
Shell-operator — это инструмент для запуска произвольных скриптов по событиям в кластерах Kubernetes. Частным случаем таких произвольных скриптов является подписка на события через Kubernetes API и запуск хуков по таким событиям. А частным случаем запуска хуков является экспорт произвольных метрики для их дальнейшего scraping'а Prometheus’ом.
В этой статье об обновлениях shell-оператора, там же в конце статьи ссылки на описание этого инструмента.
В этой статье об обновлениях shell-оператора, там же в конце статьи ссылки на описание этого инструмента.
Хабр
Простое создание Kubernetes-операторов с shell-operator: прогресс проекта за год
Kubernetes-операторы — удобный механизм для расширения возможностей этой контейнерной платформы, по праву снискавший широкое признание в среде инженеров эксплу...
SRE: Observability: Metric Namespaces and Structures
В этой статье о тайном оружии SRE — древовидном структурировании метрик в Prometheus. На заметку тем, кто не структурирует.
В этой статье о тайном оружии SRE — древовидном структурировании метрик в Prometheus. На заметку тем, кто не структурирует.
{kind=link}
Как бороться с дублями в Elasticsearch при использовании FluentD читайте в этой статье на Хабре.
Хабр
Fluentd: почему важно настроить выходной буфер
В наше время невозможно представить проект на базе Kubernetes без стека ELK, с помощью которого сохраняются логи как приложений, так и системных компонентов кла...
Про Skydive — инструмент для визуализации сетевой топологии на основе netflow, я уже как-то писал. Сегодня на Хабре вышла статья о добавлении ноды в Skydive топологию вручную через Skydive client. Эта возможность появилась благодаря Node rule API, которая появилась начиная с версии 0.20
{kind=link}
{kind=link}
Для линукс-админов — An Introduction to File System Monitoring Tools.
В этой статье про утилиты inotifywait и iwatch
В этой статье про утилиты inotifywait и iwatch
Medium
An Introduction to File System Monitoring Tools
All about inotifywait and iwatch utilities
Centralize Your Docker Logging With FluentD
О том как взять FluentD и положить логи docker в одно место
О том как взять FluentD и положить логи docker в одно место
{kind=link}
Если хотите подробнее про FluentD — вот неплохая статья на том же Медиуме.
{kind=link}
{kind=link}
SRE: Performance Analysis: Tuning Methodology Using a Simple HTTP Webserver In Go
Методика работы SRE на примере тюнинга простого веб-сервера.
Методика работы SRE на примере тюнинга простого веб-сервера.
{kind=link}
Tracing and Observability
Небольшая, но достаточно подробная статья о том, как устроены tracing и observability.
Небольшая, но достаточно подробная статья о том, как устроены tracing и observability.
{kind=link}
Для обеспечения высокой доступности мы используем два кластера K8s. Графики ниже показывают эти кластеры: region-1 и region-2. Это создает дополнительную сложность, когда речь идет об автомасштабировании, поскольку кластеры полностью разделены и не имеют общих метрик. Наш веб-сайт работает в режиме active-active и сбалансирован по нагрузке на оба региона.
Из-за проблемы в приложении инженеры по инфраструктуре перевели все запросы к приложению в один регион. Зеленая линия показывает общее количество запросов, которые обслуживает служба, а две другие относятся к каждому региону. Сразу после 16:20 произошло аварийное переключение: оранжевая линия соединилась с зеленой линией, а синяя линия, идущая в ноле, начала расти.
В этой статье об изменении подходов компании к алертингу после максимального масштабирования сервиса из-за нештатной ситуации.
Из-за проблемы в приложении инженеры по инфраструктуре перевели все запросы к приложению в один регион. Зеленая линия показывает общее количество запросов, которые обслуживает служба, а две другие относятся к каждому региону. Сразу после 16:20 произошло аварийное переключение: оранжевая линия соединилась с зеленой линией, а синяя линия, идущая в ноле, начала расти.
В этой статье об изменении подходов компании к алертингу после максимального масштабирования сервиса из-за нештатной ситуации.
Medium
Kubernetes Lessons in Alerting
Live issues are a great opportunity to learn and improve. Here’s what happened to us
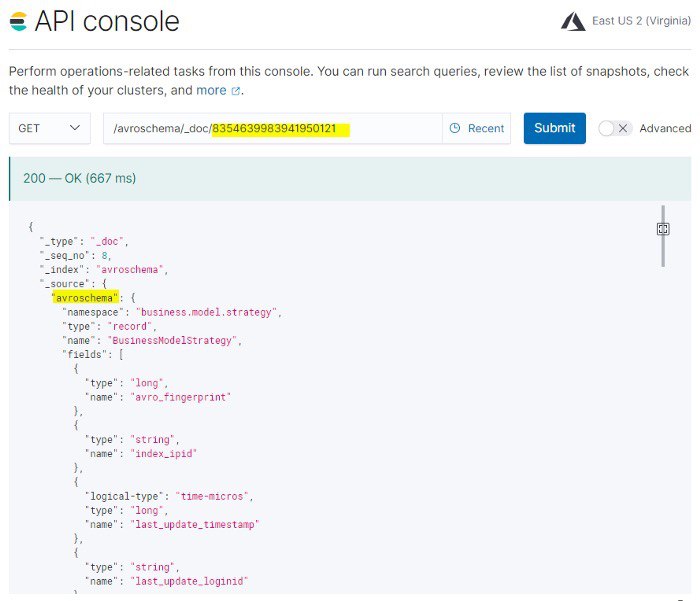
ElasticSearch On Steroids With Avro Schemas
https://towardsdatascience.com/elasticsearch-on-steroids-with-avro-schemas-3bfc483e3b30
https://towardsdatascience.com/elasticsearch-on-steroids-with-avro-schemas-3bfc483e3b30
{kind=link}
Увлекательная 4-серийная сага «Practical Monitoring with Prometheus & Grafana».
Часть 1: Installing Prometheus + Grafana via Helm in 5 Minutes
Часть 2: Using Prometheus blackbox exporter for free uptime checks
Часть 3: Applying simple statistics for anomaly detection using Prometheus
Часть 4: Securing Grafana with Identity-Award Proxy
Часть 1: Installing Prometheus + Grafana via Helm in 5 Minutes
Часть 2: Using Prometheus blackbox exporter for free uptime checks
Часть 3: Applying simple statistics for anomaly detection using Prometheus
Часть 4: Securing Grafana with Identity-Award Proxy
{kind=link}
А в этом репозитории одна штука, чтобы генерить дашборды Grafana из Python-скриптов. Полезно? Не то слово!
Lessons learned about monitoring the JVM in the era of containers
В этой статье об опыте использования бесплатных профилировщиков JVM VisualVM и Universal GC Log Analyzer.
В этой статье об опыте использования бесплатных профилировщиков JVM VisualVM и Universal GC Log Analyzer.
{kind=link}
How we scaled Graphite to 100,000 writes per second
В этой статье о вертикальном масштабировании вычислений до 100 000 операций записи в секунду.
А кто-то использует Graphite в своём стеке мониторинга?
👍 — использую
👎 — не использую
👀 — карандаши как-то не очень, обычно ручкой пользуюсь
В этой статье о вертикальном масштабировании вычислений до 100 000 операций записи в секунду.
А кто-то использует Graphite в своём стеке мониторинга?
👍 — использую
👎 — не использую
👀 — карандаши как-то не очень, обычно ручкой пользуюсь
{kind=link}
Forwarded from /usr/bin
В этой статье несколько слов о мониторинге контейнеров Docker при помощи docker stats и cAdvisor.
{kind=link}
How the cortex and thanos projects collaborate to make scaling prometheus better for all
Коллаборация Cortex и Thanos для масштабирования Prometheus (в блоге Grafana)
А ещё есть запись выступления «Two Households, Both Alike in Dignity: Cortex and Thanos» с PromCon 2019 (выступают сооснователи Cortex и Thanos Tom Wilkie и Bartek Plotka соответственно)
Коллаборация Cortex и Thanos для масштабирования Prometheus (в блоге Grafana)
А ещё есть запись выступления «Two Households, Both Alike in Dignity: Cortex and Thanos» с PromCon 2019 (выступают сооснователи Cortex и Thanos Tom Wilkie и Bartek Plotka соответственно)
Grafana Labs
How the Cortex and Thanos projects collaborate to make scaling Prometheus better for all | Grafana Labs
At PromCon Online, Marco Pracucci and Bartek Plotka talked about how Cortex and Thanos started to learn from and even influence each other – thanks to open source.
Monitoring Application Metrics With Nutanix Karbon
Пошаговое руководство по настройке кластера Karbon для мониторинга кластера и приложений и настройка представлений в Grafana.
Пошаговое руководство по настройке кластера Karbon для мониторинга кластера и приложений и настройка представлений в Grafana.