana Mimir?
Обзорная статья. Grafana Mimir — это инструмент масштабируемого долговременного хранение данных для Prometheus. Благодаря простоте установки и обслуживания, масштабируемости, глобальному представлению метрик, дешевому и долговечному хранилищу, высокой доступности и многопользовательскому режиму, Grafana Mimir является мощным дополнением к Prometheus. Читать дальше.
Обзорная статья. Grafana Mimir — это инструмент масштабируемого долговременного хранение данных для Prometheus. Благодаря простоте установки и обслуживания, масштабируемости, глобальному представлению метрик, дешевому и долговечному хранилищу, высокой доступности и многопользовательскому режиму, Grafana Mimir является мощным дополнением к Prometheus. Читать дальше.
{kind=link}
Observability strategies to not overload engineering teams — OpenTelemetry Strategy
В этой статье о том как собирать метрики и трассировки из python-сервиса без изменений кода. Читать дальше.
В этой статье о том как собирать метрики и трассировки из python-сервиса без изменений кода. Читать дальше.
{kind=link}
Развертывание копий Zabbix на Ansible
Недавно выпала задача по развертке копий основного Zabbix-server на несколько машин, дабы хранить конфиги на разных серверах, да и еще всунуть это в CI/CD GitLab. Взял Ansible и начал писать плейбук. Читать дальше.
Недавно выпала задача по развертке копий основного Zabbix-server на несколько машин, дабы хранить конфиги на разных серверах, да и еще всунуть это в CI/CD GitLab. Взял Ansible и начал писать плейбук. Читать дальше.
Step-by-Step Guide to Setting up Prometheus Operator in Your Kubernetes Cluster
Пошаговая инструкция настройки Prometheus Operator для кластера Kubernetes. Читать дальше.
Пошаговая инструкция настройки Prometheus Operator для кластера Kubernetes. Читать дальше.
{kind=link}
Kubernetes Monitoring Metrics: What Metrics Should You Monitor?
Статья о ключевых метриках Kubernetes и инструментах для наблюдения за ними. Читать дальше.
Статья о ключевых метриках Kubernetes и инструментах для наблюдения за ними. Читать дальше.
Becoming SRE
Гайд о том, как стать SRE. Автор приводит требования, инструменты и литературу. Всё в одном месте. Читать дальше.
Гайд о том, как стать SRE. Автор приводит требования, инструменты и литературу. Всё в одном месте. Читать дальше.
{kind=link}
A Deep Dive into Logging Mechanisms in Ansible
В этой статье рассмотрены некоторые важные методы настройки журналирования Ansible и лучшие практики, которым следует следовать. Читать дальше.
В этой статье рассмотрены некоторые важные методы настройки журналирования Ansible и лучшие практики, которым следует следовать. Читать дальше.
{kind=link}
Using ChatGPT for DevOps
Как и многие, автор этого поста слышал слухи о том, что с помощью ChatGPT можно написать полноценное приложение с нуля, и, подумав "не может быть, чтобы это было так хорошо", решил протестировать его и убедиться в этом сам.
Сначала он начал просить его создавать небольшие скрипты на Python и Bash, просто чтобы окунуть пальцы ног в воды OpenAI/ChatGPT. Читать дальше.
Как и многие, автор этого поста слышал слухи о том, что с помощью ChatGPT можно написать полноценное приложение с нуля, и, подумав "не может быть, чтобы это было так хорошо", решил протестировать его и убедиться в этом сам.
Сначала он начал просить его создавать небольшие скрипты на Python и Bash, просто чтобы окунуть пальцы ног в воды OpenAI/ChatGPT. Читать дальше.
{kind=link}
Prometheus Push Gateway and Python
Воркшоп по настройке Push Gateway из docker-контейнера. Читать дальше.
Воркшоп по настройке Push Gateway из docker-контейнера. Читать дальше.
{kind=link}
Monitoring docker Containers and Logs via Grafana, Promtail, Prometheus and Loki, sending alerts to slack
Описание решения для мониторинга контейнеров Docker и логов и при помощи Prometheus, Grafana, Loki, cAdvisor, NodeExporter и отправки оповещений с помощью AlertManager. Читать дальше.
Описание решения для мониторинга контейнеров Docker и логов и при помощи Prometheus, Grafana, Loki, cAdvisor, NodeExporter и отправки оповещений с помощью AlertManager. Читать дальше.
{kind=link}
Конспект материалов про SLO и SLI
После прохождения одного из серии собеседований на SRE мне анонсировали, что на следующем будут задачки про SLO/SLI. Задач не было, но в ходе подготовки я сделал тематический конспект нескольких материалов, посвященных этой теме. Возможно, он будет вам полезен. Читать дальше.
После прохождения одного из серии собеседований на SRE мне анонсировали, что на следующем будут задачки про SLO/SLI. Задач не было, но в ходе подготовки я сделал тематический конспект нескольких материалов, посвященных этой теме. Возможно, он будет вам полезен. Читать дальше.
{kind=link}
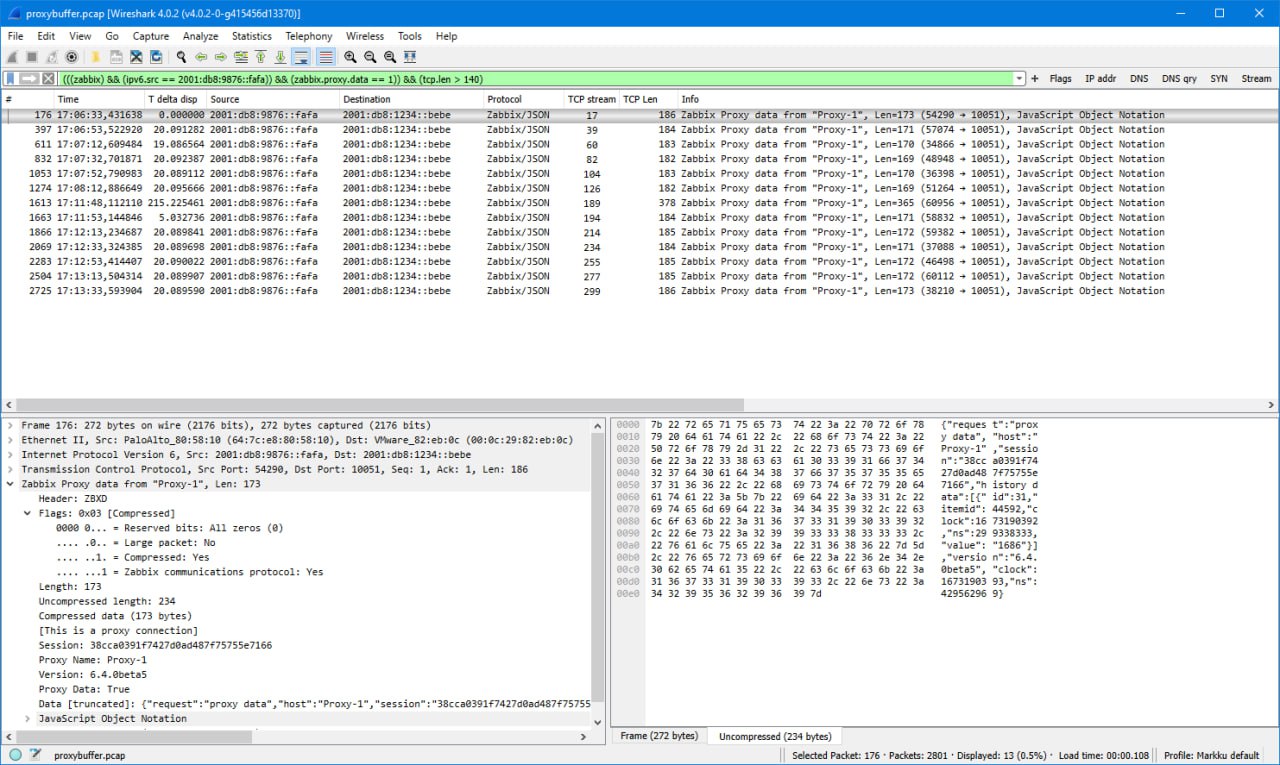
Data Buffering in Zabbix Proxy
Одна из особенностей Zabbix-прокси заключается в том, что он может буферизировать собранные данные мониторинга при потере соединения с сервером Zabbix. В этом посте в блоге Zabbix показано, как это происходит, используя захват пакетов, или анализ пакетов. Читать дальше.
Одна из особенностей Zabbix-прокси заключается в том, что он может буферизировать собранные данные мониторинга при потере соединения с сервером Zabbix. В этом посте в блоге Zabbix показано, как это происходит, используя захват пакетов, или анализ пакетов. Читать дальше.
{kind=link}
OpenTelemetry in Python — A Full Guide
В этой статье рассмотрено, как инструментировать OT в сервисе Python с помощью Jaeger. Читать дальше.
В этой статье рассмотрено, как инструментировать OT в сервисе Python с помощью Jaeger. Читать дальше.
{kind=link}