
Forwarded from Machinelearning
Бесплатные курсы и руководства, для погружения в искусственный интеллект.
📂Elements of AI
https://elementsofai.com
📂Learn Prompting
https://learnprompting.org
📂Machine Learning
https://edx.org/learn/machine-learning/harvard-university-data-science-machine-learning
📂AI for everyone
https://coursera.org/learn/ai-for-everyone
📂500+ AI Chatbot Prompt Templates
https://theveller.gumroad.com/l/ChatGPTPromptTemplates-byTheVeller
📂Prompt Engineering
https://youtu.be/_ZvnD73m40o
📂ChatGPT Prompt Engineering for Developers
https://deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers
📂Google — AI for Anyone
https://edx.org/learn/artificial-intelligence/google-google-ai-for-anyone
📂Microsoft — AI For Beginners
https://microsoft.github.io/AI-For-Beginners
📂IBM — AI for Everyone: Master the Basics
https://edx.org/learn/artificial-intelligence/ibm-ai-for-everyone-master-the-basics
📂Google — Introduction to Generative AI
https://cloudskillsboost.google/journeys/118
📂DeepLearning — Finetuning LLMs
https://deeplearning.ai/short-courses/finetuning-large-language-models
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Enthought-v1.0.2.pdf
2.4 MB
Без лишних слов, просто посмотрите, на какой милый чит-лист по pandas мы наткнулись сегодня утром!
😻 #advice
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
This media is not supported in your browser
VIEW IN TELEGRAM
Сенсация! Мы серьезно, лучше присядьте...
Nvidia выпустили новую библиотеку RAPIDS, которая делает Pandas в 150 раз быстрее. Она автоматически определяет, работаете ли вы на GPU или CPU, и ускоряет код. При этом нет абсолютно никаких изменений в синтаксисе, просто перед импортом пандаса запускаем эту команду:
Новости, которые мы заслужили
😻 #news
Nvidia выпустили новую библиотеку RAPIDS, которая делает Pandas в 150 раз быстрее. Она автоматически определяет, работаете ли вы на GPU или CPU, и ускоряет код. При этом нет абсолютно никаких изменений в синтаксисе, просто перед импортом пандаса запускаем эту команду:
%load_ext cudf.pandasНовости, которые мы заслужили
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
На фото – Грег Брокман, ко-фаундер OpenAI, изучающий ML в далеком 2018
Деталями своего пути в ML он делится в своем блоге. Мы проресерчили его посты и вот список бесплатных образовательных ресурсов, которыми он пользовался:
🔘 Глубокое обучение с подкреплением от Беркли. Базовое и продвинутое RL.
🔘 Глубокое обучение для компьютерного зрения от Стэнфорда. Базис + погружение в архитектуры.
🔘 Глубокое обучение – книга MIT от Я.Гудфеллоу, И.Бенджио и А.Курвилль. Алгебра, теорвер, база ML, best practices, теория DL и разборы известных архитектур. Эту книгу вы можете получить бесплатно, поучаствовав в нашем розыгрыше.
🔘 Глубокое обучение на практике – курс от университета Квинсленда. Много кода и практических задач.
😻 #advice
Деталями своего пути в ML он делится в своем блоге. Мы проресерчили его посты и вот список бесплатных образовательных ресурсов, которыми он пользовался:
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Гарвард тоже радует подарками к Новому Году
Мы об их свежем курсе, конечно. Абсолютно бесплатном, как вы любите. Он посвящен AI: в программе теорвер, классический ML, нейросети, NLP, CV, модели Маркова и еще много чего. В числе преподов крутой David J. Malan.
Стартует сегодня! Не советуем упускать возможность.
😻 #advice
Мы об их свежем курсе, конечно. Абсолютно бесплатном, как вы любите. Он посвящен AI: в программе теорвер, классический ML, нейросети, NLP, CV, модели Маркова и еще много чего. В числе преподов крутой David J. Malan.
Стартует сегодня! Не советуем упускать возможность.
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Электроинженерия ИТМО
https://youtu.be/j5sjf6Et-o4?si=FAgLpJsn_upByDMb
Обещали выложить одну из лекций в рамках Зимней Школы Робототехники Факультета Систем Управления и Робототехники Университета ИТМО (https://roboticsai.ru/).
ТЕМА: Машинное обучение в системах электроприводов
СПИКЕР: Демидова Галина Львовна, к.т.н., руководитель онлайн-программы магистратуры "Инженерия приводных систем"
Обещали выложить одну из лекций в рамках Зимней Школы Робототехники Факультета Систем Управления и Робототехники Университета ИТМО (https://roboticsai.ru/).
ТЕМА: Машинное обучение в системах электроприводов
СПИКЕР: Демидова Галина Львовна, к.т.н., руководитель онлайн-программы магистратуры "Инженерия приводных систем"
YouTube
Машинное обучение в системах электроприводов Демидова ГЛ (Зимняя Школа Робототехники 2024)
Лекция в рамках Зимней Школы Робототехники факультета Систем Управления и Робототехники Университета ИТМО
Forwarded from Data Secrets
Kaggle – это огромное количество открытых полезных датасетов, и конечно, все мы любим использовать этот кладезь.
Но многие, чтобы загрузить kaggle датасет, например, на Colab, скачивают его "вручную", а потом загружают в фолд ноутбука. Это оооочень долгий, да и ненадежный способ.
Лучше давайте мы расскажем, как легким движением руки сделать это в сотки раз быстрее и элегантнее, используя kaggle API.
Но многие, чтобы загрузить kaggle датасет, например, на Colab, скачивают его "вручную", а потом загружают в фолд ноутбука. Это оооочень долгий, да и ненадежный способ.
Лучше давайте мы расскажем, как легким движением руки сделать это в сотки раз быстрее и элегантнее, используя kaggle API.
Forwarded from Нейроканал
У всех в IT был индус, который их чему-то научил
А если вы ещё не нашли такого, то не расстраивайтесь, у нас есть отличный вариант. Дело в том, что FreeCodeCamp выпустил полноценный 30-часовой курс по генеративному искусственному интеллекту.
В нём под руководством трёх замечательных спикеров вы с головой окунётесь в мир генеративок, узнаете о библиотеках, структурах моделей и других аспектах, лежащих в основе ИИ. И конечно же, будете применять эти знания в реальных проектах: от чат-ботов до продвинутых приложений.
@neuro_channel #ai #nlp
А если вы ещё не нашли такого, то не расстраивайтесь, у нас есть отличный вариант. Дело в том, что FreeCodeCamp выпустил полноценный 30-часовой курс по генеративному искусственному интеллекту.
В нём под руководством трёх замечательных спикеров вы с головой окунётесь в мир генеративок, узнаете о библиотеках, структурах моделей и других аспектах, лежащих в основе ИИ. И конечно же, будете применять эти знания в реальных проектах: от чат-ботов до продвинутых приложений.
@neuro_channel #ai #nlp
YouTube
Generative AI Full Course – Gemini Pro, OpenAI, Llama, Langchain, Pinecone, Vector Databases & More
Learn about generative models and different frameworks, investigating the production of text and visual material produced by artificial intelligence. This course was originally recorded live.
Instructors: Krish Naik, Sunny Savita, and Boktiar Ahmed Bappy.…
Instructors: Krish Naik, Sunny Savita, and Boktiar Ahmed Bappy.…
Forwarded from Data Secrets
Step-by-step гайд по изучению основ алгоритмов машинного обучения с ссылками на посты нашего канала:
1. Обычно все подобные списки начинаются с регрессии, но мы советуем начать с KNN. Простой и интересный алгоритм, который поймет любой.
2. А вот теперь регрессия:
– Линейная регрессия
– Пуассоновская регрессия
– Гребневая и лассо регрессия
– Elastic Net регрессия
3. Линейная классификация:
– Логистическая регрессия
– LDA
– SGD классификация
4. Метод опорных векторов
5. Деревья и ансамбли:
– Cart, ID3 и С4.5
– Случайный лес
6. Бустинг:
– Градиентный бустинг
– Adaboost
7. Кластеризация:
– K-means
– DBSCAN
– Иерархическая кластеризация
– BIRCH
8. Finally: нейросети
- Перцептрон
- CNN
- RNN
- LSTM
- GAN
- Трансформеры
Есть среди нас новички? Отзовитесь в комментариях😻
1. Обычно все подобные списки начинаются с регрессии, но мы советуем начать с KNN. Простой и интересный алгоритм, который поймет любой.
2. А вот теперь регрессия:
– Линейная регрессия
– Пуассоновская регрессия
– Гребневая и лассо регрессия
– Elastic Net регрессия
3. Линейная классификация:
– Логистическая регрессия
– LDA
– SGD классификация
4. Метод опорных векторов
5. Деревья и ансамбли:
– Cart, ID3 и С4.5
– Случайный лес
6. Бустинг:
– Градиентный бустинг
– Adaboost
7. Кластеризация:
– K-means
– DBSCAN
– Иерархическая кластеризация
– BIRCH
8. Finally: нейросети
- Перцептрон
- CNN
- RNN
- LSTM
- GAN
- Трансформеры
Есть среди нас новички? Отзовитесь в комментариях
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Привет всем тем, кто хотел поглубже познакомиться с новым хайповым KAN, но осилить статью на 50 страниц с формулами не сумел
Для вас, любимые подписчики, мы менее чем за сутки с момента выхода статьи написали на нее обзор! В нем вы найдете:
– Легкое и непринужденное объяснение теоремы Колмогорова-Арнольда
– Ответ на вопрос «а почему до этого раньше никто не додумался?»
– Объяснение архитектуры KAN на пальцах
– Сравнение KAN с перцептроном
– Туториал по запуску KAN из коробки на Python
Прочитать разбор можно на нашем сайте: https://datasecrets.ru/articles/9
Для вас, любимые подписчики, мы менее чем за сутки с момента выхода статьи написали на нее обзор! В нем вы найдете:
– Легкое и непринужденное объяснение теоремы Колмогорова-Арнольда
– Ответ на вопрос «а почему до этого раньше никто не додумался?»
– Объяснение архитектуры KAN на пальцах
– Сравнение KAN с перцептроном
– Туториал по запуску KAN из коробки на Python
Прочитать разбор можно на нашем сайте: https://datasecrets.ru/articles/9
Forwarded from Data Secrets
Итак, разбор статьи про xLSTM уже можно найти на нашем сайте! В тексте вы найдете:
➡️ Пошаговое объяснение того, как работает ванильная LSTM. Разберетесь, даже если вы ничего не слышали про эту архитектуру до этого.
➡️ Структурированный разбор каждого улучшения, которое предложили ученые в xLSTM.
➡️ Множество схем и примеров.
➡️ Сравнение xLSTM с трансформерами.
➡️ Рассуждение на тему "имеют ли xLSTM шансы стать будущим LLM?"
Сохраняйте и читайте, не пожалеете: https://datasecrets.ru/articles/10
Сохраняйте и читайте, не пожалеете: https://datasecrets.ru/articles/10
Please open Telegram to view this post
VIEW IN TELEGRAM
datasecrets.ru
Погружение в xLSTM – обновленную LSTM, которая может оказаться заменой трансформера | Data Secrets
Исследователи, которые в 1997 году изобрели архитектуру LSTM, спустя 27 лет выпустили «обновление». Разбираемся, как это работает, и почему может стать прорывом для больших языковых моделей.
Forwarded from Нейроканал
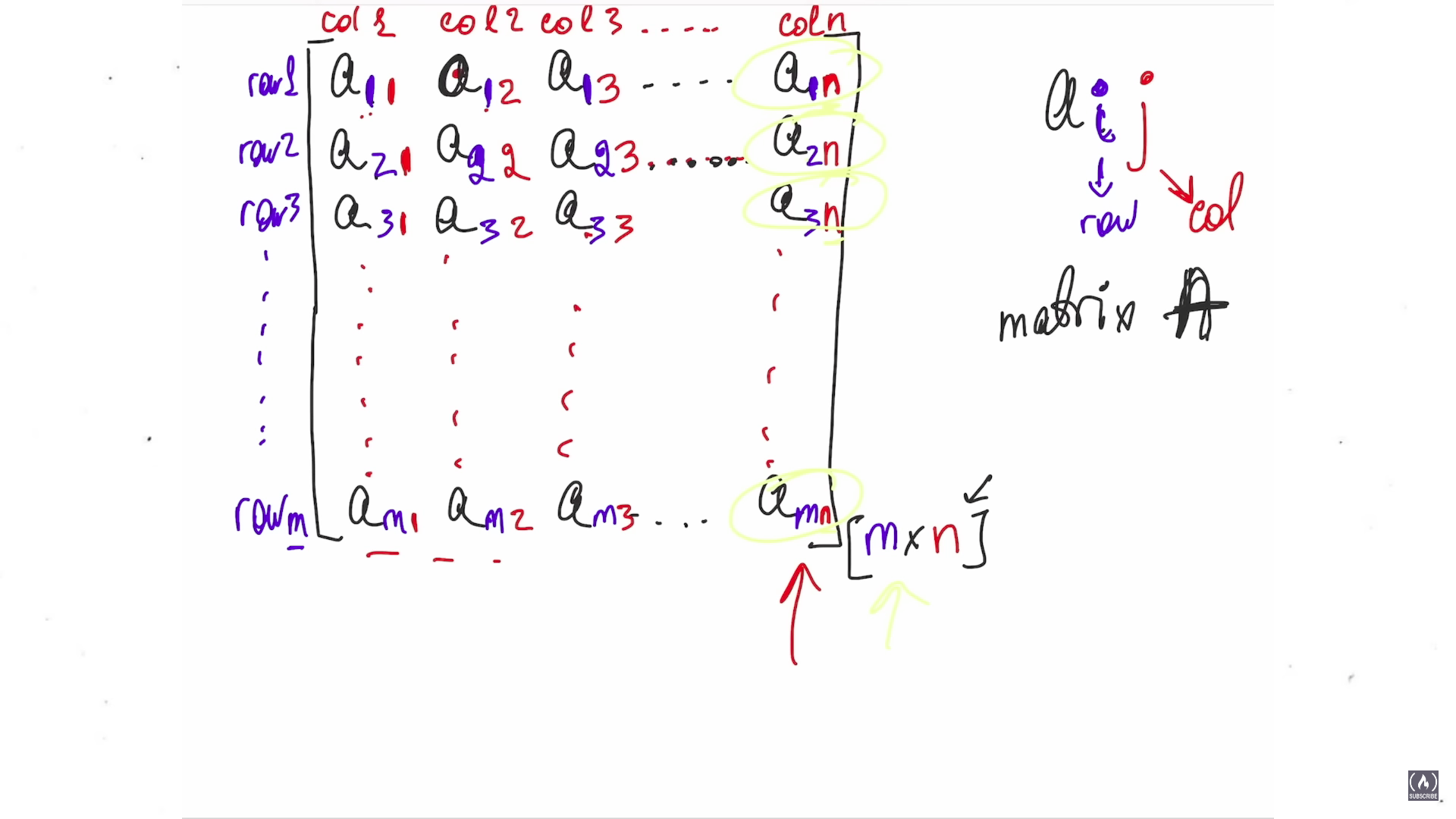
Линейная алгебра для дата-сайентиста
Шестичасовой англоязычный туториал — starter pack для тех, кто планирует собирать модели. В курсе будет про:
— векторы;
— Евклидово расстояние;
— скалярное произведение;
— матричные операции.
#основы
@neuro_channel
Шестичасовой англоязычный туториал — starter pack для тех, кто планирует собирать модели. В курсе будет про:
— векторы;
— Евклидово расстояние;
— скалярное произведение;
— матричные операции.
#основы
@neuro_channel
{kind=link}
Forwarded from Machinelearning
OpenVLA 7B (vision-language-action) — это open-source модель, обученная на 970K эпизодах манипулирования роботами из набора данных Open X-Embodiment. Модель принимает на вход текстовый промпт и изображения с камеры и генерирует действия робота.
OpenVLA 7B из коробки поддерживает управление несколькими роботами и может быть быстро адаптирована к новым областям робототехники с помощью тонкой настройки.
@ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Secrets
Помните, мы рассказывали про профессора, который пилит крутые визуальные схемы внутрянок ML-алгоритмов?
Так вот появилась еще одна хорошая новость. Ученый начал реализовать некоторые из своих схем в Google Sheets и теперь с ними можно поиграться самостоятельно. Вот ссылка.
Пока что там есть только трансформер, но и на это уже можно залипнуть на весь вечер. Ответы записаны прописным шрифтом, их можно скрыть и посчитать результаты операций самому, руками, а потом сверить.
Очень прикольное и полезное упражнение для освежения знаний.
Так вот появилась еще одна хорошая новость. Ученый начал реализовать некоторые из своих схем в Google Sheets и теперь с ними можно поиграться самостоятельно. Вот ссылка.
Пока что там есть только трансформер, но и на это уже можно залипнуть на весь вечер. Ответы записаны прописным шрифтом, их можно скрыть и посчитать результаты операций самому, руками, а потом сверить.
Очень прикольное и полезное упражнение для освежения знаний.
Forwarded from Machinelearning
SALSA (Stable Armijo Line Search Adaptation) — метод, разработанный для оптимизации Learning Rate (LR) во время обучения.
Основная концепция метода построена вокруг выполнения линейного поиска для определения наилучшего возможного LR для каждого шага обучения, что дает быструю сходимость и улучшенное обобщение.
Чтобы уменьшить вычислительную нагрузку, Salsa предлагает пошаговый миниатюрный линейный поиск. В нем LR постепенно увеличивается с каждым шагом, а критерий линейного поиска постоянно переоценивается.
Дополнительно, Salsa включает экспоненциальное сглаживание в процесс линейного поиска и устанавливает два экспоненциальных скользящих средних для скорости обучения. Это помогает стабилизировать оптимизацию и уменьшить нестабильность от мини-пакетирования.
Экспериментальные результаты показывают, что Salsa превосходит другие методы оптимизации: 50% сокращение final loss и 1,25 average rank в языковых и графических задачах.
Вычислительные издержки Salsa всего на 3% выше, чем у базового LR метода, что можно воспринимать как незначительным увеличением, учитывая показатели производительности. Salsa достаточно универсален, чтобы использоваться с различными оптимизаторами, и особенно эффективен при обучении современных архитектур, которые чувствительны к скорости обучения.
# Clone repository:
git clone https://github.com/TheMody/No-learning-rates-needed-Introducing-SALSA-Stable-Armijo-Line-Search-Adaptation.git
# Create & activate env:
conda env create -f environment.yml
conda activate sls3
# Install dependencies:
pip install pytorch numpy transformers datasets tensorflow-datasets wandb
# NOTE: custom optimizer is in \salsa\SaLSA.py,comparison version are in \salsa\adam_sls.py:
from salsa.SaLSA import SaLSA
self.optimizer = SaLSA(model.parameters())
# NOTE: typical pytorch forward pass needs to be changed to:
def closure(backwards = False):
y_pred = model(x)
loss = criterion(y_pred, y)
if backwards: loss.backward()
return loss
optimizer.zero_grad()
loss = optimizer.step(closure = closure)
@ai_machinelearning_big_data
#AI #LLM #ML #Train #SALSA
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM