
Scaling Prometheus: How we’re pushing Cortex blocks storage to its limit and beyond
В Grafana Labs мы используем блочное хранилище хранилище в относительно большом масштабе, при этом некоторые из наших клиентов удаленно записывают от 10 до 30 миллионов активных серий (~ 1 млн выборок в секунду) и до 200 ГБ блоков данных от каждого клиента каждый день сохраняется в долговременном хранилище. Читать дальше…
В Grafana Labs мы используем блочное хранилище хранилище в относительно большом масштабе, при этом некоторые из наших клиентов удаленно записывают от 10 до 30 миллионов активных серий (~ 1 млн выборок в секунду) и до 200 ГБ блоков данных от каждого клиента каждый день сохраняется в долговременном хранилище. Читать дальше…
{kind=link}
New in Grafana 7.1: Gain new data insights with InfluxDB and Flux query support
Наблюдаемость между стеками и источниками данных упрощает идентификацию паттернов и добавление контекста к данным временных рядов из других источников, таких как реляционные базы данных или логи. Этот контекст является ключом к правильной интерпретации шаблонов данных и получения информации, которая затем может помочь улучшить процессы, повысить эффективность, выявить аномалии и помочь определить основные причины сбоев в обслуживании. Читать дальше…
Наблюдаемость между стеками и источниками данных упрощает идентификацию паттернов и добавление контекста к данным временных рядов из других источников, таких как реляционные базы данных или логи. Этот контекст является ключом к правильной интерпретации шаблонов данных и получения информации, которая затем может помочь улучшить процессы, повысить эффективность, выявить аномалии и помочь определить основные причины сбоев в обслуживании. Читать дальше…
{kind=link}
🗓 19 августа в 10:00 Axoft и Gals Software приглашают принять участие в вебинаре по универсальной системе мониторинга Solarwinds.
Если у вас разнородная инфраструктура, которая создавалась на протяжении длительного периода времени, Solarwinds сможет закрыть вопрос мониторинга в максимально возможном объёме. Поддерживается мониторинг сетевых и серверных устройств различных вендоров, систем виртуализации, баз данных, анализ трафика и логов. Есть модули для управления конфигурациями серверов и сетевых устройств, управления адресным пространством и другие.
На вебинаре вы узнаете:
⚡️ как выявить и предотвратить сбои в работе оборудования (сервера, банкоматы, кассовые аппараты, платежные терминалы и другое);
⚡️ если сбой все-таки произошел, как быстро найти причину и устранить ее прямо из панели задач;
⚡️ как организовать удаленную работу сотрудников;
⚡️ как организовать мониторинг приложений и сайтов.
Во второй части вебинара будет доклад о реальных кейсах внедрения системы Solarwinds в крупном российском банке и компаниях нефтегазового сектора.
Регистрация на вебинар
Если у вас разнородная инфраструктура, которая создавалась на протяжении длительного периода времени, Solarwinds сможет закрыть вопрос мониторинга в максимально возможном объёме. Поддерживается мониторинг сетевых и серверных устройств различных вендоров, систем виртуализации, баз данных, анализ трафика и логов. Есть модули для управления конфигурациями серверов и сетевых устройств, управления адресным пространством и другие.
На вебинаре вы узнаете:
⚡️ как выявить и предотвратить сбои в работе оборудования (сервера, банкоматы, кассовые аппараты, платежные терминалы и другое);
⚡️ если сбой все-таки произошел, как быстро найти причину и устранить ее прямо из панели задач;
⚡️ как организовать удаленную работу сотрудников;
⚡️ как организовать мониторинг приложений и сайтов.
Во второй части вебинара будет доклад о реальных кейсах внедрения системы Solarwinds в крупном российском банке и компаниях нефтегазового сектора.
Регистрация на вебинар
{kind=link}
Envoy 1.15 introduces a new Postgres extension with monitoring support
Новый плагин Envoy для PostgreSQL.
Новый плагин Envoy для PostgreSQL.
Мониторинг вашей инфраструктуры с помощью Grafana, InfluxDB и CollectD
Как это устроено в одной компании.
Как это устроено в одной компании.
Cameron McCloskey рассказывает в блоге Grafana как устроен его дашборд для домашнего использования. Особенно интересно в части отображения видеопотока.
{kind=link}
Grafana уже приглашает на ObservabilityCON, который состоится 26-29 октября. Обещают рассказать о новинках в своих решениях и юзкейсах Grafana & Prometheus & Loki & Cortex.
{kind=link}
PRTG объявил об альянсе с Flowmon. В практическом плане это означает интеграцию двух решений. Работает на основе встроенных в PRTG сенсорах:
- Сенсор SNMP, который контролирует устройства Flowmon.
- Сенсор Python Script для отображения значений мониторинга из Flowmon в PRTG.
События из Flowmon будут видны в PRTG, из которого будет возможен переход в Flowmon для диагностики проблемы. Если хотите узнать подробнее о работе этой интеграции, приходите 16 сентября на вебинар, который проводят совместно PRTG и Flowmon.
- Сенсор SNMP, который контролирует устройства Flowmon.
- Сенсор Python Script для отображения значений мониторинга из Flowmon в PRTG.
События из Flowmon будут видны в PRTG, из которого будет возможен переход в Flowmon для диагностики проблемы. Если хотите узнать подробнее о работе этой интеграции, приходите 16 сентября на вебинар, который проводят совместно PRTG и Flowmon.
Чем мониторить кластеры на Kubernetes: три открытых инструмента — один из них в формате игры
Это — наша компактная подборка бесплатных инструментов, позволяющих оценить производительность и стабильность контейнеризированных приложений. Читать дальше на Хабре...
Это — наша компактная подборка бесплатных инструментов, позволяющих оценить производительность и стабильность контейнеризированных приложений. Читать дальше на Хабре...
Как сократить объем дискового пространства, занимаемого БД Zabbix? Есть несколько способов:
1. Включить троттлинг (throttling). Троттлинг — это возможность пропуска одинаковых значений. То есть если значение метрики не изменилось, оно не записывается хранилище и, соответственно, не занимает место на диске. Работает с версии 4.2.
Где искать. В правилах препроцессинга.
В Zabbix возможна настройка троттлинга двух видов:
⚡️ Discard unchanged — игнор повторяющихся значений. В этом случае график будет пустым, если метрика не меняется.
⚡️ Discard unchanged with heartbeat — игнор повторяющихся значений, но с регулярной проверкой жива ли метрика. На графике будут значения. Этот параметр препроцессинга требует ввода периода проверки. Если данные собираются раз в секунду, а интервал задан одной минутой, то Zabbix превратит ежесекундный поток единичек в ежеминутный поток.
2. Настроить переменное значение периода сбора данных. Любой элемент данных можно собирать с разной периодичностью (или вообще не собирать) в зависимости от времени суток, дня недели или дня месяца. Примеры эпизодического сбора:
wd1-5h9 — каждый день с понедельника по пятницу в 9:00.
h9m/30;h11 — каждый день в 9:00, 9:30, 10:00, 10:30, 11:00.
h9-10m10-40/30 — каждый день в 9:10, 9:40, 10:10, 10:40.
md1wd1h9m30 — каждый первый день месяца в 9:30 если это понедельник.
Где искать. В настройках элементов данных (items), раздел пользовательский интервал (custom interval).
3. Удалять значение исходного элемента данных для зависимых элементов данных. Простой пример: вы выполняете команду, которая возвращает портянку с данными, которые вы потом распознаёте при помощи зависимых метрик. Нет никакого смысла хранить эти данные. тем более если это большой текстовый блок.
Где искать. В настройках элементов данных, раздел период хранения истории. Установить значение в «не хранить».
👍 — спасибо, буду использовать
👎 — спасибо, уже использую
👀 — у меня резиновые диски
1. Включить троттлинг (throttling). Троттлинг — это возможность пропуска одинаковых значений. То есть если значение метрики не изменилось, оно не записывается хранилище и, соответственно, не занимает место на диске. Работает с версии 4.2.
Где искать. В правилах препроцессинга.
В Zabbix возможна настройка троттлинга двух видов:
⚡️ Discard unchanged — игнор повторяющихся значений. В этом случае график будет пустым, если метрика не меняется.
⚡️ Discard unchanged with heartbeat — игнор повторяющихся значений, но с регулярной проверкой жива ли метрика. На графике будут значения. Этот параметр препроцессинга требует ввода периода проверки. Если данные собираются раз в секунду, а интервал задан одной минутой, то Zabbix превратит ежесекундный поток единичек в ежеминутный поток.
2. Настроить переменное значение периода сбора данных. Любой элемент данных можно собирать с разной периодичностью (или вообще не собирать) в зависимости от времени суток, дня недели или дня месяца. Примеры эпизодического сбора:
wd1-5h9 — каждый день с понедельника по пятницу в 9:00.
h9m/30;h11 — каждый день в 9:00, 9:30, 10:00, 10:30, 11:00.
h9-10m10-40/30 — каждый день в 9:10, 9:40, 10:10, 10:40.
md1wd1h9m30 — каждый первый день месяца в 9:30 если это понедельник.
Где искать. В настройках элементов данных (items), раздел пользовательский интервал (custom interval).
3. Удалять значение исходного элемента данных для зависимых элементов данных. Простой пример: вы выполняете команду, которая возвращает портянку с данными, которые вы потом распознаёте при помощи зависимых метрик. Нет никакого смысла хранить эти данные. тем более если это большой текстовый блок.
Где искать. В настройках элементов данных, раздел период хранения истории. Установить значение в «не хранить».
👍 — спасибо, буду использовать
👎 — спасибо, уже использую
👀 — у меня резиновые диски
Это не реклама, но я случайно наткнулся на пост на Хабре, что у издательства Питер распродажа до 22 сентября (50% на электрокниги, 30% на бумагу). По запросу «Site Reliability» на их сайте выдаются две книги и вы уже, думаю, догадываетесь какие. Неплохой шанс все-таки их прочитать, если на английском не очень-то и хотелось читать.
Купон на бумагу — Бумажная книга, купон на электрокниги — Электронная книга. Да, вот так вот незатейливо.
Купон на бумагу — Бумажная книга, купон на электрокниги — Электронная книга. Да, вот так вот незатейливо.
# zabbix_get -s my.prod.host -k system.run["rm -rf /var/log/applog/"]
Эту команду и не только её можно выполнить удаленно на Linux сервере, отправив запрос через Zabbix-агент. Но т.к. на Linux агент выполняется без прав суперпользователя, это еще не так страшно, но с Windows дело может принять совсем другой оборот.
В этой статье на Хабре Тихон Усков, Инженер интеграции Zabbix, рассказывает о работе с черными и белыми списками для метрик на стороне агента. Советую прочитать, особенно, если используете активные проверки. Мониторинг — это хорошо, а безопасный мониторинг — ещё лучше.
Эту команду и не только её можно выполнить удаленно на Linux сервере, отправив запрос через Zabbix-агент. Но т.к. на Linux агент выполняется без прав суперпользователя, это еще не так страшно, но с Windows дело может принять совсем другой оборот.
В этой статье на Хабре Тихон Усков, Инженер интеграции Zabbix, рассказывает о работе с черными и белыми списками для метрик на стороне агента. Советую прочитать, особенно, если используете активные проверки. Мониторинг — это хорошо, а безопасный мониторинг — ещё лучше.
{kind=link}
Creating Monitoring Dashboards
Недавно наши команды в Hotels.com, входящей в Expedia Group, начали переходить с Graphite на платформу внутренних показателей, основанную на Prometheus. Мы увидели в этом возможность улучшить нашу наблюдаемость и, среди прочего, предоставили набор простых рекомендаций, которые помогут с миграцией. Читать на Медиуме.
Недавно наши команды в Hotels.com, входящей в Expedia Group, начали переходить с Graphite на платформу внутренних показателей, основанную на Prometheus. Мы увидели в этом возможность улучшить нашу наблюдаемость и, среди прочего, предоставили набор простых рекомендаций, которые помогут с миграцией. Читать на Медиуме.
Medium
Creating Monitoring Dashboards
Guidelines for developers
Monitoring memory usage of a running Python program
В Survata мы обрабатываем много данных, используя Python и его библиотеки pandas и scikit-learn. Это означает, что мы используем большое количество облачных ресурсов и, в результате, наш ежемесячный счет за хостинг может быть огромным.
Один из способов сократить расходы на облачные ресурсы — убедиться, что мы не используем большее ресурсов, чем фактически необходимо. Облачные провайдеры позволяют легко развернуть сервер с несколькими ГБ ОЗУ, но если фактический рабочий процесс использует только часть этой памяти, вы тратите ресурсы и деньги впустую. Читать дальше на Медиуме.
В Survata мы обрабатываем много данных, используя Python и его библиотеки pandas и scikit-learn. Это означает, что мы используем большое количество облачных ресурсов и, в результате, наш ежемесячный счет за хостинг может быть огромным.
Один из способов сократить расходы на облачные ресурсы — убедиться, что мы не используем большее ресурсов, чем фактически необходимо. Облачные провайдеры позволяют легко развернуть сервер с несколькими ГБ ОЗУ, но если фактический рабочий процесс использует только часть этой памяти, вы тратите ресурсы и деньги впустую. Читать дальше на Медиуме.
{kind=link}
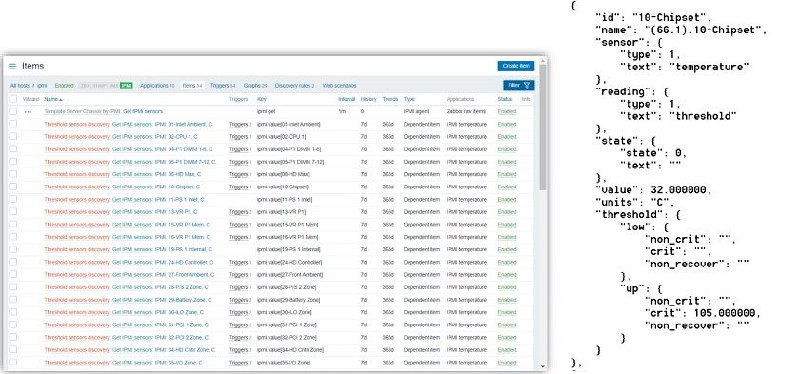
Новые шаблоны в Zabbix — IPMI, Mikrotik, MSSQL
В этой статье на Хабре расшифровка доклада Максима Чудинова с Zabbix Meetup, который был 28 августа 2020 года.
В этой статье на Хабре расшифровка доклада Максима Чудинова с Zabbix Meetup, который был 28 августа 2020 года.
{kind=link}
Вернуть пропавший скутер, или история одного IoT мониторинга
Интересная статья о подборе системы мониторинга для электроскутеров (остановились в итоге на TICK) и история о пропавшем скутере. Читайте на Хабре.
Интересная статья о подборе системы мониторинга для электроскутеров (остановились в итоге на TICK) и история о пропавшем скутере. Читайте на Хабре.
{kind=link}