
Becoming SRE
Гайд о том, как стать SRE. Автор приводит требования, инструменты и литературу. Всё в одном месте. Читать дальше.
Гайд о том, как стать SRE. Автор приводит требования, инструменты и литературу. Всё в одном месте. Читать дальше.
{kind=link}
A Deep Dive into Logging Mechanisms in Ansible
В этой статье рассмотрены некоторые важные методы настройки журналирования Ansible и лучшие практики, которым следует следовать. Читать дальше.
В этой статье рассмотрены некоторые важные методы настройки журналирования Ansible и лучшие практики, которым следует следовать. Читать дальше.
{kind=link}
Using ChatGPT for DevOps
Как и многие, автор этого поста слышал слухи о том, что с помощью ChatGPT можно написать полноценное приложение с нуля, и, подумав "не может быть, чтобы это было так хорошо", решил протестировать его и убедиться в этом сам.
Сначала он начал просить его создавать небольшие скрипты на Python и Bash, просто чтобы окунуть пальцы ног в воды OpenAI/ChatGPT. Читать дальше.
Как и многие, автор этого поста слышал слухи о том, что с помощью ChatGPT можно написать полноценное приложение с нуля, и, подумав "не может быть, чтобы это было так хорошо", решил протестировать его и убедиться в этом сам.
Сначала он начал просить его создавать небольшие скрипты на Python и Bash, просто чтобы окунуть пальцы ног в воды OpenAI/ChatGPT. Читать дальше.
{kind=link}
Prometheus Push Gateway and Python
Воркшоп по настройке Push Gateway из docker-контейнера. Читать дальше.
Воркшоп по настройке Push Gateway из docker-контейнера. Читать дальше.
{kind=link}
Monitoring docker Containers and Logs via Grafana, Promtail, Prometheus and Loki, sending alerts to slack
Описание решения для мониторинга контейнеров Docker и логов и при помощи Prometheus, Grafana, Loki, cAdvisor, NodeExporter и отправки оповещений с помощью AlertManager. Читать дальше.
Описание решения для мониторинга контейнеров Docker и логов и при помощи Prometheus, Grafana, Loki, cAdvisor, NodeExporter и отправки оповещений с помощью AlertManager. Читать дальше.
{kind=link}
Конспект материалов про SLO и SLI
После прохождения одного из серии собеседований на SRE мне анонсировали, что на следующем будут задачки про SLO/SLI. Задач не было, но в ходе подготовки я сделал тематический конспект нескольких материалов, посвященных этой теме. Возможно, он будет вам полезен. Читать дальше.
После прохождения одного из серии собеседований на SRE мне анонсировали, что на следующем будут задачки про SLO/SLI. Задач не было, но в ходе подготовки я сделал тематический конспект нескольких материалов, посвященных этой теме. Возможно, он будет вам полезен. Читать дальше.
{kind=link}
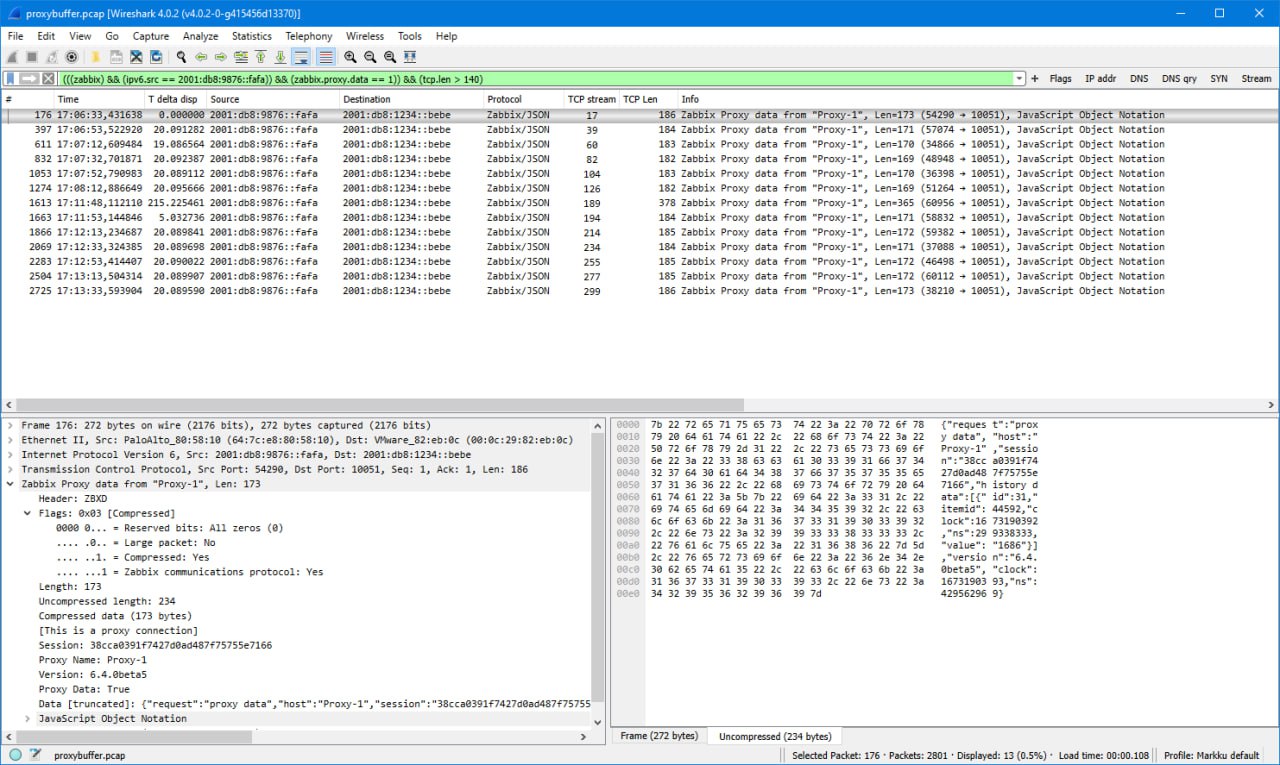
Data Buffering in Zabbix Proxy
Одна из особенностей Zabbix-прокси заключается в том, что он может буферизировать собранные данные мониторинга при потере соединения с сервером Zabbix. В этом посте в блоге Zabbix показано, как это происходит, используя захват пакетов, или анализ пакетов. Читать дальше.
Одна из особенностей Zabbix-прокси заключается в том, что он может буферизировать собранные данные мониторинга при потере соединения с сервером Zabbix. В этом посте в блоге Zabbix показано, как это происходит, используя захват пакетов, или анализ пакетов. Читать дальше.
{kind=link}
OpenTelemetry in Python — A Full Guide
В этой статье рассмотрено, как инструментировать OT в сервисе Python с помощью Jaeger. Читать дальше.
В этой статье рассмотрено, как инструментировать OT в сервисе Python с помощью Jaeger. Читать дальше.
{kind=link}
Top 8 Open-Source Observability & Testing Tools
Tracetest, Malabi, Prometheus, Jaeger, Grafana Tempo, OpenSearch, SigNoz, Postman. Читать дальше.
Tracetest, Malabi, Prometheus, Jaeger, Grafana Tempo, OpenSearch, SigNoz, Postman. Читать дальше.
Monitoring vs Observability with Example
В этой статье дано практическое понимание наблюдаемости и различий между наблюдаемостью и мониторингом с помощью различных сценариев и примеров. Читать дальше.
В этой статье дано практическое понимание наблюдаемости и различий между наблюдаемостью и мониторингом с помощью различных сценариев и примеров. Читать дальше.
{kind=link}
Spring Boot monitoring with Prometheus Operator
В этой статье описана установка Prometheus Operator, который будет автоматически определять цели мониторинга.
В демонстрации будет использовано приложение Spring Boot. Однако, следуя этой статье, вы сможете настроить любое другое приложение. Если в вашем стеке нет Spring Boot, просто пропустите первый абзац. Читать дальше.
В этой статье описана установка Prometheus Operator, который будет автоматически определять цели мониторинга.
В демонстрации будет использовано приложение Spring Boot. Однако, следуя этой статье, вы сможете настроить любое другое приложение. Если в вашем стеке нет Spring Boot, просто пропустите первый абзац. Читать дальше.
{kind=link}
SRE/DevOps Interview Questions — Linux Troubleshooting
Опытный человек рассказывает про вопросы, которые ему задавали на собеседовании на позицию SRE/DevOps. Читать дальше.
Опытный человек рассказывает про вопросы, которые ему задавали на собеседовании на позицию SRE/DevOps. Читать дальше.
SRE: паттерны Reliability
Давайте рассмотрим некоторые из сложных методов, которые SRE может принять и внедрить при разработке системы, способствующей повышению надежности. Некоторые из этих методов решают компромиссы по‑разному, так что последствия не являются значительными. Несколько новых методов и стратегий компенсируют неудачи. В статье о: Circuit Breaker, Sidecar, Exponential backoff, Waterfall, Partitioning или “Sharding”, Fail static, Caching, Queuing, Throttling, Load Shedding, Bulkhead, Waiting room, Compensating transaction, Event-driven architecture. Читать дальше.
Давайте рассмотрим некоторые из сложных методов, которые SRE может принять и внедрить при разработке системы, способствующей повышению надежности. Некоторые из этих методов решают компромиссы по‑разному, так что последствия не являются значительными. Несколько новых методов и стратегий компенсируют неудачи. В статье о: Circuit Breaker, Sidecar, Exponential backoff, Waterfall, Partitioning или “Sharding”, Fail static, Caching, Queuing, Throttling, Load Shedding, Bulkhead, Waiting room, Compensating transaction, Event-driven architecture. Читать дальше.
OpenTelemetry — Mastering the basic main concepts
Несколько слов об OpenTelemetry — распространенном движке для Observability. Читать дальше.
Несколько слов об OpenTelemetry — распространенном движке для Observability. Читать дальше.
Building a resilient SRE process
Мы хотели достичь следующих результатов, внедрив процесс SRE, обеспечивающий устойчивость к внешним воздействиям:
⚡️Определение SLO и SLI уровня обслуживания
⚡️Автоматизировать отслеживание SLI
⚡️Создание информационных панелей SLO
⚡️Повышение надежности сервиса с помощью данных SLO
Читать дальше.
Мы хотели достичь следующих результатов, внедрив процесс SRE, обеспечивающий устойчивость к внешним воздействиям:
⚡️Определение SLO и SLI уровня обслуживания
⚡️Автоматизировать отслеживание SLI
⚡️Создание информационных панелей SLO
⚡️Повышение надежности сервиса с помощью данных SLO
Читать дальше.
{kind=link}
Ура! Вышел новый Zabbix 6.4! Это означает, что Zabbix проведет вебинар и расскажет что же там интересного. Вебинар будет 9 марта в 18 часов МСК. Регистрация.
Пока суть да дело, давайте посмотрим что же нового там появилось.
⚡️ улучшенная интеграция с LDAP. То, что многие очень давно просили. И это, действительно, бомбезно. Появилось сопоставление группы пользователей LDAP и SAML с группами пользователей Zabbix. Теперь можно автоматически назначать группы пользователей и роли пользователей пользователям LDAP и SAML.
⚡️ новая фича для управления событиями — причины и симптома. События теперь могут быть отмечены как причины или симптомы. По умолчанию все новые проблемы рассматриваются как события-причины. Одно или несколько событий симптомов могут быть связаны с событием причины
Введено несколько новых макросов {EVENT.CAUSE} для представления данных о событиях-причинах.
⚡️мгновенное распространение изменений конфигурации. Активные и пассивные прокси Zabbix теперь могут практически мгновенно подхватывать любые изменения конфигурации, внесенные в Zabbix: ProxyConfigFrequency поддерживает интервалы до 1 секунды. Прокси Zabbix теперь получают только дельту конфигурации — изменения конфигурации, выполненные в течение интервала обновления конфигурации. Активный агент Zabbix теперь получает полную копию конфигурации только в том случае, если изменения конфигурации были сделаны между интервалами синхронизации конфигурации:
⚡️обновление Zabbix с нулевым временем простоя
Для улучшения рабочих процессов обновления компонентов Zabbix (особенно для больших сред) прокси теперь обратно совместимы в рамках одного цикла выпуска LTS. Прокси полностью поддерживается, если он имеет ту же основную версию, что и сервер Zabbix. Для версий без LTS (например: Zabbix server 6.4) прокси помечается как устаревший, если его основная версия старше, чем у сервера Zabbix, но находится в пределах того же выпуска LTS (например: Zabbix proxy 6.0/6.2).
Для версий LTS (например: Zabbix server 7.0) прокси помечается как устаревший, если его основная версия старше сервера Zabbix, но не старше предыдущего выпуска LTS (например: Zabbix proxy 6.0).
⚡️потоковая передача метрик и событий в реальном времени по HTTP. Передача метрик и события в брокеры сообщений: Kafka, RabbitMQ или Amazon Kinesis. Потоковая передача осуществляется по HTTP через REST API. Можно передавать только те данные, которые соответствуют фильтру тегов.
⚡️версионность шаблонов. Версионность шаблонов можно использовать для оптимизации конвейера CI/CD и автоматического обновления шаблонов с помощью Zabbix API.
Новые поля в списке шаблонов - Vendor и Version.
И другое. Подробнее можно узнать на странице с описанием выпуска.
Пока суть да дело, давайте посмотрим что же нового там появилось.
⚡️ улучшенная интеграция с LDAP. То, что многие очень давно просили. И это, действительно, бомбезно. Появилось сопоставление группы пользователей LDAP и SAML с группами пользователей Zabbix. Теперь можно автоматически назначать группы пользователей и роли пользователей пользователям LDAP и SAML.
⚡️ новая фича для управления событиями — причины и симптома. События теперь могут быть отмечены как причины или симптомы. По умолчанию все новые проблемы рассматриваются как события-причины. Одно или несколько событий симптомов могут быть связаны с событием причины
Введено несколько новых макросов {EVENT.CAUSE} для представления данных о событиях-причинах.
⚡️мгновенное распространение изменений конфигурации. Активные и пассивные прокси Zabbix теперь могут практически мгновенно подхватывать любые изменения конфигурации, внесенные в Zabbix: ProxyConfigFrequency поддерживает интервалы до 1 секунды. Прокси Zabbix теперь получают только дельту конфигурации — изменения конфигурации, выполненные в течение интервала обновления конфигурации. Активный агент Zabbix теперь получает полную копию конфигурации только в том случае, если изменения конфигурации были сделаны между интервалами синхронизации конфигурации:
⚡️обновление Zabbix с нулевым временем простоя
Для улучшения рабочих процессов обновления компонентов Zabbix (особенно для больших сред) прокси теперь обратно совместимы в рамках одного цикла выпуска LTS. Прокси полностью поддерживается, если он имеет ту же основную версию, что и сервер Zabbix. Для версий без LTS (например: Zabbix server 6.4) прокси помечается как устаревший, если его основная версия старше, чем у сервера Zabbix, но находится в пределах того же выпуска LTS (например: Zabbix proxy 6.0/6.2).
Для версий LTS (например: Zabbix server 7.0) прокси помечается как устаревший, если его основная версия старше сервера Zabbix, но не старше предыдущего выпуска LTS (например: Zabbix proxy 6.0).
⚡️потоковая передача метрик и событий в реальном времени по HTTP. Передача метрик и события в брокеры сообщений: Kafka, RabbitMQ или Amazon Kinesis. Потоковая передача осуществляется по HTTP через REST API. Можно передавать только те данные, которые соответствуют фильтру тегов.
⚡️версионность шаблонов. Версионность шаблонов можно использовать для оптимизации конвейера CI/CD и автоматического обновления шаблонов с помощью Zabbix API.
Новые поля в списке шаблонов - Vendor и Version.
И другое. Подробнее можно узнать на странице с описанием выпуска.
{kind=link}
Observability beyond the three pillars — Profiling in da house
Статья о том, для чего нужно профилирование запросов и какие инструменты для этого существуют. Читать дальше.
Статья о том, для чего нужно профилирование запросов и какие инструменты для этого существуют. Читать дальше.
{kind=link}
Four Golden Signals Of Monitoring: Site Reliability Engineering (SRE) Metrics
Мониторинг золотых сигналов с помощью FastAPI на k8s. Читать дальше.
Мониторинг золотых сигналов с помощью FastAPI на k8s. Читать дальше.
{kind=link}
Monitoring MongoDB with Prometheus using the MongoDB Exporter
Короткий гайд по настройке мониторинга MongoDB через Prometheus. Читать дальше.
Короткий гайд по настройке мониторинга MongoDB через Prometheus. Читать дальше.
{kind=link}
Приглашаю вас на вебинар о нетипичных сценариях использования Yandex Data Transfer
14 марта, 12:00–13:00
На мероприятии будут разобраны:
🔸 какие задачи можно решить с помощью Yandex Data Transfer;
🔸 как построить пайплайны внутри платформы данных и между сервисами облака;
🔸 какие особенности трансферов стоит учесть в работе.
Будут продемонстрированы сценарии для CDC, поставки из очередей и загрузки данных в витрины, которые вы сможете реализовать самостоятельно.
Вас также ждёт Q&A-сессия. Вопросы можно прислать в чат трансляции — спикер ответит на них в прямом эфире.
Участие бесплатное, нужно зарегистрироваться ➡️
14 марта, 12:00–13:00
На мероприятии будут разобраны:
🔸 какие задачи можно решить с помощью Yandex Data Transfer;
🔸 как построить пайплайны внутри платформы данных и между сервисами облака;
🔸 какие особенности трансферов стоит учесть в работе.
Будут продемонстрированы сценарии для CDC, поставки из очередей и загрузки данных в витрины, которые вы сможете реализовать самостоятельно.
Вас также ждёт Q&A-сессия. Вопросы можно прислать в чат трансляции — спикер ответит на них в прямом эфире.
Участие бесплатное, нужно зарегистрироваться ➡️