
В мире сумасшедшее количество систем мониторинга. Постоянно появляются новые и все они чем-то да и отличаются. Но есть одна характеристика, которая свойственна любой системе мониторинга — место установки: облачная или локальная. Я сейчас про коммерческие системы. Извечный спор: какая лучше? Иногда (но не всегда) эти два подхода можно комбинировать и создать гибридного монстра. Однозначный совет или рекомендацию по выбору сложно дать. Могу поделиться одним наблюдением: если у вас есть локальная среда, это не значит, что нужно применять локальное решение для мониторинга. Очевидная вещь, правда, звучит странновато.
Серьёзное сомнение, которое может обуревать — а как же чувствительные данные, которые могут утечь к какой-то матери за пределы какого-то контура PCI DSS? Обычно, в облачной системе мониторинга предусмотрены такие сценарии, поэтому все чувствительные данные маскируются на уровне агента-сборщика и за пределы организации ни за что не попадут.
Все остальные сомнения касаются безопасности передачи и хранения данных мониторинга. Их можно рассеять рассказами о шифровании, многократном резервировании в датацентре с ядром такой системы и т.д. и т.п. У каждого такого облачного провайдера обычно есть специальная страница с такой информацией.
А теперь резко перейдём к преимуществам. Они, в целом, понятны, но всё же вот:
Стоимость. SaaS предлагает гораздо более низкую совокупную стоимость владения, за счёт времени, затрачиваемого на установку, обслуживание и модернизацию локальных решений для мониторинга.
Масштабирование. Локальные решения не всегда могут быстро и эффективно масштабироваться, чтобы справиться с чёрными пятницами и другими периодами пиковых нагрузок. Использование локальных решений означает избыточную мощность инфраструктуры в непиковые периоды и трату денег на это.
Быстрота разворачивания. SaaS разворачивается за часы или минуты в отличии от времени на настройку локального решения.
Обновления без даунтайма и изысканий. Когда у SaaS-решения появляется новый функционал, он тут становится доступным для использования. Локальные решения по мониторингу требуют тщательной подготовки к обновлению, времени на само обновление и дальнейший контроль в стиле «как бы чего не отвалилось».
Если будет нужен совет с выбором системы мониторинга — пишите в личку.
Серьёзное сомнение, которое может обуревать — а как же чувствительные данные, которые могут утечь к какой-то матери за пределы какого-то контура PCI DSS? Обычно, в облачной системе мониторинга предусмотрены такие сценарии, поэтому все чувствительные данные маскируются на уровне агента-сборщика и за пределы организации ни за что не попадут.
Все остальные сомнения касаются безопасности передачи и хранения данных мониторинга. Их можно рассеять рассказами о шифровании, многократном резервировании в датацентре с ядром такой системы и т.д. и т.п. У каждого такого облачного провайдера обычно есть специальная страница с такой информацией.
А теперь резко перейдём к преимуществам. Они, в целом, понятны, но всё же вот:
Стоимость. SaaS предлагает гораздо более низкую совокупную стоимость владения, за счёт времени, затрачиваемого на установку, обслуживание и модернизацию локальных решений для мониторинга.
Масштабирование. Локальные решения не всегда могут быстро и эффективно масштабироваться, чтобы справиться с чёрными пятницами и другими периодами пиковых нагрузок. Использование локальных решений означает избыточную мощность инфраструктуры в непиковые периоды и трату денег на это.
Быстрота разворачивания. SaaS разворачивается за часы или минуты в отличии от времени на настройку локального решения.
Обновления без даунтайма и изысканий. Когда у SaaS-решения появляется новый функционал, он тут становится доступным для использования. Локальные решения по мониторингу требуют тщательной подготовки к обновлению, времени на само обновление и дальнейший контроль в стиле «как бы чего не отвалилось».
Если будет нужен совет с выбором системы мониторинга — пишите в личку.
New Relic уже знает, что их объявили лидером квадранта Gartner по APM-решениям в 2020 году и 8 год подряд. Эту картинку они разместили вчера в своём фиде в линкедине. На сайте Gartner квадрант пока не опубликован, но, подозреваю, это будет сделано в ближайшую неделю.
Предлагаю вашему вниманию мой прошлогодний бриф на Хабре о квадранте APM за 2019 год. Среди лидеров 2019 года оказались Appdynamics, Dynatrace, New Relic и Broadcom (бывший CA). Последний почему-то не очень избалован вниманием на российском рынке.
А теперь вопрос: как изменится сектор с лидерами в этом году?
♾ — ничего не изменится.
➕ — добавится ещё один (или несколько) лидер.
➖ — один из лидеров 2019 года перестанет быть лидером в 2020 году.
🤷♂️ — я пользуюсь другим коммерческим/бесплатным решением и мне до 🔦 эти ваши APM.
Предлагаю вашему вниманию мой прошлогодний бриф на Хабре о квадранте APM за 2019 год. Среди лидеров 2019 года оказались Appdynamics, Dynatrace, New Relic и Broadcom (бывший CA). Последний почему-то не очень избалован вниманием на российском рынке.
А теперь вопрос: как изменится сектор с лидерами в этом году?
♾ — ничего не изменится.
➕ — добавится ещё один (или несколько) лидер.
➖ — один из лидеров 2019 года перестанет быть лидером в 2020 году.
🤷♂️ — я пользуюсь другим коммерческим/бесплатным решением и мне до 🔦 эти ваши APM.
{kind=link}
Чё там в линуксе за 60 секунд
Статья в техблоге Нетфликс о командах, которые дадут наиболее полное представление о состоянии линукс-сервера. Говорят, что выполняют их для диагностики непосредственно на сервере в результате получения алерта и утверждают, что весь список можно осмысленно пройти за 60 секунд. Попробуете?
Полный список 60-секундных команд:
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
👍 — успел за 60 секунд
👎 — не успел за 60 секунд
👀 — метрики в моём мониторинге мне и так всё скажут, заходить на сервер для диагностики смысла не вижу
Статья в техблоге Нетфликс о командах, которые дадут наиболее полное представление о состоянии линукс-сервера. Говорят, что выполняют их для диагностики непосредственно на сервере в результате получения алерта и утверждают, что весь список можно осмысленно пройти за 60 секунд. Попробуете?
Полный список 60-секундных команд:
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
👍 — успел за 60 секунд
👎 — не успел за 60 секунд
👀 — метрики в моём мониторинге мне и так всё скажут, заходить на сервер для диагностики смысла не вижу
Medium
Linux Performance Analysis in 60,000 Milliseconds
You log in to a Linux server with a performance issue: what do you check in the first minute?
Кир Шатров в своём блоге рассказывает о подходе к повышению информативности трейса запросов в MySQL с помощью добавления метаданных к запросу.
Было: SELECT * FROM users WHERE id=?
Станет: SELECT * FROM users WHERE id=? /* controller:users,action:show,method:find_user,api_client_id:42 */
Было: SELECT * FROM users WHERE id=?
Станет: SELECT * FROM users WHERE id=? /* controller:users,action:show,method:find_user,api_client_id:42 */
Kir Shatrov
Scaling MySQL stack, ep. 3: Observability
I’ve spent a good part of last year collaborating with different people at work on the theme of scaling our MySQL stack to the next level. For background, like many other companies founded in the mid-2000s (Facebook, YouTube, GitHub, Basecamp), Shopify is…
Теперь (хоть и временно) бесплатно
Некоторые вендоры запустили специальные программы, которые позволяют пользоваться бесплатно их решениями длительное время. Если хотели попробовать и не хотелось размениваться на 14 дней, то вот сейчас самое время.
BigPanda — облачное AIOps решение для корреляции событий и автоматизации обработки инцидентов. Дают 90 дней полной версии (со всеми доступными интеграциями) по программе «IT Ops from home». Сюда же включена вендорская техническая поддержка нп этот период и бесплатный онлайн-тренинг. Регистрация в программе.
Appdynamics — инструмент для мониторинга производительности приложений (APM). В рамках программы «COVID-19 Assist Program» даёт пользоваться облачной версией своей платформы абсолютно бесплатно до 15 июля 2020 года. Кроме этого они предоставляют доступ к AppDynamics Premium University до 31 мая 2020 года. Неплохя возможность поближе узнать продукт. Работает только для новых пользователей. Регистрация в программе.
Dynatrace — инструмент для мониторинга производительности приложений (APM). Вендор включил «COVID-19 Continuity Support» и даёт свои продукты в бесплатное пользование до 19 мая 2020. Регистрация в программе.
Некоторые вендоры запустили специальные программы, которые позволяют пользоваться бесплатно их решениями длительное время. Если хотели попробовать и не хотелось размениваться на 14 дней, то вот сейчас самое время.
BigPanda — облачное AIOps решение для корреляции событий и автоматизации обработки инцидентов. Дают 90 дней полной версии (со всеми доступными интеграциями) по программе «IT Ops from home». Сюда же включена вендорская техническая поддержка нп этот период и бесплатный онлайн-тренинг. Регистрация в программе.
Appdynamics — инструмент для мониторинга производительности приложений (APM). В рамках программы «COVID-19 Assist Program» даёт пользоваться облачной версией своей платформы абсолютно бесплатно до 15 июля 2020 года. Кроме этого они предоставляют доступ к AppDynamics Premium University до 31 мая 2020 года. Неплохя возможность поближе узнать продукт. Работает только для новых пользователей. Регистрация в программе.
Dynatrace — инструмент для мониторинга производительности приложений (APM). Вендор включил «COVID-19 Continuity Support» и даёт свои продукты в бесплатное пользование до 19 мая 2020. Регистрация в программе.
{kind=link}
9 платных, условно-бесплатных и бесплатных программ для трекинга кода приложений. Публиковал эту статью почти 2 года назад, а список по-прежнему актуален.
Хабр
9 платных, условно-бесплатных и бесплатных программ для трекинга кода приложений
Трекинг кода must-have в среде разработки. Но вот насколько нужен этот же инструмент в продуктиве? Тот, кто лишь кропотливо собирает логи скажет «ну его нафиг, мой ELK меня не подводит» и будет...
❤1
Статья с готовым рецептом приготовления мониторинга MySQL в Grafana
Мониторинг производительности MySQL для Grafana на изичах за 20 минут.
Мониторинг производительности MySQL для Grafana на изичах за 20 минут.
{kind=link}
О том, как организовать оперативный мониторинг ошибок и событий появляющихся в журнале PostgreSQL используя Prometheus и экспортер метрик grok_exporter.
Мониторинг ошибок и событий в журнале PostgreSQL (grok_exporter).
Мониторинг ошибок и событий в журнале PostgreSQL (grok_exporter).
Хабр
Мониторинг ошибок и событий в журнале PostgreSQL (grok_exporter)
Доброго дня, коллеги и хаброчитатели! Сегодня, хотел бы поделиться с Вами небольшой заметкой о том, как можно организовать оперативный мониторинг ошибок и событи...
К 2025 году 50% новых облачных приложений мониторинга будут использовать инструментарий с открытым исходным кодом вместо вендорских агентов, для повышения совместимости, по сравнению с 5% в 2019 году.
И, действительно, большинство вендоров коммерческих решений постепенно добавляют поддержку открытых решений. Опубликовал на Хабре краткое описание основных моментов в свежем отчёте Gartner 2020 года по APM-системам.
И, действительно, большинство вендоров коммерческих решений постепенно добавляют поддержку открытых решений. Опубликовал на Хабре краткое описание основных моментов в свежем отчёте Gartner 2020 года по APM-системам.
Хабр
Квадрант Gartner 2020 года по решениям для мониторинга приложений (APM)
Несколько дней назад Gartner опубликовал новый отчёт по APM-системам (Application Performance Management). У себя в телеграм-канале я задавал вопрос подписчикам об их прогнозах по лидерам этого...
Выступление Goutham Veeramachaneni на PromCon EU 2019 в Мюнхене. Рассказывает о союзе Промитиуса и Егеря, который как бы случился на небесах (тема выступления Prometheus and Jaeger: A Match Made in Heaven!). Рассказывает о том как они проверяют влияние на приложение после выкатывания релиза, используя Jaeger и Prometheus, об использование метаданных для дальнейшей фильтрации трассировок и обо многом другом. По ссылке видео и слайды.
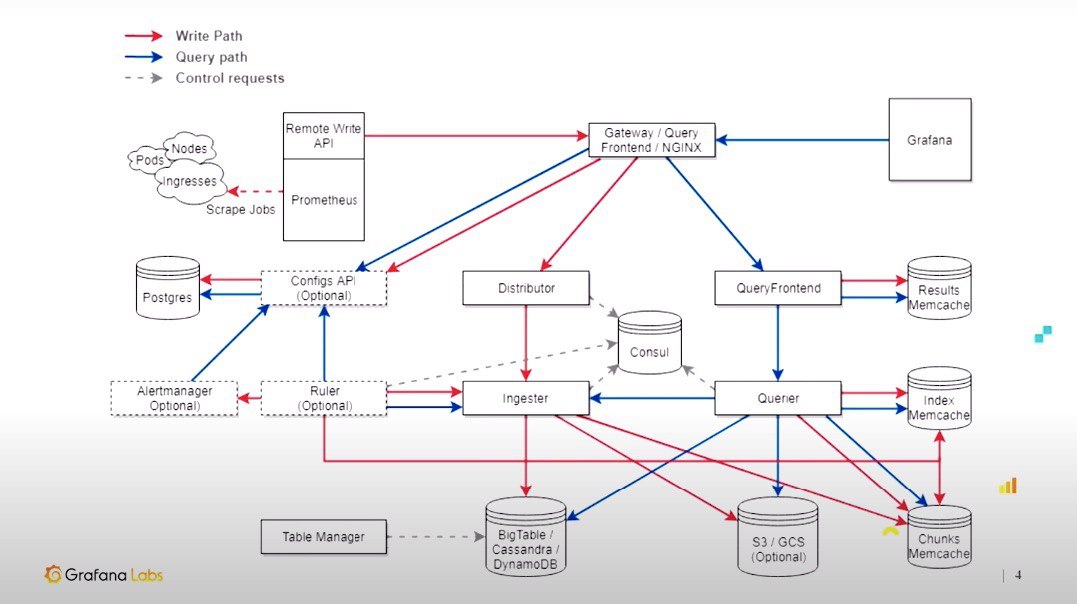{kind=link}
На Медиуме есть автор Стив Мушеро (Steve Mushero), который много пишет о SRE и о подходах к мониторингу по этой методологии. Здесь он пишет про золотые сигналы SRE (Latency, Traffic, Errors, and Saturation), методики USE и RED, но есть и статьи о метриках, которые он рекомендует собирать в контексте SRE по конкретным элементам систем. Ниже подборка таких статей.
Метрики балансировщика (AWS ALB/ELB, HAProxy)
Метрики веб-серверов (Apache & Nginx)
Метрики серверов приложений (PHP, FPM, Java, Ruby, Node, Go, Python)
Метрики серверов баз данных (MySQL & AWS RDS и AWS Aurora)
Метрики Линукс-серверов (Linux)
Метрики балансировщика (AWS ALB/ELB, HAProxy)
Метрики веб-серверов (Apache & Nginx)
Метрики серверов приложений (PHP, FPM, Java, Ruby, Node, Go, Python)
Метрики серверов баз данных (MySQL & AWS RDS и AWS Aurora)
Метрики Линукс-серверов (Linux)
{kind=link}
Обнаружение аномалий в Prometheus — выступление Andrew Newdigate на Monitorama PDX 2019. Расскажет о своём опыте и подходах. А здесь слайды презентации.
{kind=link}
Кто-то слышал про колоночную БД Apache Druid? Она из коробки поддерживает ролл-апы (это усреднение данных за периоды, чтобы не хранить длительное время сырые данные) для экономии места в БД и имеет немудрёный скейлинг (простое добавление нод) и . В этой статье на Медиуме пишут про совместное использование этой с БД с открытой BI-системой Superset. В итоге получается производительное хранилище и гибкие дашборды.
Страница проекта Druid
Страница проекта Superset
Примеры визуализаций в Superset
P.S. На основе Druid работает аналитическая платформа Imply.
Страница проекта Druid
Страница проекта Superset
Примеры визуализаций в Superset
P.S. На основе Druid работает аналитическая платформа Imply.
{kind=link}
Регистрируйтесь на онлайн-митап Zabbix «Что нового в Zabbix 5.0». Среди выступающих Алексей Владышев, который расскажет о новинках в Zabbix 5.0. Участие бесплатное.
Регистрация и программа мероприятия
Регистрация и программа мероприятия
Eventbrite
Zabbix Meetup Online - Что нового в Zabbix 5.0
На этом видео Nic Jansma рассказывает о бесплатном и открытом инструменте для мониторинга пользвательских транзакций (он же RUM он же Real User Monitoring) Boomerang от Akamai.
Boomerang представляет из себя JavaScript-библиотеку, которая встраивается в код веб-страницы, выполняет измерения времени загрузки элементов страницы и отслеживает пользовательский опыт. По-моему самый лучший способ мониторинга это именно наблюдение за пользовательским опытом.
Репозиторий Boomerang на Github
Выступление было на конференции открытых решений Fosdem 2020. Да, сейчас трудно поверить, что в 2020 могут быть какие-то офлайн конференции.
Boomerang представляет из себя JavaScript-библиотеку, которая встраивается в код веб-страницы, выполняет измерения времени загрузки элементов страницы и отслеживает пользовательский опыт. По-моему самый лучший способ мониторинга это именно наблюдение за пользовательским опытом.
Репозиторий Boomerang на Github
Выступление было на конференции открытых решений Fosdem 2020. Да, сейчас трудно поверить, что в 2020 могут быть какие-то офлайн конференции.
{kind=link}
Наблюдаю за развитием APM-решения Instana уже давно. Его основали выходцы из немецкого интегратора, которые занимались (работая в этом самом интеграторе) другим APM-решением Appdynamics. Появилась идея сделать круче, лучше, задорнее, веселее и стать сильным конкурентом. В этом году их оценил Gartner и включил в свой магический квадрант APM-решений. Можно порадоваться за ребят.
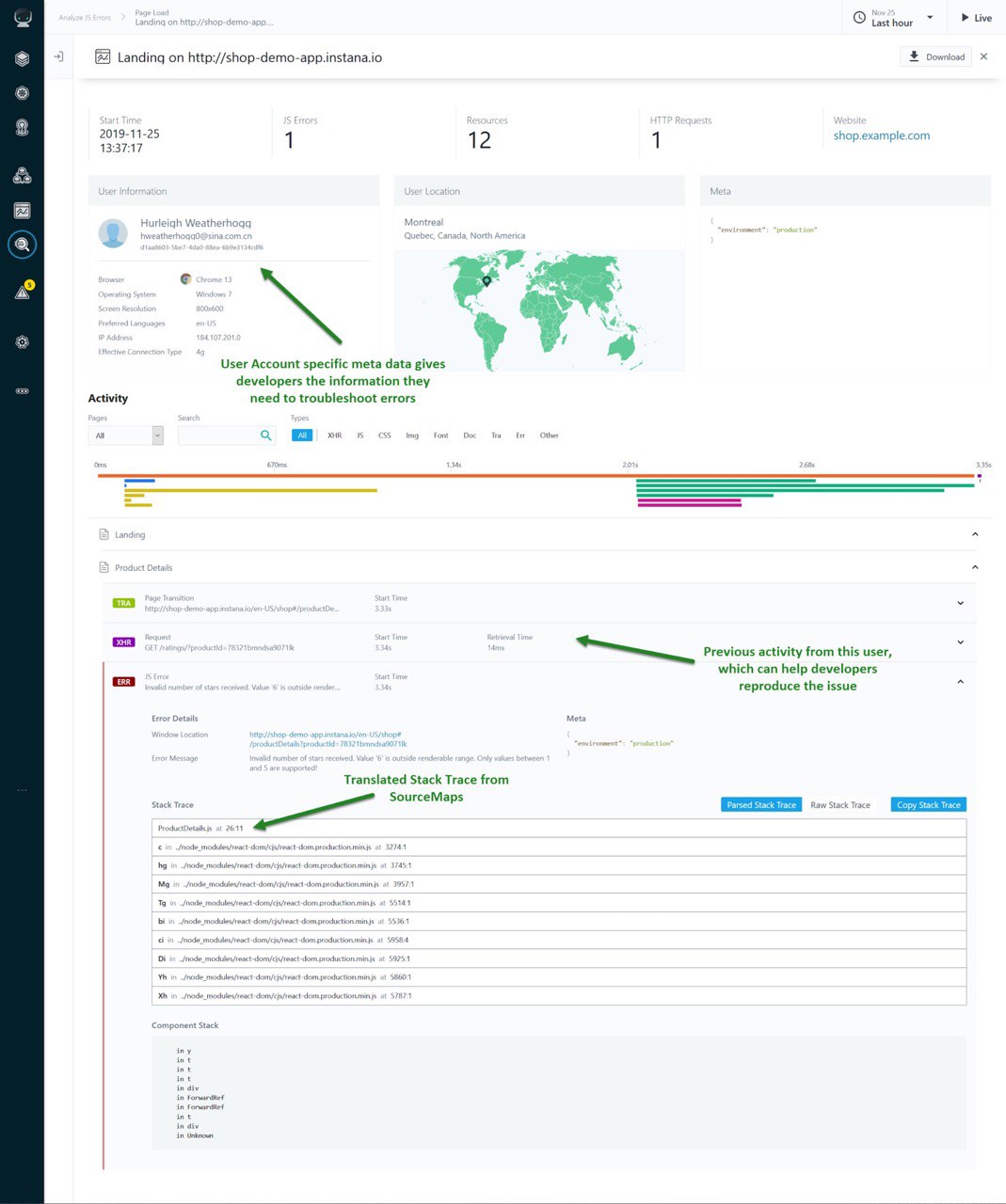
В продолжение вчерашней темы с RUM. В этой статье от Mozilla для веб-разработчиков, рассказывают о возможностях просмотра source map в браузере Firefox (если разработчики добавили соответствующую строку в код страницы). Когда строка с JS для мониторинга уже инжектирована в веб-проект, диагностика проблем с производительностью сильно упростится, если этот JS умеет распознавать source map и работать с конечными скриптами. В своём блоге Instana пишет о преимуществах наличия в коде source maps и возможностях работы с ними в Instana.
Если нужна помощь с подбором решения для мониторинга (APM или неважно какого) — пишите в личку.
Расскажите, используете ли в своём стеке мониторинга инжекцию JS-кода с мониторингом в веб-страницы. Неважно, коммерческое (Instana, Appdynamics, NewRelic, Ключ-Астром) решение или открытое (как вчерашний Boomerang)
👍 — использую
👎 — не использую, но пора бы начать
👀 — нет необходимости в таком способе мониторинга
В продолжение вчерашней темы с RUM. В этой статье от Mozilla для веб-разработчиков, рассказывают о возможностях просмотра source map в браузере Firefox (если разработчики добавили соответствующую строку в код страницы). Когда строка с JS для мониторинга уже инжектирована в веб-проект, диагностика проблем с производительностью сильно упростится, если этот JS умеет распознавать source map и работать с конечными скриптами. В своём блоге Instana пишет о преимуществах наличия в коде source maps и возможностях работы с ними в Instana.
Если нужна помощь с подбором решения для мониторинга (APM или неважно какого) — пишите в личку.
Расскажите, используете ли в своём стеке мониторинга инжекцию JS-кода с мониторингом в веб-страницы. Неважно, коммерческое (Instana, Appdynamics, NewRelic, Ключ-Астром) решение или открытое (как вчерашний Boomerang)
👍 — использую
👎 — не использую, но пора бы начать
👀 — нет необходимости в таком способе мониторинга
{kind=link}
Вместе с уже известным квадрантом по APM-решениям, Gartner также выкатил отчёт по критичным возможностям этих же решений. В этом отчёте те же самые участники квадранта APM сравниваются по следующим критериям:
⚡️ Business analysis
⚡️ IT services monitoring
⚡️ Root cause analysis
⚡️ Anomaly detection
⚡️ Distributed profiling
⚡️ Application debugging
в контексте их применения для следующих целей:
⚡️ IT operations
⚡️ DevOps release
⚡️ Application support
⚡️ Application development
⚡️ Application owner or line of business (LOB)
⚡️ CloudOps
Если вы сейчас выбираете APM-решение, это сравнение может быть полезным для формирования шорт-листа.
⚡️ Business analysis
⚡️ IT services monitoring
⚡️ Root cause analysis
⚡️ Anomaly detection
⚡️ Distributed profiling
⚡️ Application debugging
в контексте их применения для следующих целей:
⚡️ IT operations
⚡️ DevOps release
⚡️ Application support
⚡️ Application development
⚡️ Application owner or line of business (LOB)
⚡️ CloudOps
Если вы сейчас выбираете APM-решение, это сравнение может быть полезным для формирования шорт-листа.
Что нового в Zabbix 5.0?
По итогам прошедшего сегодня митапа, оказалось много приятных улучшений. Из ключевого:
⚡️ официальная поддержка Zabbix Agent2 (агент на Go) для Windows и Linux
⚡️ улучение инструментов визуализации (+ экспорт в PNG)
⚡️ фильтр по тегам
⚡️ массовое изменение макросов для хостов &
шаблонов
⚡️ триггерные выражения работают с текстом
⚡️ обнаружение счётчиков Windows и сенсоров IPMI
⚡️ макросы для прототипов хостов
⚡️ совместимость с Float64 от Prometheus
⚡️ исключения из правил LLD
Более подробно в презентации следом. Ещё больше презентаций на странице митапа.
По итогам прошедшего сегодня митапа, оказалось много приятных улучшений. Из ключевого:
⚡️ официальная поддержка Zabbix Agent2 (агент на Go) для Windows и Linux
⚡️ улучение инструментов визуализации (+ экспорт в PNG)
⚡️ фильтр по тегам
⚡️ массовое изменение макросов для хостов &
шаблонов
⚡️ триггерные выражения работают с текстом
⚡️ обнаружение счётчиков Windows и сенсоров IPMI
⚡️ макросы для прототипов хостов
⚡️ совместимость с Float64 от Prometheus
⚡️ исключения из правил LLD
Более подробно в презентации следом. Ещё больше презентаций на странице митапа.
{kind=link}
Whats_New_in_Zabbix_5.0_RU.pdf
2.3 MB
Презентация «Что нового в Zabbix 5.0»
Смотрю я на этот репозиторий и радуюсь — столько полезного о SRE можно узнать.
GitHub
GitHub - zeroc0d3lab/awesome-sre: A curated list of awesome Site Reliability and Production Engineering resources.
A curated list of awesome Site Reliability and Production Engineering resources. - zeroc0d3lab/awesome-sre