
Forwarded from Нейроканал
У всех в IT был индус, который их чему-то научил
А если вы ещё не нашли такого, то не расстраивайтесь, у нас есть отличный вариант. Дело в том, что FreeCodeCamp выпустил полноценный 30-часовой курс по генеративному искусственному интеллекту.
В нём под руководством трёх замечательных спикеров вы с головой окунётесь в мир генеративок, узнаете о библиотеках, структурах моделей и других аспектах, лежащих в основе ИИ. И конечно же, будете применять эти знания в реальных проектах: от чат-ботов до продвинутых приложений.
@neuro_channel #ai #nlp
А если вы ещё не нашли такого, то не расстраивайтесь, у нас есть отличный вариант. Дело в том, что FreeCodeCamp выпустил полноценный 30-часовой курс по генеративному искусственному интеллекту.
В нём под руководством трёх замечательных спикеров вы с головой окунётесь в мир генеративок, узнаете о библиотеках, структурах моделей и других аспектах, лежащих в основе ИИ. И конечно же, будете применять эти знания в реальных проектах: от чат-ботов до продвинутых приложений.
@neuro_channel #ai #nlp
YouTube
Generative AI Full Course – Gemini Pro, OpenAI, Llama, Langchain, Pinecone, Vector Databases & More
Learn about generative models and different frameworks, investigating the production of text and visual material produced by artificial intelligence. This course was originally recorded live.
Instructors: Krish Naik, Sunny Savita, and Boktiar Ahmed Bappy.…
Instructors: Krish Naik, Sunny Savita, and Boktiar Ahmed Bappy.…
Forwarded from Data Secrets
Step-by-step гайд по изучению основ алгоритмов машинного обучения с ссылками на посты нашего канала:
1. Обычно все подобные списки начинаются с регрессии, но мы советуем начать с KNN. Простой и интересный алгоритм, который поймет любой.
2. А вот теперь регрессия:
– Линейная регрессия
– Пуассоновская регрессия
– Гребневая и лассо регрессия
– Elastic Net регрессия
3. Линейная классификация:
– Логистическая регрессия
– LDA
– SGD классификация
4. Метод опорных векторов
5. Деревья и ансамбли:
– Cart, ID3 и С4.5
– Случайный лес
6. Бустинг:
– Градиентный бустинг
– Adaboost
7. Кластеризация:
– K-means
– DBSCAN
– Иерархическая кластеризация
– BIRCH
8. Finally: нейросети
- Перцептрон
- CNN
- RNN
- LSTM
- GAN
- Трансформеры
Есть среди нас новички? Отзовитесь в комментариях😻
1. Обычно все подобные списки начинаются с регрессии, но мы советуем начать с KNN. Простой и интересный алгоритм, который поймет любой.
2. А вот теперь регрессия:
– Линейная регрессия
– Пуассоновская регрессия
– Гребневая и лассо регрессия
– Elastic Net регрессия
3. Линейная классификация:
– Логистическая регрессия
– LDA
– SGD классификация
4. Метод опорных векторов
5. Деревья и ансамбли:
– Cart, ID3 и С4.5
– Случайный лес
6. Бустинг:
– Градиентный бустинг
– Adaboost
7. Кластеризация:
– K-means
– DBSCAN
– Иерархическая кластеризация
– BIRCH
8. Finally: нейросети
- Перцептрон
- CNN
- RNN
- LSTM
- GAN
- Трансформеры
Есть среди нас новички? Отзовитесь в комментариях
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Привет всем тем, кто хотел поглубже познакомиться с новым хайповым KAN, но осилить статью на 50 страниц с формулами не сумел
Для вас, любимые подписчики, мы менее чем за сутки с момента выхода статьи написали на нее обзор! В нем вы найдете:
– Легкое и непринужденное объяснение теоремы Колмогорова-Арнольда
– Ответ на вопрос «а почему до этого раньше никто не додумался?»
– Объяснение архитектуры KAN на пальцах
– Сравнение KAN с перцептроном
– Туториал по запуску KAN из коробки на Python
Прочитать разбор можно на нашем сайте: https://datasecrets.ru/articles/9
Для вас, любимые подписчики, мы менее чем за сутки с момента выхода статьи написали на нее обзор! В нем вы найдете:
– Легкое и непринужденное объяснение теоремы Колмогорова-Арнольда
– Ответ на вопрос «а почему до этого раньше никто не додумался?»
– Объяснение архитектуры KAN на пальцах
– Сравнение KAN с перцептроном
– Туториал по запуску KAN из коробки на Python
Прочитать разбор можно на нашем сайте: https://datasecrets.ru/articles/9
Forwarded from Data Secrets
Итак, разбор статьи про xLSTM уже можно найти на нашем сайте! В тексте вы найдете:
➡️ Пошаговое объяснение того, как работает ванильная LSTM. Разберетесь, даже если вы ничего не слышали про эту архитектуру до этого.
➡️ Структурированный разбор каждого улучшения, которое предложили ученые в xLSTM.
➡️ Множество схем и примеров.
➡️ Сравнение xLSTM с трансформерами.
➡️ Рассуждение на тему "имеют ли xLSTM шансы стать будущим LLM?"
Сохраняйте и читайте, не пожалеете: https://datasecrets.ru/articles/10
Сохраняйте и читайте, не пожалеете: https://datasecrets.ru/articles/10
Please open Telegram to view this post
VIEW IN TELEGRAM
datasecrets.ru
Погружение в xLSTM – обновленную LSTM, которая может оказаться заменой трансформера | Data Secrets
Исследователи, которые в 1997 году изобрели архитектуру LSTM, спустя 27 лет выпустили «обновление». Разбираемся, как это работает, и почему может стать прорывом для больших языковых моделей.
Forwarded from Нейроканал
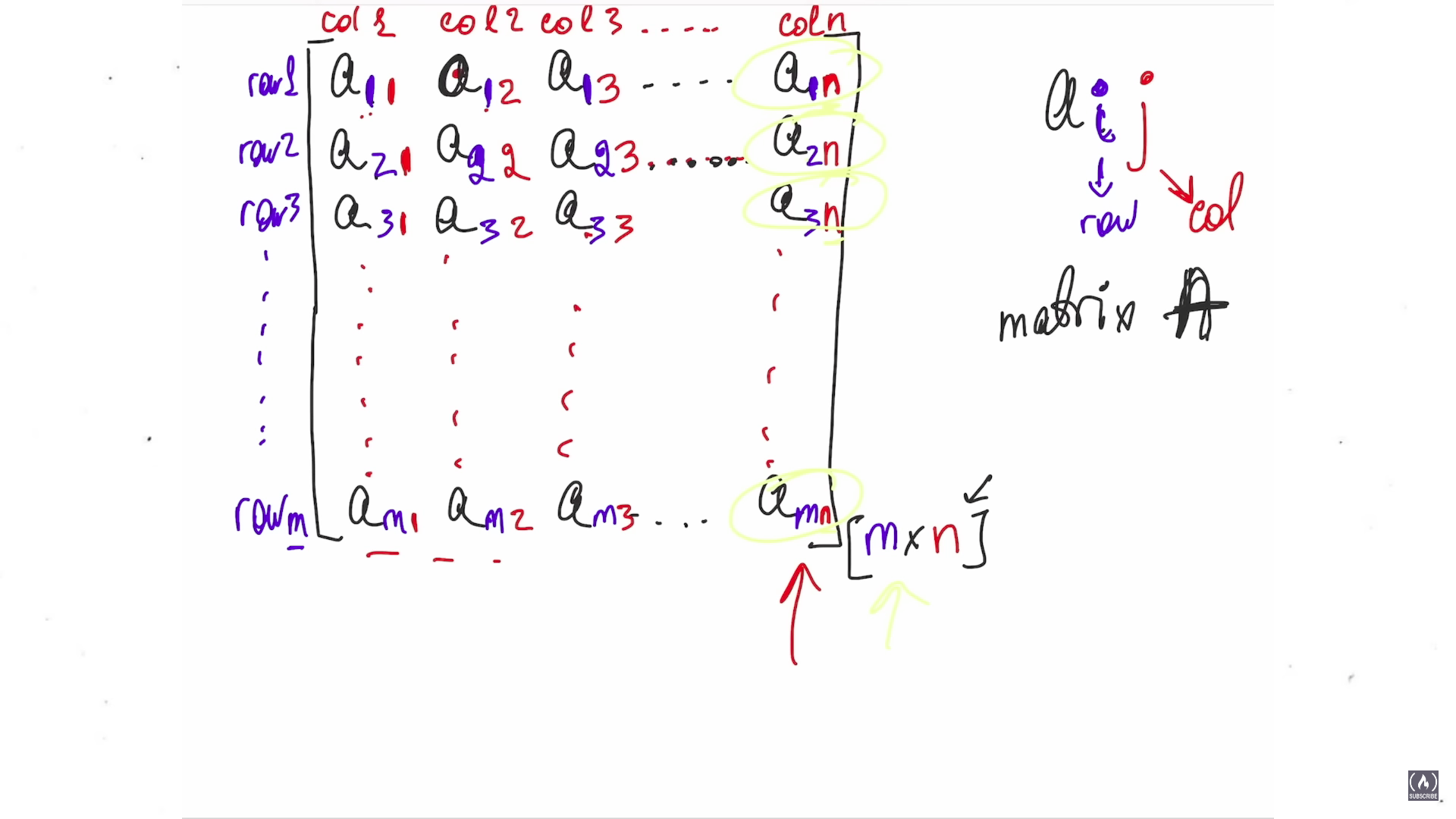
Линейная алгебра для дата-сайентиста
Шестичасовой англоязычный туториал — starter pack для тех, кто планирует собирать модели. В курсе будет про:
— векторы;
— Евклидово расстояние;
— скалярное произведение;
— матричные операции.
#основы
@neuro_channel
Шестичасовой англоязычный туториал — starter pack для тех, кто планирует собирать модели. В курсе будет про:
— векторы;
— Евклидово расстояние;
— скалярное произведение;
— матричные операции.
#основы
@neuro_channel
{kind=link}
Forwarded from Machinelearning
OpenVLA 7B (vision-language-action) — это open-source модель, обученная на 970K эпизодах манипулирования роботами из набора данных Open X-Embodiment. Модель принимает на вход текстовый промпт и изображения с камеры и генерирует действия робота.
OpenVLA 7B из коробки поддерживает управление несколькими роботами и может быть быстро адаптирована к новым областям робототехники с помощью тонкой настройки.
@ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Помните, мы рассказывали про профессора, который пилит крутые визуальные схемы внутрянок ML-алгоритмов?
Так вот появилась еще одна хорошая новость. Ученый начал реализовать некоторые из своих схем в Google Sheets и теперь с ними можно поиграться самостоятельно. Вот ссылка.
Пока что там есть только трансформер, но и на это уже можно залипнуть на весь вечер. Ответы записаны прописным шрифтом, их можно скрыть и посчитать результаты операций самому, руками, а потом сверить.
Очень прикольное и полезное упражнение для освежения знаний.
Так вот появилась еще одна хорошая новость. Ученый начал реализовать некоторые из своих схем в Google Sheets и теперь с ними можно поиграться самостоятельно. Вот ссылка.
Пока что там есть только трансформер, но и на это уже можно залипнуть на весь вечер. Ответы записаны прописным шрифтом, их можно скрыть и посчитать результаты операций самому, руками, а потом сверить.
Очень прикольное и полезное упражнение для освежения знаний.
Forwarded from Machinelearning
SALSA (Stable Armijo Line Search Adaptation) — метод, разработанный для оптимизации Learning Rate (LR) во время обучения.
Основная концепция метода построена вокруг выполнения линейного поиска для определения наилучшего возможного LR для каждого шага обучения, что дает быструю сходимость и улучшенное обобщение.
Чтобы уменьшить вычислительную нагрузку, Salsa предлагает пошаговый миниатюрный линейный поиск. В нем LR постепенно увеличивается с каждым шагом, а критерий линейного поиска постоянно переоценивается.
Дополнительно, Salsa включает экспоненциальное сглаживание в процесс линейного поиска и устанавливает два экспоненциальных скользящих средних для скорости обучения. Это помогает стабилизировать оптимизацию и уменьшить нестабильность от мини-пакетирования.
Экспериментальные результаты показывают, что Salsa превосходит другие методы оптимизации: 50% сокращение final loss и 1,25 average rank в языковых и графических задачах.
Вычислительные издержки Salsa всего на 3% выше, чем у базового LR метода, что можно воспринимать как незначительным увеличением, учитывая показатели производительности. Salsa достаточно универсален, чтобы использоваться с различными оптимизаторами, и особенно эффективен при обучении современных архитектур, которые чувствительны к скорости обучения.
# Clone repository:
git clone https://github.com/TheMody/No-learning-rates-needed-Introducing-SALSA-Stable-Armijo-Line-Search-Adaptation.git
# Create & activate env:
conda env create -f environment.yml
conda activate sls3
# Install dependencies:
pip install pytorch numpy transformers datasets tensorflow-datasets wandb
# NOTE: custom optimizer is in \salsa\SaLSA.py,comparison version are in \salsa\adam_sls.py:
from salsa.SaLSA import SaLSA
self.optimizer = SaLSA(model.parameters())
# NOTE: typical pytorch forward pass needs to be changed to:
def closure(backwards = False):
y_pred = model(x)
loss = criterion(y_pred, y)
if backwards: loss.backward()
return loss
optimizer.zero_grad()
loss = optimizer.step(closure = closure)
@ai_machinelearning_big_data
#AI #LLM #ML #Train #SALSA
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Ничего необычного, просто 16-летний парень и его 5-часовое видео с полным руководством по математике для глубокого обучения
Внутри – все про якобианы, производные, градиенты, алгоритм обратного распространения ошибки, функции активации и др. Автор – Адам Дхалла из Канады, и на момент создания видео ему только исполнилось 16.
Сейчас парню 19, он создал очень перспективный алгоритм для классификации местоположений белков в клетках и уже имеет пожизненное финансирование исследований от Schmidt Futures😦
Внутри – все про якобианы, производные, градиенты, алгоритм обратного распространения ошибки, функции активации и др. Автор – Адам Дхалла из Канады, и на момент создания видео ему только исполнилось 16.
Сейчас парню 19, он создал очень перспективный алгоритм для классификации местоположений белков в клетках и уже имеет пожизненное финансирование исследований от Schmidt Futures
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Как работают SSM – главные конкуренты трансформеров?
SSM (State space models) были изобретены еще в 60-е годы. Тогда они использовались для моделирования непрерывных процессов. Но не так давно было придумано, как использовать SSM в глубоком обучении, и теперь они – главные кандидаты на роль новой серебряной пули архитектур. Например, Mistral недавно сделали на основе SSM модель Codestral, которая на метриках разбила почти все другие открытые модели.
Понятная схема того, как работает архитектура – наверху. Если присмотреться, то станет понятно, что SSM – это умный вариант RNN, а матрицы А, В, С и D – аналоги гейтов забывания, входного состояния и выходного состояния из LSTM.
Но главная прелесть SSM в том, что она построена на стыке двух мощных архитектур: сверточных нейросетей и рекуррентных. Да, все обучаемые параметры можно собрать в единое ядро и использовать его для свертки. Получается, что мы можем использовать все плюсы (и в частности линейность) рекуррентных нейронных сетей, но при этом представлять их как сверточные, которые в свою очередь можно распараллелить.
Если хотите немного подробнее прочитать об SSM – загляните в нашу статью про конкурентов трансформерам. Там найдете и понятное объяснение принципа работы RNN, и пошаговую экскурсию по SSM, и даже про самые свежие Mamba и Hawk сможете почитать.
SSM (State space models) были изобретены еще в 60-е годы. Тогда они использовались для моделирования непрерывных процессов. Но не так давно было придумано, как использовать SSM в глубоком обучении, и теперь они – главные кандидаты на роль новой серебряной пули архитектур. Например, Mistral недавно сделали на основе SSM модель Codestral, которая на метриках разбила почти все другие открытые модели.
Понятная схема того, как работает архитектура – наверху. Если присмотреться, то станет понятно, что SSM – это умный вариант RNN, а матрицы А, В, С и D – аналоги гейтов забывания, входного состояния и выходного состояния из LSTM.
Но главная прелесть SSM в том, что она построена на стыке двух мощных архитектур: сверточных нейросетей и рекуррентных. Да, все обучаемые параметры можно собрать в единое ядро и использовать его для свертки. Получается, что мы можем использовать все плюсы (и в частности линейность) рекуррентных нейронных сетей, но при этом представлять их как сверточные, которые в свою очередь можно распараллелить.
Если хотите немного подробнее прочитать об SSM – загляните в нашу статью про конкурентов трансформерам. Там найдете и понятное объяснение принципа работы RNN, и пошаговую экскурсию по SSM, и даже про самые свежие Mamba и Hawk сможете почитать.
Forwarded from Data Secrets
Прямо сейчас в Корейском технологическом KAIST проходит крутой курс по генеративным нейросетям, и мы нашли страницу, на которой выкладывают все записи и презентации
Вот ссылка. В программе курса GAN, VAE, диффузионки, дистилляция... В общем, все от А до Я, и базовое, и продвинутое, с особенным упором на актуальные сегодня архитектуры и техники.
На странице также выложен список полезных материалов и полный список статей, которые упоминаются в ходе курса (кладезь!). А еще туда прикреляют ссылки на домашки и блокноты с очень детально объясненным в ридми и откоментированным кодом с семинаров.
Такое сохраняем
Вот ссылка. В программе курса GAN, VAE, диффузионки, дистилляция... В общем, все от А до Я, и базовое, и продвинутое, с особенным упором на актуальные сегодня архитектуры и техники.
На странице также выложен список полезных материалов и полный список статей, которые упоминаются в ходе курса (кладезь!). А еще туда прикреляют ссылки на домашки и блокноты с очень детально объясненным в ридми и откоментированным кодом с семинаров.
Такое сохраняем
Forwarded from Data Secrets
Anthropic написали интересную статью о том, как нам на самом деле следует оценивать модели
Сейчас бенчмаркинг происходит довольно наивно: у нас есть список вопросов, на каждый из которых модель отвечает и получает за ответ определенный балл, а общая оценка обычно представляет из себя просто среднее по всем таким баллам. Но действительно ли нам интересно только среднее?
Антропики утверждают, что с точки зрения статистики такой классический эвал слишком упрощен, и дают пять советов о том, как сделать свои оценки статистически значимыми и более глубокими. В основе их подхода привычное предположение матстата: все вопросы, которые у нас есть – это какая-то случайная подвыборка генеральной совокупности всевозможных вопросов, которые вообще можно задать. А значит, называть среднее на каком-то бенчмарке оценкой навыка модели – слишком грубо. Вот что на самом деле стоит делать:
1. Использовать ЦПТ. Основываясь на центральной предельной теореме, средние значения нескольких выборок, взятых из одного и того же распределения, будут распределены нормально. А значит, мы можем взять из нашего бенчмарка несколько подмножеств (можно даже пересекающихся), оценить каждое из них, а на получившихся средних подсчитать SEM (стандартную ошибку среднего) и доверительный интервал.
2. Если вопросы в бенчмарке не независимы (например задаются вопросы по одному и тому же тексту), то ЦПТ исполользовать уже нельзя. Здесь предлагается вспомнить про Cluster standard errors.
3. Если дисперсия вашей модели высокая, то это важно учитывать в эвале, потому что дисперсия – это по сути оценка надежности модели. Поэтому исследователи предлагают также изменить стратегию оценки каждого отдельного вопроса. Вместо наивной оценки они предлагают двусоставную, состоящую из среднего балла (задаем вопрос много-много раз и считаем среднее) плюс ошибки отклонения (разница между реализованным баллов вопроса и средним баллом для этого вопроса).
4. Вместо обычного "больше-меньше" для сравнения двух моделей использовать статистические тесты. Однако использовать t-test все-таки не рекомендуется, вместо этого в статье предлагается более сложная формула, которая также учитывает корреляцию Пирсона и минимизирует mean difference error.
5. Не забывать про мощность критериев в оценках и формулировать правильные гипотезы для сравнения моделей.
Рекомендации, в общем, действительно стоящие. Другой вопрос – сколько времени постребуется, чтобы ресерчеры действительно стали соблюдать что-то подобное
Сейчас бенчмаркинг происходит довольно наивно: у нас есть список вопросов, на каждый из которых модель отвечает и получает за ответ определенный балл, а общая оценка обычно представляет из себя просто среднее по всем таким баллам. Но действительно ли нам интересно только среднее?
Антропики утверждают, что с точки зрения статистики такой классический эвал слишком упрощен, и дают пять советов о том, как сделать свои оценки статистически значимыми и более глубокими. В основе их подхода привычное предположение матстата: все вопросы, которые у нас есть – это какая-то случайная подвыборка генеральной совокупности всевозможных вопросов, которые вообще можно задать. А значит, называть среднее на каком-то бенчмарке оценкой навыка модели – слишком грубо. Вот что на самом деле стоит делать:
1. Использовать ЦПТ. Основываясь на центральной предельной теореме, средние значения нескольких выборок, взятых из одного и того же распределения, будут распределены нормально. А значит, мы можем взять из нашего бенчмарка несколько подмножеств (можно даже пересекающихся), оценить каждое из них, а на получившихся средних подсчитать SEM (стандартную ошибку среднего) и доверительный интервал.
2. Если вопросы в бенчмарке не независимы (например задаются вопросы по одному и тому же тексту), то ЦПТ исполользовать уже нельзя. Здесь предлагается вспомнить про Cluster standard errors.
3. Если дисперсия вашей модели высокая, то это важно учитывать в эвале, потому что дисперсия – это по сути оценка надежности модели. Поэтому исследователи предлагают также изменить стратегию оценки каждого отдельного вопроса. Вместо наивной оценки они предлагают двусоставную, состоящую из среднего балла (задаем вопрос много-много раз и считаем среднее) плюс ошибки отклонения (разница между реализованным баллов вопроса и средним баллом для этого вопроса).
4. Вместо обычного "больше-меньше" для сравнения двух моделей использовать статистические тесты. Однако использовать t-test все-таки не рекомендуется, вместо этого в статье предлагается более сложная формула, которая также учитывает корреляцию Пирсона и минимизирует mean difference error.
5. Не забывать про мощность критериев в оценках и формулировать правильные гипотезы для сравнения моделей.
Рекомендации, в общем, действительно стоящие. Другой вопрос – сколько времени постребуется, чтобы ресерчеры действительно стали соблюдать что-то подобное