
Instana — система мониторинга микросервисных архитектур. Их основное преимущество — это один агент для всего стека технологий, которые им автоматически дискаверятся на сервере. Instana контрибьютит в репозитории решений, входящих в CNCF. И не только контрибьютит, но и использует. Например, под капотом, у них работает известный OpenTracing, есть встроенная интеграция с Jaeger и ещё много чего такого, что связывает их с открытыми решениями.
В этой статье на Medium о возможностях мониторинга кластера Kubernetes в Instana.
В этой статье на Medium о возможностях мониторинга кластера Kubernetes в Instana.
Ещё одно интересное выступление с GrafanacONline 2020 — «Prometheus rate queries in Grafana». В этом докладе инженер Grafana Labs Björn Rabenstein расскажет о работе с временными рядами Prometheus в Grafana, чтобы не пропустить проблемных ситуаций на графиках.
О других интересных выступлениях с GrafanacONline 2020 писал выше.
О других интересных выступлениях с GrafanacONline 2020 писал выше.
Grafana Labs
Prometheus rate queries in Grafana - GrafanaCONline
Which range to use in a Prometheus rate query is already a bit of rocket science. When Grafana enters the game to visualize the result of such a query, …
Sentry + React = сегодняшняя статья на Хабре про отлов ошибок в React при помощи Sentry.
Это продолжение предыдущей статьи о мониторинге JavaScript в Sentry.
Это продолжение предыдущей статьи о мониторинге JavaScript в Sentry.
Хабр
Sentry удаленный мониторинг багов в фронтенд приложениях React
Мы изучаем использование Sentry с React. Эта статья является частью серии, начинающейся с сообщения об ошибках Sentry на примере: Часть 1. Реализация React Сн...
Опубликованы видео и файлы с презентациями с Zabbix Meetup Online - Russia #2. В программе:
⚡️ Разработка плагинов для Zabbix Agent 2
⚡️ Мониторинг PostgreSQL c использованием Zabbix
⚡️ Решаем практические задачи мониторинга с помощью JavaScript
⚡️ Миграция с MySQL на PostgreSQL
⚡️ Разработка плагинов для Zabbix Agent 2
⚡️ Мониторинг PostgreSQL c использованием Zabbix
⚡️ Решаем практические задачи мониторинга с помощью JavaScript
⚡️ Миграция с MySQL на PostgreSQL
Zabbix
Zabbix Meetup Online - Russia #2
В этой статье 5 опенсорсных альтернатив Slack для группового чата. Эти чаты имеют развитые сообщества и много полезных плагинов. Например, непосредственно в чате, можно запрашивать представления из Grafana.
{kind=link}
Самый простой в мире дашборд kubernetes — k1s. В этой статье на Медиум чувак рассказывает про дашборд на bash-скрипте. Там же есть ссылка на репозиторий.
А вот подъехали видосы с прошедшей 25 июня конференции ElasticON. На ней сотрудники Elastic и приглашённые клиенты рассказывают о подходах к использованию Elastic Stack и кейсах.
Слышали про бесплатный инструмент автоматизации воркфлоу n8n.io? Это как Zapier или IFTTT, только энтерпрайзнее что ли. В своём блоге на Медиум они рассказывают о мониторинге и алертинге относительно БД Postgresql. Выглядит просто, но ничего ж не мешает использовать эту штуку для более масштабных задач автоматизации, верно?
Shell-operator — это инструмент для запуска произвольных скриптов по событиям в кластерах Kubernetes. Частным случаем таких произвольных скриптов является подписка на события через Kubernetes API и запуск хуков по таким событиям. А частным случаем запуска хуков является экспорт произвольных метрики для их дальнейшего scraping'а Prometheus’ом.
В этой статье об обновлениях shell-оператора, там же в конце статьи ссылки на описание этого инструмента.
В этой статье об обновлениях shell-оператора, там же в конце статьи ссылки на описание этого инструмента.
Хабр
Простое создание Kubernetes-операторов с shell-operator: прогресс проекта за год
Kubernetes-операторы — удобный механизм для расширения возможностей этой контейнерной платформы, по праву снискавший широкое признание в среде инженеров эксплу...
SRE: Observability: Metric Namespaces and Structures
В этой статье о тайном оружии SRE — древовидном структурировании метрик в Prometheus. На заметку тем, кто не структурирует.
В этой статье о тайном оружии SRE — древовидном структурировании метрик в Prometheus. На заметку тем, кто не структурирует.
{kind=link}
Как бороться с дублями в Elasticsearch при использовании FluentD читайте в этой статье на Хабре.
Хабр
Fluentd: почему важно настроить выходной буфер
В наше время невозможно представить проект на базе Kubernetes без стека ELK, с помощью которого сохраняются логи как приложений, так и системных компонентов кла...
Про Skydive — инструмент для визуализации сетевой топологии на основе netflow, я уже как-то писал. Сегодня на Хабре вышла статья о добавлении ноды в Skydive топологию вручную через Skydive client. Эта возможность появилась благодаря Node rule API, которая появилась начиная с версии 0.20
{kind=link}
{kind=link}
Для линукс-админов — An Introduction to File System Monitoring Tools.
В этой статье про утилиты inotifywait и iwatch
В этой статье про утилиты inotifywait и iwatch
Medium
An Introduction to File System Monitoring Tools
All about inotifywait and iwatch utilities
Centralize Your Docker Logging With FluentD
О том как взять FluentD и положить логи docker в одно место
О том как взять FluentD и положить логи docker в одно место
{kind=link}
Если хотите подробнее про FluentD — вот неплохая статья на том же Медиуме.
{kind=link}
{kind=link}
SRE: Performance Analysis: Tuning Methodology Using a Simple HTTP Webserver In Go
Методика работы SRE на примере тюнинга простого веб-сервера.
Методика работы SRE на примере тюнинга простого веб-сервера.
{kind=link}
Tracing and Observability
Небольшая, но достаточно подробная статья о том, как устроены tracing и observability.
Небольшая, но достаточно подробная статья о том, как устроены tracing и observability.
{kind=link}
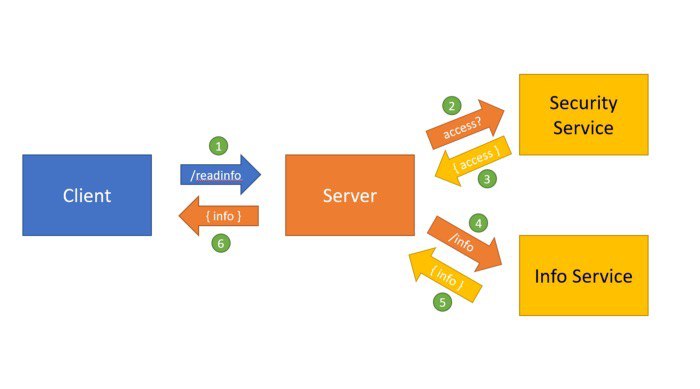
Для обеспечения высокой доступности мы используем два кластера K8s. Графики ниже показывают эти кластеры: region-1 и region-2. Это создает дополнительную сложность, когда речь идет об автомасштабировании, поскольку кластеры полностью разделены и не имеют общих метрик. Наш веб-сайт работает в режиме active-active и сбалансирован по нагрузке на оба региона.
Из-за проблемы в приложении инженеры по инфраструктуре перевели все запросы к приложению в один регион. Зеленая линия показывает общее количество запросов, которые обслуживает служба, а две другие относятся к каждому региону. Сразу после 16:20 произошло аварийное переключение: оранжевая линия соединилась с зеленой линией, а синяя линия, идущая в ноле, начала расти.
В этой статье об изменении подходов компании к алертингу после максимального масштабирования сервиса из-за нештатной ситуации.
Из-за проблемы в приложении инженеры по инфраструктуре перевели все запросы к приложению в один регион. Зеленая линия показывает общее количество запросов, которые обслуживает служба, а две другие относятся к каждому региону. Сразу после 16:20 произошло аварийное переключение: оранжевая линия соединилась с зеленой линией, а синяя линия, идущая в ноле, начала расти.
В этой статье об изменении подходов компании к алертингу после максимального масштабирования сервиса из-за нештатной ситуации.
Medium
Kubernetes Lessons in Alerting
Live issues are a great opportunity to learn and improve. Here’s what happened to us