
Половина PRO-методов из этой недели скоро озолотят счастливчиков.
Кто успел — тот съел.
Алгоритмы патчатся быстрее, чем ты принимаешь решения.
Если думал "куплю потом" — уже поздно.
Что ты упустил в @MikeBlazerPRO за неделю:
1. Реанимация позиций за 24 часа — кейс, где массовое исправление одного типа ошибок мгновенно сняло пессимизацию всего домена.
2. Топ в Google Maps через верстку — кейс: как добавление атрибутов "compliance" в верстку заменило ссылочное продвижение в перегретой нише
3. Ваши дропы мертвы — почему стандартное восстановление сайта не работает и как "разбудить" ссылочное и выжать из дропа максимум.
4. Ускорение индексации через "пустышки" — анализ логов вскрыл файлы, которые Google ищет принудительно (дайте их ему, даже пустыми).
5. Снятие спама с гарантией — скрытая метрика Local SEO, которая решает, примут вашу жалобу или отправят ваш профиль в игнор.
6. +116% к показам через JSON-код — что конкретно изменить в Schema, чтобы Google открыл кран с трафиком.
7. Фантомные рич-сниппеты — эксплуатация "слепой зоны" Гугла на популярных облачных хостингах для захвата выдачи методом подмены метаданных.
8. Уязвимость в AI Overview — схема фабрикации авторитета через свойство разметки, которая заставляет нейросеть цитировать даже свежие сайты.
9. Захват визуального поиска — метод оптимизации картинок, который бьет точно в денежные интенты (в обход стандартных alt-тегов).
10. Восстановление после апдейта — протокол "микро-дозинга" поведенческих, который "успокаивает алгоритм" и восстановливает упавшие позиции.
-
Люди не платят дважды за воду.
Одна рабочая схема окупает год подписки.
Если не можешь окупить €20 — в PRO тебе рано.
Либо ты забираешь преимущество, либо гуглишь бесплатные крохи и удивляешься, почему конкуренты быстрее.
Кто успел — тот съел.
Алгоритмы патчатся быстрее, чем ты принимаешь решения.
Если думал "куплю потом" — уже поздно.
Что ты упустил в @MikeBlazerPRO за неделю:
1. Реанимация позиций за 24 часа — кейс, где массовое исправление одного типа ошибок мгновенно сняло пессимизацию всего домена.
2. Топ в Google Maps через верстку — кейс: как добавление атрибутов "compliance" в верстку заменило ссылочное продвижение в перегретой нише
3. Ваши дропы мертвы — почему стандартное восстановление сайта не работает и как "разбудить" ссылочное и выжать из дропа максимум.
4. Ускорение индексации через "пустышки" — анализ логов вскрыл файлы, которые Google ищет принудительно (дайте их ему, даже пустыми).
5. Снятие спама с гарантией — скрытая метрика Local SEO, которая решает, примут вашу жалобу или отправят ваш профиль в игнор.
6. +116% к показам через JSON-код — что конкретно изменить в Schema, чтобы Google открыл кран с трафиком.
7. Фантомные рич-сниппеты — эксплуатация "слепой зоны" Гугла на популярных облачных хостингах для захвата выдачи методом подмены метаданных.
8. Уязвимость в AI Overview — схема фабрикации авторитета через свойство разметки, которая заставляет нейросеть цитировать даже свежие сайты.
9. Захват визуального поиска — метод оптимизации картинок, который бьет точно в денежные интенты (в обход стандартных alt-тегов).
10. Восстановление после апдейта — протокол "микро-дозинга" поведенческих, который "успокаивает алгоритм" и восстановливает упавшие позиции.
-
94% подписчиков продлевают второй месяц.Люди не платят дважды за воду.
Одна рабочая схема окупает год подписки.
Если не можешь окупить €20 — в PRO тебе рано.
Либо ты забираешь преимущество, либо гуглишь бесплатные крохи и удивляешься, почему конкуренты быстрее.
201👍14👎7❤2🙈2🔥1
Утечка Google раскрывает четырехэтапную оценку ссылок и механику контекстных анкоров
Классический линкбилдинг приоритизирует метрики корневого домена, но утекшие поисковые алгоритмы разоблачают жесткий многоуровневый конвейер оценки на уровне страницы.
Данные раскрывают: алгоритм классифицирует страницу-источник в один из трех явных классификаторов до оценки анкора.
Утекшая документация подтверждает: более низкое значение
Поскольку система проводит оценку на уровне страницы, домен
Ссылка, проставленная на таких страницах, автоматически наследует классификацию черной дыры.
Пройдя первичную классификацию уровня страницы, система оценивает сам анкор по трем дополнительным измерениям.
Алгоритм оценивает
Утекшие файлы подтверждают: качество анкора измеряется его
Эта четырехэтапная оценка объясняет, почему перелинковка и ссылки тир-2, построенные на базовых документах, работают с высокой мощностью, и почему 10 ссылок с активных редакционных страниц математически обходят 1000 ссылок с мертвых страниц на трастовых доменах.
Это расхождение обнажает ценовой эксплойт: вендоры прайсятся за нишевые вставки (niche edits) на основе метрик корневого домена, что позволяет скупать размещения на страницах
Для ссылок, выживших в этом четырехэтапном фильтре, тематическая релевантность управляется через
Утекшая документация подтверждает: алгоритм читает от 50 до 100 слов, непосредственно окружающих размещение, чтобы усилить сигнал анкора.
Обычный безанкорный "
И наоборот: идеальный анкор с точным вхождением, расположенный внутри нерелевантного абзаца, дает катастрофически сниженную ценность.
Чтобы эксплуатировать этот механизм, накачивай окружающий абзац целевыми сущностями и связанными терминами вместо оптимизации кликабельного текста.
Убери ресурсы от ссылок в био авторов, сайдбарах и футерах.
Ссылки в био автора запускают девальвацию, потому что окружающий абзац дает контекст об авторе, а не о целевой теме, заставляя алгоритм относить их к структурным ссылкам.
Ссылки в сайдбаре и футере имеют нулевой окружающий
Если блок из 50-100 слов вокруг вставки ссылки не определяет жестко целевую тему, перепиши абзац перед выкаткой.
#AnchorText #Backlinks #LinkEquity
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Классический линкбилдинг приоритизирует метрики корневого домена, но утекшие поисковые алгоритмы разоблачают жесткий многоуровневый конвейер оценки на уровне страницы.
Данные раскрывают: алгоритм классифицирует страницу-источник в один из трех явных классификаторов до оценки анкора.
TYPE_HIGH_QUALITY содержит базовые документы — страницы с собственной органикой, бэклинками, внутренними сигналами и позициями.TYPE_MEDIUM_QUALITY хранит страницы дополнительного индекса, а TYPE_LOW_QUALITY ловит документы-черные дыры.Утекшая документация подтверждает: более низкое значение
source_type указывает на более важный анкор.Поскольку система проводит оценку на уровне страницы, домен
DR70 часто хостит документы-черные дыры со статусом TYPE_LOW_QUALITY.Ссылка, проставленная на таких страницах, автоматически наследует классификацию черной дыры.
Пройдя первичную классификацию уровня страницы, система оценивает сам анкор по трем дополнительным измерениям.
Алгоритм оценивает
isLocal, чтобы отличить внутренние ссылки от исходящих на точном уровне анкора, вычисляет locality как прямое измерение качества самого анкора, и назначает уровень классификации bucket.Утекшие файлы подтверждают: качество анкора измеряется его
locality и bucket.Эта четырехэтапная оценка объясняет, почему перелинковка и ссылки тир-2, построенные на базовых документах, работают с высокой мощностью, и почему 10 ссылок с активных редакционных страниц математически обходят 1000 ссылок с мертвых страниц на трастовых доменах.
Это расхождение обнажает ценовой эксплойт: вендоры прайсятся за нишевые вставки (niche edits) на основе метрик корневого домена, что позволяет скупать размещения на страницах
TYPE_HIGH_QUALITY за копейки.Для ссылок, выживших в этом четырехэтапном фильтре, тематическая релевантность управляется через
anchorContext.Утекшая документация подтверждает: алгоритм читает от 50 до 100 слов, непосредственно окружающих размещение, чтобы усилить сигнал анкора.
Обычный безанкорный "
click here", вшитый в абзац, накачанный целевыми сущностями, передает почти идентичную тематическую релевантность, что и анкор с точным вхождением.И наоборот: идеальный анкор с точным вхождением, расположенный внутри нерелевантного абзаца, дает катастрофически сниженную ценность.
Чтобы эксплуатировать этот механизм, накачивай окружающий абзац целевыми сущностями и связанными терминами вместо оптимизации кликабельного текста.
Убери ресурсы от ссылок в био авторов, сайдбарах и футерах.
Ссылки в био автора запускают девальвацию, потому что окружающий абзац дает контекст об авторе, а не о целевой теме, заставляя алгоритм относить их к структурным ссылкам.
Ссылки в сайдбаре и футере имеют нулевой окружающий
anchorContext.Если блок из 50-100 слов вокруг вставки ссылки не определяет жестко целевую тему, перепиши абзац перед выкаткой.
#AnchorText #Backlinks #LinkEquity
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
✍10❤3
Тошнота ключей — это прокси-сигнал. Реальный сигнал — семантический охват концепций.
Та же самая статья под "
Переписанная с охватом управления жизненным циклом контактов, автоматизации процессов продаж, экосистем интеграций и основ репортинга — без единого форсирования целевой фразы — она залетела на #4.
Переменной был охват концепций, а не частотность ключа.
Классификатор Google оценивает, демонстрирует ли статья понимание понятийной вселенной топика, а не то, как часто встречается термин.
Внедрение начинается с извлечения концепций, а не с ресерча ключей.
Промпт для
Для "
Сущности и пары совместной встречаемости добавляют следующий слой.
Для
Затем вытащи пары терминов, которые появляются вместе по топ-30 выдачи — пайплайн + визуализация, контакт + сегментация, автоматизация + воркфлоу — и впиши их естественно.
Google маппит реляционную структуру, а не просто близость терминов.
Глубина концепций неоднородна.
Высокоприоритетные концепции: 300–400 слов.
Второстепенные: 150–200 слов.
Третичные: 50–100 слов.
Калибруй промптом: "Отранжируй эти концепции по частотке, важности для юзера и потенциалу отстройки. Предложи объем в словах для каждой".
Семантический аудит закрывает гэп.
Промпт: "Какие концепции покрыты хорошо, покрыты частично, отсутствуют полностью или расписаны слишком глубоко"?
Аудит статьи по "
Закрытие этих дыр бустануло ее с #29 на #6.
Реальный вопрос: "Какие концепции охватывает топ-10, которых нет в этой статье"?
Данные по 87 обновленным статьям: средний рост позиций на 11 строчек, в 3.8 раза больше вариаций ключей в топе на статью, на 29% больше фичерд сниппетов, прирост трафа на 156%, рост конверсии на 67%.
Методология не раскрывается.
Данные доказывают: статьи, покрывающие 15+ семантических концепций, ранжируются в 3 раза лучше, чем статьи с 5.
Внутренняя перелинковка подчиняется той же логике — линкуй на семантически связанный контент, а не на контент со смежными ключами.
Статья по
Структура ТЗ меняется соответственно: основной топик, базовая концепция, 10 связанных концепций, 10 обязательных сущностей, 10 вопросов из
Ключи становятся выхлопом этого процесса, а не входом.
#SemanticSEO #EntitySEO #ContentStrategy
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Та же самая статья под "
CRM software for small business" ранжировалась на #52 с повторением ключа 18 раз и оптимизированной тошнотой.Переписанная с охватом управления жизненным циклом контактов, автоматизации процессов продаж, экосистем интеграций и основ репортинга — без единого форсирования целевой фразы — она залетела на #4.
Переменной был охват концепций, а не частотность ключа.
Классификатор Google оценивает, демонстрирует ли статья понимание понятийной вселенной топика, а не то, как часто встречается термин.
Внедрение начинается с извлечения концепций, а не с ресерча ключей.
Промпт для
Claude: "Проанализируй топ-10 выдачи по [keyword]. Извлеки основные концепции, связанные сабтопики, технические термины, закрытые вопросы, упомянутые сущности, решенные проблемы юзеров. Создай семантическую карту".Для "
best CRM for small business" это вытаскивает системы скоринга лидов, визуализацию пайплайна, сегментацию контактов и автоматизацию воркфлоу — половина из которых вообще не светится в стандартных тулзах для сбора ключей.Сущности и пары совместной встречаемости добавляют следующий слой.
Для
CRM: продукты (HubSpot, Salesforce), инструменты интеграции (Zapier, Make), сегменты рынка (SMB, enterprise).Затем вытащи пары терминов, которые появляются вместе по топ-30 выдачи — пайплайн + визуализация, контакт + сегментация, автоматизация + воркфлоу — и впиши их естественно.
Google маппит реляционную структуру, а не просто близость терминов.
Глубина концепций неоднородна.
Высокоприоритетные концепции: 300–400 слов.
Второстепенные: 150–200 слов.
Третичные: 50–100 слов.
Калибруй промптом: "Отранжируй эти концепции по частотке, важности для юзера и потенциалу отстройки. Предложи объем в словах для каждой".
Семантический аудит закрывает гэп.
Промпт: "Какие концепции покрыты хорошо, покрыты частично, отсутствуют полностью или расписаны слишком глубоко"?
Аудит статьи по "
Salesforce alternatives" показал, что учет размера команды, соответствие индустрии и время на внедрение отсутствуют полностью, тогда как история компании переоптимизирована.Закрытие этих дыр бустануло ее с #29 на #6.
TF-IDF — это шелуха.Реальный вопрос: "Какие концепции охватывает топ-10, которых нет в этой статье"?
Данные по 87 обновленным статьям: средний рост позиций на 11 строчек, в 3.8 раза больше вариаций ключей в топе на статью, на 29% больше фичерд сниппетов, прирост трафа на 156%, рост конверсии на 67%.
Методология не раскрывается.
Данные доказывают: статьи, покрывающие 15+ семантических концепций, ранжируются в 3 раза лучше, чем статьи с 5.
Внутренняя перелинковка подчиняется той же логике — линкуй на семантически связанный контент, а не на контент со смежными ключами.
Статья по
HubSpot CRM ссылается на управление пайплайном, технологии трекинга email, гайды по миграции данных и воркфлоу автоматизации продаж — а не на другие списки "best CRM".Структура ТЗ меняется соответственно: основной топик, базовая концепция, 10 связанных концепций, 10 обязательных сущностей, 10 вопросов из
PAA, семантические гэпы конкурентов и целевая техническая глубина.Ключи становятся выхлопом этого процесса, а не входом.
#SemanticSEO #EntitySEO #ContentStrategy
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
✍7❤4⚡1👍1
В последнее время я проводила аудит микроразметки на некоторых сайтах и заметила очень грязную тактику, которой брендам стоит остерегаться, пишет Бет Вудкок.
Некоторые агентства вшивают себя в
Вместо того чтобы автором выступал профильный эксперт от бренда, микроразметка говорит Google: "Это SEO-агентство — эксперт в данной теме".
Микроразметка кормит Граф Знаний, и, атрибутируя контент агентству, вы говорите Google, что у вашей компании на самом деле нет внутренней экспертизы, чтобы вещать о своей же индустрии.
Что еще хуже, недавно я видела эту разметку в посте блога с советами по питанию — жесткая
По сути, агентство использует прокачанный сайт, чтобы нарастить собственный
➡️ Агентства должны быть гострайтерами, но авторитетом должна быть ваша команда.
➡️ Каждый пост в блоге должен ссылаться на #person
➡️ Страницы авторов не должны быть просто списком постов. Они обязаны линковать на профили в
➡️ Агентства, пишущие технический контент (здоровье, финансы, право, любая YMYL-ниша), должны отдавать свою работу на проверку и подпись квалифицированному специалисту.
Пока Google удваивает ставки на
Не позволяйте агентству его угнать...
#KnowledgeGraph #SchemaOrg #EEAT
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Некоторые агентства вшивают себя в
schema контента, который они пишут для клиентов.Вместо того чтобы автором выступал профильный эксперт от бренда, микроразметка говорит Google: "Это SEO-агентство — эксперт в данной теме".
Микроразметка кормит Граф Знаний, и, атрибутируя контент агентству, вы говорите Google, что у вашей компании на самом деле нет внутренней экспертизы, чтобы вещать о своей же индустрии.
Что еще хуже, недавно я видела эту разметку в посте блога с советами по питанию — жесткая
YMYL-тематика, где должен быть корректно атрибутированный автор.По сути, агентство использует прокачанный сайт, чтобы нарастить собственный
footprint сущностей в Графе Знаний за счет клиента.➡️ Агентства должны быть гострайтерами, но авторитетом должна быть ваша команда.
➡️ Каждый пост в блоге должен ссылаться на #person
@id реального человека-эксперта внутри вашей компании или верифицированного консультанта.➡️ Страницы авторов не должны быть просто списком постов. Они обязаны линковать на профили в
LinkedIn, показывать сертификаты и доказывать, почему этот чел имеет право давать советы.➡️ Агентства, пишущие технический контент (здоровье, финансы, право, любая YMYL-ниша), должны отдавать свою работу на проверку и подпись квалифицированному специалисту.
Пока Google удваивает ставки на
E-E-A-T, ваш Граф Знаний — это ваш самый ценный актив.Не позволяйте агентству его угнать...
#KnowledgeGraph #SchemaOrg #EEAT
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
👍2🔥2
Телеметрия Discover SDK раскрывает подавление до ранжирования и механику ленты в реальном времени
Классический подход предполагает, что модели прогнозируемого
Алгоритм форсирует оценку
Если юзер смахивает одну статью, этот асимметричный фильтр глобально блокирует весь домен паблишера без эквивалентного механизма для буста на уровне коллекции.
Система пишет перманентную запись
Движок рендера циклично проходит по жесткой 5-уровневой иерархии изображений —
Допуск
И наоборот: инжект мета-тегов
Свежесть работает как первичный фактор пессимизации ранжирования, падая из корзины максимального веса
Данные раскрывают два независимых механизма, которые обходят стандартные ограничения обработки.
Регистрация домена в
Аналогично,
Они работают на изолированном конвейере
Лента работает как
Телеметрия раскрывает около 150 одновременных серверных экспериментов (gws:NNNNNNN) за сессию и алгоритмы контрфактуального тестирования, включая
Во время финальной сборки система категоризирует контент на 13 различных кластеров, эксплуатируя кластер
https://metehan.ai/blog/google-discover-architecture/
#GoogleDiscover #TechnicalSEO #Mobile
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Классический подход предполагает, что модели прогнозируемого
CTR (pCTR) диктуют видимость в Discover, но телеметрия SDK на стороне клиента раскрывает 9-этапный конвейер, где подавление явно предшествует ранжированию.Алгоритм форсирует оценку
Collection Gate через бинарную проверку isCollectionHiddenFromEmberFeed до выполнения User Interest Matching.Если юзер смахивает одну статью, этот асимметричный фильтр глобально блокирует весь домен паблишера без эквивалентного механизма для буста на уровне коллекции.
Система пишет перманентную запись
/persistent/tombstone_{id}/data в логи для смахнутых URL и юзает хеш DocFingerprint для принудительной кросс-девайс дедупликации, гарантируя, что подавленный или перегретый контент больше никогда не всплывет.SDK извлекает ровно шесть тегов Open Graph для заполнения пейлоада ContentMetadata, полагаясь на захардкоженные фоллбэки при отсутствии данных.Движок рендера циклично проходит по жесткой 5-уровневой иерархии изображений —
og:image → og:image:secure_url → twitter:image:src → HTML image → twitter:image — и полностью фейлит рендер карточки, если картинка не найдена.Допуск
hero-карточки жестко требует минимальную ширину изображения 1200px.И наоборот: инжект мета-тегов
notranslate или nopagereadaloud триггерит немедленную остановку конвейера, полностью блокируя прием URL.Свежесть работает как первичный фактор пессимизации ранжирования, падая из корзины максимального веса
1_TO_7_DAYS в корзину низкого веса 15_TO_30_DAYS, после чего телеметрия staleness_in_hours отслеживает непрерывное алгоритмическое затухание.Данные раскрывают два независимых механизма, которые обходят стандартные ограничения обработки.
Регистрация домена в
Google News Publisher Center напрямую инжектит подтип WPAS (Web Publisher Articles Signal) в общий слой персонализации NAIADES, форсируя отдельную классификацию до стандартного извлечения.Аналогично,
Web Stories полностью обходят модель ранжирования pCTR.Они работают на изолированном конвейере
STAMP с выделенными местами в каруселях (INLINE_STAMP_VIEWER_SLIDE_FRAGMENT) и движком прелоада (STAMP_VIEWER_RECOMMENDATIONS), нейтрализуя прямую конкуренцию со стандартными статьями.Лента работает как
live stream через непрерывные gRPC-соединения, позволяя серверу инжектить, менять порядок или удалять карточки прямо посреди сессии без необходимости пулл-ту-рефреша юзером.Телеметрия раскрывает около 150 одновременных серверных экспериментов (gws:NNNNNNN) за сессию и алгоритмы контрфактуального тестирования, включая
background_refresh_rug_pull_count, который трекает случаи, когда Discover ретроактивно отзывает уже доставленные карточки.Во время финальной сборки система категоризирует контент на 13 различных кластеров, эксплуатируя кластер
mustntmiss как строгую очередь приоритетов и применяя внутренние фича-флаги вроде apply_fake_garamond_header для синтетической группировки независимых статей под общим заголовком темы.https://metehan.ai/blog/google-discover-architecture/
#GoogleDiscover #TechnicalSEO #Mobile
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
Архитектура контентных силосов: точная структура, которая вытащила 67% из 450 статей на первую страницу за 6 месяцев
450 статей в блоге, большинство на 3–5 страницах, реорганизованы в 6 силосов за 8 недель.
Результат на 6-м месяце: 67% контента на первой странице, органика 23 000→87 000, ключи в топ-10 127→489, буст трафа на 340%, прирост лидов на 278%, $2.1M доп выручки.
Для цифр $2.1M и 278% нет базового знаменателя — воспринимай как ориентировочные.
Структура работает в три тира: один
Это последнее ограничение — правило, которое нарушают в большинстве внедрений: поддерживающий контент никогда не ссылается напрямую на
Пропуск реле кластера дробит концентрацию авторитета, ради создания которой и выстраивалась иерархия.
Перелинковка между силосами разрешена с капом в 20%, и только там, где контекстное пересечение действительно обосновано.
Структура урлов вшивает ту же иерархию в путь краулинга:
Плоские урлы блога (/keyword-research-tips/) обрывают топическую связь еще до того, как парсится хотя бы одна внутренняя ссылка.
Консистентность каждого урла внутри силоса — не обсуждается.
Миграция текущего контента не требует массового переписывания: смаппи каждую статью в силос, обнови урлы через
Внедрение на 8 недель шло так: Недели 1–2 аудит и маппинг; Недели 3–4 создание
Количество силосов скейлится под модель: 3–5 для одного продукта/услуги, 1 на главную категорию плюс силосы юзкейсов для мультипродуктов, 1 на услугу плюс силосы зон экспертизы для агентств.
Заряжай на старте максимум 2–3 — слишком широкий охват размывает авторитет до того, как нарастет плотность.
Ритм поддержки: 2–3 новые поддерживающие статьи и проверка битых ссылок ежемесячно; апдейты
#Siloing #InternalLinking #TopicClusters
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
450 статей в блоге, большинство на 3–5 страницах, реорганизованы в 6 силосов за 8 недель.
Результат на 6-м месяце: 67% контента на первой странице, органика 23 000→87 000, ключи в топ-10 127→489, буст трафа на 340%, прирост лидов на 278%, $2.1M доп выручки.
Для цифр $2.1M и 278% нет базового знаменателя — воспринимай как ориентировочные.
Структура работает в три тира: один
Pillar (3 000–5 000 слов, широкий обзор, ссылки на каждый кластер, никакой глубокой технички), 5–10 страниц кластера (1 500–2 500 слов, по одному сабтопику на каждую, ссылки вверх на Pillar и вниз на 3–5 поддерживающих статей), и 15–30 поддерживающих страниц (800–1 500 слов, один вопрос или юзкейс, хвосты, ссылки только вверх на кластеры).Это последнее ограничение — правило, которое нарушают в большинстве внедрений: поддерживающий контент никогда не ссылается напрямую на
Pillar.Пропуск реле кластера дробит концентрацию авторитета, ради создания которой и выстраивалась иерархия.
Перелинковка между силосами разрешена с капом в 20%, и только там, где контекстное пересечение действительно обосновано.
Структура урлов вшивает ту же иерархию в путь краулинга:
/seo-guide/ (Pillar), /seo-guide/keyword-research/ (Кластер), /seo-guide/keyword-research/competitor-analysis/ (Поддерживающая страница).Плоские урлы блога (/keyword-research-tips/) обрывают топическую связь еще до того, как парсится хотя бы одна внутренняя ссылка.
Консистентность каждого урла внутри силоса — не обсуждается.
Миграция текущего контента не требует массового переписывания: смаппи каждую статью в силос, обнови урлы через
301 редирект, перепиши интро для ссылок вверх по цепочке, добавь контекстные ссылки на кластеры, вычисти каннибализирующие страницы.Внедрение на 8 недель шло так: Недели 1–2 аудит и маппинг; Недели 3–4 создание
Pillar и структуры урлов; Недели 5–6 оптимизация кластеров и перелинковка; Недели 7–8 закрытие контент-гэпов в поддерживающих страницах и добивка ссылок.Количество силосов скейлится под модель: 3–5 для одного продукта/услуги, 1 на главную категорию плюс силосы юзкейсов для мультипродуктов, 1 на услугу плюс силосы зон экспертизы для агентств.
Заряжай на старте максимум 2–3 — слишком широкий охват размывает авторитет до того, как нарастет плотность.
Ритм поддержки: 2–3 новые поддерживающие статьи и проверка битых ссылок ежемесячно; апдейты
Pillar и аудиты перформанса ежеквартально; оценка структуры и глобальные апдейты ежегодно.#Siloing #InternalLinking #TopicClusters
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
❤3😁3
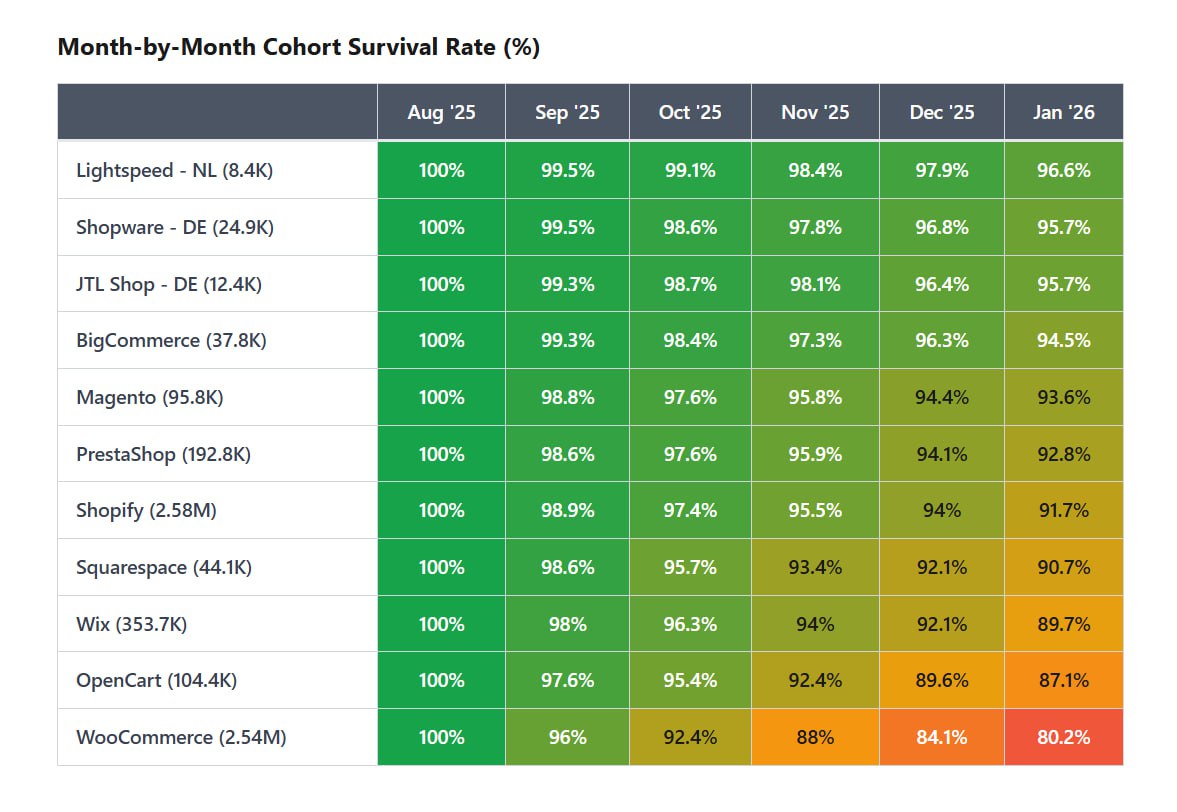
Трекинг 6.8 млн e-commerce магазинов за 6 месяцев. Вот кто выжил.
Почти миллион
Общепринятая практика считает
При общей выживаемости
Данные опровергают миграцию платформ как фактор оттока: менее 1% из 907,648 мертвых магазинов переехали на новую инфраструктуру.
Логи раскрывают точную механику краха для 502,367 убитых доменов на
Полное исчезновение домена (когда резолв DNS полностью прекращается) составляет 76% оттока платформы.
Еще 14% реклассифицируются в некоммерческие сущности вроде блогов, а 10% выкатывают заглушки о закрытии или техобслуживании.
Этот механизм приводит к тому, что 15.1% всех доменов
Отток на
Системная классификация, валидирующая активные флоу чекаута и карточки товаров, подтверждает операционный след этих мертвых доменов.
Форензика-ревью разоблачает, что около 25% убитых сайтов никогда не функционировали как реальный бизнес, работая как штампованные шаблоны под дропшиппинг или фейковые брендовые шопы на доменах
Эти сетки юзают идентичный копирайт, типа "Free Shipping, 7 days customer service", залитый на 14 языках перед быстрым сливом.
Когортные данные раскрывают, что региональные системы работают как полная противоположность этой одноразовой модели.
Развертывания на локализованных платформах вроде
https://shoprank.com/blog/platform-survival-rates
#Ecommerce #Analytics #Tools
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Почти миллион
e-commerce магазинов исчезло за 6 месяцев.Shoprank отследил 6.8 млн магазинов домен за доменом.WooCommerce потерял 1 из 5.Shopify потерял 1 из 12.Общепринятая практика считает
WooCommerce и Shopify сопоставимой базовой инфраструктурой, но когортный трекинг с ИИ-классификацией по 6.8 млн доменов с августа 2025 по январь 2026 года разоблачает WooCommerce как одноразки с гигантским оттоком.При общей выживаемости
e-commerce в 86.6%, Shopify сохранил 91.7% из своих 2.58 млн витрин, потеряв 1 из 12.WooCommerce удержал лишь 80.2% из 2.54 млн развертываний, потеряв 1 из 5.Данные опровергают миграцию платформ как фактор оттока: менее 1% из 907,648 мертвых магазинов переехали на новую инфраструктуру.
Логи раскрывают точную механику краха для 502,367 убитых доменов на
WooCommerce.Полное исчезновение домена (когда резолв DNS полностью прекращается) составляет 76% оттока платформы.
Еще 14% реклассифицируются в некоммерческие сущности вроде блогов, а 10% выкатывают заглушки о закрытии или техобслуживании.
Этот механизм приводит к тому, что 15.1% всех доменов
WooCommerce уходят к ебеням полностью за шесть месяцев.Отток на
Shopify работает иначе, равномерно распределяясь в сторону платформенных заглушек недоступности, при этом полное исчезновение доменов затрагивает лишь 6.0% инфраструктуры.Системная классификация, валидирующая активные флоу чекаута и карточки товаров, подтверждает операционный след этих мертвых доменов.
Форензика-ревью разоблачает, что около 25% убитых сайтов никогда не функционировали как реальный бизнес, работая как штампованные шаблоны под дропшиппинг или фейковые брендовые шопы на доменах
.shop.Эти сетки юзают идентичный копирайт, типа "Free Shipping, 7 days customer service", залитый на 14 языках перед быстрым сливом.
Когортные данные раскрывают, что региональные системы работают как полная противоположность этой одноразовой модели.
Развертывания на локализованных платформах вроде
Lightspeed (96.6%), Shopware (95.7%) и JTL Shop (95.7%) диктуют самые высокие показатели удержания, при этом японские и центральноевропейские системы доминируют в топ-10.Shopify занимает 17-е место в целом, но выступает единственной платформой с более чем 1 млн активных магазинов, обеспечившей выживаемость выше 91.7%, идя вплотную за легаси-системами вроде Magento (93.6%) и PrestaShop (92.8%).https://shoprank.com/blog/platform-survival-rates
#Ecommerce #Analytics #Tools
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
❤1👍1
Google не просто оценивает твои ссылки, он отслеживает, КОГДА они появились, КОГДА изменились, и помечает флагом все, что выглядит как манипуляция.
Для каждого анкора в индексе существует четыре отдельных поля с таймстемпами:
—
—
—
—
Но вот поле, на которое должен обратить внимание каждый сеошник:
Другими словами...
Google целенаправленно пытается определить, была ли ссылка частью оригинального контента или ее вшили позже.
Если страница была опубликована в 2021 году, а Google впервые видит на ней новую ссылку в 2026-м, это несовпадение фиксируется.
Ссылка все еще пашет, но Google ЗНАЕТ, что она не оригинальная.
Одно только это объясняет, почему нишевые вставки на активном, часто обновляемом контенте отрабатывают кратно мощнее, чем вклейки на мертвых страницах, которые не трогали годами...
#NicheEdits #Backlinks #LinkVelocity
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Для каждого анкора в индексе существует четыре отдельных поля с таймстемпами:
—
firstseenDate — дата, когда гуглобот впервые обнаружил ссылку—
creationDate — дата, которую Google ассоциирует с фактическим созданием ссылки—
lastUpdateTimestamp — время последнего обновления анкора при индексации—
deletionDate — когда ссылка была удаленаНо вот поле, на которое должен обратить внимание каждый сеошник:
firstseenNearCreation — булево значение, которое помечает, считает ли Google, что дата firstseen точно отражает момент, когда ссылка была ФАКТИЧЕСКИ добавлена на страницу.Другими словами...
Google целенаправленно пытается определить, была ли ссылка частью оригинального контента или ее вшили позже.
Если страница была опубликована в 2021 году, а Google впервые видит на ней новую ссылку в 2026-м, это несовпадение фиксируется.
Ссылка все еще пашет, но Google ЗНАЕТ, что она не оригинальная.
Одно только это объясняет, почему нишевые вставки на активном, часто обновляемом контенте отрабатывают кратно мощнее, чем вклейки на мертвых страницах, которые не трогали годами...
#NicheEdits #Backlinks #LinkVelocity
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
❤2
Механика "аренды" топ-1 выдачи за 24 часа для застрявших страниц
Даже с идеальным ссылочным профилем страницы часто гниют в топ-30, не принося
Классическое SEO предлагает ждать пересчета.
Агрессивный подход — взломать очередь и "арендовать" первую строку выдачи СРАЗУ!
Новая схема не пытается накачать авторитет годами.
Она посылает алгоритму мощный сигнал срочности, а Google, в ответ, бустит позиции по всему связанному кластеру запросов.
Результат — вертикальный взлет позиций за 12-24 часа.
Кейсы: ключ с
В финансовой вертикали: с 27-го на 11-е место, органика +30% за сутки.
Обычная накрутка убивает сайт, но такая "аренда" дает двойной профит: моментальный трафик по жирным ключам и закрепление на новых позициях за счет реальных юзеров.
Пока конкуренты молятся на апдейты, вы просто забираете их трафик по требованию.
Детальный инсайд → @MikeBlazerPRO
Либо вы эксплуатируете алгоритм, либо алгоритм эксплуатирует вас.
Даже с идеальным ссылочным профилем страницы часто гниют в топ-30, не принося
ROI.Классическое SEO предлагает ждать пересчета.
Агрессивный подход — взломать очередь и "арендовать" первую строку выдачи СРАЗУ!
Новая схема не пытается накачать авторитет годами.
Она посылает алгоритму мощный сигнал срочности, а Google, в ответ, бустит позиции по всему связанному кластеру запросов.
Результат — вертикальный взлет позиций за 12-24 часа.
Кейсы: ключ с
KD 86 взлетел с 89-й на 14-ю позицию, Reddit-страница по ключу с частотностью 450k/мес — прыжок на 98 позиций за ночь.В финансовой вертикали: с 27-го на 11-е место, органика +30% за сутки.
Обычная накрутка убивает сайт, но такая "аренда" дает двойной профит: моментальный трафик по жирным ключам и закрепление на новых позициях за счет реальных юзеров.
Пока конкуренты молятся на апдейты, вы просто забираете их трафик по требованию.
Детальный инсайд → @MikeBlazerPRO
Либо вы эксплуатируете алгоритм, либо алгоритм эксплуатирует вас.
👎8👍5😁2❤1
Раздутый индекс из-за фасетной навигации: точные шаги, которые срезали 89К страниц до 200 и дали буст трафика на 67%
Стандартная матрица фильтров
На масштабе у одного клиента было 127 000 проиндексированных комбинаций фильтров, из которых только 200 несли реальную ценность.
Google краулил все это, ничего нормально не ранжировал и размазывал ссылочный вес по тысячам дублей.
Решение — не отключать фильтры, а хирургически контролировать, что именно краулер закидывает в индекс.
Пять путей внедрения, в порядке специфичности:
Самый грубый рычаг — обработка параметров в
Каждому параметру задается одна из трех инструкций: No URLs для неконтентных параметров вроде трекинг-кодов и
Настройка 15 параметров таким образом сжала индекс одного клиента со 127 000 до 3 000 страниц только за счет этого.
Для параметров, которые
Более сильное архитектурное решение — каноникал со всех комбинаций фильтров обратно на главную страницу категории, что консолидирует сигналы ранжирования на одном урле.
Трейд-офф очевиден: это убивает возможность ранжироваться по запросам типа "
Заюзай это только когда комбинации фильтров имеют нулевую частотку, а страницы фильтров не должны ранжироваться независимо.
Стратегическая выборочная индексация — правильный подход для большинства сайтов.
Индексируй
Закрывай в
Автоматизируй это на уровне шаблона:
Порог в 2+ параметра — это граница внедрения.
Комбинации с одним фильтром, которые стоит ранжировать, полностью вычисти из
Двадцать комбинаций, перестроенных таким образом, отранжировались за 6 недель.
Для небольших ассортиментов до 200 товаров обойди проблему полностью: снеси пагинацию и фильтры, загрузи все товары на один индексируемый урл, а фильтрацию повесь на клиентскую часть через
Одна страница, ноль дублей.
Помониторь ежемесячно: чекай покрытие в
Без регулярных аудитов дисциплина индекса деградирует незаметно.
#IndexCoverage #Crawling #TechnicalSEO
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Стандартная матрица фильтров
e-commerce — 10 категорий × 20 цветов × 15 размеров × 10 брендов — генерит 30 000 возможных урлов, большинство из которых отдают почти идентичные сетки товаров.На масштабе у одного клиента было 127 000 проиндексированных комбинаций фильтров, из которых только 200 несли реальную ценность.
Google краулил все это, ничего нормально не ранжировал и размазывал ссылочный вес по тысячам дублей.
Решение — не отключать фильтры, а хирургически контролировать, что именно краулер закидывает в индекс.
Пять путей внедрения, в порядке специфичности:
Самый грубый рычаг — обработка параметров в
GSC (Search Console → Settings → Crawling → URL Parameters).Каждому параметру задается одна из трех инструкций: No URLs для неконтентных параметров вроде трекинг-кодов и
ID сессий; Representative URL для параметров, которые меняют контент, но где Google должен сам выбрать каноникал; Every URL только для параметров, генерирующих уникальные, индексируемые страницы.Настройка 15 параметров таким образом сжала индекс одного клиента со 127 000 до 3 000 страниц только за счет этого.
Для параметров, которые
GSC не может чисто разрулить, <meta name="robots" content="noindex"> на страницах фильтрации позволяет юзерам свободно фильтровать и сохраняет перетекание краулингового веса — Google проходит по ссылкам, но не индексирует конечный урл.Более сильное архитектурное решение — каноникал со всех комбинаций фильтров обратно на главную страницу категории, что консолидирует сигналы ранжирования на одном урле.
Трейд-офф очевиден: это убивает возможность ранжироваться по запросам типа "
red shoes size 10".Заюзай это только когда комбинации фильтров имеют нулевую частотку, а страницы фильтров не должны ранжироваться независимо.
Стратегическая выборочная индексация — правильный подход для большинства сайтов.
Индексируй
/shoes/, /shoes/red/, /shoes/nike/, /shoes/running/ — ВЧ-комбинации с одним фильтром.Закрывай в
noindex любой урл, несущий два или более параметра, либо комбинации без частотки.Автоматизируй это на уровне шаблона:
if (count($_GET) > 1) { echo '<meta name="robots" content="noindex">'; }.Порог в 2+ параметра — это граница внедрения.
Комбинации с одним фильтром, которые стоит ранжировать, полностью вычисти из
query string./shoes/?color=red становится /shoes/red/ — чистый путь директории, который выглядит как категория, поддерживает независимую оптимизацию тайтлов/мета и упрощает внутреннюю перелинковку.Двадцать комбинаций, перестроенных таким образом, отранжировались за 6 недель.
Для небольших ассортиментов до 200 товаров обойди проблему полностью: снеси пагинацию и фильтры, загрузи все товары на один индексируемый урл, а фильтрацию повесь на клиентскую часть через
JavaScript без изменения урлов.Одна страница, ноль дублей.
Помониторь ежемесячно: чекай покрытие в
GSC на предмет общего числа проиндексированных урлов (цель: только категории + ценные страницы с одним фильтром), пробивай site:example.com inurl:?, чтобы отловить просочившиеся урлы с параметрами, и краули через Screaming Frog для подсчета уникальных комбинаций параметров.Без регулярных аудитов дисциплина индекса деградирует незаметно.
#IndexCoverage #Crawling #TechnicalSEO
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
❤3😱2
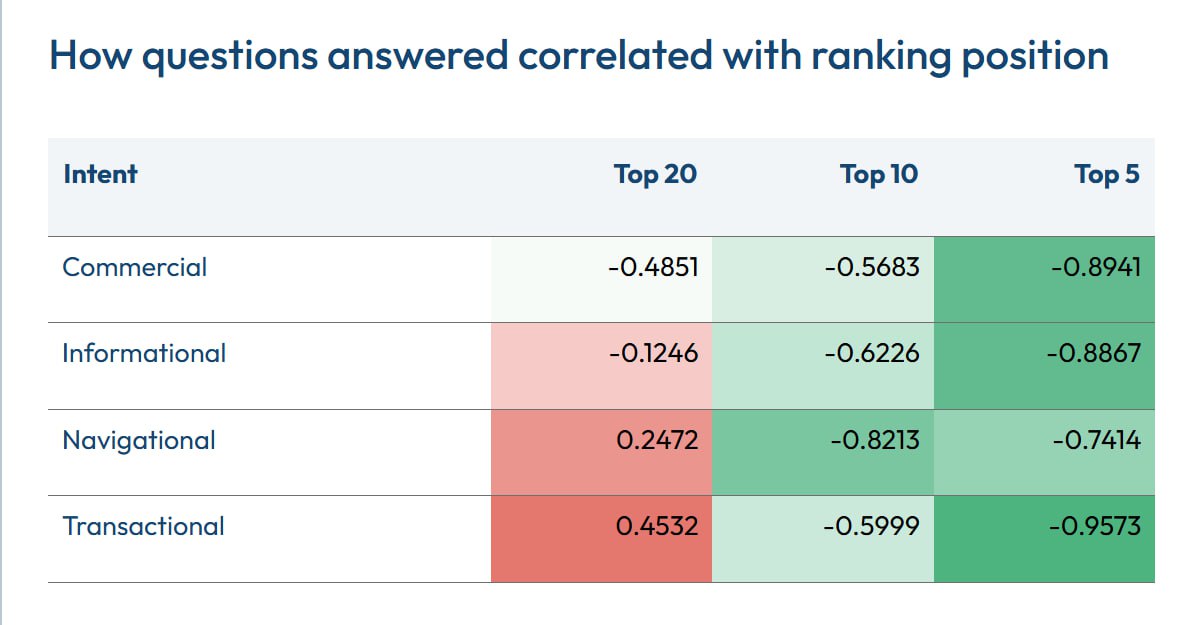
Как ответы на вопросы People Also Ask коррелируют с позициями в органике
Стандартная практика предполагает, что информационный контент требует максимально глубокого покрытия вопросов
Данные подтверждают, что транзакционные и коммерческие страницы демонстрируют самую сильную корреляцию ранжирования с точным покрытием
При измерении абсолютного количества вопросов
Информационные запросы неожиданно плетутся позади с -0.8867.
Логи раскрывают строгое разделение между полным и частичным покрытием вопроса в зависимости от интента запроса.
Когда в анализе применили взвешенный
Однако корреляция для транзакционного интента рухнула до -0.5460 при этой модели частичного скоринга.
Это подтверждает, что ранжирование в транзакционных серпах требует абсолютной полноты для связанных
Навигационные запросы стабильно демонстрируют самую слабую корреляцию с покрытием
Эта корреляция работает строго как сигнал верхнего уровня, который схлопывается за пределами первой страницы.
Полевые тесты подтверждают: корреляция резко падает после 10 позиции и полностью разворачивается на позициях с 18 по 20, где страницы с меньшим числом ответов часто ранжируются выше.
Данные раскрывают, что абсолютная полнота работает как прокси для семантической насыщенности (semantic richness), но ответы на
https://alsoasked.com/insights/paa-ranking-correlation
#PAA #SearchIntent #Rankings
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Стандартная практика предполагает, что информационный контент требует максимально глубокого покрытия вопросов
People Also Ask (PAA), но анализ 5 415 URL по 563 запросам раскрывает обратное.Данные подтверждают, что транзакционные и коммерческие страницы демонстрируют самую сильную корреляцию ранжирования с точным покрытием
PAA.При измерении абсолютного количества вопросов
PAA, на которые дан полный ответ в основном читаемом тексте, транзакционные запросы показывают корреляцию -0.9573 с топ-5 позициями в органике, за ними идет коммерческий интент с -0.8941.Информационные запросы неожиданно плетутся позади с -0.8867.
Логи раскрывают строгое разделение между полным и частичным покрытием вопроса в зависимости от интента запроса.
Когда в анализе применили взвешенный
Question Score — выделяя 1 балл за полный ответ и 0.5 балла за частичный сниппет — коммерческие страницы удержали самую сильную корреляцию с топ-5 на уровне -0.9097.Однако корреляция для транзакционного интента рухнула до -0.5460 при этой модели частичного скоринга.
Это подтверждает, что ранжирование в транзакционных серпах требует абсолютной полноты для связанных
PAA-запросов, тогда как коммерческие серпы поощряют частичную глубину.Навигационные запросы стабильно демонстрируют самую слабую корреляцию с покрытием
PAA (-0.7414) в обеих методах скоринга.Эта корреляция работает строго как сигнал верхнего уровня, который схлопывается за пределами первой страницы.
Полевые тесты подтверждают: корреляция резко падает после 10 позиции и полностью разворачивается на позициях с 18 по 20, где страницы с меньшим числом ответов часто ранжируются выше.
Данные раскрывают, что абсолютная полнота работает как прокси для семантической насыщенности (semantic richness), но ответы на
PAA-вопросы в изоляции не дают выхлопа без мощной технички и внешних сигналов, валидирующих страницу.https://alsoasked.com/insights/paa-ranking-correlation
#PAA #SearchIntent #Rankings
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
❤2👍1
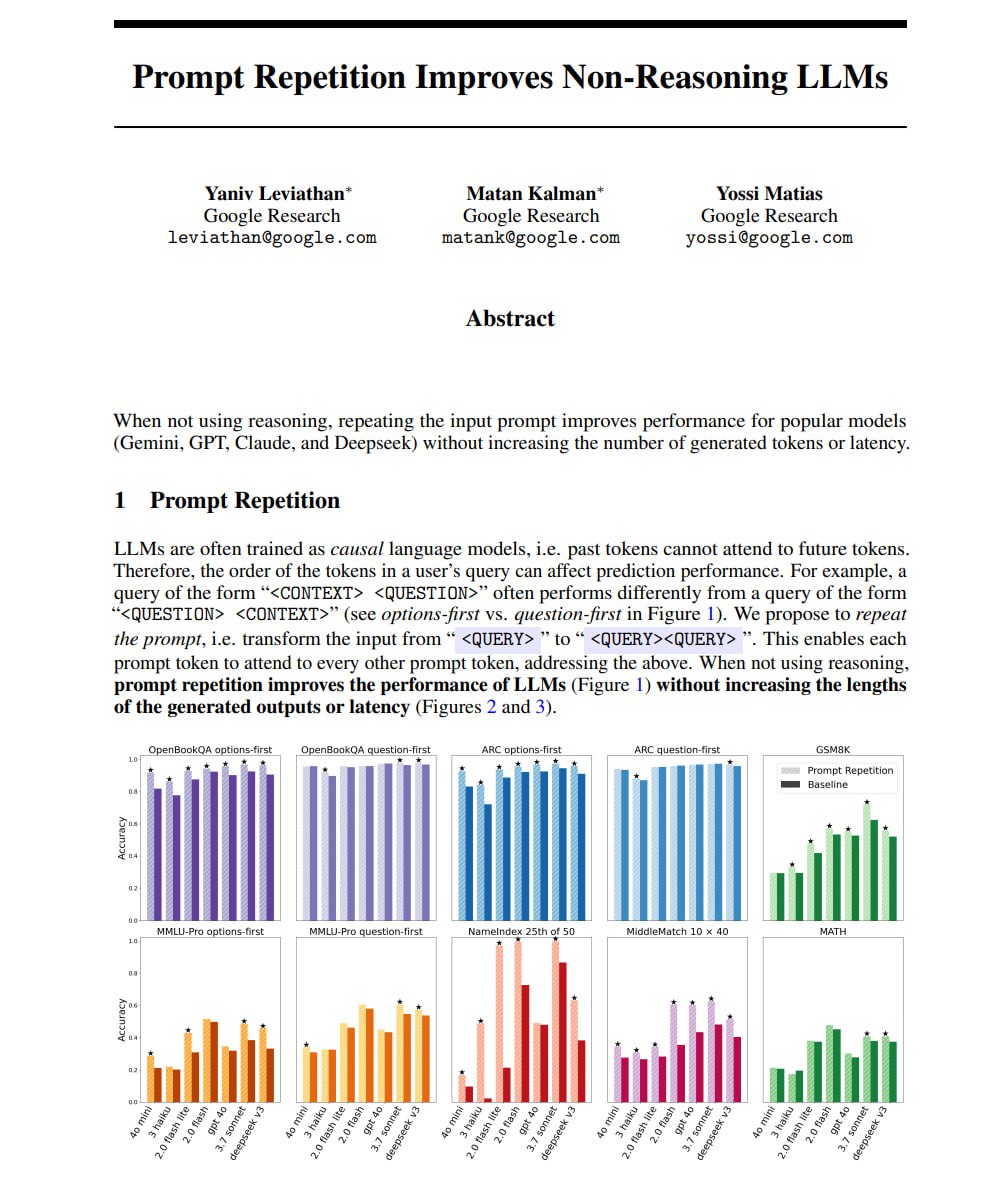
Если хочешь получать лучшие результаты от
Дублируй свой промпт!
Исследователи обнаружили, что повторение абсолютно того же самого инпута может драматически улучшить перформанс (буст до 76% на конкретных задачах).
Поэтому, когда ты пишешь длинный промпт с контекстом в начале и вопросом в конце, модель может опираться на этот контекст для ответа, но контекст был обработан до того, как модель вообще узнала вопрос.
Эта асимметрия — базовое структурное свойство того, как работают
Повторение промпта помогает обойти это ограничение, давая модели второй проход по полному контексту.
Здесь нет вычисления новых потерь и никакого замудренного промпт-инжиниринга.
Это просто структурный хак, который работает почти на каждой крупной модели, которую они тестировали.
Вот пейпер: https://arxiv.org/pdf/2512.14982
#LLM #AI #Automation
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
LLM без оплаты за длинные аутпуты или файн-тюнинг, вот конкретный, элементарный финт:Дублируй свой промпт!
Исследователи обнаружили, что повторение абсолютно того же самого инпута может драматически улучшить перформанс (буст до 76% на конкретных задачах).
LLM процессит текст слева направо, каждый токен может смотреть только на предыдущий контекст, никогда — вперед.Поэтому, когда ты пишешь длинный промпт с контекстом в начале и вопросом в конце, модель может опираться на этот контекст для ответа, но контекст был обработан до того, как модель вообще узнала вопрос.
Эта асимметрия — базовое структурное свойство того, как работают
LLM.Повторение промпта помогает обойти это ограничение, давая модели второй проход по полному контексту.
Здесь нет вычисления новых потерь и никакого замудренного промпт-инжиниринга.
Это просто структурный хак, который работает почти на каждой крупной модели, которую они тестировали.
Вот пейпер: https://arxiv.org/pdf/2512.14982
#LLM #AI #Automation
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
❤6👍1
"Мета-дескрипшн не имеет значения"!.
"Не трать время на написание мета-дескрипшнов"!
Сколько раз мы читали эти рекомендации?
Много, верно?
Переосмысли.
В этом
#MetaDescriptions #AIOverviews #SERPFeatures
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
"Не трать время на написание мета-дескрипшнов"!
Сколько раз мы читали эти рекомендации?
Много, верно?
Переосмысли.
В этом
AI Answer, а также в соответствующих AI Overviews, ссылки на источники, как правило, имеют тип "ссылка-на-выделенный-текст", и текст извлекается не из основного контента, а из... мета-дескрипшна.#MetaDescriptions #AIOverviews #SERPFeatures
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
☃5🙈2
"
"
"
Одно слово меняет весь интент.
Гугли ключ, прежде чем под него оптимизировать.
Если в топ-10 блоги — тебе нужен блог.
Если там товарки — нужна товарка.
Ты не заставишь Google поменять интент.
Кай Кромвелл говорит, что проанализировал 200+ магазинов на
И именно здесь большинство лажает.
Пытаются ранжировать карточку товара по ключу, который явно требует блог.
Это никогда не сработает.
Попадай в интент или даже не пытайся.
#SearchIntent #Keywords #ContentStrategy
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Protein powder" = статья в блоге."
Chocolate protein powder" = страница категории."
Chocolate collagen protein powder" = карточка товара.Одно слово меняет весь интент.
Гугли ключ, прежде чем под него оптимизировать.
Если в топ-10 блоги — тебе нужен блог.
Если там товарки — нужна товарка.
Ты не заставишь Google поменять интент.
Кай Кромвелл говорит, что проанализировал 200+ магазинов на
Shopify.И именно здесь большинство лажает.
Пытаются ранжировать карточку товара по ключу, который явно требует блог.
Это никогда не сработает.
Попадай в интент или даже не пытайся.
#SearchIntent #Keywords #ContentStrategy
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
3❤9🤣3👍1
Кросс-доменная агрегация товарного графа перезаписывает локальные рейтинги магазинов
Классическая сеошка
Анализ 115,582 товаров в 11,369 органических сетках выдачи разоблачает иную реальность классификатора: алгоритм форсирует жесткие пороги видимости на основе общевебного Графа Знаний о товаре, переопределяя изолированные метрики конкретной витрины.
Концентрация абсолютная: 79% товаров в органических сетках имеют рейтинг 4 звезды и выше, а 96% удерживают 3+ звезды.
Товары, падающие ниже порога в 3 звезды, отбрасываются бороться за оставшиеся 4% слотов в сетке.
Этот макро-рейтинг диктует видимость, потому что Google агрегирует сентимент, спарсенный с сайтов конкурентов, видосов с обзорами на
Эта коллективная веб-репутация нативно перезаписывает локальные данные.
Логи раскрывают конкретные случаи, когда товары с рейтингом 4.7 звезд на своем хост-домене понижаются до классификации 3.8 звезд в системе Google из-за более слабых отзывов на
Поскольку данные конкурентов и сентимент с внешних платформ напрямую перетекают в алгоритмический рейтинг, управления локальной воронкой отзывов недостаточно для попадания в сетку.
Для обеспечения органической видимости требуется аудит совокупного товарного графа, чтобы выявить точные расхождения в рейтингах, которые Google присваивает сущности во всей своей широкой экосистеме.
#Ecommerce #KnowledgeGraph #ShoppingAds
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Классическая сеошка
e-commerce предполагает, что оптимизация отзывов на самом сайте диктует перформанс в Google Shopping.Анализ 115,582 товаров в 11,369 органических сетках выдачи разоблачает иную реальность классификатора: алгоритм форсирует жесткие пороги видимости на основе общевебного Графа Знаний о товаре, переопределяя изолированные метрики конкретной витрины.
Концентрация абсолютная: 79% товаров в органических сетках имеют рейтинг 4 звезды и выше, а 96% удерживают 3+ звезды.
Товары, падающие ниже порога в 3 звезды, отбрасываются бороться за оставшиеся 4% слотов в сетке.
Этот макро-рейтинг диктует видимость, потому что Google агрегирует сентимент, спарсенный с сайтов конкурентов, видосов с обзорами на
YouTube и TikTok, таблиц спецификаций товаров и тредов на Reddit.Эта коллективная веб-репутация нативно перезаписывает локальные данные.
Логи раскрывают конкретные случаи, когда товары с рейтингом 4.7 звезд на своем хост-домене понижаются до классификации 3.8 звезд в системе Google из-за более слабых отзывов на
Amazon или негативного сентимента во внешних видосах.Поскольку данные конкурентов и сентимент с внешних платформ напрямую перетекают в алгоритмический рейтинг, управления локальной воронкой отзывов недостаточно для попадания в сетку.
Для обеспечения органической видимости требуется аудит совокупного товарного графа, чтобы выявить точные расхождения в рейтингах, которые Google присваивает сущности во всей своей широкой экосистеме.
#Ecommerce #KnowledgeGraph #ShoppingAds
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Сеошники с новой партией
#Humor
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
AI-генеренки пытаются взять топ#Humor
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
😁24❤1👍1😡1
Пока ты жуёшь сопли и экономишь на спичках, подписчики PRO уже внедрили схемы из этой недели.
Конкуренты впереди не потому что умнее — потому что знают раньше.
Кто-то ставит смайлики под этим постом, а подписчики @MikeBlazerPRO снимают сливки.
Недельный дайджест постов в PRO:
1. Пока вы сливаете бюджет на аутрич, профи пылесосят академический траст — слив изящной схемы, которая нагло эксплуатирует внутренние бюрократические регламенты закрытых организаций.
2. Скачок на 10 позиций за сутки в перегретой нише — снайперский залив копеечных визитов, который Гугл хавает как чистый органический сигнал без срабатывания спам-фильтров.
3. Динамический буст краулингового бюджета — как на лету перестраивать перелинковку, заставляя бота жестко индексировать слепые зоны сайта.
4. Рост частоты краулинга на 400% за трое суток — как настраивать транспортный протокол сервера для генерации сигнала инфраструктурного траста и повышения сканирования.
5. Идеальный силос, который бот хавает с первого раза — жесткий технический диалог с поисковиком, направляющий весь ссылочный вес прямо на главный мани-пейдж.
6. Топ-1 в конкурентной выдаче за 14 дней на чужом трасте — слив жесткой схемы накачки метрик, которая проламывает SERP без срабатывания спам-фильтров.
7. Вектор негативного SEO нового поколения — как конкуренты могут незаметно скормить нейронке токсичный нарратив про ваш продукт, обрушив ваши брендовые отчеты для инвесторов.
8. Подмена скрытого машиночитаемого слоя в медиа-форматах — как ручная набивка невидимого для юзера текстового блока позволяет ранжировать визуально пустые посты по самым жирным ключам.
9. Прыжок в топ-1 гиперлокального пака за 48 часов — серая схема накрутки органических сессий с идеальным удержанием, которую невозможно спалить классическим лог-анализом.
10. Десятки тысяч долларов пассивного дохода на выдуманном продукте — создание синтетического брендового пузыря и бесшовная маршрутизация арбитражного трафика, где поисковик выступает абсолютным гарантом доверия.
-
Для тех, кто понимает разницу между "правильно" и "эффективно".
Если платить за 💯 контент для тебя зашквар — ты не готов к этим методам - продолжай ставить смайлы.
Либо ты внутри и внедряешь, либо читаешь кейсы через полгода, когда они уже не работают.
Конкуренты впереди не потому что умнее — потому что знают раньше.
Кто-то ставит смайлики под этим постом, а подписчики @MikeBlazerPRO снимают сливки.
Недельный дайджест постов в PRO:
1. Пока вы сливаете бюджет на аутрич, профи пылесосят академический траст — слив изящной схемы, которая нагло эксплуатирует внутренние бюрократические регламенты закрытых организаций.
2. Скачок на 10 позиций за сутки в перегретой нише — снайперский залив копеечных визитов, который Гугл хавает как чистый органический сигнал без срабатывания спам-фильтров.
3. Динамический буст краулингового бюджета — как на лету перестраивать перелинковку, заставляя бота жестко индексировать слепые зоны сайта.
4. Рост частоты краулинга на 400% за трое суток — как настраивать транспортный протокол сервера для генерации сигнала инфраструктурного траста и повышения сканирования.
5. Идеальный силос, который бот хавает с первого раза — жесткий технический диалог с поисковиком, направляющий весь ссылочный вес прямо на главный мани-пейдж.
6. Топ-1 в конкурентной выдаче за 14 дней на чужом трасте — слив жесткой схемы накачки метрик, которая проламывает SERP без срабатывания спам-фильтров.
7. Вектор негативного SEO нового поколения — как конкуренты могут незаметно скормить нейронке токсичный нарратив про ваш продукт, обрушив ваши брендовые отчеты для инвесторов.
8. Подмена скрытого машиночитаемого слоя в медиа-форматах — как ручная набивка невидимого для юзера текстового блока позволяет ранжировать визуально пустые посты по самым жирным ключам.
9. Прыжок в топ-1 гиперлокального пака за 48 часов — серая схема накрутки органических сессий с идеальным удержанием, которую невозможно спалить классическим лог-анализом.
10. Десятки тысяч долларов пассивного дохода на выдуманном продукте — создание синтетического брендового пузыря и бесшовная маршрутизация арбитражного трафика, где поисковик выступает абсолютным гарантом доверия.
-
Для тех, кто понимает разницу между "правильно" и "эффективно".
Если платить за 💯 контент для тебя зашквар — ты не готов к этим методам - продолжай ставить смайлы.
Либо ты внутри и внедряешь, либо читаешь кейсы через полгода, когда они уже не работают.
🤣29❤7🌚3🤬1🙈1
Неправильная настройка CDN убивает позиции, не затрагивая Core Web Vitals
Сайт клиента показывал идеальные
Три дня диагностики свелись к кривой настройке
Фикс занял 20 минут.
Позиции восстановились за 2 недели.
Корневая причина сбоя:
Гуглобот затем натыкается на устаревшие версии документов, новые страницы всплывают в выдаче днями, а динамический контент замораживается в статические слепки.
Точные настройки: сконфигурировать
Заголовки кеша усугубляют проблему при кривой настройке.
Правильный маппинг:
Некоторые
Срез любого из них втихую ломает поведение индексации, на которое опирается Google.
Проверь, что выживает при передаче, через
Отдельно: слои защиты от ботов могут неверно идентифицировать гуглобота и заблочить его.
Симптомы: страницы проиндексированы, но не рендерятся, статус "Сканирование — пока не проиндексировано", сбои мобильной индексации и отвал рич сниппетов.
Фикс: закинь в вайтлист верифицированные
Когда
Отдавай идентичный контент всем юзерам.
Проверь через
Логика гео-редиректов, настроенная на уровне
Замени гео-редиректы уровня
На
#CDN #CloudFlare #TechnicalSEO
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Сайт клиента показывал идеальные
Core Web Vitals, пока позиции обваливались.Три дня диагностики свелись к кривой настройке
CDN.Фикс занял 20 минут.
Позиции восстановились за 2 недели.
Корневая причина сбоя:
CDN по дефолту кешируют всё, включая HTML.Гуглобот затем натыкается на устаревшие версии документов, новые страницы всплывают в выдаче днями, а динамический контент замораживается в статические слепки.
Точные настройки: сконфигурировать
CDN так, чтобы полностью исключить HTML из кеширования — кешируется только статика.Заголовки кеша усугубляют проблему при кривой настройке.
Cache-Control: max-age=31536000 примененный к HTML, заголовки Expires заданные в прошлом, принудительный no-cache для картинок или кеш public для динамических страниц — всё это генерит отдельные сценарии отказа.Правильный маппинг:
HTML получает no-cache или короткий TTL; картинки, CSS и JS получают TTL на 1 год, с версионированием CSS и JS.Некоторые
CDN срезают HTTP-заголовки при передаче — конкретно X-Robots-Tag, заголовки Link с директивами хрефленгов, Vary и Content-Type.Срез любого из них втихую ломает поведение индексации, на которое опирается Google.
Проверь, что выживает при передаче, через
curl -I yoursite.com.Отдельно: слои защиты от ботов могут неверно идентифицировать гуглобота и заблочить его.
Симптомы: страницы проиндексированы, но не рендерятся, статус "Сканирование — пока не проиндексировано", сбои мобильной индексации и отвал рич сниппетов.
Фикс: закинь в вайтлист верифицированные
IP гуглобота и проведи аудит ошибок краулинга в Search Console.Когда
CDN корректно определяет гуглобота, но отдает ему другой ответ — вырезанный JavaScript, упрощенный HTML, удаленные картинки или отсутствие интерактивных элементов — это запускает нарушение по клоакингу.Отдавай идентичный контент всем юзерам.
Проверь через
Mobile-Friendly Test.Логика гео-редиректов, настроенная на уровне
CDN, создает бесконечные циклы: запрос к .com из Германии редиректит на .de, который редиректит обратно на .com.Замени гео-редиректы уровня
CDN на теги хрефленг и дай юзерам самим выбирать локацию.На
SSL форсируй HTTPS на уровне CDN, редиректи все HTTP-запросы и обновляй небезопасные ресурсы — чекни цепочку сертификатов и смешанный контент через whynopadlock.com.Cloudflare вносит три специфичных сценария отказа поверх базовых.Rocket Loader задерживает выполнение JavaScript и может помешать гуглоботу увидеть контент, зависящий от JS — отруби его или исключи критичные скрипты.Auto Minify может сломать JavaScript и похерить CSS; вместо этого минифицируй на этапе сборки.Always Online отдает закешированную версию во время падения источника, а значит, гуглобот может проиндексировать протухшие страницы — жестко мониторь свежесть кеша и часто его обновляй.#CDN #CloudFlare #TechnicalSEO
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
❤5✍2👍2
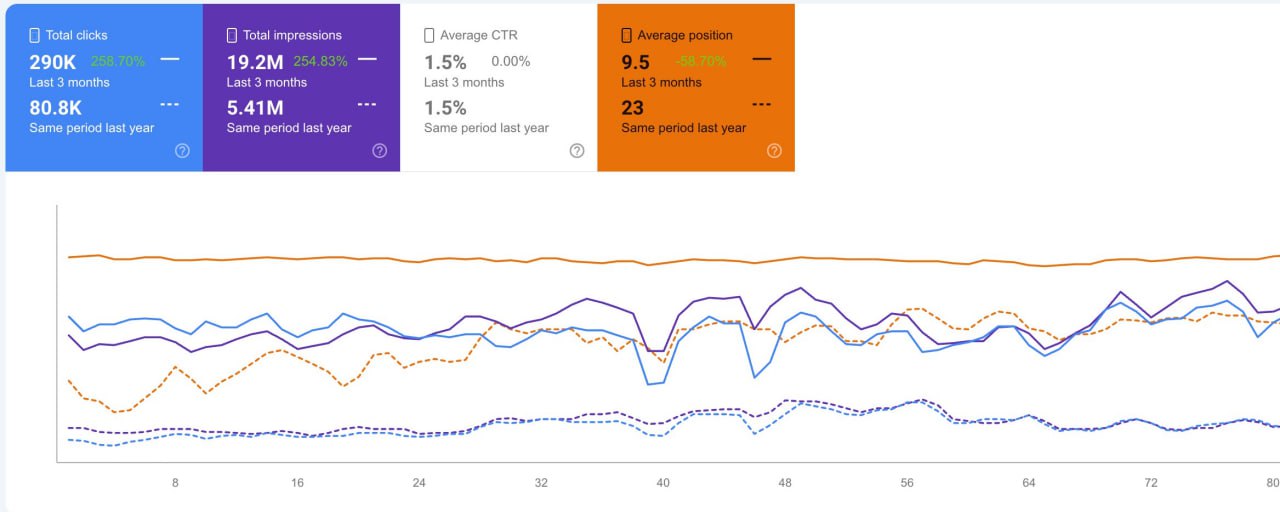
Вложенные Exact-Match сабы обходят наследование санкций HCU
Стандартное восстановление предполагает ожидание циклов широких кор-апдейтов для снятия фильтров
Данные логов ИИ-программного каталога разоблачают структурный обход: миграция идентичного контента и диза на
Этот архитектурный сдвиг изолирует восстановление от окон апдейтов, форсируя немедленную независимую оценку.
Полевые тесты подтверждают, что этот протокол отмасштабировал общие клики с 80.
Средняя позиция улучшилась с 23 до 9.5 (+13.5 позиций), в то время как
Алгоритм структурно сопротивляется мультитематическим сайтам, размывая сигналы ранжирования и раздувая
Перенос массивных блоков контента на тематически изолированные сабы выстраивает жесткие границы, форсируя классификатор тестировать интент и удовлетворенность от клика на одной сфокусированной сущности.
Чтобы вооружить это, агрессивный технический прунинг должен сконцентрировать сигнал ранжирования на каждый документ.
За счет вычищения неиндексированных урлов, критическая серая зона сжалась с 6 миллионов документов до 148,000.
Это систематически снижает
Архитектура эксплуатирует релевантность
Когда путь юзера следует последовательности
Данные подтверждают, что такое выравнивание последовательности обеспечивает более высокий апрув на индексацию и более сильные сигналы ранжирования.
Выкатка этого на мультиязычные сабы запускает латеральное распространение авторитета; когда позиции улучшаются для паттерна "
Чтобы классификатор не пометил новые сабы как чисто информационные, протокол внедряет функцию "продажи" в исходный контекст.
Это эксплуатирует запрограммированное предпочтение алгоритма к функциональным бизнесам перед сайтами, состоящими только из контента.
Слияние коммерческого интента с технической эффективностью
#HCU #EMD #Penalties
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Стандартное восстановление предполагает ожидание циклов широких кор-апдейтов для снятия фильтров
HCU.Данные логов ИИ-программного каталога разоблачают структурный обход: миграция идентичного контента и диза на
exact-match сабдомены заставляет оценивать сущность с нуля, сбрасывая историю алгоритмических санкций основного домена.Этот архитектурный сдвиг изолирует восстановление от окон апдейтов, форсируя немедленную независимую оценку.
Полевые тесты подтверждают, что этот протокол отмасштабировал общие клики с 80.
8K до 290K (+209.2K), а показы — с 5.41M до 19.2M (+13.79M).Средняя позиция улучшилась с 23 до 9.5 (+13.5 позиций), в то время как
CTR остался стабильным на уровне 1.5%.Алгоритм структурно сопротивляется мультитематическим сайтам, размывая сигналы ранжирования и раздувая
retrieval costs, из-за чего глубокие документы не проходят пороги оценки.Перенос массивных блоков контента на тематически изолированные сабы выстраивает жесткие границы, форсируя классификатор тестировать интент и удовлетворенность от клика на одной сфокусированной сущности.
Чтобы вооружить это, агрессивный технический прунинг должен сконцентрировать сигнал ранжирования на каждый документ.
За счет вычищения неиндексированных урлов, критическая серая зона сжалась с 6 миллионов документов до 148,000.
Это систематически снижает
retrieval costs и ускоряет скорость алгоритмической оценки.Архитектура эксплуатирует релевантность
exact-match domain (EMD) через вложенность, обогащенную терминами запроса.Когда путь юзера следует последовательности
Q1 → Q2 → Q3, развертывание структуры q1.q2.q3.maindomain.tld напрямую выравнивает вложенный путь с точным паттерном запроса.Данные подтверждают, что такое выравнивание последовательности обеспечивает более высокий апрув на индексацию и более сильные сигналы ранжирования.
Выкатка этого на мультиязычные сабы запускает латеральное распространение авторитета; когда позиции улучшаются для паттерна "
q1 + q2" в одном языке, система генерит исторические данные, которые валидируют тематический авторитет на уровне сущности по всей языковой матрице.Чтобы классификатор не пометил новые сабы как чисто информационные, протокол внедряет функцию "продажи" в исходный контекст.
Это эксплуатирует запрограммированное предпочтение алгоритма к функциональным бизнесам перед сайтами, состоящими только из контента.
Слияние коммерческого интента с технической эффективностью
exact-match форсирует систему реклассифицировать сабдомен как высокополезный сервис, цементируя восстановление позиций и обходя предыдущие лимиты оценки.#HCU #EMD #Penalties
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
❤4
Никто этого не знает: на тебя могут подать в суд за борьбу со спамом.
Знал ли ты, что бизнес может отправить официальный запрос в Google и затребовать записи о том, кто вносил правки в их
Да.
Это реальный юридический процесс.
И если они его запустят, Google предоставит список аккаунтов, которые вносили изменения в их профиль.
Поэтому, если ты используешь "
Именно поэтому я рекомендую юзать
Делая это таким образом, ты устраняешь риск быть раскрытым лично в рамках юридического запроса.
#GBP #LocalSEO #NegativeSEO
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Знал ли ты, что бизнес может отправить официальный запрос в Google и затребовать записи о том, кто вносил правки в их
Google Business Profile?Да.
Это реальный юридический процесс.
И если они его запустят, Google предоставит список аккаунтов, которые вносили изменения в их профиль.
Поэтому, если ты используешь "
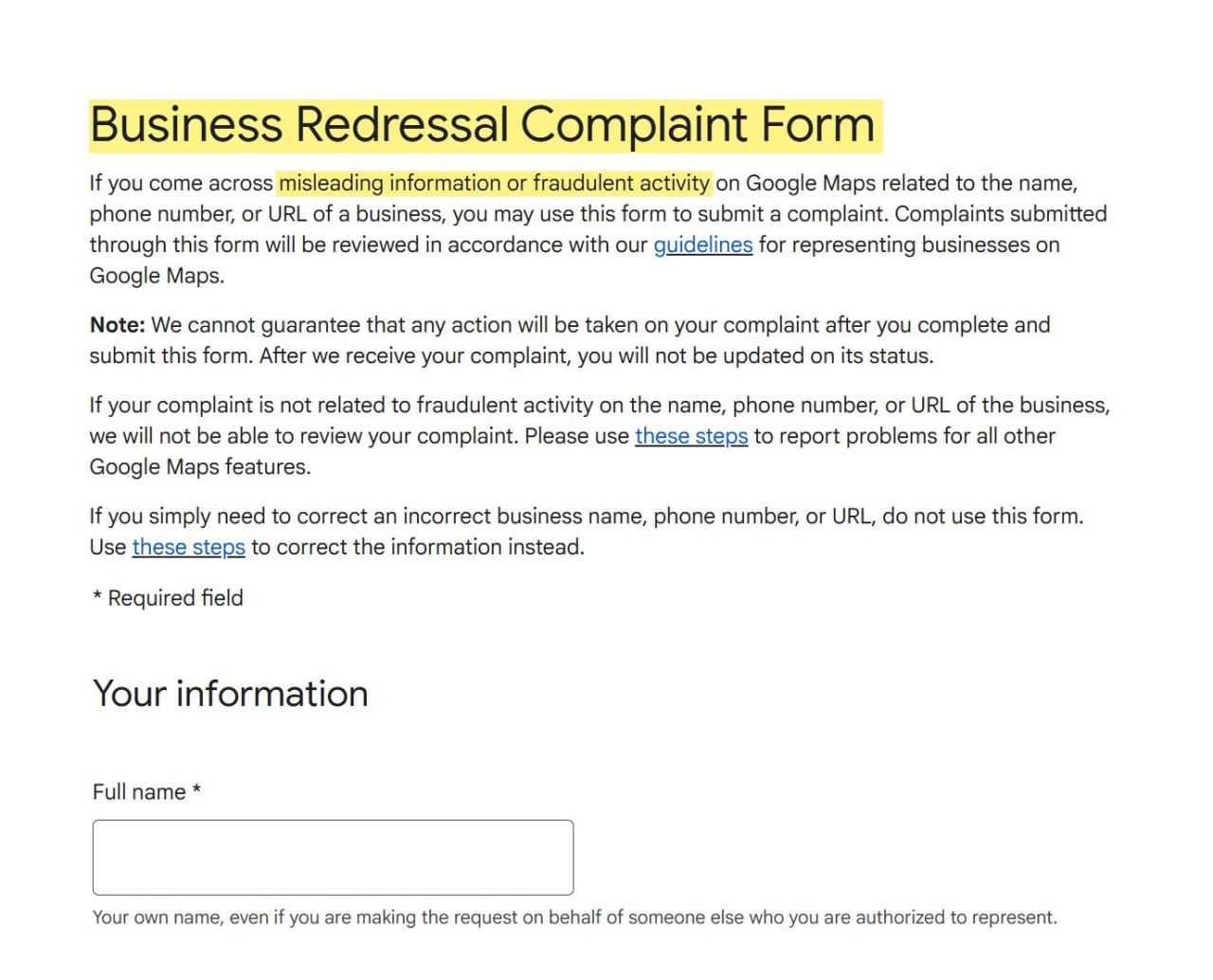
Suggest an Edit" на профилях конкурентов, меняя названия бизнесов, категории и т.д., эти компании потенциально могут узнать, что это был ты, и подать в суд.Именно поэтому я рекомендую юзать
Google Business Redressal Complaint Form, пишет Даррен Шоу.Делая это таким образом, ты устраняешь риск быть раскрытым лично в рамках юридического запроса.
#GBP #LocalSEO #NegativeSEO
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
{kind=link}
👍5❤2
Google говорил: "Все ссылки оцениваются по одним и тем же критериям качества".
Утечка доказывает обратное.
Ссылки с новостных источников не оцениваются просто как обычные ссылки.
Они проходят через отдельную систему классификации, которая тегирует их закодированными данными специально об их "новостности" (newsiness).
Данные вычисляются с использованием выделенных подпрограмм в
Это означает: когда ты получаешь ссылку с
Она не просто "лучше" из-за более высокого траста (DR).
Она КАТЕГОРИЧЕСКИ другая, потому что у Google есть целая параллельная система скоринга для новостных анкоров.
Это объясняет:
— Почему кампании
— Почему единственная ссылка из реальной новостной статьи может бустануть позиции сильнее, чем 10 ссылок с обычных блогов
— Почему пресс-релизы на сайтах новостных агентств (Reuters, AP, BusinessWire) выдают выхлоп, кратно превышающий их ссылочный вес, даже на паразитах — они запускают классификацию новостного анкора
— Почему Google дает временный буст ранжирования страницам, на которые ссылаются новостные источники во время трендовых событий (сигнал новостности усиливает свежесть)
Если ты сливаешь весь ссылочный бюджет на гестпосты и нишевые вставки (niche edits) без какого-либо компонента
Новостные ссылки — это не просто хорошие ссылки, это совершенно другой тип ссылок внутри системы Google.
#DigitalPR #Backlinks #LinkEquity
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Утечка доказывает обратное.
encodedNewsAnchorData — это поле, которое заполняется ТОЛЬКО когда анкор "классифицирован как исходящий с новостного, высококачественного сайта".Ссылки с новостных источников не оцениваются просто как обычные ссылки.
Они проходят через отдельную систему классификации, которая тегирует их закодированными данными специально об их "новостности" (newsiness).
Данные вычисляются с использованием выделенных подпрограмм в
quality/freshness/news_anchors/ — целой подсистемы исключительно для скоринга ссылок с новостных источников.Это означает: когда ты получаешь ссылку с
Reuters, BBC, редакционной статьи Forbes, The Guardian или любого сайта, который Google классифицирует как "новостной и высококачественный", эта ссылка несет фундаментально иной сигнал, чем идентичная ссылка с обычного блога.Она не просто "лучше" из-за более высокого траста (DR).
Она КАТЕГОРИЧЕСКИ другая, потому что у Google есть целая параллельная система скоринга для новостных анкоров.
Это объясняет:
— Почему кампании
digital PR с размещениями в прессе стабильно обходят кампании гестпостов с эквивалентными метриками траста и трафика— Почему единственная ссылка из реальной новостной статьи может бустануть позиции сильнее, чем 10 ссылок с обычных блогов
— Почему пресс-релизы на сайтах новостных агентств (Reuters, AP, BusinessWire) выдают выхлоп, кратно превышающий их ссылочный вес, даже на паразитах — они запускают классификацию новостного анкора
— Почему Google дает временный буст ранжирования страницам, на которые ссылаются новостные источники во время трендовых событий (сигнал новостности усиливает свежесть)
Если ты сливаешь весь ссылочный бюджет на гестпосты и нишевые вставки (niche edits) без какого-либо компонента
digital PR, ты упускаешь отдельный слой сигналов, на котором твои конкуренты, скорее всего, уже паразитируют...Новостные ссылки — это не просто хорошие ссылки, это совершенно другой тип ссылок внутри системы Google.
#DigitalPR #Backlinks #LinkEquity
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
❤3