
Семь «НЕ» мониторинга ИТ-инфраструктуры
Это повтор поста почти 4-летней давности, не потерявшего актуальность и сегодня.
Пост на Хабре от представителя Сбербанка (-теха). Его советы, конечно же, расширяются на любой проект по мониторингу (не только для инфраструктуры) и при некоторой модификации на проекты внедрения вообще любого софта.
📌1. НЕ внедряйте инструмент мониторинга
📌2. Интегратор НЕ сделает за вас всей работы
📌3. НЕ путайте мониторинг и администрирование ИТ-инфраструктуры
📌4. НЕ рассчитывайте, что ваши подчиненные будут использовать мониторинг, если вы сами этого не делаете
📌5. НЕ заставляйте сотрудников работать с системой мониторинга
📌6. НЕ концентрируйтесь на проверке функциональности системы мониторинга во время ее испытаний
📌7. Мониторинг НЕ начнет приносить пользу, пока вы не начнете работать с ним и адаптировать его под свои потребности
Особенно близким оказался для меня п.7. Очень часто, когда с начала и до конца проекта у заказчика нет понимания «а кто же будет пользоваться системой», проекты заканичваются внедрением системы, которой никто не будет пользоваться. А деньги потрачены. Лол.
Это повтор поста почти 4-летней давности, не потерявшего актуальность и сегодня.
Пост на Хабре от представителя Сбербанка (-теха). Его советы, конечно же, расширяются на любой проект по мониторингу (не только для инфраструктуры) и при некоторой модификации на проекты внедрения вообще любого софта.
📌1. НЕ внедряйте инструмент мониторинга
📌2. Интегратор НЕ сделает за вас всей работы
📌3. НЕ путайте мониторинг и администрирование ИТ-инфраструктуры
📌4. НЕ рассчитывайте, что ваши подчиненные будут использовать мониторинг, если вы сами этого не делаете
📌5. НЕ заставляйте сотрудников работать с системой мониторинга
📌6. НЕ концентрируйтесь на проверке функциональности системы мониторинга во время ее испытаний
📌7. Мониторинг НЕ начнет приносить пользу, пока вы не начнете работать с ним и адаптировать его под свои потребности
Особенно близким оказался для меня п.7. Очень часто, когда с начала и до конца проекта у заказчика нет понимания «а кто же будет пользоваться системой», проекты заканичваются внедрением системы, которой никто не будет пользоваться. А деньги потрачены. Лол.
{kind=link}
Диагностика и мониторинг Wi-Fi устройств в Grafana
В этой статье про опыт сбора метрик с устройств IoT (датчики потребления воды) и их передачи в единое хранилище. Читать на Хабре.
В этой статье про опыт сбора метрик с устройств IoT (датчики потребления воды) и их передачи в единое хранилище. Читать на Хабре.
{kind=link}
Визуальные интерфейсы для Clickhouse от сторонних разработчиков
Это страница документации Clickhouse. Читать.
Это страница документации Clickhouse. Читать.
Forwarded from /usr/bin
iperf
iperf — это инструмент для активного измерения максимально достижимой пропускной способности в IP-сетях. Он поддерживает настройку различных параметров, связанных с синхронизацией, протоколами и буферами. Для каждого теста он сообщает измеренную пропускную способность/битрейт, потери и другие параметры.
Статья с описание работы на Medium.
Репыч на Гитхабе.
@usr_bin_linux
iperf — это инструмент для активного измерения максимально достижимой пропускной способности в IP-сетях. Он поддерживает настройку различных параметров, связанных с синхронизацией, протоколами и буферами. Для каждого теста он сообщает измеренную пропускную способность/битрейт, потери и другие параметры.
Статья с описание работы на Medium.
Репыч на Гитхабе.
@usr_bin_linux
Medium
What is iPerf?
Or, how fast is localhost?
grafana-dashboard-manager
A simple cli utility for importing or exporting dashboard json definitions using the Grafana HTTP API.
Репыч на Гитхабе.
A simple cli utility for importing or exporting dashboard json definitions using the Grafana HTTP API.
Репыч на Гитхабе.
Парочка утилит для мониторинга kubernetes
Kubenurse
kubenurse is a little service that monitors all network connections in a Kubernetes cluster. Kubenurse measures request durations, records errors and exports those metrics in Prometheus format. Репыч на Гитхабе.
Goldpinger
Goldpinger makes calls between its instances to monitor your networking. It runs as a DaemonSet on Kubernetes and produces Prometheus metrics that can be scraped, visualised and alerted on. Репыч на Гитхабе.
Kubenurse
kubenurse is a little service that monitors all network connections in a Kubernetes cluster. Kubenurse measures request durations, records errors and exports those metrics in Prometheus format. Репыч на Гитхабе.
Goldpinger
Goldpinger makes calls between its instances to monitor your networking. It runs as a DaemonSet on Kubernetes and produces Prometheus metrics that can be scraped, visualised and alerted on. Репыч на Гитхабе.
{kind=link}
Performance/Load Testing with k6 +InfluxDB + Grafana on Windows
k6 — это инструмент нагрузочного тестирования с открытым исходным кодом, который предоставляет разработчикам возможности тестирования производительности API и веб-сайтов. В этой статье про использование связки k6 +InfluxDB + Grafana для целей нагрузочного тестирования. Читать дальше.
k6 — это инструмент нагрузочного тестирования с открытым исходным кодом, который предоставляет разработчикам возможности тестирования производительности API и веб-сайтов. В этой статье про использование связки k6 +InfluxDB + Grafana для целей нагрузочного тестирования. Читать дальше.
{kind=link}
The mathematics behind monitoring
Статья про использование математических функций в Prometheus. Читать дальше.
Статья про использование математических функций в Prometheus. Читать дальше.
{kind=link}
Creating context-sensitive problem thresholds with Zabbix user macros
Пороговые схемы могут различаться для одной и той же метрики на разных конечных точках мониторинга. У вас может быть сервер, на котором наличие 10% свободного места совершенно нормально, и сервер, на котором все, что ниже 20% - критичное событие. В этом видео рассказывают как модифицировать триггеры в зависимости от контекста (системы, на которой они должны сработать).
Пороговые схемы могут различаться для одной и той же метрики на разных конечных точках мониторинга. У вас может быть сервер, на котором наличие 10% свободного места совершенно нормально, и сервер, на котором все, что ниже 20% - критичное событие. В этом видео рассказывают как модифицировать триггеры в зависимости от контекста (системы, на которой они должны сработать).
{kind=link}
Multi-site monitoring with HA and dynamic scale using VictoriaMetrics. A Practical guide
Это продолжение предыдущего поста What makes VictoriaMetrics the next leading choice for open-source monitoring. Цель этой статьи — рассказать, как спроектировать и развернуть многосайтовую кластерную архитектуру VictoriaMetrics в Kubernetes, которая работает на узлах Spot и On-demand и обеспечивает высокую доступность, динамическую масштабируемость, высокую производительность и экономию средств. Читать дальше.
Это продолжение предыдущего поста What makes VictoriaMetrics the next leading choice for open-source monitoring. Цель этой статьи — рассказать, как спроектировать и развернуть многосайтовую кластерную архитектуру VictoriaMetrics в Kubernetes, которая работает на узлах Spot и On-demand и обеспечивает высокую доступность, динамическую масштабируемость, высокую производительность и экономию средств. Читать дальше.
{kind=link}
Monitoring MySQL using Prometheus, Grafana and mysqld_exporter in Kubernetes
This is a basic guide on monitoring MySQL Database containers in a Kubernetes environment. We’ll use Prometheus and Grafana here. It is an open-source monitoring solution that is widely used in Kubernetes. Читать дальше.
This is a basic guide on monitoring MySQL Database containers in a Kubernetes environment. We’ll use Prometheus and Grafana here. It is an open-source monitoring solution that is widely used in Kubernetes. Читать дальше.
{kind=link}
Karma — единый событийный дашборд для кучи Alertmanager'ов
Агрегация, дедупликация, фильтрация и много других фич в этом полезном в хозяйстве инструменте.
Репыч на Гитхабе.
Агрегация, дедупликация, фильтрация и много других фич в этом полезном в хозяйстве инструменте.
Репыч на Гитхабе.
{kind=link}
Managing Prometheus at scale with Cortex
Несколько слов про Cortex — горизонтально масштабируемое хранилище для Prometheus. Читать дальше.
Несколько слов про Cortex — горизонтально масштабируемое хранилище для Prometheus. Читать дальше.
The missing plugin to create business and industrial charts in Grafana
Apache ECharts — это бесплатная библиотека построения диаграмм и визуализации, предлагающая возможности создания интуитивно понятных, интерактивных и настраиваемых диаграмм. Она написана на чистом JavaScript и основана на zrender.
Панель Apache ECharts — это плагин для Grafana, который позволяет использовать библиотеку Apache ECharts в Grafana. Оригинальный плагин был разработан для Grafana 6.3/7.0 и ECharts 4.9.0. С тех пор он не поддерживается. В VolkovLabs этот плагин адаптировали к Grafana 9 и рассказывают об этом в статье на Медиуме.
Репыч на Гитхабе.
Apache ECharts — это бесплатная библиотека построения диаграмм и визуализации, предлагающая возможности создания интуитивно понятных, интерактивных и настраиваемых диаграмм. Она написана на чистом JavaScript и основана на zrender.
Панель Apache ECharts — это плагин для Grafana, который позволяет использовать библиотеку Apache ECharts в Grafana. Оригинальный плагин был разработан для Grafana 6.3/7.0 и ECharts 4.9.0. С тех пор он не поддерживается. В VolkovLabs этот плагин адаптировали к Grafana 9 и рассказывают об этом в статье на Медиуме.
Репыч на Гитхабе.
{kind=link}
Performance testing with Iter8, now with custom metrics
Iter8 — это оптимизатор релизов приложений и моделей машинного обучения, развернутых с помощью Kubernetes, на основе метрик с открытым исходным кодом. Можно использовать Iter8 для проведения экспериментов, которые решают различные задачи, такие как сбор метрик из разных версий сервиса, проверка этих метрик на соответствие SLO, определение наиболее эффективной версии и многое другое. Читать дальше.
Репыч на Гитхабе.
Iter8 — это оптимизатор релизов приложений и моделей машинного обучения, развернутых с помощью Kubernetes, на основе метрик с открытым исходным кодом. Можно использовать Iter8 для проведения экспериментов, которые решают различные задачи, такие как сбор метрик из разных версий сервиса, проверка этих метрик на соответствие SLO, определение наиболее эффективной версии и многое другое. Читать дальше.
Репыч на Гитхабе.
{kind=link}
Scaling Kubernetes workloads using custom Prometheus metrics
В этой статье вы узнаете про использования адаптера Prometheus для сбора метрик и передачи их в kube-api. HPA (horizontal pod autoscaler) будет использовать эти данные для принятия решений о масштабировании. Читать дальше.
В этой статье вы узнаете про использования адаптера Prometheus для сбора метрик и передачи их в kube-api. HPA (horizontal pod autoscaler) будет использовать эти данные для принятия решений о масштабировании. Читать дальше.
{kind=link}
Creating A Basic Load Test Infrastructure Via Using K6/Grafana/InfluxDB
В этой статье описано создание тестового окружения для тестирования производительности с помощью K6/Grafana/InfluxDB. Читать дальше.
В этой статье описано создание тестового окружения для тестирования производительности с помощью K6/Grafana/InfluxDB. Читать дальше.
{kind=link}
Single Prometheus job for dozens of Blackbox exporters
Эта история не про установку экспортера Blackbox, а скорее о настройке со стороны Prometheus. Цель состоит в том, чтобы получить простую, минимальную, но гибкую конфигурацию, избегая путаницы в конфигурации Prometheus.
Представьте, что у вас есть более 20 экспортеров Blackbox в разных местах мира, которые не принадлежат ни к какому кластеру или среде, а просто работают как автономные приложения для мониторинга конечных точек из разных мест. Например, вы должны отслеживать более 100 URL-адресов из всех мест, чтобы убедиться в доступности вашего веб-сайта, задержке и т. д. Читать дальше.
Эта история не про установку экспортера Blackbox, а скорее о настройке со стороны Prometheus. Цель состоит в том, чтобы получить простую, минимальную, но гибкую конфигурацию, избегая путаницы в конфигурации Prometheus.
Представьте, что у вас есть более 20 экспортеров Blackbox в разных местах мира, которые не принадлежат ни к какому кластеру или среде, а просто работают как автономные приложения для мониторинга конечных точек из разных мест. Например, вы должны отслеживать более 100 URL-адресов из всех мест, чтобы убедиться в доступности вашего веб-сайта, задержке и т. д. Читать дальше.
{kind=link}
How to Handle Terabytes of Metrics in Kubernetes Monitoring
Мы использовали Prometheus, Thanos и Grafana для обрабатки около 40 000 метрик, генерируемых каждую секунду. В этом посте наша команда инженеров делится некоторыми мыслями и знаниями о нашем пути по настройке мониторинга. Читать дальше.
Мы использовали Prometheus, Thanos и Grafana для обрабатки около 40 000 метрик, генерируемых каждую секунду. В этом посте наша команда инженеров делится некоторыми мыслями и знаниями о нашем пути по настройке мониторинга. Читать дальше.
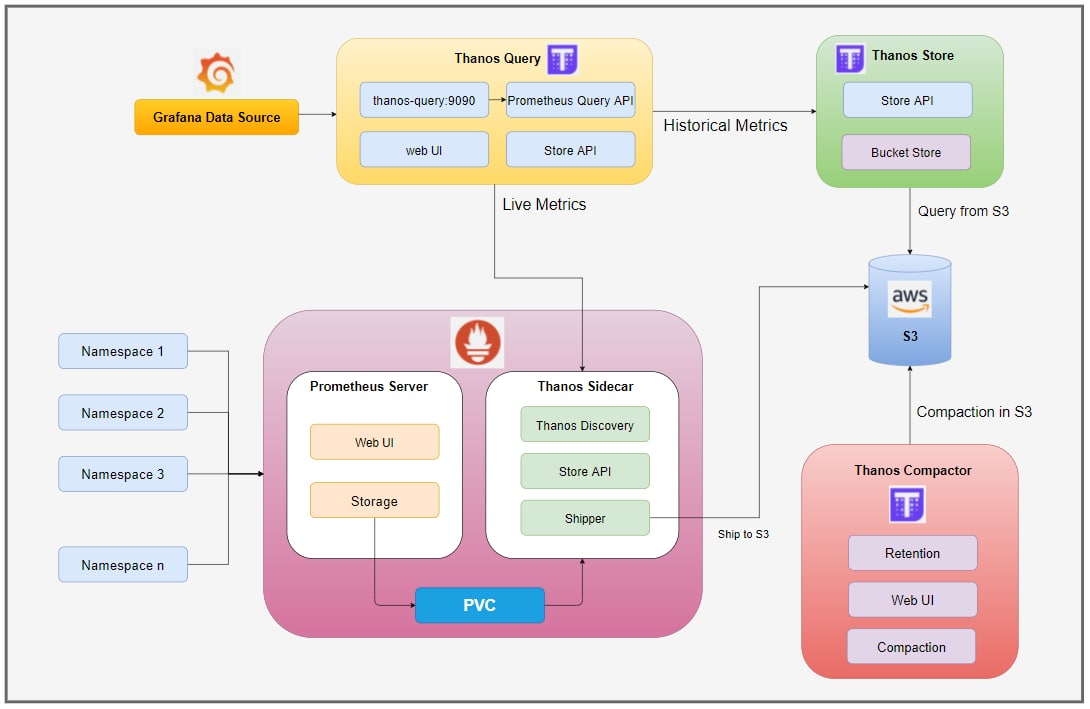{kind=link}