
Если хотите подробнее про FluentD — вот неплохая статья на том же Медиуме.
{kind=link}
{kind=link}
SRE: Performance Analysis: Tuning Methodology Using a Simple HTTP Webserver In Go
Методика работы SRE на примере тюнинга простого веб-сервера.
Методика работы SRE на примере тюнинга простого веб-сервера.
{kind=link}
Tracing and Observability
Небольшая, но достаточно подробная статья о том, как устроены tracing и observability.
Небольшая, но достаточно подробная статья о том, как устроены tracing и observability.
{kind=link}
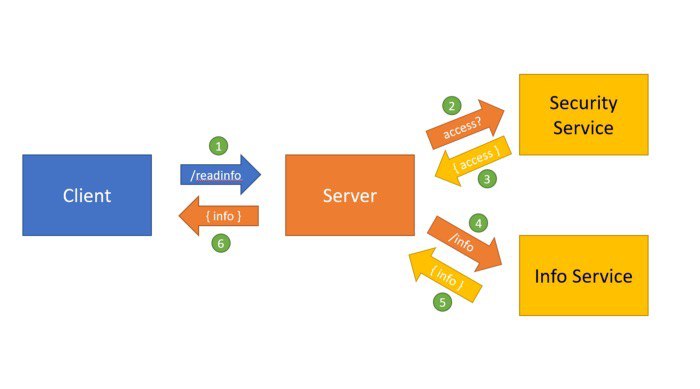
Для обеспечения высокой доступности мы используем два кластера K8s. Графики ниже показывают эти кластеры: region-1 и region-2. Это создает дополнительную сложность, когда речь идет об автомасштабировании, поскольку кластеры полностью разделены и не имеют общих метрик. Наш веб-сайт работает в режиме active-active и сбалансирован по нагрузке на оба региона.
Из-за проблемы в приложении инженеры по инфраструктуре перевели все запросы к приложению в один регион. Зеленая линия показывает общее количество запросов, которые обслуживает служба, а две другие относятся к каждому региону. Сразу после 16:20 произошло аварийное переключение: оранжевая линия соединилась с зеленой линией, а синяя линия, идущая в ноле, начала расти.
В этой статье об изменении подходов компании к алертингу после максимального масштабирования сервиса из-за нештатной ситуации.
Из-за проблемы в приложении инженеры по инфраструктуре перевели все запросы к приложению в один регион. Зеленая линия показывает общее количество запросов, которые обслуживает служба, а две другие относятся к каждому региону. Сразу после 16:20 произошло аварийное переключение: оранжевая линия соединилась с зеленой линией, а синяя линия, идущая в ноле, начала расти.
В этой статье об изменении подходов компании к алертингу после максимального масштабирования сервиса из-за нештатной ситуации.
Medium
Kubernetes Lessons in Alerting
Live issues are a great opportunity to learn and improve. Here’s what happened to us
ElasticSearch On Steroids With Avro Schemas
https://towardsdatascience.com/elasticsearch-on-steroids-with-avro-schemas-3bfc483e3b30
https://towardsdatascience.com/elasticsearch-on-steroids-with-avro-schemas-3bfc483e3b30
{kind=link}
Увлекательная 4-серийная сага «Practical Monitoring with Prometheus & Grafana».
Часть 1: Installing Prometheus + Grafana via Helm in 5 Minutes
Часть 2: Using Prometheus blackbox exporter for free uptime checks
Часть 3: Applying simple statistics for anomaly detection using Prometheus
Часть 4: Securing Grafana with Identity-Award Proxy
Часть 1: Installing Prometheus + Grafana via Helm in 5 Minutes
Часть 2: Using Prometheus blackbox exporter for free uptime checks
Часть 3: Applying simple statistics for anomaly detection using Prometheus
Часть 4: Securing Grafana with Identity-Award Proxy
{kind=link}
А в этом репозитории одна штука, чтобы генерить дашборды Grafana из Python-скриптов. Полезно? Не то слово!
Lessons learned about monitoring the JVM in the era of containers
В этой статье об опыте использования бесплатных профилировщиков JVM VisualVM и Universal GC Log Analyzer.
В этой статье об опыте использования бесплатных профилировщиков JVM VisualVM и Universal GC Log Analyzer.
{kind=link}
How we scaled Graphite to 100,000 writes per second
В этой статье о вертикальном масштабировании вычислений до 100 000 операций записи в секунду.
А кто-то использует Graphite в своём стеке мониторинга?
👍 — использую
👎 — не использую
👀 — карандаши как-то не очень, обычно ручкой пользуюсь
В этой статье о вертикальном масштабировании вычислений до 100 000 операций записи в секунду.
А кто-то использует Graphite в своём стеке мониторинга?
👍 — использую
👎 — не использую
👀 — карандаши как-то не очень, обычно ручкой пользуюсь
{kind=link}
Forwarded from /usr/bin
В этой статье несколько слов о мониторинге контейнеров Docker при помощи docker stats и cAdvisor.
{kind=link}
How the cortex and thanos projects collaborate to make scaling prometheus better for all
Коллаборация Cortex и Thanos для масштабирования Prometheus (в блоге Grafana)
А ещё есть запись выступления «Two Households, Both Alike in Dignity: Cortex and Thanos» с PromCon 2019 (выступают сооснователи Cortex и Thanos Tom Wilkie и Bartek Plotka соответственно)
Коллаборация Cortex и Thanos для масштабирования Prometheus (в блоге Grafana)
А ещё есть запись выступления «Two Households, Both Alike in Dignity: Cortex and Thanos» с PromCon 2019 (выступают сооснователи Cortex и Thanos Tom Wilkie и Bartek Plotka соответственно)
Grafana Labs
How the Cortex and Thanos projects collaborate to make scaling Prometheus better for all | Grafana Labs
At PromCon Online, Marco Pracucci and Bartek Plotka talked about how Cortex and Thanos started to learn from and even influence each other – thanks to open source.
Monitoring Application Metrics With Nutanix Karbon
Пошаговое руководство по настройке кластера Karbon для мониторинга кластера и приложений и настройка представлений в Grafana.
Пошаговое руководство по настройке кластера Karbon для мониторинга кластера и приложений и настройка представлений в Grafana.
Instana сделала 6-минутный ролик с описанием работы их инструмента для APM-мониторинга распределённых приложений. Внимание! Внутри ролика мемасики.
Если вам интересно посмотреть Instana у себя — напишите в личку.
Если вам интересно посмотреть Instana у себя — напишите в личку.
{kind=link}
Подписчик попросил разместить ролик с рассказом о предпосылках и внедрении APM-мониторинга Appdynamics в банке Санкт-Петербург (БСПБ). Рассказывает Алексей Тутуков — начальник управления мониторинга и реагирования БСПБ.
Забавно, что ребята взяли да и вставили в презентацию мою картинку с Мо шестилетней давности. Жаль, что даже лайков не отсыпали. А та картинка была в статье на Хабре о принципах мониторинга бизнес-приложений.
Забавно, что ребята взяли да и вставили в презентацию мою картинку с Мо шестилетней давности. Жаль, что даже лайков не отсыпали. А та картинка была в статье на Хабре о принципах мониторинга бизнес-приложений.
{kind=link}
NetXMS — как Solarwinds для желающих получить кое-что бесплатно. Это бесплатная система мониторинга с автоматическим дискаверингом L2 и L3, собирает метрики ОС, Oracle, MySQL, PostgreSQL, MongoDB, DB2, Tuxedo и другие. Система вроде как развивается, последний релиз был 16 июня 2020 года.
Вот тут прошлогодняя статья на Хабре.
Вот тут прошлогодняя статья на Хабре.
{kind=link}
SRE: Анализ производительности. Способ настройки с использованием простого вебсервера на Go
Анализ производительности можно применять для проверки узких мест в программе, применяя научный подход при проверке экспериментов по настройке. Эта статья определяет общий подход к анализу производительности и настройке с использованием в качестве примера вебсервера на Go. Читать дальше на Хабре
Анализ производительности можно применять для проверки узких мест в программе, применяя научный подход при проверке экспериментов по настройке. Эта статья определяет общий подход к анализу производительности и настройке с использованием в качестве примера вебсервера на Go. Читать дальше на Хабре
{kind=link}
Интересно, Ozon как-то отслеживает такие проблемы на своём сайте? То есть ты готов уже оплатить, но что-то пошло не так. Главное, не пишут что именно. Перезагрузка страницы, переход в режим инкогнито или использование другого браузера не помогает. Не знаю есть ли среди подписчиков кто-то из Ozon, но если вы расскажете как у вас отрабатываются такие проблемы на сайте, думаю всем будет интересно. Пишите мне в личку.
Fluentd — Splitting Logs
В большинстве инсталляций Kubernetes у нас есть приложения с логированием в stdout различных типов журналов. Хорошим примером являются журналы приложений и журналы контроля доступа, оба содержат очень важную информацию, но мы должны анализировать их по-разному, чтобы сделать это, мы используем возможности fluentd и некоторых его плагинов.
В этом практическом посте мы объясним, как разделить эти журналы на параллельные потоки, чтобы вы могли в дальнейшем их обрабатывать.
В большинстве инсталляций Kubernetes у нас есть приложения с логированием в stdout различных типов журналов. Хорошим примером являются журналы приложений и журналы контроля доступа, оба содержат очень важную информацию, но мы должны анализировать их по-разному, чтобы сделать это, мы используем возможности fluentd и некоторых его плагинов.
В этом практическом посте мы объясним, как разделить эти журналы на параллельные потоки, чтобы вы могли в дальнейшем их обрабатывать.
Medium
Fluentd — Splitting Logs
In most kubernetes deployments we have applications logging into stdout different type of logs. A good example are application logs and…