
Bad Observability
Антипаттерны построения системы Observability с забавными картинками и толковым описанием. Читать дальше.
Антипаттерны построения системы Observability с забавными картинками и толковым описанием. Читать дальше.
{kind=link}
Grafana agent operator
Grafana Agent Operator — это оператор Kubernetes, который упрощает развертывание Grafana Agent и сбор телеметрических данных с подов.
Grafana Agent Operator работает, отслеживая ресурсы Kubernetes, которые определяют, как собирать телеметрические данные с кластера Kubernetes и куда их отправлять. Agent Operator управляет соответствующими Grafana Agent в кластере, отслеживая изменения в ресурсах. Читать дальше.
Grafana Agent Operator — это оператор Kubernetes, который упрощает развертывание Grafana Agent и сбор телеметрических данных с подов.
Grafana Agent Operator работает, отслеживая ресурсы Kubernetes, которые определяют, как собирать телеметрические данные с кластера Kubernetes и куда их отправлять. Agent Operator управляет соответствующими Grafana Agent в кластере, отслеживая изменения в ресурсах. Читать дальше.
{kind=link}
Kubernetes Monitoring: Best Practices, Metrics and Tools
В этой статье перечислены основные метрики мониторинга Kubernetes, которые необходимо измерять, включая метрики кластера, метрики узлов, метрики подов, метрики деплоймента и метрики контейнеров. Читать дальше.
В этой статье перечислены основные метрики мониторинга Kubernetes, которые необходимо измерять, включая метрики кластера, метрики узлов, метрики подов, метрики деплоймента и метрики контейнеров. Читать дальше.
{kind=link}
Ваша электронная почта занимает слишком много места на дисках, СХД или в другом хранилище?
Приглашаем вас на вебинар, где вы получите ответы на вопросы:
⚡️ как снизить занимаемое место архивом почты на 60%
⚡️ как моментально восстановить удаленное письмо из архива одним нажатием кнопки
⚡️ как выполнить быстрый поиск по письмам и вложенным документам (120 форматов)
⚡️ как предоставить пользователям удобный интерфейс для поиска по письмам и вложениям
⚡️ как встроить историю переписки с клиентом в вашу CRM-систему
На вебинаре речь пойдет об отечественной системе архивации электронной почты Архива.
Архив — это не резервная копия, поэтому в сравнении с системами резервного копирования (например, Veeam), Архива имеет множество преимуществ. Архива поддерживает работу с почтовыми сервисами Exchange, CommuniGatePro, GSuite, Office 365. Все хранящиеся письма зашифрованы стойким к взлому алгоритмом.
Вебинар состоится 14 апреля (пятница) в 11 часов по московскому времени на платформе Zoom.
Регистрация
P.S. На картинке приведен граф связей в Архива, который позволит обнаружить основные каналы общения.
Приглашаем вас на вебинар, где вы получите ответы на вопросы:
⚡️ как снизить занимаемое место архивом почты на 60%
⚡️ как моментально восстановить удаленное письмо из архива одним нажатием кнопки
⚡️ как выполнить быстрый поиск по письмам и вложенным документам (120 форматов)
⚡️ как предоставить пользователям удобный интерфейс для поиска по письмам и вложениям
⚡️ как встроить историю переписки с клиентом в вашу CRM-систему
На вебинаре речь пойдет об отечественной системе архивации электронной почты Архива.
Архив — это не резервная копия, поэтому в сравнении с системами резервного копирования (например, Veeam), Архива имеет множество преимуществ. Архива поддерживает работу с почтовыми сервисами Exchange, CommuniGatePro, GSuite, Office 365. Все хранящиеся письма зашифрованы стойким к взлому алгоритмом.
Вебинар состоится 14 апреля (пятница) в 11 часов по московскому времени на платформе Zoom.
Регистрация
P.S. На картинке приведен граф связей в Архива, который позволит обнаружить основные каналы общения.
{kind=link}
Recruiting developers into Site Reliability Engineering (SRE)
В этой статье вы узнаете:
⚡️Почему разработчики являются отличными потенциальными SRE
⚡️Как изменится работа разработчика, когда он станет SRE
⚡️Как разработчики могут ознакомиться с практикой SRE, прежде чем подавать заявку на роль SRE
⚡️Как программы стажировки могут улучшить результаты для начинающих SRE
⚡️Советы по адаптации для плавного перехода от разработчика → SRE
Читать статью.
В этой статье вы узнаете:
⚡️Почему разработчики являются отличными потенциальными SRE
⚡️Как изменится работа разработчика, когда он станет SRE
⚡️Как разработчики могут ознакомиться с практикой SRE, прежде чем подавать заявку на роль SRE
⚡️Как программы стажировки могут улучшить результаты для начинающих SRE
⚡️Советы по адаптации для плавного перехода от разработчика → SRE
Читать статью.
Golang Monitoring 102: Distributed Tracing with Opentelemetry
В этой статье рассказывается о реализации распределенной системы трассировки с помощью opentelemetry. В ней будут рассмотрены примеры использования, терминология и фрагменты кода. Читать дальше.
Используете OpenTelemetry в своём окружении?
В этой статье рассказывается о реализации распределенной системы трассировки с помощью opentelemetry. В ней будут рассмотрены примеры использования, терминология и фрагменты кода. Читать дальше.
Используете OpenTelemetry в своём окружении?
Observability Concept in Prometheus
В этой статье рассказано о компонентах Prometheus, которые полезны для понимания и в области DevOps и SRE. Эти термины часто встречаются в Prometheus, также эти темы обсуждаются в сертификации PCA. Читать дальше.
В этой статье рассказано о компонентах Prometheus, которые полезны для понимания и в области DevOps и SRE. Эти термины часто встречаются в Prometheus, также эти темы обсуждаются в сертификации PCA. Читать дальше.
{kind=link}
Alertmanager incident response automation with n8n
Стек мониторинга prometheus включает компонент диспетчеризации оповещений под названием alertmanager. Доступно множество интеграций для отправки оповещений на мессенджер, slack и т.д... т.е. в каналы уведомлений. Но как легко и эффективно доставлять автоматизированные ответы — вот вопрос, на который отвечают в этой статье.
Для автоматизации реагирования на инциденты будет использоваться инструмент автоматизации n8n. N8n — это low-code инструмент автоматизации, с удобным пользовательским интерфейсом при сохранении высокой степени кастомизации. Читать дальше.
Стек мониторинга prometheus включает компонент диспетчеризации оповещений под названием alertmanager. Доступно множество интеграций для отправки оповещений на мессенджер, slack и т.д... т.е. в каналы уведомлений. Но как легко и эффективно доставлять автоматизированные ответы — вот вопрос, на который отвечают в этой статье.
Для автоматизации реагирования на инциденты будет использоваться инструмент автоматизации n8n. N8n — это low-code инструмент автоматизации, с удобным пользовательским интерфейсом при сохранении высокой степени кастомизации. Читать дальше.
{kind=link}
{kind=link}
How to Monitor kube-controller-manager
Как с помощью Prmetheus эффективно наблюдать за kube-controller-manager. Читать дальше.
Как с помощью Prmetheus эффективно наблюдать за kube-controller-manager. Читать дальше.
{kind=link}
Best practices for observability
В этой статье вы узнаете о:
⚡️процессе разрешения инцидента,
⚡️обоснование необходимости использования методов, основанных на гипотезах,
⚡️вариантах реализации в организации.
Читать дальше.
В этой статье вы узнаете о:
⚡️процессе разрешения инцидента,
⚡️обоснование необходимости использования методов, основанных на гипотезах,
⚡️вариантах реализации в организации.
Читать дальше.
PromQL Vendor Compatibility, Round Three
В этой статье представлен набор результатов тестирования совместимости PromQL для различных вендоров (PromsScale, Thanos, Sysdig, VictoriaMetrics и других). Читать дальше.
В этой статье представлен набор результатов тестирования совместимости PromQL для различных вендоров (PromsScale, Thanos, Sysdig, VictoriaMetrics и других). Читать дальше.
cdebug — нож швейцарской армии для отладки работы контейнеров
С помощью этого инструмента вы можете:
⚡️Устранять неполадки в контейнерах, для которых нет системной оболочки и/или инструментов отладки
⚡️Перенаправлять неопубликованные или даже локальные порты на хост-систему
⚡️Открывать конечные точки из хост-системы для контейнеров и сетей Kubernetes
⚡️Удобно экспортировать файловую систему образа и/или контейнера в локальные папки
⚡️и многое другое
Репыч на Гитхабе
С помощью этого инструмента вы можете:
⚡️Устранять неполадки в контейнерах, для которых нет системной оболочки и/или инструментов отладки
⚡️Перенаправлять неопубликованные или даже локальные порты на хост-систему
⚡️Открывать конечные точки из хост-системы для контейнеров и сетей Kubernetes
⚡️Удобно экспортировать файловую систему образа и/или контейнера в локальные папки
⚡️и многое другое
Репыч на Гитхабе
{kind=link}
Monitoring benchmark: how to generate 100 million samples/s of production-like data (статья из блога Victoria Metrics)
Не смотря на то, что VictoriaMetrics может обрабатывать данные со скоростью 100 миллионов событий в секунду для одного миллиарда активных временных рядов, эталонный инструмент, используемый для создания такой нагрузки, обычно упускается из виду. В этой статье рассказывается о проблемах масштабирования инструмента prometheus-benchmark для создания такой нагрузки. Читать дальше.
Не смотря на то, что VictoriaMetrics может обрабатывать данные со скоростью 100 миллионов событий в секунду для одного миллиарда активных временных рядов, эталонный инструмент, используемый для создания такой нагрузки, обычно упускается из виду. В этой статье рассказывается о проблемах масштабирования инструмента prometheus-benchmark для создания такой нагрузки. Читать дальше.
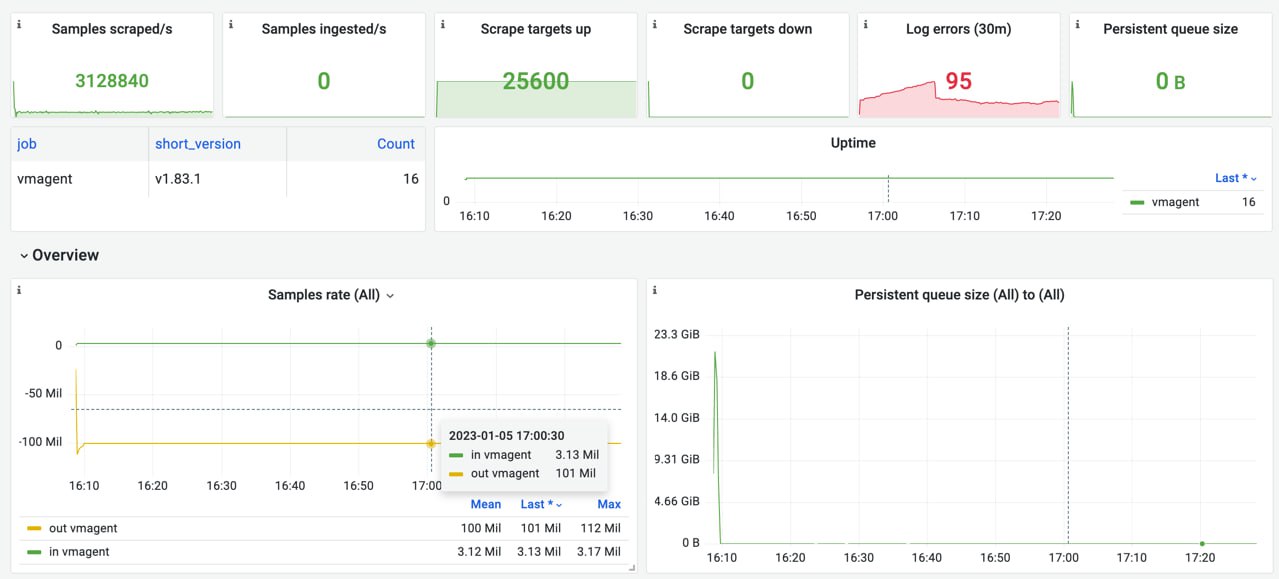{kind=link}
How to Monitor the Kubelet
Мониторинг Kubelet необходим при работе Kubernetes в проде. Kubelet—- это важная служба в кластере Kubernetes.
Этот компонент Kubernetes отвечает за обеспечение работоспособности и здоровья контейнеров, определенных в Pods. Как только планировщик назначает узел для запуска Pod, Kubelet принимает это назначение и запускает Pod. В этой статье рассказывается о том, как контролировать Kubelet и каковы наиболее важные метрики Kubelet. Читать дальше.
Мониторинг Kubelet необходим при работе Kubernetes в проде. Kubelet—- это важная служба в кластере Kubernetes.
Этот компонент Kubernetes отвечает за обеспечение работоспособности и здоровья контейнеров, определенных в Pods. Как только планировщик назначает узел для запуска Pod, Kubelet принимает это назначение и запускает Pod. В этой статье рассказывается о том, как контролировать Kubelet и каковы наиболее важные метрики Kubelet. Читать дальше.
{kind=link}
How to monitor Istio, the Kubernetes service mesh
Istio service mesh добавляет такие ключевые возможности, как наблюдаемость, безопасность и управление трафиком, в приложения без необходимости вносить изменения в код или конфигурацию. В этой статье рассказывается об основных концепциях Istio. Вы узнаете, какие метрики наиболее интересны для мониторинга Istio. Кроме того, узнаете о наборе инструментов, необходимых для управления Istio и проверки того, что находится под капотом.
В статье рассматриваются следующие темы:
⚡️Что такое Istio?
⚡️Обзор Istio
⚡️Как контролировать Istio с помощью Prometheus
⚡️Дашборды Grafana для Istio
⚡️Что такое Kiali?
⚡️Что такое Jaeger?
Читать дальше.
Istio service mesh добавляет такие ключевые возможности, как наблюдаемость, безопасность и управление трафиком, в приложения без необходимости вносить изменения в код или конфигурацию. В этой статье рассказывается об основных концепциях Istio. Вы узнаете, какие метрики наиболее интересны для мониторинга Istio. Кроме того, узнаете о наборе инструментов, необходимых для управления Istio и проверки того, что находится под капотом.
В статье рассматриваются следующие темы:
⚡️Что такое Istio?
⚡️Обзор Istio
⚡️Как контролировать Istio с помощью Prometheus
⚡️Дашборды Grafana для Istio
⚡️Что такое Kiali?
⚡️Что такое Jaeger?
Читать дальше.
{kind=link}
json_exporter
Экспортер Prometheus, который забирает JSON в формате JSONPath.
Проверка конфигурации JSONPath, поддерживаемой экспортером
Каталог примеров для примера конфигурации экспортера, конфигурации prometheus и ожидаемого формата данных.
Репыч на Гитхабе
Экспортер Prometheus, который забирает JSON в формате JSONPath.
Проверка конфигурации JSONPath, поддерживаемой экспортером
Каталог примеров для примера конфигурации экспортера, конфигурации prometheus и ожидаемого формата данных.
Репыч на Гитхабе
Что должен знать каждый SRE о внутреннем устройстве оболочки GNU/Linux: файловые дескрипторы, каналы, терминалы, пользовательские сессии, группы процессов и демоны
Несмотря на эру контейнеров, виртуализации и растущего числа пользовательских интерфейсов всех видов, SRE часто проводят значительную часть своего времени в оболочках GNU/Linux. Это может быть отладка, тестирование, разработка или подготовка новой инфраструктуры. Это может быть старый добрый bash, более новый и модный
В этой статье показаны примеры пайплайнов, файловых дескрипторов, оболочек, терминалов, процессов, заданий и сигналов, как все они взаимодействуют друг с другом для создания простой и надежной среды. И все это будет показано в контексте ядра Linux, его внутренних компонентов, а также различных инструментов и подходов к отладке. Читать дальше.
Несмотря на эру контейнеров, виртуализации и растущего числа пользовательских интерфейсов всех видов, SRE часто проводят значительную часть своего времени в оболочках GNU/Linux. Это может быть отладка, тестирование, разработка или подготовка новой инфраструктуры. Это может быть старый добрый bash, более новый и модный
zsh, или даже fish или tcsh с их интересными и уникальными возможностями.В этой статье показаны примеры пайплайнов, файловых дескрипторов, оболочек, терминалов, процессов, заданий и сигналов, как все они взаимодействуют друг с другом для создания простой и надежной среды. И все это будет показано в контексте ядра Linux, его внутренних компонентов, а также различных инструментов и подходов к отладке. Читать дальше.
{kind=link}
Мониторинг HTTP и SSL через Prometheus blackbox_exporter
Опыт наладки мониторинга статус-кодов ответов web-сервисов, а также сроков действия SSL-сертификатов. Читать дальше на Хабре.
Опыт наладки мониторинга статус-кодов ответов web-сервисов, а также сроков действия SSL-сертификатов. Читать дальше на Хабре.
{kind=link}