
#sql #databases
SQL Tuning by Dan Tow (O’Reilly)
Базы данных стараются кэшировать часто используемые куски данных (единообразного размера, по 2—16 Кб), копируя их с диска к себе в буфер. Буфер доступен всем сессиям одновременно, он общий на всех.
❓Ещё бы понимать хорошенечко, как устроены сессии — это туннель соединения юзера (приложения) с БД, в котором гоняются транзакции? А что это за протокол на уровне БД, это ведь не всегда TCP? Короче, хз, не до конца понимаю, чё там.
Буфер, как и у многих других штук, устроен по принципу LRU cache (от Least Recently Used): удаляет объекты, которые дольше всего не использовались, за ними снова придётся идти на диск. В целом, операции чтения с диска дороже, поэтому хорошо, если данные кэшируются удачно.
Маленькие таблицы (меньше 10к записей) часто кэшируются полностью, если они нужны, а если не очень, то даже это неважно, потому что достаточно нескольких физических запросов к диску, чтобы быстро всё поместить в логический кэш, да и вообще, кажется, с маленькими таблицами БД умеют работать на ура. Физический I/O обычно дополнительно оптимизируется операционной системой.
У таблиц бывает разный физический layout, в зависимости от того, как часто их данные архивируются/purge’атся. Кажется, большинство таблиц в мире работают по принципу перманентного роста: никто ничего из них не убирает, так как боятся потерять что-то нужное, и таблицы тупо растут. При этом новые строки чаще всего нужны чаще, чем старые, и они чаще попадают в кэш. А так как они записываются поступательно, то склонны быть физически сгруппированы на диске, что хорошо и удобно для кэша. Труднее всего, когда purge делается не по принципу возраста данных, тогда очищаемые строки освобождают случайные куски в памяти, и нужные (“горячие”) строки оказываются понатыканы в разных местах — при обращении к диску их можно долго собирать-читать.
High-water mark (отметка, до которой место принадлежит таблице) дропается при TRUNCATE (про Postgres это надо бы проверить, но наверняка это тоже так). DELETE, видимо, освобождает место стертых записей под новые записи, но, естественно, не может вот так просто взять и понизить high-water mark.
SQL Tuning by Dan Tow (O’Reilly)
Базы данных стараются кэшировать часто используемые куски данных (единообразного размера, по 2—16 Кб), копируя их с диска к себе в буфер. Буфер доступен всем сессиям одновременно, он общий на всех.
❓Ещё бы понимать хорошенечко, как устроены сессии — это туннель соединения юзера (приложения) с БД, в котором гоняются транзакции? А что это за протокол на уровне БД, это ведь не всегда TCP? Короче, хз, не до конца понимаю, чё там.
Буфер, как и у многих других штук, устроен по принципу LRU cache (от Least Recently Used): удаляет объекты, которые дольше всего не использовались, за ними снова придётся идти на диск. В целом, операции чтения с диска дороже, поэтому хорошо, если данные кэшируются удачно.
Маленькие таблицы (меньше 10к записей) часто кэшируются полностью, если они нужны, а если не очень, то даже это неважно, потому что достаточно нескольких физических запросов к диску, чтобы быстро всё поместить в логический кэш, да и вообще, кажется, с маленькими таблицами БД умеют работать на ура. Физический I/O обычно дополнительно оптимизируется операционной системой.
У таблиц бывает разный физический layout, в зависимости от того, как часто их данные архивируются/purge’атся. Кажется, большинство таблиц в мире работают по принципу перманентного роста: никто ничего из них не убирает, так как боятся потерять что-то нужное, и таблицы тупо растут. При этом новые строки чаще всего нужны чаще, чем старые, и они чаще попадают в кэш. А так как они записываются поступательно, то склонны быть физически сгруппированы на диске, что хорошо и удобно для кэша. Труднее всего, когда purge делается не по принципу возраста данных, тогда очищаемые строки освобождают случайные куски в памяти, и нужные (“горячие”) строки оказываются понатыканы в разных местах — при обращении к диску их можно долго собирать-читать.
High-water mark (отметка, до которой место принадлежит таблице) дропается при TRUNCATE (про Postgres это надо бы проверить, но наверняка это тоже так). DELETE, видимо, освобождает место стертых записей под новые записи, но, естественно, не может вот так просто взять и понизить high-water mark.
#sql #databases #индексы #indexes
🗄🧶🗃
Дальше Дэн пересказывает что-то похожее на документацию Оракла про индексы.
1) Индексы могут покрывать не все строки таблицы, — например, если индексируемое поле может содержать NULL. Поэтому понятие строки таблицы и индексированной строки не взаимозаменяемы.
2) Чаще всего индекс — это b-tree индекс (дерево индексакции сбалансированной глубины), примерно по триста промежутков на один уровень. То есть корень индекса содержит указатели на начало и конец трёхсот промежутков отсортированных индексируемых значений, каждый промежуток своего уровня в свою очередь покрывает триста промежутков внутри себя, и так далее, пока не достигается уровень указателей на конкретные индексируемые блоки памяти со значениями.
3) В данном случае то, что мы находим, двигаясь по уровням индекса, будет парой адреса блока в памяти и номера строки. В оракле (?) эта пара называется называется rowid. Индексы используют именно rowid для того, чтобы указывать на строки индексируемой таблицы.
4) Если условие подразумевает, что может понадобиться вернуть не одну, а несколько строк из листьев, то БД делает index range scan по блокам памяти найденных листьев и их значениям. Листья, кажется, содержат уже и значения индексируемых строк, а не только rowid, и эти значения уже отсортированы, собственно, по индексу. Так что сначала БД делает обход по дереву, находит нужный лист, дальше делает обход по значениям листа.
5) Индексы чаще всего покрывают самые часто используемые части таблиц, так что обычно у них хороший cache-hit ratio (соотношение частоты использования логического буфера к количеству нежелательных обращений к диску). Так что обычно большую часть стоимости исполнения запроса организует физическое чтение данных именно из самих таблиц. (Как вообще переводят cost?)
6) При этом просто так навешивать индексы туда-сюда не стоит, так как это может сильно повысить стоимость операций UPDATE/INSERT/DELETE. Самая дорогая операция для индексов — это UPDATE, так как в индексе надо сначала удалить старое значение, затем добавить новое, то это для индекса это целых цве операции. Удаления тоже могут снизить эффективность индексов.
7) Есть всякие более экзотические штуки, которые используются в конкретных применениях, когда условия подобрались именно для них. Партиционированные таблицы, кластера и т.д. Битмапные индексы, например, хороши именно для АХД, когда данные в основном используются для чтения, а потом ночью обновляются.
🗄🧶🗃
Дальше Дэн пересказывает что-то похожее на документацию Оракла про индексы.
1) Индексы могут покрывать не все строки таблицы, — например, если индексируемое поле может содержать NULL. Поэтому понятие строки таблицы и индексированной строки не взаимозаменяемы.
2) Чаще всего индекс — это b-tree индекс (дерево индексакции сбалансированной глубины), примерно по триста промежутков на один уровень. То есть корень индекса содержит указатели на начало и конец трёхсот промежутков отсортированных индексируемых значений, каждый промежуток своего уровня в свою очередь покрывает триста промежутков внутри себя, и так далее, пока не достигается уровень указателей на конкретные индексируемые блоки памяти со значениями.
3) В данном случае то, что мы находим, двигаясь по уровням индекса, будет парой адреса блока в памяти и номера строки. В оракле (?) эта пара называется называется rowid. Индексы используют именно rowid для того, чтобы указывать на строки индексируемой таблицы.
4) Если условие подразумевает, что может понадобиться вернуть не одну, а несколько строк из листьев, то БД делает index range scan по блокам памяти найденных листьев и их значениям. Листья, кажется, содержат уже и значения индексируемых строк, а не только rowid, и эти значения уже отсортированы, собственно, по индексу. Так что сначала БД делает обход по дереву, находит нужный лист, дальше делает обход по значениям листа.
5) Индексы чаще всего покрывают самые часто используемые части таблиц, так что обычно у них хороший cache-hit ratio (соотношение частоты использования логического буфера к количеству нежелательных обращений к диску). Так что обычно большую часть стоимости исполнения запроса организует физическое чтение данных именно из самих таблиц. (Как вообще переводят cost?)
6) При этом просто так навешивать индексы туда-сюда не стоит, так как это может сильно повысить стоимость операций UPDATE/INSERT/DELETE. Самая дорогая операция для индексов — это UPDATE, так как в индексе надо сначала удалить старое значение, затем добавить новое, то это для индекса это целых цве операции. Удаления тоже могут снизить эффективность индексов.
7) Есть всякие более экзотические штуки, которые используются в конкретных применениях, когда условия подобрались именно для них. Партиционированные таблицы, кластера и т.д. Битмапные индексы, например, хороши именно для АХД, когда данные в основном используются для чтения, а потом ночью обновляются.
#sql #databases
🌹⚾️🚏
SQL Tuning by Dan Tow (O’Reilly)
• Чаще всего СУБД сама догадается использовать индекс там, где он есть и где это удобно. Но при этом иногда она делает неверный выбор, об этом будет дальше.
• Значения границ промежутков индекса чаще всего уже закэшированы.
• Сами проиндексированные значения тоже чаще закэшированы, чем остальные.
• Index scans анализируют небольшую часть данных из блока памяти — только те строки, которые нужны, а не вообще все строки в блоке памяти. Это сокращает вычислительные затраты процессора.
• Запросы, которые используют чтение по индексу (index scans), лучше масштабируются при росте таблицы — по понятной причине.
• Неважно, насколько огромна таблица, если на ней есть индекс, то можно по умолчанию предполагать, что он будет закэширован.
• При Full table scan СУБД будут запрашивать данные с диска большими кусками, а не блоками, как при индексе, что тоже логично, так как СУБД уже знает, что ей все равно надо будет вытащить всё.
• Итоговая стоимость полного скана таблицы — в процессорной вычислительной нагрузке, так как проверяться на соответствие условиям будут все записи.
• Но при этом если вам нужно получить большой кусок большой таблицы (больше 20%), то full table scan вполне имеет смысл.
• В остальных случаях лучше стараться использовать индекс.
• Если вдруг вам нужно так много данных, это часто может оказаться неверным с точки зрения бизнес-логики, если это пользовательское приложение. В таких случаях часто стоит вернуться к осознанию бизнес-логики и постараться использовать индексы и меньше данных.
• Оптимизатор постарается сам принять верное решение о том, какой метод поиска использовать, но он не всегда угадывает верно.
📒 Дальше Дэн круто описывает, как лично он принимает решение о том, какой scan использовать:
Он просто профилирует время исполнения обоих вариантов, при этом делая паузу между ними, чтобы не было ситуации, что прогон первого варианта помещает данные в горячий кэш, за счет чего второй эксперимент может пройти гораздо быстрее. Обычно Дэн прогоняет каждый метод скана дважды и сравнивает результаты вторых прогонов каждого. Если результаты почти одинаковые, он повторяет эксперименты, выжидая не меньше десяти минут между ними.
При этом, если разница действительно невелика, то управлять execution plan'ом запроса довольно бессмысленно.
🌹⚾️🚏
SQL Tuning by Dan Tow (O’Reilly)
• Чаще всего СУБД сама догадается использовать индекс там, где он есть и где это удобно. Но при этом иногда она делает неверный выбор, об этом будет дальше.
• Значения границ промежутков индекса чаще всего уже закэшированы.
• Сами проиндексированные значения тоже чаще закэшированы, чем остальные.
• Index scans анализируют небольшую часть данных из блока памяти — только те строки, которые нужны, а не вообще все строки в блоке памяти. Это сокращает вычислительные затраты процессора.
• Запросы, которые используют чтение по индексу (index scans), лучше масштабируются при росте таблицы — по понятной причине.
• Неважно, насколько огромна таблица, если на ней есть индекс, то можно по умолчанию предполагать, что он будет закэширован.
• При Full table scan СУБД будут запрашивать данные с диска большими кусками, а не блоками, как при индексе, что тоже логично, так как СУБД уже знает, что ей все равно надо будет вытащить всё.
• Итоговая стоимость полного скана таблицы — в процессорной вычислительной нагрузке, так как проверяться на соответствие условиям будут все записи.
• Но при этом если вам нужно получить большой кусок большой таблицы (больше 20%), то full table scan вполне имеет смысл.
• В остальных случаях лучше стараться использовать индекс.
• Если вдруг вам нужно так много данных, это часто может оказаться неверным с точки зрения бизнес-логики, если это пользовательское приложение. В таких случаях часто стоит вернуться к осознанию бизнес-логики и постараться использовать индексы и меньше данных.
• Оптимизатор постарается сам принять верное решение о том, какой метод поиска использовать, но он не всегда угадывает верно.
📒 Дальше Дэн круто описывает, как лично он принимает решение о том, какой scan использовать:
Он просто профилирует время исполнения обоих вариантов, при этом делая паузу между ними, чтобы не было ситуации, что прогон первого варианта помещает данные в горячий кэш, за счет чего второй эксперимент может пройти гораздо быстрее. Обычно Дэн прогоняет каждый метод скана дважды и сравнивает результаты вторых прогонов каждого. Если результаты почти одинаковые, он повторяет эксперименты, выжидая не меньше десяти минут между ними.
При этом, если разница действительно невелика, то управлять execution plan'ом запроса довольно бессмысленно.
⏹◀️⬅️⬅️⬅️⬅️⬅️↔️➡️➡️➡️➡️➡️▶️
#крик_утки
Боже, как медленно я читаю книгу про оптимизацию запросов; боже, пусть резиновая утка моего канала станет счастливее.
🔽⏬🔽⏬🔽⏬⏹⏹⏬🔽⏬🔽⏬🔽
#крик_утки
Боже, как медленно я читаю книгу про оптимизацию запросов; боже, пусть резиновая утка моего канала станет счастливее.
🔽⏬🔽⏬🔽⏬⏹⏹⏬🔽⏬🔽⏬🔽
🌚
Короче. В разных источниках парни называют селективностью то общее количество строк, которое вернётся, держа в уме общее количество строк в таблице вообще. Тогда единица — это прекрасная селективность. И двойка тоже.
Другие же авторы, например, Дэн, сразу используют количество строк в таблице как знаменатель, и тогда хорошая селективность стремится к нулю.
🍘
Короче. В разных источниках парни называют селективностью то общее количество строк, которое вернётся, держа в уме общее количество строк в таблице вообще. Тогда единица — это прекрасная селективность. И двойка тоже.
Другие же авторы, например, Дэн, сразу используют количество строк в таблице как знаменатель, и тогда хорошая селективность стремится к нулю.
🍘
Это был показ плёночной версии фильма Метрополис на закрытой станции метро «Деловой Центр» Солнцевской линии с живой музыкой от Саши Елиной и Ивана Бушуева.
#moire_experience
#moire_experience
📄 SQL Tuning by Dan Tow (O'Reilly)
Не все предикаты одинаково эффективны с точки зрения запуска index range scan. Оператор неравенства (!=, <>) чаще всего не помогает установить, какой промежуток от индекса требуется получить, и поэтому не повышает скорость исполнения запроса. Если смешивать такие предикаты с предикатами, которые могут запустить определение нужного индексного промежутка, то, так как is NULL либо неравенство все равно требует полного скана, селективность не улучшится.
При этом главным является улучшить селективность на самой таблице, а не на ее индексе, так как за одно считывание СУБД получает около 300 промежутков индекса, но за одно считавание в таблице – всего одну строчку.
Не все предикаты одинаково эффективны с точки зрения запуска index range scan. Оператор неравенства (!=, <>) чаще всего не помогает установить, какой промежуток от индекса требуется получить, и поэтому не повышает скорость исполнения запроса. Если смешивать такие предикаты с предикатами, которые могут запустить определение нужного индексного промежутка, то, так как is NULL либо неравенство все равно требует полного скана, селективность не улучшится.
При этом главным является улучшить селективность на самой таблице, а не на ее индексе, так как за одно считывание СУБД получает около 300 промежутков индекса, но за одно считавание в таблице – всего одну строчку.
♠️ SQL Tuning by Dan Tow (O’Reilly)
#sql #databases #selectivity
Селективность условия выборки по промежутку индекса — это доля строк таблицы, которую проверяет СУБД, пока сканирует индекс. При этом у условия не всегда есть верхняя или нижняя граница. Например, предикат
Даже если у нас есть высоко селективный предикат по проиндексированной колонке, всё равно может случиться так, что использование индекса будет неэффективным. Пример: использование в предикате функций. Функцию будет сложно преобразовать в условие для поиска по индексу. Большинство СУБД не будут даже пробовать. Исключением являются оракловские функционированные индексы, когда к значению уже заранее применена конкретная функция.
Другой пример, выключающий индекс из обработки, — неявное сравнение разных типов данных:
🧶🧶 > 🧶 👍
🧶 = 🧵 👎
Даже сравнивая числа с числами, надо держать в уме, какие именно числа мы сравниваем. У разных вендоров разные реализации численных типов, но сравнение integer с decimal может оказаться проблемой для итоговой производительности и выключать использование индекса.
Это же касается эффективных быстрых джойнов. Надо следить, чтобы внешний ключ был того же типа, что и первичный. В идеале это должно достигаться не приведением типов, а правильным дизайном базы данных.
Ещё пример неудачной попытки использовать индекс:
Это не может помочь, так как не задает ни начало, ни конец индексового промежутка для скана, и надо искать по всем записям.
#sql #databases #selectivity
Селективность условия выборки по промежутку индекса — это доля строк таблицы, которую проверяет СУБД, пока сканирует индекс. При этом у условия не всегда есть верхняя или нижняя граница. Например, предикат
salary > 4000, если предполагать, что у нас висит индекс на “salary”, не ограничивает скан индекса сверху. Даже если у нас есть высоко селективный предикат по проиндексированной колонке, всё равно может случиться так, что использование индекса будет неэффективным. Пример: использование в предикате функций. Функцию будет сложно преобразовать в условие для поиска по индексу. Большинство СУБД не будут даже пробовать. Исключением являются оракловские функционированные индексы, когда к значению уже заранее применена конкретная функция.
Другой пример, выключающий индекс из обработки, — неявное сравнение разных типов данных:
CharacterColumn=94303. В Оракле такое выражение будет преобразовано к TO_NUMBER(CharacterColumn)=94303 и, предполагая, что на CharacterColumn висит индекс, он, тем не менее, использоваться не будет. Чтобы не было такой ерунды, надо приводить типы явно на стороне клиента. 🧶🧶 > 🧶 👍
🧶 = 🧵 👎
Даже сравнивая числа с числами, надо держать в уме, какие именно числа мы сравниваем. У разных вендоров разные реализации численных типов, но сравнение integer с decimal может оказаться проблемой для итоговой производительности и выключать использование индекса.
Это же касается эффективных быстрых джойнов. Надо следить, чтобы внешний ключ был того же типа, что и первичный. В идеале это должно достигаться не приведением типов, а правильным дизайном базы данных.
Ещё пример неудачной попытки использовать индекс:
Indexed_Char_Col LIKE '%ABC%'Это не может помочь, так как не задает ни начало, ни конец индексового промежутка для скана, и надо искать по всем записям.
🕳🕳💽🗜📄 Andy Pavlo speaks about databases
#sql #databases #database_memory_mechanism #Andy_Pavlo #CMU
Продолжая начатую в первом посте тему о том, как работают БД, есть отличная серия видео, видимо, ещё не законченная:
https://www.youtube.com/playlist?list=PLSE8ODhjZXjbohkNBWQs_otTrBTrjyohi
У неё незаслуженно мало просмотров. Это курс от Carnegie Mellon University, и первую лекцию Энди читает, сидя прямо в ванной в отеле.
Вы узнаёте, что несмотря на то, что реляционная алгебра называет таблицы набором кортежей, в реальности это будут не кортежи, а bags, потому что механизм установления уникальности — дополнительный по отношению к хранению записей. Итак, в реальности корректно говорить об отношении не как о неупорядоченном наборе кортежей, но как о — эээ, я не знаю, как переводится bags :) Но суть в том, что это bags.
Также вы узнаёте, что "система следует ANSI SQL-стандарту" обычно сводится к тому, что она реализовала возможности стандарта ANSI-SQL-92, а не то, что можно было бы подумать.
Третье видео (которое я смотрю сейчас) — о том, как СУБД работают на низком уровне, как обращаются с памятью и почему не надо использовать системный mmap для управления памятью. DBMS почти всегда стараются сами управлять памятью и это всегда лучше, чем позволять это делать операционной системе. Операционная система не в курсе, что у вам там по поводу семантики ваших запросов, и видит только список вызовов на чтение и запись.
#sql #databases #database_memory_mechanism #Andy_Pavlo #CMU
Продолжая начатую в первом посте тему о том, как работают БД, есть отличная серия видео, видимо, ещё не законченная:
https://www.youtube.com/playlist?list=PLSE8ODhjZXjbohkNBWQs_otTrBTrjyohi
У неё незаслуженно мало просмотров. Это курс от Carnegie Mellon University, и первую лекцию Энди читает, сидя прямо в ванной в отеле.
Вы узнаёте, что несмотря на то, что реляционная алгебра называет таблицы набором кортежей, в реальности это будут не кортежи, а bags, потому что механизм установления уникальности — дополнительный по отношению к хранению записей. Итак, в реальности корректно говорить об отношении не как о неупорядоченном наборе кортежей, но как о — эээ, я не знаю, как переводится bags :) Но суть в том, что это bags.
Также вы узнаёте, что "система следует ANSI SQL-стандарту" обычно сводится к тому, что она реализовала возможности стандарта ANSI-SQL-92, а не то, что можно было бы подумать.
Третье видео (которое я смотрю сейчас) — о том, как СУБД работают на низком уровне, как обращаются с памятью и почему не надо использовать системный mmap для управления памятью. DBMS почти всегда стараются сами управлять памятью и это всегда лучше, чем позволять это делать операционной системе. Операционная система не в курсе, что у вам там по поводу семантики ваших запросов, и видит только список вызовов на чтение и запись.
🛌 SQL Tuning by Dan Tow (O’Reilly)
#sql #databases #selectivity #indexes #database_indexes
А теперь —дальше про индексы.
Предикаты со знаком "не равно" типа
Если условие не задаёт границ для индексного промежутка по крайней мере на первой колонке индекса (если он многоатрибутный), единственный способ использовать индекс вообще — это полное чтение всего индекса, каждой его записи каждого листа. СУБД обычно избегают такого, потому что это недешево с точки зрения производительности, к тому же полное чтение индекса обычно приводит к чтению также и большей части таблицы, что вместе получается дороже, чем просто сделать full table scan.
Так, ура, разбираем пример. 🧼🧪
Пусть у нас есть таблица Persons с единственным индексом:
Мы составили запрос со следующим предикатом:
Только первое условие задаёт границы для скана индекса. Второе условие, на четвёртом атрибуте индекса, не может позволить нам сузить область поиска:
— Второй и третий атрибуты не использованы в предикате;
— Мы использовали функцию UPPER вокруг значения атрибута, это всё усложнило, и БД такая meh, чёчё.
К счастью, это всё фигня, и, на самом деле, СУБД, скорее всего, догадается проверить второе условие до того, как трогать таблицу. Так как индекс содержит нужный атрибут, БД проверит условие, используя данные из индекса. Т.е., в данном случае БД использует Area_Code, чтобы задать промежуток для чтения индеса, а затем, по мере чтения каждой записи внутри промежутка, БД будет отбрасывать записи с не интересующим пользователя атрибутом (!='IVA').
В результате мы, скорее всего, получим всего одно-два обращения чтения из самой таблицы.
#sql #databases #selectivity #indexes #database_indexes
А теперь —дальше про индексы.
Предикаты со знаком "не равно" типа
!= или <> по проиндексированной колонке не “включают" использование индекса, так как большинство СУБД заранее сочтёт такое условие малоселективным, а потому недостойным того, чтобы лезть в индекс.Если условие не задаёт границ для индексного промежутка по крайней мере на первой колонке индекса (если он многоатрибутный), единственный способ использовать индекс вообще — это полное чтение всего индекса, каждой его записи каждого листа. СУБД обычно избегают такого, потому что это недешево с точки зрения производительности, к тому же полное чтение индекса обычно приводит к чтению также и большей части таблицы, что вместе получается дороже, чем просто сделать full table scan.
Так, ура, разбираем пример. 🧼🧪
Пусть у нас есть таблица Persons с единственным индексом:
(Area_Code, Phone_Number, Last_Name, First_Name) Мы составили запрос со следующим предикатом:
WHERE Area_Code=916 AND UPPER(First_Name)='IVA'Только первое условие задаёт границы для скана индекса. Второе условие, на четвёртом атрибуте индекса, не может позволить нам сузить область поиска:
— Второй и третий атрибуты не использованы в предикате;
— Мы использовали функцию UPPER вокруг значения атрибута, это всё усложнило, и БД такая meh, чёчё.
К счастью, это всё фигня, и, на самом деле, СУБД, скорее всего, догадается проверить второе условие до того, как трогать таблицу. Так как индекс содержит нужный атрибут, БД проверит условие, используя данные из индекса. Т.е., в данном случае БД использует Area_Code, чтобы задать промежуток для чтения индеса, а затем, по мере чтения каждой записи внутри промежутка, БД будет отбрасывать записи с не интересующим пользователя атрибутом (!='IVA').
В результате мы, скорее всего, получим всего одно-два обращения чтения из самой таблицы.
⚙️
#sql #databases #joins #nested_loop_join
Самый простой способ джойнить — это nested-loops join.
🗄→🗄→🗄
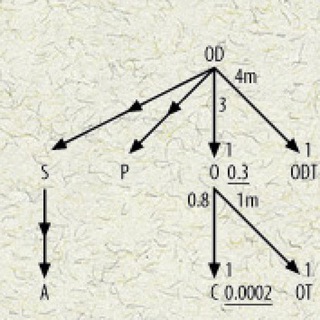
Исполнение начинается с запроса к изначальной таблице — т.н. driving table (на русском, кажется, это называется управляющая таблица) — с использованием тех условий, которые относятся именно и только к ней. Отделив нужные сроки в управляющей таблице, БД передает их в следующий “бокс”. В нём БД построчно ищет соответствующие строки во второй таблице, затем применяет предикаты второй таблицы для отсеивания ненужных записей. И так далее.
Матчинг строк первой таблицы со второй в случае nested-loop join’а обычно происходит с помощью поиска в индексе по тому ключу, по которому происходил джойн.
#sql #databases #joins #nested_loop_join
Самый простой способ джойнить — это nested-loops join.
🗄→🗄→🗄
Исполнение начинается с запроса к изначальной таблице — т.н. driving table (на русском, кажется, это называется управляющая таблица) — с использованием тех условий, которые относятся именно и только к ней. Отделив нужные сроки в управляющей таблице, БД передает их в следующий “бокс”. В нём БД построчно ищет соответствующие строки во второй таблице, затем применяет предикаты второй таблицы для отсеивания ненужных записей. И так далее.
Матчинг строк первой таблицы со второй в случае nested-loop join’а обычно происходит с помощью поиска в индексе по тому ключу, по которому происходил джойн.