
Displaying Real-Time Sensor Data in Grafana using MQTT
Начиная с Grafana 8.0 можно выполнять обновления данных в реальном времени с помощью нового потокового API. Это означает, что теперь можно создавать диаграммы, которые обновляются в режиме реального времени и по запросу.
Чтобы использовать эту функцию, можно использовать плагин MQTT, который позволяет пользователям Grafana визуализировать данные MQTT в режиме реального времени. В этой статье о том, как использовать датасорс MQTT для отображения данных датчиков в режиме реального времени. Читать дальше.
Начиная с Grafana 8.0 можно выполнять обновления данных в реальном времени с помощью нового потокового API. Это означает, что теперь можно создавать диаграммы, которые обновляются в режиме реального времени и по запросу.
Чтобы использовать эту функцию, можно использовать плагин MQTT, который позволяет пользователям Grafana визуализировать данные MQTT в режиме реального времени. В этой статье о том, как использовать датасорс MQTT для отображения данных датчиков в режиме реального времени. Читать дальше.
{kind=link}
В этих двух статьях цикла автор рассказывает о своём опыте использования связки Prometheus - Thanos - Grafana / Grafana Loki.
Storing Multiple Clusters Metrics In GCS Bucket (Thanos+Prometheus) & Clusters Monitoring/Logging With Grafana →Part-1
Logging at Scale in Kubernetes by using Grafana Loki →part-2
Storing Multiple Clusters Metrics In GCS Bucket (Thanos+Prometheus) & Clusters Monitoring/Logging With Grafana →Part-1
Logging at Scale in Kubernetes by using Grafana Loki →part-2
{kind=link}
PostgreSQL Monitoring for Application Developers: The DBA Fundamentals
В примерах этой статьи будут использован стек мониторинга на базе pgMonitor, который можно установить вместе с Postgres Operator.
Читать дальше.
В примерах этой статьи будут использован стек мониторинга на базе pgMonitor, который можно установить вместе с Postgres Operator.
Читать дальше.
{kind=link}
ioping
Инструмент для мониторинга задержки ввода-вывода в режиме реального времени. Он показывает задержку диска так же, как ping показывает задержку сети.
Репыч на Гитхабе.
Инструмент для мониторинга задержки ввода-вывода в режиме реального времени. Он показывает задержку диска так же, как ping показывает задержку сети.
Репыч на Гитхабе.
Key Kubernetes Metrics and Resources to Monitor for Peak Cluster Performance
Показатели здоровья Kubernetes делятся на две категории:
Метрики о самом кластере Kubernetes, его состоянии и узлах в кластере
Метрики развернутых приложений и подов в Kubernetes
В этой статье мы расскажем о ключевых метриках Kubernetes, которые вы можете собрать, и о том, как их интерпретировать. Читать далее.
Показатели здоровья Kubernetes делятся на две категории:
Метрики о самом кластере Kubernetes, его состоянии и узлах в кластере
Метрики развернутых приложений и подов в Kubernetes
В этой статье мы расскажем о ключевых метриках Kubernetes, которые вы можете собрать, и о том, как их интерпретировать. Читать далее.
{kind=link}
Вакансия!
Мы компания Комс – продуктовая компания, создающая собственную систему мониторинга и эксплуатации ИТ инфраструктуры. Мы ищем в команду инженера мониторинга.
У тебя будет возможность:
• Работать над клиентскими проектами для крупнейших b2b и b2g заказчиков на российском рынке;
• Работать со сложной развитой инфраструктурой (как собственной, так и клиентской);
•Решать большие и интересные задачи.
Что предстоит делать:
• Участвовать в роли инженера мониторинга в проектной деятельности компании;
• Сопровождать существующие и внедрять новые инструменты мониторинга;
• Участвовать в разборе сложных кейсов во время аварийных ситуаций;
• Принимать участие в проработке архитектуры мониторинга;
• Заниматься построением триггеров, графиков, реализацией сложных цепочек зависимостей оповещений.
Мы ожидаем:
• Опыт работы инженером мониторинга;
• Знание Linux на уровне системного администратора;
• Хорошие знания Zabbix, в том числе умение использовать препроцессинг (XMLPath, JSONPath, регулярные выражения);
• Опыт работы с Grafana - подключение источников данных, настройка дашбордов;
• Опыт работы с Kibana - просмотр логов, настройка фильтров, дашбордов;
• Опыт написания скриптов на python/bash;
• Умение работать с API (SOAP, REST, JSON-RPC) для получения различной статистики по работе веб-приложений или устройств;
• Опыт мониторинга сетевых устройств и серверного оборудования (мониторинг через SNMP, IPMI).
Будет большим плюсом:
• Понимание принципов построения мониторинга сервисов с использованием Prometheus/ VictoriaMetrics;
• Опыт мониторинга большой разветвленной инфраструктуры;
• Опыт мониторинга высоконагруженной инфраструктуры;
• Опыт работы с Ansible.
Мы предлагаем:
• Гибкий график работы;
• Офис в центре Москвы (гибридный формат);
• Повышение квалификации за счет компании;
• Компенсация ДМС, фитнеса и дополнительного образования;
• Команда профессионалов;
• Система наставничества.
Контакты для связи: @ekaterina_arimova
Мы компания Комс – продуктовая компания, создающая собственную систему мониторинга и эксплуатации ИТ инфраструктуры. Мы ищем в команду инженера мониторинга.
У тебя будет возможность:
• Работать над клиентскими проектами для крупнейших b2b и b2g заказчиков на российском рынке;
• Работать со сложной развитой инфраструктурой (как собственной, так и клиентской);
•Решать большие и интересные задачи.
Что предстоит делать:
• Участвовать в роли инженера мониторинга в проектной деятельности компании;
• Сопровождать существующие и внедрять новые инструменты мониторинга;
• Участвовать в разборе сложных кейсов во время аварийных ситуаций;
• Принимать участие в проработке архитектуры мониторинга;
• Заниматься построением триггеров, графиков, реализацией сложных цепочек зависимостей оповещений.
Мы ожидаем:
• Опыт работы инженером мониторинга;
• Знание Linux на уровне системного администратора;
• Хорошие знания Zabbix, в том числе умение использовать препроцессинг (XMLPath, JSONPath, регулярные выражения);
• Опыт работы с Grafana - подключение источников данных, настройка дашбордов;
• Опыт работы с Kibana - просмотр логов, настройка фильтров, дашбордов;
• Опыт написания скриптов на python/bash;
• Умение работать с API (SOAP, REST, JSON-RPC) для получения различной статистики по работе веб-приложений или устройств;
• Опыт мониторинга сетевых устройств и серверного оборудования (мониторинг через SNMP, IPMI).
Будет большим плюсом:
• Понимание принципов построения мониторинга сервисов с использованием Prometheus/ VictoriaMetrics;
• Опыт мониторинга большой разветвленной инфраструктуры;
• Опыт мониторинга высоконагруженной инфраструктуры;
• Опыт работы с Ansible.
Мы предлагаем:
• Гибкий график работы;
• Офис в центре Москвы (гибридный формат);
• Повышение квалификации за счет компании;
• Компенсация ДМС, фитнеса и дополнительного образования;
• Команда профессионалов;
• Система наставничества.
Контакты для связи: @ekaterina_arimova
How to build your monitoring dashboards?
Несколько полезных рекомендаций по дашбордостроению. Читать дальше.
Несколько полезных рекомендаций по дашбордостроению. Читать дальше.
VictoriaMetrics: PromQL compliance
MetricsQL — это язык запросов, основанный на PromQL. Он используется в качестве основного языка запросов в VictoriaMetrics, базе данных временных рядов для мониторинга. MetricsQL обратно совместим с PromQL. Читать далее.
MetricsQL — это язык запросов, основанный на PromQL. Он используется в качестве основного языка запросов в VictoriaMetrics, базе данных временных рядов для мониторинга. MetricsQL обратно совместим с PromQL. Читать далее.
{kind=link}
Good and Bad Monitoring
Плохой и хороший мониторинг. Несколько советов по организации эффективного мониторинга. Читать дальше.
Плохой и хороший мониторинг. Несколько советов по организации эффективного мониторинга. Читать дальше.
How to pick the best observability solution for your organization
Инженерам и разработчикам доступно множество решений для мониторинга, так как же выбрать наиболее подходящее? Часто бывает так, что ни самое дорогое, ни самое дешевое решение для мониторинга не является ответом, когда вы начинаете свой путь к наблюдаемости, поэтому давайте рассмотрим основные решения, которые вам необходимо принять при выборе решения для мониторинга. Читать дальше.
Инженерам и разработчикам доступно множество решений для мониторинга, так как же выбрать наиболее подходящее? Часто бывает так, что ни самое дорогое, ни самое дешевое решение для мониторинга не является ответом, когда вы начинаете свой путь к наблюдаемости, поэтому давайте рассмотрим основные решения, которые вам необходимо принять при выборе решения для мониторинга. Читать дальше.
{kind=link}
Kubermetrics
Kubermetrics — это инструмент с открытым исходным кодом, который обеспечивает мониторинг кластера Kubernetes, а также визуализацию данных в простом и понятном пользовательском интерфейсе. Kubermetrics объединяет Prometheus и Grafana Dashboards в одном интерфейсе.
Репыч на Гитхабе.
Kubermetrics — это инструмент с открытым исходным кодом, который обеспечивает мониторинг кластера Kubernetes, а также визуализацию данных в простом и понятном пользовательском интерфейсе. Kubermetrics объединяет Prometheus и Grafana Dashboards в одном интерфейсе.
Репыч на Гитхабе.
{kind=link}
Мониторинг Ceph
Как не пропустить падения и взлёты в жизни кластеров ceph с помощью prometheus или victoriametrics. Теория и практика мониторинга распределенного хранилища. Читать далее.
Как не пропустить падения и взлёты в жизни кластеров ceph с помощью prometheus или victoriametrics. Теория и практика мониторинга распределенного хранилища. Читать далее.
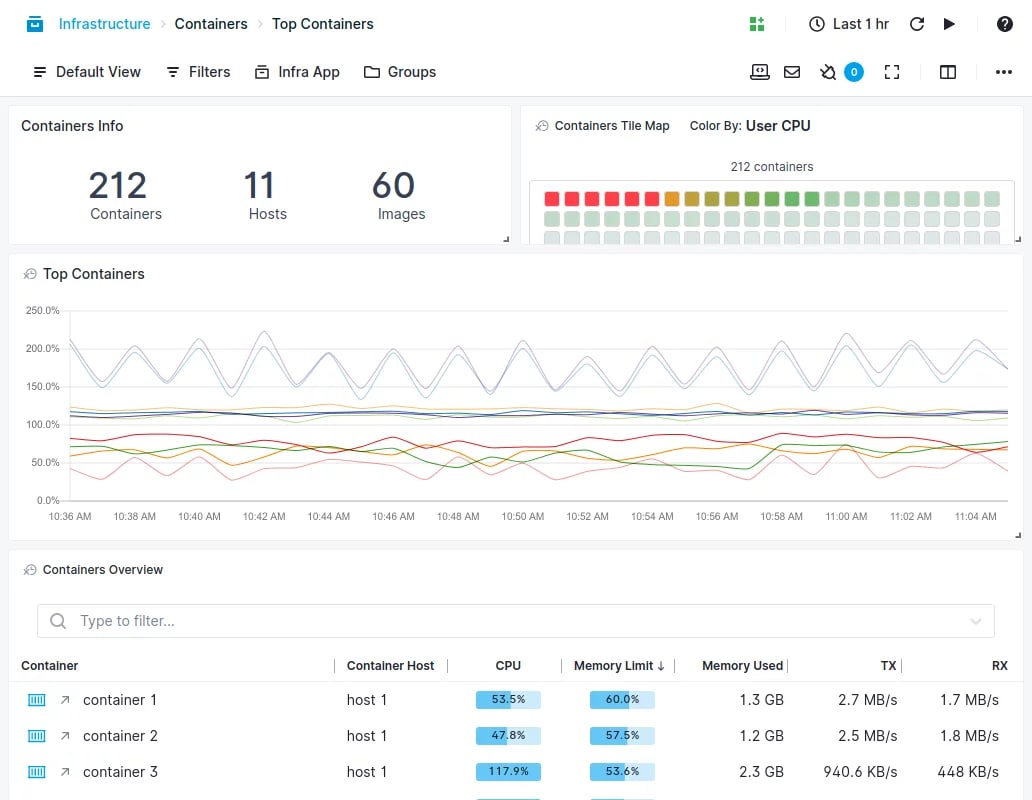
Key Kubernetes Metrics and Resources to Monitor for Peak Cluster Performance
Метрики Kubernetes, которые наиболее полно скажут о здоровье кластера. Читать дальше.
Метрики Kubernetes, которые наиболее полно скажут о здоровье кластера. Читать дальше.
{kind=link}
Grafana Loki and MinIO: A Perfect Match!
Grafana Loki становится одним из фактических стандартов для агрегации журналов в рабочих нагрузках Kubernetes, в этой статье мы покажем, как можно использовать Grafana Loki вместе с MinIO. Читать дальше.
Grafana Loki становится одним из фактических стандартов для агрегации журналов в рабочих нагрузках Kubernetes, в этой статье мы покажем, как можно использовать Grafana Loki вместе с MinIO. Читать дальше.
Configure Grafana to Use Remote Database for HA
В этой статье мы настроим Grafana с удаленной базой данных, чтобы затем её масштабировать ее до N экземпляров.
База данных SQLite по умолчанию не будет работать при масштабировании более 1 экземпляра, поскольку база данных SQLite3 встроена в Grafana. Читать дальше.
В этой статье мы настроим Grafana с удаленной базой данных, чтобы затем её масштабировать ее до N экземпляров.
База данных SQLite по умолчанию не будет работать при масштабировании более 1 экземпляра, поскольку база данных SQLite3 встроена в Grafana. Читать дальше.
{kind=link}
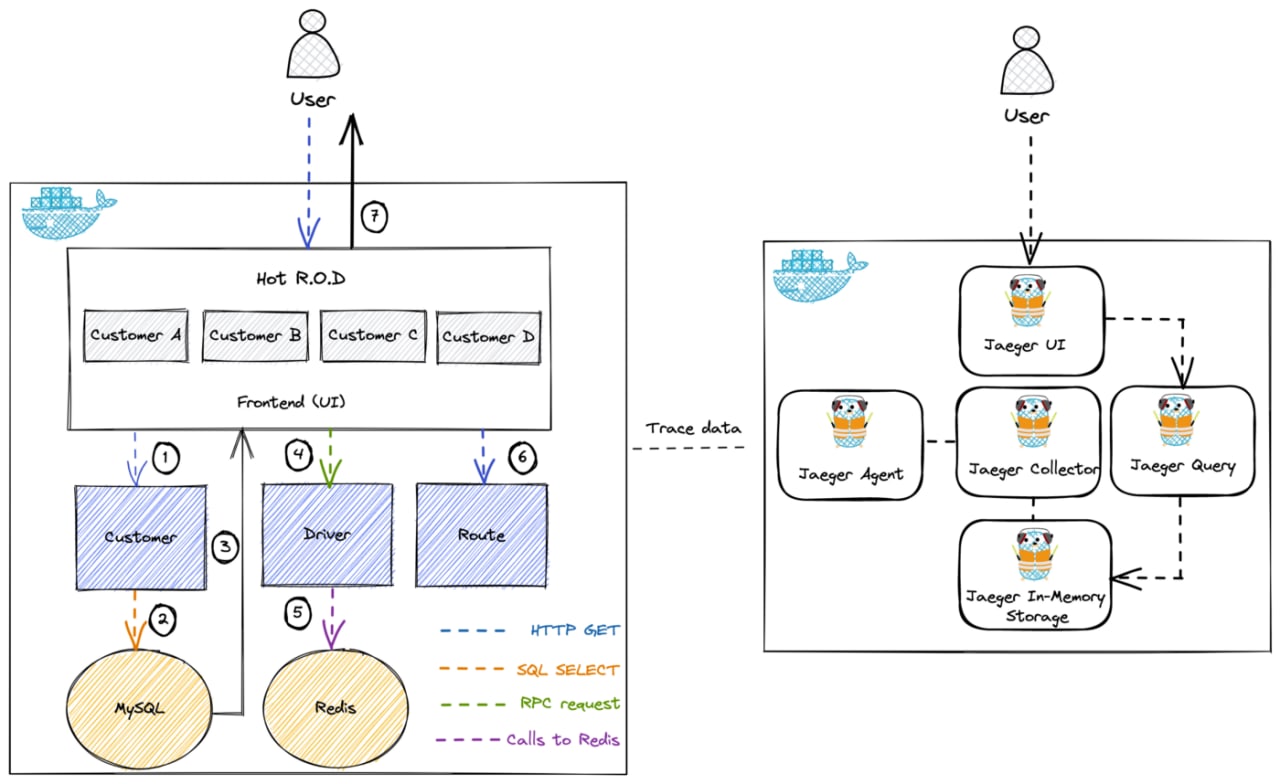
A beginner’s guide to Jaeger
Эта статься — начало серии из 5 частей. В этой части руководство для начинающих по Jaeger. Читать дальше.
Эта статься — начало серии из 5 частей. В этой части руководство для начинающих по Jaeger. Читать дальше.
{kind=link}
A beginner’s guide to OpenTelemetry
В этой статье основы работы с популярным инструментом для трассировки вызовов распределенных приложений — OpenTelemetry. Читать дальше.
В этой статье основы работы с популярным инструментом для трассировки вызовов распределенных приложений — OpenTelemetry. Читать дальше.
{kind=link}
How to set up monitoring tools for Java application
В этой вы узнаете, как настроить два инструмента мониторинга, которые широко используются для Java-приложений — Java Flight Recorder с JDK Mission Control и Prometheus с Grafana. Читать дальше.
В этой вы узнаете, как настроить два инструмента мониторинга, которые широко используются для Java-приложений — Java Flight Recorder с JDK Mission Control и Prometheus с Grafana. Читать дальше.
{kind=link}
Service Status Monitoring Using WhatsApp, Notion, and Python
В этой статье вы узнаете, как настроить автоматический мониторинг сервисов и получать уведомления WhatsApp при изменении их статуса. Будем использовать Notion для базы данных, WhatsApp Business API Twilio для получения уведомлений, GitHub Actions для выполнения задач по расписанию. Читать дальше.
В этой статье вы узнаете, как настроить автоматический мониторинг сервисов и получать уведомления WhatsApp при изменении их статуса. Будем использовать Notion для базы данных, WhatsApp Business API Twilio для получения уведомлений, GitHub Actions для выполнения задач по расписанию. Читать дальше.
{kind=link}
Top PostgreSQL monitoring metrics for Prometheus – Includes cheat sheet
В этой статье ключевые метрики, которые вы можете собирать с PostgreSQL в Prometheus. Читать дальше.
В этой статье ключевые метрики, которые вы можете собирать с PostgreSQL в Prometheus. Читать дальше.
{kind=link}